大型网站架构系列:消息队列
以下是消息队列以下的大纲,本文主要介绍消息队列概述,消息队列应用场景和消息中间件示例(电商,日志系统)。
本次分享大纲
- 消息队列概述
- 消息队列应用场景
- 消息中间件示例
- JMS消息服务(见第二篇:大型网站架构系列:分布式消息队列(二))
- 常用消息队列(见第二篇:大型网站架构系列:分布式消息队列(二))
- 参考(推荐)资料(见第二篇:大型网站架构系列:分布式消息队列(二))
- 本次分享总结(见第二篇:大型网站架构系列:分布式消息队列(二))
一、消息队列概述
消息队列中间件是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题。实现高性能,高可用,可伸缩和最终一致性架构。是大型分布式系统不可缺少的中间件。
目前在生产环境,使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ等。
二、消息队列应用场景
以下介绍消息队列在实际应用中常用的使用场景。异步处理,应用解耦,流量削锋和消息通讯四个场景。
2.1异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种1.串行的方式;2.并行方式。
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
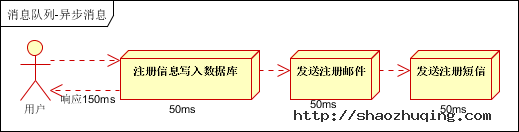
(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
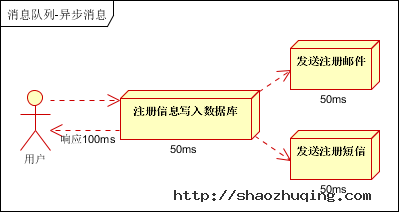
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)。
小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
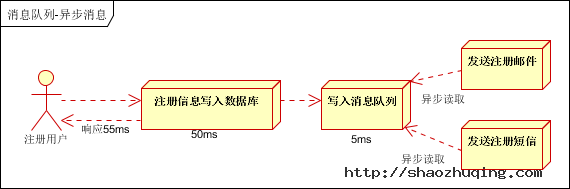
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20 QPS。比串行提高了3倍,比并行提高了两倍。
2.2应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图: 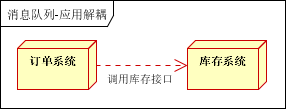
传统模式的缺点:
1) 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2) 订单系统与库存系统耦合;
如何解决以上问题呢?引入应用消息队列后的方案,如下图:

- 订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
- 库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作。
- 假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
2.3流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
- 可以控制活动的人数;
- 可以缓解短时间内高流量压垮应用;

- 用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面;
- 秒杀业务根据消息队列中的请求信息,再做后续处理。
2.4日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下:
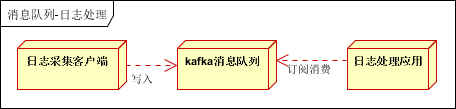
- 日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;
- Kafka消息队列,负责日志数据的接收,存储和转发;
- 日志处理应用:订阅并消费kafka队列中的日志数据;
以下是新浪kafka日志处理应用案例:
转自(http://cloud.51cto.com/art/201507/484338.htm)

(1)Kafka:接收用户日志的消息队列。
(2)Logstash:做日志解析,统一成JSON输出给Elasticsearch。
(3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
(4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
2.5消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
点对点通讯:

客户端A和客户端B使用同一队列,进行消息通讯。
聊天室通讯:
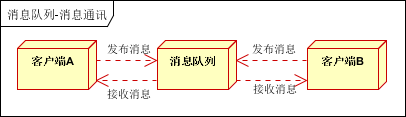
客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。模型为示意图,供参考。
三、消息中间件示例
3.1电商系统

消息队列采用高可用,可持久化的消息中间件。比如Active MQ,Rabbit MQ,Rocket Mq。
(1)应用将主干逻辑处理完成后,写入消息队列。消息发送是否成功可以开启消息的确认模式。(消息队列返回消息接收成功状态后,应用再返回,这样保障消息的完整性)
(2)扩展流程(发短信,配送处理)订阅队列消息。采用推或拉的方式获取消息并处理。
(3)消息将应用解耦的同时,带来了数据一致性问题,可以采用最终一致性方式解决。比如主数据写入数据库,扩展应用根据消息队列,并结合数据库方式实现基于消息队列的后续处理。
3.2日志收集系统

分为Zookeeper注册中心,日志收集客户端,Kafka集群和Storm集群(OtherApp)四部分组成。
- Zookeeper注册中心,提出负载均衡和地址查找服务;
- 日志收集客户端,用于采集应用系统的日志,并将数据推送到kafka队列;
- Kafka集群:接收,路由,存储,转发等消息处理;
Storm集群:与OtherApp处于同一级别,采用拉的方式消费队列中的数据;
阿里系列:OSS存储作为本地数据盘挂载
https://github.com/aliyun/ossfs#ossfs
简介
ossfs 能让您在Linux/Mac OS X 系统中把Aliyun OSS bucket 挂载到本地文件 系统中,您能够便捷的通过本地文件系统操作OSS 上的对象,实现数据的共享。
功能
ossfs 基于s3fs 构建,具有s3fs 的全部功能。主要功能包括:
- 支持POSIX 文件系统的大部分功能,包括文件读写,目录,链接操作,权限, uid/gid,以及扩展属性(extended attributes)
- 通过OSS 的multipart 功能上传大文件。
- MD5 校验保证数据完整性。
安装
预编译的安装包
我们为常见的linux发行版制作了安装包:
- Ubuntu-14.04
- CentOS-7.0/6.5/5.11
请从版本发布页面选择对应的安装包下载安装,建议选择最新版本。
- 对于Ubuntu,安装命令为:
sudo apt-get update
sudo apt-get install gdebi-core
sudo gdebi your_ossfs_package
- 对于CentOS6.5及以上,安装命令为:(安装包下载https://github.com/aliyun/ossfs/releases)
sudo yum localinstall your_ossfs_package
- 对于CentOS5,安装命令为:
sudo yum localinstall your_ossfs_package --nogpgcheck
源码安装
如果没有找到对应的安装包,您也可以自行编译安装。编译前请先安装下列依赖库:
Ubuntu 14.04:
sudo apt-get install automake autotools-dev g++ git libcurl4-gnutls-dev \
libfuse-dev libssl-dev libxml2-dev make pkg-config
CentOS 7.0:
sudo yum install automake gcc-c++ git libcurl-devel libxml2-devel \
fuse-devel make openssl-devel
然后您可以在github上下载源码并编译安装:
git clone https://github.com/aliyun/ossfs.git
cd ossfs
./autogen.sh
./configure
make
sudo make install
运行
设置bucket name, access key/id信息,将其存放在/etc/passwd-ossfs 文件中, 注意这个文件的权限必须正确设置,建议设为640。
echo my-bucket:my-access-key-id:my-access-key-secret > /etc/passwd-ossfs
chmod 640 /etc/passwd-ossfs
将oss bucket mount到指定目录
ossfs my-bucket my-mount-point -ourl=my-oss-endpoint
示例
将my-bucket这个bucket挂载到/tmp/ossfs目录下,AccessKeyId是faint, AccessKeySecret是123,oss endpoint是http://oss-cn-hangzhou.aliyuncs.com
# 安装
sudo yum localinstall ossfs_1.79.9_centos6.5_x86_64.rpm
echo wzj:nnnnnnnnnnnn:xxxxxxxxxxxxxxxxxx > /etc/passwd-ossfs
chmod 640 /etc/passwd-ossfs
mkdir /home/oss
# 启动
ossfs weizaojiao /home/oss -ourl=http://oss-cn-qingdao-internal.aliyuncs.com
/etc/init.d/目录下建立文件ossfs,放入ossfs weizaojiao /home/oss -ourl=http://oss-cn-qingdao-internal.aliyuncs.com
chmod a+x /etc/init.d/ossfs
chkconfig ossfs on
# 卸载
umount /home/oss
# 跳过扫描
我们常用到的3个查找命令分别是whereis,find,locate。
这其中,find命令是最老实巴焦的一个,直接在指定的目录下进行搜索,如果实在不知道在哪,我们就用 find / -name xxx
而另外的两个命令在搜索之前,都要读取 /etc/updatedb.conf (文件检索数据库配置信息)这个文件。
一般,我们为了加速检索,我们经常 updatedb 一下,这时候,它俩就过滤掉一些没用的东西,进行检索。
updatedb.conf下的几个变量分别是:
PRUNE_BIND_MOUNTS="yes" //是否限制搜索
#PRUNENAMES=".git .bzr .hg .svn" //跳过的文件类型,不同后缀之间用空格隔开。这个功能默认是关闭的(用#注释掉了),如果需要打开需将#去掉
PRUNEPATHS="/tmp /var/spool /media /home/.ecryptfs /home/oss" //要跳过的路径,/media 表示其他硬盘
PRUNEFS="NFS nfs nfs4 rpc_pipefs afs binfmt_misc proc smbfs autofs iso9660 ncpfs coda devpts ftpfs devfs mfs shfs sysfs cifs lustre_lite tmpfs usbfs udf fuse.ossfs" //要搜索的文件系统
常用设置
- 使用ossfs --version来查看当前版本,使用ossfs -h来查看可用的参数
- 如果使用ossfs的机器是阿里云ECS,可以使用内网域名来避免流量收费和 提高速度:
- ossfs my-bucket /tmp/ossfs -ourl=http://oss-cn-hangzhou-internal.aliyuncs.com
- 在linux系统中,updatedb会定期地扫描文件系统,如果不想 ossfs的挂载目录被扫描,可参考FAQ设置跳过挂载目录
- 如果你没有使用eCryptFs等需要XATTR的文件系统,可 以通过添加-o noxattr参数来提升性能
- ossfs允许用户指定多组bucket/access_key_id/access_key_secret信息。当 有多组信息,写入passwd-ossfs的信息格式为:
bucket1:access_key_id1:access_key_secret1
bucket2:access_key_id2:access_key_secret2
- 生产环境中推荐使用supervisor来启动并监控ossfs进程,使 用方法见FAQ
高级设置
- 可以添加-f -d参数来让ossfs运行在前台并输出debug日志
- 可以使用-o kernel_cache参数让ossfs能够利用文件系统的page cache,如 果你有多台机器挂载到同一个bucket,并且要求强一致性,请不要使用此 选项
遇到错误
遇到错误不要慌:) 按如下步骤进行排查:
- 如果有打印错误信息,尝试阅读并理解它
- 查看/var/log/syslog或者/var/log/messages中有无相关信息
- grep 's3fs' /var/log/syslog
grep 'ossfs' /var/log/syslog
- 重新挂载ossfs,打开debug log:
ossfs ... -o dbglevel=debug -f -d > /tmp/fs.log 2>&1
然后重复你出错的操作,出错后将/tmp/fs.log保留,自己查看或者发给我
局限性
ossfs提供的功能和性能和本地文件系统相比,具有一些局限性。具体包括:
- 随机或者追加写文件会导致整个文件的重写。
- 元数据操作,例如list directory,性能较差,因为需要远程访问oss服务器。
- 文件/文件夹的rename操作不是原子的。
- 多个客户端挂载同一个oss bucket时,依赖用户自行协调各个客户端的行为。例如避免多个客户端写同一个文件等等。
- 不支持hard link。
- 不适合用在高并发读/写的场景,这样会让系统的load升高
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
