Git版本恢复命令reset
reset命令有3种方式:
git reset --mixed:此为默认方式,不带任何参数的git reset,即时这种方式,它回退到某个版本,只保留源码,回退commit和index信息
git reset --soft:回退到某个版本,只回退了commit的信息,不会恢复到index file一级。如果还要提交,直接commit即可
git reset --hard:彻底回退到某个版本,本地的源码也会变为上一个版本的内容
以下是一些reset的示例:
(1) 回退所有内容到上一个版本
git reset HEAD^
(2) 回退a.py这个文件的版本到上一个版本
git reset HEAD^ a.py
(3) 向前回退到第3个版本
git reset –soft HEAD~3
(4) 将本地的状态回退到和远程的一样
git reset –hard origin/master
(5) 回退到某个版本
git reset 057d
(7) 回退到上一次提交的状态,按照某一次的commit完全反向的进行一次commit
git revert HEAD
在本地开发了一个版本,然后加入某些代码, git commit 之后再 git push 与远程版本库同步,这时出现一个问题,在这次 git commit 之前的版本内容如何找回?
首先git log显示提交的历史
- commit ee50348120302b19318ab6a564d4092dd87a85ef
- Author: ShichaoXu <gudujianjsk@gmail.com>
- Date: Mon Jun 3 15:18:16 2013 +0800
- support for printf
- commit e7a5e492c742a7b68c07f124edd4b713122c0666
- Author: ShichaoXu <gudujianjsk@gmail.com>
- Date: Tue May 7 15:44:11 2013 +0800
- del file lib/2440slib.s init/2440init.s
- commit 5a05f002ef1dfbbf118b2ffd7b829159b727ce16
- Author: ShichaoXu <gudujianjsk@gmail.com>
- Date: Tue May 7 15:26:30 2013 +0800
- change file name lib/2440slib.s init/2440init.s to lib/2440slib.S init/2440init.S
- commit a948e62c9eabd54bfc4de3c4dfd14b4fc2bb48dd
- Author: ShichaoXu <gudujianjsk@gmail.com>
- Date: Tue May 7 15:06:17 2013 +0800
- add code for this project
- commit 59a902efdef8fb3dd47264df8a666de7026d1595
- Author: ShichaoXu <gudujianjsk@gmail.com>
- Date: Mon May 6 23:15:01 2013 -0700
- Initial commit
然后用
- ~/gun-ucos$$git reset --hard e7a5e492c742a7b68c07f124edd4b713122c0666
显示如下
- HEAD is now at e7a5e49 del file lib/2440slib.s init/2440init.s
此时正常回到git commit "support for printf" 之前的状态!
图解git中的最常用命令
此页图解git中的最常用命令。如果你稍微理解git的工作原理,这篇文章能够让你理解的更透彻。 如果你想知道这个站点怎样产生,请前往GitHub repository。
正文
- 基本用法
- 约定
- 命令详解
- Diff
- Commit
- Checkout
- Detached HEAD(匿名分支提交)
- Reset
- Merge
- Cherry Pick
- Rebase
- 技术说明
基本用法
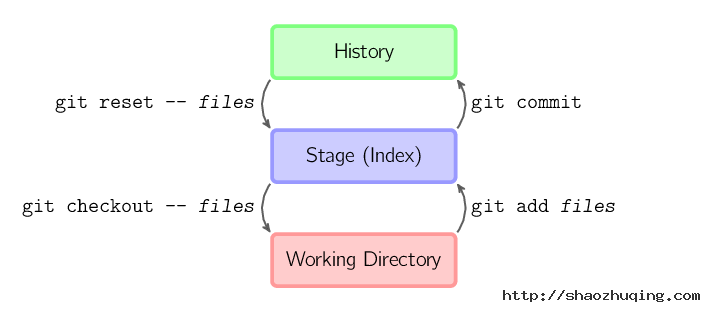
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。
你可以用 git reset -p, git checkout -p, or git add -p进入交互模式。
也可以跳过暂存区域直接从仓库取出文件或者直接提交代码。
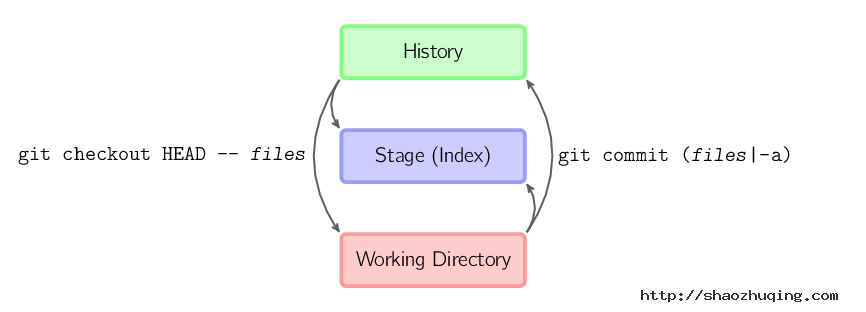
git commit -a相当于运行 git add 把所有当前目录下的文件加入暂存区域再运行。git commit.git commit files进行一次包含最后一次提交加上工作目录中文件快照的提交。并且文件被添加到暂存区域。git checkout HEAD -- files回滚到复制最后一次提交。
约定
后文中以下面的形式使用图片。
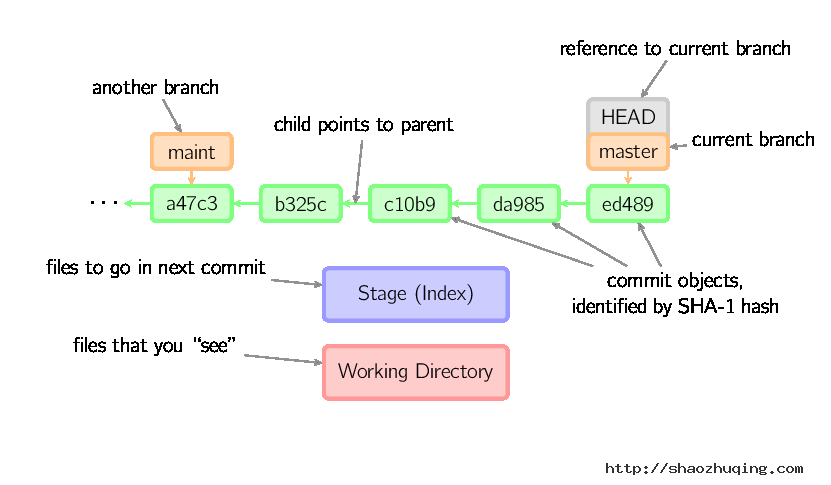
绿色的5位字符表示提交的ID,分别指向父节点。分支用橘色显示,分别指向特定的提交。当前分支由附在其上的HEAD标识。 这张图片里显示最后5次提交,ed489是最新提交。 master分支指向此次提交,另一个maint分支指向祖父提交节点。
命令详解
Diff
有许多种方法查看两次提交之间的变动。下面是一些示例。
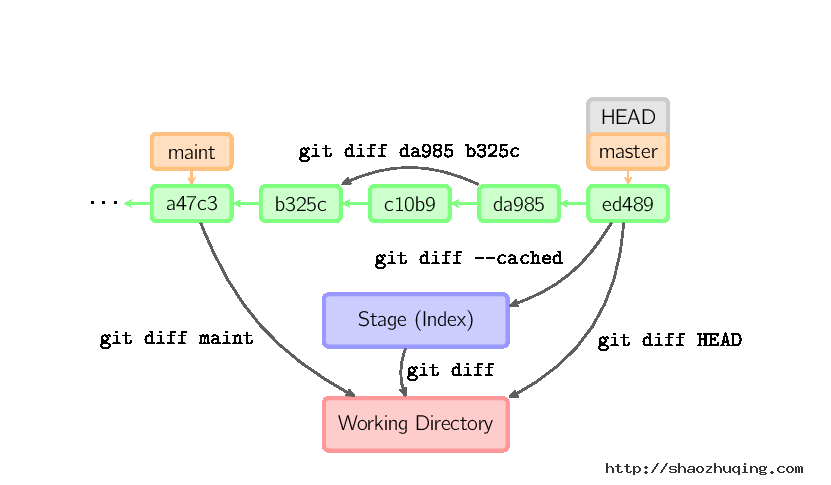
Commit
提交时,git用暂存区域的文件创建一个新的提交,并把此时的节点设为父节点。然后把当前分支指向新的提交节点。下图中,当前分支是master。 在运行命令之前,master指向ed489,提交后,master指向新的节点f0cec并以ed489作为父节点。
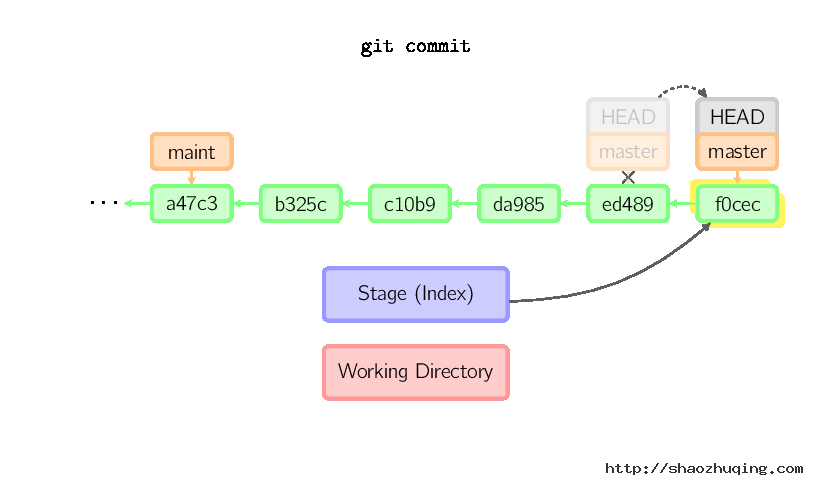
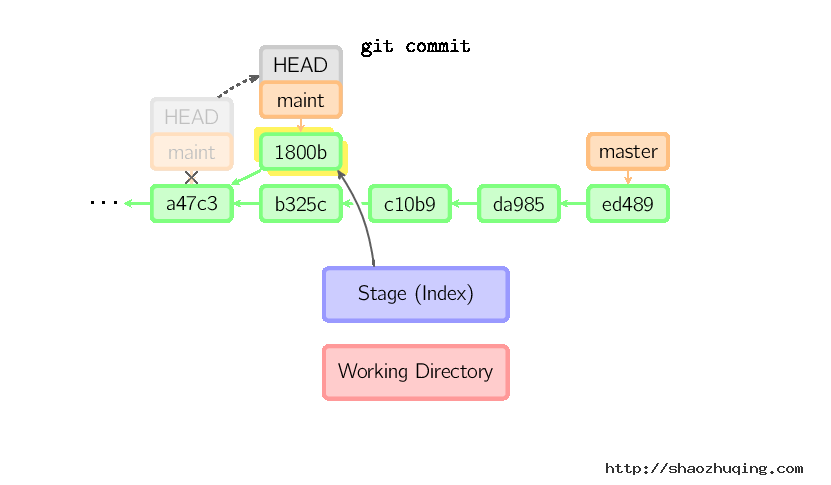
即便当前分支是某次提交的祖父节点,git会同样操作。下图中,在master分支的祖父节点maint分支进行一次提交,生成了1800b。 这样,maint分支就不再是master分支的祖父节点。此时,合并 (或者 衍合) 是必须的。
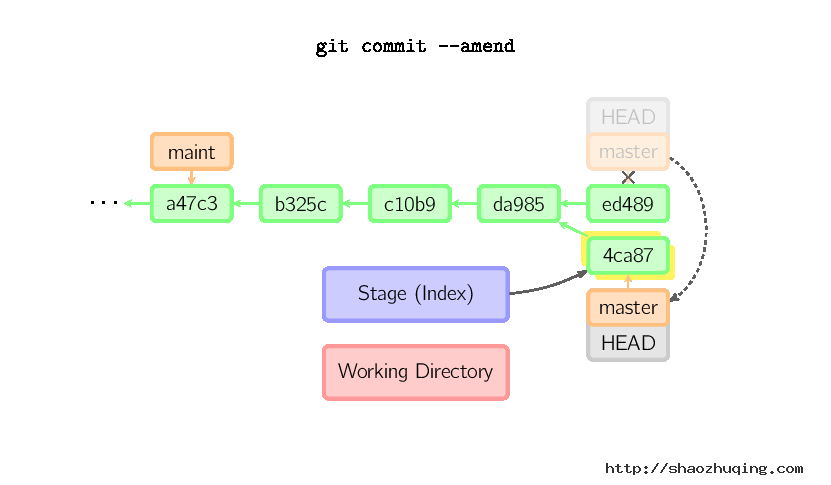
如果想更改一次提交,使用 git commit --amend。git会使用与当前提交相同的父节点进行一次新提交,旧的提交会被取消。
另一个例子是分离HEAD提交,后文讲。
Checkout
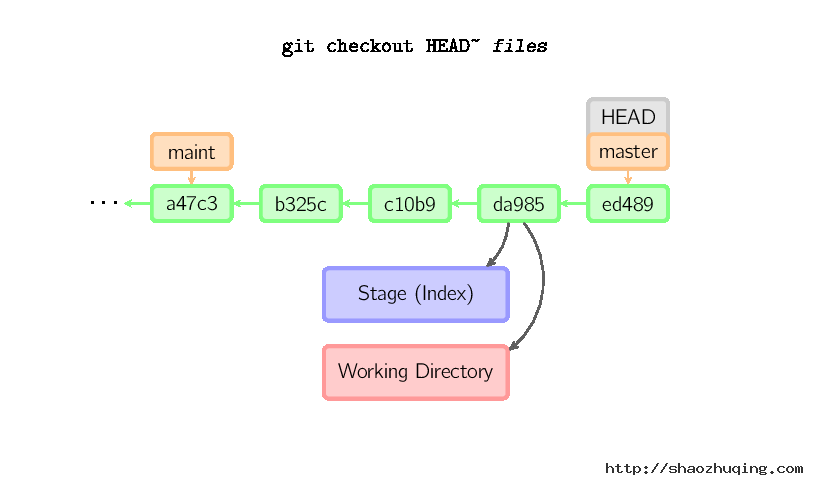
checkout命令用于从历史提交(或者暂存区域)中拷贝文件到工作目录,也可用于切换分支。
当给定某个文件名(或者打开-p选项,或者文件名和-p选项同时打开)时,git会从指定的提交中拷贝文件到暂存区域和工作目录。比如,git checkout HEAD~ foo.c会将提交节点HEAD~(即当前提交节点的父节点)中的foo.c复制到工作目录并且加到暂存区域中。(如果命令中没有指定提交节点,则会从暂存区域中拷贝内容。)注意当前分支不会发生变化。
当不指定文件名,而是给出一个(本地)分支时,那么HEAD标识会移动到那个分支(也就是说,我们“切换”到那个分支了),然后暂存区域和工作目录中的内容会和HEAD对应的提交节点一致。新提交节点(下图中的a47c3)中的所有文件都会被复制(到暂存区域和工作目录中);只存在于老的提交节点(ed489)中的文件会被删除;不属于上述两者的文件会被忽略,不受影响。
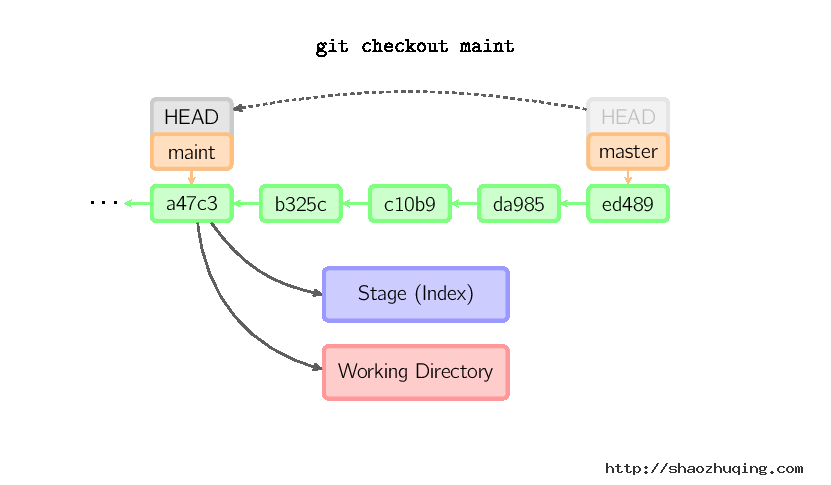
如果既没有指定文件名,也没有指定分支名,而是一个标签、远程分支、SHA-1值或者是像master~3类似的东西,就得到一个匿名分支,称作detached HEAD(被分离的HEAD标识)。这样可以很方便地在历史版本之间互相切换。比如说你想要编译1.6.6.1版本的git,你可以运行git checkout v1.6.6.1(这是一个标签,而非分支名),编译,安装,然后切换回另一个分支,比如说git checkout master。然而,当提交操作涉及到“分离的HEAD”时,其行为会略有不同,详情见在下面。
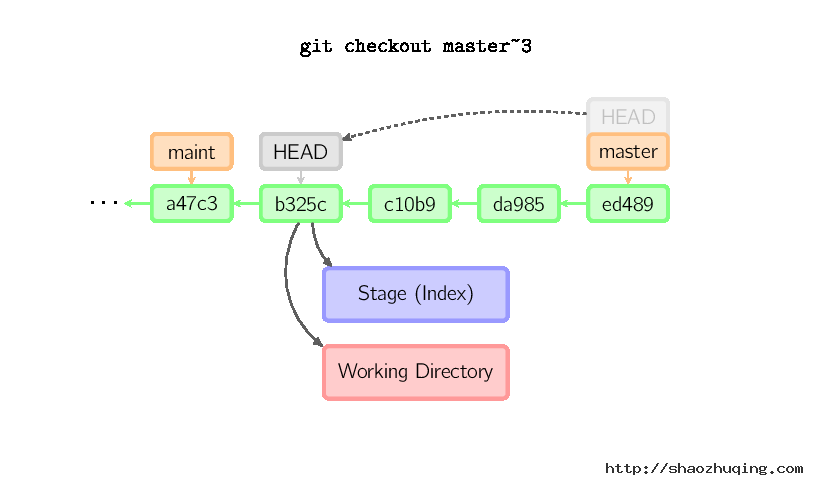
HEAD标识处于分离状态时的提交操作
当HEAD处于分离状态(不依附于任一分支)时,提交操作可以正常进行,但是不会更新任何已命名的分支。(你可以认为这是在更新一个匿名分支。)
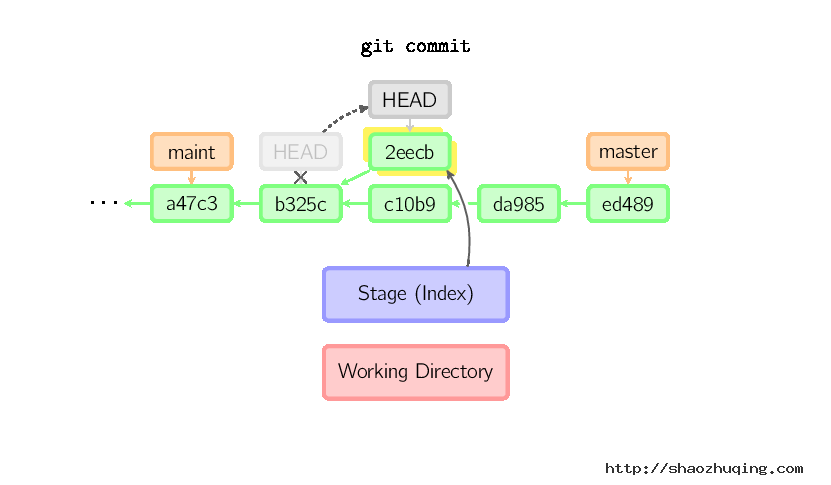
一旦此后你切换到别的分支,比如说master,那么这个提交节点(可能)再也不会被引用到,然后就会被丢弃掉了。注意这个命令之后就不会有东西引用2eecb。
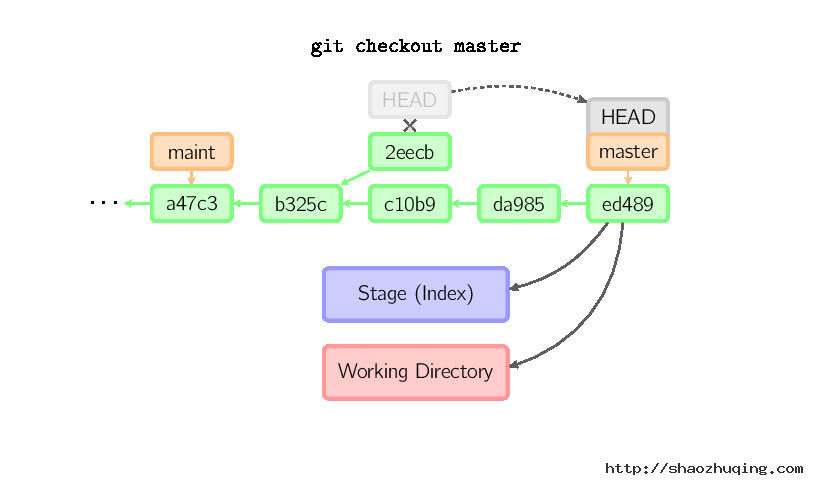
但是,如果你想保存这个状态,可以用命令git checkout -b name来创建一个新的分支。
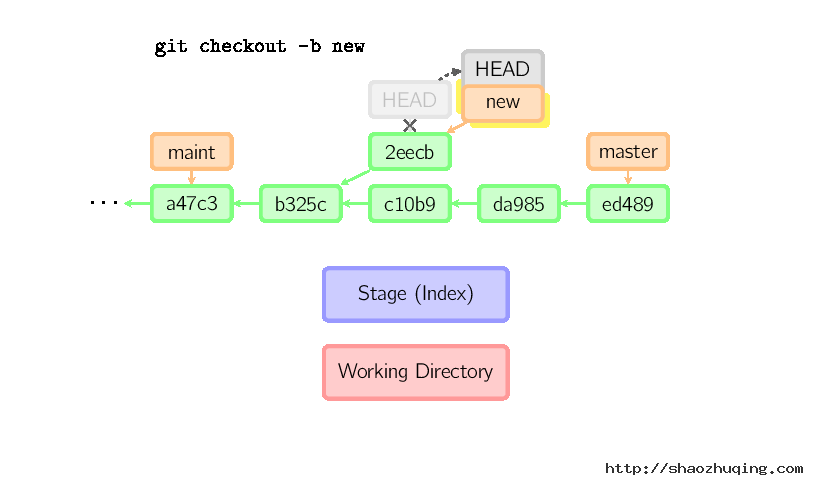
Reset
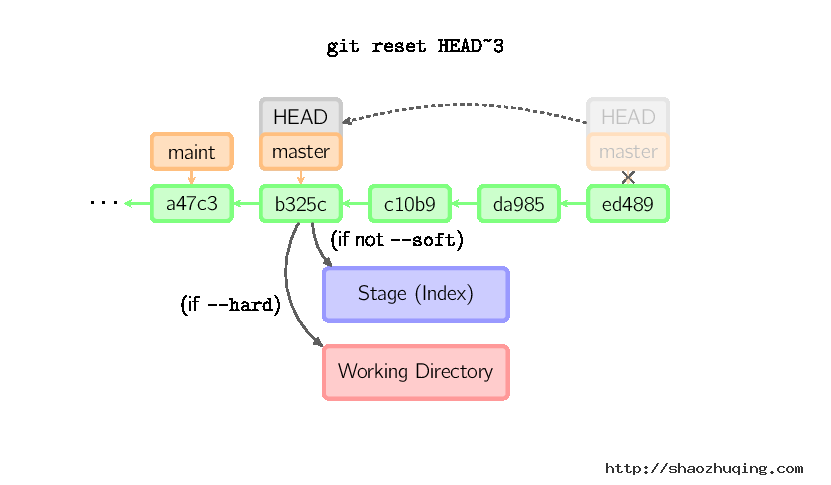
reset命令把当前分支指向另一个位置,并且有选择的变动工作目录和索引。也用来在从历史仓库中复制文件到索引,而不动工作目录。
如果不给选项,那么当前分支指向到那个提交。如果用--hard选项,那么工作目录也更新,如果用--soft选项,那么都不变。
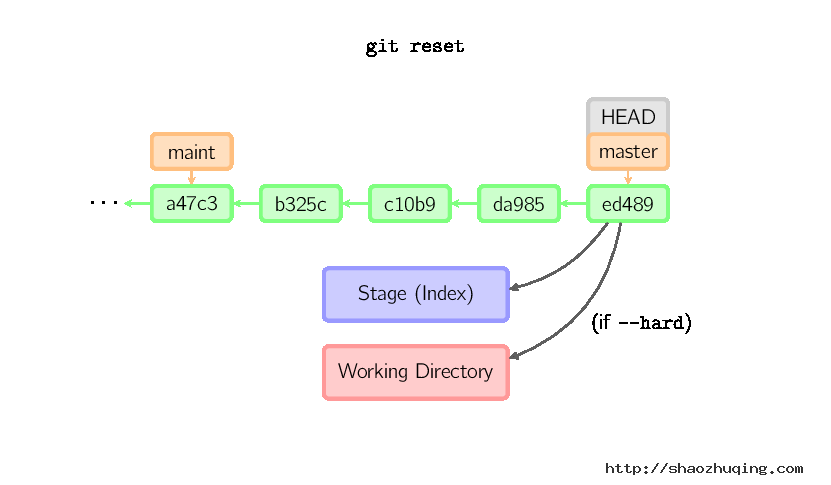
如果没有给出提交点的版本号,那么默认用HEAD。这样,分支指向不变,但是索引会回滚到最后一次提交,如果用--hard选项,工作目录也同样。
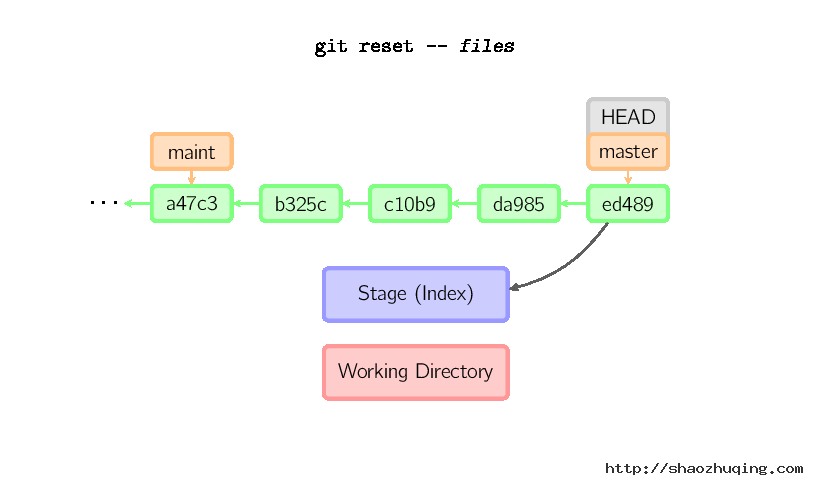
如果给了文件名(或者 -p选项), 那么工作效果和带文件名的checkout差不多,除了索引被更新。
Merge
merge 命令把不同分支合并起来。合并前,索引必须和当前提交相同。如果另一个分支是当前提交的祖父节点,那么合并命令将什么也不做。 另一种情况是如果当前提交是另一个分支的祖父节点,就导致fast-forward合并。指向只是简单的移动,并生成一个新的提交。
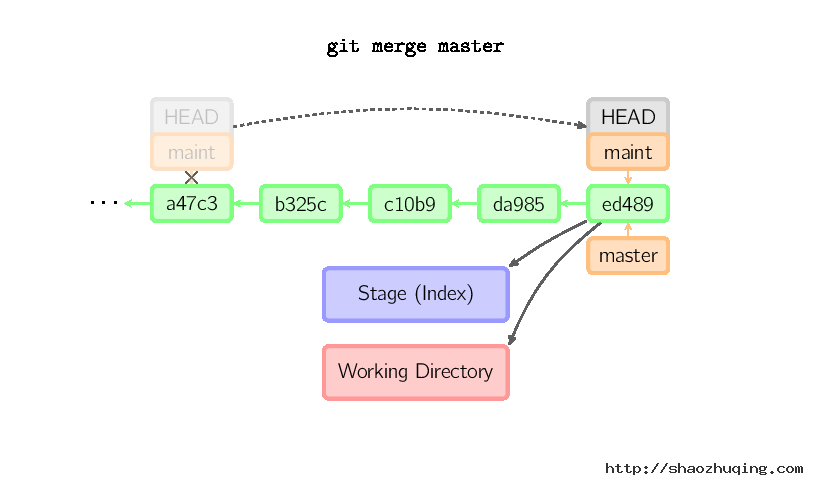
否则就是一次真正的合并。默认把当前提交(ed489 如下所示)和另一个提交(33104)以及他们的共同祖父节点(b325c)进行一次三方合并。结果是先保存当前目录和索引,然后和父节点33104一起做一次新提交。
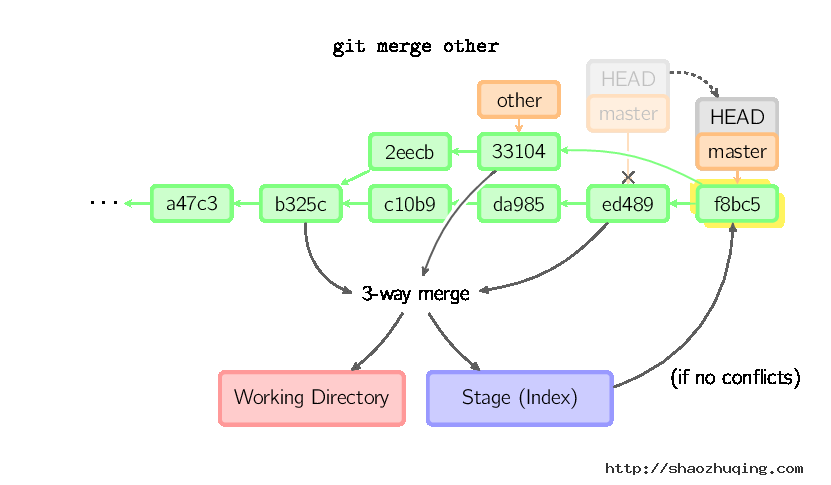
Cherry Pick
cherry-pick命令"复制"一个提交节点并在当前复制做一次完全一样的新提交。
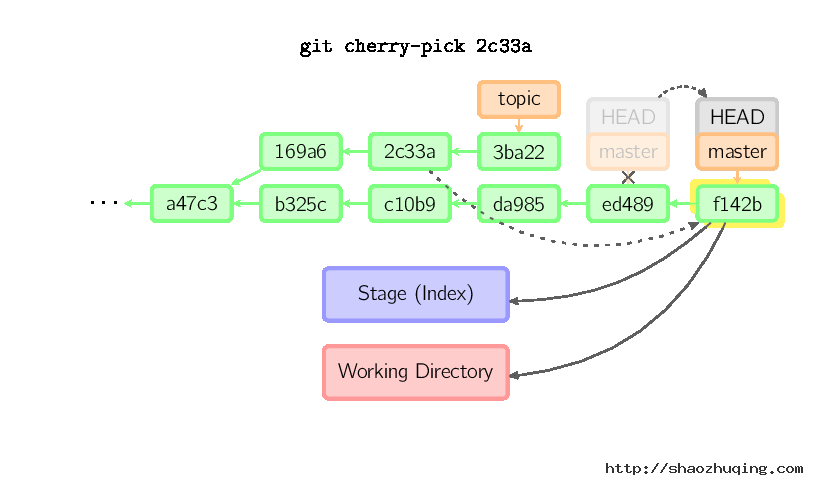
Rebase
衍合是合并命令的另一种选择。合并把两个父分支合并进行一次提交,提交历史不是线性的。衍合在当前分支上重演另一个分支的历史,提交历史是线性的。 本质上,这是线性化的自动的cherry-pick
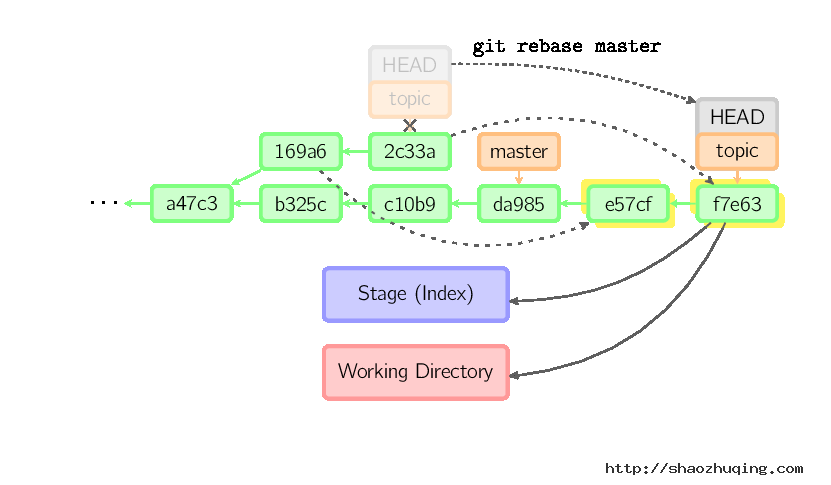
上面的命令都在topic分支中进行,而不是master分支,在master分支上重演,并且把分支指向新的节点。注意旧提交没有被引用,将被回收。
要限制回滚范围,使用--onto选项。下面的命令在master分支上重演当前分支从169a6以来的最近几个提交,即2c33a。
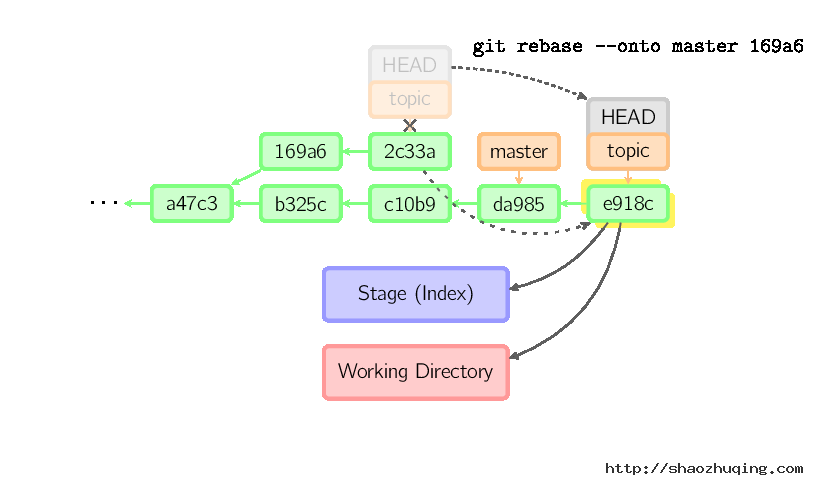
同样有git rebase --interactive让你更方便的完成一些复杂操作,比如丢弃、重排、修改、合并提交。没有图片体现这些,细节看这里:git-rebase(1)
技术说明
文件内容并没有真正存储在索引(.git/index)或者提交对象中,而是以blob的形式分别存储在数据库中(.git/objects),并用SHA-1值来校验。 索引文件用识别码列出相关的blob文件以及别的数据。对于提交来说,以树(tree)的形式存储,同样用对于的哈希值识别。树对应着工作目录中的文件夹,树中包含的 树或者blob对象对应着相应的子目录和文件。每次提交都存储下它的上一级树的识别码。
如果用detached HEAD提交,那么最后一次提交会被the reflog for HEAD引用。但是过一段时间就失效,最终被回收,与git commit --amend或者git rebase很像。
MySQL常用命令总结
++安装mysql
参见自带的INSTALL-SOURCE文件
$ ./configure ?prefix=/app/mysql-5.0.51a ?with-charset=utf8 ?with-extra-charsets=utf8,gb2312,utf8
++启动/关闭mysql
$ path/mysqld_safe -user=mysql &
$ /mysqladmin -p shutdown
++修改root口令
$ mysqladmin -u root -p password ‘新密码’
++查看服务器状态
$ path/mysqladmin version -p
++连接远端mysql服务器
$ path/mysql -u 用户名 -p #连接本机
$ path/mysql -h 远程主机IP -u 用户名 -p#连接远程MYSQL服务器
++创建/删除 数据库或表
$ mysqladmin -u root -p create xxx
mysql> create database 数据库名;
mysql> create TABLE items (
id INT(5) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
symbol CHAR(4) NOT NULL,
username CHAR(8),
INDEX sym (symbol),INDEX …..
UNIQUE(username)
) type=innodb;
mysql> drop database [if exists] 数据库名
mysql> create table 表名;
mysql> drop table 表名;
++查看数据库和查看数据库下的表
mysql> show databases;
mysql> show tables;
mysql> show table status;
mysql> desc 表名; #查看具体表结构信息
mysql> SHOW CREATE DATABASE db_name #显示创建db_name库的语句
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建用户
mysql> grant select,insert,update,delete,alter on mydb.* to test2@localhost identified by “abc”;
mysql> grant all privileges on *.* to test1@”%” identified by “abc”;
mysql> flush privileges;
++用户管理
mysql> update user set password=password (’11111′) where user=’test1′; #修改test1密码为111111
mysql> DELETE FROM user WHERE User=”testuser” and Host=”localhost”; #删除用户帐号
mysql> SHOW GRANTS FOR user1; #显示创建user1用户的grant语句
++mysql数据库的备份和恢复
$ mysqldump -uuser -ppassword -B DB_name [--tables table1 --tables table2] > exportfile.sql
$ mysql -uroot -p xxx < aaa.sql #导入表
$ mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名 ##导出单独的表
++导出一个数据库结构
$ mysqldump -u wcnc -p -d ?add-drop-table smgp_apps_wcnc >wcnc_db.sql
-d 没有数据 ?add-drop-table 在每个create语句之前增加一个drop table
++忘记mysql密码
先停止所有mysql服务进程
$ mysqld_safe ?skip-grant-tables & mysql
mysql> use mysql;
mysql> update user set password=password(’111111′) where user=’root’;
mysql> flush privileges;
然后重启mysql并以新密码登入即可
++当前使用的数据库
mysql> select database();
===数据库日常操作维护====
++创建表
mysql> create table table_name
(column_name datatype {identity |null|not null},f_time TIMESTAMP(8),…)ENGINE=MyISAM AUTO_INCREMENT=3811 DEFAULT CHARSET=utf8;
例: CREATE TABLE guest (name varchar(10),sex varchar(2),age int(3),career varchar(10));
# desc guest可查看表结构信息
# TIMESTAMP(8) YYYYMMDD 其中(2/4/6/8/10/12/14)对应不同的时间格式
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建索引
可以在建表的时候加入index indexname (列名)创建索引,
也可以手工用命令生成 create index index_name on table_name (col_name[(length)],… )
mysql> CREATE INDEX number ON guest (number(10));
mysql> SHOW INDEX FROM tbl_name [FROM db_name] #显示现有索引
mysql> repair TABLE date QUICK; #索引列相关变量变化后自动重建索引
++查询及常用函数
mysql> select t1.name, t2.salary from employee AS t1, info AS t2 where t1.name = t2.name;
mysql> select college, region, seed from tournament ORDER BY region, seed;
mysql> select col_name from tbl_name WHERE col_name > 0;
mysql> select DISTINCT …… [DISTINCT关键字可以除去重复的记录]
mysql> select DATE_FORMAT(NOW(),’%m/%d/%Y’) as DATE, DATE_FORMAT(NOW(),’%H:%m:%s’) AS TIME;
mysql> select CURDATE(),CURTIME(),YEAR(NOW()),MONTH(NOW()),DAYOFMONTH(NOW()),HOUR(NOW()),MINUTE(NOW());
mysql> select UNIX_TIMESTAMP(),UNIX_TIMESTAMP(20080808),FROM_UNIXTIME(UNIX_TIMESTAMP()); mysql> select PASSWORD(”secret”),MD5(”secret”); #加密密码用
mysql> select count(*) from tab_name order by id [DESC|ASC]; #DESC倒序/ASC正序
* 函数count,AVG,SUM,MIN,MAX,LENGTH字符长度,LTRIM去除开头的空头,RTRIM去尾部空格,TRIM(str)去除首部 尾部空格,LETF/RIGHT(str,x)返回字符串str的左边/右边x个字符,SUBSTRING(str,x,y)返回str中的x位置起至位 置y的字符mysql> select BINARY ‘ross’ IN (’Chandler’,’Joey’, ‘Ross’); #BINARY严格检查大小写
* 比较运算符IN,BETWEEN,IS NULL,IS NOT NULL,LIKE,REGEXP/RLIKE
mysql> select count(*),AVG(number_xx),Host,user from mysql.user GROUP by user [DESC|ASC] HAVING user=root; #分组并统计次数/平均值
++UNIX_TIMESTAMP(date)
返回一个Unix时间戳记(从’1970-01-01 00:00:00′GMT开始的秒数)
mysql> select UNIX_TIMESTAMP();
mysql> select UNIX_TIMESTAMP(’1997-10-04 22:23:00′);
mysql> select FROM_UNIXTIME(875996580); #根据时间戳记算出日期
++控制条件函数
mysql> select if(1<10,2,3), IF(55>100,’true’,’false’);
#IF()函数有三个参数,第一个是被判断的表达式,如果表达式为真,返回第二个参数,如果为假,返回第三个参数.
mysql> select CASE WHEN (2+2)=4 THEN “OK” WHEN (2+2)<>4 THEN ‘NOT OK’ END AS status;
++系统信息函数
mysql> select DATABASE(),VERSION(),USER();
mysql> select BENCHMARK(9999999,LOG(RAND()*PI())) AS PERFORMANACE; #一个测试mysql运算性能工具
++将wp_posts表中post_content字段中文字”old”替换为”new”
mysql> update wp_posts set post_content=replace(post_content,’old’,’new’)
++改变表结构
mysql> alter table table_name alter_spec [, alter_spec ...]
例:alter table dbname add column userid int(11) not null primary key auto_increment;
这样,就在表dbname中添加了一个字段userid,类型为int(11)。
++调整列顺序
mysql> alter table tablename CHANGE id id int(11) first;
++修改表中数据
insert [into] table_name [(column(s))] values (expression(s))
例:mysql>insert into mydatabase values(’php’,’mysql’,’asp’,’sqlserver’,’jsp’,’oracle’);
mysql> create table user select host,user from mysql.user where 1=0;
mysql> insert into user(host,user) select host,user from mysql.user;
++更改表名
命令:rename table 原表名 to 新表名;
++表的数据更新
mysql> update table01 set field04=19991022[, field05=062218] where field01=1;
++删除数据
mysql> delete from table01 where field01=3;
#如果想要清空表的所有纪录,建议用truncate table tablename而不是delete from tablename.
++SHELL提示符下运行SQL命令
$ mysql -e “show slave status\G ”
++坏库扫描修复
cd /var/lib/mysql/xxx && myisamchk playlist_block
++insert into a (x) values (’11a’)
出现: ata truncated for column ‘x’ at row 1
解决办法:
在my.ini里找到
sql-mode=”STRICT_TRANS_TABLES,NO_AUTO_Create_USER,NO_ENGINE_SUBSTITUTION”
把其中的STRICT_TRANS_TABLES,去掉,然后重启mysql就ok了
++复制表
mysql> create table target_table like source_table
++innodb支持事务
新表:create TABLE table-name (field-definitions) TYPE=INNODB;
旧表: alter TABLE table-name TYPE=INNODB;
mysql> start transaction #标记一个事务的开始
mysql> insert into….. #数据变更
mysql> ROLLBACK或commit #回滚或提交
mysql> SET AUTOCOMMIT=1; #设置自动提交
mysql> select @@autocommit; #查看当前是否自动提交
++表锁定相关
mysql> LOCK TABLE users READ; # 对user表进行只读锁定
mysql> LOCK TABLES user READ, pfolios WRITE #多表锁控制
mysql> UNLOCK TABLES; #不需要指定锁定表名字, MySQL会自动解除所有表锁定
=====一些mysql优化与管理======
++管理用命令
mysql> show variables #查看所有变量值
? max_connections 数据库允许的最大可连接数,
#需要加大max_connections可以在my.cnf中加入set-variable = max_connections=32000,可以对与下面的threads_connected值决定是否需要增大.
show status [like ....];
? threads_connected 数据库当前的连接线程数
#FLUSH STATUS 可以重置一些计数器
show processlist;
kill id;
++my.cnf配置
?Enable Slow Query Log
long_query_time=1
log-slow-queries=/var/log/mysql/log-slow-queries.log
log-queries-not-using-indexes
# mysqldumpslow -s c -t 20 host-slow.log #访问次数最多的20个sql语句
# mysqldumpslow -s r -t 20 host-slow.log #返回记录集最多的20个sql
?others
max_connections=500 #用过的最大连接数SHOW Status like ‘max_used_connection’;
wait_timeout=10 #终止所有空闲时间超过 10 秒的连接
table_cache=64 #任何时间打开表的总数
ax_binlog_size=512M #循环之前二进制日志的最大规模
max_connect_errors = 100
query_cache_size = 256M #查询缓存
#可用 SHOW STATUS LIKE ‘qcache%’;查看命中率
#FLUSH STATUS重置计数器, FLUSH QUERY CACHE清缓存
thread_cache = 40
#线程使用,SHOW STATUS LIKE ‘Threads_created %’; 值快速增加的话考虑加大
key_buffer = 16M
#show status like ‘%key_read%’; Key_reads 代表命中磁盘的关键字请求个数
#A: 到底 Key Buffer 要设定多少才够呢? Q: MySQL 只会 Cache 索引(*.MYI),因此参考所有 MYI文件的总大小
sort_buffer_size = 4M #查询排序时所能使用的缓冲区大小,每连接独享4M
#show status like ‘%sort%’; 如sort_merge_passes很大,就表示加大
sort_buffer_sizesort_buffer_size = 6M #查询排序时所能使用的缓冲区大小,这是每连接独享值6M
read_buffer_size = 4M #读查询操作所能使用的缓冲区大小
join_buffer_size = 8M #联合查询操作所能使用的缓冲区大小
skip-locking #取消文件系统的外部锁
skip-name-resolve
thread_concurrency = 8 #最大并发线程数,cpu数量*2
long_query_time = 10 #Slow_queries记数器的查询时间阀值
linux:vim 替换命令
vi/vim 中可以使用 :s 命令来替换字符串。以前只会使用一种格式来全文替换,今天发现该命令有很多种写法(vi 真是强大啊,还有很多需要学习),记录几种在此,方便以后查询。
:s/vivian/sky/ 替换当前行第一个 vivian 为 sky
:s/vivian/sky/g 替换当前行所有 vivian 为 sky
:n,$s/vivian/sky/ 替换第 n 行开始到最后一行中每一行的第一个 vivian 为 sky
:n,$s/vivian/sky/g 替换第 n 行开始到最后一行中每一行所有 vivian 为 sky
n 为数字,若 n 为 .,表示从当前行开始到最后一行
:%s/vivian/sky/(等同于 :g/vivian/s//sky/) 替换每一行的第一个 vivian 为 sky
:%s/vivian/sky/g(等同于 :g/vivian/s//sky/g) 替换每一行中所有 vivian 为 sky
可以使用 # 作为分隔符,此时中间出现的 / 不会作为分隔符
:s#vivian/#sky/# 替换当前行第一个 vivian/ 为 sky/
:%s+/oradata/apras/+/user01/apras1+ (使用+ 来 替换 / ): /oradata/apras/替换成/user01/apras1/
* ************************************
1.:s/vivian/sky/ 替换当前行第一个 vivian 为 sky
:s/vivian/sky/g 替换当前行所有 vivian 为 sky
2. :n,$s/vivian/sky/ 替换第 n 行开始到最后一行中每一行的第一个 vivian 为 sky
:n,$s/vivian/sky/g 替换第 n 行开始到最后一行中每一行所有 vivian 为 sky
(n 为数字,若 n 为 .,表示从当前行开始到最后一行)
3. :%s/vivian/sky/(等同于 :g/vivian/s//sky/) 替换每一行的第一个 vivian 为 sky
:%s/vivian/sky/g(等同于 :g/vivian/s//sky/g) 替换每一行中所有 vivian 为 sky
4. 可以使用 # 作为分隔符,此时中间出现的 / 不会作为分隔符
:s#vivian/#sky/# 替换当前行第一个 vivian/ 为 sky/
5. 删除文本中的^M
问题描述:对于换行,window下用回车换行(0A0D)来表示,Linux下是回车(0A)来表示。这样,将window上的文件拷到unix上用时,总会有个^M.请写个用在unix下的过滤windows文件的换行符(0D)的shell或c程序。
· 使用命令:cat filename1 | tr -d “^V^M” >newfile;
· 使用命令:sed -e “s/^V^M//” filename >outputfilename。需要注意的是在1、2两种方法中,^V和^M指的是Ctrl+V和Ctrl+M。你必须要手工进行输入,而不是粘贴。
· 在vi中处理:首先使用vi打开文件,然后按ESC键,接着输入命令:%s/^V^M//。
· :%s/^M$//g
如果上述方法无用,则正确的解决办法是:
· tr -d "r" <src >dest
· tr -d "5" dest
· strings A>B
6. 其它
利用 :s 命令可以实现字符串的替换。具体的用法包括:
:s/str1/str2/ 用字符串 str2 替换行中首次出现的字符串 str1
:s/str1/str2/g 用字符串 str2 替换行中所有出现的字符串 str1
:.,$ s/str1/str2/g 用字符串 str2 替换正文当前行到末尾所有出现的字符串 str1
:1,$ s/str1/str2/g 用字符串 str2 替换正文中所有出现的字符串 str1
:g/str1/s//str2/g 功能同上
从上述替换命令可以看到:g 放在命令末尾,表示对搜索字符串的每次出现进行替换;不加 g,表示只对搜索
字符串的首次出现进行替换;g 放在命令开头,表示对正文中所有包含搜索字符串的行进行替换操作。
完全认识MySQL数据库中Show命令用法
MySQL中有很多的基本命令,show命令也是其中之一,在很多使用者中对show命令的使用还容易产生混淆,本文汇集了show命令的众多用法。
a. show tables或show tables from database_name; -- 显示当前数据库中所有表的名称。
b. show databases; -- 显示mysql中所有数据库的名称。
c. show columns from table_name from database_name; 或show columns from database_name.table_name; -- 显示表中列名称。
d. show grants for user_name; -- 显示一个用户的权限,显示结果类似于grant 命令。
e. show index from table_name; -- 显示表的索引。
f. show status; -- 显示一些系统特定资源的信息,例如,正在运行的线程数量。
g. show variables; -- 显示系统变量的名称和值。
h. show processlist; -- 显示系统中正在运行的所有进程,也就是当前正在执行的查询。大多数用户可以查看他们自己的进程,但是如果他们拥有process权限,就可以查看所有人的进程,包括密码。
i. show table status; -- 显示当前使用或者指定的database中的每个表的信息。信息包括表类型和表的最新更新时间。
j. show privileges; -- 显示服务器所支持的不同权限。
k. show create database database_name; -- 显示create database 语句是否能够创建指定的数据库。
l. show create table table_name; -- 显示create database 语句是否能够创建指定的数据库。
m. show engies; -- 显示安装以后可用的存储引擎和默认引擎。
n. show innodb status; -- 显示innoDB存储引擎的状态。
o. show logs; -- 显示BDB存储引擎的日志。
p. show warnings; -- 显示最后一个执行的语句所产生的错误、警告和通知。
q. show errors; -- 只显示最后一个执行语句所产生的错误。
r. show [storage] engines; --显示安装后的可用存储引擎和默认引擎。
查整个库的状态:
select concat(truncate(sum(data_length)/1024/1024,2),’MB’) as data_size, concat(truncate(sum(max_data_length)/1024/1024,2),’MB’) as max_data_size, concat(truncate(sum(data_free)/1024/1024,2),’MB’) as data_free, concat(truncate(sum(index_length)/1024/1024,2),’MB’) as index_size from information_schema.tables where TABLE_SCHEMA = ‘databasename’;
查数据库所有表信息:
SELECT * FROM `information_schema`.`TABLES` WHERE `TABLE_SCHEMA`='数据库名‘;
查单表:
select concat(truncate(sum(data_length)/1024/1024,2),’MB’) as data_size, concat(truncate(sum(max_data_length)/1024/1024,2),’MB’) as max_data_size, concat(truncate(sum(data_free)/1024/1024,2),’MB’) as data_free, concat(truncate(sum(index_length)/1024/1024,2),’MB’) as index_size from information_schema.tables where TABLE_NAME = ‘tablename’;
awk命令小记详解
awk 用法:awk ' pattern {action} '
变量名 含义
ARGC 命令行变元个数
ARGV 命令行变元数组
FILENAME 当前输入文件名
FNR 当前文件中的记录号
FS 输入域分隔符,默认为一个空格
RS 输入记录分隔符
NF 当前记录里域个数
NR 到目前为止记录数
OFS 输出域分隔符
ORS 输出记录分隔符
1、awk '/101/' file 显示文件file中包含101的匹配行。
awk '/101/,/105/' file
awk '$1 == 5' file
awk '$1 == "CT"' file 注意必须带双引号
awk '$1 * $2 >100 ' file
awk '$2 >5 && $2<=15' file
2、awk '{print NR,NF,$1,$NF,}' file 显示文件file的当前记录号、域数和每一行的第一个和最后一个域。
awk '/101/ {print $1,$2 + 10}' file 显示文件file的匹配行的第一、二个域加10。
awk '/101/ {print $1$2}' file
awk '/101/ {print $1 $2}' file 显示文件file的匹配行的第一、二个域,但显示时域中间没有分隔符。
3、df | awk '$4>1000000 ' 通过管道符获得输入,如:显示第4个域满足条件的行。
4、awk -F "|" '{print $1}' file 按照新的分隔符“|”进行操作。
awk 'BEGIN { FS="[: \t|]" }
{print $1,$2,$3}' file 通过设置输入分隔符(FS="[: \t|]")修改输入分隔符。
Sep="|"
awk -F $Sep '{print $1}' file 按照环境变量Sep的值做为分隔符。
awk -F '[ :\t|]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表空格、:、TAB、|同时做为分隔符。
awk -F '[][]' '{print $1}' file 按照正则表达式的值做为分隔符,这里代表[、]
5、awk -f awkfile file 通过文件awkfile的内容依次进行控制。
cat awkfile
/101/{print "\047 Hello! \047"} --遇到匹配行以后打印 ' Hello! '.\047代表单引号。
{print $1,$2} --因为没有模式控制,打印每一行的前两个域。
6、awk '$1 ~ /101/ {print $1}' file 显示文件中第一个域匹配101的行(记录)。
7、awk 'BEGIN { OFS="%"}
{print $1,$2}' file 通过设置输出分隔符(OFS="%")修改输出格式。
8、awk 'BEGIN { max=100 ;print "max=" max} BEGIN 表示在处理任意行之前进行的操作。
{max=($1 >max ?$1:max); print $1,"Now max is "max}' file 取得文件第一个域的最大值。
(表达式1?表达式2:表达式3 相当于:
if (表达式1)
表达式2
else
表达式3
awk '{print ($1>4 ? "high "$1: "low "$1)}' file
9、awk '$1 * $2 >100 {print $1}' file 显示文件中第一个域匹配101的行(记录)。
10、awk '{$1 == 'Chi' {$3 = 'China'; print}' file 找到匹配行后先将第3个域替换后再显示该行(记录)。
awk '{$7 %= 3; print $7}' file 将第7域被3除,并将余数赋给第7域再打印。
11、awk '/tom/ {wage=$2+$3; printf wage}' file 找到匹配行后为变量wage赋值并打印该变量。
12、awk '/tom/ {count++;}
END {print "tom was found "count" times"}' file END表示在所有输入行处理完后进行处理。
13、awk 'gsub(/\$/,"");gsub(/,/,""); cost+=$4;
END {print "The total is $" cost>"filename"}' file gsub函数用空串替换$和,再将结果输出到filename中。
1 2 3 $1,200.00
1 2 3 $2,300.00
1 2 3 $4,000.00
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>1000&&$4<2000) c1+=$4;
else if ($4>2000&&$4<3000) c2+=$4;
else if ($4>3000&&$4<4000) c3+=$4;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过if和else if完成条件语句
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000&&$4<4000) exit;
else c4+=$4; }
END {printf "c1=[%d];c2=[%d];c3=[%d];c4=[%d]\n",c1,c2,c3,c4}"' file
通过exit在某条件时退出,但是仍执行END操作。
awk '{gsub(/\$/,"");gsub(/,/,"");
if ($4>3000) next;
else c4+=$4; }
END {printf "c4=[%d]\n",c4}"' file
通过next在某条件时跳过该行,对下一行执行操作。
14、awk '{ print FILENAME,$0 }' file1 file2 file3>fileall 把file1、file2、file3的文件内容全部写到fileall中,格式为
打印文件并前置文件名。
15、awk ' $1!=previous { close(previous); previous=$1 }
{print substr($0,index($0," ") +1)>$1}' fileall 把合并后的文件重新分拆为3个文件。并与原文件一致。
16、awk 'BEGIN {"date"|getline d; print d}' 通过管道把date的执行结果送给getline,并赋给变量d,然后打印。
17、awk 'BEGIN {system("echo \"Input your name:\\c\""); getline d;print "\nYour name is",d,"\b!\n"}'
通过getline命令交互输入name,并显示出来。
awk 'BEGIN {FS=":"; while(getline< "/etc/passwd" >0) { if($1~"050[0-9]_") print $1}}'
打印/etc/passwd文件中用户名包含050x_的用户名。
18、awk '{ i=1;while(i<NF) {print NF,$i;i++}}' file 通过while语句实现循环。
awk '{ for(i=1;i<NF;i++) {print NF,$i}}' file 通过for语句实现循环。
type file|awk -F "/" '
{ for(i=1;i<NF;i++)
{ if(i==NF-1) { printf "%s",$i }
else { printf "%s/",$i } }}' 显示一个文件的全路径。
用for和if显示日期
awk 'BEGIN {
for(j=1;j<=12;j++)
{ flag=0;
printf "\n%d月份\n",j;
for(i=1;i<=31;i++)
{
if (j==2&&i>28) flag=1;
if ((j==4||j==6||j==9||j==11)&&i>30) flag=1;
if (flag==0) {printf "%02d%02d ",j,i}
}
}
}'
19、在awk中调用系统变量必须用单引号,如果是双引号,则表示字符串
Flag=abcd
awk '{print '$Flag'}' 结果为abcd
awk '{print "$Flag"}' 结果为$Flag
总结:
求和:
$awk 'BEGIN{total=0}{total+=$4}END{print total}' a.txt -----对a.txt文件的第四个域进行求和!
-
$ awk '/^(no|so)/' test-----打印所有以模式no或so开头的行。
-
$ awk '/^[ns]/{print $1}' test-----如果记录以n或s开头,就打印这个记录。
-
$ awk '$1 ~/[0-9][0-9]$/(print $1}' test-----如果第一个域以两个数字结束就打印这个记录。
-
$ awk '$1 == 100 || $2 < 50' test-----如果第一个或等于100或者第二个域小于50,则打印该行。
-
$ awk '$1 != 10' test-----如果第一个域不等于10就打印该行。
-
$ awk '/test/{print $1 + 10}' test-----如果记录包含正则表达式test,则第一个域加10并打印出来。
-
$ awk '{print ($1 > 5 ? "ok "$1: "error"$1)}' test-----如果第一个域大于5则打印问号后面的表达式值,否则打印冒号后面的表达式值。
-
$ awk '/^root/,/^mysql/' test----打印以正则表达式root开头的记录到以正则表达式mysql开头的记录范围内的所有记录。如果找到一个新的正则表达式root开头的记 录,则继续打印直到下一个以正则表达式mysql开头的记录为止,或到文件末尾。
Linux文件查找命令find,xargs详述
前言:关于find命令
一、find 命令格式
1、find命令的一般形式为;
2、find命令的参数;
3、find命令选项;
4、使用exec或ok来执行shell命令;
1、查找当前用户主目录下的所有文件;
2、为了在当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
5、为了查找系统中所有属于root组的文件;
6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件
7、为了查找当前文件系统中的所有目录并排序;
8、为了查找系统中所有的rmt磁带设备;
1、使用name选项
2、用perm选项
3、忽略某个目录
4、使用find查找文件的时候怎么避开某个文件目录
5、使用user和nouser选项
6、使用group和nogroup选项
7、按照更改时间或访问时间等查找文件
8、查找比某个文件新或旧的文件
9、使用type选项
10、使用size选项
11、使用depth选项
12、使用mount选项
+++++++++++++++++++++++++++++++++++++++++++++++++
正文
+++++++++++++++++++++++++++++++++++++++++++++++++
版权声明
本文是zhyfly兄贴在LinuxSir.Org 的一个帖子而整理出来的,如果您对版权有疑问,请在本帖后面跟帖。谢谢;本文的HTML版本由北南南北整理;修改了整篇文档的全角及说明文字中的单词中每个字母空格的问题;为标题加了编号,方便大家阅读;
前言:关于find命令
由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。
在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)。
一、find 命令格式
1、find命令的一般形式为;
find pathname -options [-print -exec -ok ...]
2、find命令的参数;
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } /;,注意{ }和/;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
3、find命令选项
-name
按照文件名查找文件。
-perm
按照文件权限来查找文件。
-prune
使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用-depth选项,那么-prune将被find命令忽略。
-user
按照文件属主来查找文件。
-group
按照文件所属的组来查找文件。
-mtime -n +n
按照文件的更改时间来查找文件, - n表示文件更改时间距现在n天以内,+ n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime 选项,但它们都和-m time选项。
-nogroup
查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser
查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2
查找更改时间比文件file1新但比文件file2旧的文件。
-type
查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
-size n:[c] 查找文件长度为n块的文件,带有c时表示文件长度以字节计。
-depth:在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-fstype:查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount:在查找文件时不跨越文件系统mount点。
-follow:如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio:对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。
另外,下面三个的区别:
-amin n
查找系统中最后N分钟访问的文件
-atime n
查找系统中最后n*24小时访问的文件
-cmin n
查找系统中最后N分钟被改变文件状态的文件
-ctime n
查找系统中最后n*24小时被改变文件状态的文件
-mmin n
查找系统中最后N分钟被改变文件数据的文件
-mtime n
查找系统中最后n*24小时被改变文件数据的文件
4、使用exec或ok来执行shell命令
使用find时,只要把想要的操作写在一个文件里,就可以用exec来配合find查找,很方便的
在有些操作系统中只允许-exec选项执行诸如l s或ls -l这样的命令。大多数用户使用这一选项是为了查找旧文件并删除它们。建议在真正执行rm命令删除文件之前,最好先用ls命令看一下,确认它们是所要删除的文件。
exec选项后面跟随着所要执行的命令或脚本,然后是一对儿{ },一个空格和一个/,最后是一个分号。为了使用exec选项,必须要同时使用print选项。如果验证一下find命令,会发现该命令只输出从当前路径起的相对路径及文件名。
例如:为了用ls -l命令列出所匹配到的文件,可以把ls -l命令放在find命令的-exec选项中
# find . -type f -exec ls -l { } /;
-rw-r--r-- 1 root root 34928 2003-02-25 ./conf/httpd.conf
-rw-r--r-- 1 root root 12959 2003-02-25 ./conf/magic
-rw-r--r-- 1 root root 180 2003-02-25 ./conf.d/README上面的例子中,find命令匹配到了当前目录下的所有普通文件,并在-exec选项中使用ls -l命令将它们列出。
在/logs目录中查找更改时间在5日以前的文件并删除它们:
$ find logs -type f -mtime +5 -exec rm { } /;记住: 在shell中用任何方式删除文件之前,应当先查看相应的文件,一定要小心!当使用诸如mv或rm命令时,可以使用-exec选项的安全模式。它将在对每个匹配到的文件进行操作之前提示你。
在下面的例子中, find命令在当前目录中查找所有文件名以.LOG结尾、更改时间在5日以上的文件,并删除它们,只不过在删除之前先给出提示。
$ find . -name "*.conf" -mtime +5 -ok rm { } /;
< rm ... ./conf/httpd.conf > ? n按y键删除文件,按n键不删除。
任何形式的命令都可以在-exec选项中使用。
在下面的例子中我们使用grep命令。find命令首先匹配所有文件名为“ passwd*”的文件,例如passwd、passwd.old、passwd.bak,然后执行grep命令看看在这些文件中是否存在一个sam用户。
# find /etc -name "passwd*" -exec grep "sam" { } /;
sam:x:501:501::/usr/sam:/bin/bash
二、find命令的例子;
1、查找当前用户主目录下的所有文件:
下面两种方法都可以使用
$ find $HOME -print
$ find ~ -print
2、让当前目录中文件属主具有读、写权限,并且文件所属组的用户和其他用户具有读权限的文件;
$ find . -type f -perm 644 -exec ls -l { } /;
3、为了查找系统中所有文件长度为0的普通文件,并列出它们的完整路径;
$ find / -type f -size 0 -exec ls -l { } /;
4、查找/var/logs目录中更改时间在7日以前的普通文件,并在删除之前询问它们;
$ find /var/logs -type f -mtime +7 -ok rm { } /;
5、为了查找系统中所有属于root组的文件;
$find . -group root -exec ls -l { } /;
-rw-r--r-- 1 root root 595 10月 31 01:09 ./fie1
6、find命令将删除当目录中访问时间在7日以来、含有数字后缀的admin.log文件。
该命令只检查三位数字,所以相应文件的后缀不要超过999。先建几个admin.log*的文件 ,才能使用下面这个命令
$ find . -name "admin.log[0-9][0-9][0-9]" -atime -7 -ok
rm { } /;
< rm ... ./admin.log001 > ? n
< rm ... ./admin.log002 > ? n
< rm ... ./admin.log042 > ? n
< rm ... ./admin.log942 > ? n
7、为了查找当前文件系统中的所有目录并排序;
$ find . -type d | sort
8、为了查找系统中所有的rmt磁带设备;
$ find /dev/rmt -print
三、xargs
xargs - build and execute command lines from standard input
在使用find命令的-exec选项处理匹配到的文件时, find命令将所有匹配到的文件一起传递给exec执行。但有些系统对能够传递给exec的命令长度有限制,这样在find命令运行几分钟之后,就会出现溢出错误。错误信息通常是“参数列太长”或“参数列溢出”。这就是xargs命令的用处所在,特别是与find命令一起使用。
find命令把匹配到的文件传递给xargs命令,而xargs命令每次只获取一部分文件而不是全部,不像-exec选项那样。这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。
在有些系统中,使用-exec选项会为处理每一个匹配到的文件而发起一个相应的进程,并非将匹配到的文件全部作为参数一次执行;这样在有些情况下就会出现进程过多,系统性能下降的问题,因而效率不高;
而使用xargs命令则只有一个进程。另外,在使用xargs命令时,究竟是一次获取所有的参数,还是分批取得参数,以及每一次获取参数的数目都会根据该命令的选项及系统内核中相应的可调参数来确定。
来看看xargs命令是如何同find命令一起使用的,并给出一些例子。
下面的例子查找系统中的每一个普通文件,然后使用xargs命令来测试它们分别属于哪类文件
#find . -type f -print | xargs file
./.kde/Autostart/Autorun.desktop: UTF-8 Unicode English text
./.kde/Autostart/.directory: ISO-8859 text/
......在整个系统中查找内存信息转储文件(core dump) ,然后把结果保存到/tmp/core.log 文件中:
$ find / -name "core" -print | xargs echo "" >/tmp/core.log上面这个执行太慢,我改成在当前目录下查找
#find . -name "file*" -print | xargs echo "" > /temp/core.log
# cat /temp/core.log
./file6在当前目录下查找所有用户具有读、写和执行权限的文件,并收回相应的写权限:
# ls -l
drwxrwxrwx 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxrwx 2 sam adm 0 10月 31 01:01 httpd.conf
# find . -perm -7 -print | xargs chmod o-w
# ls -l
drwxrwxr-x 2 sam adm 4096 10月 30 20:14 file6
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
用grep命令在所有的普通文件中搜索hostname这个词:
# find . -type f -print | xargs grep "hostname"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your用grep命令在当前目录下的所有普通文件中搜索hostnames这个词:
# find . -name /* -type f -print | xargs grep "hostnames"
./httpd1.conf:# different IP addresses or hostnames and have them handled by the
./httpd1.conf:# VirtualHost: If you want to maintain multiple domains/hostnames
on your注意,在上面的例子中, /用来取消find命令中的*在shell中的特殊含义。
find命令配合使用exec和xargs可以使用户对所匹配到的文件执行几乎所有的命令。
四、find 命令的参数
下面是find一些常用参数的例子,有用到的时候查查就行了,像上面前几个贴子,都用到了其中的的一些参数,也可以用man或查看论坛里其它贴子有find的命令手册
1、使用name选项
文件名选项是find命令最常用的选项,要么单独使用该选项,要么和其他选项一起使用。
可以使用某种文件名模式来匹配文件,记住要用引号将文件名模式引起来。
不管当前路径是什么,如果想要在自己的根目录$HOME中查找文件名符合*.txt的文件,使用~作为 'pathname'参数,波浪号~代表了你的$HOME目录。
$ find ~ -name "*.txt" -print想要在当前目录及子目录中查找所有的‘ *.txt’文件,可以用:
$ find . -name "*.txt" -print想要的当前目录及子目录中查找文件名以一个大写字母开头的文件,可以用:
$ find . -name "[A-Z]*" -print想要在/etc目录中查找文件名以host开头的文件,可以用:
$ find /etc -name "host*" -print想要查找$HOME目录中的文件,可以用:
$ find ~ -name "*" -print 或find . -print要想让系统高负荷运行,就从根目录开始查找所有的文件。
$ find / -name "*" -print如果想在当前目录查找文件名以两个小写字母开头,跟着是两个数字,最后是.txt的文件,下面的命令就能够返回名为ax37.txt的文件:
$find . -name "[a-z][a-z][0--9][0--9].txt" -print
2、用perm选项
按照文件权限模式用-perm选项,按文件权限模式来查找文件的话。最好使用八进制的权限表示法。
如在当前目录下查找文件权限位为755的文件,即文件属主可以读、写、执行,其他用户可以读、执行的文件,可以用:
$ find . -perm 755 -print还有一种表达方法:在八进制数字前面要加一个横杠-,表示都匹配,如-007就相当于777,-006相当于666
# ls -l
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 http3.conf
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find . -perm 006
# find . -perm -006
./sam
./httpd1.conf
./temp
-perm mode:文件许可正好符合mode
-perm +mode:文件许可部分符合mode
-perm -mode: 文件许可完全符合mode
3、忽略某个目录
如果在查找文件时希望忽略某个目录,因为你知道那个目录中没有你所要查找的文件,那么可以使用-prune选项来指出需要忽略的目录。在使用-prune选项时要当心,因为如果你同时使用了-depth选项,那么-prune选项就会被find命令忽略。
如果希望在/apps目录下查找文件,但不希望在/apps/bin目录下查找,可以用:
$ find /apps -path "/apps/bin" -prune -o -print
4、使用find查找文件的时候怎么避开某个文件目录
比如要在/usr/sam目录下查找不在dir1子目录之内的所有文件
find /usr/sam -path "/usr/sam/dir1" -prune -o -print
find [-path ..] [expression] 在路径列表的后面的是表达式-path "/usr/sam" -prune -o -print 是 -path "/usr/sam" -a -prune -o
-print 的简写表达式按顺序求值, -a 和 -o 都是短路求值,与 shell 的 && 和 || 类似如果 -path "/usr/sam" 为真,则求值 -prune , -prune 返回真,与逻辑表达式为真;否则不求值 -prune,与逻辑表达式为假。如果 -path "/usr/sam" -a -prune 为假,则求值 -print ,-print返回真,或逻辑表达式为真;否则不求值 -print,或逻辑表达式为真。
这个表达式组合特例可以用伪码写为
if -path "/usr/sam" then
-prune
else
-print避开多个文件夹
find /usr/sam /( -path /usr/sam/dir1 -o -path /usr/sam/file1 /) -prune -o -print圆括号表示表达式的结合。
/ 表示引用,即指示 shell 不对后面的字符作特殊解释,而留给 find 命令去解释其意义。查找某一确定文件,-name等选项加在-o 之后
#find /usr/sam /(-path /usr/sam/dir1 -o -path /usr/sam/file1 /) -prune -o -name "temp" -print
5、使用user和nouser选项
按文件属主查找文件,如在$HOME目录中查找文件属主为sam的文件,可以用:
$ find ~ -user sam -print在/etc目录下查找文件属主为uucp的文件:
$ find /etc -user uucp -print为了查找属主帐户已经被删除的文件,可以使用-nouser选项。这样就能够找到那些属主在/etc/passwd文件中没有有效帐户的文件。在使用-nouser选项时,不必给出用户名; find命令能够为你完成相应的工作。
例如,希望在/home目录下查找所有的这类文件,可以用:
$ find /home -nouser -print
6、使用group和nogroup选项
就像user和nouser选项一样,针对文件所属于的用户组, find命令也具有同样的选项,为了在/apps目录下查找属于gem用户组的文件,可以用:
$ find /apps -group gem -print要查找没有有效所属用户组的所有文件,可以使用nogroup选项。下面的find命令从文件系统的根目录处查找这样的文件
$ find / -nogroup-print
7、按照更改时间或访问时间等查找文件
如果希望按照更改时间来查找文件,可以使用mtime,atime或ctime选项。如果系统突然没有可用空间了,很有可能某一个文件的长度在此期间增长迅速,这时就可以用mtime选项来查找这样的文件。
用减号-来限定更改时间在距今n日以内的文件,而用加号+来限定更改时间在距今n日以前的文件。
希望在系统根目录下查找更改时间在5日以内的文件,可以用:
$ find / -mtime -5 -print为了在/var/adm目录下查找更改时间在3日以前的文件,可以用:
$ find /var/adm -mtime +3 -print
8、查找比某个文件新或旧的文件
如果希望查找更改时间比某个文件新但比另一个文件旧的所有文件,可以使用-newer选项。它的一般形式为:
newest_file_name ! oldest_file_name其中,!是逻辑非符号。
查找更改时间比文件sam新但比文件temp旧的文件:
例:有两个文件
-rw-r--r-- 1 sam adm 0 10月 31 01:07 fiel
-rw-rw-rw- 1 sam adm 34890 10月 31 00:57 httpd1.conf
-rwxrwxr-x 2 sam adm 0 10月 31 01:01 httpd.conf
drw-rw-rw- 2 gem group 4096 10月 26 19:48 sam
-rw-rw-rw- 1 root root 2792 10月 31 20:19 temp
# find -newer httpd1.conf ! -newer temp -ls
1077669 0 -rwxrwxr-x 2 sam adm 0 10月 31 01:01 ./httpd.conf
1077671 4 -rw-rw-rw- 1 root root 2792 10月 31 20:19 ./temp
1077673 0 -rw-r--r-- 1 sam adm 0 10月 31 01:07 ./fiel
查找更改时间在比temp文件新的文件:
$ find . -newer temp -print
9、使用type选项
在/etc目录下查找所有的目录,可以用:
$ find /etc -type d -print在当前目录下查找除目录以外的所有类型的文件,可以用:
$ find . ! -type d -print在/etc目录下查找所有的符号链接文件,可以用
$ find /etc -type l -print
10、使用size选项
可以按照文件长度来查找文件,这里所指的文件长度既可以用块(block)来计量,也可以用字节来计量。以字节计量文件长度的表达形式为N c;以块计量文件长度只用数字表示即可。
在按照文件长度查找文件时,一般使用这种以字节表示的文件长度,在查看文件系统的大小,因为这时使用块来计量更容易转换。
在当前目录下查找文件长度大于1 M字节的文件:
$ find . -size +1000000c -print在/home/apache目录下查找文件长度恰好为100字节的文件:
$ find /home/apache -size 100c -print在当前目录下查找长度超过10块的文件(一块等于512字节):
$ find . -size +10 -print
11、使用depth选项
在使用find命令时,可能希望先匹配所有的文件,再在子目录中查找。使用depth选项就可以使find命令这样做。这样做的一个原因就是,当在使用find命令向磁带上备份文件系统时,希望首先备份所有的文件,其次再备份子目录中的文件。
在下面的例子中, find命令从文件系统的根目录开始,查找一个名为CON.FILE的文件。
它将首先匹配所有的文件然后再进入子目录中查找。
$ find / -name "CON.FILE" -depth -print
12、使用mount选项
在当前的文件系统中查找文件(不进入其他文件系统),可以使用find命令的mount选项。
从当前目录开始查找位于本文件系统中文件名以XC结尾的文件:
$ find . -name "*.XC" -mount -printLinux的chattr与lsattr命令详解
PS:有时候你发现用root权限都不能修改某个文件,大部分原因是曾经用chattr命令锁定该文件了。chattr命令的作用很大,其中一些功能是由Linux内核版本来支持的,不过现在生产绝大部分跑的linux系统都是2.6以上内核了。通过chattr命令修改属性能够提高系统的安全性,但是它并不适合所有的目录。chattr命令不能保护/、/dev、/tmp、/var目录。lsattr命令是显示chattr命令设置的文件属性。
这两个命令是用来查看和改变文件、目录属性的,与chmod这个命令相比,chmod只是改变文件的读写、执行权限,更底层的属性控制是由chattr来改变的。
chattr命令的用法:chattr [ -RVf ] [ -v version ] [ mode ] files…
最关键的是在[mode]部分,[mode]部分是由+-=和[ASacDdIijsTtu]这些字符组合的,这部分是用来控制文件的
属性。
+ :在原有参数设定基础上,追加参数。
- :在原有参数设定基础上,移除参数。
= :更新为指定参数设定。
A:文件或目录的 atime (access time)不可被修改(modified), 可以有效预防例如手提电脑磁盘I/O错误的发生。
S:硬盘I/O同步选项,功能类似sync。
a:即append,设定该参数后,只能向文件中添加数据,而不能删除,多用于服务器日志文件安全,只有root才能设定这个属性。
c:即compresse,设定文件是否经压缩后再存储。读取时需要经过自动解压操作。
d:即no dump,设定文件不能成为dump程序的备份目标。
i:设定文件不能被删除、改名、设定链接关系,同时不能写入或新增内容。i参数对于文件 系统的安全设置有很大帮助。
j:即journal,设定此参数使得当通过mount参数:data=ordered 或者 data=writeback 挂 载的文件系统,文件在写入时会先被记录(在journal中)。如果filesystem被设定参数为 data=journal,则该参数自动失效。
s:保密性地删除文件或目录,即硬盘空间被全部收回。
u:与s相反,当设定为u时,数据内容其实还存在磁盘中,可以用于undeletion。
各参数选项中常用到的是a和i。a选项强制只可添加不可删除,多用于日志系统的安全设定。而i是更为严格的安全设定,只有superuser (root) 或具有CAP_LINUX_IMMUTABLE处理能力(标识)的进程能够施加该选项。
应用举例:
1、用chattr命令防止系统中某个关键文件被修改:
# chattr +i /etc/resolv.conf
然后用mv /etc/resolv.conf等命令操作于该文件,都是得到Operation not permitted 的结果。vim编辑该文件时会提示W10: Warning: Changing a readonly file错误。要想修改此文件就要把i属性去掉: chattr -i /etc/resolv.conf
# lsattr /etc/resolv.conf
会显示如下属性
----i-------- /etc/resolv.conf
2、让某个文件只能往里面追加数据,但不能删除,适用于各种日志文件:
# chattr +a /var/log/messages
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
