Linux查看系统配置常用命令
一、linux CPU大小
cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
说明:Linux下可以在/proc/cpuinfo中看到每个cpu的详细信息。但是对于双核的cpu,在cpuinfo中会看到两个cpu。常常会让人误以为是两个单核的cpu。
其实应该通过Physical Processor ID来区分单核和双核。而Physical Processor ID可以从cpuinfo或者dmesg中找到. flags 如果有 ht 说明支持超线程技术 判断物理CPU的个数可以查看physical id 的值,相同则为
二、内存大小 cat /proc/meminfo |grep MemTotal
三、硬盘大小 fdisk -l |grep Disk
四、uname -a # 查看内核/操作系统/CPU信息的linux系统信息命令
五、head -n 1 /etc/issue # 查看操作系统版本,是数字1不是字母L
六、cat /proc/cpuinfo # 查看CPU信息的linux系统信息命令
七、hostname # 查看计算机名的linux系统信息命令
八、lspci -tv # 列出所有PCI设备
九、lsusb -tv # 列出所有USB设备的linux系统信息命令
十、lsmod # 列出加载的内核模块
十一、env # 查看环境变量资源
十二、free -m # 查看内存使用量和交换区使用量
十三、df -h # 查看各分区使用情况
十四、du -sh # 查看指定目录的大小
十五、grep MemTotal /proc/meminfo # 查看内存总量
十六、grep MemFree /proc/meminfo # 查看空闲内存量
十七、uptime # 查看系统运行时间、用户数、负载
十八、cat /proc/loadavg # 查看系统负载磁盘和分区
十九、mount | column -t # 查看挂接的分区状态
二十、fdisk -l # 查看所有分区
二十一、swapon -s # 查看所有交换分区
二十二、hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
二十三、dmesg | grep IDE # 查看启动时IDE设备检测状况网络
二十四、ifconfig # 查看所有网络接口的属性
二十五、iptables -L # 查看防火墙设置
二十六、route -n # 查看路由表
二十七、netstat -lntp # 查看所有监听端口
二十八、netstat -antp # 查看所有已经建立的连接
二十九、netstat -s # 查看网络统计信息进程
三十、ps -ef # 查看所有进程
三十一、top # 实时显示进程状态用户
三十二、w # 查看活动用户
三十三、id # 查看指定用户信息
三十四、last # 查看用户登录日志
三十五、cut -d: -f1 /etc/passwd # 查看系统所有用户
三十六、cut -d: -f1 /etc/group # 查看系统所有组
三十七、crontab -l # 查看当前用户的计划任务服务
三十七、chkconfig –list # 列出所有系统服务
三十八、chkconfig –list | grep on # 列出所有启动的系统服务程序
三十九、rpm -qa # 查看所有安装的软件包
四十、cat /proc/cpuinfo :查看CPU相关参数的linux系统命令
四十一、cat /proc/partitions :查看linux硬盘和分区信息的系统信息命令
四十二、cat /proc/meminfo :查看linux系统内存信息的linux系统命令
四十三、cat /proc/version :查看版本,类似uname -r
四十四、cat /proc/ioports :查看设备io端口
四十五、cat /proc/interrupts :查看中断
四十六、cat /proc/pci :查看pci设备的信息
四十七、cat /proc/swaps :查看所有swap分区的信息
常用排序算法的动画效果图
http://www.atool.org/sort.php
1 快速排序
介绍:
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来,且在大部分真实世界的数据,可以决定设计的选择,减少所需时间的二次方项之可能性。
步骤:
- 从数列中挑出一个元素,称为 "基准"(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
排序效果:

详细过程:
2 归并排序
介绍:
归并排序(Merge sort,台湾译作:合并排序)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用
步骤:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针达到序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
排序效果:

详细过程:
3 堆排序
介绍:
堆积排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
步骤:
(比较复杂,自己上网查吧)
排序效果:

详细过程:
(暂无)
4 选择排序
介绍:
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。
排序效果:

详细过程:
5 冒泡排序
介绍:
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
排序效果:

详细过程:
6 插入排序
介绍:
插入排序(Insertion Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
步骤:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置中
- 重复步骤2
排序效果:
(暂无)
详细过程:
7 希尔排序
介绍:
希尔排序,也称递减增量排序算法,是插入排序的一种高速而稳定的改进版本。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
排序效果:

Linux中几个在备份中常用的命令(cp,scp,rsync)
在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。
win7下几个常用的组合键
1.Win+D: 这是高手最常用的第一快捷组合键。这个快捷键组合可以将桌面上的所有窗口瞬间最小化,无论是聊天的窗口还是游戏的窗口只要再次按下这个组合键,刚才的所有窗口都回来了,而且激活的也正是你最小化之前在使用的窗口!
2.Win+F:不用再去移动鼠标点“开始→搜索→文件和文件夹”了,在任何状态下,只要一按Win+F就会弹出搜索窗口。
3.Win+R:在我们的文章中,你经常会看到这样的操作提示:“点击‘开始→运行’,打开‘运行’对话框。其实,还有一个更简单的办法,就是按Win+R
4.Alt+Tab:如果打开的窗口太多,这个组合键就非常有用了,它可以在一个窗口中显示当前打开的所有窗口的名称和图标,选中自己希望要打开的窗口,松开这个组合键就可以了。而alt+tab+shift键则可以反向显示当前打开的窗口。
5.Win+E:当你需要打开资源管理器找文件的时候,这个快捷键会让你感觉非常“爽”!再也不用腾出一只手去摸鼠标了!
6.Win:就是开始菜单咯。
很实用的几个组合键与大家分享.外加微软快捷键大全
Windows 7是微软公司即将发布的一款新一代操作系统,据悉,微软公司已于7月中旬将RTM版本交付PC生产厂商,并将在2009年10月正式上市。此前微软已经就Windows 7发布过多个测试版,根据网友试用,无论是界面,硬件需求,还是性能,相比Vista都有很大改善。
以下是微软官方发布的Windows 7操作系统快捷键的应用解释:
1. 轻松访问键盘快捷方式
按住右Shift 八秒钟: 启用和关闭筛选键
按左 Alt+左 Shift+PrtScn(或 PrtScn):启用或关闭高对比度
按左 Alt+左 Shift+Num Lock :启用或关闭鼠标键
按 Shift 五次: 启用或关闭粘滞键
按住 Num Lock 五秒钟:启用或关闭切换键
Windows 徽标键 + U : 打开轻松访问中心
2. 常规键盘快捷方式
F1 显示帮助
Ctrl+C 复制选择的项目
Ctrl+X 剪切选择的项目
Ctrl+V 粘贴选择的项目
Ctrl+Z 撤消操作
Ctrl+Y 重新执行某项操作
Delete 删除所选项目并将其移动到“回收站”
Shift+Delete 不先将所选项目移动到“回收站”而直接将其删除
F2 重命名选定项目
Ctrl+向右键 将光标移动到下一个字词的起始处
Ctrl+向左键 将光标移动到上一个字词的起始处
Ctrl+向下键 将光标移动到下一个段落的起始处
Ctrl+向上键 将光标移动到上一个段落的起始处
Ctrl+Shift 加某个箭头键 选择一块文本
Shift 加任意箭头键 在窗口中或桌面上选择多个项目,或者在文档中选择文本
Ctrl 加任意箭头键+空格键 选择窗口中或桌面上的多个单个项目
Ctrl+A 选择文档或窗口中的所有项目
F3 搜索文件或文件夹
Alt+Enter 显示所选项的属性
Alt+F4 关闭活动项目或者退出活动程序
Alt+空格键 为活动窗口打开快捷方式菜单
Ctrl+F4 关闭活动文档(在允许同时打开多个文档的程序中)
Alt+Tab 在打开的项目之间切换
Ctrl+Alt+Tab 使用箭头键在打开的项目之间切换
Ctrl+鼠标滚轮 更改桌面上的图标大小
Windows 徽标键 + Tab 使用 Aero Flip 3-D 循环切换任务栏上的程序
Ctrl + Windows 徽标键 + Tab 通过 Aero Flip 3-D 使用箭头键循环切换任务栏上的程序
Alt+Esc 以项目打开的顺序循环切换项目
F6 在窗口中或桌面上循环切换屏幕元素
F4 在 Windows 资源管理器中显示地址栏列表
Shift+F10 显示选定项目的快捷菜单
Ctrl+Esc 打开「开始」菜单
Alt+加下划线的字母 显示相应的菜单
Alt+加下划线的字母 执行菜单命令(或其他有下划线的命令)
F10 激活活动程序中的菜单栏
向右键 打开右侧的下一个菜单或者打开子菜单
向左键 打开左侧的下一个菜单或者关闭子菜单
F5 刷新活动窗口
Alt+向上键 在 Windows 资源管理器中查看上一级文件夹
Esc 取消当前任务
Ctrl+Shift+Esc 打开任务管理器
** CD 时按住 Shift 阻止 CD 自动播放
3. 对话框键盘快捷方式
Ctrl+Tab 在选项卡上向前移动
Ctrl+Shift+Tab 在选项卡上向后移动
Tab 在选项上向前移动
Shift+Tab 在选项上向后移动
Alt+加下划线的字母 执行与该字母匹配的命令(或选择选项)
Enter 对于许多选定命令代替单击鼠标
空格键 如果活动选项是复选框,则选中或清除该复选框
箭头键 如果活动选项是一组选项按钮,则选择某个按钮
F1 显示帮助
F4 显示活动列表中的项目
Backspace 如果在“另存为”或“打开”对话框中选中了某个文件夹,则打开上一级文件夹
4. Windows 徽标键相关的快捷键
Windows徽标键就是显示为Windows旗帜,或标有文字Win或Windows的按键,以下简称Win键。XP时代有4个经典的 Win 键组合:R/E/F/L。到了 Win7,花样更多了。
Win:打开或关闭开始菜单
Win + Pause:显示系统属性对话框
Win + D:显示桌面
Win + M:最小化所有窗口
Win + SHIFT + M:还原最小化窗口到桌面上
Win + E:打开我的电脑
Win + F:搜索文件或文件夹
Ctrl + Win + F:搜索计算机(如果您在网络上)
Win + L:锁定您的计算机或切换用户
Win + R:打开运行对话框
Win + T:切换任务栏上的程序(感觉是和alt+ESC 一样 )
Win + 数字:让位于任务栏指定位置(按下的数字作为序号)的程序,新开一个实例。(感觉这个比较新颖,貌似快速启动。) Shift + Windows logo key +number:Start a new instance of the program pinned to the taskbar in the position indicated by the number
Ctrl + Win + 数字:让位于任务栏指定位置(按下的数字作为序号)的程序,切换到上一次的活动窗口。 Ctrl+Windows logo key +number:Switch to the last active window of the program pinned to the taskbar in the position indicated by the number
ALT + Win + 数字:让位于任务栏指定位置(按下的数字作为序号)的程序,显示跳转清单。 Alt+Windows logo key +number: Open the Jump List for the program pinned to the taskbar in the position indicated by the number
Win + TAB:循环切换任务栏上的程序并使用的Aero三维效果
Ctrl + Win + TAB:使用方向键来循环循环切换任务栏上的程序,并使用的Aero三维效果
按Ctrl + Win + B:切换到在通知区域中显示信息的程序
Win + 空格:预览桌面
Win + ↑:最大化窗口
Win + ↓:最小化窗口
Win + ←:最大化到窗口左侧的屏幕上
Win + →:最大化窗口到右侧的屏幕上
Win + Home:最小化所有窗口,除了当前激活窗口
Win+ SHIFT + ↑:拉伸窗口的到屏幕的顶部和底部
Win+ SHIFT + →/←:移动一个窗口,从一个显示器到另一个
Win + P:选择一个演示文稿显示模式
Win + G:循环切换侧边栏的小工具
Win + U:打开轻松访问中心
Win + x:打开Windows移动中心
5. Windows Explorer相关快捷键
Ctrl+N 打开新窗口
Ctrl+Shift+N 新建文件夹
End 显示活动窗口的底部
Home 显示活动窗口的顶部
F11 最大化或最小化活动窗口
Num Lock+小键盘星号(*) 显示选中文件夹的所有子文件夹
Num Lock+小键盘加号(+) 显示选中文件夹的内容
Num Lock+小键盘减号(-) 折叠选中文件夹
左方向键 折叠当前展开的选中文件夹或选中上层文件夹
Alt+Enter 打开选中项目的属性对话框
Alt+P 显示预览窗格
Alt+左方向键 切换到前一次打开的文件夹
右方向键 显示(展开)当前选中项目或选中第一个子文件夹
Alt+右方向键 切换到下一次后打开的文件夹
Alt+上方向键 打开上层文件夹
Ctrl+鼠标滚轮 改变文件和文件夹图标的大小和外观
Alt+D 选中地址栏(定位到地址栏)
Ctrl+E 选中搜索框(定位到搜索框)
6. 放大镜键盘快捷方式
Windows 徽标键 + 加号或减号 放大或缩小
Ctrl+Alt+空格键 显示鼠标指针
Ctrl+Alt+F 切换到全屏模式
Ctrl+Alt+L 切换到镜头模式
Ctrl+Alt+D 切换到停靠模式
Ctrl+Alt+I 反色
Ctrl+Alt+箭头键 按箭头键的方向平移
Ctrl+Alt+R 调整镜头的大小
Windows 徽标键 + Esc 退出放大镜
7. 远程桌面相关快捷键
Alt+Page Up 按从左向右顺序切换程序
Alt+Page Down 按从右向左切换程序
Alt+Insert 按程序打开先后顺序循环切换程序
Alt+Home 显示“开始”菜单
Ctrl+Alt+Break 在窗口模式和全屏之间切换
Ctrl+Alt+End 显示Windows安全性对话框
Alt+Delete 显示当前窗口的系统菜单
Ctrl+Alt+-(小键盘减号) 当前活动窗口截图
Ctrl+Alt++(小键盘加号) 全屏截图
Ctrl+Alt+向右键 从远程桌面控件“跳转”到主机程序中的控件(如按钮或文本框)。将远程桌面控件嵌入到其他(主机)程序后,此功能非常有用。
Ctrl+Alt+向左键 从远程桌面控件“跳转”到主机程序中的控件(如按钮或文本框)。将远程桌面控件嵌入到其他(主机)程序后,此功能非常有用。
8. 画图键盘快捷方式
Ctrl+N 创建新的图片
Ctrl+O 打开现有图片
Ctrl+S 将更改保存到图片
F12 将此图片另存为新文件
Ctrl+P 打印图片
Alt+F4 关闭图片及其画图窗口
Ctrl+Z 撤消更改
Ctrl+Y 恢复更改
Ctrl+A 选择整个图片
Ctrl+X 剪切选择内容
Ctrl+C 将选择内容复制到剪贴板
Ctrl+V 从剪贴板粘贴选择内容
向右键 将选择内容或活动图形向右移动一个像素
向左键 将选择内容或活动图形向左移动一个像素
向下键 将选择内容或活动图形向下移动一个像素
向上键 将选择内容或活动图形向上移动一个像素
Esc 取消某个选择
Delete 删除某个选择
Ctrl+B 粗体选择文本
Ctrl++ 将画笔、直线或形状轮廓的宽度增加一个像素
Ctrl+- 将画笔、直线或形状轮廓的宽度减少一个像素
Ctrl+I 将所选文本改为斜体
Ctrl+U 为所选文本添加下划线
Ctrl+E 打开“属性”对话框
Ctrl+W 打开“调整大小和扭曲”对话框
Ctrl+Page Up 放大
Ctrl+Page Down 缩小
F11 以全屏模式查看图片
Ctrl+R 显示或隐藏标尺
Ctrl+G 显示或隐藏网格线
F10 或 Alt 显示快捷键提示
Shift+F10 显示当前快捷菜单
F1 打开“画图”帮助
9. 写字板的键盘快捷方式
Ctrl+N 新建一个文档
Ctrl+O 打开一个现有文档
Ctrl+S 将更改保存到文档
F12 将此文档另存为新文件
Ctrl+P 打印文档
Alt+F4 关闭“写字板”
Ctrl+Z 撤消更改
Ctrl+Y 恢复更改
Ctrl+A 选择整个文档
Ctrl+X 剪切选择内容
Ctrl+C 将选择内容复制到剪贴板
Ctrl+V 从剪贴板粘贴选择内容
Ctrl+B 将所选文本改为粗体
Ctrl+I 将所选文本改为斜体
Ctrl+U 为所选文本添加下划线
Ctrl+= 使选择的文本成为下标
Ctrl+Shift+= 使选择的文本成为上标
Ctrl+L 向左对齐文本
Ctrl+E 向中心对齐文本
Ctrl+R 向右对齐文本
Ctrl+J 对齐文本
Ctrl+1 设置单倍行距
Ctrl+2 设置双倍行距
Ctrl+5 将行距设置为 1.5
Ctrl+Shift+> 增加字体大小
Ctrl+Shift+< 减小字体大小
Ctrl+Shift+A 将字符更改为全部使用大写字母
Ctrl+Shift+L 更改项目符号样式
Ctrl+D ** Microsoft 画图图片
Ctrl+F 在文档中查找文本
F3 在“查找”对话框中查找文本的下一个实例
Ctrl+H 在文档中替换文本
Ctrl+向左键 将光标向左移动一个字
Ctrl+向右键 将光标向右移动一个字
Ctrl+向上键 将光标移动到上一行
Ctrl+向下键 将光标移动到下一行
Ctrl+Home 移动到文档的开头
Ctrl+End 移动到文档的结尾
Ctrl+Page Up 向上移动一个页面
Ctrl+Page Down 向下移动一个页面
Ctrl+Delete 删除下一个字
F10 显示快捷键提示
Shift+F10 显示当前快捷菜单
F1 打开“写字板”帮助
10. 计算器的键盘快捷方式
Atl+1 切换到标准模式
Alt+2 切换到科学型模式
Alt+3 切换到程序员模式
Alt+4 切换到统计信息模式
Ctrl+E 打开日期计算
Ctrl+H 将计算历史记录打开或关闭
Ctrl+U 打开单位转换
Alt+C 计算或解决日期计算和工作表
F1 打开“计算器”帮助
Ctrl+Q 按下 M- 按钮
Ctrl+P 按下 M+ 按钮
Ctrl+M 按下 MS 按钮
Ctrl+R 按下 MR 按钮
Ctrl+L 按下 MC 按钮
% 按下 % 按钮
F9 按下 +/– 按钮
/ 按下 / 按钮
* 按下 * 按钮
+ 按下 + 按钮
- 按下 – 按钮
R 按下 1/× 按钮
@ 按下平方根按钮
0-9 按下数字按钮 (0-9)
= 按下 = 按钮
. 按下 .(小数点)按钮
Backspace 按下 Backspace 按钮
Esc 按下 C 按钮
Del 按下 CE 按钮
Ctrl+Shift+D 清除计算历史记录
F2 编辑计算历史记录
向上箭头键 在计算历史记录中向上导航
向下箭头键 在计算历史记录中向下导航
Esc 取消编辑计算历史记录
Enter 编辑后重新计算计算历史记录
F3 在科学型模式下选择“角度”
F4 在科学型模式下选择“弧度”
F5 在科学型模式下选择“梯度”
I 在科学型模式下按 Inv 按钮
D 在科学型模式下按 Mod 按钮
Ctrl+S 在科学型模式下按 sinh 按钮
Ctrl+O 在科学型模式下按 cosh 按钮
Ctrl+T 在科学型模式下按 tanh 按钮
( 在科学型模式下按 ( 按钮
) 在科学型模式下按 ) 按钮
N 在科学型模式下按 ln 按钮
; 在科学型模式下按 Int 按钮
S 在科学型模式下按 sin 按钮
O 在科学型模式下按 cos 按钮
T 在科学型模式下按 tan 按钮
M 在科学型模式下按 dms 按钮
P 在科学型模式下按 pi 按钮
V 在科学型模式下按 F-E 按钮
X 在科学型模式下按 Exp 按钮
Q 在科学型模式下按 x^2 按钮
Y 在科学型模式下按 x^y 按钮
# 在科学型模式下按 x^3 按钮
L 在科学型模式下按 log 按钮
! 在科学型模式下按 n! 按钮
Ctrl+Y 在科学型模式下按 y√x 按钮
Ctrl+B 在科学型模式下按 3√x 按钮
Ctrl+G 在科学型模式下按 10x 按钮
F5 在程序员模式下选择 Hex
F6 在程序员模式下选择 Dec
F7 在程序员模式下选择 Oct
F8 在程序员模式下选择 Bin
F12 在程序员模式下选择 QWord
F2 在程序员模式下选择 Dword
F3 在程序员模式下选择 Word
F4 在程序员模式下选择 Byte
K 在程序员模式下按 RoR 按钮
J 在程序员模式下按 RoL 按钮
% 在程序员模式下按 Mod 按钮
( 在程序员模式下按 ( 按钮
) 在程序员模式下按 ) 按钮
| 在程序员模式下按 Or 按钮
^ 在程序员模式下按 Xor 按钮
~ 在程序员模式下按 Not 按钮
& 在程序员模式下按 And 按钮
A-F 在程序员模式下按 A-F 按钮
空格键 在程序员模式下切换位值
A 在统计信息模式下按 Average 按钮
Ctrl+A 在统计信息模式下按 Average Sq 按钮
S 在统计信息模式下按 Sum 按钮
Ctrl+S 在统计信息模式下按 Sum Sq 按钮
T 在统计信息模式下按 S.D. 按钮
Ctrl+T 在统计信息模式下按 Inv S.D. 按钮
D 在统计信息模式下按 CAD 按钮
11. Windows 日记本键盘快捷方式
Ctrl+N 开始新的便笺
Ctrl+O 打开最近使用的便笺
Ctrl+S 将更改保存到便笺
Ctrl+Shift+V 将便笺移动到特定的文件夹
Ctrl+P 打印便笺
Alt+F4 关闭便笺及其日记本窗口
Ctrl+Z 撤消更改
Ctrl+Y 恢复更改
Ctrl+A 选择页面上的所有项目
Ctrl+X 剪切选择内容
Ctrl+C 将选择内容复制到剪贴板
Ctrl+V 从剪贴板粘贴选择内容
Esc 取消某个选择
Delete 删除某个选择
Ctrl+F 开始基本查找
Ctrl+G 转到页面
F5 刷新查找结果
F5 刷新便笺列表
F6 在便笺列表和便笺之间切换
Ctrl+Shift+C 显示便笺列表中列标题的快捷菜单
F11 以全屏模式查看便笺
F1 打开“日记本”帮助
12. Windows 帮助查看器键盘快捷方式
Alt+C 显示目录
Alt+N 显示“连接设置”菜单
F10 显示“选项”菜单
Alt+向左键 返回先前查看过的主题
Alt+向右键 向前移动到下一个(先前已查看过的)主题
Alt+A 显示客户支持页面
Alt+Home 显示帮助和支持主页
Home 移动到主题的开头
End 移动到主题的末尾
Ctrl+F 搜索当前主题
Ctrl+P 打印主题
F3 将光标移动到搜索框
图解git中的最常用命令
此页图解git中的最常用命令。如果你稍微理解git的工作原理,这篇文章能够让你理解的更透彻。 如果你想知道这个站点怎样产生,请前往GitHub repository。
正文
- 基本用法
- 约定
- 命令详解
- Diff
- Commit
- Checkout
- Detached HEAD(匿名分支提交)
- Reset
- Merge
- Cherry Pick
- Rebase
- 技术说明
基本用法
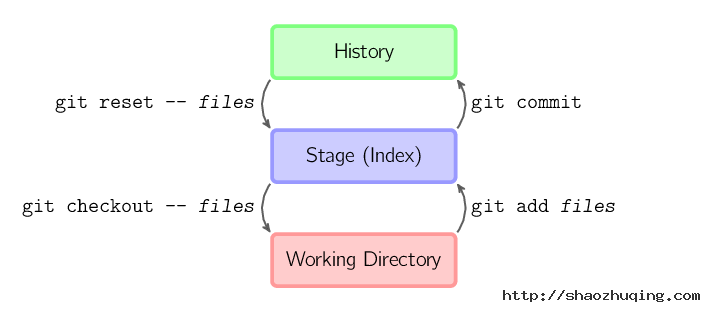
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。
你可以用 git reset -p, git checkout -p, or git add -p进入交互模式。
也可以跳过暂存区域直接从仓库取出文件或者直接提交代码。
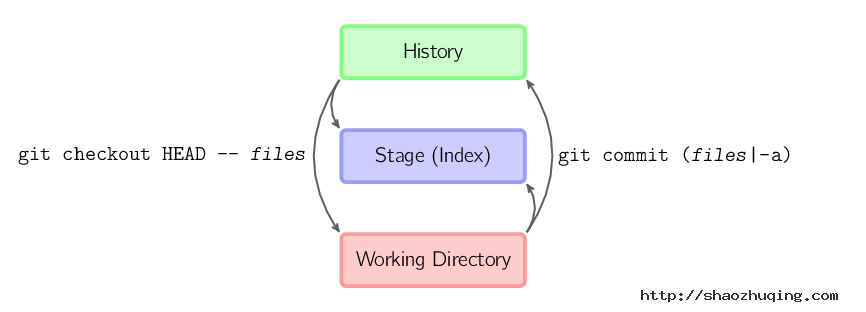
git commit -a相当于运行 git add 把所有当前目录下的文件加入暂存区域再运行。git commit.git commit files进行一次包含最后一次提交加上工作目录中文件快照的提交。并且文件被添加到暂存区域。git checkout HEAD -- files回滚到复制最后一次提交。
约定
后文中以下面的形式使用图片。
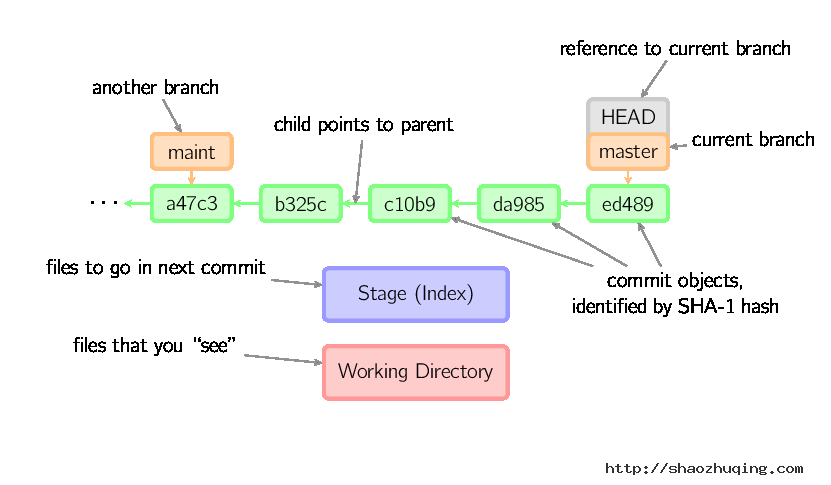
绿色的5位字符表示提交的ID,分别指向父节点。分支用橘色显示,分别指向特定的提交。当前分支由附在其上的HEAD标识。 这张图片里显示最后5次提交,ed489是最新提交。 master分支指向此次提交,另一个maint分支指向祖父提交节点。
命令详解
Diff
有许多种方法查看两次提交之间的变动。下面是一些示例。
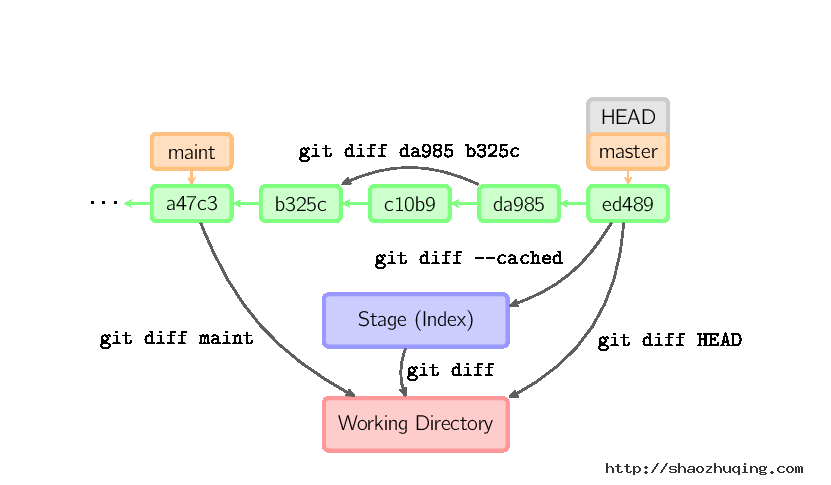
Commit
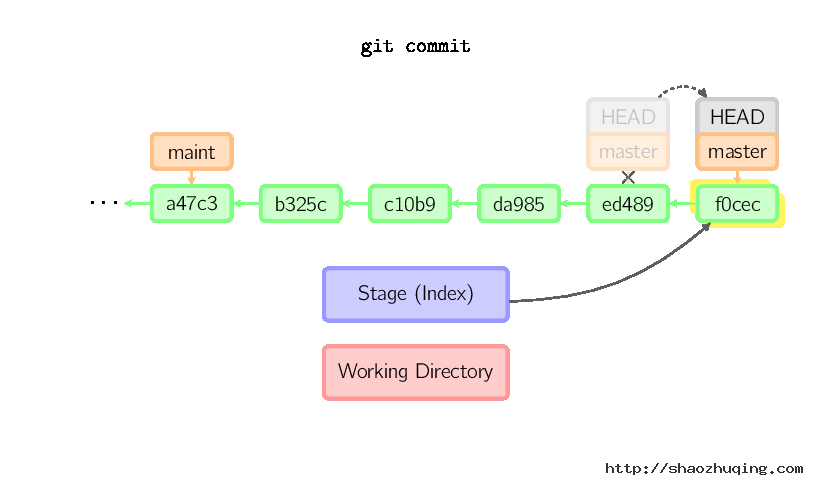
提交时,git用暂存区域的文件创建一个新的提交,并把此时的节点设为父节点。然后把当前分支指向新的提交节点。下图中,当前分支是master。 在运行命令之前,master指向ed489,提交后,master指向新的节点f0cec并以ed489作为父节点。
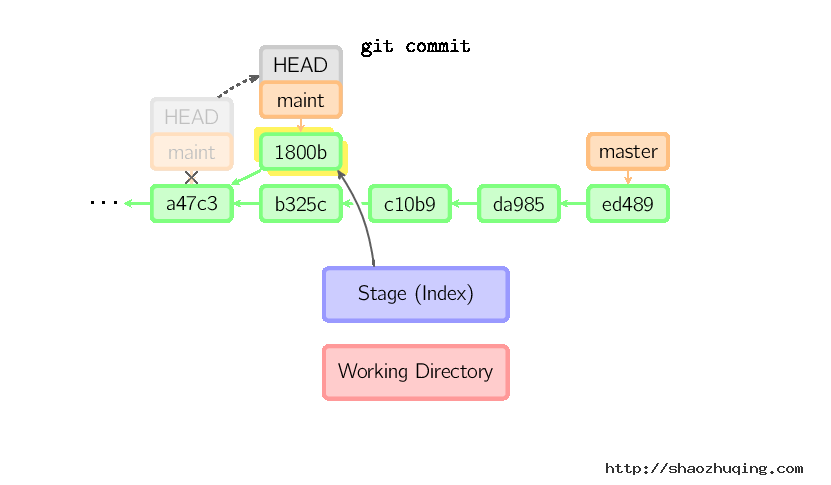
即便当前分支是某次提交的祖父节点,git会同样操作。下图中,在master分支的祖父节点maint分支进行一次提交,生成了1800b。 这样,maint分支就不再是master分支的祖父节点。此时,合并 (或者 衍合) 是必须的。
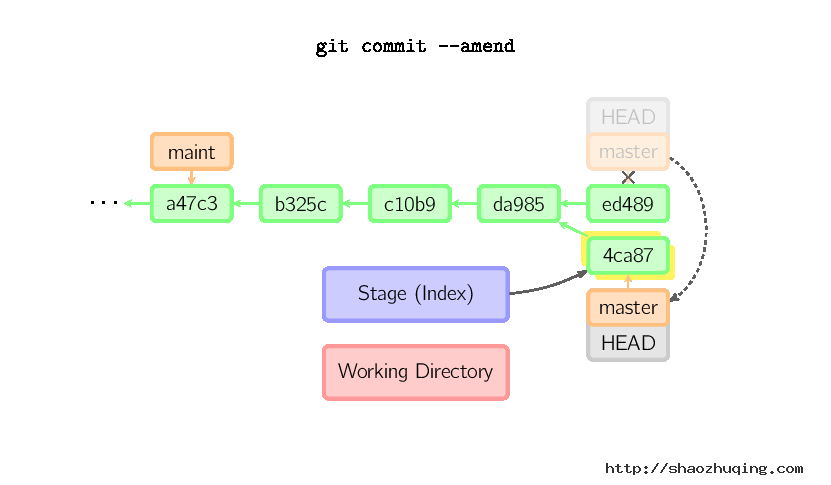
如果想更改一次提交,使用 git commit --amend。git会使用与当前提交相同的父节点进行一次新提交,旧的提交会被取消。
另一个例子是分离HEAD提交,后文讲。
Checkout
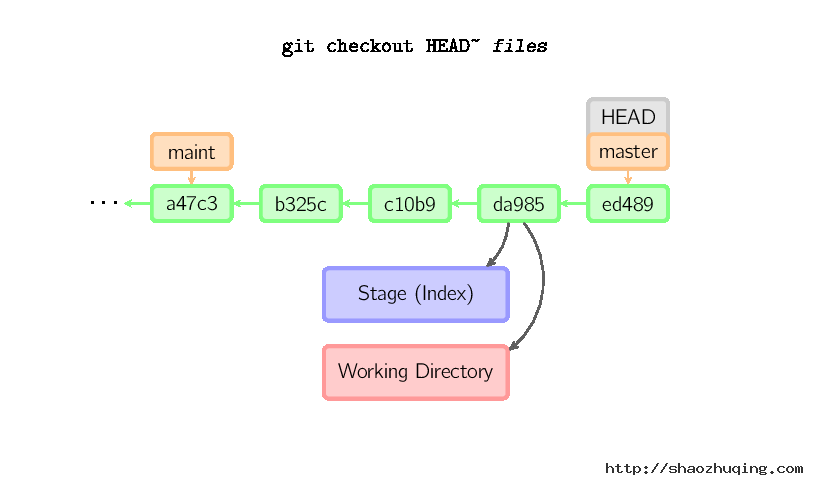
checkout命令用于从历史提交(或者暂存区域)中拷贝文件到工作目录,也可用于切换分支。
当给定某个文件名(或者打开-p选项,或者文件名和-p选项同时打开)时,git会从指定的提交中拷贝文件到暂存区域和工作目录。比如,git checkout HEAD~ foo.c会将提交节点HEAD~(即当前提交节点的父节点)中的foo.c复制到工作目录并且加到暂存区域中。(如果命令中没有指定提交节点,则会从暂存区域中拷贝内容。)注意当前分支不会发生变化。
当不指定文件名,而是给出一个(本地)分支时,那么HEAD标识会移动到那个分支(也就是说,我们“切换”到那个分支了),然后暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点(下图中的a47c3)中的所有文件都会被复制(到暂存区域和工作目录中);只存在于老的提交节点(ed489)中的文件会被删除;不属于上述两者的文件会被忽略,不受影响。
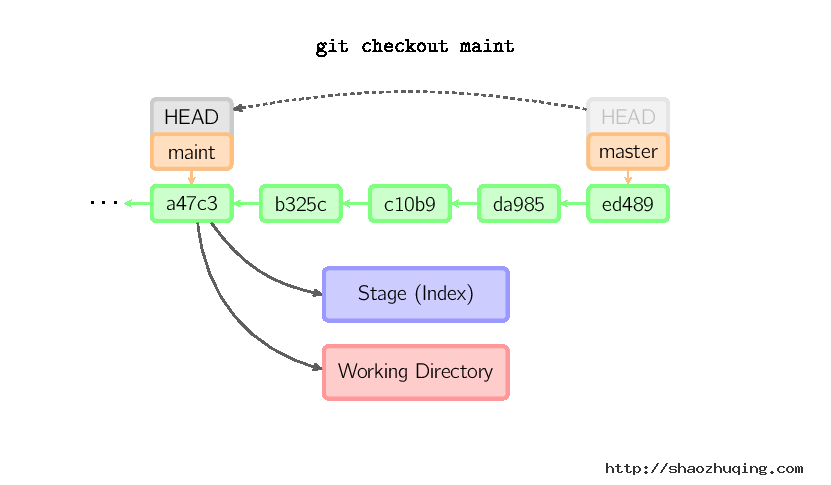
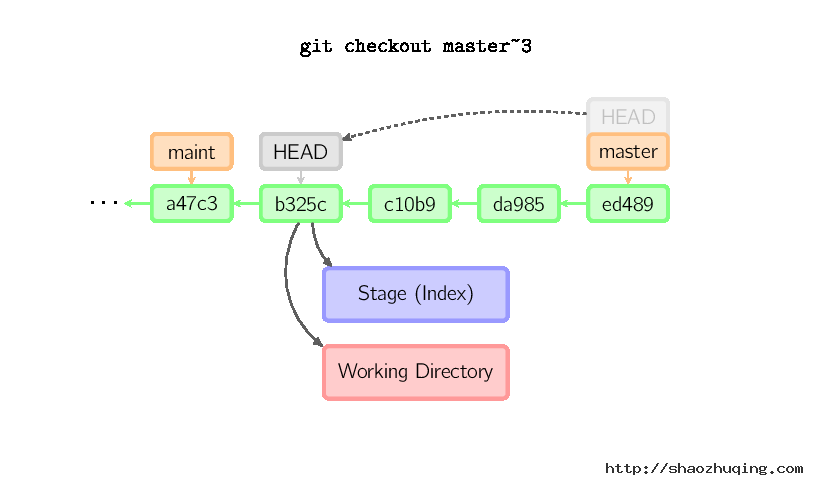
如果既没有指定文件名,也没有指定分支名,而是一个标签、远程分支、SHA-1值或者是像master~3类似的东西,就得到一个匿名分支,称作detached HEAD(被分离的HEAD标识)。这样可以很方便地在历史版本之间互相切换。比如说你想要编译1.6.6.1版本的git,你可以运行git checkout v1.6.6.1(这是一个标签,而非分支名),编译,安装,然后切换回另一个分支,比如说git checkout master。然而,当提交操作涉及到“分离的HEAD”时,其行为会略有不同,详情见在下面。
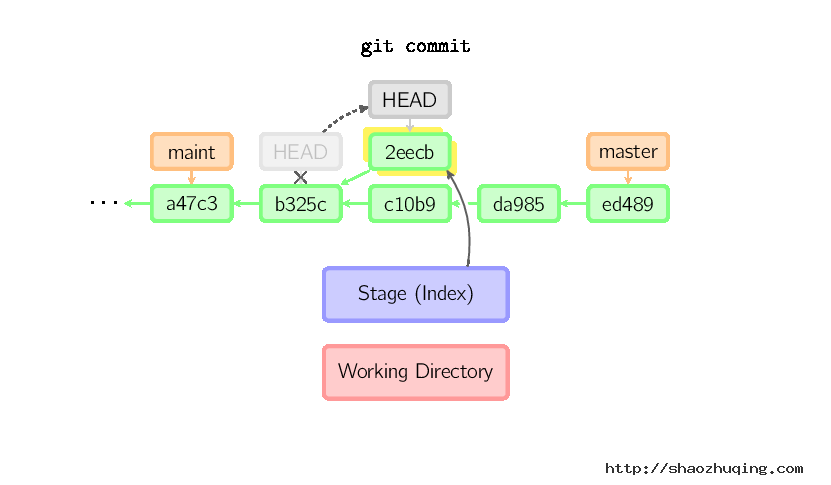
HEAD标识处于分离状态时的提交操作
当HEAD处于分离状态(不依附于任一分支)时,提交操作可以正常进行,但是不会更新任何已命名的分支。(你可以认为这是在更新一个匿名分支。)
一旦此后你切换到别的分支,比如说master,那么这个提交节点(可能)再也不会被引用到,然后就会被丢弃掉了。注意这个命令之后就不会有东西引用2eecb。
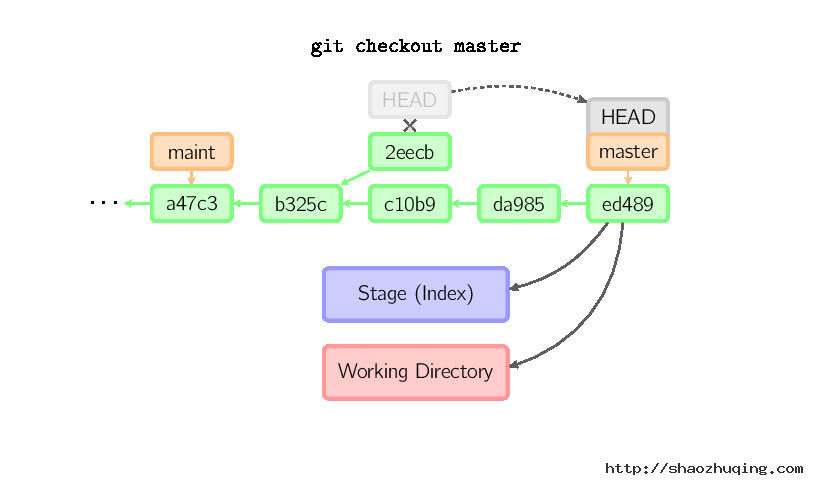
但是,如果你想保存这个状态,可以用命令git checkout -b name来创建一个新的分支。
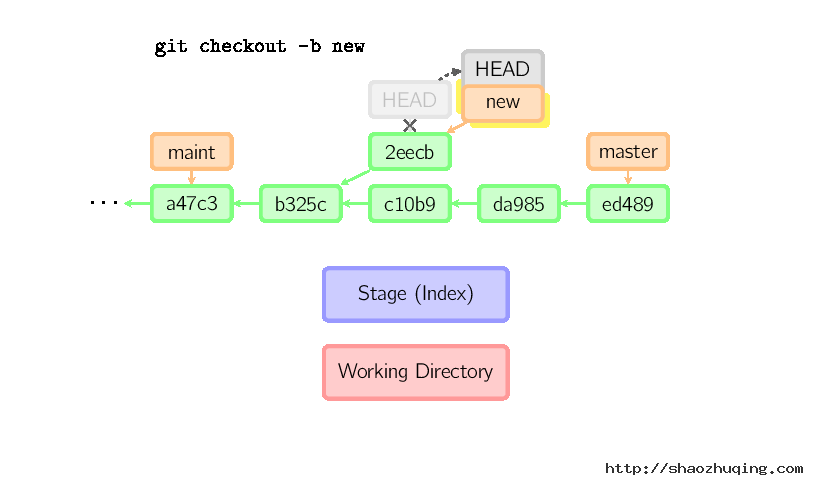
Reset
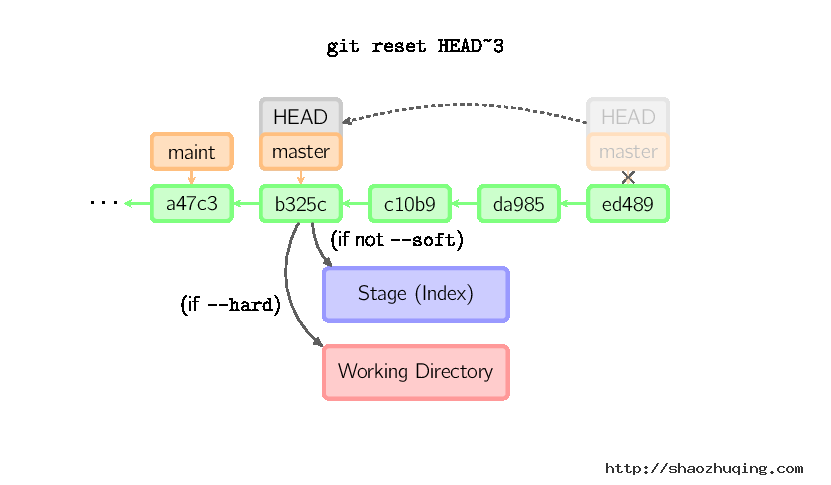
reset命令把当前分支指向另一个位置,并且有选择的变动工作目录和索引。也用来在从历史仓库中复制文件到索引,而不动工作目录。
如果不给选项,那么当前分支指向到那个提交。如果用--hard选项,那么工作目录也更新,如果用--soft选项,那么都不变。
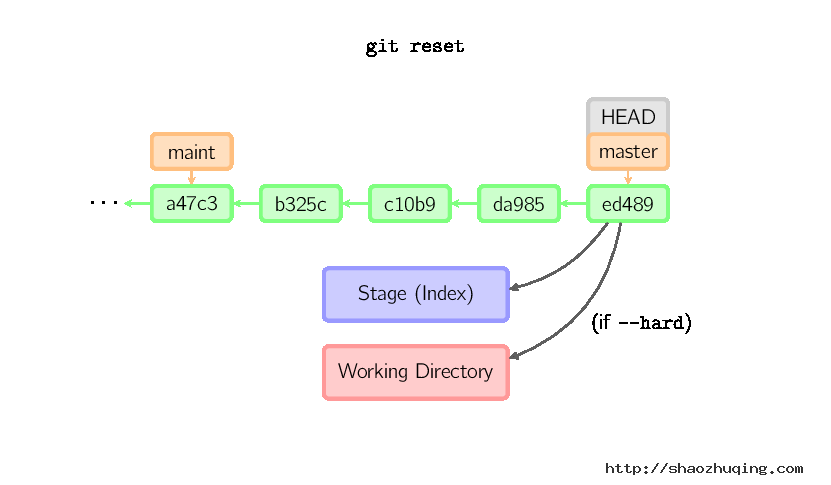
如果没有给出提交点的版本号,那么默认用HEAD。这样,分支指向不变,但是索引会回滚到最后一次提交,如果用--hard选项,工作目录也同样。
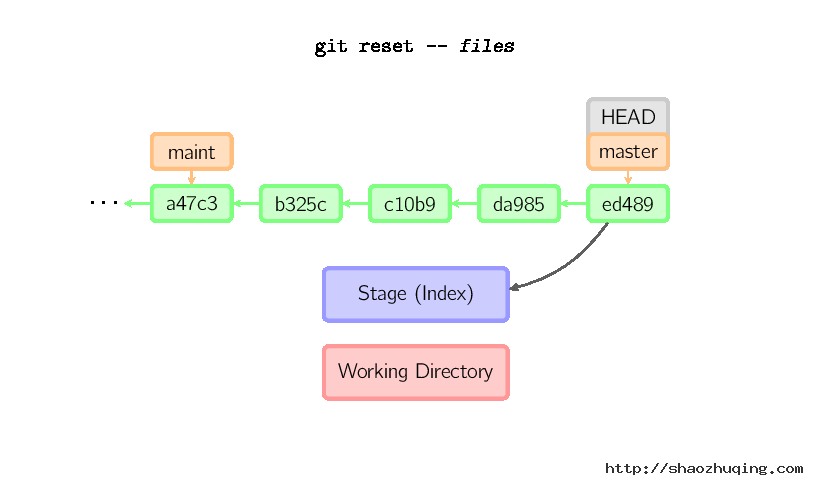
如果给了文件名(或者 -p选项), 那么工作效果和带文件名的checkout差不多,除了索引被更新。
Merge
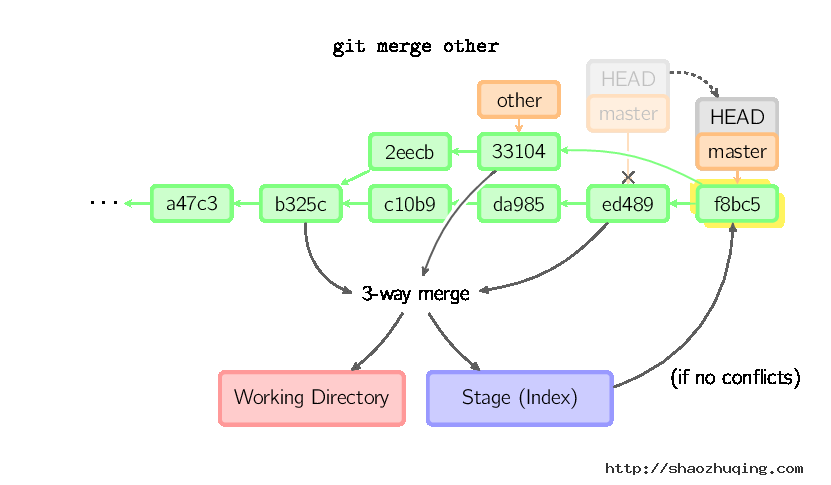
merge 命令把不同分支合并起来。合并前,索引必须和当前提交相同。如果另一个分支是当前提交的祖父节点,那么合并命令将什么也不做。 另一种情况是如果当前提交是另一个分支的祖父节点,就导致fast-forward合并。指向只是简单的移动,并生成一个新的提交。
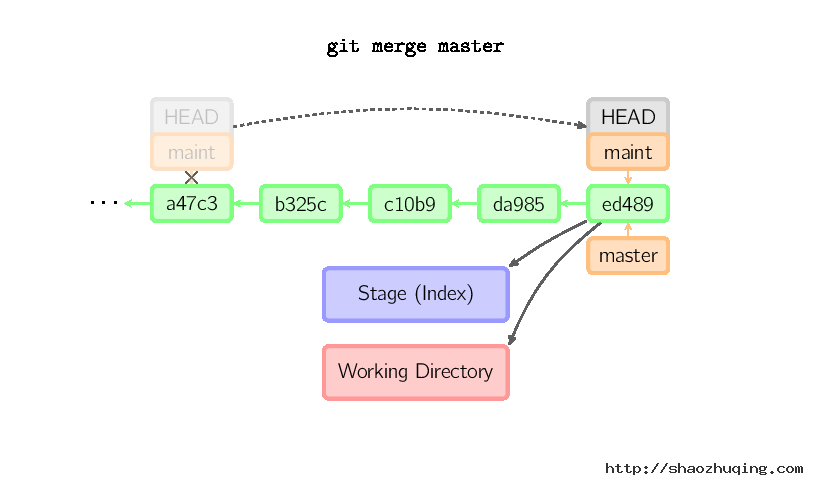
否则就是一次真正的合并。默认把当前提交(ed489 如下所示)和另一个提交(33104)以及他们的共同祖父节点(b325c)进行一次三方合并。结果是先保存当前目录和索引,然后和父节点33104一起做一次新提交。
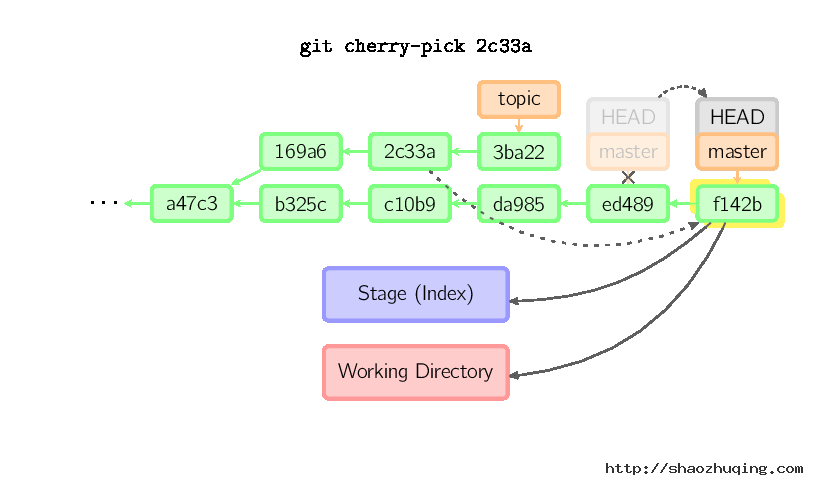
Cherry Pick
cherry-pick命令"复制"一个提交节点并在当前复制做一次完全一样的新提交。
Rebase
衍合是合并命令的另一种选择。合并把两个父分支合并进行一次提交,提交历史不是线性的。衍合在当前分支上重演另一个分支的历史,提交历史是线性的。 本质上,这是线性化的自动的cherry-pick
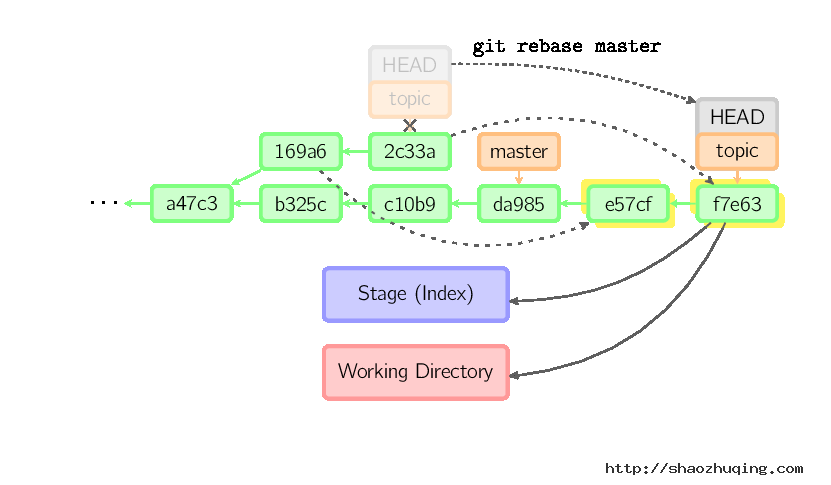
上面的命令都在topic分支中进行,而不是master分支,在master分支上重演,并且把分支指向新的节点。注意旧提交没有被引用,将被回收。
要限制回滚范围,使用--onto选项。下面的命令在master分支上重演当前分支从169a6以来的最近几个提交,即2c33a。
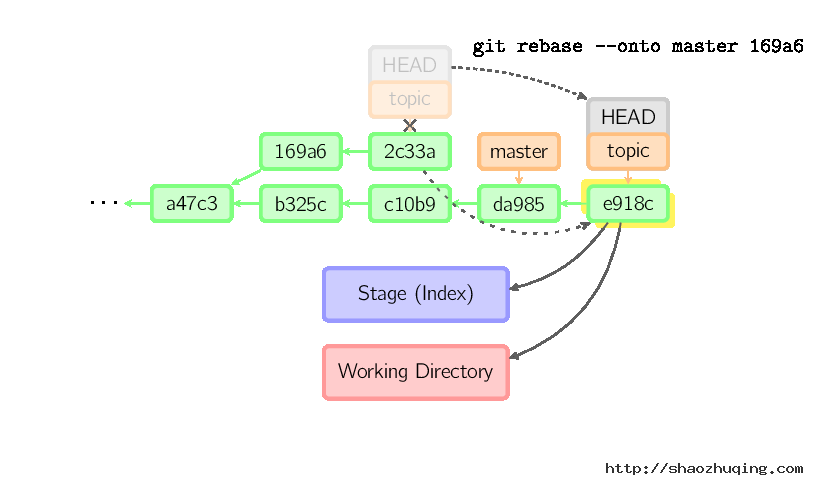
同样有git rebase --interactive让你更方便的完成一些复杂操作,比如丢弃、重排、修改、合并提交。没有图片体现这些,细节看这里:git-rebase(1)
技术说明
文件内容并没有真正存储在索引(.git/index)或者提交对象中,而是以blob的形式分别存储在数据库中(.git/objects),并用SHA-1值来校验。 索引文件用识别码列出相关的blob文件以及别的数据。对于提交来说,以树(tree)的形式存储,同样用对于的哈希值识别。树对应着工作目录中的文件夹,树中包含的 树或者blob对象对应着相应的子目录和文件。每次提交都存储下它的上一级树的识别码。
如果用detached HEAD提交,那么最后一次提交会被the reflog for HEAD引用。但是过一段时间就失效,最终被回收,与git commit --amend或者git rebase很像。
Excel常用函数大全
我们在使用Excel制作表格整理数据的时候,常常要用到它的函数功能来自动统计处理表格中的数据。这里整理了Excel中使用频率最高的函数的功能、使用方法,以及这些函数在实际应用中的实例剖析,并配有详细的介绍。
1、ABS函数
函数名称:ABS
主要功能:求出相应数字的绝对值。
使用格式:ABS(number)
参数说明:number代表需要求绝对值的数值或引用的单元格。
应用举例:如果在B2单元格中输入公式:=ABS(A2),则在A2单元格中无论输入正数(如100)还是负数(如-100),B2中均显示出正数(如100)。
特别提醒:如果number参数不是数值,而是一些字符(如A等),则B2中返回错误值“#VALUE!”。
2、AND函数
函数名称:AND
主要功能:返回逻辑值:如果所有参数值均为逻辑“真(TRUE)”,则返回逻辑“真(TRUE)”,反之返回逻辑“假(FALSE)”。
使用格式:AND(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C5单元格输入公式:=AND(A5>=60,B5>=60),确认。如果C5中返回TRUE,说明A5和B5中的数值均大于等于60,如果返回FALSE,说明A5和B5中的数值至少有一个小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
3、AVERAGE函数
函数名称:AVERAGE
主要功能:求出所有参数的算术平均值。
使用格式:AVERAGE(number1,number2,……)
参数说明:number1,number2,……:需要求平均值的数值或引用单元格(区域),参数不超过30个。
应用举例:在B8单元格中输入公式:=AVERAGE(B7:D7,F7:H7,7,8),确认后,即可求出B7至D7区域、F7至H7区域中的数值和7、8的平均值。
特别提醒:如果引用区域中包含“0”值单元格,则计算在内;如果引用区域中包含空白或字符单元格,则不计算在内。
4、COLUMN 函数
函数名称:COLUMN
主要功能:显示所引用单元格的列标号值。
使用格式:COLUMN(reference)
参数说明:reference为引用的单元格。
应用举例:在C11单元格中输入公式:=COLUMN(B11),确认后显示为2(即B列)。
特别提醒:如果在B11单元格中输入公式:=COLUMN(),也显示出2;与之相对应的还有一个返回行标号值的函数——ROW(reference)。
5、CONCATENATE函数
函数名称:CONCATENATE
主要功能:将多个字符文本或单元格中的数据连接在一起,显示在一个单元格中。
使用格式:CONCATENATE(Text1,Text……)
参数说明:Text1、Text2……为需要连接的字符文本或引用的单元格。
应用举例:在C14单元格中输入公式:=CONCATENATE(A14,"@",B14,".com"),确认后,即可将A14单元格中字符、@、B14单元格中的字符和.com连接成一个整体,显示在C14单元格中。
特别提醒:如果参数不是引用的单元格,且为文本格式的,请给参数加上英文状态下的双引号,如果将上述公式改为:=A14&"@"&B14&".com",也能达到相同的目的。
6、COUNTIF函数
函数名称:COUNTIF
主要功能:统计某个单元格区域中符合指定条件的单元格数目。
使用格式:COUNTIF(Range,Criteria)
参数说明:Range代表要统计的单元格区域;Criteria表示指定的条件表达式。
应用举例:在C17单元格中输入公式:=COUNTIF(B1:B13,">=80"),确认后,即可统计出B1至B13单元格区域中,数值大于等于80的单元格数目。
特别提醒:允许引用的单元格区域中有空白单元格出现。
7、DATE函数
函数名称:DATE
主要功能:给出指定数值的日期。
使用格式:DATE(year,month,day)
参数说明:year为指定的年份数值(小于9999);month为指定的月份数值(可以大于12);day为指定的天数。
应用举例:在C20单元格中输入公式:=DATE(2003,13,35),确认后,显示出2004-2-4。
特别提醒:由于上述公式中,月份为13,多了一个月,顺延至2004年1月;天数为35,比2004年1月的实际天数又多了4天,故又顺延至2004年2月4日。
8、函数名称:DATEDIF
主要功能:计算返回两个日期参数的差值。
使用格式:=DATEDIF(date1,date2,"y")、=DATEDIF(date1,date2,"m")、=DATEDIF(date1,date2,"d")
参数说明:date1代表前面一个日期,date2代表后面一个日期;y(m、d)要求返回两个日期相差的年(月、天)数。
应用举例:在C23单元格中输入公式:=DATEDIF(A23,TODAY(),"y"),确认后返回系统当前日期[用TODAY()表示)与A23单元格中日期的差值,并返回相差的年数。
特别提醒:这是Excel中的一个隐藏函数,在函数向导中是找不到的,可以直接输入使用,对于计算年龄、工龄等非常有效。
9、DAY函数
函数名称:DAY
主要功能:求出指定日期或引用单元格中的日期的天数。
使用格式:DAY(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=DAY("2003-12-18"),确认后,显示出18。
特别提醒:如果是给定的日期,请包含在英文双引号中。
10、DCOUNT函数
函数名称:DCOUNT
主要功能:返回数据库或列表的列中满足指定条件并且包含数字的单元格数目。
使用格式:DCOUNT(database,field,criteria)
参数说明:Database表示需要统计的单元格区域;Field表示函数所使用的数据列(在第一行必须要有标志项);Criteria包含条件的单元格区域。
应用举例:如图1所示,在F4单元格中输入公式:=DCOUNT(A1:D11,"语文",F1:G2),确认后即可求出“语文”列中,成绩大于等于70,而小于80的数值单元格数目(相当于分数段人数)。

特别提醒:如果将上述公式修改为:=DCOUNT(A1:D11,,F1:G2),也可以达到相同目的。
11、FREQUENCY函数
函数名称:FREQUENCY
主要功能:以一列垂直数组返回某个区域中数据的频率分布。
使用格式:FREQUENCY(data_array,bins_array)
参数说明:Data_array表示用来计算频率的一组数据或单元格区域;Bins_array表示为前面数组进行分隔一列数值。
应用举例:如图2所示,同时选中B32至B36单元格区域,输入公式:=FREQUENCY(B2:B31,D2:D36),输入完成后按下“Ctrl+Shift+Enter”组合键进行确认,即可求出B2至B31区域中,按D2至D36区域进行分隔的各段数值的出现频率数目(相当于统计各分数段人数)。
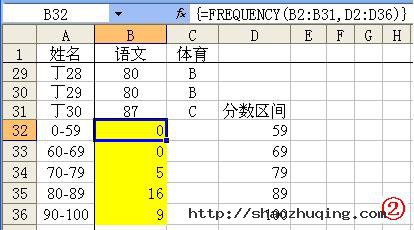
特别提醒:上述输入的是一个数组公式,输入完成后,需要通过按“Ctrl+Shift+Enter”组合键进行确认,确认后公式两端出现一对大括号({}),此大括号不能直接输入。
12、IF函数
函数名称:IF
主要功能:根据对指定条件的逻辑判断的真假结果,返回相对应的内容。
使用格式:=IF(Logical,Value_if_true,Value_if_false)
参数说明:Logical代表逻辑判断表达式;Value_if_true表示当判断条件为逻辑“真(TRUE)”时的显示内容,如果忽略返回“TRUE”;Value_if_false表示当判断条件为逻辑“假(FALSE)”时的显示内容,如果忽略返回“FALSE”。
应用举例:在C29单元格中输入公式:=IF(C26>=18,"符合要求","不符合要求"),确信以后,如果C26单元格中的数值大于或等于18,则C29单元格显示“符合要求”字样,反之显示“不符合要求”字样。
特别提醒:本文中类似“在C29单元格中输入公式”中指定的单元格,读者在使用时,并不需要受其约束,此处只是配合本文所附的实例需要而给出的相应单元格,具体请大家参考所附的实例文件。
13、INDEX函数
函数名称:INDEX
主要功能:返回列表或数组中的元素值,此元素由行序号和列序号的索引值进行确定。
使用格式:INDEX(array,row_num,column_num)
参数说明:Array代表单元格区域或数组常量;Row_num表示指定的行序号(如果省略row_num,则必须有 column_num);Column_num表示指定的列序号(如果省略column_num,则必须有 row_num)。
应用举例:如图3所示,在F8单元格中输入公式:=INDEX(A1:D11,4,3),确认后则显示出A1至D11单元格区域中,第4行和第3列交叉处的单元格(即C4)中的内容。
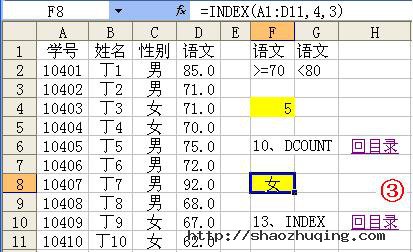
特别提醒:此处的行序号参数(row_num)和列序号参数(column_num)是相对于所引用的单元格区域而言的,不是Excel工作表中的行或列序号。
14、INT函数
函数名称:INT
主要功能:将数值向下取整为最接近的整数。
使用格式:INT(number)
参数说明:number表示需要取整的数值或包含数值的引用单元格。
应用举例:输入公式:=INT(18.89),确认后显示出18。
特别提醒:在取整时,不进行四舍五入;如果输入的公式为=INT(-18.89),则返回结果为-19。
15、ISERROR函数
函数名称:ISERROR
主要功能:用于测试函数式返回的数值是否有错。如果有错,该函数返回TRUE,反之返回FALSE。
使用格式:ISERROR(value)
参数说明:Value表示需要测试的值或表达式。
应用举例:输入公式:=ISERROR(A35/B35),确认以后,如果B35单元格为空或“0”,则A35/B35出现错误,此时前述函数返回TRUE结果,反之返回FALSE。
特别提醒:此函数通常与IF函数配套使用,如果将上述公式修改为:=IF(ISERROR(A35/B35),"",A35/B35),如果B35为空或“0”,则相应的单元格显示为空,反之显示A35/B35的结果。
16、LEFT函数
函数名称:LEFT
主要功能:从一个文本字符串的第一个字符开始,截取指定数目的字符。
使用格式:LEFT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A38单元格中保存了“我喜欢天极网”的字符串,我们在C38单元格中输入公式:=LEFT(A38,3),确认后即显示出“我喜欢”的字符。
特别提醒:此函数名的英文意思为“左”,即从左边截取,Excel很多函数都取其英文的意思。
17、LEN函数
函数名称:LEN
主要功能:统计文本字符串中字符数目。
使用格式:LEN(text)
参数说明:text表示要统计的文本字符串。
应用举例:假定A41单元格中保存了“我今年28岁”的字符串,我们在C40单元格中输入公式:=LEN(A40),确认后即显示出统计结果“6”。
特别提醒:LEN要统计时,无论中全角字符,还是半角字符,每个字符均计为“1”;与之相对应的一个函数——LENB,在统计时半角字符计为“1”,全角字符计为“2”。
18、MATCH函数
函数名称:MATCH
主要功能:返回在指定方式下与指定数值匹配的数组中元素的相应位置。
使用格式:MATCH(lookup_value,lookup_array,match_type)
参数说明:Lookup_value代表需要在数据表中查找的数值;
Lookup_array表示可能包含所要查找的数值的连续单元格区域;
Match_type表示查找方式的值(-1、0或1)。
如果match_type为-1,查找大于或等于 lookup_value的最小数值,Lookup_array 必须按降序排列;
如果match_type为1,查找小于或等于 lookup_value 的最大数值,Lookup_array 必须按升序排列;
如果match_type为0,查找等于lookup_value 的第一个数值,Lookup_array 可以按任何顺序排列;如果省略match_type,则默认为1。
应用举例:如图4所示,在F2单元格中输入公式:=MATCH(E2,B1:B11,0),确认后则返回查找的结果“9”。

特别提醒:Lookup_array只能为一列或一行。
19、MAX函数
函数名称:MAX
主要功能:求出一组数中的最大值。
使用格式:MAX(number1,number2……)
参数说明:number1,number2……代表需要求最大值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MAX(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最大值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
20、MID函数
函数名称:MID
主要功能:从一个文本字符串的指定位置开始,截取指定数目的字符。
使用格式:MID(text,start_num,num_chars)
参数说明:text代表一个文本字符串;start_num表示指定的起始位置;num_chars表示要截取的数目。
应用举例:假定A47单元格中保存了“我喜欢天极网”的字符串,我们在C47单元格中输入公式:=MID(A47,4,3),确认后即显示出“天极网”的字符。
特别提醒:公式中各参数间,要用英文状态下的逗号“,”隔开。
21、MIN函数
函数名称:MIN
主要功能:求出一组数中的最小值。
使用格式:MIN(number1,number2……)
参数说明:number1,number2……代表需要求最小值的数值或引用单元格(区域),参数不超过30个。
应用举例:输入公式:=MIN(E44:J44,7,8,9,10),确认后即可显示出E44至J44单元和区域和数值7,8,9,10中的最小值。
特别提醒:如果参数中有文本或逻辑值,则忽略。
22、MOD函数
函数名称:MOD
主要功能:求出两数相除的余数。
使用格式:MOD(number,divisor)
参数说明:number代表被除数;divisor代表除数。
应用举例:输入公式:=MOD(13,4),确认后显示出结果“1”。
特别提醒:如果divisor参数为零,则显示错误值“#DIV/0!”;MOD函数可以借用函数INT来表示:上述公式可以修改为:=13-4*INT(13/4)。
23、MONTH函数
函数名称:MONTH
主要功能:求出指定日期或引用单元格中的日期的月份。
使用格式:MONTH(serial_number)
参数说明:serial_number代表指定的日期或引用的单元格。
应用举例:输入公式:=MONTH("2003-12-18"),确认后,显示出11。
特别提醒:如果是给定的日期,请包含在英文双引号中;如果将上述公式修改为:=YEAR("2003-12-18"),则返回年份对应的值“2003”。
24、NOW函数
函数名称:NOW
主要功能:给出当前系统日期和时间。
使用格式:NOW()
参数说明:该函数不需要参数。
应用举例:输入公式:=NOW(),确认后即刻显示出当前系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期和时间格式,可以通过单元格格式进行重新设置。
25、OR函数
函数名称:OR
主要功能:返回逻辑值,仅当所有参数值均为逻辑“假(FALSE)”时返回函数结果逻辑“假(FALSE)”,否则都返回逻辑“真(TRUE)”。
使用格式:OR(logical1,logical2, ...)
参数说明:Logical1,Logical2,Logical3……:表示待测试的条件值或表达式,最多这30个。
应用举例:在C62单元格输入公式:=OR(A62>=60,B62>=60),确认。如果C62中返回TRUE,说明A62和B62中的数值至少有一个大于或等于60,如果返回FALSE,说明A62和B62中的数值都小于60。
特别提醒:如果指定的逻辑条件参数中包含非逻辑值时,则函数返回错误值“#VALUE!”或“#NAME”。
26、RANK函数
函数名称:RANK
主要功能:返回某一数值在一列数值中的相对于其他数值的排位。
使用格式:RANK(Number,ref,order)
参数说明:Number代表需要排序的数值;ref代表排序数值所处的单元格区域;order代表排序方式参数(如果为“0”或者忽略,则按降序排名,即数值越大,排名结果数值越小;如果为非“0”值,则按升序排名,即数值越大,排名结果数值越大;)。
应用举例:如在C2单元格中输入公式:=RANK(B2,$B$2:$B$31,0),确认后即可得出丁1同学的语文成绩在全班成绩中的排名结果。
特别提醒:在上述公式中,我们让Number参数采取了相对引用形式,而让ref参数采取了绝对引用形式(增加了一个“$”符号),这样设置后,选中C2单元格,将鼠标移至该单元格右下角,成细十字线状时(通常称之为“填充柄”),按住左键向下拖拉,即可将上述公式快速复制到C列下面的单元格中,完成其他同学语文成绩的排名统计。
27、RIGHT函数
函数名称:RIGHT
主要功能:从一个文本字符串的最后一个字符开始,截取指定数目的字符。
使用格式:RIGHT(text,num_chars)
参数说明:text代表要截字符的字符串;num_chars代表给定的截取数目。
应用举例:假定A65单元格中保存了“我喜欢天极网”的字符串,我们在C65单元格中输入公式:=RIGHT(A65,3),确认后即显示出“天极网”的字符。
特别提醒:Num_chars参数必须大于或等于0,如果忽略,则默认其为1;如果num_chars参数大于文本长度,则函数返回整个文本。
28、SUBTOTAL函数
函数名称:SUBTOTAL
主要功能:返回列表或数据库中的分类汇总。
使用格式:SUBTOTAL(function_num, ref1, ref2, ...)
参数说明:Function_num为1到11(包含隐藏值)或101到111(忽略隐藏值)之间的数字,用来指定使用什么函数在列表中进行分类汇总计算(如图6);ref1, ref2,……代表要进行分类汇总区域或引用,不超过29个。

应用举例:如图7所示,在B64和C64单元格中分别输入公式:=SUBTOTAL(3,C2:C63)和=SUBTOTAL103,C2:C63),并且将61行隐藏起来,确认后,前者显示为62(包括隐藏的行),后者显示为61,不包括隐藏的行。

特别提醒:如果采取自动筛选,无论function_num参数选用什么类型,SUBTOTAL函数忽略任何不包括在筛选结果中的行;SUBTOTAL函数适用于数据列或垂直区域,不适用于数据行或水平区域。
29、SUM函数
函数名称:SUM
主要功能:计算所有参数数值的和。
使用格式:SUM(Number1,Number2……)
参数说明:Number1、Number2……代表需要计算的值,可以是具体的数值、引用的单元格(区域)、逻辑值等。
应用举例:如图7所示,在D64单元格中输入公式:=SUM(D2:D63),确认后即可求出语文的总分。

特别提醒:如果参数为数组或引用,只有其中的数字将被计算。数组或引用中的空白单元格、逻辑值、文本或错误值将被忽略;如果将上述公式修改为:=SUM(LARGE(D2:D63,{1,2,3,4,5})),则可以求出前5名成绩的和。
30、SUMIF函数
函数名称:SUMIF
主要功能:计算符合指定条件的单元格区域内的数值和。
使用格式:SUMIF(Range,Criteria,Sum_Range)
参数说明:Range代表条件判断的单元格区域;Criteria为指定条件表达式;Sum_Range代表需要计算的数值所在的单元格区域。
应用举例:如图7所示,在D64单元格中输入公式:=SUMIF(C2:C63,"男",D2:D63),确认后即可求出“男”生的语文成绩和。
特别提醒:如果把上述公式修改为:=SUMIF(C2:C63,"女",D2:D63),即可求出“女”生的语文成绩和;其中“男”和“女”由于是文本型的,需要放在英文状态下的双引号("男"、"女")中。
31、TEXT函数
函数名称:TEXT
主要功能:根据指定的数值格式将相应的数字转换为文本形式。
使用格式:TEXT(value,format_text)
参数说明:value代表需要转换的数值或引用的单元格;format_text为指定文字形式的数字格式。
应用举例:如果B68单元格中保存有数值1280.45,我们在C68单元格中输入公式:=TEXT(B68, "$0.00"),确认后显示为“$1280.45”。
特别提醒:format_text参数可以根据“单元格格式”对话框“数字”标签中的类型进行确定。
32、TODAY函数
函数名称:TODAY
主要功能:给出系统日期。
使用格式:TODAY()
参数说明:该函数不需要参数。
应用举例:输入公式:=TODAY(),确认后即刻显示出系统日期和时间。如果系统日期和时间发生了改变,只要按一下F9功能键,即可让其随之改变。
特别提醒:显示出来的日期格式,可以通过单元格格式进行重新设置(参见附件)。
33、VALUE函数
函数名称:VALUE
主要功能:将一个代表数值的文本型字符串转换为数值型。
使用格式:VALUE(text)
参数说明:text代表需要转换文本型字符串数值。
应用举例:如果B74单元格中是通过LEFT等函数截取的文本型字符串,我们在C74单元格中输入公式:=VALUE(B74),确认后,即可将其转换为数值型。
特别提醒:如果文本型数值不经过上述转换,在用函数处理这些数值时,常常返回错误。
34、VLOOKUP函数
函数名称:VLOOKUP
主要功能:在数据表的首列查找指定的数值,并由此返回数据表当前行中指定列处的数值。
使用格式:VLOOKUP(lookup_value,table_array,col_index_num,range_lookup)
参数说明:Lookup_value代表需要查找的数值;Table_array代表需要在其中查找数据的单元格区域;Col_index_num为在table_array区域中待返回的匹配值的列序号(当Col_index_num为2时,返回table_array第2列中的数值,为3时,返回第3列的值……);Range_lookup为一逻辑值,如果为TRUE或省略,则返回近似匹配值,也就是说,如果找不到精确匹配值,则返回小于lookup_value的最大数值;如果为FALSE,则返回精确匹配值,如果找不到,则返回错误值#N/A。
应用举例:参见图7,我们在D65单元格中输入公式:=VLOOKUP(B65,B2:D63,3,FALSE),确认后,只要在B65单元格中输入一个学生的姓名(如丁48),D65单元格中即刻显示出该学生的语言成绩。
特别提醒:Lookup_value参见必须在Table_array区域的首列中;如果忽略Range_lookup参数,则Table_array的首列必须进行排序;在此函数的向导中,有关Range_lookup参数的用法是错误的。
35、WEEKDAY函数
函数名称:WEEKDAY
主要功能:给出指定日期的对应的星期数。
使用格式:WEEKDAY(serial_number,return_type)
参数说明:serial_number代表指定的日期或引用含有日期的单元格;return_type代表星期的表示方式[当Sunday(星期日)为1、Saturday(星期六)为7时,该参数为1;当Monday(星期一)为1、Sunday(星期日)为7时,该参数为2(这种情况符合中国人的习惯);当Monday(星期一)为0、Sunday(星期日)为6时,该参数为3]。
应用举例:输入公式:=WEEKDAY(TODAY(),2),确认后即给出系统日期的星期数。
特别提醒:如果是指定的日期,请放在英文状态下的双引号中,如=WEEKDAY("2003-12-18",2)。
国内外常用网站分析工具
1、Google Analytics http://www.google.com/analytics/
2、Clicky http://getclicky.com/
3、W3Counter http://www.w3counter.com/
4、Woopra http://www.woopra.com/
5、W3Perl http://www.w3perl.com/
6、Piwik http://piwik.org/
7、TraceWatch http://www.tracewatch.com/
8、Snoop http://snoopwpf.codeplex.com/
9、goingup http://www.goingup.gr/
10、JAWStats http://www.jawstats.com/
11、Crazyegg http://www.crazyegg.com/home5
13、Omniture http://www.omniture.com/en/
14、雅虎统计
15、Clicktale http://www.clicktale.com/
16、Open Web Analytics http://www.openwebanalytics.com/
17、AWStats http://awstats.sourceforge.net/
中国:
1、百度统计 http://tongji.baidu.com/
2、CNZZ http://www.cnzz.com/
3、国双统计
4、51la http://www.51.la/
5、量子统计 http://www.linezing.com/
6、小艾统计
7、科捷统计
8、iDigger http://www.idigger.cn/idigger/
9、gostats http://gostats.cn/
10、99click http://www.99click.com/
Google AdSense常用名词解释
广告单元
广告单元由一段AdSense 广告代码所显示的一组广告。
链接单元
链接单元是一种广告格式,可显示一系列与某一网页内容相关的链接。用户点击链接后,便进入一个相关广告的网页。在我们的广告格式页,您可以查看所有可用链接单元格式的示例。
替代广告
替代广告可以在Google 不能向您的网页投放相关广告的情况下,保证您依然能够通过广告空间获得收入。通过指定图像或者所选广告服务器,可以确保广告空间始终得到有效的利用- 要么用于投放有针对性的AdSense 广告,要么用于投放您自己选择的内容。如果指定了替代广告,当您的网页没有可用的相关广告时,就会展示替代广告。这时,广告空间不会被标记为 “Google 提供的广告”。
公益广告
公益广告是当服务器找不到有针对性的广告或者Google 无法收集网页内容时投放到网页的非盈利组织广告。发布商不能从公益广告的点击次数中获得收入。
每次点击费用(CPC)
每次点击费用是每次用户点击广告时其所属广告客户要支付的费用。Google AdWords 拥有一个以每次点击费用为依据的定价系统。
点击率(CTR, click through rate)
广告点击次数与广告页的展示次数之比。
每千次展示费用(CPM)
CPM 是广告客户在其广告得到1000 次浏览并获得展示次数记录时为之支付的金额。
网页eCPM (effective cost per mille)
eCPM指的就是每一千次展示可以获得的广告收入,展示的单位可以是网页,广告单元,甚至是单个广告(在AdSense “高级报告”的“数据展示依据”下拉框中可以选择)。默认情况下,eCPM 指的都是千次网页展示(Pageview)收入。请注意,eCPM 只是用来反映网站盈利能力的参数,不代表您的收入。它是一个与网页展示次数无关的指标,这证明一点:一个网站的AdSense 可盈利趋势与网站的大小无关,它最终是由平均广告单价和广告的点击率决定的。
报告模板
报告模板是一种高级报告,其中包含您为了便于今后快速访问而命名并保存的设置。已保存报告模板将显示在“概述”页上,只需点击一下即可访问。所有报告模板都可通过电子邮件发送给您。
热门查询
AdSense 搜索广告发布商可以查看用户使用其AdSense 搜索广告框搜索的最热门的25 个字词。只有执行过一次以上的查询才会显示。
登录信息
AdSense 登录信息指帐户电子邮件。它是您用来登录Google AdSense 帐户的电子邮件地址。
IFRAME
IFRAME 是网站设计中使用的一种HTML 标记,可以将某个网页展示在其他网页内的框架中。
JavaScript
JavaScript 是常用于网页中的脚本语言。用来向您的网站加入Google 广告的广告代码即采用JavaScript 编写,您需要在浏览器中启用JavaScript,才能查看网站上的Google 广告。
内容相关广告
Google 利用搜索技术在我们联网中(包括AdSense 网站)的内容网页和产品上投放相关的广告。借助于我们对搜索索引中数十亿网页的内容的理解以及我们的网页抓取能力,我们的技术可以明确哪些关键字能够将用户引至相关网页。然后,我们根据这些关键字将广告与网页相匹配。
广告单元展示
每当用户浏览您的网页上的广告单元时,就会生成广告单元展示。例如,如果您的某张网页上展示了三个广告单元,该网页被浏览了两次,则您会获得六次广告单元展示和两次网页展示。
网址(URL) 过滤列表
AdSense 发布商在自己的帐户中创建并存储的列表,用于防止在自己的网站上投放来自某些网址的广告。在发布商将某一网址添加到此列表后,此网站列表的广告就不会投放到发布商的网站上。
竞争性广告
竞争性广告指贵网站上模仿Google 文字广告或看来与Google 文字广告相关的以网页内容定位的广告或文字广告。根据AdSense 计划政策中的规定,竞争性广告不得与Google 广告展示在同一网页或网站上。不过,我们允许联属链接及文字数量有限的链接。
帐户类型
通常,如果您的企业有20 名或更多员工,则应申请企业帐户。个人发布商或企业员工少于20 名
的,则应注册个人帐户。个人帐户与企业帐户在产品、服务或付款结构方面没有任何差别,在付款方式和支取流程上有所不同,企业帐户目前不支持西联汇款的方式,在支票托收时,这两种帐户需要提供给银行的证明材料也不相同。
收入份额
各个AdSense 发布商会获得广告客户对其广告的用户点击次数或展示次数所付费用的某一百分比的数额。该百分数称为收入份额。Google 不能透露AdSense 的收入份额。
帐户电子邮件
也叫作帐户相关邮件,是您用来登录AdSense 帐户的电子邮件地址。我们会将所有发送给您的关于AdSense 的邮件发送到该地址。
抓取工具
抓取工具又称为Spider 或Bot,是Google 用于对网页内容进行处理和编制索引的软件。AdSense抓取工具会通过访问您的网站来确定其内容,从而提供相关的广告。
无效点击或者展示
通过我们所禁止的方式所产生,而目的是想人为地增加发布商帐户上的点击或展示次数的点击与网页展示。Google 使用自己的专有技术分析所有广告点击与展示次数,以确定是否发生了任何无效点击行为,防止人为地增加广告客户的点击次数或发布商的收益。被我们判为无效的点击不会算入您的收益里。
链接单元的点击次数
在链接单元报告中,链接点击结果页中的广告所获得的点击次数。它不同于链接点击次数,链接点击次数是用户点击的链接单元中链接的次数,用户点击的结果是浏览广告页面。
链接展示次数
在链接单元报告中,链接单元被浏览的次数,无论链接是否被点击。
广告展示次数
只要有单个广告展示在您的网站上,就报告为一次广告展示。显示的广告数量因广告格式而异;例如,竖幅广告在您的网站上每显示一次,报告就会生成两次广告展示次数。另外请注意,根据广告单元中显示的是标准文字广告、扩展文字广告还是图片广告,广告单元中的广告数量可能不同。
链接点击次数
链接单元中链接的点击次数。
调整项
您的收入可能会由于多种原因而包含借记项或贷记项,所有此类项目都会在"付款历史"页上列出。可能的调整项包括:
AdSense 搜索广告费用:您的AdSense 搜索广告收入可能会与相关费用相抵。这种情况仅适用于少数发布商。有关详情,请浏览AdSense 支持中心。
支票费用:与特殊的支票递送方式或停止付款申请相关的费用
无效点击:发布商不会从被发现为无效的点击次数上获得付款。如果目前已显示在您报告中的点击被认定为无效,我们会调整相关收入,并向广告客户退还费用。
月末余额
“付款历史”页会在每个月末显示您AdSense 帐户中的余额。此金额反映的是在相应月末时的已确认收入。如果您帐户的月末余额大于$100 美元,且帐户中没有保留付款,我们就会安排在下个月向您付款。
目标网址
广告所链接到的网址。当用户通过点击广告访问广告客户的网站时,他们将看到此网页。如果您希望将某一网址添加到自己的网址过滤列表,以阻止此广告客户的广告出现在您的网站上,则需要知道此网址。
框架
网页可以带有框架,从而将一张网页划分成采用独立HTML 代码的多个部分。放置AdSense 广告代码的框架应该包含您希望据以定位广告的文本内容。
可通过电子邮件发送的报告
可通过电子邮件发送的报告是一种已保存报告模板,您可以使用帐户中的报告管理页设置日程,让报告通过电子邮件发送给您。
调色板
AdSense 为发布商提供了对出现在自己网站上的广告颜色进行自定义的功能。调色板有助于您确保广告的文字、背景以及边框颜色能够与网站的外观相配。为了增强多样性和新颖性,您甚至可以选择每次轮流使用最多4 个不同的调色板。
渠道
“付款历史”页会在每个月末显示您AdSense 帐户中的余额。此金额反映的是在相应月末时的已确认收入。如果您帐户的月末余额大于$100 美元,且帐户中没有保留付款,我们就会安排在下个月向您付款。
目标网址
广告所链接到的网址。当用户通过点击广告访问广告客户的网站时,他们将看到此网页。如果您希望将某一网址添加到自己的网址过滤列表,以阻止此广告客户的广告出现在您的网站上,则需要知道此网址。
帐户启动
您提交了AdSense 申请并确认了您的电子邮件地址后,AdSense 小组会在一两天之内评估您的申请,并向您发送一封通知电子邮件。如果您获准参与此计划,就可以登录到自己的新帐户,并将AdSense 广告代码复制并粘贴到网页中,从而开始投放广告。此操作会启动您的AdSense 帐户。
网页展示次数
每当用户浏览展示了Google 广告的网页时,就会生成一次网页展示。不考虑网页上展示的广告数量,我们仅计为一次网页展示。例如,如果您的某张网页上展示了三个广告单元,该网页被浏览了两次,则您会获得两次网页展示和六次广告单元展示。
MySQL常用命令总结
++安装mysql
参见自带的INSTALL-SOURCE文件
$ ./configure ?prefix=/app/mysql-5.0.51a ?with-charset=utf8 ?with-extra-charsets=utf8,gb2312,utf8
++启动/关闭mysql
$ path/mysqld_safe -user=mysql &
$ /mysqladmin -p shutdown
++修改root口令
$ mysqladmin -u root -p password ‘新密码’
++查看服务器状态
$ path/mysqladmin version -p
++连接远端mysql服务器
$ path/mysql -u 用户名 -p #连接本机
$ path/mysql -h 远程主机IP -u 用户名 -p#连接远程MYSQL服务器
++创建/删除 数据库或表
$ mysqladmin -u root -p create xxx
mysql> create database 数据库名;
mysql> create TABLE items (
id INT(5) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
symbol CHAR(4) NOT NULL,
username CHAR(8),
INDEX sym (symbol),INDEX …..
UNIQUE(username)
) type=innodb;
mysql> drop database [if exists] 数据库名
mysql> create table 表名;
mysql> drop table 表名;
++查看数据库和查看数据库下的表
mysql> show databases;
mysql> show tables;
mysql> show table status;
mysql> desc 表名; #查看具体表结构信息
mysql> SHOW CREATE DATABASE db_name #显示创建db_name库的语句
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建用户
mysql> grant select,insert,update,delete,alter on mydb.* to test2@localhost identified by “abc”;
mysql> grant all privileges on *.* to test1@”%” identified by “abc”;
mysql> flush privileges;
++用户管理
mysql> update user set password=password (’11111′) where user=’test1′; #修改test1密码为111111
mysql> DELETE FROM user WHERE User=”testuser” and Host=”localhost”; #删除用户帐号
mysql> SHOW GRANTS FOR user1; #显示创建user1用户的grant语句
++mysql数据库的备份和恢复
$ mysqldump -uuser -ppassword -B DB_name [--tables table1 --tables table2] > exportfile.sql
$ mysql -uroot -p xxx < aaa.sql #导入表
$ mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名 ##导出单独的表
++导出一个数据库结构
$ mysqldump -u wcnc -p -d ?add-drop-table smgp_apps_wcnc >wcnc_db.sql
-d 没有数据 ?add-drop-table 在每个create语句之前增加一个drop table
++忘记mysql密码
先停止所有mysql服务进程
$ mysqld_safe ?skip-grant-tables & mysql
mysql> use mysql;
mysql> update user set password=password(’111111′) where user=’root’;
mysql> flush privileges;
然后重启mysql并以新密码登入即可
++当前使用的数据库
mysql> select database();
===数据库日常操作维护====
++创建表
mysql> create table table_name
(column_name datatype {identity |null|not null},f_time TIMESTAMP(8),…)ENGINE=MyISAM AUTO_INCREMENT=3811 DEFAULT CHARSET=utf8;
例: CREATE TABLE guest (name varchar(10),sex varchar(2),age int(3),career varchar(10));
# desc guest可查看表结构信息
# TIMESTAMP(8) YYYYMMDD 其中(2/4/6/8/10/12/14)对应不同的时间格式
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建索引
可以在建表的时候加入index indexname (列名)创建索引,
也可以手工用命令生成 create index index_name on table_name (col_name[(length)],… )
mysql> CREATE INDEX number ON guest (number(10));
mysql> SHOW INDEX FROM tbl_name [FROM db_name] #显示现有索引
mysql> repair TABLE date QUICK; #索引列相关变量变化后自动重建索引
++查询及常用函数
mysql> select t1.name, t2.salary from employee AS t1, info AS t2 where t1.name = t2.name;
mysql> select college, region, seed from tournament ORDER BY region, seed;
mysql> select col_name from tbl_name WHERE col_name > 0;
mysql> select DISTINCT …… [DISTINCT关键字可以除去重复的记录]
mysql> select DATE_FORMAT(NOW(),’%m/%d/%Y’) as DATE, DATE_FORMAT(NOW(),’%H:%m:%s’) AS TIME;
mysql> select CURDATE(),CURTIME(),YEAR(NOW()),MONTH(NOW()),DAYOFMONTH(NOW()),HOUR(NOW()),MINUTE(NOW());
mysql> select UNIX_TIMESTAMP(),UNIX_TIMESTAMP(20080808),FROM_UNIXTIME(UNIX_TIMESTAMP()); mysql> select PASSWORD(”secret”),MD5(”secret”); #加密密码用
mysql> select count(*) from tab_name order by id [DESC|ASC]; #DESC倒序/ASC正序
* 函数count,AVG,SUM,MIN,MAX,LENGTH字符长度,LTRIM去除开头的空头,RTRIM去尾部空格,TRIM(str)去除首部 尾部空格,LETF/RIGHT(str,x)返回字符串str的左边/右边x个字符,SUBSTRING(str,x,y)返回str中的x位置起至位 置y的字符mysql> select BINARY ‘ross’ IN (’Chandler’,’Joey’, ‘Ross’); #BINARY严格检查大小写
* 比较运算符IN,BETWEEN,IS NULL,IS NOT NULL,LIKE,REGEXP/RLIKE
mysql> select count(*),AVG(number_xx),Host,user from mysql.user GROUP by user [DESC|ASC] HAVING user=root; #分组并统计次数/平均值
++UNIX_TIMESTAMP(date)
返回一个Unix时间戳记(从’1970-01-01 00:00:00′GMT开始的秒数)
mysql> select UNIX_TIMESTAMP();
mysql> select UNIX_TIMESTAMP(’1997-10-04 22:23:00′);
mysql> select FROM_UNIXTIME(875996580); #根据时间戳记算出日期
++控制条件函数
mysql> select if(1<10,2,3), IF(55>100,’true’,’false’);
#IF()函数有三个参数,第一个是被判断的表达式,如果表达式为真,返回第二个参数,如果为假,返回第三个参数.
mysql> select CASE WHEN (2+2)=4 THEN “OK” WHEN (2+2)<>4 THEN ‘NOT OK’ END AS status;
++系统信息函数
mysql> select DATABASE(),VERSION(),USER();
mysql> select BENCHMARK(9999999,LOG(RAND()*PI())) AS PERFORMANACE; #一个测试mysql运算性能工具
++将wp_posts表中post_content字段中文字”old”替换为”new”
mysql> update wp_posts set post_content=replace(post_content,’old’,’new’)
++改变表结构
mysql> alter table table_name alter_spec [, alter_spec ...]
例:alter table dbname add column userid int(11) not null primary key auto_increment;
这样,就在表dbname中添加了一个字段userid,类型为int(11)。
++调整列顺序
mysql> alter table tablename CHANGE id id int(11) first;
++修改表中数据
insert [into] table_name [(column(s))] values (expression(s))
例:mysql>insert into mydatabase values(’php’,’mysql’,’asp’,’sqlserver’,’jsp’,’oracle’);
mysql> create table user select host,user from mysql.user where 1=0;
mysql> insert into user(host,user) select host,user from mysql.user;
++更改表名
命令:rename table 原表名 to 新表名;
++表的数据更新
mysql> update table01 set field04=19991022[, field05=062218] where field01=1;
++删除数据
mysql> delete from table01 where field01=3;
#如果想要清空表的所有纪录,建议用truncate table tablename而不是delete from tablename.
++SHELL提示符下运行SQL命令
$ mysql -e “show slave status\G ”
++坏库扫描修复
cd /var/lib/mysql/xxx && myisamchk playlist_block
++insert into a (x) values (’11a’)
出现: ata truncated for column ‘x’ at row 1
解决办法:
在my.ini里找到
sql-mode=”STRICT_TRANS_TABLES,NO_AUTO_Create_USER,NO_ENGINE_SUBSTITUTION”
把其中的STRICT_TRANS_TABLES,去掉,然后重启mysql就ok了
++复制表
mysql> create table target_table like source_table
++innodb支持事务
新表:create TABLE table-name (field-definitions) TYPE=INNODB;
旧表: alter TABLE table-name TYPE=INNODB;
mysql> start transaction #标记一个事务的开始
mysql> insert into….. #数据变更
mysql> ROLLBACK或commit #回滚或提交
mysql> SET AUTOCOMMIT=1; #设置自动提交
mysql> select @@autocommit; #查看当前是否自动提交
++表锁定相关
mysql> LOCK TABLE users READ; # 对user表进行只读锁定
mysql> LOCK TABLES user READ, pfolios WRITE #多表锁控制
mysql> UNLOCK TABLES; #不需要指定锁定表名字, MySQL会自动解除所有表锁定
=====一些mysql优化与管理======
++管理用命令
mysql> show variables #查看所有变量值
? max_connections 数据库允许的最大可连接数,
#需要加大max_connections可以在my.cnf中加入set-variable = max_connections=32000,可以对与下面的threads_connected值决定是否需要增大.
show status [like ....];
? threads_connected 数据库当前的连接线程数
#FLUSH STATUS 可以重置一些计数器
show processlist;
kill id;
++my.cnf配置
?Enable Slow Query Log
long_query_time=1
log-slow-queries=/var/log/mysql/log-slow-queries.log
log-queries-not-using-indexes
# mysqldumpslow -s c -t 20 host-slow.log #访问次数最多的20个sql语句
# mysqldumpslow -s r -t 20 host-slow.log #返回记录集最多的20个sql
?others
max_connections=500 #用过的最大连接数SHOW Status like ‘max_used_connection’;
wait_timeout=10 #终止所有空闲时间超过 10 秒的连接
table_cache=64 #任何时间打开表的总数
ax_binlog_size=512M #循环之前二进制日志的最大规模
max_connect_errors = 100
query_cache_size = 256M #查询缓存
#可用 SHOW STATUS LIKE ‘qcache%’;查看命中率
#FLUSH STATUS重置计数器, FLUSH QUERY CACHE清缓存
thread_cache = 40
#线程使用,SHOW STATUS LIKE ‘Threads_created %’; 值快速增加的话考虑加大
key_buffer = 16M
#show status like ‘%key_read%’; Key_reads 代表命中磁盘的关键字请求个数
#A: 到底 Key Buffer 要设定多少才够呢? Q: MySQL 只会 Cache 索引(*.MYI),因此参考所有 MYI文件的总大小
sort_buffer_size = 4M #查询排序时所能使用的缓冲区大小,每连接独享4M
#show status like ‘%sort%’; 如sort_merge_passes很大,就表示加大
sort_buffer_sizesort_buffer_size = 6M #查询排序时所能使用的缓冲区大小,这是每连接独享值6M
read_buffer_size = 4M #读查询操作所能使用的缓冲区大小
join_buffer_size = 8M #联合查询操作所能使用的缓冲区大小
skip-locking #取消文件系统的外部锁
skip-name-resolve
thread_concurrency = 8 #最大并发线程数,cpu数量*2
long_query_time = 10 #Slow_queries记数器的查询时间阀值
最常用的生成静态标签云网站
生成静态标签云:
这个工具同样可以生成一个静态的标签云图,你只需要输入你的网页地址,或是手动输入Tag的关键词和网页。还可以配置标签云的背景颜色,输出宽高,Tag链接的文字颜色,是否使用下划线以及是实线还是虚张,文字字体,以及Tag字体的最大尺寸和最小尺寸,标签云的排版等。
生成后的效果图:
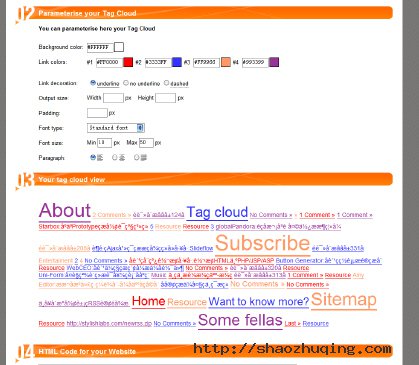
http://www.tagcloud-generator.com/
这是一个德国网站提供的标签云生成器,功能较少,不过可以加入自己的CSS样式文件,比较适合对CSS有一定基础的朋友。支持生成英文和德文的 Tag cloud。中文同样是乱码。不过我忽然想到,不管是哪个标签云生成器,所有生成的乱码,其实都可以在生成代码后再把乱码更改成中文字符就可以了。只是那 要好像就变得麻烦了
生成后的效果图:
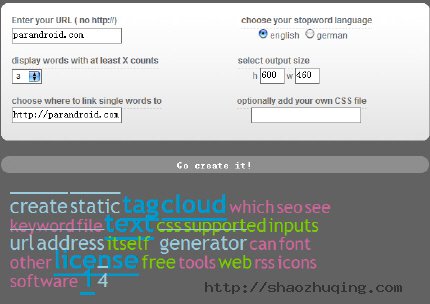
这是一个在线的网络服务应用,它可以提供把你网页的关键字密度以一个可视化、漂亮的标签云显示出来。(使用了C SS和H TML)。
支持输入文本,提交网页地址,上传文本文件,它就会自动抓取页面里面的关键词,并根据关键词的使用频率生成一个标签云和相应的代码,若要使用,你只需要把代码粘贴到你的网页就可以了。
下面我输入http://hi.baidu.com/yuanbiaoji后得到的标签云截图:
生成后的效果:

支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
