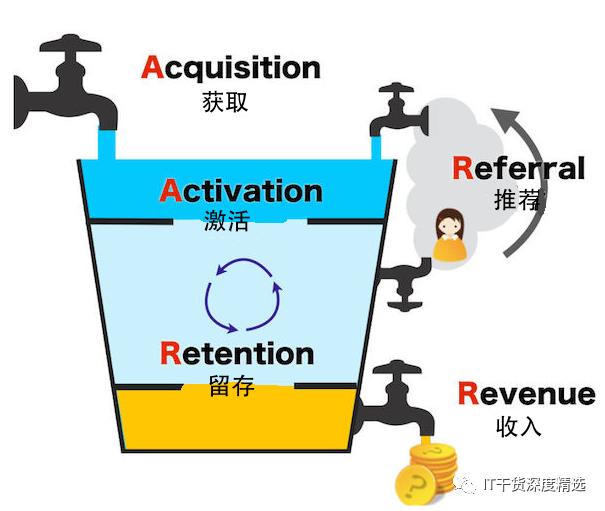
什么是AARRR
Charles 从入门到精通
简介
![]()
Mac软件下载 https://xclient.info/s/
Charles 是在 Mac 下常用的网络封包截取工具,在做
移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析。
Charles 通过将自己设置成系统的网络访问代理服务器,使得所有的网络访问请求都通过它来完成,从而实现了网络封包的截取和分析。
除了在做移动开发中调试端口外,Charles 也可以用于分析第三方应用的通讯协议。配合 Charles 的 SSL 功能,Charles 还可以分析 Https 协议。
Charles 是收费软件,可以免费试用 30 天。试用期过后,未付费的用户仍然可以继续使用,但是每次使用时间不能超过 30 分钟,并且启动时将会有 10 秒种的延时。因此,该付费方案对广大用户还是相当友好的,即使你长期不付费,也能使用完整的软件功能。只是当你需要长时间进行封包调试时,会因为 Charles 强制关闭而遇到影响。
Charles 主要的功能包括:
- 截取 Http 和 Https 网络封包。
- 支持重发网络请求,方便后端调试。
- 支持修改网络请求参数。
- 支持网络请求的截获并动态修改。
- 支持模拟慢速网络。
Charles 4 新增的主要功能包括:
- 支持 Http 2。
- 支持 IPv6。
安装 Charles
去 Charles 的官方网站(http://www.charlesproxy.com)下载最新版的 Charles 安装包,是一个 dmg 后缀的文件。打开后将 Charles 拖到 Application 目录下即完成安装。
将 Charles 设置成系统代理
之前提到,Charles 是通过将自己设置成代理服务器来完成封包截取的,所以使用 Charles 的第一步是将其设置成系统的代理服务器。
启动 Charles 后,第一次 Charles 会请求你给它设置系统代理的权限。你可以输入登录密码授予 Charles 该权限。你也可以忽略该请求,然后在需要将 Charles 设置成系统代理时,选择菜单中的 “Proxy” -> “Mac OS X Proxy” 来将 Charles 设置成系统代理。如下所示:
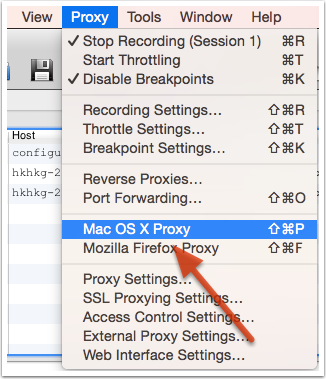
之后,你就可以看到源源不断的网络请求出现在 Charles 的界面中。
需要注意的是,Chrome 和 Firefox 浏览器默认并不使用系统的代理服务器设置,而 Charles 是通过将自己设置成代理服务器来完成封包截取的,所以在默认情况下无法截取 Chrome 和 Firefox 浏览器的网络通讯内容。如果你需要截取的话,在 Chrome 中设置成使用系统的代理服务器设置即可,或者直接将代理服务器设置成 127.0.0.1:8888 也可达到相同效果。
Charles 主界面介绍
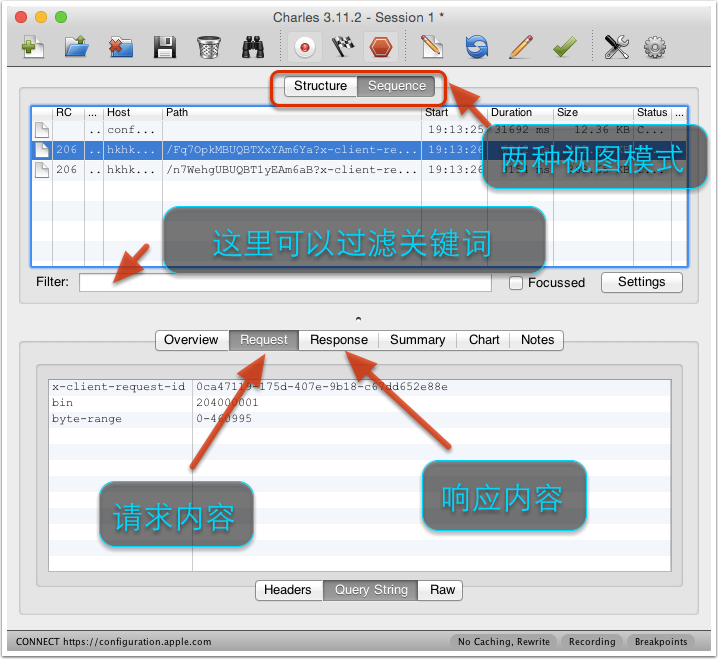
Charles 主要提供两种查看封包的视图,分别名为 “Structure” 和 “Sequence”。
- Structure 视图将网络请求按访问的域名分类。
- Sequence 视图将网络请求按访问的时间排序。
大家可以根据具体的需要在这两种视图之前来回切换。请求多了有些时候会看不过来,Charles 提供了一个简单的 Filter 功能,可以输入关键字来快速筛选出 URL 中带指定关键字的网络请求。
对于某一个具体的网络请求,你可以查看其详细的请求内容和响应内容。如果请求内容是 POST 的表单,Charles 会自动帮你将表单进行分项显示。如果响应内容是 JSON 格式的,那么 Charles 可以自动帮你将 JSON 内容格式化,方便你查看。如果响应内容是图片,那么 Charles 可以显示出图片的预览。
过滤网络请求
通常情况下,我们需要对网络请求进行过滤,只监控向指定目录服务器上发送的请求。对于这种需求,以下几种办法:
方法一:在主界面的中部的 Filter 栏中填入需要过滤出来的关键字。例如我们的服务器的地址是:http://yuantiku.com , 那么只需要在 Filter 栏中填入 yuantiku 即可。
方法二:在 Charles 的菜单栏选择 “Proxy”->”Recording Settings”,然后选择 Include 栏,选择添加一个项目,然后填入需要监控的协议,主机地址,端口号。这样就可以只截取目标网站的封包了。如下图所示:
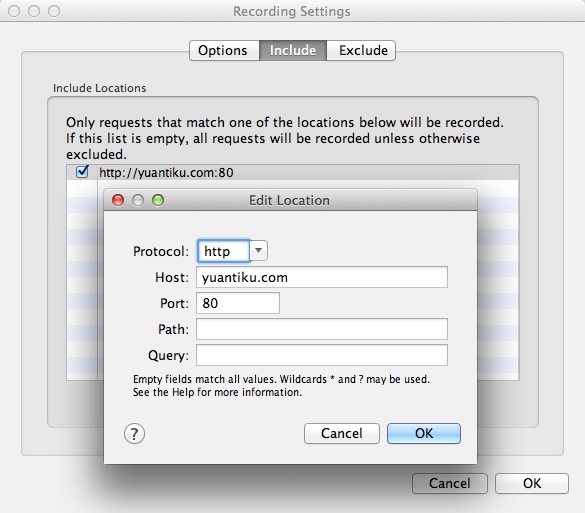
通常情况下,我们使用方法一做一些临时性的封包过滤,使用方法二做一些经常性的封包过滤。
方法三:在想过滤的网络请求上右击,选择 “Focus”,之后在 Filter 一栏勾选上 Focussed 一项,如下图所示:
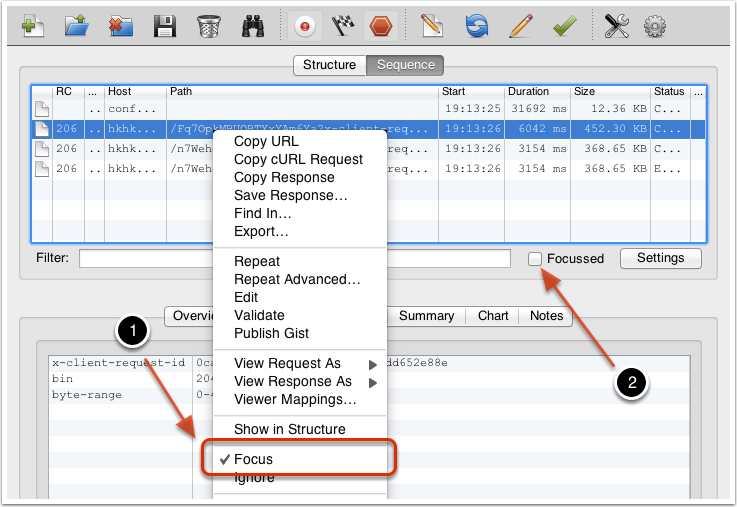
这种方式可以临时性的,快速地过滤出一些没有通过关键字的一类网络请求。
截取 iPhone 上的网络封包
Charles 通常用来截取本地上的网络封包,但是当我们需要时,我们也可以用来截取其它设备上的网络请求。下面我就以 iPhone 为例,讲解如何进行相应操作。
Charles 上的设置
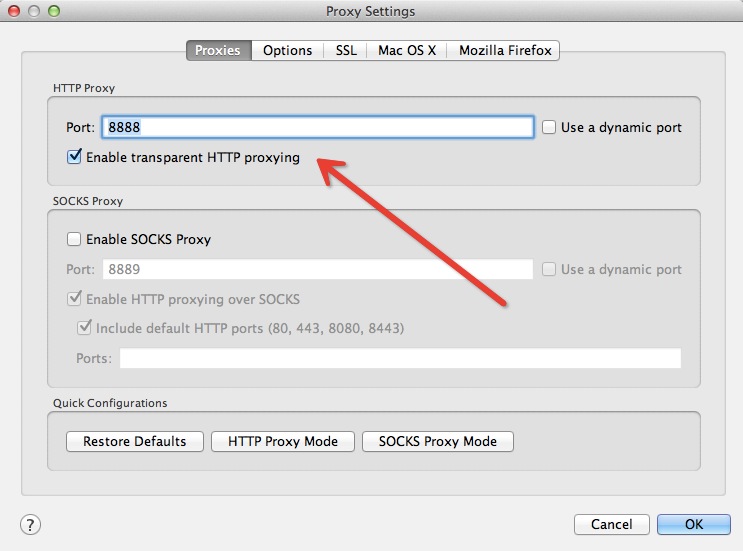
要截取 iPhone 上的网络请求,我们首先需要将 Charles 的代理功能打开。在 Charles 的菜单栏上选择 “Proxy”->”Proxy Settings”,填入代理端口 8888,并且勾上 “Enable transparent HTTP proxying” 就完成了在 Charles 上的设置。如下图所示:
iPhone 上的设置
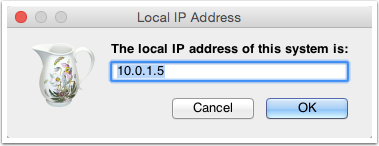
首先我们需要获取 Charles 运行所在电脑的 IP 地址,Charles 的顶部菜单的 “Help”->”Local IP Address”,即可在弹出的对话框中看到 IP 地址,如下图所示:
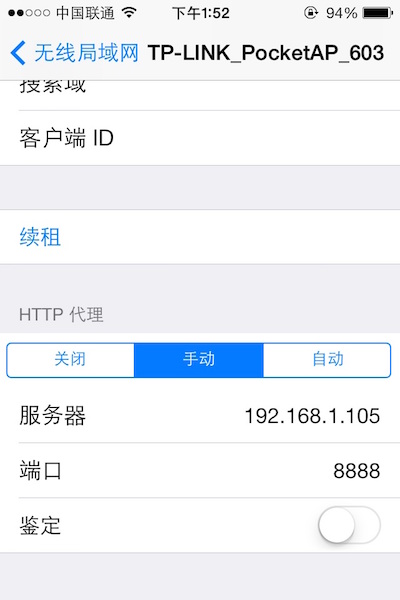
在 iPhone 的 “ 设置 “->” 无线局域网 “ 中,可以看到当前连接的 wifi 名,通过点击右边的详情键,可以看到当前连接上的 wifi 的详细信息,包括 IP 地址,子网掩码等信息。在其最底部有「HTTP 代理」一项,我们将其切换成手动,然后填上 Charles 运行所在的电脑的 IP,以及端口号 8888,如下图所示:
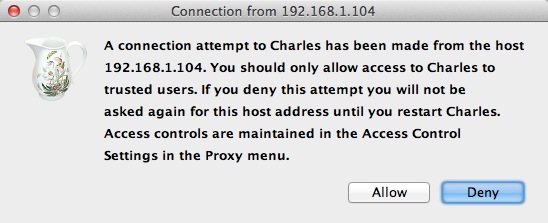
设置好之后,我们打开 iPhone 上的任意需要网络通讯的程序,就可以看到 Charles 弹出 iPhone 请求连接的确认菜单(如下图所示),点击 “Allow” 即可完成设置。
截取 Https 通讯信息
安装证书
如果你需要截取分析 Https 协议相关的内容。那么需要安装 Charles 的 CA 证书。具体步骤如下。
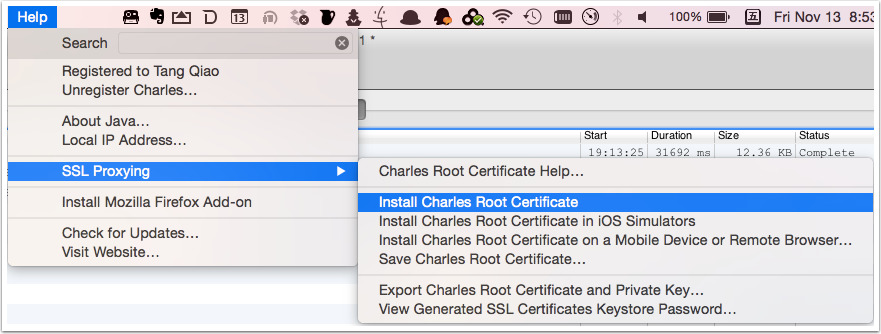
首先我们需要在 Mac 电脑上安装证书。点击 Charles 的顶部菜单,选择 “Help” -> “SSL Proxying” -> “Install Charles Root Certificate”,然后输入系统的帐号密码,即可在 KeyChain 看到添加好的证书。如下图所示:
需要注意的是,即使是安装完证书之后,Charles 默认也并不截取 Https 网络通讯的信息,如果你想对截取某个网站上的所有 Https 网络请求,可以在该请求上右击,选择 SSL proxy,如下图所示:
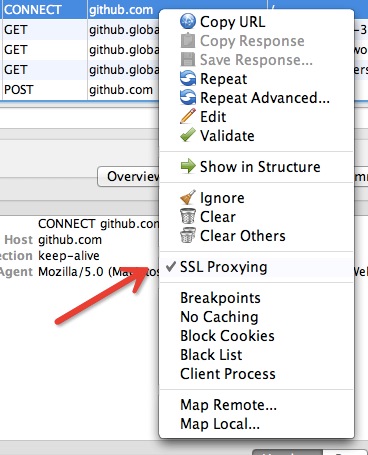
这样,对于该 Host 的所有 SSL 请求可以被截取到了。
截取移动设备中的 Https 通讯信息
如果我们需要在 iOS 或 Android 机器上截取 Https 协议的通讯内容,还需要在手机上安装相应的证书。点击 Charles 的顶部菜单,选择 “Help” -> “SSL Proxying” -> “Install Charles Root Certificate on a Mobile Device or Remote Browser”,然后就可以看到 Charles 弹出的简单的安装教程。如下图所示:
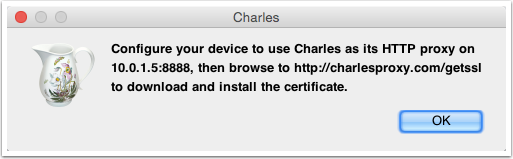
按照我们之前说的教程,在设备上设置好 Charles 为代理后,在手机浏览器中访问地址:http://charlesproxy.com/getssl,即可打开证书安装的界面,安装完证书后,就可以截取手机上的 Https 通讯内容了。不过同样需要注意,默认情况下 Charles 并不做截取,你还需要在要截取的网络请求上右击,选择 SSL proxy 菜单项。
模拟慢速网络
在做移动开发的时候,我们常常需要模拟慢速网络或者高延迟的网络,以测试在移动网络下,应用的表现是否正常。Charles 对此需求提供了很好的支持。
在 Charles 的菜单上,选择 “Proxy”->”Throttle Setting” 项,在之后弹出的对话框中,我们可以勾选上 “Enable Throttling”,并且可以设置 Throttle Preset 的类型。如下图所示:
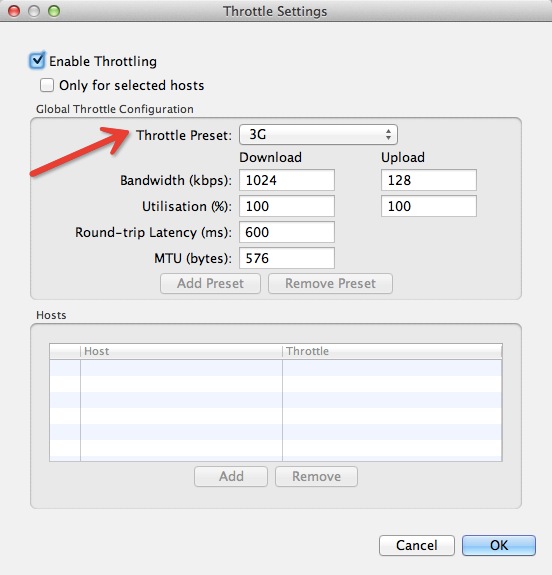
如果我们只想模拟指定网站的慢速网络,可以再勾选上图中的 “Only for selected hosts” 项,然后在对话框的下半部分设置中增加指定的 hosts 项即可。
修改网络请求内容
有些时候为了调试服务器的接口,我们需要反复尝试不同参数的网络请求。Charles 可以方便地提供网络请求的修改和重发功能。只需要在以往的网络请求上点击右键,选择 “Edit”,即可创建一个可编辑的网络请求。如下所示:
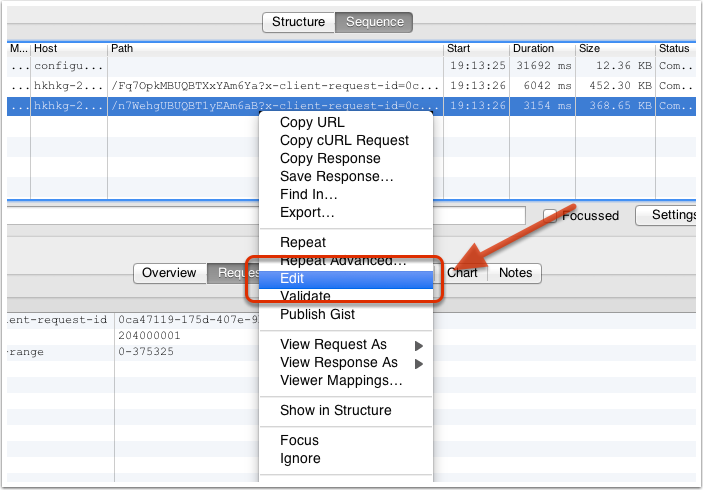
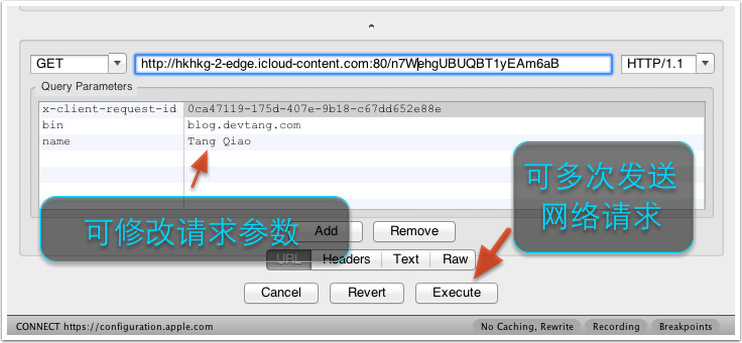
我们可以修改该请求的任何信息,包括 URL 地址、端口、参数等,之后点击 “Execute” 即可发送该修改后的网络请求(如下图所示)。Charles 支持我们多次修改和发送该请求,这对于我们和服务器端调试接口非常方便,如下图所示:
给服务器做压力测试
我们可以使用 Charles 的 Repeat 功能来简单地测试服务器的并发处理能力,方法如下。
我们在想打压的网络请求上(POST 或 GET 请求均可)右击,然后选择 「Repeat Advanced」菜单项,如下所示:
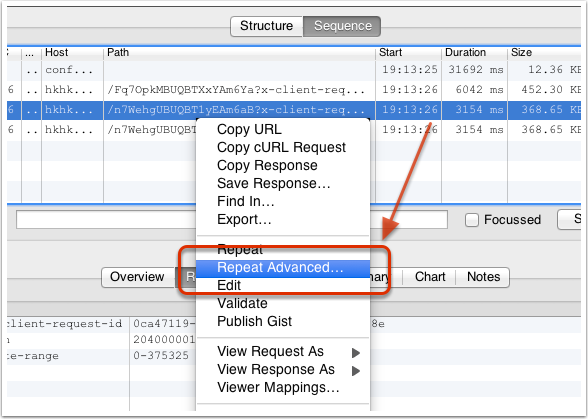
接着我们就可以在弹出的对话框中,选择打压的并发线程数以及打压次数,确定之后,即可开始打压。
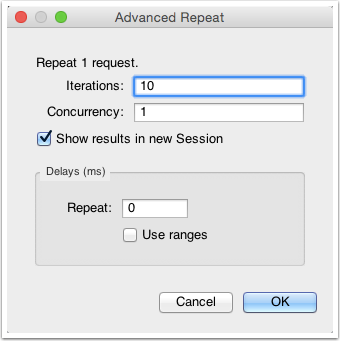
悄悄说一句,一些写得很弱的投票网站,也可以用这个办法来快速投票。当然,我也拿 Charles 的 Repeat 功能给一些诈骗的钓鱼网站喂了不少垃圾数据,上次不小心还把一个钓鱼网站的数据库打挂了,嗯,请叫我雷锋。
修改服务器返回内容
有些时候我们想让服务器返回一些指定的内容,方便我们调试一些特殊情况。例如列表页面为空的情况,数据异常的情况,部分耗时的网络请求超时的情况等。如果没有 Charles,要服务器配合构造相应的数据显得会比较麻烦。这个时候,使用 Charles 相关的功能就可以满足我们的需求。
根据具体的需求,Charles 提供了 Map 功能、 Rewrite 功能以及 Breakpoints 功能,都可以达到修改服务器返回内容的目的。这三者在功能上的差异是:
- Map 功能适合长期地将某一些请求重定向到另一个网络地址或本地文件。
- Rewrite 功能适合对网络请求进行一些正则替换。
- Breakpoints 功能适合做一些临时性的修改。
Map 功能
Charles 的 Map 功能分 Map Remote 和 Map Local 两种,顾名思义,Map Remote 是将指定的网络请求重定向到另一个网址请求地址,Map Local 是将指定的网络请求重定向到本地文件。
在 Charles 的菜单中,选择 “Tools”->”Map Remote” 或 “Map Local” 即可进入到相应功能的设置页面。
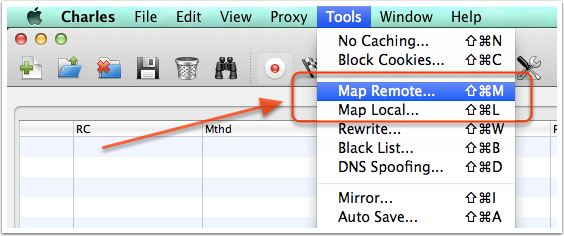
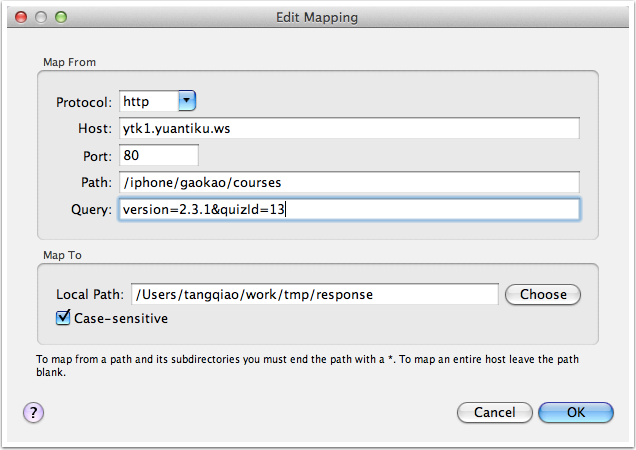
对于 Map Remote 功能,我们需要分别填写网络重定向的源地址和目的地址,对于不需要限制的条件,可以留空。下图是一个示例,我将所有 ytk1.yuanku.ws(测试服务器)的请求重定向到了 www.yuantiku.com(线上服务器)。
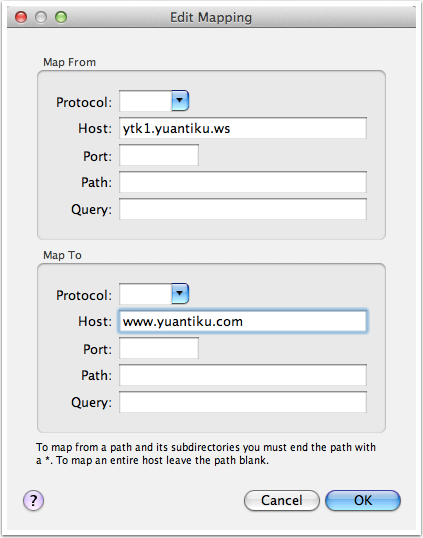
对于 Map Local 功能,我们需要填写的重定向的源地址和本地的目标文件。对于有一些复杂的网络请求结果,我们可以先使用 Charles 提供的 “Save Response…” 功能,将请求结果保存到本地(如下图所示),然后稍加修改,成为我们的目标映射文件。
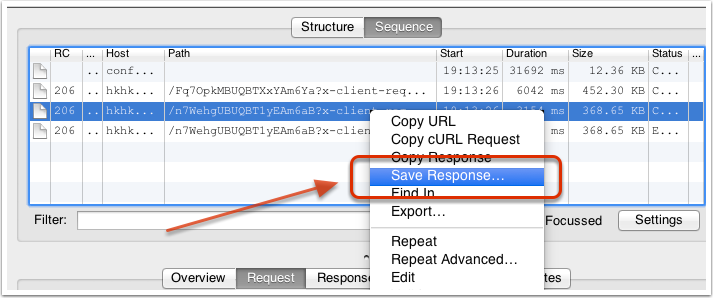
下图是一个示例,我将一个指定的网络请求通过 Map Local 功能映射到了本地的一个经过修改的文件中。
Map Local 在使用的时候,有一个潜在的问题,就是其返回的 Http Response Header 与正常的请求并不一样。这个时候如果客户端校验了 Http Response Header 中的部分内容,就会使得该功能失效。解决办法是同时使用 Map Local 以下面提到的 Rewrite 功能,将相关的 Http 头 Rewrite 成我们希望的内容。
Rewrite 功能
Rewrite 功能功能适合对某一类网络请求进行一些正则替换,以达到修改结果的目的。
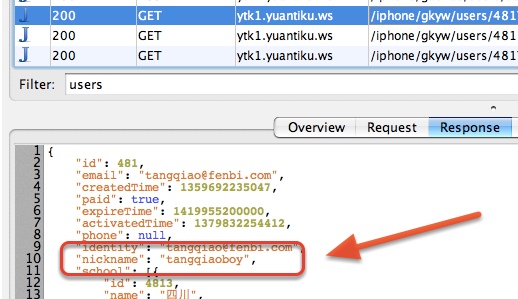
例如,我们的客户端有一个 API 请求是获得用户昵称,而我当前的昵称是 “tangqiaoboy”,如下所示:
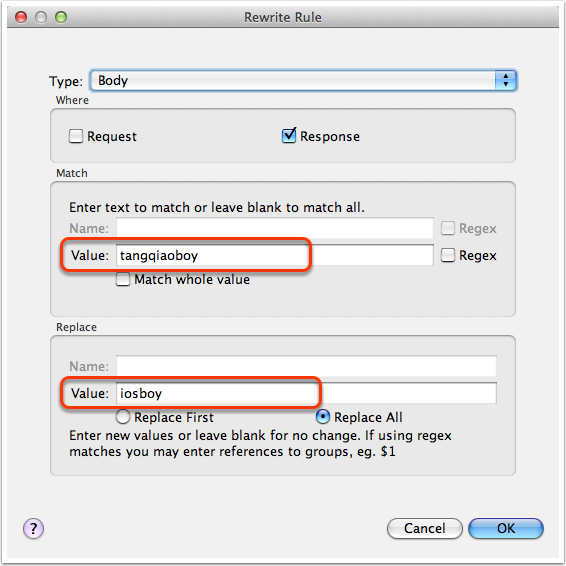
我们想试着直接修改网络返回值,将 tangqiaoboy 换成成 iosboy。于是我们启用 Rewrite 功能,然后设置如下的规则:
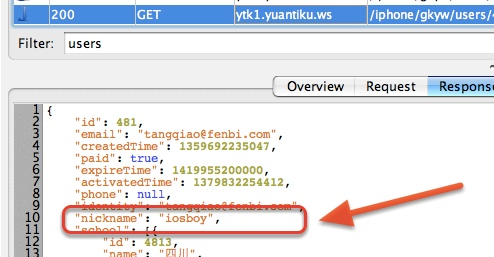
完成设置之后,我们就可以从 Charles 中看到,之后的 API 获得的昵称被自动 Rewrite 成了 iosboy,如下图所示:
Breakpoints 功能
上面提供的 Rewrite 功能最适合做批量和长期的替换,但是很多时候,我们只是想临时修改一次网络请求结果,这个时候,使用 Rewrite 功能虽然也可以达到目的,但是过于麻烦,对于临时性的修改,我们最好使用 Breakpoints 功能。
Breakpoints 功能类似我们在 Xcode 中设置的断点一样,当指定的网络请求发生时,Charles 会截获该请求,这个时候,我们可以在 Charles 中临时修改网络请求的返回内容。
下图是我们临时修改获取用户信息的 API,将用户的昵称进行了更改,修改完成后点击 “Execute” 则可以让网络请求继续进行。
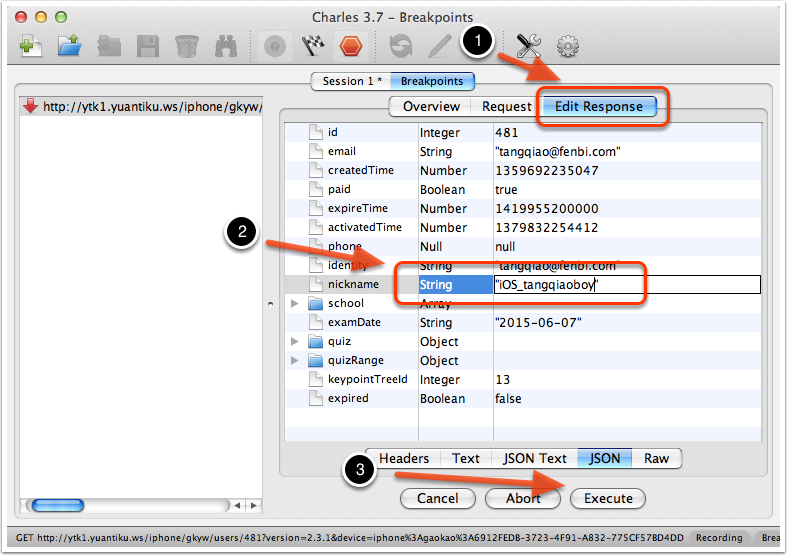
需要注意的是,使用 Breakpoints 功能将网络请求截获并修改过程中,整个网络请求的计时并不会暂停,所以长时间的暂停可能导致客户端的请求超时。
反向代理
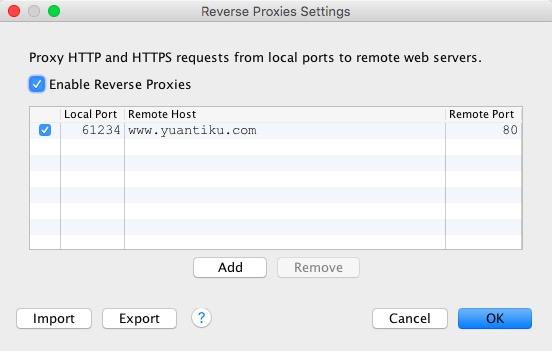
Charles 的反向代理功能允许我们将本地的端口映射到远程的另一个端口上。例如,在下图中,我将本机的 61234 端口映射到了远程(www.yuantiku.com)的80端口上了。这样,当我访问本地的 61234 端口时,实际返回的内容会由 www.yuantiku.com 的 80 端口提供。
设置外部代理,解决与翻墙软件的冲突
Charles 的原理是把自己设置成系统的代理服务器,但是在中国,由于工作需要,我们常常需要使用 Google 搜索,所以大部分程序员都有自己的翻墙软件,而这些软件的基本原理,也是把自己设置成系统的代理服务器,来做到透明的翻墙。
为了使得两者能够和平共处,我们可以在 Charles 的 External Proxy Settings 中,设置翻墙的代理端口以及相关信息。同时,我们也要关闭相关翻墙软件的自动设置,使其不主动修改系统代理,避免 Charles 失效。
总结
通过 Charles 软件,我们可以很方便地在日常开发中,截取和调试网络请求内容,分析封包协议以及模拟慢速网络。用好 Charles 可以极大的方便我们对于带有网络请求的 App 的开发和调试。
愿本文帮助大家成为 Charles 的专家,祝大家玩得开心~
logback.xml常用配置
一、logback的介绍
Logback是由log4j创始人设计的又一个开源日志组件。logback当前分成三个模块:logback-core,logback- classic和logback-access。logback-core是其它两个模块的基础模块。logback-classic是log4j的一个 改良版本。此外logback-classic完整实现SLF4J API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging。logback-access访问模块与Servlet容器集成提供通过Http来访问日志的功能。 Logback是要与SLF4J结合起来用两个组件的官方网站如下:
logback的官方网站: http://logback.qos.ch
SLF4J的官方网站:http://www.slf4j.org
本文章用到的组件如下:请自行到官方网站下载!
logback-access-1.0.0.jar
logback-classic-1.0.0.jar
logback-core-1.0.0.jar
slf4j-api-1.6.0.jar
二、logback取代 log4j的理由:
Logback和log4j是非常相似的,如果你对log4j很熟悉,那对logback很快就会得心应手。下面列了logback相对于log4j的一些优点:
1、更快的实现 Logback的内核重写了,在一些关键执行路径上性能提升10倍以上。而且logback不仅性能提升了,初始化内存加载也更小了。
2、非常充分的测试 Logback经过了几年,数不清小时的测试。Logback的测试完全不同级别的。在作者的观点,这是简单重要的原因选择logback而不是log4j。
3、Logback-classic非常自然实现了SLF4j Logback-classic实现了 SLF4j。在使用SLF4j中,你都感觉不到logback-classic。而且因为logback-classic非常自然地实现了SLF4J, 所 以切换到log4j或者其他,非常容易,只需要提供成另一个jar包就OK,根本不需要去动那些通过SLF4JAPI实现的代码。
4、非常充分的文档 官方网站有两百多页的文档。
5、自动重新加载配置文件 当配置文件修改了,Logback-classic能自动重新加载配置文件。扫描过程快且安全,它并不需要另外创建一个扫描线程。这个技术充分保证了应用程序能跑得很欢在JEE环境里面。
6、Lilith Lilith是log事件的观察者,和log4j的chainsaw类似。而lilith还能处理大数量的log数据 。
7、谨慎的模式和非常友好的恢复 在谨慎模式下,多个FileAppender实例跑在多个JVM下,能 够安全地写道同一个日志文件。RollingFileAppender会有些限制。Logback的FileAppender和它的子类包括 RollingFileAppender能够非常友好地从I/O异常中恢复。
8、配置文件可以处理不同的情况 开发人员经常需要判断不同的Logback配置文件在不同的环境下(开发,测试,生产)。而这些配置文件仅仅只有一些很小的不同,可以通过,和来实现,这样一个配置文件就可以适应多个环境。
9、Filters(过滤器) 有些时候,需要诊断一个问题,需要打出日志。在log4j,只有降低日志级别,不过这样会打出大量的日志,会影响应用性能。在Logback,你可以继续 保持那个日志级别而除掉某种特殊情况,如alice这个用户登录,她的日志将打在DEBUG级别而其他用户可以继续打在WARN级别。要实现这个功能只需 加4行XML配置。可以参考MDCFIlter 。
10、SiftingAppender(一个非常多功能的Appender) 它可以用来分割日志文件根据任何一个给定的运行参数。如,SiftingAppender能够区别日志事件跟进用户的Session,然后每个用户会有一个日志文件。
11、自动压缩已经打出来的log RollingFileAppender在产生新文件的时候,会自动压缩已经打出来的日志文件。压缩是个异步过程,所以甚至对于大的日志文件,在压缩过程中应用不会受任何影响。
12、堆栈树带有包版本 Logback在打出堆栈树日志时,会带上包的数据。
13、自动去除旧的日志文件 通过设置TimeBasedRollingPolicy或者SizeAndTimeBasedFNATP的maxHistory属性,你可以控制已经产生日志文件的最大数量。如果设置maxHistory 12,那那些log文件超过12个月的都会被自动移除。
总之,logback比log4j太优秀了,让我们的应用全部建立logback上吧 !
三、Logback的配置介绍
1、Logger、appender及layout
Logger作为日志的记录器,把它关联到应用的对应的context上后,主要用于存放日志对象,也可以定义日志类型、级别。
Appender主要用于指定日志输出的目的地,目的地可以是控制台、文件、远程套接字服务器、 MySQL、PostreSQL、 Oracle和其他数据库、 JMS和远程UNIX Syslog守护进程等。
Layout 负责把事件转换成字符串,格式化的日志信息的输出。
2、logger context
各个logger 都被关联到一个 LoggerContext,LoggerContext负责制造logger,也负责以树结构排列各logger。其他所有logger也通过org.slf4j.LoggerFactory 类的静态方法getLogger取得。 getLogger方法以 logger名称为参数。用同一名字调用LoggerFactory.getLogger 方法所得到的永远都是同一个logger对象的引用。
3、有效级别及级别的继承
Logger 可以被分配级别。级别包括:TRACE、DEBUG、INFO、WARN 和 ERROR,定义于ch.qos.logback.classic.Level类。如果 logger没有被分配级别,那么它将从有被分配级别的最近的祖先那里继承级别。root logger 默认级别是 DEBUG。
4、打印方法与基本的选择规则
打印方法决定记录请求的级别。例如,如果 L 是一个 logger 实例,那么,语句 L.info("..")是一条级别为 INFO的记录语句。记录请求的级别在高于或等于其 logger 的有效级别时被称为被启用,否则,称为被禁用。记录请求级别为 p,其 logger的有效级别为 q,只有则当 p>=q时,该请求才会被执行。
该规则是 logback 的核心。级别排序为: TRACE < DEBUG < INFO < WARN < ERROR
四、Logback的默认配置
如果配置文件 logback-test.xml 和 logback.xml 都不存在,那么 logback 默认地会调用BasicConfigurator ,创建一个最小化配置。最小化配置由一个关联到根 logger 的ConsoleAppender 组成。输出用模式为%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n 的 PatternLayoutEncoder 进行格式化。root logger 默认级别是 DEBUG。
1、Logback的配置文件
Logback 配置文件的语法非常灵活。正因为灵活,所以无法用 DTD 或 XML schema 进行定义。尽管如此,可以这样描述配置文件的基本结构:以<configuration>开头,后面有零个或多个<appender>元素,有零个或多个<logger>元素,有最多一个<root>元素。
2、Logback默认配置的步骤
(1). 尝试在 classpath 下查找文件 logback-test.xml;
(2). 如果文件不存在,则查找文件 logback.xml;
(3). 如果两个文件都不存在,logback 用 Bas icConfigurator 自动对自己进行配置,这会导致记录输出到控制台
以下为详细代码
<?xml version="1.0" encoding="UTF-8"?>
<!-- 说明: 1、日志级别及文件 日志记录采用分级记录,级别与日志文件名相对应,不同级别的日志信息记录到不同的日志文件中 例如:error级别记录到log_error_xxx.log或log_error.log(该文件为当前记录的日志文件),而log_error_xxx.log为归档日志,
日志文件按日期记录,同一天内,若日志文件大小等于或大于2M,则按0、1、2...顺序分别命名 例如log-level-2013-12-21.0.log
其它级别的日志也是如此。 2、文件路径 若开发、测试用,在Eclipse中运行项目,则到Eclipse的安装路径查找logs文件夹,以相对路径../logs。
若部署到Tomcat下,则在Tomcat下的logs文件中 3、Appender FILEERROR对应error级别,文件名以log-error-xxx.log形式命名
FILEWARN对应warn级别,文件名以log-warn-xxx.log形式命名 FILEINFO对应info级别,文件名以log-info-xxx.log形式命名
FILEDEBUG对应debug级别,文件名以log-debug-xxx.log形式命名 stdout将日志信息输出到控制上,为方便开发测试使用 -->
<configuration>
<!-- 在Eclipse中运行,请到Eclipse的安装目录中找log文件,Tomcat下,请到Tomcat目录下找 -->
<!-- <property name="LOG_PATH" value="/xebest/logs/llmj-app" /> -->
<property name="LOG_PATH" value="E:/logs/llmj-app" />
<!-- 日志记录器,日期滚动记录 -->
<appender name="FILEERROR"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/log_error.log</file>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 归档的日志文件的路径,例如今天是2013-12-21日志,当前写的日志文件路径为file节点指定,可以将此文件与file指定文件路径设置为不同路径,从而将当前日志文件或归档日志文件置不同的目录。
而2013-12-21的日志文件在由fileNamePattern指定。%d{yyyy-MM-dd}指定日期格式,%i指定索引 -->
<fileNamePattern>${LOG_PATH}/log-error-%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<!-- 除按日志记录之外,还配置了日志文件不能超过2M,若超过2M,日志文件会以索引0开始, 命名日志文件,例如log-error-2013-12-21.0.log -->
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 追加方式记录日志 -->
<append>true</append>
<!-- 日志文件的格式 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-5p [%d][%mdc{mdc_userId}] %C:%L - %m %n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录error级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>error</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="FILEWARN"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/log_warn.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log-warn-%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<append>true</append>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-5p [%d][%mdc{mdc_userId}] %C:%L - %m %n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录warn级别,不记录大于warn级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>WARN</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="FILEINFO"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/log_info.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log-info-%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<append>true</append>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-5p [%d][%mdc{mdc_userId}] %C:%L - %m %n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录info级别,不记录大于info级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="FILEDEBUG"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/log_debug.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log-debug-%d{yyyy-MM-dd}.%i.log
</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<append>true</append>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%-5p [%d][%mdc{mdc_userId}] %C:%L - %m %n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录debug级别,不记录大于debug级别的日志 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>DEBUG</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<Target>System.out</Target>
<encoder>
<pattern>%-5p [%d][%mdc{mdc_userId}] %C:%L - %m %n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级别的日志信息 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
</appender>
<appender name="FILTER_INFO"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>${LOG_PATH}/log_filter.log</File>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} : %m%n</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log_filter.%d{yyyy-MM-dd}</fileNamePattern>
</rollingPolicy>
</appender>
<logger name="FILTER_INFO_LOGGER" additivity="false" level="INFO">
<appender-ref ref="FILTER_INFO" />
</logger>
<appender name="INTEREST_BEARING_INFO"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>${LOG_PATH}/log_interest_bearing.log</File>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} : %m%n</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/log_interest_bearing.%d{yyyy-MM-dd}</fileNamePattern>
</rollingPolicy>
</appender>
<logger name="INTEREST_BEARING_LOGGER" additivity="true" level="INFO">
<appender-ref ref="INTEREST_BEARING_INFO" />
</logger>
<!-- 为单独的包配置日志级别,若root的级别大于此级别, 此处级别也会输出 应用场景:生产环境一般不会将日志级别设置为trace或debug,但是为详细的记录SQL语句的情况,
可将hibernate的级别设置为debug,如此一来,日志文件中就会出现hibernate的debug级别日志, 而其它包则会按root的级别输出日志 -->
<logger name="org.springframework" level="DEBUG" />
<logger name="com.ibatis" level="DEBUG" />
<logger name="com.ibatis.common.jdbc.SimpleDataSource" level="DEBUG" />
<logger name="com.ibatis.common.jdbc.ScriptRunner" level="DEBUG" />
<logger name="com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate" level="DEBUG" />
<logger name="java.sql.Connection" level="DEBUG" />
<logger name="java.sql.Statement" level="DEBUG" />
<logger name="java.sql.PreparedStatement" level="DEBUG" />
<!-- 生产环境,将此级别配置为适合的级别,以名日志文件太多或影响程序性能 -->
<root level="INFO">
<appender-ref ref="FILEDEBUG" />
<appender-ref ref="FILEINFO" />
<appender-ref ref="FILEWARN" />
<appender-ref ref="FILEERROR" />
<!-- 生产环境将请stdout去掉 -->
<appender-ref ref="stdout" />
</root>
</configuration>
Vue.js 单页应用部署百度统计
前言
申请百度统计后,会得到一段JS代码,需要插入到每个网页中去,在Vue.js项目首先想到的可能就是,把统计代码插入到index.html入口文件中,这样就全局插入,每个页面就都有了;这样做就涉及到一个问题,Vue.js项目是单页应用,每次用户浏览网站时,访问内页时页面是不会刷新的,也就意味着不会触发百度统计代码;所以最终在百度统计后台看到的效果就是只统计到了网页入口的流量,却无法统计到内页的访问流量。
解决方法
在main.js文件中调用vue-router的afterEach方法,将统计代码加入到这个方法里面,这样每次router发生改变的时候都会执行一下统计代码,这样就达到了目的,代码如下:
router.afterEach( ( to, from, next ) => {
setTimeout(()=>{
var _hmt = _hmt || [];
(function() {
//每次执行前,先移除上次插入的代码
document.getElementById('baidu_tj') && document.getElementById('baidu_tj').remove();
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?xxxx";
hm.id = "baidu_tj"
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
},0);
} );
GA 设置跨网域跟踪
设置跨网域跟踪
通过跨网域跟踪,Google Analytics(分析)可以将两个相关网站(例如电子商务网站和单独的购物车网站)上的会话视为一个会话。这有时称为“站点关联”。
跨网域跟踪概览
为跟踪会话,Google Analytics(分析)收集每次匹配的客户 ID 值。客户 ID 值存储在 Cookie 中。Cookie 存储在各个网域中,且一个网域中的网站不能访问为另一个网域设置的 Cookie。当跟踪跨多个网域的会话时,需要将客户 ID 值从一个网域传送到另一个。为此,Google Analytics(分析)跟踪代码具备链接功能,使源网域能够将客户 ID 加入链接的网址参数,供目标网域访问。
使用 Google 跟踪代码管理器设置跨网域跟踪
如果使用 Google 跟踪代码管理器管理 Google Analytics(分析)跟踪,请按照跨网域跟踪中的说明操作。
通过修改跟踪代码设置跨网域跟踪
要针对多个顶级网域设置跨网域跟踪,您需要在每个网域上修改 Google Analytics(分析)跟踪代码。您应掌握基本的 HTML 和 JavaScript 知识或者与开发者合作才能设置跨网域跟踪。本文中的示例使用了 Universal Analytics 跟踪代码段 (analytics.js)。
- 在 Google Analytics(分析)帐户中设置媒体资源。
要进行跨网域跟踪,请在 Google Analytics(分析)帐户中设置一个媒体资源。请为您的所有网域都使用来自该媒体资源的同一个跟踪代码段和跟踪 ID。为了让跨网域跟踪发挥作用,您需要对跟踪代码段进行修改。如果您还没有在自己的所有网页上都添加此代码段,可以先将其复制并粘贴到文本编辑器中,然后再按本文中的说明继续操作。这样一来,您只需先在文本编辑器中进行一次更改,然后再将修改后的代码段添加到您的所有网页上即可。 - 修改主网域的跟踪代码。
在代码段中找到create行。如果网站名为 example-1.com,那么这一行会显示为:ga('create', 'UA-XXXXXXX-Y', 'example-1.com');对代码段进行以下更改(您需要更改的地方以红色粗体表示):ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});请记得将示例中的跟踪 ID (UA-XXXXXX-Y) 替换为您自己的跟踪 ID,并将示例中的辅助网域 (example-2.com) 替换为您自己的辅助域名。
ga('require', 'linker');
ga('linker:autoLink', ['example-2.com'] );在您的主网域中,所有出现此跟踪代码段的地方都必须包含这些更改。
三个或更多个网域按上例所示操作,但是要为自动链接插件再添加其他网域。请注意其中额外的逗号,这个符号非常重要:ga('linker:autoLink', ['example-2.com', 'example-3.com'] );您的主域名的跟踪代码段应如下所示:
<script>(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});
ga('require', 'linker');
ga('linker:autoLink', ['example-2.com'] );
ga('send', 'pageview');</script>
- 修改辅助网域的跟踪代码。在代码段中找到
create行。对代码段进行以下更改(您需要更改的地方以红色粗体表示):ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});请记得将示例中的跟踪 ID (UA-XXXXXX-Y) 替换为您自己的跟踪 ID,并将示例中的主网域 (example-1.com) 替换为您自己的主域名。
ga('require', 'linker');
ga('linker:autoLink', ['example-1.com'] );在您的辅助网域中,所有出现此跟踪代码段的地方都必须包含这些更改。
三个或更多个网域按上例所示操作,但是要为自动链接插件再添加其他网域。请注意其中额外的逗号,这个符号非常重要:ga('linker:autoLink', ['example-1.com', 'example-3.com'] );您的辅助域名的跟踪代码段应如下所示:
<script>(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});
ga('require', 'linker');
ga('linker:autoLink', ['example-1.com'] );
ga('send', 'pageview');</script>
设置报告数据视图和添加过滤器
默认情况下,Google Analytics(分析)仅会添加网页路径和网页名称,不会添加域名。例如,您可能会在网站内容报告中看到网页如下所示:
- /about/contactUs.html
- /about/contactUs.html
- /products/buy.html
由于域名不会列出,因此您可能会很难分辨每个网页所属的网域。
要让您的报告显示域名,您需要执行以下两项操作:创建报告数据视图副本(其中应包含所有网域的数据),并向这一新的数据视图添加高级过滤器。此过滤器会让 Google Analytics(分析)在您的报告中显示域名。
在设置跨网域跟踪后,请按照以下示例设置会在您的报告中显示域名的数据视图过滤器。对于有些字段,您需要从下拉菜单中选择一个项目。对于另外一些字段,您需要输入以下字符:
- 过滤器类型:自定义过滤器 > 高级
- 字段A:主机名提取A:(.*)
- 字段 B:请求 URI 提取:(.*)
- 输出至:请求 URI 构造器:$A1$B1
点击保存以创建过滤器。
可以使用 Google Tag Assistant 记录验证该过滤器的工作状态是否符合要求。Tag Assistant 记录可以准确显示过滤器对流量的改变情况。
向引荐排除列表添加网域
当用户行为历程从第一个网域转到第二个网域,对于 Google Analytics(分析)来说,相当于通过第一个网域将用户引荐到第二个网域,并创建一个新的会话。如果您希望跨多个网域跟踪单个会话,则需要将网域添加到引荐排除列表。
检查跨网域跟踪运行情况
要验证跨网域跟踪的设置是否正确,最好的方法是使用 Google Tag Assistant 记录。只要会话跨网域,它就可以立即显示跟踪是否正常。
以下示例 Tag Assistant 记录报告显示在跨网域跟踪设置错误时,会显示哪些内容。
相关资源
大数据应用于企业运营
大数据在企业运营的不同层次有着不同的作用,也对应了不同的应用方法论。本文抽象出大数据应用于企业运营的不同层次以及相应的应用方法——大数据企业运营应用金字塔模型。大数据企业运营金字塔分为7个层面,包括数据基础平台层、业务运营监控层、用户洞察与体验优化层、精细化运营与营销层、业务市场传播层、业务经营分析层和战略分析层。企业在考虑大数据应用时,此模型可以作为基础的参考方向。

数据基础平台层。数据基础平台层是大数据企业运营应用金字塔的最底层也是整个金字塔的基础层,如果基础层搭建不好,上面的应用层也很难在企业运营中发挥效果。没有数据或者没有高质量的数据,所有的分析和数据挖掘都是误导。数据基础平台层的目标是把企业的所有用户(客户)数据用唯一的用户ID串起来,包括用户(客户)的画像(如性别、年龄等)和用户行为等,以达到全面的了解用户(客户)的目的。数据基础平台层的搭建有三大关键:
(1)确定用户唯一ID。企业需要确定打通用户(客户)数据的唯一ID,可以考虑用会员注册号,或手机号或者身份证号等。企业在构建会员注册体系时,最好是使用用户手机号作为会员账号,这样方便后期整合其他外部数据源;同时使用手机号的好处在于未来可以基于手机号向会员开展相关的营销活动;
(2)有效的解决数据孤岛问题。拥有大数据的企业常常有多个业务部门,而且不同业务部门的数据往往孤立,导致同一企业的用户各种行为和兴趣爱好数据散落在不同部门,出现不同的数据孤岛,导致企业的数据资产不能很好的整合使用。解决数据孤岛的问题,需要高层重视并授权给公司级的中立数据部门,企业从上往下,有意识强有力的去整合不同业务部门的数据,解决数据孤岛,打通数据;
(3)解决数据有效管理和计算的问题。我们可以通过技术手段和规范手段把数据管理起来。重点要解决的问题是存在数据仓库里面的数据具体的含义是什么,以及如何高效的存储和计算。通过数据接入系统和元数据管理系统,我们可以有效的管理数据的定义和相关计算逻辑;通过分布式文件系统、分布式数据库等方法解决高效存储的问题;通过大数据查询分析计算、批处理计算、流式计算和内存计算等计算模式以及大数据计算任务调度系统等方法解决高效计算的问题。
业务运营监控层。业务运营监控层主要目的是帮助企业监控业务运营情况的健康度,快速发现问题并定位问题原因。我们首先要做的是搭建业务运营的关键数据体系,在此基础上开发可视化的数据产品,监控关键数据的异动,并可以定位数据异动的原因,辅助运营决策。在业务运营监控层,如果企业构建了实时计算的能力,那么很多业务运营中问题就能更快的发现。因此,业务运营监控层的工作有两大关键:
(1)梳理数据体系。数据分析师和业务负责人一起梳理业务的数据体系,尤其是对关键数据如KPI数据进行系统化的拆解和梳理。KPI数据的梳理可以以假设该数据下跌开始进行梳理。以活跃用户为例,假设某产品的活跃用户数下跌,一方面可以通过物理拆解的方式层层下钻找出影响模块,即某产品的活跃用户下跌可能是因为该产品的子模块活跃用户下跌引起,我们可以对该子模块进一步拆解分析原因,拆解的过程也是数据体系搭建的过程;另一方面,可以对活跃用户的相关因素进行数据化梳理,如新老用户的构成、用户质量、推广渠道质量的变化等多种维度进行数据化梳理;
(2)打造数据异动监控产品。企业需要构建灵活和智能的数据异动监控产品,并把梳理好的数据体系封装在数据异动监控产品中。数据异动监控产品需要有三方面的能力:一方面,数据可视化程度高易读性好,通过该产品可以清晰的看到数据体系和数据间的脉络;第二方面,通过算法实现异动原因的定位;第三方面,智能的告警功能,一旦关键数据的关键节点出问题,并可以通过短信、邮件等方式周知相关人员。
用户洞察/体验优化层。这一层主要是通过大数据来洞察用户行为和偏好以及监控和优化用户的体验问题。这一层面既运用了结构化的数据来洞察和优化,也运用非结构化的数据(如文本)来洞察和优化。前者更多的是应用各种用户行为模型来实现,后者更多的是通过监测微博、论坛和企业内部客服系统的文本来洞察和优化。具体包括以下两大方面:
(1)用户洞察。利用大数据技术抓取微博、论坛和企业客服系统等文本数据来洞察用户对产品的关注点和走势,实时掌握用户需求及动向;基于大数据的用户行为数据分析,并结合用户调研,深度掌握用户潜在需求和预期;对企业内部数据进行系统化梳理后,为企业内部数据用户搭建自助分析工具,协助企业内部数据用户(如产品经理、营销人员)灵活提取和分析数据,帮助他们进行相关研究和决策;
(2)体验优化。我们可以通过大数据构建各种用户体验监测模型来进行用户体验优化。如电商用户购买行为的漏斗模型,监控用户进入首页、查看商品产品详情、把产品放到购物车、购买以及支付等各环节之间转化率来发现用户购物过程的体验问题;通过大数据技术监测用户使用产品的评价以及时发现产品体验问题,并提交给相关产品或服务部门进行调整和优化。
业务运营监控层和用户洞察/体验优化层这两个层面终极目标是实现企业运营健康度监控的智能化,这两层面做出的工具好比是人体的体温计、血压计、B超、CT等工具,我们用这些工具就能快速透视企业运营中那一模块或者环节发生问题,以辅助相关人员进行及时的改进。
精细化运营和营销层。这一层主要的目的是通过大数据驱动企业进行精细化运营和营销。实现精细化运营和营销有六方面关键:
(1)构建基于用户的数据提取和运营工具。运营和营销人员通过简单的条件配置(如选择男性、18-24岁以及特定兴趣爱好),便可把用户信息提取出来,对相应的用户进行营销或运营活动;
(2)构建基于大数据的CRM系统。传统的CRM系统只关注企业内部数据,而大数据时代的CRM不仅仅是整合企业内部数据,还需要整合更多的外部数据,利用大数据技术获取更多实时和多元化的用户行为和偏好数据,为企业潜在用户、存留用户打标签,构建多维度及实时的用户视图,更有效掌握不同用户的价值,对不同用户实施不同的营销策略;
(3)构建基于大数据的营销活动数据挖掘体系。通过数据挖掘提升用户对营销活动的响应(如点击率),常见的数据挖掘算法有决策树、逻辑回归等,通过这些算法有效的提前识别最有可能参与活动的用户,或者发现潜客;
(4)推广渠道质量监控和防作弊。通过大数据手段建立营销推广渠道质量的监控模型,实时的监控推广渠道的效果和质量,防止渠道作弊,及时优化和挑战推广策略和预算;
(5)通过数据挖掘的手段进行客户生命周期管理,做到实时对不同生命周期的客户进行实时标记和预警,并把有效的活动当成商品一样及时的推送给不同生命周期阶段的客户;
(6)客户个性化推荐。主要是用个性化推荐算法实现根据用户不同的兴趣和需求推荐不同的商品或者产品,以实现推广资源效率和效果最大化。
业务市场传播层。这一层面要做到通过“性感”的数据分析和挖掘来辅助产品进行传播,主要有两种实现方式:
(1)制作有趣的数据信息图谱。相信大家都不喜欢看产品的公关软文,而更喜欢看好玩的有趣的内容。互联网上内容的传播更是如此。第三方数据公司CNNIC中国互联网络信息中心2014年的数据显示,10-29岁的网民占所有中国网民的55%,而这些用户偏年轻、偏“屌丝”,所以这些受众更喜欢“性感”的内容。某电商平台曾经通过统计其购买胸罩C-Cup以上的用户地区分布,发现西安的网民相对比例最多,并发布了这个数据,暗示西安女生身材好,引起不少“屌丝”网民传播。而某社交平台在则基于其8亿多活跃用户披露“逃离北上广”数据图,发现11%的用户在春节后逃离了北上广,并引起央视的深入报道;

(2)提供数据可视化产品。如某搜索引擎厂商,提供关键词搜索指数,让关注此关键词的用户可以实时掌握该关键词被网民关注的走势,在提供此服务的同时,也形成了该搜索厂商的品牌传播效应。另外一个案例是,某互联网地图服务上基于其位置定位数据,向网民展示了春节期间的全国春运出行热度图,以可视化的大数据产品形式来展现全国春运动态,网民可以在动态的出行热度图上查看某城市的人口迁入、迁出线路排行,并能进行飞机、汽车、火车等不同出行方式的热度对比,由此来知晓某地区春运的出行热度。全国春运出行热度图被央视报道,可见这样结合社会热点的数据可视化产品更被关注。
业务经营分析层和战略分析层。这两个层面更多的是运营传统的战略分析、经营分析层面的方法论,拥有大数据的企业在这两个层面的优势在于其分析的数据可以来自大数据,并且数据更新速度快,快到可以按照小时来更新甚至是分钟级的速度更新,传统的战略分析、经营分析一般是按月来统计;另外一个优势在于大数据的数据来源更多,可以对非结构化的数据进行更多的深入挖掘和洞察。但有两方面需要注意:
(1)有很多企业错误的把“业务运营监控层”和“用户洞察/体验优化层”能做的事情放在经营分析层或者战略分析层来实施。我们认为“业务运营监控层”和“用户/客户体验优化层”更多的是通过机器、算法和数据产品来实现的,“战略分析”、“经营分析”更多的是人来实现。很多企业把机器能做的事情交给了人来做,这样导致发现问题的效率较低。我们的建议是:能用机器做的事情尽量用机器来做好,尤其是“业务运营监控层”和“用户/客户体验优化层”,在此基础上让人来做擅长的经营分析和战略判断;
(2)在变化极快的互联网领域,在业务的战略方向选择上,数据很难预测业务的大发展方向,如果有人说微信这个大方向是通过数据挖掘和分析研究出来,估计产品经理们会笑了。我们认为,如果能利用数据通过机器、算法、或者人工的手段,把经营的现状和问题及原因洞悉的特别清楚已经很不错了,这样决策层就可以基于这些情况进行更好的“拍脑袋”决策。
从本质上来说,数据在业务运营监控、用户洞察和体验优化、精细化营销和运营、辅助经营分析中能起到比较好的作用,但在产品策划、产品创意等创意性的事情上,起到的作用较小。但一旦产品创意出来,便可以通过大数据AB测试,数据验证效果了。总之,本文只是提纲挈领的介绍了大数据在企业的落地方案。还有更多的细节和方法论未能展示出来,后面的文章将继续展开。
文:傅志华
关于作者:傅志华先生曾为腾讯社交网络事业群数据中心总监以及腾讯公司数据协会会长。在腾讯前,曾任DCCI互联网数据中心副总裁。傅志华先生现就职于某美国上市互联网公司大数据中心,同时任中国信息协会大数据分会理事和中国互联网协会数据分析研究组专家。
D3.js 接触
1. 初识D3.js
相信大多数人对D3.js并不陌生。这是一个由纽约时报可视化编辑 Mike Bostock与他斯坦福的教授和同学合作开发的数据文件处理的JavaScript Library,全称叫做Data-Driven Documents。
D3的应用非常广泛,现在 成为了主流数据可视化工具之一,下图仅仅是给出了D3.js广泛应用的冰山一角。更多的作品可以访问这里。
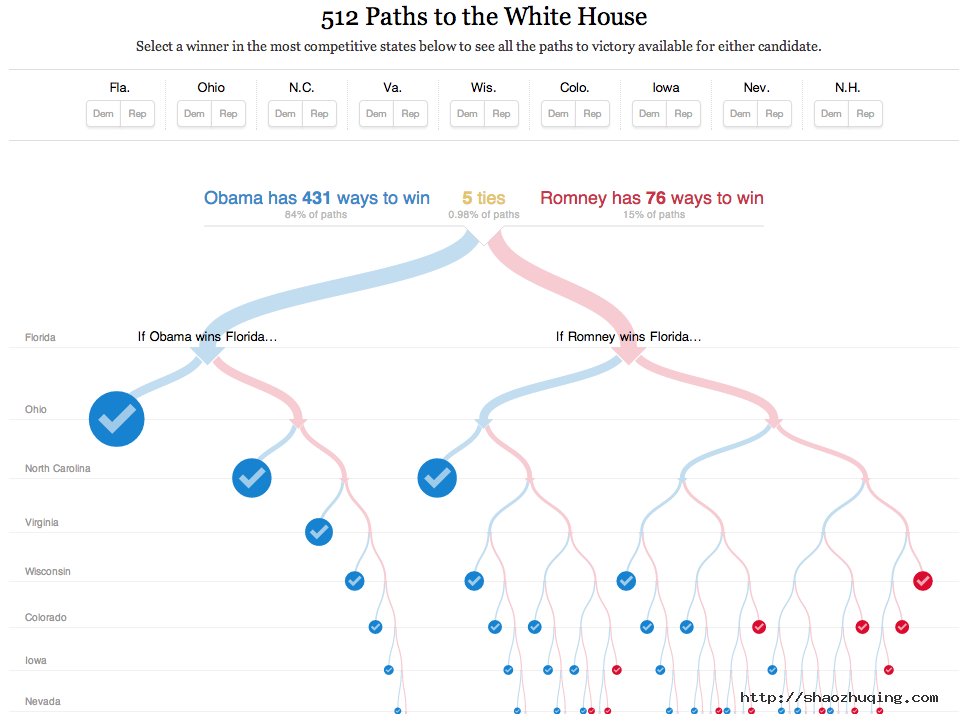
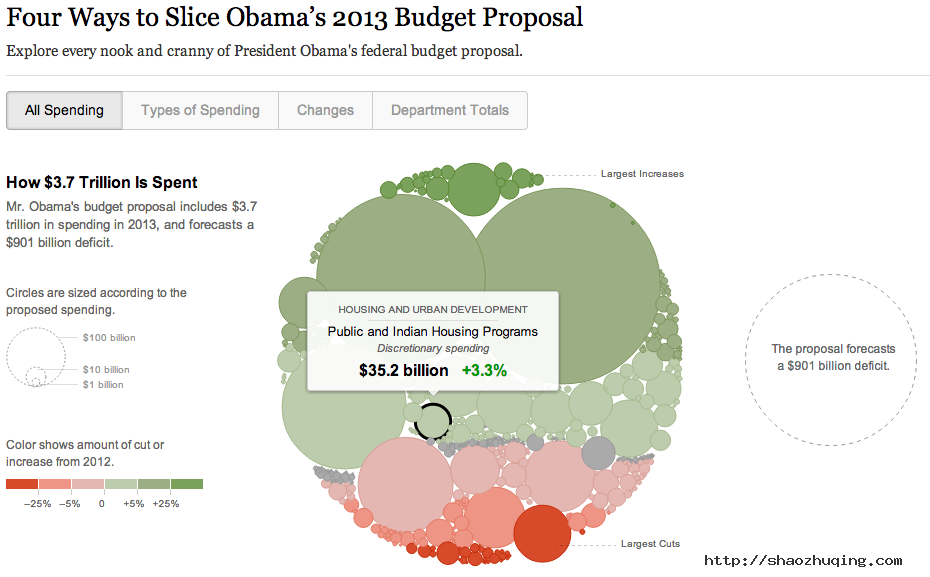
纽约时报出品的一些赫赫有名的数据产品,也都使用了D3.js,比如 “512 Paths to the White House”以及奥巴马2013财政计划:
2.用D3.js制作动态图表
笔者手里有一份美国各大投资管理公司雇员数量从2000年到2012年的数据。这是一份应该算是最简单的,不需要任何整理的数据资料 —一张Excel表格中明确列出公司名字、年份、雇员数量。从这张表格开始,到最后成功使用D3完成图表,对于一个初学JavaScript的人来讲是一个艰难而充满乐趣的过程。幸运的是,这是一份整齐简单的数据,因此笔者可以直接跳过整理数据这一步。
– 设计的重要性
在设计之前,要想清楚以下一些基本问题:
数据点(data point)有哪些?
哪些内容是读者期待的?哪些是记者想要表现的?
用什么样的形式、动态效果表现数据?
数据作为单独内容还是伴以文字报道?
最适合制作的可视化的工具是什么?
作为新手,这个步骤尤其关键,多和产品经理以及文字编辑沟通,设计好最理想的方案是进行下一步的必要条件。笔者的作品可以作为一个反面教材。

初稿

由于各公司的规模不同,如果单一展示13年来雇员数量上的变化,很难看出各家公司成长和衰落的速度。因此以在第一版设计稿中,专门将雇员数量百分比变化拿出来单做了曲线图。关于曲线图,柱状图,饼图,甚至气泡,或者使用自定义的图片、图标等等选择需要依照具体情况来确定。笔者选择了最简单的线、柱图,是为了更加容易上手。
然而,按照第一版设计,将图表做出来后,发现操作体验并不好。由于图表上每一个元素都可以用来驱动效果(坐标轴、曲线、柱状图、年份、年份指示点等),反而会使读者略感困扰。并且,即使取消某些驱动,由于上下两图分开展示,读者体验不够流畅。另外一个先前没有注意到的巧合是,公司数量和年份数目都是13,柱状图和图表最上方时间轴的意外的对应有会产生误解。所以,最后不得不放弃第一版,重新设计下面的样式。
在新闻编辑室做图表设计,由于刊物的风格,受众的特殊,会有不同的限制,但总的来说有以下一些需要注意的方面:
配色:要根据刊物的风格,选择合适且不超过三个以上的主色调。(一个由于元素过多令人难以消- 化的例子是卫报的同性恋权益报道)。
字体:考虑读者的年龄群。笔者所在的集团主要做商业投资和养老保险的报道,读者群主要是中年= 人士。这样便不易选择较小字号和较浅的颜色。
操作功能:操作越人性化、越明确越好。尽量让读者在不超过三次点击的情况下呈现出所有的数据变化可能性。
有关数据可视化设计的一些原则,可以参考本站《数据可视化三大致命错误》和《信息图四宗罪》,以及 “Stephen Few on Data Visualization: 8 Core Principles”。
– 程序编写以及与IE的斗争
由于笔者第一次从头开始写 JavaScript 脚本,所以先学习了许多网上的资源,列表附在本文结尾。然而,除去外部参考资料,最核心也是最重要的资源就是D3 API Reference了。这是一个在编写D3文件时应该永远打开的页面。
JavaScript不是一个非常严谨的语言,因而比较容易上手。这里说的严谨,仅指在编写过程中,对格式、标点等要求没有其他语言要求那么精确。这是一把双刃剑,一方面,大多数现代浏览器可以自动识别并且运行一份不完美的JavaScript文件(当然,这里只是说少量的符号小错误);另一方面,这样的不严谨会令后期修改文件、功能变得更加复杂,同时,稍旧一点的浏览器无法实现许多功能。
不幸的是,“稍旧一点的浏览器”中就包括了现在仍然在各大公司中广泛使用的Windows IE8浏览器。D3.js生来不兼容IE8及以下的浏览器,但一个产品推出之际,很少有公司能够像纽约时报那样大笔一挥,放弃掉众多IE8用户。这个时候,R2D3就显示出了他强大的兼容功能。R2D3是一个以Raphael.js支持的D3兼容包。使用起来也非常简单,只需要在文件的head中增加一行指向文件,让IE8-用户不运行d3.js而改为运行R2D3.js即可。

前端工程师大牛Paul Irish讽刺IE浏览器 >>>
与IE的斗争不仅在使用D3.js过程中会遇到,IE8及以下的浏览器(以及安卓2.3及以下版本)不支持可伸缩向量图形(SVG)以及HTML5 canvas,那么,所有在这些“画布”上的创作,都需要借助其他JS library来向下兼容。更多关于浏览器支持元素的查询可以点击这里。
在程序的编写过程中,笔者得到了许多帮助,作为一个没有“程序员逻辑”的记者,无数次的返工让我体会到了“大局观”的重要性。以下几点是在编写程序过程中笔者的体悟:
“懒”是生产力:因为懒,所以希望电脑自动来做一切。正确的程序代码是可以实现这个目标的(在可视化范畴内),因此不要因为觉得“实现不了某项功能”而轻易放弃想法。
特殊情况也要自动解决:在遇到个别特殊数据时(比如空白数据),不应手动解决每个特殊问题,而要让程序拥有识别特殊性的能力,这是一套dynamic的程序应该有的功能。
3.新闻工作室的未来 — 人人都是多面手?
制作完人生第一个D3动态图表之后,笔者过足了写JavaScript的瘾,却觉得有些茫然。
记者本身是写作者、记录者,不断追求探索的是“事实”二字。没有什么比白纸黑字的数字更令人信服的,于是一直以来记者们对数据的探索趋之若鹜。随着大数据时代的到来,媒体对记者们的要求不断增加:既要有新闻记者敏锐的嗅觉和精准的写作,也要有利用数据的能力。这个“利用”的程度到底是怎样的呢?找到数据?展示数据?解释数据?可视化还是纯文字?
放眼各个新闻名校,都在不断加强着培养学生的“数据能力”。看新闻院校毕业后求职情况,会发现越多的数据处理能力意味着越高的求职成功率。彼此竞争、纸媒衰落的时代里,当每个记者都意识到数据的重要性而开始探索时,记者必备的能力中会不会有“编程”这一项?当未来的记者都成为了半个程序员的时候,在职记者又该学些什么,以免落后于时代呢?
有兴趣的读者可以参考各大新闻院校开设的数据新闻课程,数据新闻网授权转载了几家新闻院校的课程:
– 《斯坦福纪录片 -数据时代的新闻学》
资料附录:
书籍类:
– Interactive Data Visualization for the Web
教程类:
具体例子:
– Population Pyramids (参考了键盘控制功能)
– Horizon Chart (对,我们还做出过horizon chart的版本)
其他:
如何跟踪用户在WAP页面的浏览
一、背景
在网站分析工具基本的工作原理 这篇文章我们有讲到过,目前主流的网站分析工具都是使用页面标记法来收集网站数据的,一般使用的是JavaScript 代码的方式,我们可以称之为客户端实现。WAP 页面,在本文中特指使用WML编写的用于在功能手机和低端类手机显示的页面。对于WAP 页面,前端实现的方法显然是不可行的,这是因为:1)功能手机和其他低端类手机的网页浏览器很多不支持JavaScript;2)页面标记法代码执行时通常要伴加载一个超过10Kb的JavaScript文件,而这类手机内存非常之小,10Kb 对于它们来说太大了!
那么,如何才能跟踪这些手机上WAP 页面的数据呢?答案就是HTML 页面标记+服务端实现。
二、实现方法
方法一:
1)根据服务器环境选择对应文件放到服务器上;
如服务器环境是PHP,用百度统计跟踪的话,将百度统计后台提供的hm.php 放到网站根目录。
2)在所需跟踪页面(动态页面)的<head>前用脚本定义好后边发送数据所需必要信息;
如引用hm.php 定义的方法,定义百度统计收数使用的站点ID。
3)在所需跟踪的页面的</body>结束之前插入一个img标签,其src属性使用第二步中定义好的方法来指定;
如src 的值指向百度统计的收数地址,即类似这种形式http://hm.baidu.com/hm.gif?……
具体案例:
多米音乐WAP页面:http://wap.duomi.com/
本站WAP(img) 测试页面:http://jeffshow.com/test/bd/wap_img.php

方法二:
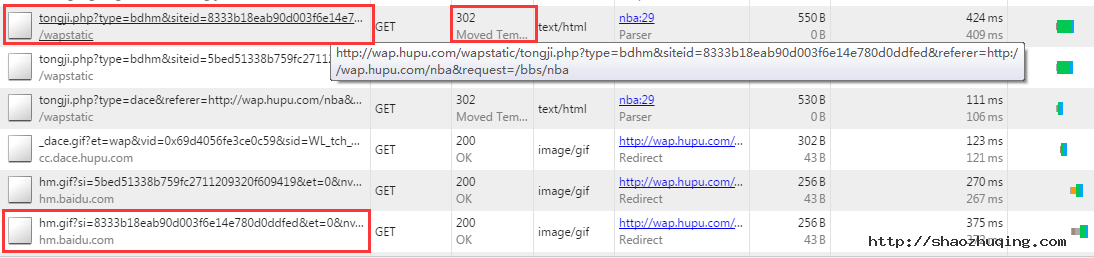
第1步、第2步和方法一相同,但是第3步不指向统计工具的收数地址,而指向本站的一个地址,再通过服务器设置302跳转,使之指向统计工具的收数地址。
具体案例:
虎扑体育论坛WAP页面:http://wap.hupu.com/bbs/nba
方法三:
为了帮用户节省流量,不少移动端浏览器可以开启无图模式,而前两种方式都是基于img标记来实现的,开启了无图模式之后,数据不能被发送出去,因而可能导致较大的误差。为了避免这种情况造成数据较大的误差,需要引入link标签代替img标签。
第1步和第2步和第二种方法一样,只是在第3步这里使用link标签来代替,相应的img标签的相关属性也被替换,如src被替换为href等。
具体案例:
手机瑞丽网:http://wap.rayli.com/
本站WAP(link)测试页面:http://jeffshow.com/test/bd/wap_link.php

三、GA 中的实现方法
以上介绍的三种方法是通用型的,为了方便说明是以百度统计为例来介绍的。那么在GA 中,其实现方式如何?是否有什么不同之处?
本质上说,GA 中的实现方式与上述一样,不过细节方面又稍有不同。根据GA 帮助文档,在GA 中WAP 页面跟踪的实现方式分为两种:一种是基于ga.php;另一种是基于Measurement Protocol,GA 推荐的实现方法;
我们分别来看下这两种方法(以PHP环境为例):
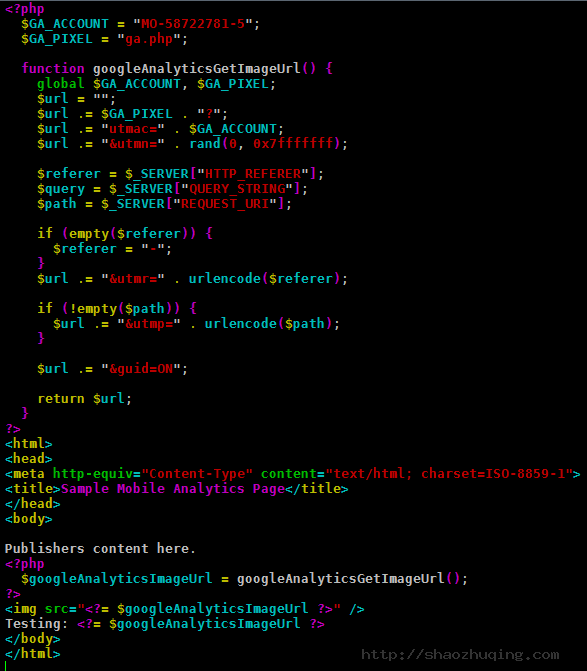
基于ga.php
这种方法跟前面介绍的第一种方法相似,前两步是一样的,第3步在GA 中稍有不同。GA 中的实现并不是让img直接请求收数地址,而是附加查询参数请求已经上传的ga.php文件。当服务器收到这个请求后,会解析并执行携带参数的ga.php文件,ga.php文件中定义了发送数据到GA 服务器的方法,执行后相关数据就被发送到了GA 收数服务器。
需要注意的是:
1)不能直接使用property ID,需要把UA-替换为MO-;
2)此方法在2014-4-2 即已被GA 官方弃用,不过经测试,依然可以收数;
3)仅能满足pageview类型hit的发送,因此流量来源和会话相关报表可以正常使用,但是事件统计之类的满足不了;
具体案例:
多米音乐WAP页面:http://wap.duomi.com/
本站WAP测试页面:http://jeffshow.com/test/ga/wap_img.php
基于Measurement Protocol
GA 对于Measurement Protocol 的用处描述如下:
- Measure user activity in new environments.
- Tie online to offline behavior.
- Send data from both the client and server.
即Measurement Protocol 可以用来衡量新场景下的用户的行为,打通线上和线下,从客户端或服务端发送数据。相比前一种方法,使用Measurement Protocol的方法可以实现复杂的事件统计、电商统计等功能。其具体使用方法和前述类似,即构造http请求发送到GA 收数服务器即可。
四、总结与扩展
随着智能手机的普及,不支持JavaScript 的情况越来越少,相应的,WAP 页面也几乎消失殆尽。尽管如此,服务端实现的方法依然有其价值所在。比如说,我们要实现某些敏感数据的统计,但是这些数据又不能出现在页面源代码中;或者要统计一些文档(如PDF文档)被用户直接浏览或下载的次数,这些文档对应的地址显然是用不了JavaScript代码的;再比如说,我们要尽可能完整地收集使用无图模式的用户的浏览页面的数据。
以上举例,只是实际可能碰到情况的一个很小的子集。当使用客户端实现的方法难以较好地解决当前的问题,或许是时候考虑下服务端实现的方法了。
五、参考资料
1. Google Analytics for Mobile Websites
2. Measurement Protocol – Using a Proxy -Server
3. 百度统计贴吧
4. Tracking PDFs & Downloads Inside Google Analytics, Server-Side!
Read more: http://jeffshow.com/how-to-track-wap-based-site-in-ga.html#ixzz3gPkMwsaX
缔元信:用户画像技术助推大数据落地
 [原文:IT专家网] 企业要如何快速地从大数据的发展中获益?日前,北京缔元信互联网数据技术有限公司(以下简称“缔元信”)产品副总裁、曾长期担任新浪网数据分析部总监的牛程先生做客IT专家网《专家会客室》,分享了他心目中的企业释放大数据潜能的最佳实践。
[原文:IT专家网] 企业要如何快速地从大数据的发展中获益?日前,北京缔元信互联网数据技术有限公司(以下简称“缔元信”)产品副总裁、曾长期担任新浪网数据分析部总监的牛程先生做客IT专家网《专家会客室》,分享了他心目中的企业释放大数据潜能的最佳实践。
牛程表示,对于大多数企业而言,自建大数据平台并非明智的选择,通过第三方专业的数据服务来实现大数据的价值,可以低成本、快速、准确地获得专属的商业洞见,能够有效地跨越数据分析人才匮乏的现状。目前的阶段,要借助大数据来影响市场营销资源的投放,基于传统的贴标签功能依托IT技术进行聚类分析而成的网络用户画像是一项出色的应用,能够帮助企业实现高效运营和精准营销。
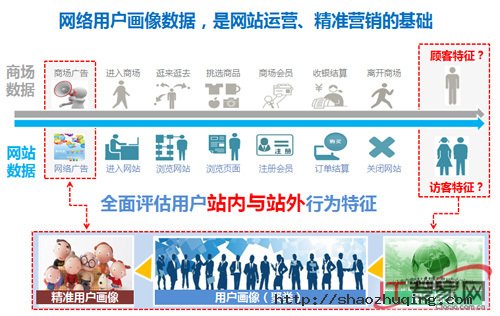
网络用户画像数据成网站运营、精准营销的基础
企业上马大数据有两道坎
根据市场调研机构IDC的统计数据,2013年全球产生的数据大约为2.72ZB,但分析过的数据仅占其中的12%。如果我们再套用“二八定律”来分析,则能够从数据分析中受益的更是少之又少了。
要想获得新的应用,中国企业往往选择新建自己的平台,但在牛程看来,企业想要自主搭建大数据平台,从交易和互联产生的几何级增长的数据中获益,还存在两个难题:数据和人才。
从大数据的4V来说,我们需要大量、多样和快速的数据,才能真正地体现价值。牛程表示,企业除了内部CRM平台的数据,还需要用户离开这些平台以后的数据,需要各种终端产生的数据,但企业自建平台,往往只有CRM数据,即便有一些企业采集了SNS数据,也还是不够全面,不利于产生需要的结果。
IDC大数据与分析、数据管理及企业应用高级项目经理Daniel-Zoe Jimenez亦有类似观点:真正的机遇在于将客户数据等内部数据源与社交网络和站点等外部数据源加以整合。这有助于企业全面了解他们的客户业务和环境,让他们能够掌握客户的喜好、习惯和未来需求。
另一方面,数据-知识-决策的转换,需要有数据处理、数据挖掘和决策的人才的支撑。目前,尽管开源软件目前非常发达,硬件变得廉价,但若没有BAT那样的研发实力,搭建企业级大数据平台所需要的兼容性、稳定性和安全性都很困难,更不用说实时分析和决策了。一项调查显示,83% 的人认为数据分析对业务至关重要,但65% 的人表示他们无力自建数据分析系统、无力聘请数据分析师。
用户画像数据成网站运营的基础
如前所述,缺乏相关技能集和最佳工具以及流程方面的差距对中国企业构成了挑战。我国在数据的开放性、流动性和交互性以及原有大量积累数据缺乏真实性是我们的挑战。但从缔元信看来,利用互联网服务平台和用户行为数据,可以很容易规避数据的问题,则剩下的就是技能和工具。
我们知道,互联网服务平台能够汇聚海量的生产信息、交易信息与消费者信息 ,使信息这一核心生产要素广泛应用于经济生产活动。因此,平台型互联网企业更能为大数据应用做出有效探索,有的企业已经在这个领域有所建树,如阿里、百度都有相关案例。
当然,阿里、百度、京东等更多的是为自身业务的发展来利用数据,尽管百度也开放了其大数据引擎,但对于一般企业来说,它们未必是普适的平台。针对企业大数据通用的解决方案,牛程提出了一个用户分群画像的概念,通过用户画像与分群的研究,为网站运营、营销策略、广告运营、推广提供数据支持。
网站用户分群画像核心价值在于精细化的定位人群特征,挖掘潜在的用户群体,为媒体网站、广告主、企业及广告公司充分认知群体用户的差异化特征,根据族群的差异化特征,帮助客户找到营销机会、运营方向,全面提高客户的核心影响力。
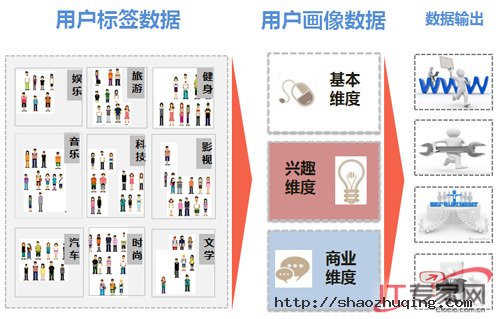
基于用户画像技术的数据服务原理
传统的对用户贴标签的功能,往往局限于静态的结果,用户画像则是动态、立体的解决方案,通过精细化人群定位,多维度交叉筛选查询,客户根据数据分析、挖掘潜在用户群。
缔元信的实践分享
目前,缔元信已经将牛程分享的这套理论进行产品化,发布了“网站用户分群画像”和“缔元信DMP”两款产品,前者为媒体网站、广告主、企业及广告公司提供网站营销、网站运营的数据支持服务;后者针对DSP(精准投放)平台提供数据服务,通过可视化的操作界面方便客户对目标用户人群数据的选取并将该数据输出给DSP平台,为精准投放的实施提供数据,提高转化率。
两款产品依托缔元信先前开发的缔元信数据管理平台(DDMP),将第一方标签与第三方标签相结合,对每一个用户标签化,然后按不同的评估维度和模型算法,通过聚类方式将具有相同特征的用户划分成不同属性的族群,用特定的名称作为实际用户群的虚拟代表,并进行画像描绘,洞察其商业价值及用户价值。
用户画像技术的出现,能够帮助客户了解群体的差异化特征,根据族群的差异化特征设计并提供有针对性的产品及服务。缔元信用户分群画像系统以TGI指数(目标群体指数)和用户构成两大核心指标,分析消费者的购买行为、态度、生活形态和媒体接触习惯,以及目标用户群体在指定范围内占有的比例,多维度判别目标用户群在媒体的优、劣势及用户价值。
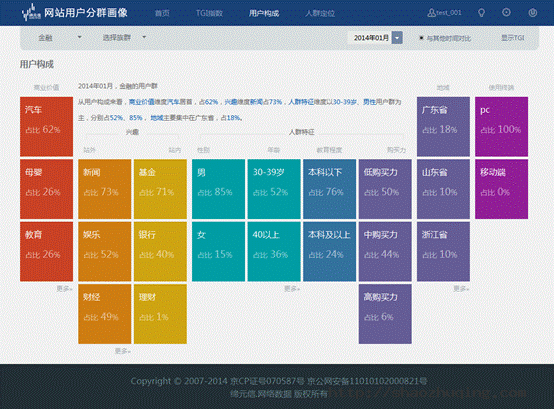
缔元信网络用户分群画像的用户构成界面
通过TGI指数,可以为销售团队的客户定位、营销策略和方案的制定提供支撑;评估网站资源优劣态势,为内容运营、产品规划提供支撑;评估网站资源之间(频道、栏目、内容、产品等)的优势关联关系。
谈及缔元信产品的优势,牛程表示,主要来自于拥有全样本第三方标签,精细化的人群定位,具有7年的数据积累,并拥有为数据管理而生的专业的技术团队,能够为企业提供大数据时代数据化、高效精良的服务。
视频链接:《牛程:专业数据服务助推大数据落地》
数据论水浒:解析108名梁山好汉
梁山一百单八将都是如何落草为寇的?他们都是什么”学历”?除了大碗喝酒大块吃肉,他们真的是替天行道吗?
落草的成了”好汉”,入仕的成了”奸佞”,这之间有一个什么样的衡量标准?
他们,为什么上梁山?
纵观梁山一百单八将,他们上山的原因,大致可以分为以下五种。
第一种:被自己人陷害–以卢俊义为代表。
这里的”自己人”是指一百单八将里的人,如杨志被晁盖、吴用等劫了生辰纲。虽然那时杨志还没走上革命道路,但是日后却在一起了,所以也算是被自己人陷害的。
这种人里,有卢俊义、秦明、李应、朱仝、杨志、徐宁、燕青、萧让、安道全、金大坚、杜兴、李云,共十二人,其中天罡有七人,地煞有五人。
需要说明的是燕青。燕青是跟随主人一起的,若主人不被陷害,他还会在卢俊义府上做他的高级白领。
第二种:被官府(或者与官府有勾结的人)陷害,被迫上山–以林冲为代表。
这些人里,有宋江、林冲、花荣、柴进、鲁智深、武松、戴宗、解珍、解宝、朱武、裴宣、欧鹏、陈达、杨春、宋清、施恩,共十六人,其中天罡九人,地煞七人。可以从一定层次上直接代表着官逼民反的人数。
说明一下,朱武、陈达、杨春是否有这么悲惨,不得而知,原著只交代了他们三人”累被官司逼迫,不得已上山落草”。那么我们就姑且认为他们是被官府逼的吧。宋清是宋江的弟弟,自然跟他哥一样。鲁智深倒不是因为杀了人而上山,他是因为救了林冲被官府通缉才落草的。
第三种:被俘上山,由于个人意志、信仰不坚定,甘愿为梁山效力–以关胜为代表。
这些人里,有关胜、呼延灼、董平、张清、索超、宣赞、郝思文、韩滔、彭玘、单廷珪、魏定国、凌振、扈三娘、龚旺、丁得孙、蔡福、蔡庆、郁保四,共十八人,其中天罡五人,地煞十三人。
有些人可能会对蔡福、蔡庆有异议。实际上在攻打大名府的时候,他俩已经被软禁了,和被俘又有何区别?值得注意的是,梁山军此时正在大名府烧杀抢掠,还是蔡福说了句”大官人可救一城百姓,休教残害”。等传下令时,”城中将及伤损一半”。从这话可以看出梁山军的一贯作风。可惜兄弟俩只有蔡庆活到了”解放后”(平了方腊)。
郁保四是作为人质和曾生一起上梁山谈判的,实际上也是俘虏的一种。
第四种:因杀人越货触犯了法律,为逃避法律制裁不得已而上山–以晁盖、吴用等人为代表。
晁盖、吴用、公孙胜等人在劫了生辰纲之后,是因为东窗事发,不得已才上山的。若不是白胜拿着分到的银子去赌博不小心露了馅儿,他们一时半会还是不会上山的。
这批人里,有吴用、公孙胜、刘唐、李逵、史进、穆弘、雷横、李俊、阮小二、张横、阮小五、张顺、阮小七、杨雄、石秀、黄信、孙立、燕顺、吕方、郭盛、王英、孔明、孔亮、童威、童猛、孟康、侯健、乐和、穆春、杜迁、薛永、朱富、李立、石勇、孙新、顾大嫂、白胜,共三十七人。其中,天罡十五人,地煞二十二人。
有一些革命同志,如李逵等,也不是主动要上山的。虽然说上山可以大碗喝酒大块吃肉大肆砍人,不过他那时还是一个小小的国家干部,还当着小牢子,虽然无赖,但还不至于把脑袋别在裤腰带上干造反工作。只有劫法场救了宋江、戴宗之后,他才真正犯下不赦之罪,只好上山了。
第五种:无明显上山理由。
比如向往梁山大碗喝酒痛快–这和当年很多青年参加红军的道理是一样的;还有一些人,原著中没有交代,一出场即是土匪。我以为,这一批人天生革命觉悟极高,为造反而生,以造反为乐。
这批人里,有邓飞、杨林、蒋敬、皇甫端、鲍旭、樊瑞、项充、李衮、马麟、郑天寿、陶宗旺、曹正、宋万、李忠、周通、汤隆、邹渊、邹润、朱贵、焦挺、张青、孙二娘、王定六、时迁、段景住,共二十五人。没有一个天罡,全是地煞。
梁山革命根据地的两个创始人杜迁、宋万为何不在一起?因为杜迁和王伦是受了”鸟气”来到梁山落草的,而宋万后来才到。所以杜迁是个人原因,而宋万没有交代,只好”革命觉悟高”了。
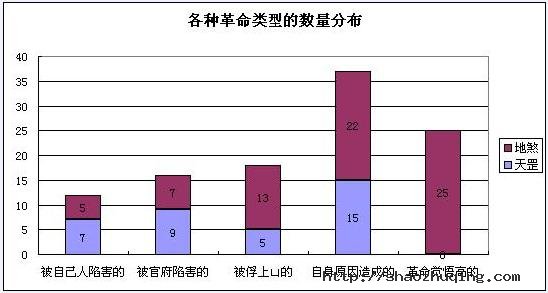
上述五种原因如果列成表的话,将会更直观:
一、各种革命类型的数量、百分比分布
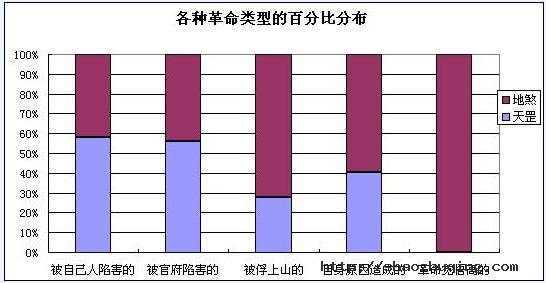
二、各种革命类型,在天罡、地煞中的分布

根据上图,我们可以得出什么结论?
一、在总人数中,由于自身触犯法律,为了逃避大宋法律制裁而投奔梁山的人数最多。这些人,在天罡中占据主导地位,在地煞中也高据第二。
那么我们基本上可以认定,这些人,大部分都是无事生非、九处响锣十处有他的那种人。他们的活跃度很高,唯恐天下不乱,而个人能力又很强。这些人,占据了天罡数的42%。
这批人为何在天罡中有如此之多的票数?主要是劫生辰纲,产生了六个天罡,劫法场救宋江,又产生了五个天罡,所以,票数很多。
二、天罡星中,革命觉悟都很低,没有一个是主动上山的。在天罡星中,人群从高到低依次是:由于自身原因上山的、被官府陷害被迫上山的、被自己人陷害上山的,最后是被俘上山的。
由于革命意志不是很坚定,所以,梁山集团最后的被招安,也是不可避免的了。
三、地煞星的革命觉悟最高,很多人在梁山还没有发展壮大的情况下,已经有了自己的一片革命根据地。但也正是由于大伙的文化程度不高,光有热情没有能力是不够的,所以避免不了最后被梁山吞并的结局。同时大伙能力普遍不是很高,只好排到地煞星去了。低天罡星一等啊!
四、 被自己人陷害的一类中,天罡星的比例明显比地煞星要高。这是由于天罡星中的多是能厮杀的人,他们对正处于成长阶段的梁山集团来说是多多益善。
五、总体来看,真正”官逼民反”的,只占总数的15%。这在一定程度上证明了大家一直认为的”官逼民反”是成立的,但我们还应该看到,其中的绝大多数人,要么是无事生非之辈,要么是杀人越货之徒,再就是被俘的原大宋公务员,他们并非都是官逼民反。像王英之流,”原是车家出身。为因半路里见财起意,就势劫了客人。事发到官,越狱走了”,这是死活都和革命沾不上边的。
总结了这么多,实际上结论只有一条,在《水浒传》里,只有造反才是那些人最好的选择。如果不造反,大部分的革命同志只能死于非命,而造反是一项投入产出比小、风险大收益小的特殊工种,除了头几年有把脑袋别在裤腰带上的危险之外,之后还有两条路可以走:
A. 招安;
B. 自己打出一片天地,当了开国元勋。
施老爷子没把他们的造反写成功,估计也是知道哪怕就算是成功,最后也免不了来一个”杯酒释兵权”吧。这还算是文明的,要是学朱元璋同学最后大肆屠杀功臣,那就更完蛋了。

附梁山一百单八将落草原因
1. 宋 江:利用职权,私放晁盖;与梁山勾结,被二奶阎婆惜发觉;不甘被敲诈,杀了二奶;事发后被捉拿归案,刺配江州;题反诗被黄文炳识破,判处死刑;后被梁山好汉救出,上山落草。
2. 卢俊义:因名头太大,被宋江看中欲赚之上山;遂被吴用诬造反,并怂恿其家人出首告发;获罪被判刺配沙门岛,李固和贾氏贿赂董超、薛霸欲在路上将其杀害,被燕青救出;奔赴梁山途中再次落入官兵之手,梁山好汉打破大名府将其救出,上山落草。
3. 吴 用:劫生辰纲事发,上山落草。
4. 公孙胜:劫生辰纲事发,上山落草。
5. 关 胜:被呼延灼设计引入埋伏圈,被俘,上山落草。
6. 林 冲:被高俅害得家破人亡,无家可归,经柴进介绍,上山落草。
7. 秦 明:被花荣用计生俘,灌醉后宋江派小卒假扮他攻打青州,害其一家老小被慕容知府杀害;最后无处可去,上山落草。
8. 呼延灼:攻打梁山泊被徐宁破了连环马,不得已去青州借兵,又被三山聚义好汉戏弄;后被宋江生俘,上山落草。
9. 花 荣:原为清风寨武知寨(副职),本与刘高文知寨(正职)有隙,为解救宋江,与刘高彻底决裂,又被黄信生俘;解送途中被清风山燕顺、王英、郑天寿救出;后生俘秦明,又通过秦明说服黄信,三人一同上山落草。
10. 柴 进:未上山之前,已与梁山有私交;后因殷天锡(高俅叔伯兄弟、高唐州知府高廉老婆的兄弟)强占其叔父柴皇城花园,与李逵一起前与高唐州看望;殷天锡作威作福,李逵怒从胆边生,杀了殷天锡并逃回梁山;柴进被控指使李逵打死殷天锡,被打入死囚牢,柴皇城家产被抄;李逵从梁山搬救兵救出柴进,柴进上山落草。
11. 李 应:三打祝家庄时被萧让、戴宗等假扮官人捉拿,押解途中被林冲等人”解救”上山;吴用派人将李家庄烧成白地,并取其家眷;后路被断,只得上山落草。
12. 朱 仝:未上山之前,与梁山已有往来;后因私放雷横,刺配沧州,每日陪小衙内玩耍,被吴用、雷横、李逵等用计杀了小衙内,不得已只好上山。
13. 鲁智深:因救林冲恶了高俅,被迫远走江湖;被张青、孙二娘麻翻,介绍投奔二龙山;原二龙山头领邓龙不接纳,与杨志、曹正设计占了二龙山宝珠寺,上山落草。
14. 武 松:因杀死潘金莲等被刺配孟州;替施恩做打手得罪了蒋门神,蒋门神买通张都监诬陷武松做贼,将其刺配恩州;路上张都监、蒋门神派人欲结果武松性命,反被武松大闹飞云浦,血溅鸳鸯楼;事发后,经孙二娘、张青介绍上二龙山落草。
15. 董 平:原为东平府兵马都监,因求婚一事与太守程万里不和;后被宋江用计生俘,为梁山所用;以其原有身份,赚开东平府城门,杀程太守抢其女,从此上山落草。
16. 张 清:原为东昌府猛将,打东昌府时被林冲赶下水,被三阮生俘,上山落草。
17. 杨 志:三代将门之后,因丢失花石纲逃往他处避难,后被赦;欲行贿高俅求官复原职,高俅(及下人)收了钱不办事;杨志穷困潦倒,草市卖刀不料误杀牛二,被刺配大名府;因与索超比武被梁中书赏识,做了管军提辖使;替梁中书押送生辰纲被劫,不得已与鲁智深一同用计夺了二龙山宝珠寺落草。
18. 徐 宁:本是随驾金枪班教师,懂得使钩镰枪;不幸被时迁盗了家传宝甲,后被其表弟汤隆等用计赚上山落草。
19. 索 超:宋江攻打大名府时被俘,上山落草。
20. 戴 宗:欲用假信救宋江,被黄文炳识破,同罪判处死刑;后被梁山好汉救出,上山落草。
21. 刘 唐:劫生辰纲事发,上山落草。
22. 李 逵:劫法场救宋江后,上山落草。
23. 史 进:本与少华山勾结,事发后杀死俩都头并李吉,不愿意落草而去投奔王进;寻王进不得结识鲁智深,因鲁智深拳打镇关西而离开渭州;后至延州、北京,盘缠用尽,与鲁智深一起火烧瓦罐寺后分手,投少华山落草。
24. 穆 弘:劫法场救宋江后,上山落草。
25. 雷 横:本与梁山勾结;因打了白玉乔,被知县姘头告了一状,戴枷示众;后因白秀英与其母亲厮打,用枷打死白秀英;被朱仝私放,上山落草。
26. 李 俊:劫法场救宋江后,上山落草。
27. 阮小二:劫生辰纲事发,上山落草。
28. 张 横:劫法场救宋江后,上山落草。
29. 阮小五:劫生辰纲事发,上山落草。
30. 张 顺:劫法场救宋江后,上山落草。
31. 阮小七:劫生辰纲事发,上山落草。
32. 杨 雄:杀了与和尚裴如海私通的老婆潘巧云,投奔梁山落草。
33. 石 秀:杀了与杨雄老婆潘巧云勾搭的头陀和报晓和尚,与杨雄一起杀了潘巧云,无处可去,投奔梁山落草。
34. 解 珍:因官府下令限期捉拿大虫,打死老虎后被毛太公诬陷入狱;毛太公勾结王正、包吉等欲结果其性命,得乐和等救出,杀了毛太公一家老小,投奔梁山落草。
35. 解 宝:同解珍。
36. 燕 青:被李固赶出家门,因救卢俊义杀了董超薛霸;投奔梁山途中,卢俊义被官兵劫走,遂上梁山搬救兵,救出卢俊义后一同上山落草。
37. 朱 武:”累被官司逼迫,不得已上山落草”。
38. 黄 信:为救宋江,打破清风寨,一同上山落草。
39. 孙 立:为劫狱救解氏兄弟,上山落草。
40. 宣 赞:被秦明生擒,上山落草。
41. 郝思文:被扈三娘生擒,上山落草。
42. 韩 滔:被刘唐、杜迁生擒,上山落草。
43. 彭 玘:被扈三娘生擒,上山落草。
44. 单廷珪:被关胜生擒,上山落草。
45. 魏定国:被围,向关胜投降,上山落草。
46. 萧 让:梁山欲救宋江,被戴宗赚上梁山落草。
47. 裴 宣:”为因朝廷除将一员贪滥知府到来,把他寻事,刺配沙门岛。”路过饮马川被救上山落草。
48. 欧 鹏: “因恶了本官,逃走在江湖上。”原著中未交代为何落草,出场即为黄门山头领。
49. 邓 飞:原著并未交代,开场即为饮马川头领。
50. 燕 顺:原是贩羊马客人出身,因为消折了本钱,占据清风山落草。
51. 杨 林:原本也是绿林中人,后遇公孙胜,被举荐上梁山。
52. 凌 振:攻打梁山时落水被生俘,上山落草。
53. 蒋 敬:原著未交代,只说:”原是落科举子出身。科举不弟,弃文就武。颇有谋略,精通书算,积万累千,纤毫不差。亦能刺枪使棒,布阵排兵。”
54. 吕 方:”因贩生药到山东,消折了本钱,不能够还乡”,占对影山落草,后上梁山。
55. 郭 盛:”因贩水银货卖,黄河里遭风翻了船,回乡不得”,占对影山落草,后上梁山。
56. 安道全:被张顺杀死姘头并题”杀人者安道全也”,被迫上山落草。
57. 皇甫端:被张清举荐,上山落草。
58. 王 英:”原是车家出身。为因半路里见财起意,就势劫了客人。事发到官,越狱走了”,上清风山落草。
59. 扈三娘:二打祝家时被林冲生擒上山,被宋太公认为义女,上山落草。
60. 鲍 旭:原著未交代,原为枯树山头领,被李逵说服上梁山落草。
61. 樊 瑞:原著未交代,原为芒砀山头领,后被项充、李衮说服,一同上梁山。
62. 孔 明:因与本村财主争执而杀其全家,逃上白虎山落草。
63. 孔 亮:同孔明。
64. 项 充:原著未交代,原为芒砀头领,后被俘虏,留在梁山。
65. 李 衮:同项充。
66. 金大坚:梁山欲救宋江,被戴宗赚上梁山落草。
67. 马 麟:原著未交代,只说”原是小番子闲汉出身,吹得双铁笛,使得好大滚刀,百十人近他不得”。
68. 童 威:劫法场救宋江后,上山落草。
69. 童 猛:劫法场救宋江后,上山落草。
70. 孟 康:”原因押送花石纲,要造大舡,嗔怪这提调官催并责罚他,把本官一时杀了,弃家逃走在江湖上。”
71. 候 健:提供捉拿黄文炳线索,为宋江出气,后一同上山落草。
72. 陈 达:”累被官司逼迫,不得已上山落草”。
73. 杨 春:也是”累被官司逼迫,不得已上山落草”。
74. 郑天寿:路过清风山时与王英斗五六十回合不分胜负,被燕顺请上山落草。
75. 陶宗旺:原著未交代,只说”庄家田户出身。惯使一把铁锹,有的是气力,亦能使枪轮刀”。
76. 宋 清:与宋太公一起被同取上山落草。
77. 乐 和:为劫狱救解氏兄弟,上山落草。
78. 龚 旺:梁山打东昌府时被林冲、花荣生俘,上山落草。
79. 丁得孙:梁山打东昌府时被燕青打中马蹄,被吕方、郭盛生擒,上山落草。
80. 穆 春:劫法场救宋江后,上山落草。
81. 曹 正:”为因本处一个财主,将五千贯钱教小人来此山东做客,不想折本,回乡不得”,后助鲁智深打破二龙山,一并上山落草。
82. 宋 万:原著未交代,开场即为梁山泊头领。
83. 杜 迁:”因鸟气合着杜迁来这里落草。”
84. 薛 永:劫法场救宋江后,上山落草。
85. 施 恩:”因武松杀了张都监一家人口,官司着落他家追捉凶身,以此连夜拿家逃走在江湖上。”后投二龙山入伙。
86. 李 忠:与鲁智深在渭州分手之后,经过桃花山,被周通劫道;杀退周通,被请上桃花山落草。
87. 周 通:原著未交代,出场即为桃花山原主人,后投梁山。
88. 汤 隆:流落江湖,遇李逵,跟随上山落草。
89. 杜 兴:”因一口气上打死了同伙的客人,吃官司监在蓟州府里。杨雄见他说起拳棒都省得,一力维持,救了他。”后在李应家落草,”每日拨万论千”,后随李应上山落草。
90. 邹 渊:开场即为登云山头领,与邓飞、杨林、石勇为旧识,后救解氏弟兄一起上梁山。
91. 邹 润:开场即为登云山头领。
92. 朱 贵:”因在江湖上做客,消折了本钱,就于梁山泊落草。”
93. 朱 富:与哥哥朱贵一起,为救李逵麻翻师傅李云,后劝说李云与他一起上山落草。
94. 蔡 福:宋江攻破大名府,因照顾卢俊义有功,被硬请上山落草。
95. 蔡 庆:宋江攻破大名府,因照顾卢俊义有功,被硬请上山落草。
96. 李 立:原开黑店,因闹江州救宋江而上山落草。
97. 李 云:因押解李逵,被朱富麻倒,无法交差,只好上山落草。
98. 焦 挺:”平生最无面目(不顾面子,不讲交情),到处投人不着”,被李逵劝上梁山落草。
99. 石 勇:”为因赌博上一拳打死了个人,逃走在柴大官人庄上。”送信给宋江,一同上山。
100. 孙 新:为劫狱救解氏兄弟,上山落草。
101. 顾大嫂:为劫狱救解氏兄弟,上山落草。
102. 张 青:原在孟州道上开黑店,后投奔二龙山落草。
103. 孙二娘:原在孟州道上开黑店,后投奔二龙山落草。
104. 王定六:随张顺在取安道全时一同上山落草。
105. 郁保四:原为曾头市人马,随曾生一同上梁山谈判,被说服落草。
106. 白 胜:劫生辰纲事发被捉拿,后被解救,上山落草。
107. 时 迁:”流落在此,则一地里做些飞檐走壁,跳篱骗马的勾当。曾在苏州府里吃官司,却得杨雄救了他。”听说石秀、杨雄欲上梁山,便一同跟去上山落草。
108. 段景住:以盗马为生,欲盗好马送给宋江作见面礼,因被劫了马而直接投奔梁山。
摘自《盗寇的潜规则:从数据看水浒》一书。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
