Google Analytics UTM参数
Google Analytics UTM参数
我们知道,页面设置好Google Analytics基本跟踪代码后,用以下UTM广告些列参数对着陆页面的url进行标注,可以区别衡量各种营销渠道所带来的访客价值。因此,我们需要想法在访客分享页面时,在被分享的url后添加UTM参数。
| 参数 | 说明 | 描述 |
|---|---|---|
| 广告系列来源(utm_source) | 必填 | 使用 utm_source 来标识 搜索 引擎、简报名称或其他来源。 示例:utm_source=google |
| 广告系列媒介(utm_medium) | 必填 | 使用 utm_medium 来标识 电子邮件 或每次点击 费用等媒介。 示例:utm_medium=cpc |
| 广告系列字词 (utm_term) | 用于付费搜索。 | 使用 utm_term 来注明此广告的关键字。 示例: utm_term=running+shoes |
| 广告系列内容 (utm_content) | 用于 A/B 测试和 以网页内容定位的 广告。 | 使用 utm_content 区分指向同一网址的 广告或链接。 示例:utm_content=logolink 或utm_content=textlink |
| 广告系列名称 (utm_campaign) | 必填,用于关键字分析。 | 使用 utm_campaign 来标识特定的产品促销活动或战略性广告系列。 示例:utm_campaign=spring_sale |
关于自定义广告系列
https://support.google.com/analytics/answer/1033863?hl=zh-Hans
网址构建工具
https://support.google.com/analytics/answer/1033867?hl=zh-Hans&ref_topic=1032998
linux下批量替换文件内容
1、网络上现成的资料
格式: sed -i "s/查找字段/替换字段/g" `grep 查找字段 -rl 路径`
linux sed 批量替换多个文件中的字符串
sed -i "s/oldstring/newstring/g" `grep oldstring -rl yourdir`
例如:替换/home下所有文件中的www.admin99.net为admin99.net
sed -i "s/www.admin99.net/admin99.net/g" `grep www.admin99.net -rl /home`
exp:sed -i "s/shabi/$/g" `grep shabi -rl ./`
2、自己额外附加
2.1 将文件1.txt内的文字“garden”替换成“mirGarden”
# sed -i "s/garden/mirGarden/g" 1.txt //sed -i 很简单
2.2 将当前目录下的所有文件内的“garden”替换成“mirGarden”
## sed -i "s/garden/mirGarden/g" `ls` //其实也就是ls出多个文件名而已
【原创】PHP超时处理全面总结
【 概述 】
在PHP开发中工作里非常多使用到超时处理到超时的场合,我说几个场景:
1. 异步获取数据如果某个后端数据源获取不成功则跳过,不影响整个页面展现
2. 为了保证Web服务器不会因为当个页面处理性能差而导致无法访问其他页面,则会对某些页面操作设置
3. 对于某些上传或者不确定处理时间的场合,则需要对整个流程中所有超时设置为无限,否则任何一个环节设置不当,都会导致莫名执行中断
4. 多个后端模块(MySQL、Memcached、HTTP接口),为了防止单个接口性能太差,导致整个前面获取数据太缓慢,影响页面打开速度,引起雪崩
5. 。。。很多需要超时的场合
这些地方都需要考虑超时的设定,但是PHP中的超时都是分门别类,各个处理方式和策略都不同,为了系统的描述,我总结了PHP中常用的超时处理的总结。
【Web服务器超时处理】
[ Apache ]
一般在性能很高的情况下,缺省所有超时配置都是30秒,但是在上传文件,或者网络速度很慢的情况下,那么可能触发超时操作。
目前 apache fastcgi php-fpm 模式 下有三个超时设置:
fastcgi 超时设置:
修改 httpd.conf 的fastcgi连接配置,类似如下:
| <IfModule mod_fastcgi.c> FastCgiExternalServer /home/forum/apache/apache_php/cgi-bin/php-cgi -socket /home/forum/php5/etc/php-fpm.sock
ScriptAlias /fcgi-bin/ "/home/forum/apache/apache_php/cgi-bin/" AddHandler php-fastcgi .php Action php-fastcgi /fcgi-bin/php-cgi AddType application/x-httpd-php .php </IfModule> |
缺省配置是 30s,如果需要定制自己的配置,需要修改配置,比如修改为100秒:(修改后重启 apache):
| <IfModule mod_fastcgi.c>
FastCgiExternalServer /home/forum/apache/apache_php/cgi-bin/php-cgi -socket /home/forum/php5/etc/php-fpm.sock -idle-timeout 100 ScriptAlias /fcgi-bin/ "/home/forum/apache/apache_php/cgi-bin/" AddHandler php-fastcgi .php Action php-fastcgi /fcgi-bin/php-cgi AddType application/x-httpd-php .php </IfModule>
|
如果超时会返回500错误,断开跟后端php服务的连接,同时记录一条apache错误日志:
[Thu Jan 27 18:30:15 2011] [error] [client 10.81.41.110] FastCGI: comm with server "/home/forum/apache/apache_php/cgi-bin/php-cgi" aborted: idle timeout (30 sec)
[Thu Jan 27 18:30:15 2011] [error] [client 10.81.41.110] FastCGI: incomplete headers (0 bytes) received from server "/home/forum/apache/apache_php/cgi-bin/php-cgi"
其他 fastcgi 配置参数说明:
| IdleTimeout 发呆时限ProcessLifeTime 一个进程的最长生命周期,过期之后无条件kill
MaxProcessCount 最大进程个数 DefaultMinClassProcessCount 每个程序启动的最小进程个数 DefaultMaxClassProcessCount 每个程序启动的最大进程个数 IPCConnectTimeout 程序响应超时时间 IPCCommTimeout 与程序通讯的最长时间,上面的错误有可能就是这个值设置过小造成的 MaxRequestsPerProcess 每个进程最多完成处理个数,达成后自杀 |
[ Lighttpd ]
配置:lighttpd.conf
Lighttpd配置中,关于超时的参数有如下几个(篇幅考虑,只写读超时,写超时参数同理):
主要涉及选项:
server.max-keep-alive-idle = 5
server.max-read-idle = 60
server.read-timeout = 0
server.max-connection-idle = 360
| --------------------------------------------------
# 每次keep-alive 的最大请求数, 默认值是16 server.max-keep-alive-requests = 100
# keep-alive的最长等待时间, 单位是秒,默认值是5 server.max-keep-alive-idle = 1200
# lighttpd的work子进程数,默认值是0,单进程运行 server.max-worker = 2
# 限制用户在发送请求的过程中,最大的中间停顿时间(单位是秒), # 如果用户在发送请求的过程中(没发完请求),中间停顿的时间太长,lighttpd会主动断开连接 # 默认值是60(秒) server.max-read-idle = 1200
# 限制用户在接收应答的过程中,最大的中间停顿时间(单位是秒), # 如果用户在接收应答的过程中(没接完),中间停顿的时间太长,lighttpd会主动断开连接 # 默认值是360(秒) server.max-write-idle = 12000
# 读客户端请求的超时限制,单位是秒, 配为0表示不作限制 # 设置小于max-read-idle时,read-timeout生效 server.read-timeout = 0
# 写应答页面给客户端的超时限制,单位是秒,配为0表示不作限制 # 设置小于max-write-idle时,write-timeout生效 server.write-timeout = 0
# 请求的处理时间上限,如果用了mod_proxy_core,那就是和后端的交互时间限制, 单位是秒 server.max-connection-idle = 1200 -------------------------------------------------- |
说明:
对于一个keep-alive连接上的连续请求,发送第一个请求内容的最大间隔由参数max-read-idle决定,从第二个请求起,发送请求内容的最大间隔由参数max-keep-alive-idle决定。请求间的间隔超时也由max-keep-alive-idle决定。发送请求内容的总时间超时由参数read-timeout决定。Lighttpd与后端交互数据的超时由max-connection-idle决定。
延伸阅读:
http://www.snooda.com/read/244
[ Nginx ]
配置:nginx.conf
| http {
#Fastcgi: (针对后端的fastcgi 生效, fastcgi 不属于proxy模式) fastcgi_connect_timeout 5; #连接超时 fastcgi_send_timeout 10; #写超时 fastcgi_read_timeout 10; #读取超时
#Proxy: (针对proxy/upstreams的生效) proxy_connect_timeout 15s; #连接超时 proxy_read_timeout 24s; #读超时 proxy_send_timeout 10s; #写超时 } |
说明:
Nginx 的超时设置倒是非常清晰容易理解,上面超时针对不同工作模式,但是因为超时带来的问题是非常多的。
延伸阅读:
http://hi.baidu.com/pibuchou/blog/item/a1e330dd71fb8a5995ee3753.html
http://hi.baidu.com/pibuchou/blog/item/7cbccff0a3b77dc60b46e024.html
http://hi.baidu.com/pibuchou/blog/item/10a549818f7e4c9df703a626.html
【PHP本身超时处理】
[ PHP-fpm ]
配置:php-fpm.conf
| <?xml version="1.0" ?>
<configuration> //... Sets the limit on the number of simultaneous requests that will be served. Equivalent to Apache MaxClients directive. Equivalent to PHP_FCGI_CHILDREN environment in original php.fcgi Used with any pm_style. #php-cgi的进程数量 <value name="max_children">128</value>
The timeout (in seconds) for serving a single request after which the worker process will be terminated Should be used when 'max_execution_time' ini option does not stop script execution for some reason '0s' means 'off' #php-fpm 请求执行超时时间,0s为永不超时,否则设置一个 Ns 为超时的秒数 <value name="request_terminate_timeout">0s</value>
The timeout (in seconds) for serving of single request after which a php backtrace will be dumped to slow.log file '0s' means 'off' <value name="request_slowlog_timeout">0s</value>
</configuration>
|
说明:
在 php.ini 中,有一个参数 max_execution_time 可以设置 PHP 脚本的最大执行时间,但是,在 php-cgi(php-fpm) 中,该参数不会起效。真正能够控制 PHP 脚本最大执行时:
<value name="request_terminate_timeout">0s</value>
就是说如果是使用 mod_php5.so 的模式运行 max_execution_time 是会生效的,但是如果是php-fpm模式中运行时不生效的。
延伸阅读:
http://blog.s135.com/file_get_contents/
[ PHP ]
配置:php.ini
选项:
max_execution_time = 30
或者在代码里设置:
ini_set("max_execution_time", 30);
set_time_limit(30);
说明:
对当前会话生效,比如设置0一直不超时,但是如果php的 safe_mode 打开了,这些设置都会不生效。
效果一样,但是具体内容需要参考php-fpm部分内容,如果php-fpm中设置了 request_terminate_timeout 的话,那么 max_execution_time 就不生效。
【后端&接口访问超时】
【HTTP访问】
一般我们访问HTTP方式很多,主要是:curl, socket, file_get_contents() 等方法。
如果碰到对方服务器一直没有响应的时候,我们就悲剧了,很容易把整个服务器搞死,所以在访问http的时候也需要考虑超时的问题。
[ CURL 访问HTTP]
CURL 是我们常用的一种比较靠谱的访问HTTP协议接口的lib库,性能高,还有一些并发支持的功能等。
CURL:
curl_setopt($ch, opt) 可以设置一些超时的设置,主要包括:
*(重要) CURLOPT_TIMEOUT 设置cURL允许执行的最长秒数。
*(重要) CURLOPT_TIMEOUT_MS 设置cURL允许执行的最长毫秒数。 (在cURL 7.16.2中被加入。从PHP 5.2.3起可使用。 )
CURLOPT_CONNECTTIMEOUT 在发起连接前等待的时间,如果设置为0,则无限等待。
CURLOPT_CONNECTTIMEOUT_MS 尝试连接等待的时间,以毫秒为单位。如果设置为0,则无限等待。 在cURL 7.16.2中被加入。从PHP 5.2.3开始可用。
CURLOPT_DNS_CACHE_TIMEOUT 设置在内存中保存DNS信息的时间,默认为120秒。
curl普通秒级超时:
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, 60); //只需要设置一个秒的数量就可以
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_USERAGENT, $defined_vars['HTTP_USER_AGENT']);
curl普通秒级超时使用:
curl_setopt($ch, CURLOPT_TIMEOUT, 60);
curl如果需要进行毫秒超时,需要增加:
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
或者是:
curl_setopt ( $ch, CURLOPT_NOSIGNAL, true); 是可以支持毫秒级别超时设置的
curl一个毫秒级超时的例子:
| <?php
if (!isset($_GET['foo'])) { // Client $ch = curl_init('http://example.com/'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_NOSIGNAL, 1); //注意,毫秒超时一定要设置这个 curl_setopt($ch, CURLOPT_TIMEOUT_MS, 200); //超时毫秒,cURL 7.16.2中被加入。从PHP 5.2.3起可使用 $data = curl_exec($ch); $curl_errno = curl_errno($ch); $curl_error = curl_error($ch); curl_close($ch);
if ($curl_errno > 0) { echo "cURL Error ($curl_errno): $curl_error\n"; } else { echo "Data received: $data\n"; } } else { // Server sleep(10); echo "Done."; } ?> |
其他一些技巧:
1. 按照经验总结是:cURL 版本 >= libcurl/7.21.0 版本,毫秒级超时是一定生效的,切记。
2. curl_multi的毫秒级超时也有问题。。单次访问是支持ms级超时的,curl_multi并行调多个会不准
[流处理方式访问HTTP]
除了curl,我们还经常自己使用fsockopen、或者是file操作函数来进行HTTP协议的处理,所以,我们对这块的超时处理也是必须的。
一般连接超时可以直接设置,但是流读取超时需要单独处理。
自己写代码处理:
$tmCurrent = gettimeofday();
$intUSGone = ($tmCurrent['sec'] - $tmStart['sec']) * 1000000
+ ($tmCurrent['usec'] - $tmStart['usec']);
if ($intUSGone > $this->_intReadTimeoutUS) {
return false;
}
或者使用内置流处理函数 stream_set_timeout() 和 stream_get_meta_data() 处理:
| <?php // Timeout in seconds
$timeout = 5; $fp = fsockopen("example.com", 80, $errno, $errstr, $timeout); if ($fp) { fwrite($fp, "GET / HTTP/1.0\r\n"); fwrite($fp, "Host: example.com\r\n"); fwrite($fp, "Connection: Close\r\n\r\n"); stream_set_blocking($fp, true); //重要,设置为非阻塞模式 stream_set_timeout($fp,$timeout); //设置超时 $info = stream_get_meta_data($fp); while ((!feof($fp)) && (!$info['timed_out'])) { $data .= fgets($fp, 4096); $info = stream_get_meta_data($fp); ob_flush; flush(); } if ($info['timed_out']) { echo "Connection Timed Out!"; } else { echo $data; } } |
file_get_contents 超时:
| <?php$timeout = array(
'http' => array( 'timeout' => 5 //设置一个超时时间,单位为秒 ) ); $ctx = stream_context_create($timeout); $text = file_get_contents("http://example.com/", 0, $ctx); ?> |
fopen 超时:
| <?php$timeout = array(
'http' => array( 'timeout' => 5 //设置一个超时时间,单位为秒 ) ); $ctx = stream_context_create($timeout); if ($fp = fopen("http://example.com/", "r", false, $ctx)) { while( $c = fread($fp, 8192)) { echo $c; } fclose($fp); } ?> |
【MySQL】
php中的mysql客户端都没有设置超时的选项,mysqli和mysql都没有,但是libmysql是提供超时选项的,只是我们在php中隐藏了而已。
那么如何在PHP中使用这个操作捏,就需要我们自己定义一些MySQL操作常量,主要涉及的常量有:
MYSQL_OPT_READ_TIMEOUT=11;
MYSQL_OPT_WRITE_TIMEOUT=12;
这两个,定义以后,可以使用 options 设置相应的值。
不过有个注意点,mysql内部实现:
1. 超时设置单位为秒,最少配置1秒
2. 但mysql底层的read会重试两次,所以实际会是 3 秒
重试两次 + 自身一次 = 3倍超时时间,那么就是说最少超时时间是3秒,不会低于这个值,对于大部分应用来说可以接受,但是对于小部分应用需要优化。
查看一个设置访问mysql超时的php实例:
| <?php//自己定义读写超时常量
if (!defined('MYSQL_OPT_READ_TIMEOUT')) { define('MYSQL_OPT_READ_TIMEOUT', 11); } if (!defined('MYSQL_OPT_WRITE_TIMEOUT')) { define('MYSQL_OPT_WRITE_TIMEOUT', 12); } //设置超时 $mysqli = mysqli_init(); $mysqli->options(MYSQL_OPT_READ_TIMEOUT, 3); $mysqli->options(MYSQL_OPT_WRITE_TIMEOUT, 1);
//连接数据库 $mysqli->real_connect("localhost", "root", "root", "test"); if (mysqli_connect_errno()) { printf("Connect failed: %s/n", mysqli_connect_error()); exit(); } //执行查询 sleep 1秒不超时 printf("Host information: %s/n", $mysqli->host_info); if (!($res=$mysqli->query('select sleep(1)'))) { echo "query1 error: ". $mysqli->error ."/n"; } else { echo "Query1: query success/n"; } //执行查询 sleep 9秒会超时 if (!($res=$mysqli->query('select sleep(9)'))) { echo "query2 error: ". $mysqli->error ."/n"; } else { echo "Query2: query success/n"; } $mysqli->close(); echo "close mysql connection/n"; ?> |
延伸阅读:
http://blog.csdn.net/heiyeshuwu/article/details/5869813
【Memcached】
[PHP扩展]
php_memcache 客户端:
连接超时:bool Memcache::connect ( string $host [, int $port [, int $timeout ]] )
在get和set的时候,都没有明确的超时设置参数。
libmemcached 客户端:在php接口没有明显的超时参数。
说明:所以说,在PHP中访问Memcached是存在很多问题的,需要自己hack部分操作,或者是参考网上补丁。
[C&C++访问Memcached]
客户端:libmemcached 客户端
说明:memcache超时配置可以配置小点,比如5,10个毫秒已经够用了,超过这个时间还不如从数据库查询。
下面是一个连接和读取set数据的超时的C++示例:
| //创建连接超时(连接到Memcached)
memcached_st* MemCacheProxy::_create_handle() { memcached_st * mmc = NULL; memcached_return_t prc; if (_mpool != NULL) { // get from pool mmc = memcached_pool_pop(_mpool, false, &prc); if (mmc == NULL) { __LOG_WARNING__("MemCacheProxy", "get handle from pool error [%d]", (int)prc); } return mmc; }
memcached_st* handle = memcached_create(NULL); if (handle == NULL){ __LOG_WARNING__("MemCacheProxy", "create_handle error"); return NULL; }
// 设置连接/读取超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_HASH, MEMCACHED_HASH_DEFAULT); memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_NO_BLOCK, _noblock); //参数MEMCACHED_BEHAVIOR_NO_BLOCK为1使超时配置生效,不设置超时会不生效,关键时候会悲剧的,容易引起雪崩 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_CONNECT_TIMEOUT, _connect_timeout); //连接超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_RCV_TIMEOUT, _read_timeout); //读超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_SND_TIMEOUT, _send_timeout); //写超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_POLL_TIMEOUT, _poll_timeout);
// 设置一致hash // memcached_behavior_set_distribution(handle, MEMCACHED_DISTRIBUTION_CONSISTENT); memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_DISTRIBUTION, MEMCACHED_DISTRIBUTION_CONSISTENT);
memcached_return rc; for (uint i = 0; i < _server_count; i++){ rc = memcached_server_add(handle, _ips[i], _ports[i]); if (MEMCACHED_SUCCESS != rc) { __LOG_WARNING__("MemCacheProxy", "add server [%s:%d] failed.", _ips[i], _ports[i]); } }
_mpool = memcached_pool_create(handle, _min_connect, _max_connect); if (_mpool == NULL){ __LOG_WARNING__("MemCacheProxy", "create_pool error"); return NULL; }
mmc = memcached_pool_pop(_mpool, false, &prc); if (mmc == NULL) { __LOG_WARNING__("MyMemCacheProxy", "get handle from pool error [%d]", (int)prc); } //__LOG_DEBUG__("MemCacheProxy", "get handle [%p]", handle); return mmc; }
//设置一个key超时(set一个数据到memcached) bool MemCacheProxy::_add(memcached_st* handle, unsigned int* key, const char* value, int len, unsigned int timeout) { memcached_return rc;
char tmp[1024]; snprintf(tmp, sizeof (tmp), "%u#%u", key[0], key[1]); //有个timeout值 rc = memcached_set(handle, tmp, strlen(tmp), (char*)value, len, timeout, 0); if (MEMCACHED_SUCCESS != rc){ return false; } return true; } |
//Memcache读取数据超时 (没有设置)
libmemcahed 源码中接口定义:
LIBMEMCACHED_API char *memcached_get(memcached_st *ptr,const char *key, size_t key_length,size_t *value_length,uint32_t *flags,memcached_return_t *error);
LIBMEMCACHED_API memcached_return_t memcached_mget(memcached_st *ptr,const char * const *keys,const size_t *key_length,size_t number_of_keys);
从接口中可以看出在读取数据的时候,是没有超时设置的。
延伸阅读:
http://hi.baidu.com/chinauser/item/b30af90b23335dde73e67608
http://libmemcached.org/libMemcached.html
【如何实现超时】
程序中需要有超时这种功能,比如你单独访问一个后端Socket模块,Socket模块不属于我们上面描述的任何一种的时候,它的协议也是私有的,那么这个时候可能需要自己去实现一些超时处理策略,这个时候就需要一些处理代码了。
[PHP中超时实现]
一、初级:最简单的超时实现 (秒级超时)
思路很简单:链接一个后端,然后设置为非阻塞模式,如果没有连接上就一直循环,判断当前时间和超时时间之间的差异。
php socket 中实现原始的超时:(每次循环都当前时间去减,性能会很差,cpu占用会较高)
| <? $host = "127.0.0.1";
$port = "80"; $timeout = 15; //timeout in seconds
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP) or die("Unable to create socket\n");
socket_set_nonblock($socket) //务必设置为阻塞模式 or die("Unable to set nonblock on socket\n");
$time = time(); //循环的时候每次都减去相应值 while (!@socket_connect($socket, $host, $port)) //如果没有连接上就一直死循环 { $err = socket_last_error($socket); if ($err == 115 || $err == 114) { if ((time() - $time) >= $timeout) //每次都需要去判断一下是否超时了 { socket_close($socket); die("Connection timed out.\n"); } sleep(1); continue; } die(socket_strerror($err) . "\n"); } socket_set_block($this->socket) //还原阻塞模式 or die("Unable to set block on socket\n"); ?> |
二、升级:使用PHP自带异步IO去实现(毫秒级超时)
说明:
异步IO:异步IO的概念和同步IO相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。异步IO将比特分成小组进行传送,小组可以是8位的1个字符或更长。发送方可以在任何时刻发送这些比特组,而接收方从不知道它们会在什么时候到达。
多路复用:复用模型是对多个IO操作进行检测,返回可操作集合,这样就可以对其进行操作了。这样就避免了阻塞IO不能随时处理各个IO和非阻塞占用系统资源的确定。
使用 socket_select() 实现超时
socket_select(..., floor($timeout), ceil($timeout*1000000));
select的特点:能够设置到微秒级别的超时!
使用socket_select() 的超时代码(需要了解一些异步IO编程的知识去理解)
| ### 调用类 ####
<?php $server = new Server; $client = new Client;
for (;;) { foreach ($select->can_read(0) as $socket) {
if ($socket == $client->socket) { // New Client Socket $select->add(socket_accept($client->socket)); } else { //there's something to read on $socket } } } ?>
### 异步多路复用IO & 超时连接处理类 ### <?php class select { var $sockets;
function select($sockets) {
$this->sockets = array();
foreach ($sockets as $socket) { $this->add($socket); } }
function add($add_socket) { array_push($this->sockets,$add_socket); }
function remove($remove_socket) { $sockets = array();
foreach ($this->sockets as $socket) { if($remove_socket != $socket) $sockets[] = $socket; }
$this->sockets = $sockets; }
function can_read($timeout) { $read = $this->sockets; socket_select($read,$write = NULL,$except = NULL,$timeout); return $read; }
function can_write($timeout) { $write = $this->sockets; socket_select($read = NULL,$write,$except = NULL,$timeout); return $write; } } ?> |
[C&C++中超时实现]
一般在Linux C/C++中,可以使用:alarm() 设置定时器的方式实现秒级超时,或者:select()、poll()、epoll() 之类的异步复用IO实现毫秒级超时。也可以使用二次封装的异步io库(libevent, libev)也能实现。
一、使用alarm中用信号实现超时 (秒级超时)
说明:Linux内核connect超时通常为75秒,我们可以设置更小的时间如10秒来提前从connect中返回。这里用使用信号处理机制,调用alarm,超时后产生SIGALRM信号 (也可使用select实现)
用 alarym 秒级实现 connect 设置超时代码示例:
| //信号处理函数static void connect_alarm(int signo)
{ debug_printf("SignalHandler"); return; }
//alarm超时连接实现 static void conn_alarm() { Sigfunc * sigfunc ; //现有信号处理函数 sigfunc=signal(SIGALRM, connect_alarm); //建立信号处理函数connect_alarm,(如果有)保存现有的信号处理函数 int timeout = 5;
//设置闹钟 if( alarm(timeout)!=0 ){ //... 闹钟已经设置处理 }
//进行连接操作 if (connect(m_Socket, (struct sockaddr *)&addr, sizeof(addr)) < 0 ) { if ( errno == EINTR ) { //如果错误号设置为EINTR,说明超时中断了 debug_printf("Timeout"); m_connectionStatus = STATUS_CLOSED; errno = ETIMEDOUT; //防止三次握手继续进行 return ERR_TIMEOUT; } else { debug_printf("Other Err"); m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } } alarm(0);//关闭时钟 signal(SIGALRM, sigfunc); //(如果有)恢复原来的信号处理函数 return; } |
//读取数据的超时设置
同样可以为 recv 设置超时,5秒内收不到任何应答就中断
signal( ... );
alarm(5);
recv( ... );
alarm(0);
static void sig_alarm(int signo){return;}
当客户端阻塞于读(readline,...)时,如果此时服务器崩了,客户TCP试图从服务器接收一个ACK,持续重传 数据分节,大约要等9分钟才放弃重传,并返回一个错误。因此,在客户读阻塞时,调用超时。
二、使用异步复用IO使用 (毫秒级超时)
异步IO执行流程:
1.首先将标志位设为Non-blocking模式,准备在非阻塞模式下调用connect函数
2.调用connect,正常情况下,因为TCP三次握手需要一些时间;而非阻塞调用只要不能立即完成就会返回错误,所以这里会返回EINPROGRESS,表示在建立连接但还没有完成。
3.在读套接口描述符集(fd_set rset)和写套接口描述符集(fd_set wset)中将当前套接口置位(用FD_ZERO()、FD_SET()宏),并设置好超时时间(struct timeval *timeout)
4.调用select( socket, &rset, &wset, NULL, timeout )
返回0表示connect超时,如果你设置的超时时间大于75秒就没有必要这样做了,因为内核中对connect有超时限制就是75秒。
//select 实现毫秒级超时示例:
| static void conn_select() {
// Open TCP Socket m_Socket = socket(PF_INET,SOCK_STREAM,0); if( m_Socket < 0 ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; }
struct sockaddr_in addr; inet_aton(m_Host.c_str(), &addr.sin_addr); addr.sin_port = htons(m_Port); addr.sin_family = PF_INET;
// Set timeout values for socket struct timeval timeouts; timeouts.tv_sec = SOCKET_TIMEOUT_SEC ; // const -> 5 timeouts.tv_usec = SOCKET_TIMEOUT_USEC ; // const -> 0 uint8_t optlen = sizeof(timeouts);
if( setsockopt( m_Socket, SOL_SOCKET, SO_RCVTIMEO,&timeouts,(socklen_t)optlen) < 0 ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; }
// Set the Socket to TCP Nodelay ( Send immediatly after a send / write command ) int flag_TCP_nodelay = 1; if ( (setsockopt( m_Socket, IPPROTO_TCP, TCP_NODELAY, (char *)&flag_TCP_nodelay, sizeof(flag_TCP_nodelay))) < 0) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } // Save Socket Flags int opts_blocking = fcntl(m_Socket, F_GETFL); if ( opts_blocking < 0 ) { return ERR_NET_SOCKET; } //设置为非阻塞模式 int opts_noblocking = (opts_blocking | O_NONBLOCK); // Set Socket to Non-Blocking if (fcntl(m_Socket, F_SETFL, opts_noblocking)<0) { return ERR_NET_SOCKET; } // Connect if ( connect(m_Socket, (struct sockaddr *)&addr, sizeof(addr)) < 0) { // EINPROGRESS always appears on Non Blocking connect if ( errno != EINPROGRESS ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } // Create a set of sockets for select fd_set socks; FD_ZERO(&socks); FD_SET(m_Socket,&socks); // Wait for connection or timeout int fdcnt = select(m_Socket+1,NULL,&socks,NULL,&timeouts); if ( fdcnt < 0 ) { return ERR_NET_SOCKET; } else if ( fdcnt == 0 ) { return ERR_TIMEOUT; } } //Set Socket to Blocking again if(fcntl(m_Socket,F_SETFL,opts_blocking)<0) { return ERR_NET_SOCKET; }
m_connectionStatus = STATUS_OPEN; return 0; } |
说明:在超时实现方面,不论是什么脚本语言:PHP、Python、Perl 基本底层都是C&C++的这些实现方式,需要理解这些超时处理,需要一些Linux 编程和网络编程的知识。
延伸阅读:
http://blog.sina.com.cn/s/blog_4462f8560100tvgo.html
http://blog.csdn.net/thimin/article/details/1530839
http://hi.baidu.com/xjtdy888/item/93d9daefcc1d31d1ea34c992
http://blog.csdn.net/byxdaz/article/details/5461142
http://blog.163.com/xychenbaihu@yeah/blog/static/13222965520112163171778/
http://hi.baidu.com/suyupin/item/df10004decb620e91f19bcf5
http://stackoverflow.com/questions/7092633/connect-timeout-with-alarm
http://stackoverflow.com/questions/7089128/linux-tcp-connect-with-select-fails-at-testserver?lq=1
http://cppentry.com/bencandy.php?fid=54&id=1129
【 总结 】
1. PHP应用层如何设置超时?
PHP在处理超时层次有很多,不同层次,需要前端包容后端超时:
浏览器(客户端) -> 接入层 -> Web服务器 -> PHP -> 后端 (MySQL、Memcached)
就是说,接入层(Web服务器层)的超时时间必须大于PHP(PHP-FPM)中设置的超时时间,不然后面没处理完,你前面就超时关闭了,这个会很杯具。还有就是PHP的超时时间要大于PHP本身访问后端(MySQL、HTTP、Memcached)的超时时间,不然结局同前面。
2. 超时设置原则是什么?
如果是希望永久不超时的代码(比如上传,或者定期跑的程序),我仍然建议设置一个超时时间,比如12个小时这样的,主要是为了保证不会永久夯住一个php进程或者后端,导致无法给其他页面提供服务,最终引起所有机器雪崩。
如果是要要求快速响应的程序,建议后端超时设置短一些,比如连接500ms,读1s,写1s,这样的速度,这样能够大幅度减少应用雪崩的问题,不会让服务器负载太高。
3. 自己开发超时访问合适吗?
一般如果不是万不得已,建议用现有很多网络编程框架也好、基础库也好,里面一般都带有超时的实现,比如一些网络IO的lib库,尽量使用它们内置的,自己重复造轮子容易有bug,也不方便维护(不过如是是基于学习的目的就当别论了)。
4. 其他建议
超时在所有应用里都是大问题,在开发应用的时候都要考虑到。我见过一些应用超时设置上百秒的,这种性能就委实差了,我举个例子:
比如你php-fpm开了128个php-cgi进程,然后你的超时设置的是32s,那么我们如果后端服务比较差,极端情况下,那么最多每秒能响应的请求是:
128 / 32 = 4个
你没看错,1秒只能处理4个请求,那服务也太差了!虽然我们可以把php-cgi进程开大,但是内存占用,还有进程之间切换成本也会增加,cpu呀,内存呀都会增加,服务也会不稳定。所以,尽量设置一个合理的超时值,或者督促后端提高性能。
利用人性弱点的互联网服务
在人类社会发展的长河中,贪婪推动了这个社会的进步。无论是团购,点购,秒杀,还是抽奖,该类网站统一的制胜法宝就是价格极其低廉,巧妙的运用了低价这一特点,充分的激发人类贪婪的本性,一次次心甘情愿的点击购买。
一个伟大的产品发明离不开对人性的深刻探索。你可能不知道到底为什么某个产品让你着迷,你也可能不知道为什么一些公司总能制造出你想要的产品。来让我们看看这些公司到底用什么东西吸引着你。
极客观察本期的话题是:利用人性弱点的互联网服务,我们将会从“贪婪”、“色欲”、“虚荣”、“窥视”、“懒惰”等角度来间隙各种互联网产品如何利用人性的弱点来推广、前进。
这是第四期极客观察的第一部分:
贪婪
在人类社会发展的长河中,贪婪也推动了这个社会的进步。有关销售的网站都巧妙的利用这人性的弱点,在某种意义上来说,贪婪是推动销售的中坚力量。从总体来说,无论是团购,点购,秒杀,还是抽奖,该类网站统一的制胜法宝就是价格极其低廉,巧妙的运用了低价这一特点,充分的激发人类贪婪的本性,一次次心甘情愿的点击购买。贪婪也让这个社会的大量资源被无情的给浪费了。

最近非常流行一种新型的购物形式:点购。用户可以按照一定价格购买竞拍权利(一般为1-2元),每次竞拍将使该产品价格增加0.01元,并且同时增加20秒竞拍时间。当竞拍倒计时归0时,当时的领先者即最后出价的用户便赢得该竞拍,最终用户以非常低廉的价格买走该产品。这种类型的网站以非常低的成交价格吸引着众多用户。例如,价值5000元的 iPhone 4 手机竟以200元的价格成交,如此低廉的价格,激发了用户贪婪一面。使得很多用户不计金钱和时间成本的无限制投入,为网站创造了大把大把的利润。赢得产品的人变得更加贪婪,想去赢得更多的产品。没有赢得产品的人因为已经投入了很多金钱和时间,不得不再次投入让收支平衡。这种恶性循环正是贪婪的魔力。3、秒杀
同样很多网站也非常流行一种叫ʻ秒杀ʼ的购物形式。所谓“秒杀”,就是网络卖家发布一些限量的超低价格商品只能在有限的时间内购买。这恰恰激发了人们无限的贪婪欲望。由于商品价格低廉,往往一上架就被抢购一空,有时甚至只用一两秒钟。“秒杀”从无到有、从有到强不过三个月时间。这种购物形式同样的会吸引很多人购买本不需要的产品,并且真正优惠的精品提供量都很少,很难抢到。这就没有满足广大客户的贪婪需求,使得类似这种活动很难再次激发出人们的购买欲望,所以这种购物形式正在走向落末。4、抽奖
虽然秒杀越来越不给力,但是ʻ抽奖ʼ这种非常普通的行销手段却长盛不衰。特别是大量的出现在团购网站上的各类抽奖活动。形形色色的网站都推出过类似“0元购IPad”等活动,甚至于去抽奖“一套房”。这里也是利用人们贪婪的心里,去让客户注册,购买。并且与此同时获得大量的用户资料,之后在对其进行大量的团购宣传,重新满足他们贪婪的欲望。就像人人都想中彩票,但是不知自己浪费了时间以及进入了下一个贪婪陷阱。5、下载
我们身边或自己或许都有这么一种习惯,如果宽带是包月的话,就不舍得浪费每一秒钟,无时无刻的在下载根本不需要的内容。比如一个用户想下载一本书,后来发现自己下载了上千本书,到最后估计一本书也没看成。但是这种贪婪的心态给他们带来了满足感。这样就造成了大量的用户半夜挂机下载一堆将来有可能会用到的文件,从而推动了下载软件的发展和移动硬盘的发展。6、存储空间
虚荣
人生的价值就是获得别人的肯定,过分的追求不合理的或者虚假的表扬就是虚荣。虚荣心是人类一种普通的心理状态。虚荣使一个人上瘾,同时也极易容易影响他人,这就是虚荣强大的力量。现在众多网站都注意到了这一点,下大力气在体现用户价值上面做足了文章。
1、等级制度
使用QQ的用户都知道,如果你的QQ上有多个太阳,这证明了你的QQ资深身份。用户不得不长期的定时的使用产品来证明自己的高人一等的身份。腾讯巧妙的利用这种等级制度满足了大家虚荣的渴求,导致长时间的活跃用户在线,并让腾讯获利无穷。用户之间互相攀比导致更多的人追求更高的等级,也影响了周围的人。

这也是把游戏的等级部分延伸到游戏外。现在有更多的网站加入进来,人人也开始的自己的等级划分,各种消费的金银虚拟卡等等,无一例外的利用了人们虚荣的弱点,迫使人们做出了原本不愿意做的事情来证明自己的强大。
2、号码抢占
抢占各种资源也是虚荣的一种表现。不惜代价的搞到并维持漂亮的QQ号码,例如,现在身边有些朋友每个月迫不得已支付10元来保持住自己7位的QQ靓号,并且使用了越长时间的东西就越难以放弃,这都是因为当初的虚荣。更有甚者,当初为了证明自己多么厉害,竟然花费上百元点亮各种QQ标示。这就是腾讯利用虚荣这一人性的弱点演奏出来的一首首好曲。
3、位置服务
原本LBS是很无聊的,但是正因为加入了各种勋章,虚拟称号之后就变得火热起来。这同样满足了人类的虚荣的心里,用户为了各种徽章和称号,自愿去自己原本不想去的地方去Checkin(签到)。同样因为是虚荣,用户会向周围的朋友宣传自己的成就导致更多的人加入进来。这就是虚荣强大之处,需要别人的认可才能满足自己的虚荣。
用户通常都有持续登录Foursquar、Gowalla以及Facebook地理服务的心理需求,并不是因为想要告诉朋友他们在哪,而是为了保护自己在某一地盘上的领主地位不被他人取代。同时,对于那些没有成为领主的用户,他们也会努力去从现任的领主手中夺取这一称号。如果你因为经常忘记check-in而让自己没有机会成为你所在的办公室或者咖啡馆的领主,沮丧感将随之而来。
4、微博
微博也非常巧妙的利用了虚荣。用户可以炫耀自己的粉丝数量,这就激发起互相攀比自己的粉丝数量。同时网站也提供一项服务“分配粉丝”,这就是在新用户刚刚注册时候分配一些用户给他们,这就给网站提供了另外一条吸金途径。
用户会特别注意自己的发送内容的转发数量,转发的越多越能满足他们内在虚荣的需求。这就迫使用户提供更多的高质量的内容去吸引自己的粉丝转发自己的内容,从而进行了一个良性循环。
色欲是人类发展繁殖的基础和动力,同样也是网站发展壮大秘密法宝。从目前来看,厂家利用美女对那些饥渴的玩家进行心理上的刺激。其实色欲不应当只有美女这一种形式,所谓食色性也,或许我们今后更多会看到由帅哥组成的营销手段,更或者是美食。
色欲
色欲是人类发展繁殖的基础和动力,同样也是网站发展壮大秘密法宝。从目前来看,厂家利用美女对那些饥渴的玩家进行心理上的刺激。其实色欲不应当只有美女这一种形式,所谓食色性也,或许我们今后更多会看到由帅哥组成的营销手段,更或者是美食。

1、美女社区
美女人人爱看,美女多的地方,人气自然也就旺。于是,一个以遍布美女为标榜的社区类网站——美空网,在没有任何宣传的情况下,不到半年流量就超过了百万大关。很多兄弟们在美色的诱惑下登陆查看美空中的美女,并且非常积极的传播给身边的朋友。
这个网站恰到好处挑选出了精品美女,不仅有图片还有视频,充分满足了各位仁兄的欲望。从而推动这个网站的发展,而且是几何级数的增长。
这就是美女的魅力,这就是色欲的强大。
2、美女ID
在网站推广里,“美女ID”起着极其重要的作用。
几乎现在各个社区网站或者SNS网站,充斥这各种美女ID,从头像到相册,从诱惑发言到激情日记。全方位的激活大众色欲需求,激活网站流量的增长。其实我们或多或少的是因为某个美女ID从而注册某个网站或服务,在注册之后会发现更多的美女ID向你扑来。最近有一个好玩的现象就是在社交网站经常有美女ID要加为你的好友,你在不忍心之余就遭受了大量的垃圾广告。这就是色欲惹的祸。
3、胸
社区通常举办各种活动来吸引用户的参与。例如,猫扑网站之前举办的“美胸大赛”,吸引了众多眼球。各种各样的有关美女的帖子也为社区填“色”不少。
4、美女玩家
很多游戏也以色欲作为出发点,推广自己的产品。首当其冲的就是某款游戏给“美女玩家”发工资。美女玩家只有通过严格的审核才能通过,每个月都能收到游戏公司发的红包。这样的举措极大的鼓励和吸引了大量的美女玩家来玩这些游戏,正是大量的美女陪伴左右,在此同时也吸引了广大群众参与进来。色欲这个欲望满足了双方的情感。从而让游戏发展壮大火爆起来。
5、美女工会
更有甚者,看出了厂家利用色欲来吸引玩家的手段后,自行组织了“美女工会”,就像是经纪人公司一样。这种美女工会不仅吸引了各个游戏厂家争先恐后邀约他们入住自己的游戏,同时工会也创造出了自己的生存价值。
不只是厂家可以利用色欲这种人性的弱点,群众也可以团结起来,形成强大的组织来满足各个方面的需求。
强大的好奇心引发了各种各样的窥视行为,了解别人成为窥视的最大动力,同时窥视成为了社交网站中最强驱动力。因为满足了窥视这种心里需求,使得人人网,开心网等众多社交网站发展迅速。
窥视
强大的好奇心引发了各种各样的窥视行为,了解别人成为窥视的最大动力,同时窥视成为了社交网站中最强驱动力。
1、博客
博客天生就是用来被人窥视的,以方便可以来展现自己的风采,以及可以让想要了解你的人提供一种渠道。这就导致了很多人因为想去窥视某些人的博客从而使用某种服务。并且用户可以利用各种各样的博客信息去推测,例如,你可以通过观察你女朋友的博客,去了解到谁经常浏览她的博客,又有可能和谁建立了比较亲密的关系等。因为满足了窥视这种心里需求,使得人人网,开心网等众多社交网站发展迅速。
2、隐身
正是因为网站提供了详细的信息,使得可以从这些信息中挖掘出很多有价值的信息。比如谁看了这个照片,谁在这个月内浏览你的博客过多少次等。这就使得有些人不愿意留下自己的痕迹去窥视别人,从而隐身这项功能就诞生了。它可以充分的满足人们窥视的心里,让他们安心的去看自己想看的内容从而不留下任何痕迹。

3、名人博客/微博
名人博客的快速发展必须充分满足群众对于窥视他们的渴望。
名博经常会爆一些小料来让更多的人去关注他们的博客,粉丝们也想了解名人的私生活,会经常去看名人的博客,窥探他们的生活。
懒懒定律:凡是优秀的用户体验,必定是满足人性懒惰的。懒惰是社会发展的根本动力。正是因为懒惰,汽车代替了步行,计算器代替了算盘,电子邮件代替了传统邮件。现在有越来越多的服务都专门向懒人提供,况且懒惰是人类的天性,人人都是懒人。人人都需要可以让其可以懒惰的服务。
懒惰
懒懒定律:凡是优秀的用户体验,必定是满足人性懒惰的。
懒惰是社会发展的根本动力。正是因为懒惰,汽车代替了步行,计算器代替了算盘,电子邮件代替了传统邮件。现在有越来越多的服务都专门向懒人提供,况且懒惰是人类的天性,人人都是懒人。人人都需要可以让其可以懒惰的服务。
1、快捷键
一个拥有大量可以快捷键的产品总是受人欢迎的。
比如Google的各个产品都是用统一的快捷键,你可以快速高效的完成任务,懒惰的你可以尽量减少手臂的移动。大量的快捷键也可以让操作变得更加流畅,手可以呆在一个区域内去完成尽可能多的任务。耳熟能详的快捷键有复制,黏贴,撤销等。
2、网购
男人袜是一个网站给懒惰的男人设计的网购网站。很多男人都不在乎穿怎样的袜子,因为袜子一般不会露出来。也很少专门为了袜子去商场,最终可能很长一段时间都穿着有两个窟窿的袜子。

“男人袜”用极其简单的步骤满足了这帮懒惰的人的需求。这个网站甚至不用注册,直接使用支付宝支付一年的袜子费用,然后每三个月收到三双袜子。这样就非常完美的解决了“穿洞袜”的问题,中间的过程也极其简单。人类懒惰的本性让不懒惰的人找到了商业契机。
3、简单
当遇到新的事物的时候,大多数人都以懒惰为借口拒绝学习。但是苹果公司对这点把握的极其出色,它制造出了很多学习门槛极低的设备,这让这些懒人得到了充分的满足。这种极其简单的产品或者服务现在越来越受到人们的欢迎,比如说,最简单的文件共享网站Ge.tt,只需点击四下鼠标就可以把自己的文件共享给别人了。
Twitter为何流行?两个字:简单。简单是表象,隐藏的是懒惰。140字,不是限制,是自由。只能输入文字?很好,我本就这么懒。懒对于用户体验来说,就如五弦琴的第六弦,看不见但却至关重要。

QQDocshao47346124ImageV%WLH}11A56]H6EQP80SCFH.jpg)
让你的IE6、7、8 都很好的支持HTML5标签
在旧有的浏览器里面,很多元素都是不支持的,即使解析出来也是内联标签。所以某位外国大牛就写了JS把文本中的一些标记替换成了块标签,从而解决了IE的很多历史遗留问题。这对于HTML5的使用推广来说是一个历史性的变革,也能很好的解决一些兼容性问题。
https://github.com/sebastianbergmann/php-code-coverage/pull/128
JS代码:
001 |
/** |
002 |
* @preserve HTML5 Shiv v3.6.2pre | @afarkas @jdalton @jon_neal @rem | MIT/GPL2 Licensed |
003 |
*/ |
004 |
;(function(window, document) { |
005 |
/*jshint evil:true */ |
006 |
/** version */ |
007 |
var version = '3.6.2pre'; |
008 |
009 |
/** Preset options */ |
010 |
var options = window.html5 || {}; |
011 |
012 |
/** Used to skip problem elements */ |
013 |
var reSkip = /^<|^(?:button|map|select|textarea|object|iframe|option|optgroup)$/i; |
014 |
015 |
/** Not all elements can be cloned in IE **/ |
016 |
var saveClones = /^(?:a|b|code|div|fieldset|h1|h2|h3|h4|h5|h6|i|label|li|ol|p|q|span|strong|style|table|tbody|td|th|tr|ul)$/i; |
017 |
018 |
/** Detect whether the browser supports default html5 styles */ |
019 |
var supportsHtml5Styles; |
020 |
021 |
/** Name of the expando, to work with multiple documents or to re-shiv one document */ |
022 |
var expando = '_html5shiv'; |
023 |
024 |
/** The id for the the documents expando */ |
025 |
var expanID = 0; |
026 |
027 |
/** Cached data for each document */ |
028 |
var expandoData = {}; |
029 |
030 |
/** Detect whether the browser supports unknown elements */ |
031 |
var supportsUnknownElements; |
032 |
033 |
(function() { |
034 |
try { |
035 |
var a = document.createElement('a'); |
036 |
a.innerHTML = '<xyz></xyz>'; |
037 |
//if the hidden property is implemented we can assume, that the browser supports basic HTML5 Styles |
038 |
supportsHtml5Styles = ('hidden' in a); |
039 |
040 |
supportsUnknownElements = a.childNodes.length == 1 || (function() { |
041 |
// assign a false positive if unable to shiv |
042 |
(document.createElement)('a'); |
043 |
var frag = document.createDocumentFragment(); |
044 |
return ( |
045 |
typeof frag.cloneNode == 'undefined' || |
046 |
typeof frag.createDocumentFragment == 'undefined' || |
047 |
typeof frag.createElement == 'undefined' |
048 |
); |
049 |
}()); |
050 |
} catch(e) { |
051 |
supportsHtml5Styles = true; |
052 |
supportsUnknownElements = true; |
053 |
} |
054 |
055 |
}()); |
056 |
057 |
/*--------------------------------------------------------------------------*/ |
058 |
059 |
/** |
060 |
* Creates a style sheet with the given CSS text and adds it to the document. |
061 |
* @private |
062 |
* @param {Document} ownerDocument The document. |
063 |
* @param {String} cssText The CSS text. |
064 |
* @returns {StyleSheet} The style element. |
065 |
*/ |
066 |
function addStyleSheet(ownerDocument, cssText) { |
067 |
var p = ownerDocument.createElement('p'), |
068 |
parent = ownerDocument.getElementsByTagName('head')[0] || ownerDocument.documentElement; |
069 |
070 |
p.innerHTML = 'x<style>' + cssText + '</style>'; |
071 |
return parent.insertBefore(p.lastChild, parent.firstChild); |
072 |
} |
073 |
074 |
/** |
075 |
* Returns the value of `html5.elements` as an array. |
076 |
* @private |
077 |
* @returns {Array} An array of shived element node names. |
078 |
*/ |
079 |
function getElements() { |
080 |
var elements = html5.elements; |
081 |
return typeof elements == 'string' ? elements.split(' ') : elements; |
082 |
} |
083 |
|
084 |
/** |
085 |
* Returns the data associated to the given document |
086 |
* @private |
087 |
* @param {Document} ownerDocument The document. |
088 |
* @returns {Object} An object of data. |
089 |
*/ |
090 |
function getExpandoData(ownerDocument) { |
091 |
var data = expandoData[ownerDocument[expando]]; |
092 |
if (!data) { |
093 |
data = {}; |
094 |
expanID++; |
095 |
ownerDocument[expando] = expanID; |
096 |
expandoData[expanID] = data; |
097 |
} |
098 |
return data; |
099 |
} |
100 |
101 |
/** |
102 |
* returns a shived element for the given nodeName and document |
103 |
* @memberOf html5 |
104 |
* @param {String} nodeName name of the element |
105 |
* @param {Document} ownerDocument The context document. |
106 |
* @returns {Object} The shived element. |
107 |
*/ |
108 |
function createElement(nodeName, ownerDocument, data){ |
109 |
if (!ownerDocument) { |
110 |
ownerDocument = document; |
111 |
} |
112 |
if(supportsUnknownElements){ |
113 |
return ownerDocument.createElement(nodeName); |
114 |
} |
115 |
if (!data) { |
116 |
data = getExpandoData(ownerDocument); |
117 |
} |
118 |
var node; |
119 |
120 |
if (data.cache[nodeName]) { |
121 |
node = data.cache[nodeName].cloneNode(); |
122 |
} else if (saveClones.test(nodeName)) { |
123 |
node = (data.cache[nodeName] = data.createElem(nodeName)).cloneNode(); |
124 |
} else { |
125 |
node = data.createElem(nodeName); |
126 |
} |
127 |
128 |
// Avoid adding some elements to fragments in IE < 9 because |
129 |
// * Attributes like `name` or `type` cannot be set/changed once an element |
130 |
// is inserted into a document/fragment |
131 |
// * Link elements with `src` attributes that are inaccessible, as with |
132 |
// a 403 response, will cause the tab/window to crash |
133 |
// * Script elements appended to fragments will execute when their `src` |
134 |
// or `text` property is set |
135 |
return node.canHaveChildren && !reSkip.test(nodeName) ? data.frag.appendChild(node) : node; |
136 |
} |
137 |
138 |
/** |
139 |
* returns a shived DocumentFragment for the given document |
140 |
* @memberOf html5 |
141 |
* @param {Document} ownerDocument The context document. |
142 |
* @returns {Object} The shived DocumentFragment. |
143 |
*/ |
144 |
function createDocumentFragment(ownerDocument, data){ |
145 |
if (!ownerDocument) { |
146 |
ownerDocument = document; |
147 |
} |
148 |
if(supportsUnknownElements){ |
149 |
return ownerDocument.createDocumentFragment(); |
150 |
} |
151 |
data = data || getExpandoData(ownerDocument); |
152 |
var clone = data.frag.cloneNode(), |
153 |
i = 0, |
154 |
elems = getElements(), |
155 |
l = elems.length; |
156 |
for(;i<l;i++){ |
157 |
clone.createElement(elems[i]); |
158 |
} |
159 |
return clone; |
160 |
} |
161 |
162 |
/** |
163 |
* Shivs the `createElement` and `createDocumentFragment` methods of the document. |
164 |
* @private |
165 |
* @param {Document|DocumentFragment} ownerDocument The document. |
166 |
* @param {Object} data of the document. |
167 |
*/ |
168 |
function shivMethods(ownerDocument, data) { |
169 |
if (!data.cache) { |
170 |
data.cache = {}; |
171 |
data.createElem = ownerDocument.createElement; |
172 |
data.createFrag = ownerDocument.createDocumentFragment; |
173 |
data.frag = data.createFrag(); |
174 |
} |
175 |
176 |
177 |
ownerDocument.createElement = function(nodeName) { |
178 |
//abort shiv |
179 |
if (!html5.shivMethods) { |
180 |
return data.createElem(nodeName); |
181 |
} |
182 |
return createElement(nodeName, ownerDocument, data); |
183 |
}; |
184 |
185 |
ownerDocument.createDocumentFragment = Function('h,f','return function(){' + |
186 |
'var n=f.cloneNode(),c=n.createElement;' + |
187 |
'h.shivMethods&&(' + |
188 |
// unroll the `createElement` calls |
189 |
getElements().join().replace(/\w+/g, function(nodeName) { |
190 |
data.createElem(nodeName); |
191 |
data.frag.createElement(nodeName); |
192 |
return 'c("' + nodeName + '")'; |
193 |
}) + |
194 |
');return n}' |
195 |
)(html5, data.frag); |
196 |
} |
197 |
198 |
/*--------------------------------------------------------------------------*/ |
199 |
200 |
/** |
201 |
* Shivs the given document. |
202 |
* @memberOf html5 |
203 |
* @param {Document} ownerDocument The document to shiv. |
204 |
* @returns {Document} The shived document. |
205 |
*/ |
206 |
function shivDocument(ownerDocument) { |
207 |
if (!ownerDocument) { |
208 |
ownerDocument = document; |
209 |
} |
210 |
var data = getExpandoData(ownerDocument); |
211 |
212 |
if (html5.shivCSS && !supportsHtml5Styles && !data.hasCSS) { |
213 |
data.hasCSS = !!addStyleSheet(ownerDocument, |
214 |
// corrects block display not defined in IE6/7/8/9 |
215 |
'article,aside,figcaption,figure,footer,header,hgroup,nav,section{display:block}'+ |
216 |
// adds styling not present in IE6/7/8/9 |
217 |
'mark{background:#FF0;color:#000}' |
218 |
); |
219 |
} |
220 |
if (!supportsUnknownElements) { |
221 |
shivMethods(ownerDocument, data); |
222 |
} |
223 |
return ownerDocument; |
224 |
} |
225 |
226 |
/*--------------------------------------------------------------------------*/ |
227 |
228 |
/** |
229 |
* The `html5` object is exposed so that more elements can be shived and |
230 |
* existing shiving can be detected on iframes. |
231 |
* @type Object |
232 |
* @example |
233 |
* |
234 |
* // options can be changed before the script is included |
235 |
* html5 = { 'elements': 'mark section', 'shivCSS': false, 'shivMethods': false }; |
236 |
*/ |
237 |
var html5 = { |
238 |
239 |
/** |
240 |
* An array or space separated string of node names of the elements to shiv. |
241 |
* @memberOf html5 |
242 |
* @type Array|String |
243 |
*/ |
244 |
'elements': options.elements || 'abbr article aside audio bdi canvas data datalist details figcaption figure footer header hgroup mark meter nav output progress section summary time video', |
245 |
246 |
/** |
247 |
* current version of html5shiv |
248 |
*/ |
249 |
'version': version, |
250 |
251 |
/** |
252 |
* A flag to indicate that the HTML5 style sheet should be inserted. |
253 |
* @memberOf html5 |
254 |
* @type Boolean |
255 |
*/ |
256 |
'shivCSS': (options.shivCSS !== false), |
257 |
258 |
/** |
259 |
* Is equal to true if a browser supports creating unknown/HTML5 elements |
260 |
* @memberOf html5 |
261 |
* @type boolean |
262 |
*/ |
263 |
'supportsUnknownElements': supportsUnknownElements, |
264 |
265 |
/** |
266 |
* A flag to indicate that the document's `createElement` and `createDocumentFragment` |
267 |
* methods should be overwritten. |
268 |
* @memberOf html5 |
269 |
* @type Boolean |
270 |
*/ |
271 |
'shivMethods': (options.shivMethods !== false), |
272 |
273 |
/** |
274 |
* A string to describe the type of `html5` object ("default" or "default print"). |
275 |
* @memberOf html5 |
276 |
* @type String |
277 |
*/ |
278 |
'type': 'default', |
279 |
280 |
// shivs the document according to the specified `html5` object options |
281 |
'shivDocument': shivDocument, |
282 |
283 |
//creates a shived element |
284 |
createElement: createElement, |
285 |
286 |
//creates a shived documentFragment |
287 |
createDocumentFragment: createDocumentFragment |
288 |
}; |
289 |
290 |
/*--------------------------------------------------------------------------*/ |
291 |
292 |
// expose html5 |
293 |
window.html5 = html5; |
294 |
295 |
// shiv the document |
296 |
shivDocument(document); |
297 |
298 |
}(this, document)); |
然后把html5shiv.js在head里面引入:
01 |
<!DOCTYPE HTML> |
02 |
<html lang="en-US"> |
03 |
<head> |
04 |
<meta charset="UTF-8"> |
05 |
<title></title> |
06 |
<script type="text/javascript" src="html5.js"></script> |
07 |
<style type="text/css"> |
08 |
nav { |
09 |
width:200px; |
10 |
height:100px; |
11 |
background:#f12; |
12 |
} |
13 |
</style> |
14 |
</head> |
15 |
<body> |
16 |
<nav>Springload</nav>Springload |
17 |
</body> |
18 |
</html> |
在IE8中打开查看你就会发现nav这个HTML5元素标签,可以正常使用和显示。
PHP 正则表达式简单笔记
1.简单介绍
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的语法。
例:在判断用户邮件地址格式、手机号码格式或者采集别人网页内容时
主要的作用是:分割、匹配、查找、替换
注:正则表达式对于一个程序员来讲是至关重要的一个知识点,所以学好正则是每一个程序员必须具备的。不仅可以帮助我们完成一些通过函数无法实现的工作,还可以帮助我们减轻很多工作量。
2、PHP中两个常用的正则函数
preg_match 正则函数,以perl语言为基础
preg_match ( mode, string subject , array matches )
ereg 正则函数,以POSIX基础 (Unix 、 Script)
ereg ( mode, string subject , array regs )
3、正则表达式中包括的元素
(1)、原子(普通字符:a-z A-Z 0-9 、原子表、 转义字符)
(2)、元字符 (有特殊功能的字符)
(3)、模式修正符 (系统内置部分字符 i 、m、S、U…)
4、正则表达式中的“原子”
①a-z A-Z _ 0-9 //最常见的字符
②(abc) (skd) //用圆括号包含起来的单元符合
③[abcs] [^abd] //用方括号包含的原子表,原子表中的^代表排除或相反内容
④转义字符
\d 包含所有数字[0-9]
\D 除所有数字外[^0-9]
\w 包含所有英文字符[a-zA-Z_0-9]
\W 除所有英文字符外[^a-zA-Z_0-9] \s 包含空白区域如回车、换行、分页等 [\f\n\r]
5、正则表达式元字符
* 匹配前一个内容的0次1次或多次
. 匹配内容的0次1次或多次,但不包含回车换行
+ 匹配前一个内容的1次或多次
?匹配前一个内容的0次或1次
| 选择匹配类似PHP中的| (因为这个运算符合是弱类型导致前面最为整体匹配)
^ 匹配字符串首部内容
$ 匹配字符串尾部内容
\b 匹配单词边界,边界可以是空格或者特殊符合
\B 匹配除带单词边界意外内容
{m} 匹配前一个内容的重复次数为M次
{m,} 匹配前一个内容的重复次数大于等于M次
{m,n} 匹配前一个内容的重复次数M次到N次
( ) 合并整体匹配,并放入内存,可使用\1 \2…依次获取
6、运算顺序
依然遵循从左到→右的运算规则
优先级
①( ) 圆括号因为是内存处理所以最高
②* ? + { } 重复匹配内容其次
③^ $ \b 边界处理第三
④| 条件处理第四
最后按照运算顺序计算匹配
7、模式修正符,是为正则表达式增强和补充的一个功能。
常用修正符
i 正则内容在匹配时候不区分大小写(默认是区分的)
m 在匹配首内容或者尾内容时候采用多行识别匹配
S 将转义回车取消是为单行匹配如. 匹配的时候
x 忽略正则中的空白
A 强制从头开始匹配
D 强制$匹配尾部无任何内容 \n
U 禁止贪婪匹配 只跟踪到最近的一个匹配符并结束
匹配指定的标签对,标签对间可以有内容:/<\s*h4[^>]*>(.*?)<\s*/\s*h4>/g
匹配所有的标签和标签属性:/<(.|\n)*?>/g
匹配所有的开始标签,标签里可以有属性:/<\s*\w.*?>/g
匹配所有的结束标签:/<\s*\/\s*\w\s*.*?>|<\s*br\s*>/g
匹配指定的开始标签,标签里可以有属性:/<\s*div.*?>/g
匹配标签对间有内容的结束标签:/<\s*\/\s*div\s*.*?>/g
匹配所有指定的标签(不管开始或结束标签),标签里有可以有属性:/<\s*\/?\s*span\s*.*?>/g
匹配有指定属性的开始标签:/<\s*\w*\s*style.*?>/g
匹配有指定属性和指定的属性值的开始标签:/<\s*\w*\s*href\s*=\s*”?\s*([\w\s%#\/\.;:_-]*)\s*”?.*?>/g
simple_html_dom使用小结
<?php
include "simple_html_dom.php" ; // Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '<br>';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '<br>';
// Create DOM from URL
$html = file_get_html('http://slashdot.org/');
// Find all article blocks
foreach($html->find('div.article') as $article) {
$item['title'] = $article->find('div.title', 0)->plaintext;
$item['intro'] = $article->find('div.intro', 0)->plaintext;
$item['details'] = $article->find('div.details', 0)->plaintext;
$articles[] = $item;
}
print_r($articles);
// Create DOM from string
$html = str_get_html('<div id="hello">Hello</div><div id="world">World</div>'); $html->find('div', 1)->class = 'bar';
$html->find('div[id=hello]', 0)->innertext = 'foo';
echo $html; // Output: <div id="hello">foo</div><div id="world" class="bar">World</div>
| Name | Description |
|---|---|
|
void
__construct ( [string $filename] ) |
Constructor, set the filename parameter will automatically load the contents, either text or file/url. |
|
string
plaintext |
Returns the contents extracted from HTML. |
|
void
clear () |
Clean up memory. |
|
void
load ( string $content ) |
Load contents from a string. |
|
string
save ( [string $filename] ) |
Dumps the internal DOM tree back into a string. If the $filename is set, result string will save to file. |
|
void
load_file ( string $filename ) |
Load contents from a from a file or a URL. |
|
void
set_callback ( string $function_name ) |
Set a callback function. |
|
mixed
find ( string $selector [, int $index] ) |
Find elements by the CSS selector. Returns the Nth element object if index is set, otherwise return an array of object. |
$ret = $html->find('a');
// Find (N)th anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', 0);
// Find lastest anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', -1);
// Find all <div> with the id attribute
$ret = $html->find('div[id]');
// Find all <div> which attribute id=foo
$ret = $html->find('div[id=foo]');
$ret = $html->find('#foo');
// Find all element which class=foo
$ret = $html->find('.foo');
// Find all element has attribute id
$ret = $html->find('*[id]');
// Find all anchors and images
$ret = $html->find('a, img');
// Find all anchors and images with the "title" attribute
$ret = $html->find('a[title], img[title]');
$es = $html->find('ul li');
// Find Nested <div> tags
$es = $html->find('div div div');
// Find all <td> in <table> which
$es = $html->find('table.hello td');
// Find all td tags with attribite align=center in table tags
$es = $html->find(''table td[align=center]');
| Attribute Name | Usage |
|---|---|
| $e->tag | Read or write the tag name of element. |
| $e->outertext | Read or write the outer HTML text of element. |
| $e->innertext | Read or write the inner HTML text of element. |
| $e->plaintext | Read or write the plain text of element. |
$html = str_get_html("<div>foo <b>bar</b></div>");
$e = $html->find("div", 0);
echo $e->outertext; // Returns: " <div>foo <b>bar</b></div>"
echo $e->innertext; // Returns: " foo <b>bar</b>"
echo $e->plaintext; // Returns: " foo bar"
6.DOM traversing 方法
| Method | Description |
|---|---|
|
mixed
$e->children ( [int $index] ) |
Returns the Nth child object if index is set, otherwise return an array of children. |
|
element
$e->parent () |
Returns the parent of element. |
|
element
$e->first_child () |
Returns the first child of element, or null if not found. |
|
element
$e->last_child () |
Returns the last child of element, or null if not found. |
|
element
$e->next_sibling () |
Returns the next sibling of element, or null if not found. |
|
element
$e->prev_sibling () |
Returns the previous sibling of element, or null if not found. |
echo $html->find("#div1", 0)->children(1)->children(1)->children(2)->id;
// or
echo $html->getElementById("div1")->childNodes(1)->childNodes(1)->childNodes(2)->getAttribute('id');
function my_callback($element) {
// Hide all <b> tags
if ($element->tag=='b')
$element->outertext = '';
}
// Register the callback function with it's function name
$html->set_callback('my_callback');
// Callback function will be invoked while dumping
echo $html;
地方门户网站的盈利模式
第一个,也是最基础的一个:网络广告。网络广告的实质在于如何利用互联网挖掘到目标客户,更有针对性地传播信息,提高广告的效果。因此,显而易见的事实是地方生活门户网站能够提供更具个性化和针对性的网上广告手段,城市网上广告市场将呈现爆炸式增长。
广告形式可多种多样,如展示广告收入:通过前期运营,使网站达到一定影响力、知名度,拥有客观的访问量的时候,页面展示广告将是最简单、最基础的利润来源;有偿信息收入,这将是又一收入来源,主要是利用平台优势,在各相关频道重点推荐付费信息,这种模式中,还可以包括社区营销收入。
第二个盈利点在于电子商务。首先,在发展较大用户群基础上,通过我们自己的商家开展B2C电子商务,建设B2C网上商城,会员可以以会员价购买时尚生活消费品。
第三个盈利点在于与城市商业的融合,社区带动,单点突破,做足消费卡、团购、预定、消费分成、电子优惠券等商业模式文章。
第四个盈利点在于个性化增值服务。这个主要是面向企业客户的网络营销需求提供的增值服务,因为网站方而在通过运营积累,有人量用户数据,用户消费习惯分析,这些都可以助力于企业网络营销,网站同时还有大量的企业数据,包括用户点评分析等,这样,一方面,既可以给企业定制网络营销方案,另一方而也可以给用户定制个性化消费方案。这个需要有一段时期的运营积累。
第五个盈利点:便民服务。如当地的各种分类信息发布,地产中介、征婚交友、配送、家政、培训机构、美容等,通过“付费获得推荐或更好的展示效果”来实现盈利。
未来的盈利拓展有:免费《城市消费指南杂志》,用广告招商的形式盈利。作为地方门户来说,务必要切实做到“落地”,先把人气做起来,第一步考虑如何从商家盈利,比如房产家居方面栏目和版块应该很容易从房产商、家居用品设计、生产、销售、施工等企业获得盈利,具体的栏目根据各地情况的不同,可能会有不同的策划形式和运营形式。还有餐饮娱乐、汽车交易等等。
只要能做大,成为地方生活第一网络平台,那么,商家的广告就是一个巨大的盈利点,在针对当地商家进行广告展示服务之上,还可以为他们提供一些深度的服务,比如隶属于地方生活门户的商家展示网站、博客等,商家可自助管理,自助发布信息并推送到相应的位置,还有,上面已经说过,通过平台的运营,网站应该积累了大量的数据,可以针对商家的需求,做商家网络营销的整合包装与策划。
以上说的很多是一些广告盈利模式,其实我们从长远来想想,网络除了具有媒体属性之外,还可以开展电子商务,大家买一些东西不再去拥挤的商场,直接在我们的B2C网络商城订购。
此外,还有其他一些盈利模式,举下面的例子来说:
1、政府政务、商务:比如招商引资、旅游服务、经贸洽谈、项目招投标、政府性行为招标,政府性行为采购、新闻、信息发布等。
2、企业服务:自行联系或地方政府相关单位牵头成立企业会员俱乐部,协助完成对企业的全方位服务。比如项目及相关信息的发布、融资项目分析报告、投资商推荐、项目包装、项目推荐、项目测评、企业信息化建设、企业广告推广、产品的推广、为企业提供有效客户及合作者。3、信息中介服务、信息咨询业务:本地市场信息的中介有偿服务及专利、技术、项目等推广信息宣传。开办信息中介服务中介房产、中介车辆、中介闲置设备、中介家政服务等信息业务。
4、网络游戏:加盟网络游戏业务或产品加盟项目或产品:利用自身媒体的优势,加盟全国各地的中国创业联盟成员单位或其他单位的项目在本地的推广销售。
5、网络增值业务:域名、企业网站制作、企业电子邮箱、虚拟空间业务等。
6、会展服务:商业门户的品牌具有强大的市场号召力,可以结合地面会展的形式,结合网站推广,策划各种会展活动盈利。
7、培训服务:随着企业对互联网和电子商务知识的渴求,各地运营中心可以开设各种电子商务培训班,即可通过培训直接盈利,又培养了准客户。
8、个人会员:教育、医疗、娱乐、购物、交友、旅游等会员服务。
9、其他:还有网络商城、网上开店和物流配送等等其它业务。很多传统的商业模式,网络经济进行嫁接改良的,比如,网上订票、网络订餐。
从全国范围看,真正把这些都做到盈利的几乎没有,因为这些从理论上是可行的,但是网络发展阶段,当地网络发展情况、市场竞争情况,网站的运营发展情况等等,决定了不太可能一上来就全而开花,但是可以重点突破,根据我们自己的发展情况,摸索尝试出几个盈利点,然后规模化它,就很不错。
与商家合作的盈利方式包括:组织网友一起参加产品发布会、组织网友参加商品试用团、组织网友团购等。下而就以团购为例讲讲地方社区通过与商家合作取得盈利。在团购活动中,相对成熟的盈利模式主要有以下六种:
1、商品直销
以“团购”的名义直接在社区上刊登商品信息,进行直接销售,这里的货源也可以是自己进货、或跟商家合作代销,直接获得商品销售利润。商品直销是在网站运作中实现基本盈利的传统方式。
2、活动回扣
社区作为商家与买家的中间桥梁,组织有共同需求的买家向商家集体采购,事后商家向社区支付利润回报,即大家生活中常见的“回扣”形式。团购商品小到生活用品,大到电器、建材、装修、汽车、房产等,如果成功组织了一个大型采购团、如买车团、买房团,仅一次活动的商家利润回报小到上万,大到十几万甚至更多。现在一些大型团购网站号称有千人团购会甚至有万人团购会,这种人规模的采购其产生的利润回报之大,可想而之。
3、商家展会
可以不定期举办商家展览交流会,商家可以借此机会在社区进行新产品的推广、试用,可以面对面一与客户交流、接受咨询一与订单并借此了解客户的需求与建议,社区向商家收取展位费获得收益。
4、 广告服务
社区除了具有区域性特征外、它的受众一般都是具备消费、购买能力、欲购买的人群,对于商家来说定位精准、目标明确,成本低廉,故必将成为商家广告宣传的最佳平台。
5、售会员卡
“VIP会员”是用来凸显用户“尊贵身份”常见方式,在年轻人,特别是学生人群中非常的受欢迎。社区可以通过发放会员卡的形式来让用户提升“身份”,社区可以为持卡会员提供更低廉的商品价格,更贴心的服务,可以让持卡会员直接在合作的商家实体店铺进行“团购”。
6、分站加盟
当社区发展到一定影响力,无形中已经在为我们做项目招商了。此时可以提供授权给加盟者成立分站,为加盟者提供网络平台、运作经验、共享网站品牌等,在获得加盟费的同时也扩大了自身规模的影响力。
对地方社区举办利用团购盈利的建议:
1、不要一开始就搞全地区性的,尽量选择自己所在的区域或熟悉的区域范围进行运作,这样无论是推广、交流、交易、活动组织等操作起来都会非常的方便,而且也能最快的时间内被民众所接受。在初期,我们的人力、财力肯定不是非常的充足,都应该采取以小到大的发展策略。
2、在商品类别上应该采取以点到面的策略,不要一开始就想着做个最全面的,什么类型的商家都去联系合作,什么商品都搞,应该在某一行业或某一类别上做出你的价格、质量优势和特色来。
3、利用我们自己集团的各种现有资源,比如雨具,酒店,咖啡店,他们都可以为我们提供货源,那么我们可以很好的利用这个资源优势。
4、如果我们是某品牌的经销商、代理商,那么这无疑是最好的资源了,借助自身品牌与价格的绝对优势,以及对这个行业的熟悉度,无疑为你打开了一条新的营销大门和新的发展项目。目前万城网的模式加盟还是最有创新与前景.
5、如果上述的优势都不具备,先期可以自己寻找一些低成本的小商品货源进行直接销售,在这个过程中我们不断的积累客户、接触供货商、行业知识、将为你下一步的发展奠定稳定的基础。
6、不要把所有的事情寄于在网上完成。社区是你的主体平台,要多做线下形式的沟通与交流。如果在线下的沟通能力有限,建议可以找个擅长业务的人来合作互补。
7、社区网站成功的关键在于效率、运营。切记千万不要把过多的时间耗费在技术上,采用现成的建站系统应该做为首选,例如Discuz!等,记住我们的重点是运营,赢利!一定要从“技术员”的位置中走出来!
8、学会善用你身边一切可利用的资源。
速度型山地车的选型
很多新手和我一样,头痛于如何选择一款跑的轻快的山地自行车,当然了,真正的高速山地是改装出来的,后者显然是高端玩法,对于入门而言,无论从经验和银子哪方面进行考虑,选择一款速度型的整车或者稍加改造会更靠谱一些。
既然讲到了速度,有必要先简单讲一下山地车和公路车的区别:
从设计上来讲,前者以通过性为方向,后者以速度为方向。
山地车的优点是适应各种路面,避震,骑行舒适,操控性好,长途骑行的稳定/安全性高;缺点是速度相对较慢。公路车的优点是阻力小,速度快;缺点是对路况适应能力差,骑行的舒适感相对较低尤其是屁股,长途骑行的稳定/安全性相对较低。
根据使用需求选择山地or公路,有人只是城市代步,竟也买个公路,我靠,你以为爬那么低很帅么?如果你是中短途压马路,那就推荐买公路。如果是超过1000公里的长途骑行,哪种都让人纠结,一般是根据路况、速度、舒适度、体力、安全性、资金投入等综合考虑,像我这样疼惜屁股又热爱牛仔裤又怕爆胎的人肯定倾向于速度型山地车多一些。
速度,是由车子性能、个人体力/心肺功能、对变速器的灵活运用决定的。车子再好,你人不行,那也只能顶个球用。而山地车无论怎么配置,怎么改装,也赶不上公路车的速度。对比山地车和公路车的特点,我们可以通过减小阻力、减少车体重量等方式来提升山地车的速度。
下面个人经验和大家分享一下,欢迎指正。
【车架】
(1)材料
选择铝合金车架,比钢车架的重量轻,不仅起步、加速、爬坡时省力,而且易搬动,对于外出旅行,随时会需要扛起车子~
但铝合金车架的弹性不如钢车架,如果你有钱的话,可以选择更好的材料,比如钛合金或碳纤维车架。
铝合金车架的车子一般在1.4公斤左右。
(2)尺寸
车架尺寸的标示法是:车轮直径x车架立管长度
再具体,车架的参数可真不少,根据身高、腿长计算最合适的车架尺寸,那会搞迷糊的,对入门来讲完全无必要。
下面简单例个对应表,厂家不同会稍微有所不同,具体去车行试骑为准:
24"x15" 适合150-165cm
26"x16" 适合155-165cm
26"x17" 适合160-175cm
26"x18" 适合170-185cm
26"x19" 适合180cm以上
车架小,易操控;车架大,易舒展。
如果是城市代步和长途骑行,碰到的交通或路况复杂,建议易小不易大。如果是路面很好的压马路,那大点也行。
(3)工艺
看焊接工艺如何,做工是否精致,感受整个车体结不结实。
【避震器】
山地车之所以安装避震系统当然是为了避震(抗冲击/抓地),但是它有个很讨厌的副作用,就是泄力。
(1)后避震
如果您不是做特技表演或者用来跑山路什么的,后避震就不需要安装,减少车身重量,并避免不必要的泄力。
(2)前避震
就是前叉。这是比较有科技含量的一个装置了,对于山地车来讲,这个装置是非常的重要,也是最烧钱的一个玩意了。
建议1:直接用硬叉,不仅重量轻,而且便宜,没有压缩/回弹功能,减少泄力,很多高速山地配的就是硬前叉。缺点也是没有压缩/回弹功能,路面不好时手就有点麻了。
建议2:选一个好一点的气叉,最大优点是重量轻,但是。。。一个字,贵!
建议3:选一个带自锁功能的前叉,在平路和爬坡时可以把前叉锁死。如果是带自锁的气叉那就更棒了,但是、、、、一个字,贵!
对入门来讲,上述2和3入手太贵,市场上原配硬叉的车子也很少见,那就车子买来配的是什么叉就什么叉吧,弹簧、油簧、阻力胶什么的都行,等了解之后再改装
【变速/传动系统】
我们用双腿踩踏踏板(以某个踩踏频率),通过链条,让前牙盘带动后飞轮(以某个齿轮比),从而带动后车轮转动,而让车子向前移动。
(1)速别
山地车的前牙盘一般是3个齿轮,后飞轮目前常见的是6片、7片、8片、9片这四种不同的数量,前齿轮数量x后飞轮数量,就形成了目前我们常见的18速、21速、24速、27速这些速别。
18速和21速常见于中低档车,21速和24速常见于中高档车,27速我觉得就有点偏执狂的意思了,个人认为无必要。
速别的多少和速度没有直接关系,它和能够产生的齿轮比的数量有关系。合适的齿轮比是让骑行者能够节省体力,能够踩踏的更舒适,而不是改变速度。就像本文一开始所说的,速度是在某种路况条件下,由车子性能、踏频(腿部力量)、该时段的齿轮比(对变速系统的灵活运用)形成的,当换到某个齿轮比的档位时,你要增加的是踏频,才能增加速度。事实上,我们常用的后飞轮也就是中间几个,最大飞轮和最小飞轮一般情况更是不去用它,也就是说无论是何种速别的车子,常用的齿轮比数量并没有大的区别。
那速别的真正作用是什么呢,18速的车有18个档位,21速的车有21个档位,以此类推,档位越多的山地车变速(即换挡)越细腻、越顺滑,让你变速时不容易感觉到很突然。
所以如果你只是城市代步,那18速足够,没必要为某种细腻感而多花钱。如果你的骑行距离较大,推荐21速或24速,这种变速的细腻感能够让你骑行愉悦。而在一些特殊的情况,比如爬长坡,而且还是逆风,这种时候或许你就能体会到大飞轮的作用了。
(2)变速器
变速器的作用就是让你及时、准确地获得你想要的齿轮比。
所以一款稳定可靠的变速器对山地车是非常重要的。变速器由指拨、前拨、后拨组成。国内常见的两个牌子,一是喜马诺Shimano,二是SRAM。
入门的话,建议选用Shimano吧,个人认为后拨比前拨重要,所以一定要留意后拨的品质。另外,就入门而言,我还是推荐飞轮和后拨用一个品牌,甚至一个套件的,这样兼容性是否好些?
一般新买的车,对变速系统都要进行细微的调校,使所有档位的变速顺滑,并且让自己最常用的齿轮比的链条位置处于相对安静、舒服的位置,这个有机会再另文阐述吧。
【刹车系统】
V刹和碟刹,所谓萝卜青菜各有所爱,并不是碟刹就一定比V刹好。
总体而言,V刹重要轻,价格便宜,容易保养维护;碟刹制动性好,恶劣天气和环境对刹车性能的影响小。
我个人还是觉得碟刹比较有愉悦感,尤其不喜欢V刹在车圈上留下擦痕。
但对于速度型的山地,特别是长途骑行,个人还是推荐双V刹好些,不仅减轻重量,维修容易,另外,V刹+前硬叉这俩一搭配,既简单又高速啊~
还有一种选择就是混搭型,前V刹+后碟刹,或者前碟刹+后V刹。无论何种搭配,大家都要留心下坡时前轮不要抱死,除了V刹这种很难避免的制动缺陷,还在于大家对刹车技巧的掌握吧?
【车轮】
(1)胎纹:
对于速度型的山地车,外胎的选择实在太重要了,是抓地能力和速度的完美结合。
胎纹越凸,阻力越大,当速度越大时,在山地上的抓地力越强;
胎纹越平,阻力越小,当速度越大时,在平地上的抓地力越强。
所以要想提升山地车的速度,首要的就是选用光头胎。推荐使用轮胎中间平滑,两边突兀强厚的光头胎,这样前行的纵向阻力不大,侧滑和转弯的横向阻力大,适应公路、越野、雪天等不同环境的需求。
(2)尺寸:
外胎的标示法是:车轮直径x外胎胎宽
公路车用的都是窄胎,山地车常见的胎宽尺寸是1.75、1.95、2,125英寸。
山地车不可能使用公路车那么窄的胎,但是要提升速度,能窄点就窄点。
以26寸为例,推荐使用26"x1.5,26"x1.75,26"x1.95的光头胎,26x1.25我觉得又有点偏执狂了,无必要吧。
(3)车圈
毫无疑问,双层圈是必须的,比单层的要结实。而外形方面,刀圈是不错的选择,不仅抗冲击而且风阻小。都说刀圈的缺点是重,我觉得问题不大,在车轮的外围适当增加点重量,虽然起步和上坡时吃点亏,但是车轮的行驶惯性也更好,越不容易降低速度,在平地骑行中,保持速度或加速是否会更加省力呢?
【自锁】
自锁就是一套蹬踏系统,骑车时和脚踏“锁”在一起,这种方式绝对能够省力并提高速度,就是解锁需要练习,刚开始很容易摔车。至于能提高多少速度,我也没用过自锁,不好说,相信这里有很多人比我有经验的多。
【车锁】
呵呵,工欲利其器,必先固其锁。
现在市场上主流的安全锁是“抗液压剪+空转锁芯”,是否抗的住12吨、14吨甚至16吨以上的液压剪,你又不好拿来试,尽量挑选吧。几乎所有的传统锁芯都抗不住挤开和暴开工具,空转锁芯就是针对开锁工具设计的,但是,如果你对中国人民的“聪明才智”有足够信心的话,空转锁芯既已成为主流防盗锁芯,总有一天会被暴开掉的,而且我听说已经出了针对空转锁芯的暴开工具。
推荐找那种把锁芯藏起来的空转锁芯,本人用的是“抗液压剪+磁卡开锁”,嘿嘿嘿嘿~
ok,其他就不多说了。
坎坷,宁静,高山、大海。
选择单车,选择了一个朋友。
选择单车,选择了一种情感。
选择单车,选择了一种向往。
图解git中的最常用命令
此页图解git中的最常用命令。如果你稍微理解git的工作原理,这篇文章能够让你理解的更透彻。 如果你想知道这个站点怎样产生,请前往GitHub repository。
正文
- 基本用法
- 约定
- 命令详解
- Diff
- Commit
- Checkout
- Detached HEAD(匿名分支提交)
- Reset
- Merge
- Cherry Pick
- Rebase
- 技术说明
基本用法
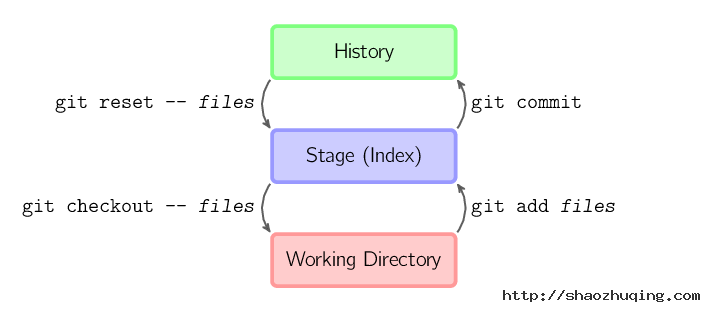
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。
你可以用 git reset -p, git checkout -p, or git add -p进入交互模式。
也可以跳过暂存区域直接从仓库取出文件或者直接提交代码。
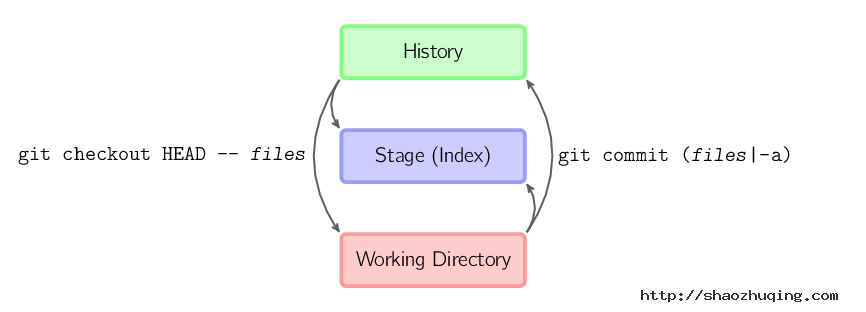
git commit -a相当于运行 git add 把所有当前目录下的文件加入暂存区域再运行。git commit.git commit files进行一次包含最后一次提交加上工作目录中文件快照的提交。并且文件被添加到暂存区域。git checkout HEAD -- files回滚到复制最后一次提交。
约定
后文中以下面的形式使用图片。
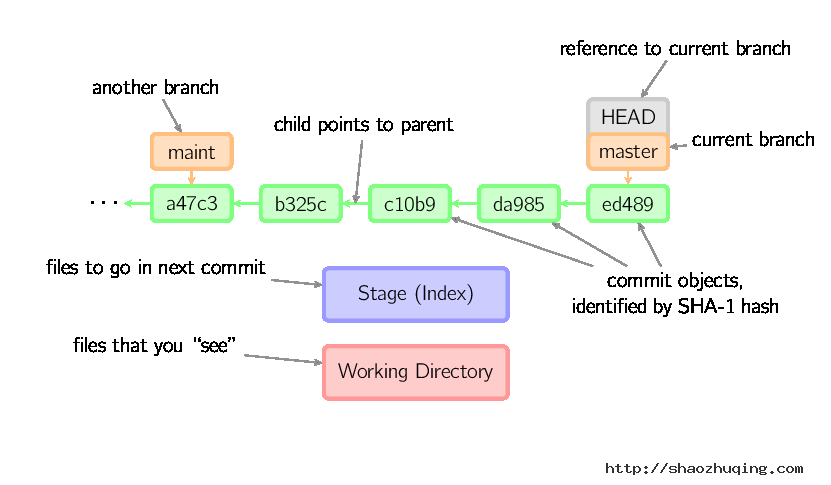
绿色的5位字符表示提交的ID,分别指向父节点。分支用橘色显示,分别指向特定的提交。当前分支由附在其上的HEAD标识。 这张图片里显示最后5次提交,ed489是最新提交。 master分支指向此次提交,另一个maint分支指向祖父提交节点。
命令详解
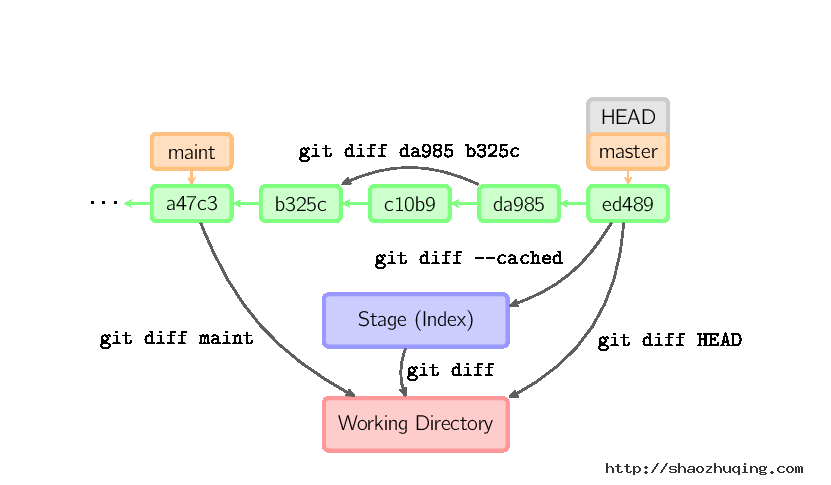
Diff
有许多种方法查看两次提交之间的变动。下面是一些示例。
Commit
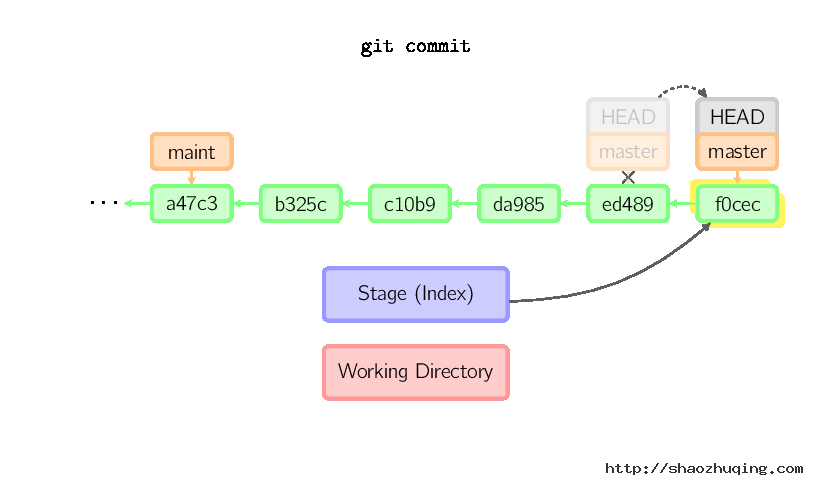
提交时,git用暂存区域的文件创建一个新的提交,并把此时的节点设为父节点。然后把当前分支指向新的提交节点。下图中,当前分支是master。 在运行命令之前,master指向ed489,提交后,master指向新的节点f0cec并以ed489作为父节点。
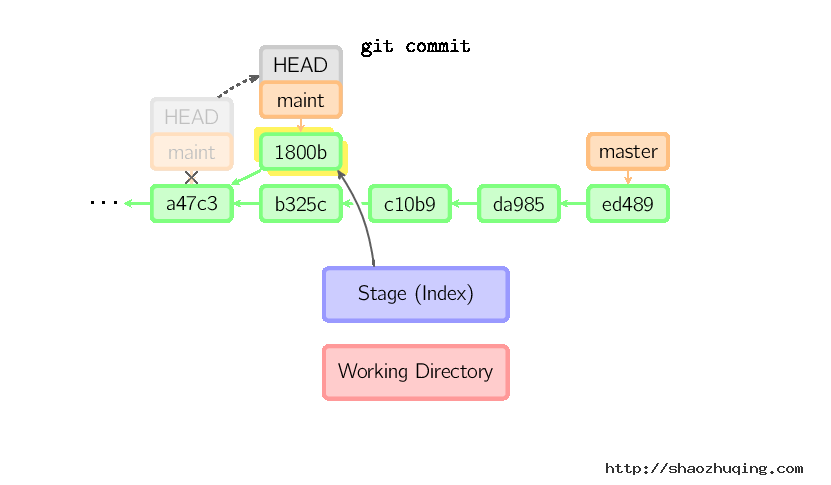
即便当前分支是某次提交的祖父节点,git会同样操作。下图中,在master分支的祖父节点maint分支进行一次提交,生成了1800b。 这样,maint分支就不再是master分支的祖父节点。此时,合并 (或者 衍合) 是必须的。
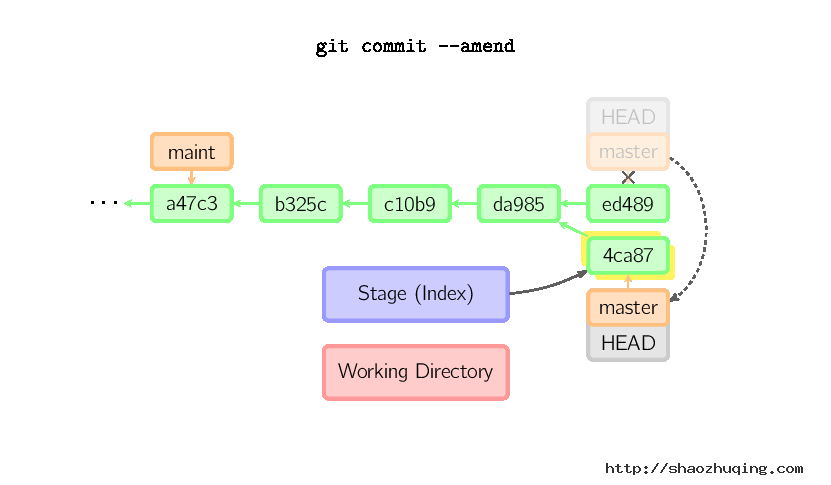
如果想更改一次提交,使用 git commit --amend。git会使用与当前提交相同的父节点进行一次新提交,旧的提交会被取消。
另一个例子是分离HEAD提交,后文讲。
Checkout
checkout命令用于从历史提交(或者暂存区域)中拷贝文件到工作目录,也可用于切换分支。
当给定某个文件名(或者打开-p选项,或者文件名和-p选项同时打开)时,git会从指定的提交中拷贝文件到暂存区域和工作目录。比如,git checkout HEAD~ foo.c会将提交节点HEAD~(即当前提交节点的父节点)中的foo.c复制到工作目录并且加到暂存区域中。(如果命令中没有指定提交节点,则会从暂存区域中拷贝内容。)注意当前分支不会发生变化。
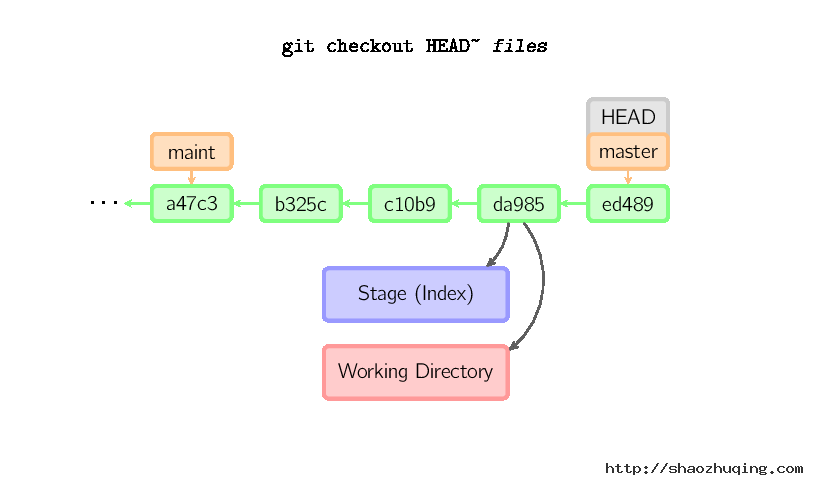
当不指定文件名,而是给出一个(本地)分支时,那么HEAD标识会移动到那个分支(也就是说,我们“切换”到那个分支了),然后暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点(下图中的a47c3)中的所有文件都会被复制(到暂存区域和工作目录中);只存在于老的提交节点(ed489)中的文件会被删除;不属于上述两者的文件会被忽略,不受影响。
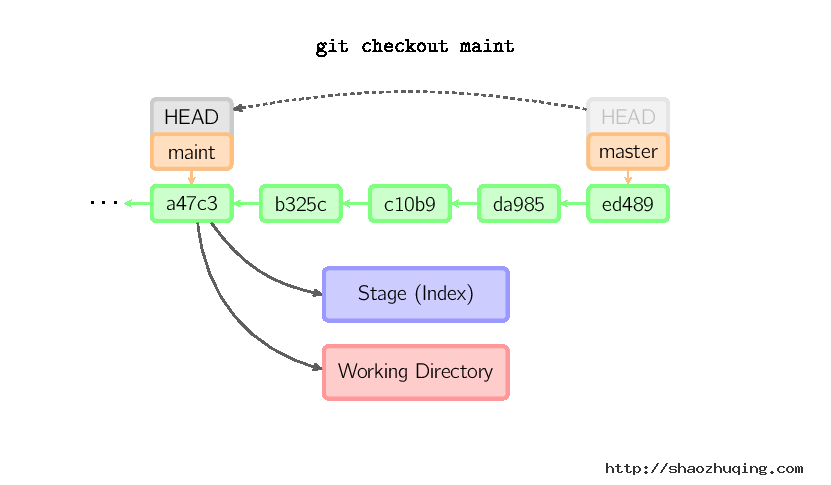
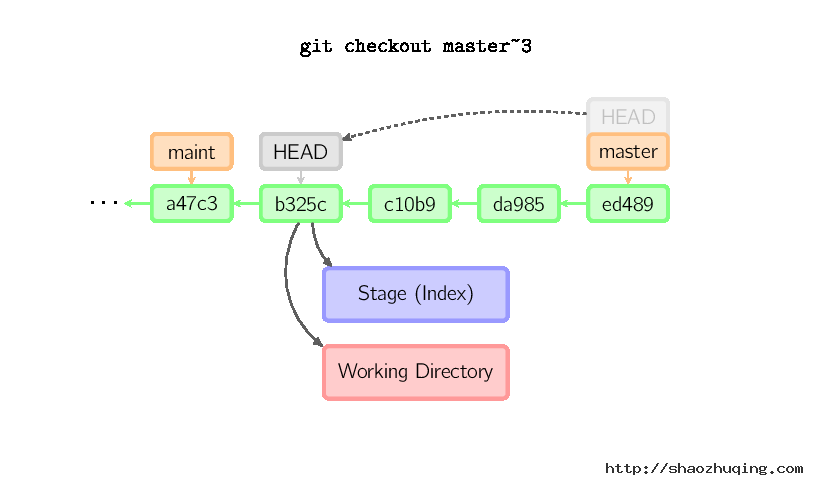
如果既没有指定文件名,也没有指定分支名,而是一个标签、远程分支、SHA-1值或者是像master~3类似的东西,就得到一个匿名分支,称作detached HEAD(被分离的HEAD标识)。这样可以很方便地在历史版本之间互相切换。比如说你想要编译1.6.6.1版本的git,你可以运行git checkout v1.6.6.1(这是一个标签,而非分支名),编译,安装,然后切换回另一个分支,比如说git checkout master。然而,当提交操作涉及到“分离的HEAD”时,其行为会略有不同,详情见在下面。
HEAD标识处于分离状态时的提交操作
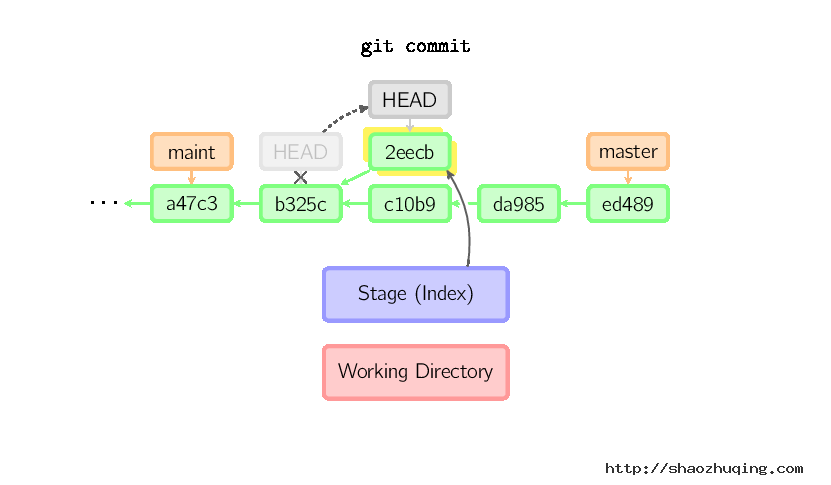
当HEAD处于分离状态(不依附于任一分支)时,提交操作可以正常进行,但是不会更新任何已命名的分支。(你可以认为这是在更新一个匿名分支。)
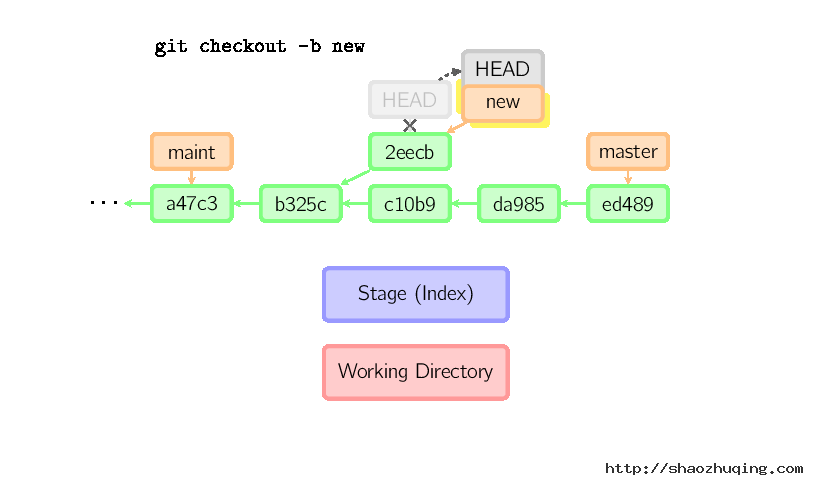
一旦此后你切换到别的分支,比如说master,那么这个提交节点(可能)再也不会被引用到,然后就会被丢弃掉了。注意这个命令之后就不会有东西引用2eecb。
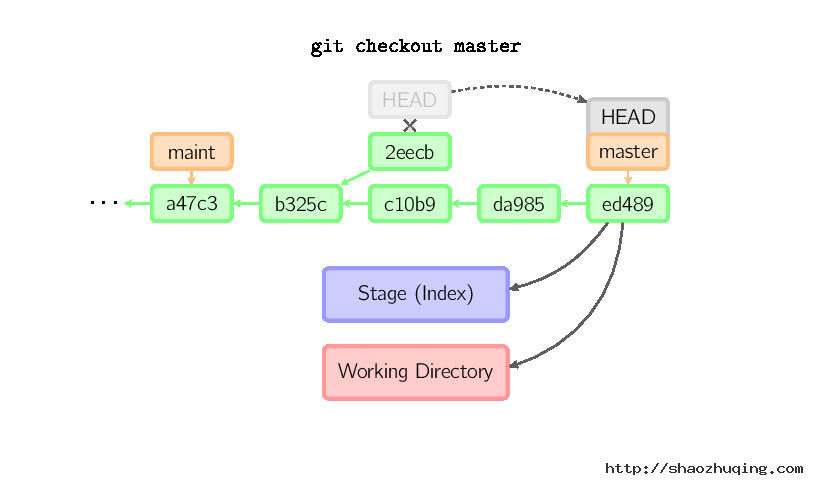
但是,如果你想保存这个状态,可以用命令git checkout -b name来创建一个新的分支。
Reset
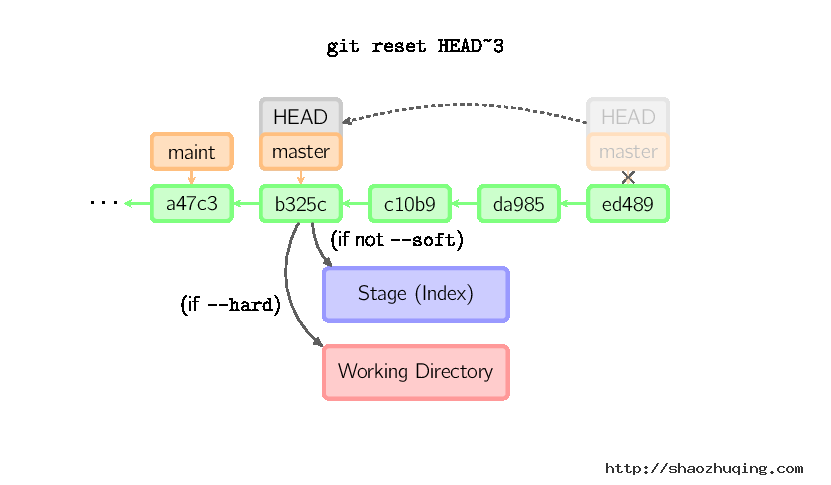
reset命令把当前分支指向另一个位置,并且有选择的变动工作目录和索引。也用来在从历史仓库中复制文件到索引,而不动工作目录。
如果不给选项,那么当前分支指向到那个提交。如果用--hard选项,那么工作目录也更新,如果用--soft选项,那么都不变。
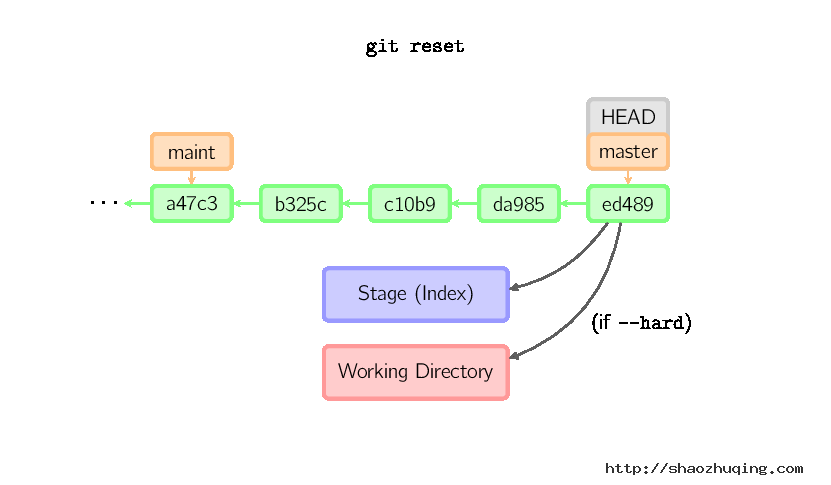
如果没有给出提交点的版本号,那么默认用HEAD。这样,分支指向不变,但是索引会回滚到最后一次提交,如果用--hard选项,工作目录也同样。
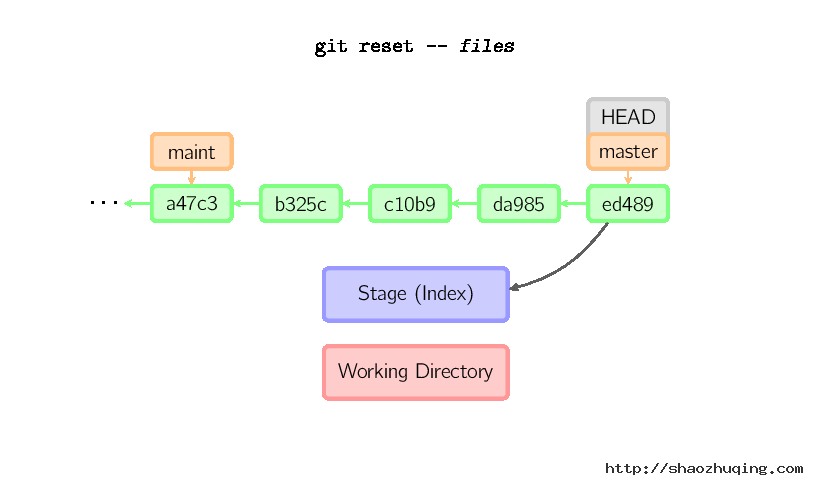
如果给了文件名(或者 -p选项), 那么工作效果和带文件名的checkout差不多,除了索引被更新。
Merge
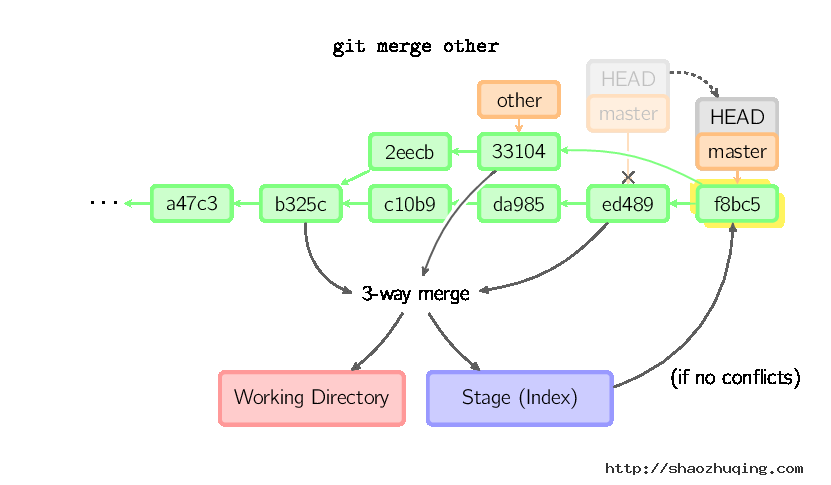
merge 命令把不同分支合并起来。合并前,索引必须和当前提交相同。如果另一个分支是当前提交的祖父节点,那么合并命令将什么也不做。 另一种情况是如果当前提交是另一个分支的祖父节点,就导致fast-forward合并。指向只是简单的移动,并生成一个新的提交。
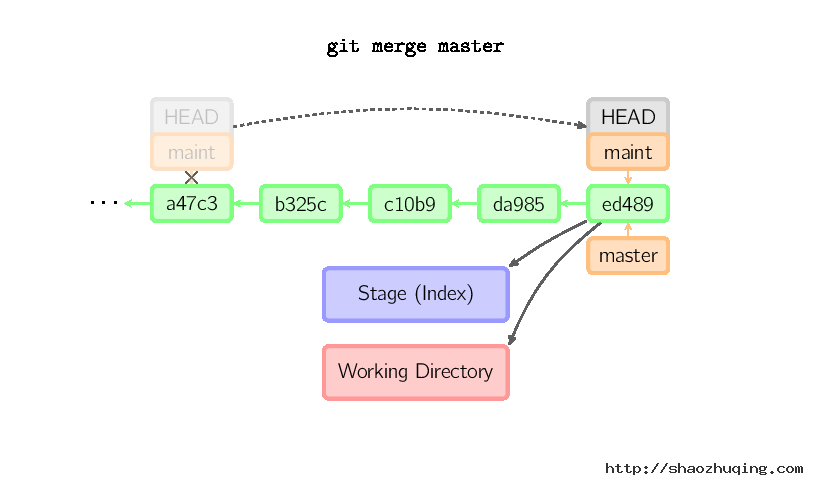
否则就是一次真正的合并。默认把当前提交(ed489 如下所示)和另一个提交(33104)以及他们的共同祖父节点(b325c)进行一次三方合并。结果是先保存当前目录和索引,然后和父节点33104一起做一次新提交。
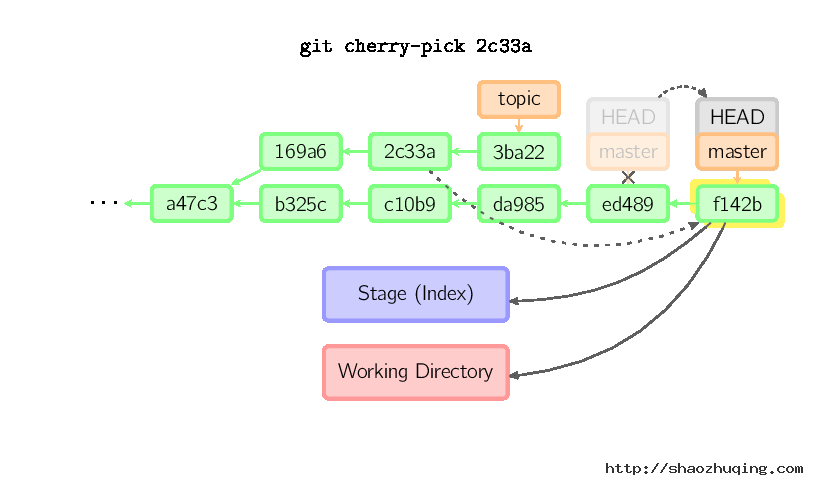
Cherry Pick
cherry-pick命令"复制"一个提交节点并在当前复制做一次完全一样的新提交。
Rebase
衍合是合并命令的另一种选择。合并把两个父分支合并进行一次提交,提交历史不是线性的。衍合在当前分支上重演另一个分支的历史,提交历史是线性的。 本质上,这是线性化的自动的cherry-pick
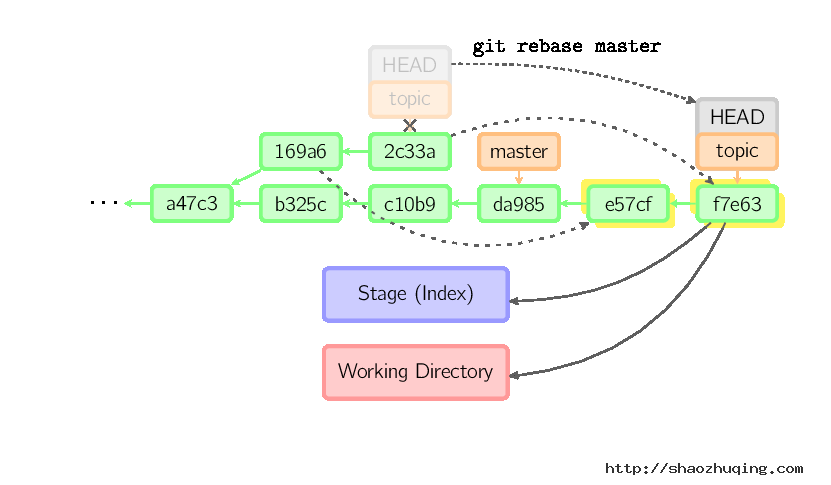
上面的命令都在topic分支中进行,而不是master分支,在master分支上重演,并且把分支指向新的节点。注意旧提交没有被引用,将被回收。
要限制回滚范围,使用--onto选项。下面的命令在master分支上重演当前分支从169a6以来的最近几个提交,即2c33a。
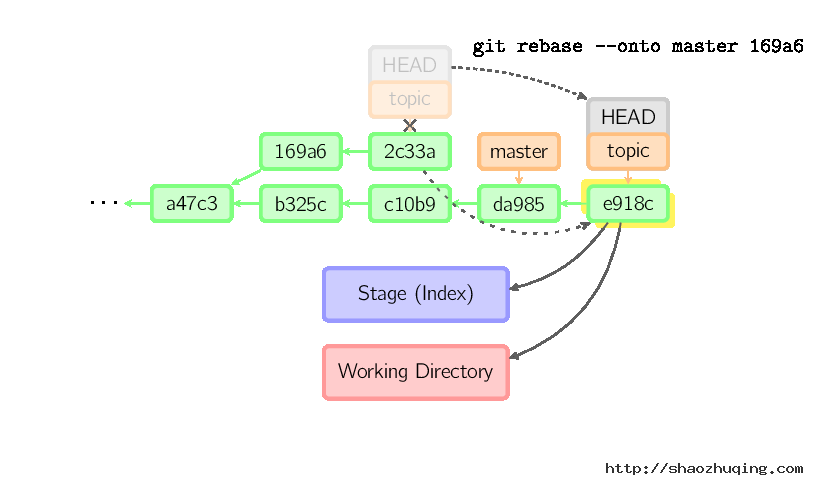
同样有git rebase --interactive让你更方便的完成一些复杂操作,比如丢弃、重排、修改、合并提交。没有图片体现这些,细节看这里:git-rebase(1)
技术说明
文件内容并没有真正存储在索引(.git/index)或者提交对象中,而是以blob的形式分别存储在数据库中(.git/objects),并用SHA-1值来校验。 索引文件用识别码列出相关的blob文件以及别的数据。对于提交来说,以树(tree)的形式存储,同样用对于的哈希值识别。树对应着工作目录中的文件夹,树中包含的 树或者blob对象对应着相应的子目录和文件。每次提交都存储下它的上一级树的识别码。
如果用detached HEAD提交,那么最后一次提交会被the reflog for HEAD引用。但是过一段时间就失效,最终被回收,与git commit --amend或者git rebase很像。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
