Linux查看系统配置常用命令
一、linux CPU大小
cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
说明:Linux下可以在/proc/cpuinfo中看到每个cpu的详细信息。但是对于双核的cpu,在cpuinfo中会看到两个cpu。常常会让人误以为是两个单核的cpu。
其实应该通过Physical Processor ID来区分单核和双核。而Physical Processor ID可以从cpuinfo或者dmesg中找到. flags 如果有 ht 说明支持超线程技术 判断物理CPU的个数可以查看physical id 的值,相同则为
二、内存大小 cat /proc/meminfo |grep MemTotal
三、硬盘大小 fdisk -l |grep Disk
四、uname -a # 查看内核/操作系统/CPU信息的linux系统信息命令
五、head -n 1 /etc/issue # 查看操作系统版本,是数字1不是字母L
六、cat /proc/cpuinfo # 查看CPU信息的linux系统信息命令
七、hostname # 查看计算机名的linux系统信息命令
八、lspci -tv # 列出所有PCI设备
九、lsusb -tv # 列出所有USB设备的linux系统信息命令
十、lsmod # 列出加载的内核模块
十一、env # 查看环境变量资源
十二、free -m # 查看内存使用量和交换区使用量
十三、df -h # 查看各分区使用情况
十四、du -sh # 查看指定目录的大小
十五、grep MemTotal /proc/meminfo # 查看内存总量
十六、grep MemFree /proc/meminfo # 查看空闲内存量
十七、uptime # 查看系统运行时间、用户数、负载
十八、cat /proc/loadavg # 查看系统负载磁盘和分区
十九、mount | column -t # 查看挂接的分区状态
二十、fdisk -l # 查看所有分区
二十一、swapon -s # 查看所有交换分区
二十二、hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
二十三、dmesg | grep IDE # 查看启动时IDE设备检测状况网络
二十四、ifconfig # 查看所有网络接口的属性
二十五、iptables -L # 查看防火墙设置
二十六、route -n # 查看路由表
二十七、netstat -lntp # 查看所有监听端口
二十八、netstat -antp # 查看所有已经建立的连接
二十九、netstat -s # 查看网络统计信息进程
三十、ps -ef # 查看所有进程
三十一、top # 实时显示进程状态用户
三十二、w # 查看活动用户
三十三、id # 查看指定用户信息
三十四、last # 查看用户登录日志
三十五、cut -d: -f1 /etc/passwd # 查看系统所有用户
三十六、cut -d: -f1 /etc/group # 查看系统所有组
三十七、crontab -l # 查看当前用户的计划任务服务
三十七、chkconfig –list # 列出所有系统服务
三十八、chkconfig –list | grep on # 列出所有启动的系统服务程序
三十九、rpm -qa # 查看所有安装的软件包
四十、cat /proc/cpuinfo :查看CPU相关参数的linux系统命令
四十一、cat /proc/partitions :查看linux硬盘和分区信息的系统信息命令
四十二、cat /proc/meminfo :查看linux系统内存信息的linux系统命令
四十三、cat /proc/version :查看版本,类似uname -r
四十四、cat /proc/ioports :查看设备io端口
四十五、cat /proc/interrupts :查看中断
四十六、cat /proc/pci :查看pci设备的信息
四十七、cat /proc/swaps :查看所有swap分区的信息
Redis内存数据库操作命令详解
默认无权限控制:
远程服务连接:
$ redis-cli -h 127.0.0.1 -p 6379
windows下 :redis-cli.exe -h 127.0.0.1 -p 6379
redis 127.0.0.1:6379>
远程服务停止:
$ redis-cli -h 172.168.10.254 -p6379 shutdown
2) 有权限控制时(加上-a 密码):
redis-cli -h 127.0.0.1 -p 6379 -a 123456
除了在登录时通过 -a 参数制定密码外,还可以登录时不指定密码,而在执行操作前进行认证。

Redis默认端口号为127.0.0.1,端口号默认为:6379。
此处本机访问远程IP为132.1.114.44的计算机,则首先要在已经安装了Redis的远程计算机上打开其服务器,redis.server.exe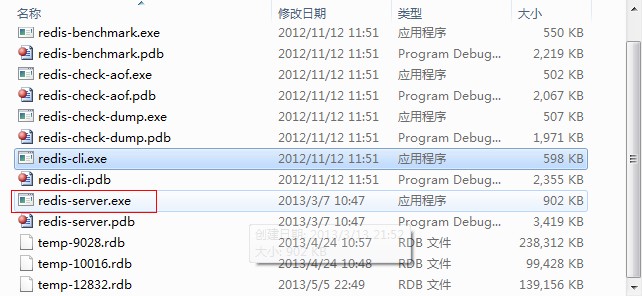
接下来在本机运行redis.cli.exe,也可以通过命令行实现:输入-h 远程计算机IP -p 6379即可连接:

OK了,接下来如果想用自己写的客户端什么的连接远程Redis数据库也只需要输入远程计算机的IP就可以了~
Redis系列-远程连接redis
用法:redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <主机ip>,默认是127.0.0.1
-p <端口>,默认是6379
-a <密码>,如果redis加锁,需要传递密码
--help,显示帮助信息
通过对rendis-cli用法介绍,在101上连接103应该很简单:
[root@linuxidc001 ~]# redis-cli -h 192.168.1.103 -p 6379
redis 192.168.1.103:6379>
在101上对103设置个个string值 user.1.name=zhangsan
redis 192.168.1.103:6379> set user.1.name zhangsan
OK
看到ok,表明设置成功了。然后直接在103上登陆,看能不能获取到这个值。
redis 192.168.1.103:6379> keys *
redis 192.168.1.103:6379> select 1
1、连接操作相关的命令
- quit:关闭连接(connection)
- auth:简单密码认证
2、对value操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个key
- rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
3、对String操作的命令
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
- setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
- setex(key, time, value):向库中添加string(名称为key,值为value)同时,设定过期时间time
- mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
- msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
4、对List操作的命令
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
- ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值为value
- lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从 头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对 keyi 1开始的list执行pop操作。
- brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
- zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
- zrem(key, member) :删除名称为key的zset中的元素member
- zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
- zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
- zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
- zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
- zunionstore / zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行 AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素 的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
Redis内存分析方法
一般会采用 bgsave 生成 dump.rdb 文件,再结合 redis-rdb-tools 和 sqlite 来进行静态分析。
BGSAVE:在后台异步(Asynchronously)保存当前数据库的数据到磁盘。
BGSAVE 命令执行之后立即返回 OK ,然后 Redis fork 出一个新子进程,原来的 Redis 进程(父进程)继续处理客户端请求,而子进程则负责将数据保存到磁盘,然后退出。
生成内存快照:redis-rdb-tools 是一个 python 的解析 rdb 文件的工具,在分析内存的时候,主要用它生成内存快照。
redis-rdb-tools 安装:
使用 PYPI 安装:
pip install rdbtools
使用 源码安装:
git clone https://github.com/sripathikrishnan/redis-rdb-tools cd redis-rdb-tools sudo python setup.py install
使用 redis-rdb-tools 生成内存快照:
rdb -c memory dump.rdb > memory.csv
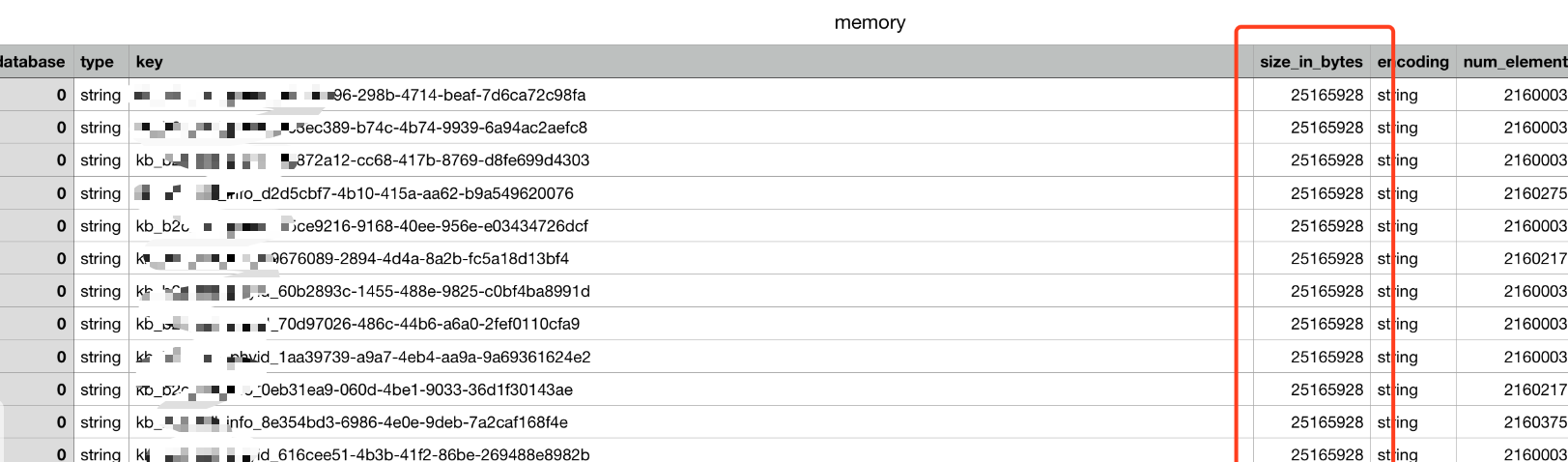
生成 CSV 格式的内存报告。包含的列有:数据库 ID,数据类型,key,内存使用量(byte),编码。内存使用量包含 key、value 和其他值。
内存使用量是理论上的近似值,在一般情况下,略低于实际值。
[ares:~/Desktop$head memory.csv database,type,key,size_in_bytes,encoding,num_elements,len_largest_element 0,string,trade.coupon.id:653601465,112,string,8,8 0,string,trade.coupon.id:631354838,112,string,8,8 0,string,trade.coupon.id:632477800,112,string,8,8 0,string,trade.coupon.id:620802294,112,string,8,8 0,string,trade.coupon.id:631432959,112,string,8,8 0,string,trade.coupon.id:632933399,112,string,8,8 0,string,trade.coupon.id:632117725,112,string,8,8 0,string,trade.coupon.id:634240609,112,string,8,8 0,string,trade.coupon.id:646317603,112,string,8,8
注:若csv文件不大,可直接用相关软件打开,以size_in_bytes列排序,可以看到大致内存使用。
使用SQLite分析内存快照:
SQLite版本必须是3.16.0以上。
导入memory.csv数据库:
$sqlite3 memory.db SQLite version 3.19.3 2017-06-27 16:48:08 Enter ".help" for usage hints. sqlite> create table memory(database int,type varchar(128),key varchar(128),size_in_bytes int,encoding varchar(128),num_elements int,len_largest_element varchar(128)); sqlite> .mode csv memory sqlite> .import memory.csv memory 数据导入后,可以随处理:
查询key总数:
sqlite> select count(*) from memory; 31143847
查询key总占用内存:
sqlite> select sum(size_in_bytes) from memory; 17391950414.0
查询内容占用最高的几个key:
sqlite> select key,size_in_bytes from memory order by size_in_bytes desc limit 10; key,size_in_bytes public.xx.xx:xx,7860169636 public.xx.xx:xx,3043206524 public.xx.xx:xx,1866022916 public.xx.xx:xx,420931316 public.xx.xx:idxx171118172 xx,162984940 xx,133443892 public.xx.xx:xx,80925132 public.xx.xx:xx,28340356
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
