百度员工离职总结:如何做个好员工?
本文来源于泰然野狐禅,在此感谢!
2014年7月4日,我从百度离职了。
这是第一次,我不是因为和老板闹翻而离职;
这是第一次,我带着晋升的喜悦而离职;
这是第一次,我带着满满的收获而离职。
我曾经认为,我永远不会成为一个好员工,因为我太独、太挑剔、不喜欢听话的好孩子、而且讨厌一切想要改变我的人。但是三年过去,我改变了不少,我必须承认,所谓“进步”的过程,就是被认可的过程,也是被“驯化”的过程。
所谓“驯化”,就是了解规则、遵守规则、利用规则的过程。我并非被某些人“驯化”,而是被社会与职场的规律驯化。我曾经鄙视这个过程,但今天看来,作为一个资质平庸的人,如果你想在这个社会里做成点儿什么,“被驯化”是不可避免的。
我也曾自诩“卓尔不群”,又受了老罗“彪悍的人生不需要解释”的“蛊惑”。但在现实中,这个路子不一定行得通。你不得不向很多人解释、用他们(而不是自己)喜欢的方式解释,因为只有得到他们的认可和支持,你才能继续工作下去。如果你是一个资质平庸的人,你不得不这样做,美剧《犯罪心理》中有一句话:“凡按自己的方式追求理想者,无不树敌。”
树敌多了,你就死了。
现在,我不敢说自己是个“好员工”,我只是觉得我是个比曾经的自己更好的员工。在离职的时候,我打算把自己这几年的职场心得总结一下,算是给自己的一个礼物。
我是一个资质平庸的人,以下这些心得只适用于愚钝且资质平庸的我,对于才华横溢的天才们并不适用。
一、你有“同理心”吗?
什么叫“同理心”?
说复杂点儿,同理心就是站在当事人的角度和位置上,客观地理解当事人的内心感受,且把这种理解传达给当事人的一种沟通交流方式。
说简单点儿,同理心就是“己所不欲,勿施于人”。将心比心,也就是设身处地去感受、去体谅他人。
说白了,同理心就是“情商”。
具体点说:
同理心就是,领导交办一项工作,你要读懂他的目的、看清他的用意。我经常遇到这样的情况:给团队成员安排工作时,一再询问“我说明白了吗”“有没有问题”,再三确认后,提交上来的东西仍然答非所问。所以我在接受任务时,总会向领导确认:你想要的是什么?你的目的是什么?了解这个以后,就可以站在他的角度,有效的帮他解决问题。
同理心就是,在激励员工时,点准他们的“兴奋点”,不揭“伤疤”。每个人都有认真工作的理由,家庭富裕的为了证明自己的能力,家境贫寒的为了改善自己的生活,吊儿郎当的爱面子怕丢工作。了解不同人的不同心理需求,才能调动大家的积极性。若是不问青红皂白,拿着鞭子大喊加油,只能是徒劳无功。
同理心就是,在与他人合作时,了解对方的需求和心理,潜移默化的说服对方,双方为了同一个目标而努力。想用强势压服别人,通常不好使。
二、听话,出活;
7年前,我和北京交通台的潘久阳聊天,他说“什么叫好员工啊,好员工特简单,就四个字:听话、出活”。这话我一直记着,这是至理名言。
什么叫“听话”?有句老话叫“干活不由东,累死也无功”,谁是“东”啊?你的直属领导就是“东”,大部分时候,听他的话准没错儿。
有朋友说:我有能力,我比领导水平高,我就不听领导的!咱先不说到底谁水平高——既然他能当你领导,肯定有比你强的地方——咱就说水平和能力这事儿,什么叫“有能力”啊?领导用你,你就有能力。不用你,甭管您有再大的能力,都是白费。
根据我的经验,一般来说,领导都比你水平高,起码在一点上是这样:他比你信息更全面、判断的更准确。因为领导更容易接触到更高层,更了解更高层的意图,他知道的你不知道,你在自己的角度上认为“这么做对”,但领导在更高的层面,并不一定这么看。
还有朋友说我领导就是瞎指挥,明摆着不对,我干嘛要听他的?这是另外一个问题,咱们最后一条会谈到,如果你觉得现在的环境无法进步,就可以考虑离职了。
什么叫“出活”?就是领导给你的工作,你得按时完成并且汇报总结。如果这个工作要持续较长时间,那么你需要阶段性的给领导反馈。我们经常犯一个错误,领导安排的工作,他不问你也不说,黑不提白不提这事儿就算过去了。
过去了?哪儿那么容易啊!领导都记着呢,你等他问你的时候——“诶小陈,上次安排你做的那事儿怎么样了?”——他就已经在心里给你写上了标签:“不靠谱”。
一个“不靠谱”需要用十个“靠谱”来扭转,两个“不靠谱”就很难转变印象,三个“不靠谱”你就没有机会了。
“出活”还有一层含义,就是“超预期”。这个咱们在下一点聊。
三、要想人前显贵,必须背地里受罪;
在公司里上班,大家的智商都差不多,谁也不比谁强多少,拼的都是努力和用心的程度。你下功夫了,就比别人做得好。哦,本来就不比别人聪明,别人下班你也下班、别人玩儿你也玩儿、别人搞对象你也泡马子,你凭什么比别人干得好?
“要想人前显贵,必须背地里受罪”的道理并不难懂。就是真到受苦的时候就含糊了,有的人会说,我年纪轻轻的为什么不好好享受生活啊?这种想法很普遍,这本是一个价值观的问题,没什么可说的,一个人想怎么生活都对。但是有一些朋友是在追求理想和享受生活中纠结的,和这些朋友,是可以聊的。
马云曾经说过:我们追求的应是人生的大平衡,而不是一时一日的小平衡(大意如此)。新东方也有一句话说:怕吃苦吃苦一辈子,不怕苦吃苦半辈子。两句话大意相同,值得深思。
一件工作,你用心想了做了,领导一看就知道,你想糊弄,也是一看就知道,这个没侥幸。领导在判断这个问题的时候,标准很简单:我想到的,你都没想到,肯定没用心;我想到的,你想到了一部分,用心不够;我没想到的,你想到了,这是用心了——这就是“超预期”。如果你每次都能给你的老板一个超预期的结果,那你无疑就是一个好员工。
四、能忍多大事儿,就能成多大事儿;
讲一个笑话:
在电梯里,领导放了个屁,回头问秘书,谁放的?秘书忙答道:“不是我!”领导不说话,这事儿过去了。不久,秘书被调离,领导在谈起调离原因时说道:“屁大的委屈都受不了,还能做的了啥?”
在工作上想受到领导的赏识和重用,除了要有过硬的工作能力外,更重要的,要有足够的涵养(抗压力或者回血能力)。能受多大委屈,才能成多大事儿,这是一定的。为了考察你的“抗压力”,领导有时会故意试你,你可一定要经得住考验。
我自己也经历过类似的事情:
有一天加班,晚上2点钟到家,收到老板的一封邮件,批评我工作不到位。我收到邮件后就很崩溃,还很委屈。于是当即奋笔疾书,回邮件!解释我是如何工作的,我做的如何有道理,我做的如何有效果……写了2000多字。
写完了,我好像冷静了一些,我就琢磨一个事儿:如果我是老板,我对一个员工工作不满意,于是我给他写了封邮件批评他,我想看到的是他洋洋洒洒的解释和辩解吗?显然不是啊。然后我就突然明白了,于是我把那2000多字都删了,简单回复了一句话,大意是:我会反思工作的问题,然后尽快整改。
两个月后我晋升了。在我的晋升仪式上,我对我老板说起这件事,他对我说,我知道你很委屈,我就是想看看你在面对委屈和压力时,会有怎样的反应,这体现了一个人的成熟程度。
多说一句,人们会感叹“钱难赚,屎难吃”,人人都想“站着把钱赚了”,我更相信他跪着的时候你没看见。我们总是强调“尊严”,比尔盖茨说过一句话:“没有人会在乎你的尊严,你只能在自我感觉良好之前取得尽可能多成就。”
对于比尔盖茨这样的天才姑且如此,况且我这样资质平庸的碌碌之辈呢?
五、总躲着领导,你就危险了;
不少人躲着领导,尽量少跟领导说话、绕着领导走。因为跟领导近了事儿就多,不跟领导多接触,事儿少,多清闲。这是“一叶障目,不见泰山”。
如果你想在工作上取得一些成绩,我建议还是应该主动的多和领导沟通。领导在平时开会时说的多是大面儿上的话,真话、有用的话、有价值的话不一定说。这并不是他不想说,而是没机会说。
有心的员工会随时抽时间和领导沟通、增加私人交流的机会:一起吃饭、一起抽烟、一起上下班、甚至一起打球K歌……通过这样的机会,你可以了解领导对于你的看法、对于工作的观点,这些都有益于你调整自己的工作的方式。
有朋友担心这样做会引起领导反感,其实完全不会,领导们多是孤独的,如果他发现有一个员工虚心向他请教、积极分享工作的思考,他是非常高兴的。
有朋友说,我不想那么累,我就想混混日子。即便是这样,你最好也主动和领导沟通、主动汇报。你追着他,你是主动的一方,其实你不累;等到他追你的时候,你就被动了,最终就累死了。
老罗曾经讲过一个故事,说你进入单位,见到老板就低头过去、不理他,他当然也不理你。等到年终考核、或者裁员的时候,老板隐约记得有你这么个人,但不知道你的名字、更不知道你做了什么。老板会想:这是你的错,不是我的错。不开除你开除谁?
老板也是人,大家用人类的方式沟通,一切会变得简单很多。
六、帮助别人千万别吝啬;
马云曾经说,成功就是成就自己帮助别人。这话没错。
如果你在一家公司工作,你发现你的工作不用任何人协助就能自己独立完成,那你多半是个打杂的。相反,你的工作需要越多人协作,就越复杂、越高级。在实际工作中我发现,我处在一个协作关系网中,如果没有别人的帮助,我就无法工作下去。
当你正在忙于某项工作时,有同事来向你“求助”,很多时候我们会很直接、甚至粗暴的拒绝,殊不知这样做正在给你今后的工作种下麻烦的种子。风水轮流转,在一家公司里,大家的工作互相交叉的几率很大,说不定你会用上谁,这些人脉关系需要平时去维护。今天你帮助了人家,说不定明天对方就会成为你的救命稻草,这非常可能。
有一天我正在疲于应付一个项目总结,这时有个其他部门的同事来找我聊合作的事儿,我并不认识他,我耐心的和他介绍了情况,并且真的形成了几次愉快的合作,半年后,我的晋升答辩会上,我发现他是我的答辩委员……
七、目标再目标,量化再量化;
没有目标的,都不叫工作;没有量化的,都不叫目标。
在接受一项工作时,先问目标是什么;在布置一项工作时,先交代目标是什么。这个不说清楚,都是扯淡。
不想成为蒙着眼睛拉磨的驴?那么除了清楚的知道自己的目标外,还得知道你的部门、你的公司的目标,最关键的,你需要知道,你的工作在总体目标中处在什么地位、扮演什么角色。如果你发现,你工作的目标和总体目标关系很小、甚至没有关系,那么你就很容易被拿掉。
辞退员工,或给员工绩效打分“不合格”是很令人头疼的,但其实这事儿并不难。关键就在于事先和每个员工一起制定量化的工作目标,并且随时提醒员工,他的工作是否达到了要求。没有达到量化指标,辞退或“不合格”是令所当然事儿,在数据面前,再矫情的人也无话可说。相反,如果谈感觉、聊希望,这事儿就没法办了。
八、找到解决问题的办法是我的义务;
领导安排的工作,不能说“我做不了”、“我做不到”。
公司请我们来工作,是为了解决问题的,如果不能解决问题,我们就没有价值。工作推进中遇到困难,无法继续进行,这是很正常的事儿,我们需要做的是主动寻找答案和办法,哪怕你的办法不妥,那么就去问,但无论如何不能对你的领导说,我不会。
前天,我在公司里听见隔壁团队的领导安排同事定一个会议室,有公司工作经验的人都知道,会议室是很难订到的,弄不好还需要“托关系,走后门”。这个小同学可能是没有订到,于是和他的领导说“我没订到”,他的领导直接就急了,说:“那怎么办?需要我来订吗?”
这位领导发火是有道理的,这位小同学在发现自己订不到会议室后,应该做的是自己想办法解决问题——最简单的就是向老同事咨询。
解决问题的能力是员工最关键的能力,没有之一。在工作中遇到困难特别正常,在这时,我们有一项义务,就是找到解决问题的办法。
九、尽量不说“不是我,我没有”;
绝大多数人在面对批评的时候,本能反应都是推卸责任,此时的口头禅就是“不是我”、“没有我”。我总觉得,很多时候,越成熟的人,就越少用本能反应面对问题,因为他们有更强的自控力。
尽量不说“不是我”、“没有我”这样的话,因为这些话毫无作用,领导听惯了这样的推卸之词,丝毫不会为之所动。此时如果能够主动承担责任,反而体现了一种担
当。即便真是被冤枉了,当场辩解往往也不是最明智的选择,可以先保持沉默,私下找机会和领导进行沟通。这个详见第三条。
十、“言多必失”死得惨;
在公司里,少说闲话,不说是非话,不做是非人。
你就相信一点:你说的每句话,你的老板都会知道。好话可能不一定,坏话则是一定的。
还是做个正直的人吧,这样最简单,也受益最大。正直人的原则是:批评当面说,赞美背后讲。
十一、知道什么时候离开。
好多同事和朋友和我聊过离职的话题,我对朋友们的建议是,如果你因为觉得工作不爽,那就别离职,因为甭管到哪里,都会不爽:老板不喜欢、同事不可爱、工作太劳累、关系太复杂……我以我在多家大公司工作的经历担保:几乎所有我工作过的公司,令人不爽的事儿都是一样的。
那么什么时候离开呢?我想,有两种情况:
1、在这家公司,你已经没有上升的空间、无法学习到更多的东西了;
2、在这家公司,你已学到足够的知识,可以在新领域或新平台上一展身手了。
JavaScript 语言基础知识点总结(思维导图)
温故而知新 ———— 最近温习了一遍Javascript 语言,故把一些基础、概念性的东西分享一下。
(下面内容大都为条目、索引,是对知识点的概括,帮助梳理知识点,具体内容需要查阅资料)
JavaScript 数组 |
JavaScript 函数基础 |
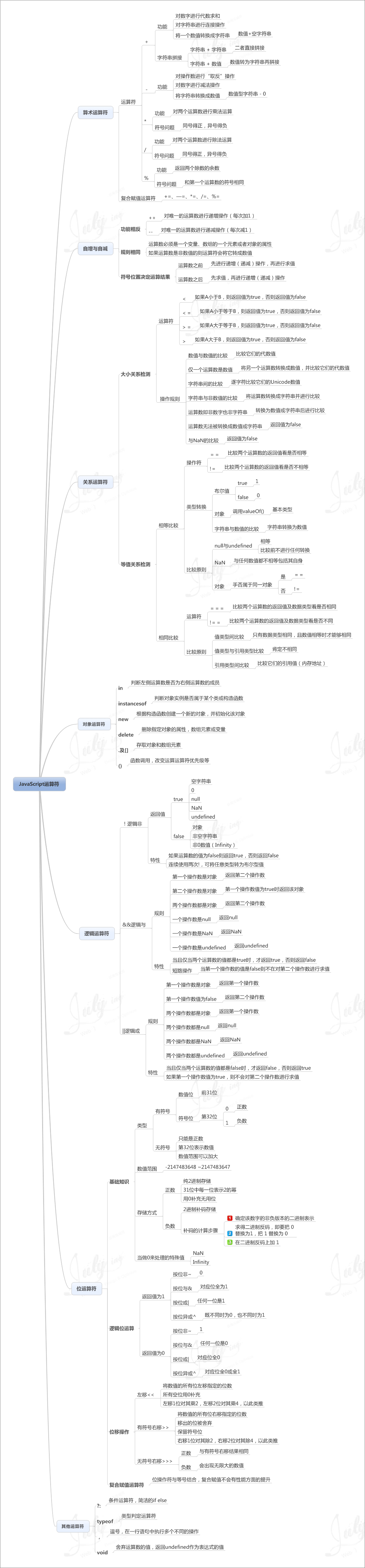
Javascript 运算符 |
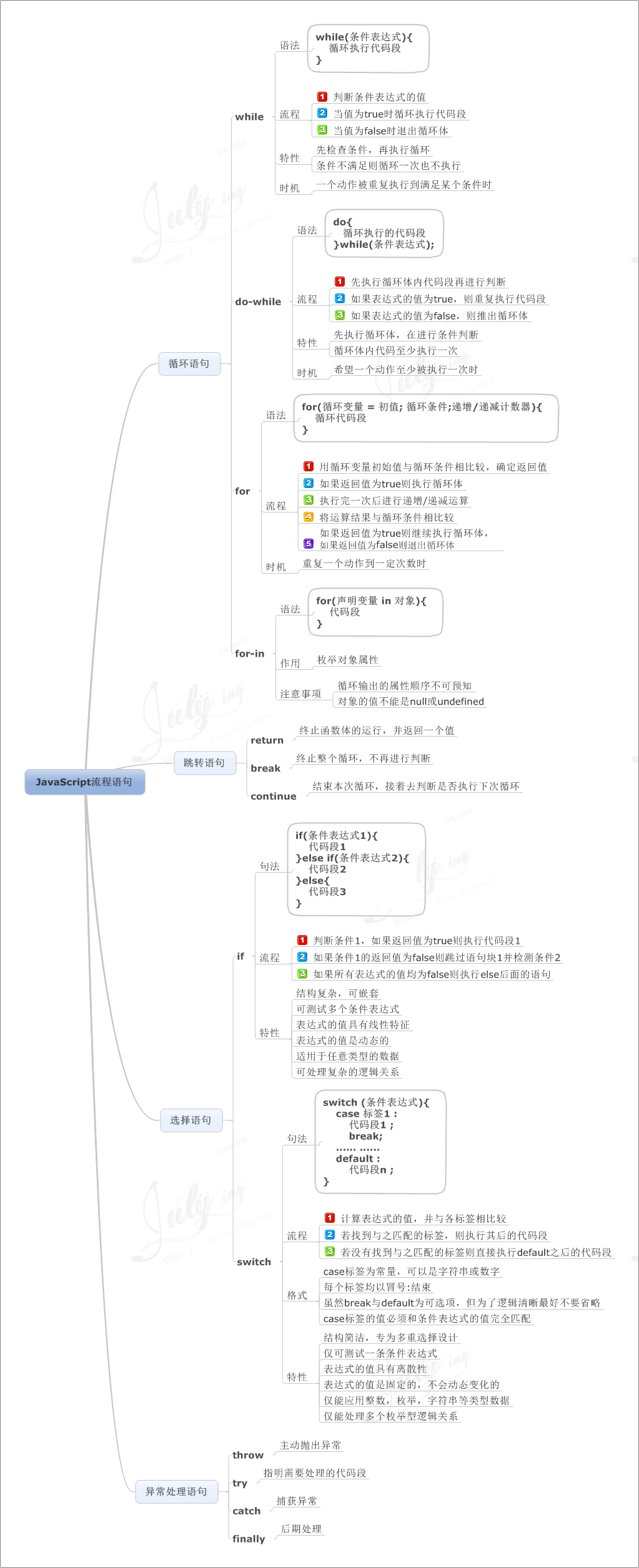
JavaScript 流程控制 |
JavaScript 正则表达式 |
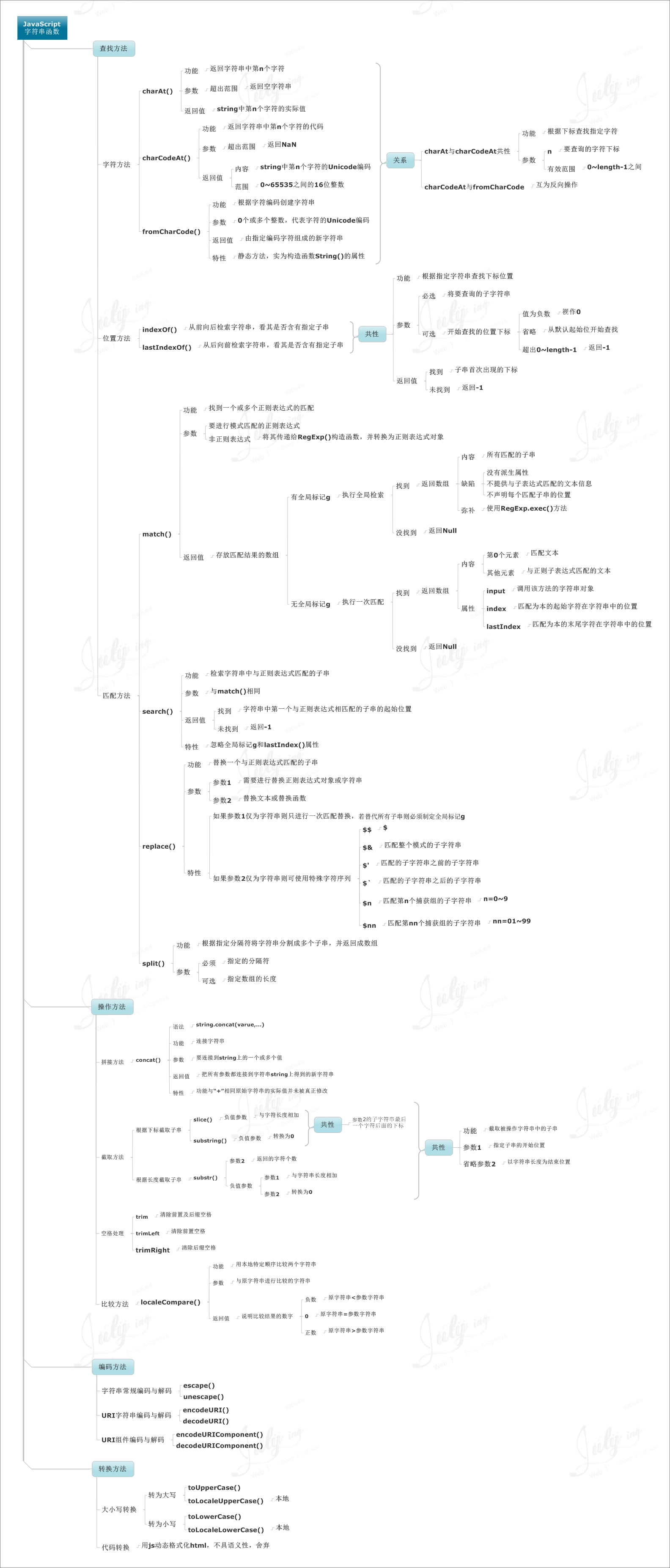
JavaScript 字符串函数 |
| JavaScript 数据类型 |
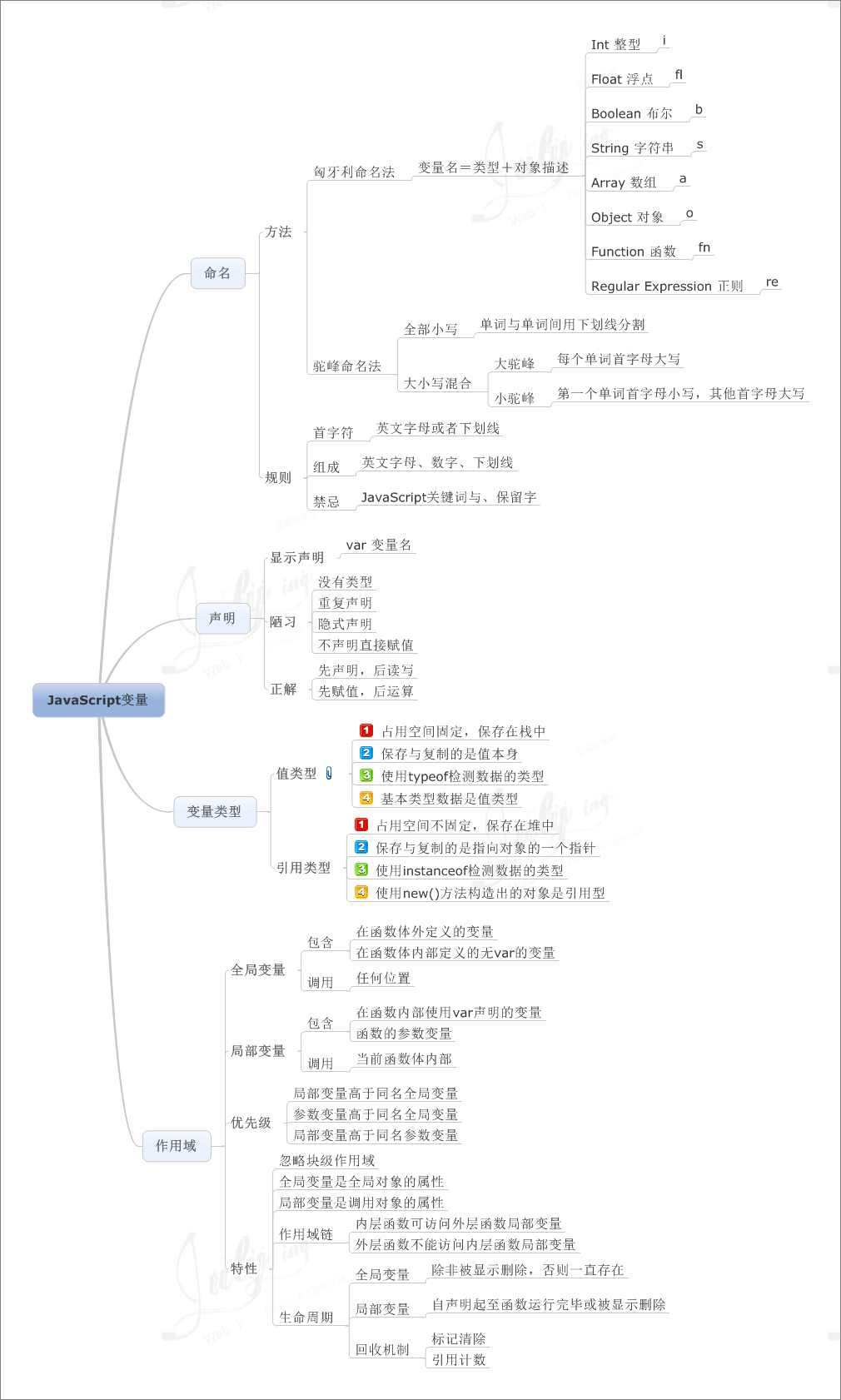
JavaScript 变量 |
Window 对象 |
DOM 基本操作 |
1.DOM基础操作

2.数组基础

3.函数基础

4.运算符
5.流程控制语句
6.正则表达式
7.字符串函数
8.数据类型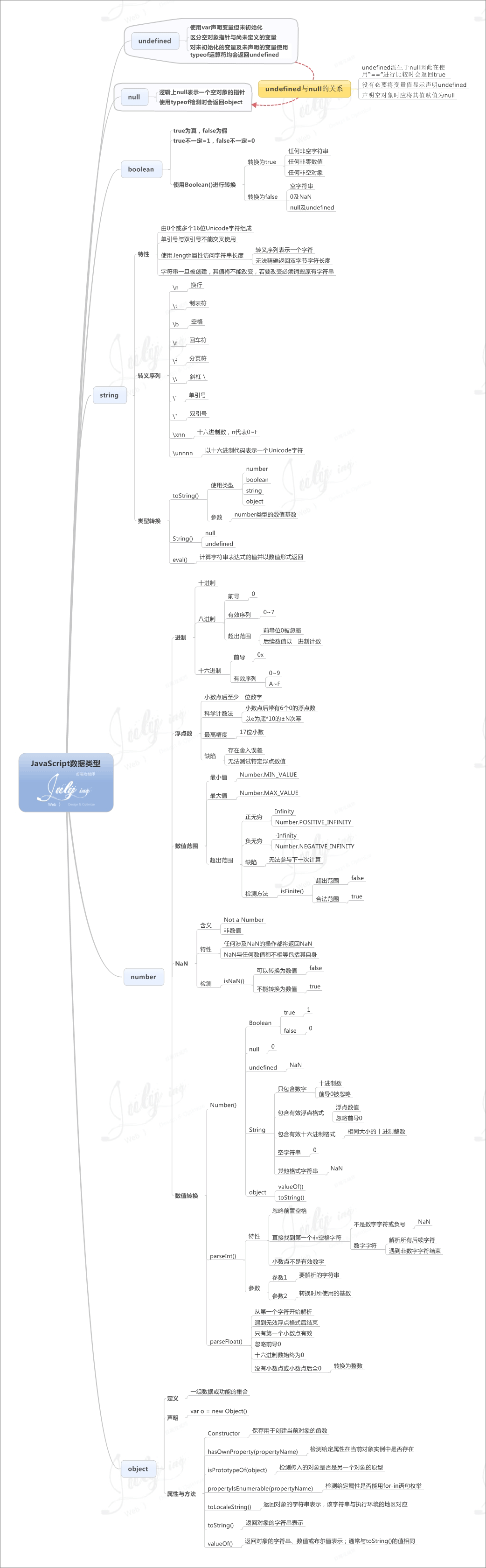
9.变量
10.window对象
JavaScript跨域总结与解决办法
- 什么是跨域
- 1、document.domain+iframe的设置
- 2、动态创建script
- 3、利用iframe和location.hash
- 4、window.name实现的跨域数据传输
- 5、使用HTML5 postMessage
- 6、利用flash
本文来自网络(http://f2e.me/200904/cross-scripting/,该网址已不能访问),仅作个人读书笔记之用,并稍作修改和补充。
什么是跨域
JavaScript出于安全方面的考虑,不允许跨域调用其他页面的对象。但在安全限制的同时也给注入iframe或是ajax应用上带来了不少麻烦。这里把涉及到跨域的一些问题简单地整理一下:
首先什么是跨域,简单地理解就是因为JavaScript同源策略的限制,a.com 域名下的js无法操作b.com或是c.a.com域名下的对象。更详细的说明可以看下表:
| URL | 说明 | 是否允许通信 |
|---|---|---|
| http://www.a.com/a.js http://www.a.com/b.js |
同一域名下 | 允许 |
| http://www.a.com/lab/a.js http://www.a.com/script/b.js |
同一域名下不同文件夹 | 允许 |
| http://www.a.com:8000/a.js http://www.a.com/b.js |
同一域名,不同端口 | 不允许 |
| http://www.a.com/a.js https://www.a.com/b.js |
同一域名,不同协议 | 不允许 |
| http://www.a.com/a.js http://70.32.92.74/b.js |
域名和域名对应ip | 不允许 |
| http://www.a.com/a.js http://script.a.com/b.js |
主域相同,子域不同 | 不允许 |
| http://www.a.com/a.js http://a.com/b.js |
同一域名,不同二级域名(同上) | 不允许(cookie这种情况下也不允许访问) |
| http://www.cnblogs.com/a.js http://www.a.com/b.js |
不同域名 | 不允许 |
- 特别注意两点:
- 第一,如果是协议和端口造成的跨域问题“前台”是无能为力的,
- 第二:在跨域问题上,域仅仅是通过“URL的首部”来识别而不会去尝试判断相同的ip地址对应着两个域或两个域是否在同一个ip上。
“URL的首部”指window.location.protocol +window.location.host,也可以理解为“Domains, protocols and ports must match”。
接下来简单地总结一下在“前台”一般处理跨域的办法,后台proxy这种方案牵涉到后台配置,这里就不阐述了,有兴趣的可以看看yahoo的这篇文章:《JavaScript: Use a Web Proxy for Cross-Domain XMLHttpRequest Calls》
1、document.domain+iframe的设置
对于主域相同而子域不同的例子,可以通过设置document.domain的办法来解决。具体的做法是可以在http://www.a.com/a.html和http://script.a.com/b.html两个文件中分别加上document.domain = ‘a.com’;然后通过a.html文件中创建一个iframe,去控制iframe的contentDocument,这样两个js文件之间就可以“交互”了。当然这种办法只能解决主域相同而二级域名不同的情况,如果你异想天开的把script.a.com的domian设为alibaba.com那显然是会报错地!代码如下:
www.a.com上的a.html
document.domain = 'a.com';
var ifr = document.createElement('iframe');
ifr.src = 'http://script.a.com/b.html';
ifr.style.display = 'none';
document.body.appendChild(ifr);
ifr.onload = function(){
var doc = ifr.contentDocument || ifr.contentWindow.document;
// 在这里操纵b.html
alert(doc.getElementsByTagName("h1")[0].childNodes[0].nodeValue);
};
script.a.com上的b.html
document.domain = 'a.com';
这种方式适用于{www.kuqin.com, kuqin.com, script.kuqin.com, css.kuqin.com}中的任何页面相互通信。
备注:某一页面的domain默认等于window.location.hostname。主域名是不带www的域名,例如a.com,主域名前面带前缀的通常都为二级域名或多级域名,例如www.a.com其实是二级域名。 domain只能设置为主域名,不可以在b.a.com中将domain设置为c.a.com。
- 问题:
- 1、安全性,当一个站点(b.a.com)被攻击后,另一个站点(c.a.com)会引起安全漏洞。
- 2、如果一个页面中引入多个iframe,要想能够操作所有iframe,必须都得设置相同domain。
2、动态创建script
虽然浏览器默认禁止了跨域访问,但并不禁止在页面中引用其他域的JS文件,并可以自由执行引入的JS文件中的function(包括操作cookie、Dom等等)。根据这一点,可以方便地通过创建script节点的方法来实现完全跨域的通信。具体的做法可以参考YUI的Get Utility
这里判断script节点加载完毕还是蛮有意思的:ie只能通过script的readystatechange属性,其它浏览器是script的load事件。以下是部分判断script加载完毕的方法。
js.onload = js.onreadystatechange = function() {
if (!this.readyState || this.readyState === 'loaded' || this.readyState === 'complete') {
// callback在此处执行
js.onload = js.onreadystatechange = null;
}
};
3、利用iframe和location.hash
这个办法比较绕,但是可以解决完全跨域情况下的脚步置换问题。原理是利用location.hash来进行传值。在url: http://a.com#helloword中的‘#helloworld’就是location.hash,改变hash并不会导致页面刷新,所以可以利用hash值来进行数据传递,当然数据容量是有限的。假设域名a.com下的文件cs1.html要和cnblogs.com域名下的cs2.html传递信息,cs1.html首先创建自动创建一个隐藏的iframe,iframe的src指向cnblogs.com域名下的cs2.html页面,这时的hash值可以做参数传递用。cs2.html响应请求后再将通过修改cs1.html的hash值来传递数据(由于两个页面不在同一个域下IE、Chrome不允许修改parent.location.hash的值,所以要借助于a.com域名下的一个代理iframe;Firefox可以修改)。同时在cs1.html上加一个定时器,隔一段时间来判断location.hash的值有没有变化,一点有变化则获取获取hash值。代码如下:
先是a.com下的文件cs1.html文件:
function startRequest(){
var ifr = document.createElement('iframe');
ifr.style.display = 'none';
ifr.src = 'http://www.cnblogs.com/lab/cscript/cs2.html#paramdo';
document.body.appendChild(ifr);
}
function checkHash() {
try {
var data = location.hash ? location.hash.substring(1) : '';
if (console.log) {
console.log('Now the data is '+data);
}
} catch(e) {};
}
setInterval(checkHash, 2000);
cnblogs.com域名下的cs2.html:
//模拟一个简单的参数处理操作
switch(location.hash){
case '#paramdo':
callBack();
break;
case '#paramset':
//do something……
break;
}
function callBack(){
try {
parent.location.hash = 'somedata';
} catch (e) {
// ie、chrome的安全机制无法修改parent.location.hash,
// 所以要利用一个中间的cnblogs域下的代理iframe
var ifrproxy = document.createElement('iframe');
ifrproxy.style.display = 'none';
ifrproxy.src = 'http://a.com/test/cscript/cs3.html#somedata'; // 注意该文件在"a.com"域下
document.body.appendChild(ifrproxy);
}
}
a.com下的域名cs3.html
//因为parent.parent和自身属于同一个域,所以可以改变其location.hash的值 parent.parent.location.hash = self.location.hash.substring(1);
当然这样做也存在很多缺点,诸如数据直接暴露在了url中,数据容量和类型都有限等……
4、window.name实现的跨域数据传输
文章较长列在此处不便于阅读,详细请看 window.name实现的跨域数据传输。
5、使用HTML5 postMessage
HTML5中最酷的新功能之一就是 跨文档消息传输Cross Document Messaging。下一代浏览器都将支持这个功能:Chrome 2.0+、Internet Explorer 8.0+, Firefox 3.0+, Opera 9.6+, 和 Safari 4.0+ 。 Facebook已经使用了这个功能,用postMessage支持基于web的实时消息传递。
- otherWindow.postMessage(message, targetOrigin);
- otherWindow: 对接收信息页面的window的引用。可以是页面中iframe的contentWindow属性;window.open的返回值;通过name或下标从window.frames取到的值。
message: 所要发送的数据,string类型。
targetOrigin: 用于限制otherWindow,“*”表示不作限制
a.com/index.html中的代码:
b.com/index.html中的代码:
参考文章:《精通HTML5编程》第五章——跨文档消息机制、https://developer.mozilla.org/en/dom/window.postmessage
6、利用flash
这是从YUI3的IO组件中看到的办法,具体可见http://wiht.link/YUI-intro。
可以看在Adobe Developer Connection看到更多的跨域代理文件规范:ross-Domain Policy File Specifications、HTTP Headers Blacklist。
网站排名算法总结绝对精华中的精华
下面总结网站排名经验,能看懂就看懂,看不懂的,自己琢磨,试验。
1.每个网页标题简洁,不超过30字。
2.每个网页核心关键词不超过3个。如果可以,你要学会放弃。
3.最重要的关键词放在标题首位,依次类推。
4.网站的描述,简洁,明了,最开始和结束部分自然出现关键词。
5.网站导航采用文字导航。
6.网站图片原创,添加alt标签,切忌讳乱加。搜索引擎能读懂图片。
7.与主题无关内容作成JS或者图片。
8.网站内容简洁,信息丰厚。关键词分布其中合理,自然。如果你自己都读不懂,那就放弃。
9.网站联系人信息要原创,比如邮箱,电话,姓名等。
10.网站代码简洁。
11.与主题相关的JS,框架,做兼容优化。
12.网站设计大方,美观。
13.网站域名时间超过2年以上,最好是3年。
14.域名最好出行最核心关键词,针对除百度以外搜索引擎有效。
15.如果新域名,联系人信息一定要公布,切为新信息。
16.空间要稳定,那种经常网站打不开的网站,肯定没有排名。
17.友情链接要找外地的网站。
18.友情链接不看PR,看快照,看核心关键词排名,看SITE首页是否存在。
19.网站外链要丰富,新闻类的,行业类的,生活类的,公关类的,越丰厚越好。
20.网站外链不在数量,在质量。增加要掌握好节奏。
21.网站外链要出现网址,占70%,锚文本要适当。原因自己去想。
22.网站外链要首先提高首页权重,首页快照在7天内,核心关键词在前3页,则网站权重及格。
23.网站外链要出现在流行度较高的地方。
24.网站外链出现的地方,切忌垃圾链接,链接过多。
25.网站添加流量统计,大概数据要公开。
26.适当刷网站IP和来路,切忌网站流量来自某一个搜索引擎。
27.网站内容要围绕主题展开。切忌发布无关内容。
28.网站添加XML和HTML格式地图,有助于各大搜索引擎收录抓取。
29.网站按规律更新,切忌一个不更新,或者一下更新上百篇。
30.分布好网站内链接。核心关键词指向核心关键词页面。
31.网页内容中出现关键词加粗效果并不好,避免全加粗加链接。
32.每个页面最好出现一次H标签,此内容和网友标题一致。
33.网站404页面。
34.与主题无关页面,运用Robots.txt禁止。
35.制造网站主题相关的PDF,doc,exe等文档和软件提供下载。在这些资源上写上自己的网站。
36.网站最开始内容,最好一次性完成,切忌收录后经常更改。
37.网站页面切忌经常更改主题,和关键词密度,95%被K都是这个原因。
38.网站外链切忌同一个账号,同一个名字去发布。比如博客,全是同一个人的博客。论坛全是同一个账号。
39.这些工作做完了,你需要等待!一边持续更新,维持,添加外链和内链。
40.还是等待,直到网站排名出现。
MySQL常用命令总结
++安装mysql
参见自带的INSTALL-SOURCE文件
$ ./configure ?prefix=/app/mysql-5.0.51a ?with-charset=utf8 ?with-extra-charsets=utf8,gb2312,utf8
++启动/关闭mysql
$ path/mysqld_safe -user=mysql &
$ /mysqladmin -p shutdown
++修改root口令
$ mysqladmin -u root -p password ‘新密码’
++查看服务器状态
$ path/mysqladmin version -p
++连接远端mysql服务器
$ path/mysql -u 用户名 -p #连接本机
$ path/mysql -h 远程主机IP -u 用户名 -p#连接远程MYSQL服务器
++创建/删除 数据库或表
$ mysqladmin -u root -p create xxx
mysql> create database 数据库名;
mysql> create TABLE items (
id INT(5) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
symbol CHAR(4) NOT NULL,
username CHAR(8),
INDEX sym (symbol),INDEX …..
UNIQUE(username)
) type=innodb;
mysql> drop database [if exists] 数据库名
mysql> create table 表名;
mysql> drop table 表名;
++查看数据库和查看数据库下的表
mysql> show databases;
mysql> show tables;
mysql> show table status;
mysql> desc 表名; #查看具体表结构信息
mysql> SHOW CREATE DATABASE db_name #显示创建db_name库的语句
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建用户
mysql> grant select,insert,update,delete,alter on mydb.* to test2@localhost identified by “abc”;
mysql> grant all privileges on *.* to test1@”%” identified by “abc”;
mysql> flush privileges;
++用户管理
mysql> update user set password=password (’11111′) where user=’test1′; #修改test1密码为111111
mysql> DELETE FROM user WHERE User=”testuser” and Host=”localhost”; #删除用户帐号
mysql> SHOW GRANTS FOR user1; #显示创建user1用户的grant语句
++mysql数据库的备份和恢复
$ mysqldump -uuser -ppassword -B DB_name [--tables table1 --tables table2] > exportfile.sql
$ mysql -uroot -p xxx < aaa.sql #导入表
$ mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名 ##导出单独的表
++导出一个数据库结构
$ mysqldump -u wcnc -p -d ?add-drop-table smgp_apps_wcnc >wcnc_db.sql
-d 没有数据 ?add-drop-table 在每个create语句之前增加一个drop table
++忘记mysql密码
先停止所有mysql服务进程
$ mysqld_safe ?skip-grant-tables & mysql
mysql> use mysql;
mysql> update user set password=password(’111111′) where user=’root’;
mysql> flush privileges;
然后重启mysql并以新密码登入即可
++当前使用的数据库
mysql> select database();
===数据库日常操作维护====
++创建表
mysql> create table table_name
(column_name datatype {identity |null|not null},f_time TIMESTAMP(8),…)ENGINE=MyISAM AUTO_INCREMENT=3811 DEFAULT CHARSET=utf8;
例: CREATE TABLE guest (name varchar(10),sex varchar(2),age int(3),career varchar(10));
# desc guest可查看表结构信息
# TIMESTAMP(8) YYYYMMDD 其中(2/4/6/8/10/12/14)对应不同的时间格式
mysql> SHOW CREATE TABLE tbl_name #显示创建tbl_name表的语句
++创建索引
可以在建表的时候加入index indexname (列名)创建索引,
也可以手工用命令生成 create index index_name on table_name (col_name[(length)],… )
mysql> CREATE INDEX number ON guest (number(10));
mysql> SHOW INDEX FROM tbl_name [FROM db_name] #显示现有索引
mysql> repair TABLE date QUICK; #索引列相关变量变化后自动重建索引
++查询及常用函数
mysql> select t1.name, t2.salary from employee AS t1, info AS t2 where t1.name = t2.name;
mysql> select college, region, seed from tournament ORDER BY region, seed;
mysql> select col_name from tbl_name WHERE col_name > 0;
mysql> select DISTINCT …… [DISTINCT关键字可以除去重复的记录]
mysql> select DATE_FORMAT(NOW(),’%m/%d/%Y’) as DATE, DATE_FORMAT(NOW(),’%H:%m:%s’) AS TIME;
mysql> select CURDATE(),CURTIME(),YEAR(NOW()),MONTH(NOW()),DAYOFMONTH(NOW()),HOUR(NOW()),MINUTE(NOW());
mysql> select UNIX_TIMESTAMP(),UNIX_TIMESTAMP(20080808),FROM_UNIXTIME(UNIX_TIMESTAMP()); mysql> select PASSWORD(”secret”),MD5(”secret”); #加密密码用
mysql> select count(*) from tab_name order by id [DESC|ASC]; #DESC倒序/ASC正序
* 函数count,AVG,SUM,MIN,MAX,LENGTH字符长度,LTRIM去除开头的空头,RTRIM去尾部空格,TRIM(str)去除首部 尾部空格,LETF/RIGHT(str,x)返回字符串str的左边/右边x个字符,SUBSTRING(str,x,y)返回str中的x位置起至位 置y的字符mysql> select BINARY ‘ross’ IN (’Chandler’,’Joey’, ‘Ross’); #BINARY严格检查大小写
* 比较运算符IN,BETWEEN,IS NULL,IS NOT NULL,LIKE,REGEXP/RLIKE
mysql> select count(*),AVG(number_xx),Host,user from mysql.user GROUP by user [DESC|ASC] HAVING user=root; #分组并统计次数/平均值
++UNIX_TIMESTAMP(date)
返回一个Unix时间戳记(从’1970-01-01 00:00:00′GMT开始的秒数)
mysql> select UNIX_TIMESTAMP();
mysql> select UNIX_TIMESTAMP(’1997-10-04 22:23:00′);
mysql> select FROM_UNIXTIME(875996580); #根据时间戳记算出日期
++控制条件函数
mysql> select if(1<10,2,3), IF(55>100,’true’,’false’);
#IF()函数有三个参数,第一个是被判断的表达式,如果表达式为真,返回第二个参数,如果为假,返回第三个参数.
mysql> select CASE WHEN (2+2)=4 THEN “OK” WHEN (2+2)<>4 THEN ‘NOT OK’ END AS status;
++系统信息函数
mysql> select DATABASE(),VERSION(),USER();
mysql> select BENCHMARK(9999999,LOG(RAND()*PI())) AS PERFORMANACE; #一个测试mysql运算性能工具
++将wp_posts表中post_content字段中文字”old”替换为”new”
mysql> update wp_posts set post_content=replace(post_content,’old’,’new’)
++改变表结构
mysql> alter table table_name alter_spec [, alter_spec ...]
例:alter table dbname add column userid int(11) not null primary key auto_increment;
这样,就在表dbname中添加了一个字段userid,类型为int(11)。
++调整列顺序
mysql> alter table tablename CHANGE id id int(11) first;
++修改表中数据
insert [into] table_name [(column(s))] values (expression(s))
例:mysql>insert into mydatabase values(’php’,’mysql’,’asp’,’sqlserver’,’jsp’,’oracle’);
mysql> create table user select host,user from mysql.user where 1=0;
mysql> insert into user(host,user) select host,user from mysql.user;
++更改表名
命令:rename table 原表名 to 新表名;
++表的数据更新
mysql> update table01 set field04=19991022[, field05=062218] where field01=1;
++删除数据
mysql> delete from table01 where field01=3;
#如果想要清空表的所有纪录,建议用truncate table tablename而不是delete from tablename.
++SHELL提示符下运行SQL命令
$ mysql -e “show slave status\G ”
++坏库扫描修复
cd /var/lib/mysql/xxx && myisamchk playlist_block
++insert into a (x) values (’11a’)
出现: ata truncated for column ‘x’ at row 1
解决办法:
在my.ini里找到
sql-mode=”STRICT_TRANS_TABLES,NO_AUTO_Create_USER,NO_ENGINE_SUBSTITUTION”
把其中的STRICT_TRANS_TABLES,去掉,然后重启mysql就ok了
++复制表
mysql> create table target_table like source_table
++innodb支持事务
新表:create TABLE table-name (field-definitions) TYPE=INNODB;
旧表: alter TABLE table-name TYPE=INNODB;
mysql> start transaction #标记一个事务的开始
mysql> insert into….. #数据变更
mysql> ROLLBACK或commit #回滚或提交
mysql> SET AUTOCOMMIT=1; #设置自动提交
mysql> select @@autocommit; #查看当前是否自动提交
++表锁定相关
mysql> LOCK TABLE users READ; # 对user表进行只读锁定
mysql> LOCK TABLES user READ, pfolios WRITE #多表锁控制
mysql> UNLOCK TABLES; #不需要指定锁定表名字, MySQL会自动解除所有表锁定
=====一些mysql优化与管理======
++管理用命令
mysql> show variables #查看所有变量值
? max_connections 数据库允许的最大可连接数,
#需要加大max_connections可以在my.cnf中加入set-variable = max_connections=32000,可以对与下面的threads_connected值决定是否需要增大.
show status [like ....];
? threads_connected 数据库当前的连接线程数
#FLUSH STATUS 可以重置一些计数器
show processlist;
kill id;
++my.cnf配置
?Enable Slow Query Log
long_query_time=1
log-slow-queries=/var/log/mysql/log-slow-queries.log
log-queries-not-using-indexes
# mysqldumpslow -s c -t 20 host-slow.log #访问次数最多的20个sql语句
# mysqldumpslow -s r -t 20 host-slow.log #返回记录集最多的20个sql
?others
max_connections=500 #用过的最大连接数SHOW Status like ‘max_used_connection’;
wait_timeout=10 #终止所有空闲时间超过 10 秒的连接
table_cache=64 #任何时间打开表的总数
ax_binlog_size=512M #循环之前二进制日志的最大规模
max_connect_errors = 100
query_cache_size = 256M #查询缓存
#可用 SHOW STATUS LIKE ‘qcache%’;查看命中率
#FLUSH STATUS重置计数器, FLUSH QUERY CACHE清缓存
thread_cache = 40
#线程使用,SHOW STATUS LIKE ‘Threads_created %’; 值快速增加的话考虑加大
key_buffer = 16M
#show status like ‘%key_read%’; Key_reads 代表命中磁盘的关键字请求个数
#A: 到底 Key Buffer 要设定多少才够呢? Q: MySQL 只会 Cache 索引(*.MYI),因此参考所有 MYI文件的总大小
sort_buffer_size = 4M #查询排序时所能使用的缓冲区大小,每连接独享4M
#show status like ‘%sort%’; 如sort_merge_passes很大,就表示加大
sort_buffer_sizesort_buffer_size = 6M #查询排序时所能使用的缓冲区大小,这是每连接独享值6M
read_buffer_size = 4M #读查询操作所能使用的缓冲区大小
join_buffer_size = 8M #联合查询操作所能使用的缓冲区大小
skip-locking #取消文件系统的外部锁
skip-name-resolve
thread_concurrency = 8 #最大并发线程数,cpu数量*2
long_query_time = 10 #Slow_queries记数器的查询时间阀值
上月总结最近关注的关键词1110
P3P:浏览器记录Cookie时的关注关键词,部署有啊机票部分Cookie无法获取
推荐 http://ipneter.blog.51cto.com/341177/150968
协调过滤、聚类、特征值、切词:基础数据分析关键词
Mybase:时间管理工具
todoList:优秀任务管理软件
DynaTrack:优秀IE浏览器性能分析工具
PDCA:戴明环,科学管理做事方法
Idashboards:不错的数据展现工具
推荐 http://www.idashboards.com/
网络营销顾问:贾思军博客
推荐 http://jiasijun.com
十道海量数据处理面试题与十个方法总结
第一部分、十道海量数据处理面试题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法, 比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大 的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
算法思想:分而治之+Hash
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
典型的Top K算法,还是在这篇文章里头有所阐述,详情请参见:十一、从头到尾彻底解析Hash表算法。
文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27);
第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别 和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。
如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结 点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
还是典型的TOP K算法,解决方案如下:
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的 query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
5、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小 文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的 url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bloom filter日后会在本BLOG内详细阐述。
6、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看 bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
7、腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:oo,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
dizengrong:
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;
这里我们把40亿个数中的每一个用32位的二进制来表示
假设这40亿个数开始放在一个文件中。
然后将这40亿个数分成两类:
1.最高位为0
2.最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);
与要查找的数的最高位比较并接着进入相应的文件再查找
再然后把这个文件为又分成两类:
1.次最高位为0
2.次最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了);
与要查找的数的次最高位比较并接着进入相应的文件再查找。
.......
以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
附:这里,再简单介绍下,位图方法:
使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上 1,如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这 种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效 率还能提高一倍。
欢迎,有更好的思路,或方法,共同交流。
8、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
9、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
10、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10 个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一 个。
附、100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的 要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
致谢:http://www.cnblogs.com/youwang/。
第二部分、十个海量数据处理方法大总结
ok,看了上面这么多的面试题,是否有点头晕。是的,需要一个总结。接下来,本文将简单总结下一些处理海量数据问题的常见方法,而日后,本BLOG内会具体阐述这些方法。
下面的方法全部来自http://hi.baidu.com/yanxionglu/blog/博客,对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎讨论。
一、Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将 hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不 支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数 个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集 合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340 亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些 urlip是一一对应的,就可以转换成ip,则大大简单了。
二、Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
三、bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
四、堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前 元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较 小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
五、双层桶划分----其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们 将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第 几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受 的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里 的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
六、数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
七、倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what","is"和"it"将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序 频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档 指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
八、外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
九、trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
十、分布式处理 mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1).The canonical example application of MapReduce is a process to count the appearances of
each different word in a set of documents:
2).海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3).一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以放入 内存,我们可以为数据建立字典,比如通过 map,hashmap,trie,然后直接进行统计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多的前N个数据,当 然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程, 首先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最好可以让数据划分后可以一次读入内存,这样不同的机子负责处 理各种的数值范围,实际上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数 据,这实际上就是reduce过程。
实际上可能想直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。因为 一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我 们将1000万的数据分布到10台机器上,找到每台出现次数最多的前 100个,归并之后这样不能保证找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了10台机子,这样在每台上只有1千 个,假设这些机子排名在1000个之前的那些都是单独分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们让每台机子选 出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash 后的值将它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
而外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归并过程。
另外还可以考虑近似计算,也就是我们可以通过结合自然语言属性,只将那些真正实际中出现最多的那些词作为一个字典,使得这个规模可以放入内存。
ThinkPHP单字母函数(快捷方法)使用总结
1.U() URL组装 支持不同URL模式
U($url='',$vars='',$suffix=true,$domain=false)
@param string $url URL表达式,格式:'[模块/控制器/操作#锚点@域名]?参数1=值1&参数2=值2...'
@param string|array $vars 传入的参数,支持数组和字符串
@param string $suffix 伪静态后缀,默认为true表示获取配置值
@param boolean $domain 是否显示域名
@return string
2.D() D函数用于实例化模型类 格式 [资源://][模块/]模型
D($name='',$layer='')
@param string $name 资源地址
@param string $layer 模型层名称
@return Model
3.M() M函数用于实例化一个没有模型文件的Model
M($name='',$tablePrefix='',$connection='')
@param string $name Model名称 支持指定基础模型 例如MongoModel:User
@param string $tablePrefix 表前缀
@param mixed $connection 数据库连接信息
@return Model
4.I() 获取输入参数 支持过滤和默认值
I($name,$default='',$filter=null)
使用方法:
I('id',0); //获取id参数 自动判断get或者post
I('post.name','','htmlspecialchars'); //获取$_POST['name']
I('get.'); //获取$_GET
5.B() 执行某个行为
B($name,$tag='',&$params=NULL)
@param string $name 行为名称
@param string $tag 标签名称(行为类无需传入)
@param Mixed $params 传入的参数
@return void
6.C() 读取及设置配置参数
C($name=null,$value=null,$default=null)
@param string|array $name 配置变量
@param mixed $value 配置值
@param mixed $default 默认值
@return mixed
7.E() 抛出异常处理
E($msg, $code=0)
@param string $msg 异常消息
@param integer $code 异常代码 默认为0
@return void
8.G() 记录和统计时间(微秒)和内存使用情况
G($start,$end='',$dec=4)
使用方法:
G('begin'); // 记录开始标记位
// ... 区间运行代码
G('end'); // 记录结束标签位
echo G('begin','end',6); //统计区间运行时间 精确到小数后6位
echo G('begin','end','m'); // 统计区间内存使用情况
如果end标记位没有定义,则会自动以当前作为标记位
其中统计内存使用需要 MEMORY_LIMIT_ON 常量为true才有效
@param string $start 开始标签
@param string $end 结束标签
@param integer|string $dec 小数位或者m
@return mixed
9.L()获取和设置语言定义(不区分大小写)
L($name=null,$value=null)
@param string|array $name 语言变量
@param mixed $value 语言值或者变量
@return mixed
10.T()获取模版文件 格式 资源://模块@主题/控制器/操作
T($template='',$layer='')
@param string $name 模版资源地址
@param string $layer 视图层(目录)名称
@return string
11.N() 设置和获取统计数据
N($key,$step=0,$save=false)
使用方法:
N('db',1); // 记录数据库操作次数
N('read',1); // 记录读取次数
echo N('db'); // 获取当前页面数据库的所有操作次数
echo N('read'); // 获取当前页面读取次数
@param string $key 标识位置
@param integer $step 步进值
@return mixed
12.A()A函数用于实例化控制器
格式:[资源://][模块/]控制器
A($name,$layer='',$level='')
@param string $name 资源地址
@param string $layer 控制层名称
@param integer $level 控制器层次
@return Controller|false
13.R() 远程调用控制器的操作方法
URL 参数格式 [资源://][模块/]控制器/操作
R($url,$vars=array(),$layer='')
@param string $url 调用地址
@param string|array $vars 调用参数 支持字符串和数组
@param string $layer 要调用的控制层名称
@return mixed
14.W()渲染输出Widget
W($name,$data=array())
@param string $name Widget名称
@param array $data 传入的参数
@return void
15.S()缓存管理
S($name,$value='',$options=null)
@param mixed $name 缓存名称,如果为数组表示进行缓存设置
@param mixed $value 缓存值
@param mixed $options 缓存参数
@return mixed
16.F() 快速文件数据读取和保存 针对简单类型数据 字符串、数组
F($name, $value='',$path=DATA_PATH)
@param string $name 缓存名称
@param mixed $value 缓存值
@param string $path 缓存路径
@return mixed
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
