浅谈围绕业务和资源的成熟度,设计团队和项目管理模型
房如华: 从五人到五十人:浅谈围绕业务和资源的成熟度,设计团队和项目管理模型
如何度量研发和项目管理模型是否良好的支持了业务发展?
互联网的产品植根于高度充分竞争的土壤中,对外界环境的变化是非常敏感的,我们不能保证时刻都做正确的事,因为正确是相对的。在传统软件行业里,通常软件会被交付给明确的客户群体,那么软件的品质只与是否满足了客户需求,以及与同类产品的相对优势有关。而一款互联网产品,在出生之日起,就面临着用户的不确定性,用户需求迁移的不确定及复杂性,竞品可能来自多个领域等因素,我们唯一能够确定的就是变化本身。
研发和项目的管理模型,实际上就是团队的能力成熟度模型。我们既不能在缺人的时候才开始招人、培养人,也不能在业务尚未成熟时招到无法施展拳脚的专家,同时还要确认团队中的大多数同学的潜力能够跟随业务一起成长,否则团队在早期的波动会严重影响甚至毁灭整个业务的进程。因此,业务的成熟度与团队的能力成熟度是呈双螺旋不断迭代的,两者不能产生较大的偏差。
评估两者是否匹配的标准,我认为主要有以下两点:
- 敏捷性:能够控制从“决定做某种修改”到“该修改结果正式上线”的这段时间,也叫做周期时间(cycle time)
- 灵活性:只有当能够控制每一次从引入变更到发布的整个过程时,你才能开始优化和改进软件交付的速度和质量。
下面,为了简化表述,我们把业务和团队的成熟度分为四个阶段,每个阶段有其自身的特点和面临的挑战,接受并克服了这些挑战,团队将变得更为强大。
0-5人:挖下成功的第一锹泥土
当你想办法向你的老板或者投资人讲完一个美妙的故事之后,你就拥有资源了,这时你需要的是招募(确切的说是说服)一个能够把事情做起来的初始团队,也许一开始只有5个人,但不要紧,明确好从0到1的目标,马上开始工作吧。
这一步通常是用最小的抛弃成本来验证目标、团队的可行性。你要想办法在团队没有产生自我怀疑之前,把事情尽快做成。此时,应遵循INVEST原则,即独立的(Independent)、可协商的(Negotiable)、有价值的(Valuable)、可估计的(Estimable)、小的(Small)并且可测试的(Testable)。
对于这5个人,角色分工很简单,你是项目经理,其他成员都是研发人员,一切资源面向把事情做成。沟通方式是次要的,大家坐在一起,早期不会有太大的沟通障碍。此时人员的单点不是最大的风险,没人测试也不是最大的风险,因为很多项目没等第一个Demo做出来就已经失败了。
但不关心沟通不代表工具是次要的。好的工具可以极大的提高工作的效率,例如代码控制、Wiki这些基本的工具还是要使用的,而且等团队成型之后,容易成为团队文化基因的一部分。
这个阶段对团队的技能和经验也提出了一些必要的挑战:
- 需要有解决问题能力很强的人,在项目因各种原因停滞的时候需要有人站出来解决;
- 需要有较强项目过程管理能力的人,在优先级、项目品质等方面受资源影响需要调整计划时,要能基于不全面的信息做出合理的决定。
- 要从一开始就让团队养成持续交付的习惯。持续交付就是要形成需求、开发、测试、部署的流水线。对于早期团队来说,就要想办法让部署的工作流水线化。首先,版本控制是必要的,它能够保证随时checkout一个版本用于上线,并且随时回滚;其次,配置管理也是必要的,方便我们基于部署环境编写不同的配置文件;最后,部署的变更管理也是重要的,而且需要尽可能的自动化,为什么要自动化?因为早期你的产品很显然会出现大量的缺陷,你唯一能做到的就是把缺陷在代码里修复之后,以秒级的速度发布到线上。目前国内有很多初始成本低廉的公有云产品可以使用,通过写一些简单的脚本,可以把程序和配置快速发布到一个高可用的环境中。
5-20人:踌躇满志,更快的奔跑
初始的业务模式得到验证,团队活下来了,可以沿着预计的大方向前进了,这时候,终于可以把之前的Demo细化了,因为Demo只是跑通了流程,但此时产品可能连可用性还谈不上呢。
你招来了一名产品经理,他开始兴致勃勃的编制未来半年,甚至一年的路线图。假设能够完成这些需求,并保证品质,那么前途是一片光明,并有望领先大部分竞争对手。
这时,作为项目负责人的你,欣慰的发现产品经理在大多数方面和你的业务见解是一致的,因为都提出了大量不得不做的需求,我们确实辜负了用户太多的期待,但你突然意识到一个更关键的问题,完成这些的资源远远不够!
要开始做取舍了,你知道在这个冗长的列表里,永远存在“更有价值“的需求。
好的,列一个Excel,我们开始排个序。
判断优先级的标准是什么?很简单,做两个极端的假设,一个是:哪个需求不做会死人?另一个是:哪个需求带来的预期收益更大?
可能有的需求需要加三个月的班才能完成呢,浪费了时间,贻误战机怎么办?其实不用担心,先把可用性做好,再找你的目标用户群体不晚,在此之前,患得患失是无意义的。
与其患得患失,不如多花点开发量,做点更“精益”的事吧。比如通过小范围的用户测试、灰度发布等方法,快速验证产品的可用性,使用尽可能多的用户行为分析软件来评估你的用户按照你的预期使用了功能并且留存下来。这样万一你先前的决定是错误的,你也可以用较小的抛弃成本来调整方向,少留些遗憾给未来。
努力奔跑的日子总是充满期待的,但你也经常会从资深的员工嘴里听到些许纠结:“我是不是该重构了?”先重构后开发总是没坏处的,这正是素养优秀的表现。然而此时你仍需要帮助他们进行取舍,合理的留下一些技术负债。
如何判断要留下哪些负债呢?
负债产生利息吗?也就是未来团队和业务复杂度不断增加的情况下,是否会让技术问题的影响范围扩大,或是优化成本不断升高直至失控?如果负债会产生短期的利息,那么把精力花在减少利息和让业务加速奔跑相比,哪个更合算?
当前的负债,能够通过后期招募一名专业、资深的成员,用更少的时间、更好的经验或者更成熟的组件来一次性解决它吗?
如果某个业务模块的需求变化本身是频繁的,那么此处产生的负债也是不确定的,刻舟求剑的优化之后,发现需求已经变化了,也是一种浪费。
在这个阶段,因为引入了制定需求和跟踪缺陷的角色—产品经理,所以需要使用工具来对需求和确信进行追踪,一个类似Bugzilla的开源缺陷跟踪软件就能满足你大部分的需求了。
20-35人:总体产出随人数增加减缓,团队能力出现瓶颈
你的团队成型了,80%的成员都是工程师,他们努力的实现着一个一个小的目标,照此速度运转下去,似乎你脑海中的那个路线图就要实现了!
“继续招人吧!多一倍的资源投入就能换来多一倍的回报,因为他们负责的业务模块是不同的,不会产生沟通上的麻烦。”
观点听起来很有道理,但实际是错误的,你的团队毕竟不是流水线上的组装工人,更何况,随着事情越来越复杂,沟通的交集是不可避免的。这就好比一片森林,地表以上的树干都是笔直挺拔,互不影响,但地表以下的树根已不可避免的盘根错节在一起,更可怕的是,没人能完整的掌握这种交集的状态,更不要提如何改进了。于是,一辆战车抛锚了,而看起来任何人都没做错什么。
瓶颈到来了。
我们知道在早期的网络通信技术里有一个名词叫做“广播风暴”,指的是在集线器组成的共享网络下,所有用户的实际可用带宽,随用户数的增加而递减,并且在争抢信道的时候产生用户的等待。
这是不是很像目前你的未被治理的早期团队遇到的情况?为了确保每个人都得到足够的信息,全员会议在增加,人数越多,会议议程越复杂导致沟通成本的进一步增加,这还不包括团队成员随时被打断、叫到某个会议中的情况。
集线器最终被交换机和路由器彻底的取代了。随着团队增长,也需要主动革新现有的成员之间的沟通协作方式。
沟通的本质是解决信息传递问题,让信息的生产者能够尽快抵达必要的受众。但自发的信息传递并不保证效率,也不保证可达,所以需要一个协调员来优化沟通的效率,当然协调员就不能总是组织全体会议了。
- 必要的信息,还是要广播出去,提到Dashboard的概念,Dashboard是团队成员需要得到的信息的最小子集,通过这些信息,团队成员能够基于自身角色和目标的考量,迅速开展后续行动。如何让Dashboard的变更成本最小化?就必须协作了,一开始这种协作是痛苦的,因为并没有流程来保证不同角色间信息传递是一致的,所以只好让团队中的每个角色的关键成员都来更新Dashboard,刚开始会出现大量的信息不完善、不一致甚至自相矛盾的情况,但不要怕,频繁的去做,坚持两三周,情况一定会好转,管理就是不断重复,把主观上想做好变为真正有能力做好的过程。
- 局部的信息传递给团队中局部的群体,该如何来操作呢?如果你的团队中有几个人具备项目经验和较强的责任心,还是可以通过定期的会议和不定期的沟通来解决的,但你一定觉得在这个阶段投入专职的项目管理或流程优化的人员还是过于奢侈了,那么不要紧,充分利用好工作流这个IT界的伟大发明吧。工作流能够让你的团队根据一系列预先设定好的过程规则,将文档、信息、任务在不同的执行者之间进行传递与执行,避免人工的方式造成的低效、等待和错误。可以考虑购买Atlassian的Jira软件,这可能是你的第一笔软件投资了,或许觉得有些昂贵,但这一定比你招募一个专职的员工便宜多了。
- 加强团队不同角色对信息中“一致”的部分的约定,例如版本,版本用于识别一篇文档、一份代码的各个时间点的历史快照,不同角色的成员基于对版本的一致命名,可以有效的识别需求、实现、部署工作之间的对应关系。
35-50人:重装上阵,提高整体交付品质和团队成熟度
你拖着沉重的身躯,靠一己之力把团队带到了一个执行力和结果都还不错的状态,终于可以停下来歇一歇了。
这是大多数业务负责人梦寐以求的状态,但要想从同行中杀出血路,保持进一步的竞争优势,这还不够完美。
你望着窗外鳞次栉比的建筑物,发现大多数二三十层的楼房并没有什么不同,但鹤立鸡群的几幢摩天大楼,让你意识到,一定有一些工作是只有某些人才能完成的,而当你的进取心激发你要建造摩天大楼的时候,你也需要他们。这就是专家的价值。
如果你想停止修修补补的民工游击队的日子,就在这个时候引入专家团队,来让团队变得更加高大上吧。
专家能扮演怎样的角色,取决于你需要他们发挥怎样的作用,每位专家都有自己擅长的工作模式,你需要了解他们的工作偏好,以帮助你改善团队的能力基因。
- 架构师:具备一定的理论高度,并在相当规模的环境下,成功的完成过研发或管理能力的升级。他倾向于了解到具体情况后去务实的推进解决问题,并怀着积极和包容的沟通心态获取团队的支持。这种工作模式的优势是目标明确,执行有力;劣势是可能过程中需要调用较多的资源,会与业务线的资源调配产生优先级上的冲突。
- 咨询师:他不是最主动或者最敏感解决问题的人,也许平常他只是收到各个项目组抄送给他的邮件,但遇到紧急情况时,能够快速亲自解决,或者叫上其他同学一起会诊,对于可能会重复出现的问题,或者重复产生的工作量,会设法通过优化流程来降低内部消耗。这种工作模式的优势是面向问题持续迭代团队,确保短期的成果总是可被衡量的;劣势是受团队现有成员的视野的限制较大,总是踩过坑后才能促使团队意识到问题并统一思想。
此外,还要使用IT管理的思想来提高团队的流程成熟度和专业度,从而提高整体交付品质。
互联网的商业化只经历了短短的不到二十年的时间,但在此之前,IT的信息化就已经在国外很多企业中普及开来了,企业中的大部分员工是使用IT设备作为生产力工具和协作沟通的渠道,那么如何支持好IT基础设施就变成了很重要的工作,并由此催生了IT服务管理的概念,在20世纪80年代末期,还由英国政府部门发起制订了一个信息技术基础架构库即ITIL,到目前已修订至第3版,从流程的规范制订,发展为面向全生命周期的服务管理。
虽然前面反复提到:互联网与IT企业对于需求的管理存在相当大的差异,但这只会促使我们思考如何吸取面向交付品质的ITIL的理念,并在此基础上让一切环节运转在一条流水线上,并想方设法让流水线变得更快。
让流水线变的更快,可以从两个角度进行优化,一个是提高效率,一个是减少损耗。工具的高度自动化,把尽可能多的事情交给机器去做是提高效率的最显而易见的方法。那么减少损耗呢?通常因为测试资源、环境复杂性等问题,导致原本在测试环境运转正常的软件,在服务器或者用户的手机上出现了问题,你几乎没有办法在生产运行环境下远程调试和修改程序,但这些问题又无法复现,所以捕获现场就变成了非常重要的事。日志和监控是经无数团队和项目证明的最重要的两种捕获现场、衡量线上交付品质的方式,所以在你的团队有允许的资源时,一定要有专人面向其进行持续的分析、优化和质量评价。
总结
- 在业务还比较小的时候,要面向成功率最大化进行团队资源配置,随着业务的逐步发展,资源配置的原则要逐步倾斜至执行效率、交付品质,直至从理论的高度设计相应的流程和角色来固化你的团队,使之变得优质、高效、稳定、可控。
- 充分利用工具,尽可能将一切工作自动化。
- 重复、频繁的做一件事,尤其是你发现这件事情既重要又困难的时候。
- 在你的团队没有强大到能够筑巢引凤的时候,不用花精力弥补技能的短板,因为成功率低,回报也有限,反而对团队的项目管理要亲力亲为,识别损耗并推动改进。
编程思想的理解(POP,OOP,SOA,AOP)
1)POP--面向过程编程(Process-oriented programming ):
面向过程编程是以功能为中心来进行思考和组织的一种编程方法,它强调的是系统的数据被加工和处理的过程,在程序设计中主要以函数或者过程为程序的基本组织方式,系统功能是由一组相关的过程和函数序列构成。面向过程强调的是功能(加工),数据仅仅作为输入和输出存在。这种过程化的思想是一种很朴素和普遍的思想和方法,人类很多活动都是这种组织模式,比如工厂生产,企业服务等。面向过程以数据的加工处理过程为主线,忽略了过程的所属、边界和环境,混淆了服务功能和自我功能(比如人可以砍树,这就是一种服务功能,有输入也有输出;它可以提供给外部,而行走,则是自我功能,没有输入也没有输出),外部环境和内部组织,以及环境数据和原料性数据之间的区别。从思维上来讲,面向过程更强调细节,忽视了整体性和边界性,但这与现实世界有很大的出入,因为现实世界中,这种过程都不是孤立存在的,而是从属于某个对象,因此,面向过程虽然反映了现实世界的而一个方面(功能),但无法更加形象的模拟或者表示现实世界。
2)OOP--面向对象编程(Object Oriented Programming):
世界是由一个个对象组成的,因此面向对象的思维方式更加接近现实世界,面向对象编程的组织方式也更加贴近现实世界。面向对象以对象为中心,将对象的内部组织与外部环境区分开来,将表征对象的内部属性数据与外部隔离开来,其行为与属性构成一个整体,而系统功能则表现为一系列对象之间的相互作用的序列,能更加形象的模拟或表达现实世界。在编程组织中,对象的属性与方法不再像面向过程那样分开存放,而是视为一个整体(程序的最终实现其实还是分离的,但这仅仅是物理实现上的,不影响将对象的这两个部分视为一个整体),因此具有更好的封装性和安全性(表征内部的属性数据需要通过对象的提供的方法来访问)。面向对象强调的是整体性,因此面向对象与面向过程在很多方面是可以互补的。同时由于对象继承和多态技术的引入,使得面向对象具有更强、更简洁的对现实世界的表达能力。从而增强了编程的组织性,重用性和灵活性。
面向对象依然保留着面向过程的特性,面向过程中的功能变成了对象的方法,加工处理功能变成了对象的服务性方法,而这部分方法依然需要外界的输入,同时也对外界进行输出,只是输入和输出也变成了对象。在面向对象编程中,大多时候,我们并不需要关心一个对象对象的方方面面,有些对象在整个系统中都是充当“原料”和“成品”的角色,其本身的行为并不在我们关心的范围,而另外有些对象处于一种加工厂地位,我们也仅关心这些对象的服务性功能,不需要太多关注对象内部属性和自我行为,针对这些对象关注点的不同会对对象进行分类,比如前面提到的两类对象,就是从在系统中所处的角色不同而分类,前者叫实体对象,后者称为操作对象。
从方法论来讲,我们可以将面向过程与面向对象看做是事物的两个方面--局部与整体(注意:局部与整体是相对的),在实际应用中,两者方法都同样重要。
面向过程和面向对象是编程方法中最基本的两种方法,处于编程方法体系的底层。
3)SOA--面向服务架构
面向服务以服务为出发点,组织和协调相关的对象来提供目标服务,对外提供必要的参数输入接口,将服务的结果作为输出,而“服务”本身的计算过程和组织则被封装在一起,对用户透明。其实面向服务也是以功能(服务)为中心,但其强调的是功能的整体性,封装性、自包性,而不是过程性和协作性,整体性指的是服务对外是作为一整体来体现的;封装性指的是服务完成的计算和处理过程、自有属性都不直接暴露给外部,除了通过公共的服务接口进行交互外,用户无法也不用知道内部的具体组织和协调的;自包性指的是服务的完成不依赖于服务的调用方,服务系统的本身就可以完成服务所需的功能;因此面向服务在程序组织上处于更高的层次,是一种粗粒度的组织方法。面向服务与面向过程、面向对象本质上没有什么不同,区别就在于考虑问题的层面不同。面向对象和面向过程多用于系统内部的组织和管理,而面向服务主要用于系统间的组织和管理。面向服务是更大的对象或者过程。
面向服务设计的三大原则是无状态、单一实例和明确的服务接口。明确的服务接口是强制和必须的,但无状态和单一实例则不属于强制性原则,虽然说服务提供状态管理会增加服务的复杂性,多实例也一样会增加服务的复杂性(需要增加同步并发处理等,而且会导致访问不确定性),但很多情况下这又是无法避免的。
现在的面向服务架构,主要用于系统间的交互和集成,有一系列的标准(XML,SOAP,WSDL,XSD,WS-policy,WS-BPEL等)。
4)AOP--面向方面.
面向方面应该属于面向对象的范畴,从对象组织角度来讲,我们一般采用的分类方法都是使用类似生物学分类的方法,以“继承”关系为主线,我们称之为纵向。但事实上,对象之间除了这种纵向分类之外,我们同样可以从横向的角度去观察这些对象,这就是面向方面(切面)编程的基本出发点。原来要解决这类问题,我们一般是采用接口来完成,但这有两个问题,一是对象设计的时候一般都是纵向思维,如果这个时候需要就需要考虑这些不同类的对象的这些共性,不仅会增加设计的难度和复杂性,还会造成类的接口过多而难以维护,二是需要对现有的对象动态增加这种行为或者责任的时候非常困难。现在很多程序的都是以中间语言存在,执行的时候是解释执行或者即时编译执行,这也为增加这种切面行为或者责任提供了比较好的切入口。面向方面跟Api hook很类似。面向方面编程的具体一些原理和做法,可以参考我前面的博文。
域名解析生效原理及时间
一、域名解析生效原理
域名解析生效的过程,是域名与IP绑定的过程。当解析生效后,用户访问域名时的实现机制是:由 DNS 服务器询问域名指向了哪个 IP 地址,再由 DNS 服务器告诉客户端打开对应网站空间。
万网域名的解析生效,第一步是万网 DNS 必须首先生效,然后等待世界各地 Local DNS 生效,可以通俗的理解为各大电信运营管理的 DNS 需要及时同步万网 DNS 解析记录,才能最终生效。 网站是否能访问,直接相关的是 Local DNS,万网云解析都是实时生效的,一般只需几秒即可同步到各地 Local DNS 上,但各地 Local DNS 均有缓存机制,解析的最终生效取决于各运营商刷新时间。见下图。

出于对域名安全的保证,万网云解析的解析记录数据并非直接修改 DNS 后台数据,而是修改万网控制中心数据,然后同步至DNS服务器。从而避免了因DNS服务器漏洞所造成的安全隐患。
二、域名解析生效时间
全球有无数的互联网节点与 DNS 服务器,在设置域名解析记录后,将此结果同步至全球各个 DNS 服务器,这一过程所需要的时间即为解析生效时间。
域名解析记录生效的时间可以分为如下三种情况:
1、新增解析记录生效时间
使用万网云解析新增解析记录,实时生效。
2、修改解析记录生效时间
使用万网云解析修改解析记录,最终生效时间取决于各地运营商的 DNS 服务器缓存刷新时间(各地 ISP 的 DNS 上缓存了修改前的解析记录,不会实时更新),一般情况下等同于您之前设置解析时的 TTL 时间。例如你之前的解析设置中 TTL 值为 10 分钟,修改解析后将在 10 分钟内实现全球生效。
3、修改 DNS 后,设置解析记录生效时间
如修改了 DNS 地址后使用万网云解析修改解析记录,最终生效时间同样取决于各地运营商的DNS服务器缓存刷新时间。但各地 DNS 的刷新时间不一致,且刷新时间较长,导致解析在全球生效时间需要 24~48 小时。(.com 等国际域名需要 48 小时,.cn 等国内域名需要 24 小时)
https://help.aliyun.com/knowledge_detail/39837.html
Unbelievable ! 30 Linux TOP Command Examples With Screenshots
看不懂的来这里 http://os.51cto.com/art/201312/423220.htm
The top command in Linux displays the running processes on the system. One of the most important tools for a system administrator. It is used extensively for monitoring the load on a server. In this article, we explore the top command in detail. The top command is an interactive command. Many commands are available when top is running. We will explore these commands as well.
1. Top Command output:
First of all, let us understand what the output says. Top command displays a lot of information about the running system. But we need to under stand the meaning of different sections of this output:
Running by default, the top command displays output like this:

First few lines are horizontal showing summary about different system parameters, and following these are the processes and their attributes in columns.
1.1 Uptime and Load Averages:
![]()
At the top of top command is displayed the output similar to uptime command.
The fields display:
* current time
* the time your system is been up
* number of users logged in
* load average of 5, 10 and 15 minutes respectively.
This uptime display can be toggled with 'l' command.
1.2 Tasks:
![]()
The second line shows summary of tasks or processes. The processes can be in different states. It shows total number of the processes. Out of these, the processes can be running, sleeping, stopped or in zombie (zombie is the state of a process state, These process summary can be toggled with 't' command.
1.3 CPU States:
![]()
Next is shown the CPU state. Here, %age of CPU time in different modes is shown. The meaning of different CPU times are:
* us, user: CPU time in running (un-niced) user processes
* sy, system: CPU time in running kernel processes
* ni, niced: CPU time in running niced user processes
* wa, IO wait: CPU time waiting for IO completion
* hi: CPU time serving hardware interrupts
* si: CPU time serving software interrupts
* st: CPU time stolen for this vm by the hipervisor.
This can be toggled with 't' command.
1.4 Memory Usage:
![]()
Next two lines show memory usage, somewhat like 'free' command. 1st of these lines is for physical memory and the second for virtual memory (swap space).
The physical memory is displayed as: total available memory, used memory, free memory, and memory used for buffers
Similarly, swap reflects: total, used, free and cached swap space.
The memory can be toggled with 'm' command.
1.5 Fields/Columns:

After these horizontal system properties and states, the processes are shown in columns. The different columns represent different properties discussed below.
By default, top shows these attributes associated with processes:
PID
The Process ID, to uniquely identify a processes.
USER
The effective user name of the owner of the processes.
PR
The scheduling priority of the process. Some values in this field are 'rt'. It means that the process is running under real-time.
NI
The nice value of the process. Lower values mean higher priority.
VIRT
The amount of virtual memory used by the process.
RES
The resident memory size. Resident memory is the amount of non-swapped physical memory a task is using.
SHR
SHR is the shared memory used by the process.
S
This is the process status. It can have one of the following values:
D - uninterruptible sleep
R - running
S - sleeping
T - traced or stopped
Z - zombie
%CPU
It is the percentage of CPU time the task has used since last update.
%MEM
Percentage of available physical memory used by the process.
TIME+
The total CPU time the task has used since it started, with precision upto hundredth of a second.
COMMAND
The command which was used to start the process.
There are many other outputs which are not displayed by default which can display information about page faults, effective group and group ID of the process, and many more.
2. Interactive Commands:
We discussed earlier that the top command is interactive commands. Some of the commands we encountered in the last section. Here we explore these commands further.
2.1 'h': Help
First of all, you can press 'h' or '?' to display the help menu for interactive commands.

2.2 '' or '': Refresh Display
The top command by default refreshes after a certain interval (3 seconds). To refresh manually, user can press enter or space key.
2.3 A: Toggle Alternate Display Mode
This command switches between full-screen Mode and alternate-display mode. In alternate display mode, 4 windows are available:
1. Def
2. Job
3. Mem
4. Usr
Each of the 4 field groups has a unique separately configurable summary area and its own configurable task area. Only one of these 4 windows will be the current window. The current window is displayed on the top left corner.

You can switch between 4 windows with 'a' and 'w' keys. 'a' moves to next and 'w' to previous window. With 'g' command, you can enter a number to select the current window.

2.4 B: Toggle Bold Display
Some important information is shown in bold characters. This command toggles use of bold.

2.5 'd' or 's': Set Display Time interval
When 'd' or 's' is pressed, you will be prompted to enter a value ( in seconds ) which will be set as display interval. If you enter 1 here, top will refresh every second.

2.6 'l', 't', 'm': Toggle Load, Task, Memory Info
These will toggle load average, task/cpu status and mem info respectively as discussed.




2.7 'f': Field Management
This is used to chose what field you want to display on the output screen. The fields marked as * are selected.

'<' and="" br=""> The '<' command="" moves="" the="" sorted="" field="" to="" left="" and="" right="" p="">
2.8 'R': Reverse Sort
Toggle Reverse/Normal sort order
2.9 'c': Toggle Command
Toggle full path of command that started the process and program name.

2.10 'i': Idle Tasks
Toggle idle tasks.

2.11 'V': Forest View
Toggle forest view mode.

2.12 'Z': Change color map
Pressing the 'Z' key takes the user to a screen where the display color can be changed for top command. There are 8 task areas to chose from and 8 colors.

The below screen shows full colored top view with all 4 screens on.

2.13 'z': Toggle Color
Toggle color, i.e. turn on or off the colored display.
2.14 'x' or 'y'
Toggle highlights: 'x' sort field; 'y' running tasks. Depending upon your display settings, You might have to make the output colored in order to notice these highlights.

2.15 'u': Processes of a User
Show processes for a particular user. You are prompted to enter the username. Blank will show for all users.

2.16 'n' or '#': Number of tasks
Set maximum number of tasks displayed.

2.17 'k': Kill tasks
One of the most important commands of top. Used to send signals to tasks (Usually kill tasks).

2.18 'r': Renice
Renice a task to change the scheduling priority.
3. Command line options:
Most of these command line options are similar to the commands discussed above. Top output can be manipulated interactively with commands. But you can start top with some parameters set to your convenience with these options.
3.1 -b: Batch mode
The -b option starts top command in batch mode. It can be useful when you want to save the output in a file.
3.2 -c: Command/Program-name toggle:
As discussed in the above commands, this option will toggle from the last remembered state of command/program name display.
3.3 -d: Set delay interval
Set the delay interval for top (in seconds). For example:
$ top -d 1
will start the top command with 1 sec delay interval.
3.4 -i: idle process toggle
This option sets the top command with last remembered 'i' state reversed.
3.5 -n: Set number of iterations
With -n option, you can set the number of iterations after which top willl end.
$ top -n 3
will exit top automatically after 3 outputs.
3.6 -p: monitor specific PIDs
You can specify what PIDs you want to monitor with -p option. PID value 0 will be treated as process ID of top command itself.
3.7 -u or -U: username or UID
The process of a particular user can be viewed with these options. Username or UID can be specified to the option. The -p, -u and -U options are mutually exclusive. Only one of the options can be used at a time. You get error when you try to use any combination of these options:
$ top -p 28453 -u raghu
top: conflicting process selections (U/p/u)
设计API接口注意事项
总结一下API接口开发过程中的注意事项
1、跨平台性
所谓跨平台是指我们的接口要能够支持不同的终端,比如android、ios、windowsphone以及桌面软件、网站等。如:不同的终端每页显示的记录数不同

采用通用的解决方案,比如通信协议就采用最常用的HTTP协议,如果是即时通信,可以采用开放的XMPP协议,做游戏的可以采用可靠的TCP协议,除非TCP不够用了,再采用定制的UDP协议。
数据交换采用xml或者json格式或者webservice等等。总之,要达到的目标就是让不同的端能够很方便的使用你的接口。
2、良好的响应速度
接口应该以最快的速度将数据返回给请求者,要达到的目标就是快,一个页面,秒开最好,超过三秒就需要找找原因了。数据量按需分配,APP客户端需要什么数据就返回什么数据,过多的数据量影响处理速度,最重要的是影响传输效率
3、接口要为移动客户端考虑
比如,在移动端里,下拉刷新和上拉加载更多是很常见的功能,如果接口仍然按照传统的web思路,
只提供按页读取的话,就会造成移动端的额外的数据请求和计算。 这时,接口就应该针对这两种类型的操作提供额外的支持。
4、考虑移动端的网络情况和耗电量
如果让我们说出哪类app比较好,可能还不大好说,但是如果让我们说出哪些app很差,我们肯定会说出那些体积很大、占用内存多、界面很卡、费电的app 不好。对于网络情况,接口应该具备为不同的网络提供不同的内容的能力如果我们能够知道用户的网络情况,只有在wifi的情况下才给用户传输封面图、缩略图 之类的,
是不是可以帮用户节省很多流量呢
5、通用的数据交换格式
目前,对于接口和客户端的数据交换格式,基本上就是三种,xml和json和webservice,而现在使用json的应该占大多数最麻烦的就是处理Date类型,因为JSON本身没有Date类型,因此,JSON库将Date类型的数据序列化时会转为String。这时,不同环境, 不同平台,以及用不同的JSON解析库,转换后的结果经常会不同。比如,你在开发机上可能得到的结果是”2016-1-1 17:11:11”,但放到服务器后结果却变成了“Jan 1,2016 5:11:11 PM” ,客户端进行反序列化时无疑会失败。后来,我取消了所有Date类型,统一采用时间戳表示,就再没有转化的烦恼了。 另外,接口的开发人员有时候会将一些数据错误地转换为了String,导致客户端使用时因类型错误而异常。例如,本来是数字的1,被转成 了”1″,客户端做运算时就会出错,或用switch判断时也会出错,或其他无法转换的情况发生时;例如,为空时JSON正确地表示应该是null,但如 果转为了String就变成了”null”,那问题就来了,我遇到的因为这个错误的转换导致的程序奔溃已经好几次了,第一次的时候,查了一整天才定位到问题所在
6、接口统计功能
在做PC端网站的时候,我们都会给我们的网站加上个统计功能,要么自己写统计系统,要么使用第三方的比如GA
移 动端接口API则需要我们自己实现统计功能,这时就需要我们尽可能多的收集客户端的信息,除了传统的IP、User-Agent之外,还应该收集一些移动 相关的信息,比如手机操作系统,是android还是ios,都是什么版本,用户使用的网络状况,是2G、3G、4G还是WIFI。客户端APP是什么版 本信息。
7、客户端与服务端的肥瘦平衡
在移动开发中,由于客户端的修改会很费时费力,特 别是IOS应用还要经过Apple审核,另外,当前IOS开发人员、Android开发人员的人工成本普遍较高,人才紧缺,基于这两点,能在服务器端实现 的功能就不要放在客户端,毕竟服务器端程序的修改要比客户端方便、灵活、快捷的多。
8、隐式用户与显式用户
显式用户指的是,APP程序中有用户系统,一个username、password正确的合法用户,称之为显式的用户,
通常显式用户都需要注册,登录以后能完成一些个人相关的操作。
隐式用户指的是,APP程序本身就没有用户系统,或者一个在没有登录的情况下,使用我们APP的用户。
在这种情况下,可以通过客户端生成的UDID来标识一个用户。
有了用户信息,我们就能够了解不同用户的使用习惯,而不仅仅是全体用户的一个整体的统计信息,
有了这些个体的信息之后,就可以做一些用户分群、个性化推荐之类的事情。
9、安全问题
设计API第一个需要考虑的是API的安全机制。我负责的上一个项目,因为API的安全问题,就被人攻击了两次。之后经过分析,主要存在两个漏洞: 一是因 为缺少对调用者进行安全验证的方式,二是因为数据传输不够安全。那么,制定API的安全机制,主要就是为了解决这两个问题:
- 保证API的调用者是经过自己授权的App;
- 保证数据传输的安全。
第一个问题的解决方案,我主要采用设计签名的方式。对每个客户端分别分配一个AppKey和AppSecret。需要调用API时,将AppKey加入请求参数列表,并将AppSecret和所有参数一起,根据某种签名算法生成一个签名字符串,然后调用API时把该签名字符串也一起带上。服务端收到请求之后,根据请求中的AppKey查询相应的AppSecret,按照同样的签名算法,也生成一个签名字符串,当服务端生成的签名和请求带过来的签名一致的时候,那就表示这个请求的调用者是经过自己授权的,证明这个请求是安全的。而且,每个端都有一个Key,也方便不同端的标识和统计。为了防止AppSecret被别人获取,这个AppSecret一般写死在代码里面。另外,签名算法也需要有一定的复杂度,不能轻易被别人破解,最好是采用自己规 定的一套签名算法,而不是采用外部公开的签名算法。另外,在参数列表中再加入一个时间戳,还可以防止部分重放攻击。
接口不能直接调用OAuth认证(rsa加密),ip白名单接口的安全工作不能马虎,暴力破解啊、SQL Injection啊、伪造请求和数据啊、重复提交啊也要考虑到,
如果数据特别敏感,可以考虑采用SSL/TLS等加密传输,或者客户端、服务器端约定一个加密算法和密钥,对来往传输的数据进行加密、解密。如将所有参数加签名算法得到一个签名验证参数signhttp://www.webvist.com/blog/2287954
表单类接口防止重复提交:调用过的接口sign存起来,检查sign是否存在
10、良好的接口说明文档和测试程序
接口文档要清晰、明了,包含多少个接口,每个接口的地址、参数、请求方式、数据交换格式、参数是否必填、编码格式UTF8,返回值等都要写清楚。
接口测试程序,有条件的话,也可以提供,方便前后端的调试

11、版本的维护
随着业务的变化,客户端APP和服务器端API都会发生变化,增加新的功能,修改已有的功能,
增加功能还好说, 如果是接口需要修改,那么就面临着同一个接口要同时为不同版本的客户端服务的问题。
因此,服务器端接口也要做好相应的版本维护。
主版本更新可以把版本号放入API的URL中/api-v2来指出所使用的API版本
次要版本的修改是通过客户在API调用时发起请求的HTTP头部做指定的头部的版本元素看起来是这样的:
Element-Version: 1
12、接口数据、状态
接口必须提供明确的数据状态信息,不管是成功的,还是失败的,都必须返回给APP客户端。
13、接口、参数命名准确。
无论是接口还是参数,命名都应该有意义,让人一目了然。
用Git撤销任何操作
任何版本控制系统的一个最有的用特性就是“撤销 (undo)”你的错误操作的能力。在 Git 里,“撤销” 蕴含了不少略有差别的功能。
当你进行一次新的提交的时候,Git 会保存你代码库在那个特定时间点的快照;之后,你可以利用 Git 返回到你的项目的一个早期版本。
在本篇博文里,我会讲解某些你需要“撤销”已做出的修改的常见场景,以及利用 Git 进行这些操作的最佳方法。
撤销一个“已公开”的改变
场景: 你已经执行了 git push, 把你的修改发送到了 GitHub,现在你意识到这些 commit 的其中一个是有问题的,你需要撤销那一个 commit.
方法: git revert <SHA>
原理: git revert 会产生一个新的 commit,它和指定 SHA 对应的 commit 是相反的(或者说是反转的)。如果原先的 commit 是“物质”,新的 commit 就是“反物质” — 任何从原先的 commit 里删除的内容会在新的 commit 里被加回去,任何在原先的 commit 里加入的内容会在新的 commit 里被删除。
这是 Git 最安全、最基本的撤销场景,因为它并不会改变历史 — 所以你现在可以 git push 新的“反转” commit 来抵消你错误提交的 commit。
修正最后一个 commit 消息
场景: 你在最后一条 commit 消息里有个笔误,已经执行了 git commit -m "Fxies bug #42",但在 git push 之前你意识到消息应该是 “Fixes bug #42″。
方法: git commit --amend 或 git commit --amend -m "Fixes bug #42"
原理: git commit --amend 会用一个新的 commit 更新并替换最近的 commit ,这个新的 commit 会把任何修改内容和上一个 commit 的内容结合起来。如果当前没有提出任何修改,这个操作就只会把上次的 commit 消息重写一遍。
撤销“本地的”修改
场景: 一只猫从键盘上走过,无意中保存了修改,然后破坏了编辑器。不过,你还没有 commit 这些修改。你想要恢复被修改文件里的所有内容 — 就像上次 commit 的时候一模一样。
方法: git checkout -- <bad filename>
原理: git checkout 会把工作目录里的文件修改到 Git 之前记录的某个状态。你可以提供一个你想返回的分支名或特定 SHA ,或者在缺省情况下,Git 会认为你希望 checkout 的是 HEAD,当前 checkout 分支的最后一次 commit。
记住:你用这种方法“撤销”的任何修改真的会完全消失。因为它们从来没有被提交过,所以之后 Git 也无法帮助我们恢复它们。你要确保自己了解你在这个操作里扔掉的东西是什么!(也许可以先利用 git diff 确认一下)
重置“本地的”修改
场景: 你在本地提交了一些东西(还没有 push),但是所有这些东西都很糟糕,你希望撤销前面的三次提交 — 就像它们从来没有发生过一样。
方法: git reset <last good SHA> 或 git reset --hard <last good SHA>
原理: git reset 会把你的代码库历史返回到指定的 SHA 状态。 这样就像是这些提交从来没有发生过。缺省情况下, git reset 会保留工作目录。这样,提交是没有了,但是修改内容还在磁盘上。这是一种安全的选择,但通常我们会希望一步就“撤销”提交以及修改内容 — 这就是 --hard 选项的功能。
在撤销“本地修改”之后再恢复
场景: 你提交了几个 commit,然后用 git reset --hard 撤销了这些修改(见上一段),接着你又意识到:你希望还原这些修改!
方法: git reflog 和 git reset 或 git checkout
原理: git reflog 对于恢复项目历史是一个超棒的资源。你可以恢复几乎 任何东西 — 任何你 commit 过的东西 — 只要通过 reflog。
你可能已经熟悉了 git log 命令,它会显示 commit 的列表。 git reflog 也是类似的,不过它显示的是一个 HEAD 发生改变的时间列表.
一些注意事项:
它涉及的只是 HEAD的改变。在你切换分支、用git commit进行提交、以及用git reset撤销 commit 时,HEAD会改变,但当你用git checkout -- <bad filename>撤销时(正如我们在前面讲到的情况),HEAD 并不会改变 — 如前所述,这些修改从来没有被提交过,因此 reflog 也无法帮助我们恢复它们。git reflog不会永远保持。Git 会定期清理那些 “用不到的” 对象。不要指望几个月前的提交还一直躺在那里。- 你的
reflog就是你的,只是你的。你不能用git reflog来恢复另一个开发者没有 push 过的 commit。

那么…你怎么利用 reflog 来“恢复”之前“撤销”的 commit 呢?它取决于你想做到的到底是什么:
- 如果你希望准确地恢复项目的历史到某个时间点,用
git reset --hard <SHA> - 如果你希望重建工作目录里的一个或多个文件,让它们恢复到某个时间点的状态,用
git checkout <SHA> -- <filename> - 如果你希望把这些 commit 里的某一个重新提交到你的代码库里,用
git cherry-pick <SHA>
利用分支的另一种做法
场景: 你进行了一些提交,然后意识到你开始 check out 的是 master 分支。你希望这些提交进到另一个特性(feature)分支里。
方法: git branch feature, git reset --hard origin/master, and git checkout feature
原理: 你可能习惯了用 git checkout -b <name> 创建新的分支 — 这是创建新分支并马上 check out 的流行捷径 — 但是你不希望马上切换分支。这里, git branch feature 创建一个叫做 feature 的新分支并指向你最近的 commit,但还是让你 check out 在 master 分支上。
下一步,在提交任何新的 commit 之前,用 git reset --hard 把 master 分支倒回 origin/master 。不过别担心,那些 commit 还在 feature 分支里。
最后,用 git checkout 切换到新的 feature 分支,并且让你最近所有的工作成果都完好无损。
及时分支,省去繁琐
场景: 你在 master 分支的基础上创建了 feature 分支,但 master 分支已经滞后于 origin/master 很多。现在 master 分支已经和 origin/master 同步,你希望在 feature 上的提交是从现在开始,而不是也从滞后很多的地方开始。
方法: git checkout feature 和 git rebase master
原理: 要达到这个效果,你本来可以通过 git reset (不加 --hard, 这样可以在磁盘上保留修改) 和 git checkout -b <new branch name> 然后再重新提交修改,不过这样做的话,你就会失去提交历史。我们有更好的办法。
git rebase master 会做如下的事情:
- 首先它会找到你当前 check out 的分支和
master 分支的共同祖先。 - 然后它 reset 当前 check out 的分支到那个共同祖先,在一个临时保存区存放所有之前的提交。
- 然后它把当前 check out 的分支提到
master的末尾部分,并从临时保存区重新把存放的 commit 提交到master分支的最后一个 commit 之后。
大量的撤销/恢复
场景: 你向某个方向开始实现一个特性,但是半路你意识到另一个方案更好。你已经进行了十几次提交,但你现在只需要其中的一部分。你希望其他不需要的提交统统消失。
方法: git rebase -i <earlier SHA>
原理: -i 参数让 rebase 进入“交互模式”。它开始类似于前面讨论的 rebase,但在重新进行任何提交之前,它会暂停下来并允许你详细地修改每个提交。
rebase -i 会打开你的缺省文本编辑器,里面列出候选的提交。如下所示:

前面两列是键:第一个是选定的命令,对应第二列里的 SHA 确定的 commit。缺省情况下, rebase -i 假定每个 commit 都要通过 pick 命令被运用。
要丢弃一个 commit,只要在编辑器里删除那一行就行了。如果你不再需要项目里的那几个错误的提交,你可以删除上例中的1、3、4行。
如果你需要保留 commit 的内容,而是对 commit 消息进行编辑,你可以使用 reword 命令。 把第一列里的 pick 替换为 reword (或者直接用 r)。有人会觉得在这里直接重写 commit 消息就行了,但是这样不管用 —rebase -i 会忽略 SHA 列前面的任何东西。它后面的文本只是用来帮助我们记住 0835fe2 是干啥的。当你完成 rebase -i 的操作之后,你会被提示输入需要编写的任何 commit 消息。
如果你需要把两个 commit 合并到一起,你可以使用 squash 或 fixup 命令,如下所示:

squash 和 fixup 会“向上”合并 — 带有这两个命令的 commit 会被合并到它的前一个 commit 里。在这个例子里, 0835fe2 和 6943e85 会被合并成一个 commit, 38f5e4e 和 af67f82 会被合并成另一个。
如果你选择了 squash, Git 会提示我们给新合并的 commit 一个新的 commit 消息; fixup 则会把合并清单里第一个 commit 的消息直接给新合并的 commit 。 这里,你知道 af67f82 是一个“完了完了….” 的 commit,所以你会留着 38f5e4e as的 commit 消息,但你会给合并了 0835fe2 和 6943e85 的新 commit 编写一个新的消息。
在你保存并退出编辑器的时候,Git 会按从顶部到底部的顺序运用你的 commit。你可以通过在保存前修改 commit 顺序来改变运用的顺序。如果你愿意,你也可以通过如下安排把 af67f82 和 0835fe2 合并到一起:

修复更早期的 commit
场景: 你在一个更早期的 commit 里忘记了加入一个文件,如果更早的 commit 能包含这个忘记的文件就太棒了。你还没有 push,但这个 commit 不是最近的,所以你没法用 commit --amend.
方法: git commit --squash <SHA of the earlier commit> 和 git rebase --autosquash -i <even earlier SHA>
原理: git commit --squash 会创建一个新的 commit ,它带有一个 commit 消息,类似于 squash! Earlier commit。 (你也可以手工创建一个带有类似 commit 消息的 commit,但是 commit --squash 可以帮你省下输入的工作。)
如果你不想被提示为新合并的 commit 输入一条新的 commit 消息,你也可以利用 git commit --fixup 。在这个情况下,你很可能会用commit --fixup ,因为你只是希望在 rebase 的时候使用早期 commit 的 commit 消息。
rebase --autosquash -i 会激活一个交互式的 rebase 编辑器,但是编辑器打开的时候,在 commit 清单里任何 squash! 和 fixup! 的 commit 都已经配对到目标 commit 上了,如下所示:

在使用 --squash 和 --fixup 的时候,你可能不记得想要修正的 commit 的 SHA 了— 只记得它是前面第 1 个或第 5 个 commit。你会发现 Git 的 ^ 和 ~ 操作符特别好用。HEAD^ 是 HEAD 的前一个 commit。 HEAD~4 是 HEAD 往前第 4 个 – 或者一起算,倒数第 5 个 commit。
停止追踪一个文件
场景: 你偶然把 application.log 加到代码库里了,现在每次你运行应用,Git 都会报告在 application.log 里有未提交的修改。你把 *.login 放到了 .gitignore 文件里,可文件还是在代码库里 — 你怎么才能告诉 Git “撤销” 对这个文件的追踪呢?
方法: git rm --cached application.log
原理: 虽然 .gitignore 会阻止 Git 追踪文件的修改,甚至不关注文件是否存在,但这只是针对那些以前从来没有追踪过的文件。一旦有个文件被加入并提交了,Git 就会持续关注该文件的改变。类似地,如果你利用 git add -f 来强制或覆盖了 .gitignore, Git 还会持续追踪改变的情况。之后你就不必用-f 来添加这个文件了。
如果你希望从 Git 的追踪对象中删除那个本应忽略的文件, git rm --cached 会从追踪对象中删除它,但让文件在磁盘上保持原封不动。因为现在它已经被忽略了,你在 git status 里就不会再看见这个文件,也不会再偶然提交该文件的修改了。
这就是如何在 Git 里撤销任何操作的方法。要了解更多关于本文中用到的 Git 命令,请查看下面的有关文档:
最好的 ss-panel 部署教程
续・为最好的 ss-panel 部署教程献上更新!
本文最后更新与 2016-02-08,更新内容详见博文底部。
今天折腾了好久 ss-panel,期间遇到了一些奇奇怪怪的问题,但是网上都没有好的解决方法。
网上那么多教程有些是写得笼统,有些还是瞎复制的。
由此萌生了想要写一篇配置 ss-panel 和 ss-manyuser 的教程,希望能够帮到需要的人。
注意,本教程 不是 图文并茂的面向小白的教程,窝希望你能够有足够的 linux 操作经验再来看这篇教程。
至少你需要熟悉 ssh 连接,熟悉 web 环境的配置,最好可以看得懂一些代码。
一、安装并配置 ss-panel
本教程打算先配置好前端,当然你想要先配置后端可以拉下去。
0x01 环境要求
作为前端的 ss-panel 是使用 PHP 编写的网页应用程序,它对你的主机运行环境有一定的要求。
- PHP 5.6 或更高
- MySQL 5.5 或更高
- 支持 URL 重写的 Web 服务器(Nginx / Apache 均可)
本教程所使用的环境是 NGINX + PHP 7 + MariaDB 10。
当然其他主流 LNMP/LAMP 架构都可以(个人推荐使用 OneinStack),确保你的站点可以访问后就继续吧。
什么?你不知道上面说的那些东西是什么?那你为什么不问问神奇海螺呢?
注意,接下来的操作大部分都是在【目标服务器】的 shell 中进行的。继续阅读之前,你需要通过 SSH 等工具连接至你的服务器,它一般长这样:

如果你不晓得这是什么,神奇海螺……以下略。
0x02 下载 ss-panel 源码
ss-panel 的 GitHub 项目地址:orvice/ss-panel
使用 cd 进入你站点的 web 根目录,从 git 上 clone 源码:
# 最前面的美元符号是命令提示符,别把这个给一起输进去了
$ git clone https://github.com/orvice/ss-panel.git
当然你也可以下载源码再用 SCP/FPS 传到服务器上去。
注意源码下载完成后的目录结构,请务必保证 /public 目录在站点的根目录下。
你可以使用 $ mv ss-panel/{.,}* ./ 命令将子目录的内容移动到当前目录来。正确的目录结构应该类似于这样:

0x03 配置 ss-panel
执行完上面的步骤之后,你兴高采烈地访问了你的站点,却得到了无情的 403 Forbidden —— 站点根目录下竟然没有 index.php!
好吧其实没什么好奇怪的,大部分 MVC 框架都将 index.php 的入口文件放到其他子目录下了,
这样做是为了保护根目录下的配置文件等可能会导致信息泄露的敏感文件无法被访问。
接下来请按照 官方文档的说明 正确配置你的 Web 服务器。正确配置后的 NGINX 配置应该长这样:

编辑完后重载你的 Web 服务器,然后访问你的站点……
于是你得到了一个 500 Internal Server Error(如果你没开启 display_errors 可能看不到详细报错):
Warning: require(/home/wwwroot/ss.prinzeugen.net/vendor/autoload.php): failed to open stream: No such file or directory in /home/wwwroot/ss.prinzeugen.net/bootstrap.php on line 18 Fatal error: require(): Failed opening required '/home/wwwroot/ss.prinzeugen.net/vendor/autoload.php' (include_path='.:/usr/local/php/lib/php') in /home/wwwroot/ss.prinzeugen.net/bootstrap.php on line 18
这是我们还未安装 ss-panel 所需的依赖库导致的。遂安装之:
$ curl -sS https://getcomposer.org/installer | php $ php composer.phar install

等待它安装完毕后接着进行配置:
$ cp .env.example .env
将 .env.example 复制一份重命名为 .env,自行修改其中的数据库等信息。
# database 数据库配置
db_driver = 'mysql'
db_host = 'localhost'
db_port = '3306'
db_database = 'ss-panel'
db_username = 'ss-panel'
db_password = 'secret'
db_charset = 'utf8'
db_collation = 'utf8_general_ci'
db_prefix = ''
数据库的创建我就不多说了,建站的一般都玩过数据库吧?
将根目录下的 db.sql 导入到数据库中即可。其他配置自行修改。

你还需要修改 .env 中的 muKey 字段,修改为任意字符串(最好只包含 ASCII 字符),
下面配置后端的时候我们需要使用到这个 muKey:
muKey = 'api_key_just_for_test'
接下来,确保 storage 目录可写入(否则 Smarty 会报错):
$ chown -R www storage 现在访问你的站点,就可以看到 ss-panel 的首页啦:
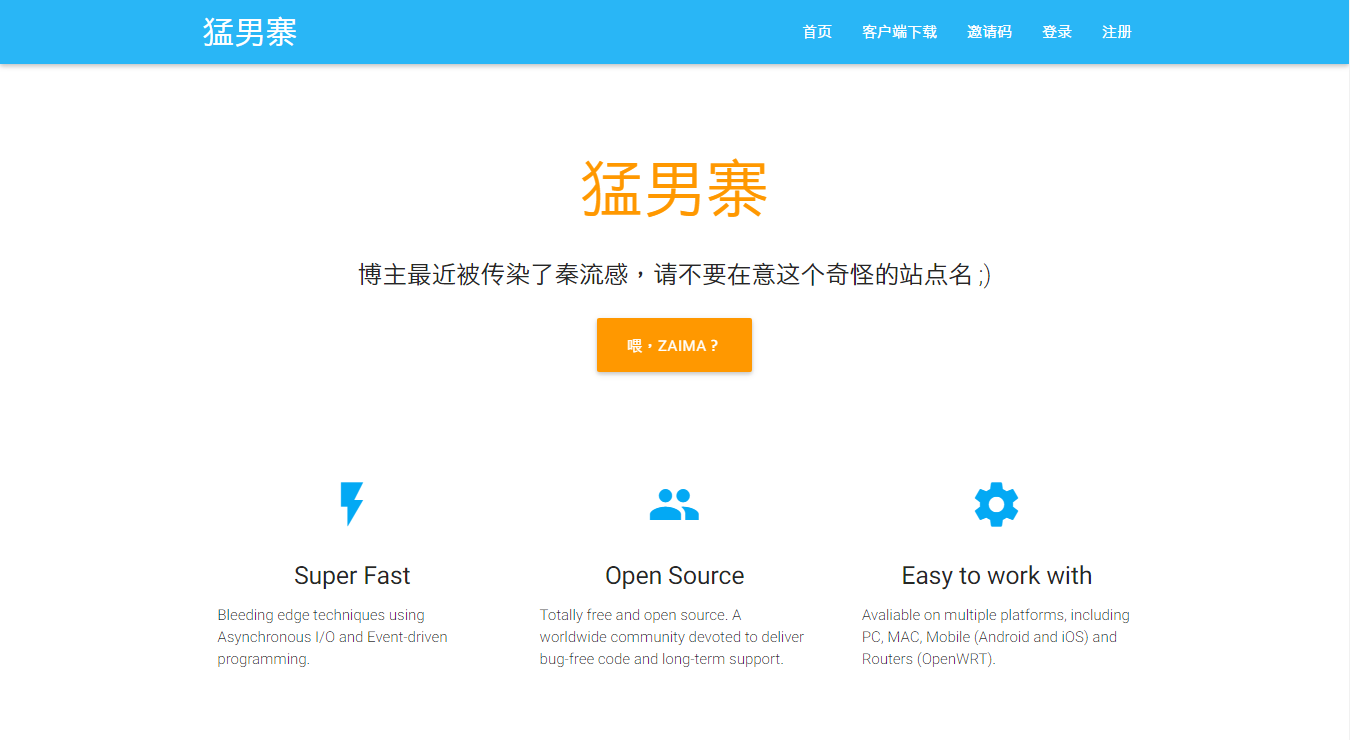
0x03 进入 ss-panel 后台 现在访问 http://your-domain/admin 就可以进入 ss-panel 后台了。
不过细心的你可能会注意到,刚才导入数据表的时候,user 表并没有添加记录,那要咋进管理后台呢?
当然你可以在数据库中手动加一条记录,不过作者已经提供了一个更方便的方式:
$ php xcat createAdmin 在站点根目录下运行,根据提示即可创建管理员账号 (这个文字对齐真鸡儿 shi):

使用刚才填写的邮箱和密码进入后台:
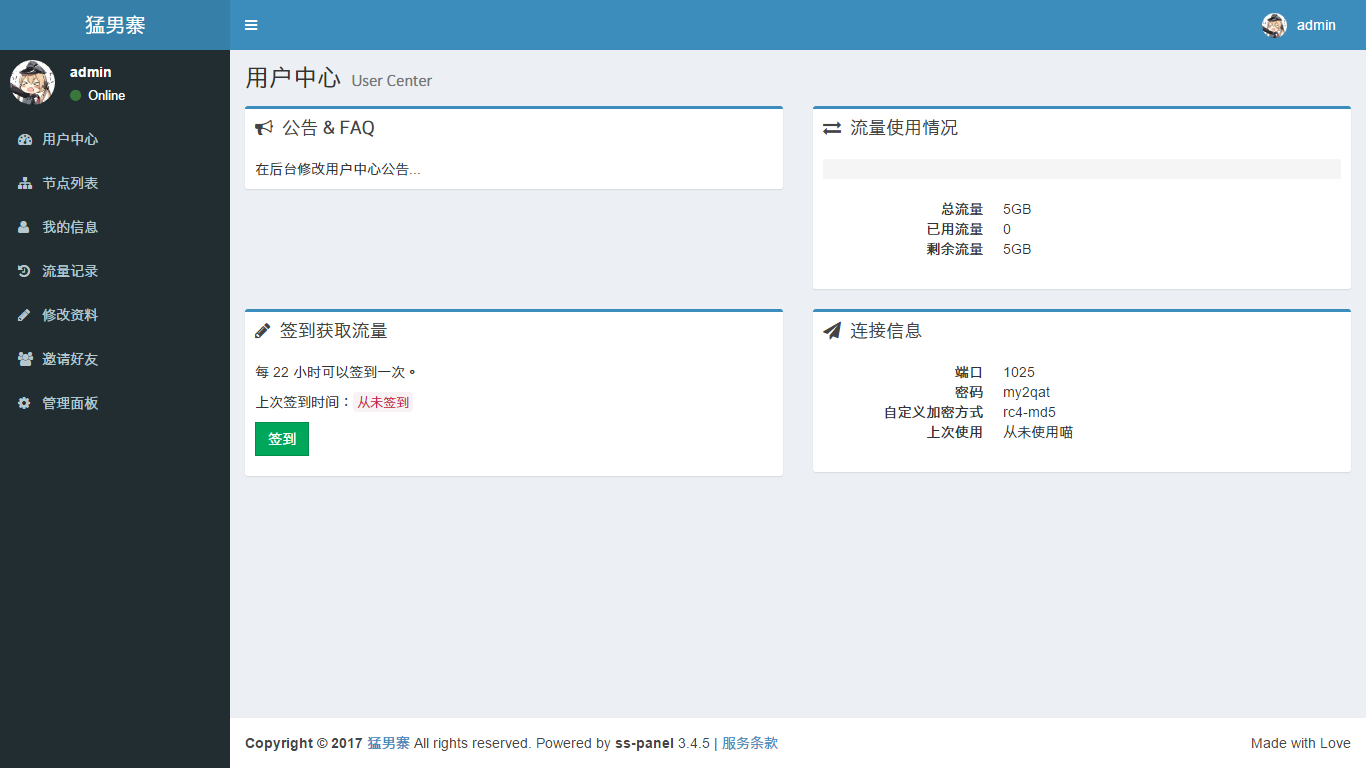
到这里,作为前端的 ss-panel 就已经配置完成了。下面开始部署作为后端的 shadowsocks-manyuser。
二、部署并配置 shadowsocks-manyuser
在本篇教程中我们使用 fsgmhoward/shadowsocks-py-mu 这个版本的后端。
不同于这篇教程原先推荐的 @mengskysama 版本,这个后端支持使用 MultiUser API 与前端的 ss-panel 进行用户信息交互。
这个 API 的官方介绍在这里。简单来讲,如果你通过 API 来与前端通信,你就不需要修改后端的数据库配置了,
并且可以使用「自定义加密」、「流量记录」等高级功能。
下面我只介绍使用 API 的方法,另外那个比较麻烦的方法可以在这里查看。
0x01 安装 shadowsocks-manyuser
先将代码 clone 到本地:
$ git clone https://github.com/fsgmhoward/shadowsocks-py-mu.git 源码 clone 后,
你的目录结构应该是这样的:

其中的 shadowsocks 子目录才是我们需要的,外面的是 setup.py 的相关文件。
0x02 配置 shadowsocks-manyuser
进入 shadowsocks 目录,将 config_example.py 复制一份到 config.py:
$ cp config_example.py config.py
修改其中第 15 行和第 29~31 行的内容:
# 启用 MultiUser API API_ENABLED = True
# 就是在你的站点地址后面加个 /mu
API_URL = 'http://ss.prinzeugen.net/mu'
# 还记得上面在 .env 中填写的 muKey 吗?把它填在这里
API_PASS = 'api_key_just_for_test'
由于我们选择使用 Mu API 来与前端通信,所以我们不需要修改 config.py 中任何关于数据库的配置。
好了,现在可以试着运行一下 $ python servers.py 了(注意,是 servers.py 而不是 server.py)。
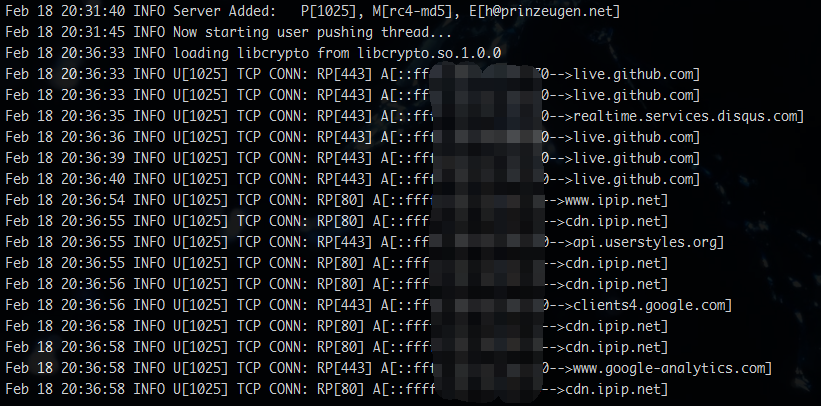
如果没错的话,应该可以看到这样的输出:

其中 P[XXX] 表示用户端口,M[XXX] 表示加密方式,E[XXX] 表示用户的邮箱地址。
这些都会随着 ss-panel 前端中用户配置的改变而实时变化。
0x03 常见错误 FAQ
连接上 shadowsocks 试试看能不能翻墙了?八成不能。
虽然你成功的把 servers.py 跑起来了,但还可能有各种神奇的错误阻止你翻出伟大的墙。
首先国际惯例查看连接:
$ netstat -anp | grep
你的端口 正常的话,应该是这样的:
Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:62111 0.0.0.0:* LISTEN 32083/python tcp 0 0 162.233.122.111:62111 115.233.233.140:47177 TIME_WAIT - tcp 0 0 162.233.122.111:62111 115.233.233.140:47161 TIME_WAIT - tcp 0 0 162.233.122.111:62111 115.233.233.140:47160 TIME_WAIT - tcp 0 0 162.233.122.111:62111 115.233.233.140:47157 TIME_WAIT -
如果没有来自你的 IP 的 TCP 连接的话,那八成就是防火墙的锅了,
执行 iptables 放行你的端口:
$ iptables -I INPUT -p tcp -m tcp --dport 你的端口 -j ACCEPT
$ iptables-save
ss-panel 新注册的用户所分配的端口均为其 id-1 的用户的端口号 + 1。
比如说你把 admin 用户(uid 为1)的端口改为 12450(ss-panel 中不能改,去数据库改),
那么后面注册的新用户的端口就会是 12451, 12452 这样递增的。
所以如果你要开放注册,就要这样配置你的 iptables:
# 注意是半角冒号,意为允许 12450 及以上的端口
# 也可以指定 12450:15550 这样的范围
$ iptables -I INPUT -p tcp -m tcp --dport 12450: -j ACCEPT
现在再连接 shadowsocks 就应该可以看到 TCP 连接信息了。
并且你可以在 ss-mu 后端的输出信息中看到详细的连接日志:
日志格式的详细介绍在这里:
Explanation of the log output。
三、配置 ss-manyuser 守护进程以及多节点配置
0x01 使用 supervisor 监控 ss-manyuser 运行
如果你只是想让 ss-manyuser 在后台运行的话,可以参考我写的这篇文章。
安装 supervisor (用的是上面安装过的 pip):
# 先安装 pip 包管理器
$ sudo apt-get install python-pip
# For Debian/Ubuntu
$ sudo yum install python-pip
# For CentOS
$ pip install supervisor
创建 supervisor 配置文件
# 输出至 supervisor 的默认配置路径
$ echo_supervisord_conf > /etc/supervisord.conf
运行 supervisor 服务
$ supervisord
配置 supervisor 以监控 ss-manyuser 运行
$ vim /etc/supervisord.conf
在文件尾部(当然也可以新建配置文件,不过这样比较方便)添加如下内容并酌情修改:
[program:ss-manyuser] command = python /root/shadowsocks-py-mu/shadowsocks/servers.py user = root autostart = true autorestart = true
其中 command 里的目录请自行修改为你的 servers.py 所在的绝对路径。
重启 supervisor 服务以加载配置
$ killall -HUP supervisord
查看 shadowsocks-manyuser 是否已经运行:
$ ps -ef | grep servers.py root 952 739 0 15:40 ? 00:00:00
python /root/shadowsocks-rm/shadowsocks/servers.py
可以通过以下命令管理shadowsock-manyuser 的状态
$ supervisorctl {start|stop|restart} ss-manyuser
0x02 ss-panel 的多节点配置
其实多节点也没咋玄乎,说白了就是多个后端共用一个前端而已。
而且我们的后端是使用 Mu API 来与前端进行交互的,所以多节点的配置就更简单了:
只要把所有后端的 config.py 中的 API_URL 和 API_PASS 都改成一样即可(记得 API_ENABLED = True)。
四、写在后面
其他可用的前端:
esdeathlove/ss-panel-v3-mod,修改版的 ss-panel,修改了蛮多东西的,有兴趣的朋友可以去看看,他那边安装说明都写得很详细了;
sendya/shadowsocks-panel,另外一个全新的 ss-manyuser 前端,有用户等级、套餐、支付等功能,不支持使用 Mu API,部署教程在这里。
其他可用的后端:
shadowsocks-go mu,Go 语言实现,性能比 Python 版好,也支持 Mu API;
shadowsocksR manyuser SSR 版本,见仁见智。
这几个后端的部署方法大同小异,我这里就不再赘述了。
文章更新日志 2017-03-15
根据评论区推荐将后端由 mengskysama/shadowsocks-rm/manyuser 切换至 fsgmhoward/shadowsocks-py-mu; 所有后端配置均改用 Mu API v2 的方法;
使用了更加严谨的文法。

至此,你已完成对 ss-panel 的部署。叫上小伙伴们一起享受自由的互联网吧 😉
如果碰到什么奇怪的错误,请评论留言(带上你的日志)
jQuery源码分析
前言
有时候我在想jQuery为什么可以直接$操作,可以拥有比原生js更便利的DOM操作,而且只要你想就可以直接链式操作下去
核心框架
揭开一万多行代码的jQuery核心代码:
(function(window, undefined) {
function jQuery(selector){
return new jQuery.fn.init(selector)
}
jQuery.fn = jQuery.prototype = {
init: function () {
}
}
jQuery.fn.init.prototype = jQuery.fn;
window.jQuery = window.$ = jQuery;
})(window)
- 闭包结构传参window
- 闭包结构传入实参window,然后里面用形参接收
- 减少内部每次引用window的查询时间
- 方便压缩代码
- 闭包结构传入实参window,然后里面用形参接收
- 形参undefined
- 因为ie低版本的浏览器可以给undefined赋值成功,所以为了保证undefined的纯洁给它一个形参的位置而没有实参,保证了它一定是undefined
- jQuery传参selector
- selector可以是一对标签,可以是id、类、后代、子代等等,可以是jQuery对象,
- jQuery原型对象赋值
- 方便扩展jQuery的原型方法
- return 实例化原型方法init
- 其实就是为了我们每次使用$不用new $();
- 为什么jQuery要new自己的原型方法呢,因为不new自己的就要new其他的函数返回,那干嘛不自己利用自己
- jQuery原型对象赋值给jQuery原型方法init的原型
- 因为内部给jQuery原型每扩展一个方法init也会有该方法,是不是很酷炫,init有了那么$()出来的jQuery对象是不是也有啦
- 给window暴露可利用成员jQuery,$
- 给window暴露后那么全局都可以直接使用了jQuery和$了
- 至于为什么有$,因为短啊,当然你也可以每次jQuery()来使用
御用选择器-Sizzle
- Sizzle也是jQuery的根本,当然了你也单独使用Sizzle
- 上面说过$(selector)的参数selector可以是id、类、后代、子代等等,可以是jQuery对象,那么咱们每次$一下就可以心想事成的得到我们想要的jQuery对象是怎么办到的呢,没错,就是因为Sizzle,Sizzle封装了获取各种dom对象的方法,并且会把他们包装成jQuery对象
- 浏览器能力测试
- Sizzle内部有个support对象,support对象存储着正则测试浏览器能力的结果
- 对于有能力问题的选择器使用通用兼容方案解决(繁琐的判断代码)
- 正则
- 正则表达式在jQuery中使用的还是比较多的,正则的使用可以很大的提交我们对数据的处理效率
- 判断
- 判断是在init内部判断selector的类型,
- 列如可能是个html标签,那么直接create一个selector标签的DOM对象包装成jQuery对象return出去
- 列如可能是个id名、类名、标签名等等,那么直接通过Sizzle获取到DOM对象包装成jQuery对象return出去
- 判断是在init内部判断selector的类型,
- 包装
- 我已经说了很多次的包装了,没错,jQuery对象其实也是个伪数组,这也是它的设计巧妙之处,因为用数组存储数据方便我们去进行更多的数据处理,比如
$("div").css("color": "red"),那么jQuery会自动帮我们隐式迭代、再给页面上所有div包含的文字颜色设置为red,简单粗暴的一行代码搞定简直是程序猿的最爱
- 我已经说了很多次的包装了,没错,jQuery对象其实也是个伪数组,这也是它的设计巧妙之处,因为用数组存储数据方便我们去进行更多的数据处理,比如
对外扩展-extend
- jQuery核心的结构处理完毕之后基本上就可以对外使用了,但是我们知道我们是可以基于jQuery来实现插件的,包括jQuery自己可扩展性也必须要求他要对外提供一个接口方便进行二次开发,所以有了extend方法
- 简单的extend就是混入,列子:
function extend(obj) {
var k;
for(k in obj) {
this[k] = obj[k];
}
}
Baiya.extend = extend;
Baiya.fn.extend = extend;
对静态方法的和实例方法的扩展都要有,比如each方法,可以$.each来使用,也可以是$("div").each来使用
- 之后jQuery一些方法都是基于extend来扩展的,当然我们自己也可以基于jQuery扩展方法
DOM操作
- DOM操作也是jQuery的一大特点,因为它太好用了,包含了我们所能想到的所有使用场景,完善了增删查改常用的方法
- jQuery获取和设置类的方法如html()/css()/val()等等这些传参是设置值不传参是获取值
##链式编程
- jQuery是支持链式编程的,只要你想你就可以一行代码写完所有的功能,这是怎么做到的呢
- 每一个改变原型链的方法都会把当前的this对象保存成他自己的属性,然后可以调用end方法找到上一级链从而方便我们可以进行链式操作
事件操作
- jQuery的事件操作一般可以通过click类(mouseover/mouseleave等等)和on来使用,但是click类的实现是调用on的
- on的实现是对原生的onclick类的处理,因为相同的原生的事件在同一个DOM对象上只能被绑定一次,如果再次绑定会覆盖掉上一次的,所以jQuery帮我们封装了事件的存储,把相同的事件分成一个数组存储在一个对象里面,然后对数组进行遍历,依次调用数组里存储的每个方法
- on实现之后会把所有的事件处理字符串处理一下用on来改造一下,如下:
Baiya.each(("onclick,onmousedown,onmouseenter,onmouseleave," +
"onmousemove,onmouseout,onmouseover,onmouseup,onfocus," +
"onmousewheel,onkeydown,onkeypress,onkeyup,onblur").split(","), function (i, v) {
var event = v.slice(2);
Baiya.fn[event] = function (callback) {
return this.on(event, callback);
}
});
属性操作
- jQuery也提供给了我们方便的属性操作,底层就是对原生方法的包装,处理兼容性问题,如果jQuery不对IE浏览器的兼容处理的话,那么它的代码量可能会缩一半,当然锅不能全部甩给IE,比如innerText方法火狐是不支持的,但是支持textContent方法,所以jQuery会尽可能的处理这种浏览器带来的差异
样式操作
- 基本思想如上
Ajax操作
- Ajax可以说是前端的跨越性进步,毫不夸张的说如果没有Ajax的发展,那么今天的前端可能不叫前端,可能是美工……
- Ajax是什么?
- 在我的理解来看Ajax就是一个方法,这个方法遵循着http协议的规范,我们可以使用这个方法来向服务器请求少量的数据,有了数据之后我们就可以操作DOM来达到局部更新网页的目的,这是一个非常酷的事情
- jQuery的Ajax是基于XMLHttpRequest的封装,当然了他也有兼容性问题,具体的封装见我之前的文章简单的ajax封装
- 具体就是区别get和post请求的区别,get请求的传参是直接拼接在url结尾,而post请求需要在send()里面传递,并且post请求还要设置请求头setRequestHeader("content-type", "application/x-www-form-urlencoded")
- 请求后对json或者text或者xml的数据进行处理就可以渲染到页面了
提到Ajax就不得不提到跨域了
- 跨域简单的来说限制了非同源(ip/域名/端口/协议)的数据交互,当然这肯定是极好的,因为如果不限制那么你的网页别人也可以操作是不是很恐怖
- 但是有些情况下我们需要调用别人的服务器数据,而且别人也愿意怎么办呢,程序员是很聪明的,html标签中img,script,link等一些带有src属性的标签是可以请求外部资源的,img和link得到的数据是不可用的,只有script标签请求的数据我们可以通过函数来接收,函数的参数传递可以是任何类型,所以创建一个函数,来接收,参数就是请求到的数据,而对方的数据也要用该函数来调用就可以实现跨域了
- 简单封装jsonp实现
// url是请求的接口
// params是传递的参数
// fn是回调函数
function jsonp(url, params, fn){
// cbName实现给url加上哈希,防止同一个地址请求出现缓存
var cbName = `jsonp_${(Math.random() * Math.random()).toString().substr(2)}`;
window[cbName] = function (data) {
fn(data);
// 获取数据后移除script标签
window.document.body.removeChild(scriptElement);
};
// 组合最终请求的url地址
var querystring = '';
for (var key in params) {
querystring += `${key}=${params[key]}&`;
}
// 告诉服务端我的回调叫什么
querystring += `callback=${cbName}`;
url = `${url}?${querystring}`;
// 创建一个script标签,并将src设置为url地址
var scriptElement = window.document.createElement('script');
scriptElement.src = url;
// appendChild(执行)
window.document.body.appendChild(scriptElement);
}
Animate
- 很抱歉的是jQuery的动画源码我并没有阅读,但是我自己封装了一个动画函数,之后的源码阅读会补上的
- 封装的代码
// element设置动画的DOM对象
// attrs设置动画的属性 object
// fn是回调函数
function animate(element, attrs, fn) {
//清除定时器
if(element.timerId) {
clearInterval(element.timerId);
}
element.timerId = setInterval(function () {
//设置开关
var stop = true;
//遍历attrs对象,获取所有属性
for(var k in attrs) {
//获取样式属性 对应的目标值
var target = parseInt(attrs[k]);
var current = 0;
var step = 0;
//判断是否是要修改透明度的属性
if(k === "opacity") {
current = parseFloat( getStyle(element, k)) * 100 || 0;
target = target * 100;
step = (target - current) / 10;
step = step > 0 ? Math.ceil(step) : Math.floor(step);
current += step;
element.style[k] = current / 100;
//兼容ie
element.style["filter"] = "alpha(opacity="+ current +")";
}else if(k === "zIndex") {
element.style[k] = target;
} else {
//获取任意样式属性的值,如果转换数字失败,返回为0
current = parseInt(getStyle(element, k)) || 0;
step = (target - current) / 10;
console.log("current:" + current + " step:" + step);
step = step > 0 ? Math.ceil(step) : Math.floor(step);
current += step;
//设置任意样式属性的值
element.style[k] = current + "px";
}
if(step !== 0) {
//如果有一个属性的值没有到达target ,设置为false
stop = false;
}
}
//如果所有属性值都到达target 停止定时器
if(stop) {
clearInterval(element.timerId);
//动画执行完毕 回调函数
if(fn) {
fn();
}
}
},30);
}
//获取计算后的样式的值
function getStyle(element, attr) {
//能力检测
if(window.getComputedStyle) {
return window.getComputedStyle(element, null)[attr];
}else{
return element.currentStyle[attr];
}
}
Linux技巧:Vimdiff 使用

在 IBM Bluemix 云平台上开发并部署您的下一个应用。
源程序文件(通常是纯文本文件)比较和合并工具一直是软件开发过程中比较重要的组成部分。现在市场上很多功能很强大的专用比较和合并工具,比如 BeyondCompare;很多IDE 或者软件配置管理系统,比如Eclipse, Rational ClearCase都提供了内建的功能来支持文件的比较和合并。
当远程工作在Unix/Linux平台上的时候,恐怕最简单而且到处存在的就是命令行工具,比如diff。可惜diff的功能有限,使用起来也不是很方便。作为命令行的比较工具,我们仍然希望能拥有简单明了的界面,可以使我们能够对比较结果一目了然;我们还希望能够在比较出来的多处差异之间快速定位,希望能够很容易的进行文件合并……。而Vim提供的diff模式,通常称作vimdiff,就是这样一个能满足所有这些需求,甚至能够提供更多的强力工具。在最近的工作中,因为需要做很多的文件比较和合并的工作,因此对Vimdiff的使用做了一个简单的总结。我们先来看看vimdiff的基本使用。
启动方法
首先保证系统中的diff命令是可用的。Vim的diff模式是依赖于diff命令的。Vimdiff的基本用法就是:
# vimdiff FILE_LEFT FILE_RIGHT
或者
# vim -d FILE_LEFT FILE_RIGHT
图一就是vimdiff命令的执行结果的画面。
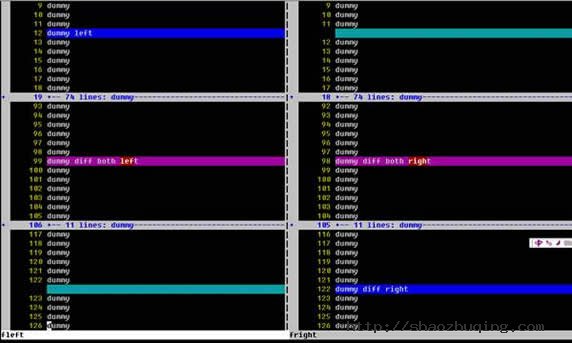
从上图我们可以看到一个清晰的比较结果。屏幕被垂直分割,左右两侧分别显示被比较的两个文件。两个文件中连续的相同的行被折叠了起来,以便使用者能把注意力集中在两个文件的差异上。只在某一文件中存在的行的背景色被设置为蓝色,而在另一文件中的对应位置被显示为绿色。两个文件中都存在,但是包含差异的行显示为粉色背景,引起差异的文字用红色背景加以突出。
除了用这种方法启动vim的diff模式之外,我们还可以用分割窗口命令来启动diff模式:
# vim FILE_LEFT
然后在vim的ex模式(也就是"冒号"模式)下输入:
:vertical diffsplit FILE_RIGHT
也可以达到同样的效果。如果希望交换两个窗口的位置,或者希望改变窗口的分割方式,可以使用下列命令:
1. Ctrl-w K(把当前窗口移到最上边)
2. Ctrl-w H(把当前窗口移到最左边)
3. Ctrl-w J(把当前窗口移到最下边)
4. Ctrl-w L(把当前窗口移到最右边)
其中1和3两个操作会把窗口改成水平分割方式。
光标移动
接下来试试在行间移动光标,可以看到左右两侧的屏幕滚动是同步的。这是因为"scrollbind"选项被设置了的结果,vim会尽力保证两侧文件的对齐。如果不想要这个特性,可以设置:
:set noscrollbind
可以使用快捷键在各个差异点之间快速移动。跳转到下一个差异点:
]c
反向跳转是:
文件合并
文件比较的最终目的之一就是合并,以消除差异。如果希望把一个差异点中当前文件的内容复制到另一个文件里,可以使用命令
dp (diff "put")
如果希望把另一个文件的内容复制到当前行中,可以使用命令
do (diff "get",之所以不用dg,是因为dg已经被另一个命令占用了)
如果希望手工修改某一行,可以使用通常的vim操作。如果希望在两个文件之间来回跳转,可以用下列命令序列:
Ctrl-w, w
在修改一个或两个文件之后,vimdiff会试图自动来重新比较文件,来实时反映比较结果。但是也会有处理失败的情况,这个时候需要手工来刷新比较结果:
:diffupdate
如果希望撤销修改,可以和平常用vim编辑一样,直接
<ESC>, u
但是要注意一定要将光标移动到需要撤销修改的文件窗口中。
同时操作两个文件
在比较和合并告一段落之后,可以用下列命令对两个文件同时进行操作。比如同时退出:
:qa (quit all)
如果希望保存全部文件:
:wa (write all)
或者是两者的合并命令,保存全部文件,然后退出:
:wqa (write, then quit all)
如果在退出的时候不希望保存任何操作的结果:
:qa! (force to quit all)
上下文的展开和查看
比较和合并文件的时候经常需要结合上下文来确定最终要采取的操作。Vimdiff 缺省是会把不同之处上下各 6 行的文本都显示出来以供参考。其他的相同的文本行被自动折叠。如果希望修改缺省的上下文行数,可以这样设置:
:set diffopt=context:3
可以用简单的折叠命令来临时展开被折叠的相同的文本行:
zo (folding open,之所以用z这个字母,是因为它看上去比较像折叠着的纸)
然后可以用下列命令来重新折叠:
zc (folding close)
下图是设置上下文为3行,并展开了部分相同文本的vimdiff屏幕:

结论
在无法使用图形化的比较工具的时候,或者在需要快速比较和合并少量文件的时候,Vimdiff是最好的选择。
大型网站架构系列:消息队列
以下是消息队列以下的大纲,本文主要介绍消息队列概述,消息队列应用场景和消息中间件示例(电商,日志系统)。
本次分享大纲
- 消息队列概述
- 消息队列应用场景
- 消息中间件示例
- JMS消息服务(见第二篇:大型网站架构系列:分布式消息队列(二))
- 常用消息队列(见第二篇:大型网站架构系列:分布式消息队列(二))
- 参考(推荐)资料(见第二篇:大型网站架构系列:分布式消息队列(二))
- 本次分享总结(见第二篇:大型网站架构系列:分布式消息队列(二))
一、消息队列概述
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
二、消息队列应用场景
以下介绍消息队列在实际应用中常用的使用场景。异步处理,应用解耦,流量削锋和消息通讯四个场景。
2.1异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种1.串行的方式;2.并行方式。
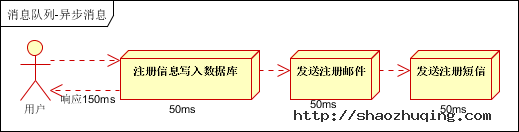
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
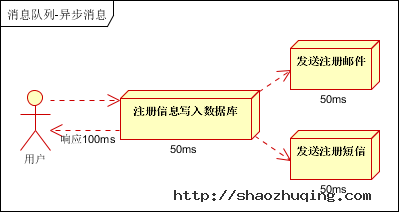
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)。
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
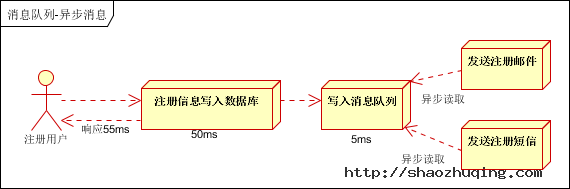
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。
2.2应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图: 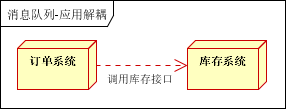
传统模式的缺点:
1) 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2) 订单系统与库存系统耦合;
如何解决以上问题呢?引入应用消息队列后的方案,如下图:

- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作。
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
2.3流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
- 可以控制活动的人数;
- 可以缓解短时间内高流量压垮应用;

- 用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面;
- 秒杀业务根据消息队列中的请求信息,再做后续处理。
2.4日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下:
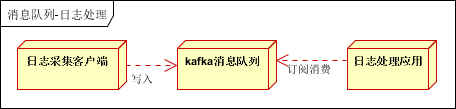
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
- Kafka消息队列,负责日志数据的接收,存储和转发;
- 日志处理应用:订阅并消费kafka队列中的日志数据;
以下是新浪kafka日志处理应用案例:
转自(http://cloud.51cto.com/art/201507/484338.htm)

(1)Kafka:接收用户日志的消息队列。
(2)Logstash:做日志解析,统一成JSON输出给Elasticsearch。
(3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
2.5消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
点对点通讯:

客户端A和客户端B使用同一队列,进行消息通讯。
聊天室通讯:
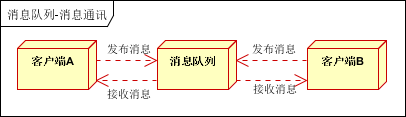
客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。模型为示意图,供参考。
三、消息中间件示例
3.1电商系统

消息队列采用高可用,可持久化的消息中间件。比如Active MQ,Rabbit MQ,Rocket Mq。
(1)应用将主干逻辑处理完成后,写入消息队列。消息发送是否成功可以开启消息的确认模式。(消息队列返回消息接收成功状态后,应用再返回,这样保障消息的完整性)
(2)扩展流程(发短信,配送处理)订阅队列消息。采用推或拉的方式获取消息并处理。
(3)消息将应用解耦的同时,带来了数据一致性问题,可以采用最终一致性方式解决。比如主数据写入数据库,扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理。
3.2日志收集系统

分为Zookeeper注册中心,日志收集客户端,Kafka集群和Storm集群(OtherApp)四部分组成。
- Zookeeper注册中心,提出负载均衡和地址查找服务;
- 日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列;
- Kafka集群:接收,路由,存储,转发等消息处理;
Storm集群:与OtherApp处于同一级别,采用拉的方式消费队列中的数据;
{kind=link}
{kind=link}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
