配置ab为Nginx服务器压力测试
在运维工作中,压力测试是一项非常重要的工作。比如在一个网站上线之前,能承受多大访问量、在大访问量情况下性能怎样,这些数据指标好坏将会直接影响用户体验。
但是,在压力测试中存在一个共性,那就是压力测试的结果与实际负载结果不会完全相同,就算压力测试工作做的再好,也不能保证100%和线上性能指标相同。面对这些问题,我们只能尽量去想方设法去模拟。所以,压力测试非常有必要,有了这些数据,我们就能对自己做维护的平台做到心中有数。
目前较为常见的网站压力测试工具有webbench、ab(apache bench)、tcpcopy、loadrunner。
webbench由Lionbridge公司开发,主要测试每秒钟请求数和每秒钟数据传输量,同时支持静态、动态、SSL,部署简单,静动态均可测试。适用于小型网站压力测试(单例最多可模拟3万并发) 。
ab(apache bench)Apache自带的压力测试工具,主要功能用于测试网站每秒钟处理请求个数,多见用于静态压力测试,功能较弱,非专业压力测试工具。
tcpcopy基于底层应用请求复制,可转发各种在线请求到测试服务器,具有分布式压力测试功能,所测试数据与实际生产数据较为接近后起之秀,主要用于中大型压力测试,所有基于tcp的packets均可测试。
loadrunner压力测试界的泰斗,可以创建虚拟用户,可以模拟用户真实访问流程从而录制成脚本,其测试结果也最为逼真模拟最为逼真,并可进行独立的单元测试,但是部署配置较为复杂,需要专业人员才可以。
下面,笔者就以ab为例,来讲解一下网站在上线之前压力测试是如何做的。
ab是针对apache的性能测试工具,可以只安装ab工具。
ubuntu安装ab
apt-get install apache2-utils
centos安装ab
yum install httpd-tools
测试之前需要准备一个简单的html、一个php、一个图片文件。
分别对他们进行测试。
我们把这个三个文件放到nginx安装目录默认的html目录下,

准备之后我们就可以测试了
ab -kc 1000 -n 1000 http://localhost/ab.html
这个指令会使用1000个并发,进行连接1000次。结果如下
root@~# ab -kc 1000 -n 1000 http://www.nginx.cn/ab.html
This is ApacheBench, Version 2.3 <$Revision: 655654 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking www.nginx.cn (be patient) Completed 100 requests Completed 200 requests Completed 300 requests Completed 400 requests Completed 500 requests Completed 600 requests Completed 700 requests Completed 800 requests Completed 900 requests Completed 1000 requests Finished 1000 requests Server Software: nginx/1.2.3 Server Hostname: www.nginx.cn Server Port: 80 Document Path: /ab.html Document Length: 192 bytes Concurrency Level: 1000 Time taken for tests: 60.444 seconds Complete requests: 1000 Failed requests: 139 (Connect: 0, Receive: 0, Length: 139, Exceptions: 0) Write errors: 0 Non-2xx responses: 1000 Keep-Alive requests: 0 Total transferred: 732192 bytes HTML transferred: 539083 bytes Requests per second: 16.54 [#/sec] (mean) Time per request: 60443.585 [ms] (mean) Time per request: 60.444 [ms] (mean, across all concurrent requests) Transfer
rate: 11.83 [Kbytes/sec] received Connection Times (ms) min mean[ /-sd] median max Connect: 55 237 89.6 261 328 Processing: 58 5375 13092.8 341 60117 Waiting: 57 5337 12990.0 341 59870 Total: 386 5611 13083.7 572 60443 Percentage of the requests served within a certain time (ms) 50% 572 66% 606 75% 635 80% 672 90% 30097 95% 42004 98% 47250 99% 49250 100% 60443 (longest request)
对于php文件和图片文件可以使用同样指令进行,结果我就不贴出来了。
ab -kc 500 -n 5000 http://localhost/ab.php ab -kc 500 -n 5000 http://localhost/ab.gif
输出结果我们可以从字面意思就可以理解。
这里对两个比较重要的指标做下说明
比如
Requests per second: 16.54 [#/sec] (mean) Time per request: 60443.585 [ms] (mean) Requests per second: 16.54 [#/sec] (mean)
表示当前测试的服务器每秒可以处理16.54个静态html的请求事务,后面的mean表示平均。这个数值表示当前机器的整体性能,值越大越好。
Time per request: 60443.585 [ms] (mean)
单个并发的延迟时间,后面的mean表示平均。
隔离开当前并发,单独完成一个请求需要的平均时间。
顺带说一下两个Time per request区别
Time per request: 60443.585 [ms] (mean) Time per request: 60.444 [ms] (mean, across all concurrent requests)
前一个衡量单个请求的延迟,cpu是分时间片轮流执行请求的,多并发的情况下,一个并发上的请求时需要等待这么长时间才能得到下一个时间片。
计算方法Time per request: 60.444 [ms] (mean, across all concurrent requests)*并发数
通俗点说就是当以-c 10的并发下完成-n 1000个请求的同时,额外加入一个请求,完成这个求平均需要的时间。
后一个衡量性能的标准,它反映了完成一个请求需要的平均时间,在当前的并发情况下,增加一个请求需要的时间。
计算方法Time taken for tests: 60.444 seconds/Complete requests: 1000
通俗点说就是当以-c 10的并发下完成-n 1001个请求时,比完成-n1000个请求多花的时间。
你可以适当调节-c 和-n大小来测试服务器性能,借助htop指令来直观的查看机器的负载情况。
我的机器是盛大云的超微主机,平时负载cpu是1.7%,htop命令结果截图

加压后的负载100%,负载基本已经上来了。htop命令结果截图

看来我需要好好优化一下,或者就换台机器了。
ab的参数详细解释
普通的测试,使用-c -n参数配合就可以完成任务
格式: ./ab [options] [http://]hostname[:port]/path
参数:
-n 测试的总请求数。默认时,仅执行一个请求
-c 一次并发请求个数。默认是一次一个。
-H 添加请求头,例如 ‘Accept-Encoding: gzip\',以gzip方式请求。
-t 测试所进行的最大秒数。其内部隐含值是-n 50000。它可以使对服务器的测试限制在一个固定的总时间以内。默认时,没有时间限制。
-p 包含了需要POST的数据的文件.
-T POST数据所使用的Content-type头信息。
-v 设置显示信息的详细程度 – 4或更大值会显示头信息, 3或更大值可以显示响应代码(404, 200等), 2或更大值可以显示警告和其他信息。 -V 显示版本号并退出。
-w 以HTML表的格式输出结果。默认时,它是白色背景的两列宽度的一张表。
-i 执行HEAD请求,而不是GET。
-C -C cookie-name=value 对请求附加一个Cookie:行。 其典型形式是name=value的一个参数对。此参数可以重复。
Vue.js 单页应用部署百度统计
前言
申请百度统计后,会得到一段JS代码,需要插入到每个网页中去,在Vue.js项目首先想到的可能就是,把统计代码插入到index.html入口文件中,这样就全局插入,每个页面就都有了;这样做就涉及到一个问题,Vue.js项目是单页应用,每次用户浏览网站时,访问内页时页面是不会刷新的,也就意味着不会触发百度统计代码;所以最终在百度统计后台看到的效果就是只统计到了网页入口的流量,却无法统计到内页的访问流量。
解决方法
在main.js文件中调用vue-router的afterEach方法,将统计代码加入到这个方法里面,这样每次router发生改变的时候都会执行一下统计代码,这样就达到了目的,代码如下:
router.afterEach( ( to, from, next ) => {
setTimeout(()=>{
var _hmt = _hmt || [];
(function() {
//每次执行前,先移除上次插入的代码
document.getElementById('baidu_tj') && document.getElementById('baidu_tj').remove();
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?xxxx";
hm.id = "baidu_tj"
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
},0);
} );
【架构设计】微服务的4大设计原则和19个解决方案

作者|郝炎峰
编辑|小智
本文将介绍微服务架构的演进、优缺点和微服务应用的设计原则,然后着重介绍作为一个“微服务应用平台”需要提供哪些能力、解决哪些问题才能更好的支撑企业应用架构。
注:本文转载自公众号 EAWorld,已获授权。
写在前面
微服务架构现在是谈到企业应用架构时必聊的话题,微服务之所以火热也是因为相对之前的应用开发方式有很多优点,如更灵活、更能适应现在需求快速变更的大环境。
微服务平台也是我目前正在参与的,还在研发过程中的平台产品,平台是以 SpringCloud 为基础,结合了普元多年来对企业应用的理解和产品的设计经验,逐步孵化的一个微服务应用平台。
微服务架构演进过程

近年来我们大家都体会到了互联网、移动互联带来的好处,作为 IT 从业者,在生活中时刻感受互联网好处的同时,在工作中可能感受的却是来自自互联网的一些压力,那就是我们传统企业的 IT 建设也是迫切需要转型,需要面向外部客户,我们也需要应对外部环境的快速变化、需要快速创新,那么我们的 IT 架构也需要向互联网企业学习作出相应的改进,来支撑企业的数字化转型。
我们再看一下应用架构的演进过程,回忆一下微服务架构是如何一步一步进化产生的,最早是应用是单块架构,后来为了具备一定的扩展和可靠性,就有了垂直架构,也就是加了个负载均衡,接下来是前几年比较火的 SOA,主要讲了应用系统之间如何集成和互通,而到现在的微服务架构则是进一步在探讨一个应用系统该如何设计才能够更好的开发、管理更加灵活高效。
微服务架构的基本思想就是“围绕业务领域组件来创建应用,让应用可以独立的开发、管理和加速”。
微服务架构的好处

我们总结了四个方面的优点,分别如下:
是每个微服务组件都是简单灵活的,能够独立部署。不再像以前一样,应用需要一个庞大的应用服务器来支撑。
可以由一个小团队负责更专注专业,相应的也就更高效可靠。
微服务之间是松耦合的,微服务内部是高内聚的,每个微服务很容易按需扩展。
微服务架构与语言工具无关,自由选择合适的语言和工具,高效的完成业务目标即可。
看到这里,大家会觉得微服务架构挺不错,然而还会有一些疑问,什么样的应用算是一个微服务架构的应用?该怎样设计一个微服务架构的应用?那我们来一起看看我们推荐的微服务应用的设计原则。
微服务应用 4 个设计原则

我们总结了四个原则推荐给大家:
AKF 拆分原则
前后端分离
无状态服务
Restful 通信风格
AKF 拆分原则

AKF 扩展立方体(参考《The Art of Scalability》),是一个叫 AKF 的公司的技术专家抽象总结的应用扩展的三个维度。理论上按照这三个扩展模式,可以将一个单体系统,进行无限扩展。
X 轴 :指的是水平复制,很好理解,就是讲单体系统多运行几个实例,做个集群加负载均衡的模式。
Z 轴 :是基于类似的数据分区,比如一个互联网打车应用突然或了,用户量激增,集群模式撑不住了,那就按照用户请求的地区进行数据分区,北京、上海、四川等多建几个集群。
Y 轴 :就是我们所说的微服务的拆分模式,就是基于不同的业务拆分。
场景说明:比如打车应用,一个集群撑不住时,分了多个集群,后来用户激增还是不够用,经过分析发现是乘客和车主访问量很大,就将打车应用拆成了三个乘客服务、车主服务、支付服务。三个服务的业务特点各不相同,独立维护,各自都可以再次按需扩展。
前后端分离

前后端分离原则,简单来讲就是前端和后端的代码分离也就是技术上做分离,我们推荐的模式是最好直接采用物理分离的方式部署,进一步促使进行更彻底的分离。不要继续以前的服务端模板技术,比如 JSP ,把 Java JS HTML CSS 都堆到一个页面里,稍复杂的页面就无法维护。这种分离模式的方式有几个好处:
前后端技术分离,可以由各自的专家来对各自的领域进行优化,这样前端的用户体验优化效果会更好。
分离模式下,前后端交互界面更加清晰,就剩下了接口和模型,后端的接口简洁明了,更容易维护。
前端多渠道集成场景更容易实现,后端服务无需变更,采用统一的数据和模型,可以支撑前端的 web UI 移动 App 等访问。
无状态服务

对于无状态服务,首先说一下什么是状态:如果一个数据需要被多个服务共享,才能完成一笔交易,那么这个数据被称为状态。进而依赖这个“状态”数据的服务被称为有状态服务,反之称为无状态服务。
那么这个无状态服务原则并不是说在微服务架构里就不允许存在状态,表达的真实意思是要把有状态的业务服务改变为无状态的计算类服务,那么状态数据也就相应的迁移到对应的“有状态数据服务”中。
场景说明:例如我们以前在本地内存中建立的数据缓存、Session 缓存,到现在的微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。迁移后,就可以做到按需动态伸缩,微服务应用在运行时动态增删节点,就不再需要考虑缓存数据如何同步的问题。
Restful 通信风格

作为一个原则来讲本来应该是个“无状态通信原则”,在这里我们直接推荐一个实践优选的 Restful 通信风格 ,因为他有很多好处:
无状态协议 HTTP,具备先天优势,扩展能力很强。例如需要安全加密是,有现成的成熟方案 HTTPS 可用。
JSON 报文序列化,轻量简单,人与机器均可读,学习成本低,搜索引擎友好。
语言无关,各大热门语言都提供成熟的 Restful API 框架,相对其他的一些 RPC 框架生态更完善。
当然在有些特殊业务场景下,也需要采用其他的 RPC 框架,如 thrift、avro-rpc、grpc。但绝大多数情况下 Restful 就足够用了。
微服务架构带来的问题
做到了前面讲的四个原则,那么就可以说是构建了一个微服务应用,感觉上也不复杂。但实际上微服务也不是个万金油,也是有利有弊的,接下来我们来看看引入微服务架构后带来的问题有哪些。

依赖服务变更很难跟踪,其他团队的服务接口文档过期怎么办?依赖的服务没有准备好,如何验证我开发的功能。
部分模块重复构建,跨团队、跨系统、跨语言会有很多的重复建设。
微服务放大了分布式架构的系列问题,如分布式事务怎么处理?依赖服务不稳定怎么办?
运维复杂度陡增,如:部署物数量多、监控进程多导致整体运维复杂度提升。
上面这些问题我们应该都遇到过,并且也会有一些解决方案,比如提供文档管理、服务治理、服务模拟的工具和框架; 实现统一认证、统一配置、统一日志框架、分布式汇总分析; 采用全局事务方案、采用异步模拟同步;搭建持续集成平台、统一监控平台等等。
这些解决方案折腾到最后终于搞明白了,原来我们是需要一个微服务应用平台才能整体性的解决这些问题。
微服务平台的 19 个落地实践
企业 IT 建设的三大基础环境
我们先来宏观的看一下,一个企业的 IT 建设非常重要的三大基础环境:团队协作环境、个人基础环境、IT 基础设施。

团队协作环境:主要是 DevOps 领域的范畴,负责从需求到计划任务,团队协作,再到质量管理、持续集成和发布。
个人基础环境:就是本文介绍的微服务应用平台,他的目标主要就是要支撑微服务应用的设计开发测试,运行期的业务数据处理和应用的管理监控。
IT 基础设施:就是我们通常说的各种运行环境支撑如 IaaS (VM 虚拟化) 和 CaaS (容器虚拟化) 等实现方式。
微服务应用平台总体架构

微服务应用平台的总体架构,主要是从开发集成、微服务运行容器与平台、运行时监控治理和外部渠道接入等维度来划分的。
开发集成:主要是搭建一个微服务平台需要具备的一些工具和仓库
运行时:要有微服务平台来提供一些基础能力和分布式的支撑能力,我们的微服务运行容器则会运行在这个平台之上。
监控治理:则是致力于在运行时能够对受管的微服务进行统一的监控、配置等能力。
服务网关: 则是负责与前端的 WEB 应用 移动 APP 等渠道集成,对前端请求进行认真鉴权,然后路由转发。
微服务应用平台的运行视图

参考上图,在运行期,作为一个微服务架构的平台与业务系统,除了业务应用本身外,还需要有接入服务、统一门户、基础服务等平台级服务来保障业务系统的可靠运行。图中的公共服务就是业务处理过程中需要用到的一些可选服务。
微服务平台的设计目标

微服务平台的主要目标主要就是要支撑微服务应用的全生命周期管理,从需求到设计开发测试,运行期的业务数据处理和应用的管理监控等,后续将从应用生命周期的几个重要阶段切入,结合前面提到的设计原则和问题,介绍平台提供的能力支撑情况。
微服务开发:前端、后端、混合

我们一起看一下我们正在开发中的微服务应用平台 EOS8.0 的一些开发工具截图,了解一下开发期提供了哪些关键的能力支撑。
前面的设计原则中提到了一个前后端分离的原则,那么我们的开发环境中,目前支持创建前端项目、后端项目和混合项目。其中前端项目、后端项目就对应前后端分离的原则,利用平台中集成的开发工具和框架可以做到前后端开发分离,利用持续集成工具可以方便的将前端、后端项目编译打包成可独立运行的程序。混合项目则是为了兼容传统模式而保留的,为企业应用向微服务架构演进提供过渡方案。
服务契约与 API 管理
对于前面提到的微服务带来的依赖管理问题,我们可以通过平台提供的 API 管理能力来解决。说到 API 管理,那首先就用提到服务契约。平台开发工具中提供了方便的服务发布能力,能够快速的将业务功能对外发布,生成服务的规格契约,当然也可以先设计服务契约,在根据契约来生成服务的默认实现代码。
这里强调一下,我们提到的服务契约是一个很重要的东西,他有点类似 web service 的 wsdl 描述,主要描述服务接口的输入输出规格标准和其他一些服务调用集成相关的规格内容。

服务契约与服务模拟
有了服务契约,我们就可以根据契约自动生成服务的文档和服务模拟测试环境,这样,开发者就可以方便的获取到依赖服务变更的情况,能够及时的根据依赖服务的变化调整自己的程序,并且能够方便的进行模拟测试验证。

根据契约生成模拟服务也就是我们常说的服务挡板,这样即使依赖的其他服务还无法提供功能,我们也可以通过挡板来进行联调测试。
服务契约与服务编排

有了服务契约,那就有了服务接口的输入输出规格,那么 restful 的服务编排也就变得可行。在我们设计的契约标准中,还定义了调用集成相关的内容,比如服务支持的事务模式等等。通过这些约定,我们就可以采用简单图形化的方式来对业务服务流程进行编排。编排能够很大程度上简化分布式服务调用的复杂度,如同步、异步、异步模拟同步、超时重试、事务补偿等,均有服务编排引擎完成,不再完全依赖老师傅的编码能力。
服务编排的作用和意义很大,可以快速的将已经提供的微服务能力进行组合发布,非常适合业务的快速创新。
但是大家要注意,逻辑流编排的是业务流程,尽量能够简单明了,一眼看上去就明白业务含义。而业务规则推荐采用服务内部进行编码实现。千万不要将我们的 “逻辑流” 图形化服务编排完全取代程序编码,这样就会可能会走入另外一个极端,比如设计出像蜘蛛网一样的逻辑流图,简直就是灾难。
微服务容器

我们再来看一下微服务运行容器的一个逻辑图,大家可以看到,我们要做微服务架构的应用,可靠高效的微服务应用,实际上我们需要做的事情还是非常多的。如果没有一个统一的微服务容器,这些能力在每个微服务组件中都需要建设一遍,而且会五花八门,也很难集成到一起。有了统一的微服务运行容器和一些公共的基础服务,前面所提到的微服务架构下部分组件重复建设的问题也迎刃而解。
三方能力集成说明
我们的 API 管理契约文档 API 模拟我们是集成了 Swagger 的工具链。微服务应用平台的基础就是 SpringCloud,从容器框架到注册发现再到安全认证这些基础方案均采用了他的能力来支撑。下面简单看下我们集成的一些开源框架和工具。

SpringCloud 在微服务平台中的定位是基础框架,本文重点是要介绍一个企业级的微服务平台在落地过程中的一些设计原则和解决方案。具体 Spring Cloud 相关的技术就不在文中多做介绍了,大家可以在我们的公众号里面查看相关文章。
服务注册发现路由

接下来我们聊一下注册发现,以前的单块应用之间互相调用时配置个 IP 就行了,但在微服务架构下,服务提供者会有很多,手工配置 IP 地址又变成了一个不可行的事情。那么服务自动注册发现的方案就解决了这个问题。
我们的服务注册发现能力是依赖 SpringCloud Eureka 组件实现的。服务在启动的时候,会将自己要发布的服务注册到服务注册中心,运行时,如果需要调用其他微服务的接口,那么就要先到注册中心获取服务提供者的地址,拿到地址后,通过微服务容器内部的简单负载均衡期进行路由用。
一般情况,系统内微服务的调用都通过这种客户端负载的模式进行,否则就需要有很多的负载均衡进程。跨业务系统的服务调用,也可以采用这种去中心化的路由方式。当然采用 SOA 的模式,由中心化的服务网管来管理系统间的调用也是另一种选择,要结合企业的 IT 现状和需求来决定。
统一认证鉴权

安全认证方面,我们基于 Spring Security 结合 Auth2 再加上 JWT(Json web token)做安全令牌,实现统一的安全认证与鉴权,使得微服务之间能够按需隔离和安全互通。后续在统一认证和权限方面我们产品会陆续推出较完善并且扩展性良好的微服务组件,可以作为微服务平台的公共的认证和鉴权服务。再啰嗦一句,认证鉴权一定是个公共的服务,而不是多个系统各自建设。
日志与流水设计

作为一个微服务应用平台除了提供支撑开发和运行的技术组件和框架之外,我们还提供一些运维友好的经验总结,我们一起来看一下我们推荐的日志与流水实现,先来看日志,平台默认回会提供的日志主要有三种,系统日志,引擎日志还有跟踪日志。有了这些日志,在出问题的时候能够帮助我们获取一些关键信息进行问题定位。
要想做到出了问题能够追根溯源,那么右边的这些流水号的设计也是非常重要的,日志与各种流水号配合,能够让我们快速定位问题发生的具体时间地点以及相关信息,能够快速还原业务交易全链路。对这些日志与流水的细节处理,对于系统运维问题定位有非常大的帮助,没有这些有用的日志内容,ELK 日志收集套件搭建的再漂亮,收一对垃圾日志也是没用的。通常开源框架只是提供个框架有开发人员自由发挥,而设计一个平台则一定要考虑直接提供统一规范的基础能力。
集中配置管理

微服务分布式环境下,一个系统拆分为很多个微服务,一定要告别投产或运维手工修改配置配置的方式。需要采用集中配置管理的方式来提升运维的效率。
配置文件主要有运行前的静态配置和运行期的动态配置两种。静态配置通常是在编译部署包之前设置好。动态配置则是系统运行过程中需要调整的系统变量或者业务参数。要想做到集中的配置管理,那么需要注意以下几点:
是配置与介质分离,这个就需要通过制定规范的方式来控制。千万别把配置放在 Jar 包里;
是配置的方式要统一,格式、读写方式、变更热更新的模式尽量统一,要采用统一的配置框架;
就是需要运行时需要有个配置中心来统一管理业务系统中的配置信息,这个就需要平台来提供配置中心服务和配置管理门户。
统一管理门户

微服务架构下,一个大的 EAR、WAR 应用被拆为了多个小的可独立运行的微服务程序,通常这些微服务程序都不再依赖应用服务器,不依赖传统应用服务器的话,应用服务器提供管理控制台也就没得用了,所以微服务的运行时管理需要有统一的管理门户来支撑。我们规划了的统一集中的微服务门户,可以支撑 应用开发、业务处理、应用管理、系统监控等。上图是应用管理页面,就是对我们传统意义上的业务系统进行管理,点击一个业务系统,我们就能够看到系统下有哪些微服务,每个微服务有几个节点实例再运行,可以监控微服务的子节点状态,对微服务进行配置管理和监控。
分布式事务问题

微服务架构的系统下,进程成倍增多,那么也分布式事务一致性的问题也就更加明显。我们这里说的事务一致性,不是传统说的基于数据库实现的技术事务。微服务之间是独立的、调用协议也是无状态的,因此数据库事务方案在一开始就已经不再我们考虑的范围内。我们要解决的是一定时间后的数据达到最终一致状态,准确的说就是采用传统的业务补偿与冲正方式。
推荐的事务一致性方案有三种:
可靠事件模式:即事件的发送和接收保障高可靠性,来实现事务的一致性。
补偿模式:Confirm Cancel ,如果确认失败,则全部逆序取消。
TCC 模式:Try Confirm Cancel ,补偿模式的一种特殊实现 通常转账类交易会采用这种模式。
分布式同步调用问题

微服务架构下,相对于传统部署方式,存在更多的分布式调用,那么“如何在不确定的环境中交付确定的服务”,这句话可以简单理解为,我所依赖的服务的可靠性是无法保证的情况下,我如何保证自己能够正常的提供服务,不被我依赖的其他服务拖垮?
我们推荐 SEDA 架构来解决这个问题。

SEDA : staged event-driven architecture 本质上就是采用分布式事件驱动的模式,用异步模拟来同步,无阻塞等待,再加上资源分配隔离结起来的一个解决方案。
持续集成与持续交付设计

在运维方面,首先我们要解决的就是持续集成和持续交付,而微服务应用平台的职责范围目前规划是只做持续集成,能够方便的用持续集成环境把程序编译成介质包和部署包。(目前规划持续部署由 DevOps 平台提供相应能力,微服务平台可与 DevOps 平台集成)
这里要厘清一个概念:介质,是源码编译后的产物,与环境无关,多环境下应该是可以共用的,如:jar、dockerfile;配置:则是环境相关的信息。配置 介质 = 部署包。
获取到部署包之后,微服务应用平台的职责就完成了,接下来就是运维人员各显神通来进行上线部署操作。
微服务平台与容器云、DevOps 的关系

就微服务应用平台本身来说,并不依赖 DevOps 和容器云,开发好的部署包可以运行在物理机、虚拟机或者是容器中。
然而当微服务应用平台结合了 DevOps 和容器云之后,我们就会发现,持续集成和交付变成了一个非常简单便捷并且又可靠的过程。
简单几步操作,整套开发、测试、预发或者生产环境就能够搭建完成。整个过程的复杂度都由平台给屏蔽掉了,通过三大基础环境的整合,我们能够使分散的微服务组件更简单方便的进行统一管理和运维交付。
总结展望
我们再来回顾一下,三大基础环境的关系。微服务应用平台负责应用开发、运行以及管理;DevOps 负责项目管理、计划管理、CI、CD 和团队沟通协作等;容器云平台则负责基础设置管理,屏蔽环境的复杂度。
这三大基础环境的建设情况,直接反应出了企业 IT 能力水平。这三大基础环境是技术人员和企业都希望拥有的,是企业赢得竞争、驱动业务创新的基础,是企业加速数字化转型的必由之路。
最后,我们一起看一下普元正在研发的新一代 The Platform 平台。

上图红框中的内容是与我们今天分享的微服务应用平台相关的部分。整个 The Platform 平台是我们站在企业整体架构规划的角度,从多个维度入手,目标是为企业搭建一个持续发展的 IT 生态环境,加速企业的数字化型。
【架构】微服务架构设计
微服务
软件架构是一个包含各种组织的系统组织,这些组件包括 Web服务器, 应用服务器, 数据库,存储, 通讯层), 它们彼此或和环境存在关系。系统架构的目标是解决利益相关者的关注点。
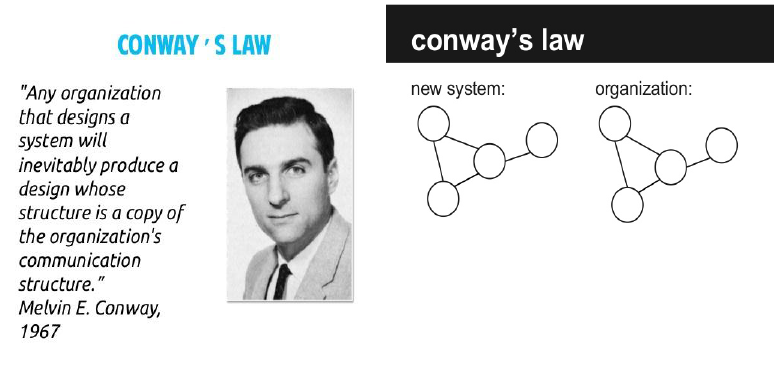
Conway’s law: Organizations which design systems[...] are constrained to produce designs which are copies of the communication structures of these organizations.
(设计系统的组织,其产生的设计和架构等价于组织间的沟通结构。)
Monolithic架构
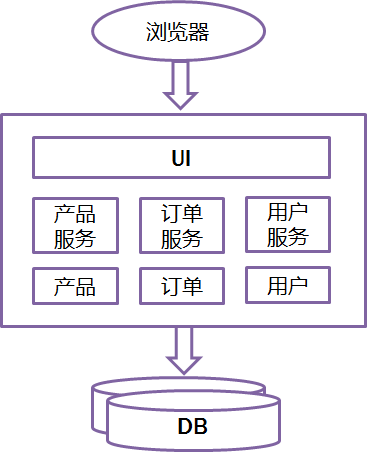
Monolithic比较适合小项目,优点是:
开发简单直接,集中式管理, 基本不会重复开发
功能都在本地,没有分布式的管理开销和调用开销。它的缺点也非常明显,特别对于互联网公司来说(不一一列举了):
开发效率低:所有的开发在一个项目改代码,递交代码相互等待,代码冲突不断
代码维护难:代码功能耦合在一起,新人不知道何从下手
部署不灵活:构建时间长,任何小修改必须重新构建整个项目,这个过程往往很长
稳定性不高:一个微不足道的小问题,可以导致整个应用挂掉
扩展性不够:无法满足高并发情况下的业务需求
微服务架构
微服务是指开发一个单个小型的但有业务功能的服务,每个服务都有自己的处理和轻量通讯机制,可以部署在单个或多个服务器上。微服务也指一种种松耦合的、有一定的有界上下文的面向服务架构。也就是说,如果每个服务都要同时修改,那么它们就不是微服务,因为它们紧耦合在一起;如果你需要掌握一个服务太多的上下文场景使用条件,那么它就是一个有上下文边界的服务,这个定义来自DDD领域驱动设计。
相对于单体架构和SOA,它的主要特点是组件化、松耦合、自治、去中心化,体现在以下几个方面:
- 一组小的服务
服务粒度要小,而每个服务是针对一个单一职责的业务能力的封装,专注做好一件事情。 - 独立部署运行和扩展
每个服务能够独立被部署并运行在一个进程内。这种运行和部署方式能够赋予系统灵活的代码组织方式和发布节奏,使得快速交付和应对变化成为可能。 - 独立开发和演化
技术选型灵活,不受遗留系统技术约束。合适的业务问题选择合适的技术可以独立演化。服务与服务之间采取与语言无关的API进行集成。相对单体架构,微服务架构是更面向业务创新的一种架构模式。 - 独立团队和自治
团队对服务的整个生命周期负责,工作在独立的上下文中,自己决策自己治理,而不需要统一的指挥中心。团队和团队之间通过松散的社区部落进行衔接。
我们可以看到整个微服务的思想就如我们现在面对信息爆炸、知识爆炸是一样的:通过解耦我们所做的事情,分而治之以减少不必要的损耗,使得整个复杂的系统和组织能够快速的应对变化。
我们为什么采用微服务呢?
"让我们的系统尽可能快地响应变化" - Rebecca Parson
让我们的系统尽可能快地去响应变化。其实几十年来我们一直在尝试解决这个问题。如果一定要在前面加个限制的话,那就是低成本的快速响应变化。上世纪90年代Kent Beck提出要拥抱变化,在同期出现了诸多轻量级开发方法(诸如 XP、Scrum);2001年敏捷宣言诞生,之后又出现了精益、看板等新的管理方式。如果说,这些是为了尽快的响应变化,在软件开发流程和实践方面提出的解决方案,那么微服务架构就是在软件技术和架构层面提出的应对之道。

Autonomous
A Microservice is a unit of functionality; it provides an API for a set of capabilities oriented around a business domain or common utility
Isolated
A Microservice is a unit of deployment; it can be modified, tested and deployed as a unit without impacting other areas of a solution
Elastic
A Microservice is stateless; it can be horizontally scaled up and down as needed
Resilient
A Microservice is designed for failure; it is fault tolerant and highly available
Responsive
A Microservice responds to requests in a reasonable amount of time
Intelligent
The intelligence in a system is found in the Microservice endpoints not ‘on the wire’
Message Oriented
Microservices rely on HTTP or a lightweight message bus to establish a boundary between components; this ensures loose coupling, isolation, location transparency, and provides the means to delegate errors as messages
Programmable
Microservices provide API’s for access by developers and administrators
Composable
Applications are composed from multiple Microservices
Automated
The lifecycle of a Microservice is managed through automation that includes development, build, test, staging, production and distribution
服务之间如何通信

一般同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。RESTful和RPC的比较也是一个很有意 思的话题。一般REST基于HTTP,更容易实现,更容易被接受,服务端实现技术也更灵活些,各个语言都能支持,同时能跨客户端,对客户端没有特殊的要 求,只要封装了HTTP的SDK就能调用,所以相对使用的广一些。RPC也有自己的优点,传输协议更高效,安全更可控,特别在一个公司内部,如果有统一个 的开发规范和统一的服务框架时,他的开发效率优势更明显些。就看各自的技术积累实际条件,自己的选择了。而异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能 保证调用方的服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据最终一致性;还有就是后台服务一般要 实现幂等性,因为消息发送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的broker,如 果公司内部没有技术积累,对broker分布式管理也是一个很大的挑战。

微服务优点
- 每个微服务都很小,这样能聚焦一个指定的业务功能或业务需求。
- 微服务能够被小团队单独开发,这个小团队是2到5人的开发人员组成。
- 微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的。
- 微服务能使用不同的语言开发。
- 微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,如Jenkins, bamboo 。
- 一个团队的新成员能够更快投入生产。
- 微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作才能体现价值。
- 微服务允许你利用融合最新技术。
- 微服务只是业务逻辑的代码,不会和HTML,CSS 或其他界面组件混合。
- 微服务能够即时被要求扩展。
- 微服务能部署中低端配置的服务器上。
- 易于和第三方集成。
- 每个微服务都有自己的存储能力,可以有自己的数据库。也可以有统一数据库。
微服务架构的缺点
- 微服务架构可能带来过多的操作。
- 需要DevOps技巧 (http://en.wikipedia.org/wiki/DevOps).
- 可能双倍的努力。
- 分布式系统可能复杂难以管理。
- 因为分布部署跟踪问题难。
- 当服务数量增加,管理复杂性增加。
需要考虑的问题
- 单个微服务代码量小,易修改和维护。但是,系统复杂度的总量是不变的,每个服务代码少了,但服务的个数肯定就多了。就跟拼图游戏一样,切的越碎,越难拼出整幅图。一个系统被拆分成零碎的微服务,最后要集成为一个完整的系统,其复杂度肯定比大块的功能集成要高很多。
- 单个微服务数据独立,可独立部署和运行。虽然微服务本身是可以独立部署和运行的,但仍然避免不了业务上的你来我往,这就涉及到要对外通信,当微服务的数量达到一定量级的时候,如何提供一个高效的集群通信机制成为一个问题。
- 单个微服务拥有自己的进程,进程本身就可以动态的启停,为无缝升级的打好了基础,但谁来启动和停止进程,什么时机,选择在哪台设备上做这件事情才是无缝升级的关键。这个能力并不是微服务本身提供的,而是需要背后强大的版本管理和部署能力。
- 多个相同的微服务可以做负载均衡,提高性能和可靠性。正是因为相同微服务可以有多个不同实例,让服务按需动态伸缩成为可能,在高峰期可以启动更多的相同的微服务实例为更多用户服务,以此提高响应速度。同时这种机制也提供了高可靠性,在某个微服务故障后,其他相同的微服务可以接替其工作,对外表现为某个设备故障后业务不中断。同样的道理,微服务本身是不会去关心系统负载的,那么什么时候应该启动更多的微服务,多个微服务的流量应该如何调度和分发,这背后也有一套复杂的负载监控和均衡的系统在起作用。
- 微服务可以独立部署和对外提供服务,微服务的业务上线和下线是动态的,当一个新的微服务上线时,用户是如何访问到这种新的服务?这就需要有一个统一的入口,新的服务可以动态的注册到这个入口上,用户每次访问时可以从这个入口拿到系统所有服务的访问地址。这个统一的系统入口并不是微服务本身的一部分,所以这种能力需要系统单独提供。
- 还有一些企业级关注的系统问题,比如,安全策略如何集中管理?系统故障如何快速审计和跟踪到具体服务?整个系统状态如何监控?服务之间的依赖关系如何管理?等等这些问题都不是单个微服务考虑的范畴,而需要有一个系统性的考虑和设计,让每个微服务都能够按照系统性的要求和约束提供对应的安全性,可靠性,可维护性的能力。

API为什么很重要
•服务价值的精华体现
•可靠、可用、可读
•只有一次机会

实现一个API网关作为所有客户端的唯一入口。API网关有两种方式来处理请求。有些请求被简单地代理/路由到合适的服务上,其他的请求被转给到一组服务。

相比于提供普适的API,API网关根据不同的客户端开放不同的API。比如,Netflix API网关运行着客户端特定的适配器代码,会向客户端提供最适合其需求的API。
API网关也可以实现安全性,比如验证客户端是否被授权进行某请求。
设计要素
•Version
•RequstID
•Auth&Signature
•RateLimit
•Docs
•ErrorCode&Message
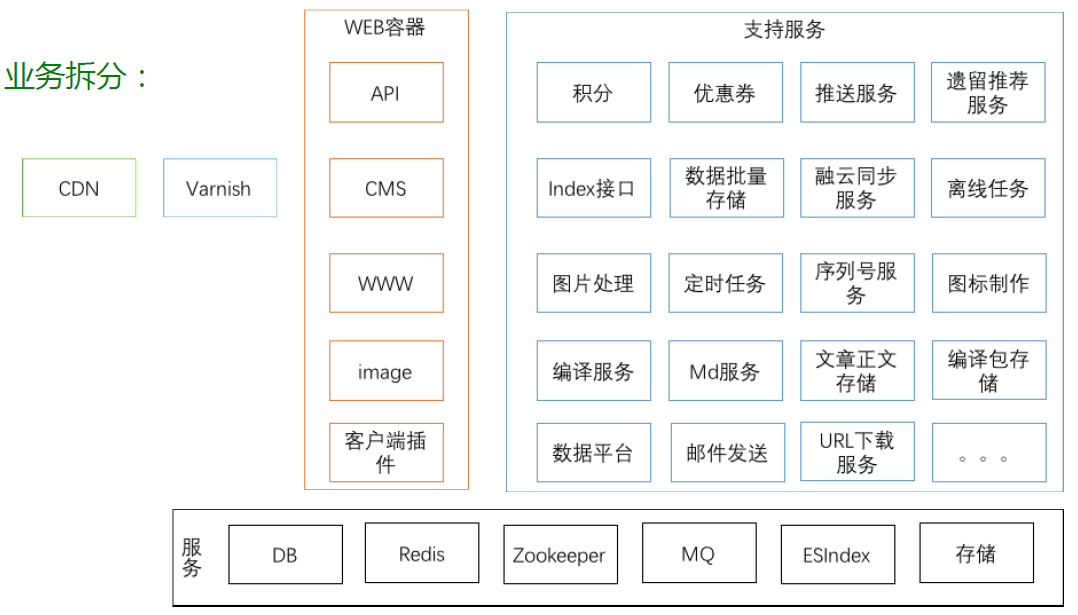
微服务治理
•按需伸缩
–部署与监控运维成本
•独立部署
–机器数量与部署成本
•业务独立
–服务依赖、治理,版本管理、事务处理
•技术多样性
–环境部署成本、约定成本
•运行状态治理
–监控、限流、SLA、LB、日志分析
•服务注册与发现
•部署
–快速、复制、扩容
–单机开发
•调用
–安全、容错、服务降级、调用延时


服务容错
当企业微服务化以后,服务之间会有错综复杂的依赖关系,例如,一个前端请求一般会依赖于多个后端服务,技术上称为1 -> N扇出. 在实际生产环境中,服务往往不是百分百可靠,服务可能会出错或者产生延迟,如果一个应用不能对其依赖的故障进行容错和隔离,那么该应用本身就处在被拖垮的风险中。在一个高流量的网站中,某个单一后端一旦发生延迟,可能在数秒内导致所有应用资源(线程,队列等)被耗尽,造成所谓的雪崩效应(Cascading Failure),严重时可致整个网站瘫痪。
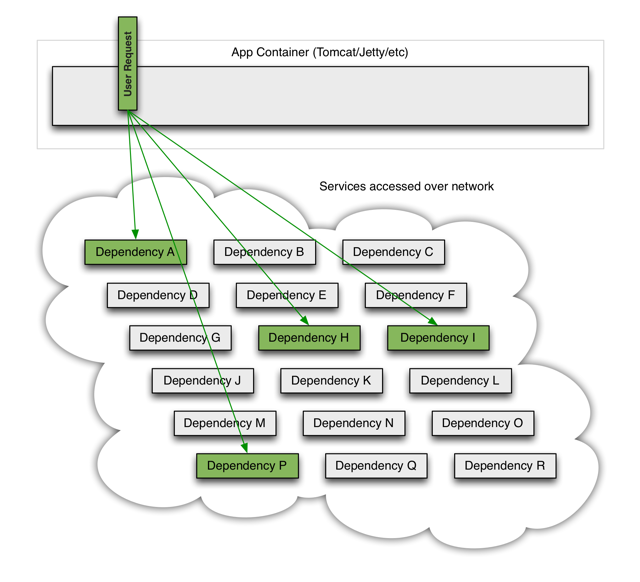
服务依赖

服务框架
- 服务注册、发现、负载均衡和健康检查,假定采用进程内LB方案,那么服务自注册一般统一做在服务器端框架中,健康检查逻辑由具体业务服务定制,框架层提供调用健康检查逻辑的机制,服务发现和负载均衡则集成在服务客户端框架中。
- 监控日志,框架一方面要记录重要的框架层日志、metrics和调用链数据,还要将日志、metrics等接口暴露出来,让业务层能根据需要记录业务日志数据。在运行环境中,所有日志数据一般集中落地到企业后台日志系统,做进一步分析和处理。
- REST/RPC和序列化,框架层要支持将业务逻辑以HTTP/REST或者RPC方式暴露出来,HTTP/REST是当前主流API暴露方式,在性能要求高的场合则可采用Binary/RPC方式。针对当前多样化的设备类型(浏览器、普通PC、无线设备等),框架层要支持可定制的序列化机制,例如,对浏览器,框架支持输出Ajax友好的JSON消息格式,而对无线设备上的Native App,框架支持输出性能高的Binary消息格式。
- 配置,除了支持普通配置文件方式的配置,框架层还可集成动态运行时配置,能够在运行时针对不同环境动态调整服务的参数和配置。
- 限流和容错,框架集成限流容错组件,能够在运行时自动限流和容错,保护服务,如果进一步和动态配置相结合,还可以实现动态限流和熔断。
- 管理接口,框架集成管理接口,一方面可以在线查看框架和服务内部状态,同时还可以动态调整内部状态,对调试、监控和管理能提供快速反馈。Spring Boot微框架的Actuator模块就是一个强大的管理接口。
- 统一错误处理,对于框架层和服务的内部异常,如果框架层能够统一处理并记录日志,对服务监控和快速问题定位有很大帮助。
- 安全,安全和访问控制逻辑可以在框架层统一进行封装,可做成插件形式,具体业务服务根据需要加载相关安全插件。
- 文档自动生成,文档的书写和同步一直是一个痛点,框架层如果能支持文档的自动生成和同步,会给使用API的开发和测试人员带来极大便利。Swagger是一种流行Restful API的文档方案。
微服务系统底座
一个完整的微服务系统,它的底座最少要包含以下功能:
- 日志和审计,主要是日志的汇总,分类和查询
- 监控和告警,主要是监控每个服务的状态,必要时产生告警
- 消息总线,轻量级的MQ或HTTP
- 注册发现
- 负载均衡
- 部署和升级
- 事件调度机制
- 资源管理,如:底层的虚拟机,物理机和网络管理
以下功能不是最小集的一部分,但也属于底座功能:
- 认证和鉴权
- 微服务统一代码框架,支持多种编程语言
- 统一服务构建和打包
- 统一服务测试
- 微服务CI/CD流水线
- 服务依赖关系管理
- 统一问题跟踪调试框架,俗称调用链
- 灰度发布
- 蓝绿部署
容器(Docker)与微服务
•容器够小
–解决微服务对机器数量的诉求
•容器独立
–解决多语言问题
•开发环境与生产环境相同
–单机开发、提升效率
•容器效率高
–省钱
•代码/image一体化
–可复用管理系统
•容器的横向与纵向扩容
–可复制
–可动态调节CPU与内存
容器(Docker)与微服务
•Image管理
•系统安全管理
•授权管理
•系统成熟度
•社区成熟度
开发方式影响
随着持续交付概念推广以及Docker容器普及,微服务将这两种理念和技术结合起来,形成新的微服务 API 平台的开发模式,提出了容器化微服务的持续交付概念。
下图传统Monolithic的DevOps开发队伍方式:
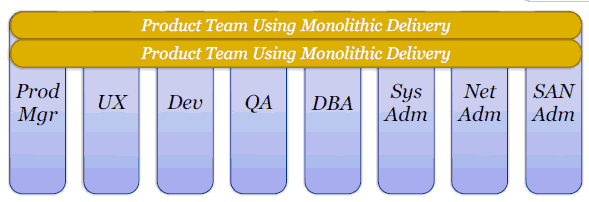
这种整体型架构要求产品队伍横跨产品管理 Dev开发 QA DBA 以及系统运营管理,而微服务架构引入以后,如下图:
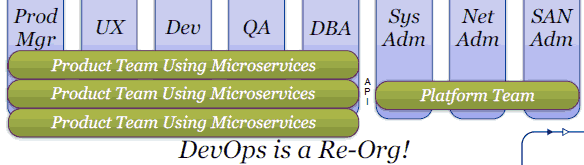
微服务促进了DevOps方式的重组,将一个大臃肿的整体产品开发队伍切分为根据不同微服务的划分的产品队伍,以及一个大的整体的平台队伍负责运营管理,两者之间通过API交互,做到了松耦合隔绝。

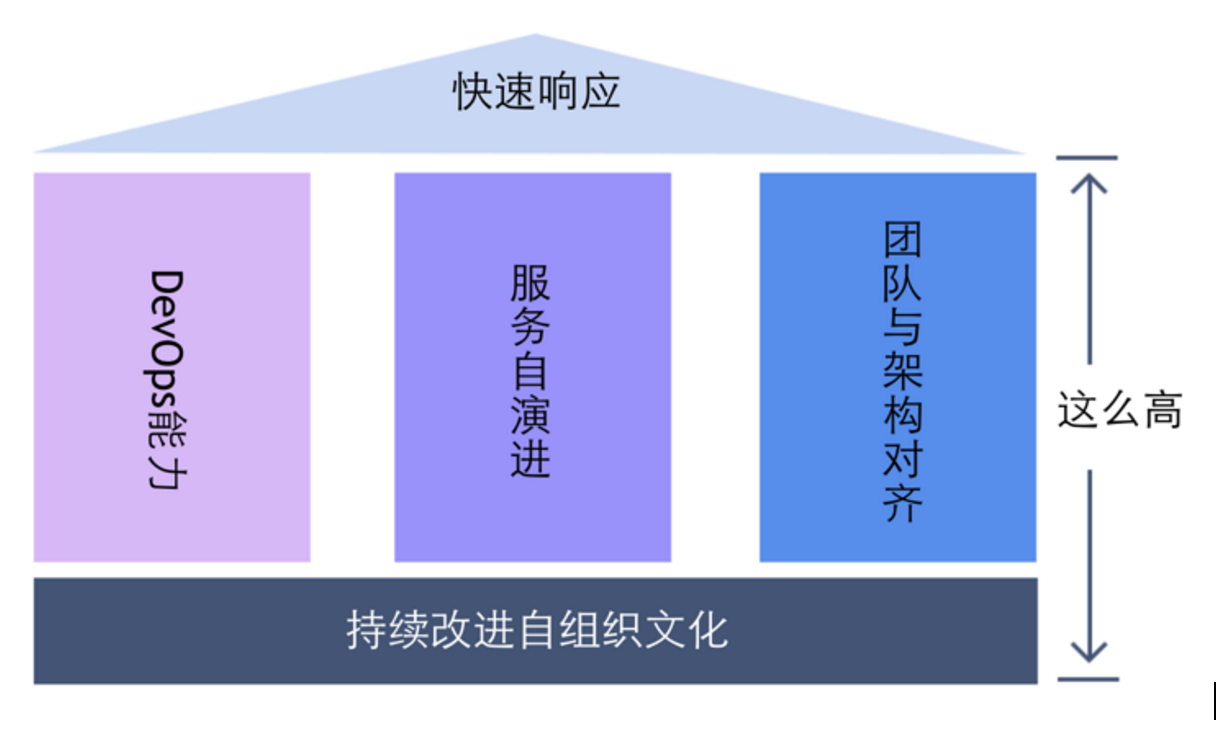
- 首先需要考虑构建DevOps能力,这是保证微服务架构在持续交付和应对复杂运维问题的动力之源;
- 其次保持服务持续演进,使之能够快速、低成本地被拆分和合并,以快速响应业务的变化;
- 同时要保持团队和架构对齐。微服务貌似是技术层面的变革,但它对团队结构和组织文化有很强的要求和影响。识别和构建匹配架构的团队是解决问题的另一大支柱。
- 最后,打造持续改进的自组织文化是实施微服务的关键基石。只有持续改进,持续学习和反馈,持续打造这样一个文化氛围和团队,微服务架构才能持续发展下去,保持新鲜的生命力,从而实现我们的初衷。
微服务的实施是有一定的先决条件:基础的运维能力(如监控、快速配置、快速部署)需提前构建,否则就会陷入如我们般被动的局面。推荐采用基础设施及代码的实践,通过代码来描述计算和网络基础设施的方法,使得图案度i可以快速安全的搭建和处理由新的配置代替的服务器,服务器之间可以拥有更高的一致性,降低了在“我的环境工作,而你的环境不工作”的可能,也是为后续的发布策略和运维提供更好的支撑。
由于Docker引入,不同的微服务可以使用不同的技术架构,比如Node.js Java Ruby Python等等,这些单个的服务都可以独立完成交付生命周期,如下:
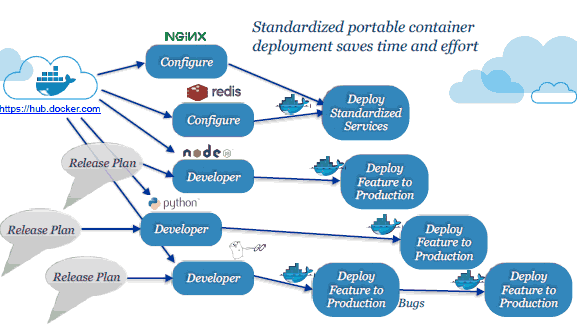
微服务案例
Netflix的微服务架构如下,着重全球分发 高可扩展性和可用性:

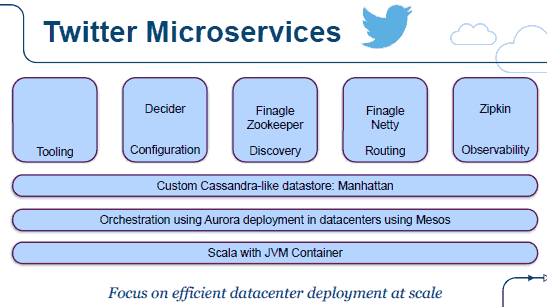
Twitter的微服务架构,注重高效的可扩展的数据中心:
一分钟让你明白DevOps

历史回顾
为了能够更好的理解什么是DevOps,我们很有必要对当时还只有程序员(此前还没有派生出开发者,前台工程师,后台工程师之类)这个称号存在的历史进行一下回顾。
如编程之道中所言:
老一辈的程序员是神秘且深奥的。我们没法揣摩他们的想法,我们所能做的只是描述一下他们的表象。
清醒的像一只游过水面的狐狸
警惕的像一位战场上的将军
友善的像一位招待客人的女主人
单纯的像一块未经雕琢的木头
深邃的像一潭幽深洞穴中漆黑的池水
程序员开发了机器语言,机器语言又产生了汇编语言,汇编语言产生了编译器,如今的语言已经多不胜数。每一种语言都有其各自的谦卑用途。每一种语言都表达出软件的阴和阳。每一种语言都在此道之中有其一席之地。
遥想当年,软件程序员的大部分办公司那时还被称作实验室,程序员那时还叫做科学家。为了开发出一套优秀的软件,程序员们必须深入了解他们需要的应用相关的所有问题。他们必须清楚知道这个软件应用在什么场合,这个软件是必须在什么系统上运行。本质上说,程序员对所要开发的软件的所有环节都有透彻的了解,从规格说明书编写、到软件开发、到测试、到部署、再到技术支持。
过了不久,人类(客户)贪婪的特性就开始表现出来,他们开始不断的进行更多的索求。更快的速度,更多的功能,更多的用户,更多的所有所有。
作为一类谦虚、谦卑、且平静的生物,我们的老一辈程序员们将很难在这种爆发性的过度的需求索取中幸存。最好的取胜办法就是往不同的方向进化成不同的新物种。很快,程序员这个称号就开始绝迹于江湖,而那些叫做开发者、软件工程师、网络管理员、数据库开发者、网页开发者、系统架构师、测试工程师等等更多的新物种就开始诞生。快速进化和快速适应外界的挑战成为了他们的DNA的一部分。这些新的种族可以在几个星期内就完成进化。网页开发者很快就能进化成后台开发者,前台开发者,PHP开发者,Ruby开发者,Angular开发者…多得让人侧目。
很快他们就都忘却了他们都是起源于程序员这个共同的祖先的事实,忘却了曾经有过这么一个单纯且平静的,想要让这个世界变得更好的科学家。然后他们开始不断的剑拔弩张,都声称自己才是“程序员”的纯血统继承人。
随着时间的转移,各门各派开始独占山头,很少进行交流互动,只有在迫不得已的时刻才会进行沟通。他们开始不再为同源的遥远的同宗兄弟们的成功而欢呼雀跃,甚至再也不会时把的遥寄张明信片进行嘘寒问暖。
但是在深夜仰望星空的时候,他们还是会发现他们的心底深处的程序员基因还是会不停的闪烁着,期盼着这闪烁的火花能照亮整个银河系并带来和平。

在这场自私且以自我为中心的欲征服世界的赛跑旅程里,程序员的子孙们早把他们真正的工作目标置之脑后-为客户解决问题。面对一拖再拖的项目交付日期,昂贵的开发代价,甚至最终失败的项目,客户们开始对这种情况深恶痛绝。
偶尔,也会有一个闪亮的明星站出来,灵机一动的提供一种办法来尝试结束这种混乱并带来和平。所以瀑布开发流程就应运而生了。这是一个非常了不起的创意,因为它利用了不同团队的开发者们只在必须的时候才进行沟通的这个事实。当一个团队完成了他们的工作的时候,它就会和下游的团队进行交流并把任务进行往下传,如此一级接一级的传递下去,永不回首。

这种方式在一段时间内发挥了效用,但很快,一如既往,贪婪的人们(客户)又开始提出更多的诉求。他们希望能够更多地参加到整个软件的开发流程中来,不时的提出他们的建议,甚至在很晚的时候还提出改需求这种丧心病狂的事情来。
结果就是如大家有目共睹的事实一样,软件项目非常容易失败这个说法已经作为一个行业标准被人们所接受。数据表明超过50%的项目最终都是以失败告终的。更可悲的是,在当时看来,人们对这种情况是束手无策。
值得庆幸的是,每一个时代总会有那么几个思想开放的英雄如漆黑中的萤火虫般冒出来。他们知道这些不同团队的开发者们必须要找到一个可以协同工作、进行交流、并且能够弹性的向客户保证对方将会拿到最优的解决方案的方式。这种尝试最早可以追溯到1957年,伟大的约翰·冯·诺依曼和同行们的努力。但是我们最终却是等到2001年才收获到革命的果实,当时行业的十多个精英创造出了如今闻名世界的“敏捷宣言”。
敏捷宣言基于以下十二条原则:
我们的首要任务是通过尽早地、持续地交付可评价的软件来使客户满意。
乐于接受需求变更,即使是在开发后期也应如此。敏捷过程能够驾驭变化,从而为客户赢得竞争优势。
频繁交付可使用的软件,交付间隔越短越好,可以从几个星期到几个月。
在整个项目开发期间,业务人员和开发人员必须朝夕工作在一起。
围绕那些有推动力的人们来构建项目。给予他们所需的环境和支持,并且信任他们能够把工作完成好。
与开发团队以及在开发团队内部最快速、有效的传递信息的方法就是,面对面的交谈。
可使用的软件是进度的主要衡量指标。
敏捷过程提倡可持续发展。出资人、开发人员以及使用者应该总是共同维持稳定的开发速度。
为了增强敏捷能力,应持续关注技术上的杰出成果和良好的设计。
简洁——最大化不必要工作量的艺术——是至关重要的。
最好的架构、需求和设计都源自自我组织的团队。
团队应该定期反思如何能变得更有战斗力,然后相应地转变并调整其行为。
敏捷宣言是为银河系带来和平以及维护各自的平衡所迈出的很重要的第一步。在很长的时间里,相比此前基于流程和机械化的方式,这是第一次基于文化和“人性”来将不同的关键项目关系人连接在一起的方式。人们开始互相交流,进行基本的碰头会议,并开始不断的交流意见和看法。他们开始意识到他们是有着很多比想象中还多的共同点的,客户也开始成为他们之中的一员,而不再是像以往一样只是往项目砸钱然后开始求神拜佛祈求一切顺利如愿。

尽管前面还是有不少的障碍需要克服,但是未来已经光明了许多。敏捷意味着开放和拥抱(需求)改变。但是,如果改变过多的话,人们就很难专注到最终的目标和交付上来。此时精益软件开发就开始破土而出了。
因为对精益软件开发的着迷以及为了达成放逐和驱赶风险的目的,一些程序员的子孙们就开始探首窗外,开始向软件之外的行业进行取经。他们从一家主要的汽车生产商身上找到了救赎。丰田生产系统在精益上面的成就是不可思议的,同时它们的精益生产的经验也是很容易应用到软件开发上来的。
精益有以下7个原则:
杜绝浪费
内建质量
创建知识(放大学习)
延迟决策(尽量延迟决定)
快速交付
尊重人员(团队授权)
全局优化
将这些放到敏捷上去的话,精益原则就能让人们在从精神上关注做正确的事情,同时还能够让整个开发流程拥有足够的弹性。
一旦敏捷和精益软件开发被软件开发团队采纳,那么下一步就是把这一套原则应用到IT团队上来。把IT也纳入到整体战略上,然后我们就来到了DevOps跟前了!
进入DevOps – 高速公路的三条车道
老一派的软件开发团队成员会包含业务分析员,系统架构师,前端开发者,后端开发者,测试员,等等。优化如敏捷和精益原则等的软件开发流程的关注点就在这些地方。比如,软件一旦达到”可以生产“的程度,就会发到系统工程师、发布工程师、DBA、网络工程师,安全专家这些“运维人员”的手上。这里该如何将横在Dev(开发)和Ops(运维)之间的鸿沟给填平,这就是DevOps的主要关注点了。
DevOps是在整个IT价值流中实施精益原则的结果。IT价值流将开发延伸至生产,将由程序员这个遥远的祖宗所繁衍的所有子孙给联合在一起。
这是来自Gene Kim的对DevOps的最好的解析,如果你还没有看过他的《凤凰项目》这本书的话,我建议你真的该好好花时间看看。
你不应该重新招聘DevOps工程师,且DevOps也不应该是一个IT的新部门。DevOps是一种文化,一种理念,且是和IT糅合成一整体的。世间没有任何工具可以把你的IT变成一个DevOps组织,也没有任何自动化方式可以指引你该如何为你的客户提供最大化的效益。
DevOps通常作为下面这三个方式而为人所熟知,而在我眼里我是把它们看成是一条高速公路上的三条车道。你从第一条车道开始,然后加速进入到第二条车道,最终在第三车道上高速行驶。
车道1 – 系统级别的整体效率考量是最主要的关注点,这超过对系统中任何一个单独个体元素的考虑
车道2 – 确保能提供持续不断的反馈循环,且这些反馈不被忽视。
车道3 – 持续的学习和吸取经验,不停的进步,快速的失败。
车道1 – 获取速度
要采纳DevOps的原则,理解整个运作系统的重要性并对工作事项进行合适的优先级排序是组织首先要学的事情。在整个价值流中不能允许任何人产生瓶颈并降低整个工作流程。

确保工作流程的不可中断是身处流程中的所有成员的终极目标。无论一个成员或者团队的角色是什么,他们都必须力图对整个系统进行深入的理解。这种思维方式对质量会有着直接的影响,因为缺陷永远不会被下放到“下游“中,这样做的话将会导致瓶颈的产生。
确保整个工作流程不会被瓶颈堵塞住还不够。一个高产的组织应该时常考虑该如何提升整个工作流程。有很多方法论可以做到这一点,你不妨去看下“约束理论”,“六西格玛”,精益,或者丰田生产系统。
DevOps原则不关心你身处哪个团队,你是否是系统架构师,DBA,QA,或者是网络管理员。相同的规则覆盖所有的成员,每个成员都应该遵循两个简单的原则:
保持系统运作流程不可中断
随时提升和优化工作流程
车道2 – 换挡加速
不可中断的系统流程是定向的,且预期是从开发流向运维。在一个理想的世界中,这就意味着快速的开发出高质量的软件,部署,并为客户提供价值。
但是,DevOps并非乌托邦式的理想国。如果单向的交付方式是可行的话,我们的瀑布模式早就能胜任了。评估可交付产品和整个流程中的交流对确保质量是至关重要的。这里首个必须实现的”面向上游”的交流通道是从Ops到Dev。

我们独自意淫是件非常容易的事情,但是获取别人的反馈和提供反馈给别人才是探究事实真相的正确方法。下游的每一步(反馈)都必须紧跟着有一个上游的确定。
你如何建立反馈循环机制并不重要。你可以邀请开发人员加入技术支持团队的会议,或者将网络管理员放到Sprint计划会议中去。一旦你的反馈机制就绪,反馈能够被接收并被处理,你就已经可以说是走到了DevOps高速车道上来了。
车道3 – 飞速前进
DevOps这条快速车道并不适合意志脆弱的人。为了进入这条车道,你的组织必须要足够的成熟。这里充满了冒险和对失败教训的学习,不断的尝试,并认同屡败屡战和不断的实践是走向成功这条康庄大道的前提条件。在这里你应该会经常听到”套路“这个词,这是有原因的。不断的训练和重复所以能培养出大师,是因为其让复杂的动作常规化。
但是在你要将这些复杂的动作连接起来之前,你很有必要先去掌握好每一个单独步骤。
“适合大师的动作并不适合新手,脱胎换骨之前你必须先要明白道的真谛。“

DevOps的第三个方式/快速车道包括每天分配时间来持续的进行试验,时常的奖励敢于冒险的团队,并将缺陷特意引入到运作系统上来以增加系统的抗击打能力。
为了确保你的组织能够消化好这些方法,你必须在每个团队之间建立好频繁的反馈循环,同时需要确保所有的瓶颈都能够及时的被清理掉,并确保整个系统的运作流程是不可中断的。
实施好这些措施可以让你的组织时刻保持警惕,并能够快速且高效的应对挑战。
概要 – DevOps清单
下面是一张你可以用来检验你的组织对DevOps的应用情况的清单。当然你也可以在文章评论后面给出你的观点。
开发团队和运维团队之间没有障碍。两者皆是DevOps统一流程的一部分。
从一个团队流到另一个团队的工作都能够得到高质量的验证
工作没有堆积,所有的瓶颈都已经被处理好。
开发团队没有占用运维团队的时间,因为部署和维护都是处于同一个时间盒里面的。
开发团队不会在周五下午5点后把代码交付进行部署,剩下运维团队周末加班加点来给他们擦屁股
开发环境标准化,运维人员可以很容易將之扩展并进行部署
开发团队可以找到合适的方式交付新版本,且运维团队可以轻易的进行部署。
每个团队之间的通信线路都很明确
所有的团队成员都有时间去为改善系统进行试验和实践
常规性的引入(或者模拟)缺陷到系统中来并得到处理。每次学习到的经验都应该文档化下来并分享给相关人员。事故处理成为日常工作的一部分,且处理方式是已知的
总结
使用现代化的DevOps工具,如Chef、Docker、Ansible、Packer、Troposphere、Consul、Jenkins、SonarQube、AWS等,并不代表你就在正确的应用DevOps的原则。DevOps是一种思维方式。我们所有人都是该系统流程的一部分,我们一起分享共同的时光和交付价值。每个参加到这个软件交付流程上来的成员都能够加速或减缓整个系统的运作速度。系统出现的一个缺陷,以及错误配置的团队之间的“防火墙”,都可能会使得整个系统瘫痪,
所有的人都是DevOps的一部分,一旦你的组织明白了这一点,能够帮你管理好这些的工具和技术栈就自然而然的会出现在你眼前了。
23种设计模式总结
1.单例模式(Singleton Pattern)
public class Singleton {
private static final Singleton singleton = new Singleton();
//限制产生多个对象
private Singleton(){
}
//通过该方法获得实例对象
public static Singleton getSingleton(){
return singleton;
}
//类中其他方法,尽量是static
public static void doSomething(){
}
}
public class Singleton {
private static Singleton singleton = null;
//限制产生多个对象
private Singleton(){
}
//通过该方法获得实例对象
public static Singleton getSingleton(){
if(singleton == null){
singleton = new Singleton();
}
return singleton;
}
}
2.工厂模式
public class ConcreteCreator extends Creator {
public <T extends Product> T createProduct(Class<T> c){
Product product=null;
try {
product = (Product)Class.forName(c.getName()).newInstance();
} catch (Exception e) {
//异常处理
}
return (T)product;
}
}
3.抽象工厂模式(Abstract Factory Pattern)
public abstract class AbstractCreator {
//创建A产品家族
public abstract AbstractProductA createProductA();
//创建B产品家族
public abstract AbstractProductB createProductB();
}
4.模板方法模式(Template Method Pattern)
5.建造者模式(Builder Pattern)
6.代理模式(Proxy Pattern)
7.原型模式(Prototype Pattern)
public class PrototypeClass implements Cloneable{
//覆写父类Object方法
@Override
public PrototypeClass clone(){
PrototypeClass prototypeClass = null;
try {
prototypeClass = (PrototypeClass)super.clone();
} catch (CloneNotSupportedException e) {
//异常处理
}
return prototypeClass;
}
}
8.中介者模式
public abstract class Mediator {
//定义同事类
protected ConcreteColleague1 c1;
protected ConcreteColleague2 c2;
//通过getter/setter方法把同事类注入进来
public ConcreteColleague1 getC1() {
return c1;
}
public void setC1(ConcreteColleague1 c1) {
this.c1 = c1;
}
public ConcreteColleague2 getC2() {
return c2;
}
public void setC2(ConcreteColleague2 c2) {
this.c2 = c2;
}
//中介者模式的业务逻辑
public abstract void doSomething1();
public abstract void doSomething2();
}
9.命令模式
10.责任链模式
public abstract class Handler {
private Handler nextHandler;
//每个处理者都必须对请求做出处理
public final Response handleMessage(Request request){
Response response = null;
//判断是否是自己的处理级别
if(this.getHandlerLevel().equals(request.getRequestLevel())){
response = this.echo(request);
}else{ //不属于自己的处理级别
//判断是否有下一个处理者
if(this.nextHandler != null){
response = this.nextHandler.handleMessage(request);
}else{
//没有适当的处理者,业务自行处理
}
}
return response;
}
//设置下一个处理者是谁
public void setNext(Handler _handler){
this.nextHandler = _handler;
}
//每个处理者都有一个处理级别
protected abstract Level getHandlerLevel();
//每个处理者都必须实现处理任务
protected abstract Response echo(Request request);
}
11.装饰模式(Decorator Pattern)
12.策略模式(Strategy Pattern)
public enum Calculator {
//加法运算
ADD("+"){
public int exec(int a,int b){
return a+b;
}
},
//减法运算
SUB("-"){
public int exec(int a,int b){
return a - b;
}
};
String value = "";
//定义成员值类型
private Calculator(String _value){
this.value = _value;
}
//获得枚举成员的值
public String getValue(){
return this.value;
}
//声明一个抽象函数
public abstract int exec(int a,int b);
}
13.适配器模式(Adapter Pattern)
14.迭代器模式(Iterator Pattern)
15.组合模式((Composite Pattern))
public class Composite extends Component {
//构件容器
private ArrayList<Component> componentArrayList = new ArrayList<Component>();
//增加一个叶子构件或树枝构件
public void add(Component component){
this.componentArrayList.add(component);
}
//删除一个叶子构件或树枝构件
public void remove(Component component){
this.componentArrayList.remove(component);
}
//获得分支下的所有叶子构件和树枝构件
public ArrayList<Component> getChildren(){
return this.componentArrayList;
}
}
16.观察者模式(Observer Pattern)
public abstract class Subject {
//定义一个观察者数组
private Vector<Observer> obsVector = new Vector<Observer>();
//增加一个观察者
public void addObserver(Observer o){
this.obsVector.add(o);
}
//删除一个观察者
public void delObserver(Observer o){
this.obsVector.remove(o);
}
//通知所有观察者
public void notifyObservers(){
for(Observer o:this.obsVector){
o.update();
}
}
}
17.门面模式(Facade Pattern)
客户端可以调用这个角色的方法。此角色知晓子系统的所有功能和责任。一般情况下,本角色会将所有从客户端发来的请求委派到相应的子系统去,也就说该角色没有实际的业务逻辑,只是一个委托类。
● subsystem子系统角色
可以同时有一个或者多个子系统。每一个子系统都不是一个单独的类,而是一个类的集合。子系统并不知道门面的存在。对于子系统而言,门面仅仅是另外一个客户端而已。
18.备忘录模式(Memento Pattern)
public class BeanUtils {
//把bean的所有属性及数值放入到Hashmap中
public static HashMap<String,Object> backupProp(Object bean){
HashMap<String,Object> result = new HashMap<String,Object>();
try {
//获得Bean描述
BeanInfo beanInfo=Introspector.getBeanInfo(bean.getClass());
//获得属性描述
PropertyDescriptor[] descriptors=beanInfo.getPropertyDescriptors();
//遍历所有属性
for(PropertyDescriptor des:descriptors){
//属性名称
String fieldName = des.getName();
//读取属性的方法
Method getter = des.getReadMethod();
//读取属性值
Object fieldValue=getter.invoke(bean,new Object[]{});
if(!fieldName.equalsIgnoreCase("class")){
result.put(fieldName, fieldValue);
}
}
} catch (Exception e) {
//异常处理
}
return result;
}
//把HashMap的值返回到bean中
public static void restoreProp(Object bean,HashMap<String,Object> propMap){
try {
//获得Bean描述
BeanInfo beanInfo = Introspector.getBeanInfo(bean.getClass());
//获得属性描述
PropertyDescriptor[] descriptors = beanInfo.getPropertyDescriptors();
//遍历所有属性
for(PropertyDescriptor des:descriptors){
//属性名称
String fieldName = des.getName();
//如果有这个属性
if(propMap.containsKey(fieldName)){
//写属性的方法
Method setter = des.getWriteMethod();
setter.invoke(bean, new Object[]{propMap.get(fieldName)});
}
}
} catch (Exception e) {
//异常处理
System.out.println("shit");
e.printStackTrace();
}
}
}
19.访问者模式(Visitor Pattern)
20.状态模式(复杂)
21.解释器模式(Interpreter Pattern)(少用)
22.享元模式(Flyweight Pattern)
public class FlyweightFactory {
//定义一个池容器
private static HashMap<String,Flyweight> pool= new HashMap<String,Flyweight>();
//享元工厂
public static Flyweight getFlyweight(String Extrinsic){
//需要返回的对象
Flyweight flyweight = null;
//在池中没有该对象
if(pool.containsKey(Extrinsic)){
flyweight = pool.get(Extrinsic);
}else{
//根据外部状态创建享元对象
flyweight = new ConcreteFlyweight1(Extrinsic);
//放置到池中
pool.put(Extrinsic, flyweight);
}
return flyweight;
}
}
23.桥梁模式(Bridge Pattern)
设计原则:
●Single Responsibility Principle:单一职责原则
● Liskov Substitution Principle:里氏替换原则
● Dependence Inversion Principle:依赖倒置原则
●Open Closed Principle:开闭原则
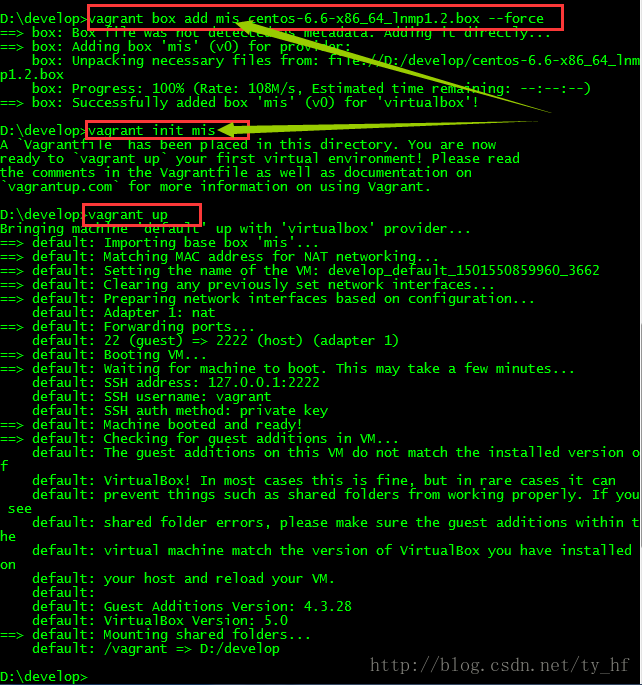
Vagrant-安装教程及常见问题
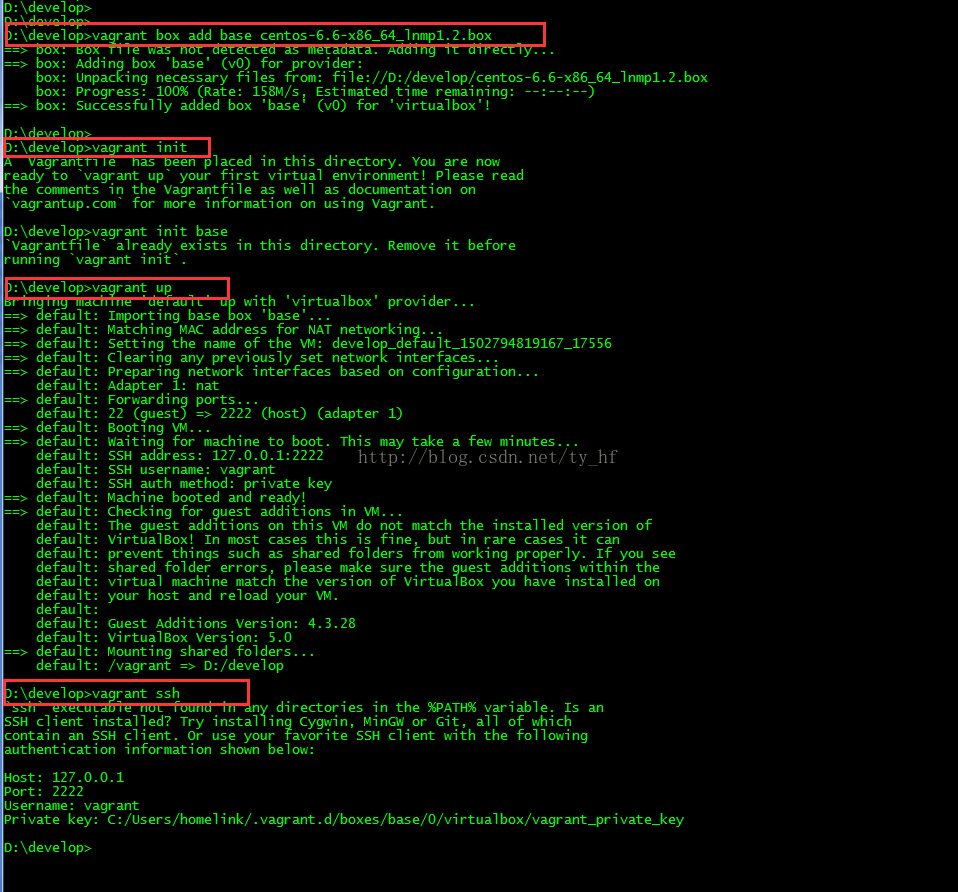

{kind=link}
- vagrant up (启动虚拟机)
- vagrant halt (关闭虚拟机——对应就是关机)
- vagrant suspend (暂停虚拟机——只是暂停,虚拟机内存等信息将以状态文件的方式保存在本地,可以执行恢复操作后继续使用)
- vagrant resume (恢复虚拟机—— 与前面的暂停相对应)
- vagrant destroy (删除虚拟机,删除后在当前虚拟机所做进行的除开Vagrantfile中的配置都不会保留)
在我们的开发目录下有一个文件Vagrantfile,里面包含有大量的配置信息,主要包括三个方面的配置,虚拟机的配置、SSH配置、Vagrant的一些基础配置。Vagrant是使用Ruby开发的,所以它的配置语法也是Ruby的,但是我们没有学过Ruby的人还是可以跟着它的注释知道怎么配置一些基本项的配置。
具体介绍,参考:http://blog.csdn.net/chajinglong/article/details/52805915
- # -*- mode: ruby -*-
- # vi: set ft=ruby :
- # All Vagrant configuration is done below. The "2" in Vagrant.configure
- # configures the configuration version (we support older styles for
- # backwards compatibility). Please don\'t change it unless you know what
- # you\'re doing.
- Vagrant.configure(2) do |config|
- # The most common configuration options are documented and commented below.
- # For a complete reference, please see the online documentation at
- # https://docs.vagrantup.com.
- # Every Vagrant development environment requires a box. You can search for
- # boxes at https://atlas.hashicorp.com/search.
- config.vm.box = "base"
- # Disable automatic box update checking. If you disable this, then
- # boxes will only be checked for updates when the user runs
- # `vagrant box outdated`. This is not recommended.
- # config.vm.box_check_update = false
- # Create a forwarded port mapping which allows access to a specific port
- # within the machine from a port on the host machine. In the example below,
- # accessing "localhost:8080" will access port 80 on the guest machine.
- # config.vm.network "forwarded_port", guest: 80, host: 80
- # Create a private network, which allows host-only access to the machine
- # using a specific IP.
- config.vm.network "private_network", ip: "192.168.33.10"
- # Create a public network, which generally matched to bridged network.
- # Bridged networks make the machine appear as another physical device on
- # your network.
- # config.vm.network "public_network"
- # Share an additional folder to the guest VM. The first argument is
- # the path on the host to the actual folder. The second argument is
- # the path on the guest to mount the folder. And the optional third
- # argument is a set of non-required options.
- config.vm.synced_folder "D:/all_code/", "/home/www"
- # Provider-specific configuration so you can fine-tune various
- # backing providers for Vagrant. These expose provider-specific options.
- # Example for VirtualBox:
- #
- # config.vm.provider "virtualbox" do |vb|
- # # Display the VirtualBox GUI when booting the machine
- # vb.gui = true
- #
- # # Customize the amount of memory on the VM:
- # vb.memory = "1024"
- # end
- #
- # View the documentation for the provider you are using for more
- # information on available options.
- # Define a Vagrant Push strategy for pushing to Atlas. Other push strategies
- # such as FTP and Heroku are also available. See the documentation at
- # https://docs.vagrantup.com/v2/push/atlas.html for more information.
- # config.push.define "atlas" do |push|
- # push.app = "YOUR_ATLAS_USERNAME/YOUR_APPLICATION_NAME"
- # end
- # Enable provisioning with a shell script. Additional provisioners such as
- # Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
- # documentation for more information about their specific syntax and use.
- # config.vm.provision "shell", inline: <
- # sudo apt-get update
- # sudo apt-get install -y apache2
- # SHELL
- end
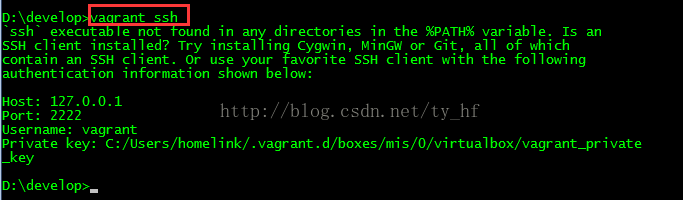
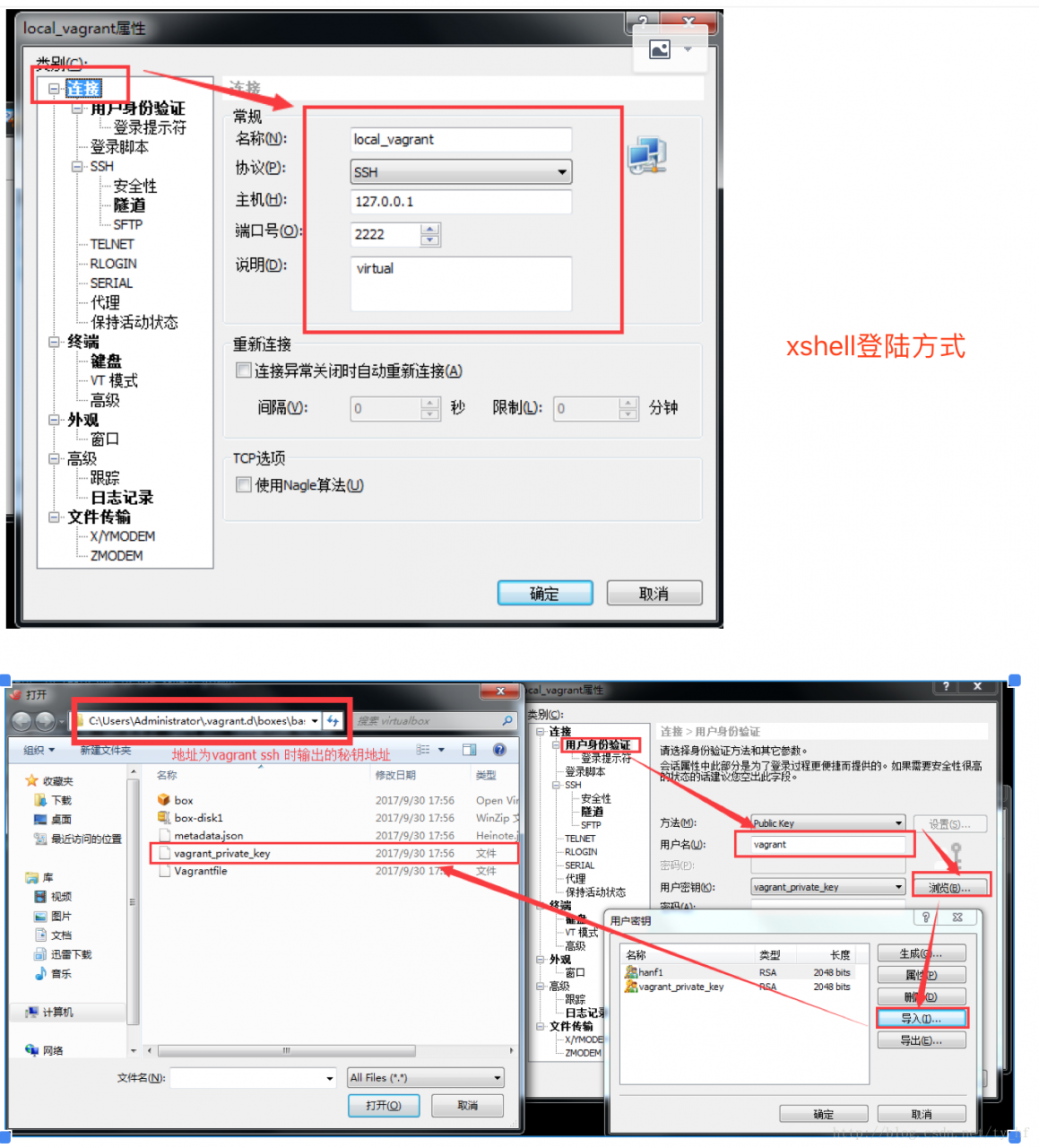
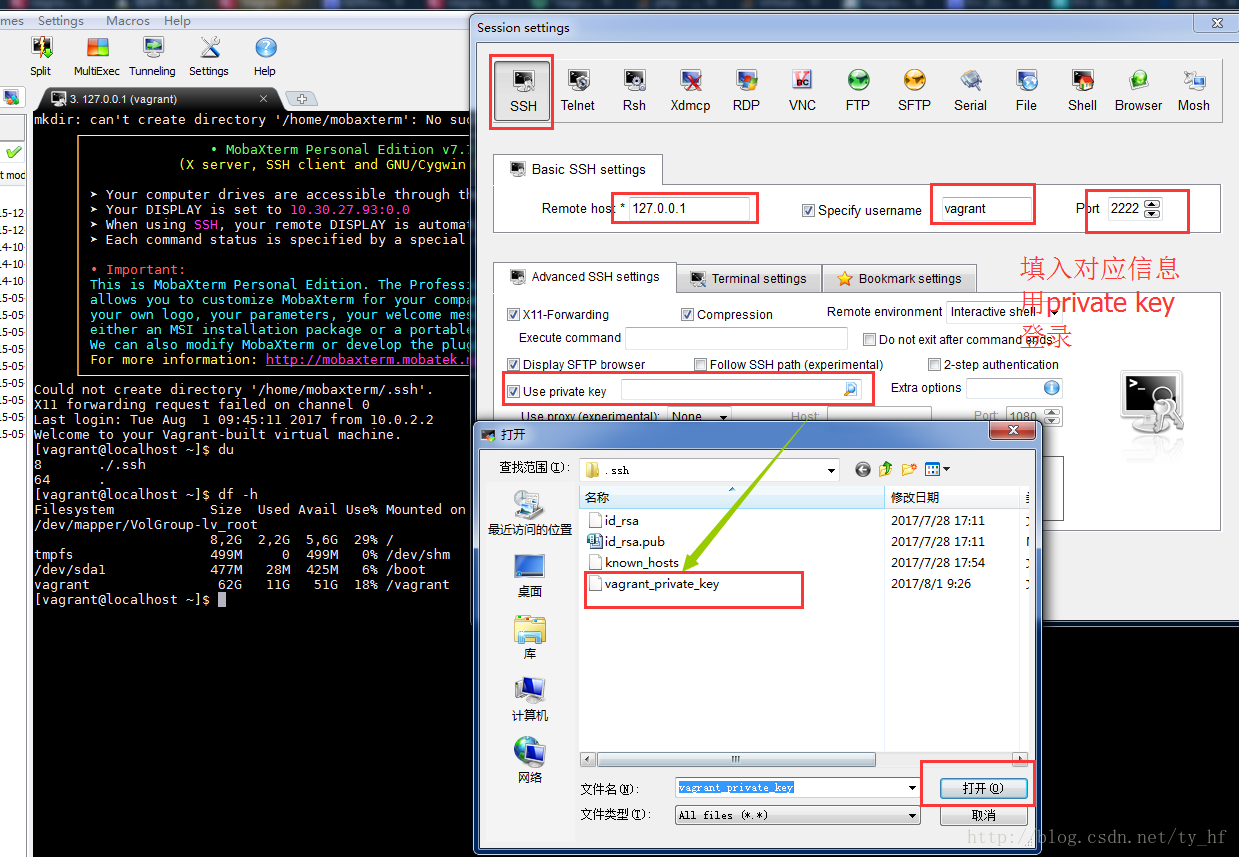
- ssh: 127.0.0.1
- 端口: 2222
- 用户名: vagrant
- 密码: vagrant
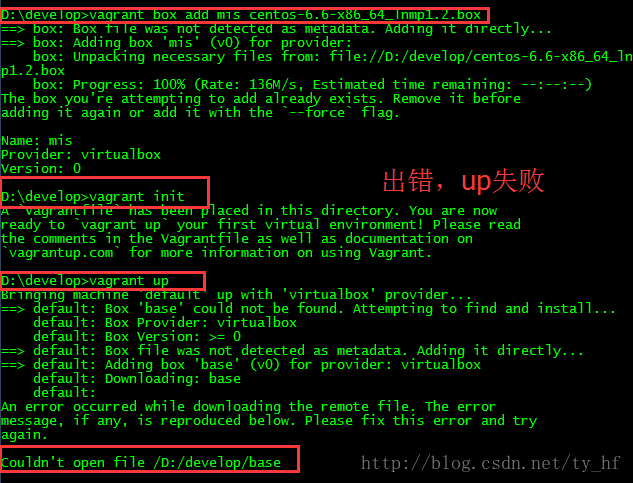
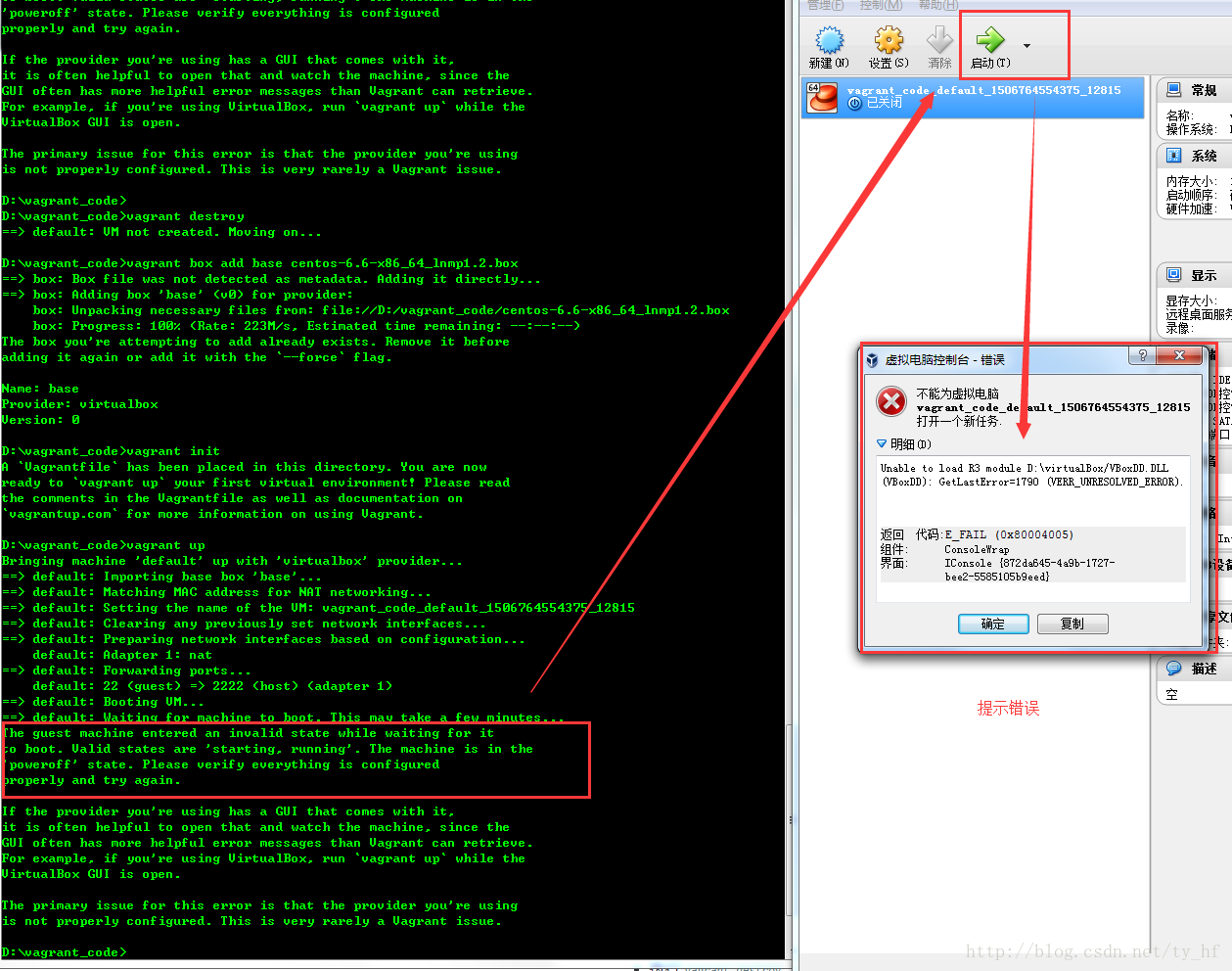
- The guest machine entered an invalid state while waiting for it
- to boot. Valid states are \'starting, running\'. The machine is in the
- \'poweroff\' state. Please verify everything is configured
- properly and try again.
- If the provider you\'re using has a GUI that comes with it,
- it is often helpful to open that and watch the machine, since the
- GUI often has more helpful error messages than Vagrant can retrieve.
- For example, if you\'re using VirtualBox, run `vagrant up` while the
- VirtualBox GUI is open.
- The primary issue for this error is that the provider you\'re using
- is not properly configured. This is very rarely a Vagrant issue.
- Unable to load R3 module D:\virtualBox/VBoxDD.DLL (VBoxDD): GetLastError=1790 (VERR_UNRESOLVED_ERROR).
- sudo rm -f /etc/udev/rules.d/70-persistent-net.rules
- vi /etc/hosts
3.问题 default: Warning: Authentication failure. Retrying...
- Bringing machine \'default\' up with \'virtualbox\' provider...
- ==> default: Clearing any previously set forwarded ports...
- ==> default: Clearing any previously set network interfaces...
- ==> default: Preparing network interfaces based on configuration...
- default: Adapter 1: nat
- default: Adapter 2: hostonly
- ==> default: Forwarding ports...
- default: 22 (guest) => 2222 (host) (adapter 1)
- ==> default: Booting VM...
- ==> default: Waiting for machine to boot. This may take a few minute
- default: SSH address: 127.0.0.1:2222
- default: SSH username: vagrant
- default: SSH auth method: private key
- default: Warning: Remote connection disconnect. Retrying...
- default: Warning: Authentication failure. Retrying...
- default: Warning: Authentication failure. Retrying...
- default: Warning: Authentication failure. Retrying...
- Timed out while waiting for the machine to boot. This means that
- Vagrant was unable to communicate with the guest machine within
- the configured ("config.vm.boot_timeout" value) time period.
- If you look above, you should be able to see the error(s) that
- Vagrant had when attempting to connect to the machine. These errors
- are usually good hints as to what may be wrong.
- If you\'re using a custom box, make sure that networking is properly
- working and you\'re able to connect to the machine. It is a common
- problem that networking isn\'t setup properly in these boxes.
- Verify that authentication configurations are also setup properly,
- as well.
- If the box appears to be booting properly, you may want to increase
- the timeout ("config.vm.boot_timeout") value.
解决:
- config.ssh.username = "vagrant"
- config.ssh.password = "vagrant"
- vagrant halt
- vagrant up
注意登陆的时候看下 vagrant ssh 看下你的登录信息,端口号
4.报错问题:
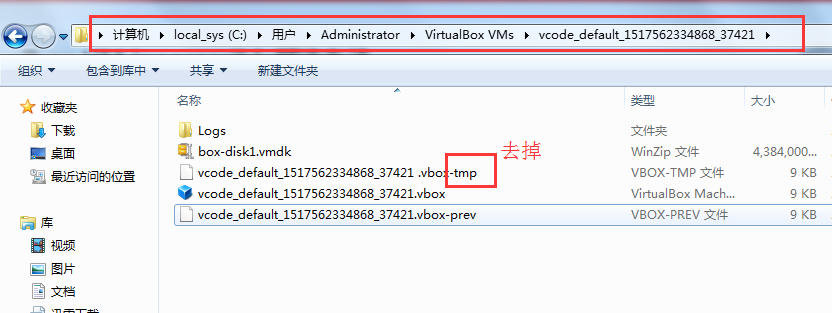
- Bringing machine \'default\' up with \'virtualbox\' provider...
- Your VM has become "inaccessible." Unfortunately, this is a critical error
- with VirtualBox that Vagrant can not cleanly recover from. Please open VirtualBox
- and clear out your inaccessible virtual machines or find a way to fix
- A Vagrant environment or target machine is required to run this
- command. Run vagrant init to create a new Vagrant environment. Or,
- get an ID of a target machine from vagrant global-status to run
- this command on. A final option is to change to a directory with a
- Vagrantfile and to try again.
少前边步骤了,比如vagrant init;或者没有进入对应vagrant init的文件夹
- config.vm.provider :virtualbox do |vb|
- vb.customize ["modifyvm", :id, "--natdnshostresolver1", "on"]
- vb.customize ["modifyvm", :id, "--natdnsproxy1", "on"]
- D:\vcode>vagrant up
- Bringing machine \'default\' up with \'virtualbox\' provider...
- Your VM has become "inaccessible." Unfortunately, this is a critical error
- with VirtualBox that Vagrant can not cleanly recover from. Please open VirtualBo
- x
- and clear out your inaccessible virtual machines or find a way to fix
- them.
【第三方工具】Gogs使用详解
https://gogs.io
Gogs使用介绍
Gogs是一款类似Github(国内有码市)的开源文件/代码管理系统(基于Git)
目前功能基本介绍
远程代码仓库管理
代码仓库权限分配、管理
团队管理
代码审查
(1)注册

(2)基本功能介绍
主面板说明

图中1表示自己个人账户下的仓库(所有权属于自己)
图中2表示自己参与的仓库(所有权不属于自己)
注意
自己个人账户下的仓库一般为自己创建,或者其他仓库所有者转让仓库。自己对该仓库具有全部权限(写入/删除文件、增加成员、删除成员、合并分之、审核分之)
新建仓库

在主面板中点击我的仓库右侧的” ”按钮后进入新建仓库页面,在此页面中我们需哟啊输入仓库的基本描述,并设置可见属性.
注意
在创建仓库按钮的上方有一个复选框“使用选定文件和模板初始化仓库”。
这里如果不选,则会生成一个空仓库,我们需要在本地生成一个仓库(或者原有仓库),然后将本地仓库的远程仓库地址设置成我们在Gogs中新建的仓库地址。
仓库使用基介绍

图中1仓库中的文件管理页面
图中2仓库的工单管理页面
图中3仓库的合并请求管理(代码审查、合并)
图中4查看代码的分支
图中5在浏览器中上传和下载文件(不依赖Git)
图中6当前仓库的远程地址(将其拷贝下来,将本地的对应仓库的origin地址设置)
图中7当前仓库的文件阅览
基于浏览器进行文件上传下载

可以直接在浏览器中进行文件上传

可以直接在浏览器查看对应文档,或者下载文档
(4)组织管理
Git魅力不仅仅体现在对代码的管理,还有有效的管理团队合作上
组织管理介绍
Gogs也专门提供了组织管理功能(组织可以代表一个公司,可以在组织下建立仓库、添加组织成员,然后通过创建和设置团队,将组织名下的仓库分别授权给不同的成员)

图中点击”我的组织”后面的“+”号可以新建组织

图中1显示当前组织下的仓库,点击创建新仓库可以添加新的组织
图中2显示当前组织中的成员,可以点击邀请其他人,添加新的成员
图中3显示当前组织下设置的团队(每个团对可以分别添加组织下的不同仓库和不同成员,并设置该团队权限(写入、阅读))

图中1显示该团队有4名成员
图中2显示该团队拥有当前组织的2个仓库的权限
图中3显示该团队对yo拥有的2个仓库具有读取和写入的权限
【公众号】说说技术总监三板斧(十年肺腑之言)
技术人员职业发展路线图,按照管理路线和技术路线区分。在国外管理路线和技术路线的职位会按照IT Manager和TechLead去区分,但在国内其实是没有纯粹的管理路线,管理岗位中一定有具体技术工作的要求。今天我说说对“技术总监”岗位职能要求的理解。

我理解技术总监的权责范畴应该包括技术性工作和管理性工作,管理性工作又分为人员管理(即团队管理)和项目管理。在技术型工作中,我认为更多考验的是一个技术管理者的技术深度和广度,而管理性工作中,更多考验的是一个技术管理者对于复杂人和事的协调能力。
对于一位优秀的技术人员而言,应该具备几种技术能力,包括:关键性技术能力、架构设计能力、工程管理能力;而一位技术管理者首先应该是一名优秀的技术人员,必须能在这三种技术能力之间游刃有余。
你也可以把它理解为技术难点的攻克。我曾看到过朋友圈包括饿了么CTO张雪峰、钉钉CTO一粟等,在团队面前现场coding演示某些难啃骨头的解决场景。不要求技术管理者写代码,但是在某些风险性大的技术场景里,技术管理者必须能亲自上阵,以免团队成员解决不了“甩锅”的时候可以接得起来。而且了解团队的代码情况,融入团队的代码编写,也方便对系统架构的掌控。另外,作为示范代码,能够让管理者在团队中更好的立威。
我们在说到架构设计的时候,一般会提到“技术架构”和“业务架构”,脱离业务架构的技术架构一定不会成功。这就要求技术管理者对业务有良好的理解能力。而且架构的设计不仅仅是指能画架构图,能写架构文档,能把热门技术堆砌到图纸上;一个没在工地上跑过的建筑设计师一定不会造出好的大楼。反之,一个不做架构设计就想写出好系统的技术人员不是天才就是傻子。架构的设计要更好的考虑运行效率、业务的可拓展性/伸缩性,特殊场景的分模块管理等;如果做不到这些,系统将随业务的进展越来越冗余,最终将为如何“解耦”操碎心,“重构”往往就在这样的场景下被提出来,这其实是对系统和业务的具有伤害性的选择。
所以作为技术总监,必须要有大的视野去组织模块和架构,避免早期的设计缺陷造成痛苦不堪的晚期“重构”。
很多人对“工程管理能力”感到陌生,如果我把这块分开说为“性能”、“运维”和“效率”大家就好理解了。我们更多的认为工程管理能力关系到稳定性和效率上。小团队当中,工程管理能力往往价值体现不大,但当遇到一个大团队的时候,大团队的运转稳定性和效率就会成为突出问题。这里面主要包括持续性优化的能力和工具化使用的能力。并且需要较多的靠近流程管理和业务理解,有比较多的细小和琐碎事情。我见过很多技术管理者开发出身,但是晋升到管理者的岗位后,不得不去了解运维之类的事情。这些都属于工程管理能力的范畴。
很多技术人员都很厌恶管理工作,让一个常年跟没有脾气和情绪的机器打交道的技术人员,去应付心思千万的人员管理,听上去确实很有挑战。但你要知道,管理的目标是实现组织目标,最重要的是制定管理标准、贯彻执行和校验结果。而这些也并非非要管理者亲力亲为,我们在组织的构建中强调的搭班子,就可以安排一些在这方面擅长的人以“副总监”甚至是“项目经理”“助理”的职位存在。
我觉得一个技术总监要分出30%-40%的精力在团队的管理工作上,主要包括这些方面:
关于技术人员的KPI一直是一个千古难题,并且热度不减。难就难在技术人员工作的质量难以量化,并且受不可控因素的影响太多。我认为给技术人员的绩效指标达到两个目的即可,一个是量化可量化的东西,一个是鼓励他的积极性。
所谓量化可量化的东西,通常我们会认为是指在时间进度上量化或者bug数量、项目数量等;但其实也可以将能保证“质量”的因素模块化,分模块量化,当然这个要求比较高,因为所谓保证质量的模块,是需要技术总监确定至少是建议性,而不是丢给技术人员自行设置,比如设置必须要完成的单元测试指标、质量监控指标等。
很多人会问需不需要在技术人员的考核指标中设置业务指标,我认为在业务相对稳定的情况下是有一定可行性的,可以帮助技术人员更好的理解大团队的目标,知道在业务环节中技术价值的体现,更好的发挥主动能动性。
我认为组织结构设计更好的关乎团队的效率和能力发挥,包括岗位的增删减,扁平化结构还是梯度化结构,什么样的人安插在什么样的岗位上,这也是管理者应该懂得一门大课程。
而招聘上,我只想说,对于技术总监而言抓重点岗位,普通岗位的招聘可以由经理去进行,但不要小觑招聘,寻找团队平均能力以上的人是一个团队走的远的基础。
我比较在乎这点,就像我并不认为一个人的成长是顺其自然,我认为每个人的成长中都是受到重要的人和事的影响的。环境对于一个人的成长非常重要,要尽可能的去创造可持续成长的环境。包括:
1.code review,我认为有必要性;
2. 技术团队内部技术方案的评审,最好的学习往往源于把手里的工作做好;
3. 外部的学习和讲座,最怕坐井观天,最后被时代抛弃,不要抱着工作不放,要想象一下未来的世界和你的位置。
对于技术总监而言,除了处理部门内的事情,部门外的事情也需要一定的协调沟通,但是我并不建议多花时间在外部的会议和沟通上,更多的沟通是跟随项目走,由项目负责人去跟进和反馈即可。你只需要协调那些别人要不来的资源,当然你能要的来,大部分原因是因为你在公司的威信你曾给过别人的帮助。
很多公司会设立有项目经理的角色,这块就不怎么需要技术总监来操心;但反过来讲,每一位技术人员也都身兼项目经理的角色,而技术总监一定是最大的项目负责人。有关项目的事情会比较琐碎,但完全可以按照项目负责人分配下去,技术总监需要的是指定负责人、过问项目计划和进度,另外就是在项目推进遇到阻力的时候,去解决问题。主要包括这两方面:
第一,项目进度
1. 项目评审,确定项目计划;
2. 检查进度,进度延迟预警
3. 项目验收和总结
第二,资源协调
1. 人员协调,包括项目组人员以及编外人员的支持
2. IT设施协调,包括硬件、软件系统等,公司内资源还有公司外资源
有一种说法,领导就是要拿别人拿不到的资源,做别人做不了的决定,承担别人承担不了的责任。
但是,我想说技术管理者难度更胜一层,技术管理者是要先有专业性,再来领导力,是需要像医者一样的仁心仁术,而不是简单粗暴的工厂管理。
我也不认同很多人认为随着时间的增长,技术人终将成为技术管理者,否则何来的“中年危机”,不是时间的累积就能得到质的变化。我身边也有很多技术管理者经常感叹:“感觉自己做到技术总监就到头了,未来乏力。”只想说,从技术能力的成长,到复杂事物管理能力的成长,再到视野和决策能力的成长,这才是一个技术人员,从程序员到中层管理者(技术总监)再到高层管理者(CTO)的能力成长过程。
如果你觉得乏力,或许应该多出来看看,毕竟有些东西是靠钻研出来的,有些东西是靠多行路、多交流得出来的,比如情商和视野,见闻的东西多了就知道该如何处理了。
大型互联网架构演化
前言
一个成熟的大型网站(如淘宝、京东等)的系统架构并不是开始设计就具备完整的高性能、高可用、安全等特性,它总是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随业务扩展而完善出来的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝,要解决海量的商品信息的搜索、下单、支付,例如腾讯,要解决数亿的用户实时消息传输,百度它要处理海量的搜索请求,他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段可以广泛运行在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:

二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Memcached、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。

常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx是七层负载均衡和HAProxy支持四层、七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切换则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务不同来切换,如用户业务、商品业务相关的表放在不同的数据库中。

六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。
而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有没有缓存数据才会继续走应用服务器获取,也减少了获取数据的成本。反向代理有Squid,Nginx。

七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求。需要分布式的文件系统支撑。常用的分布式文件系统有NFS。

八、使用NoSql和搜索引擎
对于海量数据的查询,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb和redis,搜索引擎有lucene。

九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者同享数据库来实现。

十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。淘宝的Dubbo是一个不错的选择。

小结
大型网站的架构是根据业务需求不断完善的,根据不同的业务特征会做特定的设计和考虑,本文只是讲述一个常规大型网站会涉及的一些技术和手段。
{kind=link}
{kind=link}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
