周鸿祎:如何做好产品经理
我刚才来的时候,会议主办方跟我讲,今天来交流的很多人是设计师、产品经理,据说还有 50 位公司的高管,我今天希望跟大家有一个交流,对很多公司高管来讲,我其实有一个建议,过去这种公司分工特别明确,做一个产品好像变成一个生产线,有人负责策划,称为产品经理,有人负责项目实施,称为项目经理,还有专门做 UE,我后来没搞清 UX 和 UE 怎么区分,曾经有一个大公司跟我讲半天,UX 是用户体验,UE 做 UED,分的非常细,我听了半天,这两个角色至少从我的从业生涯来说,我觉得很难区分,最后可能还有负责做研发的人,负责拿到产品规划,用代码堆出来。
今天在座更多是设计师,我也非常反对在一个公司里,很多人把设计师贯一个美工,说设计师产品做好了,你给我美化一下,润色一下,调一下颜色,看一下像素,设计师本身应该成为产品经理。

我有几个个人的心得,不是因为我有多么成功,而是因为我曾经是最大的失败者,我在用户体验上犯了非常巨大的错误,甚至被别人骂得狗血喷头,大家看到我有投资和参与做的成功产品,那是因为你们没有看到背后还有很多不成功的功能,不成功的产品,没有被大家所关注和记得。所以正是有很多经验教训,我总结出几个简单的心得,就是几个“心”字:
一是说起来最简单,就是用心。
很多人笑了,我们做事不用心吗?很多人原来在公司里只是一颗螺丝钉,很多时候做产品,真是为自己在做,还是觉得在执行老板旨意,还是执行上级的命令,真的在用心吗?
如果一个人把自己看得太小,只看把自己看成一个打工的,你是这样的层次和胸怀,你不可能成为一个真正能做好产品的产品经理,所以我希望如果各位听了我的心得,回去在公司上班的时候,也不用管公司是不是你自己的,你拿出一点创业精神。很多人讲我又不是创业者,我干吗要创业精神,难道非要你自己办公司才能把一个产品做好吗?其实在别人的平台上花着老板的钱,花着公司资源,做不成是公司交学费,如果我们都不能把自己充分调动起来,想把一个产品做到极致,让这个产品在市场获得成功,给自己积累,无论是声望,无论是积累人脉关系,更多的是积累经验教训。难道你今天从公司出去拿一笔钱,自己再做一个公司,你真的觉得你做产品的能力就有所提升吗?我跟产品经理讲,你心里要有一个大我,要对这个产品负责任,要把这个产品看成你自己的产品,我认为每个人都是有潜力的,我经常给员工举一个例子,很多员工,很多产品经理做产品,能挑出很多问题,但是他也尽到了他工作职责,仅仅靠尽到工作职责很难成为优秀产品经理。
在座诸位,我知道北京买房很难,当然来 360 有点机会,我可以告诉大家,我做公司这么多年里,看到很多同事好不容易买一个小房子,然后装修,他们都成了装修专家,瓷砖专家,马桶专家,为什么呢?因为这是他的房子,他每天花很多时间在网上搜索,每天到建材城和卖建材的人斗智,只要拿出装修自己家的精神,一个外行能够成为瓷砖专家、浴缸专家,没有理由不成为一个产品专家。很多人问我,我先讲一个大家觉得特虚的用心,即便大家觉得我在产品上有一些心得,实话说每次做一个新的产品,我也不是拿出几个锦囊,也不能在那三分钟有灵感,我也花很多时间看同行的东西,去论坛看用户评论,花很长时间用这个产品,每个产品都是要呕心沥血,有时候感觉做一个产品像一个妈妈十月怀胎生一个孩子,就算你成功养育了三个孩子,第四个孩子不用十个月,三个月就生出来,可能吗?还是要经历十个月的痛苦的孕育过程,我觉得用心,对自己负责任,对自己做的产品负责任,是一个产品经理的基本前提。
尽管你在公司的头衔不高,职位不高,产品经理是最委屈的,因为他头衔最低,经常要协调很多人,要忍受技术部门的白眼,要忍受公司不同高管不同方面给他近乎矛盾的要求,甚至有时候不得不忍受一些所谓白痴领导给他的指令,而且很多时候还要协调公司内部不同的部门,包括市场、传播。但是我认为产品经理就是总经理,就应该把自己当成一个总经理,就要通过人微言轻,但是你要敢于说话,要能够表达自己的意愿,敢于对一些意见说不,要能够鼓起勇气去推动很多事情的进展,哪怕非常难。
所以一个人如果在公司里历经很多波折扯皮,最后能够把一个产品往前推动,并不意味着一定要贯一个头衔,我认为产品经理就是总经理,能够这么做一回,恭喜你,有一天你去创业,发现美国那些创业公司,其实根本没有产品经理这个头衔,主程序员就是产品经理。换句话说一个优秀的产品经理,如果有一天想创业,想拥有自己的生意,想拥有自己的事业,如果不能够成为一个优秀的产品经理,坦率的说很难,成为产品经理是一个最重要的前提。
二是将心比心
我刚才讲完了一个大我,比较自我,敢于承担责任,将心比心讲的是小我、忘我、无我,我们做产品无论有多么好的技术卖给用户,有多么好的设计感觉给用户很酷的设计,其实都要把握一个理论,所有用户体验,什么叫用户体验,为什么不叫产品经理体验,不叫老板用户体验,因为所有体验从用户角度出发,从用户来看产品,你觉得好的产品用户不一定买,用户选择一个产品理由跟行业专家选择一个产品的理由,有的时候是大相径庭。用户选择一个产品,有时候非常简单,如何学会从用户的角度出发思考,我觉得对很多人来说,说起来是一件很简单的事,但是实际上很难做到。因为每个人不管成不成功,随着自己经验的增加、阅历的提升,每个人讲的最多的是什么?是我认为,我以为,我觉得,我们自我太多了,很多时候做产品,是给自己做。
我们很多时候讨论产品的时候,在激烈争论不下的时候,争论双方可能没有站在用户角度,都是激烈的认为自己是对的,对方是错的。如何能够让自己将心比心,这个心理学上有很多这种词,叫同理心,从用户角度出发来考虑问题,这对很多人来说不是能力问题,也是一个心态问题。原来我有一句话,我教育公司里的很多人,像小白用户一样去思考,思考完了得出结论,像专家一样采取行动。很多人颠倒过来了,像专家一样思考,像白痴一样采取行动。
最近微信产品的负责人张小龙的观点,他的观点,跟我几年前说的观点是不谋而合的,三年前我在主导这个话题,大道理是一样的,进入白痴状态或者进入傻瓜模式,你们每个人有没有一个按纽,能够快速的进入傻瓜模式,我在公司里很多时候讨论产品,我对产品经理一个挑战,也是因为我能够这么多年被用户骂得多,经常到第一线看用户的帖子,在微博做用户的客服,这不是为了作秀,为了保持真正掌握用户的想法,我最喜欢的杂志不是行业高端杂志,类似电脑迷、电脑爱好者、电脑软件,在地摊上卖的中低用户的普及杂志,上面有很可笑的文章,这么简单的功能早就用了,为什么写一篇文章教育用户,那是用户真的不知道怎么用。
通过不断的历练,我自己养成一种心得,我的手下做出一个软件,给我用的时候,我好歹也是一个程序员出身,也干了这么多年技术和产品,一个功能多动两下鼠标找到了,能难得住我吗?或者说一个按纽文字写的很晦涩,我看一遍,我稍微动脑筋一想就想明白了,但是我脑子里有第二个白痴的我起作用了,如果我看什么东西能够不加思索的去用,我就觉得这个产品很顺畅,但是突然我怔了一下,大家不要笑我,有的时候我亲手设计的产品,设计完了,我用的时候,我就精神分裂了,一个周鸿祎设计的,但是另外一个白痴周鸿祎开始用,用一下怎么就觉得别扭,这几个文字看一下,我就进入了小白状态,我怎么看不懂这几个字什么意思呢,我马上会告诉产品经理,这个体验有问题。
我做产品,至少有一半的灵感从用户那来的,不是说用户会具体告诉你一个产品应该怎么做,这可不能直接问用户,用户具体需求,一个个案需求不能听,那样会被用户牵着鼻子走,用户需求同理性,把自己置于用户情景中,用户为什么会这么想,用户为什么会这么来抱怨,这个抱怨的根源是什么,就会发现,你想得再好的产品,这里都会有很多问题,自己自觉不自觉,做着做着按照自己想法做,从用户出发的思维模式,不断的在内心有天人交战,不断自我挑战,使用户体验能找到最好的感觉。
我一直强调用户体验,所有的体验都是要从用户出发,作为我们行业专家,特别是各位最容易犯的一个错,是因为你在行业里混久了,经常参加行业高端论坛,结果同行讨论问题,往往同行加强,你讲一个道理,同行一定是认同,你做一个产品,同行一定觉得很认同。但是在中国,往往一个高端人群都很认同的产品,有的时候在中国大量的中低端人群,我们经常说的小白用户,往往觉得很难认同,在中国互联网经常有一个巨大的鸿沟,在高端用户和真正的主流用户,谁能够跨越这个鸿沟,就是谁能够从用户角度出发。
三是处处留心
很多人觉得在公司工作的时候,在开产品讨论会的时候才叫改善用户体验,下了班或者没事的时候,这事跟我没关系了,这种人很难成为优秀的产品经理。产品体验无处不在,任何事情都是产品体验。比如新进到一个酒店,比如坐航空公司的飞机,整个登机过程,机场安检的流程,最糟糕的用户体验,如果不幸摔伤了腿,拄着拐杖去医院,当然很多现代化的医院改善了,但是传统医院的流程,永远不知道先到哪儿划价,然后再去交费、拍片子,让你楼上楼下跑很多来回,包括著名的笑话在北京西直门的桥上,所有司机都会觉得走入了丛林一样会迷路。如果去过美国,美国的路牌和中国的路牌,中国的路牌总是等你看清楚以后,恭喜你已经上错的道路或者你已经意识到这是一个出口,但是美国路牌在你离还有一定距离的时候会提醒你。
在日常生活中体验无处不在,如果能够处处留心,把自己当成一个抱怨的用户,但是把它再上升一个层次,抱怨完了之后,想想为什么会抱怨,这个东西怎么改善,从而看成一个头脑体操,如果我是这个道路设计师,如果我来设计医院,如果我来设计摇控器,大家用的手机、车钥匙,会发现这里面有太多的体验做得很糟糕的东西,但是你来思考的过程,我觉得就是一个提升自己对体验的感觉。
行业专家容易有行业误区,因为在这个行业里太熟悉了,审美疲劳了,已经形成惯性思维,有时候做一个小白用户,没有耐心,很暴躁,想想餐馆吃饭,在菜里发现苍蝇,各位怎么感觉,当时就跳起来,恨不得马上跳起来,在你的行业里,用户用你的产品出错了,你会很不以为然,这有什么大不了的事,不就程序出错了吗,你再重装一遍不就得了嘛。
大家买车的时候,你对车不了解,就会听着推销员天花乱坠,你可能就不关心这个车的某个螺丝是什么做的,可是到自己产品的时候,你巴不得把你的技术细节都展现给用户,也不管用户懂不懂。很多人买家电,真正懂家电的技术吗?很多人因为家电长得好看,或者现场推销员一顿天花乱坠忽悠了,把彩电买回家,买了很多功能回家,回家自己最能用的还是音量键、开关键和频道键,摇控器上大部分键都摸过吗?电视机一定有看照片的功能,你是否把 SD 卡往里插了呢,你如果插了一次,就会知道这个功能不是给人设计的。
我有时候会说,很多功能做得像找抽型功能,说你没做吧,你做了,这功能都有,功能都能完成任务,说你做了吧,用户用起来很难用,但是在你自己的领域里,产品都是你做的,你知道细节,你知道流程,你绝对不会骂,你会觉得自己的孩子做得多好,用户不会用,我们研究出一本书 21 天学会使用什么,我们没准公司靠办培训还能再产生一个产业,今天修手机比卖手机赚钱,这个笑话都知道。
为什么鼓励大家在日常生活中,不熟悉的领域处处留心,这是发现用户感受,培养同理心一个非常好的机会。如果在日常生活中,不仅仅是在上班那几个小时,或者开会那几十分钟里,能让自己无处不在的处在一种小白用户的模式,能让自己在不断的生活中发现体验不好的地方,有人在微博抱怨,射灯不好,这个细节真的留心,处处留心皆体验。过去一个好的诗人,不是天天在屋里看唐诗三百首照着抄就能写出伟大的诗篇,他有赤子之心,有胸怀,到处采风,游历名山大川,和朋友喝酒,像李白一样,才能有这种灵感,很多产品的灵感来自于在产品之外。据说苹果设计师来苹果之前,设计最酷的产品是马桶,很多人觉得很奇怪,怎么设计苹果的人是一个设计马桶的人,你们不觉得在白色上有共同的灵感吗?
四是没心没肺
就是脸皮要厚,不要怕人骂,最好的产品不是完美的,是优美的,是优雅的,能解决用户问题,但是一定不完美,苹果的产品还是有很多缺点,但是有一点或者几点能够对你进行强大的诱惑和感动,这就够了。所以没有缺点的产品不存在,很多设计师做事要求完美,我做产品要求做到极致,而不是完美,完美不可能,要有这种开放的胸怀,能够听到别人骂。甚至竞争对手雇水军来骂我,虽然再难听,我会咬着牙跟团队说说想想产品有什么改进的,让他骂不出。很多设计师出身的产品经理,设计出身,有一颗敏感的心,被老板一批评就蔫了,被同行一挑战,就说我不跟你讨论了,你不懂。
我觉得做一个好的产品经理,要对产品的结果负责,心要粗糙一点,要迟钝一点,不要管别人怎么说,要能够经受这种失败,因为好的产品,是经过不断的失败,不断的打磨,好的体验绝对不是一次到位,你是要不断的一点一滴的去改进,只是很多产品的成功,当你们今天去谈论苹果的时候,谈论成功公司的产品时候,一定不要看今天的成功去模仿,一定看他刚起步的时候多么粗糙的原型,读读乔布斯传,看看苹果的真实历史,第一代 iPod 很多是粗糙,第一代苹果手机跟摩托合作不成功的例子。今天 Facebook 这么成功,很多人举它做例子,这么美丽的产品,很多人都在抄他的表现,Facebook 第一版是什么样子,第一版就这么漂亮吗,第一版有很高明的设计师吗?其实不是,我相信它的第一版,就是为了哈佛女生和哈佛男生做的都是,是一个非常简单的让大家上传照片分享照片的一个简单应用。
所以每一个产品最后能成功,都不是一招制敌,更不是一炮而红,而是至少经过三年五年不间断的打磨、不间断失败、不间断的尝试,没有坚韧不拔的心态产品经理很难做出来,做产品某种角度来说,是做艺术品,但是某种角度来说,因为艺术品可以给少数人看,甚至艺术品可以孤芳自赏,但是最终的产品成功还是要获得商业上的成功,它再是艺术品,还是要获得大众的认同,不得不去做很多跟大众沟通,跟市场抗争,跟竞争对手做竞争,原来很多设计师认为自己很不懈干这个事,不得不忍受来自市场各种用户建议、正常的反馈,甚至包括恶毒的攻击。所以没有一颗粗糙的心,有时候我也觉得自己没心没肺的,别人骂我多了,刚开始有感触,后来看多了就习惯了。
所以有这样几个心就具备了产品经理的基本素质:用心、将心比心、处处留心、没心没肺。
五点用户体验
我还预备了第二部分的问题,我的时间可长可短。关于将心比心我稍微补充一点,今天来的有没有技术人员,我认为技术人员出身的产品经理也是非常有潜力的,因为他懂技术,跟技术人员能更好的挑选技术方案,我看到很多技术人员在做产品中犯的一个错误,太多的要把自己的技术展现给用户,把技术先进的概念给用户,这就是忘了从用户角度出发,用户到今天,特别是体验时代,什么叫体验时代?在电脑还是即刻时代的时候,电脑越复杂越好,能够输入复杂的指令,但是当一个产业,比如今天苹果都成了街机,电脑已经成了标配情况下,电脑从专家时代进入到大众时代,这时候体验就变得更加重要,用户甚至都不知道苹果用了什么 CPU,很多拿苹果的白富美、高富帅不知道苹果是四核还是双核,只觉得用的很爽。每个用谷歌的人,只看到谷歌简单搜索框,谁知道谷歌背后是什么样的服务器模型,谷歌用了第几代搜索引擎技术。很多技术人员做的产品,标榜说这是第四代技术,我也不知道第四代用户能不能理解,很多时候过于自己出发,我们就犯了一个教育用户的错误,我的观点是用户不可教育的,用户习惯是你需要观察适应的。要适应用户的习惯,最可怕的是纠正用户养成多年的习惯,这几乎不可能的。从用户出发,将心比心,是下面如何用户体验几个观点的一个基础。
用户体验有五点:
一是用户体验的核心,我们都是设计师,是不是设计?很遗憾,第一核心的不是设计,用户体验最基础的是用户需求,如果脱离了用户需求,一个设计再漂亮的产品,是无法和用户共鸣,我在外国转了一圈,很多大学生创意团队做的很多东西,我举个例子,在过去两年一个曾经很热的概念 LBS,还有一个概念叫 O2O,大家看到什么成功的产品了吗?没有,很简单,用户选择一个产品,你们做一个小白用户去一个饭馆吃饭或者决定买一个电视,设计师可能因为设计好看买回家,绝大多数小白用户问一个简单问题,我用这个产品解决什么问题,这个产品给我什么价值,说人话就是有啥用,如果这个问题不能解决,用户不会想跟你谈,但是有太多的用户体验忽略了这个产品,而是说最近有一个 O2O 的概念,所以基于 O2O 做了一个设计,或者说最近想了一个需求,我们做了一个什么产品。
我在外面看了几个这样的产品,我第一反应不是看界面,我是看描述,用户在什么场景下来用,这是用户体验最重要的,大家所谓的用户调研、用户分析、用户访谈,都不是用户上来看你的界面,而是上来想用户什么场景下才会用,这里很多产品经理的弱点,用户场景是经不住推敲的,用户根本没有这种需求,这种需求是他想象出来的,我跟很多产品经理讲,你的产品第一版界面可以不漂亮,设计上可以有瑕疵,功能可以很简陋,这些都不成为用户拒绝产品的理由,用户拒绝产品的唯一理由是跟你无法共鸣,看了半天不知道这玩意儿有什么用。
比如今天腾讯的产品已经做得很漂亮,第一版的产品很简陋,功能少很多,确实解决了一个中国当时年轻人缺乏沟通工具,360今天的功能也做的极其庞大,甚至有点庞杂,产品也很多,但是 360 第一版功能极其简陋,跟任何杀毒软件没有办法比,功能也极其简单,能力也很薄弱,甚至一个流氓软件都能把它给卸掉,连基本自我保护能力都没有,但是当时能够起来,不是做得有多好,是当时有一个巨大的市场需求,2006年流氓软件在祸害中国,几乎 99% 的互联网公司,无论大小,无论中外,都集体在做流氓软件,而且没有人管这个事情,所以它能杀流氓软件,就能够解决用户的痛,我认为最好的产品是能解决用户的痛,这个痛越大这个产品就受到用户欢迎,受到用户欢迎,又有用户,有用户能成长,就有机会去改善。
大家奉为设计大师的乔布斯,他刚回苹果的时候,不是今天这么牛,他 1997 年回苹果了,最先做的几个彩壳电脑,得的工业大奖,问题是改变了苹果吗?没有,因为没有真正达到用户的需求,为什么后来 iPod 打入了需求,iPod 真的是一个蓝海市场吗?错,是一个新发明的需求吗?根本不是,听音乐是每一个人的基本需求,所有在美国的官司,当时都反映了美国大学生都要在网上下载歌曲听歌的需求,iPod 顺应了这个需求,没有这个需求去空谈 iPod 触摸、外形白色漂亮,这都是空洞的东西。我反复强调,当你们决定参与策划做一个产品的时候,第一步想到的不是配色,不是外形,是用户到底有没有这样的需求,如果弱需求,这个产品将来推广起来非常难,如果是强需求,是用户拦不住的需求,这个需求就会很大的成功。
举三个例子,比如最火的微信,一个竞争产品曾经做了一个设计上很酷的东西涂鸦,把一种心情发给别人,并没有用户角度出发,每个用户都是专业设计人员,每个用户每天花很多时间涂鸦吗,可能真的不去讲一句话,当时不太懂用户心理,从这个产品上从来不在网上泡妞,也不用类似的产品,我一点用户的感觉都没有,微信摇一摇,男生能摇出妹子,女生能摇出自己的魅力感觉,这个产品是微信中一个强需求,成为一个爆炸点。网上有很多人用盗版的 QVOD,有人重新打包之后,装一些病毒和木马的播放器,来播放爱情动作片,这个 360 弹出提示,不能播这个东西,有病毒,他们听 360 的吗?没有,把 360 关掉,如果 360 再弹,就把 360 彻底的卸掉,看完了之后再把 360 装上,这种需求叫强需求。
但是我再给大家举一个例子,最近微信谈二维码,二维码是强需求吗,手机里没有装二维码的应用似乎也不影响,为什么在微信之前所有做二维码的公司都不太成功,因为是弱需求,装二维码干什么,很方便,到处都扫,哪有啊,跟商家谈,商家说二维码可以试一试,但是你有用户吗,又没有用户,就变成了一个死结。今天微信加二维码应用,微信做二维码成功了,说明二维码是好东西,错,你装微信是因为有二维码,不是,你装微信,它有朋友圈,能交友,我非常尊重微信这个产品,我一直作为产品成功的范例,在我们内部进行反思和学习。
有了一个强需求之后,在 2 亿用户基础之上,加上一个二维码的应用,大家自然延展使用了,但是很多创业公司,没有仔细分析用户需求,只是看到别人做二维码,我也做,殊不知别人做就能成功,别人有 2 亿的基础,你做不成功,因为你没有强大的需求。最近唱吧为什么火?是说明中国人对音乐的追求到达一个新境界吗?如果真的这么想就错了,仔细分析一下,唱吧还是强需求,大家不要笑,很多成功的产品,是强需求,所以会有用户,有用户,用户不断的提要求,不断的持续改进体验,体验越改进越好,最后就成功了,最后成功的时候,中国企业家宣传的时候,不会像我这样讲真话了,就会说当年我多么高瞻远瞩,用户的交互多么漂亮,我们投入了巨大的力量,我们用户体验、用户交互多么好,最后我们获得了成功。可能各位听了这种分享之后,回去玩命的打造界面,调整颜色,最后产品还是不成功,为什么?因为我们没有抓到用户本质的东西需求,所有离开了用户需求的用户体验改进都是耍流氓。
看到外面一些产品谈 O2O 的概念,我再强调概念害死人,在公司内部讨论产品的时候,如果 CEO 也谈概念,这个公司就垮了,如果产品经理谈概念,这个公司就更要完蛋了,因为概念是正确的废话,谁能够解释 O2O、B2C,这种概念在互联网这么多年,全部都是马后炮的总结,概念离用户很远,用户不会因为叫 ios 才来用,用户最早上 Facebook 是因为能泡妞。所以忘掉那些概念,而是去观察用户。
什么叫形成体验?体验一定要超出预期的才叫体验,如果做的跟别人产品一样,但是功能不叫体验,很多人在抄袭别人产品的时候,经常说某某公司做了什么功能,老板说照着做一个,但是想没想过,如果做的一样是没有机会的,如果用户用完了,感觉及格良好,用户不会形成真正的体验。什么的体验像拿一个针刺一下,或者踢一脚,感觉被针扎了一下,它会形成一种口碑,这种超出预期的东西,是不是很大?不说产品了,很多人模仿微信摇一摇,我问过产品经理,他说最大体验的是什么?有的人说在酒店里用微信摇一摇能摇出几十个,用某些产品摇一摇,十公里之内都摇不出一个,哪一个超出预期,你就跟别人说兄弟用这个,它就能超出预期。
我原来写微博,我推荐大家看一本书,我在微博里说叫《商业秀》,副标题是所有的行业都是娱乐业,因为娱乐业是最靠体验的,我们在日常生活中,卖一瓶水,你喝了你有体验,反正能解渴,不超出体验,好歹有一个东西,但是花 70 元看一场电影,在拉斯维加斯看一场秀,得到了什么,什么都没买到,买到的是一个标准体验,所有电影、所有秀能不能成功,在于能不能给你一个巨大的情感冲击。
在拉斯维加斯有一个酒店,客人已经离店,在他走出酒店的时候,门童会塞上几瓶冰冻的矿泉水,这个酒店都是免费给水的,都是自己罐装的,成本几乎为零。但是这两瓶水给客人的感觉是无微不至的关怀和超出预期,我已经结过账了。住酒店,即便大家觉得我比大家有点钱,我住酒店我也很紧张,我也不敢动东西,到了酒店,到处放着水,这个水一打开,这瓶水是免费的,那瓶是消费的,消费还特昂贵,我把它喝完了,我到楼下超时买一瓶可乐给它倒进去,这就是正常的体验。但是在我离店的时候,能够给你送水,这就叫超出体验。或者房间里两瓶免费的水喝完了,能及时补上更多的矿泉水也叫体验,所以超出体验,不要给用户一万块钱,也是你要想用户的期望和用户的满意度。
再举一个例子海底捞,真正吸引很多人去,是因为给大家提供的食材都是金枝玉叶吗?不是,海底捞吃的东西跟其他饭馆差不多,为什么大家去海底捞?服务好。这个服务好好在哪里?只不过做了一些同行没有做的事情,给你擦眼镜,给你擦鞋,饭前免费磕瓜子,饭后免费吃西瓜,能举出很多例子,你没有女朋友,走的时候带一个服务员走?网上有很多营销的例子,如果你做的体验能够超出用户,就能形成口碑。360做了一个开机小助手,变成了一个流行的范式,恭喜你,你的工资超越了中国1% 的人,所以本月你要继续努力,恭喜你,你的起床时间击败了寝室里其他三个同学,还有同学起床失败,正在重启。
想超出用户的预期,才能形成体验,不一件很难的事。还有一点,体验一定是用户可以感知的,我们太多的误区是我们做了体验是我们自说自话,举个例子,360做了一个小功能,虽然有人不喜欢,但是绝大多数用户感觉很好,因为我们就在想,怎么告诉用户电脑里状况不太好,因为用户的电脑不是 1 跟0,不是很好,没有问题,要不就是有病毒有木马,有很多是灰色的状态,有很多专业的文字告诉用户,用户还很有耐心,看微博只看 140 字的情况下,看文章都看标题,用户哪有时间看专业的描述呢?好在我们发现中国用户,从小受应试教育长大,我们都是应试教育的受害者,虽然痛恨应试,但是我们都渴望得分,我们都知道不及格不好,都希望得一百分,绝对不能得 99,要不然被其他小朋友嘲笑,所以我们就给大家定了一个体检的分数,很多人一看体检分数很愤怒,怎么才得 60 分、70分,我要优化,一优化,我们就自动扫描解决很多问题。用户不能感知,但是你要创造感知。
同样,苹果里面很多动作,iPad 翻屏的时候,不是一个简单的匀速运动,是一个加速变速运动,到边的时候,甚至会有一个反弹,为什么苹果会做得这么细致?我们做一个产品,360安全桌面,在 PC 上试图模仿苹果的 iPad 的体验,我们第一版做的是一切换把画面切换回来,做完了之后,怎么跟苹果的感觉山寨味很浓,一点感觉都没有,我们找到一个研究苹果的专家,仔细给我们上了一课,我们才发现,真的苹果里有一个加速的函数,有一个运动的模型,苹果为什么要下工夫?让他的体验可以被你感知。
讲两个负面的例子,有一年一个运营商推 CDMA 手机,找了很多卖点,最早说叫绿色无辐射或者辐射少,这个卖点好不好?很多人一定说好,绿色是主旋律,手机有辐射,打多了得脑癌,为什么这个卖点没有成功呢?是因为各位同学你对一个手机的辐射感受,你能感觉到吗?你拿一个 CDMA 手机打电话,能知道辐射大辐射小,其实你是没有感知,在非用户体验的时代,很多产品热中热衷于找卖点,主要策划卖点,就是忽悠用户的,卖点怎么传播呢?卖点通过广告教育用户,通过在卖场一对一忽悠用户灌输,把用户忽悠到手,用户交了钱,拿回家了。卖电视的,还在搞卖点,智能电视有九大功能,可以干十个事,但是回到家一个都不用,有体验吗?用户不用的东西,没有体验。
虽然靠强大的广告,忽悠卖点的做法,在一些行业还是会存在,这个时代会逐渐过去,有了互联网用户不再是被动的弱者,可以获得更多体验的交流。一定要让用户能够感受到的东西才叫卖点。当你在家里策划卖点的时候,它是真的吗,它是事实吗,它是不是用户能够感知到的东西,后来那家运营商又找到一个卖点,可以防窃听,安全保密,各位你们的电话被别人窃听了吗?大家会讲,我是什么人,别人怎么会窃听我的电话,就算窃听了,无所谓,我的电话没有什么反党反社会的内容,你觉得窃听是用户被感知的点吗?就算你的电话被窃听,你也不知道,他们也不能被证明用了这个不能被窃听了,所以这个卖点依然失败了。
我们也有过失败的教训,曾经有用户,我估计陈冠希逆名提要求,我们需要一个密盘,我放在密盘的那些图片都需要加密,我们就做了一个功能叫 360 密盘,最后就找到了几万用户,这几万用户确实很忠实,我猜他们的密盘上一定有很多爱情动作片,一定有很多类似李宗瑞,他们确实有这种需求,但是对绝大多数用户来说,这是一个伪需求,用户用完了没有感知的需求。要做用户可以感受,而且可以强烈感知和认同的需求。
最后再补充两点,用户体验,我也没有特别系统的总结,说起来有很多点,最后再总结三点。
一是体验都在细节,做体验要关注细节。
这个例子不再多讲,乔布斯的传记有一个例子,这个例子已经到达了变态的程度,乔布斯有一天给谷歌高管打电话,在苹果 ios 有一个谷歌地图图标,放大多少倍之后,第三行一个像素颜色不对,他认为这影响了 ios 的美观,这是对细节的一种坚持。这个例子当然极端,但是很多用户体验往往会毁在细节上,也往往成在细节上,为什么这么讲?当你跟同行竞争的时候,大的功能方面大家不会差的太多,其实用户感知的东西,往往是细节,这时候就需要你们发挥设计师的敏感心去感受这种细节的内容。海底捞提供的涮牛肉都是日本神户的A级牛肉吗?好像不是,磕瓜子、擦皮鞋、带小孩是不是细节。
比如两个负面细节例子,如果坐中国航空公司的航班,我不知道他们为什么,很多航空公司都说亏损,大谈长远策略,没有人关注座椅的距离,很多公司的经济舱,稍微胖一点塞在里面很痛苦,这种细节没人管,最后不得不坐头等舱,伙食跟三十块钱一份盒饭是一个水平,多加三十块钱可以让你吃的很好,在飞机上本来没有期望,如果吃的很好,就超出预期,对这家航空公司有好的期望或者有好的体验,但是给你的食品让你觉得很糟。有很多人来北京参加这个会,可能住在一些酒店,有些酒店真的很贵,倒是经济型酒店提供免费上网,很多酒店四五千一晚上,消费者的心里很奇怪,他觉得你是大客户,都不在乎花五千住一个套间,为什么吝啬两百块钱上一个晚上网呢,可是我每次住在酒店里,我一发现上网不免费,要给一百块钱,就特心疼,我也不知道我的心疼哪来的,你们想是不是这个道理。请朋友吃饭,十个人一桌,可能吃一千,对不起一包餐饮纸两块钱,就会感受非常不好,这就是很奇怪,不是用逻辑来做解释,是一种消费的心理,也是用户的心理。很多企业不关注这种细节,最后就失去了用户。最可恶的是住酒店的时候,我后来自带无线的 WIFI,如果留心观察,很多时候细节在别人注意不到的地方,你如果能够找到与众不同的力量,你就能够创造出来我前面说的一种超出预期,如果在产品的大面方面,别人都做了很多年,基本做到了无懈可击,你的体验恐怕就很难。
我前面讲过体验就是力量,实际上也是讲细节,比如 360 做杀毒,我认为我们技术超越同行,但是你们各位可能也不一定相信,为什么?因为你不是行业专家,你判断不了哪一个杀毒引擎更好,我如果讲杀毒引擎的技术你也听不明白,但是我们成功的颠覆了整个杀毒的行业,靠的是用户体验,这个用户体验广义来说不仅仅是我刚才说的体检、开机加速、一键优化,最重要的体验是什么?给用户超出预期的体验是免费,商业模式颠覆不错,但是马后炮,对用户来说不管什么商业模式,你怎么赚钱我不管,我知道我过去花一两百买一套杀毒,周鸿祎给我免费了,不仅免费,还是终身免费,永远免费,当时杀毒厂商说我们降价一半,我们变得更便宜,这个不叫超出预期,只是说在不断的改善,只有彻底免费才叫超出预期。
当年 3Q 大战的时候,也是一场由体验引发的血案,我们做的一个产品 QQ 保镖,不是让 QQ 的体验更差,是让 QQ 体验更好,比如弹广告,会影响其他公司的广告收入,但是用户体验很好,所以受到用户的追捧。最近做搜索,坦率的说,如果我说我们的技术是第四代技术,我真的不好意思,因为这是撒谎,搜索技术十年来,从谷歌到百度,大家的技术没有本质性的变化,而且全世界搜索技术最好的公司显然是谷歌,不是中国这几家公司,他们也不是靠技术打败谷歌的,你们也都明白。
但是我为什么看到了体验改变的机会,是因为今天的搜索引擎越来越像广告引擎,广告和搜索混在一起,你们可能分的清,你们的父母绝对分不清,竞价排名这种模式,谁有钱谁排在最前面,很多欺诈网站就排在最前面。医疗行业绝对是重灾区,你们各位看过病吗?你们到医院觉得很舒服吗?在北京协和、同仁永远人满为患,永远看不上病,排队加塞才能弄个专家号,说明医疗资源在中国是匮乏的,协和、同仁好的医院需要花五百块钱一个点击,需要到互联网上买用户吗?不需要。花几百块钱一个点击,需要到他医院里看白癜风、不孕不育,我不能说这种医院都是假医院吧,但是是什么货色,大家也知道。所以这种体验,已经变成了,一方面搜索引擎帮助大家找到知识,找到很多信息的同时,一方面也出来了,搜索一下你就上当,这就是用户体验的问题。即便技术差不多,谁能够在这个细节体验上下决心做的不一样,就不放医疗行业的广告,敢于向谷歌学习,打广告和搜索明显分开,每页就放三条广告,绝不多放,这种体验的改进也可能成为改变一个行业的力量。每次做这种重大体验改变的时候,大家要有点没心没肺,因为你的对手可能雇大量的水军,我是中国骂的最多的人,我估计中国很多水军公司靠骂我一年能赚好几千万。
二是体验一定要聚焦,伤其十指,不如断其一指
昨天在我的公司内部一个创新大赛里面,有一组产品用户体验部门提的方案,我点评说做了四个功能,我说有一个功能能够打动用户已经很不简单了,把这个功能想办法做到极致,不是说一个功能觉得不够,再做五六个功能,手机没有五个图标都觉得不好意思拿出去,用户选择你的产品,经常为一个理由特别简单,一个理由足够去选择,我们做产品体验的时候,很多时候应该面面俱到,应该全方位系统性思考,不错,应该考虑面面俱到,全方位思考,但思考完了,如何在众多的功能中找到一个点作为突破点,再大的一个市场也需要一个针尖一样点的做切入,所有成功的产品都要找到一个点,通过聚焦,把有限的资源聚焦到一个点上,才能形成压强,而有的时候你觉得找了几个点,当跟用户说有五大功能,有六个体系的时候,你觉得你能够记住,你作为老板也可以要求公司员工学习记住,大家都变成顺口溜,但是对于用户来说真的记得住吗?
有一次看智能电视的广告,有六大功能,我晃了一眼,我作为普通消费者,肯定回忆不出来六大功能,把一个功能做到极致,大家推荐你的产品说,在这个电视上免费电影随便看,用起来比优酷还简单,可能还是一个卖点。电视遥控器极端的反映了用户体验的时候,巴不得把很多功能推给用户,用户常用的功能就是调台键、音量键、开关键。怎么样在用户用常用的功能做出极致,我说的这个聚焦,集中一点,和前面说的做到极致、超出预期、关注细节高度一致,每个人都不是天才,更不是通才,如果不能聚焦一点,面面俱到,平均用力同时做三个产品,每个产品同时铺开做五个功能,怎么验证产品聚焦,特别简单,看用户发帖,看用户骂你,或者倾听用户的声音,用户用他们一种最朴素的语言,总结你产品能够被他们打动的一个点。
当年百度超越谷歌的时候,百度在刚起步的时候,真的搜索技术比谷歌做得好?不是,是因为 MP3 搜索,会听到很多民工级用户在交流的时候,不会说我去用一个搜索引擎,会说有一个网站上面可以免费听歌,可以免费下歌,如果能听到用户这样的声音,就恭喜你,说明你找到了一个值得聚焦的一个点,因为这是用户关心的。
关于产品的体验,体验为王的时代,谁能够掌握好体验的力量,从小处可以改善一个产品,可以做出一个受欢迎的产品,从大处讲,甚至能颠覆一个产业,可以改变一个格局,产品的创新,总是把创新理解成做一个研究院,雇很多专家博士,发明一个类似可口可乐的新秘方,或者申请多少专利,我觉得是不现实的,所谓的创新就是从用户出发,从用户体验的细节出发,从很多细微之处出发,能够对用户体验做出持续的改进。
我这个演讲的标题,我临时改主意了,已经很多人讲过这个道理,所有的企业都归结于一句话大道至简,对所有理念归结为给用户一个特别简单的使用,简单就是力量,今天没有从大道至简的角度反复强调,还是从用户的角度讲了如何做好产品经理,用户体验的改进应该做哪几点。谢谢大家!
百度人搜,阿里巴巴,腾讯,华为,小米,搜狗,笔试面试
9月11日, 京东:
谈谈你对面向对象编程的认识
8月20日,金山面试,题目如下:
数据库1中存放着a类数据,数据库2中存放着以天为单位划分的表30张(比如table_20110909,table_20110910,table_20110911),总共是一个月的数据。表1中的a类数据中有一个字段userid来唯一判别用户身份,表2中的30张表(每张表结构相同)也有一个字段userid来唯一识别用户身份。如何判定a类数据库的多少用户在数据库2中出现过?
来源:http://topic.csdn.net/u/20120820/23/C6B16CCF-EE15-47C0-9B15-77497291F2B9.html。
百度实习笔试题(2012.5.6)
1、一个单词单词字母交换,可得另一个单词,如army->mary,成为兄弟单词。提供一个单词,在字典中找到它的兄弟。描述数据结构和查询过程。评点:同去年9月份的一道题,见此文第3题:http://blog.csdn.net/v_july_v/article/details/6803368。
2、线程和进程区别和联系。什么是“线程安全”
3、C和C++怎样分配和释放内存,区别是什么
4、算法题1
一个url指向的页面里面有另一个url,最终有一个url指向之前出现过的url或空,这两种情形都定义为null。这样构成一个单链表。给两条这样单链表,判断里面是否存在同样的url。url以亿级计,资源不足以hash。
5、算法题2
数组al[0,mid-1] 和 al[mid,num-1],都分别有序。将其merge成有序数组al[0,num-1],要求空间复杂度O(1)
6、系统设计题
百度搜索框的suggestion,比如输入“北京”,搜索框下面会以北京为前缀,展示“北京爱情故事”、“北京公交”、“北京医院”等等搜索词,输入“结构之”,会提示“结构之法”,“结构之法 算法之道”等搜索词。
请问,如何设计此系统,使得空间和时间复杂度尽量低。

评点:老题,直接上Trie树「Trie树的介绍见:从Trie树(字典树)谈到后缀树」+TOP K「hashmap+堆,hashmap+堆 统计出如10个近似的热词,也就是说,只存与关键词近似的比如10个热词」? or Double-array trie tree?同时,StackOverflow上也有两个讨论帖子:http://stackoverflow.com/questions/2901831/algorithm-for-autocomplete,http://stackoverflow.com/questions/1783652/what-is-the-best-autocomplete-suggest-algorithm-datastructure-c-c。此外,这里有一篇关于“拼写错误检查”问题的介绍,或许对你有所启示:http://blog.afterthedeadline.com/2010/01/29/how-i-trie-to-make-spelling-suggestions/。
人搜笔试1. 快排每次以第一个作为主元,问时间复杂度是多少?(O(N*logN))
2. T(N) = N + T(N/2)+T(2N), 问T(N)的时间复杂度是多少? 点评:O(N*logN) or O(N)?
3. 从(0,1)中平均随机出几次才能使得和超过1?(e)
4.编程题:
一棵树的节点定义格式如下:
struct Node{
Node* parent;
Node* firstChild; // 孩子节点
Node* sibling; // 兄弟节点
}
要求非递归遍历该树。
思路:采用队列存储,来遍历节点。
5. 算法题:
有N个节点,每两个节点相邻,每个节点只与2个节点相邻,因此,N个顶点有N-1条边。每一条边上都有权值wi,定义节点i到节点i+1的边为wi。
求:不相邻的权值和最大的边的集合。
人搜面试,所投职位:搜索研发工程师:面试题回忆
1、删除字符串开始及末尾的空白符,并且把数组中间的多个空格(如果有)符转化为1个。
2、求数组(元素可为正数、负数、0)的最大子序列和。
3、链表相邻元素翻转,如a->b->c->d->e->f-g,翻转后变为:b->a->d->c->f->e->g
4、链表克隆。链表的结构为:
typedef struct list {
int data; //数据字段
list *middle; //指向链表中某任意位置元素(可指向自己)的指针
list *next;//指向链表下一元素
} list;
5、100万条数据的数据库查询速度优化问题,解决关键点是:根据主表元素特点,把主表拆分并新建副表,并且利用存储过程保证主副表的数据一致性。(不用写代码)
6、求正整数n所有可能的和式的组合(如;4=1+1+1+1、1+1+2、1+3、2+1+1、2+2)。点评:这里有一参考答案:http://blog.csdn.net/wumuzi520/article/details/8046350。
7、求旋转数组的最小元素(把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个排好序的数组的一个旋转,输出旋转数组的最小元素。例如数组{3, 4, 5, 1, 2}为{1, 2, 3, 4, 5}的一个旋转,该数组的最小值为1)
8、找出两个单链表里交叉的第一个元素
9、字符串移动(字符串为*号和26个字母的任意组合,把*号都移动到最左侧,把字母移到最右侧并保持相对顺序不变),要求时间和空间复杂度最小
10、时间复杂度为O(1),怎么找出一个栈里的最大元素
11、线程、进程区别
12、static在C和C++里各代表什么含义
13、const在C/C++里什么意思
14、常用linux命令
15、解释Select/Poll模型
网易有道二面:
判断一个数字序列是BST后序遍历的结果,现场写代码。
来源:http://blog.csdn.net/hopeztm/article/category/1201028;
8月30日,网易有道面试题
var tt = 'aa';
function test()
{
alert(tt);
var tt = 'dd';
alert(tt);
}
test();
8月31日,百度面试题:不使用随机数的洗牌算法,详情:http://topic.csdn.net/u/20120831/10/C837A419-DFD4-4326-897C-669909BD2086.html;
9月6日,阿里笔试题:平面上有很多点,点与点之间有可能有连线,求这个图里环的数目。
9月7日,一道华为上机题:
题目描述: 选秀节目打分,分为专家评委和大众评委,score[] 数组里面存储每个评委打的分数,judge_type[] 里存储与 score[] 数组对应的评委类别,judge_type == 1,表示专家评委,judge_type == 2,表示大众评委,n表示评委总数。打分规则如下:专家评委和大众评委的分数先分别取一个平均分(平均分取整),然后,总分 = 专家评委平均分 * 0.6 + 大众评委 * 0.4,总分取整。如果没有大众评委,则 总分 = 专家评委平均分,总分取整。函数最终返回选手得分。
函数接口 int cal_score(int score[], int judge_type[], int n)
上机题目需要将函数验证,但是题目中默认专家评委的个数不能为零,但是如何将这种专家数目为0的情形排除出去。
来源:http://topic.csdn.net/u/20120907/15/c30eead8-9e49-41c2-bd11-c277030ad17a.html;
9月8日,腾讯面试题:
假设两个字符串中所含有的字符和个数都相同我们就叫这两个字符串匹配,
比如:abcda和adabc,由于出现的字符个数都是相同,只是顺序不同,
所以这两个字符串是匹配的。要求高效!
又是跟上述第3题中简单题一的兄弟节点类似的一道题,我想,你们能想到的,这篇blog里:http://blog.csdn.net/v_JULY_v/article/details/6347454都已经有了。
阿里云,搜索引擎中5亿个url怎么高效存储;
一道C++笔试题,求矩形交集的面积:
在一个平面坐标系上,有两个矩形,它们的边分别平行于X和Y轴。
其中,矩形A已知, ax1(左边), ax2(右边), ay1(top的纵坐标), ay2(bottom纵坐标). 矩形B,类似,就是 bx1, bx2, by1, by2。这些值都是整数就OK了。
要求是,如果矩形没有交集,返回-1, 有交集,返回交集的面积。
int area(rect const& a, rect const& b)
{
...
}
点评:
healer_kx:
补齐代码,最好是简洁的,别用库。你可以写你的辅助函数,宏定义,代码风格也很重要。
ri_aje:
- struct rect
- {
- // axis alignment assumed
- // bottom left is (x[0],y[0]), top right is (x[1],y[1])
- double x [2];
- double y [2];
- };
- template <typename T> T const& min (T const& x, T const& y) { return x<y ? x : y; }
- template <typename T> T const& max (T const& x, T const& y) { return x>y ? x : y; }
- // return type changed to handle non-integer rects
- double area (rect const& a, rect const& b)
- {
- // perfectly adjacent rects are considered having an intersection of 0 area
- double const dx = min(a.x[1],b.x[1]) - max(a.x[0],b.x[0]);
- double const dy = min(a.y[1],b.y[1]) - max(a.y[0],b.y[0]);
- return dx>=0&&dy>=0 ? dx*dy : -1;
- }
下面是一个简短的证明。
对于平行于坐标轴的矩形 r,假设其左下角点坐标为 (rx0,ry0),右上角点坐标为 (rx1,ry1),那么由 r 定义的无限有界点集为:{(x,y)|x in [rx0,rx1] && y in [ry0,ry1]}。
根据交集的定义,则任意二维点 (x,y) 在矩形 a,b 的交集内等价于
{(x,y)|(x,y) in a 并且 (x,y) in b} <==>
{(x,y)|x in [ax0,ax1] && x in [bx0,bx1] 并且 y in [ay0,ay1] && y in [by0,by1]} <==>
{(x,y)|x in [max(ax0,bx0),min(ax1,bx1)] 并且 y in [max(ay0,by0),min(ay1,by1)]}
因此,交集矩形的边长分别为 min(ax1,bx1)-max(ax0,bx0) 和 min(ay1,by1)-max(ay0,by0)。注意当交集为空时(a,b 不相交),则经此法计算出来的交集边长为负值,此事实可用于验证 a,b 的相交性。
鉴于笛卡尔积各个维度上的不相关性,此方法可扩展到任意有限维线性空间,比如,三维空间中平行于坐标轴的长方体的交集体积可以用类似的方法计算。
来源:http://topic.csdn.net/u/20120913/18/bc669d60-b70a-4008-be65-7c342789b925.html。
2012年创新工场校园招聘最后一道笔试题:工场很忙
创新工场每年会组织同学与项目的双选会,假设现在有M个项目,编号从1到M,另有N名同学,编号从1到N,每名同学能选择最多三个、最少一个感兴趣的项目。选定之后,HR会安排项目负责人和相应感兴趣的同学一对一面谈,每次面谈持续半小时。由于大家平时都很忙,所以咱们要尽量节约时间,请你按照以下的条件设计算法,帮助HR安排面试。
1)同学很忙。项目负责人一次只能与一名同学面谈,而同学会在自己第一个面试开始时达到工场,最后一个面试结束后离开工场,如果参加一个项目组的面试后不能立即参加下一个项目组的面试,就必须在工场等待。所以请尽可能让同学的面试集中在某一时间段,减少同学在工场等待的时间。
2)项目负责人很忙。众所周知,创业团队的负责人会有很多事情要做,所以他们希望能够将自己参与的面试集中在某一段时间内,请在保证1)的情况下,使得项目负责人等待的时间最少。
3)HR很忙。从第一轮面试开始以后,所有HR都必须等到最后一轮面试结束,所以需要在保证1)和2)的同时,也能尽快解放掉所有的HR,即让第一轮面试到最后一轮面试之间持续的时间最短。
输入(以文件方式输入,文件名为iw,例如iw.in):
第1行...第n行:同学的编号 项目的编号
样例(数据间用空格隔开,两个0表示输入结束):
1 1
1 2
1 3
2 1
3 1
3 2
0 0
表示M=3,N=3,编号为1的同学选择了项目1,2和3,编号为2的同学选择了项目1,编号为3的同学选了项目1和2
输出(以文件方式输出,文件名为iw,例如iw.out):
第1行:编号为1的项目依次面试新同学的编号序列
第2行:编号为2的项目依次面试新同学的编号序列
...
第n行:编号为n的项目依次面试新同学的编号序列
样例(数据间用空格隔开,0表示没有面试):
1 3 2
3 1 0
0 0 1
表示编号为1的项目在第一轮面试编号为1的同学,第二轮面试编号为3的同学,第三轮面试编号为2的同学
编号为2的项目在第一轮面试编号为3的同学,第二轮面试编号为1的同学,第二轮不用面试
编号为3的项目在第一轮和第二轮都不用面试,第三轮面试编号为1的同学
链接:http://t.qq.com/p/t/108332110988802;
4**9 的笔试题,比较简单:
1.求链表的倒数第二个节点
2.有一个整数数组,求数组中第二大的数
对于给定的整数集合S,求出最大的d,使得a+b+c=d。a,b,c,d互不相同,且都属于S。集合的元素个数小于等于2000个,元素的取值范围在[-2^28,2^28 - 1],假定可用内存空间为100MB,硬盘使用空间无限大,试分析时间和空间复杂度,找出最快的解决方法。
点评:
@绿色夹克衫:两两相加转为多项式乘法,比如(1 2 4 6) + (2 3 4 5) => (x + x^2 + x^4 + x^6)*(x^2 + x^3 + x^4 + x^5) 。更多思路请见这:http://www.51nod.com/answer/index.html#!answerId=569。
笔试题1,原题大致描述有一大批数据,百万级别的。数据项内容是:用户ID、科目ABC各自的成绩。其中用户ID为0~1000万之间,且是连续的,可以唯一标识一条记录。科目ABC成绩均在0~100之间。有两块磁盘,空间大小均为512M,内存空间64M。
1) 为实现快速查询某用户ID对应的各科成绩,问磁盘文件及内存该如何组织;
2) 改变题目条件,ID为0~10亿之间,且不连续。问磁盘文件及内存该如何组织;
3) 在问题2的基础上,增加一个需求。在查询各科成绩的同时,获取该用户的排名,问磁盘文件及内存该如何组织。
笔试题2:代码实现计算字符串的相似度。
点评:和计算两字符串的最长公共子序列相似。
设Ai为字符串A(a1a2a3 … am)的前i个字符(即为a1,a2,a3 … ai)
设Bj为字符串B(b1b2b3 … bn)的前j个字符(即为b1,b2,b3 … bj)
设 L(i , j)为使两个字符串和Ai和Bj相等的最小操作次数。
当ai等于bj时 显然L(i, j)=L(i-1, j-1)
当ai不等于bj时
若将它们修改为相等,则对两个字符串至少还要操作L(i-1, j-1)次
若删除ai或在Bj后添加ai,则对两个字符串至少还要操作L(i-1, j)次
若删除bj或在Ai后添加bj,则对两个字符串至少还要操作L(i, j-1)次
此时L(i, j)=min( L(i-1, j-1), L(i-1, j), L(i, j-1) ) + 1
显然,L(i, 0)=i,L(0, j)=j, 再利用上述的递推公式,可以直接计算出L(i, j)值。具体代码请见这:http://blog.csdn.net/flyinghearts/article/details/5605996。
9月14日,小米笔试,给一个浮点数序列,取最大乘积子序列的值,例如 -2.5,4,0,3,0.5,8,-1,则取出的最大乘积子序列为3,0.5,8。
点评:
解法一、
或许,读者初看此题,自然会想到最大乘积子序列问题类似于最大子数组和问题:http://blog.csdn.net/v_JULY_v/article/details/6444021,然实则具体处理起来诸多不同,为什么呢,因为乘积子序列中有正有负也还可能有0。
既如此,我们可以把问题简化成这样:数组中找一个子序列,使得它的乘积最大;同时找一个子序列,使得它的乘积最小(负数的情况)。因为虽然我们只要一个最大积,但由于负数的存在,我们同时找这两个乘积做起来反而方便。也就是说,不但记录最大乘积,也要记录最小乘积。So,
我们让maxCurrent表示当前最大乘积的candidate,
minCurrent反之,表示当前最小乘积的candidate。
(用candidate这个词是因为只是可能成为新一轮的最大/最小乘积),
而maxProduct则记录到目前为止所有最大乘积candidates的最大值。
由于空集的乘积定义为1,在搜索数组前,maxCurrent,minCurrent,maxProduct都赋为1。
假设在任何时刻你已经有了maxCurrent和minCurrent这两个最大/最小乘积的candidates,新读入数组的元素x(i)后,新的最大乘积candidate只可能是maxCurrent或者minCurrent与x(i)的乘积中的较大者,如果x(i)<0导致maxCurrent<minCurrent,需要交换这两个candidates的值。
当任何时候maxCurrent<1,由于1(空集)是比maxCurrent更好的candidate,所以更新maxCurrent为1,类似的可以更新minCurrent。任何时候maxCurrent如果比最好的maxProduct大,更新maxProduct。
具体代码如下:
- template <typename Comparable>
- Comparable maxprod( const vector<Comparable>&v)
- {
- int i;
- Comparable maxProduct = 1;
- Comparable minProduct = 1;
- Comparable maxCurrent = 1;
- Comparable minCurrent = 1;
- //Comparable t;
- for( i=0; i< v.size() ;i++)
- {
- maxCurrent *= v[i];
- minCurrent *= v[i];
- if(maxCurrent > maxProduct)
- maxProduct = maxCurrent;
- if(minCurrent > maxProduct)
- maxProduct = minCurrent;
- if(maxCurrent < minProduct)
- minProduct = maxCurrent;
- if(minCurrent < minProduct)
- minProduct = minCurrent;
- if(minCurrent > maxCurrent)
- swap(maxCurrent,minCurrent);
- if(maxCurrent<1)
- maxCurrent = 1;
- //if(minCurrent>1)
- // minCurrent =1;
- }
- return maxProduct;
- }
解法二、
本题除了上述类似最大子数组和的解法,也可以直接用动态规划求解(其实,上述的解法一本质上也是动态规划,只是解题所表现出来的具体形式与接下来的解法二不同罢了。这个不同就在于下面的解法二会写出动态规划问题中经典常见的状态转移方程,而解法一是直接求解)。具体解法如下:
假设数组为a[],直接利用动归来求解,考虑到可能存在负数的情况,我们用Max[i]来表示以a[i]结尾的最大连续子序列的乘积值,用Min[i]表示以a[i]结尾的最小的连续子序列的乘积值,那么状态转移方程为:
Max[i]=max{a[i], Max[i-1]*a[i], Min[i-1]*a[i]};
Min[i]=min{a[i], Max[i-1]*a[i], Min[i-1]*a[i]};
初始状态为Max[1]=Min[1]=a[1]。代码如下:
- /*
- 给定一个整数数组,有正有负数,0,正数组成,数组下标从1算起
- 求最大连续子序列乘积,并输出这个序列,如果最大子序列乘积为负数,那么就输出-1
- 用Max[i]表示以a[i]结尾乘积最大的连续子序列
- 用Min[i]表示以a[i]结尾乘积最小的连续子序列 因为有复数,所以保存这个是必须的
- */
- void longest_multiple(int *a,int n){
- int *Min=new int[n+1]();
- int *Max=new int[n+1]();
- int *p=new int[n+1]();
- //初始化
- for(int i=0;i<=n;i++){
- p[i]=-1;
- }
- Min[1]=a[1];
- Max[1]=a[1];
- int max_val=Max[1];
- for(int i=2;i<=n;i++){
- Max[i]=max(Max[i-1]*a[i],Min[i-1]*a[i],a[i]);
- Min[i]=min(Max[i-1]*a[i],Min[i-1]*a[i],a[i]);
- if(max_val<Max[i])
- max_val=Max[i];
- }
- if(max_val<0)
- printf("%d",-1);
- else
- printf("%d",max_val);
- //内存释放
- delete [] Max;
- delete [] Min;
- }
变种
此外,此题还有另外的一个变种形式,即给定一个长度为N的整数数组,只允许用乘法,不能用除法,计算任意(N-1)个数的组合中乘积最大的一组,并写出算法的时间复杂度。
我们可以把所有可能的(N-1)个数的组合找出来,分别计算它们的乘积,并比较大小。由于总共有N个(N-1)个数的组合,总的时间复杂度为O(N2),显然这不是最好的解法。
OK,以下解答来自编程之美
解法1

解法2
此外,还可以通过分析,进一步减少解答问题的计算量。假设N个整数的乘积为P,针对P的正负性进行如下分析(其中,AN-1表示N-1个数的组合,PN-1表示N-1个数的组合的乘积)。
1.P为0
那么,数组中至少包含有一个0。假设除去一个0之外,其他N-1个数的乘积为Q,根据Q的正负性进行讨论:
Q为0
说明数组中至少有两个0,那么N-1个数的乘积只能为0,返回0;
Q为正数
返回Q,因为如果以0替换此时AN-1中的任一个数,所得到的PN-1为0,必然小于Q;
Q为负数
如果以0替换此时AN-1中的任一个数,所得到的PN-1为0,大于Q,乘积最大值为0。
2. P为负数
根据“负负得正”的乘法性质,自然想到从N个整数中去掉一个负数,使得PN-1为一个正数。而要使这个正数最大,这个被去掉的负数的绝对值必须是数组中最小的。我们只需要扫描一遍数组,把绝对值最小的负数给去掉就可以了。
3. P为正数
类似地,如果数组中存在正数值,那么应该去掉最小的正数值,否则去掉绝对值最大的负数值。
上面的解法采用了直接求N个整数的乘积P,进而判断P的正负性的办法,但是直接求乘积在编译环境下往往会有溢出的危险(这也就是本题要求不使用除法的潜在用意),事实上可做一个小的转变,不需要直接求乘积,而是求出数组中正数(+)、负数(-)和0的个数,从而判断P的正负性,其余部分与以上面的解法相同。
在时间复杂度方面,由于只需要遍历数组一次,在遍历数组的同时就可得到数组中正数(+)、负数(-)和0的个数,以及数组中绝对值最小的正数和负数,时间复杂度为O(N)。
9月15日,中兴面试:
小端系统
- union{
- int i;
- unsigned char ch[2];
- }Student;
- int main()
- {
- Student student;
- student.i=0x1420;
- printf("%d %d",student.ch[0],student.ch[1]);
- return 0;
- }
输出结果为?(答案:32 20)
一道有趣的Facebook面试题:
给一个二叉树,每个节点都是正或负整数,如何找到一个子树,它所有节点的和最大?
点评:
@某猛将兄:后序遍历,每一个节点保存左右子树的和加上自己的值。额外一个空间存放最大值。
@陈利人:同学们,如果你面试的是软件工程师的职位,一般面试官会要求你在短时间内写出一个比较整洁的,最好是高效的,没有什么bug的程序。所以,光有算法不够,还得多实践。
写完后序遍历,面试官可能接着与你讨论,a). 如果要求找出只含正数的最大子树,程序该如何修改来实现?b). 假设我们将子树定义为它和它的部分后代,那该如何解决?c). 对于b,加上正数的限制,方案又该如何?总之,一道看似简单的面试题,可能能变换成各种花样。
比如,面试管可能还会再提两个要求:第一,不能用全局变量;第一,有个参数控制是否要只含正数的子树。其它的,随意,当然,编程风格也很重要。
谷歌面试题:
有几百亿的整数,分布的存储到几百台通过网络连接的计算机上,你能否开发出一个算法和系统,找出这几百亿数据的中值?就是在一组排序好的数据中居于中间的数。显然,一台机器是装不下所有的数据。也尽量少用网络带宽。
小米,南京站笔试(原第20题):
一个数组里,数都是两两出现的,但是有三个数是唯一出现的,找出这三个数。
点评:
3个数唯一出现,各不相同。由于x与a、b、c都各不相同,因此x^a、x^b、x^c都不等于0。具体答案请参看这两篇文章:1、http://blog.csdn.net/w397090770/article/details/8032898,2、http://zhedahht.blog.163.com/blog/static/25411174201283084246412/。
9月19日,IGT面试:你走到一个分叉路口,有两条路,每个路口有一个人,一个说假话,一个说真话,你只能问其中一个人仅一个问题,如何问才能得到正确答案?点评:答案是,问其中一个人:另一个人会说你的路口是通往正确的道路么?
9月19日,创新工厂笔试题:
给定一整型数组,若数组中某个下标值大的元素值小于某个下标值比它小的元素值,称这是一个反序。
即:数组a[]; 对于i < j 且 a[i] > a[j],则称这是一个反序。
给定一个数组,要求写一个函数,计算出这个数组里所有反序的个数。
点评:
归并排序,至于有的人说是否有O(N)的时间复杂度,我认为答案是否定的,正如老梦所说,下限就是nlgn,n个元素的数组的排列共有的排列是nlgn,n!(算法导论里面也用递归树证明了:O(n*logn)是最优的解法,具体可以看下这个链接:)。然后,我再给一个链接,这里有那天笔试的两道题目:http://blog.csdn.net/luno1/article/details/8001892。
9月20日,创新工厂南京站笔试:
已知字符串里的字符是互不相同的,现在任意组合,比如ab,则输出aa,ab,ba,bb,编程按照字典序输出所有的组合。
点评:非简单的全排列问题(跟全排列的形式不同,abc 全排列的话,只有6个不同的输出:http://blog.csdn.net/v_july_v/article/details/6879101)。本题可用递归的思想,设置一个变量表示已输出的个数,然后当个数达到字符串长度时,就输出。
- //假设str已经有序,from 一直很安静
- void perm(char *str, int size, int resPos)
- {
- if(resPos == size)
- print(result);
- else
- {
- for(int i = 0; i < size; ++i)
- {
- result[resPos] = str[i];
- perm(str, size, resPos + 1);
- }
- }
- }
9月21日,小米,电子科大&西安交通大学笔试题:
- void fun()
- {
- unsigned int a = 2013;
- int b = -2;
- int c = 0;
- while (a + b > 0)
- {
- a = a + b;
- c++;
- }
- printf("%d", c);
- }
问:最后程序输出是多少?点评:此题有陷阱,答题需谨慎!


点评:
针对上述第3题朋友圈的问题,读者@互联网的飞虫提供的解法及代码如下(有任何问题,欢迎指正,多谢):
- #include <STDIO.H>
- #include <WINDOWS.H>
- int Friends(int n, int m , int* r[]);
- int main(int argc,char** argv)
- {
- int r[5][2] = {{1,2},{4,3},{6,5},{7,8},{7,9}};
- printf("有%d个朋友圈。n",Friends(0,5,(int**)r));
- return 0;
- }
- int Friends(int n, int m, int* r[]) // 注意这里的参数很奇葩
- {
- int *p = (int*)malloc(sizeof(int)*m*3);
- memset(p,0,sizeof(int)*m*3);
- int i = 0;
- int iCount = 0;
- int j = 0;
- int * q = (int*)r; // 这里很巧妙 将二维指针 强转为一维指针
- for (i=0;i<m;++i)
- {
- for (j=0;j<2;++j)
- {
- p[i*3+j]=q[i*2+j]; // 注意这里二维数组向一维数组的转换
- }
- p[i*3+j] = 0;
- }
- bool bFlag = false;
- for (i=0;i<m;++i)
- {
- bFlag = false;
- if (p[i*3+2]==1)
- {
- bFlag = true;
- }
- p[i*3+2] = 1;
- for (j=0;j<m;++j)
- {
- if (i==j)
- {
- continue;
- }
- if (p[i*3]==p[j*3] ||
- p[i*3] == p[j*3+1] ||
- p[i*3+1] == p[j*3+0] ||
- p[i*3+1] == p[j*3+1])
- {
- if (p[j*3+2]==1)
- {
- bFlag = true;
- }
- p[j*3+2] = 1;
- }
- }
- if (!bFlag)
- {
- ++iCount;
- }
- }
- free(p);
- return iCount;
- }
9月21日晚,海豚浏览器笔试题:
1、有两个序列A和B,A=(a1,a2,...,ak),B=(b1,b2,...,bk),A和B都按升序排列,对于1<=i,j<=k,求k个最小的(ai+bj),要求算法尽量高效。
2、输入:
L:“shit”“fuck”“you”
S:“shitmeshitfuckyou”
输出:S中包含的L一个单词,要求这个单词只出现一次,如果有多个出现一次的,输出第一个这样的单词
怎么做?
9月22日上午,百度西安站全套笔试题如下:
点评:上述的系统设计题简单来讲,是建立起按键号码数字到人名(手机号)的映射关系,具体讲,步骤解法如下图所示:

3.算法与程序设计
第一题:
某个公司举行一场羽毛球赛,有1001个人参加,现在为了评比出“最厉害的那个人”,进行淘汰赛,请问至少需要进行多少次比赛。
第二题
有100个灯泡,第一轮把所有灯泡都开启,第二轮把奇数位的灯泡灭掉,第三轮每隔两个灯泡,灭一个,开一个,依此类推。求100轮后还亮的灯泡。
点评:完全平方数,本人去58面试时,也遇到过与此类似的题。
第三题
有20个数组,每个数组里面有500个数组,降序排列,每个数字是32位的unit,求出这10000个数字中最大的500个。
点评:http://www.51nod.com/question/index.html#!questionId=647。
4.系统设计题
类似做一个手机键盘,上面有1到9个数字,每个数字都代表几个字母(比如1代表abc三个字母,z代表wxyz等等),现在要求设计当输入某几个数字的组合时,查找出通讯录中的人名及电话号码。
其它的还有三道简答题,比如线程的死锁,内存的管理等等。最后,附一讨论帖子:http://topic.csdn.net/u/20120923/18/7fd148b2-c000-4326-93a6-cb3bb8675702.html。
9月22日,微软笔试:
T(n)=1(n<=1),T(n) = 25*T(n/5) + n^2,求算法的时间复杂度。更多题目请参见:http://blog.csdn.net/wonderwander6642/article/details/8008209。
9月23日,腾讯校招部分笔试题(特别提醒:下述试卷上的答案只是一考生的解答,非代表正确答案.如下面第11题答案选D,第12题答案选C,至于解释可看这里:http://coolshell.cn/articles/7965.html):


点评:根号九说,不过最后两道大的附加题,全是秒杀99%海量数据处理面试题里的:http://blog.csdn.net/v_july_v/article/details/7382693,太感谢July了。
9月23日,搜狗校招武汉站笔试题:
一、已知计算机有以下原子操作
1、 赋值操作:b = a;
2、 ++a和a+1;
3、for( ){ ***}有限循环;
4、操作数只能为0或者正整数;
5、定义函数
实现加减乘操作
二、对一个链表进行排序,效率越高越好,LinkedList<Integer>.

附:9月15日,搜弧校招笔试题:http://blog.csdn.net/hackbuteer1/article/details/8015964。
搜狗校招笔试题:
100个任务,100个工人每人可做一项任务,每个任务每个人做的的费用为t[100][100],求一个分配任务的方案使得总费用最少。
点评:匈牙利算法,可以看看这篇文章:http://www.byvoid.com/blog/hungary/,及这个链接:http://www.51nod.com/question/index.html#!questionId=641。
9月24日,Google南京等站全套笔试题如下:





点评:
谷歌的笔试从易到难,基础到复杂,涵盖操作系统 网络 数据结构 语言 数学思维 编程能力 算法能力,基本上能把一个人的能力全面考察出来。
至于上述2.1寻找3个数的中位数,请看读者sos-phoenix给出的思路及代码:
- 2.1 // 采用两两比较的思路(目前没想到更好的)
- if (a <= b) {
- if (b <= c)
- return b;
- else {
- if (a <=c)
- return c;
- else
- return a;
- }
- }
- else {
- if (a <= c)
- return a;
- else {
- if (b <= c)
- return c;
- else
- return b;
- }
- }
最坏情况下的比较次数:3 (次)
平均情况下的比较次数:(2×2 + 4*3)/6 = 8/3 (次)
此外这题,微博上的左耳朵耗子后来也给出了一个链接:http://stackoverflow.com/questions/1582356/fastest-way-of-finding-the-middle-value-of-a-triple,最后是微博上的梁斌penny的解答:http://weibo.com/1497035431/yFusm7obQ。其余更多参考答案请看本文评论下第93楼。
读者来信,提供的几个hulu面试题:
9月19号,hulu电面:
问题1 两个骰子,两个人轮流投,直到点数和大于6就停止,最终投的那个人获胜。问先投那个人获胜概率?
问题2 平面上n个圆,任意两个都相交,是否有一条直线和所有的圆都有交点。
9月22号,上午hulu面试
问题1 100个人,每人头上戴一顶帽子,写有0..99的一个数,数可能重复,每个人都只能看到除自己以外其他人的帽子。每个人需要说出自己的帽子的数,一个人说对就算赢。点评:参考答案请看这个链接:http://www.51nod.com/question/index.html#!questionId=642。
问题2 n台机器,每台有负载,以和负载成正比的概率,随机选择一台机器。「原题是希望设计O(1)的算法(预处理O(n)不可少,要算出每台机器的比例),因为非O(1)的话,就trivial了:可以产生随机数例如[0,1)然后,根据负载比例,2分或者直接循环检查落入哪个区间,决定机器。 面试官想问,有没更好的办法,避免那种查找。即能否多次(常数次)调用随机函数,拟合出一个概率分布」
问题3 行列都递增的矩阵,求中位数。点评:http://www.51nod.com/question/index.html#!questionId=643,http://blog.csdn.net/v_july_v/article/details/7085669(杨氏矩阵查找问题)。
西安百度软件研发工程师:
一面(2012.9.24):
问的比较广,涉及操作系统、网络、数据结构。比较难的就2道题。
(1)10亿个int型整数,如何找出重复出现的数字;
(2)有2G的一个文本文档,文件每行存储的是一个句子,每个单词是用空格隔开的。问:输入一个句子,如何找到和它最相似的前10个句子。(提示:可用倒排文档)。
二面(2012.9.25):
(1)一个处理器最多能处理m个任务。现在有n个任务需要完成,每个任务都有自己完成所需的时间。此外每个任务之间有依赖性,比如任务A开始执行的前提是任务B必须完成。设计一个调度算法,使得这n这任务的完成时间最小;
(2)有一个排序二叉树,数据类型是int型,如何找出中间大的元素;
(3)一个N个元素的整形数组,如何找出前K个最大的元素。
(4)给定一个凸四边形,如何判断一个点在这个平面上。
点评:本题的讨论及参考答案请见这:http://www.51nod.com/question/index.html#!questionId=669。
运维部(2012.9.27):
(1)堆和栈的区别;
(2)问如何数出自己头上的头发。
9月25日,人人网笔试题:

点评:参考答案请见,http://www.51nod.com/question/index.html#!questionId=671。
9月25日晚,创新工场校园招聘北邮站笔试:




9月25日,小米大连站笔试题:
1一共有100万,抽中的2万,每月增加4万,问20个月能抽中的概率为:?
2 for(int i=0;i<strlen(s);i++){n+=I;}时间复杂度O(n)
3 手机wifi(A)….wifi ap….局域网(B)…..路由器…ADSL(C)…..互联网…..服务器
断掉上述ABC哪些点TCP链接会立刻断掉?
4 12345入栈,出栈结果 21543 31245 43215 12534 可能的为?(第一个和第三个)
5 x^n+a1x^n-1+…+an-1x+an,最少要做—乘法?题目中a1,a2,an为常数。
9月26日,百度一二面:
1、给定一数组,输出满足2a=b(a,b代表数组中的数)的数对,要求时间复杂度尽量低。
2、搜索引擎多线程中每个线程占用多少内存?如果搜索引擎存储网页内存占用太大怎么解决?
3、有很多url,例如*.baidu.com,*.sina.com ......
现在给你一个sports.sina.com 快速匹配出是*.sina.com。点评:老题,此前blog内曾整理过。
4、找出字符串的编辑距离,即把一个字符串s1最少经过多少步操作变成编程字符串s2,操作有三种,添加一个字符,删除一个字符,修改一个字符(只要听过编辑距离,知道往动态规划上想,很快就可以找到解法)。

点评:请看链接:http://blog.csdn.net/Lost_Painting/article/details/6457334。
5、编程实现memcopy,注意考虑目标内存空间和源空间重叠的时候。
6、实现简单的一个查找二叉树的深度的函数。
9月26日晚,优酷土豆笔试题一道:
优酷是一家视频网站,每天有上亿的视频被观看,现在公司要请研发人员找出最热门的视频。
该问题的输入可以简化为一个字符串文件,每一行都表示一个视频id,然后要找出出现次数最多的前100个视频id,将其输出,同时输出该视频的出现次数。
1.假设每天的视频播放次数为3亿次,被观看的视频数量为一百万个,每个视频ID的长度为20字节,限定使用的内存为1G。请简述做法,再写代码。
2.假设每个月的视频播放次数为100亿次,被观看的视频数量为1亿,每个视频ID的长度为20字节,一台机器被限定使用的内存为1G。
点评:有关海量数据处理的题目,请到此文中找方法(无论题目形式怎么变,基本方法不变,当然,最最常用的方法是:分而治之/Hash映射 + Hash统计 + 堆/快速/归并排序):http://blog.csdn.net/v_july_v/article/details/7382693。注:上题第二问文件太大,则可如模1000,把整个大文件映射为1000个小文件再处理 ....
9月26日,baidu面试题:
1.进程和线程的区别
2.一个有序数组(从小到大排列),数组中的数据有正有负,求这个数组中的最小绝对值
3.链表倒数第n个元素
4.有一个函数fun能返回0和1两个值,返回0和1的概率都是1/2,问怎么利用这个函数得到另一个函数fun2,使fun2也只能返回0和1,且返回0的概率为1/4,返回1的概率为3/4。(如果返回0的概率为0.3而返回1的概率为0.7呢)
5.有8个球,其中有7个球的质量相同,另一个与其他球的质量不同(且不知道是比其他球重还是轻),请问在最坏的情况下,最少需要多少次就能找出这个不同质量的球
6.数据库索引
7.有一个数组a,设有一个值n。在数组中找到两个元素a[i]和a[j],使得a[i]+a[j]等于n,求出所有满足以上条件的i和j。
8.1万个元素的数组,90%的元素都是1到100的数,10%的元素是101--10000的数,如何高效排序。
小米的web开发笔试题:
一场星际争霸比赛,共8个人,每个人的实力用分数表示,要分成两队,如何保证实力最平均?给定一个浮点数的序列,F1,F2,……,Fn(1<=n<=1000),定义P(s,e)为子序列Fi(s<=i<=e)的积,求P的最大值。
9月27日,趋势科技面试题:
马路口,30分钟内看到汽车的概率是95%,那么在10分钟内看不到汽车的概率是?
9月27日晚,IGT笔试题:
给定一个字符串里面只有"R" "G" "B" 三个字符,请排序,最终结果的顺序是R在前 G中 B在后。
要求:空间复杂度是O(1),且只能遍历一次字符串。
点评:本质是荷兰国旗问题,类似快排中partition过程,具体思路路分析及代码可以参考此文第8节:http://blog.csdn.net/v_july_v/article/details/6211155。
9月27日,人人两面:
一面
1 实现atoi
2 单链表变形 如 1 2 3 4 5 变为 1 3 5 4 2 如1 2 3 4 变为 1 3 4 2
(就是拆分链表 把偶数为反过来接在奇数位后面)
二面
1 二叉树查找不严格小于一个值的最大值(返回节点)。
2 有序数组里二分查找一个数(如果有相同的找最后一次出现的)。
3 等价于n*n的矩阵,填写0,1,要求每行每列的都有偶数个1 (没有1也是偶数个),问有多少种方法。
评论:开始以为是算法题,想了狂搜,递推(dp,可以用xor表示一行的列状态,累加),分治,(拆两半,然后上半段下半段的列有相同的奇偶性)。后来,自己算了几个发现n = 1 n = 2 n = 3 的结果,他告诉了我n = 4是多少,然后发现f(n) = 2^((n - 1) ^2) 。最后我给出了一个巧妙的证明。然后发现如果是m*n的矩阵也是类似的答案,不局限于方阵。此外,题目具体描述可以看看这里:http://blog.himdd.com/?p=2480。
9月27日,小米两面:
一面:
除了聊研究,就一道题
1 数组里找到和最接近于0的两个值。
二面:
1 行列有序的矩阵查找一个数
2 直方图最大矩形。点评:这里有此题的具体表述及一份答案:http://blog.csdn.net/xybsos/article/details/8049048。
3 next_permutation
4 字符串匹配 含有* ? (写代码)
5 实现strcpy memmove (必须写代码)
- //void * memmove ( void * destination, const void * source, size_t num );)
- //是<string.h>的标准函数,其作用是把从source开始的num个字符拷贝到destination。
- //最简单的方法是直接复制,但是由于它们可能存在内存的重叠区,因此可能覆盖了原有数据。
- //比如当source+count>=dest&&source<dest时,dest可能覆盖了原有source的数据。
- //解决办法是从后往前拷贝。
- //对于其它情况,则从前往后拷贝。
- void* memmove(void* dest, void* source, size_t count)
- {
- void* ret = dest;
- if (dest <= source || dest >= (source + count))
- {
- //正向拷贝
- //copy from lower addresses to higher addresses
- while (count --)
- *dest++ = *source++;
- }
- else
- {
- //反向拷贝
- //copy from higher addresses to lower addresses
- dest += count - 1;
- source += count - 1;
- while (count--)
- *dest-- = *source--;
- }
- return ret;
- }
更多,还可以参见此文第三节节末:http://blog.csdn.net/v_july_v/article/details/6417600,或此文:http://www.360doc.com/content/11/0317/09/6329704_101869559.shtml。
6 读数 (千万亿,百万亿……)变为数字 (说思路即可,字符串查找,填写各个权值的字段,然后判断是否合法,读前面那些×权值,累加)。
9月27日,Hulu 2013北京地区校招笔试题
填空题:
1、中序遍历二叉树,结果为ABCDEFGH,后序遍历结果为ABEDCHGF,那么前序遍历结果为?
2、对字符串HELL0_HULU中的字符进行二进制编码,使得字符串的编码长度尽可能短,最短长度为?
3、对长度12的有序数组进行二分查找,目标等概率出现在数组的每个位置上,则平均比较次数为?
4、一副扑克(去王),每个人随机的摸两张,则至少需要多少人摸牌,才能保证有两个人抽到同样的花色。
5、x个小球中有唯一一个球较轻,用天平秤最少称量y次能找出这个较轻的球,写出y和x的函数表达式y=f(x)
6、3的方幂及不相等的3的方幂的和排列成递增序列1,3,4,9,10,12,13……,写出数列第300项
7、无向图G有20条边,有4个度为4的顶点,6个度为3的顶点,其余顶点度小于3,则G有多少个顶点
8、桶中有M个白球,小明每分钟从桶中随机取出一个球,涂成红色(无论白或红都涂红)再放回,问小明将桶中球全部涂红的期望时间是?
9、煤矿有3000吨煤要拿到市场上卖,有一辆火车可以用来运煤,火车最多能装1000吨煤,且火车本身需要烧煤做动力,每走1公里消耗1吨煤,如何运煤才能使得运到市场的煤最多,最多是多少?
10、1,2,3,4…..n,n个数进栈,有多少种出栈顺序,写出递推公式(写出通项公式不得分)
11、宇宙飞船有100,000位的存储空间,其中有一位有故障,现有一种Agent可以用来检测故障,每个Agent可以同时测试任意个位数,若都没有故障,则返回OK,若有一位有故障,则失去响应。如果有无限多个Agent可供使用,每个Agent进行一次检测需要耗费1小时,现在有2个小时时间去找出故障位,问最少使用多少个Agent就能找出故障。
(总共12道填空题,还有一道太复杂,题目很长,还有示意图,这里没有记录下来)
大题:
1、n个数,找出其中最小的k个数,写出代码,要求最坏情况下的时间复杂度不能高于O(n logk)
2、写程序输出8皇后问题的所有排列,要求使用非递归的深度优先遍历
3、有n个作业,a1,a2…..an,作业aj的处理时间为tj,产生的效益为pj,最后完成期限为dj,作业一旦被调度则不能中断,如果作业aj在dj前完成,则获得效益pj,否则无效益。给出最大化效益的作业调度算法。点评:参考答案请看这个链接:http://www.51nod.com/question/index.html#!questionId=645。
有道的一个笔试题,1-9,9个数组成三个三位数,且都是完全平方数(三个三位数 占据 9个数)求解法。点评@林晚枫&归云见鸿:
(a*10+b)(a*10+b)
100a^2+20ab+b^2
a 属于 [1,2,3]
a=3,b=1 31 961,
a=2,b=3 23 529 400+40b+b^2
25 625
27 729
28 784
29 841
a=1,b=3 13 169 100+20b+b^2
14 196
16 256
17 289
18 324
19 361
=>最终唯一解 529 784 361
具体代码如下(3个for循环,然后hash):

9月28日,大众点评北京笔试题目:
1.一个是跳台阶问题,可以1次一级,1次两级,1次三级,求N级的跳法一共多少种?
点评:老题,参考答案请见:http://blog.csdn.net/v_july_v/article/details/6879101。
2.一个文件有N个单词,每行一个,其中一个单词出现的次数大于N/2,怎么样才能快速找出这个单词?
点评:还是老题,参见:http://blog.csdn.net/v_july_v/article/details/6890054。
大众点评前面还有30道逻辑题,15道文字推理,15道数学推理,一共只给20min。
9月28日,网易笔试题:
1、英雄升级,从0级升到1级,概率100%。
从1级升到2级,有1/3的可能成功;1/3的可能停留原级;1/3的可能下降到0级;
从2级升到3级,有1/9的可能成功;4/9的可能停留原级;4/9的可能下降到1级。
每次升级要花费一个宝石,不管成功还是停留还是降级。
求英雄从0级升到3级平均花费的宝石数目。
点评:题目的意思是,从第n级升级到第n+1级成功的概率是(1/3)^n(指数),停留原级和降级的概率一样,都为[1-(1/3)^n]/2)。
2、将一个很长的字符串,分割成一段一段的子字符串,子字符串都是回文字符串。
有回文字符串就输出最长的,没有回文就输出一个一个的字符。
例如:
habbafgh
输出h,abba,f,g,h。
点评:编程艺术第十五章有这个回文问题的解答,参见:http://blog.csdn.net/v_july_v/article/details/6712171。此外,一般的人会想到用后缀数组来解决这个问题,其余更多的方法请见:http://dsqiu.iteye.com/blog/1688736。最后,还可以看下这个链接:http://www.51nod.com/question/index.html#!questionId=672。
10月9日,腾讯一面试题:
有一个log文件,里面记录的格式为:
QQ号: 时间: flag:
如123456 14:00:00 0
123457 14:00:01 1
其中flag=0表示登录 flag=1表示退出
问:统计一天平均在线的QQ数。
点评:类似于此文中:http://blog.csdn.net/hackbuteer1/article/details/7348968,第8题后的腾讯面试题,读者可以参看之。
10月9日,腾讯面试题:
1.有一亿个数,输入一个数,找出与它编辑距离在3以内的书,比如输入6(0110),找出0010等数,数是32位的。
2.每个城市的IP段是固定的,新来一个IP,找出它是哪个城市的,设计一个后台系统。
10月9日,YY笔试题:
1 输出一个字符串中没有重复的字符。如“baaca”输出“bac”。
2 对于一个多叉树,设计TreeNode节点和函数,返回先序遍历情况下的下一个节点。
函数定义为TreeNode* NextNode(TreeNode* node)
3 分割字符串。
对于一个字符串,根据分隔符seperator,把字符串分割,如果存在多个分隔符连在一起,则当做一个分隔符。如果分隔符出现在" "符号之间,则不需要分割" "之间的字符。
比如a++abc ,分隔符为+,输出a abc
a+"hu+" 输出a hu+
a++"HU+JI 输出a "HU JI。
请根据上述需求完成函数:void spiltString(string aString,char aSeperator)。
10月9日,赶集网笔试
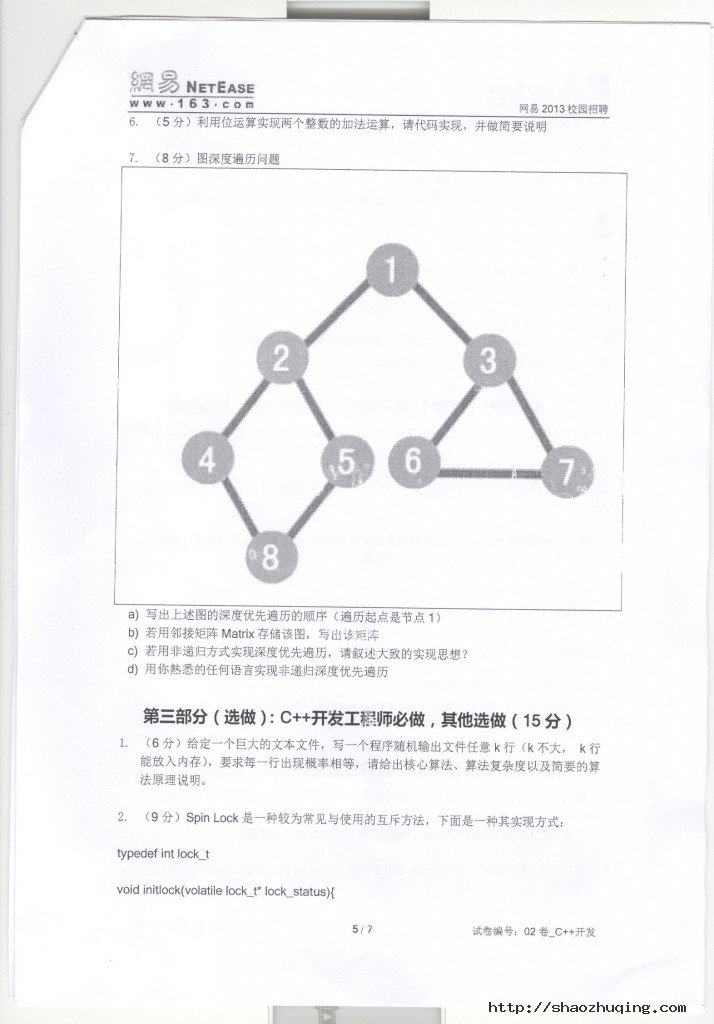
10月9日,阿里巴巴2013校园招聘全套笔试题(注:下图中所标答案不代表标准答案,有问题,欢迎留言评论)



上述第15题,填空:lower+ (upper-lower)/2
lower mid upper
0 6 12
7 9 12
7 7 8
8 8 8
比较4次
上述第16题,解答如下图所示:
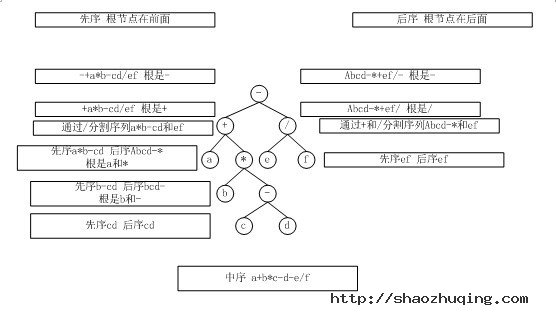
上述第17题,解答如下图所示:

18、甲包8个红球 2个蓝球,乙包2个红球 8个蓝球。抛硬币决定从哪个包取球,取了11次,7红4蓝。注,每次取后还放进去,只抛一次硬币。问选的是甲包的概率?
点评:
贝叶斯公式 + 全概率公式作答(参看链接:http://www.doc88.com/p-132711202556.html)。具体解答如下图所示:

注:上述第15~18的解答全部来自读者Lei Lei来信给出的解答,他的博客地址是:http://blog.csdn.net/nwpulei,特此感谢。有任何问题,欢迎随时讨论&指正,同时,更欢迎其他朋友也一起来做这些题目(你的答案一经选用,我可以根据你的要求,贴出你的个人主页或微博地址或博客地址)。
19、已知一个n个元素的数组,第i个元素在排序后的位置在[i-k,i+k]区间,k<<n .让你设计一个算法对数组排序,要求时间复杂度最小,O (nlogn)不得分,O(nk)得2分,如下图所示:


读者twtsa毛遂自荐,这是他给出的上述第19~20题的个人题解:http://blog.csdn.net/twtsa/article/details/8055143。有任何问题,欢迎随时讨论&指正。
10月10日,暴风影音笔试:
都是非常基础的题目,这是其中一道:一个整数转换成二进制后,问里面有多少个1。
10月10日,2013亚马逊在线笔试题目
题目及参考答案请见这:http://blog.chinaunix.net/uid-26750075-id-3370694.html。(感谢读者freeloki来信提供)。
10月10日人人网面试题
第一面:
1、(1)++i 和 i++,那个效率高?
(2)++++i,i++++,哪个是合法的?
(3)实现int型的++i 和 i++操作。
2、一段程序,求输出。(考察静态变量和模版类)
- int g = 0;
- template<typename T>
- class B
- {
- public:
- int static fun()
- {
- static int value = ++g;
- return value;
- }
- };
- int main()
- {
- cout << B<int>::fun() << endl;
- cout << B<char>::fun() << endl;
- cout << B<float>::fun() << endl;
- cout << B<int>::fun() << endl;
- cout << B<long>::fun() << endl;
- return 0;
- }
3、(1)实现二进制转十进制。
(2)如果有下面这种能直接求二进制转十进制的代码,是怎么实现的?
binary<1>::value; // 结果为1
binary<11>::value; // 结果为3
4、volatile、explicit、mutable表示的含义。
5、求整形数组的一个子数组,使得该子数组所有元素的和的绝对值最大。
6、(1)写求单链表是否有环的算法。
(2)如果有环,如何找出环的第一个结点。
7、实现单例模式。
二面:
1、一个文本,一万行,每行一个词,统计出现频率最高的前10个词(词的平均长度为Len)。并分析时间复杂度。
2、求数组中最长递增子序列。
10月10日,网易2013校园招聘全套笔试题:






10月10日,网易,数据挖掘工程师:
1,简述你对数据与处理的认识;
2,简述你对中文分词的理解,说明主要难点和常用算法;
3,常见的分类算法有哪些;
4,简述K-MEANS算法;
5,设计一个智能的商品推荐系统;
6,简述你对观点挖掘的认识。
点评:其它题目与上述第56题第一部分(http://blog.csdn.net/hackbuteer1/article/details/8060917)所述相同。
10月11日,阿里巴巴笔试部分题目:
1. 甲乙两个人上街,捡到一张10块钱的购物卡,两人就想出一个办法来分配这张卡。两个分别将自己出的价格写在纸上,然后看谁出的价高就给谁,并且那个出价高的人要把出的钱给对方。现在甲有6块钱,乙有8块钱。问谁获得的钱多。(多选)
A 甲多 B 乙多 C 一样多 D 有可能出现有人赔钱的情况
2. 有一个怪物流落到一个荒岛上,荒岛上有n条鳄鱼。每条鳄鱼都有实力单独吃掉怪物。但是吃掉怪物是有风险的,会造成体力值下降,然后会有可能被掉其他鳄鱼吃。问,最后那个怪物是危险的还是安全的?
3. 算法题:
A[i]是一个有序递增数组,其中所有的数字都不相等,请设计一种算法,求出其中所有的A[i]=i的数字并分析时间复杂度,不分析复杂度不得分。
4. 大题
你在浏览器中输入网址:http://blog.csdn.net/v_JULY_v,按下回车键后,会发生什么事情,请一一描述(20分)。包括浏览器,网络,服务器等等发生的事情,及各项关键技术。
点评:这样的题考过很多次,参考答案如下图所示:
10月11日,华为一面:
1、将一个普通的二叉树转换为二叉排序树?
2、随便写一个排序算法。
10月11日,完美笔试题:
1.为什么析构函数应该设为虚函数
2.大数字乘法问题
3.双向链表模拟队列操作push pop find
4.求 a/3 不能用除法
5.多核下多线程同步问题,使用锁应该注意什么
6.三个宝箱有一个里面有珠宝,现在拿第一宝箱,然后打开第二个宝箱后发现没有珠宝,用概率论原理解释为什么现在拿第三个宝箱,里面有珠宝的概率比拿第一个宝箱高。
10月11日,搜狐畅游旗下第七大道笔试题:
算法题
1.一个数是否是另一个数的平方。
2.N进制换成M进制
3.设计一个大数乘法
综合题
1.N个数,出栈有几种情况
2.进程死锁原因及条件.
腾迅一个非常有意思的面试题:
N个数组,每个数组中的元素都是递增的顺序,现在要找出这N个数组中的公共元素部分,如何做? 注:不能用额外辅助空间。
点评:
讨论了半天:http://weibo.com/1580904460/z08mT0aFj,没个好的结果,发现还是上午想到的N个指针逐步向后移动,辅以二分,然后N路归并更靠谱,类似这里的第5题所述的办法:http://www.cnblogs.com/BeyondAnyTime/archive/2012/07/17/2593224.html。若读者有更好的思路,欢迎赐教。
10月12日,迅雷2013校园招聘「广州站」C++方向全套笔试题
(注:若照片看不清楚,请右键点击“图片另存为”到桌面,然后再打开图片,便可以随意放大缩小图片拉)







10月12日晚,微策略北京站笔试题(根据读者回忆整理):
1、魔术定义:整数N以基数B表示,如21以基数3表示为210,那么21是基数3的一个魔术,210三个位的值都不一样。设计函数,输入参数N和B(B介于2到10之间),返回是否为魔术。
2、斐波那契数列的变形,一个贼每次上楼梯1或者2,一个27层的楼梯需要多少种方法,记住贼不能经过5,8,13层,否则会被抓住。点评:还是可以用斐波那契来推算,f(n) = f(n-1) + f(n-2),只是f(5) f(8) f(13) = 0,http://www.51nod.com/answer/index.html#!answerId=596。
3、给定一棵树根节点,每个节点里面的值都不相同,查找iKEY的节点,并使用一个给定的节点将查找到的节点替换掉。节点内有两个孩子节点和一个父节点。
4、字符串数组S,全是0和1表示的,字符串都是n位的,且1的个数小于等于l,返回index的字符串。(这个比较奇怪,如果S中字符串都是符合1的个数小于等于l,则直接可以得到index的字符串啊,难道是要先求这个字符串数组?那就比较麻烦了)
5、降序排列的数组,找到其中两个不同的值,其乘积最接近一个给定的值M,感觉和加法求和很类似。
6、序列123...N,N介于3和9之间,在其中加入+-或者空格,使其和为0,
如123456 1-2 3-4 5+6 7 等价于1-23-45+67=0。请问,如何获得所有组合?
10月12日,大众点评笔试一题:

读者私信,昨日(12号)美团的笔试题:
1、一副扑克52张(去了大小王),洗牌,求最顶一张和最底一张是A的概率
2、知道两个数的异或以及这两个数的和,问可以确定这对数吗?为什么?给出推理过程
3、A、B两个文件各存50亿个商品名称,每个50个字符,求这两个文件中相同名称的商品名,内存限制4G(看过您的《教你如何迅速秒杀掉:99%的海量数据处理面试题》中的第6题,无压力,非常感谢)
4、给一个二叉树的后序遍历和中序遍历,画出这颗二叉树,写出前序遍历结果,并给出推理过程
5、一个有序数组array,给一个数x,可重复,求这个数在array中出现的区间,算法思路和代码实现
6、一个映射文件中存了ip地址区间和城市名称,形如:
10.0.0.1 10.0.1.27 北京
10.0.2.1 10.0.2.27 北京
201.0.1.12 201.0.2.124 上海
给你一个ip地址,获取城市名称,要求:1)给出算法思想 2)代码实现。
10月12日晚,360 2013校招部分笔试题(注:图中所标答案不代表正确答案):

int main()
{
fork()||fork();
return 0;
}
问,上述程序创建了几个进程?

编程题、传教士人数m,野人c,m≥c,开始都在岸左边,
①船只能载两人,传教士和野人都会划船,当然必须有人划船
②两岸边保证野人人数不能大于传教士人数
把所有人都送过河,设计一方案,要求编程实现。
点评:
读者huangxy10于本文评论下第169楼提供了一种解法:http://blog.csdn.net/huangxy10/article/details/8066408。再附一个讨论帖子:http://topic.csdn.net/u/20121012/22/70226713-A669-4F03-80B7-BFFF12A330EB.html。
10月13日,百度2013校招北京站笔试题:
一、简答题(30分)
1、用简单语句描述数据库操作的步骤
2、写出TCP/IP的四层结构
3、什么是MVC结构,并描述各层结构的作用
二、算法与程序设计题(40分)
1、字母a-z,数字0-9,现需要其中任意3个作为密码,请输出所有可能组合。(伪码CC++JAVA)(10分)
点评:如本文评论下第198楼所述,即从26+10=36个不同字符中选取3个字符的组合,用递归及非递归两种方法,可以参照以下链接:
http://blog.csdn.net/wumuzi520/article/details/8087501(从n个数中选取m个数的组合数),主要代码如下:
- //copyright @wumuzi520
- //从n个数中选取m个数的组合数
- void Combination(int arr[], int nLen, int m, int out[], int outLen)
- {
- if(m == 0)
- {
- for (int j = 0; j < outLen; j++)
- {
- cout << out[j] << "t";
- }
- cout << endl;
- return;
- }
- for (int i = nLen; i >= m; --i) //从后往前依次选定一个
- {
- out[m-1] = arr[i-1]; //选定一个后
- Combination(arr,i-1,m-1,out,outLen); // 从前i-1个里面选取m-1个进行递归
- }
- }
- void PrintCombination(int arr[], int nLen, int m)
- {
- int* out = new int[m];
- Combination(arr,nLen,m,out,m);
- delete [] out;
- }
2、实现字符串反转函数(10分)
3、给定字符函数a、插入 b、删除 c、替换
例如字符串A=acegf,字符串B=adef,最少需要2步操作将A转换为B,
即第一步将c替换为d,第二步将g删除;
(1)请问将字符串A=gumbo转换为字符串B=gambol,最少需要几步操作,列出如何操作(2分)
(2)任意字符串A和字符串B,如何计算最小操作次数,计算思路,并给出递归公式(3分)
(3)实现代码(注意代码风格与效率)(15分)
点评:请参看上文第38题第4小题:9月26日,百度一二面试题。
三、系统设计题(30分)
RSA SecurID安全系统
应用场景:这是一种用户登录验证手段,例如银行登录系统,这个设备显示6位数字,每60秒变一次,再经过服务器认证,通过则允许登录。问How to design this system?
1)系统设计思路?服务器端为何能有效认证动态密码的正确性?
2)如果是千万量级永固,给出系统设计图示或说明,要求子功能模块划分清晰,给出关键的数据结构或数据库表结构。
考虑用户量级的影响和扩展性,用户密码的随机性等,如果设计系统以支持这几个因素.
3)系统算法升级时,服务器端和设备端可能都要有所修改,如何设计系统,能够使得升级过程(包括可能的设备替换或重设)尽量平滑?
10月13日,百度移动开发笔试题
一、 1、什么是RISC;
2、通过后序、中xu求前序
3、重写与重载的区别
二、
1、反转链表
2、判断两个数组中是否有相同的数字
3、1000瓶水中找 出有毒的那瓶,毒性一周后发作,一周内最少需要多少只老鼠
三、系统设计 email客户端,支持多账户和pop3等协议
1、请写出可能的至少5个用例;
2、使用sqlite存储帐户、已收信息、已发信息、附件、草稿,请设计合理的表结构
3、pop3等协议等接口已完成,请给出email客户端的模块设计图。
10月13日,人搜2013 校招北京站部分笔试题(读者回忆+照片):


所有大于等于6的偶数都可以表示成两个(奇)素数之和。
给定1-10000,找到可以用两个素数之和表示每一个偶数的两个素数,然后输出这两个素数,如果有多对,则只需要输出其中之一对即可。
要求:复杂度较低,代码可运行。
2,城市遍历
某人家住北京,想去青海玩,可能会经过许多城市,
现已知地图上的城市连接,求经过M个城市到达青海的路线种类。
城市可以多次到达的,比如去了天津又回到北京,再去天津,即为3次。北京出发不算1次。
输入:
N M S
N为城市总数,北京为0,青海为N-1;
M为经过的城市数目;
S为之后有S行
i j
表示第i个城市可以去第j个城市,是有方向的。
输出:
N
表示路径种类。
3,分布式系统设计
有1000亿个URL,其中大约有5亿个site。每天的更新大约2%-5%。设计一个系统来解决存储和计算下面三个问题。可用分布式系统。
URL:http///site[port]*(key==?;key==?)
site:[*].domain
URL:http://www.baidu.com/baidu?word=%E5%AE%A3%E8%AE%B2%E4%BC%9A&ie=utf-8
site::www.baidu.com
domain::baidu.com
key=baidu?word
a>检测每个域名下的site数目,以及每个site下的URL数目,输出site变化超过一定阈值的域名以及URL数目变化剧烈的site。找出泛域。
泛域:该域下的site数目超过500个,且每个site下的URL数目超过100个。
b>提取URL中key的特征,对site进行聚类;
(每个site下面有多个URL,这些URL中有许多key,可以获取这些key作为site的特征,对site进行聚类,不过这应该是多机器联合的)
c>对于给定的domain,输出该domain下的所有site。
10月13日,创新工场笔试:
第一个,快排最坏情况下是O(n^2),问如何优化?
第二个,怎么样求一个数的根号
点评:你是不是会想到一系列有关数学的东西,什么泰勒级数啊,什么牛顿法啊,具体编程可以如下代码所示:
- static void Main(string[] args)
- {
- double k = 5;
- double n = 2, m = k;
- while (n != m)
- {
- m = k / n;
- n = (m + n) / 2;
- }
- }
链接:http://www.51nod.com/question/index.html#!questionId=660。
第三个,4个数字,用四则元素求结果能否为24。写出这个判断的函数。
10月14日,思科网讯旗下公司笔试题:
1、海量数据中,寻找最小的k个数。
请分情况,给出时间复杂度最优,或空间复杂度最优的方案,或时间复杂度/空间复杂度综合考虑的可行方案。
点评:参见:第三章、寻找最小的k个数。
2、有两座桥,其中一座可能是坏的,两个守桥人分别守在这两座桥的入口。他们一个总是会说实话,一个总是说谎话。
你现在需要找出哪一座桥可以通过。
1),请问最少需要问守桥人几个问题,可以找出可以通过的桥?如何问?
2),请编程解决。
10月14日,腾讯杭州站笔试题:
1、http服务器会在用户访问某一个文件的时候,记录下该文件被访问的日志,网 站管理员都会去统计每天每文件被访问的次数。写一个小程序,来遍历整个日志 文件,计算出每个文件被访问的访问次数
1)请问这个管理员设计这个算法
2)该网站管理员后来加入腾讯从事运维工作,在腾讯,单台http服务器不够用的 ,同样的内容,会分布在全国各地上百台服务器上。每台服务器上的日志数量, 都是之前的10倍之多,每天服务器的性能更好,之前他用的是单核cpu,现在用的 是8核的,管理员发现在这种的海量的分布式服务器,基本没法使用了,请重新设计一个算法。
2、腾讯的qq游戏当中,最多人玩的游戏就是斗地主了,每一句游戏开始时,服务 器端都要洗牌,以保证发牌的时每个人拿的牌都是随机的,假设用1-54来表示54 张不同的拍,请你写一个洗牌算法,保证54张牌能随机打散!
选择题:
1)、下列RAID技术无法提高可靠性的是:
A:RAID0 B:RAID1 C:RAID10 D:RAID5
2)、长度为1的线段,随机在其上选择两点,将线段分为三段,问这3个字段能组成一 个三角形的概率是:
1/2,1/3,1/4,1/8
3)、下面那种标记的包不会在三次握手的过程中出现()
A:SYN B:PSH C:ACK D:RST
10月14日,搜狗2013 校招笔试题:
1、有n*n个格子,每个格子里有正数或者0,从最左上角往最右下角走,只能向下和向右,一共走两次(即从左下角走到右下角走两趟),把所有经过的格子的数加起来,求最大值SUM,且两次如果经过同一个格子,则最后总和SUM中该格子的计数只加一次。
点评:@西芹_new,一共搜(2n-2)步,每一步有四种走法,考虑不相交等条件可以剪去很多枝,代码如下「http://blog.csdn.net/huangxy10/article/details/8071242」:
- 西芹_new<huangxy10@qq.com> 0:55:40
- // 10_15.cpp : 定义控制台应用程序的入口点。
- //
- #include "stdafx.h"
- #include <iostream>
- using namespace std;
- #define N 5
- int map[5][5]={
- {2,0,8,0,2},
- {0,0,0,0,0},
- {0,3,2,0,0},
- {0,0,0,0,0},
- {2,0,8,0,2}};
- int sumMax=0;
- int p1x=0;
- int p1y=0;
- int p2x=0;
- int p2y=0;
- int curMax=0;
- void dfs( int index){
- if( index == 2*N-2){
- if( curMax>sumMax)
- sumMax = curMax;
- return;
- }
- if( !(p1x==0 && p1y==0) && !(p2x==N-1 && p2y==N-1))
- {
- if( p1x>= p2x && p1y >= p2y )
- return;
- }
- //right right
- if( p1x+1<N && p2x+1<N ){
- p1x++;p2x++;
- int sum = map[p1x][p1y]+map[p2x][p2y];
- curMax += sum;
- dfs(index+1);
- curMax -= sum;
- p1x--;p2x--;
- }
- //down down
- if( p1y+1<N && p2y+1<N ){
- p1y++;p2y++;
- int sum = map[p1x][p1y]+map[p2x][p2y];
- curMax += sum;
- dfs(index+1);
- curMax -= sum;
- p1y--;p2y--;
- }
- //rd
- if( p1x+1<N && p2y+1<N ) {
- p1x++;p2y++;
- int sum = map[p1x][p1y]+map[p2x][p2y];
- curMax += sum;
- dfs(index+1);
- curMax -= sum;
- p1x--;p2y--;
- }
- //dr
- if( p1y+1<N && p2x+1<N ) {
- p1y++;p2x++;
- int sum = map[p1x][p1y]+map[p2x][p2y];
- curMax += sum;
- dfs(index+1);
- curMax -= sum;
- p1y--;p2x--;
- }
- }
- int _tmain(int argc, _TCHAR* argv[])
- {
- curMax = map[0][0];
- dfs(0);
- cout <<sumMax-map[N-1][N-1]<<endl;
- return 0;
- }
@绿色夹克衫:跟这个问题:http://www.51nod.com/question/index.html#!questionId=487 ,是同一个问题。
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
2 3 4 5 6 2 3 4 5 6 2 3 4 5 6 2 3 4 5 6
3 4 5 6 7 3 4 5 6 7 3 4 5 6 7 3 4 5 6 7
4 5 6 7 8 4 5 6 7 8 4 5 6 7 8 4 5 6 7 8
所以当i = j时,DP[6,2,2] = Max(DP[5,1,1],DP[5,1,2],DP[5,2,2]) + 6,2格子中对应的数值 (式二)
3、故,综合上述的(式一),(式二)最后的递推式就是
2、N个整数(数的大小为0-255)的序列,把它们加密为K个整数(数的大小为0-255).再将K个整数顺序随机打乱,使得可以从这乱序的K个整数中解码出原序列。设计加密解密算法,且要求K<=15*N.
如果是:
1,N<=16,要求K<=16*N.
2,N<=16,要求K<=10*N.
3,N<=64,要求K<=15*N.
点评:http://www.51nod.com/question/index.html#!questionId=659。
人人网面试,只面一道题,要求5分钟出思路,10分钟出代码
面试题是:
两个无序数组分别叫A和B,长度分别是m和n,求中位数,要求时间复杂度O(m+n),空间复杂度O(1) 。
10月15日,网新恒天笔试题
1.不要使用库函数,写出void *memcpy(void *dst, const void *src, size_t count),其中dst是目标地址,src是源地址。
点评:下面是nwpulei写的代码:
- void* memcpy(void *dst, const void *src, size_t count)
- {
- assert(dst != NULL);
- assert(src != NULL);
- unsigned char *pdst = (unsigned char *)dst;
- const unsigned char *psrc = (const unsigned char *)src;
- assert(!(psrc<=pdst && pdst<psrc+count));
- assert(!(pdst<=psrc && psrc<pdst+count));
- while(count--)
- {
- *pdst = *psrc;
- pdst++;
- psrc++;
- }
- return dst;
- }
链接:http://blog.csdn.net/nwpulei/article/details/8090136。
2.给定一个字符串,统计一下哪个字符出现次数最大。
3.我们不知道Object类型的变量里面会出现什么内容,请写个函数把Object类型转换为int类型。
10月15日,Google 2013 校招全套笔试题:





1.写一个函数,输出前N个素数,函数原型:void print_prime(int N); 不需要考虑整数的溢出问题,也不需要使用大数处理算法。
2.长度为N的数组乱序存放着0带N-1.现在只能进行0与其他数的swap操作,请设计并实现排序,必须通过交换实现排序。
3.给定一个源串和目标串,能够对源串进行如下操作:
1.在给定位置上插入一个字符
2.替换任意字符
3.删除任意字符
写一个程序,返回最小操作数,使得对源串进行这些操作后等于目标串,源串和目标串的长度都小于2000。
点评:
1、此题反复出现,如上文第38题第4小题9月26日百度一二面试题,10月9日腾讯面试题第1小题,及上面第69题10月13日百度2013校招北京站笔试题第二大道题第3小题,同时,还可以看下这个链接:http://www.51nod.com/question/index.html#!questionId=662。
- //动态规划:
- //f[i,j]表示s[0...i]与t[0...j]的最小编辑距离。
- f[i,j] = min { f[i-1,j]+1, f[i,j-1]+1, f[i-1,j-1]+(s[i]==t[j]?0:1) }
- //分别表示:添加1个,删除1个,替换1个(相同就不用替换)。
2、补充:上述问题类似于编程之美上的下述一题「以下内容摘自编程之美第3.3节」:
许多程序会大量使用字符串。对于不同的字符串,我们希望能够有办法判断其相似程度。我们定义了一套操作方法来把两个不相同的字符串变得相同,具体的操作方法为:
1. 修改一个字符(如把“a”替换为“b”);
2. 增加一个字符(如把“abdd ”变为“aebdd ”);
3. 删除一个字符(如把“travelling”变为“traveling”)。
比如,对于“abcdefg”和“abcdef ”两个字符串来说,我们认为可以通过增加/减少一个“g”的方式来达到目的。上面的两种方案,都仅需要一次操作。把这个操作所需要的次数定义为两个字符串的距离,而相似度等于“距离+1”的倒数。也就是说,“abcdefg”和“abcdef”的距离为1,相似度为1 / 2 = 0.5。
给定任意两个字符串,你是否能写出一个算法来计算出它们的相似度呢?
这样,很快就可以完成一个递归程序,如下所示:
- Int CalculateStringDistance(string strA, int pABegin, int pAEnd,
- string strB, int pBBegin, int pBEnd)
- {
- if(pABegin > pAEnd)
- {
- if(pBBegin > pBEnd)
- return 0;
- else
- return pBEnd – pBBegin + 1;
- }
- if(pBBegin > pBEnd)
- {
- if(pABegin > pAEnd)
- return 0;
- else
- return pAEnd – pABegin + 1;
- }
- if(strA[pABegin] == strB[pBBegin])
- {
- return CalculateStringDistance(strA, pABegin + 1, pAEnd,
- strB, pBBegin + 1, pBEnd);
- }
- else
- {
- int t1 = CalculateStringDistance(strA, pABegin, pAEnd, strB,
- pBBegin + 1, pBEnd);
- int t2 = CalculateStringDistance(strA, pABegin + 1, pAEnd,
- strB,pBBegin, pBEnd);
- int t3 = CalculateStringDistance(strA, pABegin + 1, pAEnd,
- strB,pBBegin + 1, pBEnd);
- return minValue(t1,t2,t3) + 1;
- }
- }
上面的递归程序,有什么地方需要改进呢?在递归的过程中,有些数据被重复计算了。比如,如果开始我们调用CalculateStringDistance(strA,1, 2, strB, 1, 2),下图是部分展开的递归调用。

可以看到,圈中的两个子问题被重复计算了。为了避免这种不必要的重复计算,可以把子问题计算后的解存储起来。如何修改递归程序呢?还是DP!请看此链接:http://www.cnblogs.com/yujunyong/articles/2004724.html。
3、此外,关于这个“编辑距离”问题的应用:搜索引擎关键字查询中拼写错误的提示,可以看下这篇文章:http://www.ruanyifeng.com/blog/2012/10/spelling_corrector.html。「关于什么是“编辑距离”:一个快速、高效的Levenshtein算法实现,这个是计算两个字符串的算法,Levenshtein距离又称为“编辑距离”,是指两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。当然,次数越小越相似。这里有一个BT树的数据结构,挺有意思的:http://blog.notdot.net/2007/4/Damn-Cool-Algorithms-Part-1-BK-Trees」
最后,Lucene中也有这个算法的实现(我想,一般的搜索引擎一般都应该会有此项拼写错误检查功能的实现):http://www.bjwilly.com/archives/395.html。
4、扩展:面试官还可以继续问下去:那么,请问,如何设计一个比较两篇文章相似性的算法?(这个问题的讨论可以看看这里:http://t.cn/zl82CAH)
BTW,群友braveheart89也整理了这套笔试题:http://blog.csdn.net/braveheart89/article/details/8074657。
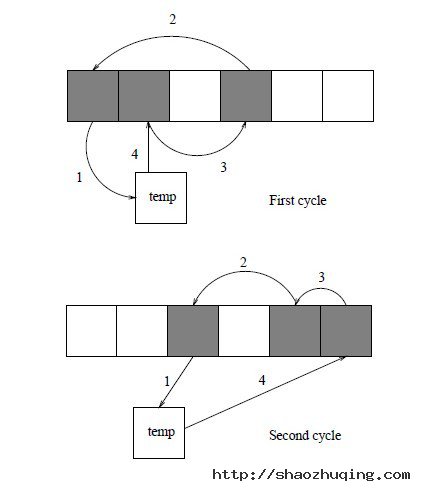
10月16日,UC的笔试题目:
1、有个长度为2n的数组{a1,a2,a3,...,an,b1,b2,b3,...,bn},希望排序后{a1,b1,a2,b2,....,an,bn},要求时间复杂度o(n),空间复杂度0(1)。
点评:@绿色夹克衫:完美洗牌问题「关于洗牌算法:http://blog.csdn.net/gogdizzy/article/details/4917488」,解决这个问题的关键在于如何解决置换群中的环。方法是微软员工那篇论文中写的:http://user.qzone.qq.com/414353346/blog/1243343118#!app=2&via=QZ.HashRefresh&pos=1243343118,大概意思是,用3的幂来弄:
@方程:
- int index = arr.length / 2;
- int temp = arr[index];
- while(index != 1){
- int tempIndex = (index + (index % 2) * (arr.length - 1)) / 2;
- arr[index] = arr[tempIndex];
- index = tempIndex;
- }
- arr[1] = temp;
链接:1,http://www.51nod.com/question/index.html#!questionId=278;2、这里也有一参考答案:http://blog.csdn.net/yuan8080/article/details/5705567。
10月17日,创新工场电话面试:
1,如何删除一个搜索二叉树的结点;
2,如何找到一个数组中的两个数,他们的和为0;
3,如何判断两条二维平面上的线段是否相交。
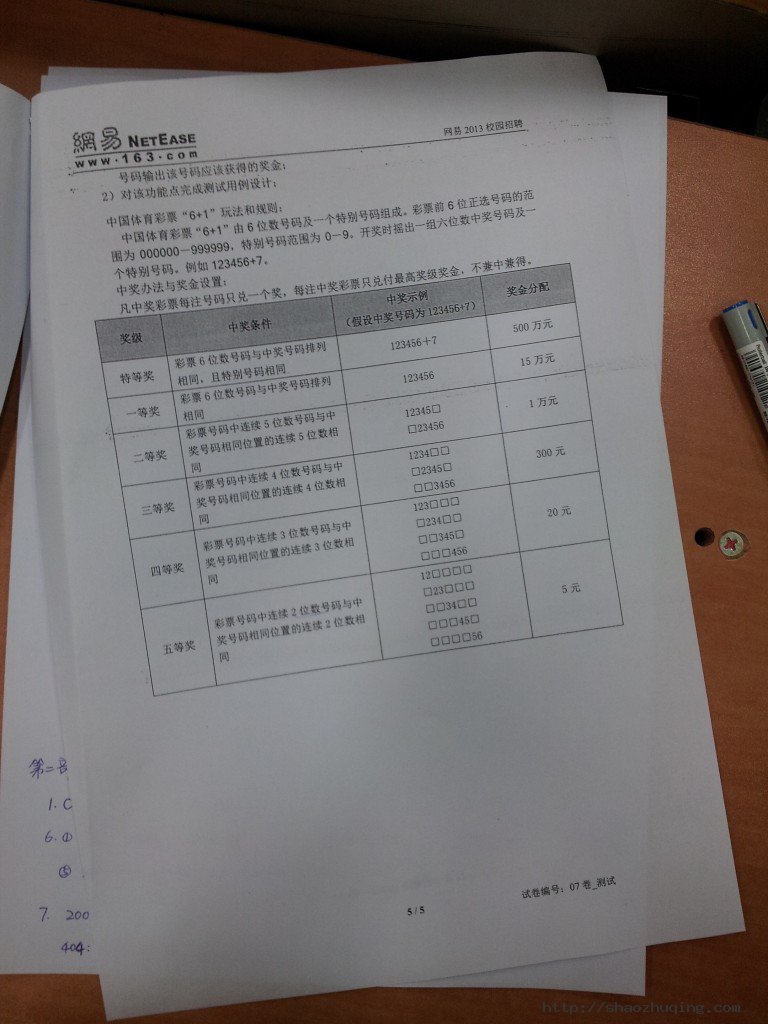
网易2013 校招笔试题:



10月19日,百度研发三面题:
百度地图里的路线查询:给定两个站点,如果没有直达的路线,如何找到换乘次数最少的路线?
点评:蚂蚁算法?还是广搜,或A*算法?
10月20日,baidu广州站笔试算法题:
1. 有一箱苹果,3个一包还剩2个,5个一包还剩3个,7个一包还剩2个,求N个满足以上条件的苹果个数。
2. 用递归算法写一个函数,求字符串最长连续字符的长度,比如aaaabbcc的长度为4,aabb的长度为2,ab的长度为1。
3. 假设一个大小为100亿个数据的数组,该数组是从小到大排好序的,现在该数组分成若干段,每个段的数据长度小于20「也就是说:题目并没有说每段数据的size 相同,只是说每个段的 size < 20 而已」,然后将每段的数据进行乱序(即:段内数据乱序),形成一个新数组。请写一个算法,将所有数据从小到大进行排序,并说明时间复杂度。
点评:
思路一、如@四万万网友所说:维护一个20个元素大小的小根堆,然后排序,每次pop取出小根堆上最小的一个元素(log20),然后继续遍历原始数组后续的(N-20)个元素,总共pop (N-20)次20个元素小根堆的log20的调整操作。
思路二@飘零虾、如果原数组是a[],那么a[i+20]>=a[i]恒成立(因为每段乱序区间都是小于20的,那么向后取20,必然是更大的区间的元素)。
第一个数组:取第0、20、40、60、80...
第二个数组:取第1、21、41、61、81...
...
第20个数组:取第19、39、59、79... (上述每个数组100亿/20 个元素)
共计20个数组,每个数组100亿/20 个元素「注:这5亿个元素已经有序,不需要再排序」,且这20个数组都是有序的,然后对这20个数组进行归并,每次归并20个元素。时间复杂度跟上述思路一一样,也是N*logK(N=100亿,K=20)。
此外,读者@木叶漂舟直接按每组20个排序,将排好的20个与前20个调整拼接,调整两端接头处的元素,写了个简单地demo: http://t.cn/zlELAzs。不过,复杂度有点高,目前来说中规中矩的思路还是如上文中@四万万网友 所说思路一「@张玮-marihees按照思路一:http://weibo.com/1580904460/z1v5jxJ9P,写了一份代码:http://codepad.org/T5jIUFPG,欢迎查看」。
10月21日,完美笔试算法题「同时,祝自己生日快乐!」:
1. 请设计一个算法,当给出在2D平面中某个三角形ABC的顶点坐标时能输出位于该三角形内的一个随机点(需要满足三角形内均匀随机),无需写出实现,只要能清楚地描述算法即可。
2. 请自己用双向链表实现一个队列,队列里节点内存的值为int,要求实现入队,出队和查找指定节点的三个功能。
3. 实现一个无符号任意大整数的类,实现两个无符号超大整数的乘法。
10月22日,CSR掌微电子笔试题:
5.给定两个字符串s1和s2,要求判定s2是否能够被通过s1做循环移位(rotate)得到字符串包含。例如,S1=AABCD和s2=CDAA,返回true;给定s1=ABCD和s2=ACBD,返回false。用伪代码或流程图叙述解法。
点评:老题,类似:http://blog.csdn.net/v_JULY_v/article/details/6322882。其余题目见:http://blog.sina.com.cn/s/blog_3eb9f72801016llt.html。
10月23日,去哪儿网笔试:
1.将IPV4转换成整数
2.定义一个栈的数据结构,实现min函数,要求push,pop,min时间复杂度是0(1);
点评:这是2010年整理的微软100题的第2题,http://blog.csdn.net/v_JULY_v/article/details/6057286,答案见此文第2题:http://blog.csdn.net/v_JULY_v/article/details/6126406。
3.数组a[n]里存有1到n的所有树,除了一个数removed,找出这个missing的树。
4.找出字符串中的最长子串,要求子串不含重复字符,并分析时间复杂度。
10月28日,微软三面题「顺祝,老妈明天生日快乐!」:
找一个点集中与给定点距离最近的点,同时,给定的二维点集都是固定的,查询可能有很多次,时间复杂度O(n)无法接受,请设计数据结构和相应的算法。
类似于@陈利人:附近地点搜索,就是搜索用户附近有哪些地点。随着GPS和带有GPS功能的移动设备的普及,附近地点搜索也变得炙手可热。在庞大的地理数据库中搜索地点,索引是很重要的。但是,我们的需求是搜索附近地点,例如,坐标(39.91, 116.37)附近500米内有什么餐馆,那么让你来设计,该怎么做?
点评:我看到这道题的时候,除了想到用R树「从B树、B+树、B*树谈到R 树」解决这个问题之外,还想起了之前一直要写的KD树仍未写,但估计快要写了,请读者朋友们耐心等待些时日吧。
11月10日,百度笔试题:
1、20个排序好的数组,每个数组500个数,按照降序排序好的,让找出500个最大的数。
2、一在线推送服务,同时为10万个用户提供服务,对于每个用户服务从10万首歌的曲库中为他们随机选择一首,同一用户不能推送重复的,设计方案,内存尽可能小,写出数据结构与算法。
一起看看网页编码的那些事
编码一直是让新手头疼的问题,特别是 GBK、GB2312、UTF-8 这三个比较常见的网页编码的区别,更是让许多新手晕头转向,怎么解释也解释不清楚。但是编码又是那么重要,特别在网页这一块。如果你打出来的不是乱码,而网页中出现了乱码,绝大部分原因就出在了编码上了。此外除了乱码之外,还会出现一些其他问题(例如:IE6 的 CSS 加载问题)等等。我写本文的目的,就是要彻底解释清楚这个编码问题!如果你遇到了类似的问题,那就要仔细的看看这篇文章。
ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
这几个编码关键词是比较常见的,虽然我把我们放在了一起说,但并不意味这这几个东西是平级的关系。本部分的内容,引用自网络略有修改,不知原文出处,故无法署名。
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物,他们把这称为”字节”。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去,他们就把这机器称为”计算机”。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。遇上 00×10, 终端就换行,遇上0×07, 终端就向人们嘟嘟叫,例好遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。他们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码”。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字 了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来计算机发展越来越广泛,世界各国为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了 最后一个状态255。从128到255这一页的字符集被称”扩展字符集”。但是原有的编号方法,已经再也放不下更多的编码。
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。于是国人就自主研发,把那些127号之后的奇异符号们直接取消掉。规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312″。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是 扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码。当时的中国人想让电脑显示汉字,就必须装上一个”汉字系统”,专门用来处理汉字的显示、输入的问题,装错了字符系统,显示就会乱了套。这怎么办?就在这时,一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “UNICODE”。
UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于 ascii 里的那些”半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高 8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得 GBK 与UNICODE 在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从UNICODE编码和另一种编码进行转换,这种转换必须通过查表来进行。UNICODE 是用两个字节来表示为一个字符,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。
UNICODE 来到时,一起到来的还有计算机网络的兴起,UNICODE 如何在网络上传输也是一个必须考虑的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF8 就是每次8个位传输数据,而 UTF16 就是每次16个位,只不过为了传输时的可靠性,从UNICODE到 UTF时并不是直接的对应,而是要过一些算法和规则来转换。
看完这些,相信你对于这几个编码关系等,了解的比较清楚了吧。我再来简单的总结一下:
● 中国人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示6000多个常用汉字。
● 汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。
● 中国是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。
● 每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
● 终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。
● UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。
于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。但是目前的电脑来看,硬盘都是白菜价,电脑性能也已经足够无视这点性能的消耗了。所以推荐所有的网页使用统一编码:UTF-8。
关于记事本无法单独保存“联通”的问题
当你新建一个 文本文档 之后,在里面输入 “联通” 两个字,然后保存。当你再次打开的时候,原来输入的 “联通” 会变成两个乱码。

这个问题就是因为 GB2312 编码与 UTF8 编码产生了编码冲撞造成的。从网上引来一段从UNICODE到UTF8的转换规则:
UTF-8
0000 – 007F
0xxxxxxx
0080 – 07FF
110xxxxx 10xxxxxx
0800 – FFFF
1110xxxx 10xxxxxx 10xxxxxx
例如”汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是其UTF8的编码。
而当你新建一个文本文件时,记事本的编码默认是ANSI, 如果你在ANSI的编码输入汉字,那么他实际就是GB系列的编码方式,在这种编码下,”联通”的内码是:
c1 1100 0001
aa 1010 1010
cd 1100 1101
a8 1010 1000
注意到了吗?第一二个字节、第三四个字节的起始部分的都是”110″和”10″,正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本 时,记事本就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节的10去掉,我们就得到了”00001 101010″,再把各位对齐,补上前导的0,就得到了”0000 0000 0110 1010″,不好意思,这是UNICODE的006A,也就是小写的字母”j”,而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。这就 是只有”联通”两个字的文件没有办法在记事本里正常显示的原因。
由这个问题,可以发散出很多问题。比较常见的一个问题就是:我已经把文件保存成了 XX 编码,为什么每次打开,还是原来的 YY 编码?!原因就在于此,你虽然保存成了 XX 编码,但是系统识别的时候,却误识别为了 YY 编码,所以还是显示为 YY 编码。为了避免这个问题,微软公司弄出了一个叫 BOM 头的东西。
关于文件 BOM 头的问题
当使用类似 WINDOWS 自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。它是一串隐藏的字符,用于让记事本等编辑器识别这个文件是否以UTF-8编码。这样就可以避免这个问题了。对于一般的文件,这样并不会产生什么麻烦。
这样做,也有弊处,尤其体现在网页中。PHP并不会忽略BOM,所以在读取、包含或者引用这些文件时,会把BOM作为该文件开头正文 的一部分。根据嵌入式语言的特点,这串字符将被直接执行(显示)出来。由此造成即使页面的 top padding 设置为0,也无法让整个网页紧贴浏览器顶部,因为在html一开头有这3个字符。如果你在网页中,发现了由未知的空白等,很有可能就是由于文件有 BOM 头造成的。遇到这种问题,把文件保存的时候,不要带有 BOM 头!
如何查看和修改某文档的编码
1,直接使用记事本查看和修改。我们可以用记事本打开文件,然后点击左上角的 “文件” =》“另存为”,这时候就会弹出一个保存的窗口。在下面选择好编码之后,点击保存就可以了。

但是这种方式的选择余地非常小,通常用来快速查看文件是什么编码。我更推荐使用下面的方法。
2,使用其他文本编辑器(例如:notepad ++)来查看修改。几乎所有的成熟的文本编辑器(例如:Dreamweaver、Emeditor等),都可以快速查看或修改文件编码。这一点尤其体现在 notepad++ 上面。
打开一个文件之后,会在右下角显示当前文件的编码。
![]()
点击上面菜单栏中的 “encoding” 即可把当前文档转换成其他编码

IE6 的加载 CSS 文件 BUG
当 HTML 文件的编码 与想要加载 CSS 的文件不一致的时候,IE6 将无法读取 CSS 文件,即 HTML 文件没有样式。就本人的观察,这个问题从未在其他浏览器中出现过,只在 IE6 中出现过。只需要把 CSS 文件,保存成 HTML 文件的编码即可。
我眼中的四叶新媒体
四叶新媒体,2011年9月成立独立团队。这个团队在成立之初只有6人,但在头两个月里先后推出了四款应用:中文摄影杂志、每日壁纸、iDaily、每日星座运程,其中iDaily目前的下载量已经超过250万。截至本月,四叶新媒体共计发布16款应用,累计用户达到1500万。在春节前,他们还有4-5款应用会上线。
在团队中,85年出生的沈一鸣成了公司里面“最老”的员工,而另外一名联合创始人@Sai则出生在90年。Sai曾是公司里面最年轻的孩子,但随着一名91年的实习生的加入,Sai目前已经屈居二线…
四叶的团队观
在沈一鸣看来,一个理想的团队就应该是成员人数“少”。他们的团队目前包括9名全职人员和1名实习生,而这名实习生则是从两三百号申请者中百里挑一。
之所以要执行如此苛严的人才选拔制度,沈一鸣提到了两点:
- 为了将沟通成本降到最低。根据沈一鸣的个人经验,沟通成本通常是很多团队“最大”的一部分成本,尽管他们或许根本没有意识这一点。在沈一鸣看来,只有当团队中的每个个体能力都很强,每个个体都能轻松认同大家的工作方式时,这个沟通成本才能降到最低。
- 团队的价值是每个个体相乘而非相加的结果。在这个前提下,团队对每个个体的价值要求都应该是>1,而非是0.*的。所以,假如他们吸纳了一个个体价值<1的成员,那么这次吸纳反而降低了团队的整体价值,对其他同事来说就很不公平。一个团队里面能够发生的最好的事情是,每个人都能为其他人所取得的成就感到惊讶、大家能够相互促进、相互加成。
四叶的团队观,我总结了一下就是下面几个短句:
量少而精致,人才选拔苛严;宁缺毋滥,团队价值相乘原则;赶鸭子上架,从实习生开始进阶;追求多样化,给产品注入更多风格;还有一点,正如我在编者按中提到的,尊重团队价值,不凸显个人。
执行:
下面一个你我都很关心的问题是,为什么四叶可以这么快地推出新产品。沈一鸣用一句话做了概括:生产力和生产关系要匹配。四叶的团队成员都很棒,素质很高,在此基础上,他们会确定这样一个生产关系:
- 不开会,大部分的沟通都是仅限于3到4个人。很多团队存在的最大问题是“沟通”,但四叶基本不存在一个决策流程的成本。团队的每个人都很明确自己的分工、职权,他们在做一款产品前,也会对它的前景有一个很明确的预估,甚至包括用户量的目标。
- 沈一鸣说,从架构、UI设计、功能实现到测试,这是一个链条关系。要尽量避免前面环节的无效和不确定,这样就不会做无用功。
- 还有一点需要澄清的是,虽然四叶几乎每月推新,但他们的项目实际是交替进行的。一款产品从策划到上架,通常也需要3-4个月的时间,但多线程对他们来说似乎并不是个问题。
四叶的产品观,同样可以总结成几句话:
- 设计:遵循、吃透苹果官方guideline,但风格化实际无定论;让用户觉得“愉悦”,不过,具体还要适应产品“功能”;
- 定位:最先从自己的需求出发,兼顾群体用户需求;
- 执行:明晰职权,最小化沟通成本;前一个环节牵好线、带好队;产品交替进行、多线程工作;
小米总裁林斌:我们是怎么做互联网营销的
通过互联网模式的运营手段使得一个新生产不久的手机品牌变成了广为人知的甚至被疯狂追捧的知名品牌,小米手机的运营模式一直为业界津津乐道。不久前,在中国国际通信展ICT论坛移动互联网分论坛上,小米科技总裁林斌分享了小米是如何利用互联网手段做营销的。
林斌表示,首先,在产品的设计过程中,小米创新性的引入了用户的观点。在小米手机论坛上,每周都可以看到两三千篇用户反馈的帖子,其中不乏一些深度的使用体验报告。在一些重要功能的确定上,小米工程师通过在论坛上发起投票等方式收集用户反馈,最终确定产品功能形态。林斌说“有大量的功能讨论是用户参与的功能讨论,在我们的论坛上进行的”。
其次,小米在各种的媒体论坛上,都是零距离贴近用户的。林斌表示,包括雷军在内的小米合伙人每天都在做一系列的客服的工作,亲自解答用户的一些提问。
此外,林斌还重点强调了微博传播的功效。林斌表示,贴近用户最核心的优势是能够第一时间掌握用户对小米产品的反馈,微博最大的价值是能够产生很大量的用户对产品的真实意见。小米团队每天都会在微博上搜索相关信息,收集用户反馈。
通过微博营销也可以很好的为企业节约成本。林斌举例说,小米青春版发布时,由于没有足够的宣传经费,他们选择了微博营销的方式。几个合伙人花了一下午的时间拍了一组与青春有关的照片,在微博上短短两天达到了转发200多万次,评论90多万条的成绩。
林斌对这样的结果非常满意,他说“我们能不能用传统的方式能够做到两三百万的用户,真正看到我们产品的宣传?除了花了天文数字的广告费之外,效果能不能像微博这么好都是问号”。
林斌表示,互联网上做推广不是卖广告,广告是没有传播性的,更多的是带有一种互联网化的创意加一点恶搞、平民文化和有趣等各种各样的结合,只有这样的帖子才能有传播性。最核心的是如何能够有一种非常强的互联网文化的创意,能够在微博上流行起来。
最后,林斌总结道:
“第一,作为一家互联网的创新公司创新是根本,离开了创新的产品,无论有多强的推广的能力、忽悠能力,别的方面的创新都没有。产品是核心。产品的技术和产品的创新是整家公司的核心。
第二,小米虽然取得了一点小成绩,但是我们是很幸运的,我们是站在互联网潮流快速发展中的一员,两年多我们走下来还有很多地方做得不好,产品、质量、售后和公司内部的管理上有很多不完善的地方,我们也在全力弥补这些不足,希望将来越做越好,不足的地方也请大家谅解。
第三,移动互联网是个很大的产业,我们觉得这个产业只凭小米一家是不可能做起来的,我们希望很多的公司跟我们一起来把产业做大,大到能够足以容纳下非常多的很成功的企业,这些企业互相促进、互相竞争,把整个产业做起来,才能一起成长。”
三个故事看懂了再结婚

三个故事看懂了再结婚
妻子出门旅游去了,留下了男人一个人在家。妻子不在家,男人喝着啤酒,不停地换着电视频道。这时,女孩的电话打来了,她说:“我闲着没事,到你家坐坐吧!”男人说:“这……不行,我正要出去。”女孩其实已经在男人的楼下了。女孩是男人的部下,女孩很多次对他表示了好感,男人都巧妙地拒绝了。
女孩手里提着很多东西,还有一瓶红酒,站在了男人的家门口。男人说:“那我下厨吧!”女孩说:“不用。”便在厨房里忙碌起来。
在另一间房子里,他开始打电话约熟悉的朋友来家里吃饭,可是朋友们都不在。
过一会,女孩已经在喊他了,他到厨房猛地愣了,女孩端给他的是一盘热腾腾的饺子,他最爱吃饺子了,可是,平时他和妻子都太忙,没有时间包饺子,两盘饺子、几碟小菜、一瓶红酒,女孩的脸上柔柔的笑,搅动了他的心。
说不清为什么,他在女孩不注意的时候,关掉了手机,拉上了阳台的窗帘,他能听到自己心跳的声音。一瓶红酒喝完了,女孩说头晕,就软绵绵地倒在了男人怀里。
男人承认女孩是美丽的,他紧紧地把她抱在怀里,也就在那一刻,他才感觉到女孩的身体是那样的弱小。他的心猛地一颤。女孩在他的床上睡去了,他轻轻地带上了门。
这时,客厅的电话响了,是妻子和孩子打来的。男人仍然喝着啤酒,不停地换着频道,他分明听到了女孩轻微的呼吸,但是,他努力地让自己的心冷静、再冷静。
女孩醒来的时候已经是第二天早上,男人一夜未眠,男人为女孩准备了早餐。吃饭的时候,女孩问:“你不喜欢我吗?”男人说:“喜欢。”“那你不寂寞吗?”女孩追问。“有点!”“可是……怕我纠缠你?”女孩扁着嘴失望地问道。
男人认真地说:“生活是一种责任,就像这碗稀饭和煎蛋,尽管老吃觉得没有什么味道,可是你每天还得做、还得吃,有时甚至觉得它难吃,可是不吃心里空荡荡的。”女孩沉默了。
送走了女孩,男人觉得从未有过的轻松。爱是一种诚信,是需要付出代价的,如果不爱,或无法承受,那么就别轻易地将自己的心打开。诱惑和寂寞,本就不是出轨的理由。
故事二
男孩结婚后对自己的妻子比结婚前更好。一次聚会,朋友笑他:怎么结婚了还那么腻。
他讪讪地笑着说道:“结婚前,很多男生都想追她,有很多男生会对她好,我只有对她更好才能追到她;结婚后,对她好的男生越来越少,我只有对她更好,才能不让她失落。我所做的一切就是想让她幸福。”说完,所有在场的朋友都沉默了,没有嘲笑,只有敬佩。
故事三
丈夫在床边护理即将临盆的妻子。妻子问丈夫:“你希望是男孩还是女孩?”丈夫:“如果是男孩,我们爷俩保护你;如果是女孩,我保护你们娘俩。”
都说婚姻是爱情的坟墓。原来是好女嫁错了郎!爱情不是荣华富贵,而是相濡以沫。
结婚本是一件幸福的事,前提是嫁给了会把你当宝的人。
Excel常用函数大全
我们在使用Excel制作表格整理数据的时候,常常要用到它的函数功能来自动统计处理表格中的数据。这里整理了Excel中使用频率最高的函数的功能、使用方法,以及这些函数在实际应用中的实例剖析,并配有详细的介绍。
1、ABS函数
函数名称:ABS
主要功能:求出相应数字的绝对值。
使用格式:ABS(number)
参数说明:number代表需要求绝对值的数值或引用的单元格。
应用举例:如果在B2单元格中输入公式:=ABS(A2),则在A2单元格中无论输入正数(如100)还是负数(如-100),B2中均显示出正数(如100)。
特别提醒:如果number参数不是数值,而是一些字符(如A等),则B2中返回错误值“#VALUE!”。
2、AND函数
函数名称:AND
主要功能:返回逻辑值:如果所有参数值均为逻辑“真(TRUE)”,则返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。
使用格式:AND(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C5单元格输入公式:=AND(A5>=60,B5>=60),确认。如果C5中返回TRUE,说明A5和B5中的数值均大于等于60,如果返回FALSE,说明A5和B5中的数值至少有一个小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
3、AVERAGE函数
函数名称:AVERAGE
主要功能:求出所有参数的算术平均值。
使用格式:AVERAGE(number1,number2,……)
参数说明:number1,number2,……:需要求平均值的数值或引用单元格(区域),参数不超过30个。
应用举例:在B8单元格中输入公式:=AVERAGE(B7:D7,F7:H7,7,8),确认后,即可求出B7至D7区域、F7至H7区域中的数值和7、8的平均值。
特别提醒:如果引用区域中包含“0”值单元格,则计算在内;如果引用区域中包含空白或字符单元格,则不计算在内。
4、COLUMN 函数
函数名称:COLUMN
主要功能:显示所引用单元格的列标号值。
使用格式:COLUMN(reference)
参数说明:reference为引用的单元格。
应用举例:在C11单元格中输入公式:=COLUMN(B11),确认后显示为2(即B列)。
特别提醒:如果在B11单元格中输入公式:=COLUMN(),也显示出2;与之相对应的还有一个返回行标号值的函数——ROW(reference)。
5、CONCATENATE函数
函数名称:CONCATENATE
主要功能:将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。
使用格式:CONCATENATE(Text1,Text……)
参数说明:Text1、Text2……为需要连接的字符文本或引用的单元格。
应用举例:在C14单元格中输入公式:=CONCATENATE(A14,"@",B14,".com"),确认后,即可将A14单元格中字符、@、B14单元格中的字符和.com连接成一个整体,显示在C14单元格中。
特别提醒:如果参数不是引用的单元格,且为文本格式的,请给参数加上英文状态下的双引号,如果将上述公式改为:=A14&"@"&B14&".com",也能达到相同的目的。
6、COUNTIF函数
函数名称:COUNTIF
主要功能:统计某个单元格区域中符合指定条件的单元格数目。
使用格式:COUNTIF(Range,Criteria)
参数说明:Range代表要统计的单元格区域;Criteria表示指定的条件表达式。
应用举例:在C17单元格中输入公式:=COUNTIF(B1:B13,">=80"),确认后,即可统计出B1至B13单元格区域中,数值大于等于80的单元格数目。
特别提醒:允许引用的单元格区域中有空白单元格出现。
7、DATE函数
函数名称:DATE
主要功能:给出指定数值的日期。
使用格式:DATE(year,month,day)
参数说明:year为指定的年份数值(小于9999);month为指定的月份数值(可以大于12);day为指定的天数。
应用举例:在C20单元格中输入公式:=DATE(2003,13,35),确认后,显示出2004-2-4。
特别提醒:由于上述公式中,月份为13,多了一个月,顺延至2004年1月;天数为35,比2004年1月的实际天数又多了4天,故又顺延至2004年2月4日。
8、函数名称:DATEDIF
主要功能:计算返回两个日期参数的差值。
使用格式:=DATEDIF(date1,date2,"y")、=DATEDIF(date1,date2,"m")、=DATEDIF(date1,date2,"d")
参数说明:date1代表前面一个日期,date2代表后面一个日期;y(m、d)要求返回两个日期相差的年(月、天)数。
应用举例:在C23单元格中输入公式:=DATEDIF(A23,TODAY(),"y"),确认后返回系统当前日期[用TODAY()表示)与A23单元格中日期的差值,并返回相差的年数。
特别提醒:这是Excel中的一个隐藏函数,在函数向导中是找不到的,可以直接输入使用,对于计算年龄、工龄等非常有效。
9、DAY函数
函数名称:DAY
主要功能:求出指定日期或引用单元格中的日期的天数。
使用格式:DAY(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=DAY("2003-12-18"),确认后,显示出18。
特别提醒:如果是给定的日期,请包含在英文双引号中。
10、DCOUNT函数
函数名称:DCOUNT
主要功能:返回数据库或列表的列中满足指定条件并且包含数字的单元格数目。
使用格式:DCOUNT(database,field,criteria)
参数说明:Database表示需要统计的单元格区域;Field表示函数所使用的数据列(在第一行必须要有标志项);Criteria包含条件的单元格区域。
应用举例:如图1所示,在F4单元格中输入公式:=DCOUNT(A1:D11,"语文",F1:G2),确认后即可求出“语文”列中,成绩大于等于70,而小于80的数值单元格数目(相当于分数段人数)。

特别提醒:如果将上述公式修改为:=DCOUNT(A1:D11,,F1:G2),也可以达到相同目的。
11、FREQUENCY函数
函数名称:FREQUENCY
主要功能:以一列垂直数组返回某个区域中数据的频率分布。
使用格式:FREQUENCY(data_array,bins_array)
参数说明:Data_array表示用来计算频率的一组数据或单元格区域;Bins_array表示为前面数组进行分隔一列数值。
应用举例:如图2所示,同时选中B32至B36单元格区域,输入公式:=FREQUENCY(B2:B31,D2:D36),输入完成后按下“Ctrl+Shift+Enter”组合键进行确认,即可求出B2至B31区域中,按D2至D36区域进行分隔的各段数值的出现频率数目(相当于统计各分数段人数)。
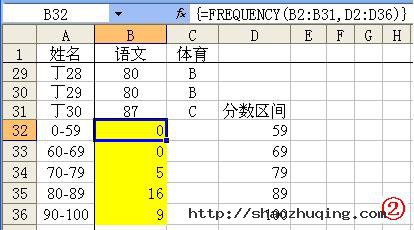
特别提醒:上述输入的是一个数组公式,输入完成后,需要通过按“Ctrl+Shift+Enter”组合键进行确认,确认后公式两端出现一对大括号({}),此大括号不能直接输入。
12、IF函数
函数名称:IF
主要功能:根据对指定条件的逻辑判断的真假结果,返回相对应的内容。
使用格式:=IF(Logical,Value_if_true,Value_if_false)
参数说明:Logical代表逻辑判断表达式;Value_if_true表示当判断条件为逻辑“真(TRUE)”时的显示内容,如果忽略返回“TRUE”;Value_if_false表示当判断条件为逻辑“假(FALSE)”时的显示内容,如果忽略返回“FALSE”。
应用举例:在C29单元格中输入公式:=IF(C26>=18,"符合要求","不符合要求"),确信以后,如果C26单元格中的数值大于或等于18,则C29单元格显示“符合要求”字样,反之显示“不符合要求”字样。
特别提醒:本文中类似“在C29单元格中输入公式”中指定的单元格,读者在使用时,并不需要受其约束,此处只是配合本文所附的实例需要而给出的相应单元格,具体请大家参考所附的实例文件。
13、INDEX函数
函数名称:INDEX
主要功能:返回列表或数组中的元素值,此元素由行序号和列序号的索引值进行确定。
使用格式:INDEX(array,row_num,column_num)
参数说明:Array代表单元格区域或数组常量;Row_num表示指定的行序号(如果省略row_num,则必须有 column_num);Column_num表示指定的列序号(如果省略column_num,则必须有 row_num)。
应用举例:如图3所示,在F8单元格中输入公式:=INDEX(A1:D11,4,3),确认后则显示出A1至D11单元格区域中,第4行和第3列交叉处的单元格(即C4)中的内容。
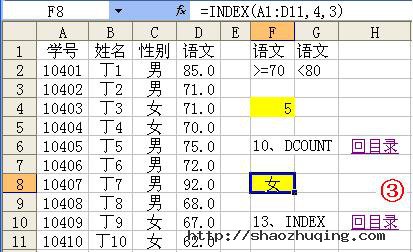
特别提醒:此处的行序号参数(row_num)和列序号参数(column_num)是相对于所引用的单元格区域而言的,不是Excel工作表中的行或列序号。
14、INT函数
函数名称:INT
主要功能:将数值向下取整为最接近的整数。
使用格式:INT(number)
参数说明:number表示需要取整的数值或包含数值的引用单元格。
应用举例:输入公式:=INT(18.89),确认后显示出18。
特别提醒:在取整时,不进行四舍五入;如果输入的公式为=INT(-18.89),则返回结果为-19。
15、ISERROR函数
函数名称:ISERROR
主要功能:用于测试函数式返回的数值是否有错。如果有错,该函数返回TRUE,反之返回FALSE。
使用格式:ISERROR(value)
参数说明:Value表示需要测试的值或表达式。
应用举例:输入公式:=ISERROR(A35/B35),确认以后,如果B35单元格为空或“0”,则A35/B35出现错误,此时前述函数返回TRUE结果,反之返回FALSE。
特别提醒:此函数通常与IF函数配套使用,如果将上述公式修改为:=IF(ISERROR(A35/B35),"",A35/B35),如果B35为空或“0”,则相应的单元格显示为空,反之显示A35/B35的结果。
16、LEFT函数
函数名称:LEFT
主要功能:从一个文本字符串的第一个字符开始,截取指定数目的字符。
使用格式:LEFT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A38单元格中保存了“我喜欢天极网”的字符串,我们在C38单元格中输入公式:=LEFT(A38,3),确认后即显示出“我喜欢”的字符。
特别提醒:此函数名的英文意思为“左”,即从左边截取,Excel很多函数都取其英文的意思。
17、LEN函数
函数名称:LEN
主要功能:统计文本字符串中字符数目。
使用格式:LEN(text)
参数说明:text表示要统计的文本字符串。
应用举例:假定A41单元格中保存了“我今年28岁”的字符串,我们在C40单元格中输入公式:=LEN(A40),确认后即显示出统计结果“6”。
特别提醒:LEN要统计时,无论中全角字符,还是半角字符,每个字符均计为“1”;与之相对应的一个函数——LENB,在统计时半角字符计为“1”,全角字符计为“2”。
18、MATCH函数
函数名称:MATCH
主要功能:返回在指定方式下与指定数值匹配的数组中元素的相应位置。
使用格式:MATCH(lookup_value,lookup_array,match_type)
参数说明:Lookup_value代表需要在数据表中查找的数值;
Lookup_array表示可能包含所要查找的数值的连续单元格区域;
Match_type表示查找方式的值(-1、0或1)。
如果match_type为-1,查找大于或等于 lookup_value的最小数值,Lookup_array 必须按降序排列;
如果match_type为1,查找小于或等于 lookup_value 的最大数值,Lookup_array 必须按升序排列;
如果match_type为0,查找等于lookup_value 的第一个数值,Lookup_array 可以按任何顺序排列;如果省略match_type,则默认为1。
应用举例:如图4所示,在F2单元格中输入公式:=MATCH(E2,B1:B11,0),确认后则返回查找的结果“9”。

特别提醒:Lookup_array只能为一列或一行。
19、MAX函数
函数名称:MAX
主要功能:求出一组数中的最大值。
使用格式:MAX(number1,number2……)
参数说明:number1,number2……代表需要求最大值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MAX(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最大值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
20、MID函数
函数名称:MID
主要功能:从一个文本字符串的指定位置开始,截取指定数目的字符。
使用格式:MID(text,start_num,num_chars)
参数说明:text代表一个文本字符串;start_num表示指定的起始位置;num_chars表示要截取的数目。
应用举例:假定A47单元格中保存了“我喜欢天极网”的字符串,我们在C47单元格中输入公式:=MID(A47,4,3),确认后即显示出“天极网”的字符。
特别提醒:公式中各参数间,要用英文状态下的逗号“,”隔开。
21、MIN函数
函数名称:MIN
主要功能:求出一组数中的最小值。
使用格式:MIN(number1,number2……)
参数说明:number1,number2……代表需要求最小值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MIN(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最小值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
22、MOD函数
函数名称:MOD
主要功能:求出两数相除的余数。
使用格式:MOD(number,divisor)
参数说明:number代表被除数;divisor代表除数。
应用举例:输入公式:=MOD(13,4),确认后显示出结果“1”。
特别提醒:如果divisor参数为零,则显示错误值“#DIV/0!”;MOD函数可以借用函数INT来表示:上述公式可以修改为:=13-4*INT(13/4)。
23、MONTH函数
函数名称:MONTH
主要功能:求出指定日期或引用单元格中的日期的月份。
使用格式:MONTH(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=MONTH("2003-12-18"),确认后,显示出11。
特别提醒:如果是给定的日期,请包含在英文双引号中;如果将上述公式修改为:=YEAR("2003-12-18"),则返回年份对应的值“2003”。
24、NOW函数
函数名称:NOW
主要功能:给出当前系统日期和时间。
使用格式:NOW()
参数说明:该函数不需要参数。
应用举例:输入公式:=NOW(),确认后即刻显示出当前系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期和时间格式,可以通过单元格格式进行重新设置。
25、OR函数
函数名称:OR
主要功能:返回逻辑值,仅当所有参数值均为逻辑“假(FALSE)”时返回函数结果逻辑“假(FALSE)”,否则都返回逻辑“真(TRUE)”。
使用格式:OR(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C62单元格输入公式:=OR(A62>=60,B62>=60),确认。如果C62中返回TRUE,说明A62和B62中的数值至少有一个大于或等于60,如果返回FALSE,说明A62和B62中的数值都小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
26、RANK函数
函数名称:RANK
主要功能:返回某一数值在一列数值中的相对于其他数值的排位。
使用格式:RANK(Number,ref,order)
参数说明:Number代表需要排序的数值;ref代表排序数值所处的单元格区域;order代表排序方式参数(如果为“0”或者忽略,则按降序排名,即数值越大,排名结果数值越小;如果为非“0”值,则按升序排名,即数值越大,排名结果数值越大;)。
应用举例:如在C2单元格中输入公式:=RANK(B2,$B$2:$B$31,0),确认后即可得出丁1同学的语文成绩在全班成绩中的排名结果。
特别提醒:在上述公式中,我们让Number参数采取了相对引用形式,而让ref参数采取了绝对引用形式(增加了一个“$”符号),这样设置后,选中C2单元格,将鼠标移至该单元格右下角,成细十字线状时(通常称之为“填充柄”),按住左键向下拖拉,即可将上述公式快速复制到C列下面的单元格中,完成其他同学语文成绩的排名统计。
27、RIGHT函数
函数名称:RIGHT
主要功能:从一个文本字符串的最后一个字符开始,截取指定数目的字符。
使用格式:RIGHT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A65单元格中保存了“我喜欢天极网”的字符串,我们在C65单元格中输入公式:=RIGHT(A65,3),确认后即显示出“天极网”的字符。
特别提醒:Num_chars参数必须大于或等于0,如果忽略,则默认其为1;如果num_chars参数大于文本长度,则函数返回整个文本。
28、SUBTOTAL函数
函数名称:SUBTOTAL
主要功能:返回列表或数据库中的分类汇总。
使用格式:SUBTOTAL(function_num, ref1, ref2, ...)
参数说明:Function_num为1到11(包含隐藏值)或101到111(忽略隐藏值)之间的数字,用来指定使用什么函数在列表中进行分类汇总计算(如图6);ref1, ref2,……代表要进行分类汇总区域或引用,不超过29个。

应用举例:如图7所示,在B64和C64单元格中分别输入公式:=SUBTOTAL(3,C2:C63)和=SUBTOTAL103,C2:C63),并且将61行隐藏起来,确认后,前者显示为62(包括隐藏的行),后者显示为61,不包括隐藏的行。

特别提醒:如果采取自动筛选,无论function_num参数选用什么类型,SUBTOTAL函数忽略任何不包括在筛选结果中的行;SUBTOTAL函数适用于数据列或垂直区域,不适用于数据行或水平区域。
29、SUM函数
函数名称:SUM
主要功能:计算所有参数数值的和。
使用格式:SUM(Number1,Number2……)
参数说明:Number1、Number2……代表需要计算的值,可以是具体的数值、引用的单元格(区域)、逻辑值等。
应用举例:如图7所示,在D64单元格中输入公式:=SUM(D2:D63),确认后即可求出语文的总分。

特别提醒:如果参数为数组或引用,只有其中的数字将被计算。数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略;如果将上述公式修改为:=SUM(LARGE(D2:D63,{1,2,3,4,5})),则可以求出前5名成绩的和。
30、SUMIF函数
函数名称:SUMIF
主要功能:计算符合指定条件的单元格区域内的数值和。
使用格式:SUMIF(Range,Criteria,Sum_Range)
参数说明:Range代表条件判断的单元格区域;Criteria为指定条件表达式;Sum_Range代表需要计算的数值所在的单元格区域。
应用举例:如图7所示,在D64单元格中输入公式:=SUMIF(C2:C63,"男",D2:D63),确认后即可求出“男”生的语文成绩和。
特别提醒:如果把上述公式修改为:=SUMIF(C2:C63,"女",D2:D63),即可求出“女”生的语文成绩和;其中“男”和“女”由于是文本型的,需要放在英文状态下的双引号("男"、"女")中。
31、TEXT函数
函数名称:TEXT
主要功能:根据指定的数值格式将相应的数字转换为文本形式。
使用格式:TEXT(value,format_text)
参数说明:value代表需要转换的数值或引用的单元格;format_text为指定文字形式的数字格式。
应用举例:如果B68单元格中保存有数值1280.45,我们在C68单元格中输入公式:=TEXT(B68, "$0.00"),确认后显示为“$1280.45”。
特别提醒:format_text参数可以根据“单元格格式”对话框“数字”标签中的类型进行确定。
32、TODAY函数
函数名称:TODAY
主要功能:给出系统日期。
使用格式:TODAY()
参数说明:该函数不需要参数。
应用举例:输入公式:=TODAY(),确认后即刻显示出系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期格式,可以通过单元格格式进行重新设置(参见附件)。
33、VALUE函数
函数名称:VALUE
主要功能:将一个代表数值的文本型字符串转换为数值型。
使用格式:VALUE(text)
参数说明:text代表需要转换文本型字符串数值。
应用举例:如果B74单元格中是通过LEFT等函数截取的文本型字符串,我们在C74单元格中输入公式:=VALUE(B74),确认后,即可将其转换为数值型。
特别提醒:如果文本型数值不经过上述转换,在用函数处理这些数值时,常常返回错误。
34、VLOOKUP函数
函数名称:VLOOKUP
主要功能:在数据表的首列查找指定的数值,并由此返回数据表当前行中指定列处的数值。
使用格式:VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)
参数说明:Lookup_value代表需要查找的数值;Table_array代表需要在其中查找数据的单元格区域;Col_index_num为在table_array区域中待返回的匹配值的列序号(当Col_index_num为2时,返回table_array第2列中的数值,为3时,返回第3列的值……);Range_lookup为一逻辑值,如果为TRUE或省略,则返回近似匹配值,也就是说,如果找不到精确匹配值,则返回小于lookup_value的最大数值;如果为FALSE,则返回精确匹配值,如果找不到,则返回错误值#N/A。
应用举例:参见图7,我们在D65单元格中输入公式:=VLOOKUP(B65,B2:D63,3,FALSE),确认后,只要在B65单元格中输入一个学生的姓名(如丁48),D65单元格中即刻显示出该学生的语言成绩。
特别提醒:Lookup_value参见必须在Table_array区域的首列中;如果忽略Range_lookup参数,则Table_array的首列必须进行排序;在此函数的向导中,有关Range_lookup参数的用法是错误的。
35、WEEKDAY函数
函数名称:WEEKDAY
主要功能:给出指定日期的对应的星期数。
使用格式:WEEKDAY(serial_number,return_type)
参数说明:serial_number代表指定的日期或引用含有日期的单元格;return_type代表星期的表示方式[当Sunday(星期日)为1、Saturday(星期六)为7时,该参数为1;当Monday(星期一)为1、Sunday(星期日)为7时,该参数为2(这种情况符合中国人的习惯);当Monday(星期一)为0、Sunday(星期日)为6时,该参数为3]。
应用举例:输入公式:=WEEKDAY(TODAY(),2),确认后即给出系统日期的星期数。
特别提醒:如果是指定的日期,请放在英文状态下的双引号中,如=WEEKDAY("2003-12-18",2)。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
