-
作者: Mukul
-
翻译: 无伤 <goghs@mail.com>
1110月/17关
LINUX中查看文本文件内容命令
cat:从第一行開始显示所有的文本内容;
tac:从最后一行開始,显示所有分文本内容,与cat相反。
nl:显示文本时,能够输出行号。
more:按页显示文本内容;
less:与more差点儿相同,也是按页显示文本内容,差别是less能够一行一行的回退。more回退仅仅能一页一页回退。
head:从头開始显示文件指定的行数;
tail:显示文件指定的结尾的行数。但每一行的位置还是原文件里的位置,不会像tac那样与原文件相反。
vi: NB的Linux文本编辑器。
样例与说明
cat
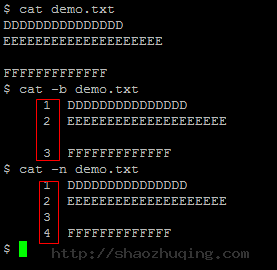
- cat demo.txt
显示demo.txt文件所有内容 - cat -b demo.txt
显示demo.txt文件所有内容。非空的行输出行号。空行会输出。但不标记行号 - cat -n demo.txt
显示demo.txt文件所有内容。所有行都输出行号
长处:简单
缺点:当文本文件内容多于一页内容时。仅仅能显示出最后一页的内容,无法看到前面的内容。
tac
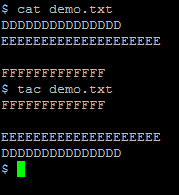
- tac demo.txt
从最后一行開始。倒序输出demo.txt的内容。本人不经常使用。
nl
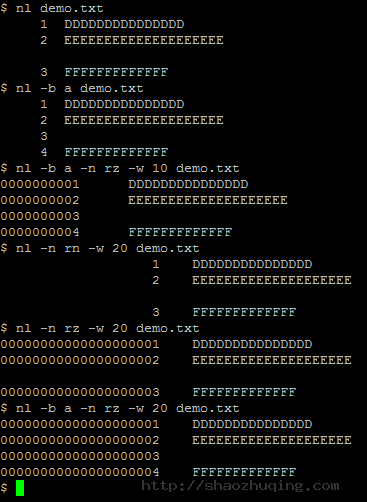
- nl demo.txt
显示文件内容。顺便输出行号。默认情况下空行不记录行号 - nl -b a demo.txt
- b a #空行也输出行号
- b t #默认设置
- n ln ##行号最左方显示
- n rn ##行号最右方显示,且不加0(然并卵,我的机器上依旧显示在左边)
- n rz ##行号最右方显示,且加0(再次然并卵,但加了0了。例如以下图所看到的)
- w ##设置行号字段占用的位数
长处:貌似非常灵活的样子
缺点:就查看下内容。输出个行号而已。搞那么复杂有卵用。。。
more
- more demo.txt
- 按一下空格则往下翻一页
- 按一下Enter则往下翻一行
- 按一下B键往上翻一页
- 不能往上一行一行的翻回去了
- :f 能够显示文件名称和如今的行数
- q退出more
less
- less demo.txt
- more命令的所有按键less都支持
- ↑↓箭头能够实现一行一行的上下翻
- PageDown/PageUp能够实现一页一页的上下翻
head
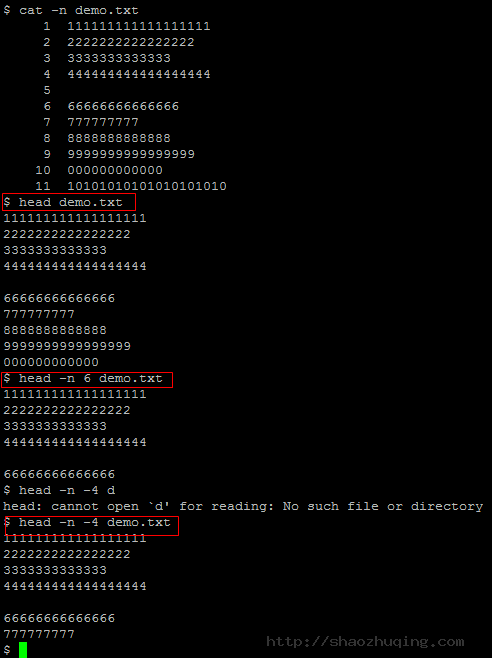
- head demo.txt
默认仅仅显示文件的前10行文本内容 - head -n 6 demo.txt
-n 6 參数指定显示文件的前6行 - head -n -4 demo.txt
-n -4 负数表示除去文件结尾的4行,其它的从头開始的所有行都显示出来
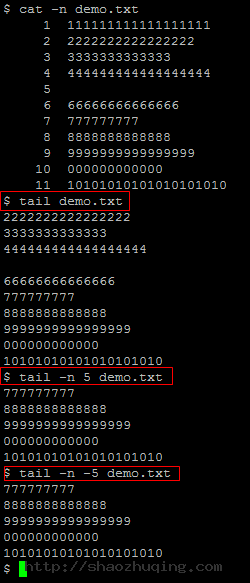
tail
- tail demo.txt
默认仅仅显示从文件最后一行開始的10行文本内容 - tail -n 5 demo.txt
-n 5 參数指定显示文件的最后5行 - tail -n -5 demo.txt
**-n -5**tail命令不支持负数。运行结果同-n 5
vi
vi命令是使用VIM文本编辑器打开文本,VIM编辑器眼下本人也是刚開始学习。仅仅记住了一些简单的命令:
- vi demo.txt 进入Normal模式查看文本
- i 进入Insert模式插入内容,编辑文本
- nG n代表行号,在Normal模式输入nG则定位到第n行
- :set number 在Normal模式输入则显示文本行号。空行也会显示行号
- ESC 退出Insert模式至Normal模式
- :wq 在Normal模式下保存退出。w保存;q退出;能够单独使用
2710月/13关
用 Flora_Pac.py 生成自动翻墙的 pac 文件
源于人们对自由的向往,翻墙技术已渐趋成熟。愿意花点钱,购买海外 VPN 和 ssh 主机用于自由获取信息是目前比较有效的手段。如我之前文章中提及,这两种方式都有需要筛选出那些网站在墙外,那些网站在墙内,以较节约、高速的方式访问网络。八仙过海,各显神通,不少帮助人们解决这一问题,降低翻墙门槛的小项目出现了。较具代表性的有 chnroutes(http://code.google.com/p/chnroutes/) 项目和 autoproxy-gfwlist(http://code.google.com/p/autoproxy-gfwlist/) 项目。前者修改路由表,配合各种 VPN 使用,后者可以配合 AutoProxy for Firefox(https://addons.mozilla.org/firefox/addon/11009) 或导出(https://autoproxy2pac.appspot.com/)为 pac 文件,配合各种代理服务器,包括 ssh -D 使用。他们的原理稍有差异,chnroutes 只区分国内外 IP 段,让国外地址全部走翻墙路线,autoproxy-gfwlist 项目则精确记录着那些网站被墙。
我以往喜欢 ssh -D 生成 SOCKS 代理后,搭配自己的 pac 文件翻墙。最近由于各种原因转到了 VPN 阵营。感觉 VPN 搭配 chnroutes 的确很舒服,不用再关心那些网站被墙,不会因为 gfwlist 更新延迟而影响访问。于是我在想,有没有办法让使用 ssh -D 或者其他翻墙代理的用户能和使用 VPN 的用户那样省心呢?于是我站在巨人的肩膀上,基于 chnroutes 项目,结合 pac 文件的 dnsResolve() 和 isInNet() 函数,开发了 Flora_Pac 这个小项目。
Flora_Pac 使用 Python 开发,能自动抓取 apnic.net 的 IP 数据,找出所有国内的 IP 地址段,生成能让浏览器自动判断国内外 IP 地址的 pac 文件,让代理用户有等价于 VPN + chnroutes 的翻墙体验。Flora_Pac 使用十分简单,兼容各种平台:
####### 获得帮助:
$ python flora_pac.py -h
usage: flora_pac.py [-h] [-x [PROXY]]
Generate proxy auto-config rules.
optional arguments:
-h, --help show this help message and exit
-x [PROXY], --proxy [PROXY]
Proxy Server, examples:
SOCKS 127.0.0.1:8964;
SOCKS5 127.0.0.1:8964;
PROXY 127.0.0.1:8964
####### 生成 pac 文件,国外 IP 通过代理 SOCKS 代理 127.0.0.1:8964 访问:
$ python flora_pac.py -x 'SOCKS 127.0.0.1:8964'
Fetching data from apnic.net, it might take a few minutes, please wait...
Rules: 3460 items.
Usage: Use the newly created flora_pac.pac as your web browser's automatic proxy configuration (.pac) file.
####### 生成 pac 文件,国外 IP 通过代理 HTTP 代理 127.0.0.1:8964 访问:
$ python flora_pac.py -x 'PROXY 127.0.0.1:8964'
Fetching data from apnic.net, it might take a few minutes, please wait...
Rules: 3460 items.
Usage: Use the newly created flora_pac.pac as your web browser's automatic proxy configuration (.pac) file.
程序跑完后,就会在当前目录产生 flora_pac.pac 文件,把它设为浏览器或系统代理设置的 pac 文件即可。
项目代码我放在 github 上开源了:https://github.com/Leask/Flora_Pac,其中 fetch_ip_data 函数 fork 自 chnroutes 项目。
不方便上 github 的朋友,直接复制以下代码保存为 flora_pac.py 就可以跑了:
#!/usr/bin/env python
#
# Flora_Pac by @leaskh
# www.leaskh.com, i@leaskh.com
#
# based on chnroutes project (by Numb.Majority@gmail.com)
#
import re
import urllib2
import argparse
import math
def generate_pac(proxy):
results = fetch_ip_data()
pacfile = 'flora_pac.pac'
rfile = open(pacfile, 'w')
strLines = (
"// Flora_Pac by @leaskh"
"\n// www.leaskh.com, i@leaskh.com"
"\n"
"\nfunction FindProxyForURL(url, host)"
"\n{"
"\n"
"\n var list = ["
)
intLines = 0
for ip,mask,_ in results:
if intLines > 0:
strLines = strLines + ','
intLines = intLines + 1
strLines = strLines + "\n ['%s', '%s']"%(ip, mask)
strLines = strLines + (
"\n ];"
"\n"
"\n var ip = dnsResolve(host);"
"\n"
"\n for (var i in list) {"
"\n if (isInNet(ip, list[i][0], list[i][1])) {"
"\n return 'DIRECT';"
"\n }"
"\n }"
"\n"
"\n return '%s';"
"\n"
"\n}"
"\n"%(proxy)
)
rfile.write(strLines)
rfile.close()
print ("Rules: %d items.\n"
"Usage: Use the newly created %s as your web browser's automatic "
"proxy configuration (.pac) file."%(intLines, pacfile))
def fetch_ip_data():
#fetch data from apnic
print "Fetching data from apnic.net, it might take a few minutes, please wait..."
url=r'http://ftp.apnic.net/apnic/stats/apnic/delegated-apnic-latest'
data=urllib2.urlopen(url).read()
cnregex=re.compile(r'apnic\|cn\|ipv4\|[0-9\.]+\|[0-9]+\|[0-9]+\|a.*',re.IGNORECASE)
cndata=cnregex.findall(data)
results=[]
for item in cndata:
unit_items=item.split('|')
starting_ip=unit_items[3]
num_ip=int(unit_items[4])
imask=0xffffffff^(num_ip-1)
#convert to string
imask=hex(imask)[2:]
mask=[0]*4
mask[0]=imask[0:2]
mask[1]=imask[2:4]
mask[2]=imask[4:6]
mask[3]=imask[6:8]
#convert str to int
mask=[ int(i,16 ) for i in mask]
mask="%d.%d.%d.%d"%tuple(mask)
#mask in *nix format
mask2=32-int(math.log(num_ip,2))
results.append((starting_ip,mask,mask2))
return results
if __name__=='__main__':
parser=argparse.ArgumentParser(description="Generate proxy auto-config rules.")
parser.add_argument('-x', '--proxy',
dest = 'proxy',
default = 'SOCKS 127.0.0.1:8964',
nargs = '?',
help = "Proxy Server, examples: "
"SOCKS 127.0.0.1:8964; "
"SOCKS5 127.0.0.1:8964; "
"PROXY 127.0.0.1:8964")
args = parser.parse_args()
generate_pac(args.proxy)
我想,应该过不了多久就要解放了。期待着有那么一天:我们能一起呼吸自由的空气,我们不再需要折腾各种翻墙玩意。那时,生活应该会更美好一些吧。
272月/13关
CI框架源码完全分析之核心文件Codeigniter.php
$assign_to_config['subclass_prefix']));
}
/*
*php 程序运行默认是30s,这里用set_time_limt延长了,关于set_time_Limit() http://www.phpddt.com/php/set_time_limit.html
* 扩展阅读,关于safe_mode:http://www.phpddt.com/php/643.html ,你会完全明白的
*/
if (function_exists("set_time_limit") == TRUE AND @ini_get("safe_mode") == 0)
{
@set_time_limit(300);
}
/*
* 加载Benchmark,它很简单,就是计算任意两点之间程序的运行时间
*/
$BM =& load_class('Benchmark', 'core');
$BM->mark('total_execution_time_start');
$BM->mark('loading_time:_base_classes_start');
//加载钩子,后期会分析到,这玩意特好,扩展它能改变CI的运行流程
$EXT =& load_class('Hooks', 'core');
//这里就是一个钩子啦,其实就是该钩子程序在这里执行
$EXT->_call_hook('pre_system');
//加载配置文件,这里面都是一些加载或获取配置信息的函数
$CFG =& load_class('Config', 'core');
// 如果在index.php中也有配置$assign_to_config,则也把它加入到$CFG
if (isset($assign_to_config))
{
$CFG->_assign_to_config($assign_to_config);
}
//加载utf8组件、URI组件、Router组件
$UNI =& load_class('Utf8', 'core');
$URI =& load_class('URI', 'core');
$RTR =& load_class('Router', 'core');
$RTR->_set_routing();
//如果在index.php中定义了$routing,那么就会覆盖上面路由
if (isset($routing))
{
$RTR->_set_overrides($routing);
}
//加载output输出组件,不然你怎么用$this->Load->view()啊
$OUT =& load_class('Output', 'core');
//又见钩子,这里你可以自己写钩子程序替代Output类的缓存输出
if ($EXT->_call_hook('cache_override') === FALSE)
{
if ($OUT->_display_cache($CFG, $URI) == TRUE)
{
exit;
}
}
//安全组件啦,防xss攻击啊,csrf攻击啊
//关于xss攻击:http://www.phpddt.com/php/php-prevent-xss.html
//关于csrf:攻击:http://www.phpddt.com/reprint/csrf.html
$SEC =& load_class('Security', 'core');
//加载输入组件,就是你常用的$this->input->post();等
$IN =& load_class('Input', 'core');
//加载语言组件啦
$LANG =& load_class('Lang', 'core');
//引入CI的控制器父类
require BASEPATH.'core/Controller.php';
function &get_instance()
{
return CI_Controller::get_instance();
}
//当然你扩展了CI_Controller控制器的话,也要引入啦
if (file_exists(APPPATH.'core/'.$CFG->config['subclass_prefix'].'Controller.php'))
{
require APPPATH.'core/'.$CFG->config['subclass_prefix'].'Controller.php';
}
//加载你自己应用中的控制器Controller,如果没有当然error啦
if ( ! file_exists(APPPATH.'controllers/'.$RTR->fetch_directory().$RTR->fetch_class().'.php'))
{
show_error('Unable to load your default controller. Please make sure the controller specified in your Routes.php file is valid.');
}
include(APPPATH.'controllers/'.$RTR->fetch_directory().$RTR->fetch_class().'.php');
// 好的基础的类都加载完毕了,咱可以mark一下
$BM->mark('loading_time:_base_classes_end');
//路由获取了控制器名和方法名,比如说默认welcome/index
$class = $RTR->fetch_class();
$method = $RTR->fetch_method();
//这里CI规定一般非公共的方法以_开头,下面是判断,如果URI不可访问就show_404()
if ( ! class_exists($class)
OR strncmp($method, '_', 1) == 0
OR in_array(strtolower($method), array_map('strtolower', get_class_methods('CI_Controller')))
)
{
if ( ! empty($RTR->routes['404_override']))
{
$x = explode('/', $RTR->routes['404_override']);
$class = $x[0];
$method = (isset($x[1]) ? $x[1] : 'index');
if ( ! class_exists($class))
{
if ( ! file_exists(APPPATH.'controllers/'.$class.'.php'))
{
show_404("{$class}/{$method}");
}
include_once(APPPATH.'controllers/'.$class.'.php');
}
}
else
{
show_404("{$class}/{$method}");
}
}
//又是钩子,该钩子发生在控制器实例化之前的
$EXT->_call_hook('pre_controller');
//又mark一个点
$BM->mark('controller_execution_time_( '.$class.' / '.$method.' )_start');
//终于实例化控制器了
$CI = new $class();
//钩子,不想多说了
$EXT->_call_hook('post_controller_constructor');
/*
* ------------------------------------------------------
* Call the requested method
* ------------------------------------------------------
*/
// Is there a "remap" function? If so, we call it instead
if (method_exists($CI, '_remap'))
{
$CI->_remap($method, array_slice($URI->rsegments, 2));
}
else
{
// is_callable() returns TRUE on some versions of PHP 5 for private and protected
// methods, so we'll use this workaround for consistent behavior
if ( ! in_array(strtolower($method), array_map('strtolower', get_class_methods($CI))))
{
// Check and see if we are using a 404 override and use it.
if ( ! empty($RTR->routes['404_override']))
{
$x = explode('/', $RTR->routes['404_override']);
$class = $x[0];
$method = (isset($x[1]) ? $x[1] : 'index');
if ( ! class_exists($class))
{
if ( ! file_exists(APPPATH.'controllers/'.$class.'.php'))
{
show_404("{$class}/{$method}");
}
include_once(APPPATH.'controllers/'.$class.'.php');
unset($CI);
$CI = new $class();
}
}
else
{
show_404("{$class}/{$method}");
}
}
// 终于调用方法了,$this->load->view()把内容放到缓存区
call_user_func_array(array(&$CI, $method), array_slice($URI->rsegments, 2));
}
$BM->mark('controller_execution_time_( '.$class.' / '.$method.' )_end');
$EXT->_call_hook('post_controller');
//这里就是把缓存区的内容输出了
if ($EXT->_call_hook('display_override') === FALSE)
{
$OUT->_display();
}
$EXT->_call_hook('post_system');
//关闭数据库的链接
if (class_exists('CI_DB') AND isset($CI->db))
{
$CI->db->close();
}
166月/12关
有效管理电脑文件
成堆的有用无用的纸、杂乱无章的书籍和办公用品散落在各处,这就是我们办公桌上的一般情形。在电脑的内部,在电脑的桌面上,在"资源管理器"中,也同样充斥着无序与混乱。这种虚拟的混乱极大地影响了电脑的性能和我们办公的效率,当许多人面临这个问题时,认为硬盘空间又不够了,电脑性能又不跟不上了,需要再换一台新的电脑了。事实上,我们真正需要的是坐下来,好好花时间将电脑里的文件真正管理起来,会为自己日后省下更多的时间。
文件管理的真谛在于方便保存和迅速提取,所有的文件将通过文件夹分类被很好地组织起来,放在你最能方便找到的地方。解决这个问题目前最理想的方法就是分类管理,从硬盘分区开始到每一个文件夹的建立,我们都要按照自己的工作和生活需要,分为大大小小、多个层级的文件夹,建立合理的文件保存架构。此外所有的文件、文件夹,都要规范化地命名,并放入最合适的文件夹中。这样,当我们需要什么文件时,就知道到哪里去寻找。这种方法,对于相当数量的人来说,并不是一件轻松的事,因为他们习惯了随手存放文件和辛苦、茫无头绪地查找文件。下面,我们将帮你制订一套分类管理的原则,并敦促您养成好的文件管理习惯。以下是我们总结出的一些基本技巧,这些技巧并不是教条,可能并不适合你,但无论如何你必须要有自己的规则,并坚持下来,形成习惯。
第一招 发挥我的文档的作用
有很多理由让我们好好地利用"我的文档",它能方便地在桌面上、开始菜单、资源管理器、保存/打开窗口中找到,有利于我们方便而快捷地打开、保存文件。我们可以利用"我的文档"中已有的目录,也可以创建自己的目录,将经常需要访问的文件存储在这里。至于"我的文档"存储在C盘,在重装系统时可能会误删除的问题,可以在非系统盘建立一个目录,然后右击桌面上的"我的文档",选择"属性"。在弹出的"我的文档 属性"窗口中,单击目标文件夹下的"移动"按钮,然后在新的窗口中指定我们刚创建的文件夹。重装系统后再次执行以上操作,再重新指向此文件夹即可,即安全又便捷。
小提示
如果你使用Windows 2000/XP,则移动"我的文档"文件夹时,其下的所有文件会自动移过去,但如果你使用Windows 9x,则需要手工将C:/My Documents下的所有文件手工移到新指定的文件夹中,否则可能会丢失数据。
第二招 建立最适合自己的文件夹结构
文件夹是文件管理系统的骨架,对文件管理来说至关重要。建立适合自己的文件夹结构,需要首先对自己接触到的各种信息、工作和生活内容进行归纳分析。每个人的工作和生活有所不同,接受的信息也会有很大差异,因此分析自己的信息类别是建立结构的前提。比如,有相当多的IT自由撰稿人和编辑就是以软件、硬件的类别建立文件夹;而很多老师,就是以自己的工作内容比如教学工作、班主任工作建立文件夹。
同类的文件名字可用相同字母前缀的文件来命名,同类的文件最好存储在同一目录,如图片目录用image,多媒体目录用media,文档用doc等等,简洁易懂,一目了然,而且方便用一个软件打开。这样,当我们想要找到一个文件时,能立刻想到它可能保存的地方。
第三招 控制文件夹与文件的数目
文件夹里的数目不应当过多,一个文件夹里面有50个以内的文件数是比较容易浏览和检索的。如果超过100个文件,浏览和打开的速度就会变慢且不方便查看了。这种情况下,就得考虑存档、删除一些文件,或将此文件夹分为几个文件或建立一些子文件夹。另一方面,如果有文件夹的文件数目长期只有少得可怜的几个文件,也建议将此文件夹合并到其他文件夹中。
第四招 注意结构的级数
分类的细化必然带来结构级别的增多,级数越多,检索和浏览的效率就会越低,建议整个结构最好控制在二、三级。另外,级别最好与自己经常处理的信息相结合。越常用的类别,级别就越高,比如负责多媒体栏目的编辑,那多媒体这个文件夹就应当是一级文件夹,老师本学期所教授的课程、所管理班级的资料文件夹,也应当是一级文件夹。文件夹的数目,文件夹里文件的数目以及文件夹的层级,往往不能两全,我们只能找一个最佳的结合点。
第五招 文件和文件夹的命名
为文件和文件夹取一个好名字至关重要,但什么是好名字,却没有固定的含义,以最短的词句描述此文件夹类别和作用,能让你自己不需要打开就能记起文件的大概内容,能就是好的名称。要为电脑中所有的文件和文件夹使用统一的命名规则,这些规则需要我们自己来制订。最开始使用这些规则时,肯定不会像往常一样随便输入几个字那样轻松,但一旦你体会到了规则命名方便查看和检索的好处时,相信你会坚持不懈地执行下去。
另外,从排序的角度上来说,我们常用的文件夹或文件在起名时,可以加一些特殊的标示符,让他们排在前面。比如当某一个文件夹或文件相比于同一级别的来说,要访问次数多得多时,笔者就会在此名字前加上一个"1"或"★",这可以使这些文件和文件夹排列在同目录下所有文件的最前面,而相对次要但也经常访问的,就可以加上"2"或"★★",以此类推。
此外,文件名要力求简短,虽然Windows已经支持长文件名了,但长文件名也会给我们的识别、浏览带来混乱。
第六招 注意分开要处理的与已经完成的
如果一年前的文件还和你现在正要处理的文件摆在一起,如果几个月前的邮件还和新邮件放在一块,那你将会很难一眼找到你想要的东西。及时地处理过期的文件,备份该备份的,删除不需要的,是一个良好的习惯。以老师为例,上学期教授课程的教案与资料,本学期使用的频率会非常小,所以应当专门将到存放后另一个级别较低的文件夹中,甚至于刻录到光盘中。而并本学期的一些文档,因为要经常访问,最好放置在"我的文档"中以方便时时访问。对于老师来说,一个学期就是一个周期,过一个周期,就相应地处理本周期的文件夹。对于其他行业的人来说,也有不同的周期,我们要根据自己的实际工作和生活需要对文件夹、文件进行归档。
小提示
为了数据安全,及时备份是必需要的
第七招 发挥快捷方式的便利
如果我们经常要快速访问文件或文件夹,那可以右击选择"创建快捷方式",再将生成的快捷方式放置到你经常停留的地方。当然,当文件和文件夹不再需要经常访问时,你需要及时将快捷方式删除,以免快捷方式塞堵了太多空间或牵扯了你的注意力。
第八招 现在开始与长期坚持
建立完善的结构、规范化地命名、周期性地归档,这就是我们要做的。这并不复杂的操作却能大大提高我们的工作效率,节省我们已经很有限的时间。
如果你现在就开始,那请首先拿出一张纸,明了你的信息类别,明确准备创建的文件夹个数与位置,还有为重要的文件夹制订文件命名规则及归档规则。然后按此规则将电脑中已经存在的大量信息进行移动、更名、删除等操作,而且要在以后操作中克服自己的陋习。
也许开头会很难,也许规则会很繁琐,但相信过不了多久,你就已经习惯于看到井井有条的文件与文件夹,并享受高效管理带来的快乐了
127月/11关
Python:读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
 file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )
file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')#第二个参数默认为rinput = open('data')
读二进制文件
input = open('data', 'rb')
读取所有内容
file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )
读固定字节
file_object = open('abinfile', 'rb')try: while True: chunk = file_object.read(100) if not chunk: break do_something_with(chunk)finally: file_object.close( )
读每行
list_of_all_the_lines = file_object.readlines( )如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object: process line
3.写文件
写文本文件
output = open('data', 'w')
写二进制文件
output = open('data', 'wb')
追加写文件
output = open('data', 'w+')
写数据
file_object = open('thefile.txt', 'w')file_object.write(all_the_text)file_object.close( )
写入多行
file_object.writelines(list_of_text_strings)注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
 file = open('test.log', 'r'
file = open('test.log', 'r'
)
sizehint = 209715200 # 200M
position = 0
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
- file(name[, mode[, buffering]])
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode 是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清 空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如 在 unix中是一个/n,而在windows中是‘/r/n’,用U模式打开文件,就是支持所有的换行模式,也就说‘/r’ '/n' '/r/n'都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用/n代替。在模式 字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
- closed #标记文件是否已经关闭,由close()改写
- encoding #文件编码
- mode #打开模式
- name #文件名
- newlines #文件中用到的换行模式,是一个tuple
- softspace #boolean型,一般为0,据说用于print
file的读写方法:
- F.read([size]) #size为读取的长度,以byte为单位
- F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分 - F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 - F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符 - F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
- F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError - F.flush()
#把缓冲区的内容写入硬盘 - F.fileno()
#返回一个长整型的”文件标签“ - F.isatty()
#文件是否是一个终端设备文件(unix系统中的) - F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点 - F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。 - F.seek(offset[,whence])
#将文件打操作标 记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为 0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操 作标记会自动返回到文件末尾。 - F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
263月/10关
PHP中文件读写操作
以下为文件读写操作的 基本PHP函数及模式(看不明白就记住他)
关于模式:
'r' - 只读方式打开, 文件指针置于文件头
'r+' - 读写方式打开,文件指针置于文件头
'w' - 只写打开,文件指针置于文件头, 文件被剪切为0字节, 如果文件不存在, 尝试建立文件
'w+' - 读写打开,文件指针置于文件头, 文件大小被剪切为0字节,如果文件不存在, 尝试建立文件
'a' - 只写方式打开,文件指针置于文件尾,如果文件不存在,尝试建立文件
'a+' - 读写打开,文件指针置于文件尾,如果文件不存在, 尝试建立文件
fgets — 从文件指针中读取一行
fgetss — 从文件指针中读取一行并过滤掉 HTML 标记
file — 把整个文件读入一个数组中
fgetcsv — 从文件指针中读入一行并解析 CSV 字段
你一定用过“网络硬盘”吧,利用它可以按自己的需要新建文件夹来分门别类地把自己的一些文件保存起来,有的还可以在线编辑文件。
PHP中提供了一系列的I/O函数,能简捷地实现我们所需要的功能,包括文件系统操作和目录操作(如“复制[copy]”)。下面给大家介绍的是基本的文件读写操作:(1)读文件;(2)写文件;(3)追加到文件。
TEXT 代码:
读文件:
写文件:
追加到文件后面:
以上只是简单介绍,下面我们要讨论一些更深层的。
有时候会发生多人写入的情况(最常见是在流量较大的网站),会产生无用的数据写入文件, 例如:
info.file文件内容如下 ->
|1|Mukul|15|Male|India (n)
|2|Linus|31|Male|Finland (n)
现在两个人同时注册,引起文件破坏->
info.file ->
|1|Mukul|15|Male|India
|2|Linus|31|Male|Finland
|3|Rob|27|Male|USA|
Bill|29|Male|USA
上例中当PHP写入Rob的信息到文件的时候,Bill正好也开始写入,这时候正好需要写入Rob纪录的'n',引起文件破坏。
我们当然不希望发生这样的情况, 所以让我们看看文件锁定:
复制内容到剪贴板
PHP 代码:
-
<?php
-
$file_name="data.dat";
-
// 我使用4.0.2,所以用LOCK_SH,你可能需要直接写成 1.
-
if($lock){
-
// 如果版本小于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
print"文件内容为 $file_read";
-
?>
上例中,如果两个文件read.php和read2.php都要存取该文件,那么它们都可以读取,但是当一个程序需要写入的时候,它必须等待,直到读操作完成,文件所释放。
-
<?php
-
$file_name="data.dat";
-
// 如果版本低于PHP4.0.2, 用 2 代替 LOCK_EX
-
if($lock){
-
// 如果版本低于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
print"数据成功写入文件";
-
?>
虽然"w"模式用来覆盖文件, 单我觉得不适用。
-
<?php
-
$file_name="data.dat";
-
// 如果版本低于PHP4.0.2, 用 2 代替 LOCK_EX
-
if($lock){
-
// 如果版本小于PHP4.0RC1, 使用 fseek($file_pointer, filsize($file_name));
-
// 如果版本低于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
?>
Hmmm..., 对于追加数据与其他操作有点不同,就是FSEEK! 确认文件指针在文件尾部总是一个好习惯。
如果是在Windows系统下, 上面的文件中文件名前面需要加上''.
232月/10关
Linux文件查找命令find,xargs详述
前言:关于find命令
一、find 命令格式
1、find命令的一般形式为;
2、find命令的参数;
3、find命令选项;
4、使用exec或ok来执行shell命令;
1、查找当前用户主目录下的所有文件;
2、为了在当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
5、为了查找系统中所有属于root组的文件;
6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件
7、为了查找当前文件系统中的所有目录并排序;
8、为了查找系统中所有的rmt磁带设备;
1、使用name选项
2、用perm选项
3、忽略某个目录
4、使用find查找文件的时候怎么避开某个文件目录
5、使用user和nouser选项
6、使用group和nogroup选项
7、按照更改时间或访问时间等查找文件
8、查找比某个文件新或旧的文件
9、使用type选项
10、使用size选项
11、使用depth选项
12、使用mount选项
+++++++++++++++++++++++++++++++++++++++++++++++++
正文
+++++++++++++++++++++++++++++++++++++++++++++++++
版权声明
本文是zhyfly兄贴在LinuxSir.Org 的一个帖子而整理出来的,如果您对版权有疑问,请在本帖后面跟帖。谢谢;本文的HTML版本由北南南北整理;修改了整篇文档的全角及说明文字中的单词中每个字母空格的问题;为标题加了编号,方便大家阅读;
前言:关于find命令
由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。
在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。
一、find 命令格式
1、find命令的一般形式为;
find pathname -options [-print -exec -ok ...]
2、find命令的参数;
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } /;,注意{ }和/;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
3、find命令选项
-name
按照文件名查找文件。
-perm
按照文件权限来查找文件。
-prune
使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user
按照文件属主来查找文件。
-group
按照文件所属的组来查找文件。
-mtime -n +n
按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup
查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser
查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2
查找更改时间比文件file1新但比文件file2旧的文件。
-type
查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-fstype:查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount:在查找文件时不跨越文件系统mount点。
-follow:如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio:对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。
另外,下面三个的区别:
-amin n
查找系统中最后N分钟访问的文件
-atime n
查找系统中最后n*24小时访问的文件
-cmin n
查找系统中最后N分钟被改变文件状态的文件
-ctime n
查找系统中最后n*24小时被改变文件状态的文件
-mmin n
查找系统中最后N分钟被改变文件数据的文件
-mtime n
查找系统中最后n*24小时被改变文件数据的文件
4、使用exec或ok来执行shell命令
使用find时,只要把想要的操作写在一个文件里,就可以用exec来配合find查找,很方便的
在有些操作系统中只允许-exec选项执行诸如l s或ls -l这样的命令。大多数用户使用这一选项是为了查找旧文件并删除它们。建议在真正执行rm命令删除文件之前,最好先用ls命令看一下,确认它们是所要删除的文件。
exec选项后面跟随着所要执行的命令或脚本,然后是一对儿{ },一个空格和一个/,最后是一个分号。为了使用exec选项,必须要同时使用print选项。如果验证一下find命令,会发现该命令只输出从当前路径起的相对路径及文件名。
例如:为了用ls -l命令列出所匹配到的文件,可以把ls -l命令放在find命令的-exec选项中
# find . -type f -exec ls -l { } /;
-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README上面的例子中,find命令匹配到了当前目录下的所有普通文件,并在-exec选项中使用ls -l命令将它们列出。
在/logs目录中查找更改时间在5日以前的文件并删除它们:
$ find logs -type f -mtime +5 -exec rm { } /;记住: 在shell中用任何方式删除文件之前,应当先查看相应的文件,一定要小心!当使用诸如mv或rm命令时,可以使用-exec选项的安全模式。它将在对每个匹配到的文件进行操作之前提示你。
在下面的例子中, find命令在当前目录中查找所有文件名以.LOG结尾、更改时间在5日以上的文件,并删除它们,只不过在删除之前先给出提示。
$ find . -name "*.conf" -mtime +5 -ok rm { } /;
< rm ... ./conf/httpd.conf > ? n按y键删除文件,按n键不删除。
任何形式的命令都可以在-exec选项中使用。
在下面的例子中我们使用grep命令。find命令首先匹配所有文件名为“ passwd*”的文件,例如passwd、passwd.old、passwd.bak,然后执行grep命令看看在这些文件中是否存在一个sam用户。
# find /etc -name "passwd*" -exec grep "sam" { } /;
sam:x:501:501::/usr/sam:/bin/bash
二、find命令的例子;
1、查找当前用户主目录下的所有文件:
下面两种方法都可以使用
$ find $HOME -print
$ find ~ -print
2、让当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
$ find . -type f -perm 644 -exec ls -l { } /;
3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
$ find / -type f -size 0 -exec ls -l { } /;
4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
$ find /var/logs -type f -mtime +7 -ok rm { } /;
5、为了查找系统中所有属于root组的文件;
$find . -group root -exec ls -l { } /;
-rw-r--r-- 1 root root 595 10月 31 01:09 ./fie1
6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件。
该命令只检查三位数字,所以相应文件的后缀不要超过999。先建几个admin.log*的文件 ,才能使用下面这个命令
$ find . -name "admin.log[0-9][0-9][0-9]" -atime -7 -ok
rm { } /;
< rm ... ./admin.log001 > ? n
< rm ... ./admin.log002 > ? n
< rm ... ./admin.log042 > ? n
< rm ... ./admin.log942 > ? n
7、为了查找当前文件系统中的所有目录并排序;
$ find . -type d | sort
8、为了查找系统中所有的rmt磁带设备;
$ find /dev/rmt -print
三、xargs
xargs - build and execute command lines from standard input
在使用find命令的-exec选项处理匹配到的文件时, find命令将所有匹配到的文件一起传递给exec执行。但有些系统对能够传递给exec的命令长度有限制,这样在find命令运行几分钟之后,就会出现溢出错误。错误信息通常是“参数列太长”或“参数列溢出”。这就是xargs命令的用处所在,特别是与find命令一起使用。
find命令把匹配到的文件传递给xargs命令,而xargs命令每次只获取一部分文件而不是全部,不像-exec选项那样。这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。
在有些系统中,使用-exec选项会为处理每一个匹配到的文件而发起一个相应的进程,并非将匹配到的文件全部作为参数一次执行;这样在有些情况下就会出现进程过多,系统性能下降的问题,因而效率不高;
而使用xargs命令则只有一个进程。另外,在使用xargs命令时,究竟是一次获取所有的参数,还是分批取得参数,以及每一次获取参数的数目都会根据该命令的选项及系统内核中相应的可调参数来确定。
来看看xargs命令是如何同find命令一起使用的,并给出一些例子。
下面的例子查找系统中的每一个普通文件,然后使用xargs命令来测试它们分别属于哪类文件
#find . -type f -print | xargs file
./.kde/Autostart/Autorun.desktop: UTF-8 Unicode English text
./.kde/Autostart/.directory: ISO-8859 text/
......在整个系统中查找内存信息转储文件(core dump) ,然后把结果保存到/tmp/core.log 文件中:
$ find / -name "core" -print | xargs echo "" >/tmp/core.log上面这个执行太慢,我改成在当前目录下查找
#find . -name "file*" -print | xargs echo "" > /temp/core.log
# cat /temp/core.log
./file6在当前目录下查找所有用户具有读、写和执行权限的文件,并收回相应的写权限:
# ls -l
drwxrwxrwx 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 httpd.conf
# find . -perm -7 -print | xargs chmod o-w
# ls -l
drwxrwxr-x 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
用grep命令在所有的普通文件中搜索hostname这个词:
# find . -type f -print | xargs grep "hostname"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your用grep命令在当前目录下的所有普通文件中搜索hostnames这个词:
# find . -name /* -type f -print | xargs grep "hostnames"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your注意,在上面的例子中, /用来取消find命令中的*在shell中的特殊含义。
find命令配合使用exec和xargs可以使用户对所匹配到的文件执行几乎所有的命令。
四、find 命令的参数
下面是find一些常用参数的例子,有用到的时候查查就行了,像上面前几个贴子,都用到了其中的的一些参数,也可以用man或查看论坛里其它贴子有find的命令手册
1、使用name选项
文件名选项是find命令最常用的选项,要么单独使用该选项,要么和其他选项一起使用。
可以使用某种文件名模式来匹配文件,记住要用引号将文件名模式引起来。
不管当前路径是什么,如果想要在自己的根目录$HOME中查找文件名符合*.txt的文件,使用~作为 'pathname'参数,波浪号~代表了你的$HOME目录。
$ find ~ -name "*.txt" -print想要在当前目录及子目录中查找所有的‘ *.txt’文件,可以用:
$ find . -name "*.txt" -print想要的当前目录及子目录中查找文件名以一个大写字母开头的文件,可以用:
$ find . -name "[A-Z]*" -print想要在/etc目录中查找文件名以host开头的文件,可以用:
$ find /etc -name "host*" -print想要查找$HOME目录中的文件,可以用:
$ find ~ -name "*" -print 或find . -print要想让系统高负荷运行,就从根目录开始查找所有的文件。
$ find / -name "*" -print如果想在当前目录查找文件名以两个小写字母开头,跟着是两个数字,最后是.txt的文件,下面的命令就能够返回名为ax37.txt的文件:
$find . -name "[a-z][a-z][0--9][0--9].txt" -print
2、用perm选项
按照文件权限模式用-perm选项,按文件权限模式来查找文件的话。最好使用八进制的权限表示法。
如在当前目录下查找文件权限位为755的文件,即文件属主可以读、写、执行,其他用户可以读、执行的文件,可以用:
$ find . -perm 755 -print还有一种表达方法:在八进制数字前面要加一个横杠-,表示都匹配,如-007就相当于777,-006相当于666
# ls -l
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find . -perm 006
# find . -perm -006
./sam
./httpd1.conf
./temp
-perm mode:文件许可正好符合mode
-perm +mode:文件许可部分符合mode
-perm -mode: 文件许可完全符合mode
3、忽略某个目录
如果在查找文件时希望忽略某个目录,因为你知道那个目录中没有你所要查找的文件,那么可以使用-prune选项来指出需要忽略的目录。在使用-prune选项时要当心,因为如果你同时使用了-depth选项,那么-prune选项就会被find命令忽略。
如果希望在/apps目录下查找文件,但不希望在/apps/bin目录下查找,可以用:
$ find /apps -path "/apps/bin" -prune -o -print
4、使用find查找文件的时候怎么避开某个文件目录
比如要在/usr/sam目录下查找不在dir1子目录之内的所有文件
find /usr/sam -path "/usr/sam/dir1" -prune -o -print
find [-path ..] [expression] 在路径列表的后面的是表达式-path "/usr/sam" -prune -o -print 是 -path "/usr/sam" -a -prune -o
-print 的简写表达式按顺序求值, -a 和 -o 都是短路求值,与 shell 的 && 和 || 类似如果 -path "/usr/sam" 为真,则求值 -prune , -prune 返回真,与逻辑表达式为真;否则不求值 -prune,与逻辑表达式为假。如果 -path "/usr/sam" -a -prune 为假,则求值 -print ,-print返回真,或逻辑表达式为真;否则不求值 -print,或逻辑表达式为真。
这个表达式组合特例可以用伪码写为
if -path "/usr/sam" then
-prune
else
-print避开多个文件夹
find /usr/sam /( -path /usr/sam/dir1 -o -path /usr/sam/file1 /) -prune -o -print圆括号表示表达式的结合。
/ 表示引用,即指示 shell 不对后面的字符作特殊解释,而留给 find 命令去解释其意义。查找某一确定文件,-name等选项加在-o 之后
#find /usr/sam /(-path /usr/sam/dir1 -o -path /usr/sam/file1 /) -prune -o -name "temp" -print
5、使用user和nouser选项
按文件属主查找文件,如在$HOME目录中查找文件属主为sam的文件,可以用:
$ find ~ -user sam -print在/etc目录下查找文件属主为uucp的文件:
$ find /etc -user uucp -print为了查找属主帐户已经被删除的文件,可以使用-nouser选项。这样就能够找到那些属主在/etc/passwd文件中没有有效帐户的文件。在使用-nouser选项时,不必给出用户名; find命令能够为你完成相应的工作。
例如,希望在/home目录下查找所有的这类文件,可以用:
$ find /home -nouser -print
6、使用group和nogroup选项
就像user和nouser选项一样,针对文件所属于的用户组, find命令也具有同样的选项,为了在/apps目录下查找属于gem用户组的文件,可以用:
$ find /apps -group gem -print要查找没有有效所属用户组的所有文件,可以使用nogroup选项。下面的find命令从文件系统的根目录处查找这样的文件
$ find / -nogroup-print
7、按照更改时间或访问时间等查找文件
如果希望按照更改时间来查找文件,可以使用mtime,atime或ctime选项。如果系统突然没有可用空间了,很有可能某一个文件的长度在此期间增长迅速,这时就可以用mtime选项来查找这样的文件。
用减号-来限定更改时间在距今n日以内的文件,而用加号+来限定更改时间在距今n日以前的文件。
希望在系统根目录下查找更改时间在5日以内的文件,可以用:
$ find / -mtime -5 -print为了在/var/adm目录下查找更改时间在3日以前的文件,可以用:
$ find /var/adm -mtime +3 -print
8、查找比某个文件新或旧的文件
如果希望查找更改时间比某个文件新但比另一个文件旧的所有文件,可以使用-newer选项。它的一般形式为:
newest_file_name ! oldest_file_name其中,!是逻辑非符号。
查找更改时间比文件sam新但比文件temp旧的文件:
例:有两个文件
-rw-r--r-- 1 sam adm 0 10月 31 01:07 fiel
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find -newer httpd1.conf ! -newer temp -ls
1077669 0 -rwxrwxr-x 2 sam adm 0 10月 31 01:01 ./httpd.conf
1077671 4 -rw-rw-rw- 1 root root 2792 10月 31 20:19 ./temp
1077673 0 -rw-r--r-- 1 sam adm 0 10月 31 01:07 ./fiel
查找更改时间在比temp文件新的文件:
$ find . -newer temp -print
9、使用type选项
在/etc目录下查找所有的目录,可以用:
$ find /etc -type d -print在当前目录下查找除目录以外的所有类型的文件,可以用:
$ find . ! -type d -print在/etc目录下查找所有的符号链接文件,可以用
$ find /etc -type l -print
10、使用size选项
可以按照文件长度来查找文件,这里所指的文件长度既可以用块(block)来计量,也可以用字节来计量。以字节计量文件长度的表达形式为N c;以块计量文件长度只用数字表示即可。
在按照文件长度查找文件时,一般使用这种以字节表示的文件长度,在查看文件系统的大小,因为这时使用块来计量更容易转换。
在当前目录下查找文件长度大于1 M字节的文件:
$ find . -size +1000000c -print在/home/apache目录下查找文件长度恰好为100字节的文件:
$ find /home/apache -size 100c -print在当前目录下查找长度超过10块的文件(一块等于512字节):
$ find . -size +10 -print
11、使用depth选项
在使用find命令时,可能希望先匹配所有的文件,再在子目录中查找。使用depth选项就可以使find命令这样做。这样做的一个原因就是,当在使用find命令向磁带上备份文件系统时,希望首先备份所有的文件,其次再备份子目录中的文件。
在下面的例子中, find命令从文件系统的根目录开始,查找一个名为CON.FILE的文件。
它将首先匹配所有的文件然后再进入子目录中查找。
$ find / -name "CON.FILE" -depth -print
12、使用mount选项
在当前的文件系统中查找文件(不进入其他文件系统),可以使用find命令的mount选项。
从当前目录开始查找位于本文件系统中文件名以XC结尾的文件:
$ find . -name "*.XC" -mount -print175月/08关
资源文件查找顺序
资源文件查找顺序
之所以说Struts 2.0的国际化更灵活是因为它可以能根据不同需要配置和获取资源(properties)文件。在Struts 2.0中有下面几种方法:
- 使用全局的资源文件,方法如上例所示。这适用于遍布于整个应用程序的国际化字符串,它们在不同的包(package)中被引用,如一些比较共用的出错提示;
- 使用包范围内的资源文件。做法是在包的根目录下新建名的package.properties和package_xx_XX.properties文件。这就适用于在包中不同类访问的资源;
- 使用Action范围的资源文件。做法为Action的包下新建文件名(除文件扩展名外)与Action类名同样的资源文件。它只能在该Action中访问。如此一来,我们就可以在不同的Action里使用相同的properties名表示不同的值。例如,在ActonOne中title为“动作一”,而同样用title在ActionTwo表示“动作二”,节省一些命名工夫;
- 使用<s:i18n>标志访问特定路径的properties文件。使用方法请参考文章《常用的Struts 2.0的标志(Tag)介绍》。在您使用这一方法时,请注意<s:i18n>标志的范围。在<s:i18n name="xxxxx">到</s:i18n>之间,所有的国际化字符串都会在名为xxxxx资源文件查找,如果找不到,Struts 2.0就会输出默认值(国际化字符串的名字)。
上面我列举了四种配置和访问资源的方法,它们的范围分别是从大到小,而Struts 2.0在查找国际化字符串所遵循的是特定的顺序,如图3所示:

图3 资源文件查找顺序图
假设我们在某个ChildAction中调用了getText("user.title"),Struts 2.0的将会执行以下的操作:
- 查找ChildAction_xx_XX.properties文件或ChildAction.properties;
- 查找ChildAction实现的接口,查找与接口同名的资源文件MyInterface.properties;
- 查找ChildAction的父类ParentAction的properties文件,文件名为ParentAction.properties;
- 判断当前ChildAction是否实现接口ModelDriven。如果是,调用getModel()获得对象,查找与其同名的资源文件;
- 查找当前包下的package.properties文件;
- 查找当前包的父包,直到最顶层包;
- 在值栈(Value Stack)中,查找名为user的属性,转到user类型同名的资源文件,查找键为title的资源;
- 查找在struts.properties配置的默认的资源文件,参考例1;
- 输出user.title。
支持博主

关于邵珠庆博客
文章标签
API
GA
Git
Google Analytics
HTML5
jquery
JS
Linux
MySQL
nginx
PHP
SaaS
web
互联网
代码
使用
分析
创业
原理
命令
好东西
如何
工具
常用
开发
总结
技巧
技术
插件
数据
文件
方法
时间
架构
框架
汇总
百度
管理
系统
网站
网站分析
设计
详解
问题
阿里云
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
