【流程规范】规范文档:新人培养方法论
Mentor的作用
新人充满了求知欲和好奇心,学习和成长的过程中容易迷失自己,从一个萝卜坑掉进另外一个萝卜坑。导师 == 队长(跑得快,投的准,带领全队,执行战术)经理 == 教练 (跑不动,投不准,不下场,有经验,定战术,担责任)职责:
- 引路人,帮助新人快速熟悉环境、融入团队,并能在团队中找准定位,充分发挥新人的价值;
- 通常说,导师对新人的指导周期是入职到能够独立承担工作(自己就能指导要解决什么问题或者能够指导找谁解决问题);
- 导师对新人在学徒期的产出质量负责,新人的成长及贡献归功于导师;
Mentor的要求
|
能力项
|
要求
|
| 专业能力 |
|
| 正能量 |
|
| 沟通能力 |
|
| 耐心 |
|
工作指南
|
时间点
|
工作指南
|
目标
|
| 入职之前 |
|
了解新人背景,提前规划工作 |
|
入职当天
|
|
开发环境能跑起来
|
|
前两周
|
【明确目标】熟悉、学习为主,但是任务明确。新建jira task并明确每个task的目标
【日常辅导】每天在新人座位上关心1~2次进展及问题,有问题现场协助解决或者帮他找到能协助解决问题的人
【增进了解,协助融入】不定期的一起吃饭,闲聊等,了解日常生活状况,告知部门活动相关信息,输出公司愿景,部门价值观等
【每周review】每周有一次正式的 1:1 沟通,讨论上一个阶段目标的完成情况,成绩和不足,并提供提升建议,明确下一个阶段的预期目标。review内容。
|
掌握jira的工作流程及良好的工作习惯
掌握开发语言,了解开发框架
了解技术部的考勤、伯乐奖、部门活动、书架计划等各类制度
|
|
前一个月
|
从第三周开始,根据新人进展情况,每天的辅导频次可增加或减少
继续每周一次的 1:1 沟通
【月度review】请新人写一个正式的月度总结,并和他就总结内容进行一次月度的一对一沟通,全面回顾一个月的进展,成绩和不足
第四周和月度review一起进行。review内容。
|
掌握git工作流程及良好的工作习惯
掌握wiki的撰写方法并有wiki产出
熟悉开发语言,掌握开发框架
熟悉至少一个子系统并能修复bug,新增小feature
理解公司愿景,部门价值观
|
|
前三个月
|
从第二个月开始,根据新人进展情况,【每周review】频次可增加或减少
【月度review】月度review仍然继续
【季度review】这也是一次转正review。review内容。
|
熟悉开发框架
完全胜任一个子系统的功能增强和bug修复的工作
|
| 三个月后 | 两周review一次 | 能够独立承担负责一个系统 |
注意事项
|
注意项
|
内容
|
| 自信心 |
根据每个新人的技术基础、学习能力,安排任务难易,把握节奏;
自信心是逐步建立起来的,注意呵护,因材施教;
|
| 自驱力 |
注重培养新人自我驱动能力:
责任心培养;
端到端负责;
追求卓越;
质量意识;
主动思考;
|
| 沟通能力 |
需求沟通:和PM谈需求时,带上新人,过程中对一些点,问问新人有什么想法;
跨团队沟通:交给一些跨团队任务,
|
| 勇于试错 |
鼓励新人表达自己的方案,坚持自己的想法,用于尝试;
在导师可控情况下,“看着”新人踩坑;
但相似的坑,要求不要重复踩,要有总结;
实习期,把坑踩一遍;
|
| 总结分享 |
养成写wiki的习惯:
较大的功能模块,尽量写wiki,组内分享;
选一些技术点(java基础,mysql,sso,死锁,性能优化,搜索等)研究,技术wiki,格式要求,分享
|
| 人情味 |
团队建设
一起运动,桌面足球,羽毛球,跨组认识一些人;
每周团队聚餐,鼓励新人和团队成员交流;
|
| 1:1沟通 |
提纲准备(eg, 放手机里);
谈话正式;
表扬要具体,比如写了一个wiki;
明确待改善的地方;
|
| 导师总结 |
在实践过程中,导师也要不断总结,多和其他导师、leader沟通学习;
|
常见问题
新人常见问题:
|
编号
|
问题
|
入职时间
|
解决方法
|
备注
|
| 1 | 环境搭建吃力,常用工具(插件,登录脚本)不清楚,口口相传 | 1月内 | 新人导航,工具导航 | |
| 2 | 常用技术,资料,文档整理得还不太好 | 1月内 | 技术栈、知识体系 | |
| 3 | 部署框架,测试环境,hostname设置,遇到的坑 | 1月内 | 技术栈、环境搭建 | |
| 4 |
有的wiki比较老,更新不太及时,文档比较老
|
1月内 | 新人导航 | |
| 5 |
项目代码,老代码(dao,APIController)没有及时清理,学习成本大
|
1月内 | 代码学习 | |
| 6 |
陌生的技术体系和接踵而来的业务,如何适可而止的把技术面补上?
|
半年 |
技术栈、知识体系
时间管理
|
|
| 7 |
如何快速适应没有测试没有OP的开发流程?
|
半年 | 开发流程 | |
| 8 | 知识体系不健全,导航连接需完善? | 半年 | 技术栈、新人导航 | |
| 9 |
开发框架,系统学习指南,知识体系梳理
|
1年 | 技术栈、新人导航 | |
| 10 |
知识学习指南,更加具体一点:比如指定一本书,博客连接,wiki
|
1年 | 技术栈、新人导航 | |
| 11 |
工具:插件、mysql操作,怎么倒表?常用操作?怎么服务器?怎么查日志?gc查看?
|
1年 | 工具导航 | |
| 12 |
规范:开发规范、代码规范、上线规范、质量意识
|
1年 | 组内规范文档 | |
| 13 |
分享:分享知识,新技术,深度控制;听不懂,跟不上问题
|
1年 | 知识分享、1v1沟通 |
导师常见问题:
|
编号
|
问题
|
问题归类
|
解决方法
|
| 1 | 怎么做培养计划? | 培养计划 |
按照职级,目标驱动:例如,P4 -> P5
能力模型:技术能力,领导力,沟通能力,针对薄弱地方不强
|
| 2 |
发review周报的目的是什么?应该从哪些方面review?
|
review周报 | |
| 3 | 有时比较累,什么时候放手? | 节奏把控 |
比较费精力,规划好方案,新人只负责实施
|
| 4 |
这个人实在培养不出来,怎么办?
|
是不是只让他干脏活累活?期望太高?
分配工作的时候,应该给谁?
应该有目的,提升新人的某方面的能力?
|
|
| 5 | 新人不太“听话”? | 自己觉得重要的事,新人觉得不重要?(除了技术,业务沟通、梳理,方向调研,不太热衷) | |
| 6 |
如何让新员工在团队中感觉到成长?
|
培养计划 | |
| 7 |
如何让新员工跟上公司的节奏?
|
培养计划 | |
| 8 |
如何看待新员工代码质量不高的问题?
|
培养方法 |
时间成本和质量的平衡
|
| 9 |
如何引导新员工快速的融入团队?
|
培养方法 | 特指工作之外的生活 |
| 10 |
知识学习体系,不太明晰,培养比较随意
|
培养计划 | |
| 11 |
零基础同学,学习路线怎么规划?
|
培养计划 | 边学边练,给压力要结果,循序渐进 |
| 12 |
wiki及时维护,使用流畅
|
新人导航 | |
| 13 |
业务知识,业务流程,业务词典,梳理问题
|
新人导航 | |
| 14 |
技术氛围和技术提升问题,怎么能让带的同学找到方向,有计划,并且有产出?
|
培养计划 | |
| 15 |
新人容易被业务拖着而缺乏积累的时间,时间怎么分配?
|
培养方法 |
问题解决办法:
【流程规范】规范文档:项目整体开发流程
流程

约定
|
序号
|
环节
|
负责人
|
参与人
|
约定
|
注意点
|
|
| 1 | 初审 | PM | RD+QA,可选参加 | 产品内需达成一致 | ||
| 2 | 复审 | PM | RD+QA | 评审->发现问题->修改->再评审 | ||
| 3 | 终审 | PM | RD+QA |
1)到达终审的前提是各方已经就需求达成一致
2)终审如果还存在需求问题则继续复审
3)终审后不再接受需求变更
4)RD需要确认设计评审时间(尽量控制在T+5之内)。
|
1)需求中需要包括demo
|
|
| 4 | 设计评审 | RD | PM+QA |
1)终审后T+3之内提供项目详细计划(包括测试计划)。
2)评审之前需要和各相关方线下达成一致。
3)设计评审时如出现重大问题则打回重审。
4)需产出设计文档、项目计划,项目相关文档沉淀在项目各个子模块中。
|
1)计划制定时需要注意考虑风险点和buffer
|
|
| 5 | 开发 | RD | PM+QA,协助 |
1)后台技术选型:http、mtthrift、medis、mysql
2)FE和后台交互方式:前端所有页面集中在一个工程中,后台所有服务通过API接口提供数据。
3)所有DAO层使用生成工具生成。
4)单元测试精力集中在service层,初期各模块负责人定义好需要单元测试的service范围。
5)项目初期定义交叉review分组,每周两次进行交叉review。
|
1)监控优先级放低 | |
| 6 | 联调 | RD | PM+QA,协助 |
1)接口需要在设计阶段定义好。
2)接口假数据由调用方自行组织。
3)接口提供方需要先进行接口的自测。
|
1)联调计划安排需要考虑各方进度情况。 | |
| 7 | 测试用例 | QA | PM+RD,协助 |
1)确认冒烟点
2)测试用例完成后需要安排用例review(PM必选,RD可选)
3)PM同学给QA开好测试task,以方便后面记录测试bug
|
||
| 8 | 测试 | QA | PM+RD |
1)提交测试之前保证冒烟点功能通过
2)提交测试之前需要完成codereview、静态代码检查
3)提测需要发送提测邮件
4)模块完成后QA即可介入测试
5)设计同学验收样式设计是否符合预期,PM和QA一起进行功能测试
6)测试完成后QA回复提测邮件,周知测试完成
|
1)压力测试优先级放低
2)确认浏览器支持情况
|
|
| 8 | 上线 | RD | PM+QA |
1)线上服务器统一收集需求统一申请
2)需要确保QA验收通过
3)上线前需要有上线计划和回滚计划
|
【开发规范】规范文档:API设计规范
负责API接近多年了,这些年中发现现有的API存在的问题越来越多,但很多API一旦发布后就不再能修改了,即时升级和维护是必须的。一旦API发生变化,就可能对相关的调用者带来巨大的代价,用户需要排查所有调用的代码,需要调整所有与之相关的部分,这些工作对他们来说都是额外的。如果辛辛苦苦完成这些以后,还发现了相关的bug,那对用户的打击就更大。如果API经常发生变化,用户就会失去对提供方失去信心,从而也会影响目前的业务。
但是我们为什么还要修改API呢?为了API看起来更加漂亮?为了提供更多功能?为了提供更好的性能?还是仅仅觉得到了改变了时候了?对于用户来说,他们更愿意使用一个稳定但是看起来不那么时髦的API,这并不意味着我们不再改进API了。当糟糕的API带来的维护成本越来越大时,我想就是我们去重构它的时候。
如果可以回头重新再做一遍,那么我心目中的优秀的API应该是怎么样的?
判断一个API是否优秀,并不是简单地根据第一个版本给出判断的,而是要看随着时间的推移,该API是否还能存在,是否仍旧保持得不错。槽糕的API接口各种各样,但是好的API接口对于用户来说必须满足以下几个点:
- 易学习:有完善的文档及提供尽可能多的示例和可copy-paste的代码,像其他设计工作一样,你应该应用最小惊讶原则。
- 易使用:没有复杂的程序、复杂的细节,易于学习;灵活的API允许按字段排序、可自定义分页、 排序和筛选等。一个完整的API意味着被期望的功能都包含在内。
- 难误用:对详细的错误提示,有些经验的用户可以直接使用API而不需要阅读文档。
而对于开发人员来说,要求又是不一样的:
- 易阅读:代码的编写只需要一次一次,但是当调试或者修改的时候都需要对代码进行阅读。
- 易开发:个最小化的接口是使用尽可能少的类以及尽可能少的类成员。这样使得理解、记忆、调试以及改变API更容易。
如何做到以上几点,以下是一些总结:
1、 面向用例设计
如果一个API被广泛使用了,那么就不可能了解所有使用该API的用户。如果设计者希望能够设计出被广泛使用的API,那么必须站在用户的角度来理解如何设计API库,以及如何才能设计出这样的API库。
2、 采用良好的设计思路
在设计过程中,如果能按照下面的方式来进行设计,会让这个API生命更长久
- 面向用例的设计,收集用户建议,把自己模拟成用户,保证API设计的易用和合理
- 保证后续的需求可以通过扩展的形式完成
- 第一版做尽量少的内容,由于新需求可以通过扩展的形式完成,因此尽量少做事情是抑制API设计错误的一个有效方案
- 对外提供清晰的API和文档规范,避免用户错误的使用API,尤其是避免API(见第一节)靠后级别的API被用户知晓与误用
除此之外,下面还列出了一些具体的设计方法:
- 方法优于属性
- 工厂方法优于构造函数
- 避免过多继承
- 避免由于优化或者复用代码影响API
- 面向接口编程
- 扩展参数应当是便利的
- 对组件进行合理定位,确定暴露多少接口
- 提供扩展点
3、 避免极端的意见
在设计API的时候,一定要避免任何极端的意见,尤其是以下几点:
- 必须漂亮(API不一定需要漂亮)
- API必须被正确地使用(用户很难理解如何正确的使用API,API的设计者要充分考虑API被误用的情况:如果一个API可能会被误用,那么它一定会被误用)
- 必须简单(我们总会面临复杂的需求,能两者兼顾的API是更好的API)
- 必须高性能(性能可以通过其他手段优化,不应该影响API的设计)
- 必须绝对兼容(尽管本文一直提到如何保证兼容,但是我们仍然要意识到,一些极少情况下会遇到的不兼容是可以容忍的)
4、 有效的API评审
API设计完成以后,需要经过周密的设计评审,评审的重点如下:
- 用例驱动,评审前必须提供完善的使用用例,确保用例的合理性和完备性。
- 一致性,是否与系统中其他模块的接口风格一致,是否与对称接口的设计一致。
- 简单明了,API应该简单好理解,容易学习和使用的API才不容易被误用,给我们带来更多的麻烦。
- API尽可能少,如果一个API可以暴露也可以不暴露,那么就不要暴露他,等到用户真正有需求的时候再将它成为一个公开接口也不迟。
- 支持持续改进,API是否能够方便地通过扩展的方式增加功能和优化。
5、 提高API的可测试性
API需要是可测试的,测试不应依赖实现,测试充分的API,尤其是经过了严格的“兼容性整合测试”的API,更能保证在升级的过程中不出现兼容性问题。兼容性整合测试,是指一组测试用例集合,这组测试用例会站在使用者的立场上使用API。在API升级以后,再检测这组测试用例是否能完全符合预期的通过测试,尽可能的发现兼容性问题。
6、 保证API的向后兼容
对于每一个API的设计者来说,都渴望做到“向后兼容”,因为不管是现在的API用户,还是潜在的API用户,都只信任那些可兼容的API。但向后兼容有多个层次上的意义,而且不同层次的向后兼容,也意味着不同的重要性和复杂度。
7、 保持逐步改善
过去我们总希望能将现有的“不合理”的设计完全推翻,然后按照现在“美好”的思路,重新设计这个API,但是在一段时间以后,又会碰到一样的状况,需要再推翻一次。 如果我们没有有效的逐步改善的办法,依靠推翻现有设计,重新设计API只能让我们回到起点,然后重现之前的过程。 要有一套行之有效的持续改善的办法来在API兼容的同时,改善API使之更好。
8、 把握API的生命周期
每一个API都是有生命周期的,我们需要让API的生命周期更长,并且在API的生命周期结束时能让其平滑的消亡。
- 告诉用户我们是如何设计的,避免误用,提供指导,错误的使用往往是缩短API寿命的一大杀手
- 提供试用期,API不可能一开始就是稳定,经过试用的API才能有更强的生命力
- 为API分级:内部使用;二次开发使用;开发或试用中;稳定;弃用API。避免API被滥用的同时,我们可以通过调整API的级别,来扩大其影响力,也能更优雅的结束一个API的生命周期。
开发API的过程其实就是一个沟通交流的过程。沟通的双方就是API用户和API设计者。
9、 一些具体的实施方案
在一个API不可避免要消亡或者改变的时候,我们应该接受并且面对这个事实,下面列举了几种保证兼容性的前提下,对API进行调整的办法:
- 将API标记为弃用,重新建立一个新的API。如果一个API不可避免要被消亡,这是唯一的办法。
- 为其添加额外的参数或者参数选项来实现功能添加
- 将现有API拆成两部分,提供一个精简的核心API,过去的API通过封装核心API上实现。这通常用于解决用户需要一个代码精简的版本时。
- 在现有的API基础上进行封装,提供一个功能更丰富的包或者类
一些好的API示例:
- Flickr API,这里是文档的示例,同时提供了一个非常方便的API测试工具。
- Mediawiki API
- Ebay API,这里有一个非常详尽的文档示例。
接口作为连通客户端与数据库进行数据流通的桥梁,起着举足轻重的作用,直接影响着程序的效率性、稳定性、可靠性以及数据的正确性、完整性。客户端注重的是界面美观,操作方便顺畅,是用户最直接的感受体验,而接口则是所有数据的提供者,是用户深层的内涵体验。
因次,设计接口在一个项目中,是非常重要的。那么我就目前的经验总结下如何合理设计接口。
一、 设计原理
1. 深入了解需求
除了设计数据库的人最了解需求外,其次就是设计接口的人了,甚至有时接口开发人员还要参与到数据库设计中。从“客户端-接口-数据库”的层次上看,接口明显扮演着承上启下的角色,一方面要明白接口要什么数据,另一方面要考虑如何从数据库获取、组织数据。所以如果不了解需求,你就无法正确抽象对象来组织数据给客户端,也无法验证数据库的数据结构能否满足需求。数据库设计者要了解需求中的数据结构,而接口则更多的要了解需求中的逻辑结构以及由此衍生出的逻辑数据结构。
2. 了解数据库结构
既然接口要明白如何从数据库获取、组织数据,就当然要了解数据库结构啦。
3. 了解客户端原型
了解原型,其实更多是为了帮助你设计接口时需要提供的数据和结构。但有时当你设计时并没有原型,所以此条并不是必须要求的。但假如设计完接口后原型出来了,我们也可以拿原型还验证接口设计是否正确、合理。
二、设计原则
1. 充分理由
不是随便一个功能就要有个接口,也不是随便一个需求就要加个接口。每新建一个接口,就要有充分的理由和考虑,即这个接口的存在是十分有意义额价值的,无意义的接口不仅增加了维护的难度,更重要是对于程序的可控性的大大降低,接口也会十分臃肿。因此我放在了第一条。
2. 职责明确
一个接口只负责一个业务功能,它与设计模式里的职责单一原则类似但却不同,因为一个业务功能里可能会包含多个操作,比如查询会员,可能除了查询会员表外还要获取该会员的其他必要信息,但不要在查询会员的同时还有修改权限等类似的其他业务功能,应该分成两个接口还做。
3. 高内聚低耦合
一个接口要包含完整的业务功能,而不同接口之间的业务关联要尽可能的小。还是查询会员的例子,有时查询会员的同时,可能该会员的相关信息要随之发生变化(如状态),如果这时一条完整的业务流水线,那么就应该在一个接口里完成,而不应再单独设立接口去操作完成。就是说一个接口不应该随着另一个变化而变化或以某几个接口为前提而存在。
4. 分析角度明确
设计接口分析的角度要统一明确。否则会造成接口结构的混乱。例如,不要一会以角色的角度设计,一会儿就要以功能的角度设计。
5. 入参格式统一
所有接口的参数格式要求及风格要统一,不要一个接口参数是逗号分隔,另一个就是数组;不要一个接口日期参数是x年x月x日风格,另一个就是x-x-x。
6. 状态及消息
提供必要的接口调用状态信息。调用是否成功?如果失败,那么失败的原因是什么。这些必要的信息必须要告诉给客户端。
7. 控制数据量
一个接口返回不应该包含过多的数据量,过多的数据量不仅处理复杂,对数据传输的压力也非常大,会导致客户端反应缓慢。过多的数据量很多时候都是接口划分不明确。
8. 禁止随意拓展参数
与第1条类似,只不过是针对参数而言了。日后拓展接口可能是难以避免的,但是不要随意就加参数,加参数一定是必要且有意义的,需求改变前首先应考虑现有接口内部维护是否能满足需求,而不要通过加个参数来方便自己实现需求的难度,因为参数的更变会直接导致客户端调用的变化,容易产生版本兼容性问题。
三、设计方法
1. 抽象业务
相比抽象对象而言,抽象业务更宏观,我觉得相对也容易一些,但抽象尺度往往不太好把握。
2. 数据格式
接口定义的数据格式必须都经过充分考虑,否则会出现数据转换失败或超出长度等错误。如果无法确定,直接设置成字符串是最合适的。
3. 有意义的命名
无论是接口还是参数,名称都应该是有意义的,让人能看明白的。
总之,接口设计是一个细致的工作,设计时也会有很多矛盾,但个人倾向于粗粒度设计方向(即内聚性更高一些),这样不仅给客户端浏览接口方便明确,维护也轻松些,这么做的缺点就是某一接口扩展时不是很灵活,但可以通过重新定义一个接口来弥补,但正如上所说,新增接口还是要三思而后行的。以上很多虽然都是理论性讲解,但牢牢记住这些,并结合实际工作,就会慢慢深刻的体会到其中的含义。即理论指导实践,实践来验证理论。
【开发规范】规范文档:MySQL规范
- 基本规范
- 命名规范
- 库表设计规范
- 索引设计规范
- 字段设计规范
- SQL设计规范
- 行为规范
- 线上操作
- 数据变更
基本规范
命名规范
库表设计规范
索引设计规范
字段设计规范
SQL设计规范
- select id from t limit 10000, 10; => select id from t where id > 10000 limit 10;
行为规范
Token 认证的来龙去脉
为什么要用 Token?
而要回答这个问题很简单——因为它能解决问题! 可以解决哪些问题呢?
- Token 完全由应用管理,所以它可以避开同源策略
- Token 可以避免 CSRF 攻击
- Token 可以是无状态的,可以在多个服务间共享
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位。如果这个 Token 在服务端持久化(比如存入数据库),那它就是一个永久的身份令牌。 于是,又一个问题产生了:需要为 Token 设置有效期吗?
需要设置有效期吗?
对于这个问题,我们不妨先看两个例子。一个例子是登录密码,一般要求定期改变密码,以防止泄漏,所以密码是有有效期的;另一个例子是安全证书。SSL 安全证书都有有效期,目的是为了解决吊销的问题,对于这个问题的详细情况,来看看知乎的回答。所以无论是从安全的角度考虑,还是从吊销的角度考虑,Token 都需要设有效期。 那么有效期多长合适呢? 只能说,根据系统的安全需要,尽可能的短,但也不能短得离谱——想像一下手机的自动熄屏时间,如果设置为 10 秒钟无操作自动熄屏,再次点亮需要输入密码,会不会疯?如果你觉得不会,那就亲自试一试,设置成可以设置的最短时间,坚持一周就好(不排除有人适应这个时间,毕竟手机厂商也是有用户体验研究的)。 然后新问题产生了,如果用户在正常操作的过程中,Token 过期失效了,要求用户重新登录……用户体验岂不是很糟糕? 为了解决在操作过程不能让用户感到 Token 失效这个问题,有一种方案是在服务器端保存 Token 状态,用户每次操作都会自动刷新(推迟) Token 的过期时间——Session 就是采用这种策略来保持用户登录状态的。然而仍然存在这样一个问题,在前后端分离、单页 App 这些情况下,每秒种可能发起很多次请求,每次都去刷新过期时间会产生非常大的代价。如果 Token 的过期时间被持久化到数据库或文件,代价就更大了。所以通常为了提升效率,减少消耗,会把 Token 的过期时保存在缓存或者内存中。 还有另一种方案,使用 Refresh Token,它可以避免频繁的读写操作。这种方案中,服务端不需要刷新 Token 的过期时间,一旦 Token 过期,就反馈给前端,前端使用 Refresh Token 申请一个全新 Token 继续使用。这种方案中,服务端只需要在客户端请求更新 Token 的时候对 Refresh Token 的有效性进行一次检查,大大减少了更新有效期的操作,也就避免了频繁读写。当然 Refresh Token 也是有有效期的,但是这个有效期就可以长一点了,比如,以天为单位的时间。
时序图表示
使用 Token 和 Refresh Token 的时序图如下:
1)登录

2)业务请求

3)Token 过期,刷新 Token
 上面的时序图中并未提到 Refresh Token 过期怎么办。不过很显然,Refresh Token 既然已经过期,就该要求用户重新登录了。 当然还可以把这个机制设计得更复杂一些,比如,Refresh Token 每次使用的时候,都更新它的过期时间,直到与它的创建时间相比,已经超过了非常长的一段时间(比如三个月),这等于是在相当长一段时间内允许 Refresh Token 自动续期。 到目前为止,Token 都是有状态的,即在服务端需要保存并记录相关属性。那说好的无状态呢,怎么实现?
上面的时序图中并未提到 Refresh Token 过期怎么办。不过很显然,Refresh Token 既然已经过期,就该要求用户重新登录了。 当然还可以把这个机制设计得更复杂一些,比如,Refresh Token 每次使用的时候,都更新它的过期时间,直到与它的创建时间相比,已经超过了非常长的一段时间(比如三个月),这等于是在相当长一段时间内允许 Refresh Token 自动续期。 到目前为止,Token 都是有状态的,即在服务端需要保存并记录相关属性。那说好的无状态呢,怎么实现?
无状态 Token
如果我们把所有状态信息都附加在 Token 上,服务器就可以不保存。但是服务端仍然需要认证 Token 有效。不过只要服务端能确认是自己签发的 Token,而且其信息未被改动过,那就可以认为 Token 有效——“签名”可以作此保证。平时常说的签名都存在一方签发,另一方验证的情况,所以要使用非对称加密算法。但是在这里,签发和验证都是同一方,所以对称加密算法就能达到要求,而对称算法比非对称算法要快得多(可达数十倍差距)。更进一步思考,对称加密算法除了加密,还带有还原加密内容的功能,而这一功能在对 Token 签名时并无必要——既然不需要解密,摘要(散列)算法就会更快。可以指定密码的散列算法,自然是 HMAC。 上面说了这么多,还需要自己去实现吗?不用!JWT 已经定义了详细的规范,而且有各种语言的若干实现。 不过在使用无状态 Token 的时候在服务端会有一些变化,服务端虽然不保存有效的 Token 了,却需要保存未到期却已注销的 Token。如果一个 Token 未到期就被用户主动注销,那么服务器需要保存这个被注销的 Token,以便下次收到使用这个仍在有效期内的 Token 时判其无效。有没有感到一点沮丧? 在前端可控的情况下(比如前端和服务端在同一个项目组内),可以协商:前端一但注销成功,就丢掉本地保存(比如保存在内存、LocalStorage 等)的 Token 和 Refresh Token。基于这样的约定,服务器就可以假设收到的 Token 一定是没注销的(因为注销之后前端就不会再使用了)。 如果前端不可控的情况,仍然可以进行上面的假设,但是这种情况下,需要尽量缩短 Token 的有效期,而且必须在用户主动注销的情况下让 Refresh Token 无效。这个操作存在一定的安全漏洞,因为用户会认为已经注销了,实际上在较短的一段时间内并没有注销。如果应用设计中,这点漏洞并不会造成什么损失,那采用这种策略就是可行的。 在使用无状态 Token 的时候,有两点需要注意:
- Refresh Token 有效时间较长,所以它应该在服务器端有状态,以增强安全性,确保用户注销时可控
- 应该考虑使用二次认证来增强敏感操作的安全性
到此,关于 Token 的话题似乎差不多了——然而并没有,上面说的只是认证服务和业务服务集成在一起的情况,如果是分离的情况呢?
分离认证服务
当 Token 无状态之后,单点登录就变得容易了。前端拿到一个有效的 Token,它就可以在任何同一体系的服务上认证通过——只要它们使用同样的密钥和算法来认证 Token 的有效性。就样这样:  当然,如果 Token 过期了,前端仍然需要去认证服务更新 Token:
当然,如果 Token 过期了,前端仍然需要去认证服务更新 Token:  可见,虽然认证和业务分离了,实际即并没产生多大的差异。当然,这是建立在认证服务器信任业务服务器的前提下,因为认证服务器产生 Token 的密钥和业务服务器认证 Token 的密钥和算法相同。换句话说,业务服务器同样可以创建有效的 Token。 如果业务服务器不能被信任,该怎么办?
可见,虽然认证和业务分离了,实际即并没产生多大的差异。当然,这是建立在认证服务器信任业务服务器的前提下,因为认证服务器产生 Token 的密钥和业务服务器认证 Token 的密钥和算法相同。换句话说,业务服务器同样可以创建有效的 Token。 如果业务服务器不能被信任,该怎么办?
不受信的业务服务器
遇到不受信的业务服务器时,很容易想到的办法是使用不同的密钥。认证服务器使用密钥1签发,业务服务器使用密钥2验证——这是典型非对称加密签名的应用场景。认证服务器自己使用私钥对 Token 签名,公开公钥。信任这个认证服务器的业务服务器保存公钥,用于验证签名。幸好,JWT 不仅可以使用 HMAC 签名,也可以使用 RSA(一种非对称加密算法)签名。 不过,当业务服务器已经不受信任的时候,多个业务服务器之间使用相同的 Token 对用户来说是不安全的。因为任何一个服务器拿到 Token 都可以仿冒用户去另一个服务器处理业务……悲剧随时可能发生。 为了防止这种情况发生,就需要在认证服务器产生 Token 的时候,把使用该 Token 的业务服务器的信息记录在 Token 中,这样当另一个业务服务器拿到这个 Token 的时候,发现它并不是自己应该验证的 Token,就可以直接拒绝。 现在,认证服务器不信任业务服务器,业务服务器相互也不信任,但前端是信任这些服务器的——如果前端不信任,就不会拿 Token 去请求验证。那么为什么会信任?可能是因为这些是同一家公司或者同一个项目中提供的若干服务构成的服务体系。 但是,前端信任不代表用户信任。如果 Token 不没有携带用户隐私(比如姓名),那么用户不会关心信任问题。但如果 Token 含有用户隐私的时候,用户得关心信任问题了。这时候认证服务就不得不再啰嗦一些,当用户请求 Token 的时候,问上一句,你真的要授权给某某某业务服务吗?而这个“某某某”,用户怎么知道它是不是真的“某某某”呢?用户当然不知道,甚至认证服务也不知道,因为公钥已经公开了,任何一个业务都可以声明自己是“某某某”。 为了得到用户的信任,认证服务就不得不帮助用户来甄别业务服务。所以,认证服器决定不公开公钥,而是要求业务服务先申请注册并通过审核。只有通过审核的业务服务器才能得到认证服务为它创建的,仅供它使用的公钥。如果该业务服务泄漏公钥带来风险,由该业务服务自行承担。现在认证服务可以清楚的告诉用户,“某某某”服务是什么了。如果用户还是不够信任,认证服务甚至可以问,某某某业务服务需要请求 A、B、C 三项个人数据,其中 A 是必须的,不然它不工作,是否允许授权?如果你授权,我就把你授权的几项数据加密放在 Token 中…… 废话了这么多,有没有似曾相识……对了,这类似开放式 API 的认证过程。开发式 API 多采用 OAuth 认证,而关于 OAuth 的探讨资源非常丰富,这里就不深究了。
如何处理好前后端分离的 API 问题
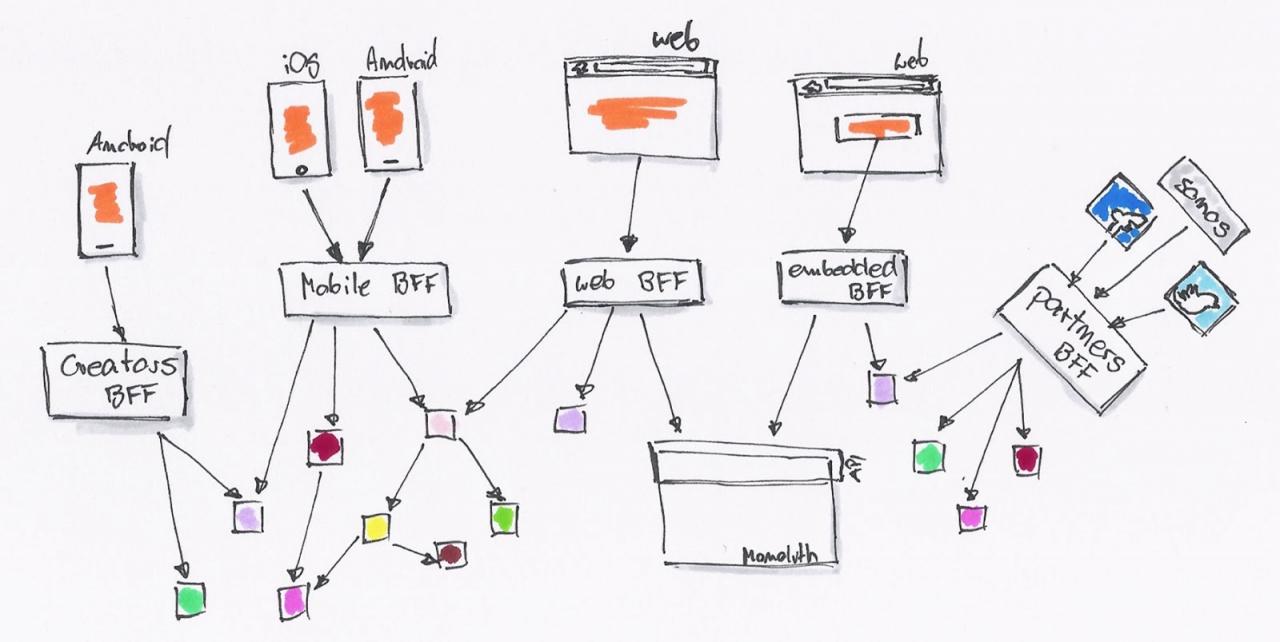
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
作为一个程序员,我讨厌那些没有文档的库。我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。
因为交付周期的原因,接入了一个第三方的库,遇到了这么一些问题:文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
对于一个库来说,文档是多种多样的:一份 demo、一个入门指南、一个 API 列表,还有一个测试。如果一个 API 有测试,那么它也相当于有一份简单的文档了——如果我们可以看到测试代码的话。而当一个库没有文档的时候,它也不会有测试。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
- API 的字段更新了
- API 的路由更新了
- API 返回了未预期的值
- API 返回由于某种原因被删除了
- 。。。
API 的维护是一件烦人的事,所以最好能一次设计好 API。可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护。
前后端分离 API 的演进史
刚毕业的时候,工作的主要内容是用 Java 写网站后台,业余写写自己喜欢的前端代码。慢慢的,随着各个公司的 Mobile First 战略的实施,项目上的主要语言变成了 JavaScript。项目开始实施了前后端分离,团队也变成了全功能团队,前端、后台、DevOps 变成了每个人需要提高的技能。于是如我们所见,当我们完成一个任务卡的时候,我们需要自己完成后台 API,还要编写相应的前端代码。
尽管当时的手机浏览器性能,已经有相当大的改善,但是仍然会存在明显的卡顿。因此,我们在设计的时候,尽可能地便将逻辑移到了后台,以减少对于前端带来的压力。可性能问题在今天看来,差异已经没有那么明显了。
如同我在《RePractise:前端演进史》中所说,前端领域及 Mobile First 的变化,引起了后台及 API 架构的一系列演进。
最初的时候,我们只有一个网站,没有 REST API。后台直接提供 Model 数据给前端模板,模板处理完后就展示了相关的数据。
当我们开始需要 API 的时候,我们就会采用最简单、直接的方式,直接在原有的系统里开一个 API 接口出来。
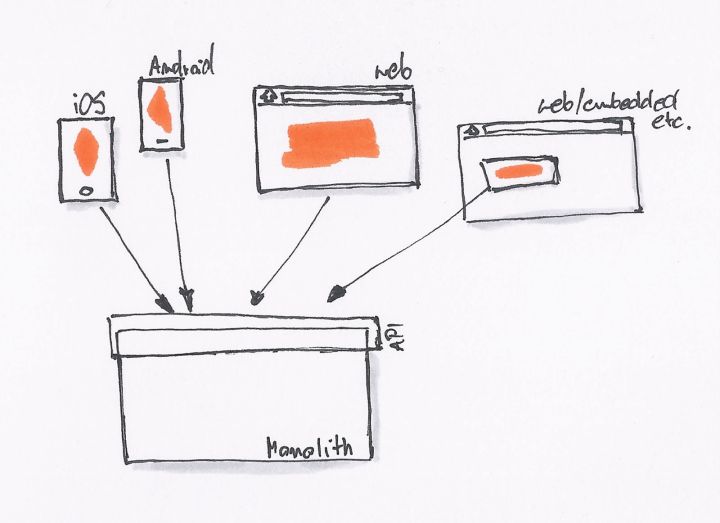
为了不破坏现有系统的架构,同时为了更快的上线,直接开出一个接口来得最为直接。我们一直在这样的模式下工作,直到有一天我们就会发现,我们遇到了一些问题:
- API 消费者:一个接口无法同时满足不同场景的业务。如移动应用,可能与桌面、手机 Web 的需求不一样,导致接口存在差异。
- API 生产者:对接多个不同的 API 需求,产生了各种各样的问题。
于是,这时候就需要 BFF(backend for frontend)这种架构。后台可以提供所有的 MODEL 给这一层接口,而 API 消费者则可以按自己的需要去封装。

API 消费者可以继续使用 JavaScript 去编写 API 适配器。后台则慢慢的因为需要,拆解成一系列的微服务。
系统由内部的类调用,拆解为基于 RESTful API 的调用。后台 API 生产者与前端 API 消费者,已经区分不出谁才是真正的开发者。
瀑布式开发的 API 设计
说实话,API 开发这种活就和传统的瀑布开发差不多:未知的前期设计,痛苦的后期集成。好在,每次这种设计的周期都比较短。
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
- 维护 API 文档很痛苦
- 需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以一个根据代码文件中中注释信息,生成应用程序或库、模块的API文档的工具。
同样的对于 API 来说,也可以采取类似的步骤,如 Swagger。它是基于 YAML语法定义 RESTful API,如:
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
schemes:
- https
host: simple.api
basePath: /openapi101
paths: {}
它会自动生成一篇排版优美的API文档,与此同时还能生成一个供前端人员使用的 Mock Server。同时,它还能支持根据 Swagger API Spec 生成客户端和服务端的代码。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
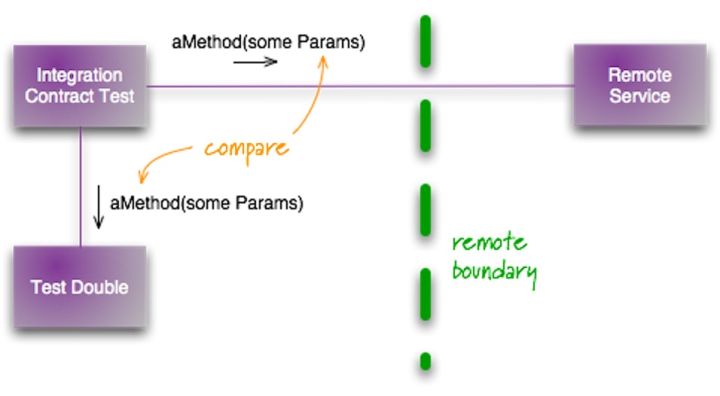
其步骤如下:
- 编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
- 根据契约编写 Mock Server。可以彩 Moco
- 编写集成测试将请求发给这个 Mock Server,并验证
如下是我们项目使用的 Moco 生成的契约,再通过 Moscow 来进行 API 测试。
[
{
"description": "should_response_text_foo",
"request": {
"method": "GET",
"uri": "/property"
},
"response": {
"status": 401,
"json": {
"message": "Full authentication is required to access this resource"
}
}
}
]
只需要在相应的测试代码里请求资源,并验证返回结果即可。
而对于前端来说,则是依赖于 UI 自动化测试。在测试的时候,启动这个 Mock Server,并借助于 Selenium 来访问浏览器相应的地址,模拟用户的行为进行操作,并验证相应的数据是否正确。

当契约发生发动的时候,持续集成便失败了。因此相应的后台测试数据也需要做相应的修改,相应的前端集成测试也需要做相应的修改。因此,这一改动就可以即时地通知各方了。
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:

这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
我们需要处理同的异常数据,不同情况下的返回值等等。因此,我之前尝试开发 DDM 来解决这样的问题,只是轮子没有造完。诸如 Redux 可以管理状态,还应该有个相应的类型检测及 Adapter 工具。
除此,还有一种情况是使用第三方 API,也需要这样的适配层。很多时候,我们需要的第三方 API 以公告的形式来通知各方,可往往我们不会及时地根据这些变化。

一般来说这种工作是后台去做代码的,不得已由前端来实现时,也需要加一层相应的适配层。
小结
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
透明代理、匿名代理、混淆代理、高匿代理区别?
这4种代理,主要是在代理服务器端的配置不同,导致其向目标地址发送请求时,REMOTE_ADDR, HTTP_VIA,HTTP_X_FORWARDED_FOR三个变量不同。
1、透明代理(Transparent Proxy)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = Proxy IP
- HTTP_X_FORWARDED_FOR = Your IP
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
2、匿名代理(Anonymous Proxy)
- REMOTE_ADDR = proxy IP
- HTTP_VIA = proxy IP
- HTTP_X_FORWARDED_FOR = proxy IP
匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
还有一种比纯匿名代理更先进一点的:混淆代理,见下节。
3、混淆代理(Distorting Proxies)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = Proxy IP
- HTTP_X_FORWARDED_FOR = Random IP address
如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真:-)
4、高匿代理(Elite proxy或High Anonymity Proxy)
- REMOTE_ADDR = Proxy IP
- HTTP_VIA = not determined
- HTTP_X_FORWARDED_FOR = not determined
可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
LBS查询某经纬度范围内的数据性能优化
在实际的使用中,不太可能会发生需要计算该用户与所有其他用户的距离,然后再排序的情况,当用户数量达到一个级别时,
就可以在一个较小的范围里进行搜索,而非在所有用户中进行搜索.
所以对于这个例子,我增加了4个where条件,只对于经度和纬度大于或小于该用户1度(111公里)范围内的用户进行距离计算,同时对数据表中的经度和纬度两个列增加了索引来优化where语句执行时的速度.
最终的sql语句如下
$sql='select * from users_location where
latitude > '.$lat.'-1 and
latitude < '.$lat.'+1 and
longitude > '.$lon.'-1 and
longitude < '.$lon.'+1
order by ACOS(SIN(('.$lat.' * 3.1415) / 180 ) *SIN((latitude * 3.1415) / 180 ) +COS(('.$lat.' * 3.1415) / 180 ) * COS((latitude * 3.1415) / 180 ) *COS(('.$lon.'* 3.1415) / 180 - (longitude * 3.1415) / 180 ) ) * 6380 asc limit 10';
经过优化的sql大大提高了运行速度,在某些情况下甚至有100倍的提升.这种从业务角度出发,缩小sql查询范围的方法也可以适用在其他地方.
正确的计算距离公式是这样的:
public static double getDistance(double lat1, double lon1, double lat2, double lon2){
double radLat1 = lat1 * Math.PI / 180;
double radLat2 = lat2 * Math.PI / 180;
double a = radLat1 - radLat2;
double b = lon1 * Math.PI / 180 - lon2 * Math.PI / 180;
double s = 2 * Math.asin(Math.sqrt(Math.pow(Math.sin(a / 2), 2) + Math.cos(radLat1) * Math.cos(radLat2)* Math.pow(Math.sin(b / 2), 2)));
s = s * 6378137.0;// 取WGS84标准参考椭球中的地球长半径(单位:m)
s = Math.round(s * 10000) / 10000;
return s;
}
Tutorial: Creating a Simple REST API
Tutorial: Creating a Simple REST API
In this tutorial, we will explain how to create a simple application that provides a RESTful API using the different HTTP methods:
GETto retrieve and search dataPOSTto add dataPUTto update dataDELETEto delete data
Defining the API
The API consists of the following methods:
| Method | URL | Action |
|---|---|---|
GET |
/api/robots | Retrieves all robots |
GET |
/api/robots/search/Astro | Searches for robots with 'Astro' in their name |
GET |
/api/robots/2 | Retrieves robots based on primary key |
POST |
/api/robots | Adds a new robot |
PUT |
/api/robots/2 | Updates robots based on primary key |
DELETE |
/api/robots/2 | Deletes robots based on primary key |
Creating the Application
As the application is so simple, we will not implement any full MVC environment to develop it. In this case, we will use a micro application to meet our goal.
The following file structure is more than enough:
my-rest-api/
models/
Robots.php
index.php
.htaccessFirst, we need a .htaccess file that contains all the rules to rewrite the request URIs to the index.php file (application entry-point):
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^((?s).*)$ index.php?_url=/$1 [QSA,L]
</IfModule>The bulk of our code will be placed in index.php. The file is created as follows:
<?php
use Phalcon\Mvc\Micro;
$app = new Micro();
// Define the routes here
$app->handle();Now we will create the routes as we defined above:
<?php
use Phalcon\Mvc\Micro;
$app = new Micro();
// Retrieves all robots
$app->get(
'/api/robots',
function () {
// Operation to fetch all the robots
}
);
// Searches for robots with $name in their name
$app->get(
'/api/robots/search/{name}',
function ($name) {
// Operation to fetch robot with name $name
}
);
// Retrieves robots based on primary key
$app->get(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to fetch robot with id $id
}
);
// Adds a new robot
$app->post(
'/api/robots',
function () {
// Operation to create a fresh robot
}
);
// Updates robots based on primary key
$app->put(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to update a robot with id $id
}
);
// Deletes robots based on primary key
$app->delete(
'/api/robots/{id:[0-9]+}',
function ($id) {
// Operation to delete the robot with id $id
}
);
$app->handle();Each route is defined with a method with the same name as the HTTP method, as first parameter we pass a route pattern, followed by a handler. In this case, the handler is an anonymous function. The following route: /api/robots/{id:[0-9]+}, by example, explicitly sets that the id parameter must have a numeric format.
When a defined route matches the requested URI then the application executes the corresponding handler.
Creating a Model
Our API provides information about robots, these data are stored in a database. The following model allows us to access that table in an object-oriented way. We have implemented some business rules using built-in validators and simple validations. Doing this will give us the peace of mind that saved data meet the requirements of our application. This model file should be placed in your Models folder.
<?php
namespace Store\Toys;
use Phalcon\Mvc\Model;
use Phalcon\Mvc\Model\Message;
use Phalcon\Mvc\Model\Validator\Uniqueness;
use Phalcon\Mvc\Model\Validator\InclusionIn;
class Robots extends Model
{
public function validation()
{
// Type must be: droid, mechanical or virtual
$this->validate(
new InclusionIn(
[
'field' => 'type',
'domain' => [
'droid',
'mechanical',
'virtual',
],
]
)
);
// Robot name must be unique
$this->validate(
new Uniqueness(
[
'field' => 'name',
'message' => 'The robot name must be unique',
]
)
);
// Year cannot be less than zero
if ($this->year < 0) {
$this->appendMessage(
new Message('The year cannot be less than zero')
);
}
// Check if any messages have been produced
if ($this->validationHasFailed() === true) {
return false;
}
}
}Now, we must set up a connection to be used by this model and load it within our app [File: index.php]:
<?php
use Phalcon\Loader;
use Phalcon\Mvc\Micro;
use Phalcon\Di\FactoryDefault;
use Phalcon\Db\Adapter\Pdo\Mysql as PdoMysql;
// Use Loader() to autoload our model
$loader = new Loader();
$loader->registerNamespaces(
[
'Store\Toys' => __DIR__ . '/models/',
]
);
$loader->register();
$di = new FactoryDefault();
// Set up the database service
$di->set(
'db',
function () {
return new PdoMysql(
[
'host' => 'localhost',
'username' => 'asimov',
'password' => 'zeroth',
'dbname' => 'robotics',
]
);
}
);
// Create and bind the DI to the application
$app = new Micro($di);Retrieving Data
The first handler that we will implement is which by method GET returns all available robots. Let's use PHQL to perform this simple query returning the results as JSON. [File: index.php]
<?php
// Retrieves all robots
$app->get(
'/api/robots',
function () use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots ORDER BY name';
$robots = $app->modelsManager->executeQuery($phql);
$data = [];
foreach ($robots as $robot) {
$data[] = [
'id' => $robot->id,
'name' => $robot->name,
];
}
echo json_encode($data);
}
);PHQL, allow us to write queries using a high-level, object-oriented SQL dialect that internally translates to the right SQL statements depending on the database system we are using. The clause use in the anonymous function allows us to pass some variables from the global to local scope easily.
The searching by name handler would look like [File: index.php]:
<?php
// Searches for robots with $name in their name
$app->get(
'/api/robots/search/{name}',
function ($name) use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots WHERE name LIKE :name: ORDER BY name';
$robots = $app->modelsManager->executeQuery(
$phql,
[
'name' => '%' . $name . '%'
]
);
$data = [];
foreach ($robots as $robot) {
$data[] = [
'id' => $robot->id,
'name' => $robot->name,
];
}
echo json_encode($data);
}
);Searching by the field id it's quite similar, in this case, we're also notifying if the robot was found or not [File: index.php]:
<?php
use Phalcon\Http\Response;
// Retrieves robots based on primary key
$app->get(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$phql = 'SELECT * FROM Store\Toys\Robots WHERE id = :id:';
$robot = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
]
)->getFirst();
// Create a response
$response = new Response();
if ($robot === false) {
$response->setJsonContent(
[
'status' => 'NOT-FOUND'
]
);
} else {
$response->setJsonContent(
[
'status' => 'FOUND',
'data' => [
'id' => $robot->id,
'name' => $robot->name
]
]
);
}
return $response;
}
);Inserting Data
Taking the data as a JSON string inserted in the body of the request, we also use PHQL for insertion [File: index.php]:
<?php
use Phalcon\Http\Response;
// Adds a new robot
$app->post(
'/api/robots',
function () use ($app) {
$robot = $app->request->getJsonRawBody();
$phql = 'INSERT INTO Store\Toys\Robots (name, type, year) VALUES (:name:, :type:, :year:)';
$status = $app->modelsManager->executeQuery(
$phql,
[
'name' => $robot->name,
'type' => $robot->type,
'year' => $robot->year,
]
);
// Create a response
$response = new Response();
// Check if the insertion was successful
if ($status->success() === true) {
// Change the HTTP status
$response->setStatusCode(201, 'Created');
$robot->id = $status->getModel()->id;
$response->setJsonContent(
[
'status' => 'OK',
'data' => $robot,
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
// Send errors to the client
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Updating Data
The data update is similar to insertion. The id passed as parameter indicates what robot must be updated [File: index.php]:
<?php
use Phalcon\Http\Response;
// Updates robots based on primary key
$app->put(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$robot = $app->request->getJsonRawBody();
$phql = 'UPDATE Store\Toys\Robots SET name = :name:, type = :type:, year = :year: WHERE id = :id:';
$status = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
'name' => $robot->name,
'type' => $robot->type,
'year' => $robot->year,
]
);
// Create a response
$response = new Response();
// Check if the insertion was successful
if ($status->success() === true) {
$response->setJsonContent(
[
'status' => 'OK'
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Deleting Data
The data delete is similar to update. The id passed as parameter indicates what robot must be deleted [File: index.php]:
<?php
use Phalcon\Http\Response;
// Deletes robots based on primary key
$app->delete(
'/api/robots/{id:[0-9]+}',
function ($id) use ($app) {
$phql = 'DELETE FROM Store\Toys\Robots WHERE id = :id:';
$status = $app->modelsManager->executeQuery(
$phql,
[
'id' => $id,
]
);
// Create a response
$response = new Response();
if ($status->success() === true) {
$response->setJsonContent(
[
'status' => 'OK'
]
);
} else {
// Change the HTTP status
$response->setStatusCode(409, 'Conflict');
$errors = [];
foreach ($status->getMessages() as $message) {
$errors[] = $message->getMessage();
}
$response->setJsonContent(
[
'status' => 'ERROR',
'messages' => $errors,
]
);
}
return $response;
}
);Testing our Application
Using curl we'll test every route in our application verifying its proper operation.
Obtain all the robots:
curl -i -X GET http://localhost/my-rest-api/api/robots
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:05:13 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 117
Content-Type: text/html; charset=UTF-8
[{"id":"1","name":"Robotina"},{"id":"2","name":"Astro Boy"},{"id":"3","name":"Terminator"}]Search a robot by its name:
curl -i -X GET http://localhost/my-rest-api/api/robots/search/Astro
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:09:23 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 31
Content-Type: text/html; charset=UTF-8
[{"id":"2","name":"Astro Boy"}]Obtain a robot by its id:
curl -i -X GET http://localhost/my-rest-api/api/robots/3
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 07:12:18 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 56
Content-Type: text/html; charset=UTF-8
{"status":"FOUND","data":{"id":"3","name":"Terminator"}}Insert a new robot:
curl -i -X POST -d '{"name":"C-3PO","type":"droid","year":1977}'
http://localhost/my-rest-api/api/robots
HTTP/1.1 201 Created
Date: Tue, 21 Jul 2015 07:15:09 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 75
Content-Type: text/html; charset=UTF-8
{"status":"OK","data":{"name":"C-3PO","type":"droid","year":1977,"id":"4"}}Try to insert a new robot with the name of an existing robot:
curl -i -X POST -d '{"name":"C-3PO","type":"droid","year":1977}'
http://localhost/my-rest-api/api/robots
HTTP/1.1 409 Conflict
Date: Tue, 21 Jul 2015 07:18:28 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 63
Content-Type: text/html; charset=UTF-8
{"status":"ERROR","messages":["The robot name must be unique"]}Or update a robot with an unknown type:
curl -i -X PUT -d '{"name":"ASIMO","type":"humanoid","year":2000}'
http://localhost/my-rest-api/api/robots/4
HTTP/1.1 409 Conflict
Date: Tue, 21 Jul 2015 08:48:01 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 104
Content-Type: text/html; charset=UTF-8
{"status":"ERROR","messages":["Value of field 'type' must be part of
list: droid, mechanical, virtual"]}Finally, delete a robot:
curl -i -X DELETE http://localhost/my-rest-api/api/robots/4
HTTP/1.1 200 OK
Date: Tue, 21 Jul 2015 08:49:29 GMT
Server: Apache/2.2.22 (Unix) DAV/2
Content-Length: 15
Content-Type: text/html; charset=UTF-8
{"status":"OK"}Conclusion
As we saw, developing a RESTful API with Phalcon is easy using micro applications and PHQL.
西方思想史谱系图
古希腊罗马哲学
古希腊罗马哲学包括自然哲学、形而上学和伦理哲学三个阶段,为西方哲学的理性思辨和形而上学打下了传统根基。它提出了逻各斯、存在、实体等成为西方哲学的经典命题,而柏拉图和亚里士多德关于共相性质的争论开启了中世纪基督教哲学关于唯名论和实在论的争论。

中世纪基督教哲学
西罗马帝国崩溃后,基督教成为西欧不可侵犯的绝对意识形态,哲学成为“神学的婢女”,被基督教信仰的浓重阴影所笼罩。从教父哲学(柏拉图-奥古斯丁体系)到经院哲学(亚里士多德-阿奎那体系)的过渡反应了希腊罗马理性精神的复苏,而唯名论和实在论的对立为近代理性主义和经验论的兴起开辟了道路。

近代早期西欧哲学
近代早期西欧哲学从文艺复兴和宗教改革运动开始,演化出欧陆唯理论同不列颠经验论的对立,其核心是理性反思和对经验(外在或内在)的重视。唯理论演变成莱布尼茨-沃尔夫体系中的独断论,而经验论则在休谟那里成为彻底的怀疑主义,这为法兰西启蒙思想和德意志古典哲学的出现埋下了伏笔。

法兰西启蒙思想和唯物主义
18世纪法国哲学包括法国自然神论和唯物主义两块,探讨的核心问题是人与自然的关系,理论上则表现为思维和存在的关系。法国自然神论奠定了西方政治学的基础,而激进的卢梭则引导了后世批判哲学(马克思和尼采)的出现。法国唯物主义者否定自由意志,但推崇人的理性,使理性主义成为法国哲学鲜明的特点。

德意志古典哲学
18C末19C初,德意志古典哲学体系的出现标志着传统西方哲学的最高成就。它将考察重点转向主体与客体的关系,实现了西方哲学继亚里士多德形而上学体系之后的第二次飞跃。康德通过对自在之物和现象的严格区分,发展出认识论的先验自我意识统摄机能和道德实践领域的纯粹理性,以及沟通两者的判断力批判。黑格尔通过辩证法三段论将整个世界容纳在绝对精神从自在状态过渡到自为状态,最终达成绝对理性自我意识的宏大历史过程。因此,黑格尔成为最后一个形而上学大体系,并引发费尔巴哈和马克思对其的反思。

过渡时期
19C中后期,形而上学和理性主义的传统西方哲学走向终结,导致了向现代西哲的过渡时期。

{kind=link}
{kind=link}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
