全国大数据交易所及数据交易平台汇总
政府类:
贵阳大数据交易所
http://www.gbdex.com/website/
我国乃至全球第一家大数据交易所, 贵阳大数据交易所发展会员数目突破2000家,已接入225家优质数据源,经过脱敏脱密,可交易的数据总量超150PB,可交易数据产品4000余个,涵盖三十多个领域,成为综合类、全品类数据交易平台。
西咸新区大数据交易所
http://www.chinabdbank.com/index.htm
西咸新区沣西大数据产业发展平台,通过构建有效的市场机制,聚合政府、企业、社会等多类数据资源,整合大数据服务能力,全面运营大秦大数据银行线上服务平台和陕西省社会数据服务大厅线下服务平台。
东湖大数据交易中心
http://www.chinadatatrading.com/
武汉东湖大数据交易中心股份有限公司的业务涵盖数据交易与流通、数据分析、数据应用和数据产品开发等,聚焦“大数据+”产业链,提供有价值的产品和解决方案,帮助用户提升核心竞争力。
华东江苏大数据交易平台
http://www.bigdatahd.com/
华东江苏大数据交易中心(简称BDEX)是在实施“国家大数据战略”大背景下,经国家批准的华东地区首个领先的跨区域、标准化、权威性省级国有大数据资产交易与流通平台,2015年11月成立于国家级大数据产业基地——江苏盐城大数据产业园,承担助推江苏省国有数据增值开放流通、大数据产业发展之重任。
哈尔滨数据交易中心
http://www.hrbdataex.com/
哈尔滨数据交易中心由黑龙江省政府办公厅组织发起并协调省金融办、省发改委、省工信委等部门批准设立。结合政府数据资源、企业数据资源,打造成为立足东三省,辐射全国的大数据交易市场,构建围绕数据的生态系统支撑平台。
上海数据交易中心
https://www.chinadep.com/index.html
上海数据交易中心有限公司(简称“上海数据交易中心”),是经上海市人民政府批准,上海市经济和信息化委、上海市商务委联合批复成立的国有控股混合所有制企业,上海数据交易中心承担着促进商业数据流通、跨区域的机构合作和数据互联、政府数据与商业数据融合应用等工作职能。
中国工信数据
http://www.miit.gov.cn/n1146312/index.html
平台类:
京东万象
https://wx.jdcloud.com/
以数据开放、数据共享、数据分析为核心的综合性数据开放平台,拥有的数据类型主要包括金融、征信、电商、质检、海关、运营商数据
聚合数据
https://www.juhe.cn/
互联网专业数据科技服务商。主要提供两种核心服务:以API数据接口的形式,提供数据服务;以大数据技术,提供数据应用服务。
数据宝
https://www.chinadatapay.com/
中国领先的国有数据资产增值运营服务商,提供 公安、运营商、银联、交通、车辆、企业、税务、气象大数据。
百度智能云云市场
https://cloud.baidu.com/market/list/125
由百度智能云建立的云计算软件或商品的交易与交付平台,下设多个商品品类,包括镜像环境、建站推广、企业应用、人工智能、数据智能、区块链、泛机器人、软件工具、安全服务、上云服务、API服务等,商品数量数千种。
数粮
http://datasl.com/
大数据领域的流通平台,供数据资源和大数据技术应用产品进行交易,支持API接口、数据包下载、定制等交易模式。
阿凡达数据
https://www.avatardata.cn/Docs
API数据接口云服务,专注于数据的采集与分析处理工作,拥有106个数据种类。
HaoService
http://www.haoservice.com/
数据互联服务平台。提供30大类以上基础数据API服务、热门源码交易服务。
发源地
http://www.finndy.com/
大数据应用平台和大数据解决方案提供商。提供数据交易服务,目前总共拥有20246个数据源。
iDataAPI
https://www.idataapi.com/
数据服务提供商,已推出1300多种数据产品和50多种数据分析产品,涵盖30000个网站平台和全球移动APP平台。
天元数据
https://www.tdata.cn/
中国领先的云计算、大数据服务商。数据商品涵盖了线上零售、生活服务、企业数据、农业、资源能化等10大类。提供17个API接口、165个数据集、56个数据报告、278个政府开放数据。
中原大数据交易
http://www.zybigdatae.cn/
数据资源提供商、数据资产运营商和数据交易服务商,向客户提供大数据全产业链平台与技术服务。提供223个API接口、177个数据集、89个数据报告、2个数据应用。
环境云
http://www.envicloud.cn/home?title=0
环境大数据开放平台。拥有3702家注册用户、收录1,041,098,354条环境数据,以积分兑换和免费下载两种方式提供数据服务。
天眼查
https://www.tianyancha.com/vipintro/?jsid=SEM-BAIDU-PZ1907-SY-000100
天眼查收录了1.8亿+家社会实体信息(含企业、事业单位、基金会、学校、律所等),90多种维度信息全量实时更新。
企查查
https://www.qichacha.com/
提供企业工商信息、法院判决信息、关联企业信息、法律诉讼、失信信息、被执行人信息、知识产权信息、公司新闻、企业年报等企业数据交易服务,覆盖全国1.8亿家企业信息。
杭州钱塘大数据交易中心
http://www.qtbigdata.com/index.html
杭州钱塘大数据交易中心有限公司(简称“钱塘数据”)成立于2015年底,是国内一家工业大数据应用和交易平台。
中关村数海大数据交易平台
http://www.shuhaidata.com/
全国第一家数据交易平台,推动数据的流通,发挥数据的商品属性,促成数据交换、整合,将真正带动大数据产业繁荣。
大数据挖掘模型交易平台
http://mx.tipdm.org/
模型算法交易平台,配套完整建模数据,模型实现过程说明及源代码。
APIX
https://www.apix.cn/services/category
APIX是黑格科技旗下的一款SaaS云服务产品,专注为机构提供实时在线用户数据分析,信用评估,第三方数据接入服务。
抓手数据
https://zhuashou.net/
运用区块链底层技术,以生产数据产品、建立数据交易生态圈为主要目标,促进数据的开放共享和数据价值的释放
千教堂
http://d.askci.com/
全球大数据众享平台
中国数据商城
http://www.chinadatastore.cn/index.html
中国领先的大数据交易平台
中国管理大数据
http://www.chn-source.com/
管理大数据RBD=平台运营商+数据供应商
数据星河
http://www.bdgstore.cn/
是全球首款大数据产业链生态平台,基于国际主流的大数据生态技术研发,结合先进的大数据资产运营理念,汇聚全球近千家大数据公司 。
相关阅读:
最全的中国开放数据(Open Data)及政府数据开放平台汇总
国外最全的开放数据(Open Data)及政府数据开放平台汇总
如何构建垂直网络爬虫平台
写一个爬虫很简单,写一个可持续稳定运行的爬虫也不难,但如何构建一个通用化的垂直网络爬虫平台?
这篇文章主要介绍垂直网络爬虫平台的构建思路。
爬虫简介
首先介绍一下什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取网页信息的程序或者脚本。
很简单,爬虫就是指定规则自动采集数据的程序脚本,目的在于拿到想要的数据。
爬虫主要分两类:
- 通用网络爬虫(搜索引擎)
- 垂直网络爬虫(特定领域)
由于第一类的开发成本较高,故只有搜索引擎公司在做,如谷歌、百度等。
而大多数企业在做的是第二类,成本低、数据价值高。例如一家做电商的公司只需要电商领域有价值的数据,那开发一个电商领域的爬虫平台,意义较大。
这篇文章主要针对第二类的平台构建提供设计与思路。
如何写爬虫
首先从最简单的开始,我们先了解一下如何写一个爬虫?
简单爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# coding: utf8
"""简单爬虫"""
import requests
from lxml import etree
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
parse_rule = "//div[@id='wrapper']/h1/span/text()"
for url in crawl_urls:
# 2. 发起HTTP请求
response = requests.get(url)
# 3. 解析HTML
result = etree.HTML(response.text).xpath(parse_rule)[0]
# 4. 保存结果
print result
if __name__ == '__main__':
run()
|
这个爬虫比较简单,大致流程为:
- 定义页面URL和解析规则
- 发起HTTP请求
- 解析HTML,拿到数据
- 保存数据
任何爬虫,要想获取网页上的数据,都是经过这几步。
当然,这个简单爬虫效率比较低,只能抓完一个网页,再去抓下一个,有没有提高效率的方式呢?
异步爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# coding: utf8
"""协程版本爬虫,提高抓取效率"""
from gevent import monkey
monkey.patch_all()
import requests
from lxml import etree
from gevent.pool import Pool
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
rule = "//div[@id='wrapper']/h1/span/text()"
# 2. 抓取
pool = Pool(size=10)
for url in crawl_urls:
pool.spawn(crawl, url, rule)
pool.join()
def crawl(url, rule):
"""抓取&解析"""
# 3. 发起HTTP请求
response = requests.get(url)
# 4. 解析HTML
result = etree.HTML(response.text).xpath(rule)[0]
# 5. 保存结果
print result
if __name__ == '__main__':
run()
|
经过优化,我们完成了异步版本的爬虫代码。
由于爬虫要抓的网页一般很多,提高效率是爬虫最基本的技能,由于下载网页都是阻塞在网络IO上,那我们可以利用多线程或异步的方式,提高抓取效率。
有了这些基础知识之后,我们看一个完整的例子,如何抓取一个整站数据?
整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
# coding: utf8
"""整站爬虫"""
from gevent import monkey
monkey.patch_all()
from urlparse import urljoin
import requests
from lxml import etree
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
def crawl(url):
"""首页"""
response = requests.get(url)
list_urls = etree.HTML(response.text).xpath(rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = requests.get(list_url).text
detail_urls = etree.HTML(html).xpath(rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = etree.HTML(html).xpath(rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = requests.get(list_url).text
title = etree.HTML(html).xpath(rules['title'])[0]
print title
def run():
"""run"""
# 1. 标签页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
此爬虫以豆瓣图书为例,抓取整站信息,大致思路为:
- 从标签页进入,提取所有标签URL
- 进入每个标签页,提取所有列表URL
- 进入每个列表页,提取每一页的详情URL和下一页列表URL
- 进入每个详情页,拿到书名
- 如此往复循环,直到数据抓取完毕
这就是抓取一个整站的思路,很简单,无非就是分析我们浏览网站的行为轨迹,用程序来进行自动化的请求、抓取。
理想情况下,我们应该能够拿到整站的数据,但实际情况对方网站往往会采取防爬虫措施,在抓取一段时间后,我们的IP就会被禁。
那如何突破这些防爬错误,拿到数据呢?我们继续优化代码。
防反爬的整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
# coding: utf8
"""防反爬的整站爬虫"""
from gevent import monkey
monkey.patch_all()
import random
from urlparse import urljoin
import requests
from lxml import etree
import gevent
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
# 定义代理池
proxy_list = [
'118.190.147.92:15524',
'47.92.134.176:17141',
'119.23.32.38:20189',
]
# 定义UserAgent
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
]
def fetch(url):
"""发起HTTP请求"""
proxies = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
headers = {'User-Agent': user_agent}
html = requests.get(url, headers=headers, proxies=proxies).text
return html
def parse(html, rule):
"""解析页面"""
return etree.HTML(html).xpath(rule)
def crawl(url):
"""首页"""
html = fetch(url)
list_urls = parse(html, rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = fetch(list_url)
detail_urls = parse(html, rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = parse(html, rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = fetch(list_url)
title = parse(html, rules['title'])[0]
print title
def run():
"""run"""
# 1. 首页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
这个版本的爬虫代码,加上了随机代理和请求头,这也是突破防爬措施的常用手段,使用此手段,加上一些质量高的代理,应对一些小网站的数据抓取,不在话下。
当然,这里只为了展示一步步写爬虫、优化爬虫的思路,来达到抓取数据的目的,现实情况的抓取与反爬比想象中的更复杂,需要具体场景具体分析。
现有问题
经过上面这几步,我们想要哪个网站的数据,分析网站网页结构,写出代码应该不成问题。
抓几个网站可以这么写,但抓几十个、几百个网站,你还能写下去吗?
由此暴露的问题:
- 爬虫脚本繁多,管理困难
- 规则定义零散,重复开发
- 后台脚本,无监控
- 数据输出困难,业务接入慢
这些问题都是我们在爬虫越写越多的情况下,难免会遇到的问题。
此时,我们迫切需要一个更好的解决方案,来更好地开发爬虫,爬虫平台应运而生。
平台架构
我们来分析每个爬虫的共同点,结果发现:写一个爬虫无非就是规则、抓取、解析、入库这几步,那我们可不可以把每一块分别拆开呢?如图:
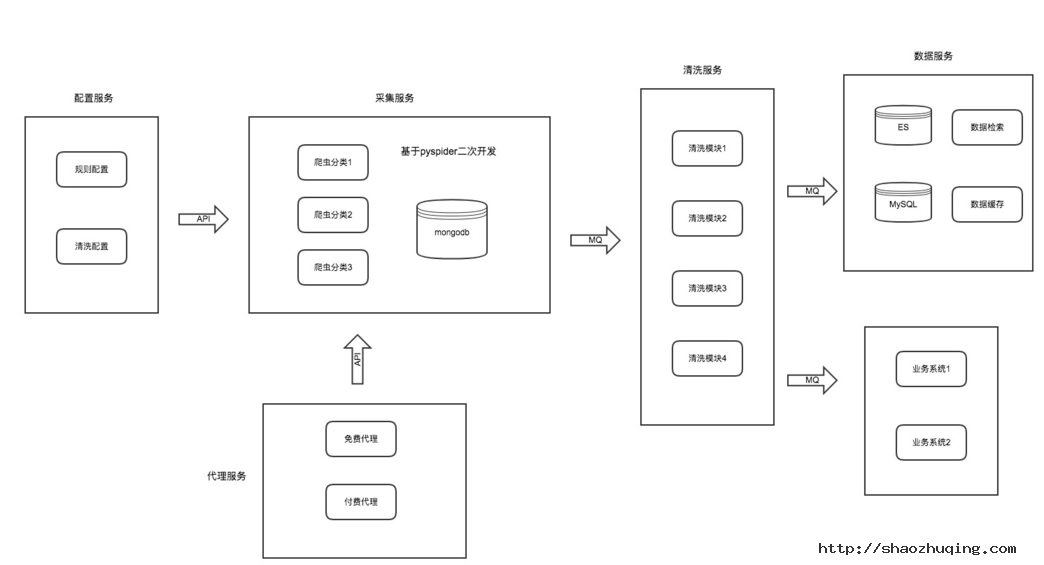
- 配置服务:包括抓取页面配置、解析规则配置、清洗配置
- 采集服务:专注网页下载与采集,并提供防爬策略
- 代理服务:提供稳定可持续输出的代理
- 清洗服务:针对同一类型业务进行字段清洗
- 数据服务:数据展示及业务数据对接
我们把一个爬虫的每一个环节,拆开做成一个个单独的服务模块,各模块各司其职。
每个模块维护属于自己领域的功能,可独立升级和优化。
详细设计
配置服务
此模块主要包括采集URL配置、页面解析规则配置、清洗配置。
我们把爬虫的规则从爬虫脚本中抽离出来,单独配置与维护,这样也便于重用与管理。
由于此模块专注配置管理,那我们可以对配置进一步拆开,配置支持各种方式的数据解析模式,如正则解析、CSS解析、XPATH解析,每种模式配置对应的表达式即可。
采集服务可以写一个配置解析器与配置服务进行对接,此配置解析器内部实现各种模式具体的解析逻辑。
清洗配置主要可配置每个爬虫输出后对应的清洗worker。
采集服务
此模块比较纯粹,就是写爬虫逻辑的模块,我们可以像之前那样开发、调试、运行爬虫脚本,但这一切工作都只能在命令行脚本进行,有没有一种好的方案是可以可视化操作的呢?
我们调研了市面上比较好的爬虫框架,发现pyspider符合我们的需求,此框架的特点:
- 支持分布式
- 配置可视化
- 可周期采集
- 支持优先级
- 任务可监控
pyspider架构图:
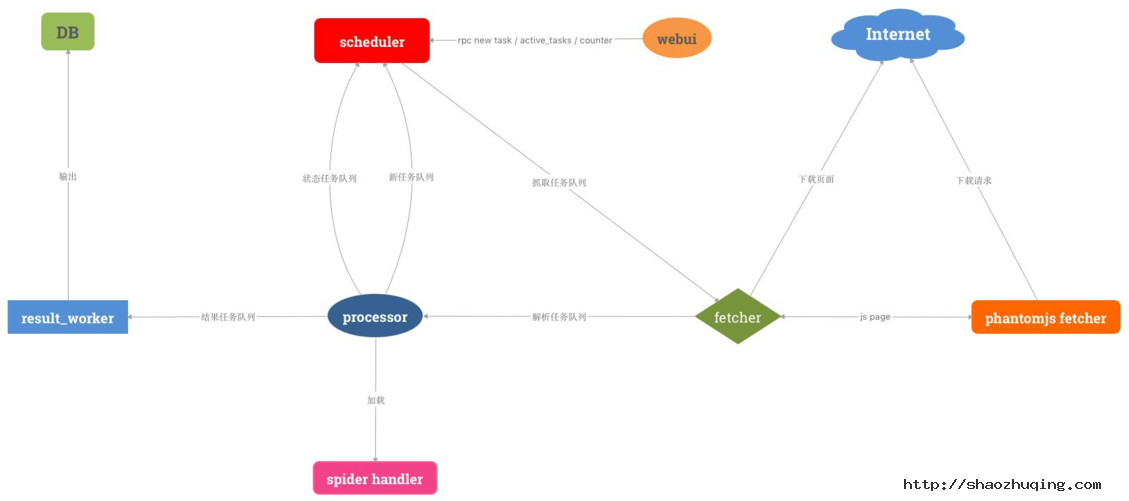
正所谓站在巨人的肩膀上。我们决定对其进行二次开发,并增强其一些组件,使爬虫开发成本更低,更符合我们的业务规则。
- 开发配置解析器,对接配置服务
spider handler定制爬虫模板,分类采集任务,生成模板,降低开发成本fetcher新增代理调度机制,对接代理服务,并增加代理调度策略result_worker输出定制化,对接清洗服务
由此我们可做出一个分布式、可视化、任务可监控、可生成爬虫模板的采集服务模块。
代理服务
做爬虫的都知道,代理是突破防抓的常用手段,如何获取稳定且持续的代理呢?
此模块内部维护代理的质量和数量,并输出给采集服务,供采集使用。
主要包括两部分:
- 免费代理
- 付费代理
免费代理
免费代理主要由我们自己的代理采集程序采集获得,大致思路为:
- 收集代理源
- 定时采集代理
- 测试代理
- 输出代理
付费代理
免费代理的质量和稳定性相对较差,对于采集防爬比较厉害的网站,还是不够用。
这时我们会购买一些付费代理,专门用于采集这类防爬的网站,此代理一般为高匿代理,并定时更新。
清洗服务
此模块比较简单,主要接收采集服务输出的数据,然后根据对应的规则执行清洗逻辑。
例如网页字段与数据库字段归一转换,特殊字段清洗定制化等。
这个服务模块运行了很多worker,最终把输出结果输送到数据服务。
数据服务
此模块会接收最终清洗后的结构化数据,统一入库。且针对其他业务系统需要的数据进行统一推送输出:
- 数据平台展示
- 数据推送
- 数据API
解决的问题
经过这个平台的构建,基本解决了最开始困扰的几个问题:
- 爬虫管理、配置可视化
- 降低开发成本
- 进度可监控、易跟踪
- 数据输出便捷
- 业务接入迅速
爬虫技巧
爬虫技巧从整体上来说,其实核心思想就一个:尽可能地模拟人的行为。
例如:
- 随机UserAgent(github fake-useragent)
- 随机代理IP(高匿代理、代理策略)
- Cookie池
- JS渲染页面(phantomjs)
- 验证码识别(OCR、机器学习)
当然,做爬虫是一个相互博弈的过程,有时没必要硬碰硬,遇到问题换个思路不免是一种解决办法。例如,对方的PC站防抓厉害,那去看一看对方的WAP站可不可以搞一下?APP端是否可以尝试一下?在有限的成本拿到数据才是爬虫的目的。
以上就是构建一个垂直网络爬虫平台的大致思路,从最简单的爬虫脚本,到写越来越多的爬虫,到难以维护,再到整个爬虫平台的构建,一步步都是遇到问题解决问题的产物,在我们真正发现核心问题时,解决思路也就不难了。
微信公众平台开发 OAuth2.0网页授权认证
一、什么是OAuth2.0
官方网站:http://oauth.net/ http://oauth.net/2/
权威定义:OAuth is An open protocol to allow secure authorization in a simple and standard method from web, mobile and desktop applications.
OAuth是一个开放协议,允许用户让第三方应用以安全且标准的方式获取该用户在某一网站、移动或桌面应用上存储的私密的资源(如用户个人信息、照片、视频、联系人列表),而无需将用户名和密码提供给第三方应用。
OAuth 2.0是OAuth协议的下一版本,但不向后兼容OAuth 1.0。 OAuth 2.0关注客户端开发者的简易性,同时为Web应用,桌面应用和手机,和起居室设备提供专门的认证流程。
OAuth允许用户提供一个令牌,而不是用户名和密码来访问他们存放在特定服务提供者的数据。每一个令牌授权一个特定的网站(例如,视频编辑网站)在特定的时段(例如,接下来的2小时内)内访问特定的资源(例如仅仅是某一相册中的视频)。这样,OAuth允许用户授权第三方网站访问他们存储在另外的服务提供者上的信息,而不需要分享他们的访问许可或他们数据的所有内容。
新浪微博API目前也使用OAuth 2.0。
二、微信公众平台OAuth2.0授权
微信公众平台OAuth2.0授权详细步骤如下:
1. 用户关注微信公众账号。
2. 微信公众账号提供用户请求授权页面URL。
3. 用户点击授权页面URL,将向服务器发起请求
4. 服务器询问用户是否同意授权给微信公众账号(scope为snsapi_base时无此步骤)
5. 用户同意(scope为snsapi_base时无此步骤)
6. 服务器将CODE通过回调传给微信公众账号
7. 微信公众账号获得CODE
8. 微信公众账号通过CODE向服务器请求Access Token
9. 服务器返回Access Token和OpenID给微信公众账号
10. 微信公众账号通过Access Token向服务器请求用户信息(scope为snsapi_base时无此步骤)
11. 服务器将用户信息回送给微信公众账号(scope为snsapi_base时无此步骤)
如果用户在微信中(Web微信除外)访问公众号的第三方网页,公众号开发者可以通过此接口获取当前用户基本信息(包括昵称、性别、城市、国家)。利用用户信息,可以实现体验优化、用户来源统计、帐号绑定、用户身份鉴权等功能。请注意,“获取用户基本信息接口是在用户和公众号产生消息交互时,才能根据用户OpenID获取用户基本信息,而网页授权的方式获取用户基本信息,则无需消息交互,只是用户进入到公众号的网页,就可弹出请求用户授权的界面,用户授权后,就可获得其基本信息(此过程甚至不需要用户已经关注公众号。)”
微信OAuth2.0授权登录让微信用户使用微信身份安全登录第三方应用或网站,在微信用户授权登录已接入微信OAuth2.0的第三方应用后,第三方可以获取到用户的接口调用凭证(access_token),通过access_token可以进行微信开放平台授权关系接口调用,从而可实现获取微信用户基本开放信息和帮助用户实现基础开放功能等。
在微信公众号请求用户网页授权之前,开发者需要先到公众平台网站的我的服务页中配置授权回调域名。请注意,这里填写的域名不要加http://
关于配置授权回调域名的说明:
授权回调域名配置规范为全域名,比如需要网页授权的域名为:www.qq.com,配置以后此域名下面的页面http://www.qq.com/music.html 、 http://www.qq.com/login.html 都可以进行OAuth2.0鉴权。但http://pay.qq.com 、 http://music.qq.com 、 http://qq.com 无法进行OAuth2.0鉴权。
具体而言,网页授权流程分为四步:
- 引导用户进入授权页面同意授权,获取code
- 通过code换取网页授权access_token(与基础支持中的access_token不同)
- 如果需要,开发者可以刷新网页授权access_token,避免过期
- 通过网页授权access_token和openid获取用户基本信息
目录[隐藏] |
第一步:用户同意授权,获取code
在确保微信公众账号拥有授权作用域(scope参数)的权限的前提下(服务号获得高级接口后,默认带有scope参数中的snsapi_base和snsapi_userinfo),引导关注者打开如下页面:
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect 若提示“该链接无法访问”,请检查参数是否填写错误,是否拥有scope参数对应的授权作用域权限。 参考链接(请在微信客户端中打开此链接体验) Scope为snsapi_base https://open.weixin.qq.com/connect/oauth2/authorize?appid=wx520c15f417810387&redirect_uri=http%3A%2F%2Fchong.qq.com%2Fphp%2Findex.php%3Fd%3D%26c%3DwxAdapter%26m%3DmobileDeal%26showwxpaytitle%3D1%26vb2ctag%3D4_2030_5_1194_60&response_type=code&scope=snsapi_base&state=123#wechat_redirect Scope为snsapi_userinfo https://open.weixin.qq.com/connect/oauth2/authorize?appid=wxf0e81c3bee622d60&redirect_uri=http%3A%2F%2Fnba.bluewebgame.com%2Foauth_response.php&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| redirect_uri | 是 | 授权后重定向的回调链接地址,请使用urlencode对链接进行处理 |
| response_type | 是 | 返回类型,请填写code |
| scope | 是 | 应用授权作用域,snsapi_base (不弹出授权页面,直接跳转,只能获取用户openid),snsapi_userinfo (弹出授权页面,可通过openid拿到昵称、性别、所在地。并且,即使在未关注的情况下,只要用户授权,也能获取其信息) |
| state | 否 | 重定向后会带上state参数,开发者可以填写a-zA-Z0-9的参数值 |
| #wechat_redirect | 是 | 无论直接打开还是做页面302重定向时候,必须带此参数 |
下图为scope等于snsapi_userinfo时的授权页面:
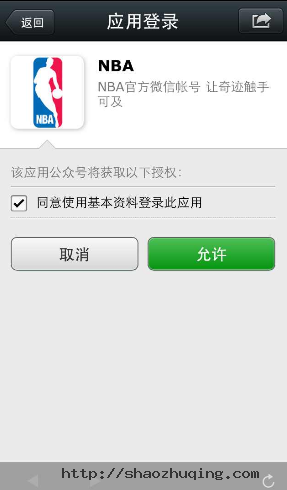
用户同意授权后
如果用户同意授权,页面将跳转至 redirect_uri/?code=CODE&state=STATE。若用户禁止授权,则重定向后不会带上code参数,仅会带上state参数redirect_uri?state=STATE
code说明 : code作为换取access_token的票据,每次用户授权带上的code将不一样,code只能使用一次,5分钟未被使用自动过期。
第二步:通过code换取网页授权access_token
首先请注意,这里通过code换取的网页授权access_token,与基础支持中的access_token不同。公众号可通过下述接口来获取网页授权access_token。如果网页授权的作用域为snsapi_base,则本步骤中获取到网页授权access_token的同时,也获取到了openid,snsapi_base式的网页授权流程即到此为止。
请求方法
获取code后,请求以下链接获取access_token: https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code
参数说明
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| secret | 是 | 公众号的appsecret |
| code | 是 | 填写第一步获取的code参数 |
| grant_type | 是 | 填写为authorization_code |
返回说明
正确时返回的JSON数据包如下:
{ "access_token":"ACCESS_TOKEN", "expires_in":7200, "refresh_token":"REFRESH_TOKEN", "openid":"OPENID", "scope":"SCOPE" }
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| expires_in | access_token接口调用凭证超时时间,单位(秒) |
| refresh_token | 用户刷新access_token |
| openid | 用户唯一标识,请注意,在未关注公众号时,用户访问公众号的网页,也会产生一个用户和公众号唯一的OpenID |
| scope | 用户授权的作用域,使用逗号(,)分隔 |
错误时微信会返回JSON数据包如下(示例为Code无效错误):
{"errcode":40029,"errmsg":"invalid code"}
第三步:刷新access_token(如果需要)
由于access_token拥有较短的有效期,当access_token超时后,可以使用refresh_token进行刷新,refresh_token拥有较长的有效期(7天、30天、60天、90天),当refresh_token失效的后,需要用户重新授权。
请求方法
获取第二步的refresh_token后,请求以下链接获取access_token: https://api.weixin.qq.com/sns/oauth2/refresh_token?appid=APPID&grant_type=refresh_token&refresh_token=REFRESH_TOKEN
| 参数 | 是否必须 | 说明 |
|---|---|---|
| appid | 是 | 公众号的唯一标识 |
| grant_type | 是 | 填写为refresh_token |
| refresh_token | 是 | 填写通过access_token获取到的refresh_token参数 |
返回说明
正确时返回的JSON数据包如下:
{ "access_token":"ACCESS_TOKEN", "expires_in":7200, "refresh_token":"REFRESH_TOKEN", "openid":"OPENID", "scope":"SCOPE" }
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| expires_in | access_token接口调用凭证超时时间,单位(秒) |
| refresh_token | 用户刷新access_token |
| openid | 用户唯一标识 |
| scope | 用户授权的作用域,使用逗号(,)分隔 |
错误时微信会返回JSON数据包如下(示例为Code无效错误):
{"errcode":40029,"errmsg":"invalid code"}
第四步:拉取用户信息(需scope为 snsapi_userinfo)
如果网页授权作用域为snsapi_userinfo,则此时开发者可以通过access_token和openid拉取用户信息了。
请求方法
http:GET(请使用https协议) https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN
参数说明
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| openid | 用户的唯一标识 |
| lang | 返回国家地区语言版本,zh_CN 简体,zh_TW 繁体,en 英语 |
返回说明
正确时返回的JSON数据包如下:
{ "openid":" OPENID", " nickname": NICKNAME, "sex":"1", "province":"PROVINCE" "city":"CITY", "country":"COUNTRY", "headimgurl": "http://wx.qlogo.cn/mmopen/g3MonUZtNHkdmzicIlibx6iaFqAc56vxLSUfpb6n5WKSYVY0ChQKkiaJSgQ1dZuTOgvLLrhJbERQQ4eMsv84eavHiaiceqxibJxCfHe/46", "privilege":[ "PRIVILEGE1" "PRIVILEGE2" ] }
| 参数 | 描述 |
|---|---|
| openid | 用户的唯一标识 |
| nickname | 用户昵称 |
| sex | 用户的性别,值为1时是男性,值为2时是女性,值为0时是未知 |
| province | 用户个人资料填写的省份 |
| city | 普通用户个人资料填写的城市 |
| country | 国家,如中国为CN |
| headimgurl | 用户头像,最后一个数值代表正方形头像大小(有0、46、64、96、132数值可选,0代表640*640正方形头像),用户没有头像时该项为空 |
| privilege | 用户特权信息,json 数组,如微信沃卡用户为(chinaunicom) |
错误时微信会返回JSON数据包如下(示例为openid无效):
{"errcode":40003,"errmsg":" invalid openid "}
附:检验授权凭证(access_token)是否有效
请求方法
http:GET(请使用https协议) https://api.weixin.qq.com/sns/auth?access_token=ACCESS_TOKEN&openid=OPENID
参数说明
| 参数 | 描述 |
|---|---|
| access_token | 网页授权接口调用凭证,注意:此access_token与基础支持的access_token不同 |
| openid | 用户的唯一标识 |
返回说明
正确的Json返回结果:
{ "errcode":0,"errmsg":"ok"}
错误时的Json返回示例:
{ "errcode":40003,"errmsg":"invalid openid"}
案例代码:
请求授权页面的构造方式
url在线编码工具:http://tool.oschina.net/encode?type=4
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=SCOPE&state=STATE#wechat_redirect
前端代码
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd";><html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /><meta name="viewport" content="width=device-width,height=device-height,inital-scale=1.0,maximum-scale=1.0,user-scalable=no;"><meta name="apple-mobile-web-app-capable" content="yes"><meta name="apple-mobile-web-app-status-bar-style" content="black"><meta name="format-detection" content="telephone=no"><title>会员注册</title><script type="text/JavaScript" src="jQuery.js"></script>
<script type="text/javascript">
function callback(result) {
alert('cucess');
alert(result); //输出openid
}
function getQueryString(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i");
var r = window.location.search.substr(1).match(reg);
if (r != null) return unescape(r[2]); return null;
}
var code = getQueryString("code");
$.ajax({
async: false, url: "http://atest.sinaapp.com/oauth2.php", //这是我的服务端处理文件php的
type: "GET", //下面几行是jsoup,如果去掉下面几行的注释,后端对应的返回结果也要去掉注释
// dataType: 'jsonp',
// jsonp: 'callback', //jsonp的值自定义,如果使用jsoncallback,那么服务器端,要返回一个jsoncallback的值对应的对象.
// jsonpCallback:'callback',
data: {code:code}, //传递本页面获取的code到后台,以便后台获取openid
timeout: 5000,
success: function (result) {
callback(result);
},
error: function (jqXHR, textStatus, errorThrown) {
alert(textStatus); }
});
</script>
</head><body></body>
后端代码
<?php
$code = $_GET['code'];//前端传来的code值
$appid = "wx468622291a1e99d6";
$appsecret = "98566dc38863aa4395fabebb0de6ecc1";//获取openid
$url = "https://api.weixin.qq.com/sns/oauth2/access_token?appid=$appid&secret=$appsecret&code=$code&grant_type=authorization_code";
$result = https_request($url);
$jsoninfo = json_decode($result, true);
$openid = $jsoninfo["openid"];//从返回json结果中读出openid
$access_token = $jsoninfo["access_token"];//从返回json结果中读出openid
$callback=$_GET['callback']; // echo $callback."({result:'".$openid."'})";
$url1 = "https://api.weixin.qq.com/sns/userinfo?access_token=$access_token&openid=$openid&lang=zh_CN";
$result1 = https_request($url1);
$jsoninfo1 = json_decode($result1, true);
$nickname=$jsoninfo1["nickname"];
echo $openid.":".$access_token.":".$nickname; //把openid 送回前端
function https_request($url,$data = null){
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
if (!empty($data)){
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($curl);
curl_close($curl);
return $output;
}
?>
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
目录分类
文章归档
- 2022年8月 (2)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)