Vagrant-安装教程及常见问题
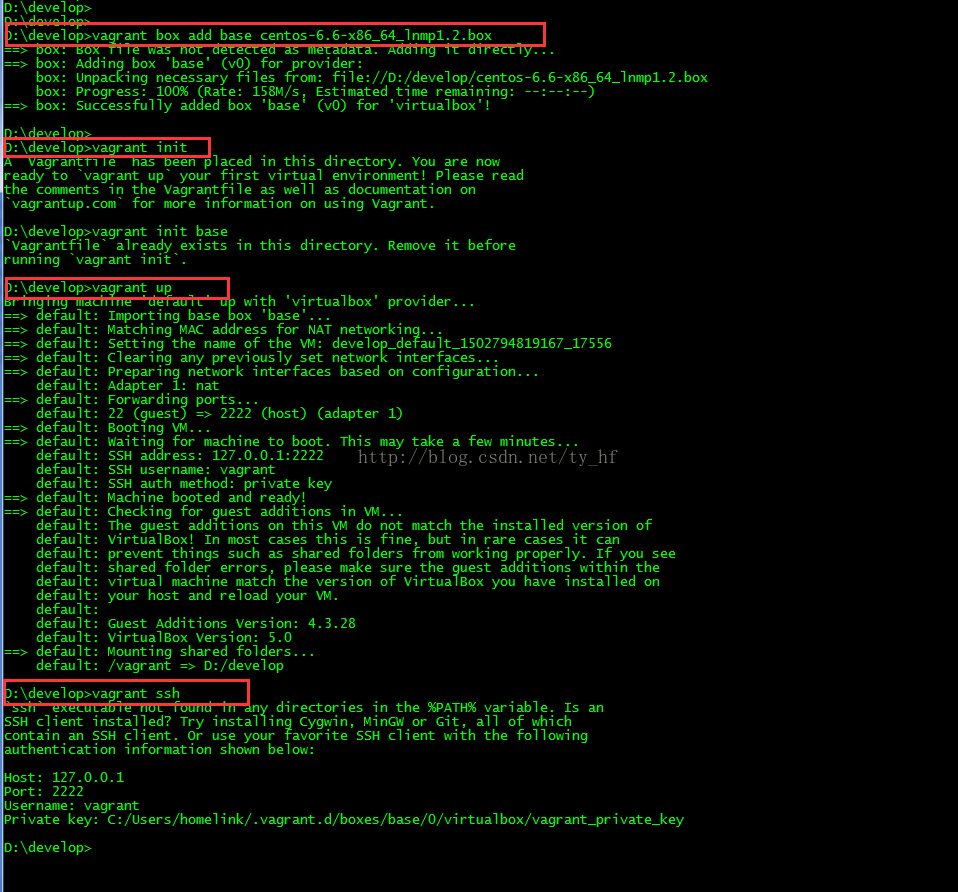

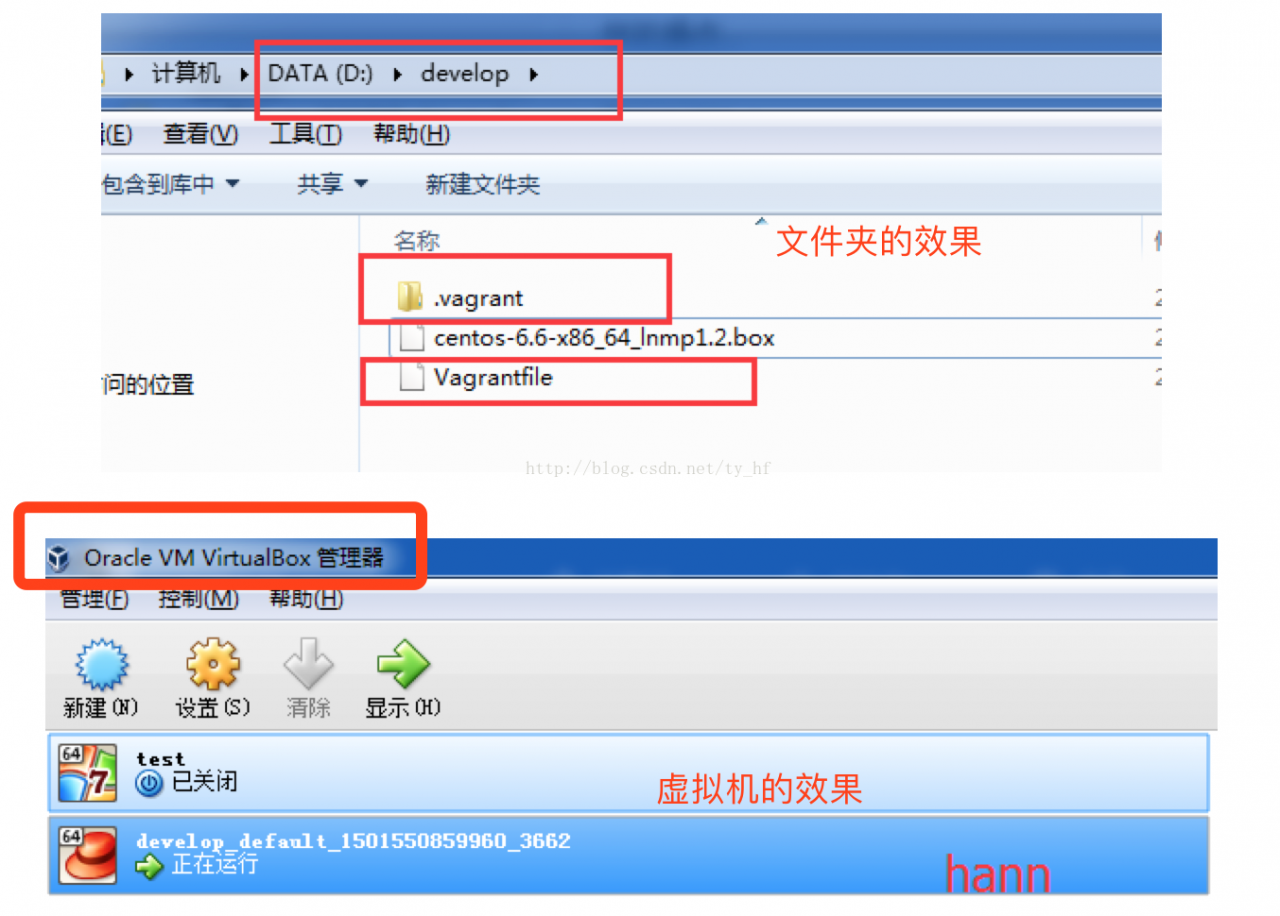
- vagrant up (启动虚拟机)
- vagrant halt (关闭虚拟机——对应就是关机)
- vagrant suspend (暂停虚拟机——只是暂停,虚拟机内存等信息将以状态文件的方式保存在本地,可以执行恢复操作后继续使用)
- vagrant resume (恢复虚拟机—— 与前面的暂停相对应)
- vagrant destroy (删除虚拟机,删除后在当前虚拟机所做进行的除开Vagrantfile中的配置都不会保留)
在我们的开发目录下有一个文件Vagrantfile,里面包含有大量的配置信息,主要包括三个方面的配置,虚拟机的配置、SSH配置、Vagrant的一些基础配置。Vagrant是使用Ruby开发的,所以它的配置语法也是Ruby的,但是我们没有学过Ruby的人还是可以跟着它的注释知道怎么配置一些基本项的配置。
具体介绍,参考:http://blog.csdn.net/chajinglong/article/details/52805915
- # -*- mode: ruby -*-
- # vi: set ft=ruby :
- # All Vagrant configuration is done below. The "2" in Vagrant.configure
- # configures the configuration version (we support older styles for
- # backwards compatibility). Please don\'t change it unless you know what
- # you\'re doing.
- Vagrant.configure(2) do |config|
- # The most common configuration options are documented and commented below.
- # For a complete reference, please see the online documentation at
- # https://docs.vagrantup.com.
- # Every Vagrant development environment requires a box. You can search for
- # boxes at https://atlas.hashicorp.com/search.
- config.vm.box = "base"
- # Disable automatic box update checking. If you disable this, then
- # boxes will only be checked for updates when the user runs
- # `vagrant box outdated`. This is not recommended.
- # config.vm.box_check_update = false
- # Create a forwarded port mapping which allows access to a specific port
- # within the machine from a port on the host machine. In the example below,
- # accessing "localhost:8080" will access port 80 on the guest machine.
- # config.vm.network "forwarded_port", guest: 80, host: 80
- # Create a private network, which allows host-only access to the machine
- # using a specific IP.
- config.vm.network "private_network", ip: "192.168.33.10"
- # Create a public network, which generally matched to bridged network.
- # Bridged networks make the machine appear as another physical device on
- # your network.
- # config.vm.network "public_network"
- # Share an additional folder to the guest VM. The first argument is
- # the path on the host to the actual folder. The second argument is
- # the path on the guest to mount the folder. And the optional third
- # argument is a set of non-required options.
- config.vm.synced_folder "D:/all_code/", "/home/www"
- # Provider-specific configuration so you can fine-tune various
- # backing providers for Vagrant. These expose provider-specific options.
- # Example for VirtualBox:
- #
- # config.vm.provider "virtualbox" do |vb|
- # # Display the VirtualBox GUI when booting the machine
- # vb.gui = true
- #
- # # Customize the amount of memory on the VM:
- # vb.memory = "1024"
- # end
- #
- # View the documentation for the provider you are using for more
- # information on available options.
- # Define a Vagrant Push strategy for pushing to Atlas. Other push strategies
- # such as FTP and Heroku are also available. See the documentation at
- # https://docs.vagrantup.com/v2/push/atlas.html for more information.
- # config.push.define "atlas" do |push|
- # push.app = "YOUR_ATLAS_USERNAME/YOUR_APPLICATION_NAME"
- # end
- # Enable provisioning with a shell script. Additional provisioners such as
- # Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
- # documentation for more information about their specific syntax and use.
- # config.vm.provision "shell", inline: <
- # sudo apt-get update
- # sudo apt-get install -y apache2
- # SHELL
- end
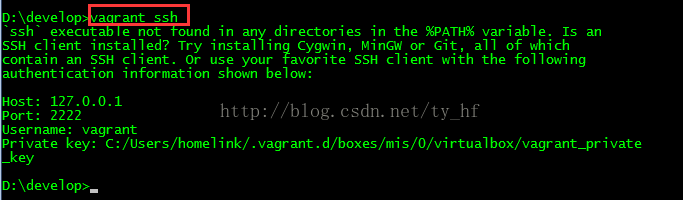
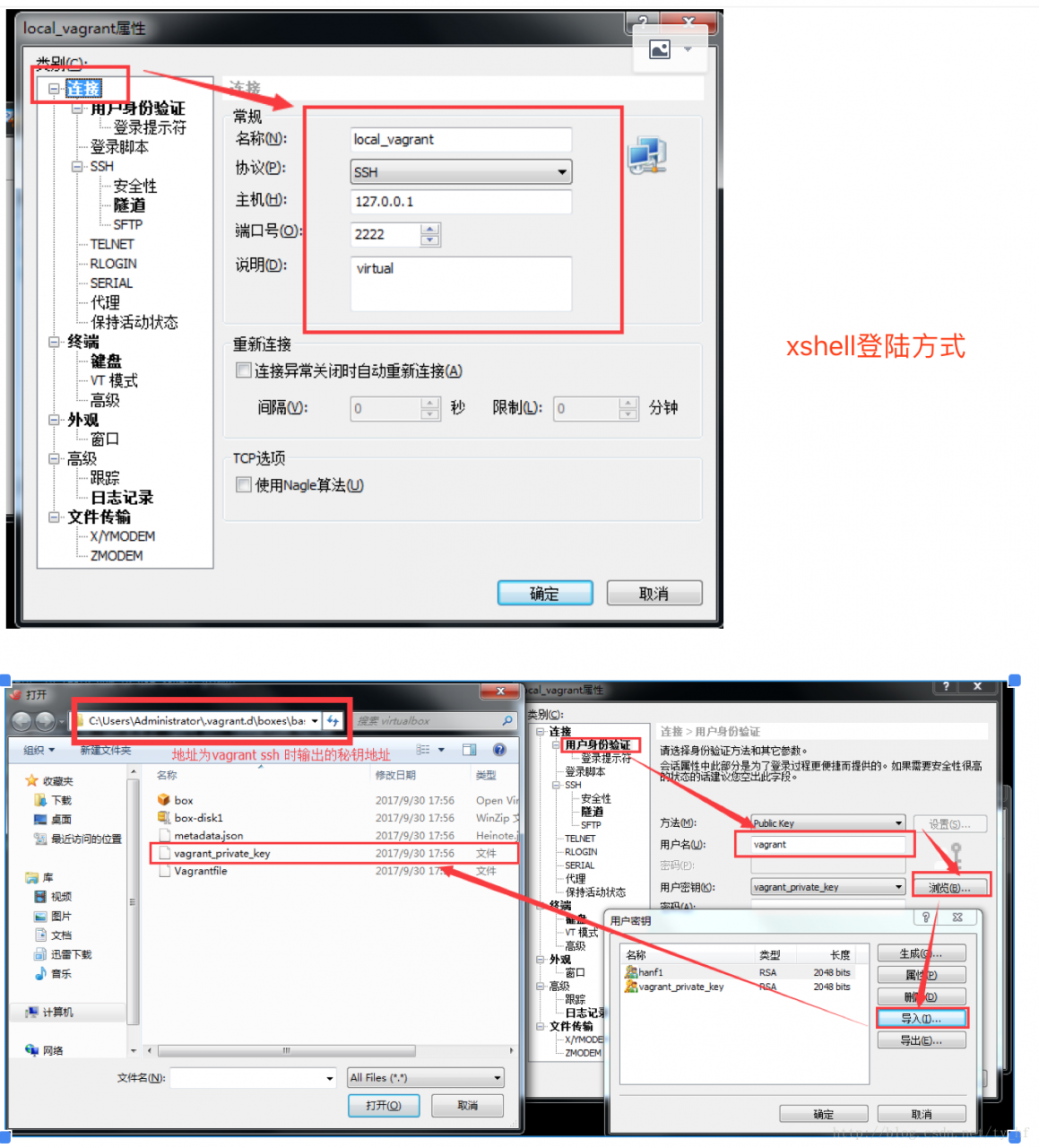
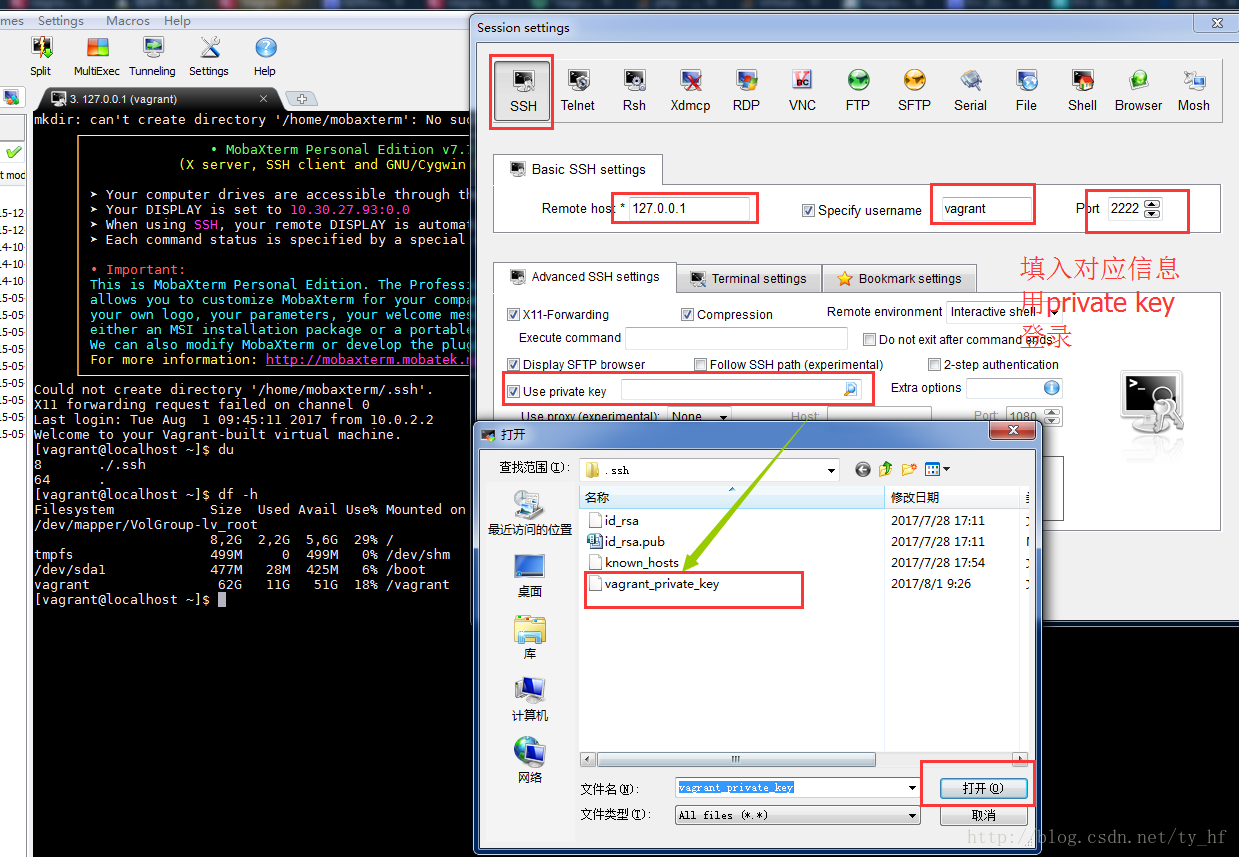
- ssh: 127.0.0.1
- 端口: 2222
- 用户名: vagrant
- 密码: vagrant
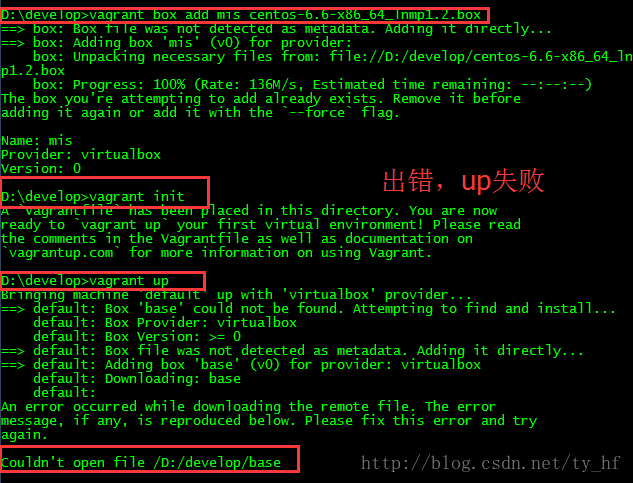
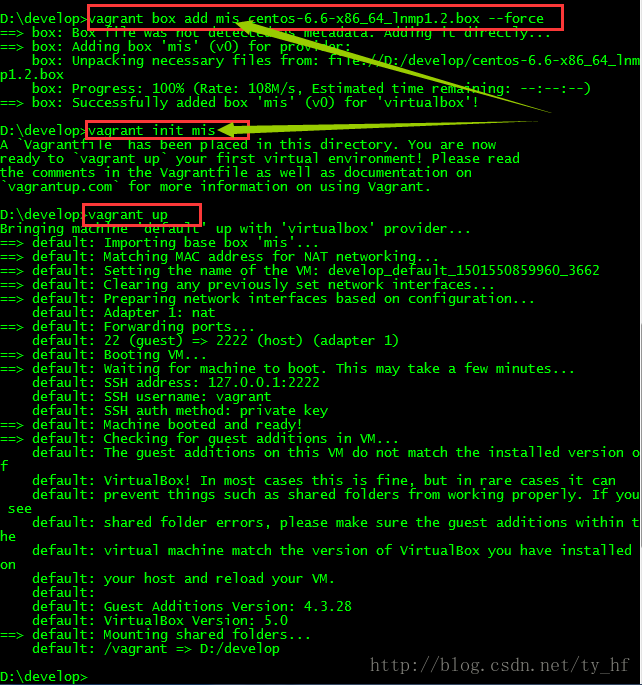
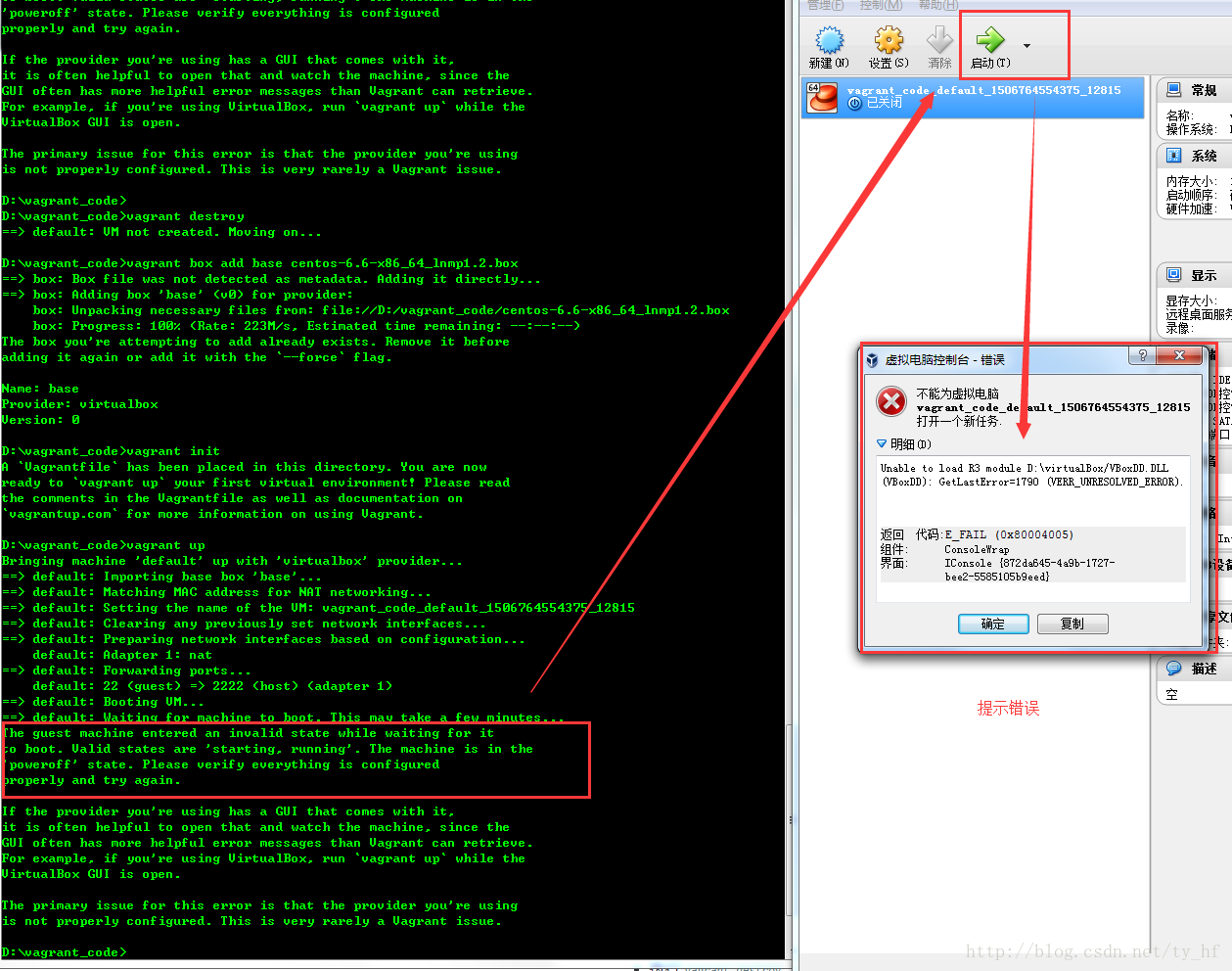
- The guest machine entered an invalid state while waiting for it
- to boot. Valid states are \'starting, running\'. The machine is in the
- \'poweroff\' state. Please verify everything is configured
- properly and try again.
- If the provider you\'re using has a GUI that comes with it,
- it is often helpful to open that and watch the machine, since the
- GUI often has more helpful error messages than Vagrant can retrieve.
- For example, if you\'re using VirtualBox, run `vagrant up` while the
- VirtualBox GUI is open.
- The primary issue for this error is that the provider you\'re using
- is not properly configured. This is very rarely a Vagrant issue.
- Unable to load R3 module D:\virtualBox/VBoxDD.DLL (VBoxDD): GetLastError=1790 (VERR_UNRESOLVED_ERROR).
- sudo rm -f /etc/udev/rules.d/70-persistent-net.rules
- vi /etc/hosts
3.问题 default: Warning: Authentication failure. Retrying...
- Bringing machine \'default\' up with \'virtualbox\' provider...
- ==> default: Clearing any previously set forwarded ports...
- ==> default: Clearing any previously set network interfaces...
- ==> default: Preparing network interfaces based on configuration...
- default: Adapter 1: nat
- default: Adapter 2: hostonly
- ==> default: Forwarding ports...
- default: 22 (guest) => 2222 (host) (adapter 1)
- ==> default: Booting VM...
- ==> default: Waiting for machine to boot. This may take a few minute
- default: SSH address: 127.0.0.1:2222
- default: SSH username: vagrant
- default: SSH auth method: private key
- default: Warning: Remote connection disconnect. Retrying...
- default: Warning: Authentication failure. Retrying...
- default: Warning: Authentication failure. Retrying...
- default: Warning: Authentication failure. Retrying...
- Timed out while waiting for the machine to boot. This means that
- Vagrant was unable to communicate with the guest machine within
- the configured ("config.vm.boot_timeout" value) time period.
- If you look above, you should be able to see the error(s) that
- Vagrant had when attempting to connect to the machine. These errors
- are usually good hints as to what may be wrong.
- If you\'re using a custom box, make sure that networking is properly
- working and you\'re able to connect to the machine. It is a common
- problem that networking isn\'t setup properly in these boxes.
- Verify that authentication configurations are also setup properly,
- as well.
- If the box appears to be booting properly, you may want to increase
- the timeout ("config.vm.boot_timeout") value.
解决:
- config.ssh.username = "vagrant"
- config.ssh.password = "vagrant"
- vagrant halt
- vagrant up
注意登陆的时候看下 vagrant ssh 看下你的登录信息,端口号
4.报错问题:
- Bringing machine \'default\' up with \'virtualbox\' provider...
- Your VM has become "inaccessible." Unfortunately, this is a critical error
- with VirtualBox that Vagrant can not cleanly recover from. Please open VirtualBox
- and clear out your inaccessible virtual machines or find a way to fix
- A Vagrant environment or target machine is required to run this
- command. Run vagrant init to create a new Vagrant environment. Or,
- get an ID of a target machine from vagrant global-status to run
- this command on. A final option is to change to a directory with a
- Vagrantfile and to try again.
少前边步骤了,比如vagrant init;或者没有进入对应vagrant init的文件夹
- config.vm.provider :virtualbox do |vb|
- vb.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
- vb.customize ["modifyvm", :id, "--natdnsproxy1", "on"]
- D:\vcode>vagrant up
- Bringing machine \'default\' up with \'virtualbox\' provider...
- Your VM has become "inaccessible." Unfortunately, this is a critical error
- with VirtualBox that Vagrant can not cleanly recover from. Please open VirtualBo
- x
- and clear out your inaccessible virtual machines or find a way to fix
- them.
如何处理好前后端分离的 API 问题
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
作为一个程序员,我讨厌那些没有文档的库。我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。
因为交付周期的原因,接入了一个第三方的库,遇到了这么一些问题:文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
对于一个库来说,文档是多种多样的:一份 demo、一个入门指南、一个 API 列表,还有一个测试。如果一个 API 有测试,那么它也相当于有一份简单的文档了——如果我们可以看到测试代码的话。而当一个库没有文档的时候,它也不会有测试。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
- API 的字段更新了
- API 的路由更新了
- API 返回了未预期的值
- API 返回由于某种原因被删除了
- 。。。
API 的维护是一件烦人的事,所以最好能一次设计好 API。可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护。
前后端分离 API 的演进史
刚毕业的时候,工作的主要内容是用 Java 写网站后台,业余写写自己喜欢的前端代码。慢慢的,随着各个公司的 Mobile First 战略的实施,项目上的主要语言变成了 JavaScript。项目开始实施了前后端分离,团队也变成了全功能团队,前端、后台、DevOps 变成了每个人需要提高的技能。于是如我们所见,当我们完成一个任务卡的时候,我们需要自己完成后台 API,还要编写相应的前端代码。
尽管当时的手机浏览器性能,已经有相当大的改善,但是仍然会存在明显的卡顿。因此,我们在设计的时候,尽可能地便将逻辑移到了后台,以减少对于前端带来的压力。可性能问题在今天看来,差异已经没有那么明显了。
如同我在《RePractise:前端演进史》中所说,前端领域及 Mobile First 的变化,引起了后台及 API 架构的一系列演进。
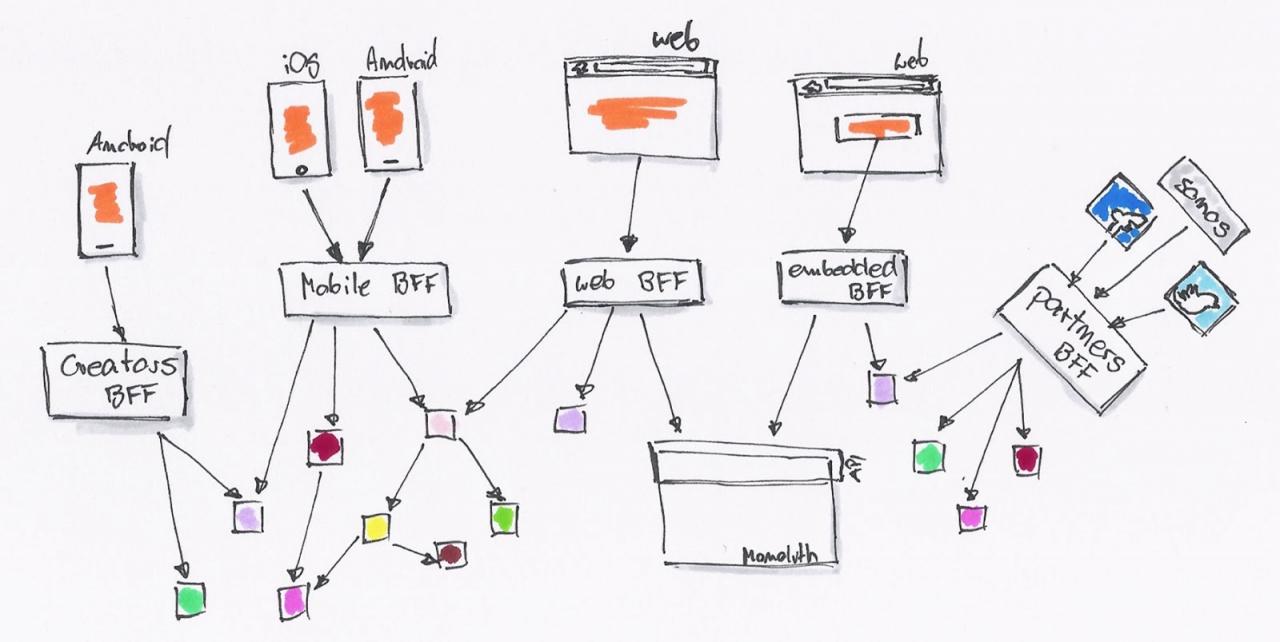
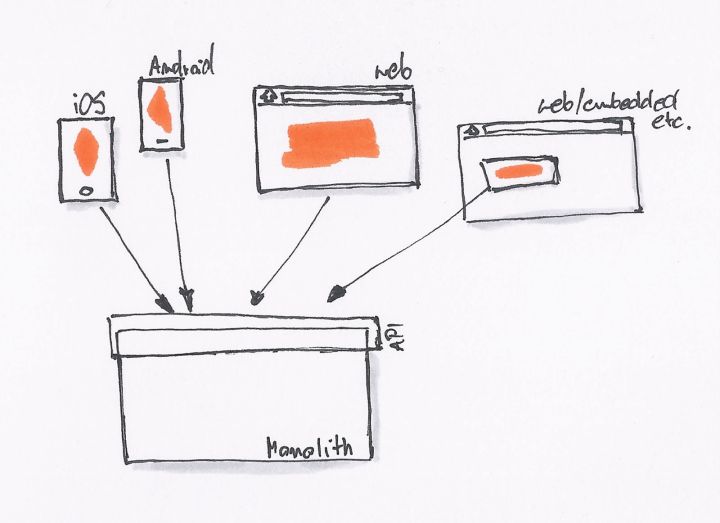
最初的时候,我们只有一个网站,没有 REST API。后台直接提供 Model 数据给前端模板,模板处理完后就展示了相关的数据。
当我们开始需要 API 的时候,我们就会采用最简单、直接的方式,直接在原有的系统里开一个 API 接口出来。
为了不破坏现有系统的架构,同时为了更快的上线,直接开出一个接口来得最为直接。我们一直在这样的模式下工作,直到有一天我们就会发现,我们遇到了一些问题:
- API 消费者:一个接口无法同时满足不同场景的业务。如移动应用,可能与桌面、手机 Web 的需求不一样,导致接口存在差异。
- API 生产者:对接多个不同的 API 需求,产生了各种各样的问题。
于是,这时候就需要 BFF(backend for frontend)这种架构。后台可以提供所有的 MODEL 给这一层接口,而 API 消费者则可以按自己的需要去封装。

API 消费者可以继续使用 JavaScript 去编写 API 适配器。后台则慢慢的因为需要,拆解成一系列的微服务。
系统由内部的类调用,拆解为基于 RESTful API 的调用。后台 API 生产者与前端 API 消费者,已经区分不出谁才是真正的开发者。
瀑布式开发的 API 设计
说实话,API 开发这种活就和传统的瀑布开发差不多:未知的前期设计,痛苦的后期集成。好在,每次这种设计的周期都比较短。
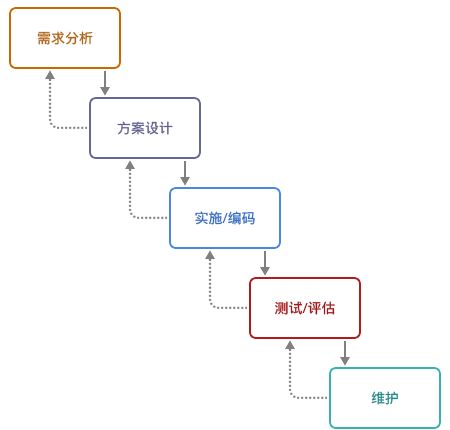
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
- 维护 API 文档很痛苦
- 需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以一个根据代码文件中中注释信息,生成应用程序或库、模块的API文档的工具。
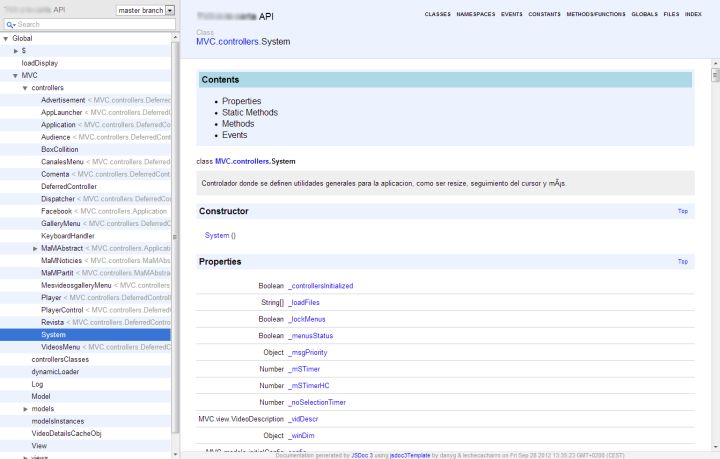
同样的对于 API 来说,也可以采取类似的步骤,如 Swagger。它是基于 YAML语法定义 RESTful API,如:
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
schemes:
- https
host: simple.api
basePath: /openapi101
paths: {}
它会自动生成一篇排版优美的API文档,与此同时还能生成一个供前端人员使用的 Mock Server。同时,它还能支持根据 Swagger API Spec 生成客户端和服务端的代码。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
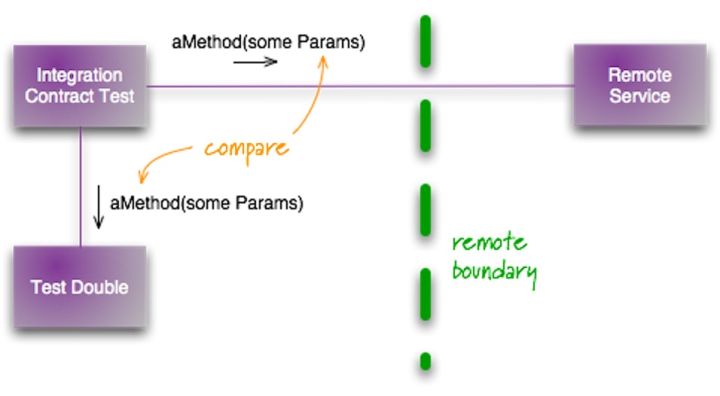
其步骤如下:
- 编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
- 根据契约编写 Mock Server。可以彩 Moco
- 编写集成测试将请求发给这个 Mock Server,并验证
如下是我们项目使用的 Moco 生成的契约,再通过 Moscow 来进行 API 测试。
[
{
"description": "should_response_text_foo",
"request": {
"method": "GET",
"uri": "/property"
},
"response": {
"status": 401,
"json": {
"message": "Full authentication is required to access this resource"
}
}
}
]
只需要在相应的测试代码里请求资源,并验证返回结果即可。
而对于前端来说,则是依赖于 UI 自动化测试。在测试的时候,启动这个 Mock Server,并借助于 Selenium 来访问浏览器相应的地址,模拟用户的行为进行操作,并验证相应的数据是否正确。

当契约发生发动的时候,持续集成便失败了。因此相应的后台测试数据也需要做相应的修改,相应的前端集成测试也需要做相应的修改。因此,这一改动就可以即时地通知各方了。
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:

这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
我们需要处理同的异常数据,不同情况下的返回值等等。因此,我之前尝试开发 DDM 来解决这样的问题,只是轮子没有造完。诸如 Redux 可以管理状态,还应该有个相应的类型检测及 Adapter 工具。
除此,还有一种情况是使用第三方 API,也需要这样的适配层。很多时候,我们需要的第三方 API 以公告的形式来通知各方,可往往我们不会及时地根据这些变化。

一般来说这种工作是后台去做代码的,不得已由前端来实现时,也需要加一层相应的适配层。
小结
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
在服务器上排除问题的头 5 分钟
遇到服务器故障,问题出现的原因很少可以一下就想到。我们基本上都会从以下步骤入手:
一、尽可能搞清楚问题的前因后果
不要一下子就扎到服务器前面,你需要先搞明白对这台服务器有多少已知的情况,还有故障的具体情况。不然你很可能就是在无的放矢。
必须搞清楚的问题有:
- 故障的表现是什么?无响应?报错?
- 故障是什么时候发现的?
- 故障是否可重现?
- 有没有出现的规律(比如每小时出现一次)
- 最后一次对整个平台进行更新的内容是什么(代码、服务器等)?
- 故障影响的特定用户群是什么样的(已登录的, 退出的, 某个地域的…)?
- 基础架构(物理的、逻辑的)的文档是否能找到?
- 是否有监控平台可用? (比如Munin、Zabbix、 Nagios、 New Relic… 什么都可以)
- 是否有日志可以查看?. (比如Loggly、Airbrake、 Graylog…)
最后两个是最方便的信息来源,不过别抱太大希望,基本上它们都不会有。只能再继续摸索了。
二、有谁在?
$ w
$ last
用这两个命令看看都有谁在线,有哪些用户访问过。这不是什么关键步骤,不过最好别在其他用户正干活的时候来调试系统。有道是一山不容二虎嘛。(ne cook in the kitchen is enough.)
三、之前发生了什么?
$ history
查看一下之前服务器上执行过的命令。看一下总是没错的,加上前面看的谁登录过的信息,应该有点用。另外作为admin要注意,不要利用自己的权限去侵犯别人的隐私哦。
到这里先提醒一下,等会你可能会需要更新 HISTTIMEFORMAT 环境变量来显示这些命令被执行的时间。对要不然光看到一堆不知道啥时候执行的命令,同样会令人抓狂的。
四、现在在运行的进程是啥?
$ pstree -a
$ ps aux
这都是查看现有进程的。 ps aux 的结果比较杂乱, pstree -a 的结果比较简单明了,可以看到正在运行的进程及相关用户。
五、监听的网络服务
$ netstat -ntlp
$ netstat -nulp
$ netstat -nxlp
我一般都分开运行这三个命令,不想一下子看到列出一大堆所有的服务。netstat -nalp倒也可以。不过我绝不会用 numeric 选项 (鄙人一点浅薄的看法:IP 地址看起来更方便)。
找到所有正在运行的服务,检查它们是否应该运行。查看各个监听端口。在netstat显示的服务列表中的PID 和 ps aux 进程列表中的是一样的。
如果服务器上有好几个Java或者Erlang什么的进程在同时运行,能够按PID分别找到每个进程就很重要了。
通常我们建议每台服务器上运行的服务少一点,必要时可以增加服务器。如果你看到一台服务器上有三四十个监听端口开着,那还是做个记录,回头有空的时候清理一下,重新组织一下服务器。
六、CPU 和内存
$ free -m
$ uptime
$ top
$ htop
注意以下问题:
- 还有空余的内存吗? 服务器是否正在内存和硬盘之间进行swap?
- 还有剩余的CPU吗? 服务器是几核的? 是否有某些CPU核负载过多了?
- 服务器最大的负载来自什么地方? 平均负载是多少?
七、硬件
$ lspci
$ dmidecode
$ ethtool
有很多服务器还是裸机状态,可以看一下:
- 找到RAID 卡 (是否带BBU备用电池?)、 CPU、空余的内存插槽。根据这些情况可以大致了解硬件问题的来源和性能改进的办法。
- 网卡是否设置好? 是否正运行在半双工状态? 速度是10MBps? 有没有 TX/RX 报错?
八、IO 性能
$ iostat -kx 2
$ vmstat 2 10
$ mpstat 2 10
$ dstat --top-io --top-bio
这些命令对于调试后端性能非常有用。
- 检查磁盘使用量:服务器硬盘是否已满?
- 是否开启了swap交换模式 (si/so)?
- CPU被谁占用:系统进程? 用户进程? 虚拟机?
- dstat 是我的最爱。用它可以看到谁在进行 IO: 是不是MySQL吃掉了所有的系统资源? 还是你的PHP进程?
九、挂载点 和 文件系统
$ mount
$ cat /etc/fstab
$ vgs
$ pvs
$ lvs
$ df -h
$ lsof +D / /* beware not to kill your box */
- 一共挂载了多少文件系统?
- 有没有某个服务专用的文件系统? (比如MySQL?)
- 文件系统的挂载选项是什么: noatime? default? 有没有文件系统被重新挂载为只读模式了?
- 磁盘空间是否还有剩余?
- 是否有大文件被删除但没有清空?
- 如果磁盘空间有问题,你是否还有空间来扩展一个分区?
十、内核、中断和网络
$ sysctl -a | grep ...
$ cat /proc/interrupts
$ cat /proc/net/ip_conntrack /* may take some time on busy servers */
$ netstat
$ ss -s
- 你的中断请求是否是均衡地分配给CPU处理,还是会有某个CPU的核因为大量的网络中断请求或者RAID请求而过载了?
- SWAP交换的设置是什么?对于工作站来说swappinness 设为 60 就很好, 不过对于服务器就太糟了:你最好永远不要让服务器做SWAP交换,不然对磁盘的读写会锁死SWAP进程。
- conntrack_max 是否设的足够大,能应付你服务器的流量?
- 在不同状态下(TIME_WAIT, …)TCP连接时间的设置是怎样的?
- 如果要显示所有存在的连接,netstat 会比较慢, 你可以先用 ss 看一下总体情况。
你还可以看一下 Linux TCP tuning 了解网络性能调优的一些要点。
十一、系统日志和内核消息
$ dmesg
$ less /var/log/messages
$ less /var/log/secure
$ less /var/log/auth
- 查看错误和警告消息,比如看看是不是很多关于连接数过多导致?
- 看看是否有硬件错误或文件系统错误?
- 分析是否能将这些错误事件和前面发现的疑点进行时间上的比对。
十二、定时任务
$ ls /etc/cron* + cat
$ for user in $(cat /etc/passwd | cut -f1 -d:); do crontab -l -u $user; done
- 是否有某个定时任务运行过于频繁?
- 是否有些用户提交了隐藏的定时任务?
- 在出现故障的时候,是否正好有某个备份任务在执行?
十三、应用系统日志
这里边可分析的东西就多了, 不过恐怕你作为运维人员是没功夫去仔细研究它的。关注那些明显的问题,比如在一个典型的LAMP(Linux+Apache+Mysql+Perl)应用环境里:
- Apache & Nginx; 查找访问和错误日志, 直接找 5xx 错误, 再看看是否有 limit_zone错误。
- MySQL; 在mysql.log找错误消息,看看有没有结构损坏的表, 是否有innodb修复进程在运行,是否有disk/index/query 问题.
- PHP-FPM; 如果设定了 php-slow 日志, 直接找错误信息 (php, mysql, memcache, …),如果没设定,赶紧设定。
- Varnish; 在varnishlog 和 varnishstat 里, 检查 hit/miss比. 看看配置信息里是否遗漏了什么规则,使最终用户可以直接攻击你的后端?
- HA-Proxy; 后端的状况如何?健康状况检查是否成功?是前端还是后端的队列大小达到最大值了?
结论
经过这5分钟之后,你应该对如下情况比较清楚了:
- 在服务器上运行的都是些啥?
- 这个故障看起来是和 IO/硬件/网络 或者 系统配置 (有问题的代码、系统内核调优, …)相关。
- 这个故障是否有你熟悉的一些特征?比如对数据库索引使用不当,或者太多的apache后台进程。
你甚至有可能找到真正的故障源头。就算还没有找到,搞清楚了上面这些情况之后,你现在也具备了深挖下去的条件。继续努力吧!
面试提问的32个开放式问题
面试官的开放式问题。
如果你是一名求职者,或者事先准备以下问题的答案会对你的面试成功起到很大的帮助作用。
如果你是一名面试官,以下的问题正是你需要问的。
1. 说说你自己吧
2. 你的短期目标是什么?你2到5年内的目标是什么?
3. 你的愿景/使命是什么?
4. 你想从这个岗位中学到什么?
5. 你为什么认为自己能胜任这个岗位?
6. 除了这个岗位,你还在找哪些岗位?
7. 你有什么样的管理或领导经验?
8. 你有什么样的团队工作经验?
9. 你最满意/不满意的经历是什么?
10. 你的强项/弱项是什么?
11. 你最擅长处理哪一类的问题?
12. 你是如何减压?如何平衡工作和生活?
13. 如果他人提出的要求有违你的道德准则或商业道德,你怎么处理?
14. 你上次试图向他人出售点子有什么样的结果?
15. 你为什么要应聘我们公司?你对我们公司了解多少?
16. 你认为加入我们公司有什么样的利弊?
17. 你最看重雇主的哪一方面?
18. 你过去遇到的主管有哪些共同点?
19. 如果要在竞争中保持领先,你认为我们公司的员工最需要哪些品质?
20. 你最喜欢/不喜欢什么课程?为什么?
21. 你的兼职/暑假/实习经历中有什么收获?
22. 你有什么样的深造计划?
23. 为什么你的成绩这么低?
24. 你是如何打发空余时间的?
25. 如果我让你的朋友们描述你,你觉得他们会怎么说呢?
26. 什么事最让你沮丧?
27. 你上次在工作中遇到恼火的事是什么时候?结果如何?
28. 你如何提高你的整体效益?
29. 去年你遇到最艰难的决定是什么?为什么它很艰难?
30. 你为什么到现在还没有找到工作?
31. 你在哪些方面没有任何经验?比如:销售、筹款或者簿记。
32. 我们为什么要雇用你?
面试是一门学问。展示自己的实力很重要。面试就如把自己卖掉。
自己就是一个产品,不但能吹,把自己吹大,还真的有两把刷子。
如果你的刷子还不够好,那么努力练习就好。
北京市小汽车摇号程序的反编译、算法及存在的问题浅析-不重复随机数列生成算法
给定一个正整数n,需要输出一个长度为n的数组,数组元素是随机数,范围为0 – n-1,且元素不能重复。比如 n = 3 时,需要获取一个长度为3的数组,元素范围为0-2,
比如 0,2,1。
这个问题的通常解决方案就是设计一个 hashtable ,然后循环获取随机数,再到 hashtable 中找,如果hashtable 中没有这个数,则输出。下面给出这种算法的代码
public static int[] GetRandomSequence0(int total)
{
int[] hashtable = new int[total];
int[] output = new int[total];
Random random = new Random();
for (int i = 0; i < total; i++)
{
int num = random.Next(0, total);
while (hashtable[num] > 0)
{
num = random.Next(0, total);
}
output[i] = num;
hashtable[num] = 1;
}
return output;
}
代码很简单,从 0 到 total - 1 循环获取随机数,再去hashtable 中尝试匹配,如果这个数在hashtable中不存在,则输出,并把这个数在hashtable 中置1,否则循环尝试获取随机数,直到找到一个不在hashtable 中的数为止。这个算法的问题在于需要不断尝试获取随机数,在hashtable 接近满时,这个尝试失败的概率会越来越高。
那么有没有什么算法,不需要这样反复尝试吗?答案是肯定的。
![]()
如上图所示,我们设计一个顺序的数组,假设n = 4
第一轮,我们取 0 – 3 之间的随机数,假设为2,这时,我们把数组位置为2的数取出来输出,并把这个数从数组中删除,这时这个数组变成了
![]()
第二轮,我们再取 0-2 之间的随机数,假设为1,并把这个位置的数输出,同时把这个数从数组删除,以此类推,直到这个数组的长度为0。这时我们就可以得到一个随机的不重复的序列。
这个算法的好处是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试。算法代码如下:
public static int[] GetRandomSequence1(int total)
{
List<int> input = new List<int>();
for (int i = 0; i < total; i++)
{
input.Add(i);
}
List<int> output = new List<int>();
Random random = new Random();
int end = total;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end);
output.Add(input[num]);
input.RemoveAt(num);
end--;
}
return output.ToArray();
}
这个算法把两个循环改成了一个循环,算法复杂度大大降低了,按说速度应该比第一个算法要快才对,然而现实往往超出我们的想象,当total = 100000 时,测试下来,第一个算法用时 44ms, 第二个用时 1038 ms ,慢了很多!这是为什么呢?问题的关键就在这个 input.RemoveAt 上了,我们知道如果要删除一个数组元素,我们需要把这个数组元素后面的所有元素都向前移动1,这个移动操作是非常耗时的,这个算法慢就慢在这里。到这里,可能有人要说了,那我们不用数组,用链表,那删除不就很快了吗?没错,链表是能解决删除元素的效率问题,但查找的速度又大大降低了,无法像数组那样根据数组元素下标直接定位到元素。所以用链表也是不行的。到这里似乎我们已经走到了死胡同,难道我们只能用hashtable 反复尝试来做吗?在看下面内容之前,请各位读者先思考5分钟。
…… 思考5分钟
算法就像一层窗户纸,隔着窗户纸,你永远无法知道里面是什么,一旦捅穿,又觉得非常简单。这个算法对于我,只用了2分钟时间想出来,因为我经常实现算法,脑子里有一些模式,如果你的大脑还没有完成这种经验的积累,也许你要花比我长很多的时间来考虑这个问题,也许永远也找不到捅穿它的方法。不过不要紧,我把这个方法公布出来,有了这个方法,你只需轻轻一动,一个完全不同的世界便出现在你的眼前。原来就这么简单……。
还是上面那个例子,假设 n = 4
![]()
第一轮,我们随机获得2时,我们不将 2 从数组中移除,而是将数组的最后一个元素移动到2的位置

这时数组变成了
![]()
第二轮我们对 0-2 取随机数,这时数组可用的最后一个元素位置已经变成了2,而不是3。假设这时取到随机数为1
我们再把下标为2 的元素移动到下标1,这时数组变成了
![]()
以此类推,直到取出n个元素为止。
这个算法的优点是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试,也不用像上一个算法那样删除数组元素,要做的只是每次把数组有效位置的最后一个元素移动到当前位置就可以了,这样算法的复杂度就降低为 O(n) ,速度大大提高。
经测试,在 n= 100000 时,这个算法的用时仅为7ms。
下面给出这个算法的实现代码
/// <summary>
/// Designed by eaglet
/// </summary>
/// <param name="total"></param>
/// <returns></returns>
public static int[] GetRandomSequence2(int total)
{
int[] sequence = new int[total];
int[] output = new int[total];
for (int i = 0; i < total; i++)
{
sequence[i] = i;
}
Random random = new Random();
int end = total - 1;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end + 1);
output[i] = sequence[num];
sequence[num] = sequence[end];
end--;
}
return output;
}
下面是n 等于1万,10万和100万时的测试数据,时间单位为毫秒。从测试数据看GetRandomSequence2的用时和n基本成正比,线性增长的,这个和理论上的算法复杂度O(n)也是一致的,另外两个算法则随着n的增大,用时超过了线性增长。在1百万时,我的算法比用hashtable的算法要快10倍以上。
| 10000 | 100000 | 1000000 | |
| GetRandomSequence0 | 5 | 44 | 1075 |
| GetRandomSequence1 | 11 | 1038 | 124205 |
| GetRandomSequence2 | 1 | 7 | 82 |
现在摇号的程序及数据都可以在官网中查看,目的就是通过信息的透明度来堵住那些说摇号系统有猫腻之类的传言,我做为一个程序员,下意识的就想看看到底是否有猫腻。
通过下载程序,导入数据,将种子数写入后,的确没有什么猫腻,但还是不死心,想研究一下算法,结果发现了惊人的事情。
此算法使用的是伪随机,简单点将就是当种子数一定,摇号数据一定,每次随机结果都是一样的。举个例子,借用某申请编码2245102443992,摇号基数序号500015,取种子数范围在100000至120000之间能中签的种子数,结果显示共132个种子数,其概率为0.66%。随机找了一个种子数100575进行计算,得出结果在左侧表中,查询2245102443992是否中签,结果显示中签,在第15916行摇中;所以大家都应该知道怎么回事了吧,只要摇号池数据确定,查询出摇号基数序号,就能算出中签的种子数都有哪些,所以公布的数据和程序又有何用?关键在于种子数的确定。

网站分析团队问题
网站分析是一个新兴的也是比较复杂的行业,以下的议题会在网站分析过程中经常碰到。
一、成功
1.如果想要把网站分析提高到一个更高的层次,你必须向所在的组织证明以下提到团队的价值。
1)如果想为公司带来价值,不应该仅停留在关注报告上
2)外包常规的报告或者让报告自动化,从而来让分析师有时间关注在有意义的项目上
3)寻找与内部团队合作的机会
2.和几个商业组织或者部门之间协同合作是很困难的,为了成功,你需要有效地管理这些团队。
1)要积极主动,不能等到其他部门提需求才被动反应
2)常规召开一个会议,确定工作优先级和检查进度
3)分配不同的组员去负责不同部门的配合活动,给每个项目分配不同的PMO(project management officer).
二、策略
关于策略,一些人可能会说:“人们通常不知道目标是什么”还有“不理解策略是什么,因为关于什么是网站的重点都没有达成一致的意见。”同时,大家也意识到明确组织策略的重要性,因为直接影响到实施所产生的数据有效性和相关性。

三、领导能力
在网站分析的项目中,很多人可能因为没有真正的决策权而很沮丧。这时候你需要有权威和影响力的人物支持你,但是这个过程最好是数据来驱动和支持,并不仅仅是人。
四、组织结构

网站分析部门与IT部门的合作是比较大的一个障碍,例如涉及代码的部署和实施方面,这就需要分析人员有一定的代码基础,但是不是应该把网站分析放 在IT部门呢?其实不是的,应该把分析组放在市场营销部门,因为商业策略的理解是最主要的,代码的实施只是执行,一般来讲,不会有太大的难度,所以放到市 场营销部门是一个很不错的选择,这样可以减少沟通成本,提高工作效率。
五、培训
很多组织认识到正式培训的重要性,但是内部没有能力可以提供。组织内很多用户进入网站分析工具未能找到所需数据后,感觉很沮丧;解决的办法是可以成立一些会议定期解答工具使用方面的问题,必要时可以提供一帮一的培训。
六、数据
1)组织需要相信数据,否则分析团队会失去支持和信任,分析工具也会被视为没有价值
2)同时分析的实施是一个不断持续的过程,不是一劳永逸的,因为有很多新的网络营销目标被创建
3) 定期地审阅报告,看看报告是否相关,或者需要提高
4)确保所有实施的项目都包含数据校对的步骤
5)在所有新的页面,网站,程序,活动跟踪测试后,再正式地发布活动,确保活动万无一失
七、沟通
沟通是成功很重要的一个因素,尤其是在内部其中一个组更改其衡量指标以后,有很好的沟通机制能够确保其他组的人也知道这个事情。同时虽然制度或者系统文件的更新有时候很困难,但
是没有它的话,组织会变得手忙脚乱,特别是关键人物突然离职的时候。
以下是沟通中需要注意的地方:
1)每个报告都应该有具体的文档,并且每一个指标和变量都必须有解释性文字介绍定义和用途
2)制定网站量度与指标白皮书,并且在内部传播,提高透明度
3)发布一封关于分析组织结构的信息
问题的思考方式有时候比问题的结论更重要-关于”沟通”的问题

一、沟通在管理上的功能及如何克服沟通的障碍
1、 沟通的模式与目的
2、 什么是有效的沟通?
3、 单向和双向沟通
4、 沟通的障碍是什么?
5、 克服沟通障碍的技巧
6、 游戏和活动
二、 沟通的原则和技巧
1、 倾听的技巧
2、 问话的技巧
3、 表达的技巧、言语表达的要诀
4、 增加认同感的技巧
5、 同事、部属与上司的沟通技巧
6、 性格模式对沟通的影响
7、 信任是沟通的基础
8、 有效沟通的五种态度
9、有效利用肢体语言
三、高效沟通的基本步骤
1、 步骤一:事前准备
2、 步骤二:确认需求
3、 步骤三:阐述观点——介绍FAB原则
4、 步骤四:处理异议
5、 步骤五:达成协议
四、工作协调及冲突管理
1、 协调时的沟通要领 2、 培养良好的心态和素质 3、 冲突管理及技巧

网站运营相关的33个问题
以下问题可根据自己的实际情况排序考虑 同时也要注意边考虑边执行毕竟实践出真知!
1、你的网站提供的内容是不是网民现在需要的内容?是不是能逐渐引导网民接受的内容?这是网站的需求分析。
2、你的网站给哪一类人群看?这一类人群有哪些共同特征?这是网站的市场细分?
3、你的网站目标市场有多大规模、是否成熟、未来前景发展如何?你是否有能力满足市场需求并获得目标利润?这是网站的目标市场评估。
4、你的网站所在行业未来会有那些政策和环境变动,会有哪些竞争对手出现?这是网站的市场预测。
5、如何向你的目标用户展示你的网站和其他同行网站的区别?你准备在目标用户心目中树立什么样的形象?这是网站市场定位。
6、你准备如何如何传播和持续加强你的网站形象?这是网站品牌策略。
7、你的网站目标群体的具体需求是什么?你准备整合什么样的功能与服务来满足他们的需求?这是网站产品概念。
8、你能像了解你的恋人一样一口气说出你的网站项目概念有哪几大特色吗?这是网站的差异化策略。
9、你了解你的目标用户搜索和使用该类网站的心理和行为模式吗?这是网站用户心理和行为模式分析。
10、你的网站如何不断开发新的功能、推广不同活动?这是你的创意机制和网站开发策略。
11、如何处理网站名称、域名、网站主题三者之间的关系?如何使你的目标用户一看就明白你的网站名称、域名、网站主题的含义?这是网站的包装和商标策略。
12、你的网站有偿服务价格依据是什么、是如何制定的?这是你的网站价格策略。
13、你知道你的网站月收入多少才能达到收支平衡吗?这是盈亏平衡点分析、网站项目运营和预算管理。
14、你的网站竞争对手有哪些?他们的特色服务是什么?不要忘了所有能满足你的目标群体需求的网站都是你的竞争对手,这是竞争对手分析。
15、你的竞争网站采取是什么样的推广方式、销售政策?你都是通过什么渠道、什么方式获得的这些信息?这是网站营销调研。
16、和你的竞争对手相比,你的竞争优势是什么?这是市场竞争策略的选择。如果没有竞争优势,你就不要去竞争。
17、你的网站使命是什么?你要帮助你的目标用户达到什么层次?这是网站使命?
18、你的网站三年、五年、十年的规划是什么?这是你的网站战略规划。
19、你的网站三个月、六个月、九个月都有什么具体工作,这是网站运营管理。
20、你是如何把你的网站优势展示出来并有效传播给你的潜在用户?你能总结出来这就是你的网站独创营销模式。
21、你的网站准备用什么样的方式切入市场?这是网站推广策略。
22、你的网站都有哪几篇为网民熟知的软文介绍?这是网站新闻推广策略。有空看看妙创网的网站点评专题。
23、你如何让你的网站项目迅速为潜在用户试用、成为商业用户?这是网站促销策略。
24、你的网站业务推广具体采用的是什么方式方法?你如何监控和评价?这是网站业务推广流程管理。
25、你总共可以采取哪些方法、创造那些事件推广、宣传你的网站?这是网站推广、网站公关和网站广告。
26、你通过什么样的奖励方式调动开发和推广人员的积极性和创造性?这是网站薪酬设计。
27、你是如何调动你的网站内部人员之外的单位和个人推广你的网站?这是网站项目分销渠道的选择和管理。
28、你的网站开发和推广分成几个阶段?谁来站掌控?这是危网站项目进度管理。
29、完全实现你的网站设想,开发和推广大概需要多少时间和多少资金?你有没有做好充分的资金准备?这是网站项目预算。
30、完全实现你的网站设想,开发和推广大概需要什么专业人员?多少专业人员?你怎么样才能准时找到他们?这是网站人力资源管理。
31、你的网站有哪几条根据你们的工作经验和行业分析总结出来的大家都认可的工作方式方法?这是网站管理文化。
32、当你的网站出现突发性危机事件的时候,你将如何采取措施面对和解决?这是网站紧急预案和网站危机公关。
33、你的网站是否专门请过第三方进行点评分析?这是网站诊断机制。
解决struts国际化和中文问题
当今Struts框架的应用已经非常的成熟了,基本的配置我就不多说了,大家上google去搜搜就有一大堆. 最近在一次项目开发中碰到了Struts的I18N问题,我来粗略谈谈基本用法,让大家有对Struts的国际化问题有一个简略的认识.(注意,以下是在struts开发环境配置好了的情况下实现国际化的步骤,顺便解决了中文问题):
1. 设置所有JSP页面的charset为UTF-8. 即在每个JSP页面前加上<%@ page language="Java" contentType="text/html;charset=UTF-8" %>. java是通过unicode实现国际化的,然而unicode和UTF-8是一一对应的关系.
2. JSP页面里面没有硬编码的文字(即页面的文字都是从*.properties资源文件里面读出来的,用<bean:message key="keyword in property file">读取即可.) 资源文件的配置也不多说了,在web.xml里面配配就好. 下面假设英文的资源文件叫ApplicationResources_en.properties ,中文的源文件叫ApplicationResources_xx.properties(value都是中文的) . 用JDK自带的native2ascii工具把中文的资源文件里面的中文转化为为用ASCII表示的Unicode编码, 命令如下: native2ascii -encoding GBK ApplicationResources_xx.properties ApplicationResources_zh.properties . (中文操作系统里面默认是GBK,它是gb2312的扩充集),好了,如果你不用form传中文,不用入库,那么你成功了.打开浏览器在internet选项里面设置一下语言试试. 容易吧,呵呵. 下面的步骤涉及到入库问题.
3. 写一个Filter类,一个最简单的代码例子如下:
import java.io.*;
import javax.servlet.*;
public class CharsetFilter implements Filter{
private FilterConfig config = null;
private String defaultEncode = "UTF-8";
public void init(FilterConfig config) throws ServletException {
this.config = config;
if(config.getInitParameter("Charset")!=null){
defaultEncode=config.getInitParameter("Charset");
}
}
public void destroy() {
this.config = null;
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
ServletRequest srequest=request;
srequest.setCharacterEncoding(defaultEncode);
chain.doFilter(srequest,response);
}
}
然后你需要在web.xml里面设置一下Filter,加入下面的即可(注意,如果你是在JBX里面开发,声明filter一定要在声明<servlet>前面,否则会报错,但是用的时候好像又没有问题.)
<filter>
<filter-name>Character Encoding</filter-name>
<filter-class>com.alex.util.CharsetEncodingFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>Character Encoding</filter-name>
<servlet-name>action</servlet-name>
</filter-mapping>
4. 接下来是写一个Converter类,在入库前调用encode(),出库的时候调用decode()就ok. 下面是一个简单例子:
public class Converter {
public Converter() {
}
public static String enCode(String str) {
byte temp [];
temp = str.getBytes();
try {
//System.out.println("in before convert: " + str);
str = new String(temp , "ISO-8859-1");
//System.out.println("in after convert: " + str);
}
catch(Exception e) {
System.err.println("convert error: " + e);
}
return str;
}
public static String deCode(String str) {
byte temp [];
try {
//System.out.println("out before convert: " + str);
temp = str.getBytes("ISO-8859-1");
str = new String(temp,"GBK");
//System.out.println("out after convert: " + str);
}
catch(Exception e) {
System.err.println("convert error: " + e);
}
return str;
}
}
5. 应该都OK了吧,我就这样解决了struts的中文问题和国际化问题.
关于广告单个点击成本和千人访问成本的计算问题
点击成本应该比较好理解,比如你买包时广告,一个周花了10块,而广告总共给你带来了100个点击,那你每次的点击成本是1毛钱,如果只带来20个,那成本就是5毛钱。
这个是说的包时广告,就是MM里大多数网站提供的服务,一买至少一周,每个周多少钱之类的。
还有种就是付费点击广告,也就是你的广告显示在对方网站上,并不按时间收费,只需要设定好每个点击要支付的费用,另外设定好上限就可以了。MM的我还没仔细看,但GOOGLE、百度就这么操作的,比如你可以存两千块钱,每个广告点击付5毛钱,每天就投50块钱的。那他们就会自动帮你投放广告,每天点够50块钱的,也就是100次,就不投放广告了,第二天继续投放。
我曾在百度买过广告,按点击付费的,每次5毛,几天就几百块钱进去了,太快了,效果一般,后来就停了。
百度好象最低设置5毛,但有的关键词可能需要设置高达几块钱,才有可能排到前面。
至于广告联盟,一般的是每次点击0.15--0.2元,我想可能MM里大多数人承受不了,但如果太低的话,站长又不干。在MM有个好处就是你可以设置的低一些,我能接受5分到1毛费用,如果少了我的站就不给放了,
当然如果买包时广告的话,呵呵,买的广告位好了,点击多,平均每个低于5分也有可能,像这样的,我认为是赚的,很值得继续投。
以前曾帮客户在新浪、搜狐、QQ等站投放过广告,位置选的不好平均几块,选得好了2毛多,成本还是相当高的。但客户还愿意投,因为这个还涉及到另一个问题,就是品牌形象宣传。比如我在新浪投放齐鲁都市网的广告,其他人看了可能不会点击,但肯定会想都在新浪投放广告了,肯定很有实力。
我们以前的客户也在一些地方的站点也投过广告,如信息港、新闻网之类的,都是三流网站,访问量高,但相对大站又低很多,甚至比不上一些个人网站,可他们要价还很高,一个月几万甚至十多万块钱,投放完广告一算,平均每个点击十几块几十块的,客户亏大了。
再说说千人访问成本,以前也帮别人投放过广告,费用不少,大概合每个显示5厘,也就是说千次显示是5块钱。当然对于MM的大多数人来说,也许难以接受,我觉得低于两块钱的都可以投,如果低于1块钱就好了,但说实在的,太低了当站长的不干,我辛苦搞站,卖个广告位就这么点钱,不值得,还不如不投。MM给的广告位建议价应该按是每千次显示2块多来的,不过好象大多数站长都砍了一半再卖。
另外你还得看广告的位置,同样是10块钱/周,一个是上面的通栏广告,一个是最下面的LOGO广告,效果当然不一样,如果你只贪便宜,买些边边角角的广告,我的意见是干脆别投,即使千次访问成本只有1毛钱也不干。试想谁会关注角落里的广告呢,你显示的次数是很多,一个周上万,可点击才几个,值得吗?
我的建议是大家投放广告时要参考千人访问成本和点击成本,两个都要算,合计好了再投放,最后效果才好。
给自己做点广告,大家没事来看看,位置很好,价格也不高,地方站,适合很多类型的客户投放广告。广告需要审核,我认为这是对MM、对客户、对自己负责。
支持博主

{kind=link}
关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
目录分类
文章归档
- 2022年8月 (2)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)