【开发规范】规范文档:MySQL规范2
1. 规范背景与目的
MySQL数据库与 Oracle、 SQL Server 等数据库相比,有其内核上的优势与劣势。我们在使用MySQL数据库的时候需要遵循一定规范,扬长避短。本规范旨在帮助或指导RD、QA、OP等技术人员做出适合线上业务的数据库设计。在数据库变更和处理流程、数据库表设计、SQL编写等方面予以规范,从而为公司业务系统稳定、健康地运行提供保障。
2. 设计规范
2.1 数据库设计
以下所有规范会按照【高危】、【强制】、【建议】三个级别进行标注,遵守优先级从高到低。
对于不满足【高危】和【强制】两个级别的设计,DBA会强制打回要求修改。
2.1.1 库名
- 【强制】库的名称必须控制在32个字符以内,相关模块的表名与表名之间尽量提现join的关系,如user表和user_login表。
- 【强制】库的名称格式:业务系统名称_子系统名,同一模块使用的表名尽量使用统一前缀。
- 【强制】一般分库名称命名格式是
库通配名_编号,编号从0开始递增,比如wenda_001以时间进行分库的名称格式是“库通配名_时间” - 【强制】创建数据库时必须显式指定字符集,并且字符集只能是utf8或者utf8mb4。创建数据库SQL举例:
create database db1 default character set utf8;。
2.1.2 表结构
- 【强制】表和列的名称必须控制在32个字符以内,表名只能使用字母、数字和下划线,一律小写。
- 【强制】表名要求模块名强相关,如师资系统采用”sz”作为前缀,渠道系统采用”qd”作为前缀等。
- 【强制】创建表时必须显式指定字符集为utf8或utf8mb4。
- 【强制】创建表时必须显式指定表存储引擎类型,如无特殊需求,一律为InnoDB。当需要使用除InnoDB/MyISAM/Memory以外的存储引擎时,必须通过DBA审核才能在生产环境中使用。因为Innodb表支持事务、行锁、宕机恢复、MVCC等关系型数据库重要特性,为业界使用最多的MySQL存储引擎。而这是其他大多数存储引擎不具备的,因此首推InnoDB。
- 【强制】建表必须有comment
- 【建议】建表时关于主键:(1)强制要求主键为id,类型为int或bigint,且为
auto_increment(2)标识表里每一行主体的字段不要设为主键,建议设为其他字段如user_id,order_id等,并建立unique key索引(可参考cdb.teacher表设计)。因为如果设为主键且主键值为随机插入,则会导致innodb内部page分裂和大量随机I/O,性能下降。 - 【建议】核心表(如用户表,金钱相关的表)必须有行数据的创建时间字段
create_time和最后更新时间字段update_time,便于查问题。 - 【建议】表中所有字段必须都是
NOT NULL属性,业务可以根据需要定义DEFAULT值。因为使用NULL值会存在每一行都会占用额外存储空间、数据迁移容易出错、聚合函数计算结果偏差等问题。 - 【建议】建议对表里的
blob、text等大字段,垂直拆分到其他表里,仅在需要读这些对象的时候才去select。 - 【建议】反范式设计:把经常需要join查询的字段,在其他表里冗余一份。如
user_name属性在user_account,user_login_log等表里冗余一份,减少join查询。 - 【强制】中间表用于保留中间结果集,名称必须以
tmp_开头。备份表用于备份或抓取源表快照,名称必须以bak_开头。中间表和备份表定期清理。 - 【强制】对于超过100W行的大表进行
alter table,必须经过DBA审核,并在业务低峰期执行。因为alter table会产生表锁,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响。
2.1.3 列数据类型优化
- 【建议】表中的自增列(
auto_increment属性),推荐使用bigint类型。因为无符号int存储范围为-2147483648~2147483647(大约21亿左右),溢出后会导致报错。 - 【建议】业务中选择性很少的状态
status、类型type等字段推荐使用tinytint或者smallint类型节省存储空间。 - 【建议】业务中IP地址字段推荐使用
int类型,不推荐用char(15)。因为int只占4字节,可以用如下函数相互转换,而char(15)占用至少15字节。一旦表数据行数到了1亿,那么要多用1.1G存储空间。
SQL:select inet_aton(\'192.168.2.12\'); select inet_ntoa(3232236044);
PHP:ip2long(‘192.168.2.12’); long2ip(3530427185); - 【建议】不推荐使用
enum,set。 因为它们浪费空间,且枚举值写死了,变更不方便。推荐使用tinyint或smallint。 - 【建议】不推荐使用
blob,text等类型。它们都比较浪费硬盘和内存空间。在加载表数据时,会读取大字段到内存里从而浪费内存空间,影响系统性能。建议和PM、RD沟通,是否真的需要这么大字段。Innodb中当一行记录超过8098字节时,会将该记录中选取最长的一个字段将其768字节放在原始page里,该字段余下内容放在overflow-page里。不幸的是在compact行格式下,原始page和overflow-page都会加载。 - 【建议】存储金钱的字段,建议用
int,程序端乘以100和除以100进行存取。因为int占用4字节,而double占用8字节,空间浪费。 - 【建议】文本数据尽量用
varchar存储。因为varchar是变长存储,比char更省空间。MySQL server层规定一行所有文本最多存65535字节,因此在utf8字符集下最多存21844个字符,超过会自动转换为mediumtext字段。而text在utf8字符集下最多存21844个字符,mediumtext最多存2^24/3个字符,longtext最多存2^32个字符。一般建议用varchar类型,字符数不要超过2700。 - 【建议】时间类型尽量选取
timestamp。因为datetime占用8字节,timestamp仅占用4字节,但是范围为1970-01-01 00:00:01到2038-01-01 00:00:00。更为高阶的方法,选用int来存储时间,使用SQL函数unix_timestamp()和from_unixtime()来进行转换。
详细存储大小参加下图:


2.1.4 索引设计
- 【强制】InnoDB表必须主键为
id int/bigint auto_increment,且主键值禁止被更新。 - 【建议】主键的名称以“
pk_”开头,唯一键以“uk_”或“uq_”开头,普通索引以“idx_”开头,一律使用小写格式,以表名/字段的名称或缩写作为后缀。 - 【强制】InnoDB和MyISAM存储引擎表,索引类型必须为
BTREE;MEMORY表可以根据需要选择HASH或者BTREE类型索引。 - 【强制】单个索引中每个索引记录的长度不能超过64KB。
- 【建议】单个表上的索引个数不能超过7个。
- 【建议】在建立索引时,多考虑建立联合索引,并把区分度最高的字段放在最前面。如列
userid的区分度可由select count(distinct userid)计算出来。 - 【建议】在多表join的SQL里,保证被驱动表的连接列上有索引,这样join执行效率最高。
- 【建议】建表或加索引时,保证表里互相不存在冗余索引。对于MySQL来说,如果表里已经存在
key(a,b),则key(a)为冗余索引,需要删除。
2.1.5 分库分表、分区表
- 【强制】分区表的分区字段(
partition-key)必须有索引,或者是组合索引的首列。 - 【强制】单个分区表中的分区(包括子分区)个数不能超过1024。
- 【强制】上线前RD或者DBA必须指定分区表的创建、清理策略。
- 【强制】访问分区表的SQL必须包含分区键。
- 【建议】单个分区文件不超过2G,总大小不超过50G。建议总分区数不超过20个。
- 【强制】对于分区表执行
alter table操作,必须在业务低峰期执行。 - 【强制】采用分库策略的,库的数量不能超过1024
- 【强制】采用分表策略的,表的数量不能超过4096
- 【建议】单个分表不超过500W行,ibd文件大小不超过2G,这样才能让数据分布式变得性能更佳。
- 【建议】水平分表尽量用取模方式,日志、报表类数据建议采用日期进行分表。
2.1.6 字符集
- 【强制】数据库本身库、表、列所有字符集必须保持一致,为
utf8或utf8mb4。 - 【强制】前端程序字符集或者环境变量中的字符集,与数据库、表的字符集必须一致,统一为
utf8。
2.1.7 程序层DAO设计建议
- 【建议】新的代码不要用model,推荐使用手动拼SQL 绑定变量传入参数的方式。因为model虽然可以使用面向对象的方式操作db,但是其使用不当很容易造成生成的SQL非常复杂,且model层自己做的强制类型转换性能较差,最终导致数据库性能下降。
- 【建议】前端程序连接MySQL或者redis,必须要有连接超时和失败重连机制,且失败重试必须有间隔时间。
- 【建议】前端程序报错里尽量能够提示MySQL或redis原生态的报错信息,便于排查错误。
- 【建议】对于有连接池的前端程序,必须根据业务需要配置初始、最小、最大连接数,超时时间以及连接回收机制,否则会耗尽数据库连接资源,造成线上事故。
- 【建议】对于log或history类型的表,随时间增长容易越来越大,因此上线前RD或者DBA必须建立表数据清理或归档方案。
- 【建议】在应用程序设计阶段,RD必须考虑并规避数据库中主从延迟对于业务的影响。尽量避免从库短时延迟(20秒以内)对业务造成影响,建议强制一致性的读开启事务走主库,或更新后过一段时间再去读从库。
- 【建议】多个并发业务逻辑访问同一块数据(innodb表)时,会在数据库端产生行锁甚至表锁导致并发下降,因此建议更新类SQL尽量基于主键去更新。
- 【建议】业务逻辑之间加锁顺序尽量保持一致,否则会导致死锁。
- 【建议】对于单表读写比大于10:1的数据行或单个列,可以将热点数据放在缓存里(如mecache或redis),加快访问速度,降低MySQL压力。
2.1.8 一个规范的建表语句示例
一个较为规范的建表语句为:
CREATE TABLE user (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_id` bigint(11) NOT NULL COMMENT ‘用户id’
`username` varchar(45) NOT NULL COMMENT \'真实姓名\',
`email` varchar(30) NOT NULL COMMENT ‘用户邮箱’,
`nickname` varchar(45) NOT NULL COMMENT \'昵称\',
`avatar` int(11) NOT NULL COMMENT \'头像\',
`birthday` date NOT NULL COMMENT \'生日\',
`sex` tinyint(4) DEFAULT \'0\' COMMENT \'性别\',
`short_introduce` varchar(150) DEFAULT NULL COMMENT \'一句话介绍自己,最多50个汉字\',
`user_resume` varchar(300) NOT NULL COMMENT \'用户提交的简历存放地址\',
`user_register_ip` int NOT NULL COMMENT ‘用户注册时的源ip’,
`create_time` timestamp NOT NULL COMMENT ‘用户记录创建的时间’,
`update_time` timestamp NOT NULL COMMENT ‘用户资料修改的时间’,
`user_review_status` tinyint NOT NULL COMMENT ‘用户资料审核状态,1为通过,2为审核中,3为未通过,4为还未提交审核’,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_id` (`user_id`),
KEY `idx_username`(`username`),
KEY `idx_create_time`(`create_time`,`user_review_status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=\'网站用户基本信息\';2.2 SQL编写
2.2.1 DML语句
- 【强制】SELECT语句必须指定具体字段名称,禁止写成
*。因为select *会将不该读的数据也从MySQL里读出来,造成网卡压力。且表字段一旦更新,但model层没有来得及更新的话,系统会报错。 - 【强制】insert语句指定具体字段名称,不要写成
insert into t1 values(…),道理同上。 - 【建议】
insert into…values(XX),(XX),(XX)…。这里XX的值不要超过5000个。值过多虽然上线很很快,但会引起主从同步延迟。 - 【建议】SELECT语句不要使用
UNION,推荐使用UNION ALL,并且UNION子句个数限制在5个以内。因为union all不需要去重,节省数据库资源,提高性能。 - 【建议】in值列表限制在500以内。例如
select… where userid in(….500个以内…),这么做是为了减少底层扫描,减轻数据库压力从而加速查询。 - 【建议】事务里批量更新数据需要控制数量,进行必要的sleep,做到少量多次。
- 【强制】事务涉及的表必须全部是innodb表。否则一旦失败不会全部回滚,且易造成主从库同步终端。
- 【强制】写入和事务发往主库,只读SQL发往从库。
- 【强制】除静态表或小表(100行以内),DML语句必须有where条件,且使用索引查找。
- 【强制】生产环境禁止使用
hint,如sql_no_cache,force index,ignore key,straight join等。因为hint是用来强制SQL按照某个执行计划来执行,但随着数据量变化我们无法保证自己当初的预判是正确的,因此我们要相信MySQL优化器! - 【强制】where条件里等号左右字段类型必须一致,否则无法利用索引。
- 【建议】
SELECT|UPDATE|DELETE|REPLACE要有WHERE子句,且WHERE子句的条件必需使用索引查找。 - 【强制】生产数据库中强烈不推荐大表上发生全表扫描,但对于100行以下的静态表可以全表扫描。查询数据量不要超过表行数的25%,否则不会利用索引。
- 【强制】WHERE 子句中禁止只使用全模糊的LIKE条件进行查找,必须有其他等值或范围查询条件,否则无法利用索引。
- 【建议】索引列不要使用函数或表达式,否则无法利用索引。如
where length(name)=\'Admin\'或where user_id 2=10023。 - 【建议】减少使用or语句,可将or语句优化为union,然后在各个where条件上建立索引。如
where a=1 or b=2优化为where a=1… union …where b=2, key(a),key(b)。 - 【建议】分页查询,当limit起点较高时,可先用过滤条件进行过滤。如
select a,b,c from t1 limit 10000,20;优化为:select a,b,c from t1 where id>10000 limit 20;。
2.2.2 多表连接
- 【强制】禁止跨db的join语句。因为这样可以减少模块间耦合,为数据库拆分奠定坚实基础。
- 【强制】禁止在业务的更新类SQL语句中使用join,比如
update t1 join t2…。 - 【建议】不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用join来代替子查询。
- 【建议】线上环境,多表join不要超过3个表。
- 【建议】多表连接查询推荐使用别名,且SELECT列表中要用别名引用字段,数据库.表格式,如
select a from db1.table1 alias1 where …。 - 【建议】在多表join中,尽量选取结果集较小的表作为驱动表,来join其他表。
2.2.3 事务
- 【建议】事务中
INSERT|UPDATE|DELETE|REPLACE语句操作的行数控制在2000以内,以及WHERE子句中IN列表的传参个数控制在500以内。 - 【建议】批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep,一般建议值5-10秒。
- 【建议】对于有
auto_increment属性字段的表的插入操作,并发需要控制在200以内。 - 【强制】程序设计必须考虑“数据库事务隔离级别”带来的影响,包括脏读、不可重复读和幻读。线上建议事务隔离级别为
repeatable-read。 - 【建议】事务里包含SQL不超过5个(支付业务除外)。因为过长的事务会导致锁数据较久,MySQL内部缓存、连接消耗过多等雪崩问题。
- 【建议】事务里更新语句尽量基于主键或
unique key,如update … where id=XX; 否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。 - 【建议】尽量把一些典型外部调用移出事务,如调用webservice,访问文件存储等,从而避免事务过长。
- 【建议】对于MySQL主从延迟严格敏感的select语句,请开启事务强制访问主库。
2.2.4 排序和分组
- 【建议】减少使用
order by,和业务沟通能不排序就不排序,或将排序放到程序端去做。order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。 - 【建议】
order by、group by、distinct这些SQL尽量利用索引直接检索出排序好的数据。如where a=1 order by可以利用key(a,b)。 - 【建议】包含了
order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
2.2.5 线上禁止使用的SQL语句
- 【高危】禁用
update|delete t1 … where a=XX limit XX;这种带limit的更新语句。因为会导致主从不一致,导致数据错乱。建议加上order by PK。 - 【高危】禁止使用关联子查询,如
update t1 set … where name in(select name from user where…);效率极其低下。 - 【强制】禁用procedure、function、trigger、views、event、外键约束。因为他们消耗数据库资源,降低数据库实例可扩展性。推荐都在程序端实现。
- 【强制】禁用
insert into …on duplicate key update…在高并发环境下,会造成主从不一致。 - 【强制】禁止联表更新语句,如
update t1,t2 where t1.id=t2.id…。
MySQL存储过程
存储过程简介
SQL语句需要先编译然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。
存储过程是可编程的函数,在数据库中创建并保存,可以由SQL语句和控制结构组成。当想要在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟,它允许控制数据的访问方式。
存储过程的优点:
(1).增强SQL语言的功能和灵活性:存储过程可以用控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).标准组件式编程:存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).较快的执行速度:如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).减少网络流量:针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织进存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大减少网络流量并降低了网络负载。
(5).作为一种安全机制来充分利用:通过对执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
MySQL的存储过程
存储过程是数据库的一个重要的功能,MySQL 5.0以前并不支持存储过程,这使得MySQL在应用上大打折扣。好在MySQL 5.0开始支持存储过程,这样即可以大大提高数据库的处理速度,同时也可以提高数据库编程的灵活性。
MySQL存储过程的创建
语法
CREATE PROCEDURE 过程名([[IN|OUT|INOUT] 参数名 数据类型[,[IN|OUT|INOUT] 参数名 数据类型…]]) [特性 ...] 过程体
DELIMITER //
CREATE PROCEDURE myproc(OUT s int)
BEGIN
SELECT COUNT(*) INTO s FROM students;
END
//
DELIMITER ;
分隔符
MySQL默认以";"为分隔符,如果没有声明分割符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //”声明当前段分隔符,让编译器把两个"//"之间的内容当做存储过程的代码,不会执行这些代码;“DELIMITER ;”的意为把分隔符还原。
参数
存储过程根据需要可能会有输入、输出、输入输出参数,如果有多个参数用","分割开。MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT:
- IN参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值
- OUT:该值可在存储过程内部被改变,并可返回
- INOUT:调用时指定,并且可被改变和返回
过程体
过程体的开始与结束使用BEGIN与END进行标识。
IN参数例子
DELIMITER //
CREATE PROCEDURE in_param(IN p_in int)
BEGIN
SELECT p_in;
SET p_in=2;
SELECT p_in;
END;
//
DELIMITER ;#调用
SET @p_in=1;
CALL in_param(@p_in);SELECT @p_in;执行结果:


以上可以看出,p_in虽然在存储过程中被修改,但并不影响@p_id的值OUT参数例子#存储过程OUT参数
DELIMITER //
CREATE PROCEDURE out_param(OUT p_out int)
BEGIN
SELECT p_out;
SET p_out=2;
SELECT p_out;
END;
//
DELIMITER ;
#调用
SET @p_out=1;
CALL out_param(@p_out);SELECT @p_out;执行结果:


INOUT参数例子#存储过程INOUT参数
DELIMITER //
CREATE PROCEDURE inout_param(INOUT p_inout int)
BEGIN
SELECT p_inout;
SET p_inout=2;
SELECT p_inout;
END;
//
DELIMITER ;
#调用
SET @p_inout=1;
CALL inout_param(@p_inout) ;
SELECT @p_inout;执行结果:


变量
语法:DECLARE 变量名1[,变量名2...] 数据类型 [默认值];
数据类型为MySQL的数据类型:
数值类型

日期和时间类型

字符串类型

变量赋值
语法:SET 变量名 = 变量值 [,变量名= 变量值 ...]
用户变量
用户变量一般以@开头
注意:滥用用户变量会导致程序难以理解及管理
#在MySQL客户端使用用户变量
SELECT \'Hello World\' into @x;
SELECT @x;SET @y=\'Goodbye Cruel World\';
SELECT @y;
SET @z=1 2 3;
SELECT @z;执行结果:


#在存储过程中使用用户变量
CREATE PROCEDURE GreetWorld() SELECT CONCAT(@greeting,\' World\');
SET @greeting=\'Hello\';
CALL GreetWorld();执行结果:

#在存储过程间传递全局范围的用户变量
CREATE PROCEDURE p1() SET @last_proc=\'p1\';
CREATE PROCEDURE p2() SELECT CONCAT(\'Last procedure was \',@last_proc);
CALL p1();
CALL p2();执行结果:

注释
MySQL存储过程可使用两种风格的注释:
- 双杠:--,该风格一般用于单行注释
- C风格: 一般用于多行注释
MySQL存储过程的调用
用call和你过程名以及一个括号,括号里面根据需要,加入参数,参数包括输入参数、输出参数、输入输出参数。
MySQL存储过程的查询
#查询存储过程
SELECT name FROM mysql.proc WHERE db=\'数据库名\';
SELECT routine_name FROM information_schema.routines WHERE routine_schema=\'数据库名\';
SHOW PROCEDURE STATUS WHERE db=\'数据库名\';#查看存储过程详细信息
SHOW CREATE PROCEDURE 数据库.存储过程名;MySQL存储过程的修改
ALTER PROCEDURE 更改用CREATE PROCEDURE 建立的预先指定的存储过程,其不会影响相关存储过程或存储功能。
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT \'string\' - sp_name参数表示存储过程或函数的名称;
- characteristic参数指定存储函数的特性。
- CONTAINS SQL表示子程序包含SQL语句,但不包含读或写数据的语句;
- NO SQL表示子程序中不包含SQL语句;
- READS SQL DATA表示子程序中包含读数据的语句;
- MODIFIES SQL DATA表示子程序中包含写数据的语句。
- SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行,DEFINER表示只有定义者自己才能够执行;INVOKER表示调用者可以执行。
- COMMENT \'string\'是注释信息。
实例:
#将读写权限改为MODIFIES SQL DATA,并指明调用者可以执行。
ALTER PROCEDURE num_from_employee
MODIFIES SQL DATA
SQL SECURITY INVOKER ;
#将读写权限改为READS SQL DATA,并加上注释信息\'FIND NAME\'。
ALTER PROCEDURE name_from_employee
READS SQL DATA
COMMENT \'FIND NAME\' ;MySQL存储过程的删除
DROP PROCEDURE [过程1[,过程2…]]从MySQL的表格中删除一个或多个存储过程。
MySQL存储过程的控制语句
变量作用域
内部变量在其作用域范围内享有更高的优先权,当执行到end时,内部变量消失,不再可见了,在存储
过程外再也找不到这个内部变量,但是可以通过out参数或者将其值指派给会话变量来保存其值。#变量作用域
DELIMITER //
CREATE PROCEDURE proc()
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT \'outer\';
BEGIN
DECLARE x1 VARCHAR(5) DEFAULT \'inner\';
SELECT x1;
END;
SELECT x1;
END;
//
DELIMITER ;
#调用
CALL proc();执行结果:

条件语句
IF-THEN-ELSE语句
#条件语句IF-THEN-ELSE
DROP PROCEDURE IF EXISTS proc3;
DELIMITER //
CREATE PROCEDURE proc3(IN parameter int)
BEGIN
DECLARE var int;
SET var=parameter 1;
IF var=0 THEN
INSERT INTO t VALUES (17);
END IF ;
IF parameter=0 THEN
UPDATE t SET s1=s1 1;
ELSE
UPDATE t SET s1=s1 2;
END IF ;
END ;
//
DELIMITER ;CASE-WHEN-THEN-ELSE语句
#CASE-WHEN-THEN-ELSE语句
DELIMITER //
CREATE PROCEDURE proc4 (IN parameter INT)
BEGIN
DECLARE var INT;
SET var=parameter 1;
CASE var
WHEN 0 THEN
INSERT INTO t VALUES (17);
WHEN 1 THEN
INSERT INTO t VALUES (18);
ELSE
INSERT INTO t VALUES (19);
END CASE ;
END ;
//
DELIMITER ;循环语句WHILE-DO…END-WHILE
DELIMITER //
CREATE PROCEDURE proc5()
BEGIN
DECLARE var INT;
SET var=0;
WHILE var INSERT INTO t VALUES (var);
SET var=var 1;
END WHILE ;
END;
//
DELIMITER ;REPEAT...END REPEAT此语句的特点是执行操作后检查结果
DELIMITER //
CREATE PROCEDURE proc6 ()
BEGIN
DECLARE v INT;
SET v=0;
REPEAT
INSERT INTO t VALUES(v);
SET v=v 1;
UNTIL v>=5
END REPEAT;
END;
//
DELIMITER ;LOOP...END LOOP
DELIMITER //
CREATE PROCEDURE proc7 ()
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
INSERT INTO t VALUES(v);
SET v=v 1;
IF v >=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END;
//
DELIMITER ;LABLES标号标号可以用在begin repeat while 或者loop 语句前,语句标号只能在合法的语句前面使用。可以跳出循环,使运行指令达到复合语句的最后一步。
ITERATE迭代
通过引用复合语句的标号,来从新开始复合语句
#ITERATE
DELIMITER //
CREATE PROCEDURE proc8()
BEGIN
DECLARE v INT;
SET v=0;
LOOP_LABLE:LOOP
IF v=3 THEN
SET v=v 1;
ITERATE LOOP_LABLE;
END IF;
INSERT INTO t VALUES(v);
SET v=v 1;
IF v>=5 THEN
LEAVE LOOP_LABLE;
END IF;
END LOOP;
END;
//
DELIMITER ;MySQL存储过程的基本函数字符串类CHARSET(str) //返回字串字符集
CONCAT (string2 [,... ]) //连接字串
INSTR (string ,substring ) //返回substring首次在string中出现的位置,不存在返回0
LCASE (string2 ) //转换成小写
LEFT (string2 ,length ) //从string2中的左边起取length个字符
LENGTH (string ) //string长度
LOAD_FILE (file_name ) //从文件读取内容
LOCATE (substring , string [,start_position ] ) 同INSTR,但可指定开始位置
LPAD (string2 ,length ,pad ) //重复用pad加在string开头,直到字串长度为length
LTRIM (string2 ) //去除前端空格
REPEAT (string2 ,count ) //重复count次
REPLACE (str ,search_str ,replace_str ) //在str中用replace_str替换search_str
RPAD (string2 ,length ,pad) //在str后用pad补充,直到长度为length
RTRIM (string2 ) //去除后端空格
STRCMP (string1 ,string2 ) //逐字符比较两字串大小,
SUBSTRING (str , position [,length ]) //从str的position开始,取length个字符,
注:mysql中处理字符串时,默认第一个字符下标为1,即参数position必须大于等于1SELECT SUBSTRING(\'abcd\',0,2);结果:
SELECT SUBSTRING(\'abcd\',1,2);结果:
TRIM([[BOTH|LEADING|TRAILING] [padding] FROM]string2) //去除指定位置的指定字符
UCASE (string2 ) //转换成大写
RIGHT(string2,length) //取string2最后length个字符
SPACE(count) //生成count个空格数学类
ABS (number2 ) //绝对值
BIN (decimal_number ) //十进制转二进制
CEILING (number2 ) //向上取整
CONV(number2,from_base,to_base) //进制转换
FLOOR (number2 ) //向下取整
FORMAT (number,decimal_places ) //保留小数位数
HEX (DecimalNumber ) //转十六进制
注:HEX()中可传入字符串,则返回其ASC-11码,如HEX(\'DEF\')返回4142143
也可以传入十进制整数,返回其十六进制编码,如HEX(25)返回19
LEAST (number , number2 [,..]) //求最小值
MOD (numerator ,denominator ) //求余
POWER (number ,power ) //求指数
RAND([seed]) //随机数
ROUND (number [,decimals ]) //四舍五入,decimals为小数位数] 注:返回类型并非均为整数,如:#默认变为整型值SELECT ROUND(1.23);
SELECT ROUND(1.56);
#设定小数位数,返回浮点型数据
SELECT ROUND(1.567,2);
SIGN (number2 ) // 正数返回1,负数返回-1日期时间类ADDTIME (date2 ,time_interval ) //将time_interval加到date2
CONVERT_TZ (datetime2 ,fromTZ ,toTZ ) //转换时区
CURRENT_DATE ( ) //当前日期
CURRENT_TIME ( ) //当前时间
CURRENT_TIMESTAMP ( ) //当前时间戳
DATE (datetime ) //返回datetime的日期部分
DATE_ADD (date2 , INTERVAL d_value d_type ) //在date2中加上日期或时间
DATE_FORMAT (datetime ,FormatCodes ) //使用formatcodes格式显示datetime
DATE_SUB (date2 , INTERVAL d_value d_type ) //在date2上减去一个时间
DATEDIFF (date1 ,date2 ) //两个日期差
DAY (date ) //返回日期的天
DAYNAME (date ) //英文星期
DAYOFWEEK (date ) //星期(1-7) ,1为星期天
DAYOFYEAR (date ) //一年中的第几天
EXTRACT (interval_name FROM date ) //从date中提取日期的指定部分
MAKEDATE (year ,day ) //给出年及年中的第几天,生成日期串
MAKETIME (hour ,minute ,second ) //生成时间串
MONTHNAME (date ) //英文月份名
NOW ( ) //当前时间
SEC_TO_TIME (seconds ) //秒数转成时间
STR_TO_DATE (string ,format ) //字串转成时间,以format格式显示
TIMEDIFF (datetime1 ,datetime2 ) //两个时间差
TIME_TO_SEC (time ) //时间转秒数]
WEEK (date_time [,start_of_week ]) //第几周
YEAR (datetime ) //年份
DAYOFMONTH(datetime) //月的第几天
HOUR(datetime) //小时
LAST_DAY(date) //date的月的最后日期
MICROSECOND(datetime) //微秒
MONTH(datetime) //月
MINUTE(datetime) //分返回符号,正负或0
SQRT(number2) //开平方



















【开发规范】规范文档:MySQL规范
- 基本规范
- 命名规范
- 库表设计规范
- 索引设计规范
- 字段设计规范
- SQL设计规范
- 行为规范
- 线上操作
- 数据变更
基本规范
命名规范
库表设计规范
索引设计规范
字段设计规范
SQL设计规范
- select id from t limit 10000, 10; => select id from t where id > 10000 limit 10;
行为规范
详细解读MySQL中的权限
一、前言
很多文章中会说,数据库的权限按最小权限为原则,这句话本身没有错,但是却是一句空话。因为最小权限,这个东西太抽象,很多时候你并弄不清楚具体他需要哪些权限。 现在很多mysql用着root账户在操作,并不是大家不知道用root权限太大不安全,而是很多人并不知道该给予什么样的权限既安全又能保证正常运行。所以,本文更多的是考虑这种情况下,我们该如何简单的配置一个安全的mysql。注:本文测试环境为mysql-5.6.4
二、Mysql权限介绍
mysql中存在4个控制权限的表,分别为user表,db表,tables_priv表,columns_priv表。
mysql权限表的验证过程为:
1.先从user表中的Host,User,Password这3个字段中判断连接的ip、用户名、密码是否存在,存在则通过验证。
2.通过身份认证后,进行权限分配,按照user,db,tables_priv,columns_priv的顺序进行验证。即先检查全局权限表user,如果user中对应的权限为Y,则此用户对所有数据库的权限都为Y,将不再检查db, tables_priv,columns_priv;如果为N,则到db表中检查此用户对应的具体数据库,并得到db中为Y的权限;如果db中为N,则检查tables_priv中此数据库对应的具体表,取得表中的权限Y,以此类推。
三、mysql有哪些权限
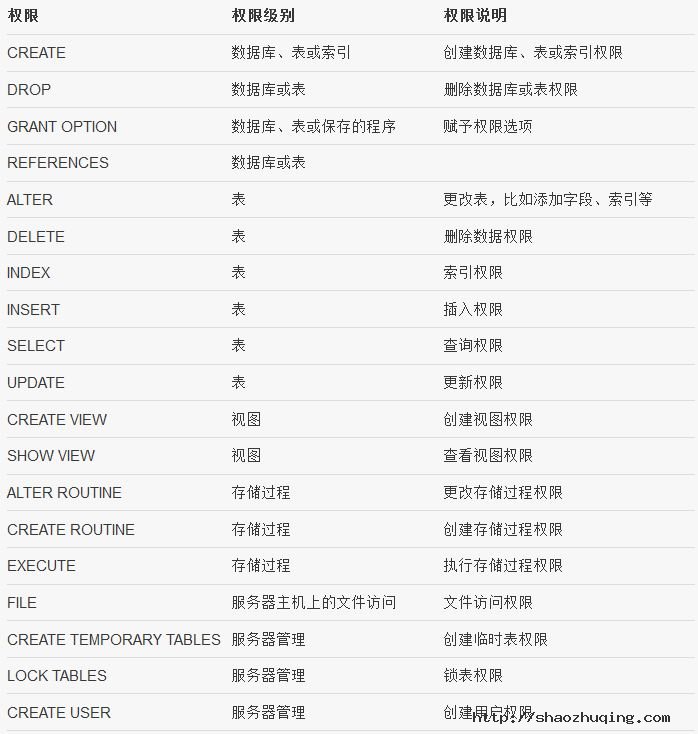
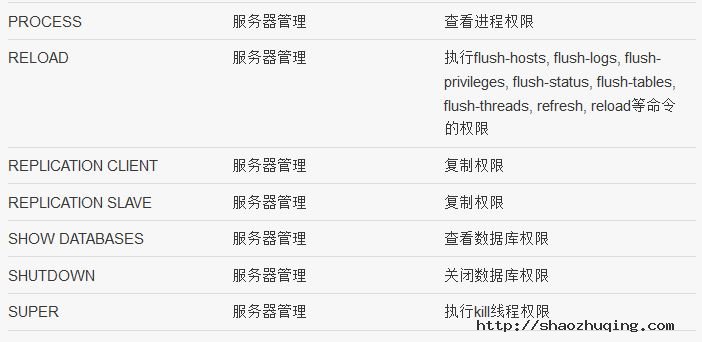
四、数据库层面(db表)的权限分析

五、mysql安全配置方案
1 限制访问mysql端口的ip
windows可以通过windows防火墙或者ipsec来限制,linux下可以通过iptables来限制。
2 修改mysql的端口
windows下可以修改配置文件my.ini来实现,linux可以修改配置文件my.cnf来实现。
3 对所有用户设置强密码并严格指定对应账号的访问ip
mysql中可在user表中指定用户的访问可访问ip
4 root特权账号的处理
建议给root账号设置强密码,并指定只容许本地登录
5 日志的处理
如需要可开启查询日志,查询日志会记录登录和查询语句。
6 mysql进程运行账号
在windows下禁止使用local system来运行mysql账户,可以考虑使用network service或者自己新建一个账号,但是必须给与mysql程序所在目录的读取权限和data目录的读取和写入权限; 在linux下,新建一个mysql账号,并在安装的时候就指定mysql以mysql账户来运行,给与程序所在目录的读取权限,data所在目录的读取和写入权限。
7 mysql运行账号的磁盘权限
1)mysql运行账号需要给予程序所在目录的读取权限,以及data目录的读取和写入权限
2)不容许给予其他目录的写入和执行权限,特别是有网站的。
3)取消mysql运行账户对于cmd,sh等一些程序的执行权限。
8 网站使用的mysql账户的处理
新建一个账户,给予账户在所使用数据库的所有权限即可。这样既能保证网站对所对应的数据库的全部操作,也能保证账户不会因为权限过高而影响安全。给予单个数据库的所有权限的账户不会拥有super, process, file等管理权限的。 当然,如果能很明确是的知道,我的网站需要哪些权限,还是不要多给权限,因为很多时候发布者并不知道网站需要哪些权限,我才建议上面的配置。而且我指的通用的,具体到只有几台机器,不多的情况下,我个人建议还是给予只需要的权限,具体可参考上面的表格的建议。
9 删除无用数据库
test数据库对新建的账户默认有权限
六、mysql入侵提权分析及防止措施
一般来说,mysql的提权有这么几种方式:
1 udf提权
此方式的关键导入一个dll文件,个人认为只要合理控制了进程账户对目录的写入权限即可防止被导入dll文件;然后如果万一被攻破,此时只要进程账户的权限够低,也没办执行高危操作,如添加账户等。
2 写入启动文件
这种方式同上,还是要合理控制进程账户对目录的写入权限。
3 当root账户被泄露
如果没有合理管理root账户导致root账户被入侵,此时数据库信息肯定是没办法保证了。但是如果对进程账户的权限控制住,以及其对磁盘的权限控制,服务器还是能够保证不被沦陷的。
4 普通账户泄露(上述所说的,只对某个库有所有权限的账户)
此处说的普通账户指网站使用的账户,我给的一个比较方便的建议是直接给予特定库的所有权限。账户泄露包括存在注入及web服务器被入侵后直接拿到数据库账户密码。
此时,对应的那个数据库数据不保,但是不会威胁到其他数据库。而且这里的普通账户无file权限,所有不能导出文件到磁盘,当然此时还是会对进程的账户的权限严格控制。
普通账户给予什么样的权限可以见上表,实在不会就直接给予一个库的所有权限。
七、安全配置需要的常用命令
1.新建一个用户并给予相应数据库的权限
grant select,insert,update,delete,create,drop privileges on database.* to user@localhost identified by 'passwd';
grant all privileges on database.* to user@localhost identified by 'passwd';
2.刷新权限
flush privileges;
3. 显示授权
show grants;
4. 移除授权
revoke delete on *.* from 'jack'@'localhost';
5. 删除用户
drop user 'jack'@'localhost';
6. 给用户改名
rename user 'jack'@'%' to 'jim'@'%';
7. 给用户改密码
SET PASSWORD FOR 'root'@'localhost' = PASSWORD('123456');
8. 删除数据库
drop database test;
9. 从数据库导出文件
select * from a into outfile "~/abc.sql"
Mysql之binlog日志说明及利用binlog日志恢复数据操作记录
众所周知,binlog日志对于mysql数据库来说是十分重要的。在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复(定时全备份+binlog日志恢复增量数据部分),化险为夷!
废话不多说,下面是梳理的binlog日志操作解说:
一、初步了解binlog
MySQL的二进制日志binlog可以说是MySQL最重要的日志,它记录了所有的DDL和DML语句(除了数据查询语句select),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
----------------------------------------------------------------------------------------------------------------------------------------------
DDL
----Data Definition Language 数据库定义语言
主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
DML
----Data Manipulation Language 数据操纵语言
主要的命令是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
----------------------------------------------------------------------------------------------------------------------------------------------
mysqlbinlog常见的选项有以下几个:
--start-datetime:从二进制日志中读取指定等于时间戳或者晚于本地计算机的时间
--stop-datetime:从二进制日志中读取指定小于时间戳或者等于本地计算机的时间 取值和上述一样
--start-position:从二进制日志中读取指定position 事件位置作为开始。
--stop-position:从二进制日志中读取指定position 事件位置作为事件截至
*********************************************************************
一般来说开启binlog日志大概会有1%的性能损耗。
binlog日志有两个最重要的使用场景:
1)MySQL主从复制:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到
master-slave数据一致的目的。
2)自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
binlog日志包括两类文件:
1)二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件
2)二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句select)语句事件。
二、开启binlog日志:
1)编辑打开mysql配置文件/etc/mys.cnf
[root@vm-002 ~]# vim /etc/my.cnf
在[mysqld] 区块添加
log-bin=mysql-bin 确认是打开状态(mysql-bin 是日志的基本名或前缀名);
2)重启mysqld服务使配置生效
[root@vm-002 ~]# /etc/init.d/mysqld stop
[root@vm-002 ~]# /etc/init.d/mysqld restart
Stopping mysqld: [ OK ]
Starting mysqld: [ OK ]
3)查看binlog日志是否开启
mysql> show variables like 'log_%';
+---------------------------------+---------------------+
| Variable_name | Value |
+---------------------------------+---------------------+
| log_bin | ON |
| log_bin_trust_function_creators | OFF |
| log_bin_trust_routine_creators | OFF |
| log_error | /var/log/mysqld.log |
| log_output | FILE |
| log_queries_not_using_indexes | OFF |
| log_slave_updates | OFF |
| log_slow_queries | OFF |
| log_warnings | 1 |
+---------------------------------+---------------------+
9 rows in set (0.00 sec)
三、常用的binlog日志操作命令
1)查看所有binlog日志列表
mysql> show master logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 149 |
| mysql-bin.000002 | 4102 |
+------------------+-----------+
2 rows in set (0.00 sec)
2)查看master状态,即最后(最新)一个binlog日志的编号名称,及其最后一个操作事件pos结束点(Position)值
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 4102 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
3)flush刷新log日志,自此刻开始产生一个新编号的binlog日志文件
mysql> flush logs;
Query OK, 0 rows affected (0.13 sec)
mysql> show master logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 149 |
| mysql-bin.000002 | 4145 |
| mysql-bin.000003 | 106 |
+------------------+-----------+
3 rows in set (0.00 sec)
注意:
每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;在mysqldump备份数据时加 -F 选项也会刷新binlog日志;
4)重置(清空)所有binlog日志
mysql> reset master;
Query OK, 0 rows affected (0.12 sec)
mysql> show master logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 106 |
+------------------+-----------+
1 row in set (0.00 sec)
四、查看binlog日志内容,常用有两种方式:
1)使用mysqlbinlog自带查看命令法:
注意:
-->binlog是二进制文件,普通文件查看器cat、more、vim等都无法打开,必须使用自带的mysqlbinlog命令查看
-->binlog日志与数据库文件在同目录中
-->在MySQL5.5以下版本使用mysqlbinlog命令时如果报错,就加上 “--no-defaults”选项
查看mysql的数据存放目录,从下面结果可知是/var/lib//mysql
[root@vm-002 ~]# ps -ef|grep mysql
root 9791 1 0 21:18 pts/0 00:00:00 /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql --socket=/var/lib/mysql/mysql.sock --pid-file=/var/run/mysqld/mysqld.pid --basedir=/usr --user=mysql
mysql 9896 9791 0 21:18 pts/0 00:00:00 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --user=mysql --log-error=/var/log/mysqld.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/lib/mysql/mysql.sock
root 9916 9699 0 21:18 pts/0 00:00:00 mysql -px xxxx
root 9919 9715 0 21:23 pts/1 00:00:00 grep --color mysql
[root@vm-002 ~]# cd /var/lib/mysql/
[root@vm-002 mysql]# ls
ibdata1 ib_logfile0 ib_logfile1 mysql mysql-bin.000001 mysql-bin.000002 mysql-bin.index mysql.sock ops test
使用mysqlbinlog命令查看binlog日志内容,下面截取其中的一个片段分析:
[root@vm-002 mysql]# mysqlbinlog mysql-bin.000002
..............
# at 624
#160925 21:29:53 server id 1 end_log_pos 796 Query thread_id=3 exec_time=0 error_code=0
SET TIMESTAMP=1474810193/*!*/;
insert into member(`name`,`sex`,`age`,`classid`) values('wangshibo','m',27,'cls1'),('guohuihui','w',27,'cls2') #执行的sql语句
/*!*/;
# at 796
#160925 21:29:53 server id 1 end_log_pos 823 Xid = 17 #执行的时间
.............
解释:
server id 1 : 数据库主机的服务号;
end_log_pos 796: sql结束时的pos节点
thread_id=11: 线程号
2)上面这种办法读取出binlog日志的全文内容比较多,不容易分辨查看到pos点信息
下面介绍一种更为方便的查询命令:
命令格式:
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
参数解释:
IN 'log_name' :指定要查询的binlog文件名(不指定就是第一个binlog文件)
FROM pos :指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)
LIMIT [offset,] :偏移量(不指定就是0)
row_count :查询总条数(不指定就是所有行)
mysql> show master logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 125 |
| mysql-bin.000002 | 823 |
+------------------+-----------+
2 rows in set (0.00 sec)
mysql> show binlog events in 'mysql-bin.000002'\G;
*************************** 1. row ***************************
Log_name: mysql-bin.000002
Pos: 4
Event_type: Format_desc
Server_id: 1
End_log_pos: 106
Info: Server ver: 5.1.73-log, Binlog ver: 4
*************************** 2. row ***************************
Log_name: mysql-bin.000002
Pos: 106
Event_type: Query
Server_id: 1
End_log_pos: 188
Info: use `ops`; drop table customers
*************************** 3. row ***************************
Log_name: mysql-bin.000002
Pos: 188
Event_type: Query
Server_id: 1
End_log_pos: 529
Info: use `ops`; CREATE TABLE IF NOT EXISTS `member` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(16) NOT NULL,
`sex` enum('m','w') NOT NULL DEFAULT 'm',
`age` tinyint(3) unsigned NOT NULL,
`classid` char(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
*************************** 4. row ***************************
Log_name: mysql-bin.000002
Pos: 529
Event_type: Query
Server_id: 1
End_log_pos: 596
Info: BEGIN
*************************** 5. row ***************************
Log_name: mysql-bin.000002
Pos: 596
Event_type: Intvar
Server_id: 1
End_log_pos: 624
Info: INSERT_ID=1
*************************** 6. row ***************************
Log_name: mysql-bin.000002
Pos: 624
Event_type: Query
Server_id: 1
End_log_pos: 796
Info: use `ops`; insert into member(`name`,`sex`,`age`,`classid`) values('wangshibo','m',27,'cls1'),('guohuihui','w',27,'cls2')
*************************** 7. row ***************************
Log_name: mysql-bin.000002
Pos: 796
Event_type: Xid
Server_id: 1
End_log_pos: 823
Info: COMMIT /* xid=17 */
7 rows in set (0.00 sec)
ERROR:
No query specified
mysql>
上面这条语句可以将指定的binlog日志文件,分成有效事件行的方式返回,并可使用limit指定pos点的起始偏移,查询条数!
如下操作示例:
a)查询第一个(最早)的binlog日志:
mysql> show binlog events\G;
b)指定查询 mysql-bin.000002这个文件:
mysql> show binlog events in 'mysql-bin.000002'\G;
c)指定查询 mysql-bin.000002这个文件,从pos点:624开始查起:
mysql> show binlog events in 'mysql-bin.000002' from 624\G;
d)指定查询 mysql-bin.000002这个文件,从pos点:624开始查起,查询10条(即10条语句)
mysql> show binlog events in 'mysql-bin.000002' from 624 limit 10\G;
e)指定查询 mysql-bin.000002这个文件,从pos点:624开始查起,偏移2行(即中间跳过2个),查询10条
mysql> show binlog events in 'mysql-bin.000002' from 624 limit 2,10\G;
五、利用binlog日志恢复mysql数据
以下对ops库的member表进行操作
mysql> use ops;
mysql> CREATE TABLE IF NOT EXISTS `member` (
-> `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
-> `name` varchar(16) NOT NULL,
-> `sex` enum('m','w') NOT NULL DEFAULT 'm',
-> `age` tinyint(3) unsigned NOT NULL,
-> `classid` char(6) DEFAULT NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.10 sec)
mysql> show tables;
+---------------+
| Tables_in_ops |
+---------------+
| member |
+---------------+
1 row in set (0.00 sec)
mysql> desc member;
+---------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------+---------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| name | varchar(16) | NO | | NULL | |
| sex | enum('m','w') | NO | | m | |
| age | tinyint(3) unsigned | NO | | NULL | |
| classid | char(6) | YES | | NULL | |
+---------+---------------------+------+-----+---------+----------------+
5 rows in set (0.00 sec)
事先插入两条数据
mysql> insert into member(`name`,`sex`,`age`,`classid`) values('wangshibo','m',27,'cls1'),('guohuihui','w',27,'cls2');
Query OK, 2 rows affected (0.08 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
+----+-----------+-----+-----+---------+
2 rows in set (0.00 sec)
下面开始进行场景模拟:
1)
ops库会在每天凌晨4点进行一次完全备份的定时计划任务,如下:
[root@vm-002 ~]# crontab -l
0 4 * * * /usr/bin/mysqldump -uroot -p -B -F -R -x --master-data=2 ops|gzip >/opt/backup/ops_$(date +%F).sql.gz
这里手动执行下,将ops数据库备份到/opt/backup/ops_$(date +%F).sql.gz文件中:
[root@vm-002 ~]# mysqldump -uroot -p -B -F -R -x --master-data=2 ops|gzip >/opt/backup/ops_$(date +%F).sql.gz
Enter password:
[root@vm-002 ~]# ls /opt/backup/
ops_2016-09-25.sql.gz
-----------------
参数说明:
-B:指定数据库
-F:刷新日志
-R:备份存储过程等
-x:锁表
--master-data:在备份语句里添加CHANGE MASTER语句以及binlog文件及位置点信息
-----------------
待到数据库备份完成,就不用担心数据丢失了,因为有完全备份数据在!!
由于上面在全备份的时候使用了-F选项,那么当数据备份操作刚开始的时候系统就会自动刷新log,这样就会自动产生
一个新的binlog日志,这个新的binlog日志就会用来记录备份之后的数据库“增删改”操作
查看一下:
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000003 | 106 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
也就是说, mysql-bin.000003 是用来记录4:00之后对数据库的所有“增删改”操作。
2)
早上9点上班了,由于业务的需求会对数据库进行各种“增删改”操作。
比如:在ops库下member表内插入、修改了数据等等:
先是早上进行插入数据:
mysql> insert into ops.member(`name`,`sex`,`age`,`classid`) values('yiyi','w',20,'cls1'),('xiaoer','m',22,'cls3'),('zhangsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6');
Query OK, 5 rows affected (0.08 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | xiaoer | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
3)
中午又执行了修改数据操作:
mysql> update ops.member set name='李四' where id=4;
Query OK, 1 row affected (0.07 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update ops.member set name='小二' where id=2;
Query OK, 1 row affected (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | 小二 | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | 李四 | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
4)
在下午18:00的时候,悲剧莫名其妙的出现了!
手贱执行了drop语句,直接删除了ops库!吓尿!
mysql> drop database ops;
Query OK, 1 row affected (0.02 sec)
5)
这种时候,一定不要慌张!!!
先仔细查看最后一个binlog日志,并记录下关键的pos点,到底是哪个pos点的操作导致了数据库的破坏(通常在最后几步);
先备份一下最后一个binlog日志文件:
[root@vm-002 ~]# cd /var/lib/mysql/
[root@vm-002 mysql]# cp -v mysql-bin.000003 /opt/backup/
`mysql-bin.000003' -> `/opt/backup/mysql-bin.000003'
[root@vm-002 mysql]# ls /opt/backup/
mysql-bin.000003 ops_2016-09-25.sql.gz
接着执行一次刷新日志索引操作,重新开始新的binlog日志记录文件。按理说mysql-bin.000003
这个文件不会再有后续写入了,因为便于我们分析原因及查找ops节点,以后所有数据库操作都会写入到下一个日志文件。
mysql> flush logs;
Query OK, 0 rows affected (0.13 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000004 | 106 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
6)
读取binlog日志,分析问题。
读取binlog日志的方法上面已经说到。
方法一:使用mysqlbinlog读取binlog日志:
[root@vm-002 ~]# cd /var/lib/mysql/
[root@vm-002 mysql]# mysqlbinlog mysql-bin.000003
方法二:登录服务器,并查看(推荐此种方法)
mysql> show binlog events in 'mysql-bin.000003';
+------------------+-----+-------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+------------------+-----+-------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------------+
| mysql-bin.000003 | 4 | Format_desc | 1 | 106 | Server ver: 5.1.73-log, Binlog ver: 4 |
| mysql-bin.000003 | 106 | Query | 1 | 173 | BEGIN |
| mysql-bin.000003 | 173 | Intvar | 1 | 201 | INSERT_ID=3 |
| mysql-bin.000003 | 201 | Query | 1 | 444 | use `ops`; insert into ops.member(`name`,`sex`,`age`,`gsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6') |
| mysql-bin.000003 | 444 | Xid | 1 | 471 | COMMIT /* xid=66 */ |
| mysql-bin.000003 | 471 | Query | 1 | 538 | BEGIN |
| mysql-bin.000003 | 538 | Query | 1 | 646 | use `ops`; update ops.member set name='李四' where id= |
| mysql-bin.000003 | 646 | Xid | 1 | 673 | COMMIT /* xid=68 */ |
| mysql-bin.000003 | 673 | Query | 1 | 740 | BEGIN |
| mysql-bin.000003 | 740 | Query | 1 | 848 | use `ops`; update ops.member set name='小二' where id= |
| mysql-bin.000003 | 848 | Xid | 1 | 875 | COMMIT /* xid=69 */ |
| mysql-bin.000003 | 875 | Query | 1 | 954 | drop database ops |
| mysql-bin.000003 | 954 | Rotate | 1 | 997 | mysql-bin.000004;pos=4 |
+------------------+-----+-------------+-----------+-------------+----------------------------------------------------------------------------------------------------------------------------+
13 rows in set (0.00 sec)
或者:
mysql> show binlog events in 'mysql-bin.000003'\G;
.........
.........
*************************** 12. row ***************************
Log_name: mysql-bin.000003
Pos: 875
Event_type: Query
Server_id: 1
End_log_pos: 954
Info: drop database ops
*************************** 13. row ***************************
Log_name: mysql-bin.000003
Pos: 954
Event_type: Rotate
Server_id: 1
End_log_pos: 997
Info: mysql-bin.000004;pos=4
13 rows in set (0.00 sec)
通过分析,造成数据库破坏的pos点区间是介于 875--954 之间(这是按照日志区间的pos节点算的),只要恢复到875前就可。
7)
先把凌晨4点全备份的数据恢复:
[root@vm-002 ~]# cd /opt/backup/
[root@vm-002 backup]# ls
mysql-bin.000003 ops_2016-09-25.sql.gz
[root@vm-002 backup]# gzip -d ops_2016-09-25.sql.gz
[root@vm-002 backup]# mysql -uroot -p -v < ops_2016-09-25.sql
Enter password:
--------------
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */
--------------
--------------
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */
--------------
.............
.............
--------------
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */
--------------
这样就恢复了截至当日凌晨(4:00)前的备份数据都恢复了。
mysql> show databases; #发现ops库已经恢复回来了
mysql> use ops;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------+
| Tables_in_ops |
+---------------+
| member |
+---------------+
1 row in set (0.00 sec)
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
+----+-----------+-----+-----+---------+
2 rows in set (0.00 sec)
mysql>
但是这仅仅只是恢复了当天凌晨4点之前的数据,在4:00--18:00之间的数据还没有恢复回来!!
怎么办呢?
莫慌!这可以根据前面提到的mysql-bin.000003的新binlog日志进行恢复。
8)
从binlog日志恢复数据
恢复命令的语法格式:
mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名
--------------------------------------------------------
常用参数选项解释:
--start-position=875 起始pos点
--stop-position=954 结束pos点
--start-datetime="2016-9-25 22:01:08" 起始时间点
--stop-datetime="2019-9-25 22:09:46" 结束时间点
--database=zyyshop 指定只恢复zyyshop数据库(一台主机上往往有多个数据库,只限本地log日志)
--------------------------------------------------------
不常用选项:
-u --user=name 连接到远程主机的用户名
-p --password[=name] 连接到远程主机的密码
-h --host=name 从远程主机上获取binlog日志
--read-from-remote-server 从某个MySQL服务器上读取binlog日志
--------------------------------------------------------
小结:实际是将读出的binlog日志内容,通过管道符传递给mysql命令。这些命令、文件尽量写成绝对路径;
a)完全恢复(需要手动vim编辑mysql-bin.000003,将那条drop语句剔除掉)
[root@vm-002 backup]# /usr/bin/mysqlbinlog /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
b)指定pos结束点恢复(部分恢复):
--stop-position=471 pos结束节点(按照事务区间算,是471)
注意:
此pos结束节点介于“member表原始数据”与更新“name='李四'”之前的数据,这样就可以恢复到更改“name='李四'”之前的数据了。
操作如下:
[root@vm-002 ~]# /usr/bin/mysqlbinlog --stop-position=471 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | xiaoer | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
恢复截止到更改“name='李四'”之间的数据(按照事务区间算,是673)
[root@vm-002 ~]# /usr/bin/mysqlbinlog --stop-position=673 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | 李四 | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
c)指定pso点区间恢复(部分恢复):
更新 name='李四' 这条数据,日志区间是Pos[538] --> End_log_pos[646],按事务区间是:Pos[471] --> End_log_pos[673]
更新 name='小二' 这条数据,日志区间是Pos[740] --> End_log_pos[848],按事务区间是:Pos[673] --> End_log_pos[875]
c1)
单独恢复 name='李四' 这步操作,可这样:
按照binlog日志区间单独恢复:
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-position=538 --stop-position=646 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
按照事务区间单独恢复
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-position=471 --stop-position=673 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
c2)
单独恢复 name='小二' 这步操作,可这样:
按照binlog日志区间单独恢复:
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-position=740 --stop-position=848 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
按照事务区间单独恢复
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-position=673 --stop-position=875 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
c3)
将 name='李四'、name='小二' 多步操作一起恢复,需要按事务区间,可这样:
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-position=471 --stop-position=875 --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
查看数据库:
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | 小二 | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | 李四 | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
这样,就恢复了删除前的数据状态了!!
-----------------
另外:
也可指定时间节点区间恢复(部分恢复):
除了用pos节点的办法进行恢复,也可以通过指定时间节点区间进行恢复,按时间恢复需要用mysqlbinlog命令读取binlog日志内容,找时间节点。
如上,误删除ops库后:
先进行全备份恢复
[root@vm-002 backup]# mysql -uroot -p -v < ops_2016-09-25.sql
查看ops数据库
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
+----+-----------+-----+-----+---------+
2 rows in set (0.00 sec)
mysql>
查看mysq-bin00003日志,找出时间节点
[root@vm-002 ~]# cd /var/lib/mysql
[root@vm-002 mysql]# mysqlbinlog mysql-bin.000003
.............
.............
BEGIN
/*!*/;
# at 173
#160925 21:57:19 server id 1 end_log_pos 201 Intvar
SET INSERT_ID=3/*!*/;
# at 201
#160925 21:57:19 server id 1 end_log_pos 444 Query thread_id=3 exec_time=0 error_code=0
use `ops`/*!*/;
SET TIMESTAMP=1474811839/*!*/;
insert into ops.member(`name`,`sex`,`age`,`classid`) values('yiyi','w',20,'cls1'),('xiaoer','m',22,'cls3'),('zhangsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6') #执行的sql语句
/*!*/;
# at 444
#160925 21:57:19 server id 1 end_log_pos 471 Xid = 66 #开始执行的时间
COMMIT/*!*/;
# at 471
#160925 21:58:41 server id 1 end_log_pos 538 Query thread_id=3 exec_time=0 error_code=0 #结束时间
SET TIMESTAMP=1474811921/*!*/;
BEGIN
/*!*/;
# at 538
#160925 21:58:41 server id 1 end_log_pos 646 Query thread_id=3 exec_time=0 error_code=0
SET TIMESTAMP=1474811921/*!*/;
update ops.member set name='李四' where id=4 #执行的sql语句
/*!*/;
# at 646
#160925 21:58:41 server id 1 end_log_pos 673 Xid = 68 #开始执行的时间
COMMIT/*!*/;
# at 673
#160925 21:58:56 server id 1 end_log_pos 740 Query thread_id=3 exec_time=0 error_code=0 #结束时间
SET TIMESTAMP=1474811936/*!*/;
BEGIN
/*!*/;
# at 740
#160925 21:58:56 server id 1 end_log_pos 848 Query thread_id=3 exec_time=0 error_code=0
SET TIMESTAMP=1474811936/*!*/;
update ops.member set name='小二' where id=2 #执行的sql语句
/*!*/;
# at 848
#160925 21:58:56 server id 1 end_log_pos 875 Xid = 69 #开始执行的时间
COMMIT/*!*/;
# at 875
#160925 22:01:08 server id 1 end_log_pos 954 Query thread_id=3 exec_time=0 error_code=0 #结束时间
SET TIMESTAMP=1474812068/*!*/;
drop database ops
/*!*/;
# at 954
#160925 22:09:46 server id 1 end_log_pos 997 Rotate to mysql-bin.000004 pos: 4
DELIMITER ;
# End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;
恢复到更改“name='李四'”之前的数据
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-datetime="2016-09-25 21:57:19" --stop-datetime="2016-09-25 21:58:41" --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | xiaoer | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-datetime="2016-09-25 21:58:41" --stop-datetime="2016-09-25 21:58:56" --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | guohuihui | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | 李四 | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
[root@vm-002 ~]# /usr/bin/mysqlbinlog --start-datetime="2016-09-25 21:58:56" --stop-datetime="2016-09-25 22:01:08" --database=ops /var/lib/mysql/mysql-bin.000003 | /usr/bin/mysql -uroot -p123456 -v ops
mysql> select * from member;
+----+-----------+-----+-----+---------+
| id | name | sex | age | classid |
+----+-----------+-----+-----+---------+
| 1 | wangshibo | m | 27 | cls1 |
| 2 | 小二 | w | 27 | cls2 |
| 3 | yiyi | w | 20 | cls1 |
| 4 | 李四 | m | 22 | cls3 |
| 5 | zhangsan | w | 21 | cls5 |
| 6 | lisi | m | 20 | cls4 |
| 7 | wangwu | w | 26 | cls6 |
+----+-----------+-----+-----+---------+
7 rows in set (0.00 sec)
这样,就恢复了删除前的状态了!
总结:
所谓恢复,就是让mysql将保存在binlog日志中指定段落区间的sql语句逐个重新执行一次而已。
MySQL 用户权限详细汇总
1,MySQL权限体系
MySQL 的权限体系大致分为5个层级:
全局层级:
全局权限适用于一个给定服务器中的所有数据库。这些权限存储在mysql.user表中。GRANT ALL ON .和REVOKE ALL ON .只授予和撤销全局权限。
数据库层级:
数据库权限适用于一个给定数据库中的所有目标。这些权限存储在mysql.db表中。GRANT ALL ON db_name.和REVOKE ALL ON db_name.只授予和撤销数据库权限。
表层级:
表权限适用于一个给定表中的所有列。这些权限存储在mysql.talbes_priv表中。GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:
列权限适用于一个给定表中的单一列。这些权限存储在mysql.columns_priv表中。当使用REVOKE时,您必须指定与被授权列相同的列。
子程序层级:
CREATE ROUTINE, ALTER ROUTINE, EXECUTE和GRANT权限适用于已存储的子程序。这些权限可以被授予为全局层级和数据库层级。而且,除了CREATE ROUTINE外,这些权限可以被授予为子程序层级,并存储在mysql.procs_priv表中。
这些权限信息存储在下面的系统表中:
mysql.user
mysql.db
mysql.host
mysql.table_priv
mysql.column_priv
mysql. procs_priv
当用户连接进来,mysqld会通过上面的这些表对用户权限进行验证!
2, 千里追踪之5表
相对于Oracle来说,mysql的特性是可以限制ip,用户user、ip地址host、密码passwd这3个是用户管理的基础,权限的细节基本在mysql.user、mysql.db、mysql.host、mysql.table_priv、mysql.column_priv这几张表就可以看到很多细节,接下来仔细分析这些表就可以知道权限的奥秘。
演示过程中需要建立用户来演示,先简单介绍下如何创建用户:
GRANT priv_type ON database.table
TO user[IDENTIFIED BY [PASSWORD] ‘password’]
[,user [IDENTIFIED BY [PASSWORD] ‘password’]…]
示例:
GRANT SELECT, INSERT, UPDATE, DELETE ON d3307.* TO zengxiaoteng@’%’ IDENTIFIED BY ‘0523’;
2.1db表
2.1.1 表结构如下:
mysql> desc mysql.db;
+-----------------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+---------------+------+-----+---------+-------+
| Host | char(60) | NO | PRI | | |
| Db | char(64) | NO | PRI | | |
| User | char(16) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
+-----------------------+---------------+------+-----+---------+-------+
22 rows in set (0.02 sec)
2.1.2分析如下:
db表存储了所有对一个数据库的所有操作权限。创建用户的时候,都会往Host字段,User字段,Password字段录入用户信息;
而当执行 GRANT SELECT,INSERT ON d3307.* TO u4@’%’ IDENTIFIED BY ‘u40523’;类似的授权语句的话,Select_priv和Insert_priv字段的值会变成Y其它字段仍然是N;
当你执行了GRANT ALL ON d3307.* TO u4@’%’ IDENTIFIED BY ‘u40523’;类似的复制语句的话,后面的字段都会变成Y的值;
2.1.3 创建单个select、insert授予权限
创建用户:
GRANT SELECT,INSERT ON d3307.* TO user4@'192.168.52' IDENTIFIED BY 'user0523';应该除了Host、db、user字段有值,除了Select_priv、Insert_priv值为Y外,其它的都是N。
查看mysql.db表的记录正是如此,如下所示:
mysql> SELECT * FROM mysql.`db` where user='user4'\G;
*************************** 1. row ***************************
Host: 192.168.52
Db: d3307
User: user4
Select_priv: Y
Insert_priv: Y
Update_priv: N
Delete_priv: N
Create_priv: N
Drop_priv: N
Grant_priv: N
References_priv: N
Index_priv: N
Alter_priv: N
Create_tmp_table_priv: N
Lock_tables_priv: N
Create_view_priv: N
Show_view_priv: N
Create_routine_priv: N
Alter_routine_priv: N
Execute_priv: N
Event_priv: N
Trigger_priv: N
1 row in set (0.01 sec)
ERROR:
No query specified
2.1.4 授予ALL权限
执行sql语句建立用户:
GRANT ALL ON d3307.* TO dba5@'192.168.52.1' IDENTIFIED BY 'dba0523';建立用户的时候,如下所示,除了Host、db、user字段外,所有的*_priv字段记录都会变成Y值,(Grant_priv仍然是N值除非加了WITH* GRANT OPTION执行GRANT ALL ON d3307.* TO dba5@’192.168.52.1’ IDENTIFIED BY ‘dba0523’ WITH GRANT OPTION 😉
如下所示:
mysql> SELECT * FROM mysql.`db` where user='dba5'\G;
*************************** 1. row ***************************
Host: 192.168.52.1
Db: d3307
User: dba5
Select_priv: Y
Insert_priv: Y
Update_priv: Y
Delete_priv: Y
Create_priv: Y
Drop_priv: Y
Grant_priv: N
References_priv: Y
Index_priv: Y
Alter_priv: Y
Create_tmp_table_priv: Y
Lock_tables_priv: Y
Create_view_priv: Y
Show_view_priv: Y
Create_routine_priv: Y
Alter_routine_priv: Y
Execute_priv: Y
Event_priv: Y
Trigger_priv: Y
1 row in set (0.00 sec)
ERROR:
No query specified
2.2 user表
2.2.1 表结构:
mysql> desc mysql.user;
+------------------------+-----------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------------+-----------------------------------+------+-----+---------+-------+
| Host | char(60) | NO | PRI | | |
| User | char(16) | NO | PRI | | |
| Password | char(41) | NO | | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
| Alter_priv | enum('N','Y') | NO | | N | |
| Show_db_priv | enum('N','Y') | NO | | N | |
| Super_priv | enum('N','Y') | NO | | N | |
| Create_tmp_table_priv | enum('N','Y') | NO | | N | |
| Lock_tables_priv | enum('N','Y') | NO | | N | |
| Execute_priv | enum('N','Y') | NO | | N | |
| Repl_slave_priv | enum('N','Y') | NO | | N | |
| Repl_client_priv | enum('N','Y') | NO | | N | |
| Create_view_priv | enum('N','Y') | NO | | N | |
| Show_view_priv | enum('N','Y') | NO | | N | |
| Create_routine_priv | enum('N','Y') | NO | | N | |
| Alter_routine_priv | enum('N','Y') | NO | | N | |
| Create_user_priv | enum('N','Y') | NO | | N | |
| Event_priv | enum('N','Y') | NO | | N | |
| Trigger_priv | enum('N','Y') | NO | | N | |
| Create_tablespace_priv | enum('N','Y') | NO | | N | |
| ssl_type | enum('','ANY','X509','SPECIFIED') | NO | | | |
| ssl_cipher | blob | NO | | NULL | |
| x509_issuer | blob | NO | | NULL | |
| x509_subject | blob | NO | | NULL | |
| max_questions | int(11) unsigned | NO | | 0 | |
| max_updates | int(11) unsigned | NO | | 0 | |
| max_connections | int(11) unsigned | NO | | 0 | |
| max_user_connections | int(11) unsigned | NO | | 0 | |
| plugin | char(64) | YES | | | |
| authentication_string | text | YES | | NULL | |
| password_expired | enum('N','Y') | NO | | N | |
+------------------------+-----------------------------------+------+-----+---------+-------+
43 rows in set (0.10 sec)
2.2.2 分析
存储用户记录的表,存储了用户的信息,每一次创建用户的时候,都会往这个表里录入记录,当你执行了,都会往Host字段,User字段,Password字段录入数据,但是后面的Select_priv、Insert_priv、Update_priv等字段的值,只有赋予GRANT ALL ON . TO timdba@’192.%’ IDENTIFIED BY ‘timdba0523’;类似的对所有库的操作权限的时候才会被记录成Y,否则都记录成N。
2.2.3 创建对库所有表有操作权限的普通用户
创建用户:
GRANT SELECT,UPDATE ON d3307.* TO user6@'192.168.52.1' IDENTIFIED BY 'user0523';分析结果:存储在mysql.user表里面的记录当中,Host、User、Password是有值的,但是其它的Select_priv等*_priv字段值都是N。
验证结果,去查看表里的存储记录,如下所示:
mysql> SELECT * FROM mysql.user where user='user6'\G;
*************************** 1. row ***************************
Host: 192.168.52.1
User: user6
Password: *A4D1F6ACEBC5D3EB0F6D33C7DCC629E8BE55B75A
Select_priv: N
Insert_priv: N
Update_priv: N
Delete_priv: N
Create_priv: N
Drop_priv: N
Reload_priv: N
Shutdown_priv: N
Process_priv: N
File_priv: N
Grant_priv: N
References_priv: N
Index_priv: N
Alter_priv: N
Show_db_priv: N
Super_priv: N
Create_tmp_table_priv: N
Lock_tables_priv: N
Execute_priv: N
Repl_slave_priv: N
Repl_client_priv: N
Create_view_priv: N
Show_view_priv: N
Create_routine_priv: N
Alter_routine_priv: N
Create_user_priv: N
Event_priv: N
Trigger_priv: N
Create_tablespace_priv: N
ssl_type:
ssl_cipher:
x509_issuer:
x509_subject:
max_questions: 0
max_updates: 0
max_connections: 0
max_user_connections: 0
plugin: mysql_native_password
authentication_string:
password_expired: N
1 row in set (0.00 sec)
ERROR:
No query specified
2.2.4 创建对于所有表有操作权限的用户
创建用户:
mysql> GRANT SELECT,UPDATE ON *.* TO user7@'%' IDENTIFIED BY 'user0523';
Query OK, 0 rows affected (0.00 sec)
分析:
基本的Host、User、Password字段有记录值,然后grant了select和update所以关于*_priv字段中select和update字段有值为Y,其它*_priv字段值应该是N。
查看记录结果,分享正确,如下所示:
mysql> SELECT * FROM mysql.user where user='user7'\G;
*************************** 1. row ***************************
Host: %
User: user7
Password: *A4D1F6ACEBC5D3EB0F6D33C7DCC629E8BE55B75A
Select_priv: Y
Insert_priv: N
Update_priv: Y
Delete_priv: N
Create_priv: N
Drop_priv: N
Reload_priv: N
Shutdown_priv: N
Process_priv: N
File_priv: N
Grant_priv: N
References_priv: N
Index_priv: N
Alter_priv: N
Show_db_priv: N
Super_priv: N
Create_tmp_table_priv: N
Lock_tables_priv: N
Execute_priv: N
Repl_slave_priv: N
Repl_client_priv: N
Create_view_priv: N
Show_view_priv: N
Create_routine_priv: N
Alter_routine_priv: N
Create_user_priv: N
Event_priv: N
Trigger_priv: N
Create_tablespace_priv: N
ssl_type:
ssl_cipher:
x509_issuer:
x509_subject:
max_questions: 0
max_updates: 0
max_connections: 0
max_user_connections: 0
plugin: mysql_native_password
authentication_string:
password_expired: N
1 row in set (0.00 sec)
ERROR:
No query specified
2.3 tables_priv表
2.3.1 查看表结构
mysql> desc mysql.tables_priv;
+-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------+
| Host | char(60) | NO | PRI | | |
| Db | char(64) | NO | PRI | | |
| User | char(16) | NO | PRI | | |
| Table_name | char(64) | NO | PRI | | |
| Grantor | char(77) | NO | MUL | | |
| Timestamp | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| Table_priv | set('Select','Insert','Update','Delete','Create','Drop','Grant','References','Index','Alter','Create View','Show view','Trigger') | NO | | | |
| Column_priv | set('Select','Insert','Update','References') | NO | | | |
+-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------+
8 rows in set (0.00 sec)
2.3.2 分析:
记录了对一个表的单独授权记录,只有执行grant insert on dbname.tablename to user1@’%’identified by ‘pwd’;类似的授权记录才会在这个表里录入授权信息;其中各个字段涵义如下:
| 字段 | 存储的数据 |
|---|---|
| Host字段 | 用户的登录ip范围 |
| User字段 | 表所在的数据库名称 |
| Table_name字段 | 授权的表的名称 |
| Grantor字段 | 执行grant建立用户的授权者 |
| Timestamp字段 | 0000-00-00 00:00:00 |
| Table_priv字段 | 所授予的操作表的权限,比如select、udate、delete等 |
| Column_priv字段 | 对这个表的某个字段单独授予的权限 |
另外当赋予all在某张表上的时候,Table_priv列会多处所有关于表的授权记录,描述如下:
Select,Insert,Update,Delete,Create,Drop,References,Index,Alter,Create View,Show view,Trigger。
2.3.3 创建单独操作这个表的用户
创建用户:
mysql> GRANT INSERT,SELECT,UPDATE ON d3307.t TO user8@'192.168.52.1' IDENTIFIED BY 'dba0523';
Query OK, 0 rows affected (0.00 sec)
分析结果:
应该是Host、Db、User、Table_name、Grantor、Timestamp、Table_priv是有值的,但是Column_priv没有值,因为没有单独对某一个列做了授权限制的。
查看权限,如下所示:
mysql> SELECT * FROM mysql.tables_priv where user='user8'\G;
*************************** 1. row ***************************
Host: 192.168.52.1
Db: d3307
User: user8
Table_name: t
Grantor: root@localhost
Timestamp: 0000-00-00 00:00:00
Table_priv: Select,Insert,Update
Column_priv:
1 row in set (0.00 sec)
ERROR:
No query specified
2.3.4 单独为某个列授权
授权语句操作:
mysql> GRANT UPDATE(created_time) ON d3307.t TO user8@'192.168.52.1';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT SELECT(uname) ON d3307.t TO user8@'192.168.52.1';
Query OK, 0 rows affected (0.00 sec)
分析:
单独为某个列授权,会记录在这个表的Column_priv字段里面,会记录下对单个列的授权操作记录
查看记录:
mysql> SELECT * FROM mysql.tables_priv where user='user8'\G;
*************************** 1. row ***************************
Host: 192.168.52.1
Db: d3307
User: user8
Table_name: t
Grantor: root@localhost
Timestamp: 0000-00-00 00:00:00
Table_priv: Select,Insert,Update
Column_priv: Select,Update
1 row in set (0.00 sec)
ERROR:
No query specified
而且还会在另外一个权限表mysql.columns_priv留下记录单独的授权记录,如下所示:
mysql> SELECT * FROM mysql.columns_priv WHERE USER='user8';
+--------------+-------+-------+------------+--------------+---------------------+-------------+
| Host | Db | User | Table_name | Column_name | Timestamp | Column_priv |
+--------------+-------+-------+------------+--------------+---------------------+-------------+
| 192.168.52.1 | d3307 | user8 | t | created_time | 0000-00-00 00:00:00 | Update |
| 192.168.52.1 | d3307 | user8 | t | uname | 0000-00-00 00:00:00 | Select |
+--------------+-------+-------+------------+--------------+---------------------+-------------+
2 rows in set (0.00 sec)
2.4 columns_priv表
2.4.1 表结构如下:
mysql> desc mysql.columns_priv;
+-------------+----------------------------------------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------------------------------------------+------+-----+-------------------+-----------------------------+
| Host | char(60) | NO | PRI | | |
| Db | char(64) | NO | PRI | | |
| User | char(16) | NO | PRI | | |
| Table_name | char(64) | NO | PRI | | |
| Column_name | char(64) | NO | PRI | | |
| Timestamp | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
| Column_priv | set('Select','Insert','Update','References') | NO | | | |
+-------------+----------------------------------------------+------+-----+-------------------+-----------------------------+
7 rows in set (0.04 sec)
2.4.2 分析
单独对某一列有操作权限的时候,会将权限信息记录在这个表里面,比如新建立一个账号GRANT UPDATE(uname) ON d3307.t TO user9@’192.168.52.%’ IDENTIFIED BY ‘user0520’; 那么就会在这个表上录入授权信息记录,重点看Column_name字段和Column_priv字段的值。
2.4.3 实际操作
创建用户操作:
mysql> GRANT UPDATE(uname) ON d3307.t TO user9@'192.168.52.%' IDENTIFIED BY 'user0520';
Query OK, 0 rows affected (0.00 sec)
查看结果,会在这个columns_priv表留下一条记录:
mysql> SELECT * FROM mysql.columns_priv WHERE USER='user9';
+--------------+-------+-------+------------+-------------+---------------------+-------------+
| Host | Db | User | Table_name | Column_name | Timestamp | Column_priv |
+--------------+-------+-------+------------+-------------+---------------------+-------------+
| 192.168.52.% | d3307 | user9 | t | uname | 0000-00-00 00:00:00 | Update |
+--------------+-------+-------+------------+-------------+---------------------+-------------+
1 row in set (0.00 sec)
2.5 procs_priv表
2.5.1 表结构
mysql> desc proxies_priv;
+--------------+------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+------------+------+-----+-------------------+-----------------------------+
| Host | char(60) | NO | PRI | | |
| User | char(16) | NO | PRI | | |
| Proxied_host | char(60) | NO | PRI | | |
| Proxied_user | char(16) | NO | PRI | | |
| With_grant | tinyint(1) | NO | | 0 | |
| Grantor | char(77) | NO | MUL | | |
| Timestamp | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+--------------+------------+------+-----+-------------------+-----------------------------+
7 rows in set (0.04 sec)
2.6.2分析:
procs_priv表可以对存储过程和存储函数进行权限设置。主要字段:proc_priv。
3,创建用户
3.1、CREATE USER创建用户
使用CREATE USER语句创建用户,必须要拥有CREATE USER权限。其格式如下:
CREATE USER user[IDENTIFIED BY [PASSWORD] 'password'],
[user[IDENTIFIED BY [PASSWORD] 'password']]...其中,user参数表示新建用户的账户,user由用户名(User)和主机名(Host)构成;IDENTIFIED BY关键字用来设置用户的密码;password参数表示用户的密码;如果密码是一个普通的字符串,就不需要使用PASSWORD关键字。可以没有初始密码。
例如
CREATE USER 'sys'@'%' IDENTIFIED BY 'sys';执行之后user表会增加一行记录,但权限暂时全部为‘N’。
3.2、用INSERT语句新建普通用户
可以使用INSERT语句直接将用户的信息添加到mysql.user表。但必须拥有mysql.user表的INSERT权限。
另外,ssl_cipher、x509_issuer、x509_subject等必须要设置值,否则INSERT语句无法执行。
示例:
INSERT INTO mysql.user(Host,User,Password,ssl_cipher,x509_issuer,x509_subject) VALUES(‘%’,’newuser1’,PASSWORD(‘123456’),”,”,”)
执行INSERT之后,要使用命令:FLUSH PRIVILEGES;命令来使用户生效。
3.3、用GRANT语句来新建普通用户
用GRANT来创建新的用户时,能够在创建用户时为用户授权。但需要拥有GRANT权限。
语法如下:
GRANT priv_type ON database.table
TO user[IDENTIFIED BY [PASSWORD] 'password']
[,user [IDENTIFIED BY [PASSWORD] 'password']...]priv_type:参数表示新yoghurt的权限;
databse.table:参数表示新用户的权限范围;
user:参数新用户的账户,由用户名和主机构成;
IDENTIFIED BY关键字用来设置密码;
password:新用户密码;
PS:GRANT语句可以同时创建多个用户。.与db.*的区别在于。.对所有数据库生效,所以user表的SELECT会变为Y。而db.*user表为’N’,更改的是Db表。
4,删除用户
4.1 drop user删除用户
DROP USER语句删除普通用户,需要拥有DROP USER权限。
语法如下:
DROP USER user[,user]...user是需要删除的用户,由用户名(User)和主机名(Host)构成。
4.2 DELETE语句删除普通用户
可以使用DELETE语句直接将用户的信息从mysql.user表中删除。但必须拥有对mysql.user表的DELETE权限。DELETE FROM mysql.user WHERE Host = ‘%’ AND User = ‘admin’; 删除完成后,一样要FLUSH PRIVILEGES才生效。
5,修改用户密码
5.1 使用mysqladmin命令来修改root用户的密码
语法:
mysqladmin -u -username -p password "new_password" 新密码(new_password)必须用括号括起来,单引号会报错。
示例,修改中要输入旧的密码来验证:
[root@data02 ~]# mysqladmin -u timman -p password "tim" --socket=/usr/local/mysql3307/mysql.sock
Enter password:
[root@data02 ~]#
[root@data02 ~]# mysql --socket=/usr/local/mysql3307/mysql.sock -utimman -ptim -e "select @@port";
+--------+
| @@port |
+--------+
| 3307 |
+--------+
[root@data02 ~]#5.2 修改user表
UPDATE user表的passwor字段的值,也可以达到修改密码的目的;
UPDATE user SET Password = PASSWORD('123') WHERE USER = 'myuser';
FLUSH PRIVILEGES;刷新后生效。
5.3 使用SET语句来修改密码
使用root用户登录到MySQL服务器后,可以使用SET语句来修改密码:
修改自己的密码,不需要用户名
SET PASSWORD = PASSWORD("123");修改其他用户密码:
SET PASSWORD FOR 'myuser'@'%'=PASSWORD("123456") FOR 用户名@主机名5.4 GRANT语句来修改普通用户的密码
使用GRANT语句修改普通用户的密码,必须拥有GRANT权限。
GRANT priv_type ON database.table TO user [IDENTIFIED BY [PASSWORD] 'password']示例:
GRANT SELECT ON *.* TO 'user10'@'%' IDENTIFIED BY '123'5.5 忘记用户密码的解决办法
普通用户,直接用root超级管理员登录进去修改密码就可以了,但是如果root密码丢失了,怎么办呢?
5.5.1 msyqld_saft方式找回密码
停止mysql:service mysqld stop;
安全模式启动:mysqld_safe –skip-grant-tables &
无密码回车键登录:mysql -uroot –p
重置密码:use mysql; update user set password=password(“”) where user=’root’ and host=’localhost’; flush privileges;
正常启动:service mysql restart
再使用mysqladmin: mysqladmin password ‘123456’
5.5.2 使用普通账号来找回密码
–>(1):有一个修改test库的用户:grant create,delete,update,insert,select on d3307.* to test@’%’ identified by ‘t1’;
–>(2):复制user表文件到test库下并且赋予mysql用户访问权限:
cp /home/data/mysql/data/mysql/user.* /home/data/mysql/data/test/;chown mysql.mysql /home/data/mysql/data/test/user.*
–>(3):mysql -utest -pt1登录修改root密码:
–>(4):将test库的user表文件覆盖 mysql库的user表文件
cp /home/data/mysql/data/mysql/user.* /tmp/; mv /home/data/mysql/data/test/user.* /home/data/mysql/data/mysql/ ; chown mysql.mysql /home/data/mysql/data/mysql/user.*;
–>(5):查找mysql进程号,并且发送SIGHUP信号,重新加载权限表。
pgrep -n mysql; kill -SIGHUP 12234;
–>(6):无密码登录,再使用mysqladmin重新设置密码。
PS:请参考第20课的视频,那里有详细的记录整个过修改密码的过程。
6,收回用户权限
查看权限:
SHOW GRANTS; SHOW GRANTS FOR user10@'%'; 或者直接执行sql命令去mysql数据库下的user表中查看存储着用户的基本权限:
SELECT * FROM mysql.user WHERE USER='user10' AND HOST='%'; 使用revoke关键字来收回权限:
REVOKE priv_type[(column_list)]
ON database.table
FROM user[,user]示例:
REVOKE EXECUTE ON d3307.* FROM user10@'%';7,数据库用户划分
7.1 普通数据管理用户:
赋予对业务表的查询维护权限即可,授权sql如下:
GRANT SELECT, INSERT, UPDATE, DELETE ON d3307.* TO zengxiaoteng@'%' IDENTIFIED BY '0523';7.2 开发人员账户:
赋予增删改查的权限,授权sql如下:
GRANT SELECT,INSERT,DELETE,UPDATE ON d3307.* TO huyan@'%' IDENTIFIED BY '0523'; 授予创建、修改、删除 MySQL 数据表结构权限。
GRANT CREATE ON d3307.* TO huyan@’192.168.52.11’;
GRANT ALTER ON d3307.* TO huyan@’192.168.52.11’;
GRANT DROP ON d3307.* TO huyan@’192.168.52.11’;授予操作 MySQL 外键权限:
GRANT REFERENCES ON d3307.* TO huyan@’192.168.52.11’;授予操作 MySQL 临时表权限:
GRANT CREATE TEMPORARY TABLES ON d3307.* TO huyan@’192.168.52.11’;授予操作 MySQL 索引权限:
GRANT INDEX ON d3307.* TO huyan@’192.168.52.11’;授予操作 MySQL 视图、查看视图源代码 权限:
GRANT CREATE VIEW ON d3307.* TO huyan@’192.168.52.11’;
GRANT SHOW VIEW ON d3307.* TO huyan@’192.168.52.11’;授予操作 MySQL 存储过程、函数 权限:
GRANT CREATE ROUTINE ON d3307.* TO huyan@’192.168.52.11’;
GRANT ALTER ROUTINE ON d3307.* TO huyan@’192.168.52.11’;
GRANT EXECUTE ON d3307.* TO huyan@’192.168.52.11’;7.3 DBA人员账户
授予普通DBA管理某个MySQL数据库(test)的权限:
GRANT ALL PRIVILEGES ON test TO sysdba@'192.168.52.%';授予高级 DBA 管理 MySQL 中所有数据库的权限:
GRANT ALL ON *.* TO sysdba@'192.168.52.%';7.4 数据分析人员只读账号
只需要分配只读的权限:
GRANT SELECT ON d3307.* TO dataquery@'192.168.52.129' IDENTIFIED BY '20150523';甚至有些用户,可以只分配读取某些表列的权限,如下所示:
GRANT SELECT ON test.* TO dataquery@’192.168.52.%’ IDENTIFIED BY ‘20150523’;
GRANT SELECT(id,uname) ON d3307.t TO dataquery@’192.168.52.%’ ;
示列权限登录操作:
[root@data02 ~]# mysql --socket=/usr/local/mysql3307/mysql.sock -u dataquery -p20150523 -h192.168.52.130 -P3307
Welcome TO the MySQL monitor. Commands END WITH ; OR \g.
Your MySQL CONNECTION id IS 18
SERVER VERSION: 5.6.12-LOG Source distribution
Copyright (c) 2000, 2013, Oracle AND/OR its affiliates. ALL rights reserved.
Oracle IS a registered trademark of Oracle Corporation AND/OR its
affiliates. Other NAMES may be trademarks of their respective
owners.
TYPE 'help;' OR '\h' FOR help. TYPE '\c' TO clear the current input statement.
mysql> SELECT * FROM d3307.t;
ERROR 1142 (42000): SELECT command denied TO USER 'dataquery'@'data02' FOR TABLE 't'
mysql>
mysql> SELECT id,uname FROM d3307.t;
+----+-------+
| id | uname |
+----+-------+
| 1 | a |
+----+-------+
1 ROW IN SET (0.00 sec)
8,权限划分一般原则
数据库一般划分为线上库,测试库,开发库。
8.1对于线上库:
DBA:有所有权限,超级管理员权限
应用程序:分配insert、delete、update、select、execute、events、jobs权限。
测试人员:select某些业务表权限
开发人员:select某些业务表权限
原则:所有对线上表的操作,除了应用程序之外,都必须经由DBA来决定是否执行、已经什么时候执行等。
8.2 测试库
DBA:所有权限。
测试人员:有insert、delete、update、select、execute、jobs权限。
数据分析人员:只有select查询权限
开发人员:有select权限。
原则:DBA有所有权限,而且严格控制表结构的变更,不允许除了dba之外的人对测试环境的库环境进行修改,以免影响测试人员测试。所有对测试库的表结构进行的修改必须由测试人员和DBA一起审核过后才能操作。
8.3 开发库
DBA:所有权限
测试人员:有库表结构以及数据的所有操作权限。
开发人员:有库表结构以及数据的所有操作权限。
数据分析人员:有库表结构以及数据的所有操作权限。
这里大家可以愉快的玩耍了,只要不mysql服务不hang不downtime都OK了。
MySQL用户权限管理
用户权限管理主要有以下作用:
1. 可以限制用户访问哪些库、哪些表
2. 可以限制用户对哪些表执行SELECT、CREATE、DELETE、DELETE、ALTER等操作
3. 可以限制用户登录的IP或域名
4. 可以限制用户自己的权限是否可以授权给别的用户
一、用户授权
mysql> grant all privileges on *.* to 'yangxin'@'%' identified by 'yangxin123456' with grant option;- all privileges:表示将所有权限授予给用户。也可指定具体的权限,如:SELECT、CREATE、DROP等。
- on:表示这些权限对哪些数据库和表生效,格式:数据库名.表名,这里写“*”表示所有数据库,所有表。如果我要指定将权限应用到test库的user表中,可以这么写:test.user
- to:将权限授予哪个用户。格式:”用户名”@”登录IP或域名”。%表示没有限制,在任何主机都可以登录。比如:”yangxin”@”192.168.0.%”,表示yangxin这个用户只能在192.168.0IP段登录
- identified by:指定用户的登录密码
- with grant option:表示允许用户将自己的权限授权给其它用户
可以使用GRANT给用户添加权限,权限会自动叠加,不会覆盖之前授予的权限,比如你先给用户添加一个SELECT权限,后来又给用户添加了一个INSERT权限,那么该用户就同时拥有了SELECT和INSERT权限。
用户详情的权限列表请参考MySQL官网说明:http://dev.mysql.com/doc/refman/5.7/en/privileges-provided.html
二、刷新权限
对用户做了权限变更之后,一定记得重新加载一下权限,将权限信息从内存中写入数据库。
mysql> flush privileges;三、查看用户权限
mysql> grant select,create,drop,update,alter on *.* to 'yangxin'@'localhost' identified by 'yangxin0917' with grant option;
mysql> show grants for 'yangxin'@'localhost';
四、回收权限
删除yangxin这个用户的create权限,该用户将不能创建数据库和表。
mysql> revoke create on *.* from 'yangxin@localhost';
mysql> flush privileges;五、删除用户
mysql> select host,user from user;
+---------------+---------+
| host | user |
+---------------+---------+
| % | root |
| % | test3 |
| % | yx |
| 192.168.0.% | root |
| 192.168.0.% | test2 |
| 192.168.0.109 | test |
| ::1 | yangxin |
| localhost | yangxin |
+---------------+---------+
8 rows in set (0.00 sec)
mysql> drop user 'yangxin'@'localhost';六、用户重命名
shell> rename user 'test3'@'%' to 'test1'@'%';七、修改密码
1> 更新mysql.user表
mysql> use mysql;
# mysql5.7之前
mysql> update user set password=password('123456') where user='root';
# mysql5.7之后
mysql> update user set authentication_string=password('123456') where user='root';
mysql> flush privileges;2> 用set password命令
语法:set password for ‘用户名’@’登录地址’=password(‘密码’)
mysql> set password for 'root'@'localhost'=password('123456');3> mysqladmin
语法:mysqladmin -u用户名 -p旧的密码 password 新密码
mysql> mysqladmin -uroot -p123456 password 1234abcd注意:mysqladmin位于mysql安装目录的bin目录下
八、忘记密码
1> 添加登录跳过权限检查配置
修改my.cnf,在mysqld配置节点添加skip-grant-tables配置
[mysqld]
skip-grant-tables2> 重新启动mysql服务
shell> service mysqld restart3> 修改密码
此时在终端用mysql命令登录时不需要用户密码,然后按照修改密码的第一种方式将密码修改即可。
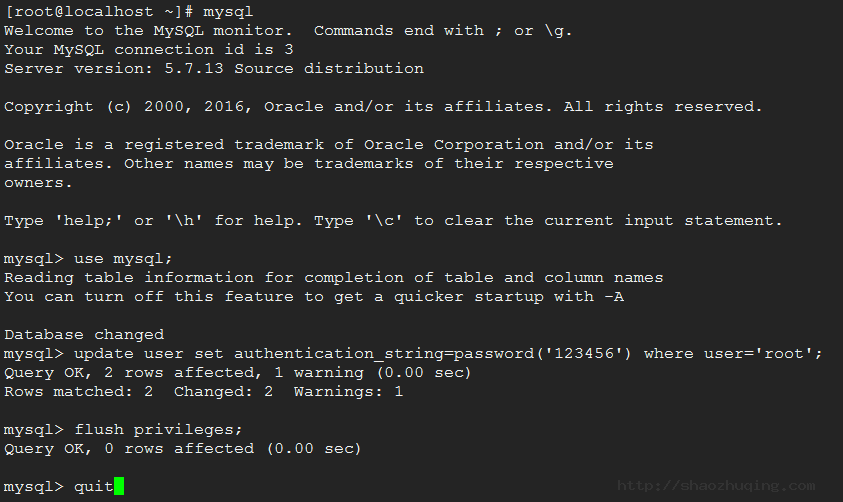
注意:mysql库的user表,5.7以下版本密码字段为password,5.7以上版本密码字段为authentication_string
4> 还原登录权限跳过检查配置
将my.cnf中mysqld节点的skip-grant-tables配置删除,然后重新启动服务即可。
MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
一篇文章学会Mysql分区表的管理与维护
定义:
表的分区指根据可以设置为任意大小的规则,跨文件系统分配单个表的多个部分。实际上,表的不同部分在不同的位置被存储为单独的表。用户所选择的、实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数。
使用场景:
1.某张表的数据量非常大,通过索引已经不能很好的解决查询性能的问题
2.表的数据可以按照某种条件进行分类,以致于在查询的时候性能得到很大的提升
优点:
1)、对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
2)、一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
3)、涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这意味着查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
4)、通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
分类:

1.检查你的Mysql是否支持分区
mysql> SHOW VARIABLES LIKE '%partition%';
若结果如下,表示你的Mysql支持表分区:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| have_partition_engine | YES |
+-----------------------+-------+
1 row in set (0.00 sec)
RANGE分区表创建方式:
- DROP TABLE IF EXISTS `my_orders`;
- CREATE TABLE `my_orders` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (YEAR(atime))
- (
- PARTITION p0 VALUES LESS THAN (2016),
- PARTITION p1 VALUES LESS THAN (2017),
- PARTITION p2 VALUES LESS THAN MAXVALUE
- );
以上是一个简单的订单表,分区字段是atime,根据RANGE分区,这样当你向该表中插入数据的时候,Mysql会根据YEAR(atime)的值进行分区存储。
检查分区是否创建成功,执行查询语句:
EXPLAIN PARTITIONS SELECT * FROM `my_orders`
若成功,结果如下:

性能分析:
1).创建同样表结构,但没有进行分区的表
- DROP TABLE IF EXISTS `my_order`;
- CREATE TABLE `my_order` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2).向两张表中插入相同的数据
- /**************************向分区表插入数据****************************/
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
- /**************************向未分区表插入数据****************************/
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
3).主从复制,大约20万条左右(主从复制的数据和真实环境有差距,但是能体现出表分区查询的性能优劣)
- /**********************************主从复制大量数据******************************/
- INSERT INTO `my_orders`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_orders`;
- INSERT INTO `my_order`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_order`;
4).查询测试
- /***************************查询性能分析**************************************/
- SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.084s****/
- SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.284s****/
通过以上查询可以明显看出进行表分区的查询性能更好,查询所花费的时间更短。
分析查询过程:
EXPLAIN PARTITIONS SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
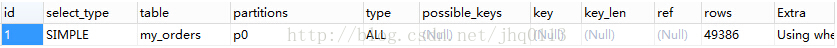
EXPLAIN PARTITIONS SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();

通过以上结果可以看出,my_orders表查询直接经过p0分区,只扫描了49386行,而my_order表没有进行分区,扫描了196983行,这也是性能得到提升的关键所在。
当然,表的分区并不是分的越多越好,当表的分区太多时找分区又是一个性能的瓶颈了,建议在200个分区以内。
LIST分区表创建方式:
- /*****************创建分区表*********************/
- CREATE TABLE `products` (
- `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '表主键' ,
- `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称' ,
- `metrial` tinyint UNSIGNED NOT NULL COMMENT '材质' ,
- `weight` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '重量' ,
- `vol` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '容积' ,
- `c_id` tinyint UNSIGNED NOT NULL COMMENT '供货公司ID' ,
- PRIMARY KEY (`id`,`c_id`)
- )ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY LIST(c_id)
- (
- PARTITION pA VALUES IN (1,3,11,13),
- PARTITION pB VALUES IN (2,4,12,14),
- PARTITION pC VALUES IN (5,7,15,17),
- PARTITION pD VALUES IN (6,8,16,18),
- PARTITION pE VALUES IN (9,10,19,20)
- );
可以看出,LIST分区和RANGE分区很类似,这里就不做性能分析了,和RANGE很类似。
HASH分区表的创建方式:
- /*****************分区表*****************/
- CREATE TABLE `msgs` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY HASH(sub_id)
- PARTITIONS 10;
以上语句代表,msgs表按照sub_id进行HASH分区,一共分了十个区。
Key分区和HASH分区很类似,不再介绍,若想了解可以参考Mysql官方文档进行详细了解。
子分区的创建方式:
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
检查子分区是否创建成功:
EXPLAIN PARTITIONS SELECT * FROM msgss;
结果如下图:

前面已经提过,Mysql支持4种表的分区,即RANGE与LIST、HASH与KEY,其中RANGE和LIST类似,按一种区间进行分区,HASH与KEY类似,是按照某种算法对字段进行分区。
RANGE与LIST分区管理:
案例:有一个聊天记录表,用户几千左右,已经对表按照用户进行一定粒度的水平分割,现仍然有部分表存储的记录比较多,于是按照下列方式有对表进行了分区,分区的好处是,可以动态改变分区,删除分区后,数据也一同被删除,如聊天记录只保存两年,那么你就可以按照时间进行分区,定期删除两年前的分区,动态创建新的的分区就能做到很好的数据维护。
分区表创建的语句如下:
- DROP TABLE IF EXISTS `msgss`;
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
上述语句创建了三个按照RANGE划分的主分区,每个主分区下面有六个按照HASH划分的子分区。
插入测试数据:
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',UNIX_TIMESTAMP(NOW()),1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',UNIX_TIMESTAMP(NOW()),2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',UNIX_TIMESTAMP(NOW()),3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',UNIX_TIMESTAMP(NOW()),10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',UNIX_TIMESTAMP(NOW()),7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',UNIX_TIMESTAMP(NOW()),5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1451577607,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1451577609,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1451577623,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1451577654,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1451577687,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1451577699,5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1514736056,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1514736066,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1514736076,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1514736086,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1514736089,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1514736098,5);
进行分区分析:
EXPLAIN PARTITIONS SELECT * FROM msgss;
可以检测到分区信息如下:

检测分区数据分布:
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`<1451577600;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1451577600 AND `atime`<1483200000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1483200000 AND `atime`<1514736000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1514736000;
结果:第一条语句只扫描了t0的所有子分区,第二条语句只扫描了t1的所有子分区,第三四条分别只扫描了t2的所有子分区,证明表的分区和数据分布成功。
需求:目前已经是2017年,需要将2015年所有的聊天记录删除,但是保留2016年的聊天记录,并且2017年的数据也能正常按照分区进行存储。
实现以上需求,需要两步,第一步删除t0分区,第二步按照新规则重建分区。
删除分区语句:
ALTER TABLE `msgss` DROP PARTITION t0;
重建分区语句:
- ALTER TABLE `msgss` PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1514736000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
查询发现,15年的数据全部被删除,剩余的数据被重新分区并分布。
重启mysql提示MySQL server PID file could not be found!
重启mysql提示MySQL server PID file could not be found!
Starting MySQL...The server quit without updating PID file (/usr/local/mysql/data/rekfan.pid).
我只能呵呵了吗?不是。
我是这样做的,先看下是不是有这个进程,然后结束,再重启,代码:
- ps -ef|grep mysqld
- kill -9 进程号
你要是没解决?好吧,继续:
(解决方法:一个个试!)
1.可能是/usr/local/mysql/data/rekfan.pid文件没有写的权限
解决方法 :给予权限,执行 “chown -R mysql:mysql /var/data” “chmod -R 755 /usr/local/mysql/data” 然后重新启动mysqld!
2.可能进程里已经存在mysql进程
解决方法:用命令“ps -ef|grep mysqld”查看是否有mysqld进程,如果有使用“kill -9 进程号”杀死,然后重新启动mysqld!
3.可能是第二次在机器上安装mysql,有残余数据影响了服务的启动。
解决方法:去mysql的数据目录/data看看,如果存在mysql-bin.index,就赶快把它删除掉吧,它就是罪魁祸首了。本人就是使用第三条方法解决的 !http://blog.rekfan.com/?p=186
4.mysql在启动时没有指定配置文件时会使用/etc/my.cnf配置文件,请打开这个文件查看在[mysqld]节下有没有指定数据目录(datadir)。
解决方法:请在[mysqld]下设置这一行:datadir = /usr/local/mysql/data
5.skip-federated字段问题
解决方法:检查一下/etc/my.cnf文件中有没有没被注释掉的skip-federated字段,如果有就立即注释掉吧。
6.错误日志目录不存在
解决方法:使用“chown” “chmod”命令赋予mysql所有者及权限
7.selinux惹的祸,如果是centos系统,默认会开启selinux
解决方法:关闭它,打开/etc/selinux/config,把SELINUX=enforcing改为SELINUX=disabled后存盘退出重启机器试试。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
