深入理解 http 反向代理(nginx)
反向代理(reverse proxy)
明白了直接访问, 明白了所谓的正向代理, 下面就可以来说说反向代理是怎么回事了.
反向代理与正向代理的一个很大区别就是, 它不需要客户端(浏览器)去做什么配置, 并没有什么配置代理服务器的操作.
如果说正向代理是主动配置, 主动走代理, 那么反向代理则是"被代理", 从这点上看, 反向代理有时又称为"透明代理", 也即是浏览器都不知道自己被代理了, 浏览器以为发给它响应的就是最终的网页服务器, 其实不过是个"代理".
还是举购物的例子来比喻. 有时你在网上购物会看到有商家声称自己就是厂家, 东西都很便宜, 属于厂家直销, 于是你下单了. 过段时间, 你又发现有另一家店声称自己才是真正的厂家直销, 然后你仔细看了两家店铺的信息, 才发现前一个商家是假的, 它不是真的厂家.
但为啥这个假的厂家直销它还是这么便宜呢? 以至于价格跟真的厂家直销的没啥区别. 原因可能则是店家直接就是坐落在厂家旁边, 然后他可能与厂家有那么点关系, 认识里面一些人之类的, 这让他能以很便宜的价格从厂家拿到货, 又因为离得近, 几乎没有任何物流成本, 从某种层面看, 它声称厂家直销也不算怎么骗人. 当然严格来说, 它属于伪厂家直销, 他依然还是个代理商
它声称是李逵, 其实它是李鬼.
用一个图对比一下这两种情形:
")
那么这样的一种模式就有点 反向代理 的味道了, 你以为自己买到了直销, 其实你还是"被代理"了, 还是经过了中间商.
只是这个中间商对你来说不是那么明显, 甚至说对你是透明的, 把你蒙在了鼓里.
虽然都是"代理", 这跟线下店面购买还是很不同的, 在线下你去商店买时, 你很清楚自己经过了代理的中间商, 也即是商店本身, 但在远程线上这种声称自己是厂家直销的情形, 有时你还真不好判断自己是不是被代理了.
那么 http 的反向代理其实也是这样一个道理. 比如你访问我的网站 https://xiaogd.net, 然后你看下主页的请求里的服务器信息, 它告诉你响应这个主页请求的是一台 Nginx server, 如下图所示:

问题是 Nginx 是最终生成这个网页的 server 吗? 其实不是的! 如果你了解 Nginx, 就会知道它通常只是一个静态资源服务器, 而我的网站主页是一个动态生成的内容, 其实你要是认真看过我网站底部的一个声明, 如下图所示:
")
就会明白这个主页其实是 php 的一个叫 wordpress 的建站应用去生成的. 在我的云主机的内部, Nginx 其实是将主页的请求转发给一个所谓的 php-fpm 网关
这个 php-fpm 网关基本可以看作是个 php 的 web 服务器, 不过严格来说它用的协议不是 http, 而是一种内部简化的 fastcgi 协议.
如果你要较真的话, 这可以算是 反向代理 模式, 但整体不全是 http 反向代理, 但对外而言则确实是.
从它那里取得最终响应的内容, 并再次转发给浏览器, 整个情形见如下的示意图:
")
这是内部配置的一个情况:
location ~ .php$ {
root /ftp/wwwroot;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root/$fastcgi_script_name;
include fastcgi_params;
}
请求被转发到内部一个在 9000 端口上监听的 php 应用服务器.
从外部浏览器的角度看, 请求直接发给了 Nginx server, 响应也从 Nginx server 里回来了, 中间没有任何的(正向)代理. 至于说你内部请求又被怎么转发了, 显然浏览器是无从知道也不需要去知道的.
站在整个体系设计者的角度去看, 当然但很多请求 Nginx 其实是没有能力去响应的, 它只不过在内部把它代理给了另一个内部的 php 应用服务器, 内部的 php 应用服务器才是最终的响应生成者.
在整个体系里面, Nginx 的角色就是一个"反向代理"服务器, 浏览器被代理了, 但它无从知道自己是否被代理了, 这一切对它而言是透明的, 反正它自己是没有主动走(正向)代理的.
当然了, 你现在知道了我内部的配置, 如果直接访问 http://xiaogd.net:9000, 那就是真正的"直接访问"了, 那就绕过了 Nginx.
不过需要说明的一点是, 直接访问是访问不通的, 因为 9000 端口并没有对外放开. 但是在内部是可以访问到的, 比如这样尝试用 wget 去访问:
wget localhost:9000这样就是真正的"直接访问"了, 没有任何的代理, 既没有正向代理, 也没有反向代理.
需要说明的一点是, 用 wget 这样去获取响应还是会报错, 因为 wget 使用的是 http 协议, php 的 cgi 网关实际使用的是 fastcgi 协议, 是一个比 http 更为简化的协议, 作为内部通讯更加高效, 不过 wget 不支持这个协议, 但 Nginx 能理解这个协议, 整个过程是这样的:
browser -- [http] --> Nginx -- [fastcgi] --> php-fpm
严格来说, 不完全是 http 代理, 内部的反向代理实际用的是 fastcgi 网关协议, 不过这个原理还是一样的, 如果内部用一个比如 tomcat 来响应, 那么全程就都可以是 http 协议.
browser -- [http] --> Nginx -- [http] --> tomcat
而如果在内部发请求 80, 比如wget localhost那就还是被反向代理, 请求先到在 80 端口监听的 Nginx, Nginx 再转给 php-fpm.
另: 关于端口及缺省端口相关知识, 可以参考这篇深入理解端口.
为什么要使用反向代理?
那么到了这一步我们又面临一个新的问题, 那就是为啥要整这个反向代理呢? 类似于碰到正向代理时的诘问那样, 直接访问不香吗? 为啥还要走这个反向代理? 关于正向代理前面已经解释了一些原因, 而反向代理的出现, 正像这个世界上没有无缘无故的爱与恨一样, 自然也有它存在的原因.
一个很直接的原因就是利用反向代理可以作为内部 负载均衡(load balance) 的手段.
举个例子来说, 假如我现在开发了一个 java web 的应用作为我的网站后台, 我直接部署它到 tomcat 服务器上, 让 tomcat 监听 80 端口, 直接对外服务. 一开始访问量也不大, 所以这样也是没有问题的, 如下图所示:
")
注: 因为 http 协议的缺省端口就是 80, 所以用户输入地址时可以省略这个端口号, 也即只需这样: http://xiaogd.net, 而不是繁琐的像这样: http://xiaogd.net:80, 关于缺省端口的话题, 还是可以参考前面所提的 深入理解端口.
但过一段时间之后, 访问量可能上来了, 一个 tomcat 进程处理不过来, 那怎么办呢? 于是我打算再起一个新的 tomcat 进程, 但这样就面临一个问题, 只有一个 80 端口, 它已经被第一个 tomcat 进程占用, 如果还要再起另外一个, 则只能选用其它的端口, 比如 8080.
当使用另外一个端口时, 确实可以启动两个 tomcat 的进程, 但用户想访问到第二个 tomcat 进程的服务, 却要这样去访问: http://xiaogd.net:8080. 显然, 这样的方案是有问题的, 用户根本不知道 8080 端口上服务的存在, 就算你有办法告诉用户, 用户也可能不太理解, 用户同时也很怕麻烦的, 为啥要我输入一个冒号加 8080 呢?
此外, 就算有些用户愿意如你所说转向访问 8080 端口, 你还是不能很好的控制把访问量平均地分配在两个 tomcat 上, 毕竟这是用户随机决定的, 也许很多用户又突然涌过来了 8080 端口的应用上, 造成了这边的拥挤.
又或者只有很少的用户愿意听从你的劝告转到新的 8080 端口上, 访问还是集中在旧的 80 端口上的, 这样旧的应用上响应还是很缓慢, 而新的应用却因为没几个用户访问而显得空闲, 没有得到充分的使用.
那么, 在这种情况下, 反向代理的好处就体现出来了, 具体的操作是这样的, 让 Nginx 作为一个前置的反向代理, 监听在 80 端口上; 而第一个 tomcat 则躲到幕后, 同时它也不再监听 80 端口(需要让给 Nginx), 而改为监听一个其它没有被使用的端口, 比如 8081, 然后让 Nginx 转发请求给它处理.
当然了, 如果只有一个 tomcat, 配置大概是这样的:
location / {
proxy_pass http://127.0.0.1:8080;
}
请求处理的流程是这样的:
请求: browser -- [http] --> Nginx -- [http] --> tomcat
响应: browser自然, 这种情形下反向代理似乎不太必要, 还加多了一个环节, 响应速度反而慢了.
但如果有两个 tomcat, 情况就不一样了, 此时就可以在 Nginx 这个反向代理的层面, 启用负载均衡的策略, 大概的配置如下:
http { upstream myapp1 { server 127.0.0.1:8080; server 127.0.0.1:8081; } server { listen 80; location / { proxy_pass http://myapp1; } } }此时, 如果同时涌入了很多请求, Nginx 会把一半的请求交给 8080 端口上的 tomcat, 另一半的请求交给 8081 端口上的 tomcat, 如下图所示:
对外来看, 所有请求还是 Nginx 来处理, 用户不需要去做选择, 也不需要知道什么 8080, 8081 端口上应用的存在, 他们还是继续访问原来的网址 http://xiaogd.net 即可, 无需做任何改变.
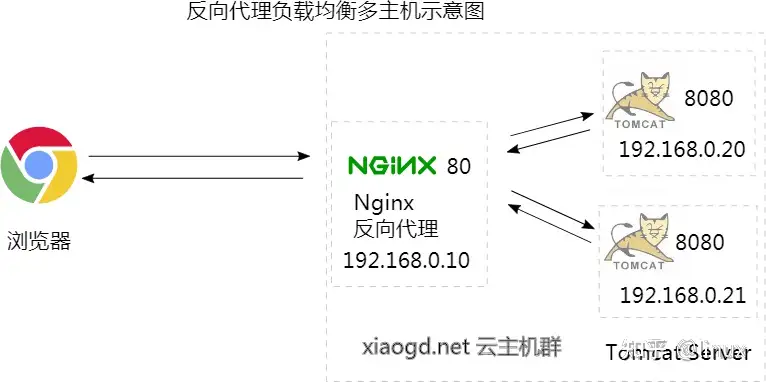
如果你在云上有好几台主机, 甚至还可以将其组成一个内网, 然后将 tomcat 部署在不同的主机上. 比如有三台主机的话, 一台运行 Nginx 监听 80 端口, 其余两台运行 tomcat, 分别监听 8080 和 8081 端口, 同时接受并处理 Nginx 反向代理过来的请求, 如下图所示:
如果两台 tomcat 主机的配置不同, 比如一台的性能更强劲些, 还可以调整负载的比例(即权重, weight), 让性能更强的一台承担更多的请求:
http { upstream myapp1 { server 192.168.0.20:8080 weight=3; server 192.168.0.21:8080 weight=2; } server { listen 80; location / { proxy_pass http://myapp1; } } }如上配置 3:2 的权重比, 让其中一台承担 60% 的请求, 而另一台性能较差的则承担 40%, 也即每 5 个请求, 3 个会被转到 ip 为 20 的主机上, 2 个会转到 ip 为 21 的主机上.
自然, 有人可能还会有疑问, 所有请求都还是要经过 Nginx, 它能处理得过来吗? 答案是可以的, 因为它的功能仅仅是转发, 这就有点像美团外卖, 虽然它每天接受成千上万的人的点餐, 但它自己不需要去买菜, 洗菜, 切菜, 炒菜等, 它仅仅需要把订单交给饭店餐馆, 然后把它们做好的饭菜配送出去, 也即那些耗时的做饭过程都交给了饭店餐馆处理.
在这种反向代理的模式中, 同样的, 生成网页这个重任交到了隐藏在背后的 tomcat, 生成一个复杂的动态网页可能需要经过一些复杂的计算, 要查询数据库, 要拼凑各个页面组件, 可能会比较耗时, 但这些请求被两个 tomcat 应用并发地处理了, 因此响应的速度还是得到了保证, 而这些就是反向代理能给我们带来的好处.
总结
至此, 关于直接访问, (正向)代理以及反向代理就介绍完了, 最后总结下三种情形及与购物例子的比喻.
在直接访问的情形中, 浏览器直接访问了最终生成响应的服务器, 类似我们以厂家直销的方式从厂商购物, 如下图所示:
在(正向)代理的情形中, 浏览器主动访问代理服务器, 通过它间接获取最终响应, 类似我们从商店购物, 而商店的物品又是从厂家购来的, 如下图所示:
在反向代理的情形中, 从浏览器的角度看还是类似于直接访问, 但它的请求在服务端被透明的代理了. 类似于我们在网上从一个声称是厂家直销的"伪厂家"那里购物, 这个伪厂家实际还是把我们的订单转给了真正的厂家, 并从中拿了货给我们, 只是我们无从知道这一切幕后的交易, 如下图所示:
在一个复杂的网络中, 浏览器的请求还可能先被正向代理了, 然后又被反向代理了, 如下图所示::
关于 http 正向代理和反向代理就讲到这里.
")
")
")
")
")
HTTP协议中的短轮询、长轮询、长连接和短连接
引言
最近刚到公司不到一个月,正处于熟悉项目和源码的阶段,因此最近经常会看一些源码。在研究一个项目的时候,源码里面用到了HTTP的长轮询。由于之前没太接触过,因此LZ便趁着这个机会,好好了解了一下HTTP的长长短短。
了解的方式主要都是LZ在网络上获取的,这里只是谈一下LZ对于这四种叫法最直观的理解。如果你之前不懂的话,可以帮你普及一下,如果你之前就懂得话,可以互相对照一下。
以前的误解
很久之前LZ就听说过长连接的说法,而且还知道HTTP1.0协议不支持长连接,从HTTP1.1协议以后,连接默认都是长连接。但LZ终究觉得对于长连接一直懵懵懂懂的,有种抓不到关键点的感觉。
今天LZ通过一番研究,终于明白了这其中的奥秘。而之前,LZ也看过长连接相关的内容,但一直都是云里雾里的。这次之所以能在这么短的时间里搞清楚,和LZ自己技术的沉淀密不可分。因此,这里LZ借着这个机会,再次强调一下,千万不要试图去研究你研究了很久都整不明白的东西,或许是你的层次不到,也或许是你从未在实际的应用场景接触过,这种情况下你去研究,只会事倍功半,徒劳一番罢了。
回到正题,既然说是误解,那么LZ的误解到底是什么?
那就是LZ一直认为,HTTP连接分为长连接和短连接,而我们现在常用的都是HTTP1.1,因此我们用的都是长连接。
这句话其实只对了一半,我们现如今的HTTP协议,大部分都是1.1的,因此我们平时用的基本上都是长连接。但是前半句是不对的,HTTP协议根本没有长短连接这一说,也正因为误解了这个,导致LZ对于长连接一直不明不白,始终不得其要领,具体下面一段会说到。
网络上很多文章都是误人子弟,根本没有说明白这个概念。这里LZ要强调一下,HTTP协议是基于请求/响应模式的,因此只要服务端给了响应,本次HTTP连接就结束了,或者更准确的说,是本次HTTP请求就结束了,根本没有长连接这一说。那么自然也就没有短连接这一说了。
之所以网络上说HTTP分为长连接和短连接,其实本质上是说的TCP连接。TCP连接是一个双向的通道,它是可以保持一段时间不关闭的,因此TCP连接才有真正的长连接和短连接这一说。
其实知道了以后,会觉得这很好理解。HTTP协议说到底是应用层的协议,而TCP才是真正的传输层协议,只有负责传输的这一层才需要建立连接。
一个形象的例子就是,拿你在网上购物来说,HTTP协议是指的那个快递单,你寄件的时候填的单子就像是发了一个HTTP请求,等货物运到地方了,快递员会根据你发的请求把货物送给相应的收货人。而TCP协议就是中间运货的那个大货车,也可能是火车或者飞机,但不管是什么,它是负责运输的,因此必须要有路,不管是地上还是天上。那么这个路就是所谓的TCP连接,也就是一个双向的数据通道。
因此,LZ现在甚至觉得,“HTTP连接”这个词就不应该出现,它只是一个应用层的协议,根本就没有所谓的连接这一说,就像FTP也是应用层的协议,但是你有听说过FTP连接吗?(恩,好像是听过,-_-,但你现在知道了,其实所谓的FTP连接,严格来说,依旧是TCP连接)
实际上,说HTTP请求和HTTP响应会更准确一些,而HTTP请求和HTTP响应,都是通过TCP连接这个通道来回传输的。
不管怎么说,一定要务必记住,长连接是指的TCP连接,而不是HTTP连接。
一个疑问
之前LZ一直对一件事有些模糊不清,首先是怎么样就算是把HTTP变成长连接了,是不是只要设置Connection为keep-alive就算是了?
如果是的话,那都说HTTP1.1默认是长连接,而观察我们平时开发的Web应用的HTTP头部,Connection也确实是keep-alive,那就是说我们大部分都是用的长连接,但是长连接不是一般用于交互比较频繁的应用吗?像我们这种普通的Web应用,比如博客园这种,或者我的个人博客这种,长连接有什么用?
如果有用那用处到底是什么,我们又不是客户端与服务器交互频繁的那种应用(毕竟你打开网页肯定要半天才打开另外一个吧),如果没用的话,那到底应不应该把Connection为keep-alive这个header值给改掉,从而改成短连接?
这个疑问,在LZ明白了长连接其实是指的TCP连接之后,基本上就明白了。而这个疑问,也正是LZ在“以前的误解”那一段所提到的,那个因为误解导致LZ一直搞不明白的问题。
为什么解决了上面那个误解之后,前面所说的这些疑问LZ都明白了?
因为长连接意味着连接会被复用,毕竟一直保持着连接不就是为了重复使用嘛。但如果长连接是指的HTTP的话,那就是说HTTP连接可以被重复利用,这个话听起来就感觉很别扭。之所以觉得别扭,其实就是LZ的一种直觉,没什么理论依据。而这种别扭的根源就在于,之前一直没有融会贯通的感觉,所以总感觉缺少点什么。不过这点疑惑,并没有影响LZ的工作,因此也就没深究过。
但现在好了,明白了长连接实际上是指的TCP连接,LZ瞬间自己就想明白了上面的那些问题。
第一个问题是,是不是只要设置Connection为keep-alive就算是长连接了?
当然是的,但要服务器和客户端都设置。
第二个问题是,我们平时用的是不是长连接?
这个也毫无疑问,当然是的。(现在用的基本上都是HTTP1.1协议,你观察一下就会发现,基本上Connection都是keep-alive。而且HTTP协议文档上也提到了,HTTP1.1默认是长连接,也就是默认Connection的值就是keep-alive)
第三个问题,也是LZ之前最想不明白的问题,那就是我们这种普通的Web应用(比如博客园,我的个人博客这种)用长连接有啥好处?需不需要关掉长连接而使用短连接?
这个问题LZ现在终于明白了,问题的答案是好处还是有的。
好处是什么?
首先,刚才已经说了,长连接是为了复用,这个在之前LZ就明白。那既然长连接是指的TCP连接,也就是说复用的是TCP连接。那这就很好解释了,也就是说,长连接情况下,多个HTTP请求可以复用同一个TCP连接,这就节省了很多TCP连接建立和断开的消耗。
比如你请求了博客园的一个网页,这个网页里肯定还包含了CSS、JS等等一系列资源,如果你是短连接(也就是每次都要重新建立TCP连接)的话,那你每打开一个网页,基本要建立几个甚至几十个TCP连接,这浪费了多少资源就不用LZ去说了吧。
但如果是长连接的话,那么这么多次HTTP请求(这些请求包括请求网页内容,CSS文件,JS文件,图片等等),其实使用的都是一个TCP连接,很显然是可以节省很多消耗的。
这样一解释,就很明白了,不知道大家看了这些解释感觉如何,反正LZ在自己想明白以后,有种豁然开朗的感觉。
另外,最后关于长连接还要多提一句,那就是,长连接并不是永久连接的。如果一段时间内(具体的时间长短,是可以在header当中进行设置的,也就是所谓的超时时间),这个连接没有HTTP请求发出的话,那么这个长连接就会被断掉。
这一点其实很容易理解,否则的话,TCP连接将会越来越多,直到把服务器的TCP连接数量撑爆到上限为止。现在想想,对于服务器来说,服务器里的这些个长连接其实很有数据库连接池的味道,大家都是为了节省连接重复利用嘛,对不对?
长轮询和短轮询
前面基本上LZ已经把长短连接说的差不多了,接下来说说长短轮询,今天也正是为了研究长短轮询,LZ才顺便研究了下长短连接这回事。
短轮询相信大家都不难理解,比如你现在要做一个电商中商品详情的页面,这个详情界面中有一个字段是库存量(相信这个大家都不陌生,随便打开淘宝或者京东都能找到这种页面)。而这个库存量需要实时的变化,保持和服务器里实际的库存一致。
这个时候,你会怎么做?
最简单的一种方式,就是你用JS写个死循环,不停的去请求服务器中的库存量是多少,然后刷新到这个页面当中,这其实就是所谓的短轮询。
这种方式有明显的坏处,那就是你很浪费服务器和客户端的资源。客户端还好点,现在PC机配置高了,你不停的请求还不至于把用户的电脑整死,但是服务器就很蛋疼了。如果有1000个人停留在某个商品详情页面,那就是说会有1000个客户端不停的去请求服务器获取库存量,这显然是不合理的。
那怎么办呢?
长轮询这个时候就出现了,其实长轮询和短轮询最大的区别是,短轮询去服务端查询的时候,不管库存量有没有变化,服务器就立即返回结果了。而长轮询则不是,在长轮询中,服务器如果检测到库存量没有变化的话,将会把当前请求挂起一段时间(这个时间也叫作超时时间,一般是几十秒)。在这个时间里,服务器会去检测库存量有没有变化,检测到变化就立即返回,否则就一直等到超时为止。
而对于客户端来说,不管是长轮询还是短轮询,客户端的动作都是一样的,就是不停的去请求,不同的是服务端,短轮询情况下服务端每次请求不管有没有变化都会立即返回结果,而长轮询情况下,如果有变化才会立即返回结果,而没有变化的话,则不会再立即给客户端返回结果,直到超时为止。
这样一来,客户端的请求次数将会大量减少(这也就意味着节省了网络流量,毕竟每次发请求,都会占用客户端的上传流量和服务端的下载流量),而且也解决了服务端一直疲于接受请求的窘境。
但是长轮询也是有坏处的,因为把请求挂起同样会导致资源的浪费,假设还是1000个人停留在某个商品详情页面,那就很有可能服务器这边挂着1000个线程,在不停检测库存量,这依然是有问题的。
因此,从这里可以看出,不管是长轮询还是短轮询,都不太适用于客户端数量太多的情况,因为每个服务器所能承载的TCP连接数是有上限的,这种轮询很容易把连接数顶满。之所以举这个例子,只是因为大家肯定都会网购,所以这个例子比较通俗一点。
哪怕轮询解决不了获取库存这个问题,但只要大家明白了长短轮询的区别,这就足够了。实际上,据LZ自己平日里购物的观察,那个库存量应该是不会变的,这个例子纯属LZ个人的意淫,-_-。
长短轮询和长短连接的区别
这里简单说一下它们的区别,LZ这里只说最根本的区别。
第一个区别是决定的方式,一个TCP连接是否为长连接,是通过设置HTTP的Connection Header来决定的,而且是需要两边都设置才有效。而一种轮询方式是否为长轮询,是根据服务端的处理方式来决定的,与客户端没有关系。
第二个区别就是实现的方式,连接的长短是通过协议来规定和实现的。而轮询的长短,是服务器通过编程的方式手动挂起请求来实现的。
结语
好了,本文就到此为止吧。LZ写这篇文章,主要也是为了避免自己遗忘。说实话,写到最后了,LZ感觉对于它们的理解又进了一步,这就是写博客的好处吧。
初识P3P

第一个阻止(阻止没有紧凑隐私策略的第三方cookie),即为ie7发现存在没有紧凑隐私策略的第三方cookie时就将这个cookie在http的request中删除然后进行http请求(get或者post),“没有紧凑隐私策略”是指没有被P3P声明;
第二个阻止(阻止保存...),即不保存这样的第三方cookie,因为有些cookie是有有效期的;
第一个限制(限制保存...),即不保存这样的第一方cookie。

支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
