社交APP的痛点及九大流派解析
“陌生社交是不是没戏了?”
当然有戏。
今天社交APP最好的切点必在“半熟人群”,既不是彻底的熟人没悬念,也不是彻底的陌生人不靠谱,而是这样一群人,有可以迅速熟悉起来的契合点,有持续交往的路径,有暧昧的小心思和羞羞的盼头,有关系升温以致(你懂的)的可能。
而这一方向和今天市场的格局完全契合,一方面熟人社交已经被腾讯的手Q和微信双向锁死,所有试图模仿path、做熟人安全私密社交的APP都遭遇了困境;另一方面纯粹的陌生匿名社交大行其道,各种炒概念、夺眼球,热潮退去之后却始终无法形成有效的用户沉淀。唯独“半熟人群的陌生社交”这个领域,完全可能出现新的巨头。试想,半熟沉淀下来就是熟人,接下来可能颠覆的就是……
陌生社交产品必须着重于解决两大痛点:
1、社交主体差距过大,我和一个舞厅里天昏地暗觉得抽烟男人才帅气的女生,确实没什么好聊。
2、缺乏有价值的场景和话题,不知道该聊什么。
让平凡而善良的广大什么丝人群摆脱枯燥乏味的生活,得到现实中没有的社交体验,只要能稳定持续地解决这两大痛点,你就有可能在大战中脱颖而出。
破冰难的解决思路呢?在此,笔者梳理了今天已有的陌生社交产品,总结出九大流派,与诸君共享。
免责条款:
1、本人是产品菜狗,很多见解未必靠谱,欢迎拍砖,恕不回应。
2、文中会列举一些APP,但不夹私货、不予评论,没有任何广告或攻击恶意。
3、本文不讨论强弱关系问题,以下分类方法互有交叉,也就是说:一个产品可能同时使用几种方法。
4、描述部分只代表一般用户心理,与笔者无关,笔者是正经人。也不要以为笔者是社交高手,其实现实中菜狗很木讷内向,才会特别留心社交领域。
一、位置流
基于LBS的破冰方案,陌生人通过地理位置彼此连接,实现信息传递,发生社交互动。
1、描述:还记得吗,一次次在陌生的城市、寂寞而空虚的夜晚,颤抖着手打开陌陌、微信附近的人,哇,好多高颜值异性哦,约吗?这是LBS社交最初的形态。
后来这个形态玩出了更多的花样。我在路上和你擦肩而过,APP里会有显示哦。每个地理位置都是广播台留言板,可以向周围扩散信息和照片哦。又或者如笔者策划过的“新大陆”项目一样,地图上的每一个位置都变成了领土,可以占领、攻防、寻宝。
2、举例:陌陌、微信附近的人、克鲁、在场
3、优点:充分运用了solomo的优势,符合“移动”特性;因为都在“附近”,转化为线下关系的“可能性”大大增加;充分满足了人们的窥探欲和好奇心,使人更兴奋、更有期待感和想象空间。
4、劣势:
遭遇一,周围最近的人在7公里,再远一点是152公里,天啊……
遭遇二,周围好多美女呀,勾搭勾搭勾搭……(一晚上过去了,没有人回音)
遭遇三,九宝山公墓,今天好冷啊墓地里空荡荡的,一看附近的人,哇全是美女!!!
基于LBS的方案最坑爹的一点是,对“冷启动”要求超高,必须基于很大的用户基数,或者至少在一定区域内形成较高的用户密度。否则,所有预期中的“神奇点”,随时随地偶遇也罢,随时随地呼叫人帮忙也罢,都将变成“用户期待与实际体验严重脱钩”。反过来说,只要用的人多了,你说什么故事都能形成现象、蔚然成风。
阿里“到位”那样的idea很多人都能想到,但最后只有阿里这种量级才玩得转啊。
这时候怎么办呢?砸钱狠推吗,创业公司烧得起吗?如果用户密度没上来,则产品体验根本不能有效兑现,反过来说,产品体验不高,用户又怎么可能增长——这不是死循环吗?所以这种项目,往往成熟的互联网公司更容易“玩得转”,你想解决这个问题,先找一个足记大片模式那样的引爆点,或者大姨吗这样的高频刚需,打迂回战术。
二、匹配流
基于匹配逻辑的破冰方案,随机匹配陌生人,或者基于兴趣等数据匹配陌生人。
1、描述:来,让我们随机匹配一个陌生人吧,管他三七二一,聊先!来,一个漂流瓶过来了,有人摇一摇了。
你觉得不靠谱?那就让系统基于大数据分析吧,找一个这样的女生:和我兴趣吻合度90%,同城以内,喜欢的男星和我长相相似(唉,好像没有)。
2、举例:11点11分、比邻、抱抱、猜么
3、优点:社交简单易行,没有负担;漂流瓶类的push会带动活跃和粘性;基于兴趣的匹配如果像一点资讯那样靠谱,会非常赞。
4、劣势:完美的匹配往往建立在理想状态下:异性、高颜值、寂寞空虚冷,和我的兴趣充分切合。但是……现实很骨感。当大家用比邻一次次匹配到同性时,又或者一个宅男在深夜打开手Q的巧遇时,听见对面传来另一个宅男响亮的脏话时,这是怎样一种失落。而匹配要想做到精准,往往需要2个条件,一是你常常用、能沉淀下兴趣数据,二是用户基数还是得很大,不然100个男生15个女生,匹配都匹配不过来。
那么问题来了,对于创业公司来说,能做到这两点,你的产品和商业思路绝对非同一般……
三、活动流
基于线下活动的破冰方案,通过发布活动、参与活动连接陌生人,并整合线下商户O2O。
1、描述:有美女发起了一次聚会哦,AA制。有妹纸要看电影哦,要求“你请客”。有投资人发起行业聚会哦,讨论一下陌生社交的话题。
2、举例:约你、会会、约饭、微聚
3、优点:符合社交习惯,易于接受;更易形成线下关系;容易与线下商户合作盈利。
4、劣势:坦白讲,这种APP是本人体验最少的,因为真的不大喜欢参加纯私人聚会,所以提出的问题都是想象出来的:对聚会的质量、安全性要求较高,否则极易影响体验;狼多肉少,一个妹纸想看电影50个男的排队报名;容易成为非法交易的温床,背负政策和法律风险。
四、暧昧流
主打男女配对的破冰方案,呵呵你懂的。
1、描述:哇,好多女神啊。哇,照片好大胆啊,全都是事业线和大长腿。来来来我打赏,给我露多一点。
觉得粗俗,那也可以这样:妹纸都是女王,我是奴仆。妹纸都有愿望,我要英雄救美。妹纸想听一首歌,我来扯嗓子了,啧啧,不是原音!
2、举例:大叔帮帮忙、哎呀、女神来了、陪我
3、优点:需求明显而突出,性和恐惧永远是营销中最不可抵挡的两大力量;相貌平凡的女性体验在生活中少有的被簇拥搭讪感,虚荣心全面满足,部分女性还可以玩玩代购,或者卖卖其他的;宅男们满足皇帝选妃一般猎艳的乐趣,尽管几乎没有人搭理,但每个用了这个APP的异性都可默认为可约对象,使他们充满期待,得到一种YY的刺激。
4、劣势:
遭遇一:“呵呵,我在你手机上发现了一个奇怪的APP哦。”如果你是一个稍微正经的人,敢把这个APP放桌面上吗?
遭遇二:“这是什么软件,不行,让我看看,不准躲,快给我看看!!”如果你有了另一半,你还敢用这种APP吗?
遭遇三:“约不约啊。”“约啊,来1912坐坐。”“那不是酒吧街吗?”“对啊,吃点夜宵喝点酒点个公主嘛。”
毫无疑问,此类APP从产生开始就打上了有色的标签,而且永远都洗不白,这使它们用户增长虽快、天花板来的也非常快——稳定适用的人群极其有限。同时,容易成为酒托、饭托、非法交易的温床,甚至带来政策法律风险被网信办直接KO也有先例。
五、游戏流
通过互动小游戏完成破冰,匿名用户先一起玩游戏,感觉好再结为好友。
1、描述:先一起玩个非诚勿扰吧?或者玩个真心话大冒险?要么你画我猜。先成为玩伴嘛,玩着玩着,就有了战火之中的“一份情”。
2、举例:碰碰、兜兜友、贝贝
3、优点:游戏确实是一个较为自然的交往途径,也可以在安全距离内展现双方才华,形成合作体验。
4、劣势:
和匹配一样,游戏流的玩法要想生效,必须建立在高密度的用户基础上,否则要么根本匹配不到玩伴,要么陪你玩的其实都不是人。
同时,玩游戏从来都需要承受一定的风险和压力,交互成本较直接聊天更高。这就要求你的游戏必须高体验,简单、有意思、利于交往,要不费了半天劲形不成一个有效社交,脸都丢地上了,妹纸也没搭理我,这样的游戏绝对玩不下去。要设计出一个大家都喜欢的社交小游戏,不容易。
六、广场派
这是最传统的类型,通过论坛社区、聊天室、秀场、群组等“广场”,让大家展示自身价值,自然而然地社交互动,逐步由弱关系转为强关系。
1、描述:这是最经典的模式了。我不擅长搭话,但是我可以在女神所在的群、论坛、聊天室里,假装和大家一起讨论问题,然后有的没的和她搭一句,一边故作正经。熟了?赶紧加私聊!
2、举例:豆瓣、知乎、QQ群
3、优点:广场派是最经典的做法,其优点已经被长期验证,非常符合人们的社交特性和习惯,更容易找的志趣相投的人,满足虚荣心和归属感,也可以缓解一上来就私聊的紧张和尴尬。
4、劣势:
遭遇一,我是新人,这个群里谁都不认识,算了不说话。
遭遇二,前几天都在说话,自从这几个人讲话之后,我就不怎么想讲话了,我不讲话他们也不讲话了。
遭遇三,这里怎么都是垃圾信息、营销和谩骂也,罢了罢了我退。
遭遇四,我费了一天,想出这么经典的一句,就10个人赞,那个名人就一句屁话10万个赞,那个美女就发了张照。
这是每个人都遭遇的情况,广场玩法对运营的要求极高,稍有不慎就会缓缓滑入信息过载的深渊,出现“蒸发效应”之类的用户集体沉默和逃离;加剧了人们之间话语权的不平等,释放了语言暴力的恐怖;容易出现敏感词,触及政策和法律高压线。
七、实名派
绝对的经过认证的实名,破冰往往围绕具体事务,利用人们身份和资源属性彼此对接,目的性强、各取所需。
1、描述:哎呀,这几家互联网公司的HR妹纸真漂亮,先加了,啧啧,我们聊工作,对接资源啊。最近要找这个院系交流下,先搜到他们的女神:“能让我们搭起两个学院友好交往的桥梁吗?”
2、举例:Facebook、脉脉
3、优点:基于真实身份,更接近工作学习的常态,交往更正当,目的更明确;可以披着正经的外衣一点点满足小心思;能产生更有利现实工作生活的收益;运营得当,则容易活跃用户的满足虚荣心和归属感。
4、劣势:
广场派的所有问题实名派都可能遭遇,好在都是实名,不负责任的言行相对可控。
认证成本高,容易形成用户门槛。
互动成本也高,氛围太正经,大家都是“有身份的人”,于是投鼠忌器,审慎聊天。
网络虚拟的优势荡然无存,身份利益的界限存在,甚至愈发明显。
八、匿名派
通过放心大胆地绝对匿名来破冰,更符合互联网的本质特征。
1、描述:我靠,这些匿名状态太劲爆了,我的朋友圈里怎么有这样的人?或者,随时随地找人聊天啊,随便什么话题,无关注无压力,想聊就聊,不聊阅后即焚。啧啧,我可不是约炮哦。
2、举例:无秘、几度、yikyark
3、优点:以相对安全的形式充分满足了人们的窥私欲、宣泄欲。
4、劣势:
容易成为语言暴力和色情信息的温床。
零成本投入的社交、归属感往往也是零,人们的连接太偶然,没关注,没名头,社交关系也就飘忽不定,很难形成深度沉淀。结果一开始新鲜时还好,久了必定粘性下降、大幅流失。
九、交互创新派
采用不同以往的交互设计,使匹配、信息流、即时通信都变得炫酷、极简、具有戏剧色彩。
1、描述:这个交互真的好帅啊,APP一打开就是相机哦,我们用图片和短视频对话哦,我的UI好萌好有品位格调!或者,这是国外最先进的tinder模式哦,你看我可以像古代的皇帝一样翻牌子哦,美女,右滑,又是美女,右滑,怎么还是美女……
2、举例:国内模仿snapchat、tinder的产品
3、优点:有可能更符合95后的审美,成为一种现象和潮流;由于交互格局与微信类迥然不同,腾讯系无法跟进,总不能把微信也做成那样子呀;非常吸引眼球,非常容易讲故事,借着国外已火的东风,通过伟大的“赛道理论”迅速拿到投资人的钱。
4、劣势:除了形式吸引眼球,这种模式并没有解决最根本的破冰问题。更可怕的是,炫酷的交互往往过于超前,或者根本不符合中国人的使用习惯,进而水土不服。在此专门讲一下仿tinder和仿snapchat交互。
最近这段时间,国外的tinder火了,国内很多APP都开始跟着学,一时间翻牌子横行。但是以本人尝试了至少15款有此交互设计的APP、翻牌子翻到手抽筋的结论,这种APP一般面对三大问题:
一是先期匹配率不高,常常翻了半天毫无结果,匹配上了也无回音,就难免让人怀疑是运营账号一堆。
二是适用人群有限。对于急躁贪婪的男性,是喜欢面前一次出现一个女生,掀起盖头,喜欢就留下,不喜欢下一个——还是,刷的一声,面前站了一排女生任君挑?做N次单选,和做一次多选,哪个耗费的精力多?
三是照片造假严重。在美图和营销号流行的时代,你怎么知道这一张张美女谁真谁假了,看久了都审美疲劳爱无能了吧——讲的是看眼缘,可谁都知道是假眼缘。
再来看拍照、短视频交互的应用,优点是非常符合读图时代的特征,视图互动的效率相较以往大幅提升,因为没有美图类的修饰,这种互动也更加真实。但缺点同样明显,在中国此类应用中最长出现的图片就是墙、地面或者天花板。
原因很简单。国人对拍照互动的需求和西方人完全不同,比起互动的真实性和高效率,他们更注重的是分享中的“面子安全”。中国人太要面子了,照片从来都是精心挑选、反复修饰才敢发出去,要是现在一不小心就会拍照发出去,或者一不小心就拍到自己的丑样子,又或者每次对话都得拍照,这实在是太可怕了,带给人们的社交压力实在过大。
这是给新一代的?别搞错了,中国的95后尽管思想更灵活开放,但也更敏感,对隐私和个人空间的关注也更加明显,面对现实冲突的孤独焦虑感也更加强烈了。
说到底,除非两个人已经熟到睡过一张床了,否则一般情况下,拍照都是审慎的行为,更多是为了分享自己的正面、提升逼格、满足虚荣心的,学snapchat的朋友应该想想它致胜的另一面。
当然,以上两种情况是有例外的,那就是你在炫目的模仿之外,更触及了用户的深层需求,以独特的玩法抓到了点,那就大不一样了。还是那句话,设计和情怀不能超过需求本身,否则就是本末倒置,耍流氓。
评估九大流派,关键看你产品的定位——针对的用户群和商业模式,进而分析需求结构、体验成本、线下转化难度、设计风格、运营依赖度等要素。
看到这里,你是否已经有了自己的选择、思路和策略了呢?陌生社交是盘大棋,人心永远是微妙难测的,你要有心理学家一般的耐心沟通、敏感度和同理心。有想法的话,就尽快设计MVP去验证吧,不然十年后你只能和孩子说,想当年我有个牛逼的想法,做出来就能颠覆腾讯。
社交网络永远是互联网产品设计中难度最高也最好玩的领域。创业聚会中,很多人听说你是做O2O、在线教育、金融之类的就两眼放光,一听你是做社交网络的,他们不是像看见外星人、就是像目光越过空气。然而必须指出的是,在可以预见的未来,几乎所有的商业领域都将被社交玩法渗透,很多吹得天花乱坠的商业模式,都必须通过广大用户的社交粘性来维持,所以不懂社交你就只有无底洞一般地烧钱致死一个选择,或许有投资人陪你吧。
创业从来都是九死一生,面对腾讯这样的巨头,社交领域的创业者更要有“向死而生”的心态,做最坏的打算,尽最大的努力。
Web App、Hybrid App与Native App的设计差异
目前主流应用程序大体分为三类:Web App、Hybrid App、 Native App。
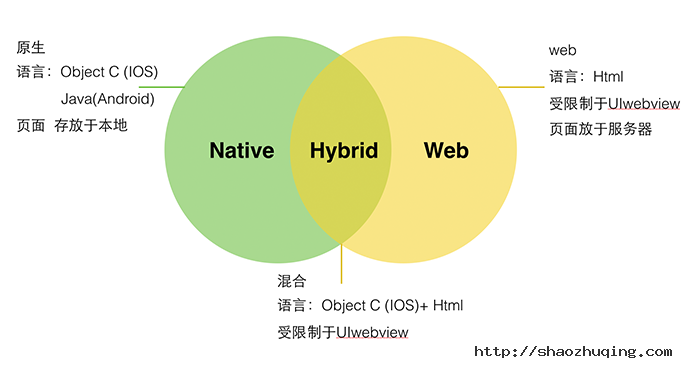
一、Web App、Hybrid App、Native App 纵向对比
首先,我们来看看什么是 Web App、Hybrid App、 Native App。
1. Web APP
Web App 指采用Html5语言写出的App,不需要下载安装。类似于现在所说的轻应用。生存在浏览器中的应用,基本上可以说是触屏版的网页应用。
优点
(1)开发成本低,
(2)更新快,
(3)更新无需通知用户,不需要手动升级
(4)能够跨多个平台和终端。
缺点:
(1)临时性的入口
(2)无法获取系统级别的通知,提醒,动效等等
(3)用户留存率低
(4)设计受限制诸多
(5)体验较差
2. Hybrid App
Hybrid APP指的是半原生半Web的混合类App。需要下载安装,看上去类似Native App,但只有很少的UI Web View,访问的内容是 Web 。
例如Store里的新闻类APP,视频类APP普遍采取的是Native的框架,Web的内容。
Hybrid App 极力去打造类似于Native App 的体验,但仍受限于技术,网速,等等很多因素。尚不完美。
3. Native App
Native APP 指的是原生程序,一般依托于操作系统,有很强的交互,是一个完整的App,可拓展性强。需要用户下载安装使用。
优点:
(1)打造完美的用户体验
(2)性能稳定
(3)操作速度快,上手流畅
(4)访问本地资源(通讯录,相册)
(5)设计出色的动效,转场,
(6)拥有系统级别的贴心通知或提醒
(7)用户留存率高
缺点:
(1)分发成本高(不同平台有不同的开发语言和界面适配)
(2)维护成本高(例如一款App已更新至V5版本,但仍有用户在使用V2, V3, V4版本,需要更多的开发人员维护之前的版本)
(3)更新缓慢,根据不同平台,提交–审核–上线 等等不同的流程,需要经过的流程较复杂
二、Web App、Hybrid App、Native App 技术特性
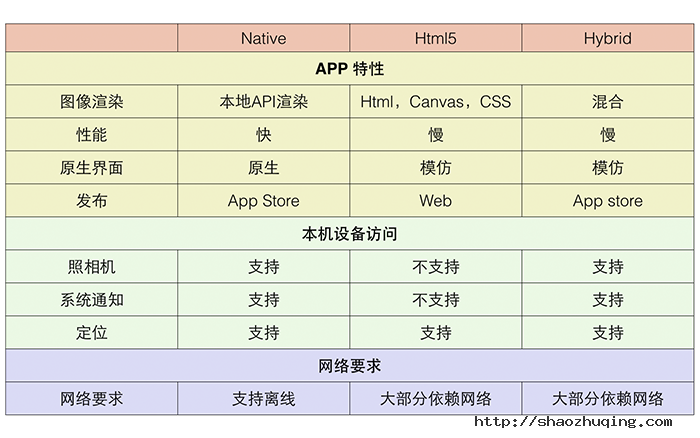
由上图可见,Web APP 的开发基于Html5语言。而Html5语言本身又有着不可避免的局限性。正是这些局限性的存在,使得Web App在体验中要逊于Native App。
三、Web App受限制因素及设计要点
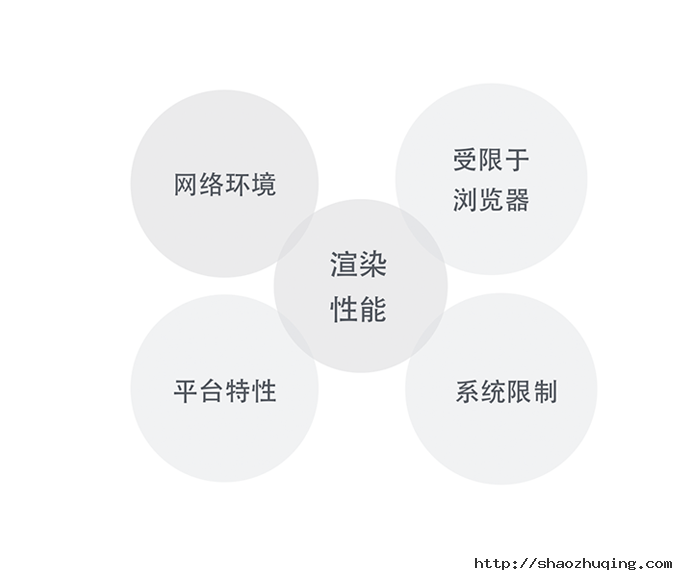
相比Native App,Web App体验中受限于以上5个因素:网络环境,渲染性能,平台特性,受限于浏览器,系统限制。
1. 网络环境,渲染性能
Web APP对网络环境的依赖性较大,因为Web APP中的H5页面,当用户使用时,去服务器请求显示页面。如果此时用户恰巧遇到网速慢,网络不稳定等其他环境时,用户请求页面的效率大打折扣,在用户使 用中会出现不流畅,断断续续的不良感受。同时,H5技术自身渲染性能较弱:对复杂的图形样式,多样的动效,自定义字体等的支持性不强。
因此,基于网络环境和渲染性能的影响,在设计H5页面时,应注意以下几点:
- 简化不重要的动画/动效
- 简化复杂的图形文字样式
- 减少页面渲染的频率和次数
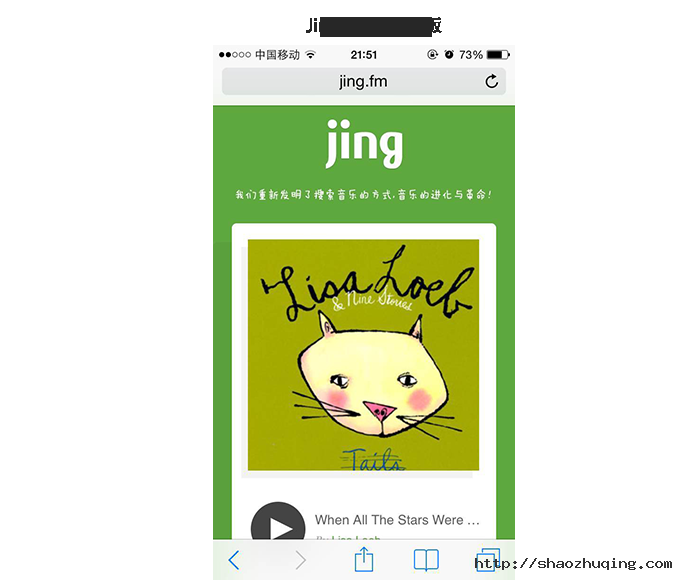
从下图移动Web版 jing.fm和Native版jing对比后可以看出:Web APP首页去除冗余的功能,回溯本源,只给用户提供了jing.fm最初的本质需求——电台。既符合H5精简功能又达到了突出核心功能的设计原则。无疑给用户眼前一亮的气息。
正如书中《瞬间之美》的一个核心观点:重要的并不是我们提供的信息量有多大,而是我们能否给他们提供真正需要的信息。

再如:百度最新推出的直达号,以良子健身为例:
从Native App和Web App(百度直达号)的对比中,我们可以看出Native良子以九宫格的形式展现,且属于双重导航,功能入口太多;弊端是用户不知道聚焦在哪里,分散用户 的注意力。而Web版良子整合并减少了导航的入口,增强用户的专注度;界面清爽,整洁,很好地传达了良子本身的寓意——轻松、愉悦、休闲、舒适。
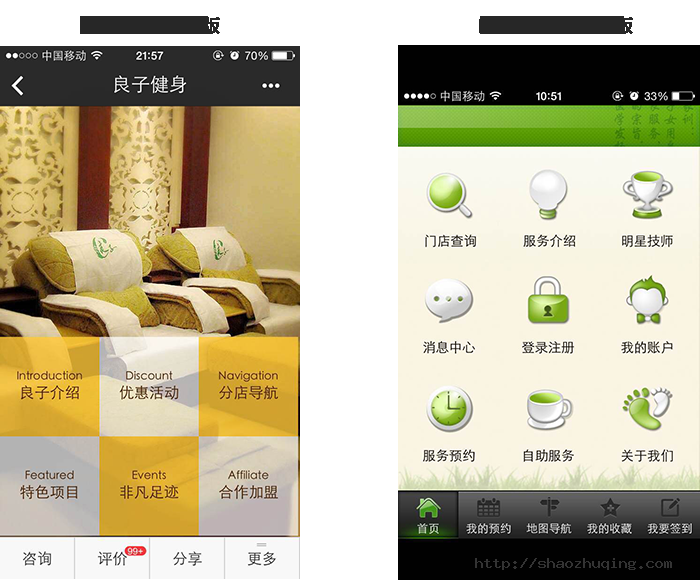
2. 受限于浏览器
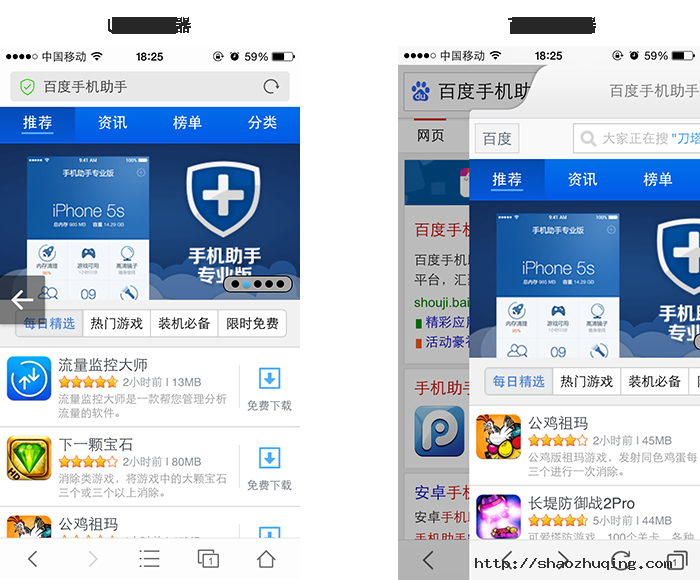
通常Web App生存于浏览器里,宿主是浏览器。不同的浏览器自身的属性不尽相同,如:浏览器自带的手势,页面切换方式,链接跳转方式,版本兼容问题等等。
例如下图:UC 浏览器和百度浏览器自身支持手势切换页面。手指从左侧滑动页面,返回至上一级。百度手机助手H5页面,顶部Banner支持手势左右滑动切换。这一操作与浏览器自身手势是冲突的。
再如,基于浏览器的Web APP在打开新的模块中的页面时,大多会新开窗口来展现。例如用户在使用购物类APP时,浏览每日精选模块时,每当打开新的商品时,默认新开一个窗口。这 样的优劣势显而易见:优势是能够记录用户浏览过的痕迹,浏览过的商品,以便后续横向对比;劣势是过多的页面容易使用户迷失在页面中。
正如Google开发手册里描述:当用户打开一个Web App的时候,他们期待这个应用就像是一个单个应用,而不是一系列网页的结合。然而,什么情况下需要跳转页面,什么情况下在当前页面展示则需要设计师细致考量。
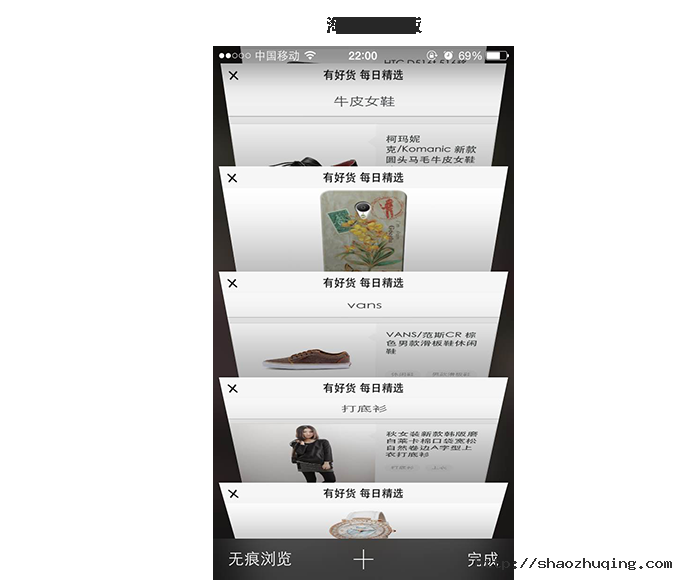
因此,Web App基于浏览器的特性,从设计角度应该遵循以下了两点:
少用手势,避免与浏览器手势冲突。
减少页面跳转次数,尽量在当前页面显示。
3. 系统限制,平台特性
由于Html5语言的技术特性,无法调用系统级别的权限。例如,系统级别的弹窗,系统级别的通知,地理信息,通讯录,语音等等。且与系统的兼容性也会存在一些问题。以上限制通常导致APP的拓展性不强,体验相对较差。例如百度地图:
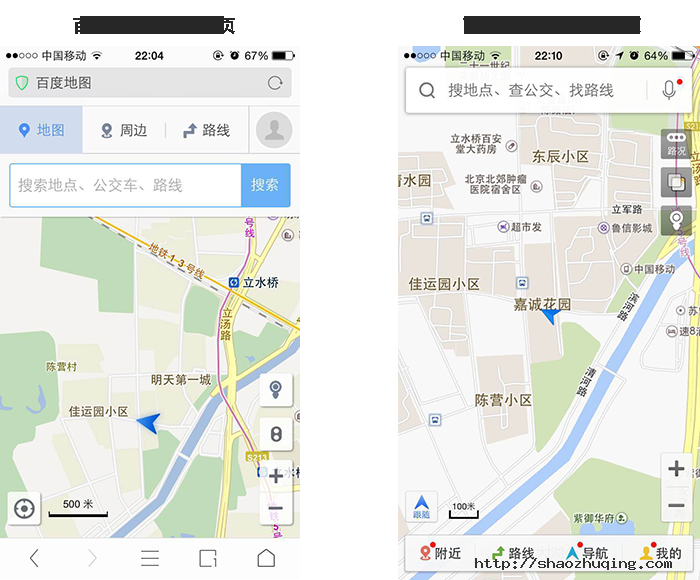
Web版地图基于浏览器展现,因此,不能全屏显示地图,给用户的眼界带来局限感;相反,Native 版地图以全屏展现的形式,很好的拓展了用户的视野。整个界面干净简洁,首页去除冗余功能。
在制定路线的体验中,如图:
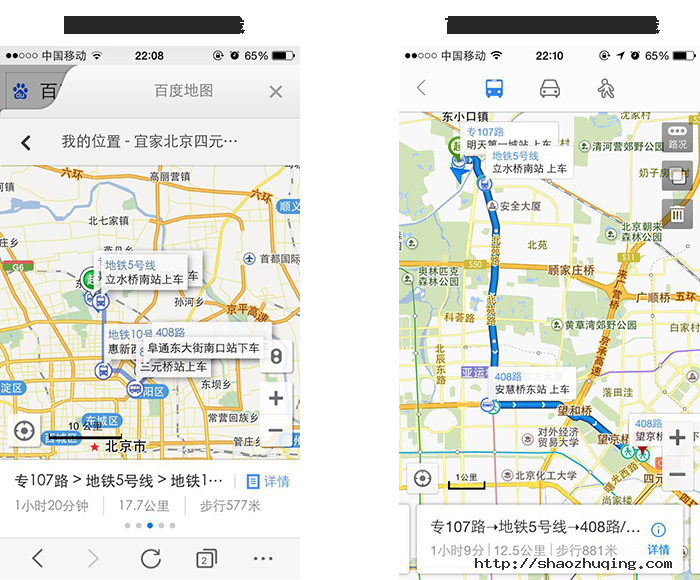
Web 版地图耗费的流量大于Native版,且不能预先缓存离线地图。对于地理位置的判断也是基于宿主浏览器,而非Web地图本身。获取路线后,对于更换到达方式,相对来说是不便利的。
相反,Native 版地图,能够直接访问用户的地理位置,能够很清晰的为用户展现App规划的路线,并能轻松的查看多种路线方案,以便做出符合自己的最佳方案。对于切换公交,走路,自驾等路线方式也是只需一键操作。
Native 版地图相对于 Web版地图增加更多情感化,易用的功能,如:能够记录用户的生活轨迹,记录用户的点滴足迹,能够享受躲避拥堵方案等。而Web版地图基于技术框架,很难实现以上功能,从用户体验角度来看,弱于Native版地图。
四、小结
综述所述,在设计Web APP时,应当遵循以下几点:
1. 简化
- 简化不重要的动画/动效
- 简化复杂的图形文字样式
2. 少用
- 少用手势,避免与浏览器手势冲突
- 少用弹窗
3. 减少
- 减少页面内容
- 减少控件数量
- 减少页面跳转次数,尽量在当前页面显示
4. 增强
- 增强Loading时的趣味性
- 增强页面主次关系
- 增强控件复用性
GA User Timings – Web Tracking (ga.js) _trackTiming
var startTime = new Date().getTime();//请求前添加
var endTime = new Date().getTime();//请求成功后添加
var timeSpent = endTime - startTime;
_gaq.push(['_trackTiming', 'Pop-up Layer', 'Get AjaxData ', timeSpent, '页面URL名称', 100]);
Setting Up User Timings
To collect user timing data, you'll need to use the _trackTiming method, which sends time data to Google Analytics.
_gaq.push([‘_trackTiming’, category, variable, time, opt_label, opt_sample]);
Where the parameters represent:
| Parameter | Value | Required | Summary |
|---|---|---|---|
category
类别 |
string |
yes | A string for categorizing all user timing variables into logical groups for easier reporting purposes. For example you might use value of jQuery if you were tracking the time it took to load that particular JavaScript library.
一个字符串进行分类的所有用户时间变量到逻辑组,便于报告的目的。例如,你可以使用jQuery,如果你跟踪它采取加载特定的JavaScript库的时间。 |
variable
变量 |
string |
yes | A string to indicate the name of the action of the resource being tracked. For example you might use the value of JavaScript Load if you wanted to track the time it took to load the jQuery JavaScript library. Note that same variables can be used across multiple categories to track timings for an event common to these categories such as Javascript Load and Page Ready Time, etc.
一个字符串,以指示该资源的操作的名称被跟踪。例如,你可以使用,如果你想跟踪它走上加载jQuery JavaScript库时的JavaScript加载的价值。需要注意的是相同的变量可以跨多个类别被用来跟踪定时共同这些类别例如JavaScript负荷和页面就绪时间等事件 |
time
时间 |
number |
yes | The number of milliseconds in elapsed time to report to Google Analytics. If the jQuery library took 20 milliseconds to load, then you would send the value of 20.
在经过时间的毫秒数报告给谷歌Analytics(分析)。如果jQuery库花了20毫秒加载,那么你会送20的值。 |
opt_label
标签 |
string |
no | A string that can be used to add flexibility in visualizing user timings in the reports. Labels can also be used to focus on different sub experiments for the same category and variable combination. For example if we loaded jQuery from the Google Content Delivery Network, we would use the value ofGoogle CDN.
可用于增加灵活性在报告中可视用户定时的字符串。标签也可用于集中为同一类别和变量的组合不同的子实验。例如,如果我们加载的jQuery从谷歌的内容交付网络,我们将使用谷歌CDN的价值。 |
opt_sampleRate
抽样比例 |
number |
no | A number to manually override the percent of visitors whose timing hits get sent to Google Analytics. The default is set at the same number as general site speed data collection and is based as a percentage of visitors. So if you wanted to track _trackTiming hits for 100% of visitors, you would use the value 100. Note that each hit counts against the general 500 hits per session limit.
一些手动覆盖游客的时机命中被发送到谷歌Analytics(分析)的百分比。缺省设定为相同数量的常规站点高速数据采集,并基于作为访问者的百分比。所以,如果你想跟踪_trackTiming命中游客100%,你会使用值100注,每命中计数对每个会话限制一般500命中。 |
jQuery下拉提示框自动完成插件flexselect
Flexselect是一个jQuery下拉自动完成填写的插件,它是把选择下拉框变成了一个具有动态匹配与增强查找控制的下拉列表,可以让用户输入部分字符时显示配置的记录,达到自动完成的目的。
如何使用
1、引入核心文件,因为本插件用到了LiquidMetal,所以必须引入,引入的顺序不能乱
|
1
2
3
4
|
<link rel="stylesheet" href="flexselect.css" type="text/css" media="screen" /><script src="jquery.min.js" type="text/javascript"><script src="liquidmetal.js" type="text/javascript"><script src="jquery.flexselect.js" type="text/javascript"> |
2、写入html代码
|
1
2
3
4
5
6
|
<select class="flexselect"> <option value="1">George Washington <option value="2">John Adams <option value="3">Thomas Jefferson ... |
3、写入JS初始化插件
|
1
2
3
|
jQuery(document).ready(function() { $("select.flexselect").flexselect();}); |
4、自定义选项
|
1
|
<select name="email" class="flexselect"> ... |
|
1
2
3
4
|
$("select.flexselect").flexselect({ allowMismatch: true, inputNameTransform: function(name) { return "new_" + name; }}); |
输入文本框不仅仅只允许替换原来定义在下拉列表存在的选项,它还可以通过字段属性配置来分配,如new_email。当然你也可以自定义 inputNameTransform函数,传送的参数name为下拉列表select的name值。
mysql 中文字段排序( 按拼音首字母排序) 的查询语句
在处理使用Mysql时,数据表采用utf8字符集,使用中发现中文不能直接按照拼音排序
如果数据表tbl的某字段name的字符编码是latin1_swedish_ci
select * from `tbl` order by birary(name) asc ;
如果数据表tbl的某字段name的字符编码是utf8_general_ci
SELECT name FROM `tbl` WHERE 1 ORDER BY CONVERT( name USING gbk ) COLLATE gbk_chinese_ci ASC
===================
$orderby="convert(`group` USING gbk) COLLATE gbk_chinese_ci,displayorder,navid"
python数据类型详解
目录
1、字符串
2、布尔类型
3、整数
4、浮点数
5、数字
6、列表
7、元组
8、字典
9、日期
1、字符串
1.1、如何在Python中使用字符串
a、使用单引号(')
用单引号括起来表示字符串,例如:
str='this is string';
print str;
b、使用双引号(")
双引号中的字符串与单引号中的字符串用法完全相同,例如:
str="this is string";
print str;
c、使用三引号(''')
利用三引号,表示多行的字符串,可以在三引号中自由的使用单引号和双引号,例如:
str='''this is string
this is pythod string
this is string'''
print str;
2、布尔类型
bool=False;
print bool;
bool=True;
print bool;
3、整数
int=20;
print int;
4、浮点数
float=2.3;
print float;
5、数字
包括整数、浮点数。
5.1、删除数字对象引用,例如:
a=1;
b=2;
c=3;
del a;
del b, c;
#print a; #删除a变量后,再调用a变量会报错
5.2、数字类型转换
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象x转换为字符串
repr(x) 将对象x转换为表达式字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
chr(x) 将一个整数转换为一个字符
unichr(x) 将一个整数转换为Unicode字符
ord(x) 将一个字符转换为它的整数值
hex(x) 将一个整数转换为一个十六进制字符串
oct(x) 将一个整数转换为一个八进制字符串
5.3、数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10 ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 pow(x, y) x**y 运算后的值。 round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
6、列表
6.1、初始化列表,例如:
list=['physics', 'chemistry', 1997, 2000];
nums=[1, 3, 5, 7, 8, 13, 20];
6.2、访问列表中的值,例如:
'''nums[0]: 1''' print "nums[0]:", nums[0] '''nums[2:5]: [5, 7, 8] 从下标为2的元素切割到下标为5的元素,但不包含下标为5的元素''' print "nums[2:5]:", nums[2:5] '''nums[1:]: [3, 5, 7, 8, 13, 20] 从下标为1切割到最后一个元素''' print "nums[1:]:", nums[1:] '''nums[:-3]: [1, 3, 5, 7] 从最开始的元素一直切割到倒数第3个元素,但不包含倒数第三个元素''' print "nums[:-3]:", nums[:-3] '''nums[:]: [1, 3, 5, 7, 8, 13, 20] 返回所有元素''' print "nums[:]:", nums[:]
6.3、更新列表,例如:
nums[0]="ljq"; print nums[0];
6.4、删除列表元素
del nums[0]; '''nums[:]: [3, 5, 7, 8, 13, 20]''' print "nums[:]:", nums[:];
6.5、列表脚本操作符
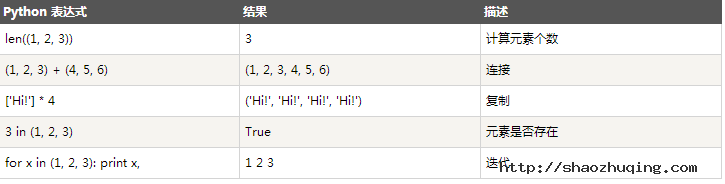
列表对+和*的操作符与字符串相似。+号用于组合列表,*号用于重复列表,例如:
print len([1, 2, 3]); #3 print [1, 2, 3] + [4, 5, 6]; #[1, 2, 3, 4, 5, 6] print ['Hi!'] * 4; #['Hi!', 'Hi!', 'Hi!', 'Hi!'] print 3 in [1, 2, 3] #True for x in [1, 2, 3]: print x, #1 2 3
6.6、列表截取
L=['spam', 'Spam', 'SPAM!']; print L[2]; #'SPAM!' print L[-2]; #'Spam' print L[1:]; #['Spam', 'SPAM!']
6.7、列表函数&方法
list.append(obj) 在列表末尾添加新的对象 list.count(obj) 统计某个元素在列表中出现的次数 list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.index(obj) 从列表中找出某个值第一个匹配项的索引位置,索引从0开始 list.insert(index, obj) 将对象插入列表 list.pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 list.remove(obj) 移除列表中某个值的第一个匹配项 list.reverse() 反向列表中元素,倒转 list.sort([func]) 对原列表进行排序
7、元组(tuple)
Python的元组与列表类似,不同之处在于元组的元素不能修改;元组使用小括号(),列表使用方括号[];元组创建很简单,只需要在括号中添加元素,并使用逗号(,)隔开即可,例如:
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";
创建空元组,例如:tup = ();
元组中只有一个元素时,需要在元素后面添加逗号,例如:tup1 = (50,);
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
7.1、访问元组
tup1 = ('physics', 'chemistry', 1997, 2000);
#tup1[0]: physics
print "tup1[0]: ", tup1[0]
#tup1[1:5]: ('chemistry', 1997)
print "tup1[1:5]: ", tup1[1:3]
7.2、修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,例如:
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# 以下修改元组元素操作是非法的。
# tup1[0] = 100;
# 创建一个新的元组
tup3 = tup1 + tup2; print tup3; #(12, 34.56, 'abc', 'xyz')
7.3、删除元组
元组中的元素值是不允许删除的,可以使用del语句来删除整个元组,例如:
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
7.4、元组运算符
与字符串一样,元组之间可以使用+号和*号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
7.5、元组索引&截取
L = ('spam', 'Spam', 'SPAM!');
print L[2]; #'SPAM!'
print L[-2]; #'Spam'
print L[1:]; #['Spam', 'SPAM!']
7.6、元组内置函数
cmp(tuple1, tuple2) 比较两个元组元素。 len(tuple) 计算元组元素个数。 max(tuple) 返回元组中元素最大值。 min(tuple) 返回元组中元素最小值。 tuple(seq) 将列表转换为元组。
8、字典
8.1、字典简介
字典(dictionary)是除列表之外python中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典由键和对应的值组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'};
也可如此创建字典:
dict1 = { 'abc': 456 };
dict2 = { 'abc': 123, 98.6: 37 };
每个键与值必须用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必;值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
8.2、访问字典里的值
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
print "dict['name']: ", dict['name'];
print "dict['age']: ", dict['age'];
8.3、修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
dict["age"]=27; #修改已有键的值
dict["school"]="wutong"; #增加新的键/值对
print "dict['age']: ", dict['age'];
print "dict['school']: ", dict['school'];
8.4、删除字典
del dict['name']; # 删除键是'name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
例如:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
del dict['name'];
#dict {'age': 7, 'class': 'First'}
print "dict", dict;
注意:字典不存在,del会引发一个异常
8.5、字典内置函数&方法
9、日期和时间
9.1、获取当前时间,例如:
import time, datetime;
localtime = time.localtime(time.time())
#Local current time : time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)
print "Local current time :", localtime
说明:time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)属于struct_time元组,struct_time元组具有如下属性:

9.2、获取格式化的时间
可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
2.1、日期转换为字符串
首选:print time.strftime('%Y-%m-%d %H:%M:%S');
其次:print datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H:%M:%S')
最后:print str(datetime.datetime.now())[:19]
2.2、字符串转换为日期
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") print d;
9.3、获取日期差
oneday = datetime.timedelta(days=1) #今天,2014-03-21 today = datetime.date.today() #昨天,2014-03-20 yesterday = datetime.date.today() - oneday #明天,2014-03-22 tomorrow = datetime.date.today() + oneday #获取今天零点的时间,2014-03-21 00:00:00 today_zero_time = datetime.datetime.strftime(today, '%Y-%m-%d %H:%M:%S') #0:00:00.001000 print datetime.timedelta(milliseconds=1), #1毫秒 #0:00:01 print datetime.timedelta(seconds=1), #1秒 #0:01:00 print datetime.timedelta(minutes=1), #1分钟 #1:00:00 print datetime.timedelta(hours=1), #1小时 #1 day, 0:00:00 print datetime.timedelta(days=1), #1天 #7 days, 0:00:00 print datetime.timedelta(weeks=1)
9.4、获取时间差
#1 day, 0:00:00 oneday = datetime.timedelta(days=1) #今天,2014-03-21 16:07:23.943000 today_time = datetime.datetime.now() #昨天,2014-03-20 16:07:23.943000 yesterday_time = datetime.datetime.now() - oneday #明天,2014-03-22 16:07:23.943000 tomorrow_time = datetime.datetime.now() + oneday 注意时间是浮点数,带毫秒。 那么要获取当前时间,需要格式化一下: print datetime.datetime.strftime(today_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(yesterday_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(tomorrow_time, '%Y-%m-%d %H:%M:%S')
9.5、获取上个月最后一天
last_month_last_day = datetime.date(datetime.date.today().year,datetime.date.today().month,1)-datetime.timedelta(1)
9.6、字符串日期格式化为秒数,返回浮点类型:
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.7、日期格式化为秒数,返回浮点类型:
d = datetime.date.today() time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.8、秒数转字符串
time_sec = time.time()
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time_sec))
GooglePlus登录添加修改操作记录
使用官方定义按钮页面自动刷新登录:
<div id="gConnect">
<button class="g−signin"
data−scope="https://www.googleapis.com/auth/plus.login https://www.googleapis.com/auth/userinfo.email"
data−requestvisibleactions="http://schemas.google.com/AddActivity"
data−clientId="申请ClientID"
data−callback="onSignInCallback"
data−theme="dark"
data−cookiepolicy="single_host_origin">
</button>
</div>
<script type="text/javascript">
var kx_google_host_config = "配置登录成功后跳转域名";
</script>
<script type="text/javascript" src="https://apis.google.com/js/client:platform.js" async defer></script>
<script type="text/javascript" src="http://简单封装/clientgoogle.so.js" ></script>
使用自己定义按钮页面不自动刷新登录:
<div id="gConnect">
<button type="button" onclick="window.render();return false;" class="btnLarge">使用Google帐号登录</button>
</div>
<script type="text/javascript">
var kx_google_host_config = "配置登录成功后跳转域名";
window.___gcfg = {
parsetags: 'explicit'
};
var render = function(){
gapi.signin.render('gConnect', {
'scope': 'https://www.googleapis.com/auth/plus.login https://www.googleapis.com/auth/userinfo.email',
'requestvisibleactions': 'http://schemas.google.com/AddActivity',
'clientId': '申请ClientID',
'callback': 'onSignInCallback',
'theme': 'dark',
'cookiepolicy': 'single_host_origin'
});
};
</script>
<script type="text/javascript" src="https://apis.google.com/js/client:platform.js" async defer></script>
<script type="text/javascript" src="http://简单封装/clientgoogle.so.js"></script>
clientgoogle.so.js文件封装内容:
var helper = (function() {
var BASE_API_PATH = 'plus/v1/';
return {
onSignInCallback: function(authResult) {
gapi.client.load('plus','v1').then(function() {
if (authResult['access_token']) {
helper.profile();
}
});
},
/**
* Gets and renders the currently signed in user's profile data.
*/
profile: function(){
gapi.client.plus.people.get({
'userId': 'me'
}).then(function(res) {
var urlmark = '?';
var profile = res.result;
var kx_google_host = kx_google_host_config;
var openid_response_nonce = profile.etag;
var openid_return_to = kx_google_host;
var openid_sig = randomString(28);
var openid_identity = "http://shaozhuqing.com/openid?id="+profile.id;
var openid_claimed_id = openid_identity;
var openid_ext1_value_first = profile.name.familyName;
var openid_ext1_value_last = profile.name.givenName;
var openid_ext1_value_email = profile.emails[0].value;
if(kx_google_host.indexOf('?') != −1){
var urlmark = '&';
}
var kx_google_url = kx_google_host+urlmark+"openid.response.nonce="+openid_response_nonce+"&openid.return.to="+
openid_return_to+"&openid.sig="+openid_sig+"&openid.identity="+openid_identity+"&openid.claimed.id="+openid_claimed_id+"&openid.
ext1.value.first="+openid_ext1_value_first+"&openid.ext1.value.last="+openid_ext1_value_last+"&openid.ext1.value.email="+
openid_ext1_value_email;
location.href =kx_google_url;
});
}
};
})();
function onSignInCallback(authResult) {
helper.onSignInCallback(authResult);
}
function randomString(len) {
len = len || 32;
var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
var maxPos = $chars.length;
var pwd = '';
for (i = 0; i < len; i++) {
pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
}
return pwd;
}
按钮自定义参数:
-
data-theme:light | dark
-
data-width :iconOnly | standard | wide
- data-height:short | standard | tall
google开发文档:https://developers.google.com/+/web/signin/
李开复:在中国创业的成功范式
中国的互联网正迎来黄金的创业时机,互联网在对各行各业去中介化、扁平化、平等化的冲击中,创业项目遍地开花。大家的机会都来了,可是是否是你的机会?哪些国家和行业变化机遇在为你的创业保驾护航?在机遇下创业成功的范式是什么?互联网的本质是垄断?如何拿着少量的钱从小垄断做到大垄断?本文整理自李开复博士在2015年创投盛典上的演讲,希望能给在创业红海中拼杀的你一点启迪。
我刚从美国硅谷回来,看了美国的一些现象。我觉得《从0到1》还有《精益创业》这两本书都是非常经典,而且在美国硅谷特别合适。在中国有一些特殊机遇和挑战,如果这些想法对于这两本书做一个补充,可能对于创业者会在中国创业会有更好的成功机会。

首先我们看一下今天全世界互联网已经带来颠覆式的作用,我们每天的生活已经被彻底颠覆。如果你不相信你可以想象自己回到十年前,见到一个十年前的自己,把你iPhone或者安卓给那个人看,看一下微信和饿了么等等的应用,会不会让十年前的你认为这个人是从科幻小说穿越过来的人,我觉得答案是肯定的。
为什么我们看到这么多颠覆?互联网是非常伟大的,它最大的作用有去中介化、扁平化、平等化等等,下面让我们从商业思维来看看互联网带给我们的创业者的机会和空间。

互联网打破了过去垂直市场的不公平现象。过去可能有很多垄断者,或许是因为品牌或者是规模优势或者信息不对称等等的理由达到了垄断。这个垄断可能区域式的垄断,比如上海、山东地区,也可能是一个品牌式垄断或者信息不对称的垄断,大家认为出租车公司或者某个餐馆特别好。但是互联网的来临,其实把整个市场扁平化了。全部都是一个非常低成本的扩张,能够把全国当做一个地域来看。如果这样讲不是特别清楚,你只要想想淘宝本身对于各个地方的地域化的商业有多么大的影响。
但是未来的机遇实际上是造就一种新的垄断。人们每个商业的机会、每个花钱的机会、每个服务的使用都可能因此而被颠覆。互联网的特色,左上是把很多分散的小市场,比如说超市、书店、商店变成一个巨大的统一的完全竞争的市场。从表象来说打破信息不对称和垄断,但是实际是造成一种新垄断。右边可以看到过去信息不对称,现在交易匹配和速度打破了这样不好的现象,而且有更多标准化的需求,非常低的交流交易进入了门槛。这些东西让互联网从商业角度来说,打破了过去不公平垄断现象,但是提供一个新垄断的机会。这是每个互联网创业者特别需要深深了解的现象。

从全球来看互联网肯定是美国领先的,如果我们看一下今天的市值。美国大概占有全世界的三分之二的所有互联网公司的市值,中国占有剩下的三分之一的三分之二。那么中国在奋起直追,现在情况呈现大好。过去五年到十年中,中国从微不足道的世界市场现在达到了九分支二的市场占有率,那么未来有怎样的机会?

今天我谈一下在中国创业的特色和机遇。当你考虑从0到1,考虑创业考虑精益创业等等机会的时候,我觉得不能用一个全球或者美国思维看这样的问题,因为中国其实有特别多的优势,但是也有特别多的挑战,现在我们讨论一下优势和挑战。

第一个优势就是人口红利。除了我们看到互联网、移动、电商,中国现在是全世界第一而且是超过美国,两倍、四倍这样的规模,但是同时不能当作两倍这样的差别。我们看一下右下角,右下角这个图告诉我们两个经济体的差别,两个网络化经济体的差别,不是看他们的个体比例,而是看个体平方比例。所以如果一个国家比另外一个国家的用户大了三倍,它的网络效益是9倍,如果大四倍效益就是16倍,所以千万不要低估人口红利的优势。

第二个优势是中国的创业领导者特别厉害。因为这个市场特别大,资金特别多,那么有一批创业者涌了上来。当然左边美国创业者他们可能在创新方面,突破式方面引领全球。但是右边这几个中国式创业者,他们在强大的领导力、快速执行力上高出一筹,他们的后劲更足。
我觉得全世界可能没有一个上市公司的CEO像雷军今天已经做到45亿,还每天工作18个小时,这样拼命的去做。可能在执行力方面,也许苹果会更创新一点,但是我们可以看到小米也好或者是腾讯、阿里、百度也好,他们从小到大,一直到大还是在不停的工作,还是不停的执行。
那么互联网经济里面,我们不要认为创新代表一切,其实一个巨大机会的环境里面,速度和执行力代表一切。尤其是在充满机会的社会里面,当机会不再那么多,当竞争更扁平化,当大家在一个所谓的创业时代,那个时候创新更重要。但是今天的中国充满机会,只要你能够抓住快速执行才是最重要的。突破式的创新,在今天的中国不是创造价值和财富最好的方法,因为今天有太多的机会和不公平。

第三点是中国的工程师其实是巨大的竞争力。我刚在硅谷看我们投资的公司,他们那些人特别聪明,但是我一个一个公司看,公司几个人?四个人,已经有一百万的投资怎么才四个人?因为工资贵,因为房租贵。这就是硅谷现象,认为创业一定非常小。当然你做一个谷歌式的公司,你慢慢招人是可以的,但是在中国这么大好的创业环境的现象,其实有一个很棒的领导者,你需要带一个团队。我们投资的项目,比如50到100万美金注入之内,可能半年之内就有20人。这20人在强大领导者带领之下能够冲锋陷阵,这是一个很特殊的国内现象。就是说老大很强的时候,他的团队相信可以跟着老大奋斗,可以改变命运,就算不能造成财务自由,也可以学到更多东西。
所以这些人是跟着老大创业的冲锋队,他们勤奋努力能干,中国工程师是没有问题的。我们可以看到左边的腾讯,到了半夜两点一大堆出租车等着员工下班。右边不但是国内的这批生力军介入,前几个礼拜在美国看到我们海归回国的浪潮又即将开始,有一段时间我觉得海归创业被整个环境不看好,认为不接地气。但是现在越来越多创业需要对接百万、千万、上亿的用户,如果没有强大技术团队是会崩溃的。所以非常需要这种顶尖的工程师,那么美国的高校是世界一流的,但是美国高校里面我们可以看到中国的留学生远远超过其他的国家。
我刚刚在CMU(卡内基梅隆大学)参加他们的毕业典礼,我看到CMU学计算机的学生里面75%是外国学生,这75%里面35%是中国学生。所以我们想象这批技术高手,他们未来回国的希望和诱惑,可以带动整个产业做可规模化高技术的创业,会带来新的一批浪潮。国内VC认为海外海归创业也好,参与创业也好,做CTO也好是越来越合适的,因为现在国内给的起,对顶尖人在给的起他们的价钱,给他们的股份,也认知新技术人才的价值,所以新一批海归回国会导致更多的创业浪潮,这是跟美国有巨大差别。当一个产品投入20个很不错的工程师,跟着老大说了算,跟着三五个工程师彼此都是天才整天辩论的时候,这个效率非常高。

第四我们谈人口规模,刚才讲过了人口红利,巨大用户群非常重要。这个用户群不仅仅是数量大,不仅仅根据数字平方的成长。更重要是一批人他们是有两个很大的特色,第一个特色是中国的城镇化,国内城镇化的成长有上百万人口的城市,他所造成的就是很多商业模式是最适合中国的土壤。
比如我们想象,你做一个饿了么或者美团你要送货。但如果你在美国,这个时候你开了多久的车,到的时候披萨都冷掉了。这时候你算人力成本,90%的时间在开车,你有汽油、能源、时间的耗损。而在国内在北京在上海在任何一个一级二级城市,配送可以非常有效率,而且尤其有优化。在海淀区一个一个骑着自行车或者摩托车甚至其他的方式,这样的配送非常有效,因为人口密集导致了O2O的模式更加成立。
下面一个情况是中国有巨大劳动力。这些劳动力都逐渐的可以进入一个我们称之为个体户的创业的行动。就像过去淘宝提供平台,很多人在淘宝开店,自己创业。这不是高科技创业,是在淘宝卖东西的掌柜创业。但是同样的一个很棒的Uber的司机他一定程度也在做一个创业,因为中国普遍的蓝领工资水平还是比较低,对于他们来说做一个个体户创业,O2O的创业过程是非常有吸引力。
在美国你很难想象一个人在福特工厂工作,他一个小时时拿30美金的收入,为什么要出来开Uber?但是国内可以想像,十分之一这样的公司,在一个非常有效的O2O的共享经济的环节里面,理所当然应该出来自我创业。所以大众创业的一种诠释和理解,并不是都是靠高科技创业,个体户创业也要算,而且在共享经济的平台之下,中国的个体户创业将会引领环球。
这里可以看到很多例子,河狸家、E代驾等等。大家已经非常清楚河狸家已经有三百个美甲员,都是个体户创业;E代驾成立三年,估值超过一亿美金,覆盖一百个城市。这些都是中国现象,我们在美国不会看到这样的速度。不会看到,是因为美国没有中国那么多的人口密集城市。美国也没有那么多一大批渴望更多财富的服务员和工作员。

第五个优势我觉得是中国政府的高效政策推出和到位的补助,无论是引导基金、中关村大街,都是引领全球的政策。但是更重要的是,比如说因为有酒驾的政策,高效的执行就有了E代驾的机会,突然有了上海自贸区的事情,就让一些聪明的创业者发现他有一个可以来做进口车电商的机会。这在过去不可能发生的,所以善于观察机会的人,在中国可以看到更多这样的机会。

第六个优势我称之为后发优势。美国是一个很成熟市场,很多竞争已经扁平化。越多人跳进来竞争,我们把利润压低,然后形成公平竞争。但是在中国过去有很多不公平的现象,零售业也好,房地产也罢,中间有很多人赚着不合理的利润。这个时候互联网创业一出来就把它打败了,房多多就是一个例子。我们看到互联网金融有很多不合理的现象,比如只有12%的中小公司可以申请贷款,而且贷款的利率非常高。于是这个就带来了国内互联网金融的繁荣。因此每个不公平,对消费者可能过去是一种剥削和迫害,但是对于互联网创业者都是一个机会,这是现有低效渠道带来的变革红利。

第七个优势我们可以称为草根优势。美国有悠久的品牌传统,像MARVEL(漫威)这样的公司在美国要经过一个很长的历练才能做出来,我们很难想象他被一个创业公司挑战。但是在国内消费领域的垄断品牌远少于美国,没有那么强大的娱乐内容的品牌,一个草根漫画家在暴走漫画、有妖气、起点中文网这样的一个新平台上,只要我有一批粉丝,就可以对粉丝推送内容,推送出来一个内容授权多个领域。比如创新工场投资的一家公司,他做了《十万个冷笑话》电影上映三个星期就有1亿多的票房收入,其制作团队非常迅速地推出了手游产品。这种内容创作在美国,还是被垄断性的巨大品牌所霸占,在国内有巨大机会。
那么有这样一个环境,有着巨大的机会和巨大的挑战,国内创业者该怎样走向成功之路?

我想说,在这么多优势和机会之下,其实中国的竞争也非常剧烈。因为市场巨大,VC钱特别多,所以人人全力以赴,拼命进去,每个创业者非常渴望成功。中国巨头跟美国不太一样,不太在乎以大欺小。这个情况会对创业者产生巨大挑战,因为你跟小公司竞争还可以,但和巨头做一样的事情,可能就会面临很大的困境。
也许有些人在国外认为,你敌人的敌人是你的朋友,但是从下面我们的竞争可以看到,这些巨头其实都是打的你死我活,包括最近周鸿祎和雷军在微博上面的口水战,也是一个案例。环境听起来很恶劣,创业者很糟糕。
但任何事情都是双面,如果我们用双面的方法来看这样的挑战,我觉得就是有这样的可怕的竞争环境才能培养无敌的角斗士,这样的环境才能逼着创业者找到更好的商业模式。今天我们看淘宝的商业模式就比美国eBay强大很多,因为eBay的卖家他要不断的付费,如果哪天出来免费模式,卖家可能会出走。虽然他现在有一定的基础,但是这个不是永远坚固。淘宝因为已经免费了,所以至少不能用价格战打败他,也是因为中国这样的环境,逼着淘宝和其他的公司走上这样的商业模式。这样的商业模式不只是在中国,在全球都是非常强大的。

第一步,找到属于自己的小垄断。中国机会这么多,跟美国不一样。我们不能只相信要找颠覆,要做彻底不同的东西。做不同事情,差异化是好事情,但是机会这么多,如果你不找机会,就硬做一个技术颠覆,可能让自己走了很多弯路。比如自由贸易区,我们可以做进口车,如果你第一个想到这个,你有很大的优势,或者很多人都想不到你执行最好的,你就有巨大的优势。
找到机会后,要形成小垄断。当你在这样的环境找到机会,你要形成小垄断。不要认为垄断是贬义词。要在互联网里面建立护城河,你找到你的滩头就是建立一个小垄断。这个小垄断变大了增长以后然后成为一个更大的垄断,不断快速地迁移,经过技术网络效应、规模经济和平台,让你有可能有一天成为像BAT这样的公司。
你在创业的时候早期要做自己的小垄断,没有什么比这句话更重要。如果只找一个广义市场,希望成为大市场的第7名、第8名都没有意义,你要在大市场里找到一个小领域,抓住这个变化,在大市场变化的一刹那介入,太早或者太晚都不可以。比如我们知道打车软件,其实在五年前也有人做,但是那个时候没有互联网,所以做不起来。所以正确时间做正确的事情,然后找到非常小的契机,切入然后用杠杆把这个事情做大。
当你找到小垄断以后,比如亚马逊当时的卖书,比如说滴滴经过出租车来启动,或者我们看到的很多的模式都是这样做起来的。包括阿里,当时先做对外贸易,都是找到一个真实市场需求你可以介入迅速执行,把小滩头抓下来,千万别做大市场的第十名。
比如我们投资的要出发,他做一个附近的驾车旅游,他是周边游的第一。但是你如果在整个旅游产品中排序的话,可能携程或者是过去的艺龙还有去哪儿,这么排的话要出发可能排到第十几位,这没有意义。你不能做大市场的第5名第10名,一定要做特别小市场里的第一名。
达到这个阶段的时候,当看到这个增长点,你就要用杠杆的作用得到一个增长。杠杆的作用不只是说去砸钱,更重要我们抓对正确时候的正确点。比如我们看58同城的成功,它的杠杆是搜索引擎,当时推广小米的杠杆是新浪微博,每个时代都有它的杠杆。现在你做一个移动社交领域,再用搜索引擎或者新浪微博,那是不够的。所以作为一个创业者,你要找一个新时代适合的杠杆然后快速打下来,因为你看到这个机会别人也会看到,所以怎样能够比别人走的快,比别人砸的准,不是谁的钱砸的多,而是是谁用适当的杠杆可以砸出这样一个效果。
找滩头阵地的秘诀:
创业公司应首先解决0-1的问题,不要试图教育市场;
范式要简单直接,找到简单真实的KPI;
避免多边市场,避免多个不可控因素;
避免生态系统思维,要首先做起来一头;
避免跳板思维 先做A再做B;

第二步就是从小垄断到大垄断,快速垄断扩大、全速前进。美图就是一个很好的例子,创新工场投资的项目。它最早创业的时候找一个非常狭窄的领域,就是女孩子在PC上想把自己弄得更漂亮,但是Photoshop很难用,它解决这么一个问题,然后达到一定的用户群。然后它从PC把用户导向移动,基于这个基础他做更多美图系列的产品,他横向纵向发展了自己的手机,美图品牌的手机,他又横向发展了一个美拍,也就是视频方面特别易用,慢慢成为专注于“美”的公司。这个公司不是一步到位,是逐步从小垄断做到起来的。
快速成长的秘诀:
避免沉迷于低质量增长,堆叠式增长;
避免过度微创新,改善式创新的误区;
避免快速迭代,但是不增长的陷阱;
要选择“增长性”性价比最高的,而不是最完美的;
创新工场本身就是帮助创业者寻找这个小垄断,所以我们的投资模式非常简单。第一我们寻找这些创业机会,这些机会不是说我们要颠覆式,要有很大创新,要做语音识别、人脸识别,当然也有这些。
我们要找的是在今天的中国有什么特别好的,经过政策经过市场红利、人口红利、创业者红利,经过中国的市场分配、城市人口大量的服务者的参与,还有经过国内这些过去国企的传统企业的垄断式不公平和不透明模式,找到哪些领域可以打出一个互联网品牌,再找到一个特别好的用户痛点。那么第二步我们就要找创业者,他看到这样的趋势,然后愿意拿我们的投资,去打出这样一个小滩头,我们所优化的模式就是帮助这样的创业者招人,招二十个人的敢死队,根据这个模式和机会打磨第一款产品,然后把这个产品推向市场,然后找它的杠杆,然后让它跟着这个杠杆快速进行,这个时候融大笔钱然后做滴滴这样的事情,所以这是我们创新工场的模式。
我今天还想说在这样一个环境下,我们不要相信中国式的创新,仅仅是技术的突破,颠覆式的突破,当然那些很重要。因为美国在突破和颠覆式的创新,将会很长的时间引领全球,这是我们非常佩服也值得学习的。美国这种创新科技帝国式的平台,将会在这里领跑世界,而且它会快速的推进澳大利亚、日本、加拿大这样的市场。但是中国的市场是巨大的,我们今天虽然谈剧烈竞争,但是有非常得天独厚的天时地利人和优势,在这样的情况下如果我们找到中国独特的机会和特色,快速的进去用刚才讲的模式,当然也参考《从0到1》书里讲的方法论。
我相信中国的独角兽,虽然我们可能比不过美国,但是两三年之内我相信会超过美国的速度。在这样的环境之下练出来的独角兽,我相信他们在商业模式上会比美国练出来的独角兽更具有兼顾的商业模式、更具可持续。当然这些公司在中国可以做的很棒,甚至达到百万级别。那么推到世界有没有希望?我个人认为推到已开发市场比较难,因为那些用户更符合美国的方式。
但是我认为下一步我们在中国做出独特商业模式的这些公司,会进入用户分布类似中国的市场,比如东南亚或者南美,所以我相信未来中国的创业是非常美好的,谢谢大家。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
