
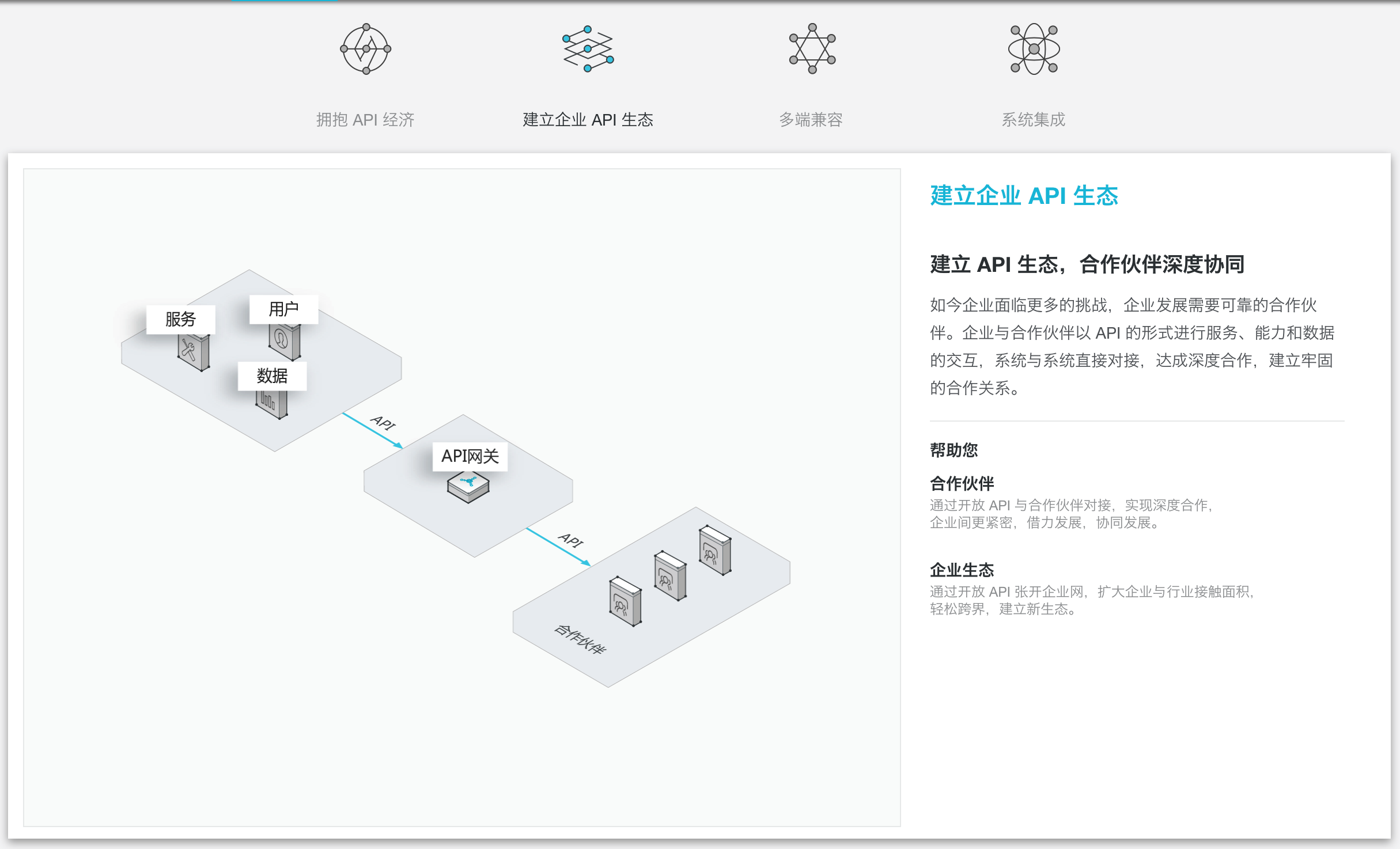
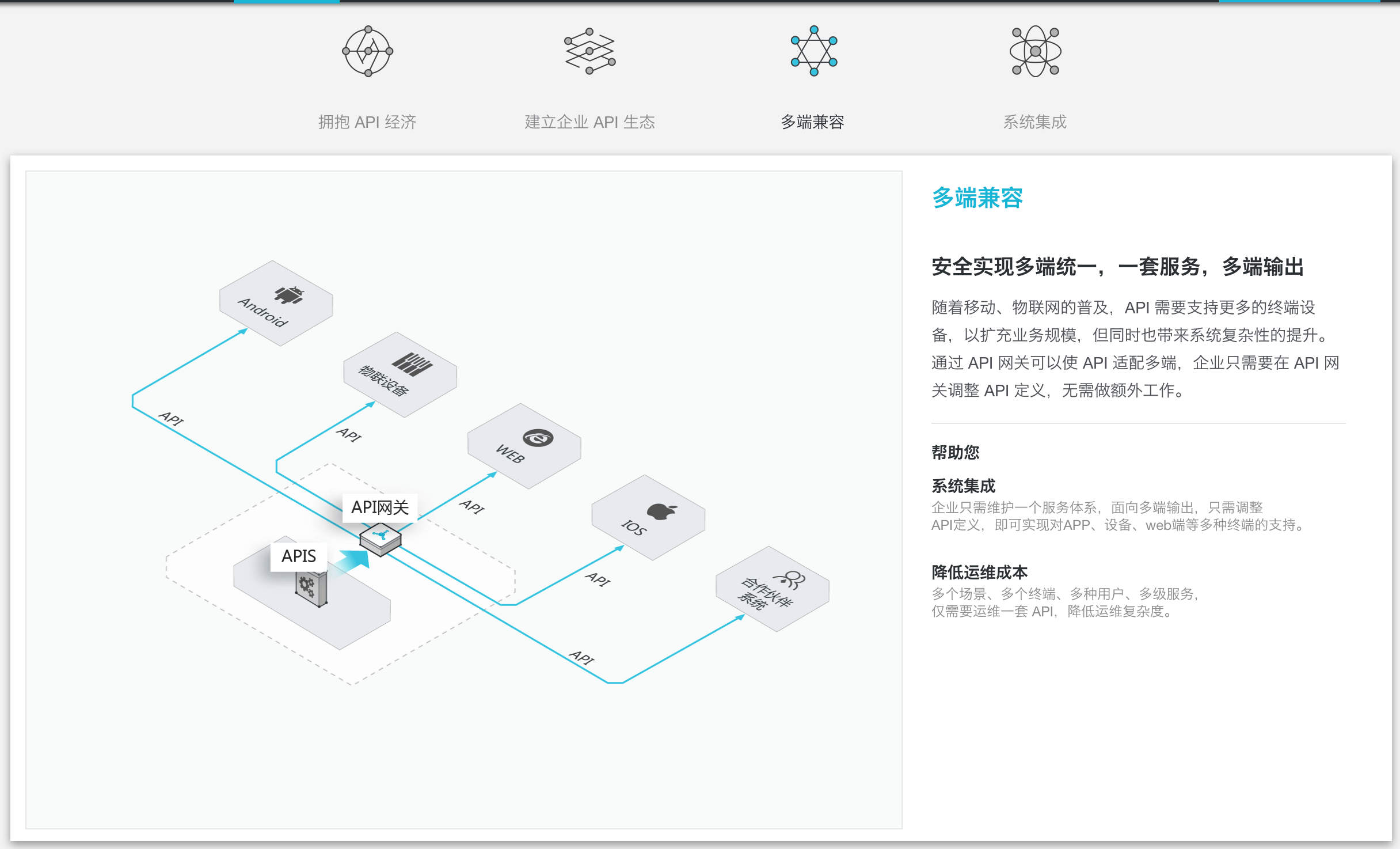
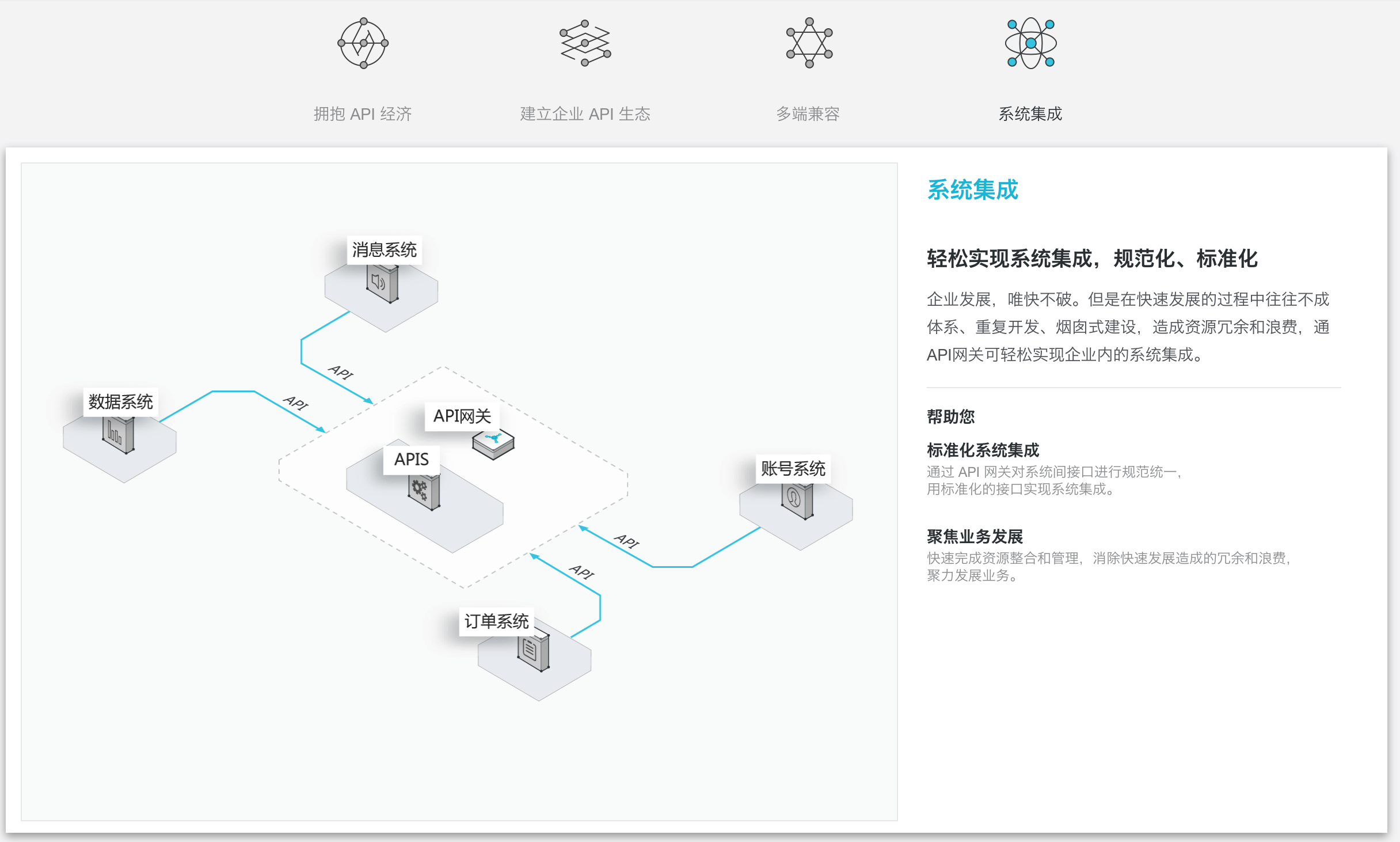
【开发规范】规范文档:API设计规范
负责API接近多年了,这些年中发现现有的API存在的问题越来越多,但很多API一旦发布后就不再能修改了,即时升级和维护是必须的。一旦API发生变化,就可能对相关的调用者带来巨大的代价,用户需要排查所有调用的代码,需要调整所有与之相关的部分,这些工作对他们来说都是额外的。如果辛辛苦苦完成这些以后,还发现了相关的bug,那对用户的打击就更大。如果API经常发生变化,用户就会失去对提供方失去信心,从而也会影响目前的业务。
但是我们为什么还要修改API呢?为了API看起来更加漂亮?为了提供更多功能?为了提供更好的性能?还是仅仅觉得到了改变了时候了?对于用户来说,他们更愿意使用一个稳定但是看起来不那么时髦的API,这并不意味着我们不再改进API了。当糟糕的API带来的维护成本越来越大时,我想就是我们去重构它的时候。
如果可以回头重新再做一遍,那么我心目中的优秀的API应该是怎么样的?
判断一个API是否优秀,并不是简单地根据第一个版本给出判断的,而是要看随着时间的推移,该API是否还能存在,是否仍旧保持得不错。槽糕的API接口各种各样,但是好的API接口对于用户来说必须满足以下几个点:
- 易学习:有完善的文档及提供尽可能多的示例和可copy-paste的代码,像其他设计工作一样,你应该应用最小惊讶原则。
- 易使用:没有复杂的程序、复杂的细节,易于学习;灵活的API允许按字段排序、可自定义分页、 排序和筛选等。一个完整的API意味着被期望的功能都包含在内。
- 难误用:对详细的错误提示,有些经验的用户可以直接使用API而不需要阅读文档。
而对于开发人员来说,要求又是不一样的:
- 易阅读:代码的编写只需要一次一次,但是当调试或者修改的时候都需要对代码进行阅读。
- 易开发:个最小化的接口是使用尽可能少的类以及尽可能少的类成员。这样使得理解、记忆、调试以及改变API更容易。
如何做到以上几点,以下是一些总结:
1、 面向用例设计
如果一个API被广泛使用了,那么就不可能了解所有使用该API的用户。如果设计者希望能够设计出被广泛使用的API,那么必须站在用户的角度来理解如何设计API库,以及如何才能设计出这样的API库。
2、 采用良好的设计思路
在设计过程中,如果能按照下面的方式来进行设计,会让这个API生命更长久
- 面向用例的设计,收集用户建议,把自己模拟成用户,保证API设计的易用和合理
- 保证后续的需求可以通过扩展的形式完成
- 第一版做尽量少的内容,由于新需求可以通过扩展的形式完成,因此尽量少做事情是抑制API设计错误的一个有效方案
- 对外提供清晰的API和文档规范,避免用户错误的使用API,尤其是避免API(见第一节)靠后级别的API被用户知晓与误用
除此之外,下面还列出了一些具体的设计方法:
- 方法优于属性
- 工厂方法优于构造函数
- 避免过多继承
- 避免由于优化或者复用代码影响API
- 面向接口编程
- 扩展参数应当是便利的
- 对组件进行合理定位,确定暴露多少接口
- 提供扩展点
3、 避免极端的意见
在设计API的时候,一定要避免任何极端的意见,尤其是以下几点:
- 必须漂亮(API不一定需要漂亮)
- API必须被正确地使用(用户很难理解如何正确的使用API,API的设计者要充分考虑API被误用的情况:如果一个API可能会被误用,那么它一定会被误用)
- 必须简单(我们总会面临复杂的需求,能两者兼顾的API是更好的API)
- 必须高性能(性能可以通过其他手段优化,不应该影响API的设计)
- 必须绝对兼容(尽管本文一直提到如何保证兼容,但是我们仍然要意识到,一些极少情况下会遇到的不兼容是可以容忍的)
4、 有效的API评审
API设计完成以后,需要经过周密的设计评审,评审的重点如下:
- 用例驱动,评审前必须提供完善的使用用例,确保用例的合理性和完备性。
- 一致性,是否与系统中其他模块的接口风格一致,是否与对称接口的设计一致。
- 简单明了,API应该简单好理解,容易学习和使用的API才不容易被误用,给我们带来更多的麻烦。
- API尽可能少,如果一个API可以暴露也可以不暴露,那么就不要暴露他,等到用户真正有需求的时候再将它成为一个公开接口也不迟。
- 支持持续改进,API是否能够方便地通过扩展的方式增加功能和优化。
5、 提高API的可测试性
API需要是可测试的,测试不应依赖实现,测试充分的API,尤其是经过了严格的“兼容性整合测试”的API,更能保证在升级的过程中不出现兼容性问题。兼容性整合测试,是指一组测试用例集合,这组测试用例会站在使用者的立场上使用API。在API升级以后,再检测这组测试用例是否能完全符合预期的通过测试,尽可能的发现兼容性问题。
6、 保证API的向后兼容
对于每一个API的设计者来说,都渴望做到“向后兼容”,因为不管是现在的API用户,还是潜在的API用户,都只信任那些可兼容的API。但向后兼容有多个层次上的意义,而且不同层次的向后兼容,也意味着不同的重要性和复杂度。
7、 保持逐步改善
过去我们总希望能将现有的“不合理”的设计完全推翻,然后按照现在“美好”的思路,重新设计这个API,但是在一段时间以后,又会碰到一样的状况,需要再推翻一次。 如果我们没有有效的逐步改善的办法,依靠推翻现有设计,重新设计API只能让我们回到起点,然后重现之前的过程。 要有一套行之有效的持续改善的办法来在API兼容的同时,改善API使之更好。
8、 把握API的生命周期
每一个API都是有生命周期的,我们需要让API的生命周期更长,并且在API的生命周期结束时能让其平滑的消亡。
- 告诉用户我们是如何设计的,避免误用,提供指导,错误的使用往往是缩短API寿命的一大杀手
- 提供试用期,API不可能一开始就是稳定,经过试用的API才能有更强的生命力
- 为API分级:内部使用;二次开发使用;开发或试用中;稳定;弃用API。避免API被滥用的同时,我们可以通过调整API的级别,来扩大其影响力,也能更优雅的结束一个API的生命周期。
开发API的过程其实就是一个沟通交流的过程。沟通的双方就是API用户和API设计者。
9、 一些具体的实施方案
在一个API不可避免要消亡或者改变的时候,我们应该接受并且面对这个事实,下面列举了几种保证兼容性的前提下,对API进行调整的办法:
- 将API标记为弃用,重新建立一个新的API。如果一个API不可避免要被消亡,这是唯一的办法。
- 为其添加额外的参数或者参数选项来实现功能添加
- 将现有API拆成两部分,提供一个精简的核心API,过去的API通过封装核心API上实现。这通常用于解决用户需要一个代码精简的版本时。
- 在现有的API基础上进行封装,提供一个功能更丰富的包或者类
一些好的API示例:
- Flickr API,这里是文档的示例,同时提供了一个非常方便的API测试工具。
- Mediawiki API
- Ebay API,这里有一个非常详尽的文档示例。
接口作为连通客户端与数据库进行数据流通的桥梁,起着举足轻重的作用,直接影响着程序的效率性、稳定性、可靠性以及数据的正确性、完整性。客户端注重的是界面美观,操作方便顺畅,是用户最直接的感受体验,而接口则是所有数据的提供者,是用户深层的内涵体验。
因次,设计接口在一个项目中,是非常重要的。那么我就目前的经验总结下如何合理设计接口。
一、 设计原理
1. 深入了解需求
除了设计数据库的人最了解需求外,其次就是设计接口的人了,甚至有时接口开发人员还要参与到数据库设计中。从“客户端-接口-数据库”的层次上看,接口明显扮演着承上启下的角色,一方面要明白接口要什么数据,另一方面要考虑如何从数据库获取、组织数据。所以如果不了解需求,你就无法正确抽象对象来组织数据给客户端,也无法验证数据库的数据结构能否满足需求。数据库设计者要了解需求中的数据结构,而接口则更多的要了解需求中的逻辑结构以及由此衍生出的逻辑数据结构。
2. 了解数据库结构
既然接口要明白如何从数据库获取、组织数据,就当然要了解数据库结构啦。
3. 了解客户端原型
了解原型,其实更多是为了帮助你设计接口时需要提供的数据和结构。但有时当你设计时并没有原型,所以此条并不是必须要求的。但假如设计完接口后原型出来了,我们也可以拿原型还验证接口设计是否正确、合理。
二、设计原则
1. 充分理由
不是随便一个功能就要有个接口,也不是随便一个需求就要加个接口。每新建一个接口,就要有充分的理由和考虑,即这个接口的存在是十分有意义额价值的,无意义的接口不仅增加了维护的难度,更重要是对于程序的可控性的大大降低,接口也会十分臃肿。因此我放在了第一条。
2. 职责明确
一个接口只负责一个业务功能,它与设计模式里的职责单一原则类似但却不同,因为一个业务功能里可能会包含多个操作,比如查询会员,可能除了查询会员表外还要获取该会员的其他必要信息,但不要在查询会员的同时还有修改权限等类似的其他业务功能,应该分成两个接口还做。
3. 高内聚低耦合
一个接口要包含完整的业务功能,而不同接口之间的业务关联要尽可能的小。还是查询会员的例子,有时查询会员的同时,可能该会员的相关信息要随之发生变化(如状态),如果这时一条完整的业务流水线,那么就应该在一个接口里完成,而不应再单独设立接口去操作完成。就是说一个接口不应该随着另一个变化而变化或以某几个接口为前提而存在。
4. 分析角度明确
设计接口分析的角度要统一明确。否则会造成接口结构的混乱。例如,不要一会以角色的角度设计,一会儿就要以功能的角度设计。
5. 入参格式统一
所有接口的参数格式要求及风格要统一,不要一个接口参数是逗号分隔,另一个就是数组;不要一个接口日期参数是x年x月x日风格,另一个就是x-x-x。
6. 状态及消息
提供必要的接口调用状态信息。调用是否成功?如果失败,那么失败的原因是什么。这些必要的信息必须要告诉给客户端。
7. 控制数据量
一个接口返回不应该包含过多的数据量,过多的数据量不仅处理复杂,对数据传输的压力也非常大,会导致客户端反应缓慢。过多的数据量很多时候都是接口划分不明确。
8. 禁止随意拓展参数
与第1条类似,只不过是针对参数而言了。日后拓展接口可能是难以避免的,但是不要随意就加参数,加参数一定是必要且有意义的,需求改变前首先应考虑现有接口内部维护是否能满足需求,而不要通过加个参数来方便自己实现需求的难度,因为参数的更变会直接导致客户端调用的变化,容易产生版本兼容性问题。
三、设计方法
1. 抽象业务
相比抽象对象而言,抽象业务更宏观,我觉得相对也容易一些,但抽象尺度往往不太好把握。
2. 数据格式
接口定义的数据格式必须都经过充分考虑,否则会出现数据转换失败或超出长度等错误。如果无法确定,直接设置成字符串是最合适的。
3. 有意义的命名
无论是接口还是参数,名称都应该是有意义的,让人能看明白的。
总之,接口设计是一个细致的工作,设计时也会有很多矛盾,但个人倾向于粗粒度设计方向(即内聚性更高一些),这样不仅给客户端浏览接口方便明确,维护也轻松些,这么做的缺点就是某一接口扩展时不是很灵活,但可以通过重新定义一个接口来弥补,但正如上所说,新增接口还是要三思而后行的。以上很多虽然都是理论性讲解,但牢牢记住这些,并结合实际工作,就会慢慢深刻的体会到其中的含义。即理论指导实践,实践来验证理论。
如何处理好前后端分离的 API 问题
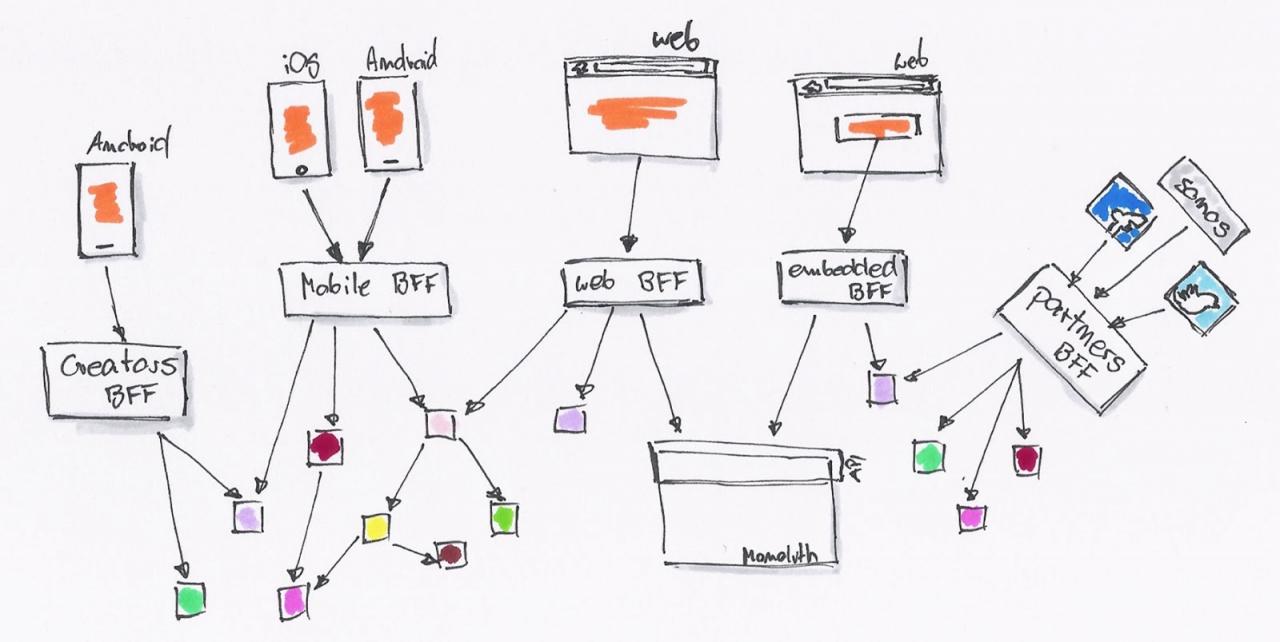
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
作为一个程序员,我讨厌那些没有文档的库。我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。
因为交付周期的原因,接入了一个第三方的库,遇到了这么一些问题:文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
对于一个库来说,文档是多种多样的:一份 demo、一个入门指南、一个 API 列表,还有一个测试。如果一个 API 有测试,那么它也相当于有一份简单的文档了——如果我们可以看到测试代码的话。而当一个库没有文档的时候,它也不会有测试。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
- API 的字段更新了
- API 的路由更新了
- API 返回了未预期的值
- API 返回由于某种原因被删除了
- 。。。
API 的维护是一件烦人的事,所以最好能一次设计好 API。可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护。
前后端分离 API 的演进史
刚毕业的时候,工作的主要内容是用 Java 写网站后台,业余写写自己喜欢的前端代码。慢慢的,随着各个公司的 Mobile First 战略的实施,项目上的主要语言变成了 JavaScript。项目开始实施了前后端分离,团队也变成了全功能团队,前端、后台、DevOps 变成了每个人需要提高的技能。于是如我们所见,当我们完成一个任务卡的时候,我们需要自己完成后台 API,还要编写相应的前端代码。
尽管当时的手机浏览器性能,已经有相当大的改善,但是仍然会存在明显的卡顿。因此,我们在设计的时候,尽可能地便将逻辑移到了后台,以减少对于前端带来的压力。可性能问题在今天看来,差异已经没有那么明显了。
如同我在《RePractise:前端演进史》中所说,前端领域及 Mobile First 的变化,引起了后台及 API 架构的一系列演进。
最初的时候,我们只有一个网站,没有 REST API。后台直接提供 Model 数据给前端模板,模板处理完后就展示了相关的数据。
当我们开始需要 API 的时候,我们就会采用最简单、直接的方式,直接在原有的系统里开一个 API 接口出来。
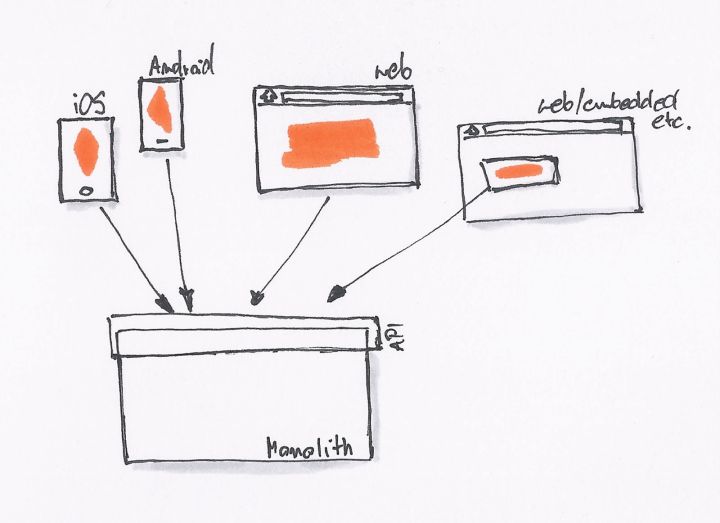
为了不破坏现有系统的架构,同时为了更快的上线,直接开出一个接口来得最为直接。我们一直在这样的模式下工作,直到有一天我们就会发现,我们遇到了一些问题:
- API 消费者:一个接口无法同时满足不同场景的业务。如移动应用,可能与桌面、手机 Web 的需求不一样,导致接口存在差异。
- API 生产者:对接多个不同的 API 需求,产生了各种各样的问题。
于是,这时候就需要 BFF(backend for frontend)这种架构。后台可以提供所有的 MODEL 给这一层接口,而 API 消费者则可以按自己的需要去封装。

API 消费者可以继续使用 JavaScript 去编写 API 适配器。后台则慢慢的因为需要,拆解成一系列的微服务。
系统由内部的类调用,拆解为基于 RESTful API 的调用。后台 API 生产者与前端 API 消费者,已经区分不出谁才是真正的开发者。
瀑布式开发的 API 设计
说实话,API 开发这种活就和传统的瀑布开发差不多:未知的前期设计,痛苦的后期集成。好在,每次这种设计的周期都比较短。
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
- 维护 API 文档很痛苦
- 需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以一个根据代码文件中中注释信息,生成应用程序或库、模块的API文档的工具。
同样的对于 API 来说,也可以采取类似的步骤,如 Swagger。它是基于 YAML语法定义 RESTful API,如:
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
schemes:
- https
host: simple.api
basePath: /openapi101
paths: {}
它会自动生成一篇排版优美的API文档,与此同时还能生成一个供前端人员使用的 Mock Server。同时,它还能支持根据 Swagger API Spec 生成客户端和服务端的代码。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
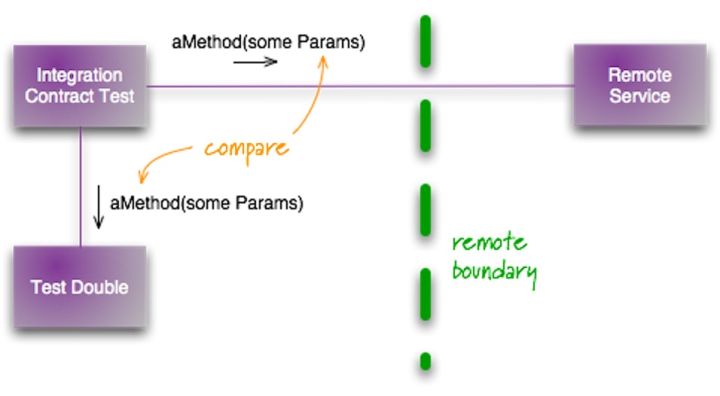
其步骤如下:
- 编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
- 根据契约编写 Mock Server。可以彩 Moco
- 编写集成测试将请求发给这个 Mock Server,并验证
如下是我们项目使用的 Moco 生成的契约,再通过 Moscow 来进行 API 测试。
[
{
"description": "should_response_text_foo",
"request": {
"method": "GET",
"uri": "/property"
},
"response": {
"status": 401,
"json": {
"message": "Full authentication is required to access this resource"
}
}
}
]
只需要在相应的测试代码里请求资源,并验证返回结果即可。
而对于前端来说,则是依赖于 UI 自动化测试。在测试的时候,启动这个 Mock Server,并借助于 Selenium 来访问浏览器相应的地址,模拟用户的行为进行操作,并验证相应的数据是否正确。

当契约发生发动的时候,持续集成便失败了。因此相应的后台测试数据也需要做相应的修改,相应的前端集成测试也需要做相应的修改。因此,这一改动就可以即时地通知各方了。
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:

这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
我们需要处理同的异常数据,不同情况下的返回值等等。因此,我之前尝试开发 DDM 来解决这样的问题,只是轮子没有造完。诸如 Redux 可以管理状态,还应该有个相应的类型检测及 Adapter 工具。
除此,还有一种情况是使用第三方 API,也需要这样的适配层。很多时候,我们需要的第三方 API 以公告的形式来通知各方,可往往我们不会及时地根据这些变化。

一般来说这种工作是后台去做代码的,不得已由前端来实现时,也需要加一层相应的适配层。
小结
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
Tutorial: Creating a Simple REST API
Tutorial: Creating a Simple REST API
In this tutorial, we will explain how to create a simple application that provides a RESTful API using the different HTTP methods:
GETto retrieve and search dataPOSTto add dataPUTto update dataDELETEto delete data
Defining the API
The API consists of the following methods:
| Method | URL | Action |
|---|---|---|
GET |
/api/robots | Retrieves all robots |
GET |
/api/robots/search/Astro | Searches for robots with 'Astro' in their name |
GET |
/api/robots/2 | Retrieves robots based on primary key |
POST |
/api/robots | Adds a new robot |
PUT |
/api/robots/2 | Updates robots based on primary key |
DELETE |
/api/robots/2 | Deletes robots based on primary key |
Creating the Application
As the application is so simple, we will not implement any full MVC environment to develop it. In this case, we will use a micro application to meet our goal.
The following file structure is more than enough:
my-rest-api/
models/
Robots.php
index.php
.htaccessFirst, we need a .htaccess file that contains all the rules to rewrite the request URIs to the index.php file (application entry-point):
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^((?s).*)$ index.php?_url=/$1 [QSA,L]
</IfModule>The bulk of our code will be placed in index.php. The file is created as follows:
<?php
use Phalcon\Mvc\Micro;
$app = new Micro();
// Define the routes here
$app->handle();Now we will create the routes as we defined above:
<?php
use Phalcon\Mvc\Micro;
$app = new Micro();
// Retrieves all robots
$app->get(
'/api/robots',
function () {
// Operation to fetch all the robots
}
);
// Searches for robots with $name in their name
$app->get(
'/api/robots/search/{name}',
function ($name) {
// Operation to fetch robot with name $name
}
);
// Retrieves robots based on primary key
$app->get(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to fetch robot with id $id
}
);
// Adds a new robot
$app->post(
'/api/robots',
function () {
// Operation to create a fresh robot
}
);
// Updates robots based on primary key
$app->put(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to update a robot with id $id
}
);
// Deletes robots based on primary key
$app->delete(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to delete the robot with id $id
}
);
$app->handle();Each route is defined with a method with the same name as the HTTP method, as first parameter we pass a route pattern, followed by a handler. In this case, the handler is an anonymous function. The following route: /api/robots/{id:[0-9]+}, by example, explicitly sets that the id parameter must have a numeric format.
When a defined route matches the requested URI then the application executes the corresponding handler.
Creating a Model
Our API provides information about robots, these data are stored in a database. The following model allows us to access that table in an object-oriented way. We have implemented some business rules using built-in validators and simple validations. Doing this will give us the peace of mind that saved data meet the requirements of our application. This model file should be placed in your Models folder.
<?php
namespace Store\Toys;
use Phalcon\Mvc\Model;
use Phalcon\Mvc\Model\Message;
use Phalcon\Mvc\Model\Validator\Uniqueness;
use Phalcon\Mvc\Model\Validator\InclusionIn;
class Robots extends Model
{
public function validation()
{
// Type must be: droid, mechanical or virtual
$this->validate(
new InclusionIn(
[
'field' => 'type',
'domain' => [
'droid',
'mechanical',
'virtual',
],
]
)
);
// Robot name must be unique
$this->validate(
new Uniqueness(
[
'field' => 'name',
'message' => 'The robot name must be unique',
]
)
);
// Year cannot be less than zero
if ($this->year < 0) {
$this->appendMessage(
new Message('The year cannot be less than zero')
);
}
// Check if any messages have been produced
if ($this->validationHasFailed() === true) {
return false;
}
}
}Now, we must set up a connection to be used by this model and load it within our app [File: index.php]:
<?php
use Phalcon\Loader;
use Phalcon\Mvc\Micro;
use Phalcon\Di\FactoryDefault;
use Phalcon\Db\Adapter\Pdo\Mysql as PdoMysql;
// Use Loader() to autoload our model
$loader = new Loader();
$loader->registerNamespaces(
[
'Store\Toys' => __DIR__ . '/models/',
]
);
$loader->register();
$di = new FactoryDefault();
// Set up the database service
$di->set(
'db',
function () {
return new PdoMysql(
[
'host' => 'localhost',
'username' => 'asimov',
'password' => 'zeroth',
'dbname' => 'robotics',
]
);
}
);
// Create and bind the DI to the application
$app = new Micro($di);Retrieving Data
The first handler that we will implement is which by method GET returns all available robots. Let's use PHQL to perform this simple query returning the results as JSON. [File: index.php]
<?php
// Retrieves all robots
$app->get(
'/api/robots',
function () use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots ORDER BY name';
$robots = $app->modelsManager->executeQuery($phql);
$data = [];
foreach ($robots as $robot) {
$data[] = [
'id' => $robot->id,
'name' => $robot->name,
];
}
echo json_encode($data);
}
);PHQL, allow us to write queries using a high-level, object-oriented SQL dialect that internally translates to the right SQL statements depending on the database system we are using. The clause use in the anonymous function allows us to pass some variables from the global to local scope easily.
The searching by name handler would look like [File: index.php]:
<?php
// Searches for robots with $name in their name
$app->get(
'/api/robots/search/{name}',
function ($name) use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots WHERE name LIKE :name: ORDER BY name';
$robots = $app->modelsManager->executeQuery(
$phql,
[
'name' => '%' . $name . '%'
]
);
$data = [];
foreach ($robots as $robot) {
$data[] = [
'id' => $robot->id,
'name' => $robot->name,
];
}
echo json_encode($data);
}
);Searching by the field id it's quite similar, in this case, we're also notifying if the robot was found or not [File: index.php]:
<?php
use Phalcon\Http\Response;
// Retrieves robots based on primary key
$app->get(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots WHERE id = :id:';
$robot = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
]
)->getFirst();
// Create a response
$response = new Response();
if ($robot === false) {
$response->setJsonContent(
[
'status' => 'NOT-FOUND'
]
);
} else {
$response->setJsonContent(
[
'status' => 'FOUND',
'data' => [
'id' => $robot->id,
'name' => $robot->name
]
]
);
}
return $response;
}
);Inserting Data
Taking the data as a JSON string inserted in the body of the request, we also use PHQL for insertion [File: index.php]:
<?php
use Phalcon\Http\Response;
// Adds a new robot
$app->post(
'/api/robots',
function () use ($app) {
$robot = $app->request->getJsonRawBody();
$phql = 'INSERT INTO Store\Toys\Robots (name, type, year) VALUES (:name:, :type:, :year:)';
$status = $app->modelsManager->executeQuery(
$phql,
[
'name' => $robot->name,
'type' => $robot->type,
'year' => $robot->year,
]
);
// Create a response
$response = new Response();
// Check if the insertion was successful
if ($status->success() === true) {
// Change the HTTP status
$response->setStatusCode(201, 'Created');
$robot->id = $status->getModel()->id;
$response->setJsonContent(
[
'status' => 'OK',
'data' => $robot,
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
// Send errors to the client
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Updating Data
The data update is similar to insertion. The id passed as parameter indicates what robot must be updated [File: index.php]:
<?php
use Phalcon\Http\Response;
// Updates robots based on primary key
$app->put(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$robot = $app->request->getJsonRawBody();
$phql = 'UPDATE Store\Toys\Robots SET name = :name:, type = :type:, year = :year: WHERE id = :id:';
$status = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
'name' => $robot->name,
'type' => $robot->type,
'year' => $robot->year,
]
);
// Create a response
$response = new Response();
// Check if the insertion was successful
if ($status->success() === true) {
$response->setJsonContent(
[
'status' => 'OK'
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Deleting Data
The data delete is similar to update. The id passed as parameter indicates what robot must be deleted [File: index.php]:
<?php
use Phalcon\Http\Response;
// Deletes robots based on primary key
$app->delete(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$phql = 'DELETE FROM Store\Toys\Robots WHERE id = :id:';
$status = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
]
);
// Create a response
$response = new Response();
if ($status->success() === true) {
$response->setJsonContent(
[
'status' => 'OK'
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Testing our Application
Using curl we'll test every route in our application verifying its proper operation.
Obtain all the robots:
curl -i -X GET http://localhost/my-rest-api/api/robots
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:05:13 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 117
Content-Type: text/html; charset=UTF-8
[{"id":"1","name":"Robotina"},{"id":"2","name":"Astro Boy"},{"id":"3","name":"Terminator"}]Search a robot by its name:
curl -i -X GET http://localhost/my-rest-api/api/robots/search/Astro
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:09:23 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 31
Content-Type: text/html; charset=UTF-8
[{"id":"2","name":"Astro Boy"}]Obtain a robot by its id:
curl -i -X GET http://localhost/my-rest-api/api/robots/3
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:12:18 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 56
Content-Type: text/html; charset=UTF-8
{"status":"FOUND","data":{"id":"3","name":"Terminator"}}Insert a new robot:
curl -i -X POST -d '{"name":"C-3PO","type":"droid","year":1977}'
http://localhost/my-rest-api/api/robots
HTTP/1.1 201 Created
Date: Tue, 21 Jul 2015 07:15:09 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 75
Content-Type: text/html; charset=UTF-8
{"status":"OK","data":{"name":"C-3PO","type":"droid","year":1977,"id":"4"}}Try to insert a new robot with the name of an existing robot:
curl -i -X POST -d '{"name":"C-3PO","type":"droid","year":1977}'
http://localhost/my-rest-api/api/robots
HTTP/1.1 409 Conflict
Date: Tue, 21 Jul 2015 07:18:28 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 63
Content-Type: text/html; charset=UTF-8
{"status":"ERROR","messages":["The robot name must be unique"]}Or update a robot with an unknown type:
curl -i -X PUT -d '{"name":"ASIMO","type":"humanoid","year":2000}'
http://localhost/my-rest-api/api/robots/4
HTTP/1.1 409 Conflict
Date: Tue, 21 Jul 2015 08:48:01 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 104
Content-Type: text/html; charset=UTF-8
{"status":"ERROR","messages":["Value of field 'type' must be part of
list: droid, mechanical, virtual"]}Finally, delete a robot:
curl -i -X DELETE http://localhost/my-rest-api/api/robots/4
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 08:49:29 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 15
Content-Type: text/html; charset=UTF-8
{"status":"OK"}Conclusion
As we saw, developing a RESTful API with Phalcon is easy using micro applications and PHQL.
设计API接口注意事项
总结一下API接口开发过程中的注意事项
1、跨平台性
所谓跨平台是指我们的接口要能够支持不同的终端,比如android、ios、windowsphone以及桌面软件、网站等。如:不同的终端每页显示的记录数不同

采用通用的解决方案,比如通信协议就采用最常用的HTTP协议,如果是即时通信,可以采用开放的XMPP协议,做游戏的可以采用可靠的TCP协议,除非TCP不够用了,再采用定制的UDP协议。
数据交换采用xml或者json格式或者webservice等等。总之,要达到的目标就是让不同的端能够很方便的使用你的接口。
2、良好的响应速度
接口应该以最快的速度将数据返回给请求者,要达到的目标就是快,一个页面,秒开最好,超过三秒就需要找找原因了。数据量按需分配,APP客户端需要什么数据就返回什么数据,过多的数据量影响处理速度,最重要的是影响传输效率
3、接口要为移动客户端考虑
比如,在移动端里,下拉刷新和上拉加载更多是很常见的功能,如果接口仍然按照传统的web思路,
只提供按页读取的话,就会造成移动端的额外的数据请求和计算。 这时,接口就应该针对这两种类型的操作提供额外的支持。
4、考虑移动端的网络情况和耗电量
如果让我们说出哪类app比较好,可能还不大好说,但是如果让我们说出哪些app很差,我们肯定会说出那些体积很大、占用内存多、界面很卡、费电的app 不好。对于网络情况,接口应该具备为不同的网络提供不同的内容的能力如果我们能够知道用户的网络情况,只有在wifi的情况下才给用户传输封面图、缩略图 之类的,
是不是可以帮用户节省很多流量呢
5、通用的数据交换格式
目前,对于接口和客户端的数据交换格式,基本上就是三种,xml和json和webservice,而现在使用json的应该占大多数最麻烦的就是处理Date类型,因为JSON本身没有Date类型,因此,JSON库将Date类型的数据序列化时会转为String。这时,不同环境, 不同平台,以及用不同的JSON解析库,转换后的结果经常会不同。比如,你在开发机上可能得到的结果是”2016-1-1 17:11:11”,但放到服务器后结果却变成了“Jan 1,2016 5:11:11 PM” ,客户端进行反序列化时无疑会失败。后来,我取消了所有Date类型,统一采用时间戳表示,就再没有转化的烦恼了。 另外,接口的开发人员有时候会将一些数据错误地转换为了String,导致客户端使用时因类型错误而异常。例如,本来是数字的1,被转成 了”1″,客户端做运算时就会出错,或用switch判断时也会出错,或其他无法转换的情况发生时;例如,为空时JSON正确地表示应该是null,但如 果转为了String就变成了”null”,那问题就来了,我遇到的因为这个错误的转换导致的程序奔溃已经好几次了,第一次的时候,查了一整天才定位到问题所在
6、接口统计功能
在做PC端网站的时候,我们都会给我们的网站加上个统计功能,要么自己写统计系统,要么使用第三方的比如GA
移 动端接口API则需要我们自己实现统计功能,这时就需要我们尽可能多的收集客户端的信息,除了传统的IP、User-Agent之外,还应该收集一些移动 相关的信息,比如手机操作系统,是android还是ios,都是什么版本,用户使用的网络状况,是2G、3G、4G还是WIFI。客户端APP是什么版 本信息。
7、客户端与服务端的肥瘦平衡
在移动开发中,由于客户端的修改会很费时费力,特 别是IOS应用还要经过Apple审核,另外,当前IOS开发人员、Android开发人员的人工成本普遍较高,人才紧缺,基于这两点,能在服务器端实现 的功能就不要放在客户端,毕竟服务器端程序的修改要比客户端方便、灵活、快捷的多。
8、隐式用户与显式用户
显式用户指的是,APP程序中有用户系统,一个username、password正确的合法用户,称之为显式的用户,
通常显式用户都需要注册,登录以后能完成一些个人相关的操作。
隐式用户指的是,APP程序本身就没有用户系统,或者一个在没有登录的情况下,使用我们APP的用户。
在这种情况下,可以通过客户端生成的UDID来标识一个用户。
有了用户信息,我们就能够了解不同用户的使用习惯,而不仅仅是全体用户的一个整体的统计信息,
有了这些个体的信息之后,就可以做一些用户分群、个性化推荐之类的事情。
9、安全问题
设计API第一个需要考虑的是API的安全机制。我负责的上一个项目,因为API的安全问题,就被人攻击了两次。之后经过分析,主要存在两个漏洞: 一是因 为缺少对调用者进行安全验证的方式,二是因为数据传输不够安全。那么,制定API的安全机制,主要就是为了解决这两个问题:
- 保证API的调用者是经过自己授权的App;
- 保证数据传输的安全。
第一个问题的解决方案,我主要采用设计签名的方式。对每个客户端分别分配一个AppKey和AppSecret。需要调用API时,将AppKey加入请求参数列表,并将AppSecret和所有参数一起,根据某种签名算法生成一个签名字符串,然后调用API时把该签名字符串也一起带上。服务端收到请求之后,根据请求中的AppKey查询相应的AppSecret,按照同样的签名算法,也生成一个签名字符串,当服务端生成的签名和请求带过来的签名一致的时候,那就表示这个请求的调用者是经过自己授权的,证明这个请求是安全的。而且,每个端都有一个Key,也方便不同端的标识和统计。为了防止AppSecret被别人获取,这个AppSecret一般写死在代码里面。另外,签名算法也需要有一定的复杂度,不能轻易被别人破解,最好是采用自己规 定的一套签名算法,而不是采用外部公开的签名算法。另外,在参数列表中再加入一个时间戳,还可以防止部分重放攻击。
接口不能直接调用OAuth认证(rsa加密),ip白名单接口的安全工作不能马虎,暴力破解啊、SQL Injection啊、伪造请求和数据啊、重复提交啊也要考虑到,
如果数据特别敏感,可以考虑采用SSL/TLS等加密传输,或者客户端、服务器端约定一个加密算法和密钥,对来往传输的数据进行加密、解密。如将所有参数加签名算法得到一个签名验证参数signhttp://www.webvist.com/blog/2287954
表单类接口防止重复提交:调用过的接口sign存起来,检查sign是否存在
10、良好的接口说明文档和测试程序
接口文档要清晰、明了,包含多少个接口,每个接口的地址、参数、请求方式、数据交换格式、参数是否必填、编码格式UTF8,返回值等都要写清楚。
接口测试程序,有条件的话,也可以提供,方便前后端的调试

11、版本的维护
随着业务的变化,客户端APP和服务器端API都会发生变化,增加新的功能,修改已有的功能,
增加功能还好说, 如果是接口需要修改,那么就面临着同一个接口要同时为不同版本的客户端服务的问题。
因此,服务器端接口也要做好相应的版本维护。
主版本更新可以把版本号放入API的URL中/api-v2来指出所使用的API版本
次要版本的修改是通过客户在API调用时发起请求的HTTP头部做指定的头部的版本元素看起来是这样的:
Element-Version: 1
12、接口数据、状态
接口必须提供明确的数据状态信息,不管是成功的,还是失败的,都必须返回给APP客户端。
13、接口、参数命名准确。
无论是接口还是参数,命名都应该有意义,让人一目了然。
RESTful API 设计指南
网络应用程序,分为前端和后端两个部分。当前的发展趋势,就是前端设备层出不穷(手机、平板、桌面电脑、其他专用设备......)。
因此,必须有一种统一的机制,方便不同的前端设备与后端进行通信。这导致API构架的流行,甚至出现"API First"的设计思想。RESTful API是目前比较成熟的一套互联网应用程序的API设计理论。我以前写过一篇《理解RESTful架构》,探讨如何理解这个概念。
今天,我将介绍RESTful API的设计细节,探讨如何设计一套合理、好用的API。我的主要参考了两篇文章(1,2)。

一、协议
API与用户的通信协议,总是使用HTTPs协议。
二、域名
应该尽量将API部署在专用域名之下。
https://api.example.com
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
https://example.org/api/
三、版本(Versioning)
应该将API的版本号放入URL。
https://api.example.com/v1/
另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。Github采用这种做法。
四、路径(Endpoint)
路径又称"终点"(endpoint),表示API的具体网址。
在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
举例来说,有一个API提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
- https://api.example.com/v1/zoos
- https://api.example.com/v1/animals
- https://api.example.com/v1/employees
五、HTTP动词
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
- GET /zoos:列出所有动物园
- POST /zoos:新建一个动物园
- GET /zoos/ID:获取某个指定动物园的信息
- PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoos/ID:删除某个动物园
- GET /zoos/ID/animals:列出某个指定动物园的所有动物
- DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
六、过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
- ?limit=10:指定返回记录的数量
- ?offset=10:指定返回记录的开始位置。
- ?page=2&per_page=100:指定第几页,以及每页的记录数。
- ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
七、状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
状态码的完全列表参见这里。
八、错误处理(Error handling)
如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{ error: "Invalid API key" }
九、返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
十、Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
{"link": { "rel": "collection https://www.example.com/zoos", "href": "https://api.example.com/zoos", "title": "List of zoos", "type": "application/vnd.yourformat+json" }}
上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型。
Hypermedia API的设计被称为HATEOAS。Github的API就是这种设计,访问api.github.com会得到一个所有可用API的网址列表。
{ "current_user_url": "https://api.github.com/user", "authorizations_url": "https://api.github.com/authorizations", // ... }
从上面可以看到,如果想获取当前用户的信息,应该去访问api.github.com/user,然后就得到了下面结果。
{ "message": "Requires authentication", "documentation_url": "https://developer.github.com/v3" }
上面代码表示,服务器给出了提示信息,以及文档的网址。
十一、其他
(1)API的身份认证应该使用OAuth 2.0框架。
(2)服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
(完)
Trello API Docs
https://api.trello.com/docs/index.html
Trello Documentation
Generating Your Developer Key
Generate a developer key by logging into Trello and visiting
Follow the Development of the API
Work on the Trello API is being tracked at https://trello.com/api
Examples
- Reading all the cards a member is assigned to: http://jsfiddle.net/nNesx/
- Add a comment to a card that you are assigned to: http://jsfiddle.net/E4rLn/
Tools and Projects using the API
- Wrappers
- Tools Using the client-side library (client.js)
- https://github.com/francois2metz/trello-calendar (Cards on a calendar, by due date)
- https://github.com/markdrago/cardorizer (Send cards from FogBugz/JIRA/github using bookmarklets)
- https://github.com/danlec/Trello-Bookmarklet (Send cards from FogBugz/JIRA/github using a single bookmarklet)
- Misc
- https://github.com/oisin/trellobo (Tiny IRC bot that pulls cards from a Trello board)
- http://www.twilio.com/gallery/projects/Twellio (Send cards to Trello via SMS)
- https://bitbucket.org/JakeGinnivan/taskboards (A WP7 Trello App)
This is not the help I was looking for.
关于API和OAuth授权验证
前两天有事去市里了,发现火狐便携版仍然那么杯具。。
订阅什么的就没管,积了好多。。
博客更新是回来后再补的,订阅的童鞋应该发现的。。
这几天有折腾腾讯微博的API,(刚蓝屏一次,话说用win7快一年了,蓝屏不到10次,MS还不错),SDK什么的都没有ASP的,而吾辈偏偏就只会一点ASP。。。
只好自己试着搞定,经过多方Google,终于明白点oauth是什么了,可是运行时总是失败。。。。。
两篇和API相关的文章:
OAuth是什么?:http://www.99ria.com/blog/?p=340
OAuth认证步骤:http://isouth.org/archives/286.html
还有就是新浪的API文档吧,腾讯的只是给出了需要的接口地址而已。。
比较麻烦的是oauth_signature(签名),我的理解就是好比你写了封信,你在信中表明了自己的身份(App Key),然后写了其他需要的内容,但是这封信是不是你写的呢?
你需要将已经写好的内容(base string)以及一个Key(App Secret)作为参数,按照指定的签名方法(oauth_signature_method)进行运算,得出一个oauth_signature值(HMAC-SHA1 [Key,base_string])写在信的未尾作为签名;
收信人在拿到信后,需要找出信中所述App Key对应的App Secret,然后自己进行下签名运算,看得出的oauth_signature值是不是和你写的一样。
App Key和App Secret就相当于帐号密码,但是oauth授权验证大部分都是跨站进行或者使用GET方式传递数据,为了安全而采用oauth_signature作为一次性密码。
base_string里包含了一个表明当前时间的时间戳(oauth_timestamp,自1970年1月1日00:00:00 GMT以来的秒数)和一个32位的的随机字符串(oauth_nonce),想要逆向算出App Secret…………
上边说了OAuth授权的安全机制,现在再来看授权过程:
API通过以下四个步骤来完成认证授权并访问或修改受限资源的流程
1. 获取未授权的Request Token(temporary credentials)
2. 请求用户授权Request Token
3. 使用授权后的Request Token换取Access Token(token credentials)
4. 使用 Access Token 访问或修改受保护资源
其中1~3步使用https方式, 第4步使用http方式。
我们注册并使用腾讯微博,帐号密码及所发布的信息都保存在腾讯微博的服务器上,但是可以通过API接口将数据拿到站外使用,
所以第一步,应用方帮用户向腾讯服务器进行“预约”,同时也是对应用方资格的一个验证,
二、三步对用户身份进行验证,“办理”将数据拿到站外使用的其他“手续”,最后就可以在应用方 “访问或修改受保护资源”。
和OpenID挺像的,,只是OpenID应用中,对用户身份进行验证的一方只负责验证,不提供资源。
关于API和OAuth授权验证《关于API和OAuth授权验证》 http://www.wdssmq.com/post/ZuoWanDeMengHaiZhenShiXuanYiJiaKeHuanTuCaoChuMei.html
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
