Excel常用函数大全
我们在使用Excel制作表格整理数据的时候,常常要用到它的函数功能来自动统计处理表格中的数据。这里整理了Excel中使用频率最高的函数的功能、使用方法,以及这些函数在实际应用中的实例剖析,并配有详细的介绍。
1、ABS函数
函数名称:ABS
主要功能:求出相应数字的绝对值。
使用格式:ABS(number)
参数说明:number代表需要求绝对值的数值或引用的单元格。
应用举例:如果在B2单元格中输入公式:=ABS(A2),则在A2单元格中无论输入正数(如100)还是负数(如-100),B2中均显示出正数(如100)。
特别提醒:如果number参数不是数值,而是一些字符(如A等),则B2中返回错误值“#VALUE!”。
2、AND函数
函数名称:AND
主要功能:返回逻辑值:如果所有参数值均为逻辑“真(TRUE)”,则返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。
使用格式:AND(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C5单元格输入公式:=AND(A5>=60,B5>=60),确认。如果C5中返回TRUE,说明A5和B5中的数值均大于等于60,如果返回FALSE,说明A5和B5中的数值至少有一个小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
3、AVERAGE函数
函数名称:AVERAGE
主要功能:求出所有参数的算术平均值。
使用格式:AVERAGE(number1,number2,……)
参数说明:number1,number2,……:需要求平均值的数值或引用单元格(区域),参数不超过30个。
应用举例:在B8单元格中输入公式:=AVERAGE(B7:D7,F7:H7,7,8),确认后,即可求出B7至D7区域、F7至H7区域中的数值和7、8的平均值。
特别提醒:如果引用区域中包含“0”值单元格,则计算在内;如果引用区域中包含空白或字符单元格,则不计算在内。
4、COLUMN 函数
函数名称:COLUMN
主要功能:显示所引用单元格的列标号值。
使用格式:COLUMN(reference)
参数说明:reference为引用的单元格。
应用举例:在C11单元格中输入公式:=COLUMN(B11),确认后显示为2(即B列)。
特别提醒:如果在B11单元格中输入公式:=COLUMN(),也显示出2;与之相对应的还有一个返回行标号值的函数——ROW(reference)。
5、CONCATENATE函数
函数名称:CONCATENATE
主要功能:将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。
使用格式:CONCATENATE(Text1,Text……)
参数说明:Text1、Text2……为需要连接的字符文本或引用的单元格。
应用举例:在C14单元格中输入公式:=CONCATENATE(A14,"@",B14,".com"),确认后,即可将A14单元格中字符、@、B14单元格中的字符和.com连接成一个整体,显示在C14单元格中。
特别提醒:如果参数不是引用的单元格,且为文本格式的,请给参数加上英文状态下的双引号,如果将上述公式改为:=A14&"@"&B14&".com",也能达到相同的目的。
6、COUNTIF函数
函数名称:COUNTIF
主要功能:统计某个单元格区域中符合指定条件的单元格数目。
使用格式:COUNTIF(Range,Criteria)
参数说明:Range代表要统计的单元格区域;Criteria表示指定的条件表达式。
应用举例:在C17单元格中输入公式:=COUNTIF(B1:B13,">=80"),确认后,即可统计出B1至B13单元格区域中,数值大于等于80的单元格数目。
特别提醒:允许引用的单元格区域中有空白单元格出现。
7、DATE函数
函数名称:DATE
主要功能:给出指定数值的日期。
使用格式:DATE(year,month,day)
参数说明:year为指定的年份数值(小于9999);month为指定的月份数值(可以大于12);day为指定的天数。
应用举例:在C20单元格中输入公式:=DATE(2003,13,35),确认后,显示出2004-2-4。
特别提醒:由于上述公式中,月份为13,多了一个月,顺延至2004年1月;天数为35,比2004年1月的实际天数又多了4天,故又顺延至2004年2月4日。
8、函数名称:DATEDIF
主要功能:计算返回两个日期参数的差值。
使用格式:=DATEDIF(date1,date2,"y")、=DATEDIF(date1,date2,"m")、=DATEDIF(date1,date2,"d")
参数说明:date1代表前面一个日期,date2代表后面一个日期;y(m、d)要求返回两个日期相差的年(月、天)数。
应用举例:在C23单元格中输入公式:=DATEDIF(A23,TODAY(),"y"),确认后返回系统当前日期[用TODAY()表示)与A23单元格中日期的差值,并返回相差的年数。
特别提醒:这是Excel中的一个隐藏函数,在函数向导中是找不到的,可以直接输入使用,对于计算年龄、工龄等非常有效。
9、DAY函数
函数名称:DAY
主要功能:求出指定日期或引用单元格中的日期的天数。
使用格式:DAY(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=DAY("2003-12-18"),确认后,显示出18。
特别提醒:如果是给定的日期,请包含在英文双引号中。
10、DCOUNT函数
函数名称:DCOUNT
主要功能:返回数据库或列表的列中满足指定条件并且包含数字的单元格数目。
使用格式:DCOUNT(database,field,criteria)
参数说明:Database表示需要统计的单元格区域;Field表示函数所使用的数据列(在第一行必须要有标志项);Criteria包含条件的单元格区域。
应用举例:如图1所示,在F4单元格中输入公式:=DCOUNT(A1:D11,"语文",F1:G2),确认后即可求出“语文”列中,成绩大于等于70,而小于80的数值单元格数目(相当于分数段人数)。

特别提醒:如果将上述公式修改为:=DCOUNT(A1:D11,,F1:G2),也可以达到相同目的。
11、FREQUENCY函数
函数名称:FREQUENCY
主要功能:以一列垂直数组返回某个区域中数据的频率分布。
使用格式:FREQUENCY(data_array,bins_array)
参数说明:Data_array表示用来计算频率的一组数据或单元格区域;Bins_array表示为前面数组进行分隔一列数值。
应用举例:如图2所示,同时选中B32至B36单元格区域,输入公式:=FREQUENCY(B2:B31,D2:D36),输入完成后按下“Ctrl+Shift+Enter”组合键进行确认,即可求出B2至B31区域中,按D2至D36区域进行分隔的各段数值的出现频率数目(相当于统计各分数段人数)。
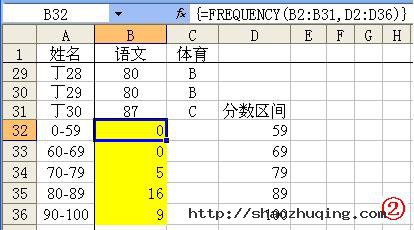
特别提醒:上述输入的是一个数组公式,输入完成后,需要通过按“Ctrl+Shift+Enter”组合键进行确认,确认后公式两端出现一对大括号({}),此大括号不能直接输入。
12、IF函数
函数名称:IF
主要功能:根据对指定条件的逻辑判断的真假结果,返回相对应的内容。
使用格式:=IF(Logical,Value_if_true,Value_if_false)
参数说明:Logical代表逻辑判断表达式;Value_if_true表示当判断条件为逻辑“真(TRUE)”时的显示内容,如果忽略返回“TRUE”;Value_if_false表示当判断条件为逻辑“假(FALSE)”时的显示内容,如果忽略返回“FALSE”。
应用举例:在C29单元格中输入公式:=IF(C26>=18,"符合要求","不符合要求"),确信以后,如果C26单元格中的数值大于或等于18,则C29单元格显示“符合要求”字样,反之显示“不符合要求”字样。
特别提醒:本文中类似“在C29单元格中输入公式”中指定的单元格,读者在使用时,并不需要受其约束,此处只是配合本文所附的实例需要而给出的相应单元格,具体请大家参考所附的实例文件。
13、INDEX函数
函数名称:INDEX
主要功能:返回列表或数组中的元素值,此元素由行序号和列序号的索引值进行确定。
使用格式:INDEX(array,row_num,column_num)
参数说明:Array代表单元格区域或数组常量;Row_num表示指定的行序号(如果省略row_num,则必须有 column_num);Column_num表示指定的列序号(如果省略column_num,则必须有 row_num)。
应用举例:如图3所示,在F8单元格中输入公式:=INDEX(A1:D11,4,3),确认后则显示出A1至D11单元格区域中,第4行和第3列交叉处的单元格(即C4)中的内容。
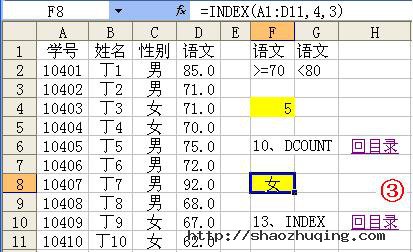
特别提醒:此处的行序号参数(row_num)和列序号参数(column_num)是相对于所引用的单元格区域而言的,不是Excel工作表中的行或列序号。
14、INT函数
函数名称:INT
主要功能:将数值向下取整为最接近的整数。
使用格式:INT(number)
参数说明:number表示需要取整的数值或包含数值的引用单元格。
应用举例:输入公式:=INT(18.89),确认后显示出18。
特别提醒:在取整时,不进行四舍五入;如果输入的公式为=INT(-18.89),则返回结果为-19。
15、ISERROR函数
函数名称:ISERROR
主要功能:用于测试函数式返回的数值是否有错。如果有错,该函数返回TRUE,反之返回FALSE。
使用格式:ISERROR(value)
参数说明:Value表示需要测试的值或表达式。
应用举例:输入公式:=ISERROR(A35/B35),确认以后,如果B35单元格为空或“0”,则A35/B35出现错误,此时前述函数返回TRUE结果,反之返回FALSE。
特别提醒:此函数通常与IF函数配套使用,如果将上述公式修改为:=IF(ISERROR(A35/B35),"",A35/B35),如果B35为空或“0”,则相应的单元格显示为空,反之显示A35/B35的结果。
16、LEFT函数
函数名称:LEFT
主要功能:从一个文本字符串的第一个字符开始,截取指定数目的字符。
使用格式:LEFT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A38单元格中保存了“我喜欢天极网”的字符串,我们在C38单元格中输入公式:=LEFT(A38,3),确认后即显示出“我喜欢”的字符。
特别提醒:此函数名的英文意思为“左”,即从左边截取,Excel很多函数都取其英文的意思。
17、LEN函数
函数名称:LEN
主要功能:统计文本字符串中字符数目。
使用格式:LEN(text)
参数说明:text表示要统计的文本字符串。
应用举例:假定A41单元格中保存了“我今年28岁”的字符串,我们在C40单元格中输入公式:=LEN(A40),确认后即显示出统计结果“6”。
特别提醒:LEN要统计时,无论中全角字符,还是半角字符,每个字符均计为“1”;与之相对应的一个函数——LENB,在统计时半角字符计为“1”,全角字符计为“2”。
18、MATCH函数
函数名称:MATCH
主要功能:返回在指定方式下与指定数值匹配的数组中元素的相应位置。
使用格式:MATCH(lookup_value,lookup_array,match_type)
参数说明:Lookup_value代表需要在数据表中查找的数值;
Lookup_array表示可能包含所要查找的数值的连续单元格区域;
Match_type表示查找方式的值(-1、0或1)。
如果match_type为-1,查找大于或等于 lookup_value的最小数值,Lookup_array 必须按降序排列;
如果match_type为1,查找小于或等于 lookup_value 的最大数值,Lookup_array 必须按升序排列;
如果match_type为0,查找等于lookup_value 的第一个数值,Lookup_array 可以按任何顺序排列;如果省略match_type,则默认为1。
应用举例:如图4所示,在F2单元格中输入公式:=MATCH(E2,B1:B11,0),确认后则返回查找的结果“9”。

特别提醒:Lookup_array只能为一列或一行。
19、MAX函数
函数名称:MAX
主要功能:求出一组数中的最大值。
使用格式:MAX(number1,number2……)
参数说明:number1,number2……代表需要求最大值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MAX(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最大值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
20、MID函数
函数名称:MID
主要功能:从一个文本字符串的指定位置开始,截取指定数目的字符。
使用格式:MID(text,start_num,num_chars)
参数说明:text代表一个文本字符串;start_num表示指定的起始位置;num_chars表示要截取的数目。
应用举例:假定A47单元格中保存了“我喜欢天极网”的字符串,我们在C47单元格中输入公式:=MID(A47,4,3),确认后即显示出“天极网”的字符。
特别提醒:公式中各参数间,要用英文状态下的逗号“,”隔开。
21、MIN函数
函数名称:MIN
主要功能:求出一组数中的最小值。
使用格式:MIN(number1,number2……)
参数说明:number1,number2……代表需要求最小值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MIN(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最小值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
22、MOD函数
函数名称:MOD
主要功能:求出两数相除的余数。
使用格式:MOD(number,divisor)
参数说明:number代表被除数;divisor代表除数。
应用举例:输入公式:=MOD(13,4),确认后显示出结果“1”。
特别提醒:如果divisor参数为零,则显示错误值“#DIV/0!”;MOD函数可以借用函数INT来表示:上述公式可以修改为:=13-4*INT(13/4)。
23、MONTH函数
函数名称:MONTH
主要功能:求出指定日期或引用单元格中的日期的月份。
使用格式:MONTH(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=MONTH("2003-12-18"),确认后,显示出11。
特别提醒:如果是给定的日期,请包含在英文双引号中;如果将上述公式修改为:=YEAR("2003-12-18"),则返回年份对应的值“2003”。
24、NOW函数
函数名称:NOW
主要功能:给出当前系统日期和时间。
使用格式:NOW()
参数说明:该函数不需要参数。
应用举例:输入公式:=NOW(),确认后即刻显示出当前系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期和时间格式,可以通过单元格格式进行重新设置。
25、OR函数
函数名称:OR
主要功能:返回逻辑值,仅当所有参数值均为逻辑“假(FALSE)”时返回函数结果逻辑“假(FALSE)”,否则都返回逻辑“真(TRUE)”。
使用格式:OR(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C62单元格输入公式:=OR(A62>=60,B62>=60),确认。如果C62中返回TRUE,说明A62和B62中的数值至少有一个大于或等于60,如果返回FALSE,说明A62和B62中的数值都小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
26、RANK函数
函数名称:RANK
主要功能:返回某一数值在一列数值中的相对于其他数值的排位。
使用格式:RANK(Number,ref,order)
参数说明:Number代表需要排序的数值;ref代表排序数值所处的单元格区域;order代表排序方式参数(如果为“0”或者忽略,则按降序排名,即数值越大,排名结果数值越小;如果为非“0”值,则按升序排名,即数值越大,排名结果数值越大;)。
应用举例:如在C2单元格中输入公式:=RANK(B2,$B$2:$B$31,0),确认后即可得出丁1同学的语文成绩在全班成绩中的排名结果。
特别提醒:在上述公式中,我们让Number参数采取了相对引用形式,而让ref参数采取了绝对引用形式(增加了一个“$”符号),这样设置后,选中C2单元格,将鼠标移至该单元格右下角,成细十字线状时(通常称之为“填充柄”),按住左键向下拖拉,即可将上述公式快速复制到C列下面的单元格中,完成其他同学语文成绩的排名统计。
27、RIGHT函数
函数名称:RIGHT
主要功能:从一个文本字符串的最后一个字符开始,截取指定数目的字符。
使用格式:RIGHT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A65单元格中保存了“我喜欢天极网”的字符串,我们在C65单元格中输入公式:=RIGHT(A65,3),确认后即显示出“天极网”的字符。
特别提醒:Num_chars参数必须大于或等于0,如果忽略,则默认其为1;如果num_chars参数大于文本长度,则函数返回整个文本。
28、SUBTOTAL函数
函数名称:SUBTOTAL
主要功能:返回列表或数据库中的分类汇总。
使用格式:SUBTOTAL(function_num, ref1, ref2, ...)
参数说明:Function_num为1到11(包含隐藏值)或101到111(忽略隐藏值)之间的数字,用来指定使用什么函数在列表中进行分类汇总计算(如图6);ref1, ref2,……代表要进行分类汇总区域或引用,不超过29个。

应用举例:如图7所示,在B64和C64单元格中分别输入公式:=SUBTOTAL(3,C2:C63)和=SUBTOTAL103,C2:C63),并且将61行隐藏起来,确认后,前者显示为62(包括隐藏的行),后者显示为61,不包括隐藏的行。

特别提醒:如果采取自动筛选,无论function_num参数选用什么类型,SUBTOTAL函数忽略任何不包括在筛选结果中的行;SUBTOTAL函数适用于数据列或垂直区域,不适用于数据行或水平区域。
29、SUM函数
函数名称:SUM
主要功能:计算所有参数数值的和。
使用格式:SUM(Number1,Number2……)
参数说明:Number1、Number2……代表需要计算的值,可以是具体的数值、引用的单元格(区域)、逻辑值等。
应用举例:如图7所示,在D64单元格中输入公式:=SUM(D2:D63),确认后即可求出语文的总分。

特别提醒:如果参数为数组或引用,只有其中的数字将被计算。数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略;如果将上述公式修改为:=SUM(LARGE(D2:D63,{1,2,3,4,5})),则可以求出前5名成绩的和。
30、SUMIF函数
函数名称:SUMIF
主要功能:计算符合指定条件的单元格区域内的数值和。
使用格式:SUMIF(Range,Criteria,Sum_Range)
参数说明:Range代表条件判断的单元格区域;Criteria为指定条件表达式;Sum_Range代表需要计算的数值所在的单元格区域。
应用举例:如图7所示,在D64单元格中输入公式:=SUMIF(C2:C63,"男",D2:D63),确认后即可求出“男”生的语文成绩和。
特别提醒:如果把上述公式修改为:=SUMIF(C2:C63,"女",D2:D63),即可求出“女”生的语文成绩和;其中“男”和“女”由于是文本型的,需要放在英文状态下的双引号("男"、"女")中。
31、TEXT函数
函数名称:TEXT
主要功能:根据指定的数值格式将相应的数字转换为文本形式。
使用格式:TEXT(value,format_text)
参数说明:value代表需要转换的数值或引用的单元格;format_text为指定文字形式的数字格式。
应用举例:如果B68单元格中保存有数值1280.45,我们在C68单元格中输入公式:=TEXT(B68, "$0.00"),确认后显示为“$1280.45”。
特别提醒:format_text参数可以根据“单元格格式”对话框“数字”标签中的类型进行确定。
32、TODAY函数
函数名称:TODAY
主要功能:给出系统日期。
使用格式:TODAY()
参数说明:该函数不需要参数。
应用举例:输入公式:=TODAY(),确认后即刻显示出系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期格式,可以通过单元格格式进行重新设置(参见附件)。
33、VALUE函数
函数名称:VALUE
主要功能:将一个代表数值的文本型字符串转换为数值型。
使用格式:VALUE(text)
参数说明:text代表需要转换文本型字符串数值。
应用举例:如果B74单元格中是通过LEFT等函数截取的文本型字符串,我们在C74单元格中输入公式:=VALUE(B74),确认后,即可将其转换为数值型。
特别提醒:如果文本型数值不经过上述转换,在用函数处理这些数值时,常常返回错误。
34、VLOOKUP函数
函数名称:VLOOKUP
主要功能:在数据表的首列查找指定的数值,并由此返回数据表当前行中指定列处的数值。
使用格式:VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)
参数说明:Lookup_value代表需要查找的数值;Table_array代表需要在其中查找数据的单元格区域;Col_index_num为在table_array区域中待返回的匹配值的列序号(当Col_index_num为2时,返回table_array第2列中的数值,为3时,返回第3列的值……);Range_lookup为一逻辑值,如果为TRUE或省略,则返回近似匹配值,也就是说,如果找不到精确匹配值,则返回小于lookup_value的最大数值;如果为FALSE,则返回精确匹配值,如果找不到,则返回错误值#N/A。
应用举例:参见图7,我们在D65单元格中输入公式:=VLOOKUP(B65,B2:D63,3,FALSE),确认后,只要在B65单元格中输入一个学生的姓名(如丁48),D65单元格中即刻显示出该学生的语言成绩。
特别提醒:Lookup_value参见必须在Table_array区域的首列中;如果忽略Range_lookup参数,则Table_array的首列必须进行排序;在此函数的向导中,有关Range_lookup参数的用法是错误的。
35、WEEKDAY函数
函数名称:WEEKDAY
主要功能:给出指定日期的对应的星期数。
使用格式:WEEKDAY(serial_number,return_type)
参数说明:serial_number代表指定的日期或引用含有日期的单元格;return_type代表星期的表示方式[当Sunday(星期日)为1、Saturday(星期六)为7时,该参数为1;当Monday(星期一)为1、Sunday(星期日)为7时,该参数为2(这种情况符合中国人的习惯);当Monday(星期一)为0、Sunday(星期日)为6时,该参数为3]。
应用举例:输入公式:=WEEKDAY(TODAY(),2),确认后即给出系统日期的星期数。
特别提醒:如果是指定的日期,请放在英文状态下的双引号中,如=WEEKDAY("2003-12-18",2)。
Excel:数据分析工具名词解释
 全部显示
全部显示 全部隐藏
全部隐藏- 如果显示“数据分析”对话框,请在“分析工具”下单击要使用的工具,然后单击“确定”。
- 在所选工具对应的对话框中输入适当的数据并单击相应选项,然后单击“确定”。
有关每种工具的说明以及如何使用每种工具的对话框的信息,请单击下面列表中的工具名:
方差分析工具提供了不同类型的方差分析。具体应使用哪一种工具需根据因素的个数以及待检验样本总体中所含样本的个数而定。
方差分析: 单因素
此工具可对两个或更多样本的数据执行简单的方差分析。此分析可提供一种假设测试,该假设的内容是:每个样本都取自相同的基础概率分布,而不是对所有样本来说基础概率分布都不相同。如果只有两个样本,则可使用工作表函数 TTEST。如果有两个以上的样本,则没有使用方便的 TTEST 归纳,可改为调用“单因素方差分析”模型。
“方差分析: 单因素”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
分组方式 若要指示数据源区域中的数据是按行还是按列排列,请单击“行”或“列”。
标志位于第一行/标志位于第一列 如果数据源区域的第一行中包含标志项,请选中“标志位于第一行”复选框。如果数据源区域的第一列中包含标志项,请选中“标志位于第一列”复选框。如果数据源区域中没有标志项,则该复选框将被清除。Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入要用来计算 F 统计的临界值的置信度。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。当输出表将替换现有数据,或是输出表超过了工作表的边界时,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
方差分析: 包含重复的双因素
此分析工具可用于当数据可沿着两个不同的维度分类时的情况。例如,在测量植物高度的实验中,可能对植物施用了不同品牌的化肥(例如 A、B 和 C),并且植物也可能处于不同温度的环境中(例如高和低)。对于这 6 对可能的组合 {化肥,温度},我们有相同数量的植物高度观察值。使用此方差分析工具,我们可检验:
- 施用不同品牌化肥的植物的高度是否取自相同的基础样本总体。此分析忽略温度。
- 处于不同温度级别环境中的植物的高度是否取自相同的基础样本总体。此分析忽略所使用的化肥品牌。
无论是否考虑在第 1 个项目符号项中发现的不同品牌化肥之间的差异的影响以及在第 2 个项目符号项中发现的不同温度之间差异的影响,代表所有 {化肥,温度} 值对的 6 个样本都取自相同的样本总体。另一种假设是除了基于化肥或温度单个因素的差异带来的影响之外,特定的 {化肥,温度} 值对也会有影响。
")
“方差分析: 包含重复的双因素”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
每一样本的行数 在此输入每个样本中包含的行数。每个样本必须包含相同的行数,因为每一行代表数据的一个副本。
α 在此输入要用来计算 F 统计的临界值的置信度。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。当输出表将替换现有数据,或是输出表超过了工作表的边界时,Microsoft Office Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
方差分析: 无重复的双因素
此分析工具可用于当数据像包含重复的双因素那样按照两个不同的维度进行分类时的情况。但是,对于此工具,假设每一对值只有一个观察值(例如,在上面的示例中的每个 {化肥,温度} 值对)。
“方差分析: 无重复的双因素”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
标志 如果数据源区域中没有标志项,则该复选框将被清除,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入要用来计算 F 统计的临界值的置信度。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。当输出表将替换现有数据,或是输出表超过了工作表的边界时,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
CORREL 和 PEARSON 工作表函数均可计算两个测量值变量之间的相关系数,条件是每种变量的测量值都是对 N 个对象进行观测所得到的。(丢失任何对象的任何观测值都会导致在分析中忽略该对象。)相关系数分析工具特别适合于当 N 个对象中的每个对象都有两个以上的测量值变量的情况。它提供一张输出表(相关矩阵),其中显示了应用于每个可能的测量值变量对的 CORREL(或 PEARSON)值。
与协方差一样,相关系数是描述两个测量值变量之间的离散程度的指标。与协方差的不同之处在于,相关系数是成比例的,因此它的值与这两个测量值变量的表示单位无关。(例如,如果两个测量值变量为重量和高度,当重量单位从磅换算成千克时,相关系数的值并不改变。)任何相关系数的值都必须介于 -1 和 +1 之间(包括 -1 和 +1)。
可以使用相关系数分析工具来检验每对测量值变量,以便确定两个测量值变量是否趋向于同时变动,即,一个变量的较大值是否趋向于与另一个变量的较大值相关联(正相关);或者一个变量的较小值是否趋向于与另一个变量的较大值相关联(负相关);或者两个变量的值趋向于互不关联(相关系数近似于零)。
“相关”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
分组方式 若要指示数据源区域中的数据是按行还是按列排列,请单击“行”或“列”。
标志位于第一行/标志位于第一列 如果数据源区域的第一行中包含标志项,请选中“标志位于第一行”复选框。如果数据源区域的第一列中包含标志项,请选中“标志位于第一列”复选框。如果数据源区域中没有标志项,则该复选框将被清除。Microsoft Office Excel 将在输出表中生成适当的数据标志。
输出区域 在此输入对输出表左上角单元格的引用。Excel 只填写输出表的一半,因为两个数据区域的相关性与区域的处理次序无关。输出表中具有相同行和列坐标的单元格包含数值 1,因为每个数据集与自身完全相关。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
当您对一组个体进行观测而获得了 N 个不同的测量值变量时,“相关”和“协方差”工具可在相同设置下使用。“相关”和“协方差”工具都会提供一张输出表(矩阵),其中分别显示每对测量值变量之间的相关系数或协方差。不同之处在于相关系数的取值在 -1 和 +1 之间(包括 -1 和 +1),而协方差没有限定的取值范围。相关系数和协方差都是描述两个变量离散程度的指标。
“协方差”工具为每对测量值变量计算工作表函数 COVAR 的值。(当只有两个测量值变量,即 N=2 时,可直接使用 COVAR,而不要使用“协方差”工具。)在“协方差”工具的输出表中的第 i 行、第 i 列的对角线上的输入值是第 i 个测量值变量与其自身的协方差;这正好是用工作表函数 VARP 计算得出的变量的总体方差。
可以使用“协方差”工具来检验每对测量值变量,以便确定两个测量值变量是否趋向于同时变动,即,一个变量的较大值是否趋向于与另一个变量的较大值相关联(正相关);或者一个变量的较小值是否趋向于与另一个变量的较大值相关联(负相关);或者两个变量中的值趋向于互不关联(协方差近似于零)。
“协方差”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
分组方式 若要指示数据源区域中的数据是按行还是按列排列,请单击“行”或“列”。
标志位于第一行/标志位于第一列 如果数据源区域的第一行中包含标志项,请选中“标志位于第一行”复选框。如果数据源区域的第一列中包含标志项,请选中“标志位于第一列”复选框。如果数据源区域中没有标志项,则该复选框将被清除。Microsoft Office Excel 将在输出表中生成适当的数据标志。
输出区域 在此输入对输出表左上角单元格的引用。Excel 只填写输出表的一半,因为两个数据区域的相关性与区域的处理次序无关。在输出表的对角线上为每个区域的方差。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“描述统计”分析工具用于生成数据源区域中数据的单变量统计分析报表,提供有关数据趋中性和易变性的信息。
“描述统计”对话框
数据源区域 在此输入待分析数据区域的单元格引用。引用必须由两个或两个以上按列或行排列的相邻数据区域组成。
分组方式 若要指示数据源区域中的数据是按行还是按列排列,请单击“行”或“列”。
标志位于第一行/标准位于第一列 如果数据源区域的第一行中包含标志项,请选中“标志位于第一行”复选框。如果数据源区域的第一列中包含标志项,请选中“标志位于第一列”复选框。如果数据源区域中没有标志项,则该复选框将被清除。Microsoft Office Excel 将在输出表中生成适当的数据标志。
平均数置信度 如果需要在输出表的某一行中包含平均数的置信度,请选中此选项。在框中,输入要使用的置信度。例如,数值 95% 可用来计算在显著性水平为 5% 时的平均数置信度。
第 K 大值 如果需要在输出表的某一行中包含每个数据区域中的第 k 大值,请选中此选项。在框中,输入 k 的数字。如果输入 1,则该行将包含数据集中的最大值。
第 K 小值 如果需要在输出表的某一行中包含每个数据区域中的第 k 小值,请选中此选项。在框中,输入 k 的数字。如果输入 1,则该行将包含数据集中的最小值。
输出区域 在此输入对输出表左上角单元格的引用。此工具将为每个数据集产生两列信息。左边一列包含统计标志,右边一列包含统计值。根据所选择的“分组方式”选项,Excel 将为数据源区域中的每一行或每一列生成一个两列的统计表。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
汇总统计 如果需要 Excel 在输出表中为下列每个统计结果生成一个字段,请选中此选项。这些统计结果有:平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差(全距)、最小值、最大值、总和、计数、最大值 (#)、最小值 (#) 和置信度。
“指数平滑”分析工具基于前期预测值导出相应的新预测值,并修正前期预测值的误差。此工具将使用平滑常数 a,其大小决定了本次预测对前期预测误差的修正程度。
注释 介于 0.2 到 0.3 的值是合理的平滑常数。这些值表明应将当前预测调整 20% 到 30% 以修正前期预测误差。常数越大响应越快,但是预测变得不稳定。常数较小将导致预测值的滞后。
“指数平滑”对话框
数据源区域 在此输入待分析数据区域的单元格引用。该区域必须为包含四个或四个以上数据单元格的单行或单列。
阻尼系数 在此输入需要用作指数平滑常数的阻尼系数。阻尼系数是用来将总体样本中收集的数据的不稳定性最小化的修正因子。默认的阻尼系数为 0.3。
注释 介于 0.2 到 0.3 的值是合理的平滑常数。这些值表明应将当前预测调整 20% 到 30% 以修正前期预测误差。常数越大响应越快,但是预测变得不稳定。常数较小将导致预测值的滞后。
标志 如果数据源区域的第一行和第一列中包含标志项,请选中此复选框。如果在数据源区域中没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
输出区域 在此输入对输出表左上角单元格的引用。如果选中了“标准误差”复选框,Excel 将生成一个两列的输出表,其中右边的一列为标准误差值。如果没有足够的历史数据来进行预测或计算标准误差值,Excel 会返回错误值 #N/A。
注释 输出区域必须与数据源区域中使用的数据位于同一张工作表中。因此,“新工作表”和“新工作簿”选项均不可用。
图表输出 选中此选项可在输出表中生成实际值与预测值的嵌入图表。
标准误差 如果要在输出表的一列中包含标准误差值,请选中此复选框。如果只需要单列输出表而不包含标准误差值,请清除此复选框。
“F-检验 双样本方差”分析工具通过双样本 F-检验对两个样本总体的方差进行比较。
例如,您可在一次游泳比赛中对每两个队的时间样本使用 F-检验工具。该工具提供空值假设的检验结果,该假设的内容是:这两个样本来自具有相同方差的分布,而不是方差在基础分布中不相等。
该工具计算 F-统计(或 F-比值)的 F 值。F 值接近于 1 说明基础总体方差是相等的。在输出表中,如果 F < 1,则当总体方差相等且根据所选择的显著水平“F 单尾临界值”返回小于 1 的临界值时,“P(F <= f) 单尾”返回 F-统计的观察值小于 F 的概率 Alpha。如果 F > 1,则当总体方差相等且根据所选择的显著水平,“F 单尾临界值”返回大于 1 的临界值时,“P(F <= f) 单尾”返回 F-统计的观察值大于 F 的概率 Alpha。
“F-检验 双样本方差”对话框
变量 1 的区域 在此输入对需要进行分析的第一列或第一行数据的引用。
变量 2 的区域 在此输入对需要进行分析的第二列或第二行数据的引用。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入检验的置信度。该值必须介于 0 到 1 之间。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“傅立叶分析”分析工具可以解决线性系统问题,并能通过快速傅立叶变换 (FFT) 进行数据变换来分析周期性的数据。此工具也支持逆变换,即通过对变换后的数据的逆变换返回初始数据。
“傅立叶分析”对话框
数据源区域 在此输入对需要进行变换的实数或复数区域的引用。复数必须表示为 x+yi 或 x+yj 的格式。数据源区域中数值的个数必须为 2 的偶数次幂。如果 x 为负数,则在前面加上一个撇号 (')。数值的最大个数为 4096。
标志位于第一行 如果数据源区域的第一行中包含标志项,请选中此复选框。如果数据源区域中没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
逆变换 如果选中此复选框,则数据源区域中的数据将被认为是经过变换后的数据,并对其进行逆变换,返回初始输入值;如果清除此复选框,则数据源区域中的数据在输出表中将进行变换。
“直方图”分析工具可计算数据单元格区域和数据接收区间的单个和累积频率。此工具可用于统计数据集中某个数值出现的次数。
例如,在一个有 20 名学生的班里,可按字母评分的分类来确定成绩的分布情况。直方图表可给出字母评分的边界,以及在最低边界和当前边界之间分数出现的次数。出现频率最多的分数即为数据集中的众数。
“直方图”对话框
数据源区域 在此输入待分析数据区域的单元格引用。
接收区域(可选) 在此输入接收区域的单元格引用,该区域包含一组可选的用来定义接收区域的边界值。这些值应当按升序排列。Microsoft Office Excel 将统计在当前边界值和相邻的较高边界值之间的数据点个数(如果存在)。如果数值等于或小于边界值,则该值将被归到以该边界值为上限的区域中进行计数。所有小于第一个边界值的数值将一同计数,同样所有大于最后一个边界值的数值也将一同计数。
如果省略此处的接收区域,Excel 将在数据的最小值和最大值之间创建一组均匀分布的接收区间。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Excel 将在输出表中生成适当的数据标志。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
柏拉图(排序直方图) 选中此复选框可在输出表中按频率的降序来显示数据。如果此复选框被清除,Excel 将按升序来显示数据并省略最右边包含排序数据的三列数据。
累积百分比 选中此复选框可在输出表中生成一列累积百分比值,并在直方图中包含一条累积百分比线。如果清除此选项,则会省略累积百分比。
图表输出 选中此选项可在输出表中生成一个嵌入直方图。
“移动平均”分析工具可以基于特定的过去某段时期中变量的平均值,对未来值进行预测。移动平均值提供了由所有历史数据的简单的平均值所代表的趋势信息。使用此工具可以预测销售量、库存或其他趋势。预测值的计算公式如下:
式中:
- N 为进行移动平均计算的过去期间的个数
- Aj 为期间 j 的实际值
- Fj 为期间 j 的预测值
“移动平均”对话框
数据源区域 在此输入待分析数据区域的单元格引用。该区域必须由包含四个或四个以上的数据单元格的单列组成。
标志位于第一行 如果数据源区域的第一行中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
间隔 在此输入需要在移动平均计算中包含的数值个数。默认间隔为 3。
输出区域 在此输入对输出表左上角单元格的引用。如果选中了“标准误差”复选框,Excel 将生成一个两列的输出表,其中右边的一列为标准误差值。如果没有足够的历史数据来进行预测或计算标准误差值,Excel 会返回错误值 #N/A。
输出区域必须与数据源区域中使用的数据位于同一张工作表中。因此,“新工作表”和“新工作簿”选项均不可用。
图表输出 选中此选项可在输出表中生成一个嵌入直方图。
标准误差 如果要在输出表的一列中包含标准误差值,请选中此复选框。如果只需要单列输出表而不包含标准误差值,请清除此复选框。
“随机数发生器”分析工具可用几个分布之一产生的独立随机数来填充某个区域。可以通过概率分布来表示总体中的主体特征。例如,可以使用正态分布来表示人体身高的总体特征,或者使用双值输出的伯努利分布来表示掷币实验结果的总体特征。
“随机数发生器”对话框
变量个数 在此输入输出表中数值列的个数。如果没有输入数字,Microsoft Office Excel 将在指定的输出区域中填充所有的列。
随机数个数 在此输入要查看的数据点个数。每一个数据点出现在输出表的一行中。如果没有输入数字,Excel 将在指定的输出区域中填充所有的行。
分布 在此单击用于创建随机数的分布方法。
均匀 以下限和上限来表征。其变量是通过对区域中的所有数值进行等概率抽取而得到的。普通的应用使用范围 0 到 1 之间的均匀分布。
正态 以平均值和标准偏差来表征。普通的应用使用平均值为 0、标准偏差为 1 的标准正态分布。
伯努利 以给定的试验中成功的概率(p 值)来表征。伯努利随机变量的值为 0 或 1。例如,可以在范围 0 到 1 之间抽取均匀分布随机变量。如果变量小于或等于成功的概率,则伯努利随机变量的值为 1;否则,随机变量的值为 0。
二项式 以一系列试验中成功的概率(p 值)来表征。例如,可以按照试验次数生成一系列伯努利随机变量,这些变量之和为一个二项式随机变量。
泊松 以值 λ 来表征,λ 等于平均值的倒数。泊松分布经常用于表示单位时间内事件发生的次数,例如,汽车到达收费停车场的平均速率。
模式 以下界和上界、步幅、数值的重复率和序列的重复率来表征。
离散 以数值及相应的概率区域来表征。该区域必须包含两列,左边一列包含数值,右边一列为与该行中的数值相对应的发生概率。所有概率的和必须为 1。
参数 在此输入用来表征所选分布的数值。
随机数基数 在此输入用来产生随机数的可选数值。可在以后重新使用该数值来生成相同的随机数。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“排位与百分比排位”分析工具可以产生一个数据表,在其中包含数据集中各个数值的顺序排位和百分比排位。该工具用来分析数据集中各数值间的相对位置关系。该工具使用工作表函数 RANK 和 PERCENTRANK。RANK 不考虑重复值。如果希望考虑重复值,请在使用工作表函数 RANK 的同时,使用帮助文件中所建议的函数 RANK 的修正因素。
“排位与百分比排位”对话框
数据源区域 在此输入待分析工作表数据区域的单元格引用。
分组方式 若要指示数据源区域中的数据是按行还是按列排列,请单击“行”或“列”。
标志位于第一行/标志位于第一列 如果单击“列”并且数据源区域的第一行中包含标志项,请选中“标志位于第一行”复选框。如果单击“行”并且数据源区域的第一列中包含标志项,请选中“标志位于第一列”复选框。如果数据源区域中没有标志项,则清除该复选框。Microsoft Office Excel 将在输出表中生成适宜的行标志和列标志。
输出区域 在此输入对输出表左上角单元格的引用。Excel 将为数据源区域中的每一个数据集生成一个输出表。每个输出表包含四列:数据点序号、数据点数值、数据点排位和数据点百分比排位(按升序排列)。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“回归”分析工具通过对一组观察值使用“最小二乘法”直线拟合来执行线性回归分析。本工具可用来分析单个因变量是如何受一个或几个自变量的值影响的。例如,观察某个运动员的运动成绩与一系列统计因素(如年龄、身高和体重等)的关系。可以基于一组已知的成绩统计数据,确定这三个因素分别在运动成绩测试中所占的比重,然后使用该结果对尚未进行过测试的运动员的表现进行预测。
“回归”工具使用工作表函数 LINEST。
“回归分析”对话框
Y 值输入区域 在此输入对因变量数据区域的引用。该区域必须由单列数据组成。
X 值输入区域 在此输入对自变量数据区域的引用。Microsoft Office Excel 将对此区域中的自变量从左到右进行升序排列。自变量的个数最多为 16。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域中没有标志项,请清除此复选框,Excel 将在输出表中生成适当的数据标志。
置信度 如果需要在汇总输出表中包含附加的置信度,请选中此选项。在框中,输入所要使用的置信度。默认值为 95%。
常数为零 如果要强制回归线经过原点,请选中此复选框。
输出区域 在此输入对输出表左上角单元格的引用。汇总输出表至少需要有七列,其中包括方差分析表、系数、y 估计值的标准误差、r2 值、观察值个数以及系数的标准误差。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
残差 如果需要在残差输出表中包含残差,请选中此复选框。
标准残差 如果需要在残差输出表中包含标准残差,请选中此复选框。
残差图 如果需要为每个自变量及其残差生成一张图表,请选中此复选框。
线性拟合图 如果需要为预测值和观察值生成一张图表,请选中此复选框。
正态概率图 如果需要生成一张图表来绘制正态概率,请选中此复选框。
“抽样”分析工具以数据源区域为总体,从而为其创建一个样本。当总体太大而不能进行处理或绘制时,可以选用具有代表性的样本。如果确认数据源区域中的数据是周期性的,还可以仅对一个周期中特定时间段中的数值进行采样。例如,如果数据源区域包含季度销售量数据,则以四为周期进行采样,将在输出区域中生成与数据源区域中相同季度的数值。
“抽样分析”对话框
数据源区域 在此输入对数据区域的引用,该区域中包含需要进行抽样的总体数据。Microsoft Office Excel 先从第一列中抽取样本,然后是第二列,依此类推。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Excel 将在输出表中生成适当的数据标志。
抽样方法 单击“周期”或“随机”来指示所需的抽样间隔。
周期 在此输入进行抽样的周期间隔。数据源区域中位于间隔点处的数值以及此后每一个间隔点处的数值将被复制到输出列中。当到达数据源区域的末尾时,抽样将停止。
样本数 在此输入需要在输出列中显示的随机数的个数。每个数值是从数据源区域中的随机位置上抽取出来的,而且任何数值都可以被多次抽取。
输出区域 在此输入对输出表左上角单元格的引用。数据将写在该单元格下方的单列里。如果选择的是“周期”,则输出表中数值的个数等于数据源区域中数值的个数除以采样率。如果选择的是“随机”,则输出表中数值的个数等于样本数。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“双样本 t-检验”分析工具基于每个样本检验样本总体平均值是否相等。这三个工具分别使用不同的假设:样本总体方差相等;样本总体方差不相等;两个样本代表处理前后同一对象上的观察值。
对于以下所有三个工具,t-统计值 t 被计算并在输出表中显示为“t Stat”。数据决定了 t 是负值还是非负值。假设基于相等的基础总体平均值,如果 t < 0,则“P(T <= t) 单尾”返回 t-统计的观察值比 t 更趋向负值的概率。如果 t >=0,则“P(T <= t) 单尾”返回 t-统计的观察值比 t 更趋向正值的概率。“t 单尾临界值”返回截止值,这样,t-统计的观察值将大于或等于“t 单尾临界值”的概率就为 Alpha。
“P(T <= t) 双尾”返回将被观察的 t-统计的绝对值大于 t 的概率。“P 双尾临界值”返回截止值,这样,被观察的 t-统计的绝对值大于“P 双尾临界值”的概率就为 Alpha。
t-检验: 成对双样本平均值
当样本中存在自然配对的观察值时(例如,对一个样本组在实验前后进行了两次检验),可以使用此成对检验。此分析工具及其公式可以进行成对双样本学生 t-检验,以确定取自处理前后的观察值是否来自具有相同总体平均值的分布。此 t-检验窗体并未假设两个总体的方差是相等的。
注释 由此工具生成的结果中包含有合并方差,亦即数据相对于平均值的离散值的累积测量值,可以由下面的公式得到:
“t-检验: 成对双样本平均值”对话框
变量 1 的区域 在此输入需要分析的第一个数据区域的单元格引用。该区域必须为单行或单列,并且包含与第二个区域相同的数据点数。
变量 2 的区域 在此输入需要分析的第二个数据区域的单元格引用。该区域必须为单行或单列,并且包含与第一个区域相同的数据点数。
假设平均差 在此输入样本平均值的差值。0(零)值表示假设样本平均值相同。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入检验的置信度。该值必须介于 0 到 1 之间。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
t-检验: 双样本等方差假设
本分析工具可进行双样本学生 t-检验。此 t-检验窗体假设两个数据集取自具有相同方差的分布,故也称作同方差 t-检验。可以使用此 t-检验来确定两个样本是否来自具有相同总体平均值的分布。
“t-检验: 双样本等方差假设”对话框
变量 1 的区域 在此输入需要分析的第一个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
变量 2 的区域 在此输入需要分析的第二个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
假设平均差 在此输入样本平均值的差值。0(零)值表示假设样本平均值相同。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入检验的置信度。该值必须介于 0 到 1 之间。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
t-检验: 双样本异方差假设
本分析工具可进行双样本学生 t-检验。此 t-检验窗体假设两个数据集取自具有不同方差的分布,故也称作异方差 t-检验。如同上面的“等方差”情况,可以使用此 t-检验来确定两个样本是否来自具有相同总体平均值的分布。当两个样本中有截然不同的对象时,可使用此检验。当对于每个对象具有唯一一组对象以及代表每个对象在处理前后的测量值的两个样本时,应使用下面的示例中所描述的成对检验。
用于确定统计值 t 的公式如下:
下面的公式可用于计算自由度 df。因为计算结果一般不是整数,所以 df 的值被舍入为最接近的整数以便从 t 表中获得临界值。因为有可能为 TTEST 计算出一个带有非整数 df 的值,所以 Excel 工作表函数 TTEST 使用计算出的、未进行舍入的 df 值。由于这些决定自由度的不同方式,TTEST 函数和此 t-检验工具的结果将与“异方差”情况中不同。
“t-检验: 双样本异方差假设”对话框
变量 1 的区域 在此输入需要分析的第一个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
变量 2 的区域 在此输入需要分析的第二个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
假设平均差 在此输入样本平均值的差值。0(零)值表示假设样本平均值相同。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入检验的置信度。该值必须介于 0 到 1 之间。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
“z-检验: 双样本平均值”分析工具可对具有已知方差的平均值进行双样本 z-检验。此工具用于检验两个总体平均值之间不存在差异的空值假设,而不是单方或双方的其他假设。如果方差未知,则应使用工作表函数 ZTEST。
当使用“z-检验”工具时,应该仔细理解输出。当总体平均值之间没有差异时,“P(Z <= z) 单尾”是 P(Z >= ABS(z)),即与 z 观察值沿着相同的方向远离 0 的 z 值的概率。当总体平均值之间没有差异时,“P(Z <= z) 双尾”是 P(Z >= ABS(z) 或 Z <= -ABS(z)),即沿着任何方向(而非与观察到的 z 值的方向一致)远离 0 的 z 值的概率。双尾结果只是单尾结果乘以 2。z-检验工具还可用于当两个总体平均值之间的差异具有特定非零值的空值假设的情况。例如,可以使用此检验确定两个汽车模型的性能差异。
“z-检验: 双样本平均值”对话框
变量 1 的区域 在此输入需要分析的第一个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
变量 2 的区域 在此输入需要分析的第二个数据区域的单元格引用。该区域必须由单列或单行的数据组成。
假设平均差 在此输入样本平均值的差值。0(零)值表示假设样本平均值相同。
变量 1 的方差(已知) 为变量 1 的数据源区域输入已知的总体方差。
变量 2 的方差(已知) 为变量 2 的数据源区域输入已知的总体方差。
标志 如果数据源区域的第一行或第一列中包含标志项,请选中此复选框。如果数据源区域没有标志项,请清除此复选框,Microsoft Office Excel 将在输出表中生成适当的数据标志。
α 在此输入检验的置信度。该值必须介于 0 到 1 之间。α 置信度为与 I 型错误发生概率相关的显著性水平(拒绝真假设)。
输出区域 在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。
新工作表 单击此选项可在当前工作簿中插入新工作表,并从新工作表的 A1 单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。
新工作簿 单击此选项可创建新工作簿并将结果添加到其中的新工作表中。
注释
- 该数据分析功能一次只能应用于一张工作表。如果对组合的工作表进行数据分析,计算结果只会显示在第一张工作表上,其余工作表上将显示带格式的空白表格。若要对其余工作表进行数据分析,分别在每张工作表上运行一次分析工具即可。
- 有关提供用于创建 Microsoft Excel 统计工具和功能的统计方法或算法详细信息的书籍列表,请参阅统计方法和算法的参考书目。
xl 使用什么方法能够分析统计信息? 使用什么方法能够分析统计信息? 使用什么方法能够分析统计信息? 使用什么方法能够分析统计信息? 使用什么方法能够分析统计信息? 双因素方差分析 双因素方差分析 双因素方差分析 双因素方差分析 双因素方差分析 数据分析结果错误 数据分析结果错误 数据分析结果错误 数据分析结果错误 数据分析结果错误 比较方法 比较方法 比较方法 比较方法 比较方法 自动散点图 自动散点图 自动散点图 自动散点图 自动散点图
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
