微信开发常见报错及解决方法
小技巧:可能过ctrl+f 进行查找您遇到的问题。
| 支付方式 | 报错提示 | 解决方法 | |
| 热点问题 | 支付返回签名错误 | 注意签名参数的大小写,支付密钥key要到商户平台设置,设置的规则是32位数字与字母大小写的组合。以下链接为签名过程。 (https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=3_1) |
|
| 支付回调 | 认证后的服务号之间支持跨号支付。 | ||
| 支付失败 | 请检查商户号是否错误或支付密钥key设置错误。 | ||
| redirect——uri参数错误 | 请进入公众平台-开发者中心,找到填写商户的支付授权域名,填写的就是商户支付授权目录上的域名。 | ||
| paysinkey如何获取? | 新版的微信支付是没有这个paysignkey参数的,具体的参数请查看文档 | ||
| (https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=3_1) | |||
| mchid是指什么? | MCHID参数指的是商户号 | ||
| openid的获取请参考文档 | openid的获取请参考文档详细介绍 | ||
| (http://mp.weixin.qq.com/wiki/14/bb5031008f1494a59c6f71fa0f319c66.html) | |||
| openid如何获取? | openid的获取请参考文档查看详细介绍: | ||
| (http://mp.weixin.qq.com/wiki/14/bb5031008f1494a59c6f71fa0f319c66.html) | |||
| Appsecret如何获取? | APPsecret参数可进入公众平台(https://mp.weixin.qq.com)开发者中心查看。 | ||
| 调用报错 get_brand_wcpay_request:fail |
签名错误,请仔细检查签名。 | ||
| spbill_create_ip 是指什么? | spbill_create_ip 指的是终端ip,在APP和网页支付提交用户端ip,Native支付填调用微信支付API的机器IP。 | ||
| 网页支付(JSAPI) | “当前公众号没有权限支付本次交易“ | 检查该公众帐号是否已经获取了支付资格。 | |
| “公众帐号支付使用了无效的商户号,无法发起该笔交易” | 检查商户号使用错误。 | ||
| “该公众号支付签名无效,无法发起该笔交易” | 调起支付MD5签名的MD5签名错误,请检查相关签名。 | ||
| “Args Error” | 提交JS时,josn传递参数必须与文档中名字一致,大小写匹配。 | ||
| “access:not_allow” | 未设置白名单,添加位置:微信公众平台=》微信支付=》开发配置 | ||
| 点击支付无反应 | 支付授权目录是否正确,如果使用的是支付测试目录,是否设置了白名单,需白名单帐号进行支付测试。 | ||
| ios系统可以正常支付,android系统支付失败 | timestamp字段值需要加上“”,传递数据必须为字符串类型。 | ||
| 调用报错 get_brand_wcpay_request:fail |
签名错误,请仔细检查签名。 | ||
| 调用报错: zhgj-2014+中涵国际分销商城及“订单满送红包无法送” |
商户设置有问题。 | ||
| IOS系统调用支付JSAPI报错 缺少参数:$key0$,android 没问题 |
提交的参数有问题,注意全部参数都得是字符串类型。 | ||
| 支付验证签名失败 | 签名错误,仔细检查签名。 | ||
| jsapi 缺少参数 key0 | 问题出在网页端调起支付API接口中timeStamp参数,必须是string类型,但是php默认生成的时间戳是int类型。 解决方法:修改下lib/Wxpay.Data.php约2731行处SetTimeStamp方法,修改为$this->values['timestamp'] = (string)$value; |
||
| 安卓手机可以收到满送红包 苹果的不行 红包虽然已经显示发送了红包但是实质资金流水没有扣除资金 | 参数错误,请仔细检查。 | ||
| 调用报错: 传输参数错误 |
推测为提交的支付请求参数不正确;以下文档有详细的参考。https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=7_7 | ||
| 调用报错: 没有获取到微信支付预支付ID,请管理员检查微信支付配置项 |
需要按照文档要求 ,先获取prepay_id。 | ||
| 支付权限检查失败 | 商户所用的参数对应的APPID是APP支付;如果商户想要JSAPI支付,需要在公众平台申请公众号,公众号支付中才有此参数。 | ||
| 原生支付(扫码支付) | “获取商户数据失败” | 请检查申请native支付时的回调URL地址是否正确,是否可以外网访问获取数据。 | |
| “商户返回数据错误” | native回调返回数据格式错误,非XML格式数据。 | ||
| “签名错误” | 检查MD5签名中参数格式及值是否正确。 | ||
| 调用报错: 获取商户订单信息超时或商户返回httpcode非200 |
签名错误,请仔细检查签名。 | ||
| 错误返回:错误码:60 | 错误通过修改文件:WxPay.Api.php解决,具体如下: 第537行 curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,TURE); curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,2);//严格校验 to curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,FALSE); curl_setopt($ch,CURLOPT_SSL_VERIFYPEER,FALSE);//严格校验2 微信支付错误两个问题的解决:curl出错,错误码:60 |
||
| APP支付 | 错误返回“-1” | 开放平台配置的报名和应用签名是否一致:(android);确认是否使用正式的keystore打包apk并安装调试;(android);提交订单部分需要在服务器端完成。 | |
| 下单报{"errcode":62621014,"errmsg":""} | Package数据MD5签名错误,请参照文档检查。 | ||
| 下单报"1001"错误 | package里缺少必要参数;金额类型为证书,单位是分。 | ||
| android签名正常,ios签名错误 | 需要注意body如果是中文,需要编码,编码格式统一为“UTF-8”。 | ||
| 支付授权地址没有经过ICP验证 | 域名需要是英文备案域名方可。(此情况针对备案域名中包含中文字符或其他) | ||
| ios系统:订单成功,无法跳转到支付界面 | 请仔细查阅参考开发文档步骤。 | ||
| 支付结果报错:errStr=null,code=-1 | 请检查开放平台配置的包名和签名是否跟APK安装后的包名签名一致,一致才会调用的。 | ||
| 支付无法调起 | 请检查开放平台配置的包名和签名是否跟你的APK安装后的包名签名一致,一致才会调用的。 | ||
| 需要V3版的app支付服务端demo,因获取prepayId失败,找不到app_key | 新版的微信支付是没有这个参数的,请查看最新版文档。 | ||
| 请求prepayid发生错误: errcode":268497023,"errmsg |
请将商户的APPID和商户号以及报错截图发送至wepayTS@tencent.com,进行深入了解。 | ||
| 支付返回报错: :"errcode":268497023,"errmsg":"您已完成交易接口升级,老接口交易权限已关闭,请使用新接口进行交易。如有疑问请联系微信支付客服咨询" |
请将商户的APPID和商户号以及报错截图发送至wepayTS@tencent.com,进行深入了解。 | ||
| 请求prepayid发生错误: 信息[{"errcode":268497023,"errmsg":"鎮ㄥ凡瀹屾垚浜ゆ槗鎺ュ彛鍗囩骇锛岃 鎺ュ彛浜ゆ槗鏉冮檺宸插叧闂紝璇蜂娇鐢ㄦ柊鎺ュ彛杩涜浜ゆ槗銆傚鏈夌枒闂鑱旂郴寰俊鏀粯瀹㈡湇鍜ㄨ"}] |
请将商户的APPID和商户号以及报错截图发送至wepayTS@tencent.com,进行深入了解。 | ||
| 根据文档下订单,调用微信支付失败。调用微信支付的时候,微信为登录状态则无反应;微信未登录状态,会调用微信登录界面。 | 请将商户的APPID和商户号以及报错截图+请求参数详情,发送至wepayTS@tencent.com,进行深入了解。 | ||
| 常见问题 | 申请正在审核中,如何可以提前调试测试? | 只需要资料审核通过,收到通知邮件即可通过配置测试目录进行联调测试。未审核通过可下载文档进行开发,但不能联调测试。 | |
| 支付授权目录是什么? | 支付授权目录是支付功能正式上线后,商户后台发起支付请求的页面所在的目录。 | ||
| 支付测试目录是什么? | 支付测试目录提供给开发者,在开发测试期间使用的临时目录。 | ||
| 支付测试目录和授权目录有何区别? | 支付授权目录将会在产品上线审核时,以及上线后长期使用的正式目录;测试目录只能配置白名单,才可以在公众号内发起支付。 | ||
| 如何配置支付目录(授权、测试)? | 登录微信公众平台-微信支付-开发配置-修改 | ||
| 支付目录有什么规则? | 头部需要包含http或https,须细化到二级或三级目录,字母小写,以左斜杠“/”结尾。 | ||
| 如何配置授权回调页面域名? | 登录微信公众平台=》开发者中心=》网页授权获取用户基本信息=》修改 | ||
| 微信支付接口的签名规则是如何的? | MD5签名,订单数据签名,所有传输的字段均需要参与签名,使用商户密钥key在签名字段排序后放入在最后组包签名。 | ||
| “订单数据签名验证失败”如何解决? | 检查参数是否一致;是否含有特殊字符;中文编码类型是否与所传参数一致;body参数是否含空格,若有空格URLencode的时需要转为%20。 | ||
| 报40001错误,如何解决? | accesstoken失效或者过期,accesstoken有效期为2小时,如果有系统或者人为重新获取,前一个accesstoken也会自动消失。请保证accesstoken为全局管理,避免重复获取。 | ||
| 签名正常,却提示fail_invalid appid | 查看支付授权目录是否设置正确,所支付页面路径是否在支付授权目录下。 | ||
| 公众号是否可以跨号支付? | 两个具有支付权限的服务号之间可以跨号支付,但不可混淆appid。 | ||
| 支付完成,Notify URL无法接收回调通知 | 需要绝对路径,外网可访问,不支持非80端口,同时注意不要被防火墙拦截;可自行用fiddler模拟post访问是否正常。 | ||
| 查询订单接口报“errcode":49001,"errmsg": | 检查accesstoken是否为同一APPID获取;POST数据必须为JSON格式, | ||
| "not same appid with appid of access_token"错误如何解决? | 避免格式不对导致获取APPID不一致。 | ||
| 支付提示“系统繁忙,请稍后再试” | 检查签名及传入参数是否与文档要求一致;尤其是MD5签名部门的正确性。 | ||
| 调用支付报错【特殊】 | 调用报错: “chooseWXPay:fail” |
此情况需要商户将提交的签名过程发送至邮箱:wepayTS@tencent.com,进行深入了解。 | |
| 调用报错: “{return_msg=支付权限检查失败, return_code=FAIL}” |
此情况需要将提交的xml发送至邮箱:wepayTS@tencent.com,进行深入了解。 | ||
| zhgj-2014+中涵国际分销商城及“订单满送红包无法送” | 请将商户的APPID和商户号以及报错截图发送至wepayTS@tencent.com,进行深入了解。 | ||
| 微信支付完成后不能执行回调 | 请将商户的APPID和商户号以及报错截图发送至wepayTS@tencent.com,进行深入了解。 | ||
| 报错:不允许跨号支付 ios上没这个问题,android上有些商品有这个问题 |
是否通过订阅号发出此请求,请将APPID,商户号,报错截图及请求参数发送至wepayTS@tencent.com,进行深入了解。 |
微信公众平台开发 OAuth2.0网页授权认证
一、什么是OAuth2.0
官方网站:http://oauth.net/ http://oauth.net/2/
权威定义:OAuth is An open protocol to allow secure authorization in a simple and standard method from web, mobile and desktop applications.
OAuth是一个开放协议,允许用户让第三方应用以安全且标准的方式获取该用户在某一网站、移动或桌面应用上存储的私密的资源(如用户个人信息、照片、视频、联系人列表),而无需将用户名和密码提供给第三方应用。
OAuth 2.0是OAuth协议的下一版本,但不向后兼容OAuth 1.0。 OAuth 2.0关注客户端开发者的简易性,同时为Web应用,桌面应用和手机,和起居室设备提供专门的认证流程。
OAuth允许用户提供一个令牌,而不是用户名和密码来访问他们存放在特定服务提供者的数据。每一个令牌授权一个特定的网站(例如,视频编辑网站)在特定的时段(例如,接下来的2小时内)内访问特定的资源(例如仅仅是某一相册中的视频)。这样,OAuth允许用户授权第三方网站访问他们存储在另外的服务提供者上的信息,而不需要分享他们的访问许可或他们数据的所有内容。
新浪微博API目前也使用OAuth 2.0。
二、微信公众平台OAuth2.0授权
微信公众平台OAuth2.0授权详细步骤如下:
1. 用户关注微信公众账号。
2. 微信公众账号提供用户请求授权页面URL。
3. 用户点击授权页面URL,将向服务器发起请求
4. 服务器询问用户是否同意授权给微信公众账号(scope为snsapi_base时无此步骤)
5. 用户同意(scope为snsapi_base时无此步骤)
6. 服务器将CODE通过回调传给微信公众账号
7. 微信公众账号获得CODE
8. 微信公众账号通过CODE向服务器请求Access Token
9. 服务器返回Access Token和OpenID给微信公众账号
10. 微信公众账号通过Access Token向服务器请求用户信息(scope为snsapi_base时无此步骤)
11. 服务器将用户信息回送给微信公众账号(scope为snsapi_base时无此步骤)
如果用户在微信中(Web微信除外)访问公众号的第三方网页,公众号开发者可以通过此接口获取当前用户基本信息(包括昵称、性别、城市、国家)。利用用户信息,可以实现体验优化、用户来源统计、帐号绑定、用户身份鉴权等功能。请注意,“获取用户基本信息接口是在用户和公众号产生消息交互时,才能根据用户OpenID获取用户基本信息,而网页授权的方式获取用户基本信息,则无需消息交互,只是用户进入到公众号的网页,就可弹出请求用户授权的界面,用户授权后,就可获得其基本信息(此过程甚至不需要用户已经关注公众号。)”
微信OAuth2.0授权登录让微信用户使用微信身份安全登录第三方应用或网站,在微信用户授权登录已接入微信OAuth2.0的第三方应用后,第三方可以获取到用户的接口调用凭证(access_token),通过access_token可以进行微信开放平台授权关系接口调用,从而可实现获取微信用户基本开放信息和帮助用户实现基础开放功能等。
在微信公众号请求用户网页授权之前,开发者需要先到公众平台网站的我的服务页中配置授权回调域名。请注意,这里填写的域名不要加http://
关于配置授权回调域名的说明:
授权回调域名配置规范为全域名,比如需要网页授权的域名为:www.qq.com,配置以后此域名下面的页面http://www.qq.com/music.html 、 http://www.qq.com/login.html 都可以进行OAuth2.0鉴权。但http://pay.qq.com 、 http://music.qq.com 、 http://qq.com 无法进行OAuth2.0鉴权。
具体而言,网页授权流程分为四步:
- 引导用户进入授权页面同意授权,获取code
- 通过code换取网页授权access_token(与基础支持中的access_token不同)
- 如果需要,开发者可以刷新网页授权access_token,避免过期
- 通过网页授权access_token和openid获取用户基本信息
目录[隐藏] |
第一步:用户同意授权,获取code
在确保微信公众账号拥有授权作用域(scope参数)的权限的前提下(服务号获得高级接口后,默认带有scope参数中的snsapi_base和snsapi_userinfo),引导关注者打开如下页面:
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect 若提示“该链接无法访问”,请检查参数是否填写错误,是否拥有scope参数对应的授权作用域权限。 参考链接(请在微信客户端中打开此链接体验) Scope为snsapi_base https://open.weixin.qq.com/connect/oauth2/authorize?appid=wx520c15f417810387&redirect_uri=http%3A%2F%2Fchong.qq.com%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect Scope为snsapi_userinfo https://open.weixin.qq.com/connect/oauth2/authorize?appid=wxf0e81c3bee622d60&redirect_uri=http%3A%2F%2Fnba.bluewebgame.com%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| redirect_uri | 是 | 授权后重定向的回调链接地址,请使用urlencode对链接进行处理 |
| response_type | 是 | 返回类型,请填写code |
| scope | 是 | 应用授权作用域,snsapi_base (不弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo (弹出授权页面,可通过openid拿到昵称、性别、所在地。并且,即使在未关注的情况下,只要用户授权,也能获取其信息) |
| state | 否 | 重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值 |
| #wechat_redirect | 是 | 无论直接打开还是做页面302重定向时候,必须带此参数 |
下图为scope等于snsapi_userinfo时的授权页面:
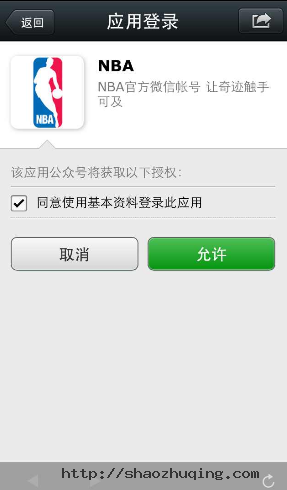
用户同意授权后
如果用户同意授权,页面将跳转至 redirect_uri/?code=CODE&state=STATE。若用户禁止授权,则重定向后不会带上code参数,仅会带上state参数redirect_uri?state=STATE
code说明 : code作为换取access_token的票据,每次用户授权带上的code将不一样,code只能使用一次,5分钟未被使用自动过期。
第二步:通过code换取网页授权access_token
首先请注意,这里通过code换取的网页授权access_token,与基础支持中的access_token不同。公众号可通过下述接口来获取网页授权access_token。如果网页授权的作用域为snsapi_base,则本步骤中获取到网页授权access_token的同时,也获取到了openid,snsapi_base式的网页授权流程即到此为止。
请求方法
获取code后,请求以下链接获取access_token: https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| secret | 是 | 公众号的appsecret |
| code | 是 | 填写第一步获取的code参数 |
| grant_type | 是 | 填写为authorization_code |
返回说明
正确时返回的JSON数据包如下:
{ "access_token":"ACCESS_TOKEN", "expires_in":7200, "refresh_token":"REFRESH_TOKEN", "openid":"OPENID", "scope":"SCOPE" }
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| expires_in | access_token接口调用凭证超时时间,单位(秒) |
| refresh_token | 用户刷新access_token |
| openid | 用户唯一标识,请注意,在未关注公众号时,用户访问公众号的网页,也会产生一个用户和公众号唯一的OpenID |
| scope | 用户授权的作用域,使用逗号(,)分隔 |
错误时微信会返回JSON数据包如下(示例为Code无效错误):
{"errcode":40029,"errmsg":"invalid code"}
第三步:刷新access_token(如果需要)
由于access_token拥有较短的有效期,当access_token超时后,可以使用refresh_token进行刷新,refresh_token拥有较长的有效期(7天、30天、60天、90天),当refresh_token失效的后,需要用户重新授权。
请求方法
获取第二步的refresh_token后,请求以下链接获取access_token: https://api.weixin.qq.com/sns/oauth2/refresh_token?appid=APPID&grant_type=refresh_token&refresh_token=REFRESH_TOKEN
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| grant_type | 是 | 填写为refresh_token |
| refresh_token | 是 | 填写通过access_token获取到的refresh_token参数 |
返回说明
正确时返回的JSON数据包如下:
{ "access_token":"ACCESS_TOKEN", "expires_in":7200, "refresh_token":"REFRESH_TOKEN", "openid":"OPENID", "scope":"SCOPE" }
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| expires_in | access_token接口调用凭证超时时间,单位(秒) |
| refresh_token | 用户刷新access_token |
| openid | 用户唯一标识 |
| scope | 用户授权的作用域,使用逗号(,)分隔 |
错误时微信会返回JSON数据包如下(示例为Code无效错误):
{"errcode":40029,"errmsg":"invalid code"}
第四步:拉取用户信息(需scope为 snsapi_userinfo)
如果网页授权作用域为snsapi_userinfo,则此时开发者可以通过access_token和openid拉取用户信息了。
请求方法
http:GET(请使用https协议) https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN
参数说明
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| openid | 用户的唯一标识 |
| lang | 返回国家地区语言版本,zh_CN 简体,zh_TW 繁体,en 英语 |
返回说明
正确时返回的JSON数据包如下:
{ "openid":" OPENID", " nickname": NICKNAME, "sex":"1", "province":"PROVINCE" "city":"CITY", "country":"COUNTRY", "headimgurl": "http://wx.qlogo.cn/mmopen/g3MonUZtNHkdmzicIlibx6iaFqAc56vxLSUfpb6n5WKSYVY0ChQKkiaJSgQ1dZuTOgvLLrhJbERQQ4eMsv84eavHiaiceqxibJxCfHe/46", "privilege":[ "PRIVILEGE1" "PRIVILEGE2" ] }
| 参数 | 描述 |
|---|---|
| openid | 用户的唯一标识 |
| nickname | 用户昵称 |
| sex | 用户的性别,值为1时是男性,值为2时是女性,值为0时是未知 |
| province | 用户个人资料填写的省份 |
| city | 普通用户个人资料填写的城市 |
| country | 国家,如中国为CN |
| headimgurl | 用户头像,最后一个数值代表正方形头像大小(有0、46、64、96、132数值可选,0代表640*640正方形头像),用户没有头像时该项为空 |
| privilege | 用户特权信息,json 数组,如微信沃卡用户为(chinaunicom) |
错误时微信会返回JSON数据包如下(示例为openid无效):
{"errcode":40003,"errmsg":" invalid openid "}
附:检验授权凭证(access_token)是否有效
请求方法
http:GET(请使用https协议) https://api.weixin.qq.com/sns/auth?access_token=ACCESS_TOKEN&openid=OPENID
参数说明
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| openid | 用户的唯一标识 |
返回说明
正确的Json返回结果:
{ "errcode":0,"errmsg":"ok"}
错误时的Json返回示例:
{ "errcode":40003,"errmsg":"invalid openid"}
案例代码:
请求授权页面的构造方式
url在线编码工具:http://tool.oschina.net/encode?type=4
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect
前端代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd";><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><meta name="viewport" content="width=device-width,height=device-height,inital-scale=1.0,maximum-scale=1.0,user-scalable=no;"><meta name="apple-mobile-web-app-capable" content="yes"><meta name="apple-mobile-web-app-status-bar-style" content="black"><meta name="format-detection" content="telephone=no"><title>会员注册</title><script type="text/JavaScript" src="jQuery.js"></script>
<script type="text/javascript">
function callback(result) {
alert('cucess');
alert(result); //输出openid
}
function getQueryString(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]); return null;
}
var code = getQueryString("code");
$.ajax({
async: false, url: "http://atest.sinaapp.com/oauth2.php", //这是我的服务端处理文件php的
type: "GET", //下面几行是jsoup,如果去掉下面几行的注释,后端对应的返回结果也要去掉注释
// dataType: 'jsonp',
// jsonp: 'callback', //jsonp的值自定义,如果使用jsoncallback,那么服务器端,要返回一个jsoncallback的值对应的对象.
// jsonpCallback:'callback',
data: {code:code}, //传递本页面获取的code到后台,以便后台获取openid
timeout: 5000,
success: function (result) {
callback(result);
},
error: function (jqXHR, textStatus, errorThrown) {
alert(textStatus); }
});
</script>
</head><body></body>
后端代码
<?php
$code = $_GET['code'];//前端传来的code值
$appid = "wx468622291a1e99d6";
$appsecret = "98566dc38863aa4395fabebb0de6ecc1";//获取openid
$url = "https://api.weixin.qq.com/sns/oauth2/access_token?appid=$appid&secret=$appsecret&code=$code&grant_type=authorization_code";
$result = https_request($url);
$jsoninfo = json_decode($result, true);
$openid = $jsoninfo["openid"];//从返回json结果中读出openid
$access_token = $jsoninfo["access_token"];//从返回json结果中读出openid
$callback=$_GET['callback']; // echo $callback."({result:'".$openid."'})";
$url1 = "https://api.weixin.qq.com/sns/userinfo?access_token=$access_token&openid=$openid&lang=zh_CN";
$result1 = https_request($url1);
$jsoninfo1 = json_decode($result1, true);
$nickname=$jsoninfo1["nickname"];
echo $openid.":".$access_token.":".$nickname; //把openid 送回前端
function https_request($url,$data = null){
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
if (!empty($data)){
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($curl);
curl_close($curl);
return $output;
}
?>
phpredis中文手册 《redis中文手册》 php版
phpredis是php的一个扩展,效率是相当高有链表排序功能,对创建内存级的模块业务关系
很有用;以下是redis官方提供的命令使用技巧:
下载地址如下:
https://github.com/owlient/phpredis(支持redis 2.0.4)
Redis::__construct构造函数
$redis = new Redis();
connect, open 链接redis服务
参数
host: string,服务地址
port: int,端口号
timeout: float,链接时长 (可选, 默认为 0 ,不限链接时间)
注: 在redis.conf中也有时间,默认为300
pconnect, popen 不会主动关闭的链接
参考上面
setOption 设置redis模式
getOption 查看redis设置的模式
ping 查看连接状态
get 得到某个key的值(string值)
如果该key不存在,return false
set 写入key 和 value(string值)
如果写入成功,return ture
setex 带生存时间的写入值
$redis->setex('key', 3600, 'value'); // sets key → value, with 1h TTL.
setnx 判断是否重复的,写入值
$redis->setnx('key', 'value');
$redis->setnx('key', 'value');
delete 删除指定key的值
返回已经删除key的个数(长整数)
$redis->delete('key1', 'key2');
$redis->delete(array('key3', 'key4', 'key5'));
ttl
得到一个key的生存时间
persist
移除生存时间到期的key
如果key到期 true 如果不到期 false
mset (redis版本1.1以上才可以用)
同时给多个key赋值
$redis->mset(array('key0' => 'value0', 'key1' => 'value1'));
multi, exec, discard
进入或者退出事务模式
参数可选Redis::MULTI或Redis::PIPELINE. 默认是 Redis::MULTI
Redis::MULTI:将多个操作当成一个事务执行
Redis::PIPELINE:让(多条)执行命令简单的,更加快速的发送给服务器,但是没有任何原子性的保证
discard:删除一个事务
返回值
multi(),返回一个redis对象,并进入multi-mode模式,一旦进入multi-mode模式,以后调用的所有方法都会返回相同的对象,只到exec()方法被调用。
watch, unwatch (代码测试后,不能达到所说的效果)
监测一个key的值是否被其它的程序更改。如果这个key在watch 和 exec (方法)间被修改,这个 MULTI/EXEC 事务的执行将失败(return false)
unwatch 取消被这个程序监测的所有key
参数,一对key的列表
$redis->watch('x');
$ret = $redis->multi() ->incr('x') ->exec();
subscribe *
方法回调。注意,该方法可能在未来里发生改变
publish *
发表内容到某一个通道。注意,该方法可能在未来里发生改变
exists
判断key是否存在。存在 true 不在 false
incr, incrBy
key中的值进行自增1,如果填写了第二个参数,者自增第二个参数所填的值
$redis->incr('key1');
$redis->incrBy('key1', 10);
decr, decrBy
做减法,使用方法同incr
getMultiple
传参
由key组成的数组
返回参数
如果key存在返回value,不存在返回false
$redis->set('key1', 'value1'); $redis->set('key2', 'value2'); $redis->set('key3', 'value3'); $redis->getMultiple(array('key1', 'key2', 'key3'));
$redis->lRem('key1', 'A', 2);
$redis->lRange('key1', 0, -1);
list相关操作
lPush
$redis->lPush(key, value);
在名称为key的list左边(头)添加一个值为value的 元素
rPush
$redis->rPush(key, value);
在名称为key的list右边(尾)添加一个值为value的 元素
lPushx/rPushx
$redis->lPushx(key, value);
在名称为key的list左边(头)/右边(尾)添加一个值为value的元素,如果value已经存在,则不添加
lPop/rPop
$redis->lPop('key');
输出名称为key的list左(头)起/右(尾)起的第一个元素,删除该元素
blPop/brPop
$redis->blPop('key1', 'key2', 10);
lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对keyi+1开始的list执行pop操作
lSize
$redis->lSize('key');
返回名称为key的list有多少个元素
lIndex, lGet
$redis->lGet('key', 0);
返回名称为key的list中index位置的元素
lSet
$redis->lSet('key', 0, 'X');
给名称为key的list中index位置的元素赋值为value
lRange, lGetRange
$redis->lRange('key1', 0, -1);
返回名称为key的list中start至end之间的元素(end为 -1 ,返回所有)
lTrim, listTrim
$redis->lTrim('key', start, end);
截取名称为key的list,保留start至end之间的元素
lRem, lRemove
$redis->lRem('key', 'A', 2);
删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素
lInsert
在名称为为key的list中,找到值为pivot 的value,并根据参数Redis::BEFORE | Redis::AFTER,来确定,newvalue 是放在 pivot 的前面,或者后面。如果key不存在,不会插入,如果 pivot不存在,return -1
$redis->delete('key1'); $redis->lInsert('key1', Redis::AFTER, 'A', 'X'); $redis->lPush('key1', 'A'); $redis->lPush('key1', 'B'); $redis->lPush('key1', 'C'); $redis->lInsert('key1', Redis::BEFORE, 'C', 'X');
$redis->lRange('key1', 0, -1);
$redis->lInsert('key1', Redis::AFTER, 'C', 'Y');
$redis->lRange('key1', 0, -1);
$redis->lInsert('key1', Redis::AFTER, 'W', 'value');
rpoplpush
返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
$redis->delete('x', 'y');
$redis->lPush('x', 'abc'); $redis->lPush('x', 'def'); $redis->lPush('y', '123'); $redis->lPush('y', '456'); // move the last of x to the front of y. var_dump($redis->rpoplpush('x', 'y'));
var_dump($redis->lRange('x', 0, -1));
var_dump($redis->lRange('y', 0, -1));
string(3) "abc"
array(1) { [0]=> string(3) "def" }
array(3) { [0]=> string(3) "abc" [1]=> string(3) "456" [2]=> string(3) "123" }
SET操作相关
sAdd
向名称为key的set中添加元素value,如果value存在,不写入,return false
$redis->sAdd(key , value);
sRem, sRemove
删除名称为key的set中的元素value
$redis->sAdd('key1' , 'set1');
$redis->sAdd('key1' , 'set2');
$redis->sAdd('key1' , 'set3');
$redis->sRem('key1', 'set2');
sMove
将value元素从名称为srckey的集合移到名称为dstkey的集合
$redis->sMove(seckey, dstkey, value);
sIsMember, sContains
名称为key的集合中查找是否有value元素,有ture 没有 false
$redis->sIsMember(key, value);
sCard, sSize
返回名称为key的set的元素个数
sPop
随机返回并删除名称为key的set中一个元素
sRandMember
随机返回名称为key的set中一个元素,不删除
sInter
求交集
sInterStore
求交集并将交集保存到output的集合
$redis->sInterStore('output', 'key1', 'key2', 'key3')
sUnion
求并集
$redis->sUnion('s0', 's1', 's2');
s0,s1,s2 同时求并集
sUnionStore
求并集并将并集保存到output的集合
$redis->sUnionStore('output', 'key1', 'key2', 'key3');
sDiff
求差集
sDiffStore
求差集并将差集保存到output的集合
sMembers, sGetMembers
返回名称为key的set的所有元素
sort
排序,分页等
参数
'by' => 'some_pattern_*',
'limit' => array(0, 1),
'get' => 'some_other_pattern_*' or an array of patterns,
'sort' => 'asc' or 'desc',
'alpha' => TRUE,
'store' => 'external-key'
例子
$redis->delete('s'); $redis->sadd('s', 5); $redis->sadd('s', 4); $redis->sadd('s', 2); $redis->sadd('s', 1); $redis->sadd('s', 3);
var_dump($redis->sort('s')); // 1,2,3,4,5
var_dump($redis->sort('s', array('sort' => 'desc'))); // 5,4,3,2,1
var_dump($redis->sort('s', array('sort' => 'desc', 'store' => 'out'))); // (int)5
string命令
getSet
返回原来key中的值,并将value写入key
$redis->set('x', '42');
$exValue = $redis->getSet('x', 'lol'); // return '42', replaces x by 'lol'
$newValue = $redis->get('x')' // return 'lol'
append
string,名称为key的string的值在后面加上value
$redis->set('key', 'value1');
$redis->append('key', 'value2');
$redis->get('key');
getRange (方法不存在)
返回名称为key的string中start至end之间的字符
$redis->set('key', 'string value');
$redis->getRange('key', 0, 5);
$redis->getRange('key', -5, -1);
setRange (方法不存在)
改变key的string中start至end之间的字符为value
$redis->set('key', 'Hello world');
$redis->setRange('key', 6, "redis");
$redis->get('key');
strlen
得到key的string的长度
$redis->strlen('key');
getBit/setBit
返回2进制信息
zset(sorted set)操作相关
zAdd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
$redis->zAdd('key', 1, 'val1');
$redis->zAdd('key', 0, 'val0');
$redis->zAdd('key', 5, 'val5');
$redis->zRange('key', 0, -1); // array(val0, val1, val5)
zRange(key, start, end,withscores):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
$redis->zAdd('key1', 0, 'val0');
$redis->zAdd('key1', 2, 'val2');
$redis->zAdd('key1', 10, 'val10');
$redis->zRange('key1', 0, -1); // with scores $redis->zRange('key1', 0, -1, true);
zDelete, zRem
zRem(key, member) :删除名称为key的zset中的元素member
$redis->zAdd('key', 0, 'val0');
$redis->zAdd('key', 2, 'val2');
$redis->zAdd('key', 10, 'val10');
$redis->zDelete('key', 'val2');
$redis->zRange('key', 0, -1);
zRevRange(key, start, end,withscores):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素.withscores: 是否输出socre的值,默认false,不输出
$redis->zAdd('key', 0, 'val0');
$redis->zAdd('key', 2, 'val2');
$redis->zAdd('key', 10, 'val10');
$redis->zRevRange('key', 0, -1); // with scores $redis->zRevRange('key', 0, -1, true);
zRangeByScore, zRevRangeByScore
$redis->zRangeByScore(key, star, end, array(withscores, limit ));
返回名称为key的zset中score >= star且score <= end的所有元素
zCount
$redis->zCount(key, star, end);
返回名称为key的zset中score >= star且score <= end的所有元素的个数
zRemRangeByScore, zDeleteRangeByScore
$redis->zRemRangeByScore('key', star, end);
删除名称为key的zset中score >= star且score <= end的所有元素,返回删除个数
zSize, zCard
返回名称为key的zset的所有元素的个数
zScore
$redis->zScore(key, val2);
返回名称为key的zset中元素val2的score
zRank, zRevRank
$redis->zRevRank(key, val);
返回名称为key的zset(元素已按score从小到大排序)中val元素的rank(即index,从0开始),若没有val元素,返回“null”。zRevRank 是从大到小排序
zIncrBy
$redis->zIncrBy('key', increment, 'member');
如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
zUnion/zInter
参数
keyOutput
arrayZSetKeys
arrayWeights
aggregateFunction Either "SUM", "MIN", or "MAX": defines the behaviour to use on duplicate entries during the zUnion.
对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
Hash操作
hSet
$redis->hSet('h', 'key1', 'hello');
向名称为h的hash中添加元素key1—>hello
hGet
$redis->hGet('h', 'key1');
返回名称为h的hash中key1对应的value(hello)
hLen
$redis->hLen('h');
返回名称为h的hash中元素个数
hDel
$redis->hDel('h', 'key1');
删除名称为h的hash中键为key1的域
hKeys
$redis->hKeys('h');
返回名称为key的hash中所有键
hVals
$redis->hVals('h')
返回名称为h的hash中所有键对应的value
hGetAll
$redis->hGetAll('h');
返回名称为h的hash中所有的键(field)及其对应的value
hExists
$redis->hExists('h', 'a');
名称为h的hash中是否存在键名字为a的域
hIncrBy
$redis->hIncrBy('h', 'x', 2);
将名称为h的hash中x的value增加2
hMset
$redis->hMset('user:1', array('name' => 'Joe', 'salary' => 2000));
向名称为key的hash中批量添加元素
hMGet
$redis->hmGet('h', array('field1', 'field2'));
返回名称为h的hash中field1,field2对应的value
redis 操作相关
flushDB
清空当前数据库
flushAll
清空所有数据库
randomKey
随机返回key空间的一个key
$key = $redis->randomKey();
select
选择一个数据库
move
转移一个key到另外一个数据库
$redis->select(0); // switch to DB 0
$redis->set('x', '42'); // write 42 to x
$redis->move('x', 1); // move to DB 1
$redis->select(1); // switch to DB 1
$redis->get('x'); // will return 42
rename, renameKey
给key重命名
$redis->set('x', '42');
$redis->rename('x', 'y');
$redis->get('y'); // → 42
$redis->get('x'); // → `FALSE`
renameNx
与remane类似,但是,如果重新命名的名字已经存在,不会替换成功
setTimeout, expire
设定一个key的活动时间(s)
$redis->setTimeout('x', 3);
expireAt
key存活到一个unix时间戳时间
$redis->expireAt('x', time() + 3);
keys, getKeys
返回满足给定pattern的所有key
$keyWithUserPrefix = $redis->keys('user*');
dbSize
查看现在数据库有多少key
$count = $redis->dbSize();
auth
密码认证
$redis->auth('foobared');
bgrewriteaof
使用aof来进行数据库持久化
$redis->bgrewriteaof();
slaveof
选择从服务器
$redis->slaveof('10.0.1.7', 6379);
save
将数据同步保存到磁盘
bgsave
将数据异步保存到磁盘
lastSave
返回上次成功将数据保存到磁盘的Unix时戳
info
返回redis的版本信息等详情
type
返回key的类型值
string: Redis::REDIS_STRING
set: Redis::REDIS_SET
list: Redis::REDIS_LIST
zset: Redis::REDIS_ZSET
hash: Redis::REDIS_HASH
other: Redis::REDIS_NOT_FOUND
有意思的面试题
1、有十筐苹果,每筐里有十个,共100个,每筐里苹果的重量都是一样,其中有九筐每个苹果的重量都是1斤,
另一筐中每个苹果的重量都是0.9斤,但是外表完全一样,用眼看或用手摸无法分辨。
现在要你用一台普通的大秤一次把这筐重量轻的找出来。
答案:从第一筐中拿出一个,第二筐中拿出两个,第十筐拿出十个,一起放在称上称。
如果每个苹果一斤重,就应该是55斤。假设称出是54.9斤,则说明,从第一筐中拿出那个苹果是九两的,也就是说第一筐的苹果是九两重的。
如果称出是54.8斤,也就是说差2两,而又只有一筐苹果中的每个都是九两重的,所以一定是第二筐中拿出两个是9两重,也就是说第二筐的苹果是九两重的。
按这样推理下去,应该明白吧!!
2、我有一堆绳子,这些绳子之间粗细长短各不相同,每一条绳子本身各处的粗细长短也各不相同。
但是每条绳子的燃烧时间都是60秒,试问我要测量15秒的时间,我该如何做?
答案:
1.同时点燃任意两根绳子,第一根绳子点两头,第二根绳子点一头;
2.等第一根绳子烧完后,点燃第二根绳子的另一头,让两头同时燃烧,并开始计时;
3.在第二根绳子烧尽时停止计时,即可得15秒的时间。
因为题目中给出一个条件:一堆绳子,长短粗细各不相同,也不均匀。
也就是说每根绳子从头到尾都是不均匀的,并非只是绳子与绳子不同。
那么~~虽然单根绳子总的燃烧时间为60秒,但若取半根则未必是30秒,四分之一根未必是15秒啊~~~~~~~
若假定了一个默认的条件:就是单根绳子是均匀的。因此,必然会导致错误的结果。
3、有一堆垃圾,规定要由张王李三户人家清理。张户因外出没能参加,留下9元钱做代劳费。
王户上午起早干了5小时,李户下午接着干了4小时刚好干完。问王户和李户应怎样分配这9元钱?
答案:不能简单地认为王户应得5元,李户应得4元。不加分析而想当然办事往往搞错。
应该知道,王李两户所做的工作中,除帮张户外,还有他们自己的任务。
很明显,每户的工作量为3小时。王帮张干了2小时,李帮张干了1小时,王帮张的工作量是李帮张的2倍,得到的报酬当然也应该是李的2倍。
因此,王应得6元,李应得3元。
4、一天有个年轻人来到王老板的店里买了一件礼物这件礼物成本是18元,标价是21元。
结果是这个年轻人掏出100元要买这件礼物。王老板当时没有零钱,用那100元向街坊换了100元的零钱,找给年轻人79元。
但是街坊後来发现那100元是假钞,王老板无奈还了街坊100元。现在问题是:王老板在这次交易中到底损失了多少钱?
答案:年轻人掏出100元假钞买这件礼物,王老板进0元!
王老板当时没有零钱,用那100元假钞向街坊换了100元的零钱,王老板进100元!
街坊後来发现那100元是假钞,王老板无奈还了街坊100元。王老板出100元!找给年轻人79元。王老板出79元!
年轻人到王老板的店里买了一件礼物礼物成本是18元,标价是21元。王老板出18元!
总计损失:97元!
5、有13个零件,外表完全一样,但有一个是不合格品,其重量和其它的不同,且轻重不知。请你用天平称3次,把它找出来。
答案:先在天平的两边各放4个零件。
一、如果天平平衡,说明坏的在另外的5个里。拿出3个好的放在天平左端,再从坏的5个中拿出3个,放在天平右端(如果不平衡,此时要记住右端是高是低,高说明坏的零件比好的轻,反之相反)。
1、如果天平平衡,则坏的在剩下的两个中,随便拿1个和好的称,则答案很明显。
2、如果天平不平衡,则坏的在那3个里面,随便拿出2个,分别放到天平两端。如果平衡,答案很明显。
如果不平衡,则可以根据(一)判断零件是轻点还是重点,答案也很明显。
二、如果天平不平衡,说明坏的在这8个中,此时要记住哪端是轻的,哪端是重的。然后把5个合格的放在天平的左端,取2个轻端的,3个重端的放在右端。
1、如果天平平衡,则拿剩下的两个轻端的,放到天平两端,如果平衡,答案很明显。如果不平衡,则说明坏的在这两个里面,而且坏的是较轻的,因为它们是从轻端取出来的。
2、如果右端低,说明坏的在重的3个里,而且坏的零件较重,再称一次就知道答案。如果右端高,说明坏的在轻的2个里面,而且坏的较轻,再称一次答案很明显。
6、1~50号运动员按顺序排成一排。
教练下令:“单数运动员出列!”剩下的运动员重新排队编号。
教练又下令:“单数运动员出列!”如此下去,最后只剩下一个人,他是几号运动员?
如果教练下的令是“双数运动员出列!”最后剩下的又是谁?
答案:单数出列最后剩下32号双数出列最后剩下1号
1、第一次单数出列,
1/3/5/7/9/11/13/15/17/19/21/23/25...../49
剩下的为
2/4/6/8/10/12/14/16/18/20/22/24/....../50
2、第二次单数出列,
2/6/10/14/18/22/26/30/34/38/42/46/50
剩下的为
4/8/12/16/20/24/28/32/36/40/44/48
3、第三次单数出列
4/12/20/28/36/44
剩下的为
8/16/24/32/40/48
4、第四次单数出列
8/24/40
剩下的为
16/32/48
5、第五次单数出列
16/48
剩下的为
32
如果教练下的令是“双数运动员出列!”最后剩下的是1。
7、一死刑犯就要执行。
行刑官对死刑犯说:“你知道我将怎样处决你吗?猜对了,我可以让你死得好受些,给你吃个枪子。要是你猜错了,那就对不起了,请你尝尝上绞刑架的滋味。”
行刑官想:“反正我说了算,说你对你就对,说你错你就错”没想到由于死刑犯聪明的回答,使得行刑官无法执行死刑,这个死刑犯绝处逢生。这个死刑犯是怎样回答的?
答案:死刑犯说:"我将要上绞刑架".这是一个不对不错的答案,行刑官要是说错了,那犯人将上绞刑架,那犯人就说对了,行刑官要是说对了,那犯人要被吃枪子,那犯人就说错了。
8、从前,有个很有钱的人家。正当全家为新的小生命即将降临而欢喜之际,丈夫突然得了不治之症。
临终前留下遗嘱:“如果生的是男孩,妻子和儿子各分家产的一半。如果是女孩,女孩分得家产的三分之一,其余归妻子。”
丈夫死后不久,妻子就临产了。出乎意料的是,妻子生下一男一女双胞胎!这下妻子为难了,这笔财产该怎样分呢?
答案:按法律的规定继承。
丈夫的遗嘱是附条件的,但其条件并没有实现,所以不按遗嘱继承,而应当按照法律的规定继承:家产先分给妻子一半(夫妻共同财产),剩余的一半,由妻子和一双子女平均继承。
即妻子得家产的三分之二,子女各得家产的六分之一。
9、有两个封闭式的小火车站,每天从甲站开到乙站的车次总是比从乙站开到甲站的车次多,时间长了,火车会不会都集中到乙站呢?
答案:不会,因为从乙站开出的车的车厢比甲站开出的车的车厢要多!
10、回到原地?
一个人从点M出发步行,前进20米就向右转15度,再前进20米,又向右转15度,......,照这样走下去,他能不能回到M点?如果能,他回到M点时,一共走了多少米?
答案:这么走下去,他可以回到M点,且他走完一圈的路线形成一个正N边形,每边都为20米。由于每次都转15度且正N边形外角和
11、我有两只桶,一只可以盛3升水,另一只可以盛5升水,试问我想要四升水,我应该用什么办法?
答案:将5升桶装满,倒入3升桶;将3升桶的水倒掉,将5升桶的剩余的(2升)水倒入3升桶;
将5升桶装满,用5升桶中的水将3升桶(此时3升桶中有2升水)装满,则5升桶中剩余4升水。
12、现在小明一家过一座桥,过桥时候是黑夜,所以必须有灯。现在小明过桥要1秒,小明的弟弟要3秒,小明的爸爸要6秒,小明的妈妈要8秒,小明的爷爷要12秒。每次此桥最多可过两人,而过桥的速度依过桥最慢者而定,而且灯在点燃后30秒就会熄灭。问小明一家如何过桥?
答案:这类智力题目,其实是考察应聘者在限制条件下解决问题的能力。
具体到这道题目来说,很多人往往认为应该由小明持灯来来去去,这样最节省时间,但最后却怎么也凑不出解决方案。
但是换个思路,我们根据具体情况来决定谁持灯来去,只要稍稍做些变动即可:
第一步,小明与弟弟过桥,小明回来,耗时4秒;
第二步,小明与爸爸过河,弟弟回来,耗时9秒;
第三步,妈妈与爷爷过河,小明回来,耗时13秒;
最后,小明与弟弟过河,耗时4秒,总共耗时30秒,多么惊险!
专家意见:这类题目多出现于跨国企业的招聘面试中,对考察一个人的思维方式及思维方式转变能力有极其明显的作用,
而据一些研究显示,这样的能力往往也与工作中的应变与创新状态息息相关。
所以回答这些题目时,必须冲破思维定式,试着从不同的角度考虑问题,不断进行逆向思维,
换位思考,并且把题目与自己熟悉的场景联系起来,切忌思路混乱。
13、过桥
有一家四口人要走过一座窄桥,窄桥一次最多只可容许两个人一起过桥,由于天色很暗,同时他们又只有一只手电筒,
过桥时必须持有手电筒,以防止跌落水中,因此就得有人把手电筒带来带去,来回桥两端,四个人得步行速度各不相同,
已知每人过桥所需要使用的时间分别为:哥哥1分钟爸爸2分钟妈妈5分钟爷爷10分钟
若两人同行则以较慢者的速度为准,请问他们最少要花多少分钟才能过桥。
答案:第一步,哥哥与爸爸过桥,哥哥回来,耗时3分钟;第二步,妈妈与爷爷过河,爸爸回来,耗时12分钟;第三步,哥哥与爸爸过桥,耗时2分钟;总共耗时17分钟。
14、卖胡萝卜
一个商人骑一头驴要穿越1000公里长的沙漠,去卖3000根萝卜。
已知驴一次性最多可驮1000根萝卜,但每走一公里又要吃掉一根萝卜。
问:商人一共可卖出多少根胡萝卜?(他可以把萝卜卸在半路上,回去再驮,假设萝卜丢不了也烂不了。)
答案:要卖出最多胡萝卜,也就是驴的共走过的路程要最短第一步,当胡萝卜数大于2000时,
路程必须来回三趟,第三趟不用回去,共走路程X,消耗胡萝卜1000根,X=1000/5,也就是走200公里,
放下1000-(200*2)=600根,
第二次1000-(200*2)=600根,第三次1000-200=800根,走了200公里,刚好共运到2000根第二步,胡萝卜数大于1000时,
路程必须来回二趟,第二趟不用回去,共走路程y,消耗胡萝卜1000根,1000/3不是整数,
而胡萝卜必须整根搬运第一种方法,y=333公里,留一根在路上,即在剩下的路程(1000-200-333=467),共有1000根胡萝卜,能运到1000-467=533根第二种方法,y=334公里,即在剩下的路程(1000-200-334=466),
共有998根胡萝卜,能运到998-466=532根所以,最多可以运到533根。
15、三个年轻人去一家旅店投宿,每人拿出十元钱交给老板。老板由于喜得贵子,决定少收5元钱,于是让服务员将5元钱转交给三个年轻人。
服务员从中扣下了2元钱,将剩余3元钱还给三人,每人分得1元。现在三个年轻人每人相当于拿出9元钱,3*9=27,加上服务员扣下的2元钱,27+2=29。
与三人最初拿出的30元钱相差1元。问这一元钱到哪儿去了?
答案:这个问题的逻辑是错误的。准确的描述是,3个人各出了10元钱,后又还回1元钱,因此共出钱27元。这27元中,2元被服务员扣下了,25元为房费。因此不存在27+2=29。
16、考考你的逻辑能力已知公式:DONALD+GERALD=ROBERT
以上共有10个字母,每一个字母都代表阿拉伯数字中0--9中的一个,已知D=5,请您在5分钟之内计算出其余9个字母代表的数字。
答案:526485+197485=723970
G=10=2B=3A=4D=5N=6R=7L=8E=9T=0步骤:
1、首先D=5,得知T=0
2、因为2L+1=R,所以R是奇数,并且由于D=5,D+G=R,所以R=7或R=9
3、因为O+E=O,所以E=0或E=9,因为T=0,所以E=9,R=7,G=1
4、因为2L+1=R,所以L=3或L=8,因为E=9,2A+1=E,所以A=4,L=8
5、剩下N、B、O还未确定,即2、3、6未知。
N+7=B或N+7=10+B所以B=3,N=6,O=2
重启mysql提示MySQL server PID file could not be found!
重启mysql提示MySQL server PID file could not be found!
Starting MySQL...The server quit without updating PID file (/usr/local/mysql/data/rekfan.pid).
我只能呵呵了吗?不是。
我是这样做的,先看下是不是有这个进程,然后结束,再重启,代码:
- ps -ef|grep mysqld
- kill -9 进程号
你要是没解决?好吧,继续:
(解决方法:一个个试!)
1.可能是/usr/local/mysql/data/rekfan.pid文件没有写的权限
解决方法 :给予权限,执行 “chown -R mysql:mysql /var/data” “chmod -R 755 /usr/local/mysql/data” 然后重新启动mysqld!
2.可能进程里已经存在mysql进程
解决方法:用命令“ps -ef|grep mysqld”查看是否有mysqld进程,如果有使用“kill -9 进程号”杀死,然后重新启动mysqld!
3.可能是第二次在机器上安装mysql,有残余数据影响了服务的启动。
解决方法:去mysql的数据目录/data看看,如果存在mysql-bin.index,就赶快把它删除掉吧,它就是罪魁祸首了。本人就是使用第三条方法解决的 !http://blog.rekfan.com/?p=186
4.mysql在启动时没有指定配置文件时会使用/etc/my.cnf配置文件,请打开这个文件查看在[mysqld]节下有没有指定数据目录(datadir)。
解决方法:请在[mysqld]下设置这一行:datadir = /usr/local/mysql/data
5.skip-federated字段问题
解决方法:检查一下/etc/my.cnf文件中有没有没被注释掉的skip-federated字段,如果有就立即注释掉吧。
6.错误日志目录不存在
解决方法:使用“chown” “chmod”命令赋予mysql所有者及权限
7.selinux惹的祸,如果是centos系统,默认会开启selinux
解决方法:关闭它,打开/etc/selinux/config,把SELINUX=enforcing改为SELINUX=disabled后存盘退出重启机器试试。
file_get_contents(“php://input”)的使用方法
$data = file_get_contents("php://input");
php://input 是个可以访问请求的原始数据的只读流。 POST 请求的情况下,最好使用 php://input 来代替 $HTTP_RAW_POST_DATA,因为它不依赖于特定的 php.ini 指令。 而且,这样的情况下 $HTTP_RAW_POST_DATA 默认没有填充, 比激活 always_populate_raw_post_data 潜在需要更少的内存。 enctype="multipart/form-data" 的时候 php://input 是无效的。
1, php://input 可以读取http entity body中指定长度的值,由Content-Length指定长度,不管是POST方式或者GET方法提交过来的数据。但是,一般GET方法提交数据 时,http request entity body部分都为空。
2,php://input 与$HTTP_RAW_POST_DATA读取的数据是一样的,都只读取Content-Type不为multipart/form-data的数据。
学习笔记
1,Coentent-Type仅在取值为application/x-www-data-urlencoded和multipart/form-data两种情况下,PHP才会将http请求数据包中相应的数据填入全局变量$_POST
2,PHP不能识别的Content-Type类型的时候,会将http请求包中相应的数据填入变量$HTTP_RAW_POST_DATA
3, 只有Coentent-Type为multipart/form-data的时候,PHP不会将http请求数据包中的相应数据填入php://input,否则其它情况都会。填入的长度,由Coentent-Length指定。
4,只有Content-Type为application/x-www-data-urlencoded时,php://input数据才跟$_POST数据相一致。
5,php://input数据总是跟$HTTP_RAW_POST_DATA相同,但是php://input比$HTTP_RAW_POST_DATA更凑效,且不需要特殊设置php.ini
6,PHP会将PATH字段的query_path部分,填入全局变量$_GET。通常情况下,GET方法提交的http请求,body为空。
例子
1.php用file_get_contents("php://input")或者$HTTP_RAW_POST_DATA可以接收xml数据
比如:
getXML.php;//接收XML地址
<?php
$xmldata = file_get_contents("php://input");
$data = (array)simplexml_load_string($xmldata);
?>
这里的$data就是包含xml数据的数组,具体php解析xml数据更新详细的方法
sendXML.php
<?php
$xml = '<xml>xmldata</xml>';//要发送的xml
$url = 'http://localhost/test/getXML.php';//接收XML地址
$header = 'Content-type: text/xml';//定义content-type为xml
$ch = curl_init(); //初始化curl
curl_setopt($ch, CURLOPT_URL, $url);//设置链接
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);//设置是否返回信息
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);//设置HTTP头
curl_setopt($ch, CURLOPT_POST, 1);//设置为POST方式
curl_setopt($ch, CURLOPT_POSTFIELDS, $xml);//POST数据
$response = curl_exec($ch);//接收返回信息
if(curl_errno($ch)){//出错则显示错误信息
print curl_error($ch);
}
curl_close($ch); //关闭curl链接
echo $response;//显示返回信息
?>
2.一个手机上传图片到服务器的小程序
上传文件
<?php
//@file phpinput_post.php
$data=file_get_contents('btn.png');
$http_entity_body = $data;
$http_entity_type = 'application/x-www-form-urlencoded';
$http_entity_length = strlen($http_entity_body);
$host = '127.0.0.1';
$port = 80;
$path = '/image.php';
$fp = fsockopen($host, $port, $error_no, $error_desc, 30);
if ($fp){
fputs($fp, "POST {$path} HTTP/1.1\r\n");
fputs($fp, "Host: {$host}\r\n");
fputs($fp, "Content-Type: {$http_entity_type}\r\n");
fputs($fp, "Content-Length: {$http_entity_length}\r\n");
fputs($fp, "Connection: close\r\n\r\n");
fputs($fp, $http_entity_body . "\r\n\r\n");
while (!feof($fp)) {
$d .= fgets($fp, 4096);
}
fclose($fp);
echo $d;
}
?>
接收文件
<?php
/**
*Recieve image data
**/
error_reporting(E_ALL);
function get_contents() {
$xmlstr= file_get_contents("php://input");
$filename=time().'.png';
if(file_put_contents($filename,$xmlstr)){
echo 'success';
}else{
echo 'failed';
}
}
get_contents();
?>
3.获取HTTP请求原文
/**
* 获取HTTP请求原文
* @return string
*/
function get_http_raw() {
$raw = '';
// (1) 请求行
$raw .= $_SERVER['REQUEST_METHOD'].' '.$_SERVER['REQUEST_URI'].' '.$_SERVER['SERVER_PROTOCOL']."\r\n";
// (2) 请求Headers
foreach($_SERVER as $key => $value) {
if(substr($key, 0, 5) === 'HTTP_') {
$key = substr($key, 5);
$key = str_replace('_', '-', $key);
$raw .= $key.': '.$value."\r\n";
}
}
// (3) 空行
$raw .= "\r\n";
// (4) 请求Body
$raw .= file_get_contents('php://input');
return $raw;
}
微信开发相关名词解释
1、
微信公众平台
微信公众平台是微信公众账号申请入口和管理后台。商户可以在公众平台提交基本资料、业务资料、财务资料申请开通微信支付功能。
平台入口:http://mp.weixin.qq.com。
2、
微信开放平台
微信开放平台是商户APP接入微信支付开放接口的申请入口,通过此平台可申请微信APP支付。
平台入口:http://open.weixin.qq.com。
3、
微信商户平台
微信商户平台是微信支付相关的商户功能集合,包括参数配置、支付数据查询与统计、在线退款、代金券或立减优惠运营等功能。
平台入口:http://pay.weixin.qq.com。
4、
微信企业号
微信企业号是企业号的申请入口和管理后台,商户可以在企业号提交基本资料、业务资料、财务资料申请开通微信支付功能。
企业号入口:http://qy.weixin.qq.com。
5、
微信支付系统
微信支付系统是指完成微信支付流程中涉及的API接口、后台业务处理系统、账务系统、回调通知等系统的总称。
6、
商户收银系统
商户收银系统即商户的POS收银系统,是录入商品信息、生成订单、客户支付、打印小票等功能的系统。接入微信支付功能主要涉及到POS软件系统的开发和测试,所以在下文中提到的商户收银系统特指POS收银软件系统。
7、
商户后台系统
商户后台系统是商户后台处理业务系统的总称,例如:商户网站、收银系统、进销存系统、发货系统、客服系统等。
8、
扫码设备
一种输入设备,主要用于商户系统快速读取媒介上的图形编码信息。按读取码的类型不同,可分为条码扫码设备和二维码扫码设备。按读取物理原理可分为红外扫码设备、激光扫码设备。
9、
商户证书
商户证书是微信提供的二进制文件,商户系统发起与微信支付后台服务器通信请求的时候,作为微信支付后台识别商户真实身份的凭据。
10、
签名
商户后台和微信支付后台根据相同的密钥和算法生成一个结果,用于校验双方身份合法性。签名的算法由微信支付制定并公开,常用的签名方式有:MD5、SHA1、SHA256、HMAC等。
11、
JSAPI网页支付
JSAPI网页支付即前文说的公众号支付,可在微信公众号、朋友圈、聊天会话中点击页面链接,或者用微信“扫一扫”扫描页面地址二维码在微信中打开商户HTML5页面,在页面内下单完成支付。
12、
Native原生支付
Native原生支付即前文说的扫码支付,商户根据微信支付协议格式生成的二维码,用户通过微信“扫一扫”扫描二维码后即进入付款确认界面,输入密码即完成支付。
13、
支付密码
支付密码是用户开通微信支付时单独设置的密码,用于确认支付完成交易授权。该密码与微信登录密码不同。
14、
Openid
用户在公众号内的身份标识,不同公众号拥有不同的openid。商户后台系统通过登录授权、支付通知、查询订单等API可获取到用户的openid。主要用途是判断同一个用户,对用户发送客服消息、模版消息等。企业号用户需要使用企业号userid转openid接口将企业成员的userid转换成openid。
二维码的生成细节和原理
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。
关于QR Code Specification,可参看这个PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
基础知识
首先,我们先说一下二维码一共有40个尺寸。官方叫版本Version。Version 1是21 x 21的矩阵,Version 2是 25 x 25的矩阵,Version 3是29的尺寸,每增加一个version,就会增加4的尺寸,公式是:(V-1)*4 + 21(V是版本号) 最高Version 40,(40-1)*4+21 = 177,所以最高是177 x 177 的正方形。
下面我们看看一个二维码的样例:
定位图案
- Position Detection Pattern是定位图案,用于标记二维码的矩形大小。这三个定位图案有白边叫Separators for Postion Detection Patterns。之所以三个而不是四个意思就是三个就可以标识一个矩形了。
- Timing Patterns也是用于定位的。原因是二维码有40种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了。
- Alignment Patterns 只有Version 2以上(包括Version2)的二维码需要这个东东,同样是为了定位用的。
功能性数据
- Format Information 存在于所有的尺寸中,用于存放一些格式化数据的。
- Version Information 在 >= Version 7以上,需要预留两块3 x 6的区域存放一些版本信息。
数据码和纠错码
- 除了上述的那些地方,剩下的地方存放 Data Code 数据码 和 Error Correction Code 纠错码。
数据编码
我们先来说说数据编码。QR码支持如下的编码:
Numeric mode 数字编码,从0到9。如果需要编码的数字的个数不是3的倍数,那么,最后剩下的1或2位数会被转成4或7bits,则其它的每3位数字会被编成 10,12,14bits,编成多长还要看二维码的尺寸(下面有一个表Table 3说明了这点)
Alphanumeric mode 字符编码。包括 0-9,大写的A到Z(没有小写),以及符号$ % * + – . / : 包括空格。这些字符会映射成一个字符索引表。如下所示:(其中的SP是空格,Char是字符,Value是其索引值) 编码的过程是把字符两两分组,然后转成下表的45进制,然后转成11bits的二进制,如果最后有一个落单的,那就转成6bits的二进制。而编码模式和字符的个数需要根据不同的Version尺寸编成9, 11或13个二进制(如下表中Table 3)
Byte mode, 字节编码,可以是0-255的ISO-8859-1字符。有些二维码的扫描器可以自动检测是否是UTF-8的编码。
Kanji mode 这是日文编码,也是双字节编码。同样,也可以用于中文编码。日文和汉字的编码会减去一个值。如:在0X8140 to 0X9FFC中的字符会减去8140,在0XE040到0XEBBF中的字符要减去0XC140,然后把结果前两个16进制位拿出来乘以0XC0,然后再加上后两个16进制位,最后转成13bit的编码。如下图示例:
Extended Channel Interpretation (ECI) mode 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码。
Structured Append mode 用于混合编码,也就是说,这个二维码中包含了多种编码格式。
FNC1 mode 这种编码方式主要是给一些特殊的工业或行业用的。比如GS1条形码之类的。
简单起见,后面三种不会在本文 中讨论。
下面两张表中,
- Table 2 是各个编码格式的“编号”,这个东西要写在Format Information中。注:中文是1101
- Table 3 表示了,不同版本(尺寸)的二维码,对于,数字,字符,字节和Kanji模式下,对于单个编码的2进制的位数。(在二维码的规格说明书中,有各种各样的编码规范表,后面还会提到)
下面我们看几个示例,
示例一:数字编码
在Version 1的尺寸下,纠错级别为H的情况下,编码: 01234567
1. 把上述数字分成三组: 012 345 67
2. 把他们转成二进制: 012 转成 0000001100; 345 转成 0101011001; 67 转成 1000011。
3. 把这三个二进制串起来: 0000001100 0101011001 1000011
4. 把数字的个数转成二进制 (version 1-H是10 bits ): 8个数字的二进制是 0000001000
5. 把数字编码的标志0001和第4步的编码加到前面: 0001 0000001000 0000001100 0101011001 1000011
示例二:字符编码
在Version 1的尺寸下,纠错级别为H的情况下,编码: AC-42
1. 从字符索引表中找到 AC-42 这五个字条的索引 (10,12,41,4,2)
2. 两两分组: (10,12) (41,4) (2)
3.把每一组转成11bits的二进制:
(10,12) 10*45+12 等于 462 转成 00111001110
(41,4) 41*45+4 等于 1849 转成 11100111001
(2) 等于 2 转成 000010
4. 把这些二进制连接起来:00111001110 11100111001 000010
5. 把字符的个数转成二进制 (Version 1-H为9 bits ): 5个字符,5转成 000000101
6. 在头上加上编码标识 0010 和第5步的个数编码: 0010 000000101 00111001110 11100111001 000010
结束符和补齐符
假如我们有个HELLO WORLD的字符串要编码,根据上面的示例二,我们可以得到下面的编码,
| 编码 | 字符数 | HELLO WORLD的编码 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
我们还要加上结束符:
| 编码 | 字符数 | HELLO WORLD的编码 | 结束 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 | 0000 |
按8bits重排
如果所有的编码加起来不是8个倍数我们还要在后面加上足够的0,比如上面一共有78个bits,所以,我们还要加上2个0,然后按8个bits分好组:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
补齐码(Padding Bytes)
最后,如果如果还没有达到我们最大的bits数的限制,我们还要加一些补齐码(Padding Bytes),Padding Bytes就是重复下面的两个bytes:11101100 00010001 (这两个二进制转成十进制是236和17,我也不知道为什么,只知道Spec上是这么写的)关于每一个Version的每一种纠错级别的最大Bits限制,可以参看QR Code Spec的第28页到32页的Table-7一表。
假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要104个bits,而我们上面只有80个bits,所以,还需要补24个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
上面的编码就是数据码了,叫Data Codewords,每一个8bits叫一个codeword,我们还要对这些数据码加上纠错信息。
纠错码
上面我们说到了一些纠错级别,Error Correction Code Level,二维码中有四种级别的纠错,这就是为什么二维码有残缺还能扫出来,也就是为什么有人在二维码的中心位置加入图标。
| 错误修正容量 | |
| L水平 | 7%的字码可被修正 |
| M水平 | 15%的字码可被修正 |
| Q水平 | 25%的字码可被修正 |
| H水平 | 30%的字码可被修正 |
那么,QR是怎么对数据码加上纠错码的?首先,我们需要对数据码进行分组,也就是分成不同的Block,然后对各个Block进行纠错编码,对于如何分组,我们可以查看QR Code Spec的第33页到44页的Table-13到Table-22的定义表。注意最后两列:
- Number of Error Code Correction Blocks :需要分多少个块。
- Error Correction Code Per Blocks:每一个块中的code个数,所谓的code的个数,也就是有多少个8bits的字节。
举个例子:上述的Version 5 + Q纠错级:需要4个Blocks(2个Blocks为一组,共两组),头一组的两个Blocks中各15个bits数据 + 各 9个bits的纠错码(注:表中的codewords就是一个8bits的byte)(再注:最后一例中的(c, k, r )的公式为:c = k + 2 * r,因为后脚注解释了:纠错码的容量小于纠错码的一半)
下图给一个5-Q的示例(因为二进制写起来会让表格太大,所以,我都用了十进制,我们可以看到每一块的纠错码有18个codewords,也就是18个8bits的二进制数)
| 组 | 块 | 数据 | 对每个块的纠错码 |
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 | 213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 | 87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 | |
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 | 148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 | 235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
注:二维码的纠错码主要是通过Reed-Solomon error correction(里德-所罗门纠错算法)来实现的。对于这个算法,对于我来说是相当的复杂,里面有很多的数学计算,比如:多项式除法,把1-255的数映射成2的n次方(0<=n<=255)的伽罗瓦域Galois Field之类的神一样的东西,以及基于这些基础的纠错数学公式,因为我的数据基础差,对于我来说太过复杂,所以我一时半会儿还有点没搞明白,还在学习中,所以,我在这里就不展开说这些东西了。还请大家见谅了。(当然,如果有朋友很明白,也繁请教教我)
最终编码
穿插放置
如果你以为我们可以开始画图,你就错了。二维码的混乱技术还没有玩完,它还要把数据码和纠错码的各个codewords交替放在一起。如何交替呢,规则如下:
对于数据码:把每个块的第一个codewords先拿出来按顺度排列好,然后再取第一块的第二个,如此类推。如:上述示例中的Data Codewords如下:
| 块 1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| 块 2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| 块 3 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| 块 4 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
我们先取第一列的:67, 246, 182, 70
然后再取第二列的:67, 246, 182, 70, 85,246,230 ,247
如此类推:67, 246, 182, 70, 85,246,230 ,247 ……… ……… ,38,6,50,17,7,236
对于纠错码,也是一样:
| 块 1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 161 | 111 | 39 |
| 块 2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| 块 3 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| 块 4 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
和数据码取的一样,得到:213,87,148,235,199,204,116,159,…… …… 39,133,141,236
然后,再把这两组放在一起(纠错码放在数据码之后)得到:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236
这就是我们的数据区。
Remainder Bits
最后再加上Reminder Bits,对于某些Version的QR,上面的还不够长度,还要加上Remainder Bits,比如:上述的5Q版的二维码,还要加上7个bits,Remainder Bits加零就好了。关于哪些Version需要多少个Remainder bit,可以参看QR Code Spec的第15页的Table-1的定义表。
画二维码图
Position Detection Pattern
首先,先把Position Detection图案画在三个角上。(无论Version如何,这个图案的尺寸就是这么大)
Alignment Pattern
然后,再把Alignment图案画上(无论Version如何,这个图案的尺寸就是这么大)
关于Alignment的位置,可以查看QR Code Spec的第81页的Table-E.1的定义表(下表是不完全表格)
下图是根据上述表格中的Version8的一个例子(6,24,42)
Timing Pattern
接下来是Timing Pattern的线(这个不用多说了)
Format Information
再接下来是Formation Information,下图中的蓝色部分。
Format Information是一个15个bits的信息,每一个bit的位置如下图所示:(注意图中的Dark Module,那是永远出现的)
这15个bits中包括:
- 5个数据bits:其中,2个bits用于表示使用什么样的Error Correction Level, 3个bits表示使用什么样的Mask
- 10个纠错bits。主要通过BCH Code来计算
然后15个bits还要与101010000010010做XOR操作。这样就保证不会因为我们选用了00的纠错级别和000的Mask,从而造成全部为白色,这会增加我们的扫描器的图像识别的困难。
下面是一个示例:
关于Error Correction Level如下表所示:
关于Mask图案如后面的Table 23所示。
Version Information
再接下来是Version Information(版本7以后需要这个编码),下图中的蓝色部分。
Version Information一共是18个bits,其中包括6个bits的版本号以及12个bits的纠错码,下面是一个示例:
而其填充位置如下:
数据和数据纠错码
然后是填接我们的最终编码,最终编码的填充方式如下:从左下角开始沿着红线填我们的各个bits,1是黑色,0是白色。如果遇到了上面的非数据区,则绕开或跳过。
掩码图案
这样下来,我们的图就填好了,但是,也许那些点并不均衡,如果出现大面积的空白或黑块,会告诉我们扫描识别的困难。所以,我们还要做Masking操作(靠,还嫌不复杂)QR的Spec中说了,QR有8个Mask你可以使用,如下所示:其中,各个mask的公式在各个图下面。所谓mask,说白了,就是和上面生成的图做XOR操作。Mask只会和数据区进行XOR,不会影响功能区。(注:选择一个合适的Mask也是有算法的)
其Mask的标识码如下所示:(其中的i,j分别对应于上图的x,y)
下面是Mask后的一些样子,我们可以看到被某些Mask XOR了的数据变得比较零散了。
Mask过后的二维码就成最终的图了。
好了,大家可以去尝试去写一下QR的编码程序,当然,你可以用网上找个Reed Soloman的纠错算法的库,或是看看别人的源代码是怎么实现这个繁锁的编码。
(全文完)
CentOS安装crontab及使用方法
安装crontab:
[root@CentOS ~]# yum install vixie-cron
[root@CentOS ~]# yum install crontabs
说明:
vixie-cron软件包是cron的主程序;
crontabs软件包是用来安装、卸装、或列举用来驱动 cron 守护进程的表格的程序。
//+++++++++++++++++++++++++++++++++++
cron 是linux的内置服务,但它不自动起来,可以用以下的方法启动、关闭这个服务:
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置
查看crontab服务状态:service crond status
手动启动crontab服务:service crond start
查看crontab服务是否已设置为开机启动,执行命令:ntsysv
加入开机自动启动:
chkconfig --level 35 crond on
一.
1.1 /etc/crontab
如:
[root@dave ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
01 * * * * root run-parts /etc/cron.hourly
02 4 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly
1.2 /etc/cron.deny
/etc/cron.deny
/etc/cron.allow
如果两个文件同时存在,那么/etc/cron.allow
如果两个文件都不存在,那么只有超级用户可以安排作业。
每个用户都会生成一个自己的crontab
如:
[root@dave ~]# cd /var/spool/cron
[root@dave cron]# ls
oracle
我们直接查看这个文件,里面的内容和对应用户显示的crontab -l
[root@dave cron]# cat oracle
00 6 * * * /u02/scripts/del_st_archive.sh >/u02/scripts/del_st_arch.log 2>&1
[root@dave cron]# cat root
0 12 * * * /root/bin/sync-clock.sh
[root@dave cron]#
二.
2.1
usage:
帮助:
[root@dave ~]# man crontab
CRONTAB(1)
NAME
SYNOPSIS
DESCRIPTION
OPTIONS
SEE ALSO
FILES
STANDARDS
DIAGNOSTICS
AUTHOR
4th Berkeley Distribution
2.2
前5个字段分别表示:
还可以用一些特殊符号:
-:表示一个段,如第二端里:
一些示例:
00 8,12,16 * * * /data/app/scripts/monitor/df.sh
30 2 * * * /data/app/scripts/hotbackup/hot_database_backup.sh
10 8,12,16 * * * /data/app/scripts/monitor/check_ind_unusable.sh
10 8,12,16 * * * /data/app/scripts/monitor/check_maxfilesize.sh
10 8,12,16 * * * /data/app/scripts/monitor/check_objectsize.sh
43 21 * * * 21:43
15 05 * * *
0 17 * * * 17:00
0 17 * * 1
0,10 17 * * 0,2,3
0-10 17 1 * *
0 0 1,15 * 1
42 4 1 * *
0 21 * * 1-6
0,10,20,30,40,50 * * * * 每隔10分
*/10 * * * *
* 1 * * *
0 1 * * *
0 */1 * * *
0 * * * *
2 8-20/3 * * * 8:02,11:02,14:02,17:02,20:02
30 5 1,15 * *
2.3
2.4
先看一个例子:
0 2 * * * /u01/test.sh >/dev/null 2>&1 &
这句话的意思就是在后台执行这条命令,并将错误输出2重定向到标准输出1,然后将标准输出1全部放到/dev/null
在这里有有几个数字的意思:
我们也可以这样写:
0 2 * * * /u01/test.sh
0 2 * * * /u01/test.sh
0 2 * * * /u01/test.sh
0 2 * * * /u01/test.sh
将tesh.sh
2>&1
&1
&
测试:
ls 2>1
ls xxx 2>1:
ls xxx 2>&1:
ls xxx >out.txt 2>&1 == ls xxx 1>out.txt 2>&1;
2.5
如果改成:
PHP高级编程之消息队列
1. 什么是消息队列
消息队列(英语:Message queue)是一种进程间通信或同一进程的不同线程间的通信方式
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读出。通过消息队列,应用程序可独立地执行,它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。
你首先需要弄清楚,消息队列与远程过程调用的区别,在很多读者咨询我的时候,我发现他们需要的是RPC(远程过程调用),而不是消息队列。
消息队列有同步或异步实现方式,通常我们采用异步方式使用消息队列,远程过程调用多采用同步方式。
MQ与RPC有什么不同? MQ通常传递无规则协议,这个协议由用户定义并且实现存储转发;而RPC通常是专用协议,调用过程返回结果。
同步需求,远程过程调用(PRC)更适合你。
异步需求,消息队列更适合你。
目前很多消息队列软件同时支持RPC功能,很多RPC系统也能异步调用。
- 存储转发
- 分布式事务
- 发布订阅
- 基于内容的路由
- 点对点连接
通常的做法,如果小的项目团队可以有一个人实现,包括消息的推送,接收处理。如果大型团队,通常是定义好消息协议,然后各自开发各自的部分,例如一个团队负责写推送协议部分,另一个团队负责写接收与处理部分。
那么为什么我们不讲消息队列框架化呢?
- 开发者不用学习消息队列接口
- 开发者不需要关心消息推送与接收
- 开发者通过统一的API推送消息
- 开发者的重点是实现业务逻辑功能
下面是作者开发的一个SOA框架,该框架提供了三种接口,分别是SOAP,RESTful,AMQP(RabbitMQ),理解了该框架思想,你很容易进一步扩展,例如增加XML-RPC, ZeroMQ等等支持。
https://github.com/netkiller/SOA
本文只讲消息队列框架部分。
消息队列框架是本地应用程序(命令行程序),我们为了让他在后台运行,需要实现守护进程。
每个实例处理一组队列,实例化需要提供三个参数,$queueName = '队列名', $exchangeName = '交换名', $routeKey = '路由'
$daemon = new \framework\RabbitDaemon($queueName = 'email', $exchangeName = 'email', $routeKey = 'email');
守护进程需要使用root用户运行,运行后会切换到普通用户,同时创建进程ID文件,以便进程停止的时候使用。
守护进程核心代码https://github.com/netkiller/SOA/blob/master/system/rabbitdaemon.class.php
消息协议是一个数组,将数组序列化或者转为JSON推送到消息队列服务器,这里使用json格式的协议。
$msg = array( 'Namespace'=>'namespace', "Class"=>"Email", "Method"=>"smtp", "Param" => array( $mail, $subject, $message, null ) );
序列化后的协议
{"Namespace":"single","Class":"Email","Method":"smtp","Param":["netkiller@msn.com","Hello"," TestHelloWorld",null]}
使用json格式是考虑到通用性,这样推送端可以使用任何语言。如果不考虑兼容,建议使用二进制序列化,例如msgpack效率更好。
消息队列处理核心代码
https://github.com/netkiller/SOA/blob/master/system/rabbitmq.class.php
所以消息的处理在下面一段代码中进行
$this->queue->consume(function($envelope, $queue) {
$speed = microtime(true);
$msg = $envelope->getBody();
$result = $this->loader($msg);
$queue->ack($envelope->getDeliveryTag()); //手动发送ACK应答
//$this->logging->info(''.$msg.' '.$result)
$this->logging->debug('Protocol: '.$msg.' ');
$this->logging->debug('Result: '. $result.' ');
$this->logging->debug('Time: '. (microtime(true) - $speed) .'');
});
public function loader($msg = null) 负责拆解协议,然后载入对应的类文件,传递参数,运行方法,反馈结果。
Time 可以输出程序运行所花费的时间,对于后期优化十分有用。
测试代码 https://github.com/netkiller/SOA/blob/master/test/queue/email.php
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
