Linux查看系统配置常用命令
一、linux CPU大小
cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
说明:Linux下可以在/proc/cpuinfo中看到每个cpu的详细信息。但是对于双核的cpu,在cpuinfo中会看到两个cpu。常常会让人误以为是两个单核的cpu。
其实应该通过Physical Processor ID来区分单核和双核。而Physical Processor ID可以从cpuinfo或者dmesg中找到. flags 如果有 ht 说明支持超线程技术 判断物理CPU的个数可以查看physical id 的值,相同则为
二、内存大小 cat /proc/meminfo |grep MemTotal
三、硬盘大小 fdisk -l |grep Disk
四、uname -a # 查看内核/操作系统/CPU信息的linux系统信息命令
五、head -n 1 /etc/issue # 查看操作系统版本,是数字1不是字母L
六、cat /proc/cpuinfo # 查看CPU信息的linux系统信息命令
七、hostname # 查看计算机名的linux系统信息命令
八、lspci -tv # 列出所有PCI设备
九、lsusb -tv # 列出所有USB设备的linux系统信息命令
十、lsmod # 列出加载的内核模块
十一、env # 查看环境变量资源
十二、free -m # 查看内存使用量和交换区使用量
十三、df -h # 查看各分区使用情况
十四、du -sh # 查看指定目录的大小
十五、grep MemTotal /proc/meminfo # 查看内存总量
十六、grep MemFree /proc/meminfo # 查看空闲内存量
十七、uptime # 查看系统运行时间、用户数、负载
十八、cat /proc/loadavg # 查看系统负载磁盘和分区
十九、mount | column -t # 查看挂接的分区状态
二十、fdisk -l # 查看所有分区
二十一、swapon -s # 查看所有交换分区
二十二、hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
二十三、dmesg | grep IDE # 查看启动时IDE设备检测状况网络
二十四、ifconfig # 查看所有网络接口的属性
二十五、iptables -L # 查看防火墙设置
二十六、route -n # 查看路由表
二十七、netstat -lntp # 查看所有监听端口
二十八、netstat -antp # 查看所有已经建立的连接
二十九、netstat -s # 查看网络统计信息进程
三十、ps -ef # 查看所有进程
三十一、top # 实时显示进程状态用户
三十二、w # 查看活动用户
三十三、id # 查看指定用户信息
三十四、last # 查看用户登录日志
三十五、cut -d: -f1 /etc/passwd # 查看系统所有用户
三十六、cut -d: -f1 /etc/group # 查看系统所有组
三十七、crontab -l # 查看当前用户的计划任务服务
三十七、chkconfig –list # 列出所有系统服务
三十八、chkconfig –list | grep on # 列出所有启动的系统服务程序
三十九、rpm -qa # 查看所有安装的软件包
四十、cat /proc/cpuinfo :查看CPU相关参数的linux系统命令
四十一、cat /proc/partitions :查看linux硬盘和分区信息的系统信息命令
四十二、cat /proc/meminfo :查看linux系统内存信息的linux系统命令
四十三、cat /proc/version :查看版本,类似uname -r
四十四、cat /proc/ioports :查看设备io端口
四十五、cat /proc/interrupts :查看中断
四十六、cat /proc/pci :查看pci设备的信息
四十七、cat /proc/swaps :查看所有swap分区的信息
Redis内存数据库操作命令详解
默认无权限控制:
远程服务连接:
$ redis-cli -h 127.0.0.1 -p 6379
windows下 :redis-cli.exe -h 127.0.0.1 -p 6379
redis 127.0.0.1:6379>
远程服务停止:
$ redis-cli -h 172.168.10.254 -p6379 shutdown
2) 有权限控制时(加上-a 密码):
redis-cli -h 127.0.0.1 -p 6379 -a 123456
除了在登录时通过 -a 参数制定密码外,还可以登录时不指定密码,而在执行操作前进行认证。

Redis默认端口号为127.0.0.1,端口号默认为:6379。
此处本机访问远程IP为132.1.114.44的计算机,则首先要在已经安装了Redis的远程计算机上打开其服务器,redis.server.exe
接下来在本机运行redis.cli.exe,也可以通过命令行实现:输入-h 远程计算机IP -p 6379即可连接:

OK了,接下来如果想用自己写的客户端什么的连接远程Redis数据库也只需要输入远程计算机的IP就可以了~
Redis系列-远程连接redis
用法:redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <主机ip>,默认是127.0.0.1
-p <端口>,默认是6379
-a <密码>,如果redis加锁,需要传递密码
--help,显示帮助信息
通过对rendis-cli用法介绍,在101上连接103应该很简单:
[root@linuxidc001 ~]# redis-cli -h 192.168.1.103 -p 6379
redis 192.168.1.103:6379>
在101上对103设置个个string值 user.1.name=zhangsan
redis 192.168.1.103:6379> set user.1.name zhangsan
OK
看到ok,表明设置成功了。然后直接在103上登陆,看能不能获取到这个值。
redis 192.168.1.103:6379> keys *
redis 192.168.1.103:6379> select 1
1、连接操作相关的命令
- quit:关闭连接(connection)
- auth:简单密码认证
2、对value操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个key
- rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
3、对String操作的命令
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
- setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
- setex(key, time, value):向库中添加string(名称为key,值为value)同时,设定过期时间time
- mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
- msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
4、对List操作的命令
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
- ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值为value
- lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从 头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对 keyi 1开始的list执行pop操作。
- brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
- zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
- zrem(key, member) :删除名称为key的zset中的元素member
- zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
- zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
- zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
- zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
- zunionstore / zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行 AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素 的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
LINUX中查看文本文件内容命令
cat:从第一行開始显示所有的文本内容;
tac:从最后一行開始,显示所有分文本内容,与cat相反。
nl:显示文本时,能够输出行号。
more:按页显示文本内容;
less:与more差点儿相同,也是按页显示文本内容,差别是less能够一行一行的回退。more回退仅仅能一页一页回退。
head:从头開始显示文件指定的行数;
tail:显示文件指定的结尾的行数。但每一行的位置还是原文件里的位置,不会像tac那样与原文件相反。
vi: NB的Linux文本编辑器。
样例与说明
cat
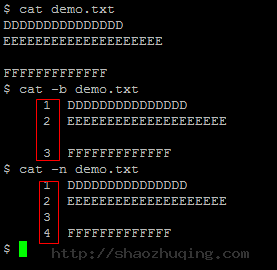
- cat demo.txt
显示demo.txt文件所有内容 - cat -b demo.txt
显示demo.txt文件所有内容。非空的行输出行号。空行会输出。但不标记行号 - cat -n demo.txt
显示demo.txt文件所有内容。所有行都输出行号
长处:简单
缺点:当文本文件内容多于一页内容时。仅仅能显示出最后一页的内容,无法看到前面的内容。
tac
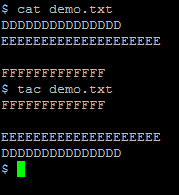
- tac demo.txt
从最后一行開始。倒序输出demo.txt的内容。本人不经常使用。
nl
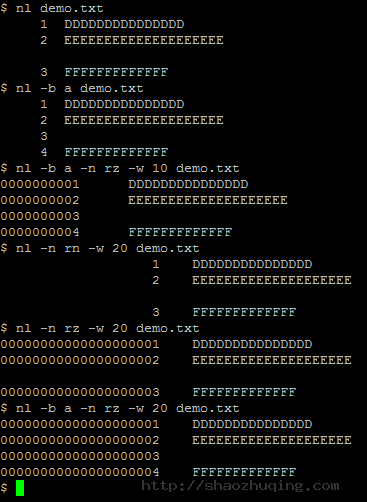
- nl demo.txt
显示文件内容。顺便输出行号。默认情况下空行不记录行号 - nl -b a demo.txt
- b a #空行也输出行号
- b t #默认设置
- n ln ##行号最左方显示
- n rn ##行号最右方显示,且不加0(然并卵,我的机器上依旧显示在左边)
- n rz ##行号最右方显示,且加0(再次然并卵,但加了0了。例如以下图所看到的)
- w ##设置行号字段占用的位数
长处:貌似非常灵活的样子
缺点:就查看下内容。输出个行号而已。搞那么复杂有卵用。。。
more
- more demo.txt
- 按一下空格则往下翻一页
- 按一下Enter则往下翻一行
- 按一下B键往上翻一页
- 不能往上一行一行的翻回去了
- :f 能够显示文件名称和如今的行数
- q退出more
less
- less demo.txt
- more命令的所有按键less都支持
- ↑↓箭头能够实现一行一行的上下翻
- PageDown/PageUp能够实现一页一页的上下翻
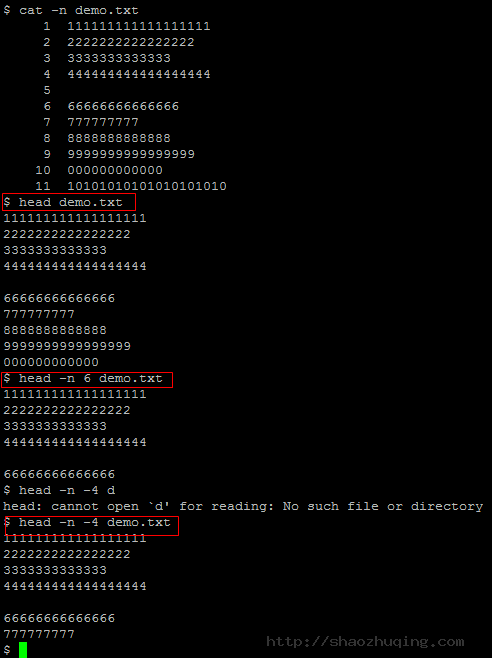
head
- head demo.txt
默认仅仅显示文件的前10行文本内容 - head -n 6 demo.txt
-n 6 參数指定显示文件的前6行 - head -n -4 demo.txt
-n -4 负数表示除去文件结尾的4行,其它的从头開始的所有行都显示出来
tail
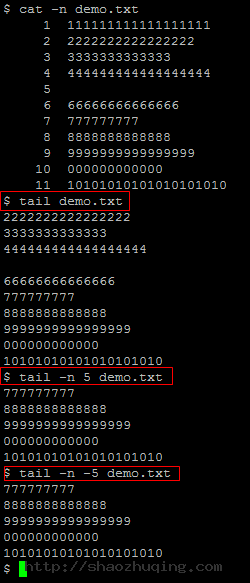
- tail demo.txt
默认仅仅显示从文件最后一行開始的10行文本内容 - tail -n 5 demo.txt
-n 5 參数指定显示文件的最后5行 - tail -n -5 demo.txt
**-n -5**tail命令不支持负数。运行结果同-n 5
vi
vi命令是使用VIM文本编辑器打开文本,VIM编辑器眼下本人也是刚開始学习。仅仅记住了一些简单的命令:
- vi demo.txt 进入Normal模式查看文本
- i 进入Insert模式插入内容,编辑文本
- nG n代表行号,在Normal模式输入nG则定位到第n行
- :set number 在Normal模式输入则显示文本行号。空行也会显示行号
- ESC 退出Insert模式至Normal模式
- :wq 在Normal模式下保存退出。w保存;q退出;能够单独使用
Linux下如何使用命令同步时钟
linux的系统时钟在很多地方都要用到,要是不准,就会出现一些奇怪的问题;
在Linux中,用于时钟查看和设置的命令主要有date、hwclock和clock。Linux时钟分为系统时钟(System Clock)和硬件(Real Time Clock,简称RTC)时钟。系统时钟: 是指当前Linux Kernel中的时钟,硬件时钟: 是主板上由电池供电的时钟,这个硬件时钟可以在BIOS中进行设置。
当Linux启动时,硬件时钟会去读取系统时钟的设置,然后系统时钟就会独立于硬件运作。
Linux 中的所有命令(包括函数)都是采用的系统时钟设置。在Linux中,用于时钟查看和设置的命令主要有date、hwclock和clock。其中,clock和hwclock用法相近,只用一个就行,只不过clock命令除了支持x86硬件体系外,还支持Alpha硬件体系。
1、 date
查看系统时间
# date
设置系统时间
# date –set “07/07/06 10:19″ //(月/日/年时:分:秒)
2、hwclock/clock
查看硬件时间
# hwclock –show //或者
# clock –show
设置硬件时间
# hwclock –set –date=”07/07/06 10:19″ (月/日/年 时:分:秒) 或者
# clock –set –date=”07/07/06 10:19″ (月/日/年 时:分:秒)
3、硬件时间和系统时间的同步
按照前面的说法,重新启动系统,硬件时间会读取系统时间,实现同步,
但是在不重新启动的时候,需要用hwclock或clock命令实现同步。
硬件时钟与系统时钟同步:
# hwclock –hctosys // (hc代表硬件时间,sys代表系统时间)或者
# clock –hctosys
系统时钟和硬件时钟同步:
# hwclock –systohc // 或者
# clock –systohc
4. 和外部的NTP时间服务器同步
$ service ntpd stop
这一步是必须的,否则出出现:
25 Nov 18:10:34 ntpdate[2106]: the NTP socket is in use, exiting
的失败提示;
$ ntpdate ntp.sjtu.edu.cn
正常返回如下:
25 Nov 18:14:34 ntpdate[2164]: adjust time server 202.120.2.101 offset -0.006107 sec
错误返回如:
25 Nov 18:13:44 ntpdate[2158]: no server suitable for synchronization found
$ service ntpd start
$ chkconfig ntpd on
$ clock -w
还可以写进定时任务中,以做定时的时钟同步:
$ crontab -e
05 * * * * /usr/sbin/ntpdate ntp.sjtu.edu.cn 》 /dev/null 2》&1
05 17 * * * /sbin/clock -w
附上中国大概能用的NTP时间服务器地址
server 133.100.11.8 prefer
server 210.72.145.44
server 203.117.180.36
server 131.107.1.10
server time.asia.apple.com
server 64.236.96.53
server 130.149.17.21
server 66.92.68.246
server www.freebsd.org
server 18.145.0.30
server clock.via.net
server 137.92.140.80
server 133.100.9.2
server 128.118.46.3
server ntp.nasa.gov
server 129.7.1.66
server ntp-sop.inria.frserver 210.72.145.44(中国国家授时中心服务器IP地址)
server ntp.sjtu.edu.cn(上海交通大学网络中心NTP服务器地址)
上面就是使用命令同步Linux时钟的方法介绍了,一般使用data、hwclock和clock命令,而data命令是比较常用的命令,如果你的系统时钟不同步,那就赶紧改过来吧。
MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
linux 查看系统信息命令(比较全)
# uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh <目录名> # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态用户
# w # 查看活动用户
# id <用户名> # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户
# cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务程序
# rpm -qa # 查看所有安装的软件包
Linux中几个在备份中常用的命令(cp,scp,rsync)
在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。在备份的操作中,拷贝,过期文件的删除是经常要做的事情。
拷贝也有本机拷贝,拷贝到别的服务器等。常用的操作有cp,scp,rsync等命令。
1、 cp(copy)命令
功能说明:复制文件或目录。
语 法:cp [-abdfilpPrRsuvx][-S <备份字尾字符串>][-V <备份方式>][--help][--spares=<使用时机>][--version][源文件或目录][目标文件或目录] [目的目录]
补充说明:cp指令用在复制文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则它会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,而最后的目的地并非是一个已存在的目录,则会出现错误信息。
参 数:
-a或--archive 此参数的效果和同时指定"-dpR"参数相同。
-b或--backup 删除,覆盖目标文件之前的备份,备份文件会在字尾加上一个备份字符串。
-d或--no-dereference 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录。
-f或--force 强行复制文件或目录,不论目标文件或目录是否已存在。
-i或--interactive 覆盖既有文件之前先询问用户。
-l或--link 对源文件建立硬连接,而非复制文件。
-p或--preserve 保留源文件或目录的属性。
-P或--parents 保留源文件或目录的路径。
-r 递归处理,将指定目录下的文件与子目录一并处理。
-R或--recursive 递归处理,将指定目录下的所有文件与子目录一并处理。
-s或--symbolic-link 对源文件建立符号连接,而非复制文件。
-S<备份字尾字符串>或--suffix=<备份字尾字符串> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,预设的备份字尾字符串是符号"~"。
-u或--update 使用这项参数后只会在源文件的更改时间较目标文件更新时或是 名称相互对应的目标文件并不存在,才复制文件。
-v或--verbose 显示指令执行过程。
-V<备份方式>或--version-control=<备份方式> 用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这字符串不仅可用"-S"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字串。
-x或--one-file-system 复制的文件或目录存放的文件系统,必须与cp指令执行时所处的文件系统相同,否则不予复制。
--help 在线帮助。
--sparse=<使用时机> 设置保存稀疏文件的时机。
--version 显示版本信息。
2. SCP
scp是 secure copy的缩写, scp是linux系统下基于ssh登陆进行安全的远程文件拷贝命令。linux的scp命令可以在linux服务器之间复制文件和目录.
scp命令的用处:
scp在网络上不同的主机之间复制文件,它使用ssh安全协议传输数据,具有和ssh一样的验证机制,从而安全的远程拷贝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file] [-l limit] [-o ssh_option] [-P port] [-S program] [[user@]host1:]file1 [...] [[user@]host2:]file2
例子:scp -r /home/soft/ root@www.mydomain.com:/home/others/
3. rsync
rysnc是一个数据镜像及备份工具,具有可使本地和远程两台主机的文件,目录之间,快速同步镜像,远程数据备份等功能。在同步过程中,rsync是根据自己独特的算法,只同步有变化的文件,甚至在一个文件里只同步有变化的部分,所以可以实现快速的同步数据的功能。
1. rsync用法
NAME
rsync - faster, flexible replacement for rcp
用法:
rsync [OPTION]... SRC [SRC]... DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST
rsync [OPTION]... SRC [SRC]... [USER@]HOST::DEST
rsync [OPTION]... SRC [SRC]... rsync://[USER@]HOST[:PORT]/DEST
rsync [OPTION]... SRC
rsync [OPTION]... [USER@]HOST:SRC [DEST]
rsync [OPTION]... [USER@]HOST::SRC [DEST]
rsync [OPTION]... rsync://[USER@]HOST[:PORT]/SRC [DEST]
参数是非常多,用man可以查询。
--delete 删除传送端已经不存在,而目的端存在的档案
--delete-excluded 除了把传送端已经不存在, 而目的端存在的档案删除之外, 也删除 --exclude 参数所包含的档案
使用例子,把192.168.1.2的/home/下的文件同步到本地的/home/下面:rsync -aSvH --delete /home/ root@192.168.1.2:/home/
主要SCR目录的写法、比如 rsync src/ 和 src 是有区别的。 src/是src文件夹下的所有文件作为传送对象。没有/的src的话是,src这个文件夹整体拷贝传送。
rsync执行中需要ssh认证等,可以实现配置,然后在cron中定时执行同步就好了。
解决PHP执行Linux命令
一、检查您的php用的是哪个用户组:
可以查看nginx配置文件或者apache配置文件
如:/etc/nginx/nginx.conf 或: /etc/httpd/conf/httpd.conf
也可以用:
比如 我的运行用户组是apache,那么,
二、
vim /etc/sudoer
1.加上www用户 www ALL=(ALL) NOPASSWD:ALL
2. vim 下 / 查找LS_COLORS 将它去掉(Ubuntu没有这个的可以省略)
然后注释掉
Defaults requiretty
Defaults env_reset
这两句!
三、
vim /etc/php.ini
检查:
safe_mode = (这个如果为off下面两个就不用管了)
disable_functions =
safe_mode_exec_dir=
done! 现在您应该可以在php跑linux命令了!
记住一定要重启php-fmp 和nginx
/etc/init.d/php-fpm restart
/etc/init.d/nginx restart
Console命令详解,让调试js代码变得更简单

控制台(Console)是Firebug的第一个面板,也是最重要的面板,主要作用是显示网页加载过程中产生各类信息。
一、显示信息的命令
Firebug内置一个console对象,提供5种方法,用来显示信息。
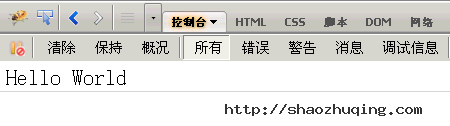
最简单的方法是console.log(),可以用来取代alert()或document.write()。比如,在网页脚本中使用console.log("Hello World"),加载时控制台就会自动显示如下内容。
另外,根据信息的不同性质,console对象还有4种显示信息的方法,分别是一般信息console.info()、除错信息console.debug()、警告提示console.warn()、错误提示console.error()。
比如,在网页脚本中插入下面四行:
console.info("这是info");
console.debug("这是debug");
console.warn("这是warn");
console.error("这是error");
加载时,控制台会显示如下内容。

可以看到,不同性质的信息前面有不同的图标,并且每条信息后面都有超级链接,点击后跳转到网页源码的相应行。
二、占位符
console对象的上面5种方法,都可以使用printf风格的占位符。不过,占位符的种类比较少,只支持字符(%s)、整数(%d或%i)、浮点数(%f)和对象(%o)四种。
比如,
console.log("%d年%d月%d日",2011,3,26);
console.log("圆周率是%f",3.1415926);

%o占位符,可以用来查看一个对象内部情况。比如,有这样一个对象:
var dog = {} ;
dog.name = "大毛" ;
dog.color = "黄色";
然后,对它使用o%占位符。
console.log("%o",dog);

三、分组显示
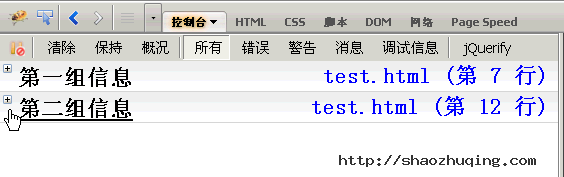
如果信息太多,可以分组显示,用到的方法是console.group()和console.groupEnd()。
console.group("第一组信息");
console.log("第一组第一条");
console.log("第一组第二条");
console.groupEnd();
console.group("第二组信息");
console.log("第二组第一条");
console.log("第二组第二条");
console.groupEnd();
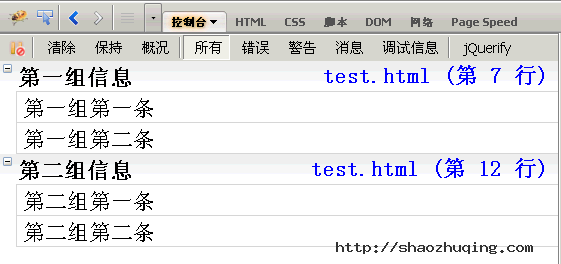
点击组标题,该组信息会折叠或展开。
四、console.dir()
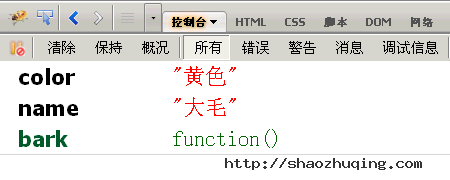
console.dir()可以显示一个对象所有的属性和方法。
比如,现在为第二节的dog对象,添加一个bark()方法。
dog.bark = function(){alert("汪汪汪");};
然后,显示该对象的内容,
console.dir(dog);
五、console.dirxml()
console.dirxml()用来显示网页的某个节点(node)所包含的html/xml代码。
比如,先获取一个表格节点,
var table = document.getElementById("table1");
然后,显示该节点包含的代码。
console.dirxml(table);

六、console.assert()
console.assert()用来判断一个表达式或变量是否为真。如果结果为否,则在控制台输出一条相应信息,并且抛出一个异常。
比如,下面两个判断的结果都为否。
var result = 0;
console.assert( result );
var year = 2000;
console.assert(year == 2011 );

七、console.trace()
console.trace()用来追踪函数的调用轨迹。
比如,有一个加法器函数。
function add(a,b){
return a+b;
}
我想知道这个函数是如何被调用的,在其中加入console.trace()方法就可以了。
function add(a,b){
console.trace();
return a+b;
}
假定这个函数的调用代码如下:
var x = add3(1,1);
function add3(a,b){return add2(a,b);}
function add2(a,b){return add1(a,b);}
function add1(a,b){return add(a,b);}
运行后,会显示add()的调用轨迹,从上到下依次为add()、add1()、add2()、add3()。

八、计时功能
console.time()和console.timeEnd(),用来显示代码的运行时间。
console.time("计时器一");
for(var i=0;i<1000;i++){
for(var j=0;j<1000;j++){}
}
console.timeEnd("计时器一");

九、性能分析
性能分析(Profiler)就是分析程序各个部分的运行时间,找出瓶颈所在,使用的方法是console.profile()。
假定有一个函数Foo(),里面调用了另外两个函数funcA()和funcB(),其中funcA()调用10次,funcB()调用1次。
function Foo(){
for(var i=0;i<10;i++){funcA(1000);}
funcB(10000);
}
function funcA(count){
for(var i=0;i<count;i++){}
}
function funcB(count){
for(var i=0;i<count;i++){}
}
然后,就可以分析Foo()的运行性能了。
console.profile('性能分析器一');
Foo();
console.profileEnd();
控制台会显示一张性能分析表,如下图。

标题栏提示,一共运行了12个函数,共耗时2.656毫秒。其中funcA()运行10次,耗时1.391毫秒,最短运行时间0.123毫秒,最长0.284毫秒,平均0.139毫秒;funcB()运行1次,耗时1.229ms毫秒。
除了使用console.profile()方法,firebug还提供了一个"概况"(Profiler)按钮。第一次点击该按钮,"性能分析" 开始,你可以对网页进行某种操作(比如ajax操作),然后第二次点击该按钮,"性能分析"结束,该操作引发的所有运算就会进行性能分析。

十、属性菜单
控制台面板的名称后面,有一个倒三角,点击后会显示属性菜单。

默认情况下,控制台只显示Javascript错误。如果选中Javascript警告、CSS错误、XML错误都送上,则相关的提示信息都会显示。
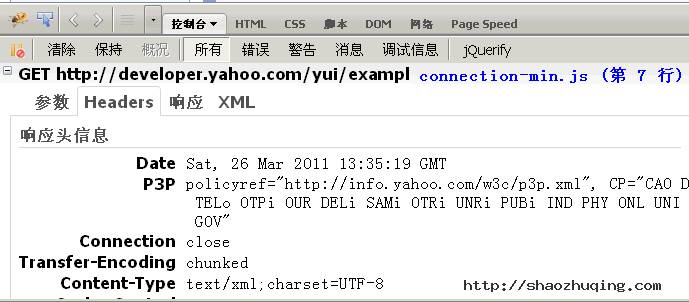
这里比较有用的是"显示XMLHttpRequests",也就是显示ajax请求。选中以后,网页的所有ajax请求,都会在控制台面板显示出来。
比如,点击一个YUI示例,控制台就会告诉我们,它用ajax方式发出了一个GET请求,http请求和响应的头信息和内容主体,也都可以看到。
linux awk命令详解
简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
调用awk
有三种方式调用awk

1.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 2.shell脚本方式 将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。 相当于shell脚本首行的:#!/bin/sh 可以换成:#!/bin/awk 3.将所有的awk命令插入一个单独文件,然后调用: awk -f awk-script-file input-file(s) 其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
本章重点介绍命令行方式。
入门实例
假设last -n 5的输出如下
[root@www ~]# last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
如果只是显示最近登录的5个帐号
#last -n 5 | awk '{print $1}'
root
root
root
dmtsai
root
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
如果只是显示/etc/passwd的账户
#cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
#cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
搜索/etc/passwd有root关键字的所有行
#awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
# awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
这里指定了action{print $7}
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符
此外,$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容:
#awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
print和printf
awk中同时提供了print和printf两种打印输出的函数。
其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
awk编程
变量和赋值
除了awk的内置变量,awk还可以自定义变量。
下面统计/etc/passwd的账户人数
awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
......
user count is 40
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。
这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0:
awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd
[start]user count is 0
root:x:0:0:root:/root:/bin/bash
...
[end]user count is 40
统计某个文件夹下的文件占用的字节数
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size}'
[end]size is 8657198
如果以M为单位显示:
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.25889 M
注意,统计不包括文件夹的子目录。
条件语句
awk中的条件语句是从C语言中借鉴来的,见如下声明方式:
if (expression) {
statement;
statement;
... ...
}
if (expression) {
statement;
} else {
statement2;
}
if (expression) {
statement1;
} else if (expression1) {
statement2;
} else {
statement3;
}
统计某个文件夹下的文件占用的字节数,过滤4096大小的文件(一般都是文件夹):
ls -l |awk 'BEGIN {size=0;print "[start]size is ", size} {if($5!=4096){size=size+$5;}} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.22339 M
循环语句
awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
数组
因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
显示/etc/passwd的账户
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
0 root
1 daemon
2 bin
3 sys
4 sync
5 games
......
这里使用for循环遍历数组
awk编程的内容极多,这里只罗列简单常用的用法,更多请参考 http://www.gnu.org/software/gawk/manual/gawk.html
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
