MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
一篇文章学会Mysql分区表的管理与维护
定义:
表的分区指根据可以设置为任意大小的规则,跨文件系统分配单个表的多个部分。实际上,表的不同部分在不同的位置被存储为单独的表。用户所选择的、实现数据分割的规则被称为分区函数,这在MySQL中它可以是模数,或者是简单的匹配一个连续的数值区间或数值列表,或者是一个内部HASH函数,或一个线性HASH函数。
使用场景:
1.某张表的数据量非常大,通过索引已经不能很好的解决查询性能的问题
2.表的数据可以按照某种条件进行分类,以致于在查询的时候性能得到很大的提升
优点:
1)、对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。相反地,在某些情况下,添加新数据的过程又可以通过为那些新数据专门增加一个新的分区,来很方便地实现。
2)、一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,这样在查找时就不用查找其他剩余的分区。因为分区可以在创建了分区表后进行修改,所以在第一次配置分区方案时还不曾这么做时,可以重新组织数据,来提高那些常用查询的效率。
3)、涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。这意味着查询可以在每个分区上同时进行,最终结果只需通过总计所有分区得到的结果。
4)、通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
分类:

1.检查你的Mysql是否支持分区
mysql> SHOW VARIABLES LIKE '%partition%';
若结果如下,表示你的Mysql支持表分区:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| have_partition_engine | YES |
+-----------------------+-------+
1 row in set (0.00 sec)
RANGE分区表创建方式:
- DROP TABLE IF EXISTS `my_orders`;
- CREATE TABLE `my_orders` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (YEAR(atime))
- (
- PARTITION p0 VALUES LESS THAN (2016),
- PARTITION p1 VALUES LESS THAN (2017),
- PARTITION p2 VALUES LESS THAN MAXVALUE
- );
以上是一个简单的订单表,分区字段是atime,根据RANGE分区,这样当你向该表中插入数据的时候,Mysql会根据YEAR(atime)的值进行分区存储。
检查分区是否创建成功,执行查询语句:
EXPLAIN PARTITIONS SELECT * FROM `my_orders`
若成功,结果如下:

性能分析:
1).创建同样表结构,但没有进行分区的表
- DROP TABLE IF EXISTS `my_order`;
- CREATE TABLE `my_order` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `pid` int(10) unsigned NOT NULL COMMENT '产品ID',
- `price` decimal(15,2) NOT NULL COMMENT '单价',
- `num` int(11) NOT NULL COMMENT '购买数量',
- `uid` int(10) unsigned NOT NULL COMMENT '客户ID',
- `atime` datetime NOT NULL COMMENT '下单时间',
- `utime` int(10) unsigned NOT NULL DEFAULT 0 COMMENT '修改时间',
- `isdel` tinyint(4) NOT NULL DEFAULT '0' COMMENT '软删除标识',
- PRIMARY KEY (`id`,`atime`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2).向两张表中插入相同的数据
- /**************************向分区表插入数据****************************/
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_orders(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
- /**************************向未分区表插入数据****************************/
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,CURRENT_TIMESTAMP());
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89757,'2018-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2015-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2016-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2017-05-01 00:00:00');
- INSERT INTO my_order(`pid`,`price`,`num`,`uid`,`atime`) VALUES(1,12.23,1,89756,'2018-05-01 00:00:00');
3).主从复制,大约20万条左右(主从复制的数据和真实环境有差距,但是能体现出表分区查询的性能优劣)
- /**********************************主从复制大量数据******************************/
- INSERT INTO `my_orders`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_orders`;
- INSERT INTO `my_order`(`pid`,`price`,`num`,`uid`,`atime`) SELECT `pid`,`price`,`num`,`uid`,`atime` FROM `my_order`;
4).查询测试
- /***************************查询性能分析**************************************/
- SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.084s****/
- SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
- /****用时0.284s****/
通过以上查询可以明显看出进行表分区的查询性能更好,查询所花费的时间更短。
分析查询过程:
EXPLAIN PARTITIONS SELECT * FROM `my_orders` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();
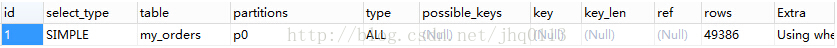
EXPLAIN PARTITIONS SELECT * FROM `my_order` WHERE `uid`=89757 AND `atime`< CURRENT_TIMESTAMP();

通过以上结果可以看出,my_orders表查询直接经过p0分区,只扫描了49386行,而my_order表没有进行分区,扫描了196983行,这也是性能得到提升的关键所在。
当然,表的分区并不是分的越多越好,当表的分区太多时找分区又是一个性能的瓶颈了,建议在200个分区以内。
LIST分区表创建方式:
- /*****************创建分区表*********************/
- CREATE TABLE `products` (
- `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '表主键' ,
- `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '产品名称' ,
- `metrial` tinyint UNSIGNED NOT NULL COMMENT '材质' ,
- `weight` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '重量' ,
- `vol` double UNSIGNED NOT NULL DEFAULT 0 COMMENT '容积' ,
- `c_id` tinyint UNSIGNED NOT NULL COMMENT '供货公司ID' ,
- PRIMARY KEY (`id`,`c_id`)
- )ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY LIST(c_id)
- (
- PARTITION pA VALUES IN (1,3,11,13),
- PARTITION pB VALUES IN (2,4,12,14),
- PARTITION pC VALUES IN (5,7,15,17),
- PARTITION pD VALUES IN (6,8,16,18),
- PARTITION pE VALUES IN (9,10,19,20)
- );
可以看出,LIST分区和RANGE分区很类似,这里就不做性能分析了,和RANGE很类似。
HASH分区表的创建方式:
- /*****************分区表*****************/
- CREATE TABLE `msgs` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY HASH(sub_id)
- PARTITIONS 10;
以上语句代表,msgs表按照sub_id进行HASH分区,一共分了十个区。
Key分区和HASH分区很类似,不再介绍,若想了解可以参考Mysql官方文档进行详细了解。
子分区的创建方式:
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
检查子分区是否创建成功:
EXPLAIN PARTITIONS SELECT * FROM msgss;
结果如下图:

前面已经提过,Mysql支持4种表的分区,即RANGE与LIST、HASH与KEY,其中RANGE和LIST类似,按一种区间进行分区,HASH与KEY类似,是按照某种算法对字段进行分区。
RANGE与LIST分区管理:
案例:有一个聊天记录表,用户几千左右,已经对表按照用户进行一定粒度的水平分割,现仍然有部分表存储的记录比较多,于是按照下列方式有对表进行了分区,分区的好处是,可以动态改变分区,删除分区后,数据也一同被删除,如聊天记录只保存两年,那么你就可以按照时间进行分区,定期删除两年前的分区,动态创建新的的分区就能做到很好的数据维护。
分区表创建的语句如下:
- DROP TABLE IF EXISTS `msgss`;
- CREATE TABLE `msgss` (
- `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '表主键',
- `sender` int(10) unsigned NOT NULL COMMENT '发送者ID',
- `reciver` int(10) unsigned NOT NULL COMMENT '接收者ID',
- `msg_type` tinyint(3) unsigned NOT NULL COMMENT '消息类型',
- `msg` varchar(225) NOT NULL COMMENT '消息内容',
- `atime` int(10) unsigned NOT NULL COMMENT '发送时间',
- `sub_id` tinyint(3) unsigned NOT NULL COMMENT '部门ID',
- PRIMARY KEY (`id`,`atime`,`sub_id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8
- /*********分区信息**************/
- PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1451577600)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
上述语句创建了三个按照RANGE划分的主分区,每个主分区下面有六个按照HASH划分的子分区。
插入测试数据:
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',UNIX_TIMESTAMP(NOW()),1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',UNIX_TIMESTAMP(NOW()),2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',UNIX_TIMESTAMP(NOW()),3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',UNIX_TIMESTAMP(NOW()),10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',UNIX_TIMESTAMP(NOW()),7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',UNIX_TIMESTAMP(NOW()),5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1451577607,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1451577609,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1451577623,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1451577654,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1451577687,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1451577699,5);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH',1514736056,1);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 2',1514736066,2);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 3',1514736076,3);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 10',1514736086,10);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 7',1514736089,7);
- INSERT INTO `msgss`(`sender`,`reciver`,`msg_type`,`msg`,`atime`,`sub_id`) VALUES(1,2,0,'Hello HASH 5',1514736098,5);
进行分区分析:
EXPLAIN PARTITIONS SELECT * FROM msgss;
可以检测到分区信息如下:

检测分区数据分布:
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`<1451577600;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1451577600 AND `atime`<1483200000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1483200000 AND `atime`<1514736000;
- EXPLAIN PARTITIONS SELECT * FROM msgss WHERE `atime`>1514736000;
结果:第一条语句只扫描了t0的所有子分区,第二条语句只扫描了t1的所有子分区,第三四条分别只扫描了t2的所有子分区,证明表的分区和数据分布成功。
需求:目前已经是2017年,需要将2015年所有的聊天记录删除,但是保留2016年的聊天记录,并且2017年的数据也能正常按照分区进行存储。
实现以上需求,需要两步,第一步删除t0分区,第二步按照新规则重建分区。
删除分区语句:
ALTER TABLE `msgss` DROP PARTITION t0;
重建分区语句:
- ALTER TABLE `msgss` PARTITION BY RANGE (atime) SUBPARTITION BY HASH (sub_id)
- (
- PARTITION t0 VALUES LESS THAN(1483200000)
- (
- SUBPARTITION s0,
- SUBPARTITION s1,
- SUBPARTITION s2,
- SUBPARTITION s3,
- SUBPARTITION s4,
- SUBPARTITION s5
- ),
- PARTITION t1 VALUES LESS THAN(1514736000)
- (
- SUBPARTITION s6,
- SUBPARTITION s7,
- SUBPARTITION s8,
- SUBPARTITION s9,
- SUBPARTITION s10,
- SUBPARTITION s11
- ),
- PARTITION t2 VALUES LESS THAN MAXVALUE
- (
- SUBPARTITION s12,
- SUBPARTITION s13,
- SUBPARTITION s14,
- SUBPARTITION s15,
- SUBPARTITION s16,
- SUBPARTITION s17
- )
- );
查询发现,15年的数据全部被删除,剩余的数据被重新分区并分布。
GA 设置跨网域跟踪
设置跨网域跟踪
通过跨网域跟踪,Google Analytics(分析)可以将两个相关网站(例如电子商务网站和单独的购物车网站)上的会话视为一个会话。这有时称为“站点关联”。
跨网域跟踪概览
为跟踪会话,Google Analytics(分析)收集每次匹配的客户 ID 值。客户 ID 值存储在 Cookie 中。Cookie 存储在各个网域中,且一个网域中的网站不能访问为另一个网域设置的 Cookie。当跟踪跨多个网域的会话时,需要将客户 ID 值从一个网域传送到另一个。为此,Google Analytics(分析)跟踪代码具备链接功能,使源网域能够将客户 ID 加入链接的网址参数,供目标网域访问。
使用 Google 跟踪代码管理器设置跨网域跟踪
如果使用 Google 跟踪代码管理器管理 Google Analytics(分析)跟踪,请按照跨网域跟踪中的说明操作。
通过修改跟踪代码设置跨网域跟踪
要针对多个顶级网域设置跨网域跟踪,您需要在每个网域上修改 Google Analytics(分析)跟踪代码。您应掌握基本的 HTML 和 JavaScript 知识或者与开发者合作才能设置跨网域跟踪。本文中的示例使用了 Universal Analytics 跟踪代码段 (analytics.js)。
- 在 Google Analytics(分析)帐户中设置媒体资源。
要进行跨网域跟踪,请在 Google Analytics(分析)帐户中设置一个媒体资源。请为您的所有网域都使用来自该媒体资源的同一个跟踪代码段和跟踪 ID。为了让跨网域跟踪发挥作用,您需要对跟踪代码段进行修改。如果您还没有在自己的所有网页上都添加此代码段,可以先将其复制并粘贴到文本编辑器中,然后再按本文中的说明继续操作。这样一来,您只需先在文本编辑器中进行一次更改,然后再将修改后的代码段添加到您的所有网页上即可。 - 修改主网域的跟踪代码。
在代码段中找到create行。如果网站名为 example-1.com,那么这一行会显示为:ga('create', 'UA-XXXXXXX-Y', 'example-1.com');对代码段进行以下更改(您需要更改的地方以红色粗体表示):ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});请记得将示例中的跟踪 ID (UA-XXXXXX-Y) 替换为您自己的跟踪 ID,并将示例中的辅助网域 (example-2.com) 替换为您自己的辅助域名。
ga('require', 'linker');
ga('linker:autoLink', ['example-2.com'] );在您的主网域中,所有出现此跟踪代码段的地方都必须包含这些更改。
三个或更多个网域按上例所示操作,但是要为自动链接插件再添加其他网域。请注意其中额外的逗号,这个符号非常重要:ga('linker:autoLink', ['example-2.com', 'example-3.com'] );您的主域名的跟踪代码段应如下所示:
<script>(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});
ga('require', 'linker');
ga('linker:autoLink', ['example-2.com'] );
ga('send', 'pageview');</script>
- 修改辅助网域的跟踪代码。在代码段中找到
create行。对代码段进行以下更改(您需要更改的地方以红色粗体表示):ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});请记得将示例中的跟踪 ID (UA-XXXXXX-Y) 替换为您自己的跟踪 ID,并将示例中的主网域 (example-1.com) 替换为您自己的主域名。
ga('require', 'linker');
ga('linker:autoLink', ['example-1.com'] );在您的辅助网域中,所有出现此跟踪代码段的地方都必须包含这些更改。
三个或更多个网域按上例所示操作,但是要为自动链接插件再添加其他网域。请注意其中额外的逗号,这个符号非常重要:ga('linker:autoLink', ['example-1.com', 'example-3.com'] );您的辅助域名的跟踪代码段应如下所示:
<script>(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){ (i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o), m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m) })(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-XXXXXXX-Y', 'auto', {'allowLinker': true});
ga('require', 'linker');
ga('linker:autoLink', ['example-1.com'] );
ga('send', 'pageview');</script>
设置报告数据视图和添加过滤器
默认情况下,Google Analytics(分析)仅会添加网页路径和网页名称,不会添加域名。例如,您可能会在网站内容报告中看到网页如下所示:
- /about/contactUs.html
- /about/contactUs.html
- /products/buy.html
由于域名不会列出,因此您可能会很难分辨每个网页所属的网域。
要让您的报告显示域名,您需要执行以下两项操作:创建报告数据视图副本(其中应包含所有网域的数据),并向这一新的数据视图添加高级过滤器。此过滤器会让 Google Analytics(分析)在您的报告中显示域名。
在设置跨网域跟踪后,请按照以下示例设置会在您的报告中显示域名的数据视图过滤器。对于有些字段,您需要从下拉菜单中选择一个项目。对于另外一些字段,您需要输入以下字符:
- 过滤器类型:自定义过滤器 > 高级
- 字段A:主机名提取A:(.*)
- 字段 B:请求 URI 提取:(.*)
- 输出至:请求 URI 构造器:$A1$B1
点击保存以创建过滤器。
可以使用 Google Tag Assistant 记录验证该过滤器的工作状态是否符合要求。Tag Assistant 记录可以准确显示过滤器对流量的改变情况。
向引荐排除列表添加网域
当用户行为历程从第一个网域转到第二个网域,对于 Google Analytics(分析)来说,相当于通过第一个网域将用户引荐到第二个网域,并创建一个新的会话。如果您希望跨多个网域跟踪单个会话,则需要将网域添加到引荐排除列表。
检查跨网域跟踪运行情况
要验证跨网域跟踪的设置是否正确,最好的方法是使用 Google Tag Assistant 记录。只要会话跨网域,它就可以立即显示跟踪是否正常。
以下示例 Tag Assistant 记录报告显示在跨网域跟踪设置错误时,会显示哪些内容。
相关资源
linux 查看系统信息命令(比较全)
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务程序
# rpm -qa # 查看所有安装的软件包
PHP下SSL加密解密、验证、签名方法(很简单)
RSA超级简单,依赖于OpenSSL扩展,这里就不多废话了,直接奉上代码
签名:
function sign($data) {
//读取私钥文件(签名一定是商户自己本地生成的私钥)
$priKey = file_get_contents('key/rsa_private_key.pem');
//转换为openssl密钥,必须是没有经过pkcs8转换的私钥(不要使用这个私钥rsa_private_key_pkcs8.pem)
$res = openssl_get_privatekey($priKey);
//调用openssl内置签名方法,生成签名$sign
openssl_sign($data, $sign, $res);
//释放资源
openssl_free_key($res);
return $sign;
}
验证:
function verify($data, $sign) {
//读取支付宝公钥文件(一定是阿里后台生成提供的公钥)
$pubKey = file_get_contents('key/alipay_public_key.pem');
//转换为openssl格式密钥
$res = openssl_get_publickey($pubKey);
//调用openssl内置方法验签,返回bool值
$result = (bool)openssl_verify($data, $sign, $res);
//释放资源
openssl_free_key($res);
return $result;
解密
function decrypt($content) {
//读取商户私钥(商户自己生成的私钥)
$priKey = file_get_contents('key/rsa_private_key.pem');
//转换为openssl密钥,必须是没有经过pkcs8转换的私钥
$res = openssl_get_privatekey($priKey);
//声明明文字符串变量
$result = '';
//循环按照128位解密
for($i = 0; $i < strlen($content)/128; $i++ ) {
$data = substr($content, $i * 128, 128);
//拆分开长度为128的字符串片段通过私钥进行解密,返回$decrypt解析后的明文
openssl_private_decrypt($data, $decrypt, $res);
//明文片段拼接
$result .= $decrypt;
}
//释放资源
openssl_free_key($res);
//返回明文
return $result;
}
AES密钥是什么
高级加密标准(英语:Advanced Encryption Standard,缩写:AES),是目前对称密钥加密中比较通用的一种加密方式。
AES密钥有什么用
支付宝开放平台所有OpenAPI均支持对接口的请求内容和响应内容进行AES加密,部分OpenAPI(芝麻信用等)强制要求AES加密。加密后,在网络上传输的接口报文内容将会由明文内容变为密文内容,可以大大提升接口内容传输的安全性。
AES密钥与RSA密钥的关系
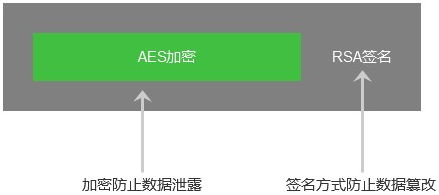
- AES密钥是对接口请求和响应内容进行加密,密文无法被第三方识别,从而防止接口传输数据泄露。
- RSA密钥是对接口请求和响应内容进行签名,开发者和支付宝开放平台分别加签验签,以确认接口传输的内容没有被篡改。不论接口内容是明文还是密文,RSA均可正常签名。
- 开发者可对请求参数先做AES加密,然后对密文进行RSA签名。
Bootstrap表单验证插件bootstrapValidator使用方法整理
文档首页 :
http://bv.doc.javake.cn/api/
$(document).ready(function() {
// 原价、现价同时双验证
$("#original_price").blur(function () {
$("#form_yanzheng").data('bootstrapValidator').resetForm().validateField('price');
});
$("#price").blur(function () {
$("#form_yanzheng").data('bootstrapValidator').resetForm().validateField('original_price');
});
//表单验证
$('#form_yanzheng').bootstrapValidator({
message: '值没有被验证',
feedbackIcons: {
valid: 'glyphicon glyphicon-ok',
invalid: 'glyphicon glyphicon-remove',
validating: 'glyphicon glyphicon-refresh'
},
fields: {
subject: {
message: 'The username is not valid',
trigger: 'blur', //失去焦点就会触发
validators: {
notEmpty: {
message: '商品名称不能为空'
},
stringLength: {
min: 2,
max: 15,
message: '输入字符数量错误'
},
callback: {
message: '商品名称有非法内容',
callback: function () {
var filter = true;
var subject = $("#subject").val();
if (subject.indexOf("储值卡") >= 0) {
filter = false;
}
if (subject.indexOf("充值卡") >= 0) {
filter = false;
}
if (subject.indexOf("会员卡") >= 0) {
filter = false;
}
if (subject.indexOf("vip卡") >= 0) {
filter = false;
}
if (subject.indexOf("打折卡") >= 0) {
filter = false;
}
if (subject.indexOf("年卡") >= 0) {
filter = false;
}
if (subject.indexOf("美容卡") >= 0) {
filter = false;
}
if (subject.indexOf("健身卡") >= 0) {
filter = false;
}
return filter;
}
}
}
},
original_price: {
trigger: 'blur', //失去焦点就会触发
message: 'The username is not valid',
validators: {
notEmpty: {
message: '输入整数或者2位小数'
},
regexp: {
regexp: /^(\d+\.\d{1,2}|\d+)$/,
message: '输入整数或者2位小数'
},
callback: {
message: '原价要大于等于现价',
callback: function () {
var op = $('#original_price').val();
var pp = $('#price').val();
return parseFloat(op) >= parseFloat(pp);
}
}
}
},
price: {
trigger: 'blur', //失去焦点就会触发
message: 'The username is not valid',
validators: {
notEmpty: {
message: '输入整数或者2位小数'
},
regexp: {
regexp: /^(\d+\.\d{1,2}|\d+)$/,
message: '输入整数或者2位小数'
},
callback: {
message: '原价要大于等于现价',
callback: function () {
var op = $('#original_price').val();
var pp = $('#price').val();
return parseFloat(op) >= parseFloat(pp);
}
}
}
},
inventory: {
trigger: 'blur', //失去焦点就会触发
message: 'The username is not valid',
validators: {
notEmpty: {
message: '输入整数或者2位小数'
},
between: {
min: 0,
max: 999999,
message: '输入有效库存数量'
}
}
},
validity_period: {
trigger: 'blur', //失去焦点就会触发
message: 'The username is not valid',
validators: {
notEmpty: {
message: '请正确填写有效天数7-360天'
},
between: {
min: 7,
max: 360,
message: '请合理输入使用有效期'
}
}
}
}
}).on('success.form.bv', function (e) {
var refertype = $('#refertype').val();
var urlpath = "{:U('Index/" + refertype + "')}";
$.ajax({
type: "POST",
url: urlpath,
data: $('#form_yanzheng').serialize(),
dataType: 'json',
success: function (data, statusText, xhr, $form) {
if (data.type == 'true') {
swal({
title: data.info,
text: "",
type: "success",
}, function () {
self.location = "{:U('Index/index')}";
});
} else {
swal(data.info, "", "error");
return false;
}
}
});
});
});
js中parseInt()与parseFloat(),Number(),Boolean(),String()转换
js将字符串转数值的方法主要有三种
转换函数、强制类型转换、利用js变量弱类型转换。
1. 转换函数:
js提供了parseInt()和parseFloat()两个转换函数。前者把值转换成整数,后者把值转换成浮点数。只有对String类型调用这些方法,这两个函数才能正确运行;对其他类型返回的都是NaN(Not a Number)。
在判断字符串是否是数字值前,parseInt()和parseFloat()都会仔细分析该字符串。
parseInt()方法首先查看位置0处的 字符,判断它是否是个有效数字;如果不是,该方法将返回NaN,不再继续执行其他操作。但如果该字符是有效数字,该方法将查看位置1处的字符,进行同样的 测试。这一过程将持续到发现非有效数字的字符为止,此时parseInt()将把该字符之前的字符串转换成数字。
例如,如果要把字符串 "1234blue "转换成整数,那么parseInt()将返回1234,因为当它检测到字符b时,就会停止检测过程。
字符串中包含的数字字面量会被正确转换为数字,因此 字符串 "0xA "会被正确转换为数字10。
不过,字符串 "22.5 "将被转换成22,因为对于整数来说,小数点是无效字符。
一些示例如下:
- parseInt("1234blue"); //returns 1234
- parseInt("0xA"); //returns 10
- parseInt("22.5"); //returns 22
- parseInt("blue"); //returns NaN
parseInt()方法还有基模式,可以把二进制、八进制、十六进制或其他任何进制的字符串转换成整数。
基是由parseInt()方法的第二个参数指定的,所以要解析十六进制的值,需如下调用parseInt()方法:
- parseInt("AF", 16); //returns 175
当然,对二进制、八进制,甚至十进制(默认模式),都可以这样调用parseInt()方法:
- parseInt("10", 2); //returns 2
- parseInt("10", 8); //returns 8
- parseInt("10", 10); //returns 10
如果十进制数包含前导0,那么最好采用基数10,这样才不会意外地得到八进制的值。例如:
- parseInt("010"); //returns 8
- parseInt("010", 8); //returns 8
- parseInt("010", 10); //returns 10
在这段代码中,两行代码都把字符串 "010 "解析成了一个数字。第一行代码把这个字符串看作八进制的值,解析它的方式与第二行代码(声明基数为8)相同。最后一行代码声明基数为10,所以iNum3最后等于10。
parseFloat()方法与parseInt()方法的处理方式相似,从位置0开始查看每个字符,直到找到第一个非有效的字符为止,然后把该字 符之前的字符串转换成数字。
不过,对于这个方法来说,第一个出现的小数点是有效字符。如果有两个小数点,第二个小数点将被看作无效的, parseFloat()方法会把这个小数点之前的字符串转换成数字。这意味着字符串 "22.34.5 "将被解析成22.34。
使用parseFloat()方法的另一不同之处在于,字符串必须以十进制形式表示浮点数,而不能用八进制形式或十六进制形式。
该方法会忽略前导0,所以八进制数0908将被解析为908。对于十六进制数0xA,该方法将返回NaN,因为在浮点数中,x不是有效字符。
此外,parseFloat()也没有基模式。
下面是使用parseFloat()方法的示例:
- parseFloat("1234blue"); //returns 1234.0
- parseFloat("0xA"); //returns NaN
- parseFloat("22.5"); //returns 22.5
- parseFloat("22.34.5"); //returns 22.34
- parseFloat("0908"); //returns 908
- parseFloat("blue"); //returns NaN
2. 强制类型转换
还可使用强制类型转换(type casting)处理转换值的类型。使用强制类型转换可以访问特定的值,即使它是另一种类型的。
ECMAScript中可用的3种强制类型转换如下:
Boolean(value)——把给定的值转换成Boolean型;
Number(value)——把给定的值转换成数字(可以是整数或浮点数);
String(value)——把给定的值转换成字符串。
用这三个函数之一转换值,将创建一个新值,存放由原始值直接转换成的值。这会造成意想不到的后果。
当要转换的值是至少有一个字符的字符串、非0数字或对象(下一节将讨论这一点)时,Boolean()函数将返回true。如果该值是空字符串、数字0、undefined或null,它将返回false。
可以用下面的代码段测试Boolean型的强制类型转换。
- Boolean(""); //false – empty string
- Boolean("hi"); //true – non-empty string
- Boolean(100); //true – non-zero number
- Boolean(null); //false - null
- Boolean(0); //false - zero
- Boolean(new Object()); //true – object
Number()的强制类型转换与parseInt()和parseFloat()方法的处理方式相似,只是它转换的是整个值,而不是部分值。
还记 得吗,parseInt()和parseFloat()方法只转换第一个无效字符之前的字符串,因此 "4.5.6 "将被转换为 "4.5 "。
用Number()进行强制类型转换, "4.5.6 "将返回NaN,因为整个字符串值不能转换成数字。
如果字符串值能被完整地转换,Number()将判断是调用parseInt()方法还是调用 parseFloat()方法。
下表说明了对不同的值调用Number()方法会发生的情况:
用法结果
- Number(false) 0
- Number(true) 1
- Number(undefined) NaN
- Number(null) 0
- Number( "5.5 ") 5.5
- Number( "56 ") 56
- Number( "5.6.7 ") NaN
- Number(new Object()) NaN
- Number(100) 100
最后一种强制类型转换方法String()是最简单的,因为它可把任何值转换成字符串。
要执行这种强制类型转换,只需要调用作为参数传递进来的值的 toString()方法,即把1转换成 "1 ",把true转换成 "true ",把false转换成 "false ",依此类推。
强制转换成字符串和调用toString()方法的唯一不同之处在于,对null或undefined值强制类型转换可以生成字符串而不引 发错误:
- var s1 = String(null); //"null"
- var oNull = null;
- var s2 = oNull.toString(); //won’t work, causes an error
3. 利用js变量弱类型转换
举个小例子,一看,就会明白了。
- <script>
- var str= '012.345 ';
- var x = str-0;
- x = x*1;
- </script>
上例利用了js的弱类型的特点,只进行了算术运算,实现了字符串到数字的类型转换,不过这个方法还是不推荐的。
rsync简明手册
!rsync同步模式
sync在进行同步或备份时,使用远程shell,或TCP连接远程daemon,有两种途经连接远程主机。
shell模式,不需要使用配置文件,也不需要启动远端rsync。远程传输时一般使用ssh作为传输工具。
daemon模式,但必须在一台机器上启动rsync。
!rsync命令调用格式
本地文件同步:
rsync [OPTION...] SRC... [DEST]
示例:
rsync -a /home/back1 /home/back2
基于远程shell同步:
拉取: rsync [OPTION...] [USER@]HOST:SRC... [DEST]
推送: rsync [OPTION...] SRC... [USER@]HOST:DEST
基于rsync daemon同步:
拉取: rsync [OPTION...] [USER@]HOST::SRC... [DEST]
rsync [OPTION...] rsync://[USER@]HOST[:PORT]/SRC... [DEST]
推送: rsync [OPTION...] SRC... [USER@]HOST::DEST
rsync [OPTION...] SRC... rsync://[USER@]HOST[:PORT]/DEST
如果只指定了源路径,而没有指定目的路径,rsync将会显示源路径中的文件列表。
源路径的最后有斜杠,则只复制目录中的文件;没有斜杠,不但要复制目录中的文件,还要复制目录本身。
目的路径的最后有没有斜杠,对传输没有影响。
!常用参数说明
-delete 刪除服务端不存在的客户端文件
-password-file=FILE 指定本机rsyncd.secrets的位置
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD
-v, --verbose 详细模式输出
-q, --quiet 精简输出模式
-c, --checksum 打开校验开关,强制对文件传输进行校验
-r, --recursive 对子目录以递归模式处理
-R, --relative 使用相对路径信息
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。
--backup-dir 将备份文件(如~filename)存放在在目录下。
-suffix=SUFFIX定义备份文件前缀
-u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件。(不覆盖更新的文件)
-l, --links 保留软链结
-L, --copy-links 想对待常规文件一样处理软链结
--copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结
--safe-links 忽略指向SRC路径目录树以外的链结
-H, --hard-links 保留硬链结
-p, --perms 保持文件权限
-o, --owner 保持文件属主信息
-g, --group 保持文件属组信息
-D, --devices 保持设备文件信息
-t, --times 保持文件时间信息
-S, --sparse 对稀疏文件进行特殊处理以节省DST的空间
-n, --dry-run 现实哪些文件将被传输
-W, --whole-file 拷贝文件,不进行增量检测
-x, --one-file-system 不要跨越文件系统边界
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节
-e, --rsh=COMMAND 指定使用rsh、ssh方式进行数据同步
--rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息
-C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件
-f, --filter=RULE 从指定文件加载过滤规则。
--existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件
--delete 删除那些DST中SRC没有的文件
--delete-excluded 同样删除接收端那些被该选项指定排除的文件
--delete-after 传输结束以后再删除
--ignore-errors 及时出现IO错误也进行删除
--max-delete=NUM 最多删除NUM个文件
-P, --partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输
--force 强制删除目录,即使不为空
--numeric-ids 不将数字的用户和组ID匹配为用户名和组名
--timeout=TIME IP超时时间,单位为秒
-I, --ignore-times 不跳过那些有同样的时间和长度的文件
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0
-T --temp-dir=DIR 在DIR中创建临时文件
--compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份
--progress 显示备份过程
-z, --compress 对备份的文件在传输时进行压缩处理
--exclude=PATTERN 指定排除不需要传输的文件模式
--include=PATTERN 指定不排除而需要传输的文件模式
--exclude-from=FILE 排除FILE中指定模式的文件
--include-from=FILE 不排除FILE指定模式匹配的文件
--version 打印版本信息
--address 绑定到特定的地址
--config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件
--port=PORT 指定其他的rsync服务端口
--blocking-io 对远程shell使用阻塞IO
-stats给出某些文件的传输状态
--progress 在传输时现实传输过程
--log-format=formAT 指定日志文件格式
--password-file=FILE 从FILE中得到密码
--bwlimit=KBPS 限制I/O带宽,KBytes per second
-h, --help 显示帮助信息
!rsyncd.conf配置,按“[]”设定的模块划分同步模块。每个模块中包含格式为name = value的参数定义。格式、参数说明及常用设置如下:
#默认存放位置/etc/rsyncd.conf
#全局参数
#指定消息文本文件,当客户端连接成功时显示该文件的内容到客户端
motd file=/usr/local/etc/rsyncdmsg
#指定pid文件
pid file=/var/run/rsyncd.pid
#指定rsync监听端口,默认为873
port=873
#指定IP
address=127.0.0.1
#模块参数,部分模块参数也可在全局段定义,作用于全部模块。
#模块名为sync_test
[sync_test]
#以nobody身份运行rsync server
uid = nobody
#指定守护程序以root方式运行时模块应当替换的文件传入和传出的组名或组ID,配合"uid"选项。
gid = nobody
#同步模块备注
comment = backup demo
#需要做鏡像的目錄
path = /opt/data
#认证用戶名,未指定为允许匿名。多个用户名可用空格或逗号分隔。
auth users = tester
#密码文件存放路径
secrets file = /usr/local/etc/rsyncd.secrets
#同步是否为只读,默认为yes
read only = yes
#同步是否为只写,默认为no
write only=no
#当客户请求可以使用的模块列表时,该模块是否应该被列出。如果设置该选项为false,可以创建隐藏的模块。默认为yes
list=yes
#不对指定类型文件压缩
dont compress = *.gz *.tgz *.zip *.z *.rpm *.deb *.iso *.bz2 *.tbz *.jpg
#如果设为true,则在传输文件时chroot到path指定的目录下。需要rsync以root权限启动,并且不能备份指向外部的符号连接所指向的目录文件。默认值为true。
use chroot=true
#指定该模块的最大并发连接数量,默认值是0。
max connections=0
#指定支持max connections参数的锁文件。
lock file=/var/run/rsyncd.lock
#指定日志记录消息级别,默认为daemon。
#常见的消息级别是:uth, authpriv, cron, daemon, ftp, kern, lpr, mail, news, security, sys-log, user, uucp, local0, local1, local2, local3,local4, local5, local6和local7。
syslog facility=daemon
#指定同步日志文件位置,不指定则将日志存入syslog
log file=/var/log/rsyncd.log
#如果为true,则密码文件只能被rsync服务器运行身份的用户访问,其他任何用户不可以访问该文件。默认值为true。
strict modes=true
# 只允许指定IP的客户端连接该模块
# 多个IP或网段用空格隔开,“*”则表示所有,默认是允许所有主机连接。
# 网段设定示例:192.168.0.0/24,也可以是192.168.0.0/255.255.255.0
hosts allow=*
# 不允许指定IP的客户端连接该模块,默认不指定
hosts deny
# 是否忽略server上的IO错误,一般来说rsync在出现IO错误时将将跳过--delete操作,以防止因为暂时的资源不足或其它IO错误导致的严重问题。
ignore errors=yes
#忽略没有访问权限的文件。
ignore nonreadable=yes
#用ftp格式的文件来记录下载和上载操作在单独的日志中。
transfer logging
# 定制日志文件的字段。其格式是一个包含格式定义符的字符串
# 主要定义符及含义:
# %h远程主机名
# %a远程IP地址
# %l文件长度字符数
# %p该次rsync会话的进程id
# %o操作类型:"send"或"recv"
# %f文件名
# %P模块路径
# %m模块名
# %t当前时间
# %u认证的用户名(匿名时是null)
# %b实际传输的字节数
# %c当发送文件时,该字段记录该文件的校验码
#默认log格式为:"%o %h [%a] %m (%u) %f %l",一般来说,在每行的头上会添加"%t [%p] "。
log format=%o %h [%a] %m (%u) %f %l
# 设定同步超时时间。单位为秒钟,0表示没有超时定义,这也是默认值。
timeout=100
# 列表禁止客户端使用的命令参数列表。必须使用命令全名。
refuse options
# 用来指定多个由空格隔开的多个文件或目录(相对路径),并将其添加到忽略列表中。一个模块只能指定一个exclude选项。
# 但是需要注意的一点是该选项有一定的安全性问题,客户很有可能绕过exclude列表,如果希望确保特定的文件不能被访问,那就最好结合uid/gid选项一起使用。
exclude
# 指定一个包含exclude模式的定义的文件名,服务器从该文件中读取exclude列表定义。
exclude from
# 用来指定不排除符合要求的文件或目录。
include
# 指定一个包含include模式的定义的文件名,服务器从该文件中读取include列表定义。
include from
!rsyncd.secrets配置,格式为用户名:密码,每一行指定一个用户。
示例:tester:123456
rsyncd.secrets文件要将权限修改为600,否则同步时会报错。
!rsync的过滤规则
rsync按照命令行中filter规则顺序建立一个有序列表。filter规则的语法如下:
rule [pattern_or_filename]
rule,modfiers [pattern_or_filename]
可以使用完整规则名称,也可以使用简写名称。如果使用简写形式,前面语法中rule和modefiers之间的逗号是可选的,紧跟着的pattern或filename(如果存在)之后必须有一个空格或下划线。
如果规则是从文件中读取的,那么文件中的空白行将被忽略,以#开头的行被视为注释。
可用rule如下:
exclude, - :排除模式
include, + :包含模式
merge, . :指定一个merge-file,供多个规则读取
dir-merge, : :指定一个per-directory merge-file
hide, H :指定一个模式,符合该模式的文件将被隐藏,以防止传输
show, S :不隐藏符合该模式的文件
protect, p :指定一个模式来防止文件被删除
risk, R :符合该模式的文件不会被保护
clear, ! :清除当前的include/exclude模式列表(该选项无参数)
exclude和include两个rule支持modfiers,可用modfiers如下:
/,指定include/exclude规则要匹配当前项目的绝对路径。例如,-/ /etc/passwd,每当从/etc目录中传输文件时,都要排除密码文件。
!,告诉rsync,当模式匹配失败时,include/exclude规则才生效。如,-! */,它将匹配所有非目录文件。
C,该修饰符指示,所有全局的CVS-exclude规则将插入到-C的地方。该修饰符后面无参数。
s,指示规则作用于发送端。当规则对发送端生效时,它将阻止文件被传输。该修饰符通常用于那些在两端都生效的规则,除非指定了--delete-excluded;它将使规则默认只在发送端生效。另一种指定发送端includes/excludes的途经是使用hide(H)和show(S)。
r,通常用来指示规则应用于接收端。当规则对接收方生效时,它将防止文件被删除。另一种指定接收端includes/excludes的方法是,使用protect(P)和risk(R)规则。
每个--filter、--include、--exclude选项只接受一个rule/pattern,如果想添加多个rule/pattern,可以在命令行中的重复这些选项,或在--filter选项中使用merge-file语法,或使用--include-from/--exclude-from选项。
--include和--exclude是--filter选项的简化版。
daemon过滤链由”filter”、”include from”、”include”、”exclude from”、”exclude”参数组成,最先匹配的模式会生效。
!rsnyc的匹配原则
1 如果”/”出现在模式的开头,那么它标记了层级中的一个特殊位置,否则,它只是匹配路径的结束。
因此,”/foo”将匹配”root of the transfer”中的foo(对全局规则而言),或者merge-file目录中的foo(对per-directory规则而言)。
而未经限定的foo将匹配文件系统中任何位置的foo,因为算法是自上而下递归地生效,就像是路径的每个部分轮流变成文件或目录的结尾。
例如foo/a/b/c,算法对该路径的解释将会是foo/a,foo/a/b,foo/a/b/c,算法依次把a、b、c作为文件或目录结尾。实际上,非锚定的”sub/foo”将会匹配层次结构中包含子目录sub的,任何位置的foo。
2 如果”/”出现在模式的结尾,那么它只匹配目录,而不匹配常规文件、链接,或设备。
3 rsync会检查模式中是否包含下列通配符,以确定做简单的字符匹配还是通配符匹配:
* :匹配路径的任何部分,遇到斜杠终止
** :匹配任何东西,包括斜杠
? :匹配任何单个字符,斜杠(“/”)除外
[ :匹配一个字符集,如[a-z],或[[:alpha:]]
4 在通配符模式中,反斜杠(“\”)对通配符进行转义,如果通配符不存在,它会被解释一个普通字符
5 如果模式包含”/”(尾部的”/”不计算在内)或”**”,它将匹配完整路径,包括前导目录(即foo/a,既匹配a,也匹配前导的foo);如果模式不包含”/”或”**”,它只匹配路径最后的部分。注意:算法是递归地应用,所以实际上“完整路径”可能是从起始目录向下,路径的任何一个部分。
6 以dir_name/***结尾的模式,既匹配目录(就像指定了dir_name/),又匹配目录中的所有文件(就像指定了dir_name/**)。
请注意:如果使用了-r选项(-a选项隐含了此选项),那么,自顶向下,路径的每一个部分都将被访问,所以,include/exclude模式会递归地对路径的每个组成部分生效(如,要包含/foo/bar/baz,就不能排除/foo和/foo/bar)。
当rsync寻找要发送的文件时,exclude模式实际上是rsync在历遍目录时的一个短路。如果一个模式排除了特定的父目录,它就能使一个更深的include模式无法生效,因为rsync无法穿过层级中的排除部分而向下(匹配文件)。 也就是说,如果模式排除一个指定的父目录,那么它将无法继续匹配该父目录下的子目录或文件。
rsync过滤及匹配单元重点参考了 rsync三:过滤规则 ,强烈建议大家认真学习一下。
阿里系列:OSS存储作为本地数据盘挂载
https://github.com/aliyun/ossfs#ossfs
简介
ossfs 能让您在Linux/Mac OS X 系统中把Aliyun OSS bucket 挂载到本地文件 系统中,您能够便捷的通过本地文件系统操作OSS 上的对象,实现数据的共享。
功能
ossfs 基于s3fs 构建,具有s3fs 的全部功能。主要功能包括:
- 支持POSIX 文件系统的大部分功能,包括文件读写,目录,链接操作,权限, uid/gid,以及扩展属性(extended attributes)
- 通过OSS 的multipart 功能上传大文件。
- MD5 校验保证数据完整性。
安装
预编译的安装包
我们为常见的linux发行版制作了安装包:
- Ubuntu-14.04
- CentOS-7.0/6.5/5.11
请从版本发布页面选择对应的安装包下载安装,建议选择最新版本。
- 对于Ubuntu,安装命令为:
sudo apt-get update
sudo apt-get install gdebi-core
sudo gdebi your_ossfs_package
- 对于CentOS6.5及以上,安装命令为:(安装包下载https://github.com/aliyun/ossfs/releases)
sudo yum localinstall your_ossfs_package
- 对于CentOS5,安装命令为:
sudo yum localinstall your_ossfs_package --nogpgcheck
源码安装
如果没有找到对应的安装包,您也可以自行编译安装。编译前请先安装下列依赖库:
Ubuntu 14.04:
sudo apt-get install automake autotools-dev g++ git libcurl4-gnutls-dev \
libfuse-dev libssl-dev libxml2-dev make pkg-config
CentOS 7.0:
sudo yum install automake gcc-c++ git libcurl-devel libxml2-devel \
fuse-devel make openssl-devel
然后您可以在github上下载源码并编译安装:
git clone https://github.com/aliyun/ossfs.git
cd ossfs
./autogen.sh
./configure
make
sudo make install
运行
设置bucket name, access key/id信息,将其存放在/etc/passwd-ossfs 文件中, 注意这个文件的权限必须正确设置,建议设为640。
echo my-bucket:my-access-key-id:my-access-key-secret > /etc/passwd-ossfs
chmod 640 /etc/passwd-ossfs
将oss bucket mount到指定目录
ossfs my-bucket my-mount-point -ourl=my-oss-endpoint
示例
将my-bucket这个bucket挂载到/tmp/ossfs目录下,AccessKeyId是faint, AccessKeySecret是123,oss endpoint是http://oss-cn-hangzhou.aliyuncs.com
# 安装
sudo yum localinstall ossfs_1.79.9_centos6.5_x86_64.rpm
echo wzj:nnnnnnnnnnnn:xxxxxxxxxxxxxxxxxx > /etc/passwd-ossfs
chmod 640 /etc/passwd-ossfs
mkdir /home/oss
# 启动
ossfs weizaojiao /home/oss -ourl=http://oss-cn-qingdao-internal.aliyuncs.com
/etc/init.d/目录下建立文件ossfs,放入ossfs weizaojiao /home/oss -ourl=http://oss-cn-qingdao-internal.aliyuncs.com
chmod a+x /etc/init.d/ossfs
chkconfig ossfs on
# 卸载
umount /home/oss
# 跳过扫描
我们常用到的3个查找命令分别是whereis,find,locate。
这其中,find命令是最老实巴焦的一个,直接在指定的目录下进行搜索,如果实在不知道在哪,我们就用 find / -name xxx
而另外的两个命令在搜索之前,都要读取 /etc/updatedb.conf (文件检索数据库配置信息)这个文件。
一般,我们为了加速检索,我们经常 updatedb 一下,这时候,它俩就过滤掉一些没用的东西,进行检索。
updatedb.conf下的几个变量分别是:
PRUNE_BIND_MOUNTS="yes" //是否限制搜索
#PRUNENAMES=".git .bzr .hg .svn" //跳过的文件类型,不同后缀之间用空格隔开。这个功能默认是关闭的(用#注释掉了),如果需要打开需将#去掉
PRUNEPATHS="/tmp /var/spool /media /home/.ecryptfs /home/oss" //要跳过的路径,/media 表示其他硬盘
PRUNEFS="NFS nfs nfs4 rpc_pipefs afs binfmt_misc proc smbfs autofs iso9660 ncpfs coda devpts ftpfs devfs mfs shfs sysfs cifs lustre_lite tmpfs usbfs udf fuse.ossfs" //要搜索的文件系统
常用设置
- 使用ossfs --version来查看当前版本,使用ossfs -h来查看可用的参数
- 如果使用ossfs的机器是阿里云ECS,可以使用内网域名来避免流量收费和 提高速度:
- ossfs my-bucket /tmp/ossfs -ourl=http://oss-cn-hangzhou-internal.aliyuncs.com
- 在linux系统中,updatedb会定期地扫描文件系统,如果不想 ossfs的挂载目录被扫描,可参考FAQ设置跳过挂载目录
- 如果你没有使用eCryptFs等需要XATTR的文件系统,可 以通过添加-o noxattr参数来提升性能
- ossfs允许用户指定多组bucket/access_key_id/access_key_secret信息。当 有多组信息,写入passwd-ossfs的信息格式为:
bucket1:access_key_id1:access_key_secret1
bucket2:access_key_id2:access_key_secret2
- 生产环境中推荐使用supervisor来启动并监控ossfs进程,使 用方法见FAQ
高级设置
- 可以添加-f -d参数来让ossfs运行在前台并输出debug日志
- 可以使用-o kernel_cache参数让ossfs能够利用文件系统的page cache,如 果你有多台机器挂载到同一个bucket,并且要求强一致性,请不要使用此 选项
遇到错误
遇到错误不要慌:) 按如下步骤进行排查:
- 如果有打印错误信息,尝试阅读并理解它
- 查看/var/log/syslog或者/var/log/messages中有无相关信息
- grep 's3fs' /var/log/syslog
grep 'ossfs' /var/log/syslog
- 重新挂载ossfs,打开debug log:
ossfs ... -o dbglevel=debug -f -d > /tmp/fs.log 2>&1
然后重复你出错的操作,出错后将/tmp/fs.log保留,自己查看或者发给我
局限性
ossfs提供的功能和性能和本地文件系统相比,具有一些局限性。具体包括:
- 随机或者追加写文件会导致整个文件的重写。
- 元数据操作,例如list directory,性能较差,因为需要远程访问oss服务器。
- 文件/文件夹的rename操作不是原子的。
- 多个客户端挂载同一个oss bucket时,依赖用户自行协调各个客户端的行为。例如避免多个客户端写同一个文件等等。
- 不支持hard link。
- 不适合用在高并发读/写的场景,这样会让系统的load升高
Linux中几个在备份中常用的命令(cp,scp,rsync)
在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
