资源平台化、O2O获客以及移动端C2C服务做定制旅游
根据去年 5 月的一份《2014中国高净值人群心灵投资白皮书》,我们可以看到越来越多的有钱人热衷于在旅游领域的投资,而且相比于大众化的旅游产品,他们更青睐定制游、主题游等个性化的产品。
目前在高端旅游市场,也已兴起了一大批定制旅游品牌,比如中青旅的耀悦,众信旅游的奇迹旅行,携程的鸿鹄逸游、太美,还有兰卡之星、主打私人健康旅行的优翔、遨乐网、帝国假日等,不过中端定制市场的选手貌似并不多,目前有无二之旅、十方旅行等,另外还有将在中高端市场掘金的游心旅行。
在游心旅行的创始人蒋松涛看来,定制旅游市场是没有巨头天花板的,而且目前太美、鸿鹄逸游等高端定制逐渐趋于标准化,并不能满足人们日益多元化的需求,再者,目前并没有同时涵盖中高端市场的定制旅游品牌,游心旅行就是想填补这个空白,为这些用户提供定制、半定制旅游产品及服务,并且以平台化资源、O2O模式获取顾客,以及打造移动端C2C服务来完善整个定制体系。
资源平台化——以自营产品为主,商家资源为辅
游心旅行会经营主要出境游业务,包括定制旅游,以及自助游中消费频次较高的目的地产品,海岛、美国、澳大利亚、新西兰等地都会主力经营,然后引进一些其他的商家,像鸿鹄逸游等高端定制的资源,游心旅行也都能获取,而至于邮轮等比较低频的产品,游心旅行就不会自己去做。
之所以将资源平台化,蒋松涛表示:一则是因为旅游的消费频次低,所以通过平台引入其他供应商可以从产品类型上进行扩张,让用户有更多选择;其次是为了把控资源和用户双方,举个栗子,像赞那度虽有调性、品位,虽然产品做得很精致,事实上它也只是一个媒介,资源并不在赞那度手中,而游心旅行通过轻重取舍则能很好的把握优质资源,并保留住忠诚用户。
开设线下体验店,以O2O的模式获取顾客
一直以来,定制都是一个重线下运作的过程,即便在互联网的冲击之下,这些单价较高、消费频次低的产品也并没能有效走到线上。所以,游心旅行也采取 O2O 的模式,通过开设线下实体店来获取用户,一方面能给用户舒适的交流环境,另一方面也增加了用户对游心旅行的信任感。
打造贴身旅行管家Mr.U,在移动端提供C2C服务
用户在目的地的体验才是真正的消费环节,因此,游心旅行在移动端提供 C2C 服务来解决用户行中问题,目前姑且称它为“游心旅行管家”。
与上述的资源平台化思路,提供目的地服务的旅行管家一部分来自游心旅行全职的旅游产品经理,也会逐渐让众信、中青旅等旅游机构的专业人士入驻;另一部分则由旅行达人组成,比如即将合作的眭澔平(具体介绍见全文末尾)。
通过这种方式,既不会让游心旅行的业务模式过重,也能保证行中服务的快速有效。当用户在行程中遇突发情况,比如临时更改行程,直接就可以通过 App 联系到旅行管家,问题不大的情况下旅行达人就能直接提供建议,如果比较复杂,那么专业人士就会帮助落实这些服务。
最后,用户还能对这些旅行管家评分,优胜劣汰之下能将有潜质的旅行管家挖掘出来,而那些起初以兼职身份存在的人也可能因为挣到钱而转作全职。
而提及未来,游心旅行不仅想做一个中高端定制旅游的服务平台,他们更希望能打造出一个中高端的品牌形象,将通过定制旅游获取到的具备极强消费力的中高端用户往其他服务进行导流,比如推出Ms.U品牌——可以提供针对女士美妆、购物、养生的产品,或者是Baby.U这样的形象来为孩子推出游学等服务。
团队情况上,游心旅行团队聚集了来自鸿鹄逸游、太美旅行、穷游网、赞那度等的成员,也吸纳了腾讯、网易等互联网人士加入。蒋松涛告诉36氪,游心旅行于 2014 年 5 月份上线,上线的当月便获得了天使投资,又于 2014 年 8 月又完成了鼎晖投资与北极光邓锋的 Pre-A 轮融资,12 月份完成千万美金级别的 A 轮融资后,又并购了转型旅游定制的五星汇。
注:报道所涉融资金额由对象公司提供保证,36氪不作任何形式背书。
注:眭澔平,台湾人,集记者、作家、歌手与主持人的身份于一身,更是一名虔诚的旅行者。他是三毛的忘年交,也为实现对三毛的承诺,二十多年已走遍180多个国家,踏遍世界的每一个角落。在《我看到的世界和你们不一样》一书中,他在南极给企鹅唱着月亮代表我的心,在菲律宾古毒体验耶稣之苦,遭受钢钉穿手的洗礼......读了他的故事之后,希望你也能“与年少初始纯真的自我相逢”。
北京市小汽车摇号程序的反编译、算法及存在的问题浅析-不重复随机数列生成算法
给定一个正整数n,需要输出一个长度为n的数组,数组元素是随机数,范围为0 – n-1,且元素不能重复。比如 n = 3 时,需要获取一个长度为3的数组,元素范围为0-2,
比如 0,2,1。
这个问题的通常解决方案就是设计一个 hashtable ,然后循环获取随机数,再到 hashtable 中找,如果hashtable 中没有这个数,则输出。下面给出这种算法的代码
public static int[] GetRandomSequence0(int total)
{
int[] hashtable = new int[total];
int[] output = new int[total];
Random random = new Random();
for (int i = 0; i < total; i++)
{
int num = random.Next(0, total);
while (hashtable[num] > 0)
{
num = random.Next(0, total);
}
output[i] = num;
hashtable[num] = 1;
}
return output;
}
代码很简单,从 0 到 total - 1 循环获取随机数,再去hashtable 中尝试匹配,如果这个数在hashtable中不存在,则输出,并把这个数在hashtable 中置1,否则循环尝试获取随机数,直到找到一个不在hashtable 中的数为止。这个算法的问题在于需要不断尝试获取随机数,在hashtable 接近满时,这个尝试失败的概率会越来越高。
那么有没有什么算法,不需要这样反复尝试吗?答案是肯定的。
![]()
如上图所示,我们设计一个顺序的数组,假设n = 4
第一轮,我们取 0 – 3 之间的随机数,假设为2,这时,我们把数组位置为2的数取出来输出,并把这个数从数组中删除,这时这个数组变成了
![]()
第二轮,我们再取 0-2 之间的随机数,假设为1,并把这个位置的数输出,同时把这个数从数组删除,以此类推,直到这个数组的长度为0。这时我们就可以得到一个随机的不重复的序列。
这个算法的好处是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试。算法代码如下:
public static int[] GetRandomSequence1(int total)
{
List<int> input = new List<int>();
for (int i = 0; i < total; i++)
{
input.Add(i);
}
List<int> output = new List<int>();
Random random = new Random();
int end = total;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end);
output.Add(input[num]);
input.RemoveAt(num);
end--;
}
return output.ToArray();
}
这个算法把两个循环改成了一个循环,算法复杂度大大降低了,按说速度应该比第一个算法要快才对,然而现实往往超出我们的想象,当total = 100000 时,测试下来,第一个算法用时 44ms, 第二个用时 1038 ms ,慢了很多!这是为什么呢?问题的关键就在这个 input.RemoveAt 上了,我们知道如果要删除一个数组元素,我们需要把这个数组元素后面的所有元素都向前移动1,这个移动操作是非常耗时的,这个算法慢就慢在这里。到这里,可能有人要说了,那我们不用数组,用链表,那删除不就很快了吗?没错,链表是能解决删除元素的效率问题,但查找的速度又大大降低了,无法像数组那样根据数组元素下标直接定位到元素。所以用链表也是不行的。到这里似乎我们已经走到了死胡同,难道我们只能用hashtable 反复尝试来做吗?在看下面内容之前,请各位读者先思考5分钟。
…… 思考5分钟
算法就像一层窗户纸,隔着窗户纸,你永远无法知道里面是什么,一旦捅穿,又觉得非常简单。这个算法对于我,只用了2分钟时间想出来,因为我经常实现算法,脑子里有一些模式,如果你的大脑还没有完成这种经验的积累,也许你要花比我长很多的时间来考虑这个问题,也许永远也找不到捅穿它的方法。不过不要紧,我把这个方法公布出来,有了这个方法,你只需轻轻一动,一个完全不同的世界便出现在你的眼前。原来就这么简单……。
还是上面那个例子,假设 n = 4
![]()
第一轮,我们随机获得2时,我们不将 2 从数组中移除,而是将数组的最后一个元素移动到2的位置

这时数组变成了
![]()
第二轮我们对 0-2 取随机数,这时数组可用的最后一个元素位置已经变成了2,而不是3。假设这时取到随机数为1
我们再把下标为2 的元素移动到下标1,这时数组变成了
![]()
以此类推,直到取出n个元素为止。
这个算法的优点是不需要用一个hashtable 来存储已获取的数字,不需要反复尝试,也不用像上一个算法那样删除数组元素,要做的只是每次把数组有效位置的最后一个元素移动到当前位置就可以了,这样算法的复杂度就降低为 O(n) ,速度大大提高。
经测试,在 n= 100000 时,这个算法的用时仅为7ms。
下面给出这个算法的实现代码
/// <summary>
/// Designed by eaglet
/// </summary>
/// <param name="total"></param>
/// <returns></returns>
public static int[] GetRandomSequence2(int total)
{
int[] sequence = new int[total];
int[] output = new int[total];
for (int i = 0; i < total; i++)
{
sequence[i] = i;
}
Random random = new Random();
int end = total - 1;
for (int i = 0; i < total; i++)
{
int num = random.Next(0, end + 1);
output[i] = sequence[num];
sequence[num] = sequence[end];
end--;
}
return output;
}
下面是n 等于1万,10万和100万时的测试数据,时间单位为毫秒。从测试数据看GetRandomSequence2的用时和n基本成正比,线性增长的,这个和理论上的算法复杂度O(n)也是一致的,另外两个算法则随着n的增大,用时超过了线性增长。在1百万时,我的算法比用hashtable的算法要快10倍以上。
| 10000 | 100000 | 1000000 | |
| GetRandomSequence0 | 5 | 44 | 1075 |
| GetRandomSequence1 | 11 | 1038 | 124205 |
| GetRandomSequence2 | 1 | 7 | 82 |
现在摇号的程序及数据都可以在官网中查看,目的就是通过信息的透明度来堵住那些说摇号系统有猫腻之类的传言,我做为一个程序员,下意识的就想看看到底是否有猫腻。
通过下载程序,导入数据,将种子数写入后,的确没有什么猫腻,但还是不死心,想研究一下算法,结果发现了惊人的事情。
此算法使用的是伪随机,简单点将就是当种子数一定,摇号数据一定,每次随机结果都是一样的。举个例子,借用某申请编码2245102443992,摇号基数序号500015,取种子数范围在100000至120000之间能中签的种子数,结果显示共132个种子数,其概率为0.66%。随机找了一个种子数100575进行计算,得出结果在左侧表中,查询2245102443992是否中签,结果显示中签,在第15916行摇中;所以大家都应该知道怎么回事了吧,只要摇号池数据确定,查询出摇号基数序号,就能算出中签的种子数都有哪些,所以公布的数据和程序又有何用?关键在于种子数的确定。

PHP魔术方法和魔术常量介绍及使用
PHP中把以两个下划线__开头的方法称为魔术方法,这些方法在PHP中充当了举足轻重的作用。 魔术方法包括:
__construct(),类的构造函数__destruct(),类的析构函数__call(),在对象中调用一个不可访问方法时调用__callStatic(),用静态方式中调用一个不可访问方法时调用__get(),获得一个类的成员变量时调用__set(),设置一个类的成员变量时调用__isset(),当对不可访问属性调用isset()或empty()时调用__unset(),当对不可访问属性调用unset()时被调用。__sleep(),执行serialize()时,先会调用这个函数__wakeup(),执行unserialize()时,先会调用这个函数__toString(),类被当成字符串时的回应方法__invoke(),调用函数的方式调用一个对象时的回应方法__set_state(),调用var_export()导出类时,此静态方法会被调用。__clone(),当对象复制完成时调用
__construct()和__destruct()
构造函数和析构函数应该不陌生,他们在对象创建和消亡时被调用。例如我们需要打开一个文件,在对象创建时打开,对象消亡时关闭
<?php
class FileRead
{
protected $handle = NULL;
function __construct(){
$this->handle = fopen(...);
}
function __destruct(){
fclose($this->handle);
}
}
?>
这两个方法在继承时可以扩展,例如:
<?php
class TmpFileRead extends FileRead
{
function __construct(){
parent::__construct();
}
function __destruct(){
parent::__destruct();
}
}
?>
__call()和__callStatic()
在对象中调用一个不可访问方法时会调用这两个方法,后者为静态方法。这两个方法我们在可变方法(Variable functions)调用中可能会用到。
<?php
class MethodTest
{
public function __call ($name, $arguments) {
echo "Calling object method '$name' ". implode(', ', $arguments). "\n";
}
public static function __callStatic ($name, $arguments) {
echo "Calling static method '$name' ". implode(', ', $arguments). "\n";
}
}
$obj = new MethodTest;
$obj->runTest('in object context');
MethodTest::runTest('in static context');
?>
__get(),__set(),__isset()和__unset()
当get/set一个类的成员变量时调用这两个函数。例如我们将对象变量保存在另外一个数组中,而不是对象本身的成员变量
<?php
class MethodTest
{
private $data = array();
public function __set($name, $value){
$this->data[$name] = $value;
}
public function __get($name){
if(array_key_exists($name, $this->data))
return $this->data[$name];
return NULL;
}
public function __isset($name){
return isset($this->data[$name])
}
public function unset($name){
unset($this->data[$name]);
}
}
?>
__sleep()和__wakeup()
当我们在执行serialize()和unserialize()时,会先调用这两个函数。例如我们在序列化一个对象时,这个对象有一个数据库链接,想要在反序列化中恢复链接状态,则可以通过重构这两个函数来实现链接的恢复。例子如下:
<?php
class Connection
{
protected $link;
private $server, $username, $password, $db;
public function __construct($server, $username, $password, $db)
{
$this->server = $server;
$this->username = $username;
$this->password = $password;
$this->db = $db;
$this->connect();
}
private function connect()
{
$this->link = mysql_connect($this->server, $this->username, $this->password);
mysql_select_db($this->db, $this->link);
}
public function __sleep()
{
return array('server', 'username', 'password', 'db');
}
public function __wakeup()
{
$this->connect();
}
}
?>
__toString()
对象当成字符串时的回应方法。例如使用echo $obj;来输出一个对象
<?php
// Declare a simple class
class TestClass
{
public function __toString() {
return 'this is a object';
}
}
$class = new TestClass();
echo $class;
?>
这个方法只能返回字符串,而且不可以在这个方法中抛出异常,否则会出现致命错误。
__invoke()
调用函数的方式调用一个对象时的回应方法。如下
<?php
class CallableClass
{
function __invoke() {
echo 'this is a object';
}
}
$obj = new CallableClass;
var_dump(is_callable($obj));
?>
__set_state()
调用var_export()导出类时,此静态方法会被调用。
<?php
class A
{
public $var1;
public $var2;
public static function __set_state ($an_array) {
$obj = new A;
$obj->var1 = $an_array['var1'];
$obj->var2 = $an_array['var2'];
return $obj;
}
}
$a = new A;
$a->var1 = 5;
$a->var2 = 'foo';
var_dump(var_export($a));
?>
__clone()
当对象复制完成时调用。例如在设计模式详解及PHP实现:单例模式一文中提到的单例模式实现方式,利用这个函数来防止对象被克隆。
<?php
public class Singleton {
private static $_instance = NULL;
// 私有构造方法
private function __construct() {}
public static function getInstance() {
if (is_null(self::$_instance)) {
self::$_instance = new Singleton();
}
return self::$_instance;
}
// 防止克隆实例
public function __clone(){
die('Clone is not allowed.' . E_USER_ERROR);
}
}
?>
魔术常量(Magic constants)
PHP中的常量大部分都是不变的,但是有8个常量会随着他们所在代码位置的变化而变化,这8个常量被称为魔术常量。
__LINE__,文件中的当前行号__FILE__,文件的完整路径和文件名__DIR__,文件所在的目录__FUNCTION__,函数名称__CLASS__,类的名称__TRAIT__,Trait的名字__METHOD__,类的方法名__NAMESPACE__,当前命名空间的名称
这些魔术常量常常被用于获得当前环境信息或者记录日志。
HTTPS连接的前几毫秒发生了什么
另外提示:英文原文写于2009年,当时的Firefox和最新版的Firefox,界面也有很大改动。
花了数小时阅读了如潮的好评,Bob最终迫不及待为他购买的托斯卡纳全脂牛奶点击了“进行结算”,然后……
哇!刚刚发生了什么?

在点击按钮过后的220毫秒时间内,发生了一系列有趣的事情,火狐浏览器(Firefox)不仅改变了地址栏颜色,而且在浏览器的右下角出现了一个小锁头的标志。在我最喜欢的互联网工具Wireshark的帮助下,我们可以通过一个经过略微调整的用于debug的火狐浏览器来探究这一过程。
根据RFC 2818标准(译者注:RFC 2818为HTTP Over TLS-网络协议),火狐浏览器自动通过连接Amazon.com的443端口来响应HTTPS请求。

很多人会把HTTPS和网景公司(Netscape)于上世纪九十年代中期创建的SSL(安全套接层)联系起来。事实上,随着时间的推移,这两者之间的关系也慢慢淡化。随着网景公司渐渐的失去市场份额,SSL的维护工作移交给了Internet工程任务组(IETF)。由网景公司发布的第一个版本被重新命名为TLS 1.0(安全传输层协议 1.0),并于1999年1月正式发布。考虑到TLS已经发布了将近10年,如今已经很难再见到真正的SSL通信了。
客户端问候(Client Hello)
TLS将全部的通信以不同方式包裹为“记录”(Records)。我们可以看到,从浏览器发出的第一个字节为0×16(十进制的22),它表示了这是一个“握手”记录。

接下来的两个字节是0×0301,它表示了这是一条版本为3.1的记录,同时也向我们表明了TLS1.0实际上是基于SSL3.1构建而来的。
整个握手记录被拆分为数条信息,其中第一条就是我们的客户端问候(Client Hello),即0×01。在客户端问候中,有几个需要着重注意的地方:
- 随机数:

在客户端问候中,有四个字节以Unix时间格式记录了客户端的协调世界时间(UTC)。协调世界时间是从1970年1月1日开始到当前时刻所经历的秒数。在这个例子中,0x4a2f07ca就是协调世界时间。在他后面有28字节的随机数,在后面的过程中我们会用到这个随机数。
- SID(Session ID):

在这里,SID是一个空值(Null)。如果我们在几秒钟之前就登陆过了Amazon.com,我们有可能会恢复之前的会话,从而避免一个完整的握手过程。
- 密文族(Cipher Suites):

密文族是浏览器所支持的加密算法的清单。整个密文族是由推荐的加密算法“TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA”和33种其他加密算法所组成。别担心其他的加密算法会出现问题,我们一会儿就会发现Amazon也没有使用推荐的加密算法。
- Server_name扩展:

通过这种方式,我们能够告诉Amazon.com:浏览器正在试图访问https://www.amazon.com。这确实方便了很多,因为我们的TLS握手时间发生在HTTP通信之前,而HTTP请求会包含一个“Host头”,从而使那些为了节约成本而将数百个网站域名解析到一个IP地址上的网络托管商能够分辨出一个网络请求对应的是哪个网站。传统意义上的SSL同样要求一个网站请求对应一个IP地址,但是Server_name扩展则允许服务器对浏览器的请求授予相对应的证书。如果没有其他的请求,Server_name扩展应该允许浏览器访问这个IPV4地址一周左右的时间。
服务器问候(Server Hello)
Amazon.com回复的握手记录由两个比较大的包组成(2551字节)。记录中包含了0×0301的版本信息,意味着Amazon同意我们使用TLS1.0访问的请求。这条记录包含了三条有趣的子信息:
1.服务器问候信息(Server Hello)(2):
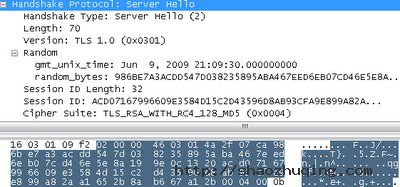
- 我们得到了服务器的以Unix时间格式记录的UTC和28字节的随机数。
- 32字节的SID,在我们想要重新连接到Amazon.com的时候可以避免一整套握手过程。
- 在我们所提供的34个加密族中,Amazon挑选了“TLS_RSA_WITH_RC4_128_MD5”(0×0004)。这就意味着Amazon会使用RSA公钥加密算法来区分证书签名和交换密钥,通过RC4加密算法来加密数据,利用Md5来校验信息。我们之后会深入的研究这一部分内容。我个人认为,Amazon选择这一密码组是有其自身的原因的。在我们所提供的密码族中,这一加密组的加密方式是CPU占用最低的,这就允许Amazon的每台服务器接受更多的连接。当然了,也许还有一个原因是,Amazon是在向这三种加密算法的发明者Ron Rivest(罗恩·李·维斯特)致敬。
2.证书信息(11):
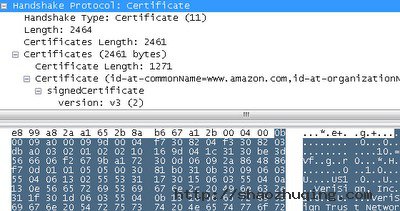
这段巨大的信息共有2464字节,其证书允许客户端在Amazon服务器上进行认证。这个证书其实并没有什么奇特之处,你能通过浏览器浏览它的大部分内容。
3.服务器问候结束信息(14):

这是一个零字节信息,用于告诉客户端整个“问候”过程已经结束,并且表明服务器不会再向客户端询问证书。
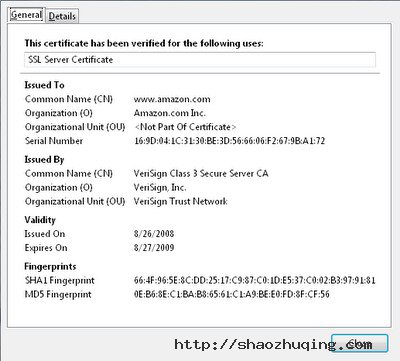
校验证书
此时,浏览器已经知道是否应该信任Amazon.com。在这个例子中,浏览器通过证书确认网站是否受信,它会检查 Amazon.com 的证书,并且确认当前的时间是在“最早时间”2008年8月26日之后,在“最晚时间”2009年8月27日之前。浏览器还会确认证书所携带的公共密钥已被授权用于交换密钥。
为什么我们要信任这个证书?
证书中所包含的签名是一串非常长的大端格式的数字:

任何人都可以向我们发送这些字节,但我们为什么要信任这个签名?为了解释这个问题,我们首先要回顾一些重要的数学知识:
RSA加密算法的基础介绍
人人常常会问,编程和数学之间有什么联系?证书就为数学在编程领域的应用提供了一个实际的例子。Amazon的服务器告诉我们需要使用RSA算法来校验证书签名。什么又是RSA算法呢?RSA算法是由麻省理工(MIT)的Ron Rivest、Adi Shamirh和Len Adleman(RSA命名各取了三人名字中的首字母)三人于上世纪70年代创建的。三位天才的学者结合了2000多年数学史上的精华,发明了这种简洁高效的算法:
选取两个较大的初值p和q,相乘得n;n = p*q 接下来选取一个较小的数作为加密指数e,d作为解密指数是e的倒数。在加密的过程中,n和e是公开信息,解密密钥d则是最高机密。至于p和q,你可以将他们公开,也可以作为机密保管。但是一定要记住,e和d是互为倒数的两个数。
假设你现在有一段信息M(转换成数字),将其加密只需要进行运算:C ≡ Me (mod n)
这个公式表示M的e次幂,mod n表示除以n取余数。当这段密文的接受者知道解密指数d的时候就可以将密文进行还原:Cd ≡ (Me)d ≡ Me*d ≡ M1 ≡ M (mod n)
有趣的是,解密指数d的持有者还可以将信息M进行用解密指数d进行加密:Md ≡ S (mod n)
加密者将S、M、e、n公开之后,任何人都可以获得这段信息的原文:Se ≡ (Md)e ≡ Md*e ≡ Me*d ≡ M1 ≡ M (mod n)
如同RSA的公共密钥加密算法经常被称之为非对称算法,因为加密密钥(在我们的例子中为e)和解密密钥(在我们的例子中是d)并不对称。取余运算的过程也不像我们平常接触的运算(诸如对数运算)那样简单。RSA加密算法的神奇之处在于你可以非常快速的进行数据的加密运算,即 ,但是如果没有解密密码d,你将很难破解出密码,即运算 将不可能实现。正如我们所看到的,通过对n进行因式分解而得到p和q,再推断出解密密钥d的过程难于上青天。
签名验证
在使用RSA加密算法的时候,最重要的一条就是要确保任何涉及到的数字都要足够复杂才能保证不被现有的计算方法所破解。这些数字要多复杂呢?Amazon.com的服务器是利用“VeriSign Class 3 Secure Server CA”来对证书进行签名的。从证书中,我们可以看到这个VeriSign(电子签名校验器,也称威瑞信公司)的系数n有2048位二进制数构成,换算成十进制足足有617位数字:
1890572922 9464742433 9498401781 6528521078 8629616064 3051642608 4317020197 7241822595 6075980039 8371048211 4887504542 4200635317 0422636532 2091550579 0341204005 1169453804 7325464426 0479594122 4167270607 6731441028 3698615569 9947933786 3789783838 5829991518 1037601365 0218058341 7944190228 0926880299 3425241541 4300090021 1055372661 2125414429 9349272172 5333752665 6605550620 5558450610 3253786958 8361121949 2417723618 5199653627 5260212221 0847786057 9342235500 9443918198 9038906234 1550747726 8041766919 1500918876 1961879460 3091993360 6376719337 6644159792 1249204891 7079005527 7689341573 9395596650 5484628101 0469658502 1566385762 0175231997 6268718746 7514321
(如果你想要对这一大串数字进行分解因式获得p和q,那就祝你好运!顺便一提,如果你真的计算出了p和q,那你就破解了Amazon.com数字签名证书了!)
这个VeriSign的加密密钥e是 。当然,他们将解密密钥d保管得十分严密,通常是在拥有视网膜扫描和荷枪实弹的警卫守护的机房当中。在签名之前,VeriSign会根据相关约定的技术文档,对Amazon.com证书上所提供的信息进行校验。一旦证书信息符合相关要求,VeriSign会利用SHA-1哈希算法获取证书的哈希值(hash),并对其进行声明。在Wireshark中,完整的证书信息会显示在“signedCertificate”(已签名证书)中:

这里应该是软件的用词不当,因为这一段实际上是指那些即将被签名的信息,而不是指那些已经包含了签名的信息。
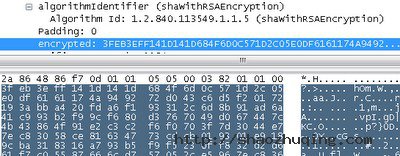
实际上经过签名的信息S,在Wireshark中被称之为“encrypted”(密文)。我们将S的e次幂除以n取余数(即公式: )就能计算出被加密的原文,其十六进制如下:
0001FFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFF FFFFFFFF00302130 0906052B0E03021A05000414C19F8786 871775C60EFE0542 E4C2167C830539DB
根据PKCS#1 v1.5标准(译者注:The Public-Key Cryptography Standards (PKCS)是由美国RSA数据安全公司及其合作伙伴制定的一组公钥密码学标准)规定:“第一个字节是00,这样就可以保证加密块在被转换为整数的时候比其加密参数要小。”第二个字节为01,表示了这是一个私有密钥操作(数字签名就是私有密钥操作的一种)。后面紧接着的一连串的FF字节是为了填充数据,使得这一串数字变得足够大(加大黑客恶意破解的难度)。填充数字以一个00字节结束。紧接着的30 21 30 09 06 05 2B 0E 03 02 1A 05 00 04 14这些字节是PKCS#1 v2.1标准中用于说明这段哈希值是通过SHA-1算法计算而出的。最后的20字节是SHA-1算法所计算出来的哈希值,即对未加密信息的摘要描述。(译者注:原文中这里使用了带引号的signedCertificate,根据作者前文描述,这应该是Wireshark软件的bug,实际上应指的是未被加密的信息。)
因为这段信息的格式正确,且最后的哈希值与我们独立计算出来的校验一致,所以我们可以断定,这一定是知道“VeriSign Class 3 Secure Server CA”的解密密钥d的人对它进行了签名。而世界上只有VeriSign公司才知道这串密钥。
当然了,我们也可以重复验证这个“VeriSign Class 3 Secure Server CA”的证书的确是通过VeriSign公司的“第三类公私证书认证(Class 3 Public Primary Certification Authority)”进行签名的。
但是,即便是这样,我们为什么要信任VeriSign公司?整个的信任链条就此断掉了。

由图可以看到,“VeriSign Class 3 Secure Server CA”对Amazon.com进行了签名,而“VeriSign Class 3 Public Primary Certification Authority”对“VeriSign Class 3 Secure Server CA”进行了签名,但是最顶部的“VeriSign Class 3 Public Primary Certification Authority”则对自己进行了签名。这是因为,这个证书自从NSS(网络安全服务)库中的certdata.txt 升级到1.4版之后就作为“受信任的根证书颁发机构”(译者注:参照微软官方翻译)被编译到了Mozilla产品中(火狐浏览器)。这段信息是由网景公司的Robert Relyea于2000年9月6日提交的,并随附以下注释:
“由仅存的NSS编译了框架。包含一个在线的certdata.txt文档,其中包含了我们受信的跟证书颁发机构(一旦我们获得了其他受信机构的许可会陆续将他们添加进去)”。
这个举动有着相当长远的影响,因为这些证书的有效日期是从1996年1月28日到2028年1月1日。
肯·汤普逊(Ken Thompson)在他的《对深信不疑的信任》(译者注:Reflections on Trusting Trust是肯汤普逊1983年获得图灵奖时的演说)的演说中解释的很好:你最终还是要绝对信任某一人,在这个问题上没有第二条路可走。在本文的例子中,我们就毫无保留的信任Robert Relyea做了一个正确的决定。我们同样希望Mozilla在自己软件中加入“受信任根证书颁发机构”这种行为也是合理的吧。
这里需要注意的是:这一系列的证书和签名只是用来形成一个信任链。在公共互联网上,VeriSign的根证书被火狐浏览器完全信任的时间远早于你接触互联网。在一个公司中,你可以创建自己的受信任的根证书颁发机构并把它安装到任何人的计算机中。
相对的,你也可以购买VeriSign公司的业务,降低整个证书信任链的信任风险。通过第三方的认证机构(在这个例子里是VeriSign公司)我们能利用证书建立起信任关系。如果你有类似于“悄悄话”的安全途径来传递一个秘密的key,那你也可以使用一个预共享密钥(PSK)来建立起信任关系。诸如TLS-PSK、或者带有安全远程密码(SRP)的TLS扩展包都能让我们使用预共享密钥。不行的是,这些扩展包在应用和支持方面远远比不上TLS,所以他们有的时候并不实用。另外,这些替代选项需要额外德尔安全途径进行保密信息的传输,这一部分的开销远比我们现在正在应用的TLS庞大。换句话说,这也就是我们为什么不应用那些其他途径构建信任关系的原因。
言归正传,我们所需要的最后确认的信息就是在证书上的主机名跟我们预想的是一样的。Nelson Bolyard在SSL_AuthCertificate 函数中的注释为我们解释其中的原因:
“SSL连接的客户端确认证书正确,并检查证书中所对应的主机名是否正确,因为这是我们应对中间人攻击的唯一方式!” (译者注:中间人攻击是一种“间接”的入侵攻击,这种攻击模式是通过各种技术手段将受入侵者控制的一台计算机虚拟放置在网络连接中的两台通信计算机之间,这台计算机就称为“中间人”。)
/* cert is OK. This is the client side of an SSL connection. * Now check the name field in the cert against the desired hostname. * NB: This is our only defense against Man-In-The-Middle (MITM) attacks! */
这样的检查是为了防止中间人攻击:因为我们对整个信任链条上的人都采取了完全信任的态度,认为他们并不会进行黑客行为,就像我们的证书中所声称它是来自Amazon.com,但是假如他的真实来源并非Amazon.com,那我们可能就有被攻击的危险。如果攻击者使用域名污染(DNS cache poisoning)等技术对你的DNS服务器进行篡改,那么你也许会把黑客的网站误认为是一个安全的受信网站(诸如Amazon.com),因为地址栏显示的信息一切正常。这最后一步对证书颁发机构的检查就是为了防止这样的事情发生。
随机密码串(Pre-Master Secret)
现在我们已经了解了Amazon.com的各项要求,并且知道了公共解密密钥e和参数n。在通信过程中的任何一方也都知道了这些信息(佐证就是我们通过Wireshark获得了这些信息)。现在我们所需要做的事情就是生成一串窃密者/攻击者都不能知道的随机密码。这并不像听上去的那么简单。早在1996年,研究人员就发现了网景浏览器1.1的伪随机数发生器仅仅利用了三个参数:当天的时间,进程ID和父进程ID。正如研究人员所指出的问题:这些用于生成随机数的参数并不具有随机性,而且他们相对来说比较容易被破解。
因为一切都是来源于这三个随机数参数,所以在1996,利用当时的机器仅需要25秒钟的时间就可以破解一个SSL通信。找到一种生成真正随机数的方法是非常困难的,如果你不相信这一点,那就去问问Debian OpenSSL的维护工程师吧。如果随机数的生成方式遭到破解,那么建立在这之上的一系列安全措施都是毫无意义的。
在Windows操作系统中,用于加密目的随机数都是利用一个叫做CryptGenRandom的函数生成的。这个函数的哈希表位对超过125个来源的数据进行抽样!火狐浏览器利用CryptGenRandom函数和它自身的函数来构成它自己的伪随机数发生器。(译者注:之所以称之为伪随机数是因为真正意义上的随机数算法并不存在,这些函数还是利用大量的时变、量变参数来通过复杂的运算生成相对意义上的随机数,但是这些数之间还是存在统计学规律的,只是想要找到生成随机数的过程并不那么容易)。
我们并不会直接利用生成的这48字节的随机密码串,但是由于很多重要的信息都是由他计算而来的,所以对随机密码串的保密就显得格外重要。正如我之前所预料到的,火狐浏览器对随机密码串的保密十分严格,所以我不得不编译了一个用于debug的版本。为了观察随机密码串,我还特地设置了SSLDEBUGFILE和SSLTRACE两个环境变量。
其中,SSLDEBUGFILE显示的就是随机密码串的值:
|
1
2
3
4
|
4456: SSL[131491792]: Pre-Master Secret [Len: 48]03 01 bb 7b 08 98 a7 49 de e8 e9 b8 91 52 ec 81 ...{...I.....R..4c c2 39 7b f6 ba 1c 0a b1 95 50 29 be 02 ad e6 L.9{......P)....ad 6e 11 3f 20 c4 66 f0 64 22 57 7e e1 06 7a 3b .n.? .f.d"W~..z; |
需要注意的是,这串数字从各种意义上来说都不是真正的随机数,就拿它的前两位来说:这就是根据TLS协议约定的TLS版本号(0301)。
密码交换(Trading Secret)
我们现在需要做的就是计算出Amazon.com所要求的密码。因为Amazon.com希望使用“TLS_RSA_WITH_RC4_128_MD5”加密组,所以我们使用RSA加密算法进行这一过程。你可以将这48字节的随机密码串作为初始参数,但是根据公共密钥密码标准(PKCS)#1 v1.5中的注释,我们需要用随机数据将随机密码串填充到实际要求的参数大小(1024位二进制/128字节)。这样的话攻击者想要破解我们的随机密码串就难上加难了。这也是我们保障自己安全的最后一道防线,以防我们在前面的步骤中犯了诸如重复使用密码这样的低级错误。如果我们重复使用了随机密码串,由于使用了随机数填充,窃密者在网络中拦截的也会是两个不同的值。
同样的,我们很难直接观察到火狐浏览器中的这一过程,所以我不得不在填充随机数的函数中增加了debug的语句,使我们能够观察这一过程:
|
1
2
3
4
5
6
7
8
|
wrapperHandle = fopen("plaintextpadding.txt", "a");fprintf(wrapperHandle, "PLAINTEXT = ");for(i = 0; i < modulusLen; i++){ fprintf(wrapperHandle, "%02X ", block[i]);}fprintf(wrapperHandle, "rn");fclose(wrapperHandle); |
在这个例子中,完整的填充后的随机密码串为:
00 02 12 A3 EA B1 65 D6 81 6C 13 14 13 62 10 53 23 B3 96 85 FF 24 FA CC 46 11 21 24 A4 81 EA 30 63 95 D4 DC BF 9C CC D0 2E DD 5A A6 41 6A 4E 82 65 7D 70 7D 50 09 17 CD 10 55 97 B9 C1 A1 84 F2 A9 AB EA 7D F4 CC 54 E4 64 6E 3A E5 91 A0 06 00 03 01 BB 7B 08 98 A7 49 DE E8 E9 B8 91 52 EC 81 4C C2 39 7B F6 BA 1C0A B1 95 50 29 BE 02 AD E6 AD 6E 11 3F20 C4 66 F0 64 22 57 7E E1 06 7A 3B
火狐浏览器使用这个值计算出 ,我们可以看到它显示在“客户端交换密钥”(Client Key Exchange)的记录中:

在这个过程的最后,火狐浏览器会发送一个不加密的信息:一条“Change Cipher Spec”记录:

通过这种方式:火狐浏览器要求Amazon.com在后面的通信过程中使用约定的加密方式传输信息。
获得主密钥(Master Secret)
如果我们正确完成了之前的过程,并且各方都获得了48字节(256二进制位)的随机密码串。从Amazon.com的角度来看,这里还有一些信任问题:随机密码串是由客户端生成的,并没有将任何服务器信息或者之前约定的信息加入其中。这一点,我们会通过生成主密钥的方式加以完善。根据协议规范约定,这个的计算过程为:
|
1
|
master_secret = PRF(pre_master_secret, "master secret", ClientHello.random + ServerHello.random) |
pre_master_secret就是我们之前传送的随机密码串,”master secret”是一串ASCII码(例如:6d 61 73 74 65 72……),再连接上在客户端问候和服务器问候(来自Amazon的)的信息。
PRF是在规范中约定的伪随机函数,它将密钥、ASCII码标签、哈希值整合在一起。各有一半的参数分别使用MD5和SHA-1获取哈希值。这是一种十分明智的做法,即使是想要单单破解相对简单MD5和SHA-1也不是那么容易的事情。而且这个函数会将返回值传给自身直至迭代到我们需要的位数。
利用这个函数,我们生成了48字节的主密钥:
4C AF 20 30 8F4C AA C5 66 4A 02 90 F2 AC 10 00 39 DB 1D E0 1F CB E0 E0 9D D7 E6 BE 62 A4 6C 18 06 AD 79 21 DB 82 1D 53 84 DB 35 A7 1F C1 01 19
生成各种密钥
现在,各方面已经有了主密钥,根据协议约定,我们需要利用PRF生成这个会话中所需要的各种密钥,称之为“密钥块”(key block):
|
1
|
key_block = PRF(SecurityParameters.master_secret, "key expansion", SecurityParameters.server_random + SecurityParameters.client_random); |
密钥块用于构成以下密钥:
|
1
2
3
4
5
6
|
client_write_MAC_secret[SecurityParameters.hash_size]server_write_MAC_secret[SecurityParameters.hash_size]client_write_key[SecurityParameters.key_material_length]server_write_key[SecurityParameters.key_material_length]client_write_IV[SecurityParameters.IV_size]server_write_IV[SecurityParameters.IV_size] |
因为我们使用了类似于高级加密标准(AES)的密码流代替了分组密码我们就不需要初始化向量(IVs)了。因此我们只需要双方的两个16字节(128二进制位)的消息认证码(Message Authentication Code,MAC),因为MD5的哈希值就是16字节的。此外,双方也需要16字节(128二进制位)的RC4码。所以我们总共需要从密码块获得2*16 + 2*16 = 64字节的数据。
运行PRF,我们能得到以下值:
|
1
2
3
4
|
client_write_MAC_secret = 80 B8 F6 09 51 74 EA DB 29 28 EF 6F 9A B8 81 B0server_write_MAC_secret = 67 7C 96 7B 70 C5 BC 62 9D 1D 1F 4A A6 79 81 61client_write_key = 32 13 2C DD 1B 39 36 40 84 4A DE E5 6C 52 46 72server_write_key = 58 36 C4 0D 8C 7C 74 DA 6D B7 34 0A 91 B6 8F A7 |
准备加密!
客户端最后一次送出的握手信息是“结束信息”。这条信息保证了没有人篡改握手信息,并且我们已经知晓所必须的密钥。客户端将整个握手过程的全部信息都放入一个名为“handshake_messages”的缓冲区。我们能通过伪随机函数利用主密钥、“client finished”标签、MD5和SHA-1的哈希值生成12字节的“区别数据”(verify_data):
|
1
|
verify_data = PRF(master_secret, "client finished", MD5(handshake_messages) + SHA-1(handshake_messages)) [12] |
我们在这个结果前面加上0×14(用于表示结束信息)和00 00 0c(用于表示verify_data 有12字节)。就像以后所有的加密过程一样,我们要在加密之前确保原始数据没有被篡改。因为我们使用的是“TLS_RSA_WITH_RC4_128_MD5”密码组,这就意味着我们需要使用MD5哈希函数。
有些人一听到MD5函数就会嗤之以鼻,因为其自身的确存在一些缺陷。我自己当然也不会推荐这种算法。但是TLS的聪明之处就在于他并不直接使用MD5函数,只是利用哈希值的版本来校验数据。只就意味着我们并未直接应用到MD5(m):
HMAC_MD5(Key, m) = MD5((Key ⊕ opad) ++ MD5((Key ⊕ ipad) ++ m)
(其中,⊕表示的是异或运算)
在实际中:
HMAC_MD5(client_write_MAC_secret, seq_num + TLSCompressed.type + TLSCompressed.version + TLSCompressed.length + TLSCompressed.fragment));
正如你所见,我们在函数中使用了一个根据明文(在这里明文叫做“TLSCompressed”)编号的序号(seq_num)。这个序号的作用就是为了阻止攻击者在数据流中间插入之前被其截获的信息。如果发生了这样的攻击,序号就能清楚的警告我们数据中的异常。同样的,这个序号也能帮助我们发现攻击者从数据流中剔除的数据。
剩下的工作只剩下啊加密这些数据了!
RC4加密
我们之前协商过的密码组是“TLS_RSA_WITH_RC4_128_MD5”。这就意味着我们需要使用RC4(Ron`s code 4)加密规则进行数据流的加密。罗纳德李威斯特(Ron Rivest)开发了这种基于一个256字节的Key产生随机加密效果的算法。这个算法简单到你几分钟就能记住。
首先,RC4生成一个256字节的数组S,并用0-255填充。接下来的工作就是将需要将KEY混合插入进数组中并反复迭代。你可以编写一个状态机,利用它来阐释随机字节。为了产生随机字节,我们需要将S数组打乱,如图所示:

为了加密一个字节,我们将其与随机字节进行异或运算。记住:一位二进制数与1作异或运算会翻转(译者注:即1^1=0;1^0=1)。因为我们利用的是随机数,所以从统计学的角度来讲,有一半的数被翻转。这种随机翻转的现象就是我们加密数据的有效方法。正如你所见,这并不复杂,而且计算速度十分快,我认为这也是Amazon.com选择它的原因之一。
记得我们有“client_write_key”和“server_write_key”吗?这就意味我们需要两个RC4实例:一个用来加密浏览器向服务器传送的数据,一个用来解密服务器向浏览器传送的数据。
“client_write_key”最初的几个字节是7E 20 7A 4D FE FB 78 A7 33 …如果我们对这些字节和未加密的数据头以及版本信息(“14 00 00 0C98 F0 AE CB C4 …”)进行异或运算,我们就能得到在Wireshark中看到的加密信息了:

服务器端做的几乎是相同的事情。它们发送了一个密钥协议的说明和一个包含全部握手过程的结束信息,其中有结束信息的解密版本。因此,这种机制就保证了客户端和服务器能成功的解密信息。
欢迎来到应用层!
现在,从我们点击了按钮之后已经过去了220毫秒,我们终于为应用层做好了准备!现在,我们发送的普通的HTTP数据流会通过TLS层的加密实例进行加密,在服务器的解密实例进行解密。而且TLS会对数据进行哈希校验,以保证数据内容的准确性。
在这个时候,整个的握手过程就结束了。我们的TLS记录内容现在有了23条(0×17)。加密数据以“17 03 01”开头,表示了记录类型和TLS版本,后面紧跟着加密数据的大小和哈希校验值。
加密的数据的明文如下:
|
1
2
3
4
5
6
7
8
9
10
|
GET /gp/cart/view.html/ref=pd_luc_mri HTTP/1.1Host: www.amazon.comUser-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.0.10) Gecko/2009060911 Minefield/3.0.10 (.NET CLR 3.5.30729)Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language: en-us,en;q=0.5Accept-Encoding: gzip,deflateAccept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7Keep-Alive: 300Connection: keep-alive... |
在Wireshark中显示如下:

唯一有趣的地方是序号是按照记录来增长,这条记录是1,下一条就是2。
服务器端利用“server_write_key”做着同样的事情。我们能看到服务器的相应结果,包括程序开头的指示位:

解密后的信息如下:
|
1
2
3
4
5
6
|
HTTP/1.1 200 OKDate: Wed, 10 Jun 2009 01:09:30 GMTServer: Server...Cneonction: closeTransfer-Encoding: chunked |
这就是一个来自Amazon负载平衡服务器的普通HTTP回应:包含了非描述性的服务器信息“Server: Server”和一个拼错了的“Cneonction: close”。
TLS层在应用层的下面,所以软件和服务器能够像正常的HTTP传输那样进行工作,唯一的区别就是传输的数据会被TLS层进行加密。
OpenSSL是一个应用很广的TLS开源库。
整个连接会一直保持,除非有一方提出了“关闭警告(closure alert)”并且关闭了连接。如果我们在连接断开后的短时间内再次提出连接请求,我们可以使用之前使用过的key来进行连接,从而避免一次新的握手过程。(这个要取决于服务器端key的有效时间。)
需要注意的是:应用程序可以发送任何数据,但是HTTPS的特殊之处在于WEB应用的广泛普及。要知道还有非常多的基于TCP/IP并且使用TLS进行数据加密的协议(如FTPS,sSMTP)。使用TLS要比你自己发明一种是数据加密方案便捷的多。况且,你所使用的安全协议一定要足够安全。
…完工!
TLS RFC的文档包含了更多的信息,有需要的朋友们可以自己查阅,我们在这里只是简单的介绍了其中的过程和原理,观察了这220毫秒内发生在火狐浏览器和Amazon服务器之间发生的故事:由Amazon.com基于速度和安全的综合考虑选择的“TLS_RSA_WITH_RC4_128_MD5”密码组在HTTPS连接建立过程中的全部流程。
正如我们所看到的那样,如果有人能对Amazon服务器的参数n进行因式分解得到p和q的话,那他就能破解全部的基于亚马逊证书的安全通信。所以Amazon为这个参数设置了有效期以防止这种事情的发生:

在我们提供的密码族中,有一组密码组“TLS_DHE_RSA_WITH_AES_256_CBC_SHA”使用了Diffie-Hellman密钥交换,并因此能提供良好的前向安全特性。这就意味着如果有人破解了交换密钥的数学运算方式,他们也不能利用这个来破解其他的会话。但是他的一个劣势在于其运算需求更大的数字和更高的运算能力。AES算法在很多密码组中都出现了,它与RC4的不同之处在于它每次使用的是16字节的“块”而RC4使用的是单字节。因为其key最高能到256位二进制位,所以一般认为它比RC4的安全性更高。
在短短的220毫秒的时间里,两个节点通过互联网连接起来,并且利用一系列手段建立起了互信机制,构建了加密算法,进行加密数据的传输。
正是因为如此,我们故事的主人公才能在Amazon上买到他想要的牛奶!
(译者注:作者所有相关的程序已经提交到Github上,地址:https://github.com/moserware/TLS-1.0-Analyzer/tree/master)
JS 循环遍历JSON数据 简单
JSON数据如:{"options":"[{/"text/":/"王家湾/",/"value/":/"9/"},{/"text/":/"李家湾/",/"value/":/"10/"},{/"text/":/"邵家湾/",/"value/":/"13/"}]"}
用js可以写成:
var data=[{name:"a",age:12},{name:"b",age:11},{name:"c",age:13},{name:"d",age:14}];
for(var o in data){
alert(o);
alert(data[o]);
alert("text:"+data[o].name+" value:"+data[o].age );
}
或是
[javascript] view plaincopyprint?
<script type="text/javascript">
function text(){
var json = {"options":"[{/"text/":/"王家湾/",/"value/":/"9/"},{/"text/":/"李家湾/",/"value/":/"10/"},{/"text/":/"邵家湾/",/"value/":/"13/"}]"}
json = eval(json.options)
for(var i=0; i<json.length; i++)
{
alert(json[i].text+" " + json[i].value)
}
}
</script>
linux awk命令详解
简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
调用awk
有三种方式调用awk

1.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 2.shell脚本方式 将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。 相当于shell脚本首行的:#!/bin/sh 可以换成:#!/bin/awk 3.将所有的awk命令插入一个单独文件,然后调用: awk -f awk-script-file input-file(s) 其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
本章重点介绍命令行方式。
入门实例
假设last -n 5的输出如下
[root@www ~]# last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
如果只是显示最近登录的5个帐号
#last -n 5 | awk '{print $1}'
root
root
root
dmtsai
root
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
如果只是显示/etc/passwd的账户
#cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
#cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
搜索/etc/passwd有root关键字的所有行
#awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
# awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
这里指定了action{print $7}
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符
此外,$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容:
#awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
print和printf
awk中同时提供了print和printf两种打印输出的函数。
其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
awk编程
变量和赋值
除了awk的内置变量,awk还可以自定义变量。
下面统计/etc/passwd的账户人数
awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
......
user count is 40
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。
这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0:
awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd
[start]user count is 0
root:x:0:0:root:/root:/bin/bash
...
[end]user count is 40
统计某个文件夹下的文件占用的字节数
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size}'
[end]size is 8657198
如果以M为单位显示:
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.25889 M
注意,统计不包括文件夹的子目录。
条件语句
awk中的条件语句是从C语言中借鉴来的,见如下声明方式:
if (expression) {
statement;
statement;
... ...
}
if (expression) {
statement;
} else {
statement2;
}
if (expression) {
statement1;
} else if (expression1) {
statement2;
} else {
statement3;
}
统计某个文件夹下的文件占用的字节数,过滤4096大小的文件(一般都是文件夹):
ls -l |awk 'BEGIN {size=0;print "[start]size is ", size} {if($5!=4096){size=size+$5;}} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.22339 M
循环语句
awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
数组
因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
显示/etc/passwd的账户
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
0 root
1 daemon
2 bin
3 sys
4 sync
5 games
......
这里使用for循环遍历数组
awk编程的内容极多,这里只罗列简单常用的用法,更多请参考 http://www.gnu.org/software/gawk/manual/gawk.html
Linux vim 随记
命令模式
三种命令模式
vim的三种命令模式:
- 命令模式:用于输入命令,简单更改
- 插入模式:用于插入文本,修改文本
- 末行模式:用于输入命令,视化操作,查找替换等
三种模式之间的切换方式:
- 命令模式进入到插入模式:输入文本插入命令(i,I,a,A,o,O)
- 插入模式退出到命令模式:ESC
- 命令模式进入到末行模式:冒号:
- 末行模式退出到命令模式:Enter或者ESC.

vim命令集合:http://www.cnblogs.com/kzloser/archive/2012/09/12/2681111.html
图释指令
光标移动-------------
按行移动:
按字符移动:

插入命令-------------
常用命令-------------



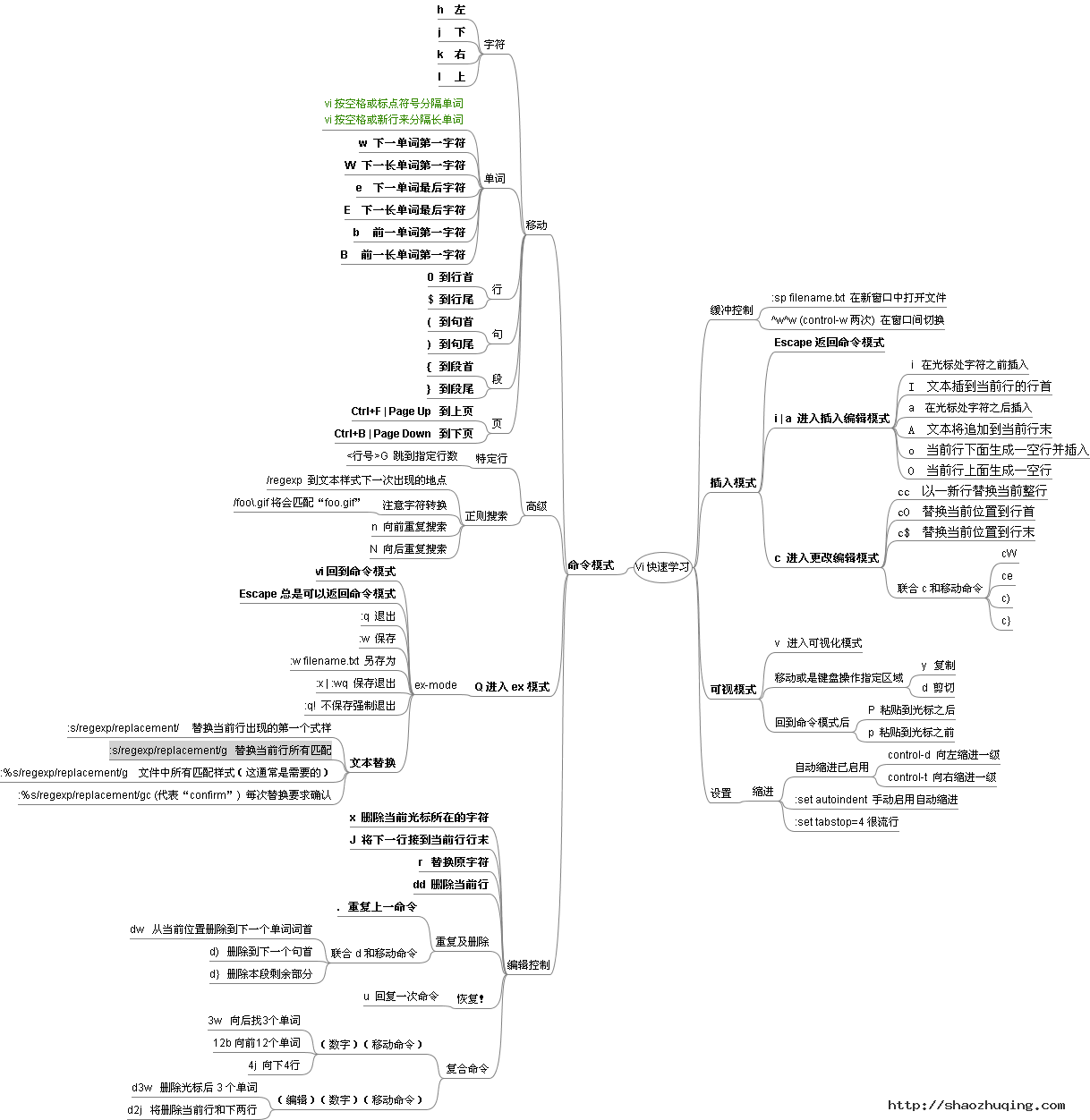
普通模式下命令
复制,删除,粘贴
- 粘贴: 把 vim 中缓存区的数据,粘贴到光标附近(即 p 为光标后, P为光标前)
- 删除: 把 vim 中选中的删除数据先拷贝到缓冲区并覆盖原有数据,然后删除选中数据
- 复制: 把 vim 中选中的数据拷贝的缓冲区并覆盖原有数据
例子:
现在有数据如下:aaaaabbbbbcccccdddddfffff
假设我们的光标在第一个 b 这个位置, 在一般模式下输入 5x (即输入删除 5 个 b 的操作) 后结果为:
aaaaacccccdddddfffff
然后在按下 p (即在光标位置处后面粘贴缓冲区的数据),结果为:
aaaaacbbbbbccccdddddfffff
删除某区域内容:
可以重复的:
[d]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
- d: 表示删除操作
- 重复操作次数: num 表示操作重复次数
- 操作区域选择:
- h 删除光标前一个字符
- l 删除光标所在处的字符
- j 删除本行与下一行
- k 删除本行与上一行
- w 删除光标开始到下一个单词词首处
- b 删除光标开始到上一个单词词首处
- e 删除光标开始到这个单词的结尾处
- ( 删除光标开始到句子结束处
- ) 删除光标开始到句子开始处
- { 删除光标开始到段落开始处
- } 删除光标开始到段落结束处
- $ 删除从光标开始处到行尾处
- G 删除从光标所在行到行尾处
- /word 删除从光标开始处到下个 word 字符串,不含 word ( word 指代任意字符串 )
- ?word 删除从光标开始处到上个 word 字符串,不含 word ( word 指代任意字符串 )
- tc 删除从光标开始处到下个 c 字符处,不含 c ( c 指代任意字符 )
- Tc 删除从光标开始处到上个 c 字符处,不含 c ( c 指代任意字符 )
- fc 删除从光标开始处到下个 c 字符处,含 c ( c 指代任意字符 )
- Fc 删除从光标开始处到上个 c 字符处,含 c ( c 指代任意字符 )
- `c 删除从光标开始到标记 c 这个位置
不可重复的:
[d]+[ 0 / ^ / H / L ]
- d: 表示删除操作
- 操作区域选择:
- d0 删除从光标所在处到某一行的开始位置
- d^ 删除到某一行的第一个字符位置(不包括空格或TAB字符)
- dL 删除直到屏幕上最后一行的内容
- dH 删除直到屏幕上第一行的内容
复制某区域内容:
可以重复的:
[y]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
含义用法如删除类似
不可重复的:
[y]+[ 0 / ^ / H / L ]
含义用法如删除类似
多加介绍个与上面用法相似的操作:
改变某区域内容:
可以重复的:
[c]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
含义用法如删除类似
不可重复的:
[c]+[ 0 / ^ / H / L ]
含义用法如删除类似
操作的组合
v 字符选择
操作流程:
v + 移动光标按键+ 数据操作键
- v 开始选择字符的标志
- 移动光标按键 移动光标确定选择区域(此处可以为多个移动光标的键值,但不能为组合键:如 [Ctrl]+[p] 等等)
- 数据操作键 对选择区域内的数据内容进行操作
例子[删除选择的字符区间 vwd(vwx)] :
现在有数据如下:
aaaaabbbbb ccccc
按下 v 键时(标志开始选择区域的操作):
aaaaa|bbbbb ccccc
按下 w 键时(选择操作区域,当然这里的 w 是可以换成 llllll [ 即六个小写的 L ]):
aaaaabbbbb ccccc
按下 d/x 键时(对数据进行操作,即删除所选择区域中的数据):
aaaaaccccc
V 列选择
操作流程:
V + 移动光标按键+ 数据操作键
- V 开始选择字符的标志
- 移动光标按键 移动光标确定选择区域(此处可以为多个移动光标的键值或者没有键值当没有键值的时候操作区域为光标所在行,但不能为组合键:如 [Ctrl]+[p] 等等)
- 数据操作键 对选择区域内的数据内容进行操作
例子[删除本行和下行数据 Vjd(Vjx)] :
现在有数据如下:
aaaaa
bbbbb
ccccc
按下 V 键时(标志开始选择区域的操作):
aaaaa
bbbbb
ccccc
按下 j 键时(选择操作区域):
aaaaa
bbbbb
ccccc
按下 d/x 键时(对数据进行操作,即删除所选择区域中的数据):
ccccc
字符串搜索
搜索字符串中的特殊字符
- ^ (行开始指示符)
当脱字符( 即 ^ ),作为搜索字符串的第一个字符时, vim 将每行的开始字符与搜索字符串进行匹配. - . (任意字符指示符)
句点( 即 . )可以与任意字符匹配,它可以出现在搜索字符串中的任意位置.当要查找句点符号时候可以用转义字符 . 来查找句点符号 - < (字符开始指示符)
这两个字符与单词的开始匹配 - > (字符结束指示符)
这两个字符与单词的结束匹配 - * (0个或者过个出现)
这个字符时一个修饰符,它与某个字符的 0 次或者多次出现相匹配 - [] (定义字符类)
单个字符匹配的区间(这里想要了解的更详细的话可以参考 正则表达式 )例如 ds[ab] 代表的是 dsa 与 dsb
示例------
句子:
being kind to yourself in everyday life is one of the best things you can do for yourself.
life will become lighter and your relationships will most likely improve
| 搜索字符串 | 描述 | 结果(以单词为单位) |
| /you | 查找字符串 you 的下一次出现的位置 | yourself, you, yourself, your |
| /<you> | 查找单词 you 的下一次出现的位置 | you |
| /^be | 查找以 be 开始的下一行 | being ... |
| /^[a-z][a-z] | 查找以两个字符开头开始的下一行 | being ... , life ... |
| /<th | 查找以 th 开头的单词 | the thing |
| /[a-m]e> | 查找以 [a-m]e 为结尾的单词 | life, the, life, become |
命令行的命令
字符替换
语法格式:
[range]s/{pattern}/{string}/[flag] [count]
格式说明:
- range 表示行数
- %表示所有行
- n1,n2 表示由 n1 行到 n2 行之间
- s 表示substitution,替换的意思
- pattern 表示被替换的字符串
- string 表示替换的字符串
- flag 表示标志,取值g,i,c等
- g 表示global,全部
- i 表示ignore,忽略大小写
- c 表示confirm,一个一个交互确认替换
- count 表示从当前行到接下来的第几行,表示范围
例子:
(1). 全部替换
参数g实现全部替换,否则只替换一个
:%s/{old-pattern}/new-text/g
(2). 行内替换
%代表所有行,去掉%表示当前行,只替换当前行
:s/{old-pattern}/new-text/g
(3). 指定行范围替换
对1到10行的结果替换
:1,10s/{old-pattern}/new-text/g
(4). 可视模式替换
如果你觉得数行数比较麻烦,可以使用可视模式,首先进入可视模式,然后选择行
列,最后输入:自动进入:'<,'>
后面加上s/{old-pattern}/new-text/g,则只替换选择区域的结果
:'<,'>s/{old-pattern}/new-text/g
(5). 整词替换,而不是部分匹配的单词
对单词匹配模式外包一个<和>
:s/<blog>/weibo/g //替换blog,但是cnblog,blogs则不会替换
(6). 多项替换
同时对多个匹配都替换成某一字符串
:%s/(good|nice)/awesome/g //good和nice都将被替换成awesome
(7). 确认式替换
参数c让替换进行交互请求,需要你选择y,n,a,l,q
选择说明:
- y 替换且跳转到下一个匹配结果
- n 不替换且跳转到下一个匹配结果
- a 替换所有并退出交互模式
- l 替换当前并退出交互模式
- q 退出交互模式
:s/{old-pattern}/new-text/gc
(8). 行首插入行号
把行首^替换成行号,可自定义具体形式
:%s/^/=line(".")/g
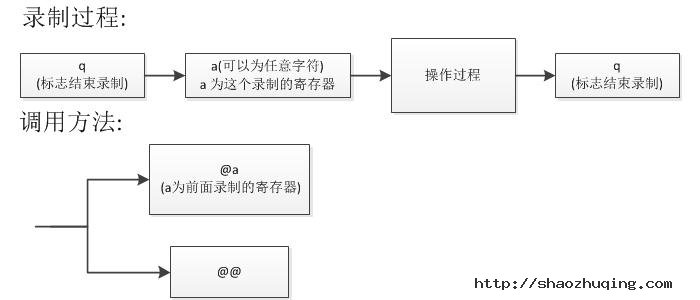
录制
这个其实很简单,但也是很强大的功能,作用是记录你的操作,并把操作过程记录起来.然后可以用 @@ 来调用出来你刚刚记录的操作集合,从而简化了复杂操作的过程
过程:
- q //标志开始录制
- x //x 是这个录制的寄存器,x 可以是其它字符
- 操作过程
- q //标志录制结束,现在dd这个操作被定义到了 @x 这个命令里了
图释:
解读大型网站系统架构的演化
前言
一个成熟的大型网站(如淘宝、京东等)的系统架构并不是开始设计就具备完整的高性能、高可用、安全等特性,它总是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随业务扩展而完善出来的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝,要解决海量的商品信息的搜索、下单、支付,例如腾讯,要解决数亿的用户实时消息传输,百度它要处理海量的搜索请求,他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段可以广泛运行在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:

二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Membercache、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。

常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx和HAProxy是七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切换则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务不同来切换,如用户业务、商品业务相关的表放在不同的数据库中。

六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。
而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有没有缓存数据才会继续走应用服务器获取,也减少了获取数据的成本。反向代理有Squid,Nginx。

七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求。需要分布式的文件系统支撑。常用的分布式文件系统有NFS。

八、使用NoSql和搜索引擎
对于海量数据的查询,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb和redis,搜索引擎有lucene。

九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者同享数据库来实现。

十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。淘宝的Dubbo是一个不错的选择。

小结
大型网站的架构是根据业务需求不断完善的,根据不同的业务特征会做特定的设计和考虑,本文只是讲述一个常规大型网站会涉及的一些技术和手段。
百度地图插件安装参考
百度地图插件安装参考:http://developer.baidu.com/map/index.php?title=jspopular
http://developer.baidu.com/map/index.php?title=%E9%A6%96%E9%A1%B5
下方有相关插件模块
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div id="map-canvas" class=""style="width:715px;height:400px"></div>
<script src="http://api.map.baidu.com/api?v=1.5&ak=3912c09d8490b8c5754aedc170955e21" type="text/javascript"></script>
<script type="text/javascript">
var map = new BMap.Map("map-canvas");
map.enableScrollWheelZoom();
var point = new BMap.Point(117.180386, 39.084208);
map.centerAndZoom(point, 15);
//加入缩放控件;
map.addControl(new BMap.NavigationControl());
//创建坐标点;
var marker1 = new BMap.Marker(point);
map.addOverlay(marker1);
</script>
</html>
php/mysql/jquery实现各系统流行的瀑布流显示方式,实现很简单的!!!!
大家在用这个东西的时候一定要计得有这么几个文件,一个是jquery.js 还有就是你自己数据库的密码。和相对应的图片才可以正常看到效果。下面就是这里所有的代码!!!
HTML文件:waterfall.html
1. [代码][PHP]代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
View Code <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>瀑布流-Derek</title> <script type="text/javascript" language="javascript" src="jquery.js"></script> <link type="text/css" rel="stylesheet" href="waterfall.css" /> <script type="text/javascript" language="javascript" src="waterfall.js"></script> </head> <body> <ul id="stage"> <li></li> <li></li> <li></li> <li></li> </ul> </body> </html>/* * Javascript文件:waterfall.js */$(function(){ jsonajax(); }); //这里就要进行计算滚动条当前所在的位置了。如果滚动条离最底部还有100px的时候就要进行调用ajax加载数据 $(window).scroll(function(){ //此方法是在滚动条滚动时发生的函数 // 当滚动到最底部以上100像素时,加载新内容 var $doc_height,$s_top,$now_height; $doc_height = $(document).height(); //这里是document的整个高度 $s_top = $(this).scrollTop(); //当前滚动条离最顶上多少高度 $now_height = $(this).height(); //这里的this 也是就是window对象 if(($doc_height - $s_top - $now_height) < 100) jsonajax(); }); //做一个ajax方法来请求data.php不断的获取数据 var $num = 0; function jsonajax(){ $.ajax({ url:'data.php', type:'POST', data:"num="+$num++, dataType:'json', success:function(json){ if(typeof json == 'object'){ var neirou,$row,iheight,temp_h; for(var i=0,l=json.length;i<l;i++){ neirou = json[i]; //当前层数据 //找了高度最少的列做添加新内容 iheight = -1; $("#stage li").each(function(){ //得到当前li的高度 temp_h = Number($(this).height()); if(iheight == -1 || iheight >temp_h){ iheight = temp_h; $row = $(this); //此时$row是li对象了 } }); $item = $('<div><img src="'+neirou.img+'" border="0" ><br/>'+neirou.title+'</div>').hide(); $row.append($item); $item.fadeIn(); } } } }); }/* * CSS文件:waterfall.css */body{text-align:center;}/*Download by http://www.codefans.net*/#stage{ margin:0 auto; padding:0; width:880px; }#stage li{ margin:0; padding:0; list-style:none;float:left; width:220px;}#stage li div{ font-size:12px; padding:10px; color:#999999; text-align:left; }/* * php文件:data.php */<?php $link = mysql_connect("localhost","root",""); $sql = "use waterfall"; mysql_query($sql,$link); $sql = "set names utf8"; mysql_query($sql,$link); $num = $_POST['num'] *10; if($_POST['num'] != 0) $num +1; $sql = "select img,title from content limit ".$num.",10"; $result = mysql_query($sql,$link); $temp_arr = array(); while($row = mysql_fetch_assoc($result)){ $temp_arr[] = $row; } $json_arr = array(); foreach($temp_arr as $k=>$v){ $json_arr[] = (object)$v; } //print_r($json_arr); echo json_encode( $json_arr ); |
2. [文件] waterfall.zip ~ 8KB 下载(850)
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
