Redis 数据类型详解适用场景场合
1. MySql+Memcached架构的问题
实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题:
1.MySQL需要不断进行拆库拆表,Memcached也需不断跟着扩容,扩容和维护工作占据大量开发时间。
2.Memcached与MySQL数据库数据一致性问题。
3.Memcached数据命中率低或down机,大量访问直接穿透到DB,MySQL无法支撑。
4.跨机房cache同步问题。
众多NoSQL百花齐放,如何选择
最近几年,业界不断涌现出很多各种各样的NoSQL产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,是我们需要深入研究和思考的问题,实际归根结底最重要的是了解这些产品的定位,并且了解到每款产品的tradeoffs,在实际应用中做到扬长避短,总体上这些NoSQL主要用于解决以下几种问题
1.少量数据存储,高速读写访问。此类产品通过数据全部in-momery 的方式来保证高速访问,同时提供数据落地的功能,实际这正是Redis最主要的适用场景。
2.海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加/删除。
3.这方面最具代表性的是dynamo和bigtable 2篇论文所阐述的思路。前者是一个完全无中心的设计,节点之间通过gossip方式传递集群信息,数据保证最终一致性,后者是一个中心化的方案设计,通过类似一个分布式锁服务来保证强一致性,数据写入先写内存和redo log,然后定期compat归并到磁盘上,将随机写优化为顺序写,提高写入性能。
4.Schema free,auto-sharding等。比如目前常见的一些文档数据库都是支持schema-free的,直接存储json格式数据,并且支持auto-sharding等功能,比如mongodb。
面对这些不同类型的NoSQL产品,我们需要根据我们的业务场景选择最合适的产品。
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
2. Redis常用数据类型
Redis最为常用的数据类型主要有以下:
- String
- Hash
- List
- Set
- Sorted set
- pub/sub
- Transactions
在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同数据类型的:
首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:
type代表一个value对象具体是何种数据类型,
encoding是不同数据类型在redis内部的存储方式,
比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
这里需要特殊说明一下vm字段,只有打开了Redis的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的,该功能会在后面具体描述。通过上图我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用,我们随后会具体讨论。
3. 各种数据类型应用和实现方式
下面我们先来逐一的分析下这7种数据类型的使用和内部实现方式:
- String:
Strings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字.常用命令: set,get,decr,incr,mget 等。
应用场景:String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类.即可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
-
- 获取字符串长度
- 往字符串append内容
- 设置和获取字符串的某一段内容
- 设置及获取字符串的某一位(bit)
- 批量设置一系列字符串的内容
实现方式:String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
- Hash
常用命令:hget,hset,hgetall 等。
应用场景:在Memcached中,我们经常将一些结构化的信息打包成HashMap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口,如下图:
也就是说,Key仍然是用户ID, value是一个Map,这个Map的key是成员的属性名,value是属性值,这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
实现方式:
上面已经说到Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。

- List
常用命令:lpush,rpush,lpop,rpop,lrange等。
应用场景:
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
Lists 就是链表,相信略有数据结构知识的人都应该能理解其结构。使用Lists结构,我们可以轻松地实现最新消息排行等功能。Lists的另一个应用就是消息队列,
可以利用Lists的PUSH操作,将任务存在Lists中,然后工作线程再用POP操作将任务取出进行执行。Redis还提供了操作Lists中某一段的api,你可以直接查询,删除Lists中某一段的元素。实现方式:
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
- Set
常用命令:
sadd,spop,smembers,sunion 等。
应用场景:
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Sets 集合的概念就是一堆不重复值的组合。利用Redis提供的Sets数据结构,可以存储一些集合性的数据,比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
实现方式:
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
- Sorted Set
常用命令:
zadd,zrange,zrem,zcard等
使用场景:
Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
另外还可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
- Pub/Sub
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
- Transactions
谁说NoSQL都不支持事务,虽然Redis的Transactions提供的并不是严格的ACID的事务(比如一串用EXEC提交执行的命令,在执行中服务器宕机,那么会有一部分命令执行了,剩下的没执行),但是这个Transactions还是提供了基本的命令打包执行的功能(在服务器不出问题的情况下,可以保证一连串的命令是顺序在一起执行的,中间有会有其它客户端命令插进来执行)。Redis还提供了一个Watch功能,你可以对一个key进行Watch,然后再执行Transactions,在这过程中,如果这个Watched的值进行了修改,那么这个Transactions会发现并拒绝执行。
4. Redis实际应用场景
Redis在很多方面与其他数据库解决方案不同:它使用内存提供主存储支持,而仅使用硬盘做持久性的存储;它的数据模型非常独特,用的是单线程。另一个大区别在于,你可以在开发环境中使用Redis的功能,但却不需要转到Redis。
转向Redis当然也是可取的,许多开发者从一开始就把Redis作为首选数据库;但设想如果你的开发环境已经搭建好,应用已经在上面运行了,那么更换数据库框架显然不那么容易。另外在一些需要大容量数据集的应用,Redis也并不适合,因为它的数据集不会超过系统可用的内存。所以如果你有大数据应用,而且主要是读取访问模式,那么Redis并不是正确的选择。
然而我喜欢Redis的一点就是你可以把它融入到你的系统中来,这就能够解决很多问题,比如那些你现有的数据库处理起来感到缓慢的任务。这些你就可以通过Redis来进行优化,或者为应用创建些新的功能。在本文中,我就想探讨一些怎样将Redis加入到现有的环境中,并利用它的原语命令等功能来解决 传统环境中碰到的一些常见问题。在这些例子中,Redis都不是作为首选数据库。
1、显示最新的项目列表
下面这个语句常用来显示最新项目,随着数据多了,查询毫无疑问会越来越慢。
- SELECT * FROM foo WHERE ... ORDER BY time DESC LIMIT 10
在Web应用中,“列出最新的回复”之类的查询非常普遍,这通常会带来可扩展性问题。这令人沮丧,因为项目本来就是按这个顺序被创建的,但要输出这个顺序却不得不进行排序操作。
类似的问题就可以用Redis来解决。比如说,我们的一个Web应用想要列出用户贴出的最新20条评论。在最新的评论边上我们有一个“显示全部”的链接,点击后就可以获得更多的评论。
我们假设数据库中的每条评论都有一个唯一的递增的ID字段。
我们可以使用分页来制作主页和评论页,使用Redis的模板,每次新评论发表时,我们会将它的ID添加到一个Redis列表:
- LPUSH latest.comments <ID>
我们将列表裁剪为指定长度,因此Redis只需要保存最新的5000条评论:
LTRIM latest.comments 0 5000
每次我们需要获取最新评论的项目范围时,我们调用一个函数来完成(使用伪代码):
- FUNCTION get_latest_comments(start, num_items):
- id_list = redis.lrange("latest.comments",start,start+num_items - 1)
- IF id_list.length < num_items
- id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
- END
- RETURN id_list
- END
这里我们做的很简单。在Redis中我们的最新ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
2、删除与过滤
我们可以使用LREM来删除评论。如果删除操作非常少,另一个选择是直接跳过评论条目的入口,报告说该评论已经不存在。
有些时候你想要给不同的列表附加上不同的过滤器。如果过滤器的数量受到限制,你可以简单的为每个不同的过滤器使用不同的Redis列表。毕竟每个列表只有5000条项目,但Redis却能够使用非常少的内存来处理几百万条项目。
3、排行榜相关
另一个很普遍的需求是各种数据库的数据并非存储在内存中,因此在按得分排序以及实时更新这些几乎每秒钟都需要更新的功能上数据库的性能不够理想。
典型的比如那些在线游戏的排行榜,比如一个Facebook的游戏,根据得分你通常想要:
- 列出前100名高分选手
- 列出某用户当前的全球排名
这些操作对于Redis来说小菜一碟,即使你有几百万个用户,每分钟都会有几百万个新的得分。
模式是这样的,每次获得新得分时,我们用这样的代码:
ZADD leaderboard <score> <username>
你可能用userID来取代username,这取决于你是怎么设计的。
得到前100名高分用户很简单:ZREVRANGE leaderboard 0 99。
用户的全球排名也相似,只需要:ZRANK leaderboard <username>。
4、按照用户投票和时间排序
排行榜的一种常见变体模式就像Reddit或Hacker News用的那样,新闻按照类似下面的公式根据得分来排序:
score = points / time^alpha
因此用户的投票会相应的把新闻挖出来,但时间会按照一定的指数将新闻埋下去。下面是我们的模式,当然算法由你决定。
模式是这样的,开始时先观察那些可能是最新的项目,例如首页上的1000条新闻都是候选者,因此我们先忽视掉其他的,这实现起来很简单。
每次新的新闻贴上来后,我们将ID添加到列表中,使用LPUSH + LTRIM,确保只取出最新的1000条项目。
有一项后台任务获取这个列表,并且持续的计算这1000条新闻中每条新闻的最终得分。计算结果由ZADD命令按照新的顺序填充生成列表,老新闻则被清除。这里的关键思路是排序工作是由后台任务来完成的。
5、处理过期项目
另一种常用的项目排序是按照时间排序。我们使用unix时间作为得分即可。
模式如下:
- 每次有新项目添加到我们的非Redis数据库时,我们把它加入到排序集合中。这时我们用的是时间属性,current_time和time_to_live。
- 另一项后台任务使用ZRANGE…SCORES查询排序集合,取出最新的10个项目。如果发现unix时间已经过期,则在数据库中删除条目。
6、计数
Redis是一个很好的计数器,这要感谢INCRBY和其他相似命令。
我相信你曾许多次想要给数据库加上新的计数器,用来获取统计或显示新信息,但是最后却由于写入敏感而不得不放弃它们。
好了,现在使用Redis就不需要再担心了。有了原子递增(atomic increment),你可以放心的加上各种计数,用GETSET重置,或者是让它们过期。
例如这样操作:
INCR user:<id> EXPIRE
user:<id> 60
你可以计算出最近用户在页面间停顿不超过60秒的页面浏览量,当计数达到比如20时,就可以显示出某些条幅提示,或是其它你想显示的东西。
7、特定时间内的特定项目
另一项对于其他数据库很难,但Redis做起来却轻而易举的事就是统计在某段特点时间里有多少特定用户访问了某个特定资源。比如我想要知道某些特定的注册用户或IP地址,他们到底有多少访问了某篇文章。
每次我获得一次新的页面浏览时我只需要这样做:
SADD page:day1:<page_id> <user_id>
当然你可能想用unix时间替换day1,比如time()-(time()%3600*24)等等。
想知道特定用户的数量吗?只需要使用SCARD page:day1:<page_id>。
需要测试某个特定用户是否访问了这个页面?SISMEMBER page:day1:<page_id>。
8、实时分析正在发生的情况,用于数据统计与防止垃圾邮件等
我们只做了几个例子,但如果你研究Redis的命令集,并且组合一下,就能获得大量的实时分析方法,有效而且非常省力。使用Redis原语命令,更容易实施垃圾邮件过滤系统或其他实时跟踪系统。
9、Pub/Sub
Redis的Pub/Sub非常非常简单,运行稳定并且快速。支持模式匹配,能够实时订阅与取消频道。
10、队列
你应该已经注意到像list push和list pop这样的Redis命令能够很方便的执行队列操作了,但能做的可不止这些:比如Redis还有list pop的变体命令,能够在列表为空时阻塞队列。
现代的互联网应用大量地使用了消息队列(Messaging)。消息队列不仅被用于系统内部组件之间的通信,同时也被用于系统跟其它服务之间的交互。消息队列的使用可以增加系统的可扩展性、灵活性和用户体验。非基于消息队列的系统,其运行速度取决于系统中最慢的组件的速度(注:短板效应)。而基于消息队列可以将系统中各组件解除耦合,这样系统就不再受最慢组件的束缚,各组件可以异步运行从而得以更快的速度完成各自的工作。
此外,当服务器处在高并发操作的时候,比如频繁地写入日志文件。可以利用消息队列实现异步处理。从而实现高性能的并发操作。
11、缓存
Redis的缓存部分值得写一篇新文章,我这里只是简单的说一下。Redis能够替代memcached,让你的缓存从只能存储数据变得能够更新数据,因此你不再需要每次都重新生成数据了。
Redis内存数据库操作命令详解
默认无权限控制:
远程服务连接:
$ redis-cli -h 127.0.0.1 -p 6379
windows下 :redis-cli.exe -h 127.0.0.1 -p 6379
redis 127.0.0.1:6379>
远程服务停止:
$ redis-cli -h 172.168.10.254 -p6379 shutdown
2) 有权限控制时(加上-a 密码):
redis-cli -h 127.0.0.1 -p 6379 -a 123456
除了在登录时通过 -a 参数制定密码外,还可以登录时不指定密码,而在执行操作前进行认证。

Redis默认端口号为127.0.0.1,端口号默认为:6379。
此处本机访问远程IP为132.1.114.44的计算机,则首先要在已经安装了Redis的远程计算机上打开其服务器,redis.server.exe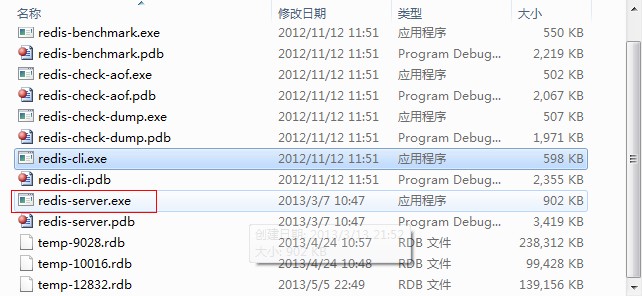
接下来在本机运行redis.cli.exe,也可以通过命令行实现:输入-h 远程计算机IP -p 6379即可连接:

OK了,接下来如果想用自己写的客户端什么的连接远程Redis数据库也只需要输入远程计算机的IP就可以了~
Redis系列-远程连接redis
用法:redis-cli [OPTIONS] [cmd [arg [arg ...]]]
-h <主机ip>,默认是127.0.0.1
-p <端口>,默认是6379
-a <密码>,如果redis加锁,需要传递密码
--help,显示帮助信息
通过对rendis-cli用法介绍,在101上连接103应该很简单:
[root@linuxidc001 ~]# redis-cli -h 192.168.1.103 -p 6379
redis 192.168.1.103:6379>
在101上对103设置个个string值 user.1.name=zhangsan
redis 192.168.1.103:6379> set user.1.name zhangsan
OK
看到ok,表明设置成功了。然后直接在103上登陆,看能不能获取到这个值。
redis 192.168.1.103:6379> keys *
redis 192.168.1.103:6379> select 1
1、连接操作相关的命令
- quit:关闭连接(connection)
- auth:简单密码认证
2、对value操作的命令
- exists(key):确认一个key是否存在
- del(key):删除一个key
- type(key):返回值的类型
- keys(pattern):返回满足给定pattern的所有key
- randomkey:随机返回key空间的一个key
- rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
- dbsize:返回当前数据库中key的数目
- expire:设定一个key的活动时间(s)
- ttl:获得一个key的活动时间
- select(index):按索引查询
- move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
- flushdb:删除当前选择数据库中的所有key
- flushall:删除所有数据库中的所有key
3、对String操作的命令
- set(key, value):给数据库中名称为key的string赋予值value
- get(key):返回数据库中名称为key的string的value
- getset(key, value):给名称为key的string赋予上一次的value
- mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
- setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
- setex(key, time, value):向库中添加string(名称为key,值为value)同时,设定过期时间time
- mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
- msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
- incr(key):名称为key的string增1操作
- incrby(key, integer):名称为key的string增加integer
- decr(key):名称为key的string减1操作
- decrby(key, integer):名称为key的string减少integer
- append(key, value):名称为key的string的值附加value
- substr(key, start, end):返回名称为key的string的value的子串
4、对List操作的命令
- rpush(key, value):在名称为key的list尾添加一个值为value的元素
- lpush(key, value):在名称为key的list头添加一个值为value的 元素
- llen(key):返回名称为key的list的长度
- lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
- ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
- lindex(key, index):返回名称为key的list中index位置的元素
- lset(key, index, value):给名称为key的list中index位置的元素赋值为value
- lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从 头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对 keyi 1开始的list执行pop操作。
- brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
- rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
- sadd(key, member):向名称为key的set中添加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
- sismember(key, member) :测试member是否是名称为key的set的元素
- sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
- zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
- zrem(key, member) :删除名称为key的zset中的元素member
- zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
- zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
- zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
- zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
- zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
- zunionstore / zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行 AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素 的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
- save:将数据同步保存到磁盘
- bgsave:将数据异步保存到磁盘
- lastsave:返回上次成功将数据保存到磁盘的Unix时戳
- shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
- info:提供服务器的信息和统计
- monitor:实时转储收到的请求
- slaveof:改变复制策略设置
- config:在运行时配置Redis服务器
【第三方工具】Gogs使用详解
https://gogs.io
Gogs使用介绍
Gogs是一款类似Github(国内有码市)的开源文件/代码管理系统(基于Git)
目前功能基本介绍
远程代码仓库管理
代码仓库权限分配、管理
团队管理
代码审查
(1)注册

(2)基本功能介绍
主面板说明

图中1表示自己个人账户下的仓库(所有权属于自己)
图中2表示自己参与的仓库(所有权不属于自己)
注意
自己个人账户下的仓库一般为自己创建,或者其他仓库所有者转让仓库。自己对该仓库具有全部权限(写入/删除文件、增加成员、删除成员、合并分之、审核分之)
新建仓库

在主面板中点击我的仓库右侧的” ”按钮后进入新建仓库页面,在此页面中我们需哟啊输入仓库的基本描述,并设置可见属性.
注意
在创建仓库按钮的上方有一个复选框“使用选定文件和模板初始化仓库”。
这里如果不选,则会生成一个空仓库,我们需要在本地生成一个仓库(或者原有仓库),然后将本地仓库的远程仓库地址设置成我们在Gogs中新建的仓库地址。
仓库使用基介绍

图中1仓库中的文件管理页面
图中2仓库的工单管理页面
图中3仓库的合并请求管理(代码审查、合并)
图中4查看代码的分支
图中5在浏览器中上传和下载文件(不依赖Git)
图中6当前仓库的远程地址(将其拷贝下来,将本地的对应仓库的origin地址设置)
图中7当前仓库的文件阅览
基于浏览器进行文件上传下载

可以直接在浏览器中进行文件上传

可以直接在浏览器查看对应文档,或者下载文档
(4)组织管理
Git魅力不仅仅体现在对代码的管理,还有有效的管理团队合作上
组织管理介绍
Gogs也专门提供了组织管理功能(组织可以代表一个公司,可以在组织下建立仓库、添加组织成员,然后通过创建和设置团队,将组织名下的仓库分别授权给不同的成员)

图中点击”我的组织”后面的“+”号可以新建组织

图中1显示当前组织下的仓库,点击创建新仓库可以添加新的组织
图中2显示当前组织中的成员,可以点击邀请其他人,添加新的成员
图中3显示当前组织下设置的团队(每个团对可以分别添加组织下的不同仓库和不同成员,并设置该团队权限(写入、阅读))

图中1显示该团队有4名成员
图中2显示该团队拥有当前组织的2个仓库的权限
图中3显示该团队对yo拥有的2个仓库具有读取和写入的权限
linux下详解ftp的常用功能
一、简介:
FTP(File Transfer Protocol, FTP)是TCP/IP网络上两台计算机传送文件的协议,FTP是在TCP/IP网络和INTERNET上最早使用的协议之一,它属于网络协议组的应用层。FTP客户机可以给服务器发出命令来下载文件,上载文件,创建或改变服务器上的目录。
 概述:
概述:
FTP是应用层的协议,它基于传输层,为用户服务,它们负责进行文件的传输。FTP是一个8位的客户端-服务器协议,能操作任何类型的文件而不需要进一步处理,就像MIME或Unencode一样。但是,FTP有着极高的延时,这意味着,从开始请求到第一次接收需求数据之间的时间会非常长,并且不时的必需执行一些冗长的登陆进程。

FTP服务一般运行在20和21两个端口。端口20用于在客户端和服务器之间传输数据流,而端口21用于传输控制流,并且是命令通向ftp服务器的进口。当数据通过数据流传输时,控制流处于空闲状态。而当控制流空闲很长时间后,客户端的防火墙会将其会话置为超时,这样当大量数据通过防火墙时,会产生一些问题。此时,虽然文件可以成功的传输,但因为控制会话会被防火墙断开,传输会产生一些错误。
主动和被动模式
FTP有两种使用模式:主动和被动。主动模式要求客户端和服务器端同时打开并且监听一个端口以建立连接。在这种情况下,客户端由于安装了防火墙会产生一些问题。所以,创立了被动模式。被动模式只要求服务器端产生一个监听相应端口的进程,这样就可以绕过客户端安装了防火墙的问题。
一个主动模式的FTP连接建立要遵循以下步骤:
1.客户端打开一个随机的端口(端口号大于1024,在这里,我们称它为x),同时一个FTP进程连接至服务器的21号命令端口。此时,源端口为随机端口x,在客户端,远程端口为21,在服务器。
2.客户端开始监听端口(x+1),同时向服务器发送一个端口命令(通过服务器的21号命令端口),此命令告诉服务器客户端正在监听的端口号并且已准备好从此端口接收数据。这个端口就是我们所知的数据端口。
3.服务器打开20号源端口并且建立和客户端数据端口的连接。此时,源端口为20,远程数据端口为(x+1)。
4.客户端通过本地的数据端口建立一个和服务器20号端口的连接,然后向服务器发送一个应答,告诉服务器它已经建立好了一个连接。
被动模式FTP:
为了解决服务器发起到客户的连接的问题,人们开发了一种不同的FTP连接方式。这就是所谓的被动方式,或者叫做PASV,当客户端通知服务器它处于被动模式时才启用。
在被动方式FTP中,命令连接和数据连接都由客户端发起,这样就可以解决从服务器到客户端的数据端口的入方向连接被防火墙过滤掉的问题。
当开启一个 FTP连接时,客户端打开两个任意的非特权本地端口(N > 1024和N+1)。第一个端口连接服务器的21端口,但与主动方式的FTP不同,客户端不会提交PORT命令并允许服务器来回连它的数据端口,而是提交 PASV命令。这样做的结果是服务器会开启一个任意的非特权端口(P > 1024),并发送PORT P命令给客户端。然后客户端发起从本地端口N+1到服务器的端口P的连接用来传送数据。
对于服务器端的防火墙来说,必须允许下面的通讯才能支持被动方式的FTP:
1. 从任何大于1024的端口到服务器的21端口 (客户端的初始化连接)
2. 服务器的21端口到任何大于1024的端口 (服务器响应到客户端的控制端口的连接)
3. 从任何大于1024端口到服务器的大于1024端口 (客户端初始化数据连接到服务器指定的任意端口)
4. 服务器的大于1024端口到远程的大于1024的端口(服务器发送ACK响应和数据到客户端的数据端口)
二、常用举例:
(注意:以下根据配置文档举出常见实例)
1.安装ftp
[root@gjp99 ~]# mkdir /mnt/cdrom
[root@gjp99 ~]# mount /dev/cdrom /mnt/cdrom
mount: block device /dev/cdrom is write-protected, mounting read-only
[root@gjp99 ~]# cd /mnt/cdrom/Server
[root@gjp99 Server]# ll vsftp*
-r--r--r-- 86 root root 143838 Jul 24 2009 vsftpd-2.0.5-16.el5.i386.rpm
[root@gjp99 Server]# rpm -qip vsftpd-2.0.5-16.el5.i386.rpm
warning: vsftpd-2.0.5-16.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Name : vsftpd Relocations: (not relocatable)
Version : 2.0.5 Vendor: Red Hat, Inc.
Release : 16.el5 Build Date: Wed 13 May 2009 08:47:15 PM CST
Install Date: (not installed) Build Host: hs20-bc1-2.build.redhat.com
Group : System Environment/Daemons Source RPM: vsftpd-2.0.5-16.el5.src.rpm
Size : 291690 License: GPL
Signature : DSA/SHA1, Fri 24 Jul 2009 08:34:20 PM CST, Key ID 5326810137017186
Packager : Red Hat, Inc. <http://bugzilla.redhat.com/bugzilla>
URL : http://vsftpd.beasts.org/
Summary : vsftpd - Very Secure Ftp Daemon
Description :
vsftpd is a Very Secure FTP daemon. It was written completely from
scratch.
[root@gjp99 Server]# rpm -ivh vsftpd-2.0.5-16.el5.i386.rpm
warning: vsftpd-2.0.5-16.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:vsftpd ################################# [100%]
[root@gjp99 Server]# rpm -ql vsftpd |less
/etc/pam.d/vsftpd 可插拔验证模块
/etc/rc.d/init.d/vsftpd 控制脚本
/etc/vsftpd/vsftpd.conf 主配置文档
/var/ftp 匿名账号的默认目录
/var/ftp/pub
[root@gjp99 Server]# man 5 vsftpd.conf 配置手册
[root@gjp99 Server]# service vsftpd start
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 Server]# chkconfig vsftpd on 开机启动
2. 关于账号的详细配置
2.1.匿名账号:
无需输入用户名和口令! 用户名:anonymous 密码:回车或者邮箱账号
支持匿名账号:配置文档
[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf
12 anonymous_enable=YES

2.2 本地账号:
有一定的危害性, 存放在:/etc/passwd /etc/shadow
14 # Uncomment this to allow local users to log in.
15 local_enable=YES
[root@gjp99 ~]# useradd gjp1
[root@gjp99 ~]# passwd gjp1
Changing password for user gjp1.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# cd /home/gjp1
[root@gjp99 gjp1]# ll
total 0
[root@gjp99 gjp1]# echo "welcome to access me " >>index.html
[root@gjp99 gjp1]# ll
total 4
-rw-r--r-- 1 root root 22 Aug 3 14:36 index.html


2.3 用户通过网络访问资源,
网络权限[ftp http] 本地权限[相当于windows下的ntfs]
网络权限与本地权限 如果相同 ,则相同,如果不同,则选择最小的!
![]() 网络权限可写
网络权限可写
如果本地权限也可写,则访问时可写!
[root@gjp99 home]# ll
total 4
drwx------ 3 gjp1 gjp1 4096 Aug 3 15:00 gjp1

还可以删除!
2.4 屏蔽某些权限
文件的权限默认是666,目录的权限默认是777
![]() 屏蔽掉某些权限: 所有者 用户 组
屏蔽掉某些权限: 所有者 用户 组
刚才上传的文件在666的基础上屏蔽022 则结果是644,查看
[root@gjp99 gjp1]# ll
total 108
-rw-r--r-- 1 root root 22 Aug 3 14:36 index.html
-rw-r--r-- 1 gjp1 gjp1 100864 Aug 3 15:00 ??目实训2.doc
网络权限已可写,为什么匿名账号还不能上传呀?

[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xr-x 2 root root 4096 May 13 2009 /var/ftp/pub
pub文件夹的所有者及组都是root,只有管理员可写,其他用户不可写,由于网络权限与本地权限不同,所以选择范围比较小的,
2.5 上传功能
![]()
[root@gjp99 home]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xr-x 2 root root 4096 May 13 2009 /var/ftp/pub
[root@gjp99 home]# chmod o+wt /var/ftp/pub 注意权限不仅加w,还加t
[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xrwt 2 root root 4096 May 13 2009 /var/ftp/pub 加t是仅有创建者能够删除文件!

改名,删除,创建文件夹都不可以了?
2.6 匿名用户可以创建文件夹
31 anon_mkdir_write_enable=YES 匿名用户创建文件夹
man 5 vsftpd.conf

32 anon_other_write_enable=YES 增加此行! //文件夹可以重命名,可以删除文件,上传

 文件却无法下载
文件却无法下载
2.7 文件如何下载?
[root@gjp99 home]# ll /var/ftp/pub //发现文件没有读取权限
[root@gjp99 home]# ll /var/ftp/pub
total 56
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw------- 1 ftp ftp 24774 Aug 3 15:55 tec.docx
任意一个文件给他个读取权限测试!
[root@gjp99 home]# chmod o+r /var/ftp/pub/tec.docx 给其他用户读权限
[root@gjp99 home]# ll /var/ftp/pub
total 56
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw----r-- 1 ftp ftp 24774 Aug 3 15:55 tec.docx
24 anon_umask=073 增加此行,问题简化
现在在上传点文件做测试!

[root@gjp99 home]# ll /var/ftp/pub 自动带了一个r(刚上传过来的文件)
total 256
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw----r-- 1 ftp ftp 165835 Aug 3 16:10 guo.docx
-rw----r-- 1 ftp ftp 32272 Aug 3 16:10 ji.docx
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw----r-- 1 ftp ftp 24774 Aug 3 15:55 tecnology.docx
2.8 如何备份交换机上的系统?


只支持命令行方式访问!

2.9 如何访问ftp服务器?



2.10 如何提示友好信息?
37 dirmessage_enable=YES
测试:友好提示!

2.11 如何开启ftp的日志功能?
日志文件默认目录 /var/log/却找不到!因为日志功能默认未打开!
打开日志功能:
![]()
![]()
![]()
service vsftpd restart
[root@gjp99 pub]# lftp 127.0.0.1 //无需验证就可以登录
lftp 127.0.0.1:~> dir
drwxr-xrwt 2 0 0 4096 Aug 03 08:38 pub
lftp 127.0.0.1:/> bye
[root@gjp99 pub]# ftp 127.0.0.1 // 需要用户验证
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password:
[root@gjp99 pub]# ll /var/log/vsftpd.log 该日志文件已存在!
-rw------- 1 root root 0 Aug 3 16:52 /var/log/vsftpd.log
2.12 如何让日志功能生效?
查手册 man 5 vsftpd.conf

56 log_ftp_protocol=YES 增加此行
57 #
58 # Switches between logging into vsftpd_log_file and xferlog_file files.
59 # NO writes to vsftpd_log_file, YES to xferlog_file
60 xferlog_std_format=NO 日志格式禁掉

[root@gjp99 pub]# tail -f /var/log/vsftpd.log //才能使用
Fri Aug 3 09:38:52 2012 [pid 21331] CONNECT: Client "192.168.10.2"
Fri Aug 3 09:38:52 2012 [pid 21331] FTP response: Client "192.168.10.2", "220 (vsFTPd 2.0.5)"
Fri Aug 3 09:38:55 2012 [pid 21331] FTP command: Client "192.168.10.2", "USER gjp1"
Fri Aug 3 09:38:55 2012 [pid 21331] [gjp1] FTP response: Client "192.168.10.2", "331 Please specify the password."
Fri Aug 3 09:38:57 2012 [pid 21331] [gjp1] FTP command: Client "192.168.10.2", "PASS <password>"
Fri Aug 3 09:38:57 2012 [pid 21330] [gjp1] OK LOGIN: Client "192.168.10.2"
Fri Aug 3 09:38:57 2012 [pid 21332] [gjp1] FTP response: Client "192.168.10.2", "230 Login successful."
2.13 拒绝服务攻击的一种方法:
拒绝某人利用某个邮箱账号作为匿名账号的密码进行登录
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password: 密码为: gjp@sina.com (即使不知道是否存在就能登录)
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,88,15)
150 Here comes the directory listing.
drwxr-xrwt 2 0 0 4096 Aug 03 09:11 pub
226 Directory send OK

[root@gjp99 pub]# echo gjp@sina.com >>/etc/vsftpd/banned_emails
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password:
530 Login incorrect.
Login failed.
[root@gjp99 ~]# useradd user1
[root@gjp99 ~]# passwd
Changing password for user root.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/home/user1"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,201,20)
150 Here comes the directory listing.
drwxr-xr-x 2 0 0 4096 Aug 03 04:05 bin
drwxr-xr-x 4 0 0 1024 Aug 02 13:26 boot
drwxr-xr-x 11 0 0 4260 Aug 03 05:42 dev
drwxr-xr-x 93 0 0 12288 Aug 03 10:06 etc
ftp> cd boot
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,89,202)
150 Here comes the directory listing.
-rw-r--r-- 1 0 0 954947 Aug 18 2009 System.map-2.6.18-164.el5
-rw-r--r-- 1 0 0 68663 Aug 18 2009 config-2.6.18-164.el5
drwxr-xr-x 2 0 0 1024 Aug 02 13:30 grub
-rw------- 1 0 0 2601298 Aug 02 13:26 initrd-2.6.18-164.el5.img
drwx------ 2 0 0 12288 Aug 02 21:18 lost+found
-rw-r--r-- 1 0 0 107405 Aug 18 2009 symvers-2.6.18-164.el5.gz
-rw-r--r-- 1 0 0 1855956 Aug 18 2009 vmlinuz-2.6.18-164.el5
226 Directory send OK.
可以查看许多内容,而且可以下载,没有安全性!
2.14 如何提高 ftp的安全性?
[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf

[root@gjp99 ~]# vim /etc/vsftpd/chroot_list
[root@gjp99 ~]# cat /etc/vsftpd/chroot_list
user1 //写入到该文件的账号都被禁锢了,没有写进来的可随意切换!
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# su – user1 该账号下存在属于自己的东西
[user1@gjp99 ~]$ ll
total 0
[user1@gjp99 ~]$ touch gjp.txt
[user1@gjp99 ~]$ vim gjp.txt
[user1@gjp99 ~]$ ll
total 4
-rw-rw-r-- 1 user1 user1 32 Sep 26 14:40 gjp.txt
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,119,140)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> bye
221 Goodbye.
[root@gjp99 ~]# useradd user2
[root@gjp99 ~]# passwd
Changing password for user root.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# su - user2
[user2@gjp99 ~]$ echo "user2" >> gjp2.txt
[user2@gjp99 ~]$ ll
total 4
-rw-rw-r-- 1 user2 user2 6 Sep 26 14:45 gjp2.txt
[user2@gjp99 ~]$ logout
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/home/user2"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,68,60)
150 Here comes the directory listing.
drwxr-xr-x 2 0 0 4096 Aug 03 04:05 bin
drwxr-xr-x 4 0 0 1024 Aug 02 13:26 boot
drwxr-xr-x 11 0 0 4220 Sep 26 06:26 dev
drwxr-xr-x 93 0 0 12288 Sep 26 06:48 etc
drwxr-xr-x 5 0 0 4096 Sep 26 06:44 home
(没有写入该文件的账号,如user2,则可以随意切换)
实现:放入该文件里的账号能够切换目录,没放进来的不能够切换目录,man 5 vsftpd.conf

[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf
增加此功能; chroot_local_user=YES
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1 放进去的却没有禁锢掉
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
257 "/home/user1"
ftp> cd /
250 Directory successfully changed.
ftp> quit
221 Goodbye.
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2 没放进去的被禁锢了
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,98,84)
150 Here comes the directory listing.
-rw-rw-r-- 1 502 502 6 Sep 26 06:45 gjp2.txt
226 Directory send OK.
ftp 的特性:
独立进程存放在: /etc/init.c /etc/rc.d/init.d 目录下!
超级守护进程:xinetd
112 listen=YES 表明独立的,不再依赖于超级守护进程
119 pam_service_name=vsftpd //ftp支持pam验证
可参考ftp的接口文件
[root@gjp99 pam.d]# vim /etc/pam.d/vsftpd 里面有相应的系统调用及参数
[root@gjp99 pam.d]# cd /etc/vsftpd
[root@gjp99 vsftpd]# ll
total 28
-rw-r--r-- 1 root root 13 Aug 3 18:00 banned_emails
-rw-r--r-- 1 root root 7 Sep 26 14:37 chroot_list
-rw------- 1 root root 125 May 13 2009 ftpusers 存入该文件的账号不能登录ftp
-rw------- 1 root root 361 May 13 2009 user_list 存入该文件的账号不能登录ftp
-rw------- 1 root root 4640 Sep 26 14:59 vsftpd.conf
-rwxr--r-- 1 root root 338 May 13 2009 vsftpd_conf_migrate.sh
[root@gjp99 vsftpd]# cat ftpusers
# Users that are not allowed to login via ftp
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
news
uucp
operator
games
nobody
user1 把user1添加进来作为测试!
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password: 需要输入密码,如果网络上有人抓包,则很不安全!
530 Login incorrect.
Login failed. 登录失败
把ftpusers中存放的账号user1删除,在user_list中输入user1测试!
[root@gjp99 vsftpd]# cat user_list
# vsftpd userlist
# If userlist_deny=NO, only allow users in this file
# If userlist_deny=YES (default), never allow users in this file, and
# do not even prompt for a password.
# Note that the default vsftpd pam config also checks /etc/vsftpd/ftpusers
# for users that are denied.
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
news
uucp
operator
games
nobody
user1
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
530 Permission denied. 没有提示让输入密码,直接拒绝掉了
Login failed.
为了防止管理员的密码被捕获,则不允许管理员ftp
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): root
530 Permission denied.
Login failed.
[root@gjp99 vsftpd]# vim user_list
# vsftpd userlist
# If userlist_deny=NO, only allow users in this file
在 /etc/vsftpd/vsftpd.conf中增加此功能: service vsftpd restart
下面测试:user1在这个文件下所以可以登录,user2不在该文件里,因此直接拒绝!
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,42,166)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> quit
221 Goodbye.
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2
530 Permission denied.
Login failed.
/etc/vsftpd/vsftpd.conf 下的
122 tcp_wrappers=YES
查看某些应用支持的链接库:
[root@gjp99 vsftpd]# ldd /usr/sbin/vsftpd
linux-gate.so.1 => (0x00164000)
libssl.so.6 => /lib/libssl.so.6 (0x00a33000)
libwrap.so.0 => /lib/libwrap.so.0 (0x0067c000)
出现此文件,即说明支持tcp_wrappers=YES
需修改 /etc/hosts.allow /etc/hosts.deny
先看hosts.allow 再看hosts.deny 默认是允许的!

[root@gjp99 vsftpd]# cat /etc/hosts.allow
#
# hosts.allow This file describes the names of the hosts which are
# allowed to use the local INET services, as decided
# by the '/usr/sbin/tcpd' server.
#
vsftpd:192.168.10.2:allow 仅有192.168.10.2允许
[root@gjp99 vsftpd]# vim /etc/hosts.deny
[root@gjp99 vsftpd]# cat /etc/hosts.deny
#
# hosts.deny This file describes the names of the hosts which are
# *not* allowed to use the local INET services, as decided
# by the '/usr/sbin/tcpd' server.
#
# The portmap line is redundant, but it is left to remind you that
# the new secure portmap uses hosts.deny and hosts.allow. In particular
# you should know that NFS uses portmap!
vsftpd:all :deny 其他人拒绝
测试:windows下ftp

linux 下测试:
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
421 Service not available.
ftp> quit
只有192.168.10.2不可以,其他的都可以!
[root@gjp99 vsftpd]# vim /etc/hosts.allow 只在该文件下操作,hosts.deny 空着
6 vsftpd:192.168.10.2:deny
7 vsftpd:all:allow
测试:windows下:

linux下:
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,208,223)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> quit
ftp的安全性
1. 协议 ftp 明文
2. 账号 匿名 本地账号(抓包,危险性较大) 最好选用虚拟账号
删除原有的安全特性,安装tshark
挂载光盘,安装抓包工具:
[root@gjp99 vsftpd]# mount /dev/cdrom /mnt/cdrom
mount: block device /dev/cdrom is write-protected, mounting read-only
[root@gjp99 vsftpd]# cd /mnt/cdrom/Server/
[root@gjp99 Server]# ll wireshark-*
-r--r--r-- 220 root root 11130359 Jun 11 2009 wireshark-1.0.8-1.el5_3.1.i386.rpm
-r--r--r-- 220 root root 686650 Jun 11 2009 wireshark-gnome-1.0.8-1.el5_3.1.i386.rpm
[root@gjp99 Server]# rpm -ivh libsmi-0.4.5-2.el5.i386.rpm 必须先安装此软件
warning: libsmi-0.4.5-2.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:libsmi ################################# [100%]
[root@gjp99 Server]# rpm -ivh wire
wireless-tools-28-2.el5.i386.rpm
wireless-tools-devel-28-2.el5.i386.rpm
wireshark-1.0.8-1.el5_3.1.i386.rpm
wireshark-gnome-1.0.8-1.el5_3.1.i386.rpm
[root@gjp99 Server]# rpm -ivh wireshark-1.0.8-1.el5_3.1.i386.rpm
warning: wireshark-1.0.8-1.el5_3.1.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:wireshark ############################### [100%]
[root@gjp99 Server]# tshark -ni eth0 -R "tcp.dstport eq 21 "
Running as user "root" and group "root". This could be dangerous.
Capturing on eth0 已经在eth0上可以抓包了~
Xshell:\> ftp 192.168.10.98
Connecting to 192.168.10.98:21...
Connection established.
Escape character is '^@]'.
220 (vsFTPd 2.0.5)
Name (192.168.10.98:Administrator): user1
331 Please specify the password.
Password:
230 Login successful.
ftp:/home/user1>
抓包抓到的情况:
115.297511 192.168.10.2 -> 192.168.10.98 FTP Request: USER user1 用户名
115.497920 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=13 Ack=55 Win=65536 Len=0
116.968029 192.168.10.2 -> 192.168.10.98 FTP Request: PASS 123 密码
116.996447 192.168.10.2 -> 192.168.10.98 FTP Request: PWD
117.196785 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=28 Ack=97 Win=65536 Len=0
测试,是否能抓到管理员密码?
Xshell:\> ftp 192.168.10.98
Connecting to 192.168.10.98:21...
Connection established.
Escape character is '^@]'.
220 (vsFTPd 2.0.5)
Name (192.168.10.98:Administrator): root
530 Permission denied.
抓包抓不到密码:
243.383605 192.168.10.2 -> 192.168.10.98 FTP Request: USER root
243.583142 192.168.10.2 -> 192.168.10.98 TCP 53369 > 21 [ACK] Seq=12 Ack=45 Win=65536 Len=0
291.498211 192.168.10.2 -> 192.168.10.98 FTP Request: PWD
291.698623 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=43 Ack=154 Win=65536 Len=0
ftps的搭建:
ftps=ftp+ssl
创建CA
[root@gjp99 Server]# cd /etc/pki
[root@gjp99 pki]# ll
total 32
drwx------ 3 root root 4096 Aug 2 21:22 CA
drwxr-xr-x 2 root root 4096 Aug 2 21:20 nssdb
drwxr-xr-x 2 root root 4096 Aug 2 21:21 rpm-gpg
drwxr-xr-x 5 root root 4096 Aug 2 21:22 tls
[root@gjp99 pki]# vim tls/openssl.cnf
45 dir = /etc/pki/CA # Where everything is kept
46 certs = $dir/certs # Where the issued certs are kept
47 crl_dir = $dir/crl # Where the issued crl are kept
48 database = $dir/index.txt # database index file.
49 #unique_subject = no # Set to 'no' to allow creation of
50 # several ctificates with same subject.
51 new_certs_dir = $dir/newcerts # default place for new certs.
52
53 certificate = $dir/cacert.pem # The CA certificate
54 serial = $dir/serial # The current serial number
55 crlnumber = $dir/crlnumber # the current crl number
56 # must be commented out to leave a V1 CRL
57 crl = $dir/crl.pem # The current CRL
58 private_key = $dir/private/cakey.pem# The private key
底行模式:![]()
88 countryName = optonal
89 stateOrProvinceName = optonal
90 organizationName = optonal

[root@gjp99 pki]# ll
total 32
drwx------ 3 root root 4096 Aug 2 21:22 CA
drwxr-xr-x 2 root root 4096 Aug 2 21:20 nssdb
drwxr-xr-x 2 root root 4096 Aug 2 21:21 rpm-gpg
drwxr-xr-x 5 root root 4096 Sep 26 17:04 tls
[root@gjp99 pki]# cd CA
[root@gjp99 CA]# ll
total 8
drwx------ 2 root root 4096 Jun 30 2009 private
[root@gjp99 CA]# mkdir crl certs newcerts
[root@gjp99 CA]# touch index.txt serial
[root@gjp99 CA]# echo "01">serial
[root@gjp99 CA]# openssl genrsa 1024 >private/cakey.pem
Generating RSA private key, 1024 bit long modulus
....++++++
......++++++
e is 65537 (0x10001)
[root@gjp99 CA]# chmod 600 private/*
[root@gjp99 CA]# openssl req -new -key private/cakey.pem -x509 -out cacert.pem
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CN]:
State or Province Name (full name) [Shang Hai]:
Locality Name (eg, city) [Shang Hai]:
Organization Name (eg, company) [My Company Ltd]:sec center
Organizational Unit Name (eg, section) []:tec
Common Name (eg, your name or your server's hostname) []:ca.net.net
Email Address []:
私钥 请求文件 证书
[root@gjp99 CA]# mkdir /etc/vsftpd/certs
[root@gjp99 CA]# cd /etc/vsftpd/certs/
[root@gjp99 certs]# openssl genrsa 1024 >vsftpd.key 创建钥匙
Generating RSA private key, 1024 bit long modulus
.......++++++
................................................................+++
e is 65537 (0x10001)
[root@gjp99 certs]# openssl req -new -key vsftpd.key -out vsftpd.csr 产生请求
You are about to be asked to enter information that will be inco
into your certificate request.
What you are about to enter is what is called a Distinguished Na
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CN]:
State or Province Name (full name) [Shang Hai]:
Locality Name (eg, city) [Shang Hai]:
Organization Name (eg, company) [My Company Ltd]:bht
Organizational Unit Name (eg, section) []:tec
Common Name (eg, your name or your server's hostname) []:ftp.bht.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
[root@gjp99 certs]# ll
total 8
-rw-r--r-- 1 root root 651 Sep 26 17:17 vsftpd.csr
-rw-r--r-- 1 root root 887 Sep 26 17:15 vsftpd.key
[root@gjp99 certs]# openssl ca -in vsftpd.csr -out vsftpd.cert 生成证书
Using configuration from /etc/pki/tls/openssl.cnf
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 1 (0x1)
Validity
Not Before: Sep 26 09:35:33 2012 GMT
Not After : Sep 26 09:35:33 2013 GMT
Subject:
countryName = CN
stateOrProvinceName = Shang Hai
organizationName = bht
organizationalUnitName = tec
commonName = ftp.bht.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
4E:10:2C:A8:BA:A8:5E:16:D1:8E:BD:85:53:87:5C:5E:1D:B6:04:C1
X509v3 Authority Key Identifier:
keyid:DF:8C:0F:8C:D0:65:31:42:FB:AF:29:7A:52:51:4C:86:09:25:91:F4
Certificate is to be certified until Sep 26 09:35:33 2013 GMT (365 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
证书在哪?私钥在哪?
用man 5 vsftpd.conf
[root@gjp99 certs]# vim /etc/vsftpd/vsftpd.conf
增加以下功能:
rsa_cert_file=/etc/vsftpd/certs/vsftpd.cert
rsa_private_key_file=/etc/vsftpd/certs/vsftpd.key
ssl_tlsv1=YES
ssl_sslv3=YES
ssl_sslv2=YES
ssl_enable=YES
force_local_logins_ssl=YES
force_local_data_ssl=YES
[root@gjp99 certs]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 certs]# tshark -ni eth0 -R "tcp.dstport eq 21 "
Running as user "root" and group "root". This could be dangerous.
Capturing on eth0
C:\Users\Administrator>ftp 192.168.10.98 命令行下无法登录(由于使用了身份验证)
连接到 192.168.10.98。
220 (vsFTPd 2.0.5)
用户(192.168.10.98:(none)): user1
530 Non-anonymous sessions must use encryption.
登录失败。
使用客户端软件:



点击应用 点击连接!

点击 “接受一次”

1331.140451 192.168.10.2 -> 192.168.10.98 FTP Request: AUTH SSL
1331.147508 192.168.10.2 -> 192.168.10.98 FTP Request: \200\310\001\003\001\000
下面都是已加密的信息,已看不到密码!
MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
MYSQL explain详解
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
先解析一条sql语句,看出现什么内容
EXPLAINSELECTs.uid,s.username,s.name,f.email,f.mobile,f.phone,f.postalcode,f.address
FROM uchome_space ASs,uchome_spacefieldASf
WHERE 1
AND s.groupid=0
AND s.uid=f.uid

1. id
SELECT识别符。这是SELECT查询序列号。这个不重要,查询序号即为sql语句执行的顺序,看下面这条sql
EXPLAINSELECT*FROM(SELECT* FROMuchome_space LIMIT10)ASs
它的执行结果为

可以看到这时的id变化了
2.select_type
select类型,它有以下几种值
2.1 simple 它表示简单的select,没有union和子查询
2.2 primary 最外面的select,在有子查询的语句中,最外面的select查询就是primary,上图中就是这样
2.3 union union语句的第二个或者说是后面那一个.现执行一条语句,explain
select * from uchome_space limit 10 union select * from uchome_space limit 10,10
会有如下结果

第二条语句使用了union
2.4 dependent union UNION中的第二个或后面的SELECT语句,取决于外面的查询
2.5 union result UNION的结果,如上面所示
还有几个参数,这里就不说了,不重要
3 table
输出的行所用的表,这个参数显而易见,容易理解
4 type
连接类型。有多个参数,先从最佳类型到最差类型介绍 重要且困难
4.1 system
表仅有一行,这是const类型的特列,平时不会出现,这个也可以忽略不计
4.2 const
表最多有一个匹配行,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快
记住一定是用到primary key 或者unique,并且只检索出两条数据的 情况下才会是const,看下面这条语句
explain SELECT * FROM `asj_admin_log` limit 1,结果是

虽然只搜索一条数据,但是因为没有用到指定的索引,所以不会使用const.继续看下面这个
explain SELECT * FROM `asj_admin_log` where log_id = 111

log_id是主键,所以使用了const。所以说可以理解为const是最优化的
4.3 eq_ref
对于eq_ref的解释,mysql手册是这样说的:"对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY"。eq_ref可以用于使用=比较带索引的列。看下面的语句
explain select * from uchome_spacefield,uchome_space where uchome_spacefield.uid = uchome_space.uid
得到的结果是下图所示。很明显,mysql使用eq_ref联接来处理uchome_space表。

目前的疑问:
4.3.1 为什么是只有uchome_space一个表用到了eq_ref,并且sql语句如果变成
explain select * from uchome_space,uchome_spacefield where uchome_space.uid = uchome_spacefield.uid
结果还是一样,需要说明的是uid在这两个表中都是primary
4.4 ref 对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
看下面这条语句 explain select * from uchome_space where uchome_space.friendnum = 0,得到结果如下,这条语句能搜出1w条数据

4.5 ref_or_null 该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
上面这五种情况都是很理想的索引使用情况
4.6 index_merge 该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
4.7 unique_subquery
4.8 index_subquery
4.9 range 给定范围内的检索,使用一个索引来检查行。看下面两条语句
explain select * from uchome_space where uid in (1,2)
explain select * from uchome_space where groupid in (1,2)
uid有索引,groupid没有索引,结果是第一条语句的联接类型是range,第二个是ALL.以为是一定范围所以说像 between也可以这种联接,很明显
explain select * from uchome_space where friendnum = 17
这样的语句是不会使用range的,它会使用更好的联接类型就是上面介绍的ref
4.10 index 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
当查询只使用作为单索引一部分的列时,MySQL可以使用该联接类型。
4.11 ALL 对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。
5 possible_keys 提示使用哪个索引会在该表中找到行,不太重要
6 keys MYSQL使用的索引,简单且重要
7 key_len MYSQL使用的索引长度
8 ref ref列显示使用哪个列或常数与key一起从表中选择行。
9 rows 显示MYSQL执行查询的行数,简单且重要,数值越大越不好,说明没有用好索引
10 Extra 该列包含MySQL解决查询的详细信息。
10.1 Distinct MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。一直没见过这个值
10.2 Not exists
10.3 range checked for each record
没有找到合适的索引
10.4 using filesort
MYSQL手册是这么解释的“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。”目前不太明白
10.5 using index 只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的信息。这个比较容易理解,就是说明是否使用了索引
explain select * from ucspace_uchome where uid = 1的extra为using index(uid建有索引)
explain select count(*) from uchome_space where groupid=1 的extra为using where(groupid未建立索引)
10.6 using temporary
为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。
出现using temporary就说明语句需要优化了,举个例子来说
EXPLAIN SELECT ads.id FROM ads, city WHERE city.city_id = 8005 AND ads.status = 'online' AND city.ads_id=ads.id ORDER BY ads.id desc
id select_type table type possible_keys key key_len ref rows filtered Extra
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- -------------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00 Using temporary; Using filesort
1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
这条语句会使用using temporary,而下面这条语句则不会
EXPLAIN SELECT ads.id FROM ads, city WHERE city.city_id = 8005 AND ads.status = 'online' AND city.ads_id=ads.id ORDER BY city.ads_id desc
id select_type table type possible_keys key key_len ref rows filtered Extra
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- ---------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00 Using where; Using filesort
1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
这是为什么呢?他俩之间只是一个order by不同,MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。EXPLAIN 结果中,第一行出现的表就是驱动表(Important!)以上两个查询语句,驱动表都是 city,如上面的执行计划所示!
1)指定了联接条件时,满足查询条件的记录行数少的表为[驱动表];
2)未指定联接条件时,行数少的表为[驱动表](Important!)。
永远用小结果集驱动大结果集
今天学到了一个很重要的一点:当不确定是用哪种类型的join时,让mysql优化器自动去判断,我们只需写select * from t1,t2 where t1.field = t2.field
10.7 using where
WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。(这个说明不是很理解,因为很多很多语句都会有where条件,而type为all或index只能说明检索的数据多,并不能说明错误,useing where不是很重要,但是很常见)
如果想要使查询尽可能快,应找出Using filesort 和Using temporary的Extra值。
10.8 Using sort_union(...), Using union(...),Using intersect(...)
这些函数说明如何为index_merge联接类型合并索引扫描
10.9 Using index for group-by
类似于访问表的Using index方式,Using index for group-by表示MySQL发现了一个索引,可以用来查询GROUP BY或DISTINCT查询的所有列,而不要额外搜索硬盘访问实际的表。并且,按最有效的方式使用索引,以便对于每个组,只读取少量索引条目。
实例讲解
通过相乘EXPLAIN输出的rows列的所有值,你能得到一个关于一个联接如何的提示。这应该粗略地告诉你MySQL必须检查多少行以执行查询。当你使用max_join_size变量限制查询时,也用这个乘积来确定执行哪个多表SELECT语句。
python数据类型详解
目录
1、字符串
2、布尔类型
3、整数
4、浮点数
5、数字
6、列表
7、元组
8、字典
9、日期
1、字符串
1.1、如何在Python中使用字符串
a、使用单引号(')
用单引号括起来表示字符串,例如:
str='this is string';
print str;
b、使用双引号(")
双引号中的字符串与单引号中的字符串用法完全相同,例如:
str="this is string";
print str;
c、使用三引号(''')
利用三引号,表示多行的字符串,可以在三引号中自由的使用单引号和双引号,例如:
str='''this is string
this is pythod string
this is string'''
print str;
2、布尔类型
bool=False;
print bool;
bool=True;
print bool;
3、整数
int=20;
print int;
4、浮点数
float=2.3;
print float;
5、数字
包括整数、浮点数。
5.1、删除数字对象引用,例如:
a=1;
b=2;
c=3;
del a;
del b, c;
#print a; #删除a变量后,再调用a变量会报错
5.2、数字类型转换
float(x ) 将x转换到一个浮点数
complex(real [,imag]) 创建一个复数
str(x) 将对象x转换为字符串
repr(x) 将对象x转换为表达式字符串
eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
chr(x) 将一个整数转换为一个字符
unichr(x) 将一个整数转换为Unicode字符
ord(x) 将一个字符转换为它的整数值
hex(x) 将一个整数转换为一个十六进制字符串
oct(x) 将一个整数转换为一个八进制字符串
5.3、数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10 ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 fabs(x) 返回数字的绝对值,如math.fabs(-10) 返回10.0 floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 max(x1, x2,...) 返回给定参数的最大值,参数可以为序列。 min(x1, x2,...) 返回给定参数的最小值,参数可以为序列。 modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 pow(x, y) x**y 运算后的值。 round(x [,n]) 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 sqrt(x) 返回数字x的平方根,数字可以为负数,返回类型为实数,如math.sqrt(4)返回 2+0j
6、列表
6.1、初始化列表,例如:
list=['physics', 'chemistry', 1997, 2000];
nums=[1, 3, 5, 7, 8, 13, 20];
6.2、访问列表中的值,例如:
'''nums[0]: 1''' print "nums[0]:", nums[0] '''nums[2:5]: [5, 7, 8] 从下标为2的元素切割到下标为5的元素,但不包含下标为5的元素''' print "nums[2:5]:", nums[2:5] '''nums[1:]: [3, 5, 7, 8, 13, 20] 从下标为1切割到最后一个元素''' print "nums[1:]:", nums[1:] '''nums[:-3]: [1, 3, 5, 7] 从最开始的元素一直切割到倒数第3个元素,但不包含倒数第三个元素''' print "nums[:-3]:", nums[:-3] '''nums[:]: [1, 3, 5, 7, 8, 13, 20] 返回所有元素''' print "nums[:]:", nums[:]
6.3、更新列表,例如:
nums[0]="ljq"; print nums[0];
6.4、删除列表元素
del nums[0]; '''nums[:]: [3, 5, 7, 8, 13, 20]''' print "nums[:]:", nums[:];
6.5、列表脚本操作符
列表对+和*的操作符与字符串相似。+号用于组合列表,*号用于重复列表,例如:
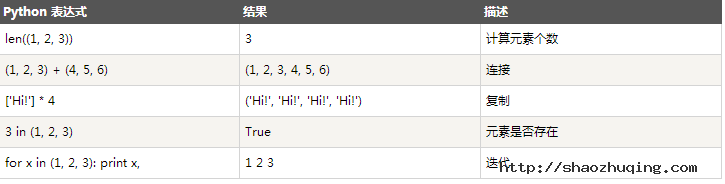
print len([1, 2, 3]); #3 print [1, 2, 3] + [4, 5, 6]; #[1, 2, 3, 4, 5, 6] print ['Hi!'] * 4; #['Hi!', 'Hi!', 'Hi!', 'Hi!'] print 3 in [1, 2, 3] #True for x in [1, 2, 3]: print x, #1 2 3
6.6、列表截取
L=['spam', 'Spam', 'SPAM!']; print L[2]; #'SPAM!' print L[-2]; #'Spam' print L[1:]; #['Spam', 'SPAM!']
6.7、列表函数&方法
list.append(obj) 在列表末尾添加新的对象 list.count(obj) 统计某个元素在列表中出现的次数 list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) list.index(obj) 从列表中找出某个值第一个匹配项的索引位置,索引从0开始 list.insert(index, obj) 将对象插入列表 list.pop(obj=list[-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 list.remove(obj) 移除列表中某个值的第一个匹配项 list.reverse() 反向列表中元素,倒转 list.sort([func]) 对原列表进行排序
7、元组(tuple)
Python的元组与列表类似,不同之处在于元组的元素不能修改;元组使用小括号(),列表使用方括号[];元组创建很简单,只需要在括号中添加元素,并使用逗号(,)隔开即可,例如:
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d";
创建空元组,例如:tup = ();
元组中只有一个元素时,需要在元素后面添加逗号,例如:tup1 = (50,);
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。
7.1、访问元组
tup1 = ('physics', 'chemistry', 1997, 2000);
#tup1[0]: physics
print "tup1[0]: ", tup1[0]
#tup1[1:5]: ('chemistry', 1997)
print "tup1[1:5]: ", tup1[1:3]
7.2、修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,例如:
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz');
# 以下修改元组元素操作是非法的。
# tup1[0] = 100;
# 创建一个新的元组
tup3 = tup1 + tup2; print tup3; #(12, 34.56, 'abc', 'xyz')
7.3、删除元组
元组中的元素值是不允许删除的,可以使用del语句来删除整个元组,例如:
tup = ('physics', 'chemistry', 1997, 2000);
print tup;
del tup;
7.4、元组运算符
与字符串一样,元组之间可以使用+号和*号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
7.5、元组索引&截取
L = ('spam', 'Spam', 'SPAM!');
print L[2]; #'SPAM!'
print L[-2]; #'Spam'
print L[1:]; #['Spam', 'SPAM!']
7.6、元组内置函数
cmp(tuple1, tuple2) 比较两个元组元素。 len(tuple) 计算元组元素个数。 max(tuple) 返回元组中元素最大值。 min(tuple) 返回元组中元素最小值。 tuple(seq) 将列表转换为元组。
8、字典
8.1、字典简介
字典(dictionary)是除列表之外python中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典由键和对应的值组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'};
也可如此创建字典:
dict1 = { 'abc': 456 };
dict2 = { 'abc': 123, 98.6: 37 };
每个键与值必须用冒号隔开(:),每对用逗号分割,整体放在花括号中({})。键必须独一无二,但值则不必;值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
8.2、访问字典里的值
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
print "dict['name']: ", dict['name'];
print "dict['age']: ", dict['age'];
8.3、修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
dict["age"]=27; #修改已有键的值
dict["school"]="wutong"; #增加新的键/值对
print "dict['age']: ", dict['age'];
print "dict['school']: ", dict['school'];
8.4、删除字典
del dict['name']; # 删除键是'name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
例如:
#!/usr/bin/python
dict = {'name': 'Zara', 'age': 7, 'class': 'First'};
del dict['name'];
#dict {'age': 7, 'class': 'First'}
print "dict", dict;
注意:字典不存在,del会引发一个异常
8.5、字典内置函数&方法
9、日期和时间
9.1、获取当前时间,例如:
import time, datetime;
localtime = time.localtime(time.time())
#Local current time : time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)
print "Local current time :", localtime
说明:time.struct_time(tm_year=2014, tm_mon=3, tm_mday=21, tm_hour=15, tm_min=13, tm_sec=56, tm_wday=4, tm_yday=80, tm_isdst=0)属于struct_time元组,struct_time元组具有如下属性:

9.2、获取格式化的时间
可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
2.1、日期转换为字符串
首选:print time.strftime('%Y-%m-%d %H:%M:%S');
其次:print datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H:%M:%S')
最后:print str(datetime.datetime.now())[:19]
2.2、字符串转换为日期
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") print d;
9.3、获取日期差
oneday = datetime.timedelta(days=1) #今天,2014-03-21 today = datetime.date.today() #昨天,2014-03-20 yesterday = datetime.date.today() - oneday #明天,2014-03-22 tomorrow = datetime.date.today() + oneday #获取今天零点的时间,2014-03-21 00:00:00 today_zero_time = datetime.datetime.strftime(today, '%Y-%m-%d %H:%M:%S') #0:00:00.001000 print datetime.timedelta(milliseconds=1), #1毫秒 #0:00:01 print datetime.timedelta(seconds=1), #1秒 #0:01:00 print datetime.timedelta(minutes=1), #1分钟 #1:00:00 print datetime.timedelta(hours=1), #1小时 #1 day, 0:00:00 print datetime.timedelta(days=1), #1天 #7 days, 0:00:00 print datetime.timedelta(weeks=1)
9.4、获取时间差
#1 day, 0:00:00 oneday = datetime.timedelta(days=1) #今天,2014-03-21 16:07:23.943000 today_time = datetime.datetime.now() #昨天,2014-03-20 16:07:23.943000 yesterday_time = datetime.datetime.now() - oneday #明天,2014-03-22 16:07:23.943000 tomorrow_time = datetime.datetime.now() + oneday 注意时间是浮点数,带毫秒。 那么要获取当前时间,需要格式化一下: print datetime.datetime.strftime(today_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(yesterday_time, '%Y-%m-%d %H:%M:%S') print datetime.datetime.strftime(tomorrow_time, '%Y-%m-%d %H:%M:%S')
9.5、获取上个月最后一天
last_month_last_day = datetime.date(datetime.date.today().year,datetime.date.today().month,1)-datetime.timedelta(1)
9.6、字符串日期格式化为秒数,返回浮点类型:
expire_time = "2013-05-21 09:50:35" d = datetime.datetime.strptime(expire_time,"%Y-%m-%d %H:%M:%S") time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.7、日期格式化为秒数,返回浮点类型:
d = datetime.date.today() time_sec_float = time.mktime(d.timetuple()) print time_sec_float
9.8、秒数转字符串
time_sec = time.time()
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time_sec))
Console命令详解,让调试js代码变得更简单

控制台(Console)是Firebug的第一个面板,也是最重要的面板,主要作用是显示网页加载过程中产生各类信息。
一、显示信息的命令
Firebug内置一个console对象,提供5种方法,用来显示信息。
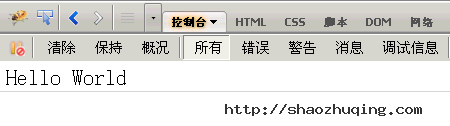
最简单的方法是console.log(),可以用来取代alert()或document.write()。比如,在网页脚本中使用console.log("Hello World"),加载时控制台就会自动显示如下内容。
另外,根据信息的不同性质,console对象还有4种显示信息的方法,分别是一般信息console.info()、除错信息console.debug()、警告提示console.warn()、错误提示console.error()。
比如,在网页脚本中插入下面四行:
console.info("这是info");
console.debug("这是debug");
console.warn("这是warn");
console.error("这是error");
加载时,控制台会显示如下内容。

可以看到,不同性质的信息前面有不同的图标,并且每条信息后面都有超级链接,点击后跳转到网页源码的相应行。
二、占位符
console对象的上面5种方法,都可以使用printf风格的占位符。不过,占位符的种类比较少,只支持字符(%s)、整数(%d或%i)、浮点数(%f)和对象(%o)四种。
比如,
console.log("%d年%d月%d日",2011,3,26);
console.log("圆周率是%f",3.1415926);

%o占位符,可以用来查看一个对象内部情况。比如,有这样一个对象:
var dog = {} ;
dog.name = "大毛" ;
dog.color = "黄色";
然后,对它使用o%占位符。
console.log("%o",dog);

三、分组显示
如果信息太多,可以分组显示,用到的方法是console.group()和console.groupEnd()。
console.group("第一组信息");
console.log("第一组第一条");
console.log("第一组第二条");
console.groupEnd();
console.group("第二组信息");
console.log("第二组第一条");
console.log("第二组第二条");
console.groupEnd();
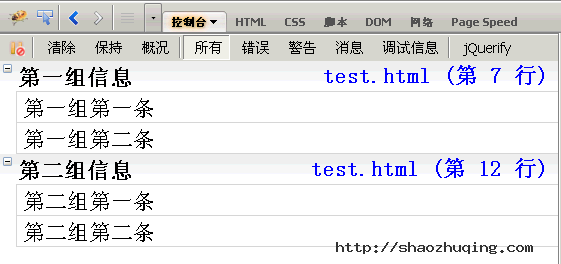
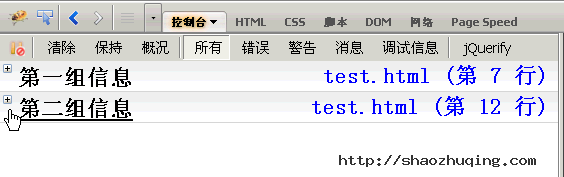
点击组标题,该组信息会折叠或展开。
四、console.dir()
console.dir()可以显示一个对象所有的属性和方法。
比如,现在为第二节的dog对象,添加一个bark()方法。
dog.bark = function(){alert("汪汪汪");};
然后,显示该对象的内容,
console.dir(dog);
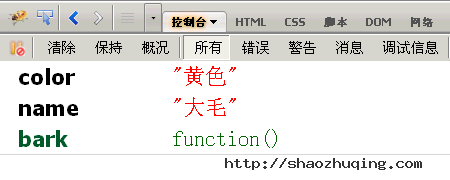
五、console.dirxml()
console.dirxml()用来显示网页的某个节点(node)所包含的html/xml代码。
比如,先获取一个表格节点,
var table = document.getElementById("table1");
然后,显示该节点包含的代码。
console.dirxml(table);

六、console.assert()
console.assert()用来判断一个表达式或变量是否为真。如果结果为否,则在控制台输出一条相应信息,并且抛出一个异常。
比如,下面两个判断的结果都为否。
var result = 0;
console.assert( result );
var year = 2000;
console.assert(year == 2011 );

七、console.trace()
console.trace()用来追踪函数的调用轨迹。
比如,有一个加法器函数。
function add(a,b){
return a+b;
}
我想知道这个函数是如何被调用的,在其中加入console.trace()方法就可以了。
function add(a,b){
console.trace();
return a+b;
}
假定这个函数的调用代码如下:
var x = add3(1,1);
function add3(a,b){return add2(a,b);}
function add2(a,b){return add1(a,b);}
function add1(a,b){return add(a,b);}
运行后,会显示add()的调用轨迹,从上到下依次为add()、add1()、add2()、add3()。

八、计时功能
console.time()和console.timeEnd(),用来显示代码的运行时间。
console.time("计时器一");
for(var i=0;i<1000;i++){
for(var j=0;j<1000;j++){}
}
console.timeEnd("计时器一");

九、性能分析
性能分析(Profiler)就是分析程序各个部分的运行时间,找出瓶颈所在,使用的方法是console.profile()。
假定有一个函数Foo(),里面调用了另外两个函数funcA()和funcB(),其中funcA()调用10次,funcB()调用1次。
function Foo(){
for(var i=0;i<10;i++){funcA(1000);}
funcB(10000);
}
function funcA(count){
for(var i=0;i<count;i++){}
}
function funcB(count){
for(var i=0;i<count;i++){}
}
然后,就可以分析Foo()的运行性能了。
console.profile('性能分析器一');
Foo();
console.profileEnd();
控制台会显示一张性能分析表,如下图。

标题栏提示,一共运行了12个函数,共耗时2.656毫秒。其中funcA()运行10次,耗时1.391毫秒,最短运行时间0.123毫秒,最长0.284毫秒,平均0.139毫秒;funcB()运行1次,耗时1.229ms毫秒。
除了使用console.profile()方法,firebug还提供了一个"概况"(Profiler)按钮。第一次点击该按钮,"性能分析" 开始,你可以对网页进行某种操作(比如ajax操作),然后第二次点击该按钮,"性能分析"结束,该操作引发的所有运算就会进行性能分析。

十、属性菜单
控制台面板的名称后面,有一个倒三角,点击后会显示属性菜单。

默认情况下,控制台只显示Javascript错误。如果选中Javascript警告、CSS错误、XML错误都送上,则相关的提示信息都会显示。
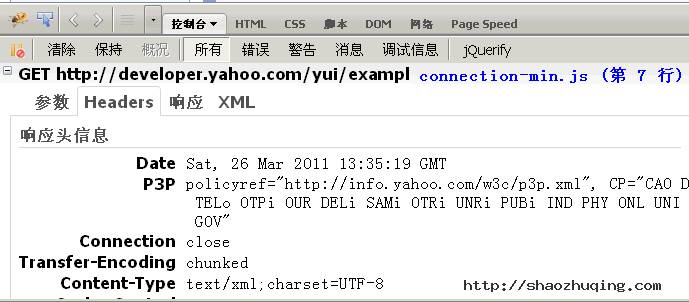
这里比较有用的是"显示XMLHttpRequests",也就是显示ajax请求。选中以后,网页的所有ajax请求,都会在控制台面板显示出来。
比如,点击一个YUI示例,控制台就会告诉我们,它用ajax方式发出了一个GET请求,http请求和响应的头信息和内容主体,也都可以看到。
linux awk命令详解
简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
调用awk
有三种方式调用awk

1.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。 在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 2.shell脚本方式 将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。 相当于shell脚本首行的:#!/bin/sh 可以换成:#!/bin/awk 3.将所有的awk命令插入一个单独文件,然后调用: awk -f awk-script-file input-file(s) 其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
本章重点介绍命令行方式。
入门实例
假设last -n 5的输出如下
[root@www ~]# last -n 5 <==仅取出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) root tty1 Fri Sep 5 14:09 - 14:10 (00:01)
如果只是显示最近登录的5个帐号
#last -n 5 | awk '{print $1}'
root
root
root
dmtsai
root
awk工作流程是这样的:读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域。默认域分隔符是"空白键" 或 "[tab]键",所以$1表示登录用户,$3表示登录用户ip,以此类推。
如果只是显示/etc/passwd的账户
#cat /etc/passwd |awk -F ':' '{print $1}'
root
daemon
bin
sys
这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为':'。
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割
#cat /etc/passwd |awk -F ':' '{print $1"\t"$7}'
root /bin/bash
daemon /bin/sh
bin /bin/sh
sys /bin/sh
如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
daemon,/bin/sh
bin,/bin/sh
sys,/bin/sh
....
blue,/bin/nosh
awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
搜索/etc/passwd有root关键字的所有行
#awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash
这种是pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
搜索支持正则,例如找root开头的: awk -F: '/^root/' /etc/passwd
搜索/etc/passwd有root关键字的所有行,并显示对应的shell
# awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
这里指定了action{print $7}
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符
此外,$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容:
#awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
filename:/etc/passwd,linenumber:1,columns:7,linecontent:root:x:0:0:root:/root:/bin/bash
filename:/etc/passwd,linenumber:2,columns:7,linecontent:daemon:x:1:1:daemon:/usr/sbin:/bin/sh
filename:/etc/passwd,linenumber:3,columns:7,linecontent:bin:x:2:2:bin:/bin:/bin/sh
filename:/etc/passwd,linenumber:4,columns:7,linecontent:sys:x:3:3:sys:/dev:/bin/sh
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
print和printf
awk中同时提供了print和printf两种打印输出的函数。
其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
awk编程
变量和赋值
除了awk的内置变量,awk还可以自定义变量。
下面统计/etc/passwd的账户人数
awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
......
user count is 40
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。
这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0:
awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd
[start]user count is 0
root:x:0:0:root:/root:/bin/bash
...
[end]user count is 40
统计某个文件夹下的文件占用的字节数
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size}'
[end]size is 8657198
如果以M为单位显示:
ls -l |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.25889 M
注意,统计不包括文件夹的子目录。
条件语句
awk中的条件语句是从C语言中借鉴来的,见如下声明方式:
if (expression) {
statement;
statement;
... ...
}
if (expression) {
statement;
} else {
statement2;
}
if (expression) {
statement1;
} else if (expression1) {
statement2;
} else {
statement3;
}
统计某个文件夹下的文件占用的字节数,过滤4096大小的文件(一般都是文件夹):
ls -l |awk 'BEGIN {size=0;print "[start]size is ", size} {if($5!=4096){size=size+$5;}} END{print "[end]size is ", size/1024/1024,"M"}'
[end]size is 8.22339 M
循环语句
awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
数组
因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
显示/etc/passwd的账户
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
0 root
1 daemon
2 bin
3 sys
4 sync
5 games
......
这里使用for循环遍历数组
awk编程的内容极多,这里只罗列简单常用的用法,更多请参考 http://www.gnu.org/software/gawk/manual/gawk.html
PHP CURL详解
目前为目最全的CURL中文说明了,学PHP的要好好掌握.有很多的参数.大部份都很有用.真正掌握了它和正则,一定就是个采集高手了.
PHP中的CURL函数库(Client URL Library Function)
curl_close — 关闭一个curl会话
curl_copy_handle — 拷贝一个curl连接资源的所有内容和参数
curl_errno — 返回一个包含当前会话错误信息的数字编号
curl_error — 返回一个包含当前会话错误信息的字符串
curl_exec — 执行一个curl会话
curl_getinfo — 获取一个curl连接资源句柄的信息
curl_init — 初始化一个curl会话
curl_multi_add_handle — 向curl批处理会话中添加单独的curl句柄资源
curl_multi_close — 关闭一个批处理句柄资源
curl_multi_exec — 解析一个curl批处理句柄
curl_multi_getcontent — 返回获取的输出的文本流
curl_multi_info_read — 获取当前解析的curl的相关传输信息
curl_multi_init — 初始化一个curl批处理句柄资源
curl_multi_remove_handle — 移除curl批处理句柄资源中的某个句柄资源
curl_multi_select — Get all the sockets associated with the cURL extension, which can then be "selected"
curl_setopt_array — 以数组的形式为一个curl设置会话参数
curl_setopt — 为一个curl设置会话参数
curl_version — 获取curl相关的版本信息
curl_init()函数的作用初始化一个curl会话,curl_init()函数唯一的一个参数是可选的,表示一个url地址。
curl_exec()函数的作用是执行一个curl会话,唯一的参数是curl_init()函数返回的句柄。
curl_close()函数的作用是关闭一个curl会话,唯一的参数是curl_init()函数返回的句柄。
$ch = curl_init("http://www.baidu.com/");
curl_exec($ch);
curl_close($ch);
?>
curl_version()函数的作用是获取curl相关的版本信息,curl_version()函数有一个参数,不清楚是做什么的
print_r(curl_version())
?>
curl_getinfo()函数的作用是获取一个curl连接资源句柄的信息,curl_getinfo()函数有两个参数,第一个参数是curl的资源句柄,第二个参数是下面一些常量:
$ch = curl_init("http://www.baidu.com/");
print_r(curl_getinfo($ch));
?>
可选的常量包括:
CURLINFO_EFFECTIVE_URL
最后一个有效的url地址
CURLINFO_HTTP_CODE
最后一个收到的HTTP代码
CURLINFO_FILETIME
远程获取文档的时间,如果无法获取,则返回值为“-1”
CURLINFO_TOTAL_TIME
最后一次传输所消耗的时间
CURLINFO_NAMELOOKUP_TIME
名称解析所消耗的时间
CURLINFO_CONNECT_TIME
建立连接所消耗的时间
CURLINFO_PRETRANSFER_TIME
从建立连接到准备传输所使用的时间
CURLINFO_STARTTRANSFER_TIME
从建立连接到传输开始所使用的时间
CURLINFO_REDIRECT_TIME
在事务传输开始前重定向所使用的时间
CURLINFO_SIZE_UPLOAD
上传数据量的总值
CURLINFO_SIZE_DOWNLOAD
下载数据量的总值
CURLINFO_SPEED_DOWNLOAD
平均下载速度
CURLINFO_SPEED_UPLOAD
平均上传速度
CURLINFO_HEADER_SIZE
header部分的大小
CURLINFO_HEADER_OUT
发送请求的字符串
CURLINFO_REQUEST_SIZE
在HTTP请求中有问题的请求的大小
CURLINFO_SSL_VERIFYRESULT
Result of SSL certification verification requested by setting CURLOPT_SSL_VERIFYPEER
CURLINFO_CONTENT_LENGTH_DOWNLOAD
从Content-Length: field中读取的下载内容长度
CURLINFO_CONTENT_LENGTH_UPLOAD
上传内容大小的说明
CURLINFO_CONTENT_TYPE
下载内容的“Content-type”值,NULL表示服务器没有发送有效的“Content-Type: header”
curl_setopt()函数的作用是为一个curl设置会话参数。curl_setopt_array()函数的作用是以数组的形式为一个curl设置会话参数。
$ch = curl_init();
$fp = fopen("example_homepage.txt", "w");
curl_setopt($ch, CURLOPT_FILE, $fp);
$options = array(
CURLOPT_URL => 'http://www.baidu.com/',
CURLOPT_HEADER => false
);
curl_setopt_array($ch, $options);
curl_exec($ch);
curl_close($ch);
fclose($fp);
?>
可设置的参数有:
CURLOPT_AUTOREFERER
自动设置header中的referer信息
CURLOPT_BINARYTRANSFER
在启用CURLOPT_RETURNTRANSFER时候将获取数据返回
CURLOPT_COOKIESESSION
启用时curl会仅仅传递一个session cookie,忽略其他的cookie,默认状况下curl会将所有的cookie返回给服务端。session cookie是指那些用来判断服务器端的session是否有效而存在的cookie。
CURLOPT_CRLF
启用时将Unix的换行符转换成回车换行符。
CURLOPT_DNS_USE_GLOBAL_CACHE
启用时会启用一个全局的DNS缓存,此项为线程安全的,并且默认为true。
CURLOPT_FAILONERROR
显示HTTP状态码,默认行为是忽略编号小于等于400的HTTP信息
CURLOPT_FILETIME
启用时会尝试修改远程文档中的信息。结果信息会通过curl_getinfo()函数的CURLINFO_FILETIME选项返回。
CURLOPT_FOLLOWLOCATION
启用时会将服务器服务器返回的“Location:”放在header中递归的返回给服务器,使用CURLOPT_MAXREDIRS可以限定递归返回的数量。
CURLOPT_FORBID_REUSE
在完成交互以后强迫断开连接,不能重用。
CURLOPT_FRESH_CONNECT
强制获取一个新的连接,替代缓存中的连接。
CURLOPT_FTP_USE_EPRT
TRUE to use EPRT (and LPRT) when doing active FTP downloads. Use FALSE to disable EPRT and LPRT and use PORT only.
Added in PHP 5.0.0.
CURLOPT_FTP_USE_EPSV
TRUE to first try an EPSV command for FTP transfers before reverting back to PASV. Set to FALSE to disable EPSV.
CURLOPT_FTPAPPEND
TRUE to append to the remote file instead of overwriting it.
CURLOPT_FTPASCII
An alias of CURLOPT_TRANSFERTEXT. Use that instead.
CURLOPT_FTPLISTONLY
TRUE to only list the names of an FTP directory.
CURLOPT_HEADER
启用时会将头文件的信息作为数据流输出。
CURLOPT_HTTPGET
启用时会设置HTTP的method为GET,因为GET是默认是,所以只在被修改的情况下使用。
CURLOPT_HTTPPROXYTUNNEL
启用时会通过HTTP代理来传输。
CURLOPT_MUTE
讲curl函数中所有修改过的参数恢复默认值。
CURLOPT_NETRC
在连接建立以后,访问~/.netrc文件获取用户名和密码信息连接远程站点。
CURLOPT_NOBODY
启用时将不对HTML中的body部分进行输出。
CURLOPT_NOPROGRESS
启用时关闭curl传输的进度条,此项的默认设置为true
CURLOPT_NOSIGNAL
启用时忽略所有的curl传递给php进行的信号。在SAPI多线程传输时此项被默认打开。
CURLOPT_POST
启用时会发送一个常规的POST请求,类型为:application/x-www-form-urlencoded,就像表单提交的一样。
CURLOPT_PUT
启用时允许HTTP发送文件,必须同时设置CURLOPT_INFILE和CURLOPT_INFILESIZE
CURLOPT_RETURNTRANSFER
讲curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
CURLOPT_SSL_VERIFYPEER
FALSE to stop cURL from verifying the peer's certificate. Alternate certificates to verify against can be specified with the CURLOPT_CAINFO option or a certificate directory can be specified with the CURLOPT_CAPATH option. CURLOPT_SSL_VERIFYHOST may also need to be TRUE or FALSE if CURLOPT_SSL_VERIFYPEER is disabled (it defaults to 2). TRUE by default as of cURL 7.10. Default bundle installed as of cURL 7.10.
CURLOPT_TRANSFERTEXT
TRUE to use ASCII mode for FTP transfers. For LDAP, it retrieves data in plain text instead of HTML. On Windows systems, it will not set STDOUT to binary mode.
CURLOPT_UNRESTRICTED_AUTH
在使用CURLOPT_FOLLOWLOCATION产生的header中的多个locations中持续追加用户名和密码信息,即使域名已发生改变。
CURLOPT_UPLOAD
启用时允许文件传输
CURLOPT_VERBOSE
启用时会汇报所有的信息,存放在STDERR或指定的CURLOPT_STDERR中
CURLOPT_BUFFERSIZE
每次获取的数据中读入缓存的大小,这个值每次都会被填满。
CURLOPT_CLOSEPOLICY
不是CURLCLOSEPOLICY_LEAST_RECENTLY_USED就是CURLCLOSEPOLICY_OLDEST,还存在另外三个,但是curl暂时还不支持。.
CURLOPT_CONNECTTIMEOUT
在发起连接前等待的时间,如果设置为0,则不等待。
CURLOPT_DNS_CACHE_TIMEOUT
设置在内存中保存DNS信息的时间,默认为120秒。
CURLOPT_FTPSSLAUTH
The FTP authentication method (when is activated): CURLFTPAUTH_SSL (try SSL first), CURLFTPAUTH_TLS (try TLS first), or CURLFTPAUTH_DEFAULT (let cURL decide).
CURLOPT_HTTP_VERSION
设置curl使用的HTTP协议,CURL_HTTP_VERSION_NONE(让curl自己判断),CURL_HTTP_VERSION_1_0(HTTP/1.0),CURL_HTTP_VERSION_1_1(HTTP/1.1)
CURLOPT_HTTPAUTH
使用的HTTP验证方法,可选的值有:CURLAUTH_BASIC,CURLAUTH_DIGEST,CURLAUTH_GSSNEGOTIATE,CURLAUTH_NTLM,CURLAUTH_ANY,CURLAUTH_ANYSAFE,可以使用“|”操作符分隔多个值,curl让服务器选择一个支持最好的值,CURLAUTH_ANY等价于CURLAUTH_BASIC | CURLAUTH_DIGEST | CURLAUTH_GSSNEGOTIATE | CURLAUTH_NTLM,CURLAUTH_ANYSAFE等价于CURLAUTH_DIGEST | CURLAUTH_GSSNEGOTIATE | CURLAUTH_NTLM
CURLOPT_INFILESIZE
设定上传文件的大小
CURLOPT_LOW_SPEED_LIMIT
当传输速度小于CURLOPT_LOW_SPEED_LIMIT时,PHP会根据CURLOPT_LOW_SPEED_TIME来判断是否因太慢而取消传输。
CURLOPT_LOW_SPEED_TIME
The number of seconds the transfer should be below CURLOPT_LOW_SPEED_LIMIT for PHP to consider the transfer too slow and abort.
当传输速度小于CURLOPT_LOW_SPEED_LIMIT时,PHP会根据CURLOPT_LOW_SPEED_TIME来判断是否因太慢而取消传输。
CURLOPT_MAXCONNECTS
允许的最大连接数量,超过是会通过CURLOPT_CLOSEPOLICY决定应该停止哪些连接
CURLOPT_MAXREDIRS
指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的。
CURLOPT_PORT
一个可选的用来指定连接端口的量
CURLOPT_PROXYAUTH
The HTTP authentication method(s) to use for the proxy connection. Use the same bitmasks as described in CURLOPT_HTTPAUTH. For proxy authentication, only CURLAUTH_BASIC and CURLAUTH_NTLM are currently supported.
CURLOPT_PROXYPORT
The port number of the proxy to connect to. This port number can also be set in CURLOPT_PROXY.
CURLOPT_PROXYTYPE
Either CURLPROXY_HTTP (default) or CURLPROXY_SOCKS5.
CURLOPT_RESUME_FROM
在恢复传输时传递一个字节偏移量(用来断点续传)
CURLOPT_SSL_VERIFYHOST
1 to check the existence of a common name in the SSL peer certificate.
2 to check the existence of a common name and also verify that it matches the hostname provided.
CURLOPT_SSLVERSION
The SSL version (2 or 3) to use. By default PHP will try to determine this itself, although in some cases this must be set manually.
CURLOPT_TIMECONDITION
如果在CURLOPT_TIMEVALUE指定的某个时间以后被编辑过,则使用CURL_TIMECOND_IFMODSINCE返回页面,如果没有被修改过,并且CURLOPT_HEADER为true,则返回一个"304 Not Modified"的header,CURLOPT_HEADER为false,则使用CURL_TIMECOND_ISUNMODSINCE,默认值为CURL_TIMECOND_IFMODSINCE
CURLOPT_TIMEOUT
设置curl允许执行的最长秒数
CURLOPT_TIMEVALUE
设置一个CURLOPT_TIMECONDITION使用的时间戳,在默认状态下使用的是CURL_TIMECOND_IFMODSINCE
CURLOPT_CAINFO
The name of a file holding one or more certificates to verify the peer with. This only makes sense when used in combination with CURLOPT_SSL_VERIFYPEER.
CURLOPT_CAPATH
A directory that holds multiple CA certificates. Use this option alongside CURLOPT_SSL_VERIFYPEER.
CURLOPT_COOKIE
设定HTTP请求中“Set-Cookie:”部分的内容。
CURLOPT_COOKIEFILE
包含cookie信息的文件名称,这个cookie文件可以是Netscape格式或者HTTP风格的header信息。
CURLOPT_COOKIEJAR
连接关闭以后,存放cookie信息的文件名称
CURLOPT_CUSTOMREQUEST
A custom request method to use instead of "GET" or "HEAD" when doing a HTTP request. This is useful for doing "DELETE" or other, more obscure HTTP requests. Valid values are things like "GET", "POST", "CONNECT" and so on; i.e. Do not enter a whole HTTP request line here. For instance, entering "GET /index.html HTTP/1.0rnrn" would be incorrect.
Note: Don't do this without making sure the server supports the custom request method first.
CURLOPT_EGBSOCKET
Like CURLOPT_RANDOM_FILE, except a filename to an Entropy Gathering Daemon socket.
CURLOPT_ENCODING
header中“Accept-Encoding: ”部分的内容,支持的编码格式为:"identity","deflate","gzip"。如果设置为空字符串,则表示支持所有的编码格式
CURLOPT_FTPPORT
The value which will be used to get the IP address to use for the FTP "POST" instruction. The "POST" instruction tells the remote server to connect to our specified IP address. The string may be a plain IP address, a hostname, a network interface name (under Unix), or just a plain '-' to use the systems default IP address.
CURLOPT_INTERFACE
在外部网络接口中使用的名称,可以是一个接口名,IP或者主机名。
CURLOPT_KRB4LEVEL
KRB4(Kerberos 4)安全级别的设置,可以是一下几个值之一:"clear","safe","confidential","private"。默认的值为"private",设置为null的时候表示禁用KRB4,现在KRB4安全仅能在FTP传输中使用。
CURLOPT_POSTFIELDS
在HTTP中的“POST”操作。如果要传送一个文件,需要一个@开头的文件名
CURLOPT_PROXY
设置通过的HTTP代理服务器
CURLOPT_PROXYUSERPWD
连接到代理服务器的,格式为“[username]:[password]”的用户名和密码。
CURLOPT_RANDOM_FILE
设定存放SSL用到的随机数种子的文件名称
CURLOPT_RANGE
设置HTTP传输范围,可以用“X-Y”的形式设置一个传输区间,如果有多个HTTP传输,则使用逗号分隔多个值,形如:"X-Y,N-M"。
CURLOPT_REFERER
设置header中"Referer: " 部分的值。
CURLOPT_SSL_CIPHER_LIST
A list of ciphers to use for SSL. For example, RC4-SHA and TLSv1 are valid cipher lists.
CURLOPT_SSLCERT
传递一个包含PEM格式证书的字符串。
CURLOPT_SSLCERTPASSWD
传递一个包含使用CURLOPT_SSLCERT证书必需的密码。
CURLOPT_SSLCERTTYPE
The format of the certificate. Supported formats are "PEM" (default), "DER", and "ENG".
CURLOPT_SSLENGINE
The identifier for the crypto engine of the private SSL key specified in CURLOPT_SSLKEY.
CURLOPT_SSLENGINE_DEFAULT
The identifier for the crypto engine used for asymmetric crypto operations.
CURLOPT_SSLKEY
The name of a file containing a private SSL key.
CURLOPT_SSLKEYPASSWD
The secret password needed to use the private SSL key specified in CURLOPT_SSLKEY.
Note: Since this option contains a sensitive password, remember to keep the PHP script it is contained within safe.
CURLOPT_SSLKEYTYPE
The key type of the private SSL key specified in CURLOPT_SSLKEY. Supported key types are "PEM" (default), "DER", and "ENG".
CURLOPT_URL
需要获取的URL地址,也可以在PHP的curl_init()函数中设置。
CURLOPT_USERAGENT
在HTTP请求中包含一个”user-agent”头的字符串。
CURLOPT_USERPWD
传递一个连接中需要的用户名和密码,格式为:“[username]:[password]”。
CURLOPT_HTTP200ALIASES
设置不再以error的形式来处理HTTP 200的响应,格式为一个数组。
CURLOPT_HTTPHEADER
设置一个header中传输内容的数组。
CURLOPT_POSTQUOTE
An array of FTP commands to execute on the server after the FTP request has been performed.
CURLOPT_QUOTE
An array of FTP commands to execute on the server prior to the FTP request.
CURLOPT_FILE
设置输出文件的位置,值是一个资源类型,默认为STDOUT (浏览器)。
CURLOPT_INFILE
在上传文件的时候需要读取的文件地址,值是一个资源类型。
CURLOPT_STDERR
设置一个错误输出地址,值是一个资源类型,取代默认的STDERR。
CURLOPT_WRITEHEADER
设置header部分内容的写入的文件地址,值是一个资源类型。
CURLOPT_HEADERFUNCTION
设置一个回调函数,这个函数有两个参数,第一个是curl的资源句柄,第二个是输出的header数据。header数据的输出必须依赖这个函数,返回已写入的数据大小。
CURLOPT_PASSWDFUNCTION
设置一个回调函数,有三个参数,第一个是curl的资源句柄,第二个是一个密码提示符,第三个参数是密码长度允许的最大值。返回密码的值。
CURLOPT_READFUNCTION
设置一个回调函数,有两个参数,第一个是curl的资源句柄,第二个是读取到的数据。数据读取必须依赖这个函数。返回读取数据的大小,比如0或者EOF。
CURLOPT_WRITEFUNCTION
设置一个回调函数,有两个参数,第一个是curl的资源句柄,第二个是写入的数据。数据写入必须依赖这个函数。返回精确的已写入数据的大小
curl_copy_handle()函数的作用是拷贝一个curl连接资源的所有内容和参数
$ch = curl_init("http://www.baidu.com/");
$another = curl_copy_handle($ch);
curl_exec($another);
curl_close($another);
?>
curl_error()函数的作用是返回一个包含当前会话错误信息的字符串。
curl_errno()函数的作用是返回一个包含当前会话错误信息的数字编号。
curl_multi_init()函数的作用是初始化一个curl批处理句柄资源。
curl_multi_add_handle()函数的作用是向curl批处理会话中添加单独的curl句柄资源。curl_multi_add_handle()函数有两个参数,第一个参数表示一个curl批处理句柄资源,第二个参数表示一个单独的curl句柄资源。
curl_multi_exec()函数的作用是解析一个curl批处理句柄,curl_multi_exec()函数有两个参数,第一个参数表示一个批处理句柄资源,第二个参数是一个引用值的参数,表示剩余需要处理的单个的curl句柄资源数量。
curl_multi_remove_handle()函数表示移除curl批处理句柄资源中的某个句柄资源,curl_multi_remove_handle()函数有两个参数,第一个参数表示一个curl批处理句柄资源,第二个参数表示一个单独的curl句柄资源。
curl_multi_close()函数的作用是关闭一个批处理句柄资源。
$ch1 = curl_init();
$ch2 = curl_init();
curl_setopt($ch1, CURLOPT_URL, "http://www.baidu.com/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.google.com/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
$mh = curl_multi_init();
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
do {
curl_multi_exec($mh,$flag);
} while ($flag > 0);
curl_multi_remove_handle($mh,$ch1);
curl_multi_remove_handle($mh,$ch2);
curl_multi_close($mh);
?>
curl_multi_getcontent()函数的作用是在设置了CURLOPT_RETURNTRANSFER的情况下,返回获取的输出的文本流。
curl_multi_info_read()函数的作用是获取当前解析的curl的相关传输信息。
curl_multi_select()
Get all the sockets associated with the cURL extension, which can then be "selected"
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
