Token 认证的来龙去脉
为什么要用 Token?
而要回答这个问题很简单——因为它能解决问题! 可以解决哪些问题呢?
- Token 完全由应用管理,所以它可以避开同源策略
- Token 可以避免 CSRF 攻击
- Token 可以是无状态的,可以在多个服务间共享
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位。如果这个 Token 在服务端持久化(比如存入数据库),那它就是一个永久的身份令牌。 于是,又一个问题产生了:需要为 Token 设置有效期吗?
需要设置有效期吗?
对于这个问题,我们不妨先看两个例子。一个例子是登录密码,一般要求定期改变密码,以防止泄漏,所以密码是有有效期的;另一个例子是安全证书。SSL 安全证书都有有效期,目的是为了解决吊销的问题,对于这个问题的详细情况,来看看知乎的回答。所以无论是从安全的角度考虑,还是从吊销的角度考虑,Token 都需要设有效期。 那么有效期多长合适呢? 只能说,根据系统的安全需要,尽可能的短,但也不能短得离谱——想像一下手机的自动熄屏时间,如果设置为 10 秒钟无操作自动熄屏,再次点亮需要输入密码,会不会疯?如果你觉得不会,那就亲自试一试,设置成可以设置的最短时间,坚持一周就好(不排除有人适应这个时间,毕竟手机厂商也是有用户体验研究的)。 然后新问题产生了,如果用户在正常操作的过程中,Token 过期失效了,要求用户重新登录……用户体验岂不是很糟糕? 为了解决在操作过程不能让用户感到 Token 失效这个问题,有一种方案是在服务器端保存 Token 状态,用户每次操作都会自动刷新(推迟) Token 的过期时间——Session 就是采用这种策略来保持用户登录状态的。然而仍然存在这样一个问题,在前后端分离、单页 App 这些情况下,每秒种可能发起很多次请求,每次都去刷新过期时间会产生非常大的代价。如果 Token 的过期时间被持久化到数据库或文件,代价就更大了。所以通常为了提升效率,减少消耗,会把 Token 的过期时保存在缓存或者内存中。 还有另一种方案,使用 Refresh Token,它可以避免频繁的读写操作。这种方案中,服务端不需要刷新 Token 的过期时间,一旦 Token 过期,就反馈给前端,前端使用 Refresh Token 申请一个全新 Token 继续使用。这种方案中,服务端只需要在客户端请求更新 Token 的时候对 Refresh Token 的有效性进行一次检查,大大减少了更新有效期的操作,也就避免了频繁读写。当然 Refresh Token 也是有有效期的,但是这个有效期就可以长一点了,比如,以天为单位的时间。
时序图表示
使用 Token 和 Refresh Token 的时序图如下:
1)登录

2)业务请求

3)Token 过期,刷新 Token
 上面的时序图中并未提到 Refresh Token 过期怎么办。不过很显然,Refresh Token 既然已经过期,就该要求用户重新登录了。 当然还可以把这个机制设计得更复杂一些,比如,Refresh Token 每次使用的时候,都更新它的过期时间,直到与它的创建时间相比,已经超过了非常长的一段时间(比如三个月),这等于是在相当长一段时间内允许 Refresh Token 自动续期。 到目前为止,Token 都是有状态的,即在服务端需要保存并记录相关属性。那说好的无状态呢,怎么实现?
上面的时序图中并未提到 Refresh Token 过期怎么办。不过很显然,Refresh Token 既然已经过期,就该要求用户重新登录了。 当然还可以把这个机制设计得更复杂一些,比如,Refresh Token 每次使用的时候,都更新它的过期时间,直到与它的创建时间相比,已经超过了非常长的一段时间(比如三个月),这等于是在相当长一段时间内允许 Refresh Token 自动续期。 到目前为止,Token 都是有状态的,即在服务端需要保存并记录相关属性。那说好的无状态呢,怎么实现?
无状态 Token
如果我们把所有状态信息都附加在 Token 上,服务器就可以不保存。但是服务端仍然需要认证 Token 有效。不过只要服务端能确认是自己签发的 Token,而且其信息未被改动过,那就可以认为 Token 有效——“签名”可以作此保证。平时常说的签名都存在一方签发,另一方验证的情况,所以要使用非对称加密算法。但是在这里,签发和验证都是同一方,所以对称加密算法就能达到要求,而对称算法比非对称算法要快得多(可达数十倍差距)。更进一步思考,对称加密算法除了加密,还带有还原加密内容的功能,而这一功能在对 Token 签名时并无必要——既然不需要解密,摘要(散列)算法就会更快。可以指定密码的散列算法,自然是 HMAC。 上面说了这么多,还需要自己去实现吗?不用!JWT 已经定义了详细的规范,而且有各种语言的若干实现。 不过在使用无状态 Token 的时候在服务端会有一些变化,服务端虽然不保存有效的 Token 了,却需要保存未到期却已注销的 Token。如果一个 Token 未到期就被用户主动注销,那么服务器需要保存这个被注销的 Token,以便下次收到使用这个仍在有效期内的 Token 时判其无效。有没有感到一点沮丧? 在前端可控的情况下(比如前端和服务端在同一个项目组内),可以协商:前端一但注销成功,就丢掉本地保存(比如保存在内存、LocalStorage 等)的 Token 和 Refresh Token。基于这样的约定,服务器就可以假设收到的 Token 一定是没注销的(因为注销之后前端就不会再使用了)。 如果前端不可控的情况,仍然可以进行上面的假设,但是这种情况下,需要尽量缩短 Token 的有效期,而且必须在用户主动注销的情况下让 Refresh Token 无效。这个操作存在一定的安全漏洞,因为用户会认为已经注销了,实际上在较短的一段时间内并没有注销。如果应用设计中,这点漏洞并不会造成什么损失,那采用这种策略就是可行的。 在使用无状态 Token 的时候,有两点需要注意:
- Refresh Token 有效时间较长,所以它应该在服务器端有状态,以增强安全性,确保用户注销时可控
- 应该考虑使用二次认证来增强敏感操作的安全性
到此,关于 Token 的话题似乎差不多了——然而并没有,上面说的只是认证服务和业务服务集成在一起的情况,如果是分离的情况呢?
分离认证服务
当 Token 无状态之后,单点登录就变得容易了。前端拿到一个有效的 Token,它就可以在任何同一体系的服务上认证通过——只要它们使用同样的密钥和算法来认证 Token 的有效性。就样这样:  当然,如果 Token 过期了,前端仍然需要去认证服务更新 Token:
当然,如果 Token 过期了,前端仍然需要去认证服务更新 Token:  可见,虽然认证和业务分离了,实际即并没产生多大的差异。当然,这是建立在认证服务器信任业务服务器的前提下,因为认证服务器产生 Token 的密钥和业务服务器认证 Token 的密钥和算法相同。换句话说,业务服务器同样可以创建有效的 Token。 如果业务服务器不能被信任,该怎么办?
可见,虽然认证和业务分离了,实际即并没产生多大的差异。当然,这是建立在认证服务器信任业务服务器的前提下,因为认证服务器产生 Token 的密钥和业务服务器认证 Token 的密钥和算法相同。换句话说,业务服务器同样可以创建有效的 Token。 如果业务服务器不能被信任,该怎么办?
不受信的业务服务器
遇到不受信的业务服务器时,很容易想到的办法是使用不同的密钥。认证服务器使用密钥1签发,业务服务器使用密钥2验证——这是典型非对称加密签名的应用场景。认证服务器自己使用私钥对 Token 签名,公开公钥。信任这个认证服务器的业务服务器保存公钥,用于验证签名。幸好,JWT 不仅可以使用 HMAC 签名,也可以使用 RSA(一种非对称加密算法)签名。 不过,当业务服务器已经不受信任的时候,多个业务服务器之间使用相同的 Token 对用户来说是不安全的。因为任何一个服务器拿到 Token 都可以仿冒用户去另一个服务器处理业务……悲剧随时可能发生。 为了防止这种情况发生,就需要在认证服务器产生 Token 的时候,把使用该 Token 的业务服务器的信息记录在 Token 中,这样当另一个业务服务器拿到这个 Token 的时候,发现它并不是自己应该验证的 Token,就可以直接拒绝。 现在,认证服务器不信任业务服务器,业务服务器相互也不信任,但前端是信任这些服务器的——如果前端不信任,就不会拿 Token 去请求验证。那么为什么会信任?可能是因为这些是同一家公司或者同一个项目中提供的若干服务构成的服务体系。 但是,前端信任不代表用户信任。如果 Token 不没有携带用户隐私(比如姓名),那么用户不会关心信任问题。但如果 Token 含有用户隐私的时候,用户得关心信任问题了。这时候认证服务就不得不再啰嗦一些,当用户请求 Token 的时候,问上一句,你真的要授权给某某某业务服务吗?而这个“某某某”,用户怎么知道它是不是真的“某某某”呢?用户当然不知道,甚至认证服务也不知道,因为公钥已经公开了,任何一个业务都可以声明自己是“某某某”。 为了得到用户的信任,认证服务就不得不帮助用户来甄别业务服务。所以,认证服器决定不公开公钥,而是要求业务服务先申请注册并通过审核。只有通过审核的业务服务器才能得到认证服务为它创建的,仅供它使用的公钥。如果该业务服务泄漏公钥带来风险,由该业务服务自行承担。现在认证服务可以清楚的告诉用户,“某某某”服务是什么了。如果用户还是不够信任,认证服务甚至可以问,某某某业务服务需要请求 A、B、C 三项个人数据,其中 A 是必须的,不然它不工作,是否允许授权?如果你授权,我就把你授权的几项数据加密放在 Token 中…… 废话了这么多,有没有似曾相识……对了,这类似开放式 API 的认证过程。开发式 API 多采用 OAuth 认证,而关于 OAuth 的探讨资源非常丰富,这里就不深究了。
如何处理好前后端分离的 API 问题
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
作为一个程序员,我讨厌那些没有文档的库。我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。
因为交付周期的原因,接入了一个第三方的库,遇到了这么一些问题:文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
对于一个库来说,文档是多种多样的:一份 demo、一个入门指南、一个 API 列表,还有一个测试。如果一个 API 有测试,那么它也相当于有一份简单的文档了——如果我们可以看到测试代码的话。而当一个库没有文档的时候,它也不会有测试。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
- API 的字段更新了
- API 的路由更新了
- API 返回了未预期的值
- API 返回由于某种原因被删除了
- 。。。
API 的维护是一件烦人的事,所以最好能一次设计好 API。可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护。
前后端分离 API 的演进史
刚毕业的时候,工作的主要内容是用 Java 写网站后台,业余写写自己喜欢的前端代码。慢慢的,随着各个公司的 Mobile First 战略的实施,项目上的主要语言变成了 JavaScript。项目开始实施了前后端分离,团队也变成了全功能团队,前端、后台、DevOps 变成了每个人需要提高的技能。于是如我们所见,当我们完成一个任务卡的时候,我们需要自己完成后台 API,还要编写相应的前端代码。
尽管当时的手机浏览器性能,已经有相当大的改善,但是仍然会存在明显的卡顿。因此,我们在设计的时候,尽可能地便将逻辑移到了后台,以减少对于前端带来的压力。可性能问题在今天看来,差异已经没有那么明显了。
如同我在《RePractise:前端演进史》中所说,前端领域及 Mobile First 的变化,引起了后台及 API 架构的一系列演进。
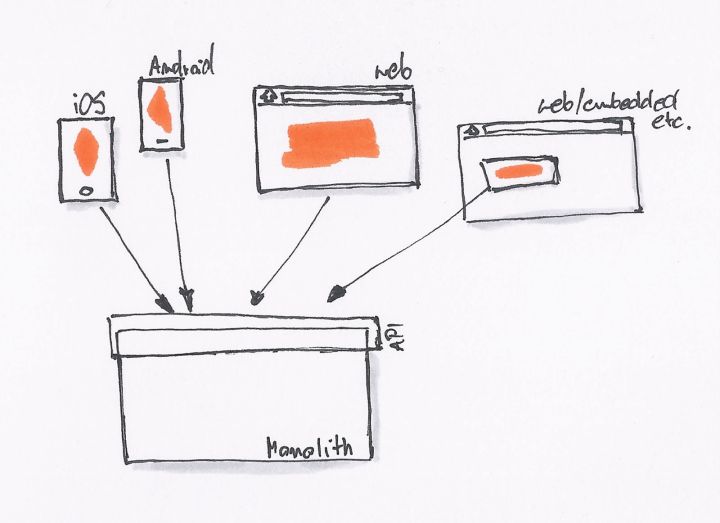
最初的时候,我们只有一个网站,没有 REST API。后台直接提供 Model 数据给前端模板,模板处理完后就展示了相关的数据。
当我们开始需要 API 的时候,我们就会采用最简单、直接的方式,直接在原有的系统里开一个 API 接口出来。
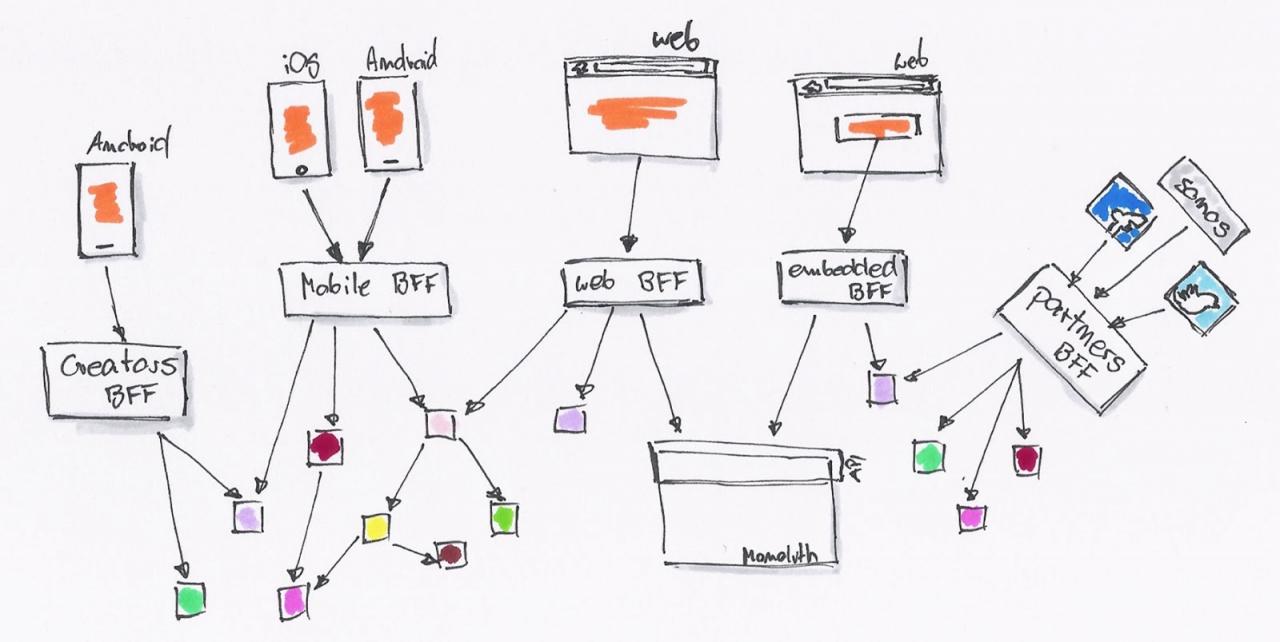
为了不破坏现有系统的架构,同时为了更快的上线,直接开出一个接口来得最为直接。我们一直在这样的模式下工作,直到有一天我们就会发现,我们遇到了一些问题:
- API 消费者:一个接口无法同时满足不同场景的业务。如移动应用,可能与桌面、手机 Web 的需求不一样,导致接口存在差异。
- API 生产者:对接多个不同的 API 需求,产生了各种各样的问题。
于是,这时候就需要 BFF(backend for frontend)这种架构。后台可以提供所有的 MODEL 给这一层接口,而 API 消费者则可以按自己的需要去封装。

API 消费者可以继续使用 JavaScript 去编写 API 适配器。后台则慢慢的因为需要,拆解成一系列的微服务。
系统由内部的类调用,拆解为基于 RESTful API 的调用。后台 API 生产者与前端 API 消费者,已经区分不出谁才是真正的开发者。
瀑布式开发的 API 设计
说实话,API 开发这种活就和传统的瀑布开发差不多:未知的前期设计,痛苦的后期集成。好在,每次这种设计的周期都比较短。
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
- 维护 API 文档很痛苦
- 需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以一个根据代码文件中中注释信息,生成应用程序或库、模块的API文档的工具。
同样的对于 API 来说,也可以采取类似的步骤,如 Swagger。它是基于 YAML语法定义 RESTful API,如:
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
schemes:
- https
host: simple.api
basePath: /openapi101
paths: {}
它会自动生成一篇排版优美的API文档,与此同时还能生成一个供前端人员使用的 Mock Server。同时,它还能支持根据 Swagger API Spec 生成客户端和服务端的代码。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
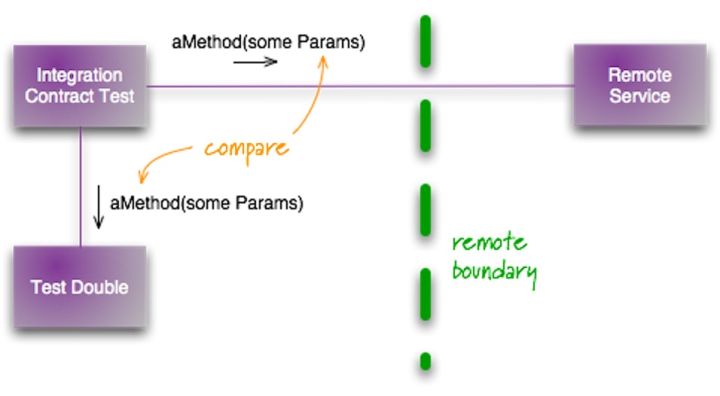
其步骤如下:
- 编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
- 根据契约编写 Mock Server。可以彩 Moco
- 编写集成测试将请求发给这个 Mock Server,并验证
如下是我们项目使用的 Moco 生成的契约,再通过 Moscow 来进行 API 测试。
[
{
"description": "should_response_text_foo",
"request": {
"method": "GET",
"uri": "/property"
},
"response": {
"status": 401,
"json": {
"message": "Full authentication is required to access this resource"
}
}
}
]
只需要在相应的测试代码里请求资源,并验证返回结果即可。
而对于前端来说,则是依赖于 UI 自动化测试。在测试的时候,启动这个 Mock Server,并借助于 Selenium 来访问浏览器相应的地址,模拟用户的行为进行操作,并验证相应的数据是否正确。

当契约发生发动的时候,持续集成便失败了。因此相应的后台测试数据也需要做相应的修改,相应的前端集成测试也需要做相应的修改。因此,这一改动就可以即时地通知各方了。
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:

这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
我们需要处理同的异常数据,不同情况下的返回值等等。因此,我之前尝试开发 DDM 来解决这样的问题,只是轮子没有造完。诸如 Redux 可以管理状态,还应该有个相应的类型检测及 Adapter 工具。
除此,还有一种情况是使用第三方 API,也需要这样的适配层。很多时候,我们需要的第三方 API 以公告的形式来通知各方,可往往我们不会及时地根据这些变化。

一般来说这种工作是后台去做代码的,不得已由前端来实现时,也需要加一层相应的适配层。
小结
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
透明代理、匿名代理、混淆代理、高匿代理区别?
这4种代理,主要是在代理服务器端的配置不同,导致其向目标地址发送请求时,REMOTE_ADDR, HTTP_VIA,HTTP_X_FORWARDED_FOR三个变量不同。
1、透明代理(Transparent Proxy)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = Proxy IP
- HTTP_X_FORWARDED_FOR = Your IP
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
2、匿名代理(Anonymous Proxy)
- REMOTE_ADDR = proxy IP
- HTTP_VIA = proxy IP
- HTTP_X_FORWARDED_FOR = proxy IP
匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
还有一种比纯匿名代理更先进一点的:混淆代理,见下节。
3、混淆代理(Distorting Proxies)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = Proxy IP
- HTTP_X_FORWARDED_FOR = Random IP address
如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真:-)
4、高匿代理(Elite proxy或High Anonymity Proxy)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = not determined
- HTTP_X_FORWARDED_FOR = not determined
可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
