如何处理好前后端分离的 API 问题
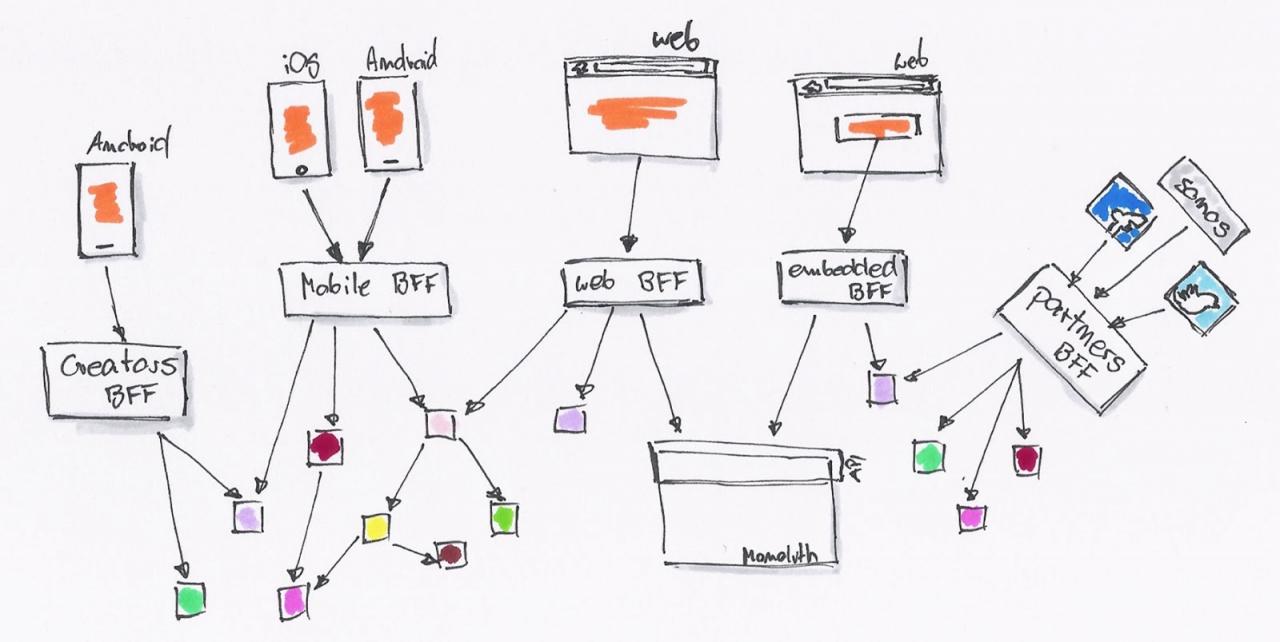
API 都搞不好,还怎么当程序员?如果 API 设计只是后台的活,为什么还需要前端工程师。
作为一个程序员,我讨厌那些没有文档的库。我们就好像在操纵一个黑盒一样,预期不了它的正常行为是什么。输入了一个 A,预期返回的是一个 B,结果它什么也没有。有的时候,还抛出了一堆异常,导致你的应用崩溃。
因为交付周期的原因,接入了一个第三方的库,遇到了这么一些问题:文档老旧,并且不够全面。这个问题相比于没有文档来说,愈加的可怕。我们需要的接口不在文档上,文档上的接口不存在库里,又或者是少了一行关键的代码。
对于一个库来说,文档是多种多样的:一份 demo、一个入门指南、一个 API 列表,还有一个测试。如果一个 API 有测试,那么它也相当于有一份简单的文档了——如果我们可以看到测试代码的话。而当一个库没有文档的时候,它也不会有测试。
在前后端分离的项目里,API 也是这样一个烦人的存在。我们就经常遇到各种各样的问题:
- API 的字段更新了
- API 的路由更新了
- API 返回了未预期的值
- API 返回由于某种原因被删除了
- 。。。
API 的维护是一件烦人的事,所以最好能一次设计好 API。可是这是不可能的,API 在其的生命周期里,应该是要不断地演进的。它与精益创业的思想是相似的,当一个 API 不合适现有场景时,应该对这个 API 进行更新,以满足需求。也因此,API 本身是面向变化的,问题是这种变化是双向的、单向的、联动的?还是静默的?
API 设计是一个非常大的话题,这里我们只讨论:演进、设计及维护。
前后端分离 API 的演进史
刚毕业的时候,工作的主要内容是用 Java 写网站后台,业余写写自己喜欢的前端代码。慢慢的,随着各个公司的 Mobile First 战略的实施,项目上的主要语言变成了 JavaScript。项目开始实施了前后端分离,团队也变成了全功能团队,前端、后台、DevOps 变成了每个人需要提高的技能。于是如我们所见,当我们完成一个任务卡的时候,我们需要自己完成后台 API,还要编写相应的前端代码。
尽管当时的手机浏览器性能,已经有相当大的改善,但是仍然会存在明显的卡顿。因此,我们在设计的时候,尽可能地便将逻辑移到了后台,以减少对于前端带来的压力。可性能问题在今天看来,差异已经没有那么明显了。
如同我在《RePractise:前端演进史》中所说,前端领域及 Mobile First 的变化,引起了后台及 API 架构的一系列演进。
最初的时候,我们只有一个网站,没有 REST API。后台直接提供 Model 数据给前端模板,模板处理完后就展示了相关的数据。
当我们开始需要 API 的时候,我们就会采用最简单、直接的方式,直接在原有的系统里开一个 API 接口出来。
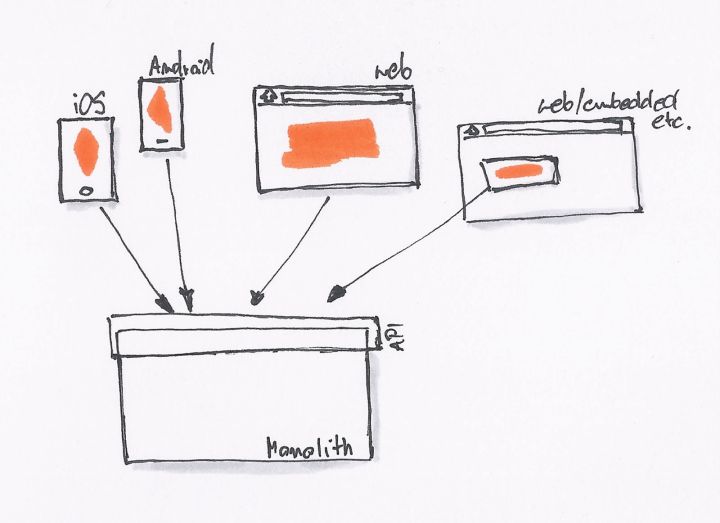
为了不破坏现有系统的架构,同时为了更快的上线,直接开出一个接口来得最为直接。我们一直在这样的模式下工作,直到有一天我们就会发现,我们遇到了一些问题:
- API 消费者:一个接口无法同时满足不同场景的业务。如移动应用,可能与桌面、手机 Web 的需求不一样,导致接口存在差异。
- API 生产者:对接多个不同的 API 需求,产生了各种各样的问题。
于是,这时候就需要 BFF(backend for frontend)这种架构。后台可以提供所有的 MODEL 给这一层接口,而 API 消费者则可以按自己的需要去封装。

API 消费者可以继续使用 JavaScript 去编写 API 适配器。后台则慢慢的因为需要,拆解成一系列的微服务。
系统由内部的类调用,拆解为基于 RESTful API 的调用。后台 API 生产者与前端 API 消费者,已经区分不出谁才是真正的开发者。
瀑布式开发的 API 设计
说实话,API 开发这种活就和传统的瀑布开发差不多:未知的前期设计,痛苦的后期集成。好在,每次这种设计的周期都比较短。
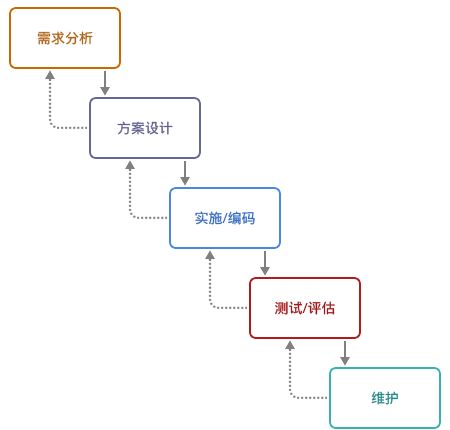
新的业务需求来临时,前端、后台是一起开始工作的。而不是后台在前,又或者前端先完成。他们开始与业务人员沟通,需要在页面上显示哪些内容,需要做哪一些转换及特殊处理。
然后便配合着去设计相应的 API:请求的 API 路径是哪一个、请求里要有哪些参数、是否需要鉴权处理等等。对于返回结果来说,仍然也需要一系列的定义:返回哪些相应的字段、额外的显示参数、特殊的 header 返回等等。除此,还需要讨论一些异常情况,如用户授权失败,服务端没有返回结果。
整理出一个相应的文档约定,前端与后台便去编写相应的实现代码。
最后,再经历痛苦的集成,便算是能完成了工作。
可是,API 在这个过程中是不断变化的,因此在这个过程中需要的是协作能力。它也能从侧面地反映中,团队的协作水平。
API 的协作设计
API 设计应该由前端开发者来驱动的。后台只提供前端想要的数据,而不是反过来的。后台提供数据,前端从中选择需要的内容。
我们常报怨后台 API 设计得不合理,主要便是因为后台不知道前端需要什么内容。这就好像我们接到了一个需求,而 UX 或者美工给老板见过设计图,但是并没有给我们看。我们能设计出符合需求的界面吗?答案,不用想也知道。
因此,当我们把 API 的设计交给后台的时候,也就意味着这个 API 将更符合后台的需求。那么它的设计就趋向于对后台更简单的结果,比如后台返回给前端一个 Unix 时间,而前端需要的是一个标准时间。又或者是反过来的,前端需要的是一个 Unix 时间,而后台返回给你的是当地的时间。
与此同时,按前端人员的假设,我们也会做类似的、『不正确』的 API 设计。
因此,API 设计这种活动便像是一个博弈。
使用文档规范 API
不论是异地,或者是坐一起协作开发,使用 API 文档来确保对接成功,是一个“低成本”、较为通用的选择。在这一点上,使用接口及函数调用,与使用 REST API 来进行通讯,并没有太大的区别。
先写一个 API 文档,双方一起来维护,文档放在一个公共的地方,方便修改,方便沟通。慢慢的再随着这个过程中的一些变化,如无法提供事先定好的接口、不需要某个值等等,再去修改接口及文档。
可这个时候因为没有一个可用的 API,因此前端开发人员便需要自己去 Mock 数据,或者搭建一个 Mock Server 来完成后续的工作。
因此,这个时候就出现了两个问题:
- 维护 API 文档很痛苦
- 需要一个同步的 Mock Server
而在早期,开发人员有同样的问题,于是他们有了 JavaDoc、JSDoc 这样的工具。它可以一个根据代码文件中中注释信息,生成应用程序或库、模块的API文档的工具。
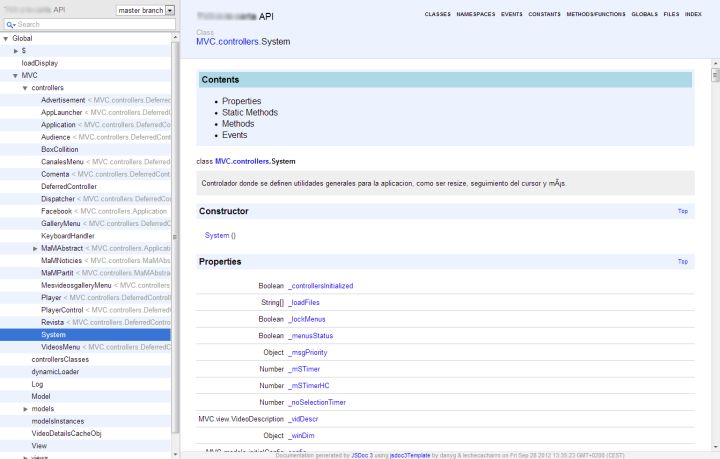
同样的对于 API 来说,也可以采取类似的步骤,如 Swagger。它是基于 YAML语法定义 RESTful API,如:
swagger: "2.0"
info:
version: 1.0.0
title: Simple API
description: A simple API to learn how to write OpenAPI Specification
schemes:
- https
host: simple.api
basePath: /openapi101
paths: {}
它会自动生成一篇排版优美的API文档,与此同时还能生成一个供前端人员使用的 Mock Server。同时,它还能支持根据 Swagger API Spec 生成客户端和服务端的代码。
然而,它并不能解决没有人维护文档的问题,并且无法及时地通知另外一方。当前端开发人员修改契约时,后台开发人员无法及时地知道,反之亦然。但是持续集成与自动化测试则可以做到这一点。
契约测试:基于持续集成与自动化测试
当我们定好了这个 API 的规范时,这个 API 就可以称为是前后端之间的契约,这种设计方式也可以称为『契约式设计』。(定义来自维基百科)
这种方法要求软件设计者为软件组件定义正式的,精确的并且可验证的接口,这样,为传统的抽象数据类型又增加了先验条件、后验条件和不变式。这种方法的名字里用到的“契约”或者说“契约”是一种比喻,因为它和商业契约的情况有点类似。
按传统的『瀑布开发模型』来看,这个契约应该由前端人员来创建。因为当后台没有提供 API 的时候,前端人员需要自己去搭建 Mock Server 的。可是,这个 Mock API 的准确性则是由后台来保证的,因此它需要共同去维护。
与其用文档来规范,不如尝试用持续集成与测试来维护 API,保证协作方都可以及时知道。
在 2011 年,Martin Folwer 就写了一篇相关的文章:集成契约测试,介绍了相应的测试方式:
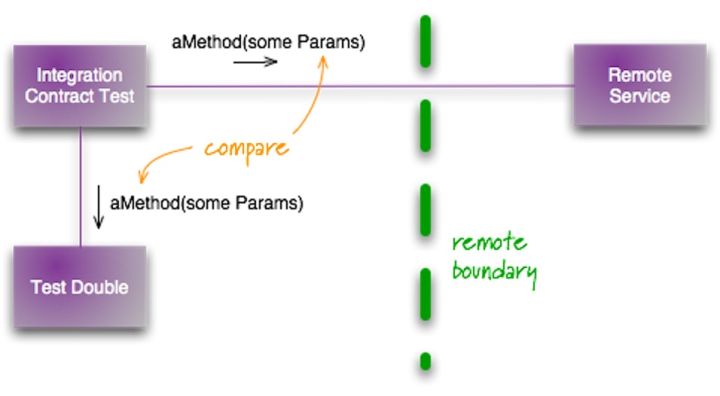
其步骤如下:
- 编写契约(即 API)。即规定好 API 请求的 URL、请求内容、返回结果、鉴权方式等等。
- 根据契约编写 Mock Server。可以彩 Moco
- 编写集成测试将请求发给这个 Mock Server,并验证
如下是我们项目使用的 Moco 生成的契约,再通过 Moscow 来进行 API 测试。
[
{
"description": "should_response_text_foo",
"request": {
"method": "GET",
"uri": "/property"
},
"response": {
"status": 401,
"json": {
"message": "Full authentication is required to access this resource"
}
}
}
]
只需要在相应的测试代码里请求资源,并验证返回结果即可。
而对于前端来说,则是依赖于 UI 自动化测试。在测试的时候,启动这个 Mock Server,并借助于 Selenium 来访问浏览器相应的地址,模拟用户的行为进行操作,并验证相应的数据是否正确。

当契约发生发动的时候,持续集成便失败了。因此相应的后台测试数据也需要做相应的修改,相应的前端集成测试也需要做相应的修改。因此,这一改动就可以即时地通知各方了。
前端测试与 API 适配器
因为前端存在跨域请求的问题,我们就需要使用代理来解决这个问题,如 node-http-proxy,并写上不同环境的配置:

这个代理就像一个适配器一样,为我们匹配不同的环境。
在前后端分离的应用中,对于表单是要经过前端和后台的双重处理的。同样的,对于前端获取到的数据来说,也应该要经常这样的双重处理。因此,我们就可以简单地在数据处理端做一层适配。
写前端的代码,我们经常需要写下各种各样的:
if(response && response.data && response.data.length > 0){}
即使后台向前端保证,一定不会返回 null 的,但是我总想加一个判断。刚开始写 React 组件的时候,发现它自带了一个名为 PropTypes 的类型检测工具,它会对传入的数据进行验证。而诸如 TypeScript 这种强类型的语言也有其类似的机制。
我们需要处理同的异常数据,不同情况下的返回值等等。因此,我之前尝试开发 DDM 来解决这样的问题,只是轮子没有造完。诸如 Redux 可以管理状态,还应该有个相应的类型检测及 Adapter 工具。
除此,还有一种情况是使用第三方 API,也需要这样的适配层。很多时候,我们需要的第三方 API 以公告的形式来通知各方,可往往我们不会及时地根据这些变化。

一般来说这种工作是后台去做代码的,不得已由前端来实现时,也需要加一层相应的适配层。
小结
总之,API 使用的第一原则:不要『相信』前端提供的数据,不要『相信』后台返回的数据。
支付宝口碑isv开发如何正确处理签名
简单的知识点
- 本文基本分初级、进阶、高级三部
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
不熟悉的同学 - 进阶适用群体:使用 SDK 开发系统,对 RSA 签名规则
熟悉的同学 - 仅使用SDK需要对开放平台签名规则略有了解。
- 适合遇到网关返回报文中描述
签名错误。 - 高级适用群体: 不使用 demo或 SDK、完全独立开发。对RSA 签名规则
熟悉的同学 - 注:推荐使用 SDK。否则请直接跳高级说明。
- 初级适用群体:使用 demo 或 SDK 开发系统,对 RSA 签名规则
- 推荐使用 demo 或者 SDK。可以节约开发同学学习RSA签名规则的时间。
- 初次对接开放平台接口时建议选择参数较少的简单接口对接,方便调查问题。
- 支付宝产品分 mapi 网关产品及 openapi 网关产品。
- mapi 网关均使用支付宝PID调用,需配置合作伙伴秘钥。
- 因 mapi 多使用 md5验签,问题较少,因此本文仅介绍开放平台签名规则。
- openapi 网关产品均使用支付宝 appid 调用,需在appid上分别配置秘钥。
- 如有多个 appid, 使用相同秘钥或者不同秘钥均可,只需保证自己调用时使用配对秘钥加签即可。
初级教程
对于新接入支付宝产品的开发,如何生成密钥、开放平台设置密钥 很重要
- 获取 PID
?点击查看- 详解如何查询 支付宝账号PID.
- RSA秘钥生成
?点击查看- 推荐使用在线地址中生成工具,该工具同样可做秘钥校验作用.(问题排查工具)
- 上传公钥
?点击查看- 在此页面可以上传商户公钥及查看支付宝公钥(支付宝公钥唯一,因此代码中不做修改最好,以免节外生枝.)
- demo&sdk使用方法
?点击查看- 参考文中的配置方法将第二步中生成的私钥填写.
- 注意最新
.netdemo 对aop.DefaultAopClient方法做了改善,添加了两个参数.最后一个参数keyFromFile.- 为true时直接写私钥本地路径.
- 默认 false, 需要将私钥内容转成一行填入方法中.
进阶教程
进阶教程主要针对在使用时碰到签名错误的同学
- 一般平台返回签名错误 个人建议按照初级教程仔细核对一遍.
- 可能原因1:账号多人使用,被其他同事或者其他公司员工修改
- 建议跟商户相关负责人沟通,看谁有可能修改秘钥,因为修改秘钥需要短信验证码,所以肯定能查出问题根源.
- 绑定手机号应该是公司相对高层人士,与其沟通不要随便将短信码给其他人.
- 可能原因2:自己误操作导致公钥不匹配
- 在开放平台有多个应用,上传公钥时需上传系统使用 appid 相同应用的商户公钥.
- 生成了多套秘钥或者其他原因导致程序里私钥与平台设置的公钥不匹配
- 该问题建议使用
初级教程:[RSA秘钥生成]中的工具做排查,校验公私钥是否匹配. - 如不匹配可使用私钥重新生成公钥配置到开放平台.
- 或者重新生成一套按
初级教程:上传公钥重新配置 - 可能原因3:如果调用api中传参包含中文,则很有可能是因为编码问题导致开放平台验签失败.
- 调查方法,将参数中所有中文替换成英文重试接口调用,如果成功说明是编码影响平台验签.
- 修改方法,参考
初级教程:demo&sdk使用方法在DefaultAopClient方法中传入相应编码集. - 下面介绍出现这个问题的原因,感兴趣的同学可以看下.
- 中文包含多种编码集,而你们系统有默认编码集,当你参数中含有中文且在调用签名方法时没有指明编码集,系统会使用默认编码集进行签名.而调用接口时需传入
charset参数, 如果你没传入,平台会使用默认编码集utf-8解签,如果你系统默认utf-8编码,那么此问题你无感知,但如果是非utf-8类型编码会导致平台算签名串与你实际传入不符. 最终验签失败
- 系统直接报错,抛出的异常建议自己先分析.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
- 使用java开发但是私钥未经过
pkcs8转码 - 使用.net开发,参考
初级教程:demo&sdk使用方法,未对keyFromFile做有效控制. - 复制私钥没复制全.
- 使用java开发但是私钥未经过
- 其他异常均属于代码错误,建议先自己排查.实在搞不定可以联系
技术支持协助解决.
- 常见的异常就是获取私钥失败.可能的原因如下(低级错误请仔细排查)
高级教程
高级教程针对不使用 SDK开发的同学(安全考虑/冷门语言等原因)
- 高级教程需要你首先了解初级教程,并且进阶教程中的常见问题也可以自己排查解决.
- 本文主要探讨开放平台签名规则,如不使用sdk开发,这些逻辑代码均需要自己开发.
- 建议开发前先参考 sdk 源代码看下实际处理
- 签名机制
?点击查看mapi网关产品签名时要去掉sign_type=RSA,这点跟openapi网关产品不同,一定要注意.- 排序时不要仅排序第一个字符,要注意第一字符相同时排第二字符,以此类推.
- 所有
空参数不在签名参数中,注意剔除.异步通知(需要解签报文)同理 - 支付宝异步通知不会有
空参数
十道海量数据处理面试题与十个方法总结
第一部分、十道海量数据处理面试题
1、海量日志数据,提取出某日访问百度次数最多的那个IP。
首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法, 比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大 的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
算法思想:分而治之+Hash
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
典型的Top K算法,还是在这篇文章里头有所阐述,详情请参见:十一、从头到尾彻底解析Hash表算法。
文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27);
第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。
即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别 和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。
或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
方案:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。
如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map等),并取出出现频率最大的100个词(可以用含100个结 点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。
4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
还是典型的TOP K算法,解决方案如下:
方案1:
顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。利用快速/堆/归并排序按照出现次数进行排序。将排序好的query和对应的 query_cout输出到文件中。这样得到了10个排好序的文件(记为)。
对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:
与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
5、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小 文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的 url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。
Bloom filter日后会在本BLOG内详细阐述。
6、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
方案1:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看 bitmap,把对应位是01的整数输出即可。
方案2:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
7、腾讯面试题:给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
与上第6题类似,我的第一反应时快速排序+二分查找。以下是其它更好的方法:
方案1:oo,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
dizengrong:
方案2:这个问题在《编程珠玑》里有很好的描述,大家可以参考下面的思路,探讨一下:
又因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;
这里我们把40亿个数中的每一个用32位的二进制来表示
假设这40亿个数开始放在一个文件中。
然后将这40亿个数分成两类:
1.最高位为0
2.最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);
与要查找的数的最高位比较并接着进入相应的文件再查找
再然后把这个文件为又分成两类:
1.次最高位为0
2.次最高位为1
并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了);
与要查找的数的次最高位比较并接着进入相应的文件再查找。
.......
以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
附:这里,再简单介绍下,位图方法:
使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上 1,如遇到5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这 种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效 率还能提高一倍。
欢迎,有更好的思路,或方法,共同交流。
8、怎么在海量数据中找出重复次数最多的一个?
方案1:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
9、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
方案1:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
10、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10 个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一 个。
附、100w个数中找出最大的100个数。
方案1:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100w*lg100)。
方案2:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100w*100)。
方案3:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的 要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100w*100)。
致谢:http://www.cnblogs.com/youwang/。
第二部分、十个海量数据处理方法大总结
ok,看了上面这么多的面试题,是否有点头晕。是的,需要一个总结。接下来,本文将简单总结下一些处理海量数据问题的常见方法,而日后,本BLOG内会具体阐述这些方法。
下面的方法全部来自http://hi.baidu.com/yanxionglu/blog/博客,对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题。下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎讨论。
一、Bloom filter
适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:
对于原理来说很简单,位数组+k个独立hash函数。将 hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不 支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。
还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数 个数。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况下,m至少要等于n*lg(1/E)才能表示任意n个元素的集 合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应该>=nlg(1/E)*lge 大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
扩展:
Bloom filter将集合中的元素映射到位数组中,用k(k为哈希函数个数)个映射位是否全1表示元素在不在这个集合中。Counting bloom filter(CBF)将位数组中的每一位扩展为一个counter,从而支持了元素的删除操作。Spectral Bloom Filter(SBF)将其与集合元素的出现次数关联。SBF采用counter中的最小值来近似表示元素的出现频率。
问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340 亿,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些 urlip是一一对应的,就可以转换成ip,则大大简单了。
二、Hashing
适用范围:快速查找,删除的基本数据结构,通常需要总数据量可以放入内存
基本原理及要点:
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展:
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例:
1).海量日志数据,提取出某日访问百度次数最多的那个IP。
IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
三、bit-map
适用范围:可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下
基本原理及要点:使用bit数组来表示某些元素是否存在,比如8位电话号码
扩展:bloom filter可以看做是对bit-map的扩展
问题实例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map。
四、堆
适用范围:海量数据前n大,并且n比较小,堆可以放入内存
基本原理及要点:最大堆求前n小,最小堆求前n大。方法,比如求前n小,我们比较当前 元素与最大堆里的最大元素,如果它小于最大元素,则应该替换那个最大元素。这样最后得到的n个元素就是最小的n个。适合大数据量,求前n小,n的大小比较 小的情况,这样可以扫描一遍即可得到所有的前n元素,效率很高。
扩展:双堆,一个最大堆与一个最小堆结合,可以用来维护中位数。
问题实例:
1)100w个数中找最大的前100个数。
用一个100个元素大小的最小堆即可。
五、双层桶划分----其实本质上就是【分而治之】的思想,重在“分”的技巧上!
适用范围:第k大,中位数,不重复或重复的数字
基本原理及要点:因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。可以通过多次缩小,双层只是一个例子。
扩展:
问题实例:
1).2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。
有点像鸽巢原理,整数个数为2^32,也就是,我们可以将这2^32个数,划分为2^8个区域(比如用单个文件代表一个区域),然后将数据分离到不同的区域,然后不同的区域在利用bitmap就可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方便的解决。
2).5亿个int找它们的中位数。
这个例子比上面那个更明显。首先我们 将int划分为2^16个区域,然后读取数据统计落到各个区域里的数的个数,之后我们根据统计结果就可以判断中位数落到那个区域,同时知道这个区域中的第 几大数刚好是中位数。然后第二次扫描我们只统计落在这个区域中的那些数就可以了。
实际上,如果不是int是int64,我们可以经过3次这样的划分即可降低到可以接受 的程度。即可以先将int64分成2^24个区域,然后确定区域的第几大数,在将该区域分成2^20个子区域,然后确定是子区域的第几大数,然后子区域里 的数的个数只有2^20,就可以直接利用direct addr table进行统计了。
六、数据库索引
适用范围:大数据量的增删改查
基本原理及要点:利用数据的设计实现方法,对海量数据的增删改查进行处理。
七、倒排索引(Inverted index)
适用范围:搜索引擎,关键字查询
基本原理及要点:为何叫倒排索引?一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
以英文为例,下面是要被索引的文本:
T0 = "it is what it is"
T1 = "what is it"
T2 = "it is a banana"
我们就能得到下面的反向文件索引:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
检索的条件"what","is"和"it"将对应集合的交集。
正向索引开发出来用来存储每个文档的单词的列表。正向索引的查询往往满足每个文档有序 频繁的全文查询和每个单词在校验文档中的验证这样的查询。在正向索引中,文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。也就是说文档 指向了它包含的那些单词,而反向索引则是单词指向了包含它的文档,很容易看到这个反向的关系。
扩展:
问题实例:文档检索系统,查询那些文件包含了某单词,比如常见的学术论文的关键字搜索。
八、外排序
适用范围:大数据的排序,去重
基本原理及要点:外排序的归并方法,置换选择败者树原理,最优归并树
扩展:
问题实例:
1).有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16个字节,内存限制大小是1M。返回频数最高的100个词。
这个数据具有很明显的特点,词的大小为16个字节,但是内存只有1m做hash有些不够,所以可以用来排序。内存可以当输入缓冲区使用。
九、trie树
适用范围:数据量大,重复多,但是数据种类小可以放入内存
基本原理及要点:实现方式,节点孩子的表示方式
扩展:压缩实现。
问题实例:
1).有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。要你按照query的频度排序。
2).1000万字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。请问怎么设计和实现?
3).寻找热门查询:查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个,每个不超过255字节。
十、分布式处理 mapreduce
适用范围:数据量大,但是数据种类小可以放入内存
基本原理及要点:将数据交给不同的机器去处理,数据划分,结果归约。
扩展:
问题实例:
1).The canonical example application of MapReduce is a process to count the appearances of
each different word in a set of documents:
2).海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
3).一共有N个机器,每个机器上有N个数。每个机器最多存O(N)个数并对它们操作。如何找到N^2个数的中数(median)?
经典问题分析
上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入。
可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
所谓的是否能一次读入内存,实际上应该指去除重复后的数据量。如果去重后数据可以放入 内存,我们可以为数据建立字典,比如通过 map,hashmap,trie,然后直接进行统计即可。当然在更新每条数据的出现次数的时候,我们可以利用一个堆来维护出现次数最多的前N个数据,当 然这样导致维护次数增加,不如完全统计后在求前N大效率高。
如果数据无法放入内存。一方面我们可以考虑上面的字典方法能否被改进以适应这种情形,可以做的改变就是将字典存放到硬盘上,而不是内存,这可以参考数据库的存储方法。
当然还有更好的方法,就是可以采用分布式计算,基本上就是map-reduce过程, 首先可以根据数据值或者把数据hash(md5)后的值,将数据按照范围划分到不同的机子,最好可以让数据划分后可以一次读入内存,这样不同的机子负责处 理各种的数值范围,实际上就是map。得到结果后,各个机子只需拿出各自的出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数 据,这实际上就是reduce过程。
实际上可能想直接将数据均分到不同的机子上进行处理,这样是无法得到正确的解的。因为 一个数据可能被均分到不同的机子上,而另一个则可能完全聚集到一个机子上,同时还可能存在具有相同数目的数据。比如我们要找出现次数最多的前100个,我 们将1000万的数据分布到10台机器上,找到每台出现次数最多的前 100个,归并之后这样不能保证找到真正的第100个,因为比如出现次数最多的第100个可能有1万个,但是它被分到了10台机子,这样在每台上只有1千 个,假设这些机子排名在1000个之前的那些都是单独分布在一台机子上的,比如有1001个,这样本来具有1万个的这个就会被淘汰,即使我们让每台机子选 出出现次数最多的1000个再归并,仍然会出错,因为可能存在大量个数为1001个的发生聚集。因此不能将数据随便均分到不同机子上,而是要根据hash 后的值将它们映射到不同的机子上处理,让不同的机器处理一个数值范围。
而外排序的方法会消耗大量的IO,效率不会很高。而上面的分布式方法,也可以用于单机版本,也就是将总的数据根据值的范围,划分成多个不同的子文件,然后逐个处理。处理完毕之后再对这些单词的及其出现频率进行一个归并。实际上就可以利用一个外排序的归并过程。
另外还可以考虑近似计算,也就是我们可以通过结合自然语言属性,只将那些真正实际中出现最多的那些词作为一个字典,使得这个规模可以放入内存。
海量数据的处理分析经验
在实际工作中,有幸接触到海量的数据处理问题,对其进行处理是一项艰巨而复杂的任务。原因有以下几个方面:
离职员工的期权处理
前一段时间,有不少朋友问到:假如有员工从公司离职,员工手中的期权应当如何处理?近期,越来越多的创业公司也都面临着类似的问题,有的离职员工甚至要把公司告上法庭,看来非常有必要向公司和员工来分享一下关于离职员工的期权问题了。
公司与员工终止劳动关系时,除了终止理由和程序的合法性之外,还涉及到工资、奖金、社保、公积金、经济补偿、保密、知识产权、不竞争义务等等一系列法律问题。如果说这些问题都是惯常的法律问题,那么,随着股权激励在创业公司中越来越广泛的使用,期权已经成为一个越来越普遍的员工离职新问题,因为期权涉及的权益潜在价值较大,再加上缺少成熟的法律规范,公司和员工双方往往都容易被期权问题所困扰。
1、期权是什么?
期权,就是公司赋予员工在满足约定条件后按照特定价格购买公司股权(份)的期待权利,目的在于通过股权来招募、激励和留存优秀人才,这已经成为越来越多创业公司甚至上市公司采用的人才激励方式。这里的特定价格往往比其他投资人购买公司股权(份)的价格要低很多,体现了公司提供给员工的奖励和优惠。
是否行使手中的期权,是员工的权利,而不是义务。员工行使期权,应当按期权文件规定的条件和程序支付行权价格,取得公司股权(份),成为公司股东;员工不行使或放弃期权,则期权到期作废。
简法帮提示:
如果离职员工手中持有公司的期权,员工在离职时就需要权衡公司前景、行权的成本(包括行权价格和税负),是否愿意行使期权从而在离开公司后继续持有公司的股权?而公司方面则需要考虑:是否愿意让离职员工继续持有公司股权?是否有权通过回购等方式收回离职员工手中的期权或股权?能收回多少?需要多大成本?
2、离职员工有多少期权?
创业公司的期权方案中,行使期权的条件通常体现为服务期限。例如,市场主流为约定激励对象四年服务期,每满一年,员工可行使1/4的期权总额;当然,也有不少公司约定为四年服务期,第一年期满可行使1/4的期权总额,剩余3/4期权在三年(36个月)内按月到位,每月到位1/36。当然,也有公司将服务期约定为五年,每年1/5,与四年的道理相同。
这种分期到位(Vesting)的机制是从国外引入,已经成为国内创业公司员工激励的主流方式。但是,这些机制是体现在公司的期权激励文件中,包括激励方案和期权授予协议等文件,而不是在任何法律规章之中,所以公司和员工都需要查阅双方签署的激励文件,以文件的约定为准。
通常情况下,员工必须满一年才能取得相应的期权,员工未满一年离开公司的,按照期权方案规定通常不能行使期权。同样,这也是市场主流实践做法,但是最终都需要以双方签署的激励文件为准。
简法帮提示:
当离职员工涉及期权问题时,公司和员工双方要做的第一件事情,就是找出双方签署的期权授予协议以及相关激励方案等文件。这也是为什么创业者发给我们几个截图想要寻求帮助时,我们通常会给出的建议就是:要全面地查看激励文件。对于公司也是一样。
我们在实践中也注意到,有些创业公司自作聪明,不让员工持有或保存激励方案甚至授予协议。且不论这样的股权激励到底给员工什么样的印象(员工自己都不知道有什么权利义务),股权激励能否达到吸引、激励和留存优秀员工的效果,更重要的是,进入诉讼争议程序后,公司最后还是要提交相关文件,在公开案件中则有可能产生更大范围的负面声誉影响。
3、期权行使的时限
期权行使期限可以说是创业公司股权激励的一个“杀手锏”,基本意思就是,员工在离开公司时或之后的一个30-90天窗口期内必须选择行使期权或者放弃期权,30天和60天都比较常见。未在规定行权窗口期间内行权,期权由公司收回。此外,期权通常都有一个最长10年的行权期限,主要是基于美国税法对激励型期权(见下文第4部分)的限制条件。
现实的情况是,让一个离职的员工(譬如二十几岁的工程师)在离职时或离职后的一两个月内找到行使期权所需要的资金,其实并不容易,尤其是还要考虑行使期权的税负。一方面,收益是纸面财富,这些期权(和行使后拿到的股权)没有市场没有流动性(创业公司的期权计划通常也限制交易),未来能否套现没人知道;但另一方面,公司和税务局却都要现金形式的行权价格和税款。所以,很多创业公司的员工在“另谋高就”时都不得不扔掉了期权这个“鸡肋”。
为了更好吸引人才,硅谷的一些创业公司已经开始采取补救措施。据外媒报道,2015年3月,独角兽Pinterest调整了期权计划,开始允许在公司工作两年以上的员工在离开公司后继续持有已经到位的股票期权,将行权时间窗口拉长了7年时间,这样到时候大部分人都有能力行权了,而且公司也可能已经上市了,行权就能立即套现,支付税费也不再是问题。
简法帮提示:
如果离职员工手中持有公司的期权,员工需要在期权文件规定的行权窗口期内决定是否行使期权,中国法院在判例中也认可了这种行权窗口期的有效性。公司方除了行权价格、手续,还需要考虑期权有关的员工税负和代扣代缴义务,因为在美国法律环境下的期权激励在引入中国后,还有一些水土不服的问题。
从中国境内的法律实践情况来看,创业公司引入更长的时间窗口则面临更多不确定性,不仅税务处理上不够明确(或者说不够优惠,见下文第4部分),而且期权会在公司治理和上市等各个方面带来困扰,所以,创业公司实践中的做法往往是在离职时一揽子解决(收回)期权和其他离职补偿问题(见下文第5部分),因此简法帮在线生成的期权文件中就针对境内架构的公司放弃了这种窗口期的约定,鼓励公司和员工在离职时达成包括期权在内的一揽子整体解决方案。
4、期权的税负
我们引入的期权激励借鉴自美国,美国的股票期权通常包括两种类型:(1)激励型期权(Incentive Stock Option, ISO)。这种期权面向员工,在满足持股期限(期权授予后满两年且行权后满一年)等限制性条件时,员工可以延迟纳税,行权时不缴纳个税(高收入员工存在一个替代性最低税问题,这里不深入讨论),转让股权时的收益按更优惠的资本利得纳税,而不是普通收入纳税,公司也不得扣除期权管理费用;(2)非法定期权(Nonqualified Stock Option, NSO)。这种期权在行权时需要按照差额个人收益(股权取得价与当时的市场价之间的差额)缴纳个人所得税,尽管这时候股票可能还没出售套现,而且作为普通收入计税,但没有法定的持股期限等限制条件,公司则可以扣除期权管理费用。前文提及的硅谷公司调整期权计划,基于上述分类就需要将激励型期权(ISO)转化为非法定期权(NSO),离职员工和公司两个方面分别面临者税负和管理费用扣除的问题。
而在中国现在的法律框架下,包括期权在内的员工股权激励税务制度跟期权的来源地国家——美国差异很大。周鸿祎等创业者曾高调呼吁国家对创新创业要放弃“惯性思维”,尤其是“期权按照个税征税不合理”的呼吁引起了无数创业公司和创业公司员工的共鸣,因为“国家是把期权收入和员工月工资收入加在一起,征收可能高达45%的个人所得税……(忽略了创业企业员工)或许在前五年甚至十年内一直拿着低工资。”
国家也在不断试验和推广改革措施,例如引入分期缴纳的规定:自2016年1月1日起,全国范围内的高新技术企业转化科技成果,给予本企业相关技术人员的股权奖励,个人一次缴纳税款有困难的,可根据实际情况自行制定分期缴税计划,在不超过5个公历年度内(含)分期缴纳,并将有关资料报主管税务机关备案。这里股权奖励是指企业无偿授予相关技术人员一定份额的股权或一定数量的股份。
该规定的局限性在于适用范围过窄,因为该文仅仅适用于高新技术企业转化科技成果给予本企业相关技术人员的股权奖励。且不论高新技术企业的认定要求,仅将该优惠限定在转化科技成果,给予本企业相关技术人员的股权奖励,就已把非技术人员排除在外了。况且规定里的股权奖励是指无偿授予的股权,那么期权算吗?看起来不算。实际上,对于无偿授予股权,这是员工激励里非常忌讳的做法,也面临着无偿授予股权对应的注册资本如何实缴的中国特色法律问题!
简法帮提示:
根据中国现有的税法规定,员工个人获得股权奖励时,按照“工资薪金所得”项目计算确定应纳税额,虽然有可能享受年底奖金类似的处理方式,仍然可能导致员工按累进税率适用最高达45%的个人所得税。但是,按照现有的个人所得税法,如果持有期权的个人不是公司员工,反倒可能根据所得税法适用于更低的20%的个税税率,公司员工作为期权的主要激励对象反而受到更高税率的“惩罚”,这岂不荒唐?!
简法帮基于现有法律框架,之前在36Kr发表过系列文章,在《关于创业公司股权激励的那些“税事儿”(之一)》中谈了创业公司应该了解的基本税收制度,在《关于创业公司股权激励的那些“税事儿”(之二) ——税收规划的秘诀》中进一步聊过有关股权激励制度设计中的税收规划问题,有兴趣的读者可以前往查看。
5、一揽子解决方案
无论是中国还是美国,实施期权而不是限制性股权来激励员工的一个重要作用就是延迟纳税。因为员工取得期权时是否产生所得仍未确定(员工不行权就不产生收入),所以一般在授予期权时不产生纳税义务。比较起来,限制性股权直接授予员工时就可能立即面临纳税义务。在实践中,大部分创业公司通过创始股东低价转让或者公司低价增发的方式,让员工像投资人一样直接或间接取得公司股权,尽管理论上可能构成“工资薪金所得”,但很少听说有创业公司按照股权取得价与当时的市场价之间的差额代扣代缴“工资薪金”个人所得税,公司可以理解为法律不完善,税务局也可能理解为偷税漏税。
鉴于中国目前针对包括期权在内的员工股权激励税务制度尚处在早期阶段,员工行权就会面临繁重的税务负担和现金压力,所以在大部分情况下,在职员工都推迟行使期权,以此观察公司发展状况来决定待(市场)价而入再待(上)市而沽。
但离职员工的期权应该如何处理呢?放弃到位的期权,员工肯定觉得不公平;行权又面临高昂的税负和现金压力。市场实践中常见的做法是在员工离职时通过一揽子协议解决,将员工资、奖金、不竞争补偿金、经济补偿金以及期权等综合考虑,谈判形成一揽子的解决方案,专业的律师还可以利用经济补偿金的税收优惠待遇为公司和个人促成双方都能够接受的合规方案。
简法帮提示:
援引一个官司最终打到最高人民法院的案例来诠释前文内容,信息来源于2013年6月21日最高院《搜房控股有限公司与被申请人孙宝云合同纠纷再审民事裁定书》。
(1)30日行权窗口:“关于孙宝云的股票期权是否失效的问题。《股票期权协议》是双方当事人真实意思表示,内容不违反我国法律、行政法规的强制性规定,合法有效。搜房公司共授予孙宝云55000股的股票期权,孙宝云在期权有效期内享有依据协议选择购买搜房公司上述股票的权利。搜房北京公司与孙宝云于2009年7月1日解除劳动关系,依据《股票期权协议》第二部分总则第3条的约定,孙宝云的股票期权于2009年7月31日失效。但孙宝云早在2009年6月23日就以电子邮件的方式向莫天全提出了行使股票期权即购买股票的要求,并于7月9日和15日分别以电话及快递方式再次提出行使股票期权的要求。而莫天全在签署《股票期权协议》时表明其身份为搜房公司的董事会主席,在本案中亦以搜房公司代表人身份出现,故其有权代表搜房公司作出意思表示。对于孙宝云在股票期权有效期内提出的购买股票请求,依据《股票期权协议》,搜房公司应当向孙宝云出售股票。”
(2)一揽子解决方案——关于《离职协议书》是否终止《股票期权协议》的问题:“《离职协议书》虽然加盖了搜房北京公司的公章和搜房公司人力资源部的印章,但该协议书的内容为搜房北京公司就协商解除劳动合同事宜向孙宝云支付经济补偿金,并未提及孙宝云的股票期权问题,不足以推定搜房公司和孙宝云合意终止股票期权关系……《离职协议书》没有明确变更或终止《股票期权协议》,孙宝云和搜房公司之间的权利义务仍受《股票期权协议》的约束。”
在该案例中,员工孙宝云就注意到了30日行权窗口的问题。但在一揽子解决方案《离职协议书》中,双方没有明确地将股票期权问题涵盖在内,只是笼统地说“双方权利义务终止,除违反本协议的行为外,任何一方不得通过任何途径向对方主张任何权利”,可能是双方故意将期权问题切分出来单独处理,也有可能是双方的误解。但无论怎样,双方错过了员工离职达成一揽子解决方案这个最佳的时机。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
