如何构建垂直网络爬虫平台
写一个爬虫很简单,写一个可持续稳定运行的爬虫也不难,但如何构建一个通用化的垂直网络爬虫平台?
这篇文章主要介绍垂直网络爬虫平台的构建思路。
爬虫简介
首先介绍一下什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取网页信息的程序或者脚本。
很简单,爬虫就是指定规则自动采集数据的程序脚本,目的在于拿到想要的数据。
爬虫主要分两类:
- 通用网络爬虫(搜索引擎)
- 垂直网络爬虫(特定领域)
由于第一类的开发成本较高,故只有搜索引擎公司在做,如谷歌、百度等。
而大多数企业在做的是第二类,成本低、数据价值高。例如一家做电商的公司只需要电商领域有价值的数据,那开发一个电商领域的爬虫平台,意义较大。
这篇文章主要针对第二类的平台构建提供设计与思路。
如何写爬虫
首先从最简单的开始,我们先了解一下如何写一个爬虫?
简单爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# coding: utf8
"""简单爬虫"""
import requests
from lxml import etree
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
parse_rule = "//div[@id='wrapper']/h1/span/text()"
for url in crawl_urls:
# 2. 发起HTTP请求
response = requests.get(url)
# 3. 解析HTML
result = etree.HTML(response.text).xpath(parse_rule)[0]
# 4. 保存结果
print result
if __name__ == '__main__':
run()
|
这个爬虫比较简单,大致流程为:
- 定义页面URL和解析规则
- 发起HTTP请求
- 解析HTML,拿到数据
- 保存数据
任何爬虫,要想获取网页上的数据,都是经过这几步。
当然,这个简单爬虫效率比较低,只能抓完一个网页,再去抓下一个,有没有提高效率的方式呢?
异步爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# coding: utf8
"""协程版本爬虫,提高抓取效率"""
from gevent import monkey
monkey.patch_all()
import requests
from lxml import etree
from gevent.pool import Pool
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
rule = "//div[@id='wrapper']/h1/span/text()"
# 2. 抓取
pool = Pool(size=10)
for url in crawl_urls:
pool.spawn(crawl, url, rule)
pool.join()
def crawl(url, rule):
"""抓取&解析"""
# 3. 发起HTTP请求
response = requests.get(url)
# 4. 解析HTML
result = etree.HTML(response.text).xpath(rule)[0]
# 5. 保存结果
print result
if __name__ == '__main__':
run()
|
经过优化,我们完成了异步版本的爬虫代码。
由于爬虫要抓的网页一般很多,提高效率是爬虫最基本的技能,由于下载网页都是阻塞在网络IO上,那我们可以利用多线程或异步的方式,提高抓取效率。
有了这些基础知识之后,我们看一个完整的例子,如何抓取一个整站数据?
整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
# coding: utf8
"""整站爬虫"""
from gevent import monkey
monkey.patch_all()
from urlparse import urljoin
import requests
from lxml import etree
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
def crawl(url):
"""首页"""
response = requests.get(url)
list_urls = etree.HTML(response.text).xpath(rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = requests.get(list_url).text
detail_urls = etree.HTML(html).xpath(rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = etree.HTML(html).xpath(rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = requests.get(list_url).text
title = etree.HTML(html).xpath(rules['title'])[0]
print title
def run():
"""run"""
# 1. 标签页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
此爬虫以豆瓣图书为例,抓取整站信息,大致思路为:
- 从标签页进入,提取所有标签URL
- 进入每个标签页,提取所有列表URL
- 进入每个列表页,提取每一页的详情URL和下一页列表URL
- 进入每个详情页,拿到书名
- 如此往复循环,直到数据抓取完毕
这就是抓取一个整站的思路,很简单,无非就是分析我们浏览网站的行为轨迹,用程序来进行自动化的请求、抓取。
理想情况下,我们应该能够拿到整站的数据,但实际情况对方网站往往会采取防爬虫措施,在抓取一段时间后,我们的IP就会被禁。
那如何突破这些防爬错误,拿到数据呢?我们继续优化代码。
防反爬的整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
# coding: utf8
"""防反爬的整站爬虫"""
from gevent import monkey
monkey.patch_all()
import random
from urlparse import urljoin
import requests
from lxml import etree
import gevent
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
# 定义代理池
proxy_list = [
'118.190.147.92:15524',
'47.92.134.176:17141',
'119.23.32.38:20189',
]
# 定义UserAgent
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
]
def fetch(url):
"""发起HTTP请求"""
proxies = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
headers = {'User-Agent': user_agent}
html = requests.get(url, headers=headers, proxies=proxies).text
return html
def parse(html, rule):
"""解析页面"""
return etree.HTML(html).xpath(rule)
def crawl(url):
"""首页"""
html = fetch(url)
list_urls = parse(html, rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = fetch(list_url)
detail_urls = parse(html, rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = parse(html, rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = fetch(list_url)
title = parse(html, rules['title'])[0]
print title
def run():
"""run"""
# 1. 首页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
这个版本的爬虫代码,加上了随机代理和请求头,这也是突破防爬措施的常用手段,使用此手段,加上一些质量高的代理,应对一些小网站的数据抓取,不在话下。
当然,这里只为了展示一步步写爬虫、优化爬虫的思路,来达到抓取数据的目的,现实情况的抓取与反爬比想象中的更复杂,需要具体场景具体分析。
现有问题
经过上面这几步,我们想要哪个网站的数据,分析网站网页结构,写出代码应该不成问题。
抓几个网站可以这么写,但抓几十个、几百个网站,你还能写下去吗?
由此暴露的问题:
- 爬虫脚本繁多,管理困难
- 规则定义零散,重复开发
- 后台脚本,无监控
- 数据输出困难,业务接入慢
这些问题都是我们在爬虫越写越多的情况下,难免会遇到的问题。
此时,我们迫切需要一个更好的解决方案,来更好地开发爬虫,爬虫平台应运而生。
平台架构
我们来分析每个爬虫的共同点,结果发现:写一个爬虫无非就是规则、抓取、解析、入库这几步,那我们可不可以把每一块分别拆开呢?如图:
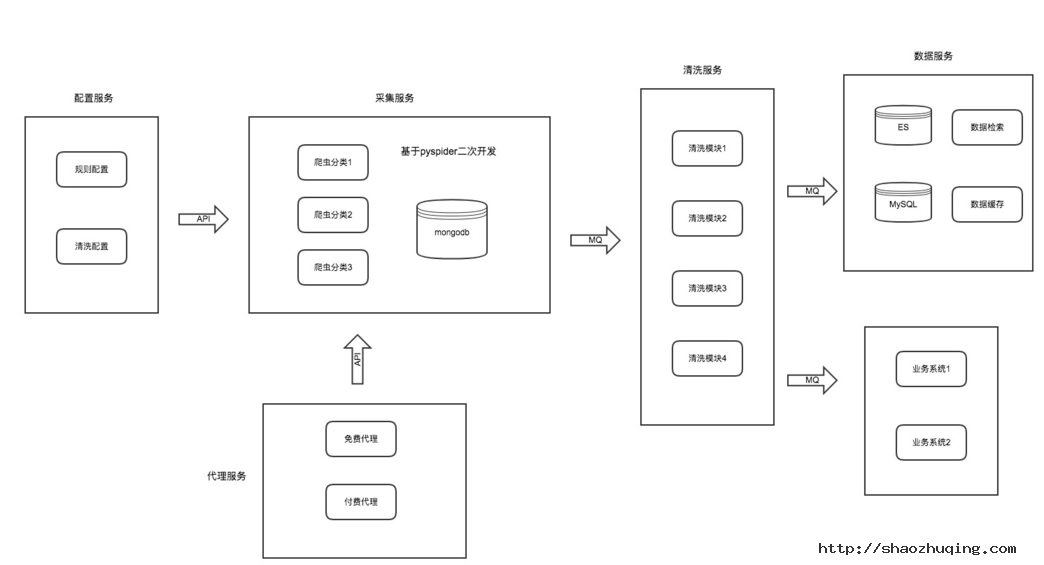
- 配置服务:包括抓取页面配置、解析规则配置、清洗配置
- 采集服务:专注网页下载与采集,并提供防爬策略
- 代理服务:提供稳定可持续输出的代理
- 清洗服务:针对同一类型业务进行字段清洗
- 数据服务:数据展示及业务数据对接
我们把一个爬虫的每一个环节,拆开做成一个个单独的服务模块,各模块各司其职。
每个模块维护属于自己领域的功能,可独立升级和优化。
详细设计
配置服务
此模块主要包括采集URL配置、页面解析规则配置、清洗配置。
我们把爬虫的规则从爬虫脚本中抽离出来,单独配置与维护,这样也便于重用与管理。
由于此模块专注配置管理,那我们可以对配置进一步拆开,配置支持各种方式的数据解析模式,如正则解析、CSS解析、XPATH解析,每种模式配置对应的表达式即可。
采集服务可以写一个配置解析器与配置服务进行对接,此配置解析器内部实现各种模式具体的解析逻辑。
清洗配置主要可配置每个爬虫输出后对应的清洗worker。
采集服务
此模块比较纯粹,就是写爬虫逻辑的模块,我们可以像之前那样开发、调试、运行爬虫脚本,但这一切工作都只能在命令行脚本进行,有没有一种好的方案是可以可视化操作的呢?
我们调研了市面上比较好的爬虫框架,发现pyspider符合我们的需求,此框架的特点:
- 支持分布式
- 配置可视化
- 可周期采集
- 支持优先级
- 任务可监控
pyspider架构图:
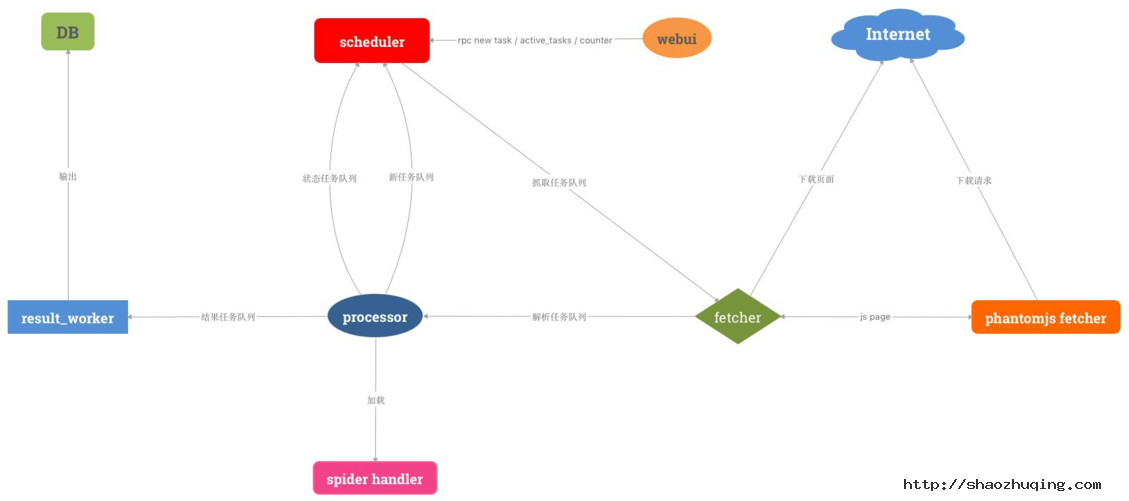
正所谓站在巨人的肩膀上。我们决定对其进行二次开发,并增强其一些组件,使爬虫开发成本更低,更符合我们的业务规则。
- 开发配置解析器,对接配置服务
spider handler定制爬虫模板,分类采集任务,生成模板,降低开发成本fetcher新增代理调度机制,对接代理服务,并增加代理调度策略result_worker输出定制化,对接清洗服务
由此我们可做出一个分布式、可视化、任务可监控、可生成爬虫模板的采集服务模块。
代理服务
做爬虫的都知道,代理是突破防抓的常用手段,如何获取稳定且持续的代理呢?
此模块内部维护代理的质量和数量,并输出给采集服务,供采集使用。
主要包括两部分:
- 免费代理
- 付费代理
免费代理
免费代理主要由我们自己的代理采集程序采集获得,大致思路为:
- 收集代理源
- 定时采集代理
- 测试代理
- 输出代理
付费代理
免费代理的质量和稳定性相对较差,对于采集防爬比较厉害的网站,还是不够用。
这时我们会购买一些付费代理,专门用于采集这类防爬的网站,此代理一般为高匿代理,并定时更新。
清洗服务
此模块比较简单,主要接收采集服务输出的数据,然后根据对应的规则执行清洗逻辑。
例如网页字段与数据库字段归一转换,特殊字段清洗定制化等。
这个服务模块运行了很多worker,最终把输出结果输送到数据服务。
数据服务
此模块会接收最终清洗后的结构化数据,统一入库。且针对其他业务系统需要的数据进行统一推送输出:
- 数据平台展示
- 数据推送
- 数据API
解决的问题
经过这个平台的构建,基本解决了最开始困扰的几个问题:
- 爬虫管理、配置可视化
- 降低开发成本
- 进度可监控、易跟踪
- 数据输出便捷
- 业务接入迅速
爬虫技巧
爬虫技巧从整体上来说,其实核心思想就一个:尽可能地模拟人的行为。
例如:
- 随机UserAgent(github fake-useragent)
- 随机代理IP(高匿代理、代理策略)
- Cookie池
- JS渲染页面(phantomjs)
- 验证码识别(OCR、机器学习)
当然,做爬虫是一个相互博弈的过程,有时没必要硬碰硬,遇到问题换个思路不免是一种解决办法。例如,对方的PC站防抓厉害,那去看一看对方的WAP站可不可以搞一下?APP端是否可以尝试一下?在有限的成本拿到数据才是爬虫的目的。
以上就是构建一个垂直网络爬虫平台的大致思路,从最简单的爬虫脚本,到写越来越多的爬虫,到难以维护,再到整个爬虫平台的构建,一步步都是遇到问题解决问题的产物,在我们真正发现核心问题时,解决思路也就不难了。
网络广告专业词汇
1. CPC(Cost Per Click;Cost Per Thousand Click-Through) 每点击成本
以每点击一次计费。这样的方法加上点击率限制可以〖WX)〗加强作弊的难度,而且是宣传网站站点的最优方式。但是,此类方法就有不少经营广告的网站觉得不公平,比如,虽然浏览者没有点击,但是他已经看到了广告,对于这些看到广告却没有点击的流量来说,网站成 了白忙活。有很多网站不愿意做这样的广告,据说,是因为传统媒体从来都没有这样干过。
2.CPM(Cost Per Mille,或者Cost Per Thousand;Cost Per Impressions) 每千人成本
网上广告收费最科学的办法是按照有多少人看到你的广告来收费。按访问人次收费已经成为网络广告的惯例。CPM(千人成本)指的是广告投放过程中,听到或者看到某广告的每一人平 均分担到多少广告成本。传统媒介多采用这种计价方式。在网上广告,CPM取决于“印象”尺度,通常理解为一个人的眼睛在一段固定的时间内注视一个广告的次数。比如说一个广告 横幅的单价是1元/CPM的话,意味着每一千个人次看到这个Ban-ner的话就收1元,如此类推 ,10,000人次访问的主页就是10元。
至于每CPM的收费究竟是多少,要根据以主页的热门程度(即浏览人数)划分价格等级,采 取固定费率。国际惯例是每CPM收费从5美元至200美元不等。
3.CPA(Cost Per Action) 每行动成本
CPA计价方式是指按广告投放实际效果,即按回应的有效问卷或定单来计费,而不限广告投 放量。CPA的计价方式对于网站而言有一定的风险,但若广告投放成功,其收益也比CPM的计 价方式要大得多。 广告主为规避广告费用风险,只有当网络用户点击旗帜广告,链接广告主网页后,才按点击 次数付给广告站点费用。
4.CPR(Cost Per Response) 每回应成本
以浏览者的每一个回应计费。这种广告计费充分体现了网络广告“及时反应、直接互动、准 确记录”的特点,但是,这个显然是属于辅助销售的广告模式,对于那些实际只要亮出名字 就已经有一半满足的品牌广告要求,大概所有的网站都会给予拒绝,因为得到广告费的机会 比CPC还要渺茫。
5.CPP(Cost Per Purchase) 每购买成本
广告主为规避广告费用风险,只有在网络用户点击旗帜广告并进行在线交易后,才按销售笔 数付给广告站点费用。
无论是CPA还是CPP,广告主都要求发生目标消费者的“点击”,甚至进一步形成购买,才予 付费:CPM则只要求发生“目击”(或称“展露”、“印象”),就产生广告付费。
6.包月方式
很多国内的网站是按照“一个月多少钱”这种固定收费模式来收费的,这对客户和网站都不 公平,无法保障广告客户的利益。虽然国际上一般通用的网络广告收费模式是CPM(千人印象 成本)和CPC(千人点击成本),但在我国,一个时期以来的网络广告收费模式始终含糊不清, 网络广告商们各自为政,有的使用CPM和CPC计费,有的干脆采用包月的形式,不管效果好坏 ,不管访问量有多少,一律一个价。尽管现在很多大的站点多已采用CPM和CPC计费,但很多 中小站点依然使用包月制。
7.PFP(Pay-For-Performance) 按业绩付费
著名市场研究机构福莱斯特(Forrerster)研究公司最近公布的一项研究报告称,在今后4年 之内,万维网将从目前的广告收费模式——即根据每千次闪现(impression)收费——CPM(这 亦是大多数非在线媒体均所采用的模式)变为按业绩收费(pay-for-performance)的模式。
虽然根据该公司研究人员的预测,未来5年网上广告将呈爆炸性增长,从1999年的28亿美元 猛增至2004年的220亿美元,但是经营模式的转变意味着盈利将成为网络广告发布商关心的 首要问题。
福莱斯特公司高级分析师尼尔说:“互联网广告的一大特点是,它是以业绩为基础的。对发 布商来说,如果浏览者不采取任何实质性的购买行动,就不可能获利。”丘比特公司分析师 格拉克说,基于业绩的定价计费基准有点击次数、销售业绩、导航情况等等,不管是哪种, 可以肯定的是这种计价模式将得到广泛的采用。
虽然基于业绩的广告模式受到广泛欢迎,但并不意味着CPM模式已经过时。相反,如果厂家 坚持这样做,那么受到损失的只会是它自已。一位资深分析家就指出,假如商家在谈判中不 能灵活处理,而坚持采取业绩模式,它将失去很多合作的机会,因为目前许多网站并不接受 这种模式。
8.其他计价方式
某些广告主在进行特殊营销专案时,会提出以下方法个别议价:
(1)CPL(Cost Per Leads):以搜集潜在客户名单多少来收费;
(2)CPS(Cost Per Sales):以实际销售产品数量来换算广告刊登金额。
总之,网络广告本身固然有自己的特点,但是玩弄一些花哨名词解决不了实际问题,一个网站要具备有广告价值,都是有着一定的发展历史,那么,在目标市场决策以后挑选不同的内容网站,进而考察其历史流量进行估算,这样,就可以概算广告在一定期限内的价格,在这个基础上,或者根据不同性质广告,可以把CPC、CPR、CPA这些东西当作为加权,如此而已 。
相比而言,CPM和包月方式对网站有利,而CPC、CPA、CPR、CPP或PFP则对广告主有利。目前 比较流行的计价方式是CPM和CPC,最为流行的则为CPM。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
