实时支付状态监控和处理结果的变更
如果2000台机器的实时用户支付状态监控和处理结果的变更,需要构建一个兼具高并发处理能力、毫秒级低延迟响应和持续高可用性的强大后端架构。
其核心设计理念在于确保实时、高效、可靠的数据流转与处理,具体涵盖实时通信、状态同步和高效存储三大关键要素。
高级整体架构设计,搭建运行服务较多,运行维护成本较高
采用分层、解耦的设计原则,由数据采集与通信层、数据接入与缓冲层、实时计算与处理层、数据存储与状态管理层以及监控与告警层构成。
1. 数据采集与通信层:与机器的实时连接
-
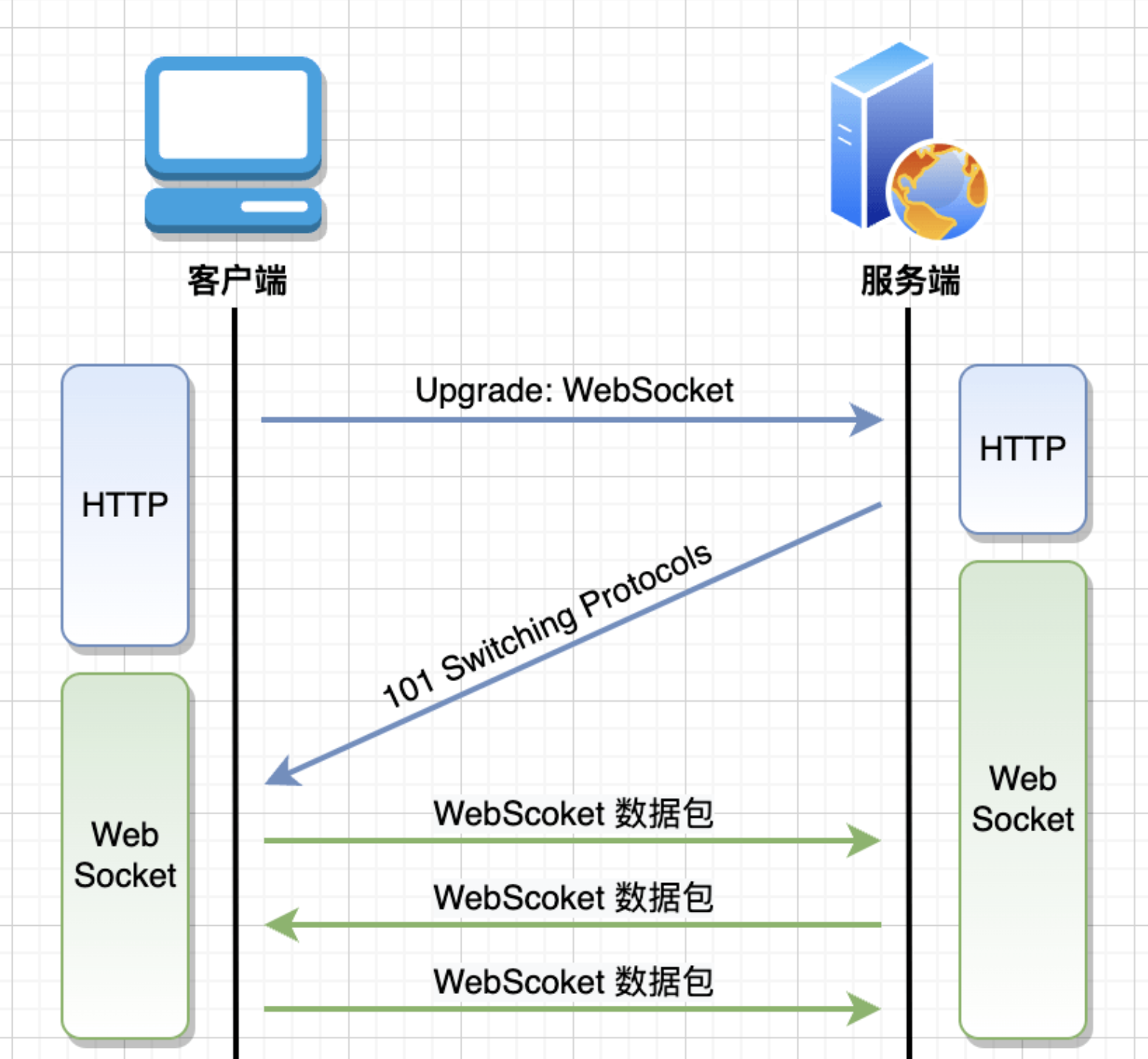
通信协议选择:WebSocket
为了实现服务器与2000台机器之间的低延迟、双向通信,推荐采用 WebSocket。相比于传统的HTTP轮询或长轮询,WebSocket建立持久化连接,允许服务器主动向机器推送状态变更通知,极大地降低了通信延迟和服务器开销。 -
客户端(机器端)设计
机器端的SDK应轻量且高效,负责维护与后端的WebSocket连接,并具备心跳检测和自动重连机制以确保连接的稳定性。当用户发起支付或支付状态发生变化时,SDK将立即通过WebSocket将事件上报。
2. 数据接入与缓冲层:削峰填谷,保证系统稳定
-
消息队列选型:Apache Kafka / RabbitMQ
来自2000台机器的并发请求可能瞬间产生巨大的流量洪峰。为了保护后端应用不被冲垮,引入消息队列进行削峰填谷至关重要。Apache Kafka 是此场景下的理想选择,其具备极高吞吐量、低延迟和高可扩展性的特点,能够轻松应对每秒数十万甚至上百万条消息。Kafka的持久化和分区机制也为数据可靠性和并行处理提供了保障。 -
数据格式
所有上报数据应采用统一的、轻量级的数据格式,如 JSON 。Protobuf在序列化/反序列化效率和数据体积上更具优势,有助于降低网络带宽消耗和处理开销。
3. 实时计算与处理层:核心业务逻辑
-
实时计算引擎:Apache Flink
对于支付状态这种对实时性要求极高的场景,推荐使用 Apache Flink 作为实时计算引擎。Flink是真正的事件驱动型流处理框架,支持事件时间(Event Time)处理和精确一次(Exactly-Once)的状态一致性保证,确保即使在乱序或延迟事件到达时也能产出正确的结果。Flink的毫秒级处理延迟远优于基于微批处理的Spark Streaming。 -
核心处理逻辑
-
支付状态机: 在Flink作业中为每一笔支付订单维护一个状态机,根据上报的事件(如“创建订单”、“支付中”、“支付成功”、“支付失败”、“订单超时”等)驱动状态流转。
-
关联外部信息: Flink作业可以实时关联外部数据源(如用户风控信息、优惠券信息等)进行复杂的业务逻辑判断。
-
处理结果变更: 处理完成后,将结果(如“允许发货”、“交易关闭”等)发送到下游的消息队列,或直接通过API通知相关业务系统。
-
4. 数据存储与状态管理层:高效读写与持久化
-
分布式缓存:Redis
为了实现状态的快速读取和更新,采用 Redis 作为分布式缓存。 Redis基于内存,读写性能极高。支付过程中的中间状态、订单的实时状态等高频访问的数据都应存储在Redis中,以减轻数据库压力。Redis丰富的数据结构(如Hashes、Sorted Sets)也能很好地满足不同业务场景的需求。 -
数据库选型:PostgreSQL /Mysql 或 NoSQL
-
关系型数据库 (PostgreSQL): 对于需要强事务保证和复杂查询的核心交易数据,PostgreSQL 是一个优秀的选择。它在并发处理和对JSON等现代数据类型的支持上表现出色。
-
NoSQL数据库 (MongoDB/ClickHouse):
-
对于支付日志、用户行为等非核心但数据量巨大的数据,可以考虑使用 MongoDB 这类文档型数据库,其灵活的模式设计易于扩展。
-
如果需要对海量历史支付数据进行实时分析和BI查询,ClickHouse 这种列式存储数据库能提供极高的查询性能。
-
-
-
数据一致性
采用数据库与缓存双写的策略,并配合消息队列实现最终一致性,确保在高并发下数据状态的正确同步。
5. 监控与告警层:保障系统健康运行
-
全链路监控: 使用如 Prometheus + Grafana 的组合,对系统各组件(Kafka、Flink、Redis、应用服务等)的核心指标(如QPS、延迟、资源使用率)进行全面监控。
-
日志聚合与分析: 通过 ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki 聚合所有服务的日志,方便快速定位和排查问题。
-
实时告警: 设置关键指标的告警阈值,一旦系统出现异常(如消息队列积压、Flink作业失败、数据库连接池耗尽等),能通过短信、电话或即时通讯工具立即通知相关人员。
高可用性设计
-
无状态服务: 核心应用服务应设计为无状态,便于水平扩展和快速故障恢复。
-
集群化部署: 所有关键组件(接入网关、Kafka、Flink、Redis、数据库)均采用集群模式部署,避免单点故障。
-
负载均衡: 在应用层前端使用 Nginx 或 LVS 等负载均衡器,将流量分发到多个服务实例。
-
故障自动转移: 利用Kubernetes等容器编排平台的健康检查和自动重启机制,以及数据库和消息队列自身的故障转移能力,实现服务的高可用性。
通过上述架构设计,可以构建一个稳定、高效且可扩展的实时支付监控系统,从容应对2000台机器带来的高并发、低延迟和高可用的挑战。
只允许单用户登录的处理方式
只允许单用户登录问题的处理方式,详细实现流程:
通过两个关键场景来详细描述实现流程:
场景一:用户在设备A首次登录
-
客户端请求登录:
-
用户在设备A上输入用户名和密码,发送登录请求到认证服务。
-
-
认证服务处理:
-
验证用户名和密码是否正确。
-
验证通过后,生成一个唯一的会话标识(Session ID),例如使用JWT (JSON Web Token)。这个Session ID将作为后续所有请求的凭证。
-
【核心步骤】 将用户的活跃会话信息存入 Redis。这里使用一个简单的Key-Value结构:
-
Key: user_active_session:<UserID> (例如: user_active_session:12345)
-
Value: SessionID_A (例如: eyJhbGciOiJIUzI1NiIsIn...)
-
Redis命令: SET user_active_session:12345 "SessionID_A"
-
-
-
建立实时连接:
-
认证服务将生成的 SessionID_A 返回给设备A。
-
设备A的客户端收到 SessionID_A 后,立即向实时通信网关 (WebSocket Gateway) 发起WebSocket连接请求,并在请求中携带 SessionID_A 进行身份验证。
-
-
通信网关注册连接:
-
WebSocket网关收到连接请求,验证 SessionID_A 的合法性(例如解析JWT)。
-
验证通过后,WebSocket网关会维护一个映射关系,用于未来能根据UserID找到对应的连接。这个映射可以存在网关的内存中,或者也存入Redis中(尤其是在网关是集群部署时)。
-
映射: UserID -> WebSocketConnectionID (例如: 12345 -> conn_xyz123)
-
-
至此,设备A登录成功并保持在线。
-
场景二:用户在设备B进行新登录(踢出设备A)
-
客户端请求登录:
-
用户在设备B上输入用户名和密码,发送登录请求到认证服务。
-
-
认证服务处理(踢出逻辑):
-
验证用户名和密码。
-
验证通过后,生成一个新的会话标识 SessionID_B。
-
【核心步骤】 在将新会话写入Redis之前,先获取并替换旧的会话。Redis的 GETSET 命令是原子性的,非常适合此场景。
-
原子操作: GETSET user_active_session:12345 "SessionID_B"
-
结果: 这个命令会返回旧的值 SessionID_A,同时将Key的值更新为 SessionID_B。现在,SessionID_B 成为了唯一合法的会话。
-
-
-
发布“强制下线”事件:
-
认证服务拿到了旧的 SessionID_A(如果存在的话)。它会立即通过一个内部的消息队列 (如Kafka或RabbitMQ) 发布一个“强制下线”事件。
-
事件内容: {"event": "FORCE_LOGOUT", "userId": "12345", "oldSessionId": "SessionID_A"}
-
消息队列为了解耦。认证服务不应该直接与WebSocket网关通信,通过消息队列可以提高系统的健壮性和可扩展性。
-
-
通信网关处理下线事件:
-
实时通信网关 (WebSocket Gateway) 订阅了“强制下线”事件。
-
当它收到该事件后,根据 userId: 12345 查找到对应的旧连接 conn_xyz123。
-
【主动踢出】 网关通过 conn_xyz123 这条WebSocket连接,向设备A的客户端主动发送一条消息。
-
消息内容: {"type": "force_logout", "message": "您已在其他设备登录"}
-
-
发送消息后,服务器主动关闭这条WebSocket连接。
-
-
设备A响应:
-
设备A的客户端收到 force_logout 消息后,应立即执行下线操作:清除本地存储的 SessionID_A 和用户信息,并跳转到登录页面。
-
即使客户端代码出现异常未能正确处理该消息,由于服务器已主动断开连接,设备A也无法再进行任何实时操作。
-
-
设备B完成登录:
-
与此同时,认证服务已将新的 SessionID_B 返回给设备B。
-
设备B走与场景一相同的流程,建立新的WebSocket连接并保持在线。
-
安全性与健壮性:最后的防线
仅仅踢出WebSocket连接是不够的。如果设备A的网络恰好在被踢出前断开,它可能不知道自己已下线。当网络恢复后,它可能会尝试使用旧的 SessionID_A 去请求普通的HTTP API(例如查询订单历史)。
因此,必须有后端防线:
-
API网关/后端服务强校验:
-
所有需要登录才能访问的API,都必须在API网关或服务内部对请求携带的Session ID进行验证。
-
验证逻辑:从Redis中根据 user_active_session:<UserID> 取出当前合法的 Session ID,与请求中携带的 Session ID进行比对。
-
如果请求携带的 SessionID_A 与Redis中存储的 SessionID_B 不匹配,则立即拒绝该请求,返回401 Unauthorized错误。
-
总结
通过以上设计,我们构建了一个三层防御体系来确保单点登录的实现:
-
权威状态层 (Redis): 利用Redis作为唯一、高速的会话状态记录中心。
-
主动通知层 (WebSocket): 在新登录发生时,通过WebSocket主动、实时地通知旧客户端下线。
-
被动验证层 (API校验): 对每一次API请求都进行会话有效性校验,作为最终的、最可靠的防线,杜绝任何使用旧会话操作的可能性。
这样不仅解决了实时T出旧客户端的问题,而且通过组件解耦和多层防御,保证了系统整体的高性能、高可用和高安全性。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
