PHP 正则表达式简单笔记
1.简单介绍
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的语法。
例:在判断用户邮件地址格式、手机号码格式或者采集别人网页内容时
主要的作用是:分割、匹配、查找、替换
注:正则表达式对于一个程序员来讲是至关重要的一个知识点,所以学好正则是每一个程序员必须具备的。不仅可以帮助我们完成一些通过函数无法实现的工作,还可以帮助我们减轻很多工作量。
2、PHP中两个常用的正则函数
preg_match 正则函数,以perl语言为基础
preg_match ( mode, string subject , array matches )
ereg 正则函数,以POSIX基础 (Unix 、 Script)
ereg ( mode, string subject , array regs )
3、正则表达式中包括的元素
(1)、原子(普通字符:a-z A-Z 0-9 、原子表、 转义字符)
(2)、元字符 (有特殊功能的字符)
(3)、模式修正符 (系统内置部分字符 i 、m、S、U…)
4、正则表达式中的“原子”
①a-z A-Z _ 0-9 //最常见的字符
②(abc) (skd) //用圆括号包含起来的单元符合
③[abcs] [^abd] //用方括号包含的原子表,原子表中的^代表排除或相反内容
④转义字符
\d 包含所有数字[0-9]
\D 除所有数字外[^0-9]
\w 包含所有英文字符[a-zA-Z_0-9]
\W 除所有英文字符外[^a-zA-Z_0-9] \s 包含空白区域如回车、换行、分页等 [\f\n\r]
5、正则表达式元字符
* 匹配前一个内容的0次1次或多次
. 匹配内容的0次1次或多次,但不包含回车换行
+ 匹配前一个内容的1次或多次
?匹配前一个内容的0次或1次
| 选择匹配类似PHP中的| (因为这个运算符合是弱类型导致前面最为整体匹配)
^ 匹配字符串首部内容
$ 匹配字符串尾部内容
\b 匹配单词边界,边界可以是空格或者特殊符合
\B 匹配除带单词边界意外内容
{m} 匹配前一个内容的重复次数为M次
{m,} 匹配前一个内容的重复次数大于等于M次
{m,n} 匹配前一个内容的重复次数M次到N次
( ) 合并整体匹配,并放入内存,可使用\1 \2…依次获取
6、运算顺序
依然遵循从左到→右的运算规则
优先级
①( ) 圆括号因为是内存处理所以最高
②* ? + { } 重复匹配内容其次
③^ $ \b 边界处理第三
④| 条件处理第四
最后按照运算顺序计算匹配
7、模式修正符,是为正则表达式增强和补充的一个功能。
常用修正符
i 正则内容在匹配时候不区分大小写(默认是区分的)
m 在匹配首内容或者尾内容时候采用多行识别匹配
S 将转义回车取消是为单行匹配如. 匹配的时候
x 忽略正则中的空白
A 强制从头开始匹配
D 强制$匹配尾部无任何内容 \n
U 禁止贪婪匹配 只跟踪到最近的一个匹配符并结束
匹配指定的标签对,标签对间可以有内容:/<\s*h4[^>]*>(.*?)<\s*/\s*h4>/g
匹配所有的标签和标签属性:/<(.|\n)*?>/g
匹配所有的开始标签,标签里可以有属性:/<\s*\w.*?>/g
匹配所有的结束标签:/<\s*\/\s*\w\s*.*?>|<\s*br\s*>/g
匹配指定的开始标签,标签里可以有属性:/<\s*div.*?>/g
匹配标签对间有内容的结束标签:/<\s*\/\s*div\s*.*?>/g
匹配所有指定的标签(不管开始或结束标签),标签里有可以有属性:/<\s*\/?\s*span\s*.*?>/g
匹配有指定属性的开始标签:/<\s*\w*\s*style.*?>/g
匹配有指定属性和指定的属性值的开始标签:/<\s*\w*\s*href\s*=\s*”?\s*([\w\s%#\/\.;:_-]*)\s*”?.*?>/g
simple_html_dom使用小结
<?php
include "simple_html_dom.php" ; // Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '<br>';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '<br>';
// Create DOM from URL
$html = file_get_html('http://slashdot.org/');
// Find all article blocks
foreach($html->find('div.article') as $article) {
$item['title'] = $article->find('div.title', 0)->plaintext;
$item['intro'] = $article->find('div.intro', 0)->plaintext;
$item['details'] = $article->find('div.details', 0)->plaintext;
$articles[] = $item;
}
print_r($articles);
// Create DOM from string
$html = str_get_html('<div id="hello">Hello</div><div id="world">World</div>'); $html->find('div', 1)->class = 'bar';
$html->find('div[id=hello]', 0)->innertext = 'foo';
echo $html; // Output: <div id="hello">foo</div><div id="world" class="bar">World</div>
| Name | Description |
|---|---|
|
void
__construct ( [string $filename] ) |
Constructor, set the filename parameter will automatically load the contents, either text or file/url. |
|
string
plaintext |
Returns the contents extracted from HTML. |
|
void
clear () |
Clean up memory. |
|
void
load ( string $content ) |
Load contents from a string. |
|
string
save ( [string $filename] ) |
Dumps the internal DOM tree back into a string. If the $filename is set, result string will save to file. |
|
void
load_file ( string $filename ) |
Load contents from a from a file or a URL. |
|
void
set_callback ( string $function_name ) |
Set a callback function. |
|
mixed
find ( string $selector [, int $index] ) |
Find elements by the CSS selector. Returns the Nth element object if index is set, otherwise return an array of object. |
$ret = $html->find('a');
// Find (N)th anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', 0);
// Find lastest anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', -1);
// Find all <div> with the id attribute
$ret = $html->find('div[id]');
// Find all <div> which attribute id=foo
$ret = $html->find('div[id=foo]');
$ret = $html->find('#foo');
// Find all element which class=foo
$ret = $html->find('.foo');
// Find all element has attribute id
$ret = $html->find('*[id]');
// Find all anchors and images
$ret = $html->find('a, img');
// Find all anchors and images with the "title" attribute
$ret = $html->find('a[title], img[title]');
$es = $html->find('ul li');
// Find Nested <div> tags
$es = $html->find('div div div');
// Find all <td> in <table> which
$es = $html->find('table.hello td');
// Find all td tags with attribite align=center in table tags
$es = $html->find(''table td[align=center]');
| Attribute Name | Usage |
|---|---|
| $e->tag | Read or write the tag name of element. |
| $e->outertext | Read or write the outer HTML text of element. |
| $e->innertext | Read or write the inner HTML text of element. |
| $e->plaintext | Read or write the plain text of element. |
$html = str_get_html("<div>foo <b>bar</b></div>");
$e = $html->find("div", 0);
echo $e->outertext; // Returns: " <div>foo <b>bar</b></div>"
echo $e->innertext; // Returns: " foo <b>bar</b>"
echo $e->plaintext; // Returns: " foo bar"
6.DOM traversing 方法
| Method | Description |
|---|---|
|
mixed
$e->children ( [int $index] ) |
Returns the Nth child object if index is set, otherwise return an array of children. |
|
element
$e->parent () |
Returns the parent of element. |
|
element
$e->first_child () |
Returns the first child of element, or null if not found. |
|
element
$e->last_child () |
Returns the last child of element, or null if not found. |
|
element
$e->next_sibling () |
Returns the next sibling of element, or null if not found. |
|
element
$e->prev_sibling () |
Returns the previous sibling of element, or null if not found. |
echo $html->find("#div1", 0)->children(1)->children(1)->children(2)->id;
// or
echo $html->getElementById("div1")->childNodes(1)->childNodes(1)->childNodes(2)->getAttribute('id');
function my_callback($element) {
// Hide all <b> tags
if ($element->tag=='b')
$element->outertext = '';
}
// Register the callback function with it's function name
$html->set_callback('my_callback');
// Callback function will be invoked while dumping
echo $html;
地方门户网站的盈利模式
第一个,也是最基础的一个:网络广告。网络广告的实质在于如何利用互联网挖掘到目标客户,更有针对性地传播信息,提高广告的效果。因此,显而易见的事实是地方生活门户网站能够提供更具个性化和针对性的网上广告手段,城市网上广告市场将呈现爆炸式增长。
广告形式可多种多样,如展示广告收入:通过前期运营,使网站达到一定影响力、知名度,拥有客观的访问量的时候,页面展示广告将是最简单、最基础的利润来源;有偿信息收入,这将是又一收入来源,主要是利用平台优势,在各相关频道重点推荐付费信息,这种模式中,还可以包括社区营销收入。
第二个盈利点在于电子商务。首先,在发展较大用户群基础上,通过我们自己的商家开展B2C电子商务,建设B2C网上商城,会员可以以会员价购买时尚生活消费品。
第三个盈利点在于与城市商业的融合,社区带动,单点突破,做足消费卡、团购、预定、消费分成、电子优惠券等商业模式文章。
第四个盈利点在于个性化增值服务。这个主要是面向企业客户的网络营销需求提供的增值服务,因为网站方而在通过运营积累,有人量用户数据,用户消费习惯分析,这些都可以助力于企业网络营销,网站同时还有大量的企业数据,包括用户点评分析等,这样,一方面,既可以给企业定制网络营销方案,另一方而也可以给用户定制个性化消费方案。这个需要有一段时期的运营积累。
第五个盈利点:便民服务。如当地的各种分类信息发布,地产中介、征婚交友、配送、家政、培训机构、美容等,通过“付费获得推荐或更好的展示效果”来实现盈利。
未来的盈利拓展有:免费《城市消费指南杂志》,用广告招商的形式盈利。作为地方门户来说,务必要切实做到“落地”,先把人气做起来,第一步考虑如何从商家盈利,比如房产家居方面栏目和版块应该很容易从房产商、家居用品设计、生产、销售、施工等企业获得盈利,具体的栏目根据各地情况的不同,可能会有不同的策划形式和运营形式。还有餐饮娱乐、汽车交易等等。
只要能做大,成为地方生活第一网络平台,那么,商家的广告就是一个巨大的盈利点,在针对当地商家进行广告展示服务之上,还可以为他们提供一些深度的服务,比如隶属于地方生活门户的商家展示网站、博客等,商家可自助管理,自助发布信息并推送到相应的位置,还有,上面已经说过,通过平台的运营,网站应该积累了大量的数据,可以针对商家的需求,做商家网络营销的整合包装与策划。
以上说的很多是一些广告盈利模式,其实我们从长远来想想,网络除了具有媒体属性之外,还可以开展电子商务,大家买一些东西不再去拥挤的商场,直接在我们的B2C网络商城订购。
此外,还有其他一些盈利模式,举下面的例子来说:
1、政府政务、商务:比如招商引资、旅游服务、经贸洽谈、项目招投标、政府性行为招标,政府性行为采购、新闻、信息发布等。
2、企业服务:自行联系或地方政府相关单位牵头成立企业会员俱乐部,协助完成对企业的全方位服务。比如项目及相关信息的发布、融资项目分析报告、投资商推荐、项目包装、项目推荐、项目测评、企业信息化建设、企业广告推广、产品的推广、为企业提供有效客户及合作者。3、信息中介服务、信息咨询业务:本地市场信息的中介有偿服务及专利、技术、项目等推广信息宣传。开办信息中介服务中介房产、中介车辆、中介闲置设备、中介家政服务等信息业务。
4、网络游戏:加盟网络游戏业务或产品加盟项目或产品:利用自身媒体的优势,加盟全国各地的中国创业联盟成员单位或其他单位的项目在本地的推广销售。
5、网络增值业务:域名、企业网站制作、企业电子邮箱、虚拟空间业务等。
6、会展服务:商业门户的品牌具有强大的市场号召力,可以结合地面会展的形式,结合网站推广,策划各种会展活动盈利。
7、培训服务:随着企业对互联网和电子商务知识的渴求,各地运营中心可以开设各种电子商务培训班,即可通过培训直接盈利,又培养了准客户。
8、个人会员:教育、医疗、娱乐、购物、交友、旅游等会员服务。
9、其他:还有网络商城、网上开店和物流配送等等其它业务。很多传统的商业模式,网络经济进行嫁接改良的,比如,网上订票、网络订餐。
从全国范围看,真正把这些都做到盈利的几乎没有,因为这些从理论上是可行的,但是网络发展阶段,当地网络发展情况、市场竞争情况,网站的运营发展情况等等,决定了不太可能一上来就全而开花,但是可以重点突破,根据我们自己的发展情况,摸索尝试出几个盈利点,然后规模化它,就很不错。
与商家合作的盈利方式包括:组织网友一起参加产品发布会、组织网友参加商品试用团、组织网友团购等。下而就以团购为例讲讲地方社区通过与商家合作取得盈利。在团购活动中,相对成熟的盈利模式主要有以下六种:
1、商品直销
以“团购”的名义直接在社区上刊登商品信息,进行直接销售,这里的货源也可以是自己进货、或跟商家合作代销,直接获得商品销售利润。商品直销是在网站运作中实现基本盈利的传统方式。
2、活动回扣
社区作为商家与买家的中间桥梁,组织有共同需求的买家向商家集体采购,事后商家向社区支付利润回报,即大家生活中常见的“回扣”形式。团购商品小到生活用品,大到电器、建材、装修、汽车、房产等,如果成功组织了一个大型采购团、如买车团、买房团,仅一次活动的商家利润回报小到上万,大到十几万甚至更多。现在一些大型团购网站号称有千人团购会甚至有万人团购会,这种人规模的采购其产生的利润回报之大,可想而之。
3、商家展会
可以不定期举办商家展览交流会,商家可以借此机会在社区进行新产品的推广、试用,可以面对面一与客户交流、接受咨询一与订单并借此了解客户的需求与建议,社区向商家收取展位费获得收益。
4、 广告服务
社区除了具有区域性特征外、它的受众一般都是具备消费、购买能力、欲购买的人群,对于商家来说定位精准、目标明确,成本低廉,故必将成为商家广告宣传的最佳平台。
5、售会员卡
“VIP会员”是用来凸显用户“尊贵身份”常见方式,在年轻人,特别是学生人群中非常的受欢迎。社区可以通过发放会员卡的形式来让用户提升“身份”,社区可以为持卡会员提供更低廉的商品价格,更贴心的服务,可以让持卡会员直接在合作的商家实体店铺进行“团购”。
6、分站加盟
当社区发展到一定影响力,无形中已经在为我们做项目招商了。此时可以提供授权给加盟者成立分站,为加盟者提供网络平台、运作经验、共享网站品牌等,在获得加盟费的同时也扩大了自身规模的影响力。
对地方社区举办利用团购盈利的建议:
1、不要一开始就搞全地区性的,尽量选择自己所在的区域或熟悉的区域范围进行运作,这样无论是推广、交流、交易、活动组织等操作起来都会非常的方便,而且也能最快的时间内被民众所接受。在初期,我们的人力、财力肯定不是非常的充足,都应该采取以小到大的发展策略。
2、在商品类别上应该采取以点到面的策略,不要一开始就想着做个最全面的,什么类型的商家都去联系合作,什么商品都搞,应该在某一行业或某一类别上做出你的价格、质量优势和特色来。
3、利用我们自己集团的各种现有资源,比如雨具,酒店,咖啡店,他们都可以为我们提供货源,那么我们可以很好的利用这个资源优势。
4、如果我们是某品牌的经销商、代理商,那么这无疑是最好的资源了,借助自身品牌与价格的绝对优势,以及对这个行业的熟悉度,无疑为你打开了一条新的营销大门和新的发展项目。目前万城网的模式加盟还是最有创新与前景.
5、如果上述的优势都不具备,先期可以自己寻找一些低成本的小商品货源进行直接销售,在这个过程中我们不断的积累客户、接触供货商、行业知识、将为你下一步的发展奠定稳定的基础。
6、不要把所有的事情寄于在网上完成。社区是你的主体平台,要多做线下形式的沟通与交流。如果在线下的沟通能力有限,建议可以找个擅长业务的人来合作互补。
7、社区网站成功的关键在于效率、运营。切记千万不要把过多的时间耗费在技术上,采用现成的建站系统应该做为首选,例如Discuz!等,记住我们的重点是运营,赢利!一定要从“技术员”的位置中走出来!
8、学会善用你身边一切可利用的资源。
速度型山地车的选型
很多新手和我一样,头痛于如何选择一款跑的轻快的山地自行车,当然了,真正的高速山地是改装出来的,后者显然是高端玩法,对于入门而言,无论从经验和银子哪方面进行考虑,选择一款速度型的整车或者稍加改造会更靠谱一些。
既然讲到了速度,有必要先简单讲一下山地车和公路车的区别:
从设计上来讲,前者以通过性为方向,后者以速度为方向。
山地车的优点是适应各种路面,避震,骑行舒适,操控性好,长途骑行的稳定/安全性高;缺点是速度相对较慢。公路车的优点是阻力小,速度快;缺点是对路况适应能力差,骑行的舒适感相对较低尤其是屁股,长途骑行的稳定/安全性相对较低。
根据使用需求选择山地or公路,有人只是城市代步,竟也买个公路,我靠,你以为爬那么低很帅么?如果你是中短途压马路,那就推荐买公路。如果是超过1000公里的长途骑行,哪种都让人纠结,一般是根据路况、速度、舒适度、体力、安全性、资金投入等综合考虑,像我这样疼惜屁股又热爱牛仔裤又怕爆胎的人肯定倾向于速度型山地车多一些。
速度,是由车子性能、个人体力/心肺功能、对变速器的灵活运用决定的。车子再好,你人不行,那也只能顶个球用。而山地车无论怎么配置,怎么改装,也赶不上公路车的速度。对比山地车和公路车的特点,我们可以通过减小阻力、减少车体重量等方式来提升山地车的速度。
下面个人经验和大家分享一下,欢迎指正。
【车架】
(1)材料
选择铝合金车架,比钢车架的重量轻,不仅起步、加速、爬坡时省力,而且易搬动,对于外出旅行,随时会需要扛起车子~
但铝合金车架的弹性不如钢车架,如果你有钱的话,可以选择更好的材料,比如钛合金或碳纤维车架。
铝合金车架的车子一般在1.4公斤左右。
(2)尺寸
车架尺寸的标示法是:车轮直径x车架立管长度
再具体,车架的参数可真不少,根据身高、腿长计算最合适的车架尺寸,那会搞迷糊的,对入门来讲完全无必要。
下面简单例个对应表,厂家不同会稍微有所不同,具体去车行试骑为准:
24"x15" 适合150-165cm
26"x16" 适合155-165cm
26"x17" 适合160-175cm
26"x18" 适合170-185cm
26"x19" 适合180cm以上
车架小,易操控;车架大,易舒展。
如果是城市代步和长途骑行,碰到的交通或路况复杂,建议易小不易大。如果是路面很好的压马路,那大点也行。
(3)工艺
看焊接工艺如何,做工是否精致,感受整个车体结不结实。
【避震器】
山地车之所以安装避震系统当然是为了避震(抗冲击/抓地),但是它有个很讨厌的副作用,就是泄力。
(1)后避震
如果您不是做特技表演或者用来跑山路什么的,后避震就不需要安装,减少车身重量,并避免不必要的泄力。
(2)前避震
就是前叉。这是比较有科技含量的一个装置了,对于山地车来讲,这个装置是非常的重要,也是最烧钱的一个玩意了。
建议1:直接用硬叉,不仅重量轻,而且便宜,没有压缩/回弹功能,减少泄力,很多高速山地配的就是硬前叉。缺点也是没有压缩/回弹功能,路面不好时手就有点麻了。
建议2:选一个好一点的气叉,最大优点是重量轻,但是。。。一个字,贵!
建议3:选一个带自锁功能的前叉,在平路和爬坡时可以把前叉锁死。如果是带自锁的气叉那就更棒了,但是、、、、一个字,贵!
对入门来讲,上述2和3入手太贵,市场上原配硬叉的车子也很少见,那就车子买来配的是什么叉就什么叉吧,弹簧、油簧、阻力胶什么的都行,等了解之后再改装
【变速/传动系统】
我们用双腿踩踏踏板(以某个踩踏频率),通过链条,让前牙盘带动后飞轮(以某个齿轮比),从而带动后车轮转动,而让车子向前移动。
(1)速别
山地车的前牙盘一般是3个齿轮,后飞轮目前常见的是6片、7片、8片、9片这四种不同的数量,前齿轮数量x后飞轮数量,就形成了目前我们常见的18速、21速、24速、27速这些速别。
18速和21速常见于中低档车,21速和24速常见于中高档车,27速我觉得就有点偏执狂的意思了,个人认为无必要。
速别的多少和速度没有直接关系,它和能够产生的齿轮比的数量有关系。合适的齿轮比是让骑行者能够节省体力,能够踩踏的更舒适,而不是改变速度。就像本文一开始所说的,速度是在某种路况条件下,由车子性能、踏频(腿部力量)、该时段的齿轮比(对变速系统的灵活运用)形成的,当换到某个齿轮比的档位时,你要增加的是踏频,才能增加速度。事实上,我们常用的后飞轮也就是中间几个,最大飞轮和最小飞轮一般情况更是不去用它,也就是说无论是何种速别的车子,常用的齿轮比数量并没有大的区别。
那速别的真正作用是什么呢,18速的车有18个档位,21速的车有21个档位,以此类推,档位越多的山地车变速(即换挡)越细腻、越顺滑,让你变速时不容易感觉到很突然。
所以如果你只是城市代步,那18速足够,没必要为某种细腻感而多花钱。如果你的骑行距离较大,推荐21速或24速,这种变速的细腻感能够让你骑行愉悦。而在一些特殊的情况,比如爬长坡,而且还是逆风,这种时候或许你就能体会到大飞轮的作用了。
(2)变速器
变速器的作用就是让你及时、准确地获得你想要的齿轮比。
所以一款稳定可靠的变速器对山地车是非常重要的。变速器由指拨、前拨、后拨组成。国内常见的两个牌子,一是喜马诺Shimano,二是SRAM。
入门的话,建议选用Shimano吧,个人认为后拨比前拨重要,所以一定要留意后拨的品质。另外,就入门而言,我还是推荐飞轮和后拨用一个品牌,甚至一个套件的,这样兼容性是否好些?
一般新买的车,对变速系统都要进行细微的调校,使所有档位的变速顺滑,并且让自己最常用的齿轮比的链条位置处于相对安静、舒服的位置,这个有机会再另文阐述吧。
【刹车系统】
V刹和碟刹,所谓萝卜青菜各有所爱,并不是碟刹就一定比V刹好。
总体而言,V刹重要轻,价格便宜,容易保养维护;碟刹制动性好,恶劣天气和环境对刹车性能的影响小。
我个人还是觉得碟刹比较有愉悦感,尤其不喜欢V刹在车圈上留下擦痕。
但对于速度型的山地,特别是长途骑行,个人还是推荐双V刹好些,不仅减轻重量,维修容易,另外,V刹+前硬叉这俩一搭配,既简单又高速啊~
还有一种选择就是混搭型,前V刹+后碟刹,或者前碟刹+后V刹。无论何种搭配,大家都要留心下坡时前轮不要抱死,除了V刹这种很难避免的制动缺陷,还在于大家对刹车技巧的掌握吧?
【车轮】
(1)胎纹:
对于速度型的山地车,外胎的选择实在太重要了,是抓地能力和速度的完美结合。
胎纹越凸,阻力越大,当速度越大时,在山地上的抓地力越强;
胎纹越平,阻力越小,当速度越大时,在平地上的抓地力越强。
所以要想提升山地车的速度,首要的就是选用光头胎。推荐使用轮胎中间平滑,两边突兀强厚的光头胎,这样前行的纵向阻力不大,侧滑和转弯的横向阻力大,适应公路、越野、雪天等不同环境的需求。
(2)尺寸:
外胎的标示法是:车轮直径x外胎胎宽
公路车用的都是窄胎,山地车常见的胎宽尺寸是1.75、1.95、2,125英寸。
山地车不可能使用公路车那么窄的胎,但是要提升速度,能窄点就窄点。
以26寸为例,推荐使用26"x1.5,26"x1.75,26"x1.95的光头胎,26x1.25我觉得又有点偏执狂了,无必要吧。
(3)车圈
毫无疑问,双层圈是必须的,比单层的要结实。而外形方面,刀圈是不错的选择,不仅抗冲击而且风阻小。都说刀圈的缺点是重,我觉得问题不大,在车轮的外围适当增加点重量,虽然起步和上坡时吃点亏,但是车轮的行驶惯性也更好,越不容易降低速度,在平地骑行中,保持速度或加速是否会更加省力呢?
【自锁】
自锁就是一套蹬踏系统,骑车时和脚踏“锁”在一起,这种方式绝对能够省力并提高速度,就是解锁需要练习,刚开始很容易摔车。至于能提高多少速度,我也没用过自锁,不好说,相信这里有很多人比我有经验的多。
【车锁】
呵呵,工欲利其器,必先固其锁。
现在市场上主流的安全锁是“抗液压剪+空转锁芯”,是否抗的住12吨、14吨甚至16吨以上的液压剪,你又不好拿来试,尽量挑选吧。几乎所有的传统锁芯都抗不住挤开和暴开工具,空转锁芯就是针对开锁工具设计的,但是,如果你对中国人民的“聪明才智”有足够信心的话,空转锁芯既已成为主流防盗锁芯,总有一天会被暴开掉的,而且我听说已经出了针对空转锁芯的暴开工具。
推荐找那种把锁芯藏起来的空转锁芯,本人用的是“抗液压剪+磁卡开锁”,嘿嘿嘿嘿~
ok,其他就不多说了。
坎坷,宁静,高山、大海。
选择单车,选择了一个朋友。
选择单车,选择了一种情感。
选择单车,选择了一种向往。
图解git中的最常用命令
此页图解git中的最常用命令。如果你稍微理解git的工作原理,这篇文章能够让你理解的更透彻。 如果你想知道这个站点怎样产生,请前往GitHub repository。
正文
- 基本用法
- 约定
- 命令详解
- Diff
- Commit
- Checkout
- Detached HEAD(匿名分支提交)
- Reset
- Merge
- Cherry Pick
- Rebase
- 技术说明
基本用法
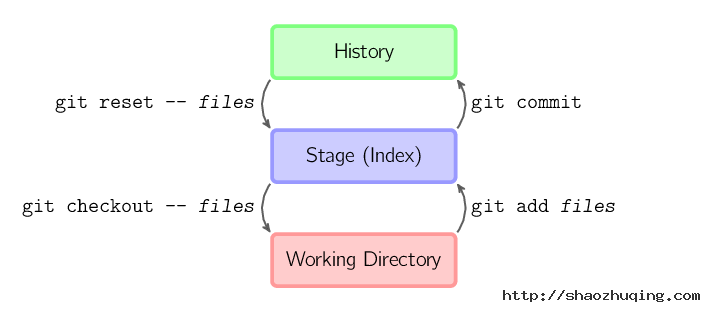
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。
你可以用 git reset -p, git checkout -p, or git add -p进入交互模式。
也可以跳过暂存区域直接从仓库取出文件或者直接提交代码。
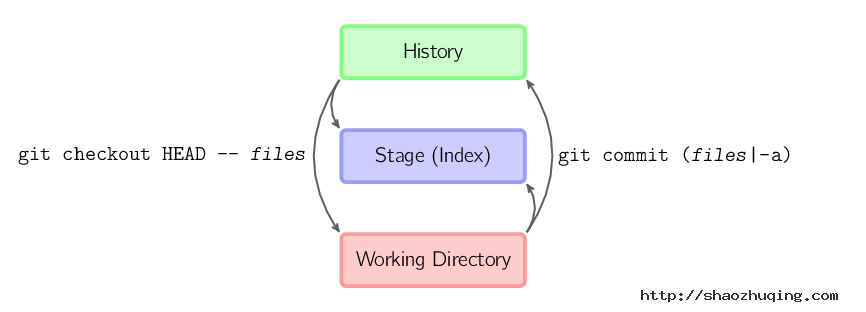
git commit -a相当于运行 git add 把所有当前目录下的文件加入暂存区域再运行。git commit.git commit files进行一次包含最后一次提交加上工作目录中文件快照的提交。并且文件被添加到暂存区域。git checkout HEAD -- files回滚到复制最后一次提交。
约定
后文中以下面的形式使用图片。
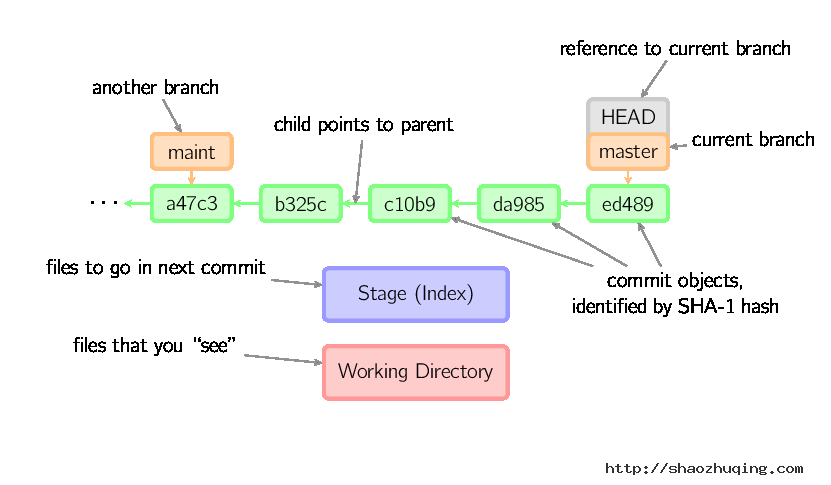
绿色的5位字符表示提交的ID,分别指向父节点。分支用橘色显示,分别指向特定的提交。当前分支由附在其上的HEAD标识。 这张图片里显示最后5次提交,ed489是最新提交。 master分支指向此次提交,另一个maint分支指向祖父提交节点。
命令详解
Diff
有许多种方法查看两次提交之间的变动。下面是一些示例。
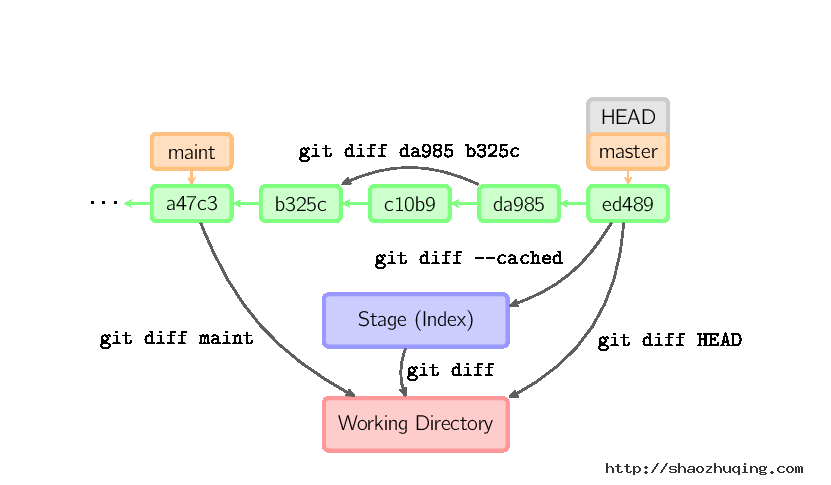
Commit
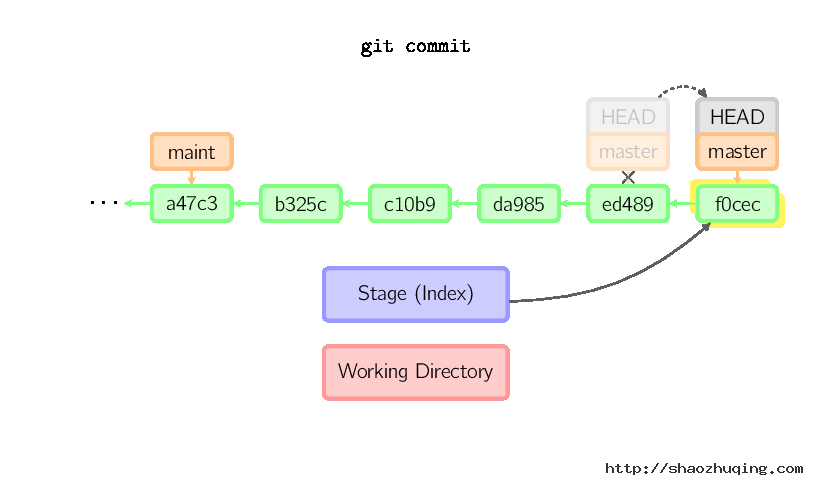
提交时,git用暂存区域的文件创建一个新的提交,并把此时的节点设为父节点。然后把当前分支指向新的提交节点。下图中,当前分支是master。 在运行命令之前,master指向ed489,提交后,master指向新的节点f0cec并以ed489作为父节点。
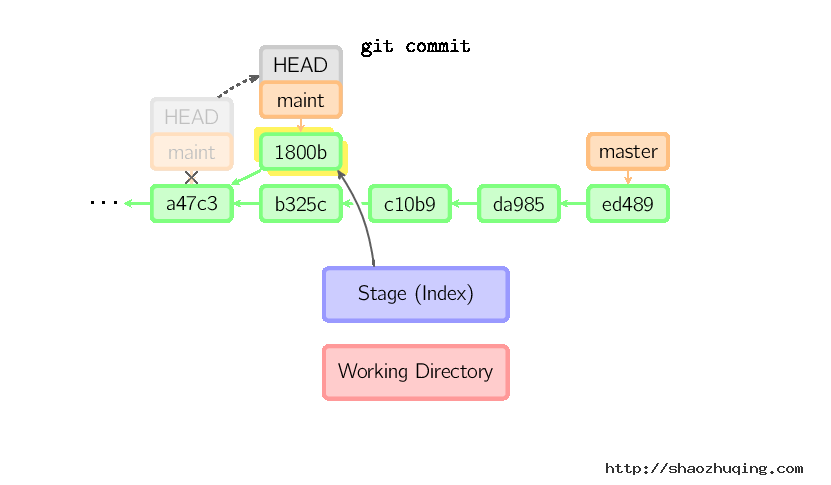
即便当前分支是某次提交的祖父节点,git会同样操作。下图中,在master分支的祖父节点maint分支进行一次提交,生成了1800b。 这样,maint分支就不再是master分支的祖父节点。此时,合并 (或者 衍合) 是必须的。
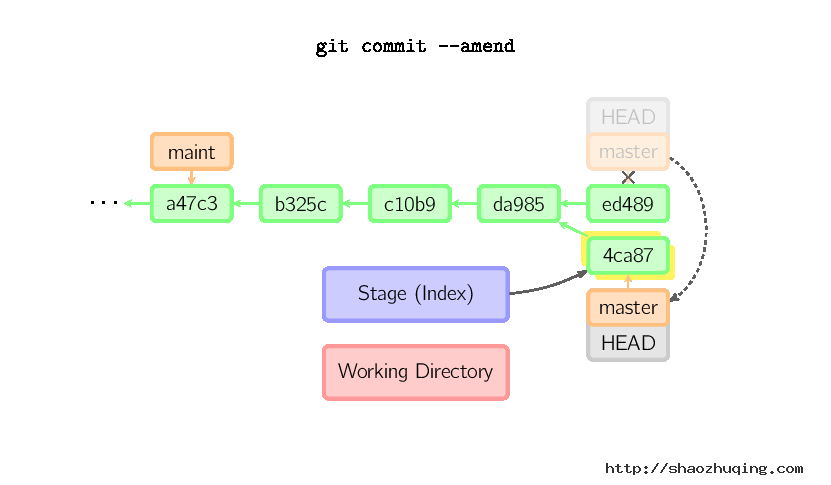
如果想更改一次提交,使用 git commit --amend。git会使用与当前提交相同的父节点进行一次新提交,旧的提交会被取消。
另一个例子是分离HEAD提交,后文讲。
Checkout
checkout命令用于从历史提交(或者暂存区域)中拷贝文件到工作目录,也可用于切换分支。
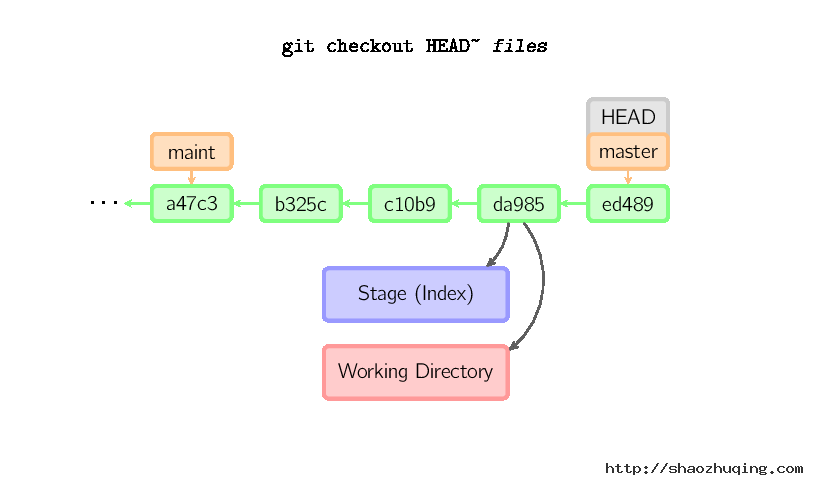
当给定某个文件名(或者打开-p选项,或者文件名和-p选项同时打开)时,git会从指定的提交中拷贝文件到暂存区域和工作目录。比如,git checkout HEAD~ foo.c会将提交节点HEAD~(即当前提交节点的父节点)中的foo.c复制到工作目录并且加到暂存区域中。(如果命令中没有指定提交节点,则会从暂存区域中拷贝内容。)注意当前分支不会发生变化。
当不指定文件名,而是给出一个(本地)分支时,那么HEAD标识会移动到那个分支(也就是说,我们“切换”到那个分支了),然后暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点(下图中的a47c3)中的所有文件都会被复制(到暂存区域和工作目录中);只存在于老的提交节点(ed489)中的文件会被删除;不属于上述两者的文件会被忽略,不受影响。
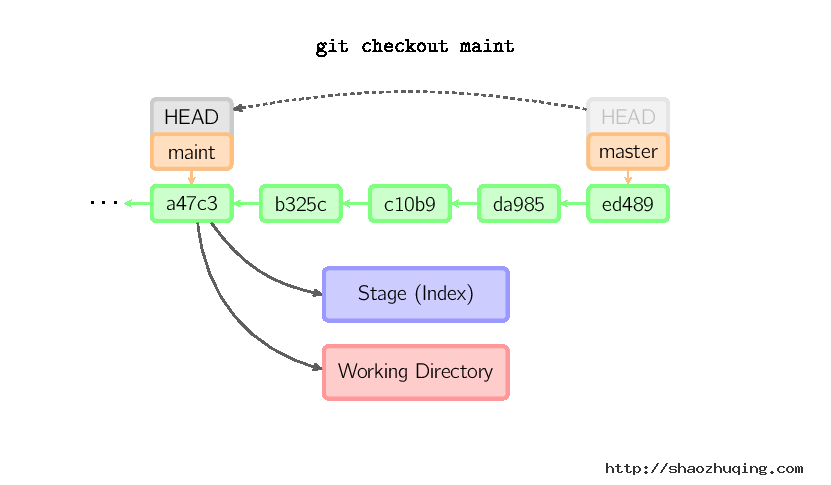
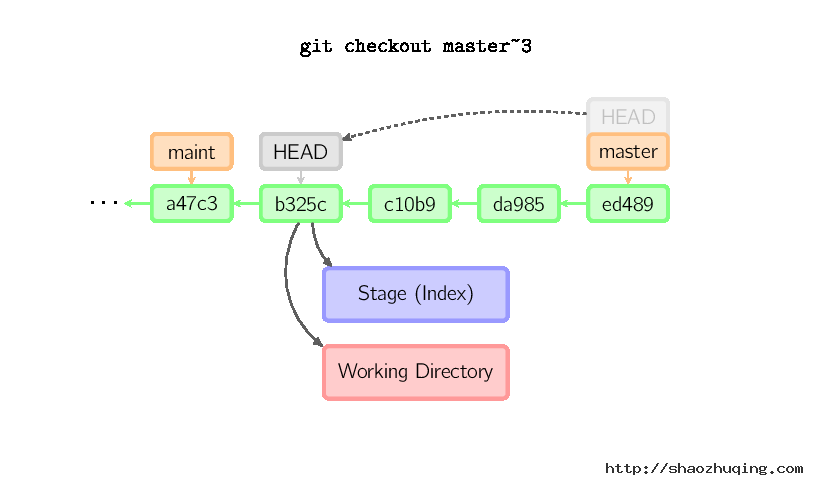
如果既没有指定文件名,也没有指定分支名,而是一个标签、远程分支、SHA-1值或者是像master~3类似的东西,就得到一个匿名分支,称作detached HEAD(被分离的HEAD标识)。这样可以很方便地在历史版本之间互相切换。比如说你想要编译1.6.6.1版本的git,你可以运行git checkout v1.6.6.1(这是一个标签,而非分支名),编译,安装,然后切换回另一个分支,比如说git checkout master。然而,当提交操作涉及到“分离的HEAD”时,其行为会略有不同,详情见在下面。
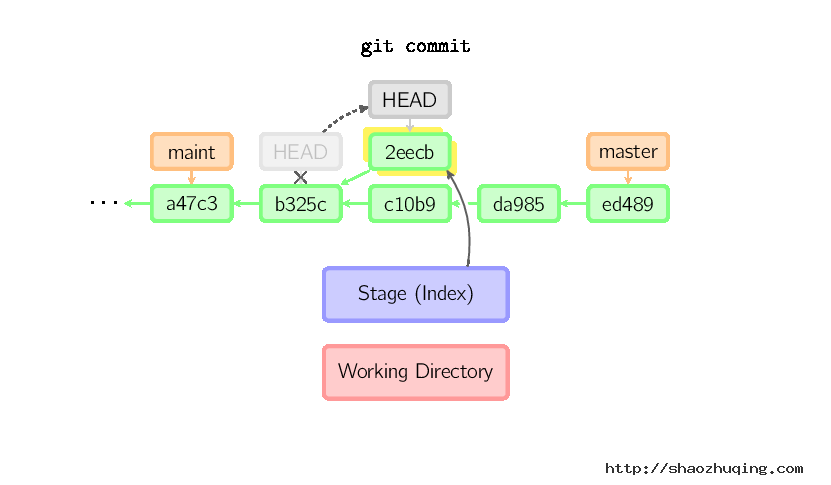
HEAD标识处于分离状态时的提交操作
当HEAD处于分离状态(不依附于任一分支)时,提交操作可以正常进行,但是不会更新任何已命名的分支。(你可以认为这是在更新一个匿名分支。)
一旦此后你切换到别的分支,比如说master,那么这个提交节点(可能)再也不会被引用到,然后就会被丢弃掉了。注意这个命令之后就不会有东西引用2eecb。
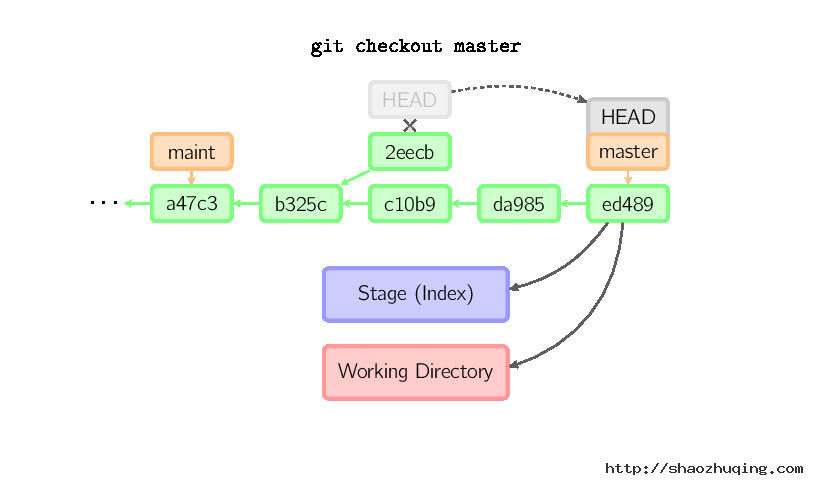
但是,如果你想保存这个状态,可以用命令git checkout -b name来创建一个新的分支。
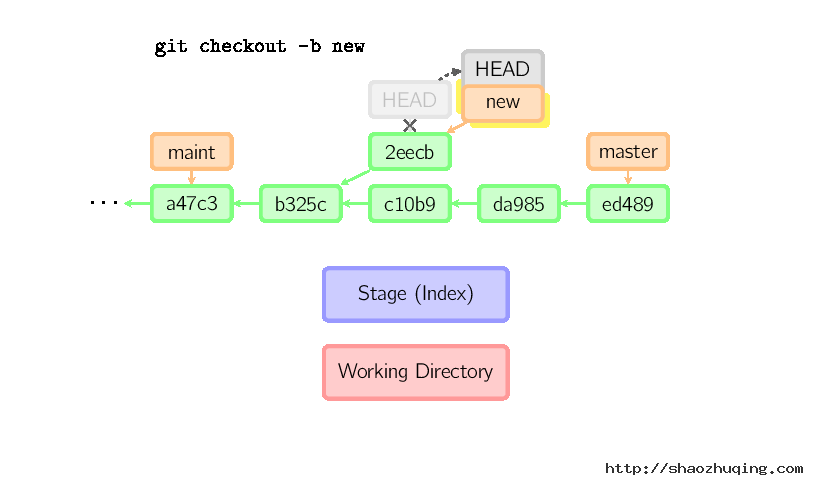
Reset
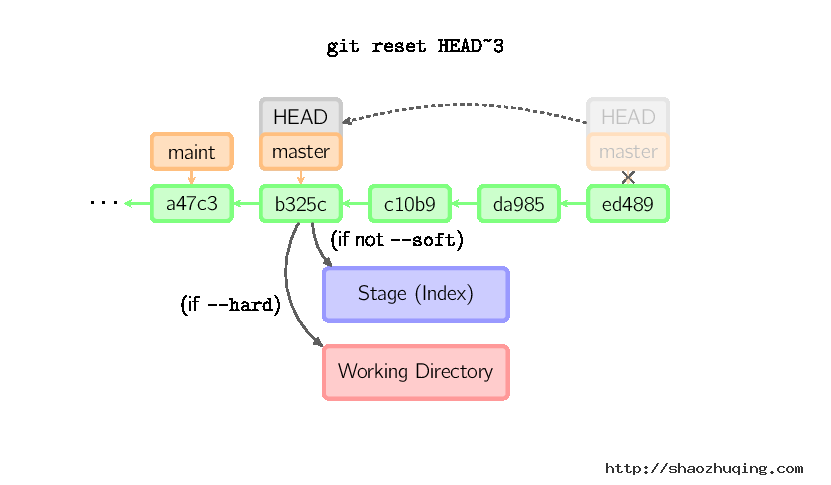
reset命令把当前分支指向另一个位置,并且有选择的变动工作目录和索引。也用来在从历史仓库中复制文件到索引,而不动工作目录。
如果不给选项,那么当前分支指向到那个提交。如果用--hard选项,那么工作目录也更新,如果用--soft选项,那么都不变。
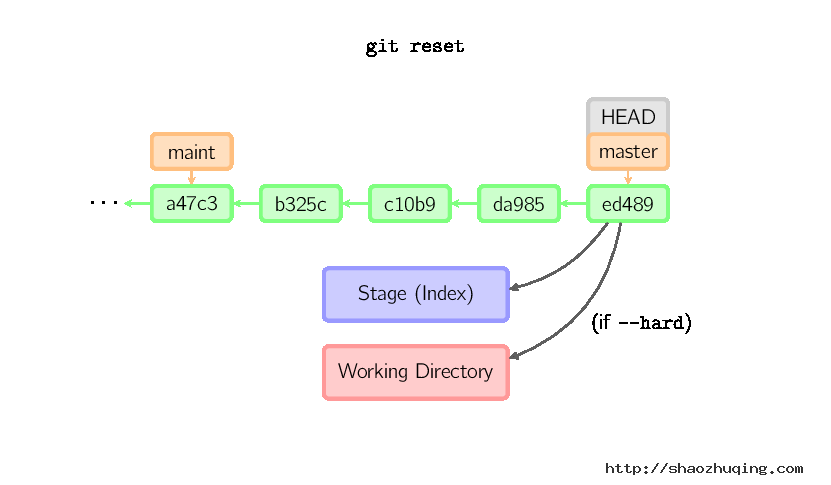
如果没有给出提交点的版本号,那么默认用HEAD。这样,分支指向不变,但是索引会回滚到最后一次提交,如果用--hard选项,工作目录也同样。
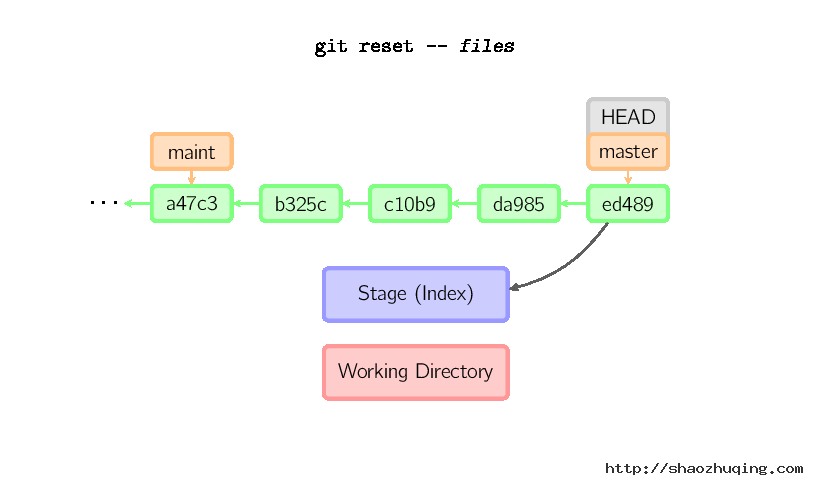
如果给了文件名(或者 -p选项), 那么工作效果和带文件名的checkout差不多,除了索引被更新。
Merge
merge 命令把不同分支合并起来。合并前,索引必须和当前提交相同。如果另一个分支是当前提交的祖父节点,那么合并命令将什么也不做。 另一种情况是如果当前提交是另一个分支的祖父节点,就导致fast-forward合并。指向只是简单的移动,并生成一个新的提交。
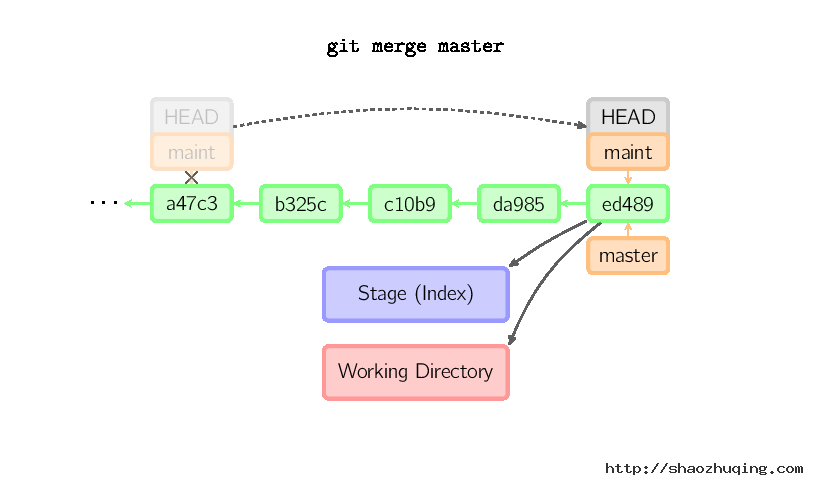
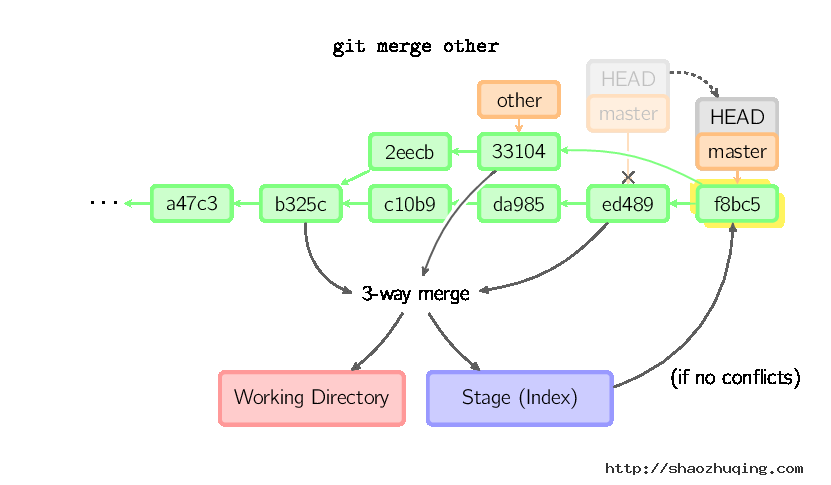
否则就是一次真正的合并。默认把当前提交(ed489 如下所示)和另一个提交(33104)以及他们的共同祖父节点(b325c)进行一次三方合并。结果是先保存当前目录和索引,然后和父节点33104一起做一次新提交。
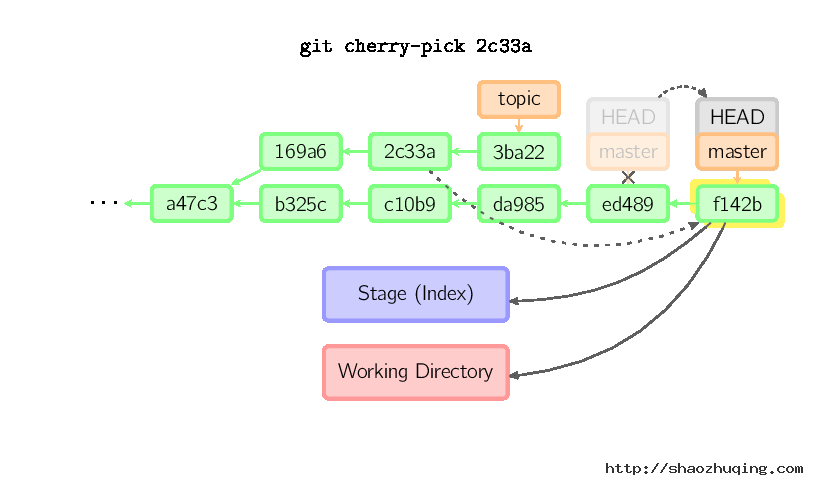
Cherry Pick
cherry-pick命令"复制"一个提交节点并在当前复制做一次完全一样的新提交。
Rebase
衍合是合并命令的另一种选择。合并把两个父分支合并进行一次提交,提交历史不是线性的。衍合在当前分支上重演另一个分支的历史,提交历史是线性的。 本质上,这是线性化的自动的cherry-pick
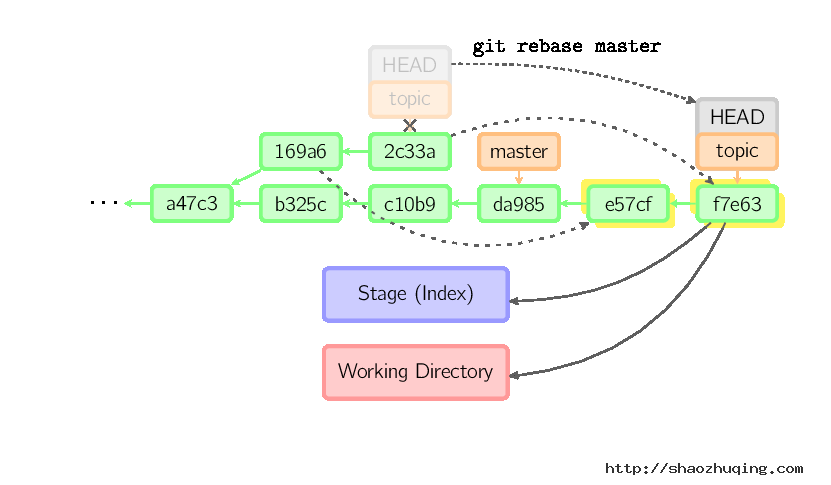
上面的命令都在topic分支中进行,而不是master分支,在master分支上重演,并且把分支指向新的节点。注意旧提交没有被引用,将被回收。
要限制回滚范围,使用--onto选项。下面的命令在master分支上重演当前分支从169a6以来的最近几个提交,即2c33a。
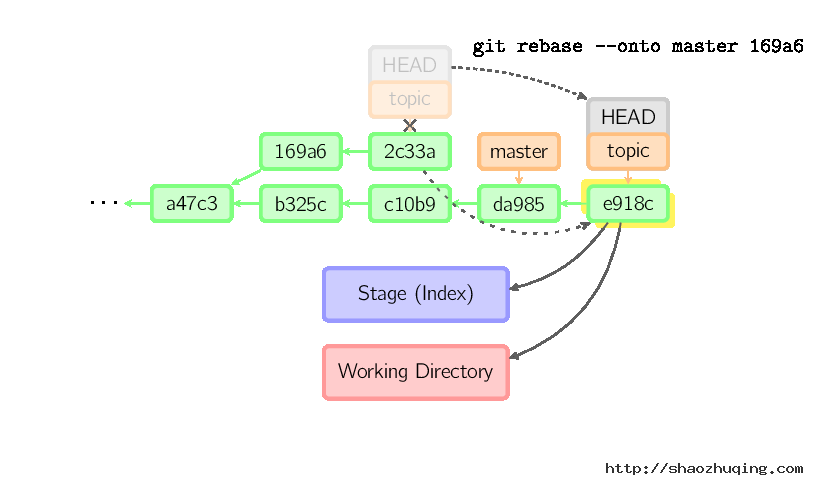
同样有git rebase --interactive让你更方便的完成一些复杂操作,比如丢弃、重排、修改、合并提交。没有图片体现这些,细节看这里:git-rebase(1)
技术说明
文件内容并没有真正存储在索引(.git/index)或者提交对象中,而是以blob的形式分别存储在数据库中(.git/objects),并用SHA-1值来校验。 索引文件用识别码列出相关的blob文件以及别的数据。对于提交来说,以树(tree)的形式存储,同样用对于的哈希值识别。树对应着工作目录中的文件夹,树中包含的 树或者blob对象对应着相应的子目录和文件。每次提交都存储下它的上一级树的识别码。
如果用detached HEAD提交,那么最后一次提交会被the reflog for HEAD引用。但是过一段时间就失效,最终被回收,与git commit --amend或者git rebase很像。
各种代码准确识别手机浏览器和Web浏览器访问
使用浏览器访问 此URL http://shaozhuqing.com/s/dmb
如果为移动设备会跳转到 http://shaozhuqing.com/s/dmb/mobile.php
本站提供以下各种代码准确识别手机浏览器和Web浏览器
下载请移步 http://shaozhuqing.com/s/dmb
"apache" => "download/detectmobilebrowser.htaccess.txt",
"asp" => "download/detectmobilebrowser.asp.txt",
"aspx" => "download/detectmobilebrowser.aspx.txt",
"coldfusion" => "download/detectmobilebrowser.cfm.txt",
"cs" => "download/detectmobilebrowser.cs.txt",
"iis" => "download/detectmobilebrowser.web.config.txt",
"jsp" => "download/detectmobilebrowser.jsp.txt",
"javascript" => "download/detectmobilebrowser.js.txt",
"jquery" => "download/detectmobilebrowser.jquery.txt",
"lasso" => "download/detectmobilebrowser.lasso.txt",
"nginx" => "download/detectmobilebrowser.conf.txt",
"node" => "download/detectmobilebrowser.nodejs.txt",
"php" => "download/detectmobilebrowser.php.txt",
"perl" => "download/detectmobilebrowser.pl.txt",
"python" => "download/detectmobilebrowser.middleware.py.txt",
"rails" => "download/detectmobilebrowser.rb.txt"
CNZZ 关键字名词解释
PV:
即PV(PageView)值,用户每次打开网站页面被记录1次。用户多次打开同一页面,访问量值累计多次。此指标衡量网站访问量情况。
IP:
指在一天之内(00:00-24:00)访问您的网站的独立IP数。一天内相同IP地址多次访问网站只被计算1次。
独立访客:
指在一天之内(00:00-24:00)访问您的网站的上网电脑数量(以cookie为依据)。一天内同一电脑多次访问网站只被计算1次。
人均浏览次数:
每个访客浏览网站页面的平均次数。人均浏览次数=PV/独立访客数。
累计总PV:
是指网站从开通cnzz统计之日起至今的PV总和。
历史最高:
是指网站从开通cnzz统计之日起至今获得最高的日访问数值。
日均PV值:
指网站开通cnzz统计之日起平均每天PV值。日均PV值=累计总PV/总统计天数
当前在线:
指15分钟内在线用户的活动信息,在线用户是按IP计算。
新独立访客:
首次访问网站的访客记为一个新独立访客。
新访客浏览次数:
您的网站页面被新独立访客浏览的次数。
平均停留时间:
从访客打开您的页面到离开页面的时间。
跳出率:
访客离开的比例。跳出率=离开次数/浏览次数
来访次数:
从外部网站点到您的网站网页的次数。
浏览次数:
您的网站页面被浏览的次数。
进入次数:
访客从其他网站到达您的网站页面,记为1次进入。
离开次数:
访客15分钟不再浏览您的页面,记为1次离开。
回头率:
用户距离上次访问超过12小时的再次访问,被记录为一次回访,回访次数越多,用户的忠实度越高。
访问深度:
某访客每多浏览网站一个页面即增加一个深度,访问深度越大,网站的粘性越高。
地区分布:
分析访客来源于哪个地区。
网络接入商:
分析访客所处的网域,如电信、网通。
IP头:
分析访客所在的IP段。
浏览器:
分析访客使用的浏览器类型。
分辨率:
分析访客使用的屏幕分辨率。
操作系统:
分析访客使用的操作系统类型。
语言:
分析访客使用的语言类型。
终端类型:
分析访客通过什么客户端上网。
Alexa安装:
分析访客是否安装alexa工具条。
升降榜:
某数据相对制定日期上升或下降幅度的排行榜。
CNZZ排名:
您的网站在参与CNZZ排行的所有网站中的综合流量名次。
统计概况:
统计概况为您提供网站今日的流量变化趋势,以及各种重要的流量数据。
当前在线:
当前在线为您提供15分钟内在线用户的活动信息,在线用户是按IP计算。包括:来访时间、访客地域、来路页面、当前停留页面等。
最近来路:
最近来源为您提供15分钟内进入网站的来路页面及带来流量。
停留页面:
停留页面为您提供15分钟内受访的页面及页面受访次数。
时段分析:
时段分析为您提供网站任意时间内的流量变化及24小时段分布情况。
搜索引擎:
搜索引擎为您提供各搜索引擎带来的搜索次数、IP、独立访客、人均搜索次数、页面停留时间等数据。
关键字:
关键字为您提供搜索关键字带来的搜索次数、IP、独立访客、新独立访客等数据。
最近来访:
最近来访为您提供最近通过搜索引擎进入网站的用户信息,包括:来访时间、访客地域、搜索引擎、关键字、停留页面等。
来路域名:
来路域名为您提供来路域名带来的来访次数、IP、独立访客、新独立访客、新访客浏览次数、站内总浏览次数等数据。
来路页面:
来路页面为您提供来路页面带来的来访次数、IP、独立访客、新独立访客、新访客浏览次数、站内总浏览次数等数据。
受访域名:
受访域名为您提供被访问域名的浏览次数、IP、独立访客、人均浏览次数、页面停留时间、跳出率等数据。受访域名默认显示全部,包括您本站域名和放置了您网站统计代码的其他域名,您可以选择显示本网站域名,过滤掉不需要的数据。
受访页面:
受访页面为您提供被访问页面的浏览次数、人均浏览次数、页面停留时间、跳出率等数据。
站内入口:
站内入口为您提供访客进入网站的进入次数、人均浏览次数、页面停留时间、跳出率等数据。
站内出口:
站内出口为您提供访客离开网站的离开次数、人均浏览次数、页面停留时间、跳出率等数据。
地区分布:
地区分布为您提供访客来源于哪个地区
网络接入商:
网络接入商为您提供访客所处的网域,如电信、网通。
IP头:
IP头为您提供访客所在的IP段。
浏览器:
浏览器为您提供访客使用的浏览器类型。
分辨率:
分辨率为您提供访客使用的屏幕分辨率。
操作系统:
操作系统为您提供访客使用的操作系统类型。
语言:
语言设置为您提供访客使用的语言类型。
终端类型:
终端类型为您提供访客通过什么客户端上网。
Alexa安装:
Alexa安装为您提供访客安装Alexa工具条情况。
用户回头率:
用户回头率为您提供访客回访次数情况,用户距离上次访问超过12小时的再次访问,被记录为一次回访,回访次数越多,用户的忠实度越高。
用户访问深度:
用户访问深度为您提供用户访问网站深度情况,访问深度越大,网站的粘性越高。
来路升降榜:
来路升降榜为您提供某日来路域名访问量相对指定日期变化幅度的排行榜。
关键字升降榜:
关键字升降榜为您提供某日搜索引擎关键字带来的访问量相对指定日期变化幅度的排行榜。
受访页升降榜:
受访页升降榜为您提供某日受访页面访问量相对指定日期变化幅度的排行榜。
短信报警:
短信报警为您提供数据变动提醒服务,每条短信0.2元。
查看密码:
当您想单独开放帐户下的某个站点给其他人(如你您网站的广告主)查看的时候,设置独立“查看密码”即可。查看者从站点统计图标进入,输入查看密码可看到该站点数据。查看密码无站点管理权限。
mysql 截取字符串
1. 字符串截取:left(str, length)
mysql> select left('linuxidc.com', 3);
+-------------------------+
| left('linuxidc.com', 3) |
+-------------------------+
| sql |
+-------------------------+
2. 字符串截取:right(str, length)
mysql> select right('linuxidc.com', 3);
+--------------------------+
| right('linuxidc.com', 3) |
+--------------------------+
| com |
+--------------------------+
3. 字符串截取:substring(str, pos); substring(str, pos, len)
3.1 从字符串的第 4 个字符位置开始取,直到结束。
mysql> select substring('linuxidc.com', 4);
+------------------------------+
| substring('linuxidc.com', 4) |
+------------------------------+
| study.com |
+------------------------------+
3.2 从字符串的第 4 个字符位置开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', 4, 2);
+---------------------------------+
| substring('linuxidc.com', 4, 2) |
+---------------------------------+
| st |
+---------------------------------+
3.3 从字符串的第 4 个字符位置(倒数)开始取,直到结束。
mysql> select substring('linuxidc.com', -4);
+-------------------------------+
| substring('linuxidc.com', -4) |
+-------------------------------+
| .com |
+-------------------------------+
3.4 从字符串的第 4 个字符位置(倒数)开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', -4, 2);
+----------------------------------+
| substring('linuxidc.com', -4, 2) |
+----------------------------------+
| .c |
+----------------------------------+
我们注意到在函数 substring(str,pos, len)中, pos 可以是负值,但 len 不能取负值。
4. 字符串截取:substring_index(str,delim,count)
4.1 截取第二个 '.' 之前的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', 2);
+------------------------------------------------+
| substring_index('www.linuxidc.com', '.', 2) |
+------------------------------------------------+
| www |
+------------------------------------------------+
4.2 截取第二个 '.' (倒数)之后的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', -2);
+-------------------------------------------------+
| substring_index('www.linuxidc.com', '.', -2) |
+-------------------------------------------------+
| com.cn |
+-------------------------------------------------+
4.3 如果在字符串中找不到 delim 参数指定的值,就返回整个字符串
mysql> select substring_index('www.linuxidc.com', '.coc', 1);
+---------------------------------------------------+
| substring_index('www.linuxidc.com', '.coc', 1) |
+---------------------------------------------------+
| www.linuxidc.com |
+---------------------------------------------------+
小米手机的两个师傅:同仁堂和海底捞
正在召开的第五届GMIC2013全球移动互联网大会上,小米手机CEO雷军坦陈,创办小米手机的时候,专门学习研究了两家企业同仁堂和海底捞。跟同仁堂学做产品,而跟海底捞学做服务。
“在做小米手机之前,我一直在思考在中国市场如何能做一家基业长青的公司?”雷军表示,为此他专门研究了同仁堂,发现其已经有了340年的历史,可谓是家伟大的公司。
同仁堂有两句话让雷军印象深刻,其一,“炮制虽繁必不敢省人工,品味虽贵必不敢减物力。”雷军将其翻译为“真材实料不偷懒。”
其二“修合无人见 存心有天知”。雷军翻译为,“你做的事情虽然没有人看见,但是老天知道。”
为此,小米手机在创办之初,就把真材实料作为小米手机的立身之本。“相信你真才实料做每件事时,老天知道。”雷军说。
此外,海底捞也是小米手机的学习的对象,核心在于其“口碑营销”。受此影响,小米手机尽量保持了低调,基本不做广告,主要依靠口碑营销。
根据相关数据显示,小米公司宣布已经售出700多万台小米手机,并且在做硬件销售的同时,涉足互联网的软件服务,尝试打造一条小米手机的生态系统。
能在几年间取得这样的成绩,雷军更愿意将其归结为对于两家企业优点的借鉴和学习。
“当今这个时代,我们更需要弘扬同仁堂精神和海底捞精神。”雷军说道。
fgetcsv读取不了中文解决办法
fgetcsv读取不了中文
已设置setlocale(LC_ALL, 'zh_CN'),但在读取csv文件的时候,有时不能读取里面的中文,这是为什么?跟系统系统好像有关系!
------解决方案--------------------------------------------------------
文档编码和系统编码相同吗,不相同的话iconv把文档编码转成系统编码。
------解决方案--------------------------------------------------------
fgetcsv有BUG。
用这个函数吧。
- PHP code
function _fgetcsv(& $handle, $length = null, $d = ',', $e = '"') {
$d = preg_quote($d);
$e = preg_quote($e);
$_line = "";
$eof=false;
while ($eof != true) {
$_line .= (empty ($length) ? fgets($handle) : fgets($handle, $length));
$itemcnt = preg_match_all('/' . $e . '/', $_line, $dummy);
if ($itemcnt % 2 == 0)
$eof = true;
}
$_csv_line = preg_replace('/(?: |[ ])?$/', $d, trim($_line));
$_csv_pattern = '/(' . $e . '[^' . $e . ']*(?:' . $e . $e . '[^' . $e . ']*)*' . $e . '|[^' . $d . ']*)' . $d . '/';
preg_match_all($_csv_pattern, $_csv_line, $_csv_matches);
$_csv_data = $_csv_matches[1];
for ($_csv_i = 0; $_csv_i < count($_csv_data); $_csv_i++) {
$_csv_data[$_csv_i] = preg_replace('/^' . $e . '(.*)' . $e . '$/s', '$1' , $_csv_data[$_csv_i]);
$_csv_data[$_csv_i] = str_replace($e . $e, $e, $_csv_data[$_csv_i]);
}
return empty ($_line) ? false : $_csv_data;
}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
