python数据类型详解
目录
1、字符串
2、布尔类型
3、整数
4、浮点数
5、数字
6、列表
7、元组
8、字典
9、日期
1、字符串
1.1、如何在Python中使用字符串
a、使用单引号(')
用单引号括起来表示字符串,例如:
str='this is string';
print str;
b、使用双引号(")
双引号中的字符串与单引号中的字符串用法完全相同,例如:
str="this is string";
print str;
c、使用三引号(''')
利用三引号,表示多行的字符串,可以在三引号中自由的使用单引号和双引号,例如:
str='''this is string
this is pythod string
this is string'''
print str;
2、布尔类型
bool=False;
print bool;
bool=True;
print bool;
3、整数
int=20;
print int;
4、浮点数
float=2.3;
print float;
5、数字
包括整数、浮点数。
5.1、删除数字对象引用,例如:
a=1;
b=2;
c=3;
del a;
del b, c;
#print a; #删除a变量后,再调用a变量会报错
5.2、数字类型转换
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象x转换为字符串
repr(x) 将对象x转换为表达式字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
chr(x) 将一个整数转换为一个字符
unichr(x) 将一个整数转换为Unicode字符
ord(x) 将一个字符转换为它的整数值
hex(x) 将一个整数转换为一个十六进制字符串
oct(x) 将一个整数转换为一个八进制字符串
5.3、数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10 ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 pow(x, y) x**y 运算后的值。 round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
6、列表
6.1、初始化列表,例如:
list=['physics', 'chemistry', 1997, 2000];
nums=[1, 3, 5, 7, 8, 13, 20];
6.2、访问列表中的值,例如:
'''nums[0]: 1''' print "nums[0]:", nums[0] '''nums[2:5]: [5, 7, 8] 从下标为2的元素切割到下标为5的元素,但不包含下标为5的元素''' print "nums[2:5]:", nums[2:5] '''nums[1:]: [3, 5, 7, 8, 13, 20] 从下标为1切割到最后一个元素''' print "nums[1:]:", nums[1:] '''nums[:-3]: [1, 3, 5, 7] 从最开始的元素一直切割到倒数第3个元素,但不包含倒数第三个元素''' print "nums[:-3]:", nums[:-3] '''nums[:]: [1, 3, 5, 7, 8, 13, 20] 返回所有元素''' print "nums[:]:", nums[:]
6.3、更新列表,例如:
nums[0]="ljq"; print nums[0];
6.4、删除列表元素
del nums[0]; '''nums[:]: [3, 5, 7, 8, 13, 20]''' print "nums[:]:", nums[:];
6.5、列表脚本操作符
列表对+和*的操作符与字符串相似。+号用于组合列表,*号用于重复列表,例如:
print len([1, 2, 3]); #3 print [1, 2, 3] + [4, 5, 6]; #[1, 2, 3, 4, 5, 6] print ['Hi!'] * 4; #['Hi!', 'Hi!', 'Hi!', 'Hi!'] print 3 in [1, 2, 3] #True for x in [1, 2, 3]: print x, #1 2 3
6.6、列表截取
L=['spam', 'Spam', 'SPAM!']; print L[2]; #'SPAM!' print L[-2]; #'Spam' print L[1:]; #['Spam', 'SPAM!']
6.7、列表函数&方法
list.append(obj) 在列表末尾添加新的对象 list.count(obj) 统计某个元素在列表中出现的次数 list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.index(obj) 从列表中找出某个值第一个匹配项的索引位置,索引从0开始 list.insert(index, obj) 将对象插入列表 list.pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 list.remove(obj) 移除列表中某个值的第一个匹配项 list.reverse() 反向列表中元素,倒转 list.sort([func]) 对原列表进行排序
7、元组(tuple)
Python的元组与列表类似,不同之处在于元组的元素不能修改;元组使用小括号(),列表使用方括号[];元组创建很简单,只需要在括号中添加元素,并使用逗号(,)隔开即可,例如:
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";
创建空元组,例如:tup = ();
元组中只有一个元素时,需要在元素后面添加逗号,例如:tup1 = (50,);
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
7.1、访问元组
tup1 = ('physics', 'chemistry', 1997, 2000);
#tup1[0]: physics
print "tup1[0]: ", tup1[0]
#tup1[1:5]: ('chemistry', 1997)
print "tup1[1:5]: ", tup1[1:3]
7.2、修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,例如:
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# 以下修改元组元素操作是非法的。
# tup1[0] = 100;
# 创建一个新的元组
tup3 = tup1 + tup2; print tup3; #(12, 34.56, 'abc', 'xyz')
7.3、删除元组
元组中的元素值是不允许删除的,可以使用del语句来删除整个元组,例如:
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
7.4、元组运算符
与字符串一样,元组之间可以使用+号和*号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
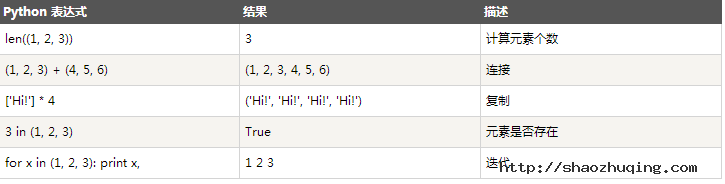
7.5、元组索引&截取
L = ('spam', 'Spam', 'SPAM!');
print L[2]; #'SPAM!'
print L[-2]; #'Spam'
print L[1:]; #['Spam', 'SPAM!']
7.6、元组内置函数
cmp(tuple1, tuple2) 比较两个元组元素。 len(tuple) 计算元组元素个数。 max(tuple) 返回元组中元素最大值。 min(tuple) 返回元组中元素最小值。 tuple(seq) 将列表转换为元组。
8、字典
8.1、字典简介
字典(dictionary)是除列表之外python中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典由键和对应的值组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'};
也可如此创建字典:
dict1 = { 'abc': 456 };
dict2 = { 'abc': 123, 98.6: 37 };
每个键与值必须用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必;值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
8.2、访问字典里的值
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
print "dict['name']: ", dict['name'];
print "dict['age']: ", dict['age'];
8.3、修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
dict["age"]=27; #修改已有键的值
dict["school"]="wutong"; #增加新的键/值对
print "dict['age']: ", dict['age'];
print "dict['school']: ", dict['school'];
8.4、删除字典
del dict['name']; # 删除键是'name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
例如:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
del dict['name'];
#dict {'age': 7, 'class': 'First'}
print "dict", dict;
注意:字典不存在,del会引发一个异常
8.5、字典内置函数&方法
9、日期和时间
9.1、获取当前时间,例如:
import time, datetime;
localtime = time.localtime(time.time())
#Local current time : time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)
print "Local current time :", localtime
说明:time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)属于struct_time元组,struct_time元组具有如下属性:

9.2、获取格式化的时间
可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
2.1、日期转换为字符串
首选:print time.strftime('%Y-%m-%d %H:%M:%S');
其次:print datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H:%M:%S')
最后:print str(datetime.datetime.now())[:19]
2.2、字符串转换为日期
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") print d;
9.3、获取日期差
oneday = datetime.timedelta(days=1) #今天,2014-03-21 today = datetime.date.today() #昨天,2014-03-20 yesterday = datetime.date.today() - oneday #明天,2014-03-22 tomorrow = datetime.date.today() + oneday #获取今天零点的时间,2014-03-21 00:00:00 today_zero_time = datetime.datetime.strftime(today, '%Y-%m-%d %H:%M:%S') #0:00:00.001000 print datetime.timedelta(milliseconds=1), #1毫秒 #0:00:01 print datetime.timedelta(seconds=1), #1秒 #0:01:00 print datetime.timedelta(minutes=1), #1分钟 #1:00:00 print datetime.timedelta(hours=1), #1小时 #1 day, 0:00:00 print datetime.timedelta(days=1), #1天 #7 days, 0:00:00 print datetime.timedelta(weeks=1)
9.4、获取时间差
#1 day, 0:00:00 oneday = datetime.timedelta(days=1) #今天,2014-03-21 16:07:23.943000 today_time = datetime.datetime.now() #昨天,2014-03-20 16:07:23.943000 yesterday_time = datetime.datetime.now() - oneday #明天,2014-03-22 16:07:23.943000 tomorrow_time = datetime.datetime.now() + oneday 注意时间是浮点数,带毫秒。 那么要获取当前时间,需要格式化一下: print datetime.datetime.strftime(today_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(yesterday_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(tomorrow_time, '%Y-%m-%d %H:%M:%S')
9.5、获取上个月最后一天
last_month_last_day = datetime.date(datetime.date.today().year,datetime.date.today().month,1)-datetime.timedelta(1)
9.6、字符串日期格式化为秒数,返回浮点类型:
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.7、日期格式化为秒数,返回浮点类型:
d = datetime.date.today() time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.8、秒数转字符串
time_sec = time.time()
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time_sec))
Python 入門語法和類型
Python的设计目标之一是让源代码具备高度的可读性。它设计时尽量使用其它语言经常使用的标点符号和英语单词,让源代码整体看起来很整洁美观。它不像静态语言如C、Pascal那样需要重复书写声明语句,也不像它们的语法那样经常有特殊情况和惊喜。
缩进
Python开发者有意让违反了缩进规则的程序不能通过编译,以此来强制程序员养成良好的编程习惯。并且在Python语言里,缩进而非花括号或者某种关键字,被用于表示语句块的开始和退出。增加缩进表示语句块的开始,而减少缩进则表示语句块的退出。缩进成为了语法的一部分。例如
if语句:
if age < 21:
print("你不能買酒。")
print("不過你能買口香糖。")
print("這句話處於if語句塊的外面。")
根据PEP的规定,必须使用4个空格来表示每级缩进。使用Tab字符和其它数目的空格虽然都可以编译通过,但不符合编码规范。支持Tab字符和其它数目的空格仅仅是为了兼容很旧的Python程序和某些有问题的编辑器。
语句和控制流
if语句,当条件成立时执行语句块。经常与else,elif(相当于else if)配合使用。for语句,遍历列表、字符串、字典、集合等迭代器,依次处理迭代器中的每个元素。while语句,当条件为真时,循环执行语句块。try语句。与except,finally配合使用处理在程序运行中出现的异常情况。class语句。用于定义类型。def语句。用于定义函数和类型的方法。pass语句。表示此行为空,不执行任何操作。assert语句。用于程序调试阶段时测试运行条件是否满足。with语句。Python2.6以后定义的语法,在一个场景中运行语句块。比如,运行语句块前加锁,然后在语句块运行结束后释放它。yield语句。在迭代器函数内使用,用于返回一个元素。自从Python 2.5版本以后。这个语句变成一个运算符。
表达式
Python的表达式写法与C/C++类似。只是在某些写法有所差别。
- 主要的算术运算符与C/C++类似。
+, -, *, /, //, **, ~, %分别表示加法或者取正、减法或者取负、乘法、除法、整除、乘方、取补、取模。>>, <<表示右移和左移。&, |, ^表示二进制的AND, OR, XOR运算。>, <, ==, !=, <=, >=用于比较两个表达式的值,分别表示大于、小于、等于、不等于、小于等于、大于等于。在这些运算符里面,~, |, ^, &, <<, >>必须应用于整数。 - Python使用
and,or,not表示逻辑运算。 is, is not用于比较两个变量是否是同一个对象。in, not in用于判断一个对象是否属于另外一个对象。- Python支持"列表推导式"(list comprehension),比如计算0-9的平方和:
>>> sum(x * x for x in range(10))285
- Python使用
lambda表示匿名函数。匿名函数体只能是表达式。比如:
>>> add=lambda x, y : x + y>>> add(3,2)5
- Python使用
y if cond else x表示条件表达式。意思是当cond为真时,表达式的值为y,否则表达式的值为x。相当于C++和Java里的cond?y:x。 - Python区分列表(list)和元组(tuple)两种类型。list的写法是
[1,2,3],而tuple的写法是(1,2,3)。可以改变list中的元素,而不能改变tuple。在某些情况下,tuple的括号可以省略。tuple对于赋值语句有特殊的处理。因此,可以同时赋值给多个变量,比如:
>>> x, y=1, 2 #同时给x,y赋值,最终结果:x=1, y=2
特别地,可以使用以下这种形式来交换两个变量的值:
>>> x, y=y, x #最终结果:y=1, x=2
- Python使用'(单引号)和"(双引号)来表示字符串。与Perl、Unix Shell语言或者Ruby、Groovy等语言不一样,两种符号作用相同。一般地,如果字符串中出现了双引号,就使用单引号来表示字符串;反之则使用双引号。如果都没有出现,就依个人喜好选择。出现在字符串中的\(反斜杠)被解释为特殊字符,比如
\n表示换行符。表达式前加r指示Python不解释字符串中出现的\。这种写法通常用于编写正则表达式或者Windows文件路径。
- Python支持列表切割(list slices),可以取得完整列表的一部分。支持切割操作的类型有
str, bytes, list, tuple等。它的语法是...[left:right]或者...[left:right:stride]。假定nums变量的值是[1, 3, 5, 7, 8, 13, 20],那么下面几个语句为真:
-
nums[2:5] == [5, 7, 8]从下标为2的元素切割到下标为5的元素,但不包含下标为2的元素。nums[1:] == [3, 5, 7, 8, 13, 20]切割到最后一个元素。nums[:-3] == [1, 3, 5, 7]从最开始的元素一直切割到倒数第3个元素。nums[:] == [1, 3, 5, 7, 8, 13, 20]返回所有元素。改变新的列表不会影响到nums。nums[1:5:2] == [3, 7]
函数
Python的函数支持递归、默认参数值、可变参数,但不支持函数重载。为了增强代码的可读性,可以在函数后书写”文档字符串“(Documentation Strings,或者简称docstrings),用于解释函数的作用、参数的类型与意义、返回值类型与取值范围等。可以使用内置函数help()打印出函数的使用帮助。比如:

1 >>> def randint(a, b): 2 ... "Return random integer in range [a, b], including both end points." 3 ... 4 >>> help(randint) 5 Help on function randint in module __main__: 6 7 randint(a, b) 8 Return random integer in range [a, b], including both end points.
对象的方法
对象的方法是指绑定到对象的函数。调用对象方法的语法是instance.method(arguments)。它等价于调用Class.method(instance, arguments)。当定义对象方法时,必须显式地定义第一个参数为self,用于访问对象的内部数据。self相当于C++, Java里面的this变量。比如:
class Fish:
def eat(self, food):
if food is not None:
self.hungry=False
#构造Fish的实例:
f=Fish()
#以下两种调用形式是等价的:
Fish.eat(f, "earthworm")
f.eat("earthworm")
Python认识一些以”__“开始并以"__"结束的特殊方法名,它们用于实现运算符重载和实现多种特殊功能。
类型
Python采用动态类型系统。在编译的时候,Python不会检查对象是否拥有被调用的方法或者属性,而是直至运行时,才做出检查。所以操作对象时可能会抛出异常。不过,虽然Python采用动态类型系统,它同时也是强类型的。Python禁止没有明确定义的操作,比如数字加字符串。
与其它面向对象语言一样,Python允许程序员定义类型。构造一个对象只需要像函数一样调用类型即可,比如,对于前面定义的Fish类型,使用Fish()。类型本身也是特殊类型type的对象(type类型本身也是type对象),这种特殊的设计允许对类型进行反射编程。
Python内置丰富的数据类型。与Java、C++相比,这些数据类型有效地减少代码的长度。下面这个列表简要地描述了Python内置数据类型(适用于Python 3.x):
| 类型 | 描述 | 例子 |
|---|---|---|
| str | 一个由字符组成的不可更改的有串行。在Python 3.x里,字符串由Unicode字符组成。 | 'Wikipedia' "Wikipedia" """Spanning multiple lines""" |
| bytes | 一个由字节组成的不可更改的有串行。 | b'Some ASCII' b"Some ASCII" |
| list | 可以包含多种类型的可改变的有串行 | [4.0, 'string', True] |
| tuple | 可以包含多种类型的不可改变的有串行 | (4.0, 'string', True) |
| set, frozenset | 与数学中集合的概念类似。无序的、每个元素唯一。 | {4.0, 'string', True} frozenset([4.0, 'string', True]) |
| dict | 一个可改变的由键值对组成的无串行。 | {'key1': 1.0, 3: False} |
| int | 精度不限的整数 | 42 |
| float | 浮点数。精度与系统相关。 | 3.1415927 |
| complex | 复数 | 3+2.7j |
| bool | 逻辑值。只有两个值:真、假 | True False |
除了各种数据类型,Python语言还用类型来表示函数、模块、类型本身、对象的方法、编译后的Python代码、运行时信息等等。因此,Python具备很强的动态性。
数学运算
Python使用与C、Java类似的运算符,支持整数与浮点数的数学运算。同时还支持复数运算与无穷位数(实际受限于计算机的能力)的整数运算。除了求绝对值函数abs()外,大多数数学函数处于math和cmath模块内。前者用于实数运算,而后者用于复数运算。使用时需要先导入它们,比如:
>>> import math >>> print(math.sin(math.pi/2)) 1.0
fractions模块用于支持分数运算;decimal模块用于支持高精度的浮点数运算。
Python定义求余运行a % b的值处于开区间[0, b)内,如果b是负数,开区间变为(b, 0]。这是一个很常见的定义方式。不过其实它依赖于整除的定义。为了让方程式:b * (a // b) + a % b = a恒真,整除运行需要向负无穷小方向取值。比如7 // 3的结果是2,而(-7) // 3的结果却是-3。这个算法与其它很多编程语言不一样,需要注意,它们的整除运算会向0的方向取值。
Python允许像数学的常用写法那样连着写两个比较运行符。比如a < b < c与a < b and b < c等价。C++的结果与Python不一样,首先它会先计算a < b,根据两者的大小获得0或者1两个值之一,然后再与c进行比较。
【Python】 如何解析json数据结构
一、JSON的格式:
1,对象:
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}
{ 属性 : 值 , 属性 : 值 , 属性 : 值 }
2,数组是有顺序的值的集合。一个数组开始于"[",结束于"]",值之间用","分隔。
[
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}, {name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"},
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}
]
3, 值可以是字符串、数字、true、false、null,也可以是对象或数组。这些结构都能嵌套。
4,json示例:
import json
# Converting Python to JSON
json_object = json.write( python_object )
# Converting JSON to Python
python_object = json.read( json_object )
5,simplejson 示例:
import simplejson
# Converting Python to JSON
json_object = simplejson.dumps( python_object )
# Converting JSON to Python
python_object = simplejson.loads( json_object )
二、python从web接口上查询信息
1,先看个例子
>>> import urllib
>>> url='http://a.bkeep.com/page/api/saInterface/searchServerInfo.htm?serviceTag=729HH2X'
>>> page=urllib.urlopen(url)
>>> data=page.read()
>>> print data //这个就是json的数据结构,str类型
{"total":1,"data":[{"outGuaranteeTime":"","assetsNum":"B50070100007003","cabinet":"H05","deviceModel":"PowerEdge 1950","hostname":"hzshterm1.alibaba.com","logicSite":"中文站","memoryInfo":{"amount":4,"size":8192},"ip":"172.16.20.163","isOnline":true,"useState":"使用中","serviceTag":"729HH2X","cpuInfo":{"amount":2,"masterFrequency":1995,"model":"Intel(R) Xeon(R) CPU E5405 @ 2.00GHz","coreNum":8,"l2CacheSize":6144},"cabinetPositionNum":"","buyTime":"2009-06-29","manageIp":"172.31.58.223","idc":"杭州德胜机房","responsibilityPerson":"张之诚"}],"errorMsg":"","isSuccess":true}
>>> type(data)
<type 'str'>
2,有了json数据结构,我却不知道怎么把它解析出来,幸亏有了李建辉的指导。大概思路是:
首先,json基本上是key/value的,python中就叫字典。既然是字典,那就应该安照读字典的方式去读。
将上面的data转为字典类型,这里用json模块的read方法。
>>> import json
>>> ddata=json.read(data)
>>> ddata
{'isSuccess': True, 'errorMsg': '', 'total': 1, 'data': [{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}]}
>>>
看看ddata已经是dict类型了
>>> type(ddata)
<type 'dict'>
其次,我们以读字典中key 为”data”对应的键值
>>> ddata['data'] //查看字典的方法!
[{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}]
>>>type(ddata[‘data’])
<type 'list'>
发现ddata[‘data’]是一个列表,列表就要用序号来查询
>>> ddata['data'][0] //查看列表的方法!
{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}
>>>
呵呵,ddata[‘data’]列表的0号元素是个字典。。
好,那我们查查key为idc的键值是多少
>>> ddata['data'][0]['idc'] //查看字典的方法!
'\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf'
>>> print ddata['data'][0]['idc'] //呵呵,为什么print搞出来的是汉字呢?
杭州德胜机房
看到这里终于明白怎么解析json数据结构了。。。
那就是”一层一层往下剥”
Python的字符串操作
1.python字符串通常有单引号('...')、双引号("...")、三引号("""...""")或 ('''...''')包围,三引 号包含的字符串可由多行组成,一般可表示大段的叙述性字符串。在使用时基本没有差别,但双引号和三引号("""...""")中可以包含单引号,三引号 ('''...''')可以包含双引号,而不需要转义。
for i, j in {'chr':'\t', ':' : '\t', '..' : '\t'}.iteritems():
text = text.replace(i, j)
print text
1.复制字符串
#strcpy(sStr1,sStr2) sStr1 = 'strcpy' sStr2 = sStr1 sStr1 = 'strcpy2' print sStr2
2.连接字符串
#strcat(sStr1,sStr2) sStr1 = 'strcat' sStr2 = 'append' sStr1 += sStr2 print sStr1
3.查找字符
#strchr(sStr1,sStr2) sStr1 = 'strchr' sStr2 = 'r' nPos = sStr1.index(sStr2) print nPos
4.比较字符串
#strcmp(sStr1,sStr2) sStr1 = 'strchr' sStr2 = 'strch' print cmp(sStr1,sStr2)
5.扫描字符串是否包含指定的字符
#strspn(sStr1,sStr2) sStr1 = '12345678' sStr2 = '456' #sStr1 and chars both in sStr1 and sStr2 print len(sStr1 and sStr2)
6.字符串长度
#strlen(sStr1) sStr1 = 'strlen' print len(sStr1)
7.将字符串中的小写字符转换为大写字符
#strlwr(sStr1) sStr1 = 'JCstrlwr' sStr1 = sStr1.upper() print sStr1
8.追加指定长度的字符串
#strncat(sStr1,sStr2,n) sStr1 = '12345' sStr2 = 'abcdef' n = 3 sStr1 += sStr2[0:n] print sStr1
9.字符串指定长度比较
#strncmp(sStr1,sStr2,n) sStr1 = '12345' sStr2 = '123bc' n = 3 print cmp(sStr1[0:n],sStr2[0:n])
10.复制指定长度的字符
#strncpy(sStr1,sStr2,n) sStr1 = '' sStr2 = '12345' n = 3 sStr1 = sStr2[0:n] print sStr1
11.字符串比较,不区分大小写
#stricmp(sStr1,sStr2) sStr1 = 'abcefg' sStr2 = 'ABCEFG' print cmp(sStr1.upper(),sStr2.upper())
12.将字符串前n个字符替换为指定的字符
#strnset(sStr1,ch,n) sStr1 = '12345' ch = 'r' n = 3 sStr1 = n * ch + sStr1[3:] print sStr1
13.扫描字符串
#strpbrk(sStr1,sStr2) sStr1 = 'cekjgdklab' sStr2 = 'gka' nPos = -1 for c in sStr1: if c in sStr2: nPos = sStr1.index(c) break print nPos
14.翻转字符串
#strrev(sStr1) sStr1 = 'abcdefg' sStr1 = sStr1[::-1] print sStr1
15.查找字符串
#strstr(sStr1,sStr2) sStr1 = 'abcdefg' sStr2 = 'cde' print sStr1.find(sStr2)
16.分割字符串
#strtok(sStr1,sStr2) sStr1 = 'ab,cde,fgh,ijk' sStr2 = ',' sStr1 = sStr1[sStr1.find(sStr2) + 1:] print sStr1
python:beautifulsoup多线程分析抓取网页
python beautifulsoup多线程分析抓取网页
Posted: 24 Jun 2011 04:51 AM PDT
最近在用python做一些网页分析方面的事情,很久没更新博客了,今天补上。下面的代码用到了
1 python 多线程
2 网页分析库:beautifulsoup ,这个库比之前分享的python SGMLParser 网页分析库要强大很多,大家有兴趣可以去了解下。
#@description:蜘蛛抓取内容。
import Queue
import threading
import urllib,urllib2
import time
from BeautifulSoup import BeautifulSoup
hosts = ["http://www.baidu.com","http://www.163.com"]#要抓取的网页
queue = Queue.Queue()
out_queue = Queue.Queue()
class ThreadUrl(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
#grabs host from queue
host = self.queue.get()
proxy_support = urllib2.ProxyHandler({'http':'http://xxx.xxx.xxx.xxxx'})#代理IP
opener = urllib2.build_opener(proxy_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#grabs urls of hosts and then grabs chunk of webpage
url = urllib.urlopen(host)
chunk = url.read()
#place chunk into out queue
self.out_queue.put(chunk)
#signals to queue job is done
self.queue.task_done()
class DatamineThread(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, out_queue):
threading.Thread.__init__(self)
self.out_queue = out_queue
def run(self):
while True:
#grabs host from queue
chunk = self.out_queue.get()
#parse the chunk
soup = BeautifulSoup(chunk)
print soup.findAll(['title']))
#signals to queue job is done
self.out_queue.task_done()
start = time.time()
def main():
#spawn a pool of threads, and pass them queue instance
t = ThreadUrl(queue, out_queue)
t.setDaemon(True)
t.start()
#populate queue with data
for host in hosts:
queue.put(host)
dt = DatamineThread(out_queue)
dt.setDaemon(True)
dt.start()
#wait on the queue until everything has been processed
queue.join()
out_queue.join()
main()
print "Elapsed Time: %s" % (time.time() - start)
运行上面的程序需要安装beautifulsoup, 这个是beautifulsou 文档,大家可以看看。
今天分享python beautifulsoup多线程分析抓取网页就到这里了,有什么运行问题可以发到下面的评论里。大家相互讨论。
Python:读写文件
1.open
使用open打开文件后一定要记得调用文件对象的close()方法。比如可以用try/finally语句来确保最后能关闭文件。
 file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )
file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )注:不能把open语句放在try块里,因为当打开文件出现异常时,文件对象file_object无法执行close()方法。
2.读文件
读文本文件
input = open('data', 'r')#第二个参数默认为rinput = open('data')
读二进制文件
input = open('data', 'rb')
读取所有内容
file_object = open('thefile.txt')try: all_the_text = file_object.read( )finally: file_object.close( )
读固定字节
file_object = open('abinfile', 'rb')try: while True: chunk = file_object.read(100) if not chunk: break do_something_with(chunk)finally: file_object.close( )
读每行
list_of_all_the_lines = file_object.readlines( )如果文件是文本文件,还可以直接遍历文件对象获取每行:
for line in file_object: process line
3.写文件
写文本文件
output = open('data', 'w')
写二进制文件
output = open('data', 'wb')
追加写文件
output = open('data', 'w+')
写数据
file_object = open('thefile.txt', 'w')file_object.write(all_the_text)file_object.close( )
写入多行
file_object.writelines(list_of_text_strings)注意,调用writelines写入多行在性能上会比使用write一次性写入要高。
在处理日志文件的时候,常常会遇到这样的情况:日志文件巨大,不可能一次性把整个文件读入到内存中进行处理,例如需要在一台物理内存为 2GB 的机器上处理一个 2GB 的日志文件,我们可能希望每次只处理其中 200MB 的内容。
在 Python 中,内置的 File 对象直接提供了一个 readlines(sizehint) 函数来完成这样的事情。以下面的代码为例:
 file = open('test.log', 'r'
file = open('test.log', 'r'
)
sizehint = 209715200 # 200M
position = 0
每次调用 readlines(sizehint) 函数,会返回大约 200MB 的数据,而且所返回的必然都是完整的行数据,大多数情况下,返回的数据的字节数会稍微比 sizehint 指定的值大一点(除最后一次调用 readlines(sizehint) 函数的时候)。通常情况下,Python 会自动将用户指定的 sizehint 的值调整成内部缓存大小的整数倍。
file在python是一个特殊的类型,它用于在python程序中对外部的文件进行操作。在python中一切都是对象,file也不例外,file有file的方法和属性。下面先来看如何创建一个file对象:
- file(name[, mode[, buffering]])
file()函数用于创建一个file对象,它有一个别名叫open(),可能更形象一些,它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。name是文件的名字。
mode 是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。用w或a模式打开文件的话,如果文件不存在,那么就自动创建。此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清 空,因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。由于历史的原因,换行符在不同的系统中有不同模式,比如 在 unix中是一个/n,而在windows中是‘/r/n’,用U模式打开文件,就是支持所有的换行模式,也就说‘/r’ '/n' '/r/n'都可表示换行,会有一个tuple用来存贮这个文件中用到过的换行符。不过,虽说换行有多种模式,读到python中统一用/n代替。在模式 字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
buffering如果为0表示不进行缓冲;如果为1表示进行“行缓冲“;如果是一个大于1的数表示缓冲区的大小,应该是以字节为单位的。
file对象有自己的属性和方法。先来看看file的属性。
- closed #标记文件是否已经关闭,由close()改写
- encoding #文件编码
- mode #打开模式
- name #文件名
- newlines #文件中用到的换行模式,是一个tuple
- softspace #boolean型,一般为0,据说用于print
file的读写方法:
- F.read([size]) #size为读取的长度,以byte为单位
- F.readline([size])
#读一行,如果定义了size,有可能返回的只是一行的一部分 - F.readlines([size])
#把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。 - F.write(str)
#把str写到文件中,write()并不会在str后加上一个换行符 - F.writelines(seq)
#把seq的内容全部写到文件中。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
file的其他方法:
- F.close()
#关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。如果一个文件在关闭后还对其进行操作会产生ValueError - F.flush()
#把缓冲区的内容写入硬盘 - F.fileno()
#返回一个长整型的”文件标签“ - F.isatty()
#文件是否是一个终端设备文件(unix系统中的) - F.tell()
#返回文件操作标记的当前位置,以文件的开头为原点 - F.next()
#返回下一行,并将文件操作标记位移到下一行。把一个file用于for ... in file这样的语句时,就是调用next()函数来实现遍历的。 - F.seek(offset[,whence])
#将文件打操作标 记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为 0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操 作标记会自动返回到文件末尾。 - F.truncate([size])
#把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
