各种代码准确识别手机浏览器和Web浏览器访问
使用浏览器访问 此URL http://shaozhuqing.com/s/dmb
如果为移动设备会跳转到 http://shaozhuqing.com/s/dmb/mobile.php
本站提供以下各种代码准确识别手机浏览器和Web浏览器
下载请移步 http://shaozhuqing.com/s/dmb
"apache" => "download/detectmobilebrowser.htaccess.txt",
"asp" => "download/detectmobilebrowser.asp.txt",
"aspx" => "download/detectmobilebrowser.aspx.txt",
"coldfusion" => "download/detectmobilebrowser.cfm.txt",
"cs" => "download/detectmobilebrowser.cs.txt",
"iis" => "download/detectmobilebrowser.web.config.txt",
"jsp" => "download/detectmobilebrowser.jsp.txt",
"javascript" => "download/detectmobilebrowser.js.txt",
"jquery" => "download/detectmobilebrowser.jquery.txt",
"lasso" => "download/detectmobilebrowser.lasso.txt",
"nginx" => "download/detectmobilebrowser.conf.txt",
"node" => "download/detectmobilebrowser.nodejs.txt",
"php" => "download/detectmobilebrowser.php.txt",
"perl" => "download/detectmobilebrowser.pl.txt",
"python" => "download/detectmobilebrowser.middleware.py.txt",
"rails" => "download/detectmobilebrowser.rb.txt"
CNZZ 关键字名词解释
PV:
即PV(PageView)值,用户每次打开网站页面被记录1次。用户多次打开同一页面,访问量值累计多次。此指标衡量网站访问量情况。
IP:
指在一天之内(00:00-24:00)访问您的网站的独立IP数。一天内相同IP地址多次访问网站只被计算1次。
独立访客:
指在一天之内(00:00-24:00)访问您的网站的上网电脑数量(以cookie为依据)。一天内同一电脑多次访问网站只被计算1次。
人均浏览次数:
每个访客浏览网站页面的平均次数。人均浏览次数=PV/独立访客数。
累计总PV:
是指网站从开通cnzz统计之日起至今的PV总和。
历史最高:
是指网站从开通cnzz统计之日起至今获得最高的日访问数值。
日均PV值:
指网站开通cnzz统计之日起平均每天PV值。日均PV值=累计总PV/总统计天数
当前在线:
指15分钟内在线用户的活动信息,在线用户是按IP计算。
新独立访客:
首次访问网站的访客记为一个新独立访客。
新访客浏览次数:
您的网站页面被新独立访客浏览的次数。
平均停留时间:
从访客打开您的页面到离开页面的时间。
跳出率:
访客离开的比例。跳出率=离开次数/浏览次数
来访次数:
从外部网站点到您的网站网页的次数。
浏览次数:
您的网站页面被浏览的次数。
进入次数:
访客从其他网站到达您的网站页面,记为1次进入。
离开次数:
访客15分钟不再浏览您的页面,记为1次离开。
回头率:
用户距离上次访问超过12小时的再次访问,被记录为一次回访,回访次数越多,用户的忠实度越高。
访问深度:
某访客每多浏览网站一个页面即增加一个深度,访问深度越大,网站的粘性越高。
地区分布:
分析访客来源于哪个地区。
网络接入商:
分析访客所处的网域,如电信、网通。
IP头:
分析访客所在的IP段。
浏览器:
分析访客使用的浏览器类型。
分辨率:
分析访客使用的屏幕分辨率。
操作系统:
分析访客使用的操作系统类型。
语言:
分析访客使用的语言类型。
终端类型:
分析访客通过什么客户端上网。
Alexa安装:
分析访客是否安装alexa工具条。
升降榜:
某数据相对制定日期上升或下降幅度的排行榜。
CNZZ排名:
您的网站在参与CNZZ排行的所有网站中的综合流量名次。
统计概况:
统计概况为您提供网站今日的流量变化趋势,以及各种重要的流量数据。
当前在线:
当前在线为您提供15分钟内在线用户的活动信息,在线用户是按IP计算。包括:来访时间、访客地域、来路页面、当前停留页面等。
最近来路:
最近来源为您提供15分钟内进入网站的来路页面及带来流量。
停留页面:
停留页面为您提供15分钟内受访的页面及页面受访次数。
时段分析:
时段分析为您提供网站任意时间内的流量变化及24小时段分布情况。
搜索引擎:
搜索引擎为您提供各搜索引擎带来的搜索次数、IP、独立访客、人均搜索次数、页面停留时间等数据。
关键字:
关键字为您提供搜索关键字带来的搜索次数、IP、独立访客、新独立访客等数据。
最近来访:
最近来访为您提供最近通过搜索引擎进入网站的用户信息,包括:来访时间、访客地域、搜索引擎、关键字、停留页面等。
来路域名:
来路域名为您提供来路域名带来的来访次数、IP、独立访客、新独立访客、新访客浏览次数、站内总浏览次数等数据。
来路页面:
来路页面为您提供来路页面带来的来访次数、IP、独立访客、新独立访客、新访客浏览次数、站内总浏览次数等数据。
受访域名:
受访域名为您提供被访问域名的浏览次数、IP、独立访客、人均浏览次数、页面停留时间、跳出率等数据。受访域名默认显示全部,包括您本站域名和放置了您网站统计代码的其他域名,您可以选择显示本网站域名,过滤掉不需要的数据。
受访页面:
受访页面为您提供被访问页面的浏览次数、人均浏览次数、页面停留时间、跳出率等数据。
站内入口:
站内入口为您提供访客进入网站的进入次数、人均浏览次数、页面停留时间、跳出率等数据。
站内出口:
站内出口为您提供访客离开网站的离开次数、人均浏览次数、页面停留时间、跳出率等数据。
地区分布:
地区分布为您提供访客来源于哪个地区
网络接入商:
网络接入商为您提供访客所处的网域,如电信、网通。
IP头:
IP头为您提供访客所在的IP段。
浏览器:
浏览器为您提供访客使用的浏览器类型。
分辨率:
分辨率为您提供访客使用的屏幕分辨率。
操作系统:
操作系统为您提供访客使用的操作系统类型。
语言:
语言设置为您提供访客使用的语言类型。
终端类型:
终端类型为您提供访客通过什么客户端上网。
Alexa安装:
Alexa安装为您提供访客安装Alexa工具条情况。
用户回头率:
用户回头率为您提供访客回访次数情况,用户距离上次访问超过12小时的再次访问,被记录为一次回访,回访次数越多,用户的忠实度越高。
用户访问深度:
用户访问深度为您提供用户访问网站深度情况,访问深度越大,网站的粘性越高。
来路升降榜:
来路升降榜为您提供某日来路域名访问量相对指定日期变化幅度的排行榜。
关键字升降榜:
关键字升降榜为您提供某日搜索引擎关键字带来的访问量相对指定日期变化幅度的排行榜。
受访页升降榜:
受访页升降榜为您提供某日受访页面访问量相对指定日期变化幅度的排行榜。
短信报警:
短信报警为您提供数据变动提醒服务,每条短信0.2元。
查看密码:
当您想单独开放帐户下的某个站点给其他人(如你您网站的广告主)查看的时候,设置独立“查看密码”即可。查看者从站点统计图标进入,输入查看密码可看到该站点数据。查看密码无站点管理权限。
mysql 截取字符串
1. 字符串截取:left(str, length)
mysql> select left('linuxidc.com', 3);
+-------------------------+
| left('linuxidc.com', 3) |
+-------------------------+
| sql |
+-------------------------+
2. 字符串截取:right(str, length)
mysql> select right('linuxidc.com', 3);
+--------------------------+
| right('linuxidc.com', 3) |
+--------------------------+
| com |
+--------------------------+
3. 字符串截取:substring(str, pos); substring(str, pos, len)
3.1 从字符串的第 4 个字符位置开始取,直到结束。
mysql> select substring('linuxidc.com', 4);
+------------------------------+
| substring('linuxidc.com', 4) |
+------------------------------+
| study.com |
+------------------------------+
3.2 从字符串的第 4 个字符位置开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', 4, 2);
+---------------------------------+
| substring('linuxidc.com', 4, 2) |
+---------------------------------+
| st |
+---------------------------------+
3.3 从字符串的第 4 个字符位置(倒数)开始取,直到结束。
mysql> select substring('linuxidc.com', -4);
+-------------------------------+
| substring('linuxidc.com', -4) |
+-------------------------------+
| .com |
+-------------------------------+
3.4 从字符串的第 4 个字符位置(倒数)开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', -4, 2);
+----------------------------------+
| substring('linuxidc.com', -4, 2) |
+----------------------------------+
| .c |
+----------------------------------+
我们注意到在函数 substring(str,pos, len)中, pos 可以是负值,但 len 不能取负值。
4. 字符串截取:substring_index(str,delim,count)
4.1 截取第二个 '.' 之前的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', 2);
+------------------------------------------------+
| substring_index('www.linuxidc.com', '.', 2) |
+------------------------------------------------+
| www |
+------------------------------------------------+
4.2 截取第二个 '.' (倒数)之后的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', -2);
+-------------------------------------------------+
| substring_index('www.linuxidc.com', '.', -2) |
+-------------------------------------------------+
| com.cn |
+-------------------------------------------------+
4.3 如果在字符串中找不到 delim 参数指定的值,就返回整个字符串
mysql> select substring_index('www.linuxidc.com', '.coc', 1);
+---------------------------------------------------+
| substring_index('www.linuxidc.com', '.coc', 1) |
+---------------------------------------------------+
| www.linuxidc.com |
+---------------------------------------------------+
小米手机的两个师傅:同仁堂和海底捞
正在召开的第五届GMIC2013全球移动互联网大会上,小米手机CEO雷军坦陈,创办小米手机的时候,专门学习研究了两家企业同仁堂和海底捞。跟同仁堂学做产品,而跟海底捞学做服务。
“在做小米手机之前,我一直在思考在中国市场如何能做一家基业长青的公司?”雷军表示,为此他专门研究了同仁堂,发现其已经有了340年的历史,可谓是家伟大的公司。
同仁堂有两句话让雷军印象深刻,其一,“炮制虽繁必不敢省人工,品味虽贵必不敢减物力。”雷军将其翻译为“真材实料不偷懒。”
其二“修合无人见 存心有天知”。雷军翻译为,“你做的事情虽然没有人看见,但是老天知道。”
为此,小米手机在创办之初,就把真材实料作为小米手机的立身之本。“相信你真才实料做每件事时,老天知道。”雷军说。
此外,海底捞也是小米手机的学习的对象,核心在于其“口碑营销”。受此影响,小米手机尽量保持了低调,基本不做广告,主要依靠口碑营销。
根据相关数据显示,小米公司宣布已经售出700多万台小米手机,并且在做硬件销售的同时,涉足互联网的软件服务,尝试打造一条小米手机的生态系统。
能在几年间取得这样的成绩,雷军更愿意将其归结为对于两家企业优点的借鉴和学习。
“当今这个时代,我们更需要弘扬同仁堂精神和海底捞精神。”雷军说道。
fgetcsv读取不了中文解决办法
fgetcsv读取不了中文
已设置setlocale(LC_ALL, 'zh_CN'),但在读取csv文件的时候,有时不能读取里面的中文,这是为什么?跟系统系统好像有关系!
------解决方案--------------------------------------------------------
文档编码和系统编码相同吗,不相同的话iconv把文档编码转成系统编码。
------解决方案--------------------------------------------------------
fgetcsv有BUG。
用这个函数吧。
- PHP code
function _fgetcsv(& $handle, $length = null, $d = ',', $e = '"') {
$d = preg_quote($d);
$e = preg_quote($e);
$_line = "";
$eof=false;
while ($eof != true) {
$_line .= (empty ($length) ? fgets($handle) : fgets($handle, $length));
$itemcnt = preg_match_all('/' . $e . '/', $_line, $dummy);
if ($itemcnt % 2 == 0)
$eof = true;
}
$_csv_line = preg_replace('/(?: |[ ])?$/', $d, trim($_line));
$_csv_pattern = '/(' . $e . '[^' . $e . ']*(?:' . $e . $e . '[^' . $e . ']*)*' . $e . '|[^' . $d . ']*)' . $d . '/';
preg_match_all($_csv_pattern, $_csv_line, $_csv_matches);
$_csv_data = $_csv_matches[1];
for ($_csv_i = 0; $_csv_i < count($_csv_data); $_csv_i++) {
$_csv_data[$_csv_i] = preg_replace('/^' . $e . '(.*)' . $e . '$/s', '$1' , $_csv_data[$_csv_i]);
$_csv_data[$_csv_i] = str_replace($e . $e, $e, $_csv_data[$_csv_i]);
}
return empty ($_line) ? false : $_csv_data;
}
HTML5 的 PLACEHOLDER 属性
HTML5对Web Form做了许多增强,比如input新增的type类型、Form Validation等。Placeholder是HTML5新增的另一个属性,当input或者textarea设置了该属性后,该值的内容将作为灰字提示显示在文本框中,当文本框获得焦点时,提示文字消失。以前要实现这效果都是用JavaScript来控制才能实现:
<input id="t1" type="text" placeholder="请输入文字" />
由于placeholder是个新增属性,目前只有少数浏览器支持,如何检测浏览器是否支持它呢?(更多HTML5/CSS3特性检测可以访问)
function hasPlaceholderSupport() {
return 'placeholder' in document.createElement('input');
}
默认提示文字是灰色的,可以通过CSS来改变文字样式:
/* all */
::-webkit-input-placeholder { color:#f00; }
input:-moz-placeholder { color:#f00; }
/* individual: webkit */
#field2::-webkit-input-placeholder { color:#00f; }
#field3::-webkit-input-placeholder { color:#090; background:lightgreen; text-transform:uppercase; }
#field4::-webkit-input-placeholder { font-style:italic; text-decoration:overline; letter-spacing:3px; color:#999; }
/* individual: mozilla */
#field2:-moz-placeholder { color:#00f; }
#field3:-moz-placeholder { color:#090; background:lightgreen; text-transform:uppercase; }
#field4:-moz-placeholder { font-style:italic; text-decoration:overline; letter-spacing:3px; color:#999; }
兼容其他不支持placeholder的浏览器:
var PlaceHolder = {
_support: (function() {
return 'placeholder' in document.createElement('input');
})(),
//提示文字的样式,需要在页面中其他位置定义
className: 'abc',
init: function() {
if (!PlaceHolder._support) {
//未对textarea处理,需要的自己加上
var inputs = document.getElementsByTagName('input');
PlaceHolder.create(inputs);
}
},
create: function(inputs) {
var input;
if (!inputs.length) {
inputs = [inputs];
}
for (var i = 0, length = inputs.length; i <length; i++) {
input = inputs[i];
if (!PlaceHolder._support && input.attributes && input.attributes.placeholder) {
PlaceHolder._setValue(input);
input.addEventListener('focus', function(e) {
if (this.value === this.attributes.placeholder.nodeValue) {
this.value = '';
this.className = '';
}
}, false);
input.addEventListener('blur', function(e) {
if (this.value === '') {
PlaceHolder._setValue(this);
}
}, false);
}
}
},
_setValue: function(input) {
input.value = input.attributes.placeholder.nodeValue;
input.className = PlaceHolder.className;
}
};
//页面初始化时对所有input做初始化
//PlaceHolder.init();
//或者单独设置某个元素
//PlaceHolder.create(document.getElementById('t1'));
使用X-UA-Compatible来设置IE浏览器兼容模式
前言
为了帮助确保你的网页在所有未来的IE版本都有一致的外观,IE8引入了文件兼容性。在IE6中引入一个增设的兼容性模式,文件兼容性使你能够在IE呈现你的网页时选择特定编译模式。
新的IE为了确保网页在未来的版本中都有一支的外观,IE8引入了文件兼容性。当你引入一个增设的兼容性模式,
此文章说明文件兼容性的必要性,列出现有版本IE能使用的文件兼容性模式并示范如何选择特定的兼容性模式。
了解文件兼容性的必要性
每个主要版本IE新增的功能都是为了让浏览器更容易使用、增加安全性及更支持业界标准。以这些作为IE的特色,其中一个风险就是旧版本网站无法正确的显示。
为了将这个风险降到最低,IE6允许网页开发人员选择IE编译和显示他们网页的方式。"Quirks mode"为预设,这会使页面以旧版本浏览器的视点显示,"Standards mode"(也称为"strict mode")特点是支持业界标准最为完善。然而要利用这个增强的支持功能,网页必须包含恰当的<!DOCTYPE>指令。
若一个网页没有包含<!DOCTYPE>指令,IE6会将它以quirks mode显示。若网页包含有效的<!DOCTYPE>指令但浏览器无法辨识,IE6会将它以IE6 standards mode显示。因为少数网站已经包含<!DOCTYPE>指令,兼容性模式的切换相当成功。这使网页开发人员能选择将他们的网页转移为standards mode的最佳时机。
随著时间经过,更多网站开始使用standards mode。它们也开始使用IE6的特性和功能来检测IE。举例来说,IE6不支持universal selector(即css之全局选择器 * {}),一些网站便使用它来针对IE做特定的对应。
当 IE7增加了对全域选择器的支持,那些依赖IE6特点的网站便无法侦测出这个新版本的浏览器。因此那些针对IE的特定对应无法应用于IE7,造成这些网站便无法如他们预期的显示。由于<!DOCTYPE>只支持两种兼容性模式,受到影响的网站拥有者被迫更新他们的网站使其能支持IE7。
IE8 比之前的任何版本浏览器都更支持业界标准,因此针对旧版本浏览器设计的网页可能无法如预期般呈现。为了帮助减轻所有问题,IE8引入文件兼容性的概念,使你能选择你的网页设计要对应的特定IE版本。文件兼容性在IE8增加了一些新的模式,这些模式能告诉浏览器如何解析和编译一个网页。若你的网页无法在 ie8正确的显示,你可以更新你的网站使它支持最新的网页标准(优先选项)或在你的页面上新增一个meta元素用于告诉IE8如何依照旧版本浏览器编译你的页面。
这能让你选择将你的网站更新支持IE8新特点的时机。
认识文件兼容性模式
IE8支持几种文件兼容性模式,它们具有不同的特性并影响内容显示的方式。
•Emulate IE8 mode指示IE使用<!DOCTYPE>指令来决定如何编译内容。Standards mode指令会显示成IE8 Standards mode而quirks mode会显示成IE5 mode。不同于IE8 mode,Emulate IE8 mode重视<!DOCTYPE>指令。
•Emulate IE7 mode指示IE使用<!DOCTYPE>指令来决定如何编译内容。Standards mode指令会显示成IE7 Standards mode而quirks mode会显示成IE5 mode。不同于IE7 mode,Emulate IE7 mode重视<!DOCTYPE>指令。对于许多网页来说这是最推荐的兼容性模式。
•IE5 mode 编译内容如同IE7的quirks mode之显示状况,和IE5中显示的非常类似。
•IE7 mode编译内容如同IE7的standards mode之显示状况,无论网页是否含有<!DOCTYPE>指令。
•IE8 mode提供对业界标准的最高支持,包含 W3C Cascading Style Sheets Level 2.1 Specification和W3C Selectors API,并有限的支持 W3C Cascading Style Sheets Level 3 Specification (Working Draft)。
•Edge mode指示IE以目前可用的最高模式显示内容。当使用IE8时其等同于IE8 mode。若(假定)未来放出支持更高兼容性模式的IE,使用Edge mode的页面会使用该版本能支持的最高模式来显示内容。同样的那些页面在使用IE8浏览时仍会照常显示。
由于edge mode使用该IE版本所能支持的最高模式来显示所浏览的网页内容,建议仅使用于测试页及其他非商用页面。
指定文件兼容性模式
要为你的网页指定文件模式,需要在你的网页中使用meta元素放入X-UA-Compatible http-equiv 标头。以下是指定为Emulate IE7 mode 兼容性之范例。
<head>
</head>
<body>
</body>
</html>
其内容随著指定的页面模式而更改,当要模拟IE7时,指定IE=EmulateIE7,指定IE=5, IE=7, 或IE=8来选择其中一种兼容性模式。你也可以指定IE=edge来指示IE8使用它支持的最高模式。
X-UA-compatible标头没有大小写之分。然而除了title元素及其他的meta元素之外,它必须出现在网页header节其它元素之前的位置,
设定网站服务器以指定预设兼容性模式
网站管理员可籍着为网站定义一个自订标头来为他们的网站预设一个特定的文件兼容性模式。这个特定的方法取决于你的网站服务器。举例来说,下列的web.config文件使Microsoft Internet Information Services (IIS)能定义一个自订标头以自动使用IE7 mode来编译所有网页。
<configuration>
</configuration>
若你已于网站服务器指定了一个预设的文件兼容性模式,你可以在个别页面上指定不同的文件兼容性模式来盖过它。在网页中指定的模式优先权高于服务器中所指定的模式。
请查阅你的网站服务器关于指定自订标头的资讯,或看更多资料:
Implementing the META Switch on Apache
Implementing the META Switch on IIS
判定文件兼容性模式
要判定网页使用IE8浏览时的文件兼容性模式,使用document object(文档对象)的documentMode功能。例如在IE8的网址列输入下列程式码会显示目前页面的文件模式。
documentMode功能会回传一个数值对应目前页面的文件兼容性模式,举例来说,若网页指定为支持IE8模式,documentMode便会回传值"8"。
在IE6引入的compatMode功能不支持在IE8引入的documentMode功能。目前使用compatMode建立的应用程式还能在IE8中作用,但它们必须更新为使用documentMode。
若你希望使用JavaScript判定一个文件的兼容性模式,引入下面范例的这段程式码可支持旧版本的IE。
if (window.navigator.appName == "Microsoft Internet Explorer")
{
}
认识内容属性值
内容属性值在接收到异于先前叙述的数值时是具有弹性的。这能使你对于IE如何显示你的网页更有操控性。举例来说,你可以设定内容属性值为IE=7.5。当你这样做的时候,IE尝试将这个值转换为version vector并选择最接近的结果。在这个例子中,IE会将其设定为IE7 mode。下面的范例显示该模式设定为其他值的状况。
<meta http-equiv="X-UA-Compatible" content="IE=7.5"> <!-- IE7 mode -->
<meta http-equiv="X-UA-Compatible" content="IE=100"> <!-- IE8 mode -->
<meta http-equiv="X-UA-Compatible" content="IE=a">
<!-- This header mimics Internet Explorer 7 and uses
<meta http-equiv="X-UA-Compatible" content="IE=EmulateIE7">
注意: 前面的范例显示单独的内容值。实际上IE只会执行网页中第一个X-UA-Compatible标头。
你也可以使用内容属性来指定复数的文件兼容性模式,这能帮助确保你的网页在未来的浏览器版本都能一致的显示。欲设定复数的文件模式,请设定内容属性以判别你想使用的模式。使用分号来分开各个模式。
如果一个特定版本的IE支持所要求的兼容性模式多于一种,将採用列于标头内容属性中最高的可用模式。你可以使用这个特性来排除特定的兼容性模式,虽然并不推荐这样做。举例来说,下列标头即会排除IE7 mode。
结论
兼容性对于网页设计师来说是非常重要的顾虑。虽然最好是可以建立一个完全不需依赖任何网页浏览器特性或功能的网站,有时候这是不可能实现的。文件兼容性模式便能将网页限制在某个特定版本的IE中。
使用X-UA-Compatible标头来指定你的页面支持的IE版本。使用document.documentMode判定页面的兼容性模式。
选择支持某个特定版本的IE,你可以确保你的页面在未来的浏览器版本中也能有显示的一致性。
PHP中设置Session过期方法
Session的有效期是随浏览器进程的,浏览器关掉后就没了,那么怎么像Cookies那样设置过期时间呢?下面这段代码就可以实现。
1 2 3 4 5 |
<?php $cookies_life_time = 24 * 3600; //过期时间,单位为秒,这里的设置即为一天 session_start(); setcookie(session_name() ,session_id(), time() + $cookies_life_time, "/"); ?> |
企业持续集成成熟度模型简介
构建—— 企业持续集成成熟度模型简介之一
当今软件开发领域的自动化推广相当显著,软件也越来越多的由大规模、分布式的团队开发完成,而严格的企业管理需求也是十分常见的。由此表现出来的敏捷软件开发和持续集成与企业开发项目的现实之间的碰撞也越来越显著。在软件开发的整个生命周期中,我们对自动化的投入在不断增加。在这方面的先行者已经跨过了团队级别的持续集成,而将他们的自动化成果与端到端的方案结合在一起了。这些在企业级持续集成方面的投入使得他们可以应对需求的变化,并快速交付高质量的软件,而且得到事半功倍的效果。尽管自动化有这么多的好处,但,对于自动化的采纳情况却并不均衡。比如,很多团队仍旧在手工、缓慢且高风险的部署中挣扎着;而某些团队却可以在一天内进行多次高效且足够安全的生产环境部署。其实,有很多方法或途径来改善我们的开发自动化,但是从哪里开始呢?
企业的多样性
当创建这篇指导书时,我们遇到的挑战就是:不同企业(甚至同一个企业的不同团队)都不具有统一性。医疗设备系统的某些需求可能就要比做游戏难,也可能比在电子商务网站上增加新功能要难,也可能会比创建一个内部SOA应用要难。因此,单一的成熟度模型不可能适应全部情况。因此,我们选择了企业持续集成的四个维度来衡量成熟度,它们分别是构建、部署、测试和报告。我们将每一个维度上所对应的实践归入某一等级之下,并解释为什么需要采纳(或不采纳)这些实践。通过这个模型,你可以了解业内在企业持续集成方面的平均水平,并可以据此反思,在哪些方面做得高于行业平均水平,还有哪些方面做得不足。这个模型所反映出来的评估尺度完全基于几年来数百个团队持第一手经验以及本领域的一些报告。为了解释如何使用这个模型,我们创建了三个有不同需求的企业案例。我们会分析他们的状况,并展示他们如何使用成熟度模型来计划哪些改进会给他们带来最高的投资回报率。
成熟度模型中的级别
在整篇文章中,企业持续集成不同维度的成熟级别会以相同的方式来阐述。级别分为:入门、新手、中等、进阶和疯狂。为了解释这些级别,下面我们举例说明各级别之间的关系。实例的出发点为:该过程为完全手工的,即某个工程师必须要手工执行一系列冗长且易出错的步骤来达到“将某个手工过程自动化”这一目标。那么对于这个“自动化某个过程”,它的成熟度模型如下所示:
团队最初是入门级,因为他们已经写了一些辅助脚本,用于该过程中那些特别慢或问题较多的部分进行了自动化。这种自动化的益处在于节省时间且减少错误。为了进一步提高,团队将所有辅助脚本串接起来,实现了整个过程的单一脚本自动化,即达到了中级。而这个单一脚本的回报就是:这个操作过程可以很容易交给别人去做。当团队打算提高到进阶级时,需要用某个应用软件来调用执行该脚本。这个应用软件可能在后台执行的,但一定是每次都在正确的条件、时机和位置上运行的。比如,这个应用软件可能只需要用户点一下鼠标,或者只需要在某个特定的时间调用这个脚本,自动传入一些参数来执行。
当然,进阶级或者疯狂级的定义都会随着时间的推移而改变。在持续集成诞生时,“代码提交后自动触发构建”就被认为是疯狂的,而在今天只能算是中级中的一个活动而已。
构建、部署、测试和报告
在我们的成熟度模型中,包括了四个维度,它们分别是构建、部署、测试和报告。这四个维度覆盖了整个端到端的构建生命周期,即从源代码直到产品。
构建
那种原始的以开发人员为中心的持续集成是为了从构建软件中得到快速的反馈。而当持续集成进入企业视角后,构建管理、项目之间的依赖以及构建过程上的管理控制都成为至关重要的元素了。大多数新项目一般在开始时,都是在开发机器上执行构建的,而且没有一个标准的过程。一个开发人员可能习惯于在他自己的IDE上进行构建,而另一个人可能写了一个构建脚本来做这件事。那些最不成熟的团队还会将那些使用这种过程构建出来的二进制文件部署并测试,甚至将其发布到生产环境中。这种因缺乏控制所导致的问题很快就显现出来了。因此,我们一开始就要找更好的方法。
成熟构建的第一步就是让构建过程标准化,并在非开发机器上进行正式的构建。使用非开发者机器进行构建意味着这种构建不会因开发者的机器环境发生了变化而导致污染。因为正式构建已经不在开发者的机器上进行,所以我们必然是每次都从某个固定的源文件控制中得到代码,并遵守一定的规则:比如每次都从某个分支签出最新版本,或者是打过某种标签的源代码等等。因些做到了这些之后,该团队就达到了入门级。
入门级的团队进一步采取行动,将构建步骤实现自动化执行。即构建服务器将指挥机器、按源代码签出规则得到源代码,并执行那些构建步骤,从而提供了初步受控的构建过程。典型的是:这些自动构建每日执行,尽管某些团队可能会一天执行两次以上。此时的团队就提高到了新手级。
而对中级的团队来说,他们开始更明显地关注并管理对于其它软件的依赖(包括子项目或第三方库)。中级使用依赖管理库来追踪这些库文件,并在构建时提供这些库文件,而不是使用某种口头约定方式。同样地,那些可能被其它构建所引用的构建也会通过依赖管理工具将其自身放在这个库中以便其它构建来引用。达到这一级别的控制后,自动构建就是很容易做到的了,而且也提供更有价值的反馈。中级团队采纳了持续构建(即每个开发人员提交时就自动构建或当依赖发生变化时)。所有的构建结果都被保存(可能放在一个网络服务器上,或干脆就在持续集成服务器上),并进行周期性的清理并标签以方便识别。规模大一些的团队将使用分布式构建设施来并行处理数量众多的构建。此时,对于很多组织来说,可以说满足了他们的需求。
对于更正规的组织(比如企业级)将会进一步做到进阶级,以控制构建过程。在这种环境下,团队象追踪源代码和依赖的变化一样,对构建过程的变化也进行记录跟踪。修改构建过程需要经过批准,对于登录官方构建机器,修改构建服务器配置等都是严格控制的。对于那种“服从是一个要素”的地方或那种将企业持续集成已成为一个生产系统的地方,应该将进阶级的受控构建过程做为目标。而对于没有这方面要求的其它团队来说,中级也就可以接受了。
另外,某些组织的管理控制规则更加严格,且要求必须能够完美地重新构建从前的发布版本(比如需要拿到与一年前的某次构建产物一模一样的产物)。这些组织将使用各种各样的技术来确保每个环境的可重复性。一些可能会有缜密细致地被版本控制化的脚本,在开始运行构建之前从安装操作系统开始来准备构建机器。另一些可能使用做好的虚拟机镜像来做类似的事情。我们把这种控制级别定义为疯狂级。因此,一些团队可能不需要达到这种方式。因为可能负担太大而收益太少。
部署—— 企业持续集成成熟度模型简介之二
部署是指将软件移动到它被测试的地方,或用户指定的某个位置,准备送给客户。对于web应用来说,这可能意味着将软件安装到某个web服务器上,并更新数据库或静态内容服务器。而对于一个视频游戏来说,这个测试部署可能是指安装这个软件版本到某些测试机器上,而产品部署则可能是指烧录一个光盘并给发行商。
部署最开始一般都是手工过程。部署工程师从某处拿到部署文件,再把它放到目标机器上,然后开始正式的安装过程。然而,这种手工过程会比较慢,而且部署失败率也可能要高一些。工程师常常被迫在晚上或周末加班,进行测试环境或生产环境的部署,因为这些环境平时需要正常运行,不能轻易地停止。更糟糕的是:每个环境很可能使用了不同的步骤进行手工操作(比如步骤前后顺序颠倒,这尤其容易发生在不同的操作人员之间),几乎无法保证:在某个环境上的成功部署表明在下一个环境中部署成功的可能性也同样高。

对于团队来说,抛弃完全的手工过程,使用一些辅助脚本或全过程脚本化是一个非常巨大的进步。纵观整个行业,大多数团队都会有一些辅助性脚本,但有完全脚本化部署方式的团队较少,特别是在受控环境中(如试运行环境或生产环境)。因此,业内在这方面的平均水平应该是在入门级。
而中级团队善于进行测试环境上的自动化部署。他们完全通过脚本以一键部署的方式在部分或全部的测试环境中进行部署。这大大解放了部署工程师,而且减少了测试人员因等待部署而浪费的时间。就像持续构建是中级构建团队的的特征一样,自动地部署到第一个测试环境是在部署这一维度上中级成熟度的标志。根据团队的动态性,在不打断测试人员工作的情况下,这种测试环境的自动部署应该发生在任何一次成功的持续构建之后或一天内的周期性部署。中级团队的最后一个特征是:建立标准化的各种环境部署顺序。虽然可能还会有一些环境变数,或两种部署方式,但在某个版本的全生命周期中(即从生产到部署上线),越早地成功部署,就意味着后续部署成功的可能性更大。达到这个级别是很多团队的目标。而进阶团队则把视线转到受控环境或生产环境上。部署到生产环境(或发布)只要按一下鼠标就行,生产环境发布就被自动触发,并有相应的发布版本可以进行灾难恢复。那些已经部署到内部测试环境的团队应该将目标定位到“进阶”:如果在所有环境中进行完全一致的部署过程,那么在生产环境部署时,会极大地减少最后一刻失败的可能性。进阶级团队的另一个特征是:将通过前面通过质量测试检验的版本全部自动地部署到部分或全部测试环境中。例如,得到测试经理的批准后,让某个构建版本自动地安装到压力测试环境中。
而疯狂级的团队的目标是“持续部署”,即自动部署到生产环境中而无需手工干预:得到一个版本后,自动部署到一系列的测试环境中。经过整个构建管道中的所有阶段,并且能通过所有的测试后,自动部署该版本到生产环境中。某些.com应用可以在一个小时之内就完成从源文件控制到发布的整个过程。显然,此时的自动化测试必须非常成熟,而且具有自动回滚和相应的监控手段。但是,在快节奏的竞争环境下,极其迅速地部署新功能也是一个核心竞争力,可以减轻大规模功能变更的风险。
测试—— 企业持续集成成熟度模型简介之三
持续集成一直同自动化测试相关联。这在马丁福勒的文章或更早期Steven McConnell对日构建和冒烟测试的相关实践描述中都有提及。而且在企业持续集成的领域中,我们会考虑很多种类型的自动化测试和手工测试。尽管如些,很多团队在测试方面还是比较弱。很常见的一个版本发布场景就是:某个团队完成一个版本后,手工测试一下基本功能就发布了。而其中的某一部分总是出错,而新功能也只做了少量测试。如果团队在测试方面比较成熟的话,他们能很快发现问题或缺陷,从而在生产率和信心方面都会有所增加。
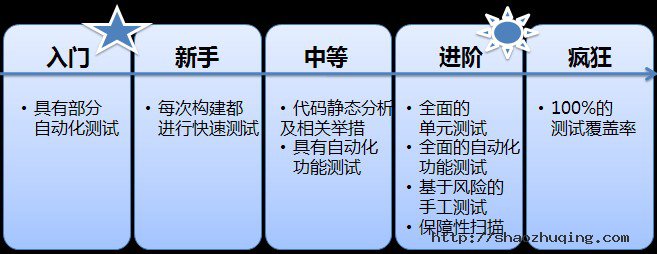
目前,大多数团队或多或少都会有某种形式的自动化测试。比如一小撮单元测试套件或一些脚本化的测试,用于确保软件的基本功能是可以工作的。这些基本的自动化回归测试能够较早及比较容易地发现那些基本功能性问题。入门级的团队 通常刚刚开始习惯于做这种自动化测试。
为了达到新手级成熟度 ,应该有一套快速测试在每次构建时都运行。这些测试给团队增加了信心:软件基本上在任何时间都能工作。测试一旦失败,开发团队会得到即时通知,从而在他们忘记这个问题的上下文之前就有机会去修复这些失败的测试。因此,对于这一级别来说,对测试失败通知的响应是非常重要的:如果一个团队测试失败却不响应的话,那它应该低于测试成熟度的入门级。
中级成熟度 的团队会在这些同快速构建同时执行的测试的基础之上,扩大测试范围。企业持续集成的成熟测试是以多种多样的测试集合为特性的。一个中级团队不仅有快速测试和手工测试,而且还有自动化的功能测试。中级团队常常让持续集成系统同时运行一些静态源代码分析。静态分析可能不是每次都运行,但一定会周期性运行。而且一旦产生了某种严重的静态质量问题的话,一定修复之后才能发布。
进阶级成熟度 是以“完整测试”为标志的。每种测试都提供其所能提供的最大价值。单元测试覆盖了系统中所有复杂代码与逻辑。功能测试覆盖了系统中所有的重要功能。也会有边界测试和随机测试。同时,还要频繁运行静态代码分析,并补充以工具支持的运行时分析和安全扫描来发现那些可能因测试不足或无法测试而遗漏的问题。测试可能被分配在多种系统下运行,以使能并行执行,从而提供快速的反馈。达到进阶级需要相当大的投入,然而对于那些缺陷的成本很高且需要能够保持高速前进的团队来说,对是非常重要的。假如没有这类需求的话,一般来说,中级可能是一个更适当的目标。
在极端的情况下(也就是疯狂级成熟度 ),某些团队追求100%的测试覆盖率。尽管100%测试覆盖率的定义在变化,但它反映出至少每行代码都被测试覆盖到。在某些软件中,存在一个收益递减的点,在这一点上,对某行代码的自动化测试的价值要小对写测试的成本。追求100%的测试覆盖率意味着团队会做一些浪费的测试,然而其目的有可能是阻止因某些测试很有价值但很难写而不写测试找藉口。满足并保持100%的测试覆盖率可能也是一个自豪感与动力的源泉。对于进阶级团队来说,如果曾经发现的确错过了一些非常重要的测试的话,要求100%的测试覆盖也未尚不可。但对于大多数团队来说,简直可以说是变态啦。
报告—— 企业持续集成成熟度模型简介之四
持续集成工具一直以来就负责报告最近一次构建的状态。报告是持续集成的一个至关重要的元素。在企业持续集成中,报告应包含所做软件的相关质量和内容方面的信息,以及与企业持续集成过程有关的度量信息。没有报告的团队就象一个没有雷达的飞机在飞行。如果没有人看测试结果的话,所有的测试都是无用的。同样,很多数据如果没有被提取成可消化利用的信息的话,就很难使用,一样可以视为无用。越成熟团队的报告,其可视化程度越高,有用的信息也会越多。

很多工具在构建过程中都会产生报告。在一个团队中,如果某人利用一些工具来产生报告,并分析它,之后会根据它来做出行动的话,这个团队就已经是入门级成熟度 了。注意:此级别上,如果团队的其他人想利用这些数据做些事情时,需要联系这个人,索要相关信息。当到了新手级成熟度 时,每个角色组(开发、测试、部署等)都会公布这类信息。一个构建服务器也可能提供一些信息,比如哪些代码变化了,源代码的分析报告、单元测试结果或编译错误等。测试人员也会公布他们自动测试和手工测试的结果报告。部署与发布人员会公布某个版本在生产环境的运行时长、记录的缺陷,以及发布速度等信息。但每个角色几乎各自为战,跨角色信息传递通常是手工完成的。事实上,这个级别应该是业内的平均水平,尽管很多企业有比较强大的跨角色或部门的展示能力。
中级成熟度 则有两个比较大的变化。第一个是每个角色组的关键信息集合可以被整个团队的其它人员访问。测试人员可以看到开发部分的信息:比如从上次测试人员测试过的版本到目前的版本有哪些文件变化了;开发人员能够知道测试人员正在测试哪个版本,目前的测试结果如何等。每个参与到版本生命周期的人都至少会得到对其有用的总结报告。有了更高的可视化程度,那么用于沟通基本数据所用的成本会减少,从而依据报告进行相应工作的时间就增加了。第二个是有历史报告。即不但有最近的活动报告,而且有过去的报告。比如可以拿出过去发布的测试数据与当前发布的数据进行对比。团队不但知道最近测试通过率是95%,还知道加了多少个测试,删除了多个测试,或者哪些测试之前通过了。95%的通过率比昨天的结果好,还是坏?我们是应该高兴,还是需要继续努力让它更高?
而进阶级团队 能够利用历史报告信息进行趋势分析。中级团队记录了每个测试的失败,而进阶级团队利用报告分析出哪些测试经常被破坏。还可能分析出修改哪些文件后更有可能使单元测试失败?哪些会让功能测试套件失败?通过识别那些经常出错的代码帮助团队来发现哪些代码应该多加测试或进行重新设计实现。在特定的报告中,会有从不同的竖井(不同的角色团队)汇总在一起得到的数据,并互相迭加引用。进阶级团队也是真正使用这些特定报告并会采取相应行动的团队。生成这些可操作的跨功能团队的报告应该是企业持续集成的目标。而疯狂级报告是关于预测的。这样的疯狂级团队会收集每次交付客户之后得到的反馈度量信息,如从缺陷报告和接收到的技术支持的需求抽取相关信息。根据当前的一次发布与过去的某次发布之间的数据对比,团队应该可以预测在发布后的第一周内技术支持的压力有多大(比如,可能会接到多少个问题反馈)。在这种模式下,他们可能问更多有意思的问题,而不只是简单的问一下“我们的特性都做完了吗?”
PHP读取文件的常见方法
整理了一下PHP中读取文件的几个方法,方便以后查阅。
1.fread
string fread ( int $handle , int $length )
fread() 从 handle 指向的文件中读取最多 length 个字节。该函数在读取完最多 length 个字节数,或到达 EOF 的时候,或(对于网络流)当一个包可用时,或(在打开用户空间流之后)已读取了 8192 个字节时就会停止读取文件,视乎先碰到哪种情况。
fread() 返回所读取的字符串,如果出错返回 FALSE。

<?php
$filename = "/usr/local/something.txt";
$handle = fopen($filename, "r");//读取二进制文件时,需要将第二个参数设置成'rb'
//通过filesize获得文件大小,将整个文件一下子读到一个字符串中
$contents = fread($handle, filesize ($filename));
fclose($handle);
?>
如果所要读取的文件不是本地普通文件,而是远程文件或者流文件,就不能用这种方法,因为,filesize不能获得这些文件的大小。此时,你需要通过feof()或者fread()的返回值判断是否已经读取到了文件的末尾。
例如:
<?php
$handle = fopen('http://www.baidu.com', 'r');
$content = '';
while(!feof($handle)){
$content .= fread($handle, 8080);
}
echo $content;
fclose($handle);
?>
或者:
<?php
$handle = fopen('http://www.baidu.com', 'r');
$content = '';
while(false != ($a = fread($handle, 8080))){//返回false表示已经读取到文件末尾
$content .= $a;
}
echo $content;
fclose($handle);
?>
2.fgets
string fgets ( int $handle [, int $length ] )
fgets()从 handle 指向的文件中读取一行并返回长度最多为 length - 1 字节的字符串。碰到换行符(包括在返回值中)、EOF 或者已经读取了 length - 1 字节后停止(看先碰到那一种情况)。如果没有指定 length,则默认为 1K,或者说 1024 字节。
<?php
$handle = fopen('./file.txt', 'r');
while(!feof($handle)){
echo fgets($handle, 1024);
}
fclose($handle);
?>
Note: length 参数从 PHP 4.2.0 起成为可选项,如果忽略,则行的长度被假定为 1024。从 PHP 4.3 开始,忽略掉 length 将继续从流中读取数据直到行结束。如果文件中的大多数行都大于 8KB,则在脚本中指定最大行的长度在利用资源上更为有效。从 PHP 4.3 开始本函数可以安全用于二进制文件。早期的版本则不行。
3.fgetss
string fgetss ( resource $handle [, int $length [, string $allowable_tags ]] )
跟fgets功能一样,但是fgetss会尝试从读取的文本中去掉任何 HTML 和 PHP 标记,可以用可选的第三个参数指定哪些标记不被去掉。
<?php
$handle = fopen('./file.txt', 'r');
while(!feof($handle)){
echo fgetss($handle, 1024, '<br>');
}
fclose($handle);
?>
4.file
array file ( string $filename [, int $use_include_path [, resource $context ]] )
将文件内容读入一个数组中,数组的每一项对应文件中的一行,包括换行符在内。不需要行结束符时可以使用 rtrim() 函数过滤换行符。
<?php
$a = file('./file.txt');
foreach($a as $line => $content){
echo 'line '.($line + 1).':'.$content;
}
?>
5.readfile
int readfile ( string $filename [, bool $use_include_path [, resource $context ]] )
读入一个文件并写入到输出缓冲。返回从文件中读入的字节数。如果出错返回 FALSE 并且除非是以 @readfile() 形式调用,否则会显示错误信息。
<?php
$size = readfile('./file.txt');
echo $size;
?>
6.file_get_contents
string file_get_contents ( string $filename [, bool $use_include_path [, resource $context [, int $offset [, int $maxlen ]]]] )
将文件读入一个字符串。第三个参数$context可以用来设置一些参数,比如访问远程文件时,设置超时等等。
另外,file_get_contents相对于以上几个函数,性能要好得多,所以应该优先考虑使用file_get_contents。但是readfile貌似比file_get_contents性能好一点(?),因为它不需要调用fopen。
<?php
$ctx = stream_context_create(array(
'http' => array(
'timeout' => 1 //设置超时
)
)
);
echo file_get_contents("http://www.baidu.com/", 0, $ctx);
?>
7.fpassthru
int fpassthru ( resource $handle )
将给定的文件指针从当前的位置读取到 EOF 并把结果写到输出缓冲区。
<?php
header("Content-Type:text/html;charset=utf-8");
$handle = fopen('./test2.php', 'r');
fseek($handle, 1024);//将指针定位到1024字节处
fpassthru($handle);
?>
8.parse_ini_file
array parse_ini_file ( string $filename [, bool $process_sections ] )
parse_ini_file() 载入一个由 filename 指定的 ini 文件,并将其中的设置作为一个联合数组返回。如果将最后的 process_sections 参数设为 TRUE,将得到一个多维数组,包括了配置文件中每一节的名称和设置。process_sections 的默认值是 FALSE。
注意:
1. 如果 ini 文件中的值包含任何非字母数字的字符,需要将其括在双引号中(")。
2. 有些保留字不能作为 ini 文件中的键名,包括:null,yes,no,true 和 false。值为 null,no 和 false 等效于 "",值为 yes 和 true 等效于 "1"。字符 {}|&~![()" 也不能用在键名的任何地方,而且这些字符在选项值中有着特殊的意义。
test.ini文件内容:
; This is a sample configuration file ; Comments start with ';', as in php.ini [first_section] one = 1 five = 5 animal = BIRD [second_section] path = "/usr/local/bin" URL = "http://www.example.com/~username
test.php内容:
<?php
$config = parse_ini_file('./test.ini', ture);
print_r($config);
?>
输出内容:
Array
(
[first_section] => Array
(
[one] => 1
[five] => 5
[animal] => BIRD
)
[second_section] => Array
(
[path] => /usr/local/bin
[URL] => http://www.example.com/~username
)
)
几个注意事项:
1. 鼓励在处理二进制文件时使用 b 标志,即使系统并不需要,这样可以使脚本的移植性更好。
2. allow_url_fopen选项激活了 URL 形式的 fopen 封装协议使得可以访问 URL 对象例如文件。默认的封装协议提供用 ftp 和 http 协议来访问远程文件,一些扩展库例如 zlib 可能会注册更多的封装协议。出于安全性考虑,此选项只能在 php.ini 中设置。
3. 如果要打开有特殊字符的 URL (比如说有空格),就需要使用 urlencode() 进行 URL 编码。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
