如何构建垂直网络爬虫平台
写一个爬虫很简单,写一个可持续稳定运行的爬虫也不难,但如何构建一个通用化的垂直网络爬虫平台?
这篇文章主要介绍垂直网络爬虫平台的构建思路。
爬虫简介
首先介绍一下什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取网页信息的程序或者脚本。
很简单,爬虫就是指定规则自动采集数据的程序脚本,目的在于拿到想要的数据。
爬虫主要分两类:
- 通用网络爬虫(搜索引擎)
- 垂直网络爬虫(特定领域)
由于第一类的开发成本较高,故只有搜索引擎公司在做,如谷歌、百度等。
而大多数企业在做的是第二类,成本低、数据价值高。例如一家做电商的公司只需要电商领域有价值的数据,那开发一个电商领域的爬虫平台,意义较大。
这篇文章主要针对第二类的平台构建提供设计与思路。
如何写爬虫
首先从最简单的开始,我们先了解一下如何写一个爬虫?
简单爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# coding: utf8
"""简单爬虫"""
import requests
from lxml import etree
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
parse_rule = "//div[@id='wrapper']/h1/span/text()"
for url in crawl_urls:
# 2. 发起HTTP请求
response = requests.get(url)
# 3. 解析HTML
result = etree.HTML(response.text).xpath(parse_rule)[0]
# 4. 保存结果
print result
if __name__ == '__main__':
run()
|
这个爬虫比较简单,大致流程为:
- 定义页面URL和解析规则
- 发起HTTP请求
- 解析HTML,拿到数据
- 保存数据
任何爬虫,要想获取网页上的数据,都是经过这几步。
当然,这个简单爬虫效率比较低,只能抓完一个网页,再去抓下一个,有没有提高效率的方式呢?
异步爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# coding: utf8
"""协程版本爬虫,提高抓取效率"""
from gevent import monkey
monkey.patch_all()
import requests
from lxml import etree
from gevent.pool import Pool
def run():
"""run"""
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://book.douban.com/subject/25862578/',
'https://book.douban.com/subject/26698660/',
'https://book.douban.com/subject/2230208/'
]
rule = "//div[@id='wrapper']/h1/span/text()"
# 2. 抓取
pool = Pool(size=10)
for url in crawl_urls:
pool.spawn(crawl, url, rule)
pool.join()
def crawl(url, rule):
"""抓取&解析"""
# 3. 发起HTTP请求
response = requests.get(url)
# 4. 解析HTML
result = etree.HTML(response.text).xpath(rule)[0]
# 5. 保存结果
print result
if __name__ == '__main__':
run()
|
经过优化,我们完成了异步版本的爬虫代码。
由于爬虫要抓的网页一般很多,提高效率是爬虫最基本的技能,由于下载网页都是阻塞在网络IO上,那我们可以利用多线程或异步的方式,提高抓取效率。
有了这些基础知识之后,我们看一个完整的例子,如何抓取一个整站数据?
整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
# coding: utf8
"""整站爬虫"""
from gevent import monkey
monkey.patch_all()
from urlparse import urljoin
import requests
from lxml import etree
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
def crawl(url):
"""首页"""
response = requests.get(url)
list_urls = etree.HTML(response.text).xpath(rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = requests.get(list_url).text
detail_urls = etree.HTML(html).xpath(rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = etree.HTML(html).xpath(rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = requests.get(list_url).text
title = etree.HTML(html).xpath(rules['title'])[0]
print title
def run():
"""run"""
# 1. 标签页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
此爬虫以豆瓣图书为例,抓取整站信息,大致思路为:
- 从标签页进入,提取所有标签URL
- 进入每个标签页,提取所有列表URL
- 进入每个列表页,提取每一页的详情URL和下一页列表URL
- 进入每个详情页,拿到书名
- 如此往复循环,直到数据抓取完毕
这就是抓取一个整站的思路,很简单,无非就是分析我们浏览网站的行为轨迹,用程序来进行自动化的请求、抓取。
理想情况下,我们应该能够拿到整站的数据,但实际情况对方网站往往会采取防爬虫措施,在抓取一段时间后,我们的IP就会被禁。
那如何突破这些防爬错误,拿到数据呢?我们继续优化代码。
防反爬的整站爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
# coding: utf8
"""防反爬的整站爬虫"""
from gevent import monkey
monkey.patch_all()
import random
from urlparse import urljoin
import requests
from lxml import etree
import gevent
from gevent.pool import Pool
from gevent.queue import Queue
base_url = 'https://book.douban.com'
# 种子URL
start_url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
# 解析规则
rules = {
# 标签页列表
'list_urls': "//table[@class='tagCol']/tbody/tr/td/a/@href",
# 详情页列表
'detail_urls': "//li[@class='subject-item']/div[@class='info']/h2/a/@href",
# 页码
'page_urls': "//div[@id='subject_list']/div[@class='paginator']/a/@href",
# 书名
'title': "//div[@id='wrapper']/h1/span/text()",
}
# 定义队列
list_queue = Queue()
detail_queue = Queue()
# 定义协程池
pool = Pool(size=10)
# 定义代理池
proxy_list = [
'118.190.147.92:15524',
'47.92.134.176:17141',
'119.23.32.38:20189',
]
# 定义UserAgent
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
]
def fetch(url):
"""发起HTTP请求"""
proxies = random.choice(proxy_list)
user_agent = random.choice(user_agent_list)
headers = {'User-Agent': user_agent}
html = requests.get(url, headers=headers, proxies=proxies).text
return html
def parse(html, rule):
"""解析页面"""
return etree.HTML(html).xpath(rule)
def crawl(url):
"""首页"""
html = fetch(url)
list_urls = parse(html, rules['list_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def list_loop():
"""采集列表页"""
while True:
list_url = list_queue.get()
pool.spawn(crawl_list_page, list_url)
def detail_loop():
"""采集详情页"""
while True:
detail_url = detail_queue.get()
pool.spawn(crawl_detail_page, detail_url)
def crawl_list_page(list_url):
"""采集列表页"""
html = fetch(list_url)
detail_urls = parse(html, rules['detail_urls'])
# 详情页
for detail_url in detail_urls:
detail_queue.put(urljoin(base_url, detail_url))
# 下一页
list_urls = parse(html, rules['page_urls'])
for list_url in list_urls:
list_queue.put(urljoin(base_url, list_url))
def crawl_detail_page(list_url):
"""采集详情页"""
html = fetch(list_url)
title = parse(html, rules['title'])[0]
print title
def run():
"""run"""
# 1. 首页
crawl(start_url)
# 2. 列表页
pool.spawn(list_loop)
# 3. 详情页
pool.spawn(detail_loop)
# 开始采集
pool.join()
if __name__ == '__main__':
run()
|
这个版本的爬虫代码,加上了随机代理和请求头,这也是突破防爬措施的常用手段,使用此手段,加上一些质量高的代理,应对一些小网站的数据抓取,不在话下。
当然,这里只为了展示一步步写爬虫、优化爬虫的思路,来达到抓取数据的目的,现实情况的抓取与反爬比想象中的更复杂,需要具体场景具体分析。
现有问题
经过上面这几步,我们想要哪个网站的数据,分析网站网页结构,写出代码应该不成问题。
抓几个网站可以这么写,但抓几十个、几百个网站,你还能写下去吗?
由此暴露的问题:
- 爬虫脚本繁多,管理困难
- 规则定义零散,重复开发
- 后台脚本,无监控
- 数据输出困难,业务接入慢
这些问题都是我们在爬虫越写越多的情况下,难免会遇到的问题。
此时,我们迫切需要一个更好的解决方案,来更好地开发爬虫,爬虫平台应运而生。
平台架构
我们来分析每个爬虫的共同点,结果发现:写一个爬虫无非就是规则、抓取、解析、入库这几步,那我们可不可以把每一块分别拆开呢?如图:
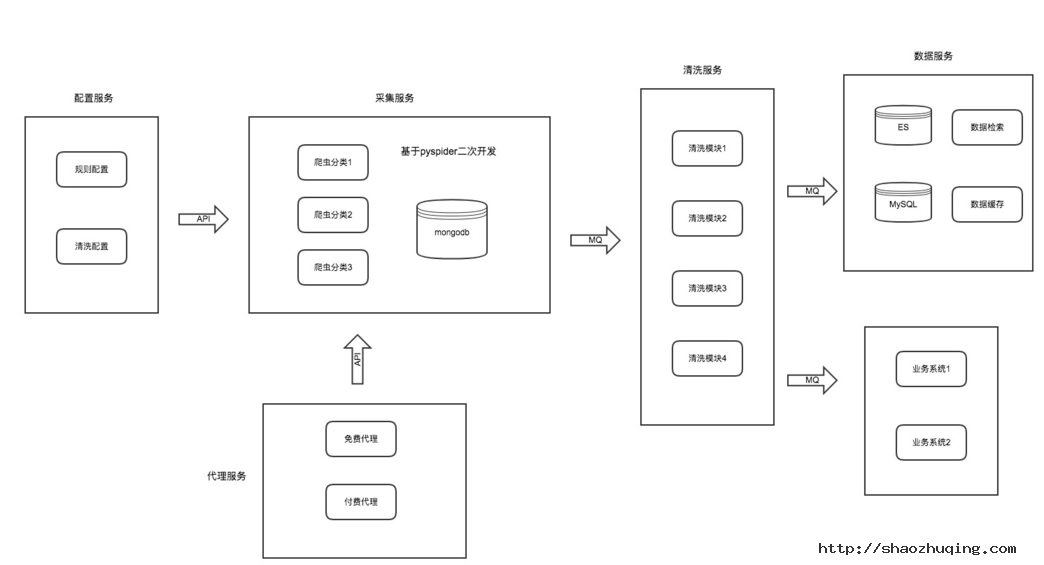
- 配置服务:包括抓取页面配置、解析规则配置、清洗配置
- 采集服务:专注网页下载与采集,并提供防爬策略
- 代理服务:提供稳定可持续输出的代理
- 清洗服务:针对同一类型业务进行字段清洗
- 数据服务:数据展示及业务数据对接
我们把一个爬虫的每一个环节,拆开做成一个个单独的服务模块,各模块各司其职。
每个模块维护属于自己领域的功能,可独立升级和优化。
详细设计
配置服务
此模块主要包括采集URL配置、页面解析规则配置、清洗配置。
我们把爬虫的规则从爬虫脚本中抽离出来,单独配置与维护,这样也便于重用与管理。
由于此模块专注配置管理,那我们可以对配置进一步拆开,配置支持各种方式的数据解析模式,如正则解析、CSS解析、XPATH解析,每种模式配置对应的表达式即可。
采集服务可以写一个配置解析器与配置服务进行对接,此配置解析器内部实现各种模式具体的解析逻辑。
清洗配置主要可配置每个爬虫输出后对应的清洗worker。
采集服务
此模块比较纯粹,就是写爬虫逻辑的模块,我们可以像之前那样开发、调试、运行爬虫脚本,但这一切工作都只能在命令行脚本进行,有没有一种好的方案是可以可视化操作的呢?
我们调研了市面上比较好的爬虫框架,发现pyspider符合我们的需求,此框架的特点:
- 支持分布式
- 配置可视化
- 可周期采集
- 支持优先级
- 任务可监控
pyspider架构图:
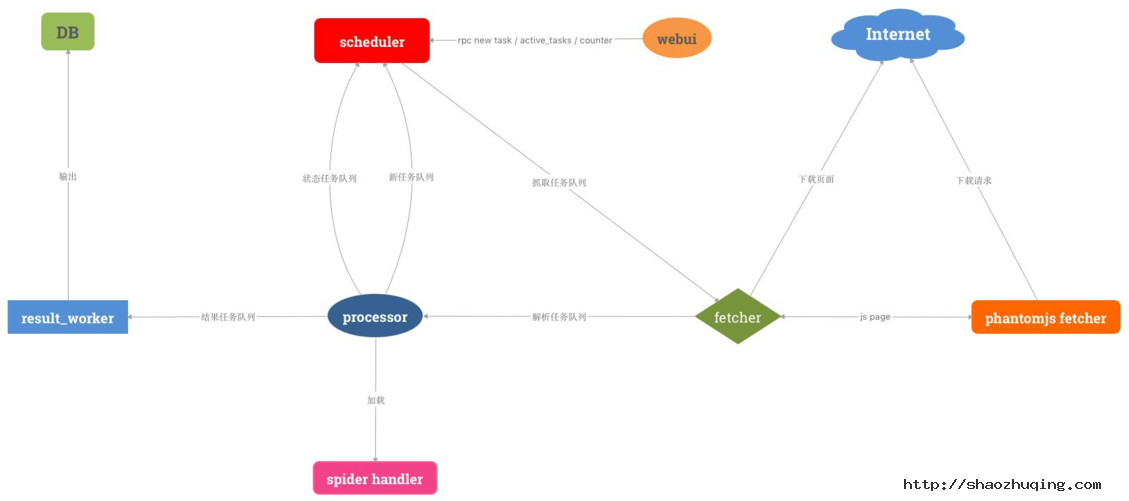
正所谓站在巨人的肩膀上。我们决定对其进行二次开发,并增强其一些组件,使爬虫开发成本更低,更符合我们的业务规则。
- 开发配置解析器,对接配置服务
spider handler定制爬虫模板,分类采集任务,生成模板,降低开发成本fetcher新增代理调度机制,对接代理服务,并增加代理调度策略result_worker输出定制化,对接清洗服务
由此我们可做出一个分布式、可视化、任务可监控、可生成爬虫模板的采集服务模块。
代理服务
做爬虫的都知道,代理是突破防抓的常用手段,如何获取稳定且持续的代理呢?
此模块内部维护代理的质量和数量,并输出给采集服务,供采集使用。
主要包括两部分:
- 免费代理
- 付费代理
免费代理
免费代理主要由我们自己的代理采集程序采集获得,大致思路为:
- 收集代理源
- 定时采集代理
- 测试代理
- 输出代理
付费代理
免费代理的质量和稳定性相对较差,对于采集防爬比较厉害的网站,还是不够用。
这时我们会购买一些付费代理,专门用于采集这类防爬的网站,此代理一般为高匿代理,并定时更新。
清洗服务
此模块比较简单,主要接收采集服务输出的数据,然后根据对应的规则执行清洗逻辑。
例如网页字段与数据库字段归一转换,特殊字段清洗定制化等。
这个服务模块运行了很多worker,最终把输出结果输送到数据服务。
数据服务
此模块会接收最终清洗后的结构化数据,统一入库。且针对其他业务系统需要的数据进行统一推送输出:
- 数据平台展示
- 数据推送
- 数据API
解决的问题
经过这个平台的构建,基本解决了最开始困扰的几个问题:
- 爬虫管理、配置可视化
- 降低开发成本
- 进度可监控、易跟踪
- 数据输出便捷
- 业务接入迅速
爬虫技巧
爬虫技巧从整体上来说,其实核心思想就一个:尽可能地模拟人的行为。
例如:
- 随机UserAgent(github fake-useragent)
- 随机代理IP(高匿代理、代理策略)
- Cookie池
- JS渲染页面(phantomjs)
- 验证码识别(OCR、机器学习)
当然,做爬虫是一个相互博弈的过程,有时没必要硬碰硬,遇到问题换个思路不免是一种解决办法。例如,对方的PC站防抓厉害,那去看一看对方的WAP站可不可以搞一下?APP端是否可以尝试一下?在有限的成本拿到数据才是爬虫的目的。
以上就是构建一个垂直网络爬虫平台的大致思路,从最简单的爬虫脚本,到写越来越多的爬虫,到难以维护,再到整个爬虫平台的构建,一步步都是遇到问题解决问题的产物,在我们真正发现核心问题时,解决思路也就不难了。
垂直搜索引擎发展的几个方向
《电子商务世界》 文/张晓宁
互联网发展至今,其间历经浮躁、追捧、泡沫、寒冬,现在正逐步向人们的日常生活消费、工作空间延伸。人们对互联网的需求也从最初的娱乐、聊天日益转为更加实际的衣、食、住、行、求医、求职等。人们获取信息的渠道从最初的几大门户发展到习惯使用Google、Baidu、Yahoo这些通用的搜索引擎。然而这些行业通用的搜索引擎能满足用户更加个性化、细化的信息需求吗?
最近很多人在讨论搜索引擎的发展趋势,普通认为垂直搜索将是下个潜力市场。从Yahoo推出旅游搜索、Goolge的本地搜索、Baidu的地图搜索、可以看出这些通用搜索巨头所面临的竞争和搜索引擎的发展趋势。如果说搜索引擎的发展方向是垂直搜索,那么垂直搜索的发展方向又是什么?
什么是垂直搜索?
所谓垂直搜索,是针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是专、精、深,且具有行业色彩。它是与通用搜索引擎截然不同的引擎类型。垂直搜索引擎专注具体、深入的纵向服务,致力于某一特定领域内信息的全面和内容的深入,这个领域外的闲杂信息不收录。比如:用户搜索上海长宁区的可带宠物就餐的川菜馆的电话、菜单价格、交通指路等这就是一种垂直搜索。
搜索领域有句名言:就是用户无法描述知道他要找什么,除非让他看到想找的东西。微软研究院一名技术专家说:“75%的内容通用搜索引擎搜索不出来”。而垂直搜索引擎的诞生则是为了更大程度的提高搜索的“查全率”和“查准率”。正如一句英文所说的“Anything you can search at google you can buy on eBay”。垂直搜索引擎通过对行业领域内的信息模型和用户模型结构化的搜集或再组织,提供更多、更专业、个性化的行业相关服务。
垂直搜索引擎的特点
垂直搜索引擎的数据来源于哪里?其一来源于所处行业的相关站点,比如:找酒店、旅游信息的搜索引擎www.qunar.com 的数据来源于:www.ctrip.com 、www.elong.com、,www.24-hotel.com 等。
其二 来源于自身平台。
可能很多人认为来源于自身平台的搜索只能称为站内搜索,不应该定义成垂直搜索。我不同意这种观点。事实当某一平台上的信息达到足够量大的时候,比如eBay、taobao上的商品数量达上百万种你能说他的搜索不是垂直搜索吗?况且垂直搜索本身就是从这些行业站点提取出数据的。
比如:找餐馆的搜索引擎 www.Gudumami.cn (咕嘟妈咪) 的数据全部来源于它的加盟商户所发布的信息。
当然,eBay、taobao、Alibaba也属于垂直搜索引擎,从用户使用的行为过程来看也是先有搜索动作而后才会有交易,不过更多时候人们愿意称他们为b2b、c2c交易平台。
跟通用搜索引擎相比,垂直搜索引擎有哪些数据特性?垂直搜索引擎的数据倾向于结构化和格式化。比如在某个购物类的垂直搜索引擎上输入“mp3”就会出现,该产品的相关属性如:内存、尺寸、大小、电池型号、价格、生产厂家等相关技术属性,有的还提供比价服务。在某餐饮搜索引擎的高级搜索针对一家餐馆的搜索属性设置多达300个选项,把你想到和没想到都列出来了,这就把搜索服务专业化、细致化、个性化了。
当然,垂直搜索引擎的广告模式也不会再仅是通用搜索引擎的那些套路。除了排名和竞价之外,还很多种广告营利模式。比如,加盟收入、订单提成、会员会费收入、交易费用收入等。由于垂直搜索引擎能提供更为集中的受众群体,因此它的“单次点击有效率”相比通用搜索引擎更为有效,风险更小。
垂直搜索引擎的几个发展方向
更深化发展后,垂直搜索未来将发展到哪几个方向,是很多业内人士都在讨论的问题。笔者认为,它今后会向这几个方向发展。
首先,目录再分类。与早期的网址分类搜索引擎相似,垂直搜索引擎只选定了某一特定行业或某一主题进行目录的细化分类,结合机器抓取行业相关站点的信息提供专业化的搜索服务。这种专业化的分类目录(或称主题指南、列表浏览),很容易让用户迅速知道自己要找的是什么,并且按目录点击就能找到。
最近Looksmart在日本推出了专门搜索饮食方面文章的垂直搜索引擎LooksmartJapanesefood,这是Looksmart第一个国外垂直搜索引擎。Looksmart甚至一口气推出了多达19个独立的垂直搜索引擎,分别涉足汽车、城市、教育、健康、家庭生活、赚钱、音乐、娱乐、运动、时尚、科技游戏、 旅行。另个五个teenja.com、gradewinner.com、21hoursholar.com、Parentsufr.com、gobelle.com分别针对青少年 、大学生、tweens、父母、女性。
其次,垂直搜索引擎的第二个发展方向是深度挖掘型搜索,其特点是“元数据模型再组织、再整合、深度数据挖掘、互动性”。
通过对元数据信息进入深度加工,该类垂直搜索引擎为用户提供网页搜索引擎无法做到的专业性、功能性、关联性、有的加入了用户信息管理以及信息发布互动功能,能很好地满足了用户对专业性、准确性、功能性、个性化的需求。 Healthline是医疗行业垂直搜索引擎它保证网上所有医疗信息都在你掌握之中。进入healthline的网站,你会发现他简直就是一个无所不知的医生。
Healthline 的医疗医疗垂直搜索平台使用使用组合语义查寻技术和全面消费健康分类学 。Healthline分类数据由超过850,000项医疗相关元数据, 和50000 条相互关连的医疗概念组成。 这些独特资源使Healthline 翻译每天用户使用语言以便精确地匹配医疗术语,使得消费者能迅速从结果中判断确切的需要信息。第三,垂直搜索可以向本地搜索拓展,其特点是借助于地图元素来发展。
到目前为止,各大搜索引擎Google、Yahoo、msn都推出了本地搜索而且都相对成熟。国内很多人把本地搜索理解等同于地图搜索,这是一种观念上错误。地图搜索只是本地搜索的一个功能元素,就像本地的天气预报一样。本地搜索的关键需求在于人们大多是在本地购物、就餐、娱乐、健身、修车、喝咖啡、工作等。简单地说,去一个什么样地方吃饭要比怎么去重要,地图只是确定和帮助你找到这个地方的工具。如果你不知道一家餐馆是否有你喜欢的菜,也不知道他的消费水平,更不知道他的服务水平及顾客评论,但你知道乘什么车能到达这家餐馆,那么你会选择这家餐馆吗?Map 不等于 local,但local一定包括map。不信你打开map.yahoo.com和Local.yahoo.com比较一下。国内的几大搜索引擎的本地搜索从2005年初开始到现在却仍停留在地图+黄页+公交指路的地图搜索水平阶段。只有中搜的“搜索北京”有点接近本地搜索,可惜没有加地图定位功能,仍停留在文本、图片展示的时代。国内做本地搜索的还有citysee等同样没提供地图定位功能。总体来说国内的本地搜索在数据挖掘、开放接口、信息共享方面和国外比存在很大差距,国外的垂直搜索已经形成了事实上的数据供应链关系。
第四种可能,垂直搜索引擎可以向搜索交易平台发展。
垂直搜索引擎由于自身对行业的专注,使得它可以提供行业信息深度和广度的整合提供更加细致周到的服务。对消费领域可以推出针对某一行业的搜索交易平台。比如美容搜索、餐饮搜索、购物搜索、机票旅游搜索。这种交易平台针对的是小型商家,比如一家川菜馆,一个只有几个人机票代理商,一家美容院。他们甚至没有自己的站点,有些电话号码都是用的是私人的,你114根本查不到,但他们确实需要通过开展电子商务来获得更多的顾客。
最近,healthline垂直搜索获得了1400万美元的融资,强力地刺激了人们对垂直搜索市场认可和期待。相信在未来几年的互联网搜索市场垂直搜索引擎一定会得到更大的发间和机会
微软MSN副总裁刘振宇也曾用一组数据说明了中文搜索的不足:
目前有35%的用户对搜索结果不满意并感到失望;50%的搜索结果不能满足用户的搜索需求;搜索结果中,有25%指向了毫不相关的网站。
一边是巨大的市场,一边是同质化环境下难以体现优势,二线搜索运营商们不约而同地盯上了垂直搜索领域。“相对综合搜索引擎的信息量大、查询不准确、深度不够等不可避免的缺陷,垂直搜索引擎则可以通过针对某一特定领域、某一特定人群或某一特定需求提供有一定价值的信息和相关服务。相比较综合搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。”
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
