冒死揭秘:腾讯、阿里和百度的薪资待遇
三大互联网巨头公司,百度腾讯跟阿里如何划分级别?薪资待遇又有多少?除非身居其位,否则很难探知,但是等你到那个位置知道了,却又不能说,至少不能在公开场合谈论。接下来就为大家揭秘,百度、阿里与腾讯内部的级别划分跟薪资待遇。这是一个群众喜闻乐见却又讳莫如深的话题。
各个公司头衔名字都不一样,级别的数目也不一样;有些扁平,有些很多level慢慢升;有些薪水范围严格跟级别挂钩,有些薪水跟级别没绝对的关系。
最近对阿里羡慕嫉妒恨的同学可不少,知乎上也开起了对阿里的批斗会--2014 年放弃阿里巴巴 offer 的人是否格外多?--个么,就重点先说说阿里吧!
1. 举个例子。校招不论,单说社招。想知道阿里内部级别和薪资待遇的题主,或许正面临offer选择,就像这位纠结阿里系offer的同学W:
最近刚通过面试,但基本薪酬也是不升反小降。 级别只有P6+,连P7都没有,非常郁闷,打算拒绝算了。小本工作9年了,这算不算loser ?
奇了怪了,阿里系的P6和P7的范围到底是多少?
不过反过来说,阿里系面试还真是有点深度的,通过不易,但拿到这个级别总感觉是否自已混的太一般了。
郁闷。
这样的纠结实在太常见了,都是工作好几年的老程序员了,好不容易动心跳个槽,猎头开始保证得好好的,怎么拿到offer的薪酬却不尽如人意?是自己能力不够,还是被HR/猎头忽悠?
专心做技术的大都是心思单纯之人,却最容易吃亏。知己知彼方可百战不殆,看看对方的级别和待遇,谋定而后动,才能跳得更远,走得更稳。
2. 先看阿里的级别定义:
P序列=技术岗 M序列=管理岗
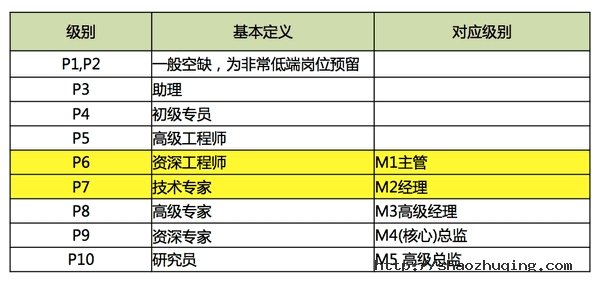
阿里的非管理岗分为10级
其中P6、P7、P8需求量最大,也是阿里占比最大的级别
前面例子中郁闷的W同学拿到了P6+的offer,正处于最庞大但又最尴尬的级别中段,至于为什么差一点儿没拿到P7,难道是HR在省招聘费?
哦,江湖传言@Fenng是P7,@鬼脚七是P9,改日向我司隔壁的P9求证。
3. 再看阿里的级别对应薪资:

股票是工作满2年才能拿,第一次拿50%,4年能全部拿完
说到股票,真是要普及下常识,别被忽悠了。股票是公司用来奖励员工忠诚度的,所以阿里分年限行权,想要离职套现真的是难。更不要高额的税收了,首先,归属要收高达45%的个税,然后得到的还是限制性股票,还不能马上卖呢。好不容易可以出售的时候,还得交20%股票增值部分的个人所得税哦!
更重要的是,你必须先缴税,才能归属,缴税还必须用现金,不能sell to cover!So,拿的越多,先拿出的cash就越多,这里面的流动性风险你自己权衡吧。
再说说级别分层和阿里类似的百度
1. 百度的技术级别:
百度有4万人,每年招聘应届生技术产品人员1000人左右,技术岗位级别和阿里类似,分为T序列12级,不赘述了,大概阿里的级别减1或2,就是百度的级别。
主要集中在T5/T6,升T7很困难,T7升T8更困难;T7以上一般就不做coding了
一般来说,在百度待3年能给到T5,很多人都等不到三年,原因下面说,社招过来的,一般是外面公司的技术骨干了
T10是技术总监,十个左右;T11是首席科学家;T12基本没见过。
2. 再看百度薪资的大概范围:

T5以上为关键岗位,另外有股票、期权
T5、T6占比最大的级别,T8、T9占比最小
级别越高,每档之间的宽幅越大
百度是一家业务定性,内部稳定,金字塔形的成熟公司。也就是说,大部分事情都是按部就班、驾轻就熟,所有人都比较轻松、稳定、舒服,尤其是对老员工而言。但是对于新员工来说,这意味着成长空间的极度压缩,机会少,上升慢。
百度工资高,福利好,但是这么多年期权已经基本发光了,只有总监以上才有,几十股几百股就算多了。问题就来了,百度新老员工的期权数量太悬殊,据说到百度楼下停车场一看,开卡宴的都是老员工,开捷达的都是新员工,其实很多新员工的贡献比老员工大得多,但是收入反而倒挂,于是很多新人等不到3年就跳了。
谈谈最南边的腾讯
1. 腾讯的技术级别:
腾讯的分级和阿里/百度都不一样,分为T1/T2/T3/T4共4级,其中又细分为3级。
员工仍然集中在中段,尤其是 T2.3 和 T3.1
想从T2跨到T3,即从2.3升3.1是非常困难的
2. 了解薪酬和级别的关系:

T3.1以上开始另外有股票
值得一提的是,腾讯是有淘汰制考核的。一般一年两次考核(6月、12月),实行末尾淘汰制,0-10%优秀,必须有5%的人转组(转组也可能出现没人接收的情况)或者被开除,这点比较狠。
升级也跟考核结果很有关系,要升一个小等级,必须最近两次考核得过一次A类考核结果。升 T3.1是内部晋升的第一道槛,要求架构在领域内优秀,被追问攻击时能无漏洞应答出来--据说只有30%的通过率。同时,腾讯好的一点在于,底层普通员工如果技术真的不错,照样升级,和是不是leader关系不大。 leader的带队价值在T3.3时才显现出来。
别问我是怎么知道答案的,我不是互联网猎头,我正在做的事就是要用互联网产品替代猎头,因为猎头不透明、不全面,还死贵。

Code Review 同行代码审查实战分析
代码审查(Code Review)是软件开发中常用的手段,和QA测试相比,它更容易发现较难发现的问题,还可以帮助团队成员提高编程技能,统一编程风格等。本文作者从实际出发,详细分析了开发者在代码审查过程中会遇到的问题及解决方法。
以下为译文:
数百万年前,人类祖先人猿学会直立行走——解放双手——最终进化到人;而代码审查在开发过程中有着异曲同工之妙——区别出野蛮开发和先进开发。

然而,在实际工作中,以下声音总不绝于耳:
- “代码审查在项目中简直就是浪费时间!”
- “我根本没有时间去做复查。”
- “由于我那个谨慎的拍档还没做好复查,进度只能延后了。”
- “你确定,我的同事要求我修改代码吗?请向他们解释一下,任何轻微地改动都会让我的代码失去原有的优雅。”
那么问题来了,我们为什么需要做代码复查?
作为专业的软件开发人员,持续提高代码质量是工作生涯不断追求的目标之一。无论我们有多么优秀,都离不开团队;而代码复查是个人与团队的润滑剂:
- 当局者迷,旁观者清。代码复查如同为我们安装了后视镜;
- 使我们的代码多了至少一个知音人;
- 能帮助新员工在这个过程中学习和领悟到前辈的代码精髓;
- 有助开展知识共享,众“智”成城。
要做就要做到最好
如果想要达成上述种种美好结果,是离不开时间和工作的科学安排的。仅仅做好代码缩进、变量命名规范等基本工作,还不能算得上完美。而如果曾经尝试过结对编程,或许你会发现其所花的时间往往都比代码复查要多。
我的建议是用开长总时长的四分之一时间来进行代码复查。举例来说,如果开发总用时为两天,那么应该花上大约四个小时来进行复查。
当然,如果能把事情做对,可不必拘泥于时间的多少。进一步说,我们必须能看明白将要复查的代码。这不仅代表要掌握基本的语言语法,更关键的是要掌握整个代码的架构,所用组件或库等细节。如果不能做到对每一行代码所做的事情都了然于胸,这样的复查工作是没有多少价值的。所以要做好这点是不能一味讲求速度的,必须花一番功夫来从头到尾对代码进行梳理分析。
此外还有两件事是务必要做到的:
- 复查工作中包含所有必须的测试工作;
- 做好设计文档的编写工作。
避免拖延症
今天的工作今天完成是最完美的工作状态,否则一旦拖延症出现,再多再好的复查都只会成为开发过程中的绊脚石。好的复查需要紧密而持久的努力,不是搞搞突击就能做好的。
因此,开发者应当尽力做到日清日结。把复查作为每天工作的开端是个不错的主意;理清旧的思路将有助于开展新的编码任务。也或许有的人喜欢在午休或下班前进行,无论在什么时候进行,以下几点是应该避免的:
- 让积压工作越积越多;
- 由于复查没有做好而导致进度延后;
- 由于代码更新频率快就放弃做复查;
- 往往在最后一刻才去做复查。
编写出可复查的代码
不应该把所有复查工作都推给复查员。如果我的同事花了一周时间添加了看起来比较乱的代码,这对复查工作无疑是重大打击,也很难让人摸清其思路和结构。
所以我们在编程时,要有意识地把代码划分为可操作单元。我们使用的方法是scrum,它为我们的开发工作做了很明晰的指导,同时使得整个开发过程有迹可循,便于进行追溯和回顾。
其次,在与复查员进行讨论前要搞好关系。这样将有助于双方对彼此有所了解,从而减少讨论时矛盾发生的机率。
再者,项目结构应当在设计文档中描述得清楚具体。这对于项目新成员的成长是大有裨益的,同时能帮助复查员提高工作效率。
最后也是最重要的一点是在自我复查过程中做好注释。换言之要先自行对代码过一遍,把需要做出说明的地方标示出来并解释清楚。有研究表明,开发者在对自己的进行复查和注释时,经常会找出不少瑕疵。
大型代码重构
有时候如果需要进行代码重构,这势必会影响到很多组件,特别是较大型的应用。在这种情况下,最好的解决方案是逐步推进重构工作。先对要做的变更进行划分,然后根据修改意图进行分段式重构。当这部分变更完成并做好复查后,再执行第二部分的重构,重复该步骤直至完成全部工作。这或许增加了重构用时,但会带来更高质量的代码同时可以减轻复查员的工作量。
如果实际情况真的不允许进行逐步重构,可以试试结对编程。
解决矛盾
在一个技术团队中,各人有各自的观点,如何达成共识是成败的关键。作为开发者,应该保持开明的心态并虚心接受不同的意见。避免固步自封,避免对自我复查工作的不屑一顾。如果有人提议把我们一些重复的代码做成一个可复用函数,这并不代表我们之前的工作是毫无价值的。
而作为复查员,要懂得人情世故。在给出修改意见前,先考虑清楚这真的会更好抑或仅仅是风格上的不同看法。提议说法可以是:“如果尝试另一种方法,或许会更好”或“有同事建议这样做”,而要避免的是:“就连我家宠物都能写出比这好的算法!”
如果真的一时僵持不下,争议双方不妨请教第三个开发人员,从他的角度来再次审度各自的观点,直到形成共识,三人行,必有我师焉。
资源平台化、O2O获客以及移动端C2C服务做定制旅游
根据去年 5 月的一份《2014中国高净值人群心灵投资白皮书》,我们可以看到越来越多的有钱人热衷于在旅游领域的投资,而且相比于大众化的旅游产品,他们更青睐定制游、主题游等个性化的产品。
目前在高端旅游市场,也已兴起了一大批定制旅游品牌,比如中青旅的耀悦,众信旅游的奇迹旅行,携程的鸿鹄逸游、太美,还有兰卡之星、主打私人健康旅行的优翔、遨乐网、帝国假日等,不过中端定制市场的选手貌似并不多,目前有无二之旅、十方旅行等,另外还有将在中高端市场掘金的游心旅行。
在游心旅行的创始人蒋松涛看来,定制旅游市场是没有巨头天花板的,而且目前太美、鸿鹄逸游等高端定制逐渐趋于标准化,并不能满足人们日益多元化的需求,再者,目前并没有同时涵盖中高端市场的定制旅游品牌,游心旅行就是想填补这个空白,为这些用户提供定制、半定制旅游产品及服务,并且以平台化资源、O2O模式获取顾客,以及打造移动端C2C服务来完善整个定制体系。
资源平台化——以自营产品为主,商家资源为辅
游心旅行会经营主要出境游业务,包括定制旅游,以及自助游中消费频次较高的目的地产品,海岛、美国、澳大利亚、新西兰等地都会主力经营,然后引进一些其他的商家,像鸿鹄逸游等高端定制的资源,游心旅行也都能获取,而至于邮轮等比较低频的产品,游心旅行就不会自己去做。
之所以将资源平台化,蒋松涛表示:一则是因为旅游的消费频次低,所以通过平台引入其他供应商可以从产品类型上进行扩张,让用户有更多选择;其次是为了把控资源和用户双方,举个栗子,像赞那度虽有调性、品位,虽然产品做得很精致,事实上它也只是一个媒介,资源并不在赞那度手中,而游心旅行通过轻重取舍则能很好的把握优质资源,并保留住忠诚用户。
开设线下体验店,以O2O的模式获取顾客
一直以来,定制都是一个重线下运作的过程,即便在互联网的冲击之下,这些单价较高、消费频次低的产品也并没能有效走到线上。所以,游心旅行也采取 O2O 的模式,通过开设线下实体店来获取用户,一方面能给用户舒适的交流环境,另一方面也增加了用户对游心旅行的信任感。
打造贴身旅行管家Mr.U,在移动端提供C2C服务
用户在目的地的体验才是真正的消费环节,因此,游心旅行在移动端提供 C2C 服务来解决用户行中问题,目前姑且称它为“游心旅行管家”。
与上述的资源平台化思路,提供目的地服务的旅行管家一部分来自游心旅行全职的旅游产品经理,也会逐渐让众信、中青旅等旅游机构的专业人士入驻;另一部分则由旅行达人组成,比如即将合作的眭澔平(具体介绍见全文末尾)。
通过这种方式,既不会让游心旅行的业务模式过重,也能保证行中服务的快速有效。当用户在行程中遇突发情况,比如临时更改行程,直接就可以通过 App 联系到旅行管家,问题不大的情况下旅行达人就能直接提供建议,如果比较复杂,那么专业人士就会帮助落实这些服务。
最后,用户还能对这些旅行管家评分,优胜劣汰之下能将有潜质的旅行管家挖掘出来,而那些起初以兼职身份存在的人也可能因为挣到钱而转作全职。
而提及未来,游心旅行不仅想做一个中高端定制旅游的服务平台,他们更希望能打造出一个中高端的品牌形象,将通过定制旅游获取到的具备极强消费力的中高端用户往其他服务进行导流,比如推出Ms.U品牌——可以提供针对女士美妆、购物、养生的产品,或者是Baby.U这样的形象来为孩子推出游学等服务。
团队情况上,游心旅行团队聚集了来自鸿鹄逸游、太美旅行、穷游网、赞那度等的成员,也吸纳了腾讯、网易等互联网人士加入。蒋松涛告诉36氪,游心旅行于 2014 年 5 月份上线,上线的当月便获得了天使投资,又于 2014 年 8 月又完成了鼎晖投资与北极光邓锋的 Pre-A 轮融资,12 月份完成千万美金级别的 A 轮融资后,又并购了转型旅游定制的五星汇。
注:报道所涉融资金额由对象公司提供保证,36氪不作任何形式背书。
注:眭澔平,台湾人,集记者、作家、歌手与主持人的身份于一身,更是一名虔诚的旅行者。他是三毛的忘年交,也为实现对三毛的承诺,二十多年已走遍180多个国家,踏遍世界的每一个角落。在《我看到的世界和你们不一样》一书中,他在南极给企鹅唱着月亮代表我的心,在菲律宾古毒体验耶稣之苦,遭受钢钉穿手的洗礼......读了他的故事之后,希望你也能“与年少初始纯真的自我相逢”。
北京市小汽车摇号程序的反编译、算法及存在的问题浅析-不重复随机数列生成算法
给定一个正整数n,需要输出一个长度为n的数组,数组元素是随机数,范围为0 – n-1,且元素不能重复。比如 n = 3 时,需要获取一个长度为3的数组,元素范围为0-2,
比如 0,2,1。
这个问题的通常解决方案就是设计一个 hashtable ,然后循环获取随机数,再到 hashtable 中找,如果hashtable 中没有这个数,则输出。下面给出这种算法的代码
public static int[] GetRandomSequence0(int total)
{
int[] hashtable = new int[total];
int[] output = new int[total];
Random random = new Random();
for (int i = 0; i < total; i++)
{
int num = random.Next(0, total);
while (hashtable[num] > 0)
{
num = random.Next(0, total);
}
output[i] = num;
hashtable[num] = 1;
}
return output;
}
代码很简单,从 0 到 total - 1 循环获取随机数,再去hashtable 中尝试匹配,如果这个数在hashtable中不存在,则输出,并把这个数在hashtable 中置1,否则循环尝试获取随机数,直到找到一个不在hashtable 中的数为止。这个算法的问题在于需要不断尝试获取随机数,在hashtable 接近满时,这个尝试失败的概率会越来越高。
那么有没有什么算法,不需要这样反复尝试吗?答案是肯定的。
![]()
如上图所示,我们设计一个顺序的数组,假设n = 4
第一轮,我们取 0 – 3 之间的随机数,假设为2,这时,我们把数组位置为2的数取出来输出,并把这个数从数组中删除,这时这个数组变成了
![]()
第二轮,我们再取 0-2 之间的随机数,假设为1,并把这个位置的数输出,同时把这个数从数组删除,以此类推,直到这个数组的长度为0。这时我们就可以得到一个随机的不重复的序列。
这个算法的好处是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试。算法代码如下:
public static int[] GetRandomSequence1(int total)
{
List<int> input = new List<int>();
for (int i = 0; i < total; i++)
{
input.Add(i);
}
List<int> output = new List<int>();
Random random = new Random();
int end = total;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end);
output.Add(input[num]);
input.RemoveAt(num);
end--;
}
return output.ToArray();
}
这个算法把两个循环改成了一个循环,算法复杂度大大降低了,按说速度应该比第一个算法要快才对,然而现实往往超出我们的想象,当total = 100000 时,测试下来,第一个算法用时 44ms, 第二个用时 1038 ms ,慢了很多!这是为什么呢?问题的关键就在这个 input.RemoveAt 上了,我们知道如果要删除一个数组元素,我们需要把这个数组元素后面的所有元素都向前移动1,这个移动操作是非常耗时的,这个算法慢就慢在这里。到这里,可能有人要说了,那我们不用数组,用链表,那删除不就很快了吗?没错,链表是能解决删除元素的效率问题,但查找的速度又大大降低了,无法像数组那样根据数组元素下标直接定位到元素。所以用链表也是不行的。到这里似乎我们已经走到了死胡同,难道我们只能用hashtable 反复尝试来做吗?在看下面内容之前,请各位读者先思考5分钟。
…… 思考5分钟
算法就像一层窗户纸,隔着窗户纸,你永远无法知道里面是什么,一旦捅穿,又觉得非常简单。这个算法对于我,只用了2分钟时间想出来,因为我经常实现算法,脑子里有一些模式,如果你的大脑还没有完成这种经验的积累,也许你要花比我长很多的时间来考虑这个问题,也许永远也找不到捅穿它的方法。不过不要紧,我把这个方法公布出来,有了这个方法,你只需轻轻一动,一个完全不同的世界便出现在你的眼前。原来就这么简单……。
还是上面那个例子,假设 n = 4
![]()
第一轮,我们随机获得2时,我们不将 2 从数组中移除,而是将数组的最后一个元素移动到2的位置

这时数组变成了
![]()
第二轮我们对 0-2 取随机数,这时数组可用的最后一个元素位置已经变成了2,而不是3。假设这时取到随机数为1
我们再把下标为2 的元素移动到下标1,这时数组变成了
![]()
以此类推,直到取出n个元素为止。
这个算法的优点是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试,也不用像上一个算法那样删除数组元素,要做的只是每次把数组有效位置的最后一个元素移动到当前位置就可以了,这样算法的复杂度就降低为 O(n) ,速度大大提高。
经测试,在 n= 100000 时,这个算法的用时仅为7ms。
下面给出这个算法的实现代码
/// <summary>
/// Designed by eaglet
/// </summary>
/// <param name="total"></param>
/// <returns></returns>
public static int[] GetRandomSequence2(int total)
{
int[] sequence = new int[total];
int[] output = new int[total];
for (int i = 0; i < total; i++)
{
sequence[i] = i;
}
Random random = new Random();
int end = total - 1;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end + 1);
output[i] = sequence[num];
sequence[num] = sequence[end];
end--;
}
return output;
}
下面是n 等于1万,10万和100万时的测试数据,时间单位为毫秒。从测试数据看GetRandomSequence2的用时和n基本成正比,线性增长的,这个和理论上的算法复杂度O(n)也是一致的,另外两个算法则随着n的增大,用时超过了线性增长。在1百万时,我的算法比用hashtable的算法要快10倍以上。
| 10000 | 100000 | 1000000 | |
| GetRandomSequence0 | 5 | 44 | 1075 |
| GetRandomSequence1 | 11 | 1038 | 124205 |
| GetRandomSequence2 | 1 | 7 | 82 |
现在摇号的程序及数据都可以在官网中查看,目的就是通过信息的透明度来堵住那些说摇号系统有猫腻之类的传言,我做为一个程序员,下意识的就想看看到底是否有猫腻。
通过下载程序,导入数据,将种子数写入后,的确没有什么猫腻,但还是不死心,想研究一下算法,结果发现了惊人的事情。
此算法使用的是伪随机,简单点将就是当种子数一定,摇号数据一定,每次随机结果都是一样的。举个例子,借用某申请编码2245102443992,摇号基数序号500015,取种子数范围在100000至120000之间能中签的种子数,结果显示共132个种子数,其概率为0.66%。随机找了一个种子数100575进行计算,得出结果在左侧表中,查询2245102443992是否中签,结果显示中签,在第15916行摇中;所以大家都应该知道怎么回事了吧,只要摇号池数据确定,查询出摇号基数序号,就能算出中签的种子数都有哪些,所以公布的数据和程序又有何用?关键在于种子数的确定。

PHP魔术方法和魔术常量介绍及使用
PHP中把以两个下划线__开头的方法称为魔术方法,这些方法在PHP中充当了举足轻重的作用。 魔术方法包括:
__construct(),类的构造函数__destruct(),类的析构函数__call(),在对象中调用一个不可访问方法时调用__callStatic(),用静态方式中调用一个不可访问方法时调用__get(),获得一个类的成员变量时调用__set(),设置一个类的成员变量时调用__isset(),当对不可访问属性调用isset()或empty()时调用__unset(),当对不可访问属性调用unset()时被调用。__sleep(),执行serialize()时,先会调用这个函数__wakeup(),执行unserialize()时,先会调用这个函数__toString(),类被当成字符串时的回应方法__invoke(),调用函数的方式调用一个对象时的回应方法__set_state(),调用var_export()导出类时,此静态方法会被调用。__clone(),当对象复制完成时调用
__construct()和__destruct()
构造函数和析构函数应该不陌生,他们在对象创建和消亡时被调用。例如我们需要打开一个文件,在对象创建时打开,对象消亡时关闭
<?php
class FileRead
{
protected $handle = NULL;
function __construct(){
$this->handle = fopen(...);
}
function __destruct(){
fclose($this->handle);
}
}
?>
这两个方法在继承时可以扩展,例如:
<?php
class TmpFileRead extends FileRead
{
function __construct(){
parent::__construct();
}
function __destruct(){
parent::__destruct();
}
}
?>
__call()和__callStatic()
在对象中调用一个不可访问方法时会调用这两个方法,后者为静态方法。这两个方法我们在可变方法(Variable functions)调用中可能会用到。
<?php
class MethodTest
{
public function __call ($name, $arguments) {
echo "Calling object method '$name' ". implode(', ', $arguments). "\n";
}
public static function __callStatic ($name, $arguments) {
echo "Calling static method '$name' ". implode(', ', $arguments). "\n";
}
}
$obj = new MethodTest;
$obj->runTest('in object context');
MethodTest::runTest('in static context');
?>
__get(),__set(),__isset()和__unset()
当get/set一个类的成员变量时调用这两个函数。例如我们将对象变量保存在另外一个数组中,而不是对象本身的成员变量
<?php
class MethodTest
{
private $data = array();
public function __set($name, $value){
$this->data[$name] = $value;
}
public function __get($name){
if(array_key_exists($name, $this->data))
return $this->data[$name];
return NULL;
}
public function __isset($name){
return isset($this->data[$name])
}
public function unset($name){
unset($this->data[$name]);
}
}
?>
__sleep()和__wakeup()
当我们在执行serialize()和unserialize()时,会先调用这两个函数。例如我们在序列化一个对象时,这个对象有一个数据库链接,想要在反序列化中恢复链接状态,则可以通过重构这两个函数来实现链接的恢复。例子如下:
<?php
class Connection
{
protected $link;
private $server, $username, $password, $db;
public function __construct($server, $username, $password, $db)
{
$this->server = $server;
$this->username = $username;
$this->password = $password;
$this->db = $db;
$this->connect();
}
private function connect()
{
$this->link = mysql_connect($this->server, $this->username, $this->password);
mysql_select_db($this->db, $this->link);
}
public function __sleep()
{
return array('server', 'username', 'password', 'db');
}
public function __wakeup()
{
$this->connect();
}
}
?>
__toString()
对象当成字符串时的回应方法。例如使用echo $obj;来输出一个对象
<?php
// Declare a simple class
class TestClass
{
public function __toString() {
return 'this is a object';
}
}
$class = new TestClass();
echo $class;
?>
这个方法只能返回字符串,而且不可以在这个方法中抛出异常,否则会出现致命错误。
__invoke()
调用函数的方式调用一个对象时的回应方法。如下
<?php
class CallableClass
{
function __invoke() {
echo 'this is a object';
}
}
$obj = new CallableClass;
var_dump(is_callable($obj));
?>
__set_state()
调用var_export()导出类时,此静态方法会被调用。
<?php
class A
{
public $var1;
public $var2;
public static function __set_state ($an_array) {
$obj = new A;
$obj->var1 = $an_array['var1'];
$obj->var2 = $an_array['var2'];
return $obj;
}
}
$a = new A;
$a->var1 = 5;
$a->var2 = 'foo';
var_dump(var_export($a));
?>
__clone()
当对象复制完成时调用。例如在设计模式详解及PHP实现:单例模式一文中提到的单例模式实现方式,利用这个函数来防止对象被克隆。
<?php
public class Singleton {
private static $_instance = NULL;
// 私有构造方法
private function __construct() {}
public static function getInstance() {
if (is_null(self::$_instance)) {
self::$_instance = new Singleton();
}
return self::$_instance;
}
// 防止克隆实例
public function __clone(){
die('Clone is not allowed.' . E_USER_ERROR);
}
}
?>
魔术常量(Magic constants)
PHP中的常量大部分都是不变的,但是有8个常量会随着他们所在代码位置的变化而变化,这8个常量被称为魔术常量。
__LINE__,文件中的当前行号__FILE__,文件的完整路径和文件名__DIR__,文件所在的目录__FUNCTION__,函数名称__CLASS__,类的名称__TRAIT__,Trait的名字__METHOD__,类的方法名__NAMESPACE__,当前命名空间的名称
这些魔术常量常常被用于获得当前环境信息或者记录日志。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
