firewalld和iptables的关系
Centos 7,发现无法使用iptables控制Linuxs的端口,而使用firewalld代替了原来的iptables
firewalld和iptables的关系
firewalld自身并不具备防火墙的功能,而是和iptables一样需要通过内核的netfilter来实现,也就是说firewalld和iptables一样,他们的作用都是用于维护规则,而真正使用规则干活的是内核的netfilter,只不过firewalld和iptables的结构以及使用方法不一样罢了。
firewalld的配置模式
firewalld的配置文件以xml格式为主(主配置文件firewalld.conf例外),他们有两个存储位置
1、/etc/firewalld/ 用户配置文件
2、/usr/lib/firewalld/ 系统配置文件,预置文件
我们知道每个zone就是一套规则集,但是有那么多zone,对于一个具体的请求来说应该使用哪个zone(哪套规则)来处理呢?这个问题至关重要,如果这点不弄明白其他的都是空中楼阁,即使规则设置的再好,不知道怎样用、在哪里用也不行。
对于一个接受到的请求具体使用哪个zone,firewalld是通过三种方法来判断的:
1、source,也就是源地址 优先级最高
2、interface,接收请求的网卡 优先级第二
3、firewalld.conf中配置的默认zone 优先级最低
这三个的优先级按顺序依次降低,也就是说如果按照source可以找到就不会再按interface去查找,如果前两个都找不到才会使用第三个,也就是学生在前面给大家讲过的在firewalld.conf中配置的默认zone。
安装firewalld,运行、停止、禁用firewalld
root执行 # yum install firewalld
启动:# systemctl start firewalld
查看状态:# systemctl status firewalld 或者 firewall-cmd --state
停止:# systemctl disable firewalld
禁用:# systemctl stop firewalld
配置firewalld
查看版本:$ firewall-cmd --version
查看帮助:$ firewall-cmd --help
查看设置:
显示状态:$ firewall-cmd --state
查看区域信息: $ firewall-cmd --get-active-zones
查看指定接口所属区域:$ firewall-cmd --get-zone-of-interface=eth0
拒绝所有包:# firewall-cmd --panic-on
取消拒绝状态:# firewall-cmd --panic-off
查看是否拒绝:$ firewall-cmd --query-panic
更新防火墙规则:# firewall-cmd --reload
# firewall-cmd --complete-reload
两者的区别就是第一个无需断开连接,就是firewalld特性之一动态添加规则,第二个需要断开连接,类似重启服务
将接口添加到区域,默认接口都在public
# firewall-cmd --zone=public --add-interface=eth0
永久生效再加上 --permanent 然后reload防火墙
设置默认接口区域
# firewall-cmd --set-default-zone=public
立即生效无需重启
打开端口(貌似这个才最常用)
查看所有打开的端口:
# firewall-cmd --zone=dmz --list-ports
加入一个端口到区域:
# firewall-cmd --zone=dmz --add-port=8080/tcp
若要永久生效方法同上
打开一个服务,类似于将端口可视化,服务需要在配置文件中添加,/etc/firewalld 目录下有services文件夹,这个不详细说了,详情参考文档
# firewall-cmd --zone=work --add-service=smtp
移除服务
# firewall-cmd --zone=work --remove-service=smtp
如何构建垂直网络爬虫平台
写一个爬虫很简单,写一个可持续稳定运行的爬虫也不难,但如何构建一个通用化的垂直网络爬虫平台?
这篇文章主要介绍垂直网络爬虫平台的构建思路。
爬虫简介
首先介绍一下什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取网页信息的程序或者脚本。
很简单,爬虫就是指定规则自动采集数据的程序脚本,目的在于拿到想要的数据。
爬虫主要分两类:
- 通用网络爬虫(搜索引擎)
- 垂直网络爬虫(特定领域)
由于第一类的开发成本较高,故只有搜索引擎公司在做,如谷歌、百度等。
而大多数企业在做的是第二类,成本低、数据价值高。例如一家做电商的公司只需要电商领域有价值的数据,那开发一个电商领域的爬虫平台,意义较大。
这篇文章主要针对第二类的平台构建提供设计与思路。
如何写爬虫
首先从最简单的开始,我们先了解一下如何写一个爬虫?
简单爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# coding: utf8
"""简单爬虫"""
import requests
from lxml import etree
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
parse_rule = "//div[@id='wrapper']/h1/span/text()"
for url in crawl_urls:
# 2. 发起HTTP请求
response = requests.get(url)
# 3. 解析HTML
result = etree.HTML(response.text).xpath(parse_rule)[0]
# 4. 保存结果
print result
if __name__ == '__main__':
run()
|
这个爬虫比较简单,大致流程为:
- 定义页面URL和解析规则
- 发起HTTP请求
- 解析HTML,拿到数据
- 保存数据
任何爬虫,要想获取网页上的数据,都是经过这几步。
当然,这个简单爬虫效率比较低,只能抓完一个网页,再去抓下一个,有没有提高效率的方式呢?
异步爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# coding: utf8
"""协程版本爬虫,提高抓取效率"""
from gevent import monkey
monkey.patch_all()
import requests
from lxml import etree
from gevent.pool import Pool
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
rule = "//div[@id='wrapper']/h1/span/text()"
# 2. 抓取
pool = Pool(size=10)
for url in crawl_urls:
pool.spawn(crawl, url, rule)
pool.join()
def crawl(url, rule):
"""抓取&解析"""
# 3. 发起HTTP请求
response = requests.get(url)
# 4. 解析HTML
result = etree.HTML(response.text).xpath(rule)[0]
# 5. 保存结果
print result
if __name__ == '__main__':
run()
|
经过优化,我们完成了异步版本的爬虫代码。
由于爬虫要抓的网页一般很多,提高效率是爬虫最基本的技能,由于下载网页都是阻塞在网络IO上,那我们可以利用多线程或异步的方式,提高抓取效率。
有了这些基础知识之后,我们看一个完整的例子,如何抓取一个整站数据?
整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
# coding: utf8
"""整站爬虫"""
from gevent import monkey
monkey.patch_all()
from urlparse import urljoin
import requests
from lxml import etree
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
def crawl(url):
"""首页"""
response = requests.get(url)
list_urls = etree.HTML(response.text).xpath(rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = requests.get(list_url).text
detail_urls = etree.HTML(html).xpath(rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = etree.HTML(html).xpath(rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = requests.get(list_url).text
title = etree.HTML(html).xpath(rules['title'])[0]
print title
def run():
"""run"""
# 1. 标签页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
此爬虫以豆瓣图书为例,抓取整站信息,大致思路为:
- 从标签页进入,提取所有标签URL
- 进入每个标签页,提取所有列表URL
- 进入每个列表页,提取每一页的详情URL和下一页列表URL
- 进入每个详情页,拿到书名
- 如此往复循环,直到数据抓取完毕
这就是抓取一个整站的思路,很简单,无非就是分析我们浏览网站的行为轨迹,用程序来进行自动化的请求、抓取。
理想情况下,我们应该能够拿到整站的数据,但实际情况对方网站往往会采取防爬虫措施,在抓取一段时间后,我们的IP就会被禁。
那如何突破这些防爬错误,拿到数据呢?我们继续优化代码。
防反爬的整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
# coding: utf8
"""防反爬的整站爬虫"""
from gevent import monkey
monkey.patch_all()
import random
from urlparse import urljoin
import requests
from lxml import etree
import gevent
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
# 定义代理池
proxy_list = [
'118.190.147.92:15524',
'47.92.134.176:17141',
'119.23.32.38:20189',
]
# 定义UserAgent
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
]
def fetch(url):
"""发起HTTP请求"""
proxies = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
headers = {'User-Agent': user_agent}
html = requests.get(url, headers=headers, proxies=proxies).text
return html
def parse(html, rule):
"""解析页面"""
return etree.HTML(html).xpath(rule)
def crawl(url):
"""首页"""
html = fetch(url)
list_urls = parse(html, rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = fetch(list_url)
detail_urls = parse(html, rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = parse(html, rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = fetch(list_url)
title = parse(html, rules['title'])[0]
print title
def run():
"""run"""
# 1. 首页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
这个版本的爬虫代码,加上了随机代理和请求头,这也是突破防爬措施的常用手段,使用此手段,加上一些质量高的代理,应对一些小网站的数据抓取,不在话下。
当然,这里只为了展示一步步写爬虫、优化爬虫的思路,来达到抓取数据的目的,现实情况的抓取与反爬比想象中的更复杂,需要具体场景具体分析。
现有问题
经过上面这几步,我们想要哪个网站的数据,分析网站网页结构,写出代码应该不成问题。
抓几个网站可以这么写,但抓几十个、几百个网站,你还能写下去吗?
由此暴露的问题:
- 爬虫脚本繁多,管理困难
- 规则定义零散,重复开发
- 后台脚本,无监控
- 数据输出困难,业务接入慢
这些问题都是我们在爬虫越写越多的情况下,难免会遇到的问题。
此时,我们迫切需要一个更好的解决方案,来更好地开发爬虫,爬虫平台应运而生。
平台架构
我们来分析每个爬虫的共同点,结果发现:写一个爬虫无非就是规则、抓取、解析、入库这几步,那我们可不可以把每一块分别拆开呢?如图:
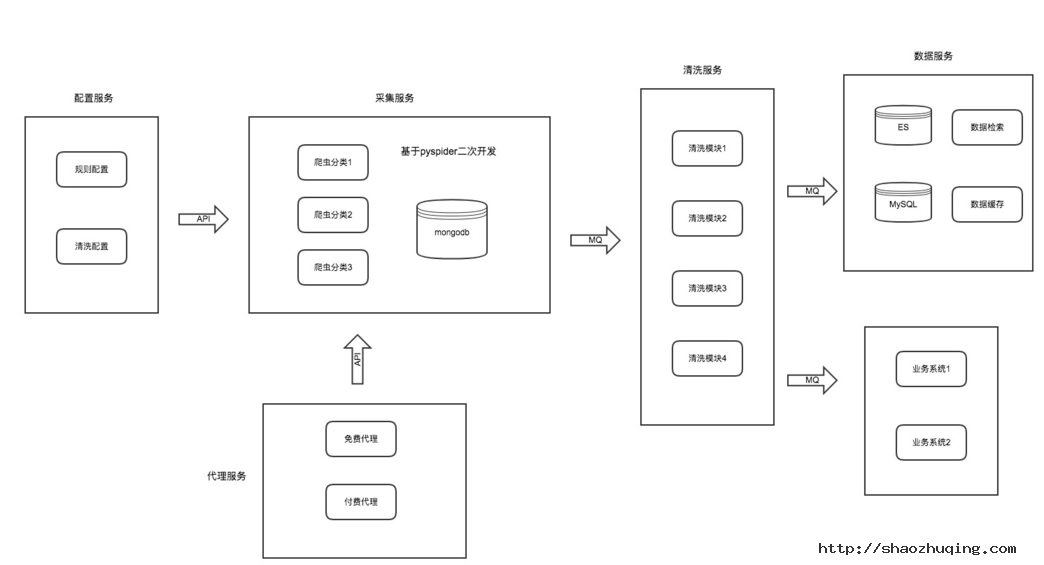
- 配置服务:包括抓取页面配置、解析规则配置、清洗配置
- 采集服务:专注网页下载与采集,并提供防爬策略
- 代理服务:提供稳定可持续输出的代理
- 清洗服务:针对同一类型业务进行字段清洗
- 数据服务:数据展示及业务数据对接
我们把一个爬虫的每一个环节,拆开做成一个个单独的服务模块,各模块各司其职。
每个模块维护属于自己领域的功能,可独立升级和优化。
详细设计
配置服务
此模块主要包括采集URL配置、页面解析规则配置、清洗配置。
我们把爬虫的规则从爬虫脚本中抽离出来,单独配置与维护,这样也便于重用与管理。
由于此模块专注配置管理,那我们可以对配置进一步拆开,配置支持各种方式的数据解析模式,如正则解析、CSS解析、XPATH解析,每种模式配置对应的表达式即可。
采集服务可以写一个配置解析器与配置服务进行对接,此配置解析器内部实现各种模式具体的解析逻辑。
清洗配置主要可配置每个爬虫输出后对应的清洗worker。
采集服务
此模块比较纯粹,就是写爬虫逻辑的模块,我们可以像之前那样开发、调试、运行爬虫脚本,但这一切工作都只能在命令行脚本进行,有没有一种好的方案是可以可视化操作的呢?
我们调研了市面上比较好的爬虫框架,发现pyspider符合我们的需求,此框架的特点:
- 支持分布式
- 配置可视化
- 可周期采集
- 支持优先级
- 任务可监控
pyspider架构图:
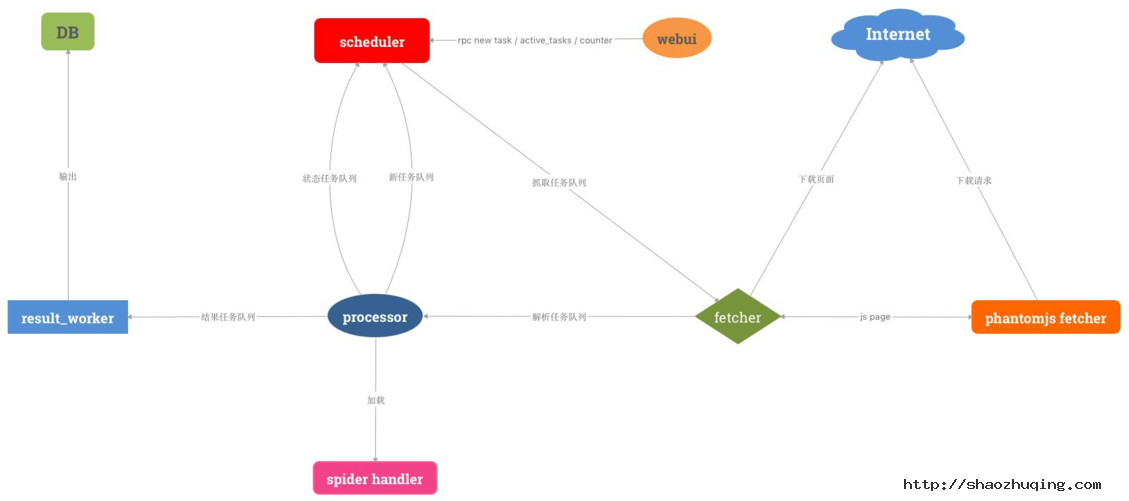
正所谓站在巨人的肩膀上。我们决定对其进行二次开发,并增强其一些组件,使爬虫开发成本更低,更符合我们的业务规则。
- 开发配置解析器,对接配置服务
spider handler定制爬虫模板,分类采集任务,生成模板,降低开发成本fetcher新增代理调度机制,对接代理服务,并增加代理调度策略result_worker输出定制化,对接清洗服务
由此我们可做出一个分布式、可视化、任务可监控、可生成爬虫模板的采集服务模块。
代理服务
做爬虫的都知道,代理是突破防抓的常用手段,如何获取稳定且持续的代理呢?
此模块内部维护代理的质量和数量,并输出给采集服务,供采集使用。
主要包括两部分:
- 免费代理
- 付费代理
免费代理
免费代理主要由我们自己的代理采集程序采集获得,大致思路为:
- 收集代理源
- 定时采集代理
- 测试代理
- 输出代理
付费代理
免费代理的质量和稳定性相对较差,对于采集防爬比较厉害的网站,还是不够用。
这时我们会购买一些付费代理,专门用于采集这类防爬的网站,此代理一般为高匿代理,并定时更新。
清洗服务
此模块比较简单,主要接收采集服务输出的数据,然后根据对应的规则执行清洗逻辑。
例如网页字段与数据库字段归一转换,特殊字段清洗定制化等。
这个服务模块运行了很多worker,最终把输出结果输送到数据服务。
数据服务
此模块会接收最终清洗后的结构化数据,统一入库。且针对其他业务系统需要的数据进行统一推送输出:
- 数据平台展示
- 数据推送
- 数据API
解决的问题
经过这个平台的构建,基本解决了最开始困扰的几个问题:
- 爬虫管理、配置可视化
- 降低开发成本
- 进度可监控、易跟踪
- 数据输出便捷
- 业务接入迅速
爬虫技巧
爬虫技巧从整体上来说,其实核心思想就一个:尽可能地模拟人的行为。
例如:
- 随机UserAgent(github fake-useragent)
- 随机代理IP(高匿代理、代理策略)
- Cookie池
- JS渲染页面(phantomjs)
- 验证码识别(OCR、机器学习)
当然,做爬虫是一个相互博弈的过程,有时没必要硬碰硬,遇到问题换个思路不免是一种解决办法。例如,对方的PC站防抓厉害,那去看一看对方的WAP站可不可以搞一下?APP端是否可以尝试一下?在有限的成本拿到数据才是爬虫的目的。
以上就是构建一个垂直网络爬虫平台的大致思路,从最简单的爬虫脚本,到写越来越多的爬虫,到难以维护,再到整个爬虫平台的构建,一步步都是遇到问题解决问题的产物,在我们真正发现核心问题时,解决思路也就不难了。
Centos安装PHP的IMAP模块LNMP
学习记录一些 Linux 上的东西:
1.首先 ssh 连接上你的服务器:然后执行以下代码:
|
1
2
3
4
|
yum install -y libc-client-devel
ln -s /usr/lib64/libc-client.so /usr/lib/libc-client.so
ln -s /usr/lib64/libkrb5.so /usr/lib/libkrb5.so
ln -s /usr/lib64/libssl.so /usr/lib/libssl.so
|
2.然后准备安装:
|
1
2
3
4
5
6
|
#根据自己的 php 安装包路径填写 如果没有发现文件请解压相关文件夹
cd /root/lnmp1.3-full/src/php-7.0.8/ext/imap
/usr/local/php/bin/phpize
./configure -with-imap -with-php-config=/usr/local/php/bin/php-config --with-kerberos=/usr --with-imap-ssl=/usr
make
make install
|
3.然后把编译好的静态模块添加进 php.ini 文件就好:
|
1
2
3
|
vim /usr/local/php/etc/php.ini
#把下面一段代码插入最底部即可
extension = "imap.so"
|
4.然后重启 PHP:
|
1
|
lnmp php-fpm restart
|
前端解决跨域问题的8种方案(最新最全)
1.同源策略如下:
| URL | 说明 | 是否允许通信 |
|---|---|---|
| http://www.a.com/a.js http://www.a.com/b.js |
同一域名下 | 允许 |
| http://www.a.com/lab/a.js http://www.a.com/script/b.js |
同一域名下不同文件夹 | 允许 |
| http://www.a.com:8000/a.js http://www.a.com/b.js |
同一域名,不同端口 | 不允许 |
| http://www.a.com/a.js https://www.a.com/b.js |
同一域名,不同协议 | 不允许 |
| http://www.a.com/a.js http://70.32.92.74/b.js |
域名和域名对应ip | 不允许 |
| http://www.a.com/a.js http://script.a.com/b.js |
主域相同,子域不同 | 不允许 |
| http://www.a.com/a.js http://a.com/b.js |
同一域名,不同二级域名(同上) | 不允许(cookie这种情况下也不允许访问) |
| http://www.cnblogs.com/a.js http://www.a.com/b.js |
不同域名 | 不允许 |
- 特别注意两点:
- 第一,如果是协议和端口造成的跨域问题“前台”是无能为力的,
- 第二:在跨域问题上,域仅仅是通过“URL的首部”来识别而不会去尝试判断相同的ip地址对应着两个域或两个域是否在同一个ip上。
- “URL的首部”指window.location.protocol +window.location.host,也可以理解为“Domains, protocols and ports must match”。
2.前端解决跨域问题
1> document.domain + iframe (只有在主域相同的时候才能使用该方法)
1) 在www.a.com/a.html中:
2) 在www.script.a.com/b.html中:
document.domain = 'a.com';
2> 动态创建script
这个没什么好说的,因为script标签不受同源策略的限制。
function loadScript(url, func) {
var head = document.head || document.getElementByTagName('head')[0];
var script = document.createElement('script');
script.src = url;
script.onload = script.onreadystatechange = function(){
if(!this.readyState || this.readyState=='loaded' || this.readyState=='complete'){
func();
script.onload = script.onreadystatechange = null;
}
};
head.insertBefore(script, 0);
}
window.baidu = {
sug: function(data){
console.log(data);
}
}
loadScript('http://suggestion.baidu.com/su?wd=w',function(){console.log('loaded')});
//我们请求的内容在哪里?
//我们可以在chorme调试面板的source中看到script引入的内容
3> location.hash + iframe
原理是利用location.hash来进行传值。
假设域名a.com下的文件cs1.html要和cnblogs.com域名下的cs2.html传递信息。
1) cs1.html首先创建自动创建一个隐藏的iframe,iframe的src指向cnblogs.com域名下的cs2.html页面
2) cs2.html响应请求后再将通过修改cs1.html的hash值来传递数据
3) 同时在cs1.html上加一个定时器,隔一段时间来判断location.hash的值有没有变化,一旦有变化则获取获取hash值
注:由于两个页面不在同一个域下IE、Chrome不允许修改parent.location.hash的值,所以要借助于a.com域名下的一个代理iframe
代码如下:
先是a.com下的文件cs1.html文件:
function startRequest(){
var ifr = document.createElement('iframe');
ifr.style.display = 'none';
ifr.src = 'http://www.cnblogs.com/lab/cscript/cs2.html#paramdo';
document.body.appendChild(ifr);
}
function checkHash() {
try {
var data = location.hash ? location.hash.substring(1) : '';
if (console.log) {
console.log('Now the data is '+data);
}
} catch(e) {};
}
setInterval(checkHash, 2000);
cnblogs.com域名下的cs2.html:
//模拟一个简单的参数处理操作
switch(location.hash){
case '#paramdo':
callBack();
break;
case '#paramset':
//do something……
break;
}
function callBack(){
try {
parent.location.hash = 'somedata';
} catch (e) {
// ie、chrome的安全机制无法修改parent.location.hash,
// 所以要利用一个中间的cnblogs域下的代理iframe
var ifrproxy = document.createElement('iframe');
ifrproxy.style.display = 'none';
ifrproxy.src = 'http://a.com/test/cscript/cs3.html#somedata'; // 注意该文件在"a.com"域下
document.body.appendChild(ifrproxy);
}
}
a.com下的域名cs3.html
//因为parent.parent和自身属于同一个域,所以可以改变其location.hash的值 parent.parent.location.hash = self.location.hash.substring(1);
4> window.name + iframe
window.name 的美妙之处:name 值在不同的页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的 name 值(2MB)。
1) 创建a.com/cs1.html
2) 创建a.com/proxy.html,并加入如下代码
<head>
<script>
function proxy(url, func){
var isFirst = true,
ifr = document.createElement('iframe'),
loadFunc = function(){
if(isFirst){
ifr.contentWindow.location = 'http://a.com/cs1.html';
isFirst = false;
}else{
func(ifr.contentWindow.name);
ifr.contentWindow.close();
document.body.removeChild(ifr);
ifr.src = '';
ifr = null;
}
};
ifr.src = url;
ifr.style.display = 'none';
if(ifr.attachEvent) ifr.attachEvent('onload', loadFunc);
else ifr.onload = loadFunc;
document.body.appendChild(iframe);
}
</script>
</head>
<body>
<script>
proxy('http://www.baidu.com/', function(data){
console.log(data);
});
</script>
</body>
3 在b.com/cs1.html中包含:
<script>
window.name = '要传送的内容';
</script>
5> postMessage(HTML5中的XMLHttpRequest Level 2中的API)
1) a.com/index.html中的代码:
<iframe id="ifr" src="b.com/index.html"></iframe>
<script type="text/javascript">
window.onload = function() {
var ifr = document.getElementById('ifr');
var targetOrigin = 'http://b.com'; // 若写成'http://b.com/c/proxy.html'效果一样
// 若写成'http://c.com'就不会执行postMessage了
ifr.contentWindow.postMessage('I was there!', targetOrigin);
};
</script>
2) b.com/index.html中的代码:
<script type="text/javascript">
window.addEventListener('message', function(event){
// 通过origin属性判断消息来源地址
if (event.origin == 'http://a.com') {
alert(event.data); // 弹出"I was there!"
alert(event.source); // 对a.com、index.html中window对象的引用
// 但由于同源策略,这里event.source不可以访问window对象
}
}, false);
</script>
6> CORS
CORS背后的思想,就是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。
IE中对CORS的实现是xdr
var xdr = new XDomainRequest();
xdr.onload = function(){
console.log(xdr.responseText);
}
xdr.open('get', 'http://www.baidu.com');
......
xdr.send(null);
其它浏览器中的实现就在xhr中
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if(xhr.readyState == 4){
if(xhr.status >= 200 && xhr.status < 304 || xhr.status == 304){
console.log(xhr.responseText);
}
}
}
xhr.open('get', 'http://www.baidu.com');
......
xhr.send(null);
实现跨浏览器的CORS
function createCORS(method, url){
var xhr = new XMLHttpRequest();
if('withCredentials' in xhr){
xhr.open(method, url, true);
}else if(typeof XDomainRequest != 'undefined'){
var xhr = new XDomainRequest();
xhr.open(method, url);
}else{
xhr = null;
}
return xhr;
}
var request = createCORS('get', 'http://www.baidu.com');
if(request){
request.onload = function(){
......
};
request.send();
}
7> JSONP
JSONP包含两部分:回调函数和数据。
回调函数是当响应到来时要放在当前页面被调用的函数。
数据就是传入回调函数中的json数据,也就是回调函数的参数了。
function handleResponse(response){
console.log('The responsed data is: '+response.data);
}
var script = document.createElement('script');
script.src = 'http://www.baidu.com/json/?callback=handleResponse';
document.body.insertBefore(script, document.body.firstChild);
/*handleResonse({"data": "zhe"})*/
//原理如下:
//当我们通过script标签请求时
//后台就会根据相应的参数(json,handleResponse)
//来生成相应的json数据(handleResponse({"data": "zhe"}))
//最后这个返回的json数据(代码)就会被放在当前js文件中被执行
//至此跨域通信完成
jsonp虽然很简单,但是有如下缺点:
1)安全问题(请求代码中可能存在安全隐患)
2)要确定jsonp请求是否失败并不容易
8> web sockets
web sockets是一种浏览器的API,它的目标是在一个单独的持久连接上提供全双工、双向通信。(同源策略对web sockets不适用)
web sockets原理:在JS创建了web socket之后,会有一个HTTP请求发送到浏览器以发起连接。取得服务器响应后,建立的连接会使用HTTP升级从HTTP协议交换为web sockt协议。
只有在支持web socket协议的服务器上才能正常工作。
var socket = new WebSockt('ws://www.baidu.com');//http->ws; https->wss
socket.send('hello WebSockt');
socket.onmessage = function(event){
var data = event.data;
}
Web前端面试题目汇总
以下是收集一些面试中经常会遇到的经典面试题以及自己面试过程中有一些未解决的问题,通过对知识的整理以及经验的总结,重新巩固自身的前端基础知识,如有错误或更好的答案,欢迎指正,水平有限,望各位不吝指教。:)
HTML/CSS部分
1、什么是盒子模型?
在网页中,一个元素占有空间的大小由几个部分构成,其中包括元素的内容(content),元素的内边距(padding),元素的边框(border),元素的外边距(margin)四个部分。这四个部分占有的空间中,有的部分可以显示相应的内容,而有的部分只用来分隔相邻的区域或区域。4个部分一起构成了css中元素的盒模型。
2、行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
行内元素:a、b、span、img、input、strong、select、label、em、button、textarea
块级元素:div、ul、li、dl、dt、dd、p、h1-h6、blockquote
空元素:即系没有内容的HTML元素,例如:br、meta、hr、link、input、img
3、CSS实现垂直水平居中
一道经典的问题,实现方法有很多种,以下是其中一种实现:
HTML结构:
<div class="wrapper">
<div class="content"></div>
</div> CSS:
.wrapper {
position: relative;
width: 500px;
height: 500px;
background-color: #ddd;
}
.content{
background-color:#6699FF;
width:200px;
height:200px;
position: absolute; //父元素需要相对定位
top: 50%;
left: 50%;
margin-top:-100px ; //二分之一的height,width
margin-left: -100px;
} 4、简述一下src与href的区别
href 是指向网络资源所在位置,建立和当前元素(锚点)或当前文档(链接)之间的链接,用于超链接。
src是指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置;在请求src资源时会将其指向的资源下载并应用到文档内,例如js脚本,img图片和frame等元素。当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执行完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将js脚本放在底部而不是头部。
5、什么是CSS Hack?
一般来说是针对不同的浏览器写不同的CSS,就是 CSS Hack。
IE浏览器Hack一般又分为三种,条件Hack、属性级Hack、选择符Hack(详细参考CSS文档:css文档)。例如:
// 1、条件Hack
<!--[if IE]>
<style>
.test{color:red;}
</style>
<![endif]-->
// 2、属性Hack
.test{
color:#090\9; /* For IE8+ */
*color:#f00; /* For IE7 and earlier */
_color:#ff0; /* For IE6 and earlier */
}
// 3、选择符Hack
* html .test{color:#090;} /* For IE6 and earlier */
* + html .test{color:#ff0;} /* For IE7 */
6、简述同步和异步的区别
同步是阻塞模式,异步是非阻塞模式。
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
7、px和em的区别
px和em都是长度单位,区别是,px的值是固定的,指定是多少就是多少,计算比较容易。em得值不是固定的,并且em会继承父级元素的字体大小。
浏览器的默认字体高都是16px。所以未经调整的浏览器都符合: 1em=16px。那么12px=0.75em, 10px=0.625em
8、什么叫优雅降级和渐进增强?
渐进增强 progressive enhancement:
针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
优雅降级 graceful degradation:
一开始就构建完整的功能,然后再针对低版本浏览器进行兼容。
区别:
a. 优雅降级是从复杂的现状开始,并试图减少用户体验的供给
b. 渐进增强则是从一个非常基础的,能够起作用的版本开始,并不断扩充,以适应未来环境的需要
c. 降级(功能衰减)意味着往回看;而渐进增强则意味着朝前看,同时保证其根基处于安全地带
9、浏览器的内核分别是什么?
IE: trident内核
Firefox:gecko内核
Safari:webkit内核
Opera:以前是presto内核,Opera现已改用Google Chrome的Blink内核
Chrome:Blink(基于webkit,Google与Opera Software共同开发)
JavaScript部分
怎样添加、移除、移动、复制、创建和查找节点?
1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
2)添加、移除、替换、插入
appendChild() //添加
removeChild() //移除
replaceChild() //替换
insertBefore() //插入
3)查找
getElementsByTagName() //通过标签名称
getElementsByName() //通过元素的Name属性的值
getElementById() //通过元素Id,唯一性
实现一个函数clone,可以对JavaScript中的5种主要的数据类型(包括Number、String、Object、Array、Boolean)进行值复制。
/**
* 对象克隆
* 支持基本数据类型及对象
* 递归方法
*/
function clone(obj) {
var o;
switch (typeof obj) {
case "undefined":
break;
case "string":
o = obj + "";
break;
case "number":
o = obj - 0;
break;
case "boolean":
o = obj;
break;
case "object": // object 分为两种情况 对象(Object)或数组(Array)
if (obj === null) {
o = null;
} else {
if (Object.prototype.toString.call(obj).slice(8, -1) === "Array") {
o = [];
for (var i = 0; i < obj.length; i++) {
o.push(clone(obj[i]));
}
} else {
o = {};
for (var k in obj) {
o[k] = clone(obj[k]);
}
}
}
break;
default:
o = obj;
break;
}
return o;
}如何消除一个数组里面重复的元素?
// 方法一:
var arr1 =[1,2,2,2,3,3,3,4,5,6],
arr2 = [];
for(var i = 0,len = arr1.length; i< len; i++){
if(arr2.indexOf(arr1[i]) < 0){
arr2.push(arr1[i]);
}
}
document.write(arr2); // 1,2,3,4,5,6在Javascript中什么是伪数组?如何将伪数组转化为标准数组?
伪数组(类数组):无法直接调用数组方法或期望length属性有什么特殊的行为,但仍可以对真正数组遍历方法来遍历它们。典型的是函数的argument参数,还有像调用getElementsByTagName,document.childNodes之类的,它们都返回NodeList对象都属于伪数组。可以使用Array.prototype.slice.call(fakeArray)将数组转化为真正的Array对象。
function log(){
var args = Array.prototype.slice.call(arguments);
//为了使用unshift数组方法,将argument转化为真正的数组
args.unshift('(app)');
console.log.apply(console, args);
};Javascript中callee和caller的作用?
caller是返回一个对函数的引用,该函数调用了当前函数;
callee是返回正在被执行的function函数,也就是所指定的function对象的正文。
请描述一下cookies,sessionStorage和localStorage的区别
sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储。而localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的。
web storage和cookie的区别
Web Storage的概念和cookie相似,区别是它是为了更大容量存储设计的。Cookie的大小是受限的,并且每次你请求一个新的页面的时候Cookie都会被发送过去,这样无形中浪费了带宽,另外cookie还需要指定作用域,不可以跨域调用。
除此之外,Web Storage拥有setItem,getItem,removeItem,clear等方法,不像cookie需要前端开发者自己封装setCookie,getCookie。但是Cookie也是不可以或缺的:Cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生。
统计字符串中字母个数或统计最多字母数。
var str = "aaaabbbccccddfgh";
var obj = {};
for(var i=0;i<str.length;i++){
var v = str.charAt(i);
if(obj[v] && obj[v].value == v){
obj[v].count = ++ obj[v].count;
}else{
obj[v] = {};
obj[v].count = 1;
obj[v].value = v;
}
}
for(key in obj){
document.write(obj[key].value +'='+obj[key].count+' '); // a=4 b=3 c=4 d=2 f=1 g=1 h=1
} jQuery的事件委托方法on、live、delegate之间有什么区别?
如何理解闭包?
跨域请求资源的方法有哪些?
谈谈垃圾回收机制方式及内存管理
开发过程中遇到的内存泄露情况,如何解决的?
HTTP
一次完整的HTTP事务是怎样的一个过程?
基本流程:
a. 域名解析
b. 发起TCP的3次握手
c. 建立TCP连接后发起http请求
d. 服务器端响应http请求,浏览器得到html代码
e. 浏览器解析html代码,并请求html代码中的资源
f. 浏览器对页面进行渲染呈现给用户
HTTP的状态码有哪些?
HTTPS是如何实现加密?
算法相关
手写数组快速排序
关于快排算法的详细说明,可以参考阮一峰老师的文章快速排序
"快速排序"的思想很简单,整个排序过程只需要三步:
(1)在数据集之中,选择一个元素作为"基准"(pivot)。
(2)所有小于"基准"的元素,都移到"基准"的左边;所有大于"基准"的元素,都移到"基准"的右边。
(3)对"基准"左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
参考代码:
var quickSort = function(arr) {
if (arr.length <= 1) { return arr; }
var pivotIndex = Math.floor(arr.length / 2);
var pivot = arr.splice(pivotIndex, 1)[0];
var left = [];
var right = [];
for (var i = 0; i < arr.length; i++){
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot], quickSort(right));
};JavaScript实现二分法查找
二分法查找,也称折半查找,是一种在有序数组中查找特定元素的搜索算法。查找过程可以分为以下步骤:
(1)首先,从有序数组的中间的元素开始搜索,如果该元素正好是目标元素(即要查找的元素),则搜索过程结束,否则进行下一步。
(2)如果目标元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半区域查找,然后重复第一步的操作。
(3)如果某一步数组为空,则表示找不到目标元素。
参考代码:
// 非递归算法
function binary_search(arr, key) {
var low = 0,
high = arr.length - 1;
while(low <= high){
var mid = parseInt((high + low) / 2);
if(key == arr[mid]){
return mid;
}else if(key > arr[mid]){
low = mid + 1;
}else if(key < arr[mid]){
high = mid -1;
}else{
return -1;
}
}
};
var arr = [1,2,3,4,5,6,7,8,9,10,11,23,44,86];
var result = binary_search(arr,10);
alert(result); // 9 返回目标元素的索引值
// 递归算法
function binary_search(arr,low, high, key) {
if (low > high){
return -1;
}
var mid = parseInt((high + low) / 2);
if(arr[mid] == key){
return mid;
}else if (arr[mid] > key){
high = mid - 1;
return binary_search(arr, low, high, key);
}else if (arr[mid] < key){
low = mid + 1;
return binary_search(arr, low, high, key);
}
};
var arr = [1,2,3,4,5,6,7,8,9,10,11,23,44,86];
var result = binary_search(arr, 0, 13, 10);
alert(result); // 9 返回目标元素的索引值 Web安全
你所了解到的Web攻击技术
(1)XSS(Cross-Site Scripting,跨站脚本攻击):指通过存在安全漏洞的Web网站注册用户的浏览器内运行非法的HTML标签或者JavaScript进行的一种攻击。
(2)SQL注入攻击
(3)CSRF(Cross-Site Request Forgeries,跨站点请求伪造):指攻击者通过设置好的陷阱,强制对已完成的认证用户进行非预期的个人信息或设定信息等某些状态更新。
前端性能
如何优化图像、图像格式的区别?
浏览器是如何渲染页面的?
设计模式
对MVC、MVVM的理解
正则表达式
写一个function,清除字符串前后的空格。(兼容所有浏览器)
function trim(str) {
if (str && typeof str === "string") {
return str.replace(/(^\s*)|(\s*)$/g,""); //去除前后空白符
}
}使用正则表达式验证邮箱格式
var reg = /^(\w)+(\.\w+)*@(\w)+((\.\w{2,3}){1,3})$/;
var email = "example@qq.com";
console.log(reg.test(email)); // true 职业规划
对前端工程师这个职位你是怎么样理解的?
a. 前端是最贴近用户的程序员,前端的能力就是能让产品从 90分进化到 100 分,甚至更好
b. 参与项目,快速高质量完成实现效果图,精确到1px;
c. 与团队成员,UI设计,产品经理的沟通;
d. 做好的页面结构,页面重构和用户体验;
e. 处理hack,兼容、写出优美的代码格式;
f. 针对服务器的优化、拥抱最新前端技术。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
