支付宝口碑isv开发如何正确处理签名
简单的知识点
- 本文基本分初级、进阶、高级三部
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
不熟悉的同学 - 进阶适用群体:使用 SDK 开发系统,对 RSA 签名规则
熟悉的同学 - 仅使用SDK需要对开放平台签名规则略有了解。
- 适合遇到网关返回报文中描述
签名错误。 - 高级适用群体: 不使用 demo或 SDK、完全独立开发。对RSA 签名规则
熟悉的同学 - 注:推荐使用 SDK。否则请直接跳高级说明。
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
- 推荐使用 demo 或者 SDK。可以节约开发同学学习RSA签名规则的时间。
- 初次对接开放平台接口时建议选择参数较少的简单接口对接,方便调查问题。
- 支付宝产品分 mapi 网关产品及 openapi 网关产品。
- mapi 网关均使用支付宝PID调用,需配置合作伙伴秘钥。
- 因 mapi 多使用 md5验签,问题较少,因此本文仅介绍开放平台签名规则。
- openapi 网关产品均使用支付宝 appid 调用,需在appid上分别配置秘钥。
- 如有多个 appid, 使用相同秘钥或者不同秘钥均可,只需保证自己调用时使用配对秘钥加签即可。
初级教程
对于新接入支付宝产品的开发,如何生成密钥、开放平台设置密钥 很重要
- 获取 PID
?点击查看- 详解如何查询 支付宝账号PID.
- RSA秘钥生成
?点击查看- 推荐使用在线地址中生成工具,该工具同样可做秘钥校验作用.(问题排查工具)
- 上传公钥
?点击查看- 在此页面可以上传商户公钥及查看支付宝公钥(支付宝公钥唯一,因此代码中不做修改最好,以免节外生枝.)
- demo&sdk使用方法
?点击查看- 参考文中的配置方法将第二步中生成的私钥填写.
- 注意最新
.netdemo 对aop.DefaultAopClient方法做了改善,添加了两个参数.最后一个参数keyFromFile.- 为true时直接写私钥本地路径.
- 默认 false, 需要将私钥内容转成一行填入方法中.
进阶教程
进阶教程主要针对在使用时碰到签名错误的同学
- 一般平台返回签名错误 个人建议按照初级教程仔细核对一遍.
- 可能原因1:账号多人使用,被其他同事或者其他公司员工修改
- 建议跟商户相关负责人沟通,看谁有可能修改秘钥,因为修改秘钥需要短信验证码,所以肯定能查出问题根源.
- 绑定手机号应该是公司相对高层人士,与其沟通不要随便将短信码给其他人.
- 可能原因2:自己误操作导致公钥不匹配
- 在开放平台有多个应用,上传公钥时需上传系统使用 appid 相同应用的商户公钥.
- 生成了多套秘钥或者其他原因导致程序里私钥与平台设置的公钥不匹配
- 该问题建议使用
初级教程:[RSA秘钥生成]中的工具做排查,校验公私钥是否匹配. - 如不匹配可使用私钥重新生成公钥配置到开放平台.
- 或者重新生成一套按
初级教程:上传公钥重新配置 - 可能原因3:如果调用api中传参包含中文,则很有可能是因为编码问题导致开放平台验签失败.
- 调查方法,将参数中所有中文替换成英文重试接口调用,如果成功说明是编码影响平台验签.
- 修改方法,参考
初级教程:demo&sdk使用方法在DefaultAopClient方法中传入相应编码集. - 下面介绍出现这个问题的原因,感兴趣的同学可以看下.
- 中文包含多种编码集,而你们系统有默认编码集,当你参数中含有中文且在调用签名方法时没有指明编码集,系统会使用默认编码集进行签名.而调用接口时需传入
charset参数, 如果你没传入,平台会使用默认编码集utf-8解签,如果你系统默认utf-8编码,那么此问题你无感知,但如果是非utf-8类型编码会导致平台算签名串与你实际传入不符. 最终验签失败
- 系统直接报错,抛出的异常建议自己先分析.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
- 使用java开发但是私钥未经过
pkcs8转码 - 使用.net开发,参考
初级教程:demo&sdk使用方法,未对keyFromFile做有效控制. - 复制私钥没复制全.
- 使用java开发但是私钥未经过
- 其他异常均属于代码错误,建议先自己排查.实在搞不定可以联系
技术支持协助解决.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
高级教程
高级教程针对不使用 SDK开发的同学(安全考虑/冷门语言等原因)
- 高级教程需要你首先了解初级教程,并且进阶教程中的常见问题也可以自己排查解决.
- 本文主要探讨开放平台签名规则,如不使用sdk开发,这些逻辑代码均需要自己开发.
- 建议开发前先参考 sdk 源代码看下实际处理
- 签名机制
?点击查看mapi网关产品签名时要去掉sign_type=RSA,这点跟openapi网关产品不同,一定要注意.- 排序时不要仅排序第一个字符,要注意第一字符相同时排第二字符,以此类推.
- 所有
空参数不在签名参数中,注意剔除.异步通知(需要解签报文)同理 - 支付宝异步通知不会有
空参数
MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
一篇文章学会Mysql分区表的管理与维护
定义:
表的分区指根据可以设置为任意大小的规则,跨文件系统分配单个表的多个部分。实际上,表的不同部分在不同的位置被存储为单独的表。用户所选择的、实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数。
使用场景:
1.某张表的数据量非常大,通过索引已经不能很好的解决查询性能的问题
2.表的数据可以按照某种条件进行分类,以致于在查询的时候性能得到很大的提升
优点:
1)、对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
2)、一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
3)、涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这意味着查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
4)、通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
分类:

1.检查你的Mysql是否支持分区
mysql> SHOW VARIABLES LIKE '%partition%';
若结果如下,表示你的Mysql支持表分区:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| have_partition_engine | YES |
+-----------------------+-------+
1 row in set (0.00 sec)
RANGE分区表创建方式:
- DROP TABLE IF EXISTS `my_orders`;
- CREATE TABLE `my_orders` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (YEAR(atime))
- (
- PARTITION p0 VALUES LESS THAN (2016),
- PARTITION p1 VALUES LESS THAN (2017),
- PARTITION p2 VALUES LESS THAN MAXVALUE
- );
以上是一个简单的订单表,分区字段是atime,根据RANGE分区,这样当你向该表中插入数据的时候,Mysql会根据YEAR(atime)的值进行分区存储。
检查分区是否创建成功,执行查询语句:
EXPLAIN PARTITIONS SELECT * FROM `my_orders`
若成功,结果如下:

性能分析:
1).创建同样表结构,但没有进行分区的表
- DROP TABLE IF EXISTS `my_order`;
- CREATE TABLE `my_order` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2).向两张表中插入相同的数据
- /**************************向分区表插入数据****************************/
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
- /**************************向未分区表插入数据****************************/
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
3).主从复制,大约20万条左右(主从复制的数据和真实环境有差距,但是能体现出表分区查询的性能优劣)
- /**********************************主从复制大量数据******************************/
- INSERT INTO `my_orders`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_orders`;
- INSERT INTO `my_order`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_order`;
4).查询测试
- /***************************查询性能分析**************************************/
- SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.084s****/
- SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.284s****/
通过以上查询可以明显看出进行表分区的查询性能更好,查询所花费的时间更短。
分析查询过程:
EXPLAIN PARTITIONS SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
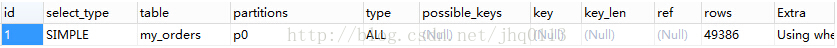
EXPLAIN PARTITIONS SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();

通过以上结果可以看出,my_orders表查询直接经过p0分区,只扫描了49386行,而my_order表没有进行分区,扫描了196983行,这也是性能得到提升的关键所在。
当然,表的分区并不是分的越多越好,当表的分区太多时找分区又是一个性能的瓶颈了,建议在200个分区以内。
LIST分区表创建方式:
- /*****************创建分区表*********************/
- CREATE TABLE `products` (
- `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '表主键' ,
- `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称' ,
- `metrial` tinyint UNSIGNED NOT NULL COMMENT '材质' ,
- `weight` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '重量' ,
- `vol` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '容积' ,
- `c_id` tinyint UNSIGNED NOT NULL COMMENT '供货公司ID' ,
- PRIMARY KEY (`id`,`c_id`)
- )ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY LIST(c_id)
- (
- PARTITION pA VALUES IN (1,3,11,13),
- PARTITION pB VALUES IN (2,4,12,14),
- PARTITION pC VALUES IN (5,7,15,17),
- PARTITION pD VALUES IN (6,8,16,18),
- PARTITION pE VALUES IN (9,10,19,20)
- );
可以看出,LIST分区和RANGE分区很类似,这里就不做性能分析了,和RANGE很类似。
HASH分区表的创建方式:
- /*****************分区表*****************/
- CREATE TABLE `msgs` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY HASH(sub_id)
- PARTITIONS 10;
以上语句代表,msgs表按照sub_id进行HASH分区,一共分了十个区。
Key分区和HASH分区很类似,不再介绍,若想了解可以参考Mysql官方文档进行详细了解。
子分区的创建方式:
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
检查子分区是否创建成功:
EXPLAIN PARTITIONS SELECT * FROM msgss;
结果如下图:

前面已经提过,Mysql支持4种表的分区,即RANGE与LIST、HASH与KEY,其中RANGE和LIST类似,按一种区间进行分区,HASH与KEY类似,是按照某种算法对字段进行分区。
RANGE与LIST分区管理:
案例:有一个聊天记录表,用户几千左右,已经对表按照用户进行一定粒度的水平分割,现仍然有部分表存储的记录比较多,于是按照下列方式有对表进行了分区,分区的好处是,可以动态改变分区,删除分区后,数据也一同被删除,如聊天记录只保存两年,那么你就可以按照时间进行分区,定期删除两年前的分区,动态创建新的的分区就能做到很好的数据维护。
分区表创建的语句如下:
- DROP TABLE IF EXISTS `msgss`;
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
上述语句创建了三个按照RANGE划分的主分区,每个主分区下面有六个按照HASH划分的子分区。
插入测试数据:
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',UNIX_TIMESTAMP(NOW()),1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',UNIX_TIMESTAMP(NOW()),2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',UNIX_TIMESTAMP(NOW()),3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',UNIX_TIMESTAMP(NOW()),10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',UNIX_TIMESTAMP(NOW()),7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',UNIX_TIMESTAMP(NOW()),5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1451577607,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1451577609,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1451577623,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1451577654,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1451577687,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1451577699,5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1514736056,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1514736066,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1514736076,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1514736086,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1514736089,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1514736098,5);
进行分区分析:
EXPLAIN PARTITIONS SELECT * FROM msgss;
可以检测到分区信息如下:

检测分区数据分布:
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`<1451577600;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1451577600 AND `atime`<1483200000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1483200000 AND `atime`<1514736000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1514736000;
结果:第一条语句只扫描了t0的所有子分区,第二条语句只扫描了t1的所有子分区,第三四条分别只扫描了t2的所有子分区,证明表的分区和数据分布成功。
需求:目前已经是2017年,需要将2015年所有的聊天记录删除,但是保留2016年的聊天记录,并且2017年的数据也能正常按照分区进行存储。
实现以上需求,需要两步,第一步删除t0分区,第二步按照新规则重建分区。
删除分区语句:
ALTER TABLE `msgss` DROP PARTITION t0;
重建分区语句:
- ALTER TABLE `msgss` PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1514736000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
查询发现,15年的数据全部被删除,剩余的数据被重新分区并分布。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
