如何获取(GET)一杯咖啡——星巴克REST案例分析
我们已习惯于在大型中间件平台(比如那些实现CORBA、Web服务协议栈和J2EE的平台)之上构建分布式系统了。在这篇文章里,我们将采取另一种做法:我们把支撑Web运行的协议和文档格式视为一种应用平台,一种可通过轻量级中间件访问的平台。我们通过一个简单的客户-服务交互的例子,展示了Web在应用集成中的作用。在这篇文章里,我们以Web为主要设计理念,提炼并分享了我们下本书《GET /connected - Web-based integration》(暂定名称)里的一些想法。
引言
我们知道,集成领域是不断变化的。Web的影响以及敏捷实践的潮流正在挑战我们的关于“良好的集成由什么构成”的观念。集成(integration)并不是一种夹在系统之间的专业活动;与此相反,现在,集成是成功方案里的不可缺少的一部分。
然而,仍有许多人误解并低估Web在企业计算中的作用。即便是那些精通Web的人士,也常常要花费很大力气才能懂得,Web不是关于支持XML over HTTP的中间件方案,也不是一种简易的RPC机制。这是相当遗憾的,因为Web不是仅能提供简单的点对点连接,它还有更大的用处;它实际上是一个健壮的集成平台。
在这篇文章里,我们将展示Web的一些值得关注的用途,我们将视之为一种可塑的、健壮的平台,它能够对企业系统做很“酷”的事。另外,工作流是企业软件最具代表性的特征。
为什么要工作流?
工作流(workflows)是企业计算的主要特征,它们基本上都是用中间件实现的(至少在计算方面)。工作流把一项工作(work)划分为多个离散的步骤(steps)以及触发步骤转移的事件(events)。工作流所实现的整个业务流程常常跨越若干企业信息系统,这给工作流带来很多集成问题。
星巴克:统一标准的咖啡需要统一标准的集成
Web若要成为可用于企业集成的技术,它就必须支持工作流——从而可靠地协调不同系统间的交互,以实现更大的业务能力。
要恰如其份地介绍工作流,就免不了讲述一大堆跟领域相关的技术细节,而这不是本文的主旨,因此,我们选择了Gregor Hohpe的星巴克工作流这个比较好理解的例子来举例说明基于Web的集成的工作原理。在这篇受到大家欢迎的博客文章里,Gregor讲述了星巴克是如何形成一个解耦合的(decoupled)盈利生产线的:
“跟大部分餐饮企业一样,星巴克也主要致力于将订单处理的吞吐量最大化。顾客订单越多,收入就越多。为此,他们采取了异步处理的办法。你在点单时,收银员取出一只咖啡杯,在上面作上记号表明你点的是什么,然后把这个杯子放到队列里去。这里的队列指的是在咖啡机前排成一列的咖啡杯。正是这个队列将收银员与咖啡师解耦开,从而,即便在咖啡师一时忙不过来的时候,收银员仍然可以为顾客点单。他们可以在繁忙时段安排多个咖啡师,就像竞争消费者模式(Competing Consumer)里那样。”
Gregor是采用EAI技术(如面向消息的中间件)来讲解星巴克案例的,而我们将采用Web资源(支持统一接口的可寻址实体)来讲解同一案例。实际上,我们将展示Web技术何以能够具有跟传统EAI工具一样的可靠性,以及何以不仅仅是请求/响应协议之上的XML消息传递!
首先,我们很抱歉擅自设想了星巴克的工作流程,因为我们的目的并不是精确无误地描述星巴克,而是用基于Web的服务来讲解工作流。好的,既然讲清楚了这一点,那么我们现在开始吧。
简明陈述
因为我们在讲工作流,所以我们有必要理解构成工作流的状态(states)以及将工作流从一个状态转移到另一个状态的事件(events)。我们的例子里有两个工作流,我们把它们用状态机(state machines)表达出来了。这两个工作流是并行执行的。一个反映了顾客与星巴克服务之间的交互(如图1),另一个刻画了由咖啡师执行的一系列动作(如图2)。
在顾客工作流里,顾客为了得到某种口味的咖啡而与星巴克服务进行交互。我们假定该工作流里包含以下动作:顾客点单,付款,然后等待饮品。在点单与付款之间,顾客通常可以修改菜单,比方说请求改用半脱脂牛奶。 /p>

图1 顾客状态机
尽管顾客看不见咖啡师,但咖啡师也有自己的状态机;这个状态机是服务实现私有的。如图2所示,咖啡师在周而复始地等待下一个订单,制作饮品,然后收取费用。当一个订单被加入到咖啡师的队列中时,一次循环实例就开始了。当咖啡师完成订单并把饮品交付给顾客时,工作流就结束了。

图2 咖啡师的状态机
尽管这些看似跟基于Web的集成毫不相干,但这两个状态机里的每一个状态迁移,都代表着与Web资源的一次交互。每一次迁移,就是通过URI对资源实施HTTP操作,从而导致状态的改变。
GET和HEAD属于特例,因为它们不引起状态迁移。它们的作用是用于查看资源的当前状态。
我们节奏稍快了点。理解状态机和Web,不是那么容易一口吃个胖子的。所以,让我们在Web的背景下,来从头回顾一下整个场景,逐步慢慢深入。
顾客视角
我们将从一张简单的故事卡片开始,它启动整个流程:

这个故事里涉及一些有用的角色与实体。首先,里面有“顾客(Customer)”角色。显然,它是(隐含的)星巴克服务(Starbucks Service)的消费者。其次,里面有两个重要的实体(“咖啡”和“订单”),以及一个重要的交互(“点单”)——我们的工作流正是由它启动的。
要把订单提交给星巴克,我们只要把订单的表示(representation)POST给下面这个众所周知的星巴克点单URI即可: http://starbucks.example.org/order。

图3 点一杯咖啡
图3显示了向星巴克点单的交互过程。星巴克采用自己的XML格式来表达有关实体;需要关注的是,这个格式允许客户往里嵌入信息,以便进行点单——稍后我们会看到。实际提交的数据如图4所示。
在面向人类的Web(human Web)上,消费者和服务使用HTML作为表示格式(representation format)。HTML有自己特定的语义,所有浏览器都理解并接受这些语义,比如:代表“一个链接到其他文档或本文档内部某个书签的锚(anchor)”。消费者应用——浏览器——只是呈现HTML,状态机(也就是你!)用
GET和POST跟随链接。对于基于Web的集成也一样,只不过服务和消费者不仅要就交互协议达成一致,还要就表示的格式与语义统一意见。

图4 POST饮品订单
星巴克服务创建一个订单资源,然后把这个新资源的位置放在HTTP报头Location里返回给消费者。为方便起见,服务还要把这个新创建的订单资源的表示(representation)也放在响应里。发给消费者的响应如下所示。

图5 创建好了订单,等待付款
201 Created状态表明星巴克已经成功接受了订单。Location报头给出了新创建订单的URI。响应主体里的表示(representation)包含了所点饮品及其价格。另外,这个表示里还包含另一个资源的URI——星巴克希望我们与这个URI交互,以完成顾客工作流;我们稍后将用到它。
注意,该URI是放在
我们已经知道
201 Created状态代码表示“成功创建资源”的意思。对于这个例子以及一般的基于Web的集成,我们还需要其他一些有用的代码:
200 OK——它的意思是:一切正常;继续执行。
201 Created——我们刚刚创建了一个资源,一切正常。
202 Accepted——服务已经接受了我们的请求,并请我们对Location响应报头里的URI进行轮询(poll)。这在异步处理中相当有用。
303 See Other——我们需要跟另一个资源交互,应该不会出错。
400 Bad Request——我们的请求格式有问题,应重新格式化后再提交。
404 Not Found——服务因为偷懒(或者保密)没有告知请求失败的真实原因,但不管什么原因,我们都得应付它。
409 Conflict——服务器拒绝了我们更新资源状态的请求。我们需要获取资源的当前状态(要么检查响应实体主体,要么做一次GET操作),然后再作打算。
412 Precondition Failed——请求未被处理,因为Etag、If-Match或类似的“哨兵(guard)”报头的值不满足条件。我们需要考虑下一步怎么走。
417 Expectation Failed——幸亏核查一下,服务器不将接受你的请求,所以别真正发送那个请求。
500 Internal Server Error——最偷懒的响应。服务器出错了,而且什么原因都没说。祝你不要碰见它。
更新订单
星巴克很不错的一点就是,你可以按无数种不同的方式来定制自己的饮品。其实,考虑到某些高端客户极高的要求,也许让他们按化学公式来点单更好。但我们别那么贪心——至少开始的时候。我们来看另一张故事卡片:

回顾图4,显然我们在那里犯了一个错误:真正爱喝咖啡的人是不喜欢往浓咖啡里放太多热牛奶的。我们要改正那个问题。幸运地是,Web(或更确切地说,HTTP)以及我们的服务均为这样的改变提供了支持。
首先,我们要确认我们仍然可以修改订单。有时咖啡师动作很快,在我们想修改订单之前,他们就已经把咖啡做好了——于是,我们只有慢慢享用这杯热咖啡风味的牛奶了。不过,有时咖啡师会比较慢,这样我们就可以在订单得到咖啡师处理之前修改它了。为了知道我们是否还能修改订单,我们通过HTTP动词OPTIONS来向订单资源查询它接受哪些操作(如图6)。
| 请求 | 响应 |
OPTIONS /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK Allow: GET, PUT |
图6 看看有哪些选择(OPTIONS)
从图6我们可以知道,订单资源既是可读的(支持GET)、也是可更新的(支持PUT)。作为好网民,我们可以拿我们的新表示来做一次试验性的PUT操作,在真正PUT之前先用Expect报头来试一试(如图7)。
| 请求 | 响应 |
PUT /order/1234 HTTP 1.1 Host: starbucks.example.com Expect: 100-Continue |
100 Continue |
图7 看好再做(Look before you leap)
若我们不能修改订单了,那么对图7所示请求的响应将是417 Expectation Failed。不过,假定我们现在得到的响应是100 Continue,也就是说,我们可以用PUT来更新订单资源(如图8)。用PUT方法来提交更新后的资源表示(representation),实际上就相当于修改现有资源。在这个例子中,PUT请求里的新描述包含一个
尽管部分更新(partial updates)属于REST社区里比较难懂的理念争论之一,但这里我们采取一种实用的做法,我们假定:增加一杯浓咖啡的请求,是在现有资源状态的上下文中被处理的。因此,我们没必要在网络上传送整个资源表示,我们只要传送变化的部分即可。

图8 更新资源状态
如果我们能够成功提交(PUT)更新,那么我们会从服务器得到响应代码200,如图9所示。

图9 成功更新资源状态
检查OPTIONS和采用Expect报头并不能令我们避免碰到“后续的修改请求失败”的情况。因此,我们并不强制使用它。作为好网民,我们会以某种方式来应付405和409响应。
OPTIONS和Expect报头的使用应当被视为可选步骤。
尽管我们明智地使用Expect和OPTIONS,但有时PUT仍将失败;毕竟咖啡师也在一刻不停地工作——有时他们动作很敏捷!
若我们落后于咖啡师,我们在试图用PUT操作把更新提交给资源时会被告知。图10显示的就是一个常见的更新失败的响应。409 Conflict状态代码表明,若接受更新,将导致资源处于不一致的状态,所以没有进行更新。响应主体里显示出了我们试图PUT的表示(representation)与服务端资源状态之间的差异。按咖啡制作的话说,加得太晚了——咖啡师已经把热牛奶倒进去了。

图10 慢了一步
我们已经讲述了使用Expect和OPTIONS来尽量防止竞争条件。除此以外,我们还可以给我们的PUT请求加上If-Unmodified-Since或If-Match报头,以表达我们对服务的期望条件。If-Unmodified-Since采用时间戳,而If-Match采用原始订单的ETag1 。若订单状态自从被我们创建以来还没有改变过——也就是说,咖啡师还没有开始制作我们的咖啡——那么更新可以处理。若订单状态已经发生改变,那么我们会得到412 Precondition Failed响应。虽然我们因为慢了咖啡师一步而只能享用牛奶咖啡,但至少我们没有把资源转移到不一致的状态。
用Web进行一致的状态更新可以采取很多种模式。HTTP PUT是幂等的(idempotent),这样我们在进行状态更新时就用不着处理一些复杂事务了,不过仍有一些选择需要我们决定。下面是正确进行状态更新的一些方法:
1. 通过发送
OPTIONS请求,查询服务是否接受PUT操作。这一步是可选的。它可以告知客户端,此刻服务器允许对该资源做哪些操作,不过这无法保证服务器将永远支持那些操作。2. 使用
If-Unmodified-Since或If-Match报头,以避免服务器执行不必要的PUT操作。假如PUT后来失败了,那么你会得到412 Precondition Failed。此方法要求:要么资源是缓慢更新的,要么支持ETag;对于前者就用If-Unmodified-Since,对于后者就用If-Match。3. 立即用
PUT操作提交更新,并应付可能出现的409 Conflict响应。就算我们使用了(1)和(2),我们可能仍得应付这些响应,因为我们的“哨兵”和检查本质上都是乐观的。关于检测和处理不一致的更新,W3C有一个非规范性文档,该文档推荐采用ETag。ETags也是我们推荐采用的方法。
在完成那些更新咖啡订单的艰苦工作之后,按理说我们应当得到额外那杯浓咖啡了。所以我们现在假定已设法得到了额外那杯浓咖啡。当然,我们要付过款后星巴克才会把咖啡递给我们(其实他们也已经暗示过了!),所以我们还需要一张故事卡片:

还记得最初那个针对原始订单的响应吗?其中有个

关于next元素,有几点是值得指出的。首先,它处于一个不同的名称空间之下,因为状态迁移并不是只有星巴克需要。在这里,我们决定把这种用于状态迁移的URI放在一个公共的名称空间里,以便于重用(或甚至最终的标准化)。
其次,rel属性里嵌入了一则语义信息(你乐意的话,也可以称之为一种私有的微格式)。能够理解http://starbucks.example.org/payment这串文字的消费者,可以使用由uri属性标识的资源转移到工作流里的下一状态(付款)。
uri指向的是一个付款资源。根据type属性,我们已经知道预期的资源表示(representation)是XML格式的。我们可以向这个付款资源发送OPTIONS请求,看看它支持哪些HTTP操作。
微格式(microformat)是一种在现有文档里嵌入结构化、语义丰富的数据的方式。微格式在人类可读的Web上相当常见,它们用于往网页里增加结构化信息(如日程表)的 表示(representations)。不过,它们同样也可以方便地被用于集成。微格式术语是在微格式社区里达成一致的,不过我们也可以自由创建自己的 私有微格式,用于特定领域的语义标记。
尽管它们看上去没多大用,但如图10里那样的简单链接正是REST社区所呼吁的“将超媒体作为应用状态的引擎(hypermedia as the engine of application state)”的关键。更简单地说,URI代表了状态机里的状态迁移。正如我们在文章开始时所看到的,客户端是通过跟随链接的方式来操作应用程序的状态 机的。
如果你一时不能理解,不要感到奇怪。这一模型的最不可思议之处在于:状态机和工作流不是像WS-BPEL或WS-CDL那样事先描述好的,而是在你 经历各个状态的过程中逐步得到描述的。不过,一旦你的想明白了,你就会发现,跟随链接(following links)这种方式使得我们可以在应用的各种状态下向前推进。每次状态迁移时,当前资源的表示里都包含了指向可能的下一状态的链接以及它们所代表的状 态。另外,由于这些代表下一状态的资源是Web资源,所以我们知道如何使用它们。
在顾客工作流里,我们下一步要做的是为咖啡付款。我们可以由订单里的
消费者需要事先掌握多少关于一个服务的知识呢?我们已经说过了,服务和消费者在交互之前需要就它们将会交换的表示(representations)的语 义达成一致。可以将这些表示格式(representation formats)看成一组可能的状态和迁移。在消费者与服务交互时,服务选择可用的状态和迁移,并构造下一个表示。步向目标的过程是 动态发现的,而把这一过程中的各个部分串起来的方式是事先达成一致的。
在设计与开发过程中,消费者会就表示和迁移的语义与服务器达成一致。但谁也不能保证服务在其演化过程中会不会采用一种客户端预期之外的表示和迁移 (不过客户端还是知道如何处理它的)——那是Web松耦合的本质特性。尽管如此,在这些情况下就资源格式和表示达成一致超出了本文的范围。
我们下一步要做的是为咖啡付款。我们可以由订单表示的
| 请求 | 响应 |
OPTIONS/payment/order/1234 HTTP 1.1 Host: starbucks.example.com |
Allow: GET, PUT |
图11 获知如何付款
服务器返回的响应告诉我们,我们既可以读取付款(通过GET)、也可以更新它(通过PUT)。既然知道了金额,那么接下来,我们就把款项PUT给那个由付款链接标识的资源。当然,付款金额属于秘密信息,所以我们将通过认证2来保护该资源。
| 请求 |
PUT /payment/order/1234 HTTP 1.1 |
| 响应 |
201 Created |
图12 付款
为成功完成付款,我们只需按图12进行交互即可。一旦经认证的PUT返回一个201 Created响应,我们就可以庆祝付款成功、并拿到我们的饮品了。
不过事情也有出错的时候。当资金处于危险状态时,我们希望要么没出错、要么可以挽救错误3。付款时可能出现很多种容易想象的出错情况:
- 由于服务器宕机或其他原因,我们无法连接上服务器了;
- 在交互过程中,与服务器的连接被切断了;
- 服务器返回一个
4xx或5xx范围的错误状态。
幸运地是,Web可以帮助我们应付以上这些情况。对前两种情况(假定连接问题是瞬间的),我们可以反复做PUT请求,直至我们收到成功响应为止。如果前次PUT操作已经得到了成功处理,那么我们将收到一个200响应(本质上是一个来自服务器的空操作确认);如果本次PUT操作成功完成了付款,那么我们将收到一个201响应。在第三种情况中,如果服务器返回的响应代码是500、503或504,那么也可以做同样处理。
4xx范围的状态代码比较难处理,不过它们仍然指出了下一步怎么办。例如,400响应表明我们通过PUT请求提交的内容无法被服务器所理解,我们需要纠正后重新发送PUT请求。403响应则相反,它表明服务器能够理解我们的请求,但不知道如何履行(fulfil)它,而且服务器希望我们不要重试。对于这些情况,我们得在响应的有效负载(payload)里寻找其他的状态迁移(链接),换其他推进状态的路线。
在这个例子中,我们已经多次使用状态代码来指引客户端步向下一个交互了。状态代码是具有丰富语义的确认信息。让服务返回有意义状态代码,并且令客户 端懂得如何处理状态代码,这样一来,我们便给HTTP简单的请求响应机制增加了一层协调协议,从而提高了分布式系统的健壮性和可靠性。
一旦我们为自己的饮品买了单,我们这个工作流就算完成了,有关顾客的故事也就到此结束了。不过整个故事还没有完。现在我们进入到服务里面,看看星巴克的内部实现。
咖啡师视角
作为顾客,我们乐于把自己放在咖啡世界的中央,不过我们并不是咖啡服务的唯一消费者。从与咖啡师的“时间竞赛”中我们已经得知,咖啡服务还为包括咖啡师在内的其他一些相关方面提供服务。按照我们循序渐进的介绍方式,现在该推出另一张故事卡片了。

用Web的格式与协议来描述饮品列表是件很容易的事。用Atom提要(feeds)来表达列表之类的东西是相当不错的选择,它几乎可描述任何列表(比如未完成的咖啡订单),所以这里我们可以也采用它。咖啡师可以通过向该Atom提要的URI发送GET请求来访问它,对于未完成的订单,URI是http://starbucks.example.org/orders(如图13)。

图13 待制作饮品的Atom提要
星巴克是家相当繁忙的店,位于/orders的Atom提要更新相当频繁,所以咖啡师要不断轮询这个提要才能保证掌握最新信息。轮询通常被认为可伸缩性很差;但是,Web支持可伸缩性极强的轮询机制——我们稍后会看到。另外,由于星巴克每分钟要制作很多咖啡,所以承受住负荷是个重要问题。
这里我们有两个相抵触的需求。一方面,我们希望咖啡师通过经常轮询订单提要,以不断掌握最新信息;另一方面,我们又不希望给服务增添负担、或者徒然增加网 络流量。为防止我们的服务因过载而崩溃,我们将在我们服务之外,用一个逆向代理(reverse proxy)来缓存并提供被频繁访问的资源表示(如图14所示)。

图14 通过缓存提升可伸缩性
对于大多数资源(尤其是那些会被很多人访问的资源,如返回饮品列表的Atom提要),在宿主服务之外缓存它们是合理的。这样可以降低服务器负 载,提升可伸缩性。我们在架构里增设了Web缓存(逆向代理),再加上有缓存元数据,这样客户端获取资源时就不会给原服务器增添很大负担了。
缓存的有利一面是,它屏蔽掉了服务器的间隙性故障,并通过提高资源可用率来帮助灾难恢复。也就是说,即便星巴克服务出现了故障,咖啡师仍然可以继续工 作,因为订单信息是被代理缓存起来的。而且,假如咖啡师漏了某个订单的话(错误),恢复也很容易进行,因为订单具有很高的可用率。
是的,缓存可以把旧订单多保留一段时间,但对于像星巴克这样吞吐量很高的商户而言,这是不太理想的。为了把太旧的订单从缓存中清除,星巴克服务用
Expires
报头来声明一个响应可以被缓存多久。任何介于消费者与服务之间的缓存都应当服从这一指示,拒绝提供过期订单4,而是把请求转发到星巴克服务上,以获取最新的订单信息。
图13所示的响应对Atom提要的Expires报头进行了相应的设置,令饮品列表在10秒钟后过期。由于这 种缓存行为,服务器每分钟最多只要响应6次请求,其余请求将由缓存机制代劳。即便对于性能比较糟糕的服务,每分钟6个请求也属于容易处理的工作量了。在最 愉快的情况下(对星巴克服务来说),咖啡师的轮询请求是由本地缓存响应的,这样就不会给增加网络活动或服务器负荷了。
在我们的例子中,我们只设置了一个缓存来帮助提升主咖啡列表的可伸缩性。然而,在真实的基于Web的场景中,我们可以从多层缓存中受益。要在大规模环境中提升可伸缩性,利用现有Web缓存的优点是至关重要的。
Web以延迟换取了高度的可伸缩性。假如你的问题对延迟很敏感的话(比如外汇交易),那么就不太适合采用基于Web的方案了。但是,假如你可以接受“秒”数量级上的延迟,那么Web也许是个不错的平台。
既然我们已经成功解决了可伸缩性问题,那么我们继续来实现更多的功能。当咖啡师开始为你制作咖啡时,应当修改订单状态,以达到禁止更新的目的。从顾客的角度来看,这相当于我们无法再对我们的订单执行PUT操作了(如图6、7、8、9、10所示)。
幸运地是,我们可以利用一个已经定义好的协议——Atom发布协议(Atom Publishing Protocol,简称APP或AtomPub)——来实现这一目标。AtomPub是一个以Web中心(基于URI)的协议,用于管理Atom提要里的 条目(entries)。我们来仔细看看Atom提要(/orders)里代表咖啡的条目。

图15 咖啡订单对应的Atom条目
在图15所示的XML里,有几点值得注意。首先,它将我们的订单与Atom提要里的其他订单区分开了。其次,其中包含订单本身,即咖啡师制作咖啡所需的全部信息——包括我们要求增加一杯浓咖啡的重要信息!该订单对应的entry元素里有个link元素,它声明了本条目(entry)的编辑URI(edit)。这个编辑URI指向的是一个可以通过HTTP编辑的订单资源。(这里,可编辑资源的地址刚好跟订单资源本身的地址一样,不过这不是必须的。)
如果咖啡师要锁定订单资源、禁止它被修改,就可以通过该编辑URI来改变订单资源的状态。具体地讲,咖啡师可以用PUT请求把经修改的资源状态提交给这个编辑URI(如图16所示)。

图16 通过AtomPub设置订单状态
服务器一旦处理了如图16所示的PUT请求,它就会拒绝对位于/orders/1234的订单资源做除GET以外的操作。
现在订单处于稳定状态了,咖啡师可以毫无顾虑地继续制作咖啡了。当然,咖啡师只有知道我们已经付过款才会把咖啡给我们,所以咖啡师还要查询我们是否已经完 成付款。在真实的星巴克里,情况会略有不同:一般来说,我们是点单后立即付款的;然后,其他顾客站在周围,以免你拿走别人点的饮品。但在我们计算机化的版 本里,增加这一检查并不麻烦,所以我们来看倒数第二张故事卡片:

咖啡师只要向付款资源(该资源的URI在订单表示里给出了)发送GET请求,即可查询付款状态。
这里,顾客和咖啡师是通过订单表示里给出的链接得知付款资源的URI的。但有时,通过URI模版来访问资源也很方便。
URI模版(URI template)是一种描述知名URI的格式。它允许消费者通过修改URI里的部分字符来访问不同的资源。
Amazon的S3存储服务就是基于URI模版的。用户可以对由以下模版生成的URIs进行HTTP操作,从而对已保存的制品进行操作:
http://s3.amazonaws.com/{bucket_name}/{key_name}。为方便咖啡师(或其他经授权的星巴克系统)不用遍历所有订单即可访问各个付款资源,我们可以在我们的模型里设计一个类似的URL模版方案:
http://starbucks.example.org/payment/order/{order_id}。URI模版就像与消费者订立的契约,服务提供者须在服务演化过程中注意维持它们的稳定。由于这一潜在的耦合,有些Web集成工作者会有意避免采用URI模版。我们的建议是,仅当可推断的URIs(inferable URIs)很有帮助而且不会改变时才使用。
对于我们的例子,另一种办法是在
/payments处暴露一个提要,用它提供包含指向各个付款资源的(不可推断的)链接。该提要只有经授权的系统才能读取。最终,URI模版是不是一个相对超媒体来说安全而有效的捷径,要由服务设计者来决定。我们的建议是:要保守地使用URI模版!
当然,不是人人都可以查看付款信息的。我们不想让咖啡社区里会动歪脑筋的人查看他人的信用卡详细信息,因此,跟其他敏感的Web系统一样,我们利用请求认证来保护敏感资源。
如有未认证的用户或系统试图获取一个具体的付款信息,那么服务器会质询(challenge)它、要求它提供证书。(如图17)
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org |
401 Unauthorized WWW-Authenticate: Digest realm="starbucks.example.org", qop="auth", nonce="ab656...", opaque="b6a9..." |
图17 对付款资源的非授权访问受到质询
401状态(及其认证元数据)告诉我们,我们应当在请求里附上正确的证书、然后重新发送请求。重新用正确的证书发送请求(图18)后,我们得到了付款信息,并将之与代表订单总金额的资源http://starbucks.example.org/total/order/1234进行比较。
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org Authorization: Digest username="barista joe" realm="starbucks.example.org“ nonce="..." uri="payment/order/1234" qop=auth nc=00000001 cnonce="..." reponse="..." opaque="..." |
200 OK |
图18 授权访问付款资源
一旦咖啡师制作好、交出咖啡并完成收款,他们就要在待处理饮品列表中删除相应的订单。如同前面一样,我们采用一个故事来讲解这个回合:

因为订单提要里的各个条目(entry)都标识着一个可编辑资源,而且有自己的URI,所以我们可以对各个订单资源做HTTP操作。如图19所示,咖啡师只要对相关条目(entry)所引用的资源做DELETE操作即可将它从列表中删除。
| 请求 | 响应 |
DELETE /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK |
图19 删除已完成的订单
在条目被删除(DELETE)之后,再对订单提要做GET操作的话,返回的表示里将不再包含已删除(DELETE)的资源。假定我们的缓存工作正常、且我们已经设置了合理的缓存过期元数据的话,那么当你试图获取(GET)那个订单条目时将直接得到404 Not Found响应。
也许你已经注意到了,Atom发布协议可以满足我们对星巴克这个问题的大部分需求。如果我们想直接把位于/orders的Atom提要暴露给顾客的话,顾客就可以用Atom发布协议来向该提要发布饮品订单、甚至修改订单了。
演化:Web上的现实情况
因为我们的咖啡店是基于自描述的状态机(state machines)构建起来的,所以我们可以方便地根据业务需要改造我们的工作流。例如,星巴克也许会提供一种免费的网上促销活动:
- 7月——我们的星巴克店开业,并提供标准的工作流以及我们前面提到的状态迁移和表示(representation)。消费者知道用这些格式与表示跟我们的服务进行交互。
- 8月——星巴克新推出了一种免费网上促销的表示(representation)。我们的咖啡工作流将进行更新,以包含指向该网上促销资源的链接。由于URI的特性,链接可以是指向第三方的——这跟指向星巴克内部的资源一样简单。

- 因为表示里仍然包含原来的迁移点,所以现有消费者仍然可以实现它们的目标,只不过它们可能无法享受促销而已,因为这部分还没有写进它们的代码里去。
- 9月——消费者应用和服务都进行了有关升级,以便能够理解并使用免费的网上促销。
成功进行演化的关键在于,服务的消费者们要能够预料到改变。在每一步,服务不是直接跟资源绑定(例如通过URI模版),而是提供指向具名资源(named resources)的URIs,以便消费者与之交互。这些具名资源,有些是消费者不认识的、将被忽略的,有些是消费者已知的、想采用的状态迁移点。不管 采用哪种方式,这种方案使得服务可以优雅地演化,同时还能维持与消费者兼容。
你将使用的是一个相当热门的技术
交付咖啡是我们工作流的最后一步。我们已经点了单、修改了订单(也可能无法修改)、付过款并最终拿到了我们的咖啡。在柜台另一侧,星巴克也已经同样完成了收款和订单处理。
我们可以用Web来描述所有必需的交互。我们可以利用现有的Web模型处理一些简单的不愉快的事(例如无法修改处理中或已处理完毕的订单),而不必 自己发明新的异常或错误处理机制——我们所需的一切都是HTTP现成提供的。而且,即便发生了那些不愉快的事,客户端仍然可以向它们的目标迈进。
HTTP提供的特性起初看来是无关紧要的。但这个协议现在已经取得广泛的一致、并得到广泛的部署了,而且所有的软件与硬件都能一定程度上理解它。当 我们看到其他分布式计算技术(如WS-*)处于割据状态的格局时,我们意识到了HTTP享有的巨大成功,以及它在系统间集成方面的潜力。
甚至在非功能性方面,Web也是有益的。在我们碰到临时故障时,HTTP操作(GET、PUT和DELETE)的幂等性质令我们可以进行安全的重试;内在的缓存机制既屏蔽了故障,又有助于灾难恢复(通过增强的可用率);HTTPS和HTTP认证有助于基本的安全需求。
尽管我们的问题域是人为制造的,但我们所强调的技术同样可以应用于分布式计算环境。我们不会伪称Web很简单(除非你是天才),Web可以解决一切问题 (除非你是超级乐观的人,或受到REST信仰的感染),但事实上,在局部、企业级和Internet级进行系统集成,Web是个健壮的框架。
致谢
本文作者要向英国卡迪夫大学(Cardiff University)的Andrew Harrison表示感谢,是他启发了我们就Web上的“对话描述”进行讨论。
About the Authors
Jim Webber博士是ThoughtWorks公司的专业服务主管,他的工作是为全球客户进行可靠的分布式系统架构设计。此 前,Jim担任英国E-Science计划高级研究员,从事将Web服务实践及可靠面向服务计算的架构模式应用于网格计算的战略设计工作,他在Web及 Web服务架构与 开发方面具有广泛的经验。Jim还担任过惠普公司和Arjuna公司的架构师,他是业界首个Web服务事务方案的首席开发者。Jim是一位活跃的演说家, 他经常受邀出席 国际会议并发言。他还是一位活跃的作家,除了《Developing Enterprise Web Services - An Architect's Guide》这本书外,目前他正在撰写一本关于基于Web的集成的新书。Jim获得英国纽卡斯尔大学(University of Newcastle)的计算机科学学士学位和并行计算博士学位。他的博客地址是:http://jim.webber.name。
Savas Parastatidis是一位软件思想家,他的思考领域涉及系统和软件。他研究技术在eResearch里的运用,他尤其对云计算、知识表示与管理、社会网络感兴趣。他目前任职于微软研究院合作研究部。Savas喜欢在http://savas.parastatidis.name上写博客。
Ian Robinson帮助客户们创建可持续的面向服务的能力,令业务与IT从开始到实际运营始终保持齐合。他为微软公司写过关于采用微软技术实现面向服务系统的指南,还发表过文章讲述消费者驱动的服务契约及其在软件开发生命周期中的作用——该文章可以在《ThoughtWorks文集(The ThoughtWorks Anthology)》(Pragmatic Programmers,2008)及InfoQ中文站上找到。他经常在会议上做有关REST式企业开发及面向服务交付的测试驱动基础的讲演。
查看英文原文:How to GET a Cup of Coffee。
Linux下如何使用命令同步时钟
linux的系统时钟在很多地方都要用到,要是不准,就会出现一些奇怪的问题;
在Linux中,用于时钟查看和设置的命令主要有date、hwclock和clock。Linux时钟分为系统时钟(System Clock)和硬件(Real Time Clock,简称RTC)时钟。系统时钟: 是指当前Linux Kernel中的时钟,硬件时钟: 是主板上由电池供电的时钟,这个硬件时钟可以在BIOS中进行设置。
当Linux启动时,硬件时钟会去读取系统时钟的设置,然后系统时钟就会独立于硬件运作。
Linux 中的所有命令(包括函数)都是采用的系统时钟设置。在Linux中,用于时钟查看和设置的命令主要有date、hwclock和clock。其中,clock和hwclock用法相近,只用一个就行,只不过clock命令除了支持x86硬件体系外,还支持Alpha硬件体系。
1、 date
查看系统时间
# date
设置系统时间
# date –set “07/07/06 10:19″ //(月/日/年时:分:秒)
2、hwclock/clock
查看硬件时间
# hwclock –show //或者
# clock –show
设置硬件时间
# hwclock –set –date=”07/07/06 10:19″ (月/日/年 时:分:秒) 或者
# clock –set –date=”07/07/06 10:19″ (月/日/年 时:分:秒)
3、硬件时间和系统时间的同步
按照前面的说法,重新启动系统,硬件时间会读取系统时间,实现同步,
但是在不重新启动的时候,需要用hwclock或clock命令实现同步。
硬件时钟与系统时钟同步:
# hwclock –hctosys // (hc代表硬件时间,sys代表系统时间)或者
# clock –hctosys
系统时钟和硬件时钟同步:
# hwclock –systohc // 或者
# clock –systohc
4. 和外部的NTP时间服务器同步
$ service ntpd stop
这一步是必须的,否则出出现:
25 Nov 18:10:34 ntpdate[2106]: the NTP socket is in use, exiting
的失败提示;
$ ntpdate ntp.sjtu.edu.cn
正常返回如下:
25 Nov 18:14:34 ntpdate[2164]: adjust time server 202.120.2.101 offset -0.006107 sec
错误返回如:
25 Nov 18:13:44 ntpdate[2158]: no server suitable for synchronization found
$ service ntpd start
$ chkconfig ntpd on
$ clock -w
还可以写进定时任务中,以做定时的时钟同步:
$ crontab -e
05 * * * * /usr/sbin/ntpdate ntp.sjtu.edu.cn 》 /dev/null 2》&1
05 17 * * * /sbin/clock -w
附上中国大概能用的NTP时间服务器地址
server 133.100.11.8 prefer
server 210.72.145.44
server 203.117.180.36
server 131.107.1.10
server time.asia.apple.com
server 64.236.96.53
server 130.149.17.21
server 66.92.68.246
server www.freebsd.org
server 18.145.0.30
server clock.via.net
server 137.92.140.80
server 133.100.9.2
server 128.118.46.3
server ntp.nasa.gov
server 129.7.1.66
server ntp-sop.inria.frserver 210.72.145.44(中国国家授时中心服务器IP地址)
server ntp.sjtu.edu.cn(上海交通大学网络中心NTP服务器地址)
上面就是使用命令同步Linux时钟的方法介绍了,一般使用data、hwclock和clock命令,而data命令是比较常用的命令,如果你的系统时钟不同步,那就赶紧改过来吧。
支付宝口碑isv开发如何正确处理签名
简单的知识点
- 本文基本分初级、进阶、高级三部
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
不熟悉的同学 - 进阶适用群体:使用 SDK 开发系统,对 RSA 签名规则
熟悉的同学 - 仅使用SDK需要对开放平台签名规则略有了解。
- 适合遇到网关返回报文中描述
签名错误。 - 高级适用群体: 不使用 demo或 SDK、完全独立开发。对RSA 签名规则
熟悉的同学 - 注:推荐使用 SDK。否则请直接跳高级说明。
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
- 推荐使用 demo 或者 SDK。可以节约开发同学学习RSA签名规则的时间。
- 初次对接开放平台接口时建议选择参数较少的简单接口对接,方便调查问题。
- 支付宝产品分 mapi 网关产品及 openapi 网关产品。
- mapi 网关均使用支付宝PID调用,需配置合作伙伴秘钥。
- 因 mapi 多使用 md5验签,问题较少,因此本文仅介绍开放平台签名规则。
- openapi 网关产品均使用支付宝 appid 调用,需在appid上分别配置秘钥。
- 如有多个 appid, 使用相同秘钥或者不同秘钥均可,只需保证自己调用时使用配对秘钥加签即可。
初级教程
对于新接入支付宝产品的开发,如何生成密钥、开放平台设置密钥 很重要
- 获取 PID
?点击查看- 详解如何查询 支付宝账号PID.
- RSA秘钥生成
?点击查看- 推荐使用在线地址中生成工具,该工具同样可做秘钥校验作用.(问题排查工具)
- 上传公钥
?点击查看- 在此页面可以上传商户公钥及查看支付宝公钥(支付宝公钥唯一,因此代码中不做修改最好,以免节外生枝.)
- demo&sdk使用方法
?点击查看- 参考文中的配置方法将第二步中生成的私钥填写.
- 注意最新
.netdemo 对aop.DefaultAopClient方法做了改善,添加了两个参数.最后一个参数keyFromFile.- 为true时直接写私钥本地路径.
- 默认 false, 需要将私钥内容转成一行填入方法中.
进阶教程
进阶教程主要针对在使用时碰到签名错误的同学
- 一般平台返回签名错误 个人建议按照初级教程仔细核对一遍.
- 可能原因1:账号多人使用,被其他同事或者其他公司员工修改
- 建议跟商户相关负责人沟通,看谁有可能修改秘钥,因为修改秘钥需要短信验证码,所以肯定能查出问题根源.
- 绑定手机号应该是公司相对高层人士,与其沟通不要随便将短信码给其他人.
- 可能原因2:自己误操作导致公钥不匹配
- 在开放平台有多个应用,上传公钥时需上传系统使用 appid 相同应用的商户公钥.
- 生成了多套秘钥或者其他原因导致程序里私钥与平台设置的公钥不匹配
- 该问题建议使用
初级教程:[RSA秘钥生成]中的工具做排查,校验公私钥是否匹配. - 如不匹配可使用私钥重新生成公钥配置到开放平台.
- 或者重新生成一套按
初级教程:上传公钥重新配置 - 可能原因3:如果调用api中传参包含中文,则很有可能是因为编码问题导致开放平台验签失败.
- 调查方法,将参数中所有中文替换成英文重试接口调用,如果成功说明是编码影响平台验签.
- 修改方法,参考
初级教程:demo&sdk使用方法在DefaultAopClient方法中传入相应编码集. - 下面介绍出现这个问题的原因,感兴趣的同学可以看下.
- 中文包含多种编码集,而你们系统有默认编码集,当你参数中含有中文且在调用签名方法时没有指明编码集,系统会使用默认编码集进行签名.而调用接口时需传入
charset参数, 如果你没传入,平台会使用默认编码集utf-8解签,如果你系统默认utf-8编码,那么此问题你无感知,但如果是非utf-8类型编码会导致平台算签名串与你实际传入不符. 最终验签失败
- 系统直接报错,抛出的异常建议自己先分析.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
- 使用java开发但是私钥未经过
pkcs8转码 - 使用.net开发,参考
初级教程:demo&sdk使用方法,未对keyFromFile做有效控制. - 复制私钥没复制全.
- 使用java开发但是私钥未经过
- 其他异常均属于代码错误,建议先自己排查.实在搞不定可以联系
技术支持协助解决.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
高级教程
高级教程针对不使用 SDK开发的同学(安全考虑/冷门语言等原因)
- 高级教程需要你首先了解初级教程,并且进阶教程中的常见问题也可以自己排查解决.
- 本文主要探讨开放平台签名规则,如不使用sdk开发,这些逻辑代码均需要自己开发.
- 建议开发前先参考 sdk 源代码看下实际处理
- 签名机制
?点击查看mapi网关产品签名时要去掉sign_type=RSA,这点跟openapi网关产品不同,一定要注意.- 排序时不要仅排序第一个字符,要注意第一字符相同时排第二字符,以此类推.
- 所有
空参数不在签名参数中,注意剔除.异步通知(需要解签报文)同理 - 支付宝异步通知不会有
空参数
How do I find my passion?- 怎样获得激情?
原文是Oliver Emberton在Quora的一个问题——How do I find my passion?下的回答。现本着学习交流的目的,将其翻译如下,欢迎指正。
Too many of us believe in a magical being called ‘passion’. “If only I could find my passion”, we cry. “Finding my passion would make me happy”.
人们总会相信一个神奇的词:激情。“只要能找到自己的激情在什么上,我一定会快乐起来!”
 |
Well, passion is real, and very powerful. But almost everything people believe about finding it is wrong.
确实,激情有这个能力;但怎么寻找激情引发点,人们却总是不得其法。
Rule 1: Passion comes from success1. 激情源自成功
All of our emotions exist for good reason. We feel hunger to ensure we don’t starve. We feel full to ensure we don’t burst. And we feel passion to ensure we concentrate our efforts on things that reward us the most.
我们所有情绪的存在,都是有原因的。我们会感觉到饥饿,才不会饿死;会感觉到饱,才不会撑死(也有例外)。而我们的激情,是驱使自己把更多的精力,花在能给我们最大回报的事情上。
Imagine you start a dance class. You find it easy. You realise you’re getting better than others, and fast. That rising excitement you feel is your passion, and that passion makes you come back for more, improving your skills, and compounding your strengths.
比如你开始上舞蹈班时,发现很轻松,你比别人做的更好,学得更快。这就会让你觉得兴奋,也就是传说中的激情,激情会让你花更多的心思去学习,去进步。
 |
The enemy of passion is frustration. If you constantly struggle with something, you’ll never become passionate about it. You learn to avoid it entirely, guaranteeing you never improve.
而激情的敌人,是沮丧。如果某件事对你来说简直就是挣扎,你是不会对它有激情的。避免沮丧,否则你是很难提高的。
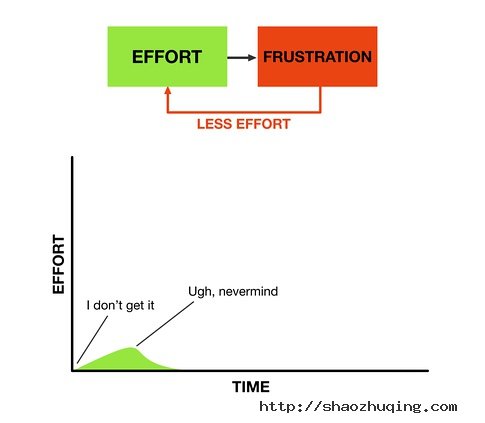 |
Most people get this backwards. They think we discover our passion, and that makes us good at something. It’s actually finding that you’re good which comes first. Passion comes from success.
反馈机制如上图,大多人是这种情况。他们觉得,我得先发现激情所在,然后才能获得成功;但实际上,成功是激情之母。
Rule 2: Childhood is where passion goes to die2. 激情卒于童年
In theory childhood provides a great opportunity to try a bit of everything, find your talents, and with them, your passions.
理论上,童年时的我们,会有很多机会涉猎各种事情,通过这种方式,我们会发现自己的天赋,发现自己的激情。
But think for a moment how badly the system is stacked against you. Say school lets you try 20 subjects, ranking you against thousands of other children. Those aren’t good odds. Most kids are, by definition, around average. And it doesn’t matter how much we improve education, because people need to feel exceptional to feel passionate, and improving education simply moves up the average.
但想一想,我们就会发现,在这个系统中,我们只是可怜的路人甲。比如,学校里你需要选20门课,但需要和数千名小伙伴们一起排名。这可就不好玩了。大多数孩子都是普通水平——因为普通的定义就是大多数所达到的水平。这样,即使教育水平提高,也无济于事,以为我们需要从独特的优越中获取激情,而教育提高的是一群人的水平,水涨船高。
 |
Say you’re one of the lucky ones, and you’re top of your junior math class. The education system will keep rising your difficulty until you find a level – like college – where you’re not exceptional anymore. Even if you actually are objectively pretty great, once you feel merely average, you’ll find your passion slipping.
再假如,你很幸运地成为了传说中的万里挑一,是你们整个八年级数学最好的那个。随着你接受的教育越来越高端,难度越来越大,总一天你会发现自己不再出色——高等数学课上,你已经泯然众人矣。即使你真的很强,又读到数学博士,但发现自己只是个“普通的”数学博士,你的热情,就像一把渐渐熄灭的火。
And that’s if you’re lucky. What if your passion was for art? From an early age that passion is compromised by its social consequences. “It’s hard to make a living from painting” say your parents. “Your cousin is doing so well from engineering. Why can’t you be more like him?” And so you put your passions to one side, and let them wither.
这还算是幸运的。如果你的激情在艺术上会怎样?你激情的小火苗还没燃起来的时候,它就已经被看衰。你爸妈会说,画画很难吃饱饭的,那谁家的谁谁,学机械工程好就业,你就不学好?于是你不得不放下你的音乐/艺术梦想,任其枯萎。
In a population of billions, it’s obvious that not everyone can be unusually great at a handful of academic subjects. What if your true skills are in speechwriting, or creative dance, or making YouTube commentaries of videogames? None of those things are even on the syllabus.
在几十亿的社会中,很明显,不是所有人都能在学校的那几门课程中表现出色的。如果你真正的特长是写演讲稿、即兴舞蹈或者在网上写游戏测评?学校可不会考这些。
And so most people grow up without much passion for anything.
所以才会有那么多人在成长中是难以发现激情的。
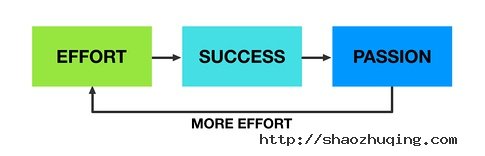
Rule 3: Passion can be created
3.创造激情
It may help to know that the most successful people in life generally didn’t pick their passion off a shelf.
最成功的那些人可不是在书中发现自己的激情的。
 |
In fact, many of the world’s most successful people dropped out of education entirely. Not because they were stupid – but because they found other areas where they were more skilled that education did not recognise.
实际上,世界上最成功的那些人,很多干脆辍学了。不是因为笨。他们发现了教育根本没顾忌到的领域。
They created their own passions.
他们自己创造了自己的激情。
Only a tiny fraction of people can expect to excel in the narrow subjects that childhood primes us for. And competition in that space is basically ‘everybody in the world who went to school’, which doesn’t help our chances.
关于我们童年教育所针对的那些事情,可能只有很少的一部分人能出类拔萃。基本上,你是在和全世界上学的孩子一起竞争。这就是说,如果你真的是万里挑一,那全世界还有几百万人和你一样万里挑一——泪奔么?
But if you look outside of that space, you’ll find less competition, and more options. And this is how you tip the odds of finding a passion in your favour.
但你得跳出圈子看这个问题,少一点竞争,多一点选择。你才可能发现激情。
Option 1: Create something方法一:创造新东西。
When you create something new, you’re inventing something to be passionate about.
当你创造出新东西时,这玩意会让你获得激情的。
You might design novelty cushions, or write Batman stories, or start a Twitter account dedicated to fact-checking politicians.
比如设计一个很新奇的坐垫,写一则蝙蝠侠往事,在微博上注册个专用于黑郭敬明的账号(作者说黑政治家,结合国情,我们还是聊郭敬明吧)。
 |
New things are relatively uncontested. By creating something new, you’ve made your odds of becoming exceptional far, far higher.
新东西就没那么多人来跟你竞争。你需要和成千上万竞争者PK,才可能进入Google/百度;但若是自己创业,专搞挖掘机专业英语培训,基本上你不用和任何人竞争。
Now it’s important to note that this doesn’t sidestep Rule #1: passion comes from success. So if your new Twitter account only has 5 followers after a year, you probably won’t be too passionate about it. If you had 5 million, you’d have quit your job. You must find success to fuel your passion.
需要注意的是,这和【第一条:激情源于成功】不太一致。你注册的“郭敬明研究院院长“长期只有几个粉丝,恐怕要不了几个月你就没劲了;但如果你有五百万粉丝,估计你干脆就辞职在家专门写段子发软文了。激情的小火苗离不开不断的成功来作为燃料。
 |
But at least you’ve drastically improved your odds, because your competition is so limited. Only a handful of people will even dare to try something new. And you can be one of them, just by starting.
不过话说回来,至少你另辟蹊径,获得激情的概率会提高。很少有人敢于尝试新鲜东西,只要去开这个头,你也能成为这少数人之一。
You see this pattern throughout history’s greats. A student called Mark was never going to be the world’s greatest programmer. But he started building cool websites, and he found he was unusually good at this because even better programmers rarely dared to try. It just so happens one of his little experiments became Facebook.
看一看历史上那些伟人,很多都是在这个模式下成其伟业的。有个叫马克的学生,本来是不可能成为世界上最好的程序员的;不过他决定去创建网站,他发现自己特别善于把网站做的很酷,比那些更出色的程序员更出色了。他的小实验叫Facebook.
Option 2: Lead a new trend方法二:引领新潮流
The older and more established an area is, the harder it will be to compete in. Millions have got there before you, and the lower your odds of standing out, the lower your odds of being passionate.
一个领域越是历史悠久,其中的竞争就越激烈。无数人已经比你先占好位置了,你很难脱颖而出,也就难以获得激情。
But there’s always a new frontier being born, a place where everyone else is hopelessly incapable, and even modest skills can be impressive.
但任何一个领域的产生,总有一个起点。在这个起点,任何人都和你一样,一无所知,一无所长。
 |
Say you were a teenager who started making YouTube videos, back in 2005. You grow a modest following, and your growing success excites you. By the time the ‘grown up’ world had realised YouTube was Kind-Of-A-Big-Deal with 4 billion views every single day, you’ve become a passionate master of an invaluable new craft.
比如,你是个喜欢鼓捣视频的小伙子,在2005的情人节闲着无事,发现另一群单身汉这天创建了个网站叫Youtube. 既然这么有缘,你就注册了自己的账号,传几段有趣的视频,刚开始没人搭理你,渐渐有人来你的主页上溜达,到后来人越来越多,你的成就感与日俱增,你的激情也越来越大。而这个时候,Youtube已经火起来了,你作为最早的使用者之一,俨然已经成为网站大V了,谈笑风生。
That isn’t fantasy. There are mountains of hugely successful YouTubers, and most started in the same way: before everybody else. It’s the same for the first bloggers, rappers, and videogame designers.
这不是做梦,Youtube上有太多太多这样的成功者,他们仅仅是比别人更早使用罢了。同样的,最早写博客的人,制作网络歌曲的人,视频游戏设计者,都有类似的情况。
If you can find something new that’s growing fast, and get skilled at it early, you’ll find it disproportionately easy to excel because of the lack of competition. And that’s your new passion right there.
如果你发现了长势喜人的新事物,赶紧掌握它吧。你会发现没有了太多竞争,出色起来,真是好轻松啊。这就是新潮流给你带来的激情。
Option 3: Fuse mediocrity方法三:熔炼平凡
One limitation of education is it’s designed to narrow your skills. Education generally finds your One Best Thing, and pushes that thing as far as you can stand it:
教育的局限之一是,它会让你的技能越来越来专一;它会让你在某个领域的某个方向上越走越远,以至于让最初的你无法想象。
 |
The problem is most of us, by definition, can’t be the best in any one area. But we can be exceptional in our combinations.
问题是,我们大多数人是不可能在一个领域里成为最好的那一个;却可以在我们自己创造的领域里做的最好。
Say you’re an average artist, with a decent sense of humour. You won’t have much hope with an art degree, and you can’t study ‘humour’ as a subject. But you could be an awesome cartoonist.
比如你是一个很一般的艺术家,不过幽默感还不错。你没法成为艺术大师,也不太可能成为一个谐星;不过你却会是一个出色的漫画家。
Or take an average business student, with some programming ability, and decent sales skills. That person is surprisingly well suited to become the boss of others who were better than them in any one of those areas.
或者你是一个普通的商科学生,会一点编程,还懂点推销技巧。那你就去做个领导者吧,让比你更懂商业的人、更懂编程、更懂推销的人,在你手下各自发挥所长。
The most successful people are almost never defined by a single skill. They are a fusion of skills, often not even exceptional skills, but they’ve made their fusion exceptional. Steve Jobs was not the world’s greatest engineer, salesperson, designer or businessman. But he was uniquely good enough at all of these things, and wove them together into something far greater.
成功者不是靠某一项技能的。他们通常是多种能力融合体,而且其中的任何一种能力可能也不会太出众,但这个融合体就非常出众了。乔布斯如果可以拆成几个部件的话,可以是工程师、销售、设计、商人,每一部件都不是最好的,不过都有其独特之处,而其组装一起后,就可以称得上伟大了。
This is the final route you have to finding your passion: combine skills into something more valuable. Remember, passion comes from success. If a new combination gets you better results, that could be your passion right there.
寻找激情的终极大法即是:把自己的技能融合成更有价值的东西。记住,激情源自成功,你的聚合物如果能让你有所成就,那它就是你要寻找的。
Why passion matters为什么要有激情?
Passion is attractive. As passion comes from believing you’re unusually good at something, being passionate is a very sincere way of saying, “by the way, I’m awesome”.
激情会让你更有魅力。对事情的激情在某种程度上就是一种自信,能向比人传递出你很在行、值得信赖的信息。
 |
Passion will persuade people to follow you. It will persuade people to believe in you. But most importantly, passion will persuade yourself. Passion is an emotion specifically intended to make you go crazy and work your ass off at something because your brain believes it could rock your world. That, like love, is a feeling worth fighting for.
人们愿意追随有激情的人。因为我们通常会信任那些充满激情的人,不过最重要的是,激情会让你自己信任自己。激情会让你为之痴迷、癫狂,愿意拿出十二分努力,因为你坚信这会改变你的一切。就像你愿意为爱痴狂。
And like love, what we’re passionate about is too important to leave to the mercy of fate. If you haven’t found your passion yet, create new things, lead new trends, and fuse new combinations. But don’t ever stop looking.
就像爱,我们注以激情的东西,对自己来说太重要了,以至于不愿听天由命。如果你还没找到激情所在,试试创造新的东西,尝试新的方式,或者在已有的技能上,看看能不能提炼出不一样的东西。Just keep looking.









百度员工离职总结:如何做个好员工?
本文来源于泰然野狐禅,在此感谢!
2014年7月4日,我从百度离职了。
这是第一次,我不是因为和老板闹翻而离职;
这是第一次,我带着晋升的喜悦而离职;
这是第一次,我带着满满的收获而离职。
我曾经认为,我永远不会成为一个好员工,因为我太独、太挑剔、不喜欢听话的好孩子、而且讨厌一切想要改变我的人。但是三年过去,我改变了不少,我必须承认,所谓“进步”的过程,就是被认可的过程,也是被“驯化”的过程。
所谓“驯化”,就是了解规则、遵守规则、利用规则的过程。我并非被某些人“驯化”,而是被社会与职场的规律驯化。我曾经鄙视这个过程,但今天看来,作为一个资质平庸的人,如果你想在这个社会里做成点儿什么,“被驯化”是不可避免的。
我也曾自诩“卓尔不群”,又受了老罗“彪悍的人生不需要解释”的“蛊惑”。但在现实中,这个路子不一定行得通。你不得不向很多人解释、用他们(而不是自己)喜欢的方式解释,因为只有得到他们的认可和支持,你才能继续工作下去。如果你是一个资质平庸的人,你不得不这样做,美剧《犯罪心理》中有一句话:“凡按自己的方式追求理想者,无不树敌。”
树敌多了,你就死了。
现在,我不敢说自己是个“好员工”,我只是觉得我是个比曾经的自己更好的员工。在离职的时候,我打算把自己这几年的职场心得总结一下,算是给自己的一个礼物。
我是一个资质平庸的人,以下这些心得只适用于愚钝且资质平庸的我,对于才华横溢的天才们并不适用。
一、你有“同理心”吗?
什么叫“同理心”?
说复杂点儿,同理心就是站在当事人的角度和位置上,客观地理解当事人的内心感受,且把这种理解传达给当事人的一种沟通交流方式。
说简单点儿,同理心就是“己所不欲,勿施于人”。将心比心,也就是设身处地去感受、去体谅他人。
说白了,同理心就是“情商”。
具体点说:
同理心就是,领导交办一项工作,你要读懂他的目的、看清他的用意。我经常遇到这样的情况:给团队成员安排工作时,一再询问“我说明白了吗”“有没有问题”,再三确认后,提交上来的东西仍然答非所问。所以我在接受任务时,总会向领导确认:你想要的是什么?你的目的是什么?了解这个以后,就可以站在他的角度,有效的帮他解决问题。
同理心就是,在激励员工时,点准他们的“兴奋点”,不揭“伤疤”。每个人都有认真工作的理由,家庭富裕的为了证明自己的能力,家境贫寒的为了改善自己的生活,吊儿郎当的爱面子怕丢工作。了解不同人的不同心理需求,才能调动大家的积极性。若是不问青红皂白,拿着鞭子大喊加油,只能是徒劳无功。
同理心就是,在与他人合作时,了解对方的需求和心理,潜移默化的说服对方,双方为了同一个目标而努力。想用强势压服别人,通常不好使。
二、听话,出活;
7年前,我和北京交通台的潘久阳聊天,他说“什么叫好员工啊,好员工特简单,就四个字:听话、出活”。这话我一直记着,这是至理名言。
什么叫“听话”?有句老话叫“干活不由东,累死也无功”,谁是“东”啊?你的直属领导就是“东”,大部分时候,听他的话准没错儿。
有朋友说:我有能力,我比领导水平高,我就不听领导的!咱先不说到底谁水平高——既然他能当你领导,肯定有比你强的地方——咱就说水平和能力这事儿,什么叫“有能力”啊?领导用你,你就有能力。不用你,甭管您有再大的能力,都是白费。
根据我的经验,一般来说,领导都比你水平高,起码在一点上是这样:他比你信息更全面、判断的更准确。因为领导更容易接触到更高层,更了解更高层的意图,他知道的你不知道,你在自己的角度上认为“这么做对”,但领导在更高的层面,并不一定这么看。
还有朋友说我领导就是瞎指挥,明摆着不对,我干嘛要听他的?这是另外一个问题,咱们最后一条会谈到,如果你觉得现在的环境无法进步,就可以考虑离职了。
什么叫“出活”?就是领导给你的工作,你得按时完成并且汇报总结。如果这个工作要持续较长时间,那么你需要阶段性的给领导反馈。我们经常犯一个错误,领导安排的工作,他不问你也不说,黑不提白不提这事儿就算过去了。
过去了?哪儿那么容易啊!领导都记着呢,你等他问你的时候——“诶小陈,上次安排你做的那事儿怎么样了?”——他就已经在心里给你写上了标签:“不靠谱”。
一个“不靠谱”需要用十个“靠谱”来扭转,两个“不靠谱”就很难转变印象,三个“不靠谱”你就没有机会了。
“出活”还有一层含义,就是“超预期”。这个咱们在下一点聊。
三、要想人前显贵,必须背地里受罪;
在公司里上班,大家的智商都差不多,谁也不比谁强多少,拼的都是努力和用心的程度。你下功夫了,就比别人做得好。哦,本来就不比别人聪明,别人下班你也下班、别人玩儿你也玩儿、别人搞对象你也泡马子,你凭什么比别人干得好?
“要想人前显贵,必须背地里受罪”的道理并不难懂。就是真到受苦的时候就含糊了,有的人会说,我年纪轻轻的为什么不好好享受生活啊?这种想法很普遍,这本是一个价值观的问题,没什么可说的,一个人想怎么生活都对。但是有一些朋友是在追求理想和享受生活中纠结的,和这些朋友,是可以聊的。
马云曾经说过:我们追求的应是人生的大平衡,而不是一时一日的小平衡(大意如此)。新东方也有一句话说:怕吃苦吃苦一辈子,不怕苦吃苦半辈子。两句话大意相同,值得深思。
一件工作,你用心想了做了,领导一看就知道,你想糊弄,也是一看就知道,这个没侥幸。领导在判断这个问题的时候,标准很简单:我想到的,你都没想到,肯定没用心;我想到的,你想到了一部分,用心不够;我没想到的,你想到了,这是用心了——这就是“超预期”。如果你每次都能给你的老板一个超预期的结果,那你无疑就是一个好员工。
四、能忍多大事儿,就能成多大事儿;
讲一个笑话:
在电梯里,领导放了个屁,回头问秘书,谁放的?秘书忙答道:“不是我!”领导不说话,这事儿过去了。不久,秘书被调离,领导在谈起调离原因时说道:“屁大的委屈都受不了,还能做的了啥?”
在工作上想受到领导的赏识和重用,除了要有过硬的工作能力外,更重要的,要有足够的涵养(抗压力或者回血能力)。能受多大委屈,才能成多大事儿,这是一定的。为了考察你的“抗压力”,领导有时会故意试你,你可一定要经得住考验。
我自己也经历过类似的事情:
有一天加班,晚上2点钟到家,收到老板的一封邮件,批评我工作不到位。我收到邮件后就很崩溃,还很委屈。于是当即奋笔疾书,回邮件!解释我是如何工作的,我做的如何有道理,我做的如何有效果……写了2000多字。
写完了,我好像冷静了一些,我就琢磨一个事儿:如果我是老板,我对一个员工工作不满意,于是我给他写了封邮件批评他,我想看到的是他洋洋洒洒的解释和辩解吗?显然不是啊。然后我就突然明白了,于是我把那2000多字都删了,简单回复了一句话,大意是:我会反思工作的问题,然后尽快整改。
两个月后我晋升了。在我的晋升仪式上,我对我老板说起这件事,他对我说,我知道你很委屈,我就是想看看你在面对委屈和压力时,会有怎样的反应,这体现了一个人的成熟程度。
多说一句,人们会感叹“钱难赚,屎难吃”,人人都想“站着把钱赚了”,我更相信他跪着的时候你没看见。我们总是强调“尊严”,比尔盖茨说过一句话:“没有人会在乎你的尊严,你只能在自我感觉良好之前取得尽可能多成就。”
对于比尔盖茨这样的天才姑且如此,况且我这样资质平庸的碌碌之辈呢?
五、总躲着领导,你就危险了;
不少人躲着领导,尽量少跟领导说话、绕着领导走。因为跟领导近了事儿就多,不跟领导多接触,事儿少,多清闲。这是“一叶障目,不见泰山”。
如果你想在工作上取得一些成绩,我建议还是应该主动的多和领导沟通。领导在平时开会时说的多是大面儿上的话,真话、有用的话、有价值的话不一定说。这并不是他不想说,而是没机会说。
有心的员工会随时抽时间和领导沟通、增加私人交流的机会:一起吃饭、一起抽烟、一起上下班、甚至一起打球K歌……通过这样的机会,你可以了解领导对于你的看法、对于工作的观点,这些都有益于你调整自己的工作的方式。
有朋友担心这样做会引起领导反感,其实完全不会,领导们多是孤独的,如果他发现有一个员工虚心向他请教、积极分享工作的思考,他是非常高兴的。
有朋友说,我不想那么累,我就想混混日子。即便是这样,你最好也主动和领导沟通、主动汇报。你追着他,你是主动的一方,其实你不累;等到他追你的时候,你就被动了,最终就累死了。
老罗曾经讲过一个故事,说你进入单位,见到老板就低头过去、不理他,他当然也不理你。等到年终考核、或者裁员的时候,老板隐约记得有你这么个人,但不知道你的名字、更不知道你做了什么。老板会想:这是你的错,不是我的错。不开除你开除谁?
老板也是人,大家用人类的方式沟通,一切会变得简单很多。
六、帮助别人千万别吝啬;
马云曾经说,成功就是成就自己帮助别人。这话没错。
如果你在一家公司工作,你发现你的工作不用任何人协助就能自己独立完成,那你多半是个打杂的。相反,你的工作需要越多人协作,就越复杂、越高级。在实际工作中我发现,我处在一个协作关系网中,如果没有别人的帮助,我就无法工作下去。
当你正在忙于某项工作时,有同事来向你“求助”,很多时候我们会很直接、甚至粗暴的拒绝,殊不知这样做正在给你今后的工作种下麻烦的种子。风水轮流转,在一家公司里,大家的工作互相交叉的几率很大,说不定你会用上谁,这些人脉关系需要平时去维护。今天你帮助了人家,说不定明天对方就会成为你的救命稻草,这非常可能。
有一天我正在疲于应付一个项目总结,这时有个其他部门的同事来找我聊合作的事儿,我并不认识他,我耐心的和他介绍了情况,并且真的形成了几次愉快的合作,半年后,我的晋升答辩会上,我发现他是我的答辩委员……
七、目标再目标,量化再量化;
没有目标的,都不叫工作;没有量化的,都不叫目标。
在接受一项工作时,先问目标是什么;在布置一项工作时,先交代目标是什么。这个不说清楚,都是扯淡。
不想成为蒙着眼睛拉磨的驴?那么除了清楚的知道自己的目标外,还得知道你的部门、你的公司的目标,最关键的,你需要知道,你的工作在总体目标中处在什么地位、扮演什么角色。如果你发现,你工作的目标和总体目标关系很小、甚至没有关系,那么你就很容易被拿掉。
辞退员工,或给员工绩效打分“不合格”是很令人头疼的,但其实这事儿并不难。关键就在于事先和每个员工一起制定量化的工作目标,并且随时提醒员工,他的工作是否达到了要求。没有达到量化指标,辞退或“不合格”是令所当然事儿,在数据面前,再矫情的人也无话可说。相反,如果谈感觉、聊希望,这事儿就没法办了。
八、找到解决问题的办法是我的义务;
领导安排的工作,不能说“我做不了”、“我做不到”。
公司请我们来工作,是为了解决问题的,如果不能解决问题,我们就没有价值。工作推进中遇到困难,无法继续进行,这是很正常的事儿,我们需要做的是主动寻找答案和办法,哪怕你的办法不妥,那么就去问,但无论如何不能对你的领导说,我不会。
前天,我在公司里听见隔壁团队的领导安排同事定一个会议室,有公司工作经验的人都知道,会议室是很难订到的,弄不好还需要“托关系,走后门”。这个小同学可能是没有订到,于是和他的领导说“我没订到”,他的领导直接就急了,说:“那怎么办?需要我来订吗?”
这位领导发火是有道理的,这位小同学在发现自己订不到会议室后,应该做的是自己想办法解决问题——最简单的就是向老同事咨询。
解决问题的能力是员工最关键的能力,没有之一。在工作中遇到困难特别正常,在这时,我们有一项义务,就是找到解决问题的办法。
九、尽量不说“不是我,我没有”;
绝大多数人在面对批评的时候,本能反应都是推卸责任,此时的口头禅就是“不是我”、“没有我”。我总觉得,很多时候,越成熟的人,就越少用本能反应面对问题,因为他们有更强的自控力。
尽量不说“不是我”、“没有我”这样的话,因为这些话毫无作用,领导听惯了这样的推卸之词,丝毫不会为之所动。此时如果能够主动承担责任,反而体现了一种担
当。即便真是被冤枉了,当场辩解往往也不是最明智的选择,可以先保持沉默,私下找机会和领导进行沟通。这个详见第三条。
十、“言多必失”死得惨;
在公司里,少说闲话,不说是非话,不做是非人。
你就相信一点:你说的每句话,你的老板都会知道。好话可能不一定,坏话则是一定的。
还是做个正直的人吧,这样最简单,也受益最大。正直人的原则是:批评当面说,赞美背后讲。
十一、知道什么时候离开。
好多同事和朋友和我聊过离职的话题,我对朋友们的建议是,如果你因为觉得工作不爽,那就别离职,因为甭管到哪里,都会不爽:老板不喜欢、同事不可爱、工作太劳累、关系太复杂……我以我在多家大公司工作的经历担保:几乎所有我工作过的公司,令人不爽的事儿都是一样的。
那么什么时候离开呢?我想,有两种情况:
1、在这家公司,你已经没有上升的空间、无法学习到更多的东西了;
2、在这家公司,你已学到足够的知识,可以在新领域或新平台上一展身手了。
快速打造一个有设计感的网站
注:拥有属于自己的网站是很多人的梦想,但大多数人只能借助像 WordPress 这样的 CMS 实现,甚至很多公司网站也是这样。但这些网站大多数看起来都比较缺乏设计感,通俗来讲就是有点“土”。那么对于像程序员以及其他对设计比较小白们来说,如何能让你的网站看起来更加前卫,有范,有设计感呢?极客公园编译了 24WAYS 的文章 How to Make Your Site Look Half-Decent in Half an Hour 为您提供解决方法。
像我这样的程序员来说经常被“设计”这个词吓到,因为我是一名程序员而不是设计师,我拥有的是计算机学位证,另外我对 Comic Sans 字体并不介意。(注:Comic Sans 字体是 Win95 附带的一种漫画字体,设计行业极为排斥,设计师或那些拥有美学情结的人不屑与之为伍。更多查看这篇为什么不要使用 Comic sans 字体)
虽然只是一名程序员,但我还是想让自己的网站看起来更加吸引人,一方面出于虚荣,因为这样可以显得我更加“专业”,而另一方面是出于现实,因为研究机构调查发现用户会更加信任那些网站“看起来”很好的网站。但是因为很长时间一直从事的是编程工作,对设计并不是熟悉,甚至害怕,因为在我这个外行看来设计是由很多只能感受不能言传身教的规则以及所谓的设计感悟组成的,知识壁垒比较高。
但是不久之前我决定要尽我最大努力让我网站看起来显得更加专业一点,即使比不上真正由设计师操刀做出来的效果,但对像我这种没有设计能力的人来说还是很有帮助的。
1. 使用 Bootstrap
如果你还没有使用 Bootstrap 的话那么赶紧开始吧,这个来自 Twitter 的开源项目使得网站设计真正进入大众化时代。

本质上 Bootstrap 是一种隔栅系统,由两名 twitter 员工 Mark Otto 和 Jacob Thornton 开发的开源前端框架[注:想了解更多请查看什么是 Twitter Bootstrap?],它集成了很多 CSS 样式的合集,可以帮助那些不懂或者不擅长 CSS 的开发人员快速的建立一个外观看起来很不错的网站。
使用 Bootstrap 的另一个好处就是网站本身就是自适应的(Responsive),可以省去各种为移动设备等的适配工作。此外,Bootstrap 还是可定制的,可以根据你的需求自己配置。(注:英文不好的可以查看中文版的 Bootstrap 文档或 Bootstrap中文网)

2. Bootstrap 定制指南
决定使用 Bootstrap 是迈出的重要一步,相比其他可以在前端开发上节省很多精力,但有利有弊,如果你决定使用 Bootstrap 的话就意味着很有可能会和其他人“撞框架”,就像默认的 WordPress 皮肤一样,如果大家都完全用 Bootstrap 的样式的话,会让不少见得多的人心生厌烦。
所以,如果实在抽不出时间的话可以去Wrap Bootstrap购买一份主题皮肤,这些主题皮肤都是由专业的设计师设计的,虽然不会成为唯一定制的,但已经看起来相当不错了,而且这种方法是最快速的。接下来就是以 Narrow marketing 这个模板(下图)为例教你如何自己定制一份完全属于你自己的 Bootstrap 。

一. 字体
修改网页字体是让网站看起来更有特色、有现代感的捷径,我们可以去谷歌的字体服务(免费正版)中随意挑选自己喜欢的字体,但是要注意字体间的搭配,在这里我们选择由 DesignShack 推荐的谷歌字体搭配中的一种:Cardo(用于标题) 和 Nobile(用于主体内文)。
- 在网页头部中加入此代码:
- 在 CSS 样式表 custom.css 中加入以下代码:h1, h2, h3, h4, h5, h6 {font-family: 'Corben', Georgia, Times, serif;} p, div {font-family: 'Nobile', Helvetica, Arial, sans-serif;}
添加完后刷新即可查看效果了,现在我们的网站样式已经变成下面这样了,看起来比默认好多了。
此外,除了谷歌的字体服务外还可以使用像 Fontdeck或 Typekit 字体服务,它们的字体更多,更多的字体搭配方案可以参考Type Connection。
二. 纹理
知道如何让一个网站看起来更加高雅优雅一些吗?是的,纹理。就像 24WAY 的背景纹理一样。

但是这些纹理效果应该去哪里寻找呢?设计师 Atle Mo 的 Subtle Patterns 网站是个不错的去处,我们接下来就使用这个网站上的 Cream Dust 纹理。点击下载,将纹理图片保存到本地,然后放到根目录下的 /img/ 目录文件夹中,最后到 CSS 样式表中加入代码 body { background: url(/img/cream_dust.png) repeat 0 0;} 即可。(如果需要更多样式的纹理或纹理的其他用法的话可以看看 Smashing 的这篇文章)
添加纹理前后对比(大图)
三. 图标
这里的图标并不是指那些透明的 PNG 图片图标,而是图标字体,其加载方式和字体一样,由 CSS 样式控制,比起图片图标来说这种图标字体加载速度更加,对资源的消耗也更低。在去年 24WAY 曾经有一篇如何在网站中使用图标字体的文章。
对于 Bootstrap 框架来说,整合的图标字体是Font Awesome(Shifticons也是一个不错的选择),和谷歌的字体服务一样也是免费开源的。要使用它只需将其下载下来,然后在根目录下创建 /fonts/ 文件夹,将其放进去。然后再将 font-awesome.css 文件放到 /css/ 目录文件夹。
接着将引用写入网页头部中,代码为 ,这时候我们可以随时在网站上任意地方自由使用这些图标字体了,如要想将一个卡车图标添加到注册按钮的话只需声明一下就可以,Sign up today。同时为了防止加入图标字体后引起按钮拉伸变形,还需要一点点额外的工作,将按钮宽度加大一点(.jumbotron .btn i { margin-right: 8px; })。最后效果如下:

四. CSS3
将上面都搞定后接下来要做的就是再加点 CSS3 特效了,如果时间不够的话简单的添加上盒阴影box-shadow和字体阴影text-shadow就可以让网站增色不少,CSS 代码如下。
h1 { text-shadow: 1px 1px 1px #ccc; } .div-that-you want-to-stand-out { box-shadow: 0 0 1em 1em #ccc; }
如果时间足够的话还可以添加一个放射渐变填充效果,可以让标题的显示效果更重一些,如下面对比图所示。(如果想要更多 CSS 效果的话可以去学习一下 CodeSchool 的在线教程)

五. jQuery
其实到这里了话网站看起来已经很不错了,但为了让它更加个性化,还需要再添加上一张背景图片。对很多程序员来说这一步是比较难以进行的,那么应该如何选择一张设计师可能会使用的图片呢?答案就是去iStockPhoto或类似的付费图库中去寻找。
这里我们将使用 Winter Sun 这张照片,为了让网站保持自适应布局,还需要使用 Backstretch 这个 jQuery 插件让背景图可以随时自动调整大小。
- 首先需要付费下载背景图片,然后放到 /img/ 文件目录中去。
- 将此图片设置为的背景图(background-image): $.backstretch("/img/winter.jpg");
- 加入背景图后网页主题部分会产生遮挡,所以可以让其透明,这样网站效果看起来会更加现代、有设计感。这里可以使用这个技巧将网站变得透明,代码见右边,.container-narrow {background: url(/img/cream_dust_transparent.png) repeat 0 0;}
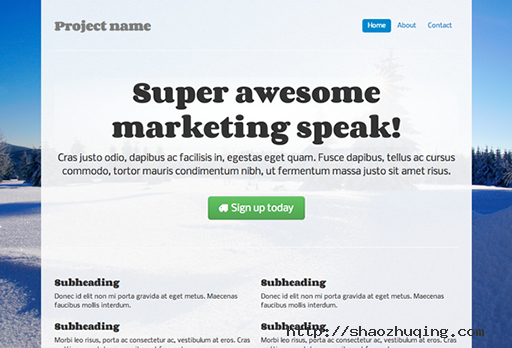 效果
效果
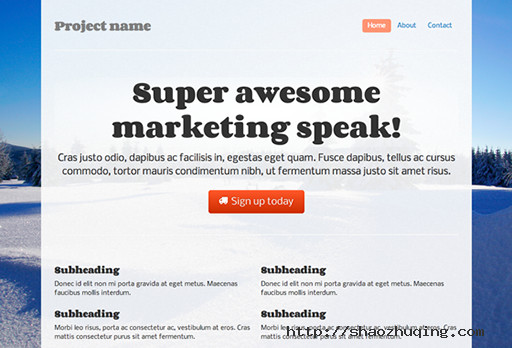
六. 色调
到这几乎差不多已经完成调整了,但如果你够细心的话会发现按钮以及导航菜单的颜色还是 Bootstrap 默认的蓝色系。在有着设计师存在网站,设计师都会负责进行网站色调的调整,为了保证网站的一致性,所有按钮和导航一般是三到四种颜色(更多可以查看极客公园之间的文章小按钮大学问)。
在这里,虽然不可能像大公司网站那样取色严谨,但还是有一些快速的方法使网站看起来很搭配的。
- 使用 GIMP 的取色器读取背景图片的主题颜色,确认其 GBR 十六进制值;
- 使用 Color Scheme Designer确认与差异大但同时又互补的颜色;
- 最后根据确定的颜色来制定按钮,可以用[Bootstrap Buttons][]等在线直接生成。
这样首页上那个大大的注册按钮就搞定了,接下来是修改导航菜单的颜色,这个比较简单,写入代码 .nav-pills > .active > a, .nav-pills > .active > a:hover {background-color: #FF9473;} 即可。看看咋样。
结语
如果经历过了上面所说的流程的话,相信你已经可以在比较短的时间内制作出了一个还能拿得出手的网站了。
如何通过数据进行网站分析
小米渣:非常荣幸邀请到您做客运营辅导在线访谈,听众朋友们都期待对您有更多的了解,请介绍一下自己及职业经历?
云统计高代鹏:
大家好,我是高代鹏,是数据平台产品经理。曾供职于国内一家第三方数据公司,主要负责大型媒体类网站统计产品的规划、网站的数据分析和行业数据的解读。
很荣幸能与大家一起交流网站的数据分析,这是一门新兴学科,05年起国内才崭露头角。希望通过本次访谈能让大家了解到一些常用的统计方法、分析思路、体会数据的魅力。
小米渣:首先,请代鹏介绍一下对于网站产品,日常监控范围内的常见数据种类及含义?
云统计高代鹏:
网站的监测指标有很多,一般的统计产品都包含大约20-30个指标。
这些指标可以分成以下五个类别:用户规模、用户粘性、用户来源、网站受众属性、网站内容属性;
用户规模主要是通过PV、UV和独立IP三个指标衡量;
用户粘性主要通过回访率、访问频率和访问深度三个指标衡量;
用户来源主要通过直接来源和站外来源两个指标衡量,其中站外来源常被分为搜索引擎和其他网站;
网站受众属性主要通过用户的性别、年龄、收入、职业以及地域分布等指标衡量;
网站内容属性主要通过最常访问内容、入口页和出口页三个指标衡量;
小米渣:感谢代鹏精彩的讲解,以上您所谈的对于互联网产品,最基础的流量指标,也就是关键数据有哪些?请结合实例谈一下这些数据的重要性。
云统计高代鹏:
其实每个数据指标都有他的实际意义,而要说最基础、最关键的流量指标那应该是PV和UV。PV和UV是反映站点的用户规模,在很多时候与收入直接相关。这两个指标的重要性就不在过多描述了,也经常有人问起对这两个指标的分析频率和如何分析。
频率可能不同的网站、站长习惯不同,之前在给新浪和搜狐提供分析时,是需要每周、每月、每季度都提供分析报告,在遇到重大事件时更需要专项的数据分析。
以月的数据为切入点,介绍三种常用的分析思路:
首先分析PV/UV的比值同最近三个月的比较。如果发现这个比值明显下降,而UV变化不大,说明PV的下将主要是每个用户单次访问的页面数减少,这种情况下网站的内容或结构急需调整,不然等用户大量流失时已晚。
其次查看PV、UV的环比变化率,分析网站最近的运营是否稳定,是否保持持续的增长。
最后还要与行业对比,才能发现自己的状况是真的好,还是表象;如某个月你的用户规模增长了10%,但行业均值确增长15%,那我们要努力的地方还有很多。
小米渣:嗯,刚才你谈到用户单次访问页面减少时可能需要进行网站内容或结构调整,那么 网站结构是否合理,具体通过什么样的数据指标去看?如何去分析用户关注的内容?
云统计高代鹏:
网站结构是指网站中页面间的层次关系;按性质可分为逻辑结构及物理结构。网站结构对网站的搜索引擎友好性及用户体验有着非常重要的影响。
小站初期往往希望更快地找到自身定位,除了站长自身的资源和优势,还需要我们通过数据找到用户最感兴趣的内容,并且最大限度地引导他们浏览、回复这些内容。
这就需要我们对网站内容和网站结构进行分析:例如可从以下几个角度分析首页的结构是否合理:
1、查看首页作为网站入口的比例;
2、查看首页流量在全站的比例;
3、查看首页的二跳率和弹出率;
4、查看首页带给其他版块或频道的流量。
经过几次这样的调整再分析的过程,最终找到最优的解决方法。
通过对用户最常访问内容的分析,更能发现运营中存在的问题。如果发现TOP5版块的主题量和流量占全站比例不足50%,或者TOP20页面的回复量和流量 占全站比例不足50%,或者流量TOP20页面中有超过10个页面来自非主流版块等等,类似的数据表现都可以说明用户的关注点太过分散,网站没能有效的引 导用户,网站的定位与用户的兴趣点存在偏差。
小米渣:感谢分享,您刚才讲解的需要分析用户偏好,那么对于网站产品,一般的用户行为相关数据有哪些?怎样通过这些数据来分析用户进而分析网站产品?
云统计高代鹏:
用户在网站的每一次点击、回复乃至鼠标的每一次滑动,都是用户的访问行为;用户的访问行为是用户心理最直白的显现,更是我们网站产品设计的试金石。
从用户行为来讲,除了注册,登陆,其他数据会有访问深度、访问次数分布、访问停留时长分布、回访天数分布、每小时访问页数分布等等;通过分析网站用户各种行为的次数和人数数据,了解用户使用你的网站和产品情况,用户使用多的是哪种行为?是否符合产品原型的设计?
譬如,注册量是衡量新用户发展的一个数据;登陆是衡量用户使用网站和产品的一个主要活跃数据;评论次数反应你的网站用户互动情况,访问深度反映用户对网站内容的兴趣度等。
那 究竟这些指标数值的多少代表什么?是否有衡量的标准?因不同行业、不同类型的网站、以及网站处于不同的发展阶段衡量的标准都不同,所以对这些指标要动态的 分析;分享一下媒体型网站的相关数据,供大家参考。一个用户平均每天访问5-7次,每次访问8-10个页面,每次停留500秒左右,回访率在 33%-38%之间。
小米渣:古语有知己知彼百战百胜,网站最核心的价值是为用户提供服务,而用户属性是我们了解用户的一条渠道。那么请教代鹏一般网站产品的用户属性数据有哪些,能否结合实例数据图表等说明如何通过分析用户属性数据优化产品、协助运营?
云统计高代鹏:
用 户属性数据一般包括用户所属的地域、用户的性别、年龄、收入、职业以及学历;通过对网站注册用户属性数据的分析,可帮助网站优化产品,协助运营,提升用户 对网站的粘性;这里会用到网站数据分析的基本思想:细分;其实细分可于用户数据分析的方方面面,对发现的问题,都要层层拨开,找出事情的缘由,这就是细分 的思想。
比如通过IP定位,知道哪些省份、城市以及哪个区域的用户在访问,不同地域的用户关注的内容是否有差异,通过对这个数据的分析,可指导市场部门具体选定在哪个城市做推广或者活动效果更好。
比 如某个地方性的网站,在春节期间PV未降反而增长了20%,提供我们对这20%新用户的监测,发现IP地址都来源于本地,进而我们可以判断这20%的用户 是从外地返乡的,我们在运营时,可为这 20%的新用户有针对性的提供信息;比如提供返城火车票的信息服务,提供儿童教育类商家的信息等等。
小米渣:嗯,很赞同细分思想,数据运营要的就是针尖上跳舞的艺术,切忌烦杂,沉迷宏观的PV、IP。
经过对网站访问情况、用户属性等数据了解和分析,我们可以更真实了解自己的网站,帮助我们及时改进网站运营。当我们需要改版或者转型的情况,请问应该如何利用现有数据分析,以便使转型工作取得更有效的成果?
云统计高代鹏:如果一个网站决定改版或转型,那可能是发现用户对现有的网站结构不满意,而具体对哪些地方不满意,怎样的数据指标能反映用户的心理呢。一般地,我们会从以下角度进行分析:
首先分析网站的小时浏览趋势、热门板块、热点内容与网站的定位和用户特征是否一致。
1、首先通过整站或者频道的小时浏览趋势来掌握网站用户的访问情况。
比 如我们持续跟踪某个网站流量的小时变化趋势,发现凌晨1-2点,博客频道的流量都会大幅增长,并且平均每个用户都会访问10个页面以上;根据这个分析,编 辑可针对性在这个时段,推荐些有思想博文和深度评论,同时也可考虑推荐些其他频道的、用户可能感兴趣的内容,引导用户对其他频道的访问。
2、其次分析首页的弹出率、二跳率等指标,评估首页的引导效果;
通过访问深度来衡量网站首页内容是不是符合网站主流的用户偏好。
通过对某网站最近一周的监测发现,70%以上用户的访问深度都低于3页,访问最热的内容TOP10中,仅有3个来自于网站首页,说明我们近期编辑发布的内容与当前热点有偏差或者首页导航、热点区域的推荐内容有问题。
3、最后我们还可分析不同板块的用户重合度、不同板块的流量引导效果
如 之前我们对XX网站的监测发现,该网站新闻频道和女性频道的用户重合度达到73%,同时女性频道的流量50%是由新闻频道带来的,根据这些数据,我们会建 议广告商在新闻频道投放广告的同时,也需在女性频道投放,这样可提升目标受众对品牌的印象,同时更可节约成本(女性频道的广告相对更便宜);
特别 地,在改版的过程中,也需时刻监测用户的访问行为,评估改版的效果;升级了 8.3的站长可以关注一下用云统计提供的页面点击热图;通过对某些特殊页面(如网站首页)部署一段监测代码,站长能获得用户在这个页面的点击轨迹,再用不 同的颜色区分用户对不同区域的点击热度,这样可直观的看出用户在这个页面的点击分布。
小米渣:感谢代鹏,我相信这方面能够帮助不少站长朋友们。另外,对于公司的领导决策层,网站的哪些数据会影响制定和修改营销策略?
云统计高代鹏:网站的营销形式有很多,这里简单粗略地分为内容营销和市场营销:
1、内容营销会更多的关注数据的时效性,如流量的小时变化趋势、帖子热门标签、意见领袖的热点话题、热点关键词等,根据这些数据指标的变化,实时调整内容营销策略:
例如通过流量的小时变化趋势发现每天在上午8-10点、下午4-6点和晚上的8-10出现三个峰值区间,可对这类用户(大部分是上班族)提供有针对性的内容;
再例如,对使用 8.3的站长可以关注云统计提供的帖子热门标签,发现当前网站的热点讨论内容,根据这个数据可让编辑对此类内容给予重点关注,如置顶、加精、首页推荐等,引导更多的用户参与到相关话题的讨论。
2、 市场营销则需持续关注投放媒体的数据延续性和效果的可持续性。比如某些网络广告投放目的是提高产品销售,首先还是选择投放媒体,投放媒体的影响力和目标用 户的吻合度同样重要;其次需对广告每次展示、点击、二跳都需要有全面的统计和分析;最后分析销售数据,购买用户究竟从哪个网站,点击了哪个位置的广告而来 的。在购买的流程过程中,在哪个步骤用户大量流失。
此外,我们也需要分析用户对什么样的内容感兴趣,分析用户的偏好;比如我们发现某一堆用户浏览的页面都是在描述5-10万元的汽车,根据这些数据,我们可将符合这个价格区间的汽车定地的投放给这一堆用户;
比 如,近期我们选择了10个合作网站推广,那么该如何评估哪个网站效果好呢,仅看带了PV\UV数据是片面的,很有可能某个网站带来了大量的用户,但这些用 户在我们网站仅访问了一页或二页,并且之后也没有回访行为。如果是这样,我们可以说这个网站带来的用户没有价值,下次也就不会考虑与这个网站在合作。所以 我们在实际的运营过程中,在掌握PV\UV等宏观指标的同时,更要仔细研究分析平均访问页数、访问次数分数等细节指标。
希望这两个例子能起到抛砖引玉的作用,让数据更多的参与到公司的决策中。
小米渣:谢谢代鹏的两个例子,我个人认为领导层的决策应该会参考网站内部的数据以及网站外部数据,内部数据更能了解一个网站的内力,外部数据能够说明这个网站在行业内的影响达到了一个什么程度。只有明确了内力和外力现状才能更好的精准营销。
小米渣:再代表站长们请教一个数据运营中比较常见的问题,就是我们时常会发现某个长尾关键词带来了不小的流量,针对这种偶发现状,站长们应该怎样面对机遇和挑战,请代鹏给予建议?
云统计高代鹏:这是一个很好的问题,我也常听一些分析师提到,经常会发现一些用户通过搜索陌生的关键词来到网站,而这些关键词初看起来和网站并没有紧密的关系。每天通过互联网会产生大量的新词,如果能及时发现这些新词并与我们每天的运营结合起来,可能会起到意想不到的效果。
先提供2个发现新词的方式:1.通过百度和谷歌的搜索风云榜能及时发现社会热点关键词和话题;2. 通过云统计提供的行业热门帖子标签和用户站内搜索热点关键词。
该如何利用这些长尾关键词我觉得可阶段性的尝试与网站内容编辑结合起来,辅以SEO,并持续的跟踪监测,评估用户对这类内容的接受程度。
【Python】 如何解析json数据结构
一、JSON的格式:
1,对象:
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}
{ 属性 : 值 , 属性 : 值 , 属性 : 值 }
2,数组是有顺序的值的集合。一个数组开始于"[",结束于"]",值之间用","分隔。
[
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}, {name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"},
{name:"Peggy",email:"peggy@gmail.com",homepage:"http://www.peggy.com"}
]
3, 值可以是字符串、数字、true、false、null,也可以是对象或数组。这些结构都能嵌套。
4,json示例:
import json
# Converting Python to JSON
json_object = json.write( python_object )
# Converting JSON to Python
python_object = json.read( json_object )
5,simplejson 示例:
import simplejson
# Converting Python to JSON
json_object = simplejson.dumps( python_object )
# Converting JSON to Python
python_object = simplejson.loads( json_object )
二、python从web接口上查询信息
1,先看个例子
>>> import urllib
>>> url='http://a.bkeep.com/page/api/saInterface/searchServerInfo.htm?serviceTag=729HH2X'
>>> page=urllib.urlopen(url)
>>> data=page.read()
>>> print data //这个就是json的数据结构,str类型
{"total":1,"data":[{"outGuaranteeTime":"","assetsNum":"B50070100007003","cabinet":"H05","deviceModel":"PowerEdge 1950","hostname":"hzshterm1.alibaba.com","logicSite":"中文站","memoryInfo":{"amount":4,"size":8192},"ip":"172.16.20.163","isOnline":true,"useState":"使用中","serviceTag":"729HH2X","cpuInfo":{"amount":2,"masterFrequency":1995,"model":"Intel(R) Xeon(R) CPU E5405 @ 2.00GHz","coreNum":8,"l2CacheSize":6144},"cabinetPositionNum":"","buyTime":"2009-06-29","manageIp":"172.31.58.223","idc":"杭州德胜机房","responsibilityPerson":"张之诚"}],"errorMsg":"","isSuccess":true}
>>> type(data)
<type 'str'>
2,有了json数据结构,我却不知道怎么把它解析出来,幸亏有了李建辉的指导。大概思路是:
首先,json基本上是key/value的,python中就叫字典。既然是字典,那就应该安照读字典的方式去读。
将上面的data转为字典类型,这里用json模块的read方法。
>>> import json
>>> ddata=json.read(data)
>>> ddata
{'isSuccess': True, 'errorMsg': '', 'total': 1, 'data': [{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}]}
>>>
看看ddata已经是dict类型了
>>> type(ddata)
<type 'dict'>
其次,我们以读字典中key 为”data”对应的键值
>>> ddata['data'] //查看字典的方法!
[{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}]
>>>type(ddata[‘data’])
<type 'list'>
发现ddata[‘data’]是一个列表,列表就要用序号来查询
>>> ddata['data'][0] //查看列表的方法!
{'isOnline': True, 'idc': '\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf', 'assetsNum': 'B50070100007003', 'responsibilityPerson': '\xe5\xbc\xa0\xe4\xb9\x8b\xe8\xaf\x9a', 'deviceModel': 'PowerEdge 1950', 'serviceTag': '729HH2X', 'ip': '172.16.20.163', 'hostname': 'hzshterm1.alibaba.com', 'manageIp': '172.31.58.223', 'cabinet': 'H05', 'buyTime': '2009-06-29', 'useState': '\xe4\xbd\xbf\xe7\x94\xa8\xe4\xb8\xad', 'memoryInfo': {'amount': 4, 'size': 8192}, 'cpuInfo': {'coreNum': 8, 'l2CacheSize': 6144, 'amount': 2, 'model': 'Intel(R) Xeon(R) CPU E5405 @ 2.00GHz', 'masterFrequency': 1995}, 'cabinetPositionNum': '', 'outGuaranteeTime': '', 'logicSite': '\xe4\xb8\xad\xe6\x96\x87\xe7\xab\x99'}
>>>
呵呵,ddata[‘data’]列表的0号元素是个字典。。
好,那我们查查key为idc的键值是多少
>>> ddata['data'][0]['idc'] //查看字典的方法!
'\xe6\x9d\xad\xe5\xb7\x9e\xe5\xbe\xb7\xe8\x83\x9c\xe6\x9c\xba\xe6\x88\xbf'
>>> print ddata['data'][0]['idc'] //呵呵,为什么print搞出来的是汉字呢?
杭州德胜机房
看到这里终于明白怎么解析json数据结构了。。。
那就是”一层一层往下剥”
教你如何破解注册码
网上有许多令人心动的共享软件,可惜的是它们或多或少都存在各种限制,对于我等贫苦一族来说,面对昂贵的注册费用只能望而却步,而且支付起来也不太方便(特别是国外的共享软件)。现在,只要利用Google强大的搜索功能,再配合一定的搜索技巧就会让你有意外的发现。
打开Google的搜索页面后,在搜索栏内填上你要搜索的软件名称、空格,并在后面加上“94fbr”的搜索代码(例如:WinZIP 94fbr),单击“搜索”按钮后你会看到所要的东西了。但该方法也并不是万能的,当没有找到合适的结果,则不妨再试试输入“软件名称 crack OR sn OR 破解”,一般都能找到了。
小提示
该方法仅为学习软件或暂时不方便注册的用户使用,切勿用于非法用途!
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
