LINUX中查看文本文件内容命令
cat:从第一行開始显示所有的文本内容;
tac:从最后一行開始,显示所有分文本内容,与cat相反。
nl:显示文本时,能够输出行号。
more:按页显示文本内容;
less:与more差点儿相同,也是按页显示文本内容,差别是less能够一行一行的回退。more回退仅仅能一页一页回退。
head:从头開始显示文件指定的行数;
tail:显示文件指定的结尾的行数。但每一行的位置还是原文件里的位置,不会像tac那样与原文件相反。
vi: NB的Linux文本编辑器。
样例与说明
cat
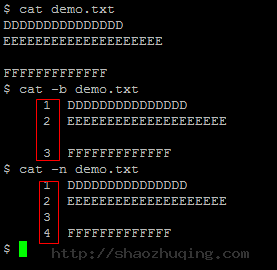
- cat demo.txt
显示demo.txt文件所有内容 - cat -b demo.txt
显示demo.txt文件所有内容。非空的行输出行号。空行会输出。但不标记行号 - cat -n demo.txt
显示demo.txt文件所有内容。所有行都输出行号
长处:简单
缺点:当文本文件内容多于一页内容时。仅仅能显示出最后一页的内容,无法看到前面的内容。
tac
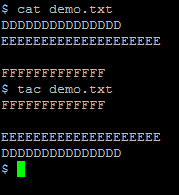
- tac demo.txt
从最后一行開始。倒序输出demo.txt的内容。本人不经常使用。
nl
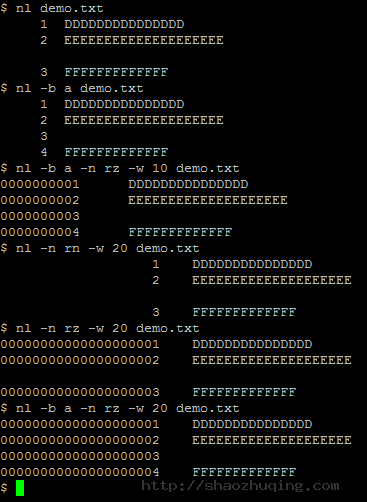
- nl demo.txt
显示文件内容。顺便输出行号。默认情况下空行不记录行号 - nl -b a demo.txt
- b a #空行也输出行号
- b t #默认设置
- n ln ##行号最左方显示
- n rn ##行号最右方显示,且不加0(然并卵,我的机器上依旧显示在左边)
- n rz ##行号最右方显示,且加0(再次然并卵,但加了0了。例如以下图所看到的)
- w ##设置行号字段占用的位数
长处:貌似非常灵活的样子
缺点:就查看下内容。输出个行号而已。搞那么复杂有卵用。。。
more
- more demo.txt
- 按一下空格则往下翻一页
- 按一下Enter则往下翻一行
- 按一下B键往上翻一页
- 不能往上一行一行的翻回去了
- :f 能够显示文件名称和如今的行数
- q退出more
less
- less demo.txt
- more命令的所有按键less都支持
- ↑↓箭头能够实现一行一行的上下翻
- PageDown/PageUp能够实现一页一页的上下翻
head
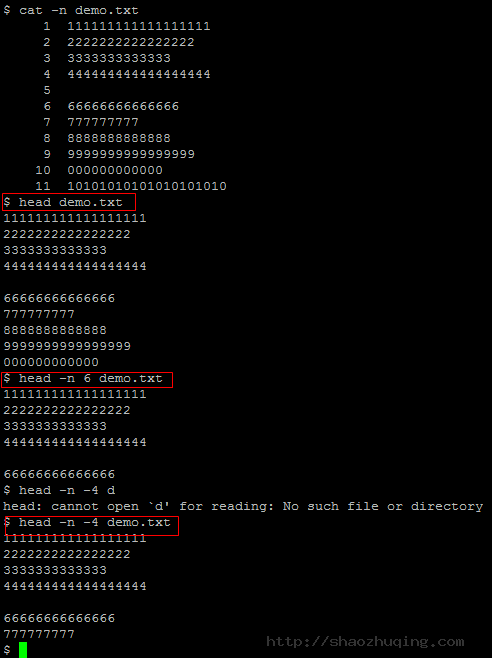
- head demo.txt
默认仅仅显示文件的前10行文本内容 - head -n 6 demo.txt
-n 6 參数指定显示文件的前6行 - head -n -4 demo.txt
-n -4 负数表示除去文件结尾的4行,其它的从头開始的所有行都显示出来
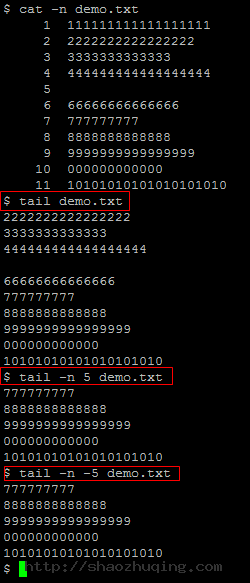
tail
- tail demo.txt
默认仅仅显示从文件最后一行開始的10行文本内容 - tail -n 5 demo.txt
-n 5 參数指定显示文件的最后5行 - tail -n -5 demo.txt
**-n -5**tail命令不支持负数。运行结果同-n 5
vi
vi命令是使用VIM文本编辑器打开文本,VIM编辑器眼下本人也是刚開始学习。仅仅记住了一些简单的命令:
- vi demo.txt 进入Normal模式查看文本
- i 进入Insert模式插入内容,编辑文本
- nG n代表行号,在Normal模式输入nG则定位到第n行
- :set number 在Normal模式输入则显示文本行号。空行也会显示行号
- ESC 退出Insert模式至Normal模式
- :wq 在Normal模式下保存退出。w保存;q退出;能够单独使用
Google Analytics cookie内容详解
cookie在WiKi上的解释是:指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
Cookie分为两种类型,第一方cookie和第三方cookie。Google Analytics使用第一方cookie
Google Analytics设置了5个不同的cookie,_utma, _utmb, _utmc, _utmz和 _utmv。分别用来存储不同的信息。所有的cookie统一使用_u-t-m开头,所以我们看到这三个字母就知道是google的cookie。
下面逐个介绍Google Analytics的cookie和功能。
_utma的主要功能:识别唯一身份访客
_utma的生存周期为2年。其中第二组的随机唯一ID和第三组的时间戳联合组成了访问者ID,Google Analytics通过这个ID来辨别网站的唯一访问者。而后面的几个时间戳用户计算网站停留时间和访问次数。
_utma Cookie存储的内容:127635166.1360367272.1264374807.1264374807.1264374807.1
第一组数字被叫做“域哈希”,是GA表示这个域的唯一代码。同一域中每个cookie的第一组数据都是“域哈希”,并且值都是一样的。
第二组数字是一个随机产生的唯一ID。
第三,四,五组数字是时间戳,其中第三组数字表示初次访问的时间。第四组数字表示上一次访问的时间,第五组数字表示本次访问开始的时间。
第六组数字是访问次数计数器。这个数字随着访问次数的增加而增加。
PS:上面的三个时间戳数字相同,并且最后的访问次数计数器是1,表示这是第一次访问。
_utmb的主要功能:和_utmc一起决定访客的Session
_utmb的生存周期为30分钟,当访问者在你的网站持续30分钟静止时,utmb将被删除。Google Analytics使用_utmb 和_utmc一起辨别一个session。
_utmb Cookie存储的内容:127635166.2.10.1264374807
第一组数字和_utma一样,是“域哈希”。
后面的几组数字是一些附加值。
_utmc的主要功能:和_utmb一起决定访客的Session

_utmc是一个临时cookie,当用户关闭浏览器时_utmc将一起被删除
_utmc和_utmb一起来识别一个session,当用户访问一个网站时,Google Analytics会检查这两个cookie,如果缺少其中任何一个,Google Analytics都将认为这是一个新的session。
_utmc的内容:127635166 代表“域哈希”。
_utmz的主要功能:存储流量来源信息和链接标记的变量值。
_utmz的生存周期是6个月,_utmz中存储了所有流量的来源信息。
_utmz的内容中一共有4组数字:127635166.1264374807.1.1
第一组数字是“域哈希”。
第二组数字是时间戳。
第三组数字是session number。
第四组数字是campaign number 记录通过不同来源访问网站的次数。
utmcsr=(direct)|utmccn=(direct)|utmcmd=(none)
这些信息代表流量的来源,因为我是直接输入域名直接访问的,所以来源和媒介都是direct
_utmv的主要功能:自定义访问者的属性。
_utmv的生存周期是2年,存储通过_setVar()自定义用户属性。
_utmv的内容:127635166.user
第一组数字是“域哈希”。
第二个值user是通过_setVar()设置的用户属性。
PS:_utmv只有在调用了_setVar()时才会出现。
此外,还有两个cookie __utmx和__utmxx。这两个cookie不是由Google Analytics设置的,而是由Google的Website Optimizer用来做A/B测试或多变量测试用的。如果在访问某个页面后看到这两个cookie,那就说明这个页面正在进行页面优化测试,而你访问的 页面可能是测试中的某一个版本。
Google Analytics中的cookie比较多,每个cookie的属性和功能也各不一样。我做了一个Google Analytics cookie速查表,请在这里下载。
Google Analytics(分析)如何使用 Cookie
Google Analytics(分析)利用 Cookie 定义用户会话,并提供 Google Analytics(分析)报告中的多种关键功能。Google Analytics(分析)设置或更新 Cookie 的目的仅在于收集报告所需数据。此外,Google Analytics(分析)仅使用第一方 Cookie。也就是说 Google Analytics(分析)针对您的域设置的所有 Cookie 仅会向您的域的服务器发送数据。这一做法有效地保证了 Google Analytics(分析)Cookie 成为您网站域的私有财产,来自其他域的任何服务器都无法篡改或获取其中的数据。
下表中列出了通过 Google Analytics(分析)Cookie 获取并在 Google Analytics(分析)报告中使用的信息类型。
| 功能 | Cookie 说明 | 使用的 Cookie |
|---|---|---|
| 设置您网站内容的范围 | 因为任何 Cookie 读/写访问都会同时受到 Cookie 名称和其所在域的限制,所以通过 Google Analytic(分析)进行的访问者跟踪会默认限制在安装跟踪代码网页所在域。一般来说,跟踪代码将安装在单个域中(并且没有其他子域),在这种情况下,通用设置是适用的。如果您希望跨多个域或子域跟踪内容,或将跟踪范围限制在单个域中更为具体的部分,您可以使用 ga.js 跟踪代码中的其他方法定义内容范围。有关详情,请参阅 Collection API 文档中的域和目录。 |
所有 Cookie |
| 确定访问者会话 | 针对 ga.js 的 Google Analytics(分析)跟踪使用两个 Cookie 来建立会话。如果这两个 Cookie 中的任一个缺失,用户的后续活动将会导致启动一个新会话。有关详细的定义以及将会终止会话的情景的列表,请参阅帮助中心中的会话一文。您可以使用 _setSessionCookieTimeout() 方法自定义默认会话时间的长度。
该描述专门针对网页的 |
__utmb |
| 识别唯一身份访问者 | __utma Cookie 会为访问您网站网页的每一个浏览器指定唯一的 ID。通过这种方式,使用同一浏览器对您网站进行的后续访问,将会视为同一(唯一身份)访问者的访问而被记录下来。因此,如果某用户同时使用 Firefox 和 Internet Explorer 与您的网站互动,Google Analytics(分析)报告会将其视为两位唯一身份访问者的活动进行跟踪。同样,如果两位访问者使用同一浏览器,但登录到各自的计算机帐户,那么这些 活动将按照两个唯一身份访问者 ID 进行记录。另一方面,如果两位访问者恰巧使用同一浏览器,同时共享同一计算机帐户,那么将按照一个唯一身份访问者 ID 进行记录,尽管事实上访问是由两个人分别进行的。 |
__utma |
| 跟踪流量来源和浏览过程 | 当用户通过搜索引擎结果、直接链接或链接到您网页的广告到达您的网站时,Google Analytics(分析)会在 Cookie 中储存引荐类型的信息。Cookie 值字符串中的参数将得到解析,并通过 GIF 请求(utmcc 变量)发送。Cookie 的有效期为 6 个月。此 Cookie 会在用户对您网站的每个网页进行后续浏览时获得更新,进而确定访问者对您网站的浏览过程。 |
__utmz |
| 自定义变量 | 您可以根据具体数据定义自己的报告细分。如果您在跟踪代码中使用 _setCustomVar() 方法定义了自定义变量,Google Analytics(分析)将使用此 Cookie 跟踪并报告这一信息。通常情况下,您可以使用此方法根据用户在您网站上选择的自定义人口统计学特点(收入、年龄范围、产品性能),对网站访问者进行细分。 |
___utmv |
| Website Optimizer | 您可以将 Google Analytics(分析)与 Google 网站优化工具配合使用,该工具可帮助您确定最有效的网站设计。网站优化脚本在您的网页中执行时,会将一个 _utmx Cookie 写入到浏览器中,并将其值发送给 Google Analytics(分析)。有关详情,请参阅 Google 网站优化工具帮助中心。 | ___utmx |
一旦在网络浏览器中设置/更新了 Cookie,其中包含的报告所需数据将通过 utmcc 参数发送到 GIF 请求网址中记录的 Google Analytics(分析)服务器。
Google Analytics(分析)设置的 Cookie
Google Analytics(分析)会设置下表中介绍的 Cookie。在默认的配置和使用情况下,Google Analytics(分析)仅会设置表中的前 4 个 Cookie。
| 名称 | 说明 | 有效期 |
|---|---|---|
__utma |
此 Cookie 通常会在该网络浏览器首次访问您的网站时写入其中。如果此 Cookie 被浏览器操作者删除,而该浏览器又对您的网站进行了后续访问,一个拥有不同唯一 ID 的 __utma Cookie 将会写入其中。此 Cookie 用于确定您网站的唯一身份访问者,并会在每次网页浏览时获得更新。此外,Google Analytics(分析)会将为此 Cookie 指定的唯一 ID 作为额外的安全措施,以确保此 Cookie 的有效性和可访问性。 |
设置/更新后 2 年。 |
__utmb |
此 Cookie 用于建立和保持用户与您的网站之间的会话。当用户浏览您网站的某个网页时,Google Analytics(分析)代码会尝试更新此 Cookie。如果未能找到此 Cookie,Google Analytics(分析)会写入一个新的该 Cookie 并建立新的会话。每当用户访问您网站中的其他网页时,此 Cookie 的有效期会重新更新为 30 分钟,因此只要在 30 分钟周期内重复发生了用户活动,单个会话就会一直持续下去。如果用户在您网站中某网页的停留时间超过了 30 分钟,此 Cookie 就会过期。您可以通过 _setSessionCookieTimeout() 方法修改默认的用户会话时间的长度。 |
设置/更新后 30 分钟。 |
__utmc |
此 Cookie 会和 __utmb Cookie 结合使用,确定是否为用户建立新的会话。具体来说,此 Cookie 没有特定的有效期,所以它将在用户退出浏览器时失效。如果某用户访问过您的网站后退出了浏览器并在 30 分钟内再次访问了您的网站,该用户将会由于缺少 __utmc Cookie 而必须建立新的会话,尽管事实上 __utmb Cookie 还尚未失效。 |
未设置。 |
__utmz |
此 Cookie 会储存访问者到达您的网站通过的引荐类型,即是否通过直接方法、引荐连接、网站搜索或广告系列(例如广告或电子邮件)到达。这些信息会用来计算您网站的搜索引擎流量、广告系列和网页的导航方式。此 Cookie 会在每次网页浏览时获得更新。 | 设置/更新后 6 个月。 |
__utmv |
此 Cookie 正常情况下在默认跟踪代码配置中不会出现。__utmv Cookie 通过 _setVar() 方法传递所提供的信息,您可以使用该方法创建自定义用户细分。然后,此字符串将通过 utmcc 参数传递到 GIF 请求网址中记录的 Google Analytics(分析)服务器。仅当您将 _setVar() 方法添加到您网站页面的跟踪代码中时,此 Cookie 才会写入浏览器中。 |
设置/更新后 2 年。 |
__utmx |
此 Cookie 用于 Google 网站优化工具,并且仅当您的网页正确安装并配置了 Google 网站优化工具跟踪代码时才会设置。当优化脚本执行时,此 Cookie 会储存该访问者针对每个实验所分配到的变量,确保用户在您的网站体验的一致性。有关详情,请参阅 Google 网站优化工具帮助中心。 | 设置/更新后 2 年。 |
通过对web日志的挖掘来实现内容推荐系统
先说一说问题,不知道大家有没有这样的经验,反正我是经常碰到。
举例1,某些网站每隔几天就发邮件给我,每次发的邮件内容都是一些我根本不感兴趣的东西,我不甚其扰,对其深恶痛绝。
举例2,添加具有某功能的一个msn机器人,每天都有几次突然蹦出一个窗口,推荐一堆我根本不想知道的内容,烦不烦啊, 我只好将你阻止掉。
每一个观众只想看他感兴趣的东西,而不是一下与之无关的事物,那么如何才能知道观众的兴趣所在呢,还是数据挖掘,经过一番思考,终于有点思路,即根据用户 以往的浏览历史来预测用户将来的行为,也就是基于内容的推荐。
基于内容的推荐(Content-based Recommendation)是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。 基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。
基于内容推荐 方法的优点是:
1)不需要其它用户的数据,没有冷开始问题和稀疏问题。
2)能为具有特殊兴趣爱好的用户进行推荐。
3)能推荐新的或不是很流行的项目,没有新项目问题。
4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。
5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。
缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情 况。
要实现内容推荐系统总体来说要经过4个大的步骤:
1 搜集数据,即搜集用户的行为资料,其中也包括很多方法,根据我找到的资料与以往的经验来看,web日志可以作为我们的切入点,即我们的数据来源。
2 过滤数据,web日志中有很多无用的信息,我们要把这些无用的信息排除掉,而且要区分出用户和日志数据之间的联系。
3 分析数据,利用分类聚类技术分析出这些日志数据之间的关联性,以及这些日志数据和用户之间的关联性,这也是最重要的一步。
4 输出结果。
有了这个思路之后,我们可以着手做第一步,即日志数据的收集
我们知道,大多数的web服务器都是有自己的日志记录的,比如说apache安装之后有一个logs目录,其中就有它的日志文件,一般说来它有自 己的一个格式,比如说:
1浏览器所在主机的 IP 地址(ip);
2访问日期和时间(date-time);
3客户机与服务器通信所用的方法(methed,get or post);
4客户机请求访问页面的 URL;
5服务器返回的状态(status);
6客户端浏览器的类型;
但是这个日志文件有一些不能克服的问题,或者我不知道如何克服,那么我先说说我的疑问,首先,这个日志文件中记录的是ip地址,据了解,网络中有很多计算 机的ip地址是相同的,因为他们在一个统一的路由后面,这个比例可能达到25%。那么我们就无法根据ip地址来唯一确定一个用户。其次,一般的web服务 器中都会用多个应用,那么其他应用的访问信息对我们来说有可能是多余的。再者,web服务器的日志形式比较单一,灵活性不大,可定制的余地很小,在日志数 据中有效数据所占的比例较小。还有,一些静态文件的请求也会被web服务器记录下来,比如说js文件,css文件,还有图片文件,等等这些东西对内容推荐 来说都是无用的资源。
基于上面3点原因,我认为可以自定义日志数据。为了解决用户唯一性,我们让应用为每一个浏览器生成一个clientId保存在对应的浏览器上,这样该浏览 器只要访问网站,我们就可以确定这个浏览器的唯一性,当然我们仍然不能确定浏览器使用者的唯一性,但是我们可以更进一步,如果浏览器的使用者登陆网站的 话,我们就可以使用用户id来确定用户的唯一性,不过大多数网站用户可能在使用网站的时候并不会登陆,我也是这样,没有关系,即使使用clientId问 题也不会太大,随着社会的发展,计算机的拥有量逐渐增加,一般来说一个人只会使用一台固定的电脑,在公司里尤其是这样。所以我认为clientId的方案 是可行的,也许有人要问,别人的浏览器禁止了cookie怎么办,那么我只能说没有办法,不过还好事实是绝大多数人都没有这样做。
接下来我们可以定义一下我们所需要的日志数据的格式,比如这样,
ip,clientId,userId,url,datetime,get or post等等。
这样数据有效性会大大提高。
在得到较为有效的数据之后,我们还需要对这些数据进行再次过滤:
1 去掉一些非内容的url,这些数据也是无效数据,这些非内容的url需要我们自己手工的统计出来,然后和日志数据中的数据进行比对,将这些非内容数据从日 志数据中清除出去。
2 同时我们也需要把post请求从日志数据中清除出去,或者我们在记录日志的时候根本不应该把post请求记录下来。
经过以上步骤之后我们就可以开始第3个阶段了,统计每个用户的访问的url,对这些url进行访问,得到对应的html中所包含的数据,这些数据都是文 本,将有用的文本提取出来,然后对这些有用的文本进行聚类。这样就可以得到每个用户喜欢的几个类别。
聚类完成之后我们就可以开始分类了,即把最新的文章或者内容和对应的类别进行匹配,匹配成功之后,我们可以认为这个新文章或者内容可以推荐给对应的用户。
问题:以上的流程只适用于没有使用缓存的系统,但是一般大型的网站都会使用varnish,squid等等,使用它们之后我们就无法得到用户访问的日志数 据了,所以如果使用了varnish或者squid,我们不得不再次面对web服务器的日志数据。
在不考虑varnish或者squid的情况下,使用lucene+jamon+htmlparse基本就可以实现以上推荐系统。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
