-
作者: Mukul
-
翻译: 无伤 <goghs@mail.com>
115月/18关
Redis内存数据库操作命令详解
默认无权限控制:
远程服务连接:
$ redis-cli -h 127.0.0.1 -p 6379
windows下 :redis-cli.exe -h 127.0.0.1 -p 6379
redis 127.0.0.1:6379>
远程服务停止:
$ redis-cli -h 172.168.10.254 -p6379 shutdown
2) 有权限控制时(加上-a 密码):
redis-cli -h 127.0.0.1 -p 6379 -a 123456
除了在登录时通过 -a 参数制定密码外,还可以登录时不指定密码,而在执行操作前进行认证。

Redis默认端口号为127.0.0.1,端口号默认为:6379。
此处本机访问远程IP为132.1.114.44的计算机,则首先要在已经安装了Redis的远程计算机上打开其服务器,redis.server.exe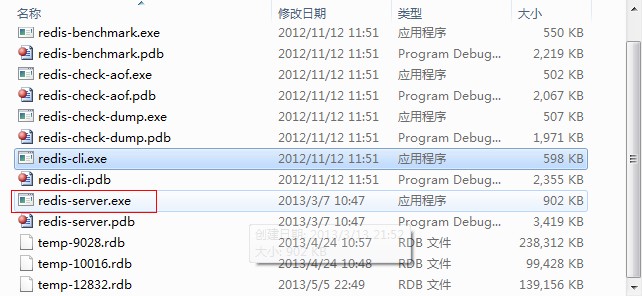
接下来在本机运行redis.cli.exe,也可以通过命令行实现:输入-h 远程计算机IP -p 6379即可连接:

OK了,接下来如果想用自己写的客户端什么的连接远程Redis数据库也只需要输入远程计算机的IP就可以了~
Redis系列-远程连接redis
用法:redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <主机ip>,默认是127.0.0.1
-p <端口>,默认是6379
-a <密码>,如果redis加锁,需要传递密码
--help,显示帮助信息
通过对rendis-cli用法介绍,在101上连接103应该很简单:
[root@linuxidc001 ~]# redis-cli -h 192.168.1.103 -p 6379
redis 192.168.1.103:6379>
在101上对103设置个个string值 user.1.name=zhangsan
redis 192.168.1.103:6379> set user.1.name zhangsan
OK
看到ok,表明设置成功了。然后直接在103上登陆,看能不能获取到这个值。
redis 192.168.1.103:6379> keys *
redis 192.168.1.103:6379> select 1
1、连接操作相关的命令
- quit:关闭连接(connection)
- auth:简单密码认证
2、对value操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个key
- rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
3、对String操作的命令
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
- setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
- setex(key, time, value):向库中添加string(名称为key,值为value)同时,设定过期时间time
- mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
- msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
4、对List操作的命令
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
- ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值为value
- lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从 头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对 keyi 1开始的list执行pop操作。
- brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
- zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
- zrem(key, member) :删除名称为key的zset中的元素member
- zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
- zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
- zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
- zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
- zunionstore / zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行 AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素 的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
313月/17关
用Git撤销任何操作
任何版本控制系统的一个最有的用特性就是“撤销 (undo)”你的错误操作的能力。在 Git 里,“撤销” 蕴含了不少略有差别的功能。
当你进行一次新的提交的时候,Git 会保存你代码库在那个特定时间点的快照;之后,你可以利用 Git 返回到你的项目的一个早期版本。
在本篇博文里,我会讲解某些你需要“撤销”已做出的修改的常见场景,以及利用 Git 进行这些操作的最佳方法。
撤销一个“已公开”的改变
场景: 你已经执行了 git push, 把你的修改发送到了 GitHub,现在你意识到这些 commit 的其中一个是有问题的,你需要撤销那一个 commit.
方法: git revert <SHA>
原理: git revert 会产生一个新的 commit,它和指定 SHA 对应的 commit 是相反的(或者说是反转的)。如果原先的 commit 是“物质”,新的 commit 就是“反物质” — 任何从原先的 commit 里删除的内容会在新的 commit 里被加回去,任何在原先的 commit 里加入的内容会在新的 commit 里被删除。
这是 Git 最安全、最基本的撤销场景,因为它并不会改变历史 — 所以你现在可以 git push 新的“反转” commit 来抵消你错误提交的 commit。
修正最后一个 commit 消息
场景: 你在最后一条 commit 消息里有个笔误,已经执行了 git commit -m "Fxies bug #42",但在 git push 之前你意识到消息应该是 “Fixes bug #42″。
方法: git commit --amend 或 git commit --amend -m "Fixes bug #42"
原理: git commit --amend 会用一个新的 commit 更新并替换最近的 commit ,这个新的 commit 会把任何修改内容和上一个 commit 的内容结合起来。如果当前没有提出任何修改,这个操作就只会把上次的 commit 消息重写一遍。
撤销“本地的”修改
场景: 一只猫从键盘上走过,无意中保存了修改,然后破坏了编辑器。不过,你还没有 commit 这些修改。你想要恢复被修改文件里的所有内容 — 就像上次 commit 的时候一模一样。
方法: git checkout -- <bad filename>
原理: git checkout 会把工作目录里的文件修改到 Git 之前记录的某个状态。你可以提供一个你想返回的分支名或特定 SHA ,或者在缺省情况下,Git 会认为你希望 checkout 的是 HEAD,当前 checkout 分支的最后一次 commit。
记住:你用这种方法“撤销”的任何修改真的会完全消失。因为它们从来没有被提交过,所以之后 Git 也无法帮助我们恢复它们。你要确保自己了解你在这个操作里扔掉的东西是什么!(也许可以先利用 git diff 确认一下)
重置“本地的”修改
场景: 你在本地提交了一些东西(还没有 push),但是所有这些东西都很糟糕,你希望撤销前面的三次提交 — 就像它们从来没有发生过一样。
方法: git reset <last good SHA> 或 git reset --hard <last good SHA>
原理: git reset 会把你的代码库历史返回到指定的 SHA 状态。 这样就像是这些提交从来没有发生过。缺省情况下, git reset 会保留工作目录。这样,提交是没有了,但是修改内容还在磁盘上。这是一种安全的选择,但通常我们会希望一步就“撤销”提交以及修改内容 — 这就是 --hard 选项的功能。
在撤销“本地修改”之后再恢复
场景: 你提交了几个 commit,然后用 git reset --hard 撤销了这些修改(见上一段),接着你又意识到:你希望还原这些修改!
方法: git reflog 和 git reset 或 git checkout
原理: git reflog 对于恢复项目历史是一个超棒的资源。你可以恢复几乎 任何东西 — 任何你 commit 过的东西 — 只要通过 reflog。
你可能已经熟悉了 git log 命令,它会显示 commit 的列表。 git reflog 也是类似的,不过它显示的是一个 HEAD 发生改变的时间列表.
一些注意事项:
它涉及的只是 HEAD的改变。在你切换分支、用git commit进行提交、以及用git reset撤销 commit 时,HEAD会改变,但当你用git checkout -- <bad filename>撤销时(正如我们在前面讲到的情况),HEAD 并不会改变 — 如前所述,这些修改从来没有被提交过,因此 reflog 也无法帮助我们恢复它们。git reflog不会永远保持。Git 会定期清理那些 “用不到的” 对象。不要指望几个月前的提交还一直躺在那里。- 你的
reflog就是你的,只是你的。你不能用git reflog来恢复另一个开发者没有 push 过的 commit。

那么…你怎么利用 reflog 来“恢复”之前“撤销”的 commit 呢?它取决于你想做到的到底是什么:
- 如果你希望准确地恢复项目的历史到某个时间点,用
git reset --hard <SHA> - 如果你希望重建工作目录里的一个或多个文件,让它们恢复到某个时间点的状态,用
git checkout <SHA> -- <filename> - 如果你希望把这些 commit 里的某一个重新提交到你的代码库里,用
git cherry-pick <SHA>
利用分支的另一种做法
场景: 你进行了一些提交,然后意识到你开始 check out 的是 master 分支。你希望这些提交进到另一个特性(feature)分支里。
方法: git branch feature, git reset --hard origin/master, and git checkout feature
原理: 你可能习惯了用 git checkout -b <name> 创建新的分支 — 这是创建新分支并马上 check out 的流行捷径 — 但是你不希望马上切换分支。这里, git branch feature 创建一个叫做 feature 的新分支并指向你最近的 commit,但还是让你 check out 在 master 分支上。
下一步,在提交任何新的 commit 之前,用 git reset --hard 把 master 分支倒回 origin/master 。不过别担心,那些 commit 还在 feature 分支里。
最后,用 git checkout 切换到新的 feature 分支,并且让你最近所有的工作成果都完好无损。
及时分支,省去繁琐
场景: 你在 master 分支的基础上创建了 feature 分支,但 master 分支已经滞后于 origin/master 很多。现在 master 分支已经和 origin/master 同步,你希望在 feature 上的提交是从现在开始,而不是也从滞后很多的地方开始。
方法: git checkout feature 和 git rebase master
原理: 要达到这个效果,你本来可以通过 git reset (不加 --hard, 这样可以在磁盘上保留修改) 和 git checkout -b <new branch name> 然后再重新提交修改,不过这样做的话,你就会失去提交历史。我们有更好的办法。
git rebase master 会做如下的事情:
- 首先它会找到你当前 check out 的分支和
master 分支的共同祖先。 - 然后它 reset 当前 check out 的分支到那个共同祖先,在一个临时保存区存放所有之前的提交。
- 然后它把当前 check out 的分支提到
master的末尾部分,并从临时保存区重新把存放的 commit 提交到master分支的最后一个 commit 之后。
大量的撤销/恢复
场景: 你向某个方向开始实现一个特性,但是半路你意识到另一个方案更好。你已经进行了十几次提交,但你现在只需要其中的一部分。你希望其他不需要的提交统统消失。
方法: git rebase -i <earlier SHA>
原理: -i 参数让 rebase 进入“交互模式”。它开始类似于前面讨论的 rebase,但在重新进行任何提交之前,它会暂停下来并允许你详细地修改每个提交。
rebase -i 会打开你的缺省文本编辑器,里面列出候选的提交。如下所示:

前面两列是键:第一个是选定的命令,对应第二列里的 SHA 确定的 commit。缺省情况下, rebase -i 假定每个 commit 都要通过 pick 命令被运用。
要丢弃一个 commit,只要在编辑器里删除那一行就行了。如果你不再需要项目里的那几个错误的提交,你可以删除上例中的1、3、4行。
如果你需要保留 commit 的内容,而是对 commit 消息进行编辑,你可以使用 reword 命令。 把第一列里的 pick 替换为 reword (或者直接用 r)。有人会觉得在这里直接重写 commit 消息就行了,但是这样不管用 —rebase -i 会忽略 SHA 列前面的任何东西。它后面的文本只是用来帮助我们记住 0835fe2 是干啥的。当你完成 rebase -i 的操作之后,你会被提示输入需要编写的任何 commit 消息。
如果你需要把两个 commit 合并到一起,你可以使用 squash 或 fixup 命令,如下所示:

squash 和 fixup 会“向上”合并 — 带有这两个命令的 commit 会被合并到它的前一个 commit 里。在这个例子里, 0835fe2 和 6943e85 会被合并成一个 commit, 38f5e4e 和 af67f82 会被合并成另一个。
如果你选择了 squash, Git 会提示我们给新合并的 commit 一个新的 commit 消息; fixup 则会把合并清单里第一个 commit 的消息直接给新合并的 commit 。 这里,你知道 af67f82 是一个“完了完了….” 的 commit,所以你会留着 38f5e4e as的 commit 消息,但你会给合并了 0835fe2 和 6943e85 的新 commit 编写一个新的消息。
在你保存并退出编辑器的时候,Git 会按从顶部到底部的顺序运用你的 commit。你可以通过在保存前修改 commit 顺序来改变运用的顺序。如果你愿意,你也可以通过如下安排把 af67f82 和 0835fe2 合并到一起:

修复更早期的 commit
场景: 你在一个更早期的 commit 里忘记了加入一个文件,如果更早的 commit 能包含这个忘记的文件就太棒了。你还没有 push,但这个 commit 不是最近的,所以你没法用 commit --amend.
方法: git commit --squash <SHA of the earlier commit> 和 git rebase --autosquash -i <even earlier SHA>
原理: git commit --squash 会创建一个新的 commit ,它带有一个 commit 消息,类似于 squash! Earlier commit。 (你也可以手工创建一个带有类似 commit 消息的 commit,但是 commit --squash 可以帮你省下输入的工作。)
如果你不想被提示为新合并的 commit 输入一条新的 commit 消息,你也可以利用 git commit --fixup 。在这个情况下,你很可能会用commit --fixup ,因为你只是希望在 rebase 的时候使用早期 commit 的 commit 消息。
rebase --autosquash -i 会激活一个交互式的 rebase 编辑器,但是编辑器打开的时候,在 commit 清单里任何 squash! 和 fixup! 的 commit 都已经配对到目标 commit 上了,如下所示:

在使用 --squash 和 --fixup 的时候,你可能不记得想要修正的 commit 的 SHA 了— 只记得它是前面第 1 个或第 5 个 commit。你会发现 Git 的 ^ 和 ~ 操作符特别好用。HEAD^ 是 HEAD 的前一个 commit。 HEAD~4 是 HEAD 往前第 4 个 – 或者一起算,倒数第 5 个 commit。
停止追踪一个文件
场景: 你偶然把 application.log 加到代码库里了,现在每次你运行应用,Git 都会报告在 application.log 里有未提交的修改。你把 *.login 放到了 .gitignore 文件里,可文件还是在代码库里 — 你怎么才能告诉 Git “撤销” 对这个文件的追踪呢?
方法: git rm --cached application.log
原理: 虽然 .gitignore 会阻止 Git 追踪文件的修改,甚至不关注文件是否存在,但这只是针对那些以前从来没有追踪过的文件。一旦有个文件被加入并提交了,Git 就会持续关注该文件的改变。类似地,如果你利用 git add -f 来强制或覆盖了 .gitignore, Git 还会持续追踪改变的情况。之后你就不必用-f 来添加这个文件了。
如果你希望从 Git 的追踪对象中删除那个本应忽略的文件, git rm --cached 会从追踪对象中删除它,但让文件在磁盘上保持原封不动。因为现在它已经被忽略了,你在 git status 里就不会再看见这个文件,也不会再偶然提交该文件的修改了。
这就是如何在 Git 里撤销任何操作的方法。要了解更多关于本文中用到的 Git 命令,请查看下面的有关文档:
94月/15关
GooglePlus登录添加修改操作记录
使用官方定义按钮页面自动刷新登录:
<div id="gConnect">
<button class="g−signin"
data−scope="https://www.googleapis.com/auth/plus.login https://www.googleapis.com/auth/userinfo.email"
data−requestvisibleactions="http://schemas.google.com/AddActivity"
data−clientId="申请ClientID"
data−callback="onSignInCallback"
data−theme="dark"
data−cookiepolicy="single_host_origin">
</button>
</div>
<script type="text/javascript">
var kx_google_host_config = "配置登录成功后跳转域名";
</script>
<script type="text/javascript" src="https://apis.google.com/js/client:platform.js" async defer></script>
<script type="text/javascript" src="http://简单封装/clientgoogle.so.js" ></script>
使用自己定义按钮页面不自动刷新登录:
<div id="gConnect">
<button type="button" onclick="window.render();return false;" class="btnLarge">使用Google帐号登录</button>
</div>
<script type="text/javascript">
var kx_google_host_config = "配置登录成功后跳转域名";
window.___gcfg = {
parsetags: 'explicit'
};
var render = function(){
gapi.signin.render('gConnect', {
'scope': 'https://www.googleapis.com/auth/plus.login https://www.googleapis.com/auth/userinfo.email',
'requestvisibleactions': 'http://schemas.google.com/AddActivity',
'clientId': '申请ClientID',
'callback': 'onSignInCallback',
'theme': 'dark',
'cookiepolicy': 'single_host_origin'
});
};
</script>
<script type="text/javascript" src="https://apis.google.com/js/client:platform.js" async defer></script>
<script type="text/javascript" src="http://简单封装/clientgoogle.so.js"></script>
clientgoogle.so.js文件封装内容:
var helper = (function() {
var BASE_API_PATH = 'plus/v1/';
return {
onSignInCallback: function(authResult) {
gapi.client.load('plus','v1').then(function() {
if (authResult['access_token']) {
helper.profile();
}
});
},
/**
* Gets and renders the currently signed in user's profile data.
*/
profile: function(){
gapi.client.plus.people.get({
'userId': 'me'
}).then(function(res) {
var urlmark = '?';
var profile = res.result;
var kx_google_host = kx_google_host_config;
var openid_response_nonce = profile.etag;
var openid_return_to = kx_google_host;
var openid_sig = randomString(28);
var openid_identity = "http://shaozhuqing.com/openid?id="+profile.id;
var openid_claimed_id = openid_identity;
var openid_ext1_value_first = profile.name.familyName;
var openid_ext1_value_last = profile.name.givenName;
var openid_ext1_value_email = profile.emails[0].value;
if(kx_google_host.indexOf('?') != −1){
var urlmark = '&';
}
var kx_google_url = kx_google_host+urlmark+"openid.response.nonce="+openid_response_nonce+"&openid.return.to="+
openid_return_to+"&openid.sig="+openid_sig+"&openid.identity="+openid_identity+"&openid.claimed.id="+openid_claimed_id+"&openid.
ext1.value.first="+openid_ext1_value_first+"&openid.ext1.value.last="+openid_ext1_value_last+"&openid.ext1.value.email="+
openid_ext1_value_email;
location.href =kx_google_url;
});
}
};
})();
function onSignInCallback(authResult) {
helper.onSignInCallback(authResult);
}
function randomString(len) {
len = len || 32;
var $chars = 'ABCDEFGHJKMNPQRSTWXYZabcdefhijkmnprstwxyz2345678';
var maxPos = $chars.length;
var pwd = '';
for (i = 0; i < len; i++) {
pwd += $chars.charAt(Math.floor(Math.random() * maxPos));
}
return pwd;
}
按钮自定义参数:
-
data-theme:light | dark
-
data-width :iconOnly | standard | wide
- data-height:short | standard | tall
google开发文档:https://developers.google.com/+/web/signin/
2210月/11关
Python的字符串操作
1.python字符串通常有单引号('...')、双引号("...")、三引号("""...""")或 ('''...''')包围,三引 号包含的字符串可由多行组成,一般可表示大段的叙述性字符串。在使用时基本没有差别,但双引号和三引号("""...""")中可以包含单引号,三引号 ('''...''')可以包含双引号,而不需要转义。
2.用(\)对特殊字符转义,如(\)、(')、(")。
3.常用字符串函数
1)str.count() //返回该字符串中某个子串出现的次数
2)str.find() //返回某个子串出现在该字符串的起始位置
3)str.lower() //将该字符串全部转化为小写
4)str.upper() //转为大写
5)str.split() //分割字符串,返回字串串列表,默认以空格分割
6)len(str) //返回字符串长度
7)迭代替换指定字符串
for i, j in {'chr':'\t', ':' : '\t', '..' : '\t'}.iteritems():
text = text.replace(i, j)
print text
for i, j in {'chr':'\t', ':' : '\t', '..' : '\t'}.iteritems():
text = text.replace(i, j)
print text
例如:
>>> str = 'Hello, world'
>>> str.count('o')
>>> 2
>>> str.find('lo')
>>> 3
>>> str.lower()
>>> 'hello, world'
>>> str.upper()
>>> 'HELLO, WORLD'
>>> str.split()
>>> ['Hello,', 'world']
>>> str.split(',')
>>> ['Hello', ' world']
>>> len(str)
>>> 13
>>> str
>>> 'Hello, world'
1.复制字符串
#strcpy(sStr1,sStr2) sStr1 = 'strcpy' sStr2 = sStr1 sStr1 = 'strcpy2' print sStr2
2.连接字符串
#strcat(sStr1,sStr2) sStr1 = 'strcat' sStr2 = 'append' sStr1 += sStr2 print sStr1
3.查找字符
#strchr(sStr1,sStr2) sStr1 = 'strchr' sStr2 = 'r' nPos = sStr1.index(sStr2) print nPos
4.比较字符串
#strcmp(sStr1,sStr2) sStr1 = 'strchr' sStr2 = 'strch' print cmp(sStr1,sStr2)
5.扫描字符串是否包含指定的字符
#strspn(sStr1,sStr2) sStr1 = '12345678' sStr2 = '456' #sStr1 and chars both in sStr1 and sStr2 print len(sStr1 and sStr2)
6.字符串长度
#strlen(sStr1) sStr1 = 'strlen' print len(sStr1)
7.将字符串中的小写字符转换为大写字符
#strlwr(sStr1) sStr1 = 'JCstrlwr' sStr1 = sStr1.upper() print sStr1
8.追加指定长度的字符串
#strncat(sStr1,sStr2,n) sStr1 = '12345' sStr2 = 'abcdef' n = 3 sStr1 += sStr2[0:n] print sStr1
9.字符串指定长度比较
#strncmp(sStr1,sStr2,n) sStr1 = '12345' sStr2 = '123bc' n = 3 print cmp(sStr1[0:n],sStr2[0:n])
10.复制指定长度的字符
#strncpy(sStr1,sStr2,n) sStr1 = '' sStr2 = '12345' n = 3 sStr1 = sStr2[0:n] print sStr1
11.字符串比较,不区分大小写
#stricmp(sStr1,sStr2) sStr1 = 'abcefg' sStr2 = 'ABCEFG' print cmp(sStr1.upper(),sStr2.upper())
12.将字符串前n个字符替换为指定的字符
#strnset(sStr1,ch,n) sStr1 = '12345' ch = 'r' n = 3 sStr1 = n * ch + sStr1[3:] print sStr1
13.扫描字符串
#strpbrk(sStr1,sStr2) sStr1 = 'cekjgdklab' sStr2 = 'gka' nPos = -1 for c in sStr1: if c in sStr2: nPos = sStr1.index(c) break print nPos
14.翻转字符串
#strrev(sStr1) sStr1 = 'abcdefg' sStr1 = sStr1[::-1] print sStr1
15.查找字符串
#strstr(sStr1,sStr2) sStr1 = 'abcdefg' sStr2 = 'cde' print sStr1.find(sStr2)
16.分割字符串
#strtok(sStr1,sStr2) sStr1 = 'ab,cde,fgh,ijk' sStr2 = ',' sStr1 = sStr1[sStr1.find(sStr2) + 1:] print sStr1
2010月/11关
shell的时间操作
#man date可以看到date的help文件
#date 获取当前时间
#date -d "-1 week" +%Y%m%d 获取上周日期(day,month,year,hour)
#date --date="-24 hour" +%Y%m%d 同上
date_now=`date +%s` shell脚本里面赋给变量值
%% 输出%符号
%a 当前域的星期缩写 (Sun..Sat)
%A 当前域的星期全写 (Sunday..Saturday)
%b 当前域的月份缩写(Jan..Dec)
%B 当前域的月份全称 (January..December)
%c 当前域的默认时间格式 (Sat Nov 04 12:02:33 EST 1989)
%C n百年 [00-99]
%d 两位的天 (01..31)
%D 短时间格式 (mm/dd/yy)
%e 短格式天 ( 1..31)
%F 文件时间格式 same as %Y-%m-%d
%h same as %b
%H 24小时制的小时 (00..23)
%I 12小时制的小时 (01..12)
%j 一年中的第几天 (001..366)
%k 短格式24小时制的小时 ( 0..23)
%l 短格式12小时制的小时 ( 1..12)
%m 双位月份 (01..12)
%M 双位分钟 (00..59)
%n 换行
%N 十亿分之一秒(000000000..999999999)
%p 大写的当前域的上下午指示 (blank in many locales)
%P 小写的当前域的上下午指示 (blank in many locales)
%r 12小时制的时间表示(时:分:秒,双位) time, 12-hour (hh:mm:ss [AP]M)
%R 24小时制的时间表示 (时:分,双位)time, 24-hour (hh:mm)
%s 自基础时间 1970-01-01 00:00:00 到当前时刻的秒数(a GNU extension)
%S 双位秒 second (00..60);
%t 横向制表位(tab)
%T 24小时制时间表示(hh:mm:ss)
%u 数字表示的星期(从星期一开始 1-7)
%U 一年中的第几周星期天为开始 (00..53)
%V 一年中的第几周星期一为开始 (01..53)
%w 一周中的第几天 星期天为开始 (0..6)
%W 一年中的第几周星期一为开始 (00..53)
%x 本地日期格式 (mm/dd/yy)
%X 本地时间格式 (%H:%M:%S)
%y 两位的年(00..99)
%Y 年 (1970…)
例子:编写shell脚本计算离自己生日还有多少天?
read -p "Input your birthday(YYYYmmdd):" date1
m=`date --date="$date1" +%m` #得到生日的月
d=`date --date="$date1" +%d` #得到生日的日
date_now=`date +%s` #得到当前时间的秒值
y=`date +%Y` #得到当前时间的年
birth=`date --date="$y$m$d" +%s` #得到今年的生日日期的秒值
internal=$(($birth-$date_now)) #计算今日到生日日期的间隔时间
if [ "$internal" -lt "0" ]; then #判断今天的生日是否已过
birth=`date --date="$(($y+1))$m$d" +%s` #得到明天的生日日期秒值
internal=$(($birth-$date_now)) #计算今天到下一个生日的间隔时间
fi
echo "There is :$((einternal/60/60/24)) days." #输出结果,秒换算为天
时间戳转换为系统时间:
date -d '1970-01-01 UTC 946684800 seconds' +"%Y-%m-%d %T %z"
263月/10关
PHP中文件读写操作
以下为文件读写操作的 基本PHP函数及模式(看不明白就记住他)
关于模式:
'r' - 只读方式打开, 文件指针置于文件头
'r+' - 读写方式打开,文件指针置于文件头
'w' - 只写打开,文件指针置于文件头, 文件被剪切为0字节, 如果文件不存在, 尝试建立文件
'w+' - 读写打开,文件指针置于文件头, 文件大小被剪切为0字节,如果文件不存在, 尝试建立文件
'a' - 只写方式打开,文件指针置于文件尾,如果文件不存在,尝试建立文件
'a+' - 读写打开,文件指针置于文件尾,如果文件不存在, 尝试建立文件
fgets — 从文件指针中读取一行
fgetss — 从文件指针中读取一行并过滤掉 HTML 标记
file — 把整个文件读入一个数组中
fgetcsv — 从文件指针中读入一行并解析 CSV 字段
你一定用过“网络硬盘”吧,利用它可以按自己的需要新建文件夹来分门别类地把自己的一些文件保存起来,有的还可以在线编辑文件。
PHP中提供了一系列的I/O函数,能简捷地实现我们所需要的功能,包括文件系统操作和目录操作(如“复制[copy]”)。下面给大家介绍的是基本的文件读写操作:(1)读文件;(2)写文件;(3)追加到文件。
TEXT 代码:
读文件:
写文件:
追加到文件后面:
以上只是简单介绍,下面我们要讨论一些更深层的。
有时候会发生多人写入的情况(最常见是在流量较大的网站),会产生无用的数据写入文件, 例如:
info.file文件内容如下 ->
|1|Mukul|15|Male|India (n)
|2|Linus|31|Male|Finland (n)
现在两个人同时注册,引起文件破坏->
info.file ->
|1|Mukul|15|Male|India
|2|Linus|31|Male|Finland
|3|Rob|27|Male|USA|
Bill|29|Male|USA
上例中当PHP写入Rob的信息到文件的时候,Bill正好也开始写入,这时候正好需要写入Rob纪录的'n',引起文件破坏。
我们当然不希望发生这样的情况, 所以让我们看看文件锁定:
复制内容到剪贴板
PHP 代码:
-
<?php
-
$file_name="data.dat";
-
// 我使用4.0.2,所以用LOCK_SH,你可能需要直接写成 1.
-
if($lock){
-
// 如果版本小于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
print"文件内容为 $file_read";
-
?>
上例中,如果两个文件read.php和read2.php都要存取该文件,那么它们都可以读取,但是当一个程序需要写入的时候,它必须等待,直到读操作完成,文件所释放。
-
<?php
-
$file_name="data.dat";
-
// 如果版本低于PHP4.0.2, 用 2 代替 LOCK_EX
-
if($lock){
-
// 如果版本低于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
print"数据成功写入文件";
-
?>
虽然"w"模式用来覆盖文件, 单我觉得不适用。
-
<?php
-
$file_name="data.dat";
-
// 如果版本低于PHP4.0.2, 用 2 代替 LOCK_EX
-
if($lock){
-
// 如果版本小于PHP4.0RC1, 使用 fseek($file_pointer, filsize($file_name));
-
// 如果版本低于PHP4.0.2, 用 3 代替 LOCK_UN
-
}
-
?>
Hmmm..., 对于追加数据与其他操作有点不同,就是FSEEK! 确认文件指针在文件尾部总是一个好习惯。
如果是在Windows系统下, 上面的文件中文件名前面需要加上''.
支持博主

关于邵珠庆博客
文章标签
API
GA
Git
Google Analytics
HTML5
jquery
JS
Linux
MySQL
nginx
PHP
SaaS
web
互联网
代码
使用
分析
创业
原理
命令
好东西
如何
工具
常用
开发
总结
技巧
技术
插件
数据
文件
方法
时间
架构
框架
汇总
百度
管理
系统
网站
网站分析
设计
详解
问题
阿里云
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
