Linux vim 随记
命令模式
三种命令模式
vim的三种命令模式:
- 命令模式:用于输入命令,简单更改
- 插入模式:用于插入文本,修改文本
- 末行模式:用于输入命令,视化操作,查找替换等
三种模式之间的切换方式:
- 命令模式进入到插入模式:输入文本插入命令(i,I,a,A,o,O)
- 插入模式退出到命令模式:ESC
- 命令模式进入到末行模式:冒号:
- 末行模式退出到命令模式:Enter或者ESC.

vim命令集合:http://www.cnblogs.com/kzloser/archive/2012/09/12/2681111.html
图释指令
光标移动-------------
按行移动:
按字符移动:

插入命令-------------
常用命令-------------



普通模式下命令
复制,删除,粘贴
- 粘贴: 把 vim 中缓存区的数据,粘贴到光标附近(即 p 为光标后, P为光标前)
- 删除: 把 vim 中选中的删除数据先拷贝到缓冲区并覆盖原有数据,然后删除选中数据
- 复制: 把 vim 中选中的数据拷贝的缓冲区并覆盖原有数据
例子:
现在有数据如下:aaaaabbbbbcccccdddddfffff
假设我们的光标在第一个 b 这个位置, 在一般模式下输入 5x (即输入删除 5 个 b 的操作) 后结果为:
aaaaacccccdddddfffff
然后在按下 p (即在光标位置处后面粘贴缓冲区的数据),结果为:
aaaaacbbbbbccccdddddfffff
删除某区域内容:
可以重复的:
[d]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
- d: 表示删除操作
- 重复操作次数: num 表示操作重复次数
- 操作区域选择:
- h 删除光标前一个字符
- l 删除光标所在处的字符
- j 删除本行与下一行
- k 删除本行与上一行
- w 删除光标开始到下一个单词词首处
- b 删除光标开始到上一个单词词首处
- e 删除光标开始到这个单词的结尾处
- ( 删除光标开始到句子结束处
- ) 删除光标开始到句子开始处
- { 删除光标开始到段落开始处
- } 删除光标开始到段落结束处
- $ 删除从光标开始处到行尾处
- G 删除从光标所在行到行尾处
- /word 删除从光标开始处到下个 word 字符串,不含 word ( word 指代任意字符串 )
- ?word 删除从光标开始处到上个 word 字符串,不含 word ( word 指代任意字符串 )
- tc 删除从光标开始处到下个 c 字符处,不含 c ( c 指代任意字符 )
- Tc 删除从光标开始处到上个 c 字符处,不含 c ( c 指代任意字符 )
- fc 删除从光标开始处到下个 c 字符处,含 c ( c 指代任意字符 )
- Fc 删除从光标开始处到上个 c 字符处,含 c ( c 指代任意字符 )
- `c 删除从光标开始到标记 c 这个位置
不可重复的:
[d]+[ 0 / ^ / H / L ]
- d: 表示删除操作
- 操作区域选择:
- d0 删除从光标所在处到某一行的开始位置
- d^ 删除到某一行的第一个字符位置(不包括空格或TAB字符)
- dL 删除直到屏幕上最后一行的内容
- dH 删除直到屏幕上第一行的内容
复制某区域内容:
可以重复的:
[y]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
含义用法如删除类似
不可重复的:
[y]+[ 0 / ^ / H / L ]
含义用法如删除类似
多加介绍个与上面用法相似的操作:
改变某区域内容:
可以重复的:
[c]+[num]+[ h / j / k / l / w / b / e / ( / ) / { / } / $ / G / /word / ?word / tc / Tc / fc / Fc / `c ]
含义用法如删除类似
不可重复的:
[c]+[ 0 / ^ / H / L ]
含义用法如删除类似
操作的组合
v 字符选择
操作流程:
v + 移动光标按键+ 数据操作键
- v 开始选择字符的标志
- 移动光标按键 移动光标确定选择区域(此处可以为多个移动光标的键值,但不能为组合键:如 [Ctrl]+[p] 等等)
- 数据操作键 对选择区域内的数据内容进行操作
例子[删除选择的字符区间 vwd(vwx)] :
现在有数据如下:
aaaaabbbbb ccccc
按下 v 键时(标志开始选择区域的操作):
aaaaa|bbbbb ccccc
按下 w 键时(选择操作区域,当然这里的 w 是可以换成 llllll [ 即六个小写的 L ]):
aaaaabbbbb ccccc
按下 d/x 键时(对数据进行操作,即删除所选择区域中的数据):
aaaaaccccc
V 列选择
操作流程:
V + 移动光标按键+ 数据操作键
- V 开始选择字符的标志
- 移动光标按键 移动光标确定选择区域(此处可以为多个移动光标的键值或者没有键值当没有键值的时候操作区域为光标所在行,但不能为组合键:如 [Ctrl]+[p] 等等)
- 数据操作键 对选择区域内的数据内容进行操作
例子[删除本行和下行数据 Vjd(Vjx)] :
现在有数据如下:
aaaaa
bbbbb
ccccc
按下 V 键时(标志开始选择区域的操作):
aaaaa
bbbbb
ccccc
按下 j 键时(选择操作区域):
aaaaa
bbbbb
ccccc
按下 d/x 键时(对数据进行操作,即删除所选择区域中的数据):
ccccc
字符串搜索
搜索字符串中的特殊字符
- ^ (行开始指示符)
当脱字符( 即 ^ ),作为搜索字符串的第一个字符时, vim 将每行的开始字符与搜索字符串进行匹配. - . (任意字符指示符)
句点( 即 . )可以与任意字符匹配,它可以出现在搜索字符串中的任意位置.当要查找句点符号时候可以用转义字符 . 来查找句点符号 - < (字符开始指示符)
这两个字符与单词的开始匹配 - > (字符结束指示符)
这两个字符与单词的结束匹配 - * (0个或者过个出现)
这个字符时一个修饰符,它与某个字符的 0 次或者多次出现相匹配 - [] (定义字符类)
单个字符匹配的区间(这里想要了解的更详细的话可以参考 正则表达式 )例如 ds[ab] 代表的是 dsa 与 dsb
示例------
句子:
being kind to yourself in everyday life is one of the best things you can do for yourself.
life will become lighter and your relationships will most likely improve
| 搜索字符串 | 描述 | 结果(以单词为单位) |
| /you | 查找字符串 you 的下一次出现的位置 | yourself, you, yourself, your |
| /<you> | 查找单词 you 的下一次出现的位置 | you |
| /^be | 查找以 be 开始的下一行 | being ... |
| /^[a-z][a-z] | 查找以两个字符开头开始的下一行 | being ... , life ... |
| /<th | 查找以 th 开头的单词 | the thing |
| /[a-m]e> | 查找以 [a-m]e 为结尾的单词 | life, the, life, become |
命令行的命令
字符替换
语法格式:
[range]s/{pattern}/{string}/[flag] [count]
格式说明:
- range 表示行数
- %表示所有行
- n1,n2 表示由 n1 行到 n2 行之间
- s 表示substitution,替换的意思
- pattern 表示被替换的字符串
- string 表示替换的字符串
- flag 表示标志,取值g,i,c等
- g 表示global,全部
- i 表示ignore,忽略大小写
- c 表示confirm,一个一个交互确认替换
- count 表示从当前行到接下来的第几行,表示范围
例子:
(1). 全部替换
参数g实现全部替换,否则只替换一个
:%s/{old-pattern}/new-text/g
(2). 行内替换
%代表所有行,去掉%表示当前行,只替换当前行
:s/{old-pattern}/new-text/g
(3). 指定行范围替换
对1到10行的结果替换
:1,10s/{old-pattern}/new-text/g
(4). 可视模式替换
如果你觉得数行数比较麻烦,可以使用可视模式,首先进入可视模式,然后选择行
列,最后输入:自动进入:'<,'>
后面加上s/{old-pattern}/new-text/g,则只替换选择区域的结果
:'<,'>s/{old-pattern}/new-text/g
(5). 整词替换,而不是部分匹配的单词
对单词匹配模式外包一个<和>
:s/<blog>/weibo/g //替换blog,但是cnblog,blogs则不会替换
(6). 多项替换
同时对多个匹配都替换成某一字符串
:%s/(good|nice)/awesome/g //good和nice都将被替换成awesome
(7). 确认式替换
参数c让替换进行交互请求,需要你选择y,n,a,l,q
选择说明:
- y 替换且跳转到下一个匹配结果
- n 不替换且跳转到下一个匹配结果
- a 替换所有并退出交互模式
- l 替换当前并退出交互模式
- q 退出交互模式
:s/{old-pattern}/new-text/gc
(8). 行首插入行号
把行首^替换成行号,可自定义具体形式
:%s/^/=line(".")/g
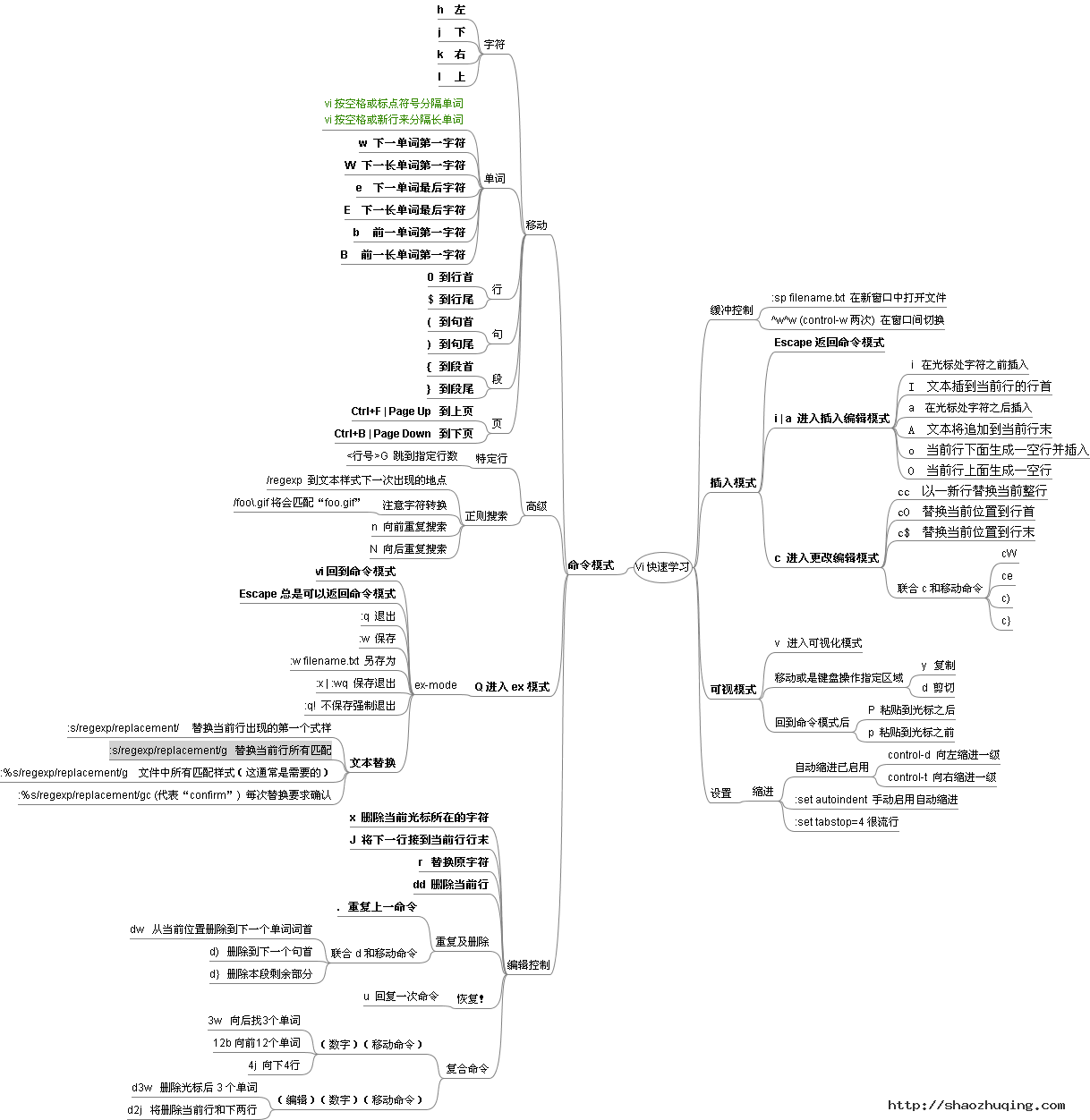
录制
这个其实很简单,但也是很强大的功能,作用是记录你的操作,并把操作过程记录起来.然后可以用 @@ 来调用出来你刚刚记录的操作集合,从而简化了复杂操作的过程
过程:
- q //标志开始录制
- x //x 是这个录制的寄存器,x 可以是其它字符
- 操作过程
- q //标志录制结束,现在dd这个操作被定义到了 @x 这个命令里了
图释:
解读大型网站系统架构的演化
前言
一个成熟的大型网站(如淘宝、京东等)的系统架构并不是开始设计就具备完整的高性能、高可用、安全等特性,它总是随着用户量的增加,业务功能的扩展逐渐演变完善的,在这个过程中,开发模式、技术架构、设计思想也发生了很大的变化,就连技术人员也从几个人发展到一个部门甚至一条产品线。所以成熟的系统架构是随业务扩展而完善出来的,并不是一蹴而就;不同业务特征的系统,会有各自的侧重点,例如淘宝,要解决海量的商品信息的搜索、下单、支付,例如腾讯,要解决数亿的用户实时消息传输,百度它要处理海量的搜索请求,他们都有各自的业务特性,系统架构也有所不同。尽管如此我们也可以从这些不同的网站背景下,找出其中共用的技术,这些技术和手段可以广泛运行在大型网站系统的架构中,下面就通过介绍大型网站系统的演化过程,来认识这些技术和手段。
一、最开始的网站架构
最初的架构,应用程序、数据库、文件都部署在一台服务器上,如图:

二、应用、数据、文件分离
随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

三、利用缓存改善网站性能
在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Membercache、Redis。
四、使用集群改善应用服务器性能
应用服务器作为网站的入口,会承担大量的请求,我们往往通过应用服务器集群来分担请求数。应用服务器前面部署负载均衡服务器调度用户请求,根据分发策略将请求分发到多个应用服务器节点。

常用的负载均衡技术硬件的有F5,价格比较贵,软件的有LVS、Nginx、HAProxy。LVS是四层负载均衡,根据目标地址和端口选择内部服务器,Nginx和HAProxy是七层负载均衡,可以根据报文内容选择内部服务器,因此LVS分发路径优于Nginx和HAProxy,性能要高些,而Nginx和HAProxy则更具配置性,如可以用来做动静分离(根据请求报文特征,选择静态资源服务器还是应用服务器)。
五、数据库读写分离和分库分表
随着用户量的增加,数据库成为最大的瓶颈,改善数据库性能常用的手段是进行读写分离以及分表,读写分离顾名思义就是将数据库分为读库和写库,通过主备功能实现数据同步。分库分表则分为水平切分和垂直切分,水平切换则是对一个数据库特大的表进行拆分,例如用户表。垂直切分则是根据业务不同来切换,如用户业务、商品业务相关的表放在不同的数据库中。

六、使用CDN和反向代理提高网站性能
假如我们的服务器都部署在成都的机房,对于四川的用户来说访问是较快的,而对于北京的用户访问是较慢的,这是由于四川和北京分别属于电信和联通的不同发达地区,北京用户访问需要通过互联路由器经过较长的路径才能访问到成都的服务器,返回路径也一样,所以数据传输时间比较长。对于这种情况,常常使用CDN解决,CDN将数据内容缓存到运营商的机房,用户访问时先从最近的运营商获取数据,这样大大减少了网络访问的路径。比较专业的CDN运营商有蓝汛、网宿。
而反向代理,则是部署在网站的机房,当用户请求达到时首先访问反向代理服务器,反向代理服务器将缓存的数据返回给用户,如果没有没有缓存数据才会继续走应用服务器获取,也减少了获取数据的成本。反向代理有Squid,Nginx。

七、使用分布式文件系统
用户一天天增加,业务量越来越大,产生的文件越来越多,单台的文件服务器已经不能满足需求。需要分布式的文件系统支撑。常用的分布式文件系统有NFS。

八、使用NoSql和搜索引擎
对于海量数据的查询,我们使用nosql数据库加上搜索引擎可以达到更好的性能。并不是所有的数据都要放在关系型数据中。常用的NOSQL有mongodb和redis,搜索引擎有lucene。

九、将应用服务器进行业务拆分
随着业务进一步扩展,应用程序变得非常臃肿,这时我们需要将应用程序进行业务拆分,如百度分为新闻、网页、图片等业务。每个业务应用负责相对独立的业务运作。业务之间通过消息进行通信或者同享数据库来实现。

十、搭建分布式服务
这时我们发现各个业务应用都会使用到一些基本的业务服务,例如用户服务、订单服务、支付服务、安全服务,这些服务是支撑各业务应用的基本要素。我们将这些服务抽取出来利用分部式服务框架搭建分布式服务。淘宝的Dubbo是一个不错的选择。

小结
大型网站的架构是根据业务需求不断完善的,根据不同的业务特征会做特定的设计和考虑,本文只是讲述一个常规大型网站会涉及的一些技术和手段。
百度地图插件安装参考
百度地图插件安装参考:http://developer.baidu.com/map/index.php?title=jspopular
http://developer.baidu.com/map/index.php?title=%E9%A6%96%E9%A1%B5
下方有相关插件模块
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<div id="map-canvas" class=""style="width:715px;height:400px"></div>
<script src="http://api.map.baidu.com/api?v=1.5&ak=3912c09d8490b8c5754aedc170955e21" type="text/javascript"></script>
<script type="text/javascript">
var map = new BMap.Map("map-canvas");
map.enableScrollWheelZoom();
var point = new BMap.Point(117.180386, 39.084208);
map.centerAndZoom(point, 15);
//加入缩放控件;
map.addControl(new BMap.NavigationControl());
//创建坐标点;
var marker1 = new BMap.Marker(point);
map.addOverlay(marker1);
</script>
</html>
php/mysql/jquery实现各系统流行的瀑布流显示方式,实现很简单的!!!!
大家在用这个东西的时候一定要计得有这么几个文件,一个是jquery.js 还有就是你自己数据库的密码。和相对应的图片才可以正常看到效果。下面就是这里所有的代码!!!
HTML文件:waterfall.html
1. [代码][PHP]代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
View Code <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>瀑布流-Derek</title> <script type="text/javascript" language="javascript" src="jquery.js"></script> <link type="text/css" rel="stylesheet" href="waterfall.css" /> <script type="text/javascript" language="javascript" src="waterfall.js"></script> </head> <body> <ul id="stage"> <li></li> <li></li> <li></li> <li></li> </ul> </body> </html>/* * Javascript文件:waterfall.js */$(function(){ jsonajax(); }); //这里就要进行计算滚动条当前所在的位置了。如果滚动条离最底部还有100px的时候就要进行调用ajax加载数据 $(window).scroll(function(){ //此方法是在滚动条滚动时发生的函数 // 当滚动到最底部以上100像素时,加载新内容 var $doc_height,$s_top,$now_height; $doc_height = $(document).height(); //这里是document的整个高度 $s_top = $(this).scrollTop(); //当前滚动条离最顶上多少高度 $now_height = $(this).height(); //这里的this 也是就是window对象 if(($doc_height - $s_top - $now_height) < 100) jsonajax(); }); //做一个ajax方法来请求data.php不断的获取数据 var $num = 0; function jsonajax(){ $.ajax({ url:'data.php', type:'POST', data:"num="+$num++, dataType:'json', success:function(json){ if(typeof json == 'object'){ var neirou,$row,iheight,temp_h; for(var i=0,l=json.length;i<l;i++){ neirou = json[i]; //当前层数据 //找了高度最少的列做添加新内容 iheight = -1; $("#stage li").each(function(){ //得到当前li的高度 temp_h = Number($(this).height()); if(iheight == -1 || iheight >temp_h){ iheight = temp_h; $row = $(this); //此时$row是li对象了 } }); $item = $('<div><img src="'+neirou.img+'" border="0" ><br/>'+neirou.title+'</div>').hide(); $row.append($item); $item.fadeIn(); } } } }); }/* * CSS文件:waterfall.css */body{text-align:center;}/*Download by http://www.codefans.net*/#stage{ margin:0 auto; padding:0; width:880px; }#stage li{ margin:0; padding:0; list-style:none;float:left; width:220px;}#stage li div{ font-size:12px; padding:10px; color:#999999; text-align:left; }/* * php文件:data.php */<?php $link = mysql_connect("localhost","root",""); $sql = "use waterfall"; mysql_query($sql,$link); $sql = "set names utf8"; mysql_query($sql,$link); $num = $_POST['num'] *10; if($_POST['num'] != 0) $num +1; $sql = "select img,title from content limit ".$num.",10"; $result = mysql_query($sql,$link); $temp_arr = array(); while($row = mysql_fetch_assoc($result)){ $temp_arr[] = $row; } $json_arr = array(); foreach($temp_arr as $k=>$v){ $json_arr[] = (object)$v; } //print_r($json_arr); echo json_encode( $json_arr ); |
2. [文件] waterfall.zip ~ 8KB 下载(850)
linux下mysql的root密码忘记解决方法
1.首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库。
因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的
状态下,其他的用户也可以任意地登录和修改MySQL的信息。可以采用将MySQL对
外的端口封闭,并且停止Apache以及所有的用户进程的方法实现服务器的准安全
状态。最安全的状态是到服务器的Console上面操作,并且拔掉网线。
2.修改MySQL的登录设置:
# vi /etc/my.cnf
在[mysqld]的段中加上一句:skip-grant-tables
例如:
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
skip-grant-tables
保存并且退出vi。
3.重新启动mysqld
# /etc/init.d/mysqld restart
Stopping MySQL: [ OK ]
Starting MySQL: [ OK ]
4.登录并修改MySQL的root密码
# /usr/bin/mysql
Welcome to the MySQL monitor. Commands end with ; or g.
Your MySQL connection id is 3 to server version: 3.23.56
Type 'help;' or 'h' for help. Type 'c' to clear the buffer.
mysql> USE mysql ;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> UPDATE user SET Password = password ( 'new-password' ) WHERE User = 'root' ;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 2 Changed: 0 Warnings: 0
mysql> flush privileges ;
Query OK, 0 rows affected (0.01 sec)
mysql> quit
Bye
5.将MySQL的登录设置修改回来
# vi /etc/my.cnf
将刚才在[mysqld]的段中加上的skip-grant-tables删除
保存并且退出vi。
6.重新启动mysqld
# /etc/init.d/mysqld restart
Stopping MySQL: [ OK ]
Starting MySQL: [ OK ]
skip-networking #注释掉 因为它是屏蔽掉一切TCP/IP连接
bind-address = 127.0.0.1 #它和上一个选项是异曲同工,要想远程连接,也得注释掉
2.如果以上工作都做过还是出现:
ERROR 2003 (HY000): Can't connect to MySQL server on '*.*.*.*' (113),那就得考虑防火墙的问题了,关掉防火墙/etc/rc.d/init.d/iptables stop
修改完后需要 restart mysql (/etc/init.d/mysql restart)
Mysqldump参数大全(参数来源于mysql5.5.19源码)
参数
参数说明
--all-databases , -A
导出全部数据库。
mysqldump -uroot -p --all-databases
--all-tablespaces , -Y
导出全部表空间。
mysqldump -uroot -p --all-databases --all-tablespaces
--no-tablespaces , -y
不导出任何表空间信息。
mysqldump -uroot -p --all-databases --no-tablespaces
--add-drop-database
每个数据库创建之前添加drop数据库语句。
mysqldump -uroot -p --all-databases --add-drop-database
--add-drop-table
每个数据表创建之前添加drop数据表语句。(默认为打开状态,使用--skip-add-drop-table取消选项)
mysqldump -uroot -p --all-databases (默认添加drop语句)
mysqldump -uroot -p --all-databases –skip-add-drop-table (取消drop语句)
--add-locks
在每个表导出之前增加LOCK TABLES并且之后UNLOCK TABLE。(默认为打开状态,使用--skip-add-locks取消选项)
mysqldump -uroot -p --all-databases (默认添加LOCK语句)
mysqldump -uroot -p --all-databases –skip-add-locks (取消LOCK语句)
--allow-keywords
允许创建是关键词的列名字。这由表名前缀于每个列名做到。
mysqldump -uroot -p --all-databases --allow-keywords
--apply-slave-statements
在'CHANGE MASTER'前添加'STOP SLAVE',并且在导出的最后添加'START SLAVE'。
mysqldump -uroot -p --all-databases --apply-slave-statements
--character-sets-dir
字符集文件的目录
mysqldump -uroot -p --all-databases --character-sets-dir=/usr/local/mysql/share/mysql/charsets
--comments
附加注释信息。默认为打开,可以用--skip-comments取消
mysqldump -uroot -p --all-databases (默认记录注释)
mysqldump -uroot -p --all-databases --skip-comments (取消注释)
--compatible
导出的数据将和其它数据库或旧版本的MySQL 相兼容。值可以为ansi、mysql323、mysql40、postgresql、oracle、mssql、db2、maxdb、no_key_options、no_tables_options、no_field_options等,
要使用几个值,用逗号将它们隔开。它并不保证能完全兼容,而是尽量兼容。
mysqldump -uroot -p --all-databases --compatible=ansi
--compact
导出更少的输出信息(用于调试)。去掉注释和头尾等结构。可以使用选项:--skip-add-drop-table --skip-add-locks --skip-comments --skip-disable-keys
mysqldump -uroot -p --all-databases --compact
--complete-insert, -c
使用完整的insert语句(包含列名称)。这么做能提高插入效率,但是可能会受到max_allowed_packet参数的影响而导致插入失败。
mysqldump -uroot -p --all-databases --complete-insert
--compress, -C
在客户端和服务器之间启用压缩传递所有信息
mysqldump -uroot -p --all-databases --compress
--create-options, -a
在CREATE TABLE语句中包括所有MySQL特性选项。(默认为打开状态)
mysqldump -uroot -p --all-databases
--databases, -B
导出几个数据库。参数后面所有名字参量都被看作数据库名。
mysqldump -uroot -p --databases test mysql
--debug
输出debug信息,用于调试。默认值为:d:t:o,/tmp/mysqldump.trace
mysqldump -uroot -p --all-databases --debug
mysqldump -uroot -p --all-databases --debug=” d:t:o,/tmp/debug.trace”
--debug-check
检查内存和打开文件使用说明并退出。
mysqldump -uroot -p --all-databases --debug-check
--debug-info
输出调试信息并退出
mysqldump -uroot -p --all-databases --debug-info
--default-character-set
设置默认字符集,默认值为utf8
mysqldump -uroot -p --all-databases --default-character-set=latin1
--delayed-insert
采用延时插入方式(INSERT DELAYED)导出数据
mysqldump -uroot -p --all-databases --delayed-insert
--delete-master-logs
master备份后删除日志. 这个参数将自动激活--master-data。
mysqldump -uroot -p --all-databases --delete-master-logs
--disable-keys
对于每个表,用/*!40000 ALTER TABLE tbl_name DISABLE KEYS */;和/*!40000 ALTER TABLE tbl_name ENABLE KEYS */;语句引用INSERT语句。这样可以更快地导入dump出来的文件,因为它是在插入所有行后创建索引的。该选项只适合MyISAM表,默认为打开状态。
mysqldump -uroot -p --all-databases
--dump-slave
该选项将导致主的binlog位置和文件名追加到导出数据的文件中。设置为1时,将会以CHANGE MASTER命令输出到数据文件;设置为2时,在命令前增加说明信息。该选项将会打开--lock-all-tables,除非--single-transaction被指定。该选项会自动关闭--lock-tables选项。默认值为0。
mysqldump -uroot -p --all-databases --dump-slave=1
mysqldump -uroot -p --all-databases --dump-slave=2
--events, -E
导出事件。
mysqldump -uroot -p --all-databases --events
--extended-insert, -e
使用具有多个VALUES列的INSERT语法。这样使导出文件更小,并加速导入时的速度。默认为打开状态,使用--skip-extended-insert取消选项。
mysqldump -uroot -p --all-databases
mysqldump -uroot -p --all-databases--skip-extended-insert (取消选项)
--fields-terminated-by
导出文件中忽略给定字段。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-terminated-by=”#”
--fields-enclosed-by
输出文件中的各个字段用给定字符包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-enclosed-by=”#”
--fields-optionally-enclosed-by
输出文件中的各个字段用给定字符选择性包裹。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p test test --tab=”/home/mysql” --fields-enclosed-by=”#” --fields-optionally-enclosed-by =”#”
--fields-escaped-by
输出文件中的各个字段忽略给定字符。与--tab选项一起使用,不能用于--databases和--all-databases选项
mysqldump -uroot -p mysql user --tab=”/home/mysql” --fields-escaped-by=”#”
--flush-logs
开始导出之前刷新日志。
请注意:假如一次导出多个数据库(使用选项--databases或者--all-databases),将会逐个数据库刷新日志。除使用--lock-all-tables或者--master-data外。在这种情况下,日志将会被刷新一次,相应的所以表同时被锁定。因此,如果打算同时导出和刷新日志应该使用--lock-all-tables 或者--master-data 和--flush-logs。
mysqldump -uroot -p --all-databases --flush-logs
--flush-privileges
在导出mysql数据库之后,发出一条FLUSH PRIVILEGES 语句。为了正确恢复,该选项应该用于导出mysql数据库和依赖mysql数据库数据的任何时候。
mysqldump -uroot -p --all-databases --flush-privileges
--force
在导出过程中忽略出现的SQL错误。
mysqldump -uroot -p --all-databases --force
--help
显示帮助信息并退出。
mysqldump --help
--hex-blob
使用十六进制格式导出二进制字符串字段。如果有二进制数据就必须使用该选项。影响到的字段类型有BINARY、VARBINARY、BLOB。
mysqldump -uroot -p --all-databases --hex-blob
--host, -h
需要导出的主机信息
mysqldump -uroot -p --host=localhost --all-databases
--ignore-table
不导出指定表。指定忽略多个表时,需要重复多次,每次一个表。每个表必须同时指定数据库和表名。例如:--ignore-table=database.table1 --ignore-table=database.table2 ……
mysqldump -uroot -p --host=localhost --all-databases --ignore-table=mysql.user
--include-master-host-port
在--dump-slave产生的'CHANGE MASTER TO..'语句中增加'MASTER_HOST=<host>,MASTER_PORT=<port>'
mysqldump -uroot -p --host=localhost --all-databases --include-master-host-port
--insert-ignore
在插入行时使用INSERT IGNORE语句.
mysqldump -uroot -p --host=localhost --all-databases --insert-ignore
--lines-terminated-by
输出文件的每行用给定字符串划分。与--tab选项一起使用,不能用于--databases和--all-databases选项。
mysqldump -uroot -p --host=localhost test test --tab=”/tmp/mysql” --lines-terminated-by=”##”
--lock-all-tables, -x
提交请求锁定所有数据库中的所有表,以保证数据的一致性。这是一个全局读锁,并且自动关闭--single-transaction 和--lock-tables 选项。
mysqldump -uroot -p --host=localhost --all-databases --lock-all-tables
--lock-tables, -l
开始导出前,锁定所有表。用READ LOCAL锁定表以允许MyISAM表并行插入。对于支持事务的表例如InnoDB和BDB,--single-transaction是一个更好的选择,因为它根本不需要锁定表。
请注意当导出多个数据库时,--lock-tables分别为每个数据库锁定表。因此,该选项不能保证导出文件中的表在数据库之间的逻辑一致性。不同数据库表的导出状态可以完全不同。
mysqldump -uroot -p --host=localhost --all-databases --lock-tables
--log-error
附加警告和错误信息到给定文件
mysqldump -uroot -p --host=localhost --all-databases --log-error=/tmp/mysqldump_error_log.err
--master-data
该选项将binlog的位置和文件名追加到输出文件中。如果为1,将会输出CHANGE MASTER 命令;如果为2,输出的CHANGE MASTER命令前添加注释信息。该选项将打开--lock-all-tables 选项,除非--single-transaction也被指定(在这种情况下,全局读锁在开始导出时获得很短的时间;其他内容参考下面的--single-transaction选项)。该选项自动关闭--lock-tables选项。
mysqldump -uroot -p --host=localhost --all-databases --master-data=1;
mysqldump -uroot -p --host=localhost --all-databases --master-data=2;
--max_allowed_packet
服务器发送和接受的最大包长度。
mysqldump -uroot -p --host=localhost --all-databases --max_allowed_packet=10240
--net_buffer_length
TCP/IP和socket连接的缓存大小。
mysqldump -uroot -p --host=localhost --all-databases --net_buffer_length=1024
--no-autocommit
使用autocommit/commit 语句包裹表。
mysqldump -uroot -p --host=localhost --all-databases --no-autocommit
--no-create-db, -n
只导出数据,而不添加CREATE DATABASE 语句。
mysqldump -uroot -p --host=localhost --all-databases --no-create-db
--no-create-info, -t
只导出数据,而不添加CREATE TABLE 语句。
mysqldump -uroot -p --host=localhost --all-databases --no-create-info
--no-data, -d
不导出任何数据,只导出数据库表结构。
mysqldump -uroot -p --host=localhost --all-databases --no-data
--no-set-names, -N
等同于--skip-set-charset
mysqldump -uroot -p --host=localhost --all-databases --no-set-names
--opt
等同于--add-drop-table, --add-locks, --create-options, --quick, --extended-insert, --lock-tables, --set-charset, --disable-keys 该选项默认开启, 可以用--skip-opt禁用.
mysqldump -uroot -p --host=localhost --all-databases --opt
--order-by-primary
如果存在主键,或者第一个唯一键,对每个表的记录进行排序。在导出MyISAM表到InnoDB表时有效,但会使得导出工作花费很长时间。
mysqldump -uroot -p --host=localhost --all-databases --order-by-primary
--password, -p
连接数据库密码
--pipe(windows系统可用)
使用命名管道连接mysql
mysqldump -uroot -p --host=localhost --all-databases --pipe
--port, -P
连接数据库端口号
--protocol
使用的连接协议,包括:tcp, socket, pipe, memory.
mysqldump -uroot -p --host=localhost --all-databases --protocol=tcp
--quick, -q
不缓冲查询,直接导出到标准输出。默认为打开状态,使用--skip-quick取消该选项。
mysqldump -uroot -p --host=localhost --all-databases
mysqldump -uroot -p --host=localhost --all-databases --skip-quick
--quote-names,-Q
使用(`)引起表和列名。默认为打开状态,使用--skip-quote-names取消该选项。
mysqldump -uroot -p --host=localhost --all-databases
mysqldump -uroot -p --host=localhost --all-databases --skip-quote-names
--replace
使用REPLACE INTO 取代INSERT INTO.
mysqldump -uroot -p --host=localhost --all-databases --replace
--result-file, -r
直接输出到指定文件中。该选项应该用在使用回车换行对(\r\n)换行的系统上(例如:DOS,Windows)。该选项确保只有一行被使用。
mysqldump -uroot -p --host=localhost --all-databases --result-file=/tmp/mysqldump_result_file.txt
--routines, -R
导出存储过程以及自定义函数。
mysqldump -uroot -p --host=localhost --all-databases --routines
--set-charset
添加'SET NAMES default_character_set'到输出文件。默认为打开状态,使用--skip-set-charset关闭选项。
mysqldump -uroot -p --host=localhost --all-databases
mysqldump -uroot -p --host=localhost --all-databases --skip-set-charset
--single-transaction
该选项在导出数据之前提交一个BEGIN SQL语句,BEGIN 不会阻塞任何应用程序且能保证导出时数据库的一致性状态。它只适用于多版本存储引擎,仅InnoDB。本选项和--lock-tables 选项是互斥的,因为LOCK TABLES 会使任何挂起的事务隐含提交。要想导出大表的话,应结合使用--quick 选项。
mysqldump -uroot -p --host=localhost --all-databases --single-transaction
--dump-date
将导出时间添加到输出文件中。默认为打开状态,使用--skip-dump-date关闭选项。
mysqldump -uroot -p --host=localhost --all-databases
mysqldump -uroot -p --host=localhost --all-databases --skip-dump-date
--skip-opt
禁用–opt选项.
mysqldump -uroot -p --host=localhost --all-databases --skip-opt
--socket,-S
指定连接mysql的socket文件位置,默认路径/tmp/mysql.sock
mysqldump -uroot -p --host=localhost --all-databases --socket=/tmp/mysqld.sock
--tab,-T
为每个表在给定路径创建tab分割的文本文件。注意:仅仅用于mysqldump和mysqld服务器运行在相同机器上。
mysqldump -uroot -p --host=localhost test test --tab="/home/mysql"
--tables
覆盖--databases (-B)参数,指定需要导出的表名。
mysqldump -uroot -p --host=localhost --databases test --tables test
--triggers
导出触发器。该选项默认启用,用--skip-triggers禁用它。
mysqldump -uroot -p --host=localhost --all-databases --triggers
--tz-utc
在导出顶部设置时区TIME_ZONE='+00:00' ,以保证在不同时区导出的TIMESTAMP 数据或者数据被移动其他时区时的正确性。
mysqldump -uroot -p --host=localhost --all-databases --tz-utc
--user, -u
指定连接的用户名。
--verbose, --v
输出多种平台信息。
--version, -V
输出mysqldump版本信息并退出
--where, -w
只转储给定的WHERE条件选择的记录。请注意如果条件包含命令解释符专用空格或字符,一定要将条件引用起来。
mysqldump -uroot -p --host=localhost --all-databases --where=” user=’root’”
--xml, -X
导出XML格式.
mysqldump -uroot -p --host=localhost --all-databases --xml
--plugin_dir
客户端插件的目录,用于兼容不同的插件版本。
mysqldump -uroot -p --host=localhost --all-databases --plugin_dir=”/usr/local/lib/plugin”
--default_auth
客户端插件默认使用权限。
mysqldump -uroot -p --host=localhost --all-databases --default-auth=”/usr/local/lib/plugin/<PLUGIN>”
Win7上Git安装及配置过程
Win7上Git安装及配置过程
| 文档名称 | Win7上Git安装及配置过程 |
| 创建时间 | 2012/8/20 |
| 修改时间 | 2012/8/20 |
| 创建人 | Baifx |
| 简介(收获) | 1、在win7上安装msysgit步骤;
2、在win7上安装TortoiseGit步骤; 3、在VS2010中集成Git方法和步骤(未)。 |
| 参考源 | Git的配置与使用
http://wenku.baidu.com/view/929d7b4e2e3f5727a5e962a8.html |
一、安装说明
1、Git在windows平台上安装说明。
Git 是 Linux Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。目前Git已经可以在windows下使用,主要方法有二:msysgit和Cygwin。Cygwin和Linux使用方法类似,Windows版本的Git提供了友好的GUI(图形界面),安装后很快可以上手,此处我们主要讨论基于msysgit的Git安装和使用。
TortoiseGit是TortoiseSVN的Git版本,TortoiseGit用于迁移TortoiseSVN到TortoiseGit。一直以来Git在Windows平台没有好用GUI客户端,现在TortoiseGit的出现给Windows开发者带来福音。我们将在64位win7操作系统上安装Git,并使用GUI界面,则需同时安装msysGit和TortoiseGit。
2、阅读TortoiseGit官方安装说明:
http://code.google.com/p/tortoisegit/wiki/SetupHowTo
- For the latest version of TortoiseGit Windows XP SP3 or newer is required.
- Admin privileges for the installation
- msysGit is required by TortoiseGit
- You do not need to download the whole msysGit development package, the "Full installer for official Git for Windows" download package is sufficient
- msysGit 1.7.10+ is recommended for TortoiseGit 1.7.9+ (msysGit 1.7.10 adds utf-8 support and is compatible to *nix git)
- minimum compatible version is 1.6.1 (for TortoiseGit < 1.7.9 you should use msysGit 1.7.6)
Just download the setup package for your system and install it. If you are running a 64 bit system, you do not need to download and install the 32 bit version: The 32 bit shell extension is included in the 64 bit installer since TortoiseGit 1.7.3.0.
If you want to use TortoiseGit in a Win2K environment (only 1.6.5 and below support Win2K), please install GDI+ before you install TortoiseGit. However, running these old versions is not recommended (no utf-8 and separate-git-dir support).
Before upgrading you should read the ReleaseNotes.
Just download the setup package for your system and install it. The old version will be replaced automatically.
If you are upgrading from 1.7.3.0 or older and you have installed the 32-bit version on a 64-bit system you have to deinstall the 32-bit version first.
Common problems (installer aborts with an error message)
"This installation package is not supported by this processor type. Contact your product vendor."
This means you are trying to install the 64-bit version of TortoiseGit on a normal 32-bit operating system. You need to download and use the correct msi file for your OS. For normal 32-bit OS, make sure the msi filename does not have "64-bit" in it.
"Please wait while the installer finishes determining your disk space requirements."
Cleanup/empty the temp-directory (e.g. C:Users<your user>AppDataLocalTemp, C:User and Settings<your user>Local SettingsTemp, c:WindowsTemp).
由如上说明,我们寻找要下载的对应安装包,如下。
二、下载安装包
1、TortoiseGit下载地址:
http://code.google.com/p/tortoisegit/downloads/list
本次下载版本——TortoiseGit-1.7.12.0-64bit.msi
TortoiseGit 1.7.12.0 64bit
x64 Featured
2、msysgit下载地址:
http://code.google.com/p/msysgit/downloads/list
本次下载版本——Git-1.7.11-preview20120710.exe
Full installer for official Git for Windows 1.7.11
Featured Beta
三、安装过程
安装顺序:首先安装msysgit;然后安装TortoiseGit。
1、安装msysgit。
a、安装包下载完成后,双击进入安装界面,如下图:

b、两步next后选择安装目录,如下图:

c、next进入Git安装模块选择,默认,如下图:

d、next进入Git setup界面,“Select start menu folder”,默认,如下图:

e、next进入Git Setup界面,“Adjusting your PATH environment”,选择默认值“Use Git Bash only”,如下图所示:

f、next进入Git Setup界面,“Configuring the line ending conversions”,选择换行格式,选择“Checkout as-is, commit Unix-style line endings”,如下图所示:

g、next进入安装界面,完成安装,如下图所示:

这个时候已经可以使用git了, 打开Git Bash可以进入linux shell,可以使用git命令进行各种操作,由于大家都习惯使用图形界面的 TortoiseSVN,下面介绍使用 TortoiseSVN的类似软件TortoiseGit,使用习惯相同,大家应该比较容易使用。
2、安装TortoiseGit。
a、双击安装程序,进入安装界面,如下如所示:

b、两步next进入“Choose SSH Client”选择界面,选择“OpenSSH,Git default SSH Client”,如下图所示:

c、next进入“Custom Setup”界面,选择默认值,如下图所示:

d、next,进入“Ready to Install”界面,选择“Install”按钮开始安装过程,完成安装。如下图所示:

e、至此,TortoiseGit安装完成。在桌面空白处点击右键,右键菜单中会加入TortoiseGit快捷键,如下图所示:

f、选择“Settings”,进入“Settings-TortoiseGit”界面,选择“General”选项卡,设置本机器的git路径,如下图所示:

g、同时选择“Network”选项卡,设置SSH路径。SSH默认在安装Git时就安装了,在如下图所示的路径中。如下图所示:

h、选择“Git”选项卡,设置用户名、邮箱和key。如下图所示:

注:如果暂时在本地使用就只需将用户名和邮箱添加,而“Signing key”会自动生成。
至此,TortoiseGit设置完成。
3、下载代码。
a、桌面空白处右键,选择git clone添加版本库地址URL和本地文件夹。如下图所示:

点击ok即可下载一份新版本库。
JavaScript的开发规范要求
作为一名开发人员(We前端JavaScript开发),不规范的开发不仅使日后代码维护变的困难,同时也不利于团队的合作,通常还会带来代码安全以及执行效率上的问题。本人在开发工作中就曾与不按规范来开发的同事合作过,与他合作就不能用“愉快”来形容了。现在本人撰写此文的目的除了与大家分享一点点经验外,更多的是希望对未来的合作伙伴能够起到一定的借鉴作用。当然,如果我说的有不科学的地方还希望各路前辈多多指教。下面分条目列出各种规范要求,这些要求都是针对同事编码毛病提出来的,好些行业约定的其它规范可能不会再提及。
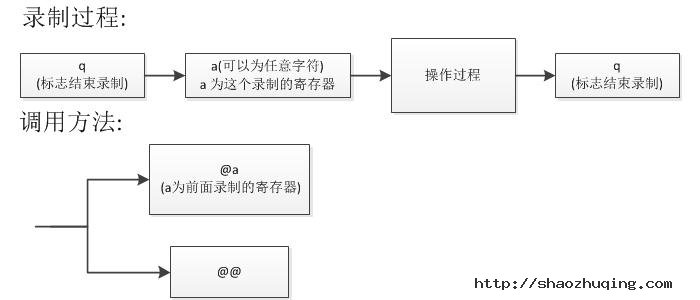
1、保证代码压缩后不出错
对于大型的JavaScript项目,一般会在产品发布时对项目包含的所有JavaScript文件进行压缩处理,比如可以利用Google Closure Compiler Service对代码进行压缩,新版jQuery已改用这一工具对代码进行压缩,这一般会去掉开发时写的注释,除去所有空格和换行,甚至可以把原来较长的变量名替换成短且无意义的变量名,这样做的目的是加快文件的下载速度,同时也减小网站访问带来的额外数据流量,另外在代码保护上也起到了一点点作用,至少压缩后的代码即使被还原还是没那么容易一下读懂的。要想代码能正确通过压缩,一般要求语句都要以分号正常结束,大括号也要严格结束等,具体还要看压缩工具的要求。所以如果一开始没有按标准来做,等压缩出错后再回去找错误那是浪费时间。
2、保证代码能通过特定IDE的自动格式化功能
一般较为完善的开发工具(比如Aptana Studio)都有代码“自动格式”化功能,这一功能帮助实现统一换行、缩进、空格等代码编排,你可以设置自己喜欢的格式标准,比如左大括号{是否另起一行。达到这个要求的目的在于方便你的开发团队成员拿你代码的一个副本用IDE自动格式化成他喜欢或熟悉的风格进行阅读。你同事需要阅读你的代码,可能是因为你写的是通用方法,他在其它模块开发过程中也要使用到,阅读你的代码能最深入了解方法调用和实现的细节,这是简单API文档不能达到的效果。

3、使用标准的文档注释
这一要求算是最基本的,这有利于在方法调用处看到方法的具体传参提示,也可以利用配套文档工具生成html或其它格式的开发文档供其他团队成员阅读,你可以尝试使用jsdoc-toolkit。如果你自动生成的API是出自一个开放平台,就像facebook.com应用,那么你的文档是给天下所有开发者看的。另外编写完整注释,也更方便团队成员阅读你的代码,通过你的参数描述,团队成员可以很容易知道你编写的方法传参与实现细节。当然也方便日后代码维护,这样即使再大的项目,过了很长时间后,回去改点东西也就不至于自己都忘记了当时自己写的代码是怎么一回事了。

4、使用规范有意义的变量名
使用规范有意义的变量名可以提高代码的可读性,作为大项目开发成员,自己写的代码不仅仅要让别人容易看懂。开发大项目,其实每个人写的代码量可能都比较大,规范命名,日后自己看回自己的代码也显的清晰易懂,比如日后系统升级或新增功能,修改起代码来也轻松多了。如果到头发现自己当初写的代码现在看不太懂了,那还真是天大的笑话了。
当然,使用有意义的变量名也尽量使用标准的命名,比如像这里:var me = this也许没有var self = this好,因为self是Python中的关键字,在Python中self就是通常语言this的用法。再看下面一个例子,加s显然比没有加来的科学些,这样可以知道这个变量名存的是复数,可能是数组等:
var li = document.getElementsByTagName('li')var lis = document.getElementsByTagName('li')

5、不使用生偏语法
JavaScript作为一门动态脚本语言,灵活性既是优点也是缺点,众所周知,动态语言不同层次开发人员对实现同样一个功能写出来的代码在规范或语法上会存在较大的差别。不管怎么样,规范编码少搞怪,不把简单问题复杂化,不违反代码易读性原则才是大家应该做的。
比如这语句:typeof(b) == 'string' && alert(b) 应该改为:if (typeof(b) == 'string') alert(b),像前面那种用法,利用了&&运算符解析机制:如果检测到&&前语句返回false就不再检测后面语句,在代码优化方面也有提到把最可能出现的情况首先判断,像这种写法如果条件少还好,如果条件较多而且语句也长,那代码可读性就相当差。
又比如:+function(a){var p = a;}( 'a') 应该改为:(function(a){var p = a;})( 'a'),其实function前面的+号与包含function的()括号作用是一样的,都是起运算优先作用,后者是常见且容易看明白的防止变量污染的做法,比如好些流行JavaScript框架就是采用后面这种方式。
再说个降低代码可读性的例子,如:function getPostionTxt(type){return type == 2 ? "野外" : (type == 3 ? "商城" : (type == 4 ? "副本" : null));} 应该改成:function getPostionTxt(type){var typeData={"2":"野外","3":"商城","4":"副本"};if (typeData[type]) return typeData[type]; else return null;}。如果type是从0开始不间断的整数,那么直接使用数组还更简单,这种结果看起来就清晰多了,看到前面那种多层三元表达式嵌套头不晕吗。
6、不在语句非赋值地方出现中文
语句中不应该出现中文我想一般人都知道,虽然这样做不影响程序运行,但是显然有背行业标准要求,当然我们也不是在使用“易语言”做开发。关于这一个问题,我本来不想把它拿出来说的,但我确实遇到有人这样做的,也不知道是不是因为他的英语实在太烂了,至少还可以用拼音吧,另外寻求翻译工具帮忙也不错的选择。我举例如下,像以下写法出现在教学中倒还可以理解:
this.user['名字'] = '张三' 或者 this.user.名字 = '张三'
7、明确定义函数固定数量的参数
固定数量参数的函数内部不使用arguments去获取参数,因为这样,你定义的方法如果包含较多的脚本,就不能一眼看到这个方法接受些什么参数以及参数的个数是多少。比如像下面:
var $ = function(){return document.getElementById(arguments[0]);} 应该改成:var $ = function(elemID){return document.getElementById(elemID);}
8、不必热衷动态事件绑定
虽然知道事件可以动态绑定,比如使用addEventListener或者使用jQuery的bind方法,也知道采用动态事件绑定可以让XHTML更干净,但是一般情况下我还是建议直接把事件写在DOM节点上,我认为这样可以使代码变得更容易维护,因为这样做,我们在查看源代码的时候就可以容易地知道什么Element绑定了什么方法,简单说这样更容易知道一个按钮或链接点击时调了什么方法脚本。

9、降低代码与XHTML的耦合性
不要过于依赖DOM的一些内容特征来调用不同的脚本代码,而应该定义不同功能的方法,然后在DOM上调用,这样不管DOM是按钮还是链接,方法的调用都是一样的,比如像下面的实现显然会存在问题:
function myBtnClick(obj)
{
if (/确定/.test(obj.innerHTML))
alert('OK');
else if (/取消/.test(obj.innerHTML))
alert('Cancel');
else alert('Other');
}<a herf="javascript:;">确定</a><a herf="javascript:;">取消</a>
上面例子其实在一个函数内处理了两件事情,应该分成两个函数,像上面的写法,如果把链接换成按钮,比如改成这样:<input type="button" value="确定" />,那么myBtnClick函数内部的obj.innerHTML就出问题了,因为此时应该obj.value才对,另外如果把按钮名称由中文改为英文也会出问题,所以这种做法问题太多了。
10、一个函数应该返回统一的数据类型
因为JavaScrip是弱类型的,在编写函数的时候有些人对于返回类型的处理显得比较随便,我觉得应该像强类型语言那样返回,看看下面的两个例子:
function getUserName(userID)
{
if (data[userID])
return data[userID];
else return false;
}
应该改为:function getUserName(userID)
{
if (data[userID])
return data[userID];
else return "";
}
这个方法如果在C#中定义,我们知道它准备返回的数据类型应该是字符串,所以如果没有找到这个数据我们就应该返回空的字符串,而不是返回布尔值或其它不合适的类型。这并没有影响到函数将来的调用,因为返回的空字符串在逻辑判断上可被认作“非”,即与false一样,除非我们使用全等于“===”或typeof进行判断。
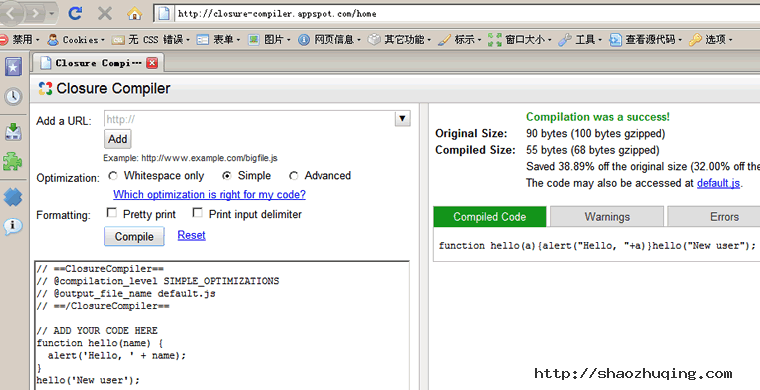
11、规范定义JSON对象,补全双引号
使用标准肯定是有好处的,那么为什么还是有人不使用标准呢?我想这可能是懒或习惯问题。也许还会有人跟我说,少写引号可以减轻文件体积,我认为这有道理但不是重点。对于服务器返回的JSON数据,使用标准结构可以利用Firefox浏览器的JSONView插件方便查看(像查看XML那样树形显示),另外你如果使用jQuery做开发,最新版本jQuery1.4+是对JSON格式有更高要求的,具体的可以自己查阅jQuery更新文档。比如:{name:"Tom"}或{'name':'Tom'}都应该改成{"name":"Tom"}。
12、不在文件中留下未来确定不再使用的代码片段
当代码调整或重构后,之前编写的不再使用的代码应该及时删除,如果认为这些代码还有一定利用价值可以把它们剪切到临时文件中。留在项目中不仅增加了文件体积,这对团队其它成员甚至自己都起到一定干扰作用,怕将来自己看回代码都搞不懂这方法是干什么的,是否有使用过。当然可以用文档注释标签@deprecated把这个方法标识为不推荐的。
13、不重复定义其他团队成员已经实现的方法
对于大型项目,一般会有部分开发成员实现一些通用方法,而另外一些开发成员则要去熟悉这些通用方法,然后在自己编写模块遇到有调用的需要就直接调用,而不是像有些开发者喜欢“单干”,根本不会阅读这些通用方法文档,在自己代码中又写了一遍实现,这不仅产生多余的代码量,当然也是会影响团队开发效率的,这是没有团队合作精神的表现,是重复造轮子的悲剧。
比如在通用类文件Common.js有定义function $(elemID){return document.getElementById(elemID)}那么就不应该在Mail.js中再次出现这一功能函数的重复定义,对于一些复杂的方法更应该如此。
14、调用合适的方法
当有几个方法都可以实现同类功能的时候,我们还是要根据场景选择使用最合适的方法。下面拿jQuery框架的两个AJAX方法来说明。如果确定服务器返回的数据是JSON应该直接使用$.getJSON,而不是使用$.get得到数据再用eval函数转成JSON对象。如果因为本次请求要传输大量的数据而不得以使用$.post也应该采用指定返回数据类型(设置dataType参数)的做法。如果使用$.getJSON,在代码中我们一眼能看出本次请求服务器返回的是JSON。
温馨提示:jQuery1.4后,如果服务器有设置数据输出的ContentType,比如ASP.NET C#设置 Response.ContentType = "application/json",那么$.get将与$.getJSON的使用没有什么区别。
15、使用合适的控件存储合适的数据
曾发现有人利用DIV来保存JSON数据,以待页面下载后将来使用,像这样:<div >{ "name":"Tom"}</div>,显然这个DIV不是用来界面显示的,如果非要这样做,达到使用HTML文件进行数据缓存的作用,至少改成用隐藏域来存这数据更合理,比如改成:<input type="hidden" value=" { "name":"Tom"}" />。
其实也可以利用window对象来保存一些数据,像上面的例子,我们可以在AJAX请求页直接包含这样的脚本块:<script>window.userData = { "name":"Tom"};</script>,当在AJAX请求回调函数中执行完$( "#MyDiv ").html(data)后,在window上就马上有了这一变量。如果采用第一种方法,将不可避免eval(document.getElementById("UserData").innerHTML)。如果在window对象存放大量数据的话,这些数据不用时要及时手动清理它们,它们是要等浏览器刷新或重启后才会消失的,这就会增加内存开销。
16、永远不要忽略代码优化工作
代码最优化是每个程序员应该努力达到的目标,也应该成为程序员永远的追求。写代码的时候,不应该急着把功能实现出来,要想一下如何写代码,代码的执行效率才是较好的。
举个例子:假设有定义getElementById的快捷方法functoin $(elemID){return document.getElementById(elemID)},那么有人可能会写出这样的代码$("MyDiv").parentNode.removeChild($("MyDiv")),其实这里执行了两次getElementById DOM查找,如果改成这样将更好:var myDiv = $("MyDiv"); myDiv.parentNode.removeChild(myDiv)。还好getElementById的DOM查找算比较快,如果换成getElementsByTagName则更应该注重优化了。jQuery开发团队也有提醒大家要注意这方面的问题。
当然,代码优化技巧也是需要个人不断积累的。曾有朋友跟我说他写网站后台代码从来不用考虑优化的,因为他们网站用的是至强四核服务器,我觉得这是很可笑的。
17、会分析策划文档,能用面向对象方法进行接口定义和代码组织
这一能力对于每一个程序员来说都是非常重要的,这也是决定一个程序员水平高低的一个重要因素。能够把需求细化并抽象出不同的类,然后有条理地编写代码,使代码结构清晰,可读性高,代码易于维护,不至于太过程化而且杂乱无章,这样才算是一个优秀的程序员。
node.js 初体验
最近写的文章收到许多朋友的反馈,感谢大家的支持和建议,让我对坚持写博客充满热情,一个月一篇文章确实有点少,所以以后尽力多做分享,做好的分享,希望能对朋友们有用。
到新公司的这段时间学到了很多新东西,有好多东西需要去总结去探索,不过事情得一件一件来,今天咱们先从Node开始。注:以后出现的Node即node.js。
先搞点前戏热热场 - 为什么写这篇文章:
1.前段时间单位有新项目启动,服务端要做的工作不多也不算麻烦,就是处理一些中间层的服务,而且我们团队里面个个都会JavaScript,领导就决定试试服务器端的JavaScript,结果本人有幸被派去研究了几天Node,怀着鸡冻的心情开始了node.js的篇章,这篇文章也就是为这几天研究的总结。
2.一个JavaScript工程师如果没听过node.js那么我想你是不是错过了什么,每个优秀的前端工程师都有必要去了解后台处理流程,那么如果又能从JavaScript出发,岂不是一件很美妙的事么。
3.互联网的火热使得JavaScript风光无限,且服务端的JavaScript也并不是什么新技术了,相关的框架也有不少,只是node.js的成功让他爆发式的出现在我们的视线中,让很多前端工程师看到了从前端写到后端的另一种实现希望。注:node.js 是一个允许开发人员使用 JavaScript 语言编写服务器端代码的框架。
4.今年8月曾在某大公司最后一轮(第五轮)的面试被问到Node.js的问题,相对应的回答那是相当之糟糕,结果怎样你们懂的,感觉这个问题是导致没有通过的关键点之一...那家公司是我在读大学的时候就无比向往的公司,现在回想起那次经历和过程,谈不上惋惜,毕竟我真的尽力了 - 其实这篇文章更多的也是为了完成自己一个小小的心结...好吧,又扯远了。
5.欢迎各种转载,不过请注明出处,谢谢。
PS:此篇文章的进阶内容在此《Nodejs初阶之express》,欢迎阅读和评论:)
Node是个啥?
写个东西还是尽量面面俱到吧,所以有关基本概念的东西我也从网上选择性的拿了些下来,有些地方针对自己的理解有所改动,对这些概念性的东西有过了解的可选择跳过这段。
1.Node 是一个服务器端 JavaScript 解释器,可是真的以为JavaScript不错的同学学习Node就能轻松拿下,那么你就错了,总结:水深不深我还不知道,不过确实不浅。
2.Node 的目标是帮助程序员构建高度可伸缩的应用程序,编写能够处理数万条同时连接到一个物理机的连接代码。处理高并发和异步I/O是Node受到开发人员的关注的原因之一。
3.Node 本身运行Google V8 JavaScript引擎,所以速度和性能非常好,看chrome就知道,而且Node对其封装的同时还改进了其处理二进制数据的能力。因此,Node不仅仅简单的使用了V8,还对其进行了优化,使其在各种环境下更加给力。(什么是V8 JavaScript 引擎?请“百度知道”)
4.第三方的扩展和模块在Node的使用中起到重要的作用。下面也会介绍下载npm,npm就是模块的管理工具,用它安装各种 Node 的软件包(如express,redis等)并发布自己为Node写的软件包 。
安装Node
在这简单说说在window7和linux两种环境下安装Node。安装的时候一定要注意Python的版本,多次因为Python版本的问题安装失败,建议2.6+的版本,低版本会出现Node安装错误,查询Python版本可在终端中输入:pyhton -v
1.先介绍linux下的安装吧,Node在Linux环境下的安装和使用都非常方便,建议在Linux下运行Node,^_^...我使用的是Ubuntu11.04
a.安装依赖包:50-100kb/s大概每个包一分钟就能下载安装完成
sudo apt-get install g++ curl libssl-dev apache2-utils sudo apt-get install git-core
b.在终端一步步运行一下命令:
git clone git://github.com/joyent/node.git cd node ./configure make sudo make install
安装顺利的话到这一步Node就算安装成功了,2M的网络用了共计12分钟。
注:如果不用git下载也可以直接下载源码,不过这样下载安装需要注意Node版本问题。使用git下载安装是最方便的,所以推荐之。
2.在Windows下使用Cygwin安装Node,这个方式不太推荐,因为真的需要较长时间和较好的人品。我的系统是 win7旗舰版
Cygwin是一个在windows平台上运行的unix模拟环境,下载地址:http://cygwin.com/setup.exe。
下载好Cygwin后开始安装,步骤:
a.选择下载的来源 - Install from Internet
b.选择下载安装的根目录
c.选择下载文件所存放的目录
d.选择连接的方式
e.选择下载的网站 - http://mirrors.163.com/cygwin
f.麻烦就麻烦在这步,考验人品的时候到了。需要的下载安装时间不确定,反正需要比较长的时间(超过20分钟),偶尔会出现安装失败的情况。单击一下各个程序包前面的旋转箭头图标选择你想要的版本,选中时会出现了"x"号表示已经选中了该程序包。选择需要下载的程序包:

Devel包: gcc-g++: C++ compiler gcc-mingw-g++: Mingw32 support headers and libraries for GCC C++ gcc4-g++: G++ subpackage git: Fast Version Control System – core files make: The GNU version of the ‘make’ utility openssl-devel: The OpenSSL development environment pkg-config: A utility used to retrieve information about installed libraries zlib-devel: The zlib compression/decompression library (development) Editor包:vim: Vi IMproved – enhanced vi editor Python包:把Default切换成install状态即可 Web包: wget: Utility to retrieve files from the WWW via HTTP and FTP curl: Multi-protocol file transfer command-line tool
上个截图,以下载zlib-devel为例:

其上几步走完才算把环境搭建完成,可是现在还没有到安装Node,还需要在Cywgin的ASH模式下执行rebaseall,步骤如下:
a. cmd命令行
b. 进入cygwin安装目录下的bin子目录
c. 运行ash进入shell模式
d. ./rebaseall -v
e. 没有错误就关闭命令行窗口
好了,现在到下载安装Node了,启动Cygwin.exe后输入:
$ wget http://nodejs.org/dist/node-v0.4.12.tar.gz $ tar xf node-v0.4.12.tar.gz $ cd node-v0.4.12 $ ./configure $ make $ make install
3.直接下载node.exe文件
nodejs.org下载较慢所以我在网盘上传了一个,下载地址:http://www.everbox.com/f/VhyL6EiGF5Lm3ZSRx85caFDIA5
听说有不太稳定的问题,不过你假如只是想先在windows下了解Node,个人感觉这个方法比你装个Cygwin好很多。
注:原本不太想写安装Node这段,可是为了这篇文章的全面性还是写了,没想到一写就是那么长一段了...茶几了
“Hello World” - 为什么每次见到这句心情都会小激动,不解...
首先,创建个hello.js的文件,在文件中copy如下代码:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, "127.0.0.1");
console.log('Server running at http://127.0.0.1:1337/');
代码逻辑:
a. 全局方法require()是用来导入模块的,一般直接把 require() 方法的返回值赋值给一个变量,在 JavaScript 代码中直接使用此变量即可 。require("http") 就是加载系统预置的 http 模块
b. http.createServer 是模块的方法,目的就是创建并返回一个新的web server对象,并且给服务绑定一个回调,用以处理请求。
c. 通过 http.listen() 方法就可以让该 HTTP 服务器在特定端口监听。
d. console.log就不用多说了,了解firebug的都应该知道,Node实现了这个方法。
注: 想了解具体细节请查看文档 cnodejs.org/cman/all.html#http.createServer
接着运行Node服务器,执行hello.js代码,成功启动会看见console.log()中的文本。有图有真相:


npm的下载和使用
除Node本身提供的API外,现在有不少第三方模块可极大的提高开发效率,npm就是Node的软件包管理器,可以用它安装所需软件包并发布自己为nodejs写的软件包。官网地址:npmjs.org
安装只需要在终端写入一行代码:
curl http://npmjs.org/install.sh | sh
npm安装node扩展包同样是一行代码:
npm install <包名> //例:npm install express
注:如果安装模块的过程中报域名错误的话,请清空缓存 >npm cache clean 或重启计算机即可。
理解Node的模块概念
在Node中,不同的功能组件被划分成不同的模块。应用可以根据自己的需要来选择使用合适的模块。每个模块都会暴露一些公共的方法或属性。模块的使用者直接使用这些方法或属性即可,对于内部的实现细节就可以不用了解。除了Node本身提供的API外,开发人员也可以利用这个机制来将应用拆分成多个模块,以提高代码的可复用性。
1.如何使用模块?
在Node中使用模块是非常方便的,在 JavaScript 代码中可以直接使用全局函数 require() 来加载一个模块。
在刚刚”Hello World"的例子中,require("http") 可以加载系统预置的 http 模块;模块名称以 "./" 开始的,如 require("./myModule.js") 用来加载与当前 JavaScript 文件同一目录下的 myModule.js 模块。
2.自己如何开发模块?
刚刚介绍使用require()导入模块的时候,模块名称以 "./" 开始的这种,就是自己开发的模块文件。需要注意的就是JS文件的系统路径。
代码中封装了模块的内部处理逻辑,一个模块一般都会暴露一些公开的方法或属性给其他的人使用。模块的内部代码需要把这些方法或属性给暴露出来。
3.来一套简单的例子。先创建一个模块文件如myModule.js,就一行代码
console.log('Hi Darren.')
然后创建一个test.js文件,导入这个JS文件,执行node看到结果

现在Node社区中已有不少第三方的模块,希望能有更多人通过学习Node,加入到这个大家庭中,为Node社区来添砖加瓦。先谢谢之,咱们继续。
4.来一个深点的例子。这个例子中将会针对 私有和共有 进行介绍。先创建一个myModule.js,代码如下:
var name = "Darren";
this.location = "Beijing";
this.showLog = function(){
console.log('Hi Darren.')
};
代码中出现了三种类型,分别是: 私用属性,共有属性和共有方法,再创建一个test.js,执行Node

结果高亮的地方很清楚的告诉我们,私有方法我们在模块以外是取不到的,所以是undefined。共有属性和共有方法的声明需要在前面加上 this 关键字。
Node能做什么和它的优势
Node核心思想: 1.非阻塞; 2.单线程; 3.事件驱动。
在目前的web应用中,客户端和服务器端之间有些交互可以认为是基于事件的,那么AJAX就是页面及时响应的关键。每次发送一个请求时(不管请求的数据多么小),都会在网络里走一个来回。服务器必须针对这个请求作出响应,通常是开辟一个新的进程。那么越多用户访问这个页面,所发起的请求个数就会越来越多,就会出现内存溢出、逻辑交错带来的冲突、网络瘫痪、系统崩溃这些问题。
Node的目标是提供一种构建可伸缩的网络应用的方案,在hello world例子中,服务器可以同时处理很多客户端连接。
Node和操作系统有一种约定,如果创建了新的链接,操作系统就将通知Node,然后进入休眠。如果有人创建了新的链接,那么它(Node)执行一个回调,每一个链接只占用了非常小的(内存)堆栈开销。
举一个简单的异步调用的例子,把test.js和myMydule.js准备好了,^_^。把以下代码拷贝到test.js中并执行:
var fs = require('fs');
fs.readFile('./myModule.js', function (err, data) {
if (err) throw err;
console.log('successfully');
});
console.log('async');

所谓的异步,大家应该都能想得到运行时会先打先显示"async",再显示"successfully"。
Node是无阻塞的,新请求到达服务器时,不需要为这个请求单独作什么事情。Node仅仅是在那里等待请求的发生,有请求就处理请求。
Node更擅长处理体积小的请求以及基于事件的I/O。
Node不仅仅是做一个Web服务的框架,它可以做更多,比如它可以做Socket服务,可以做比方说基于文件的,然后基于像一些比方说可以有子进程,然后内部的,它是一个很完整的事件机制,包括一些异步非注射的解决方案,而不仅仅局限在网络一层。同时它可能,即使作为一个Web服务来说,它也提供了更多可以深入这个服务内核、核心的一些功能,比方说Node使用的Http Agent,这块就是它可以更深入这个服务内核来去做一些功能。
Node事件流概念
因为Node 采用的是事件驱动的模式,其中的很多模块都会产生各种不同的事件,可由模块来添加事件处理方法,所有能够产生事件的对象都是事件模块中的 EventEmitter 类的实例。代码是全世界通用的语言,所以我们还是用代码说话:
var events = require("events");
var emitter = new events.EventEmitter();
emitter.on("myEvent", function(msg) {
console.log(msg);
});
emitter.emit("myEvent", "Hello World.");
简单的分析这段:
1. 使用require()方法添加了events模块并把返回值赋给了一个变量
2. new events.EventEmitter()这句创建了一个事件触发器,也就是所谓的事件模块中的 EventEmitter 类的实例
3. on(event, listener)用来为某个事件 event 添加事件处理方法监听器
4. emit(event, [arg1], [arg2], [...]) 方法用来产生事件。以提供的参数作为监听器函数的参数,顺序执行监听器列表中的每个监听器函数。
EventEmitter 类中的方法都与事件的产生和处理相关:
1. addListener(event, listener) 和 on(event, listener) 这两个方法都是将一个监听器添加到指定事件的监听器数组的末尾
2. once(event, listener) 这个方法为事件为添加一次性的监听器。该监听器在事件第一次触发时执行,过后将被移除
3. removeListener(event, listener) 该方法用来将监听器从指定事件的监听器数组中移除出去
4. emit(event, [arg1], [arg2], [...]) 刚刚提到过了。
在Node中,存在各式各样不同的数据流,Stream(流)是一个由不同对象实现的抽象接口。例如请求HTTP服务器的request是一个流,类似于stdout(标准输出);包括文件系统、HTTP 请求和响应、以及 TCP/UDP 连接等。流可以是可读的,可写的,或者既可读又可写。所有流都是EventEmitter的实例,因此可以产生各种不同的事件。
可读流主要会产生以下事件:
- data 当读取到流中的数据时,此事件被触发
- end 当流中没有数据可读时,此事件被触发
- error 当读取数据出现错误时,此事件被触发
- close 当流被关闭时,,此事件被触发,可是并不是所有流都会触发这个事件。(例如,一个连接进入的HTTP request流就不会触发'close'事件。)
还有一种比较特殊的 fd 事件,当在流中接收到一个文件描述符时触发此事件。只有UNIX流支持这个功能,其他类型的流均不会触发此事件。
相关详细文档:http://cnodejs.org/cman/all.html#events_
强大的File System 文件系统模块
Node 中的 fs 模块用来对本地文件系统进行操作。文件的I/O是由标准POSIX函数封装而成。需要使用require('fs')访问这个模块。所有的方法都提供了异步和同步两种方式。
fs 模块中提供的方法可以用来执行基本的文件操作,包括读、写、重命名、创建和删除目录以及获取文件元数据等。每个操作文件的方法都有同步和异步两个版本。
异步操作的版本都会使用一个回调方法作为最后一个参数。当操作完成的时候,该回调方法会被调用。而回调方法的第一个参数总是保留为操作时可能出现的异常。如果操作正确成功,则第一个参数的值是 null 或 undefined 。
同步操作的版本的方法名称则是在对应的异步方法之后加上一个 Sync 作为后缀。比如异步的 rename() 方法的同步版本是 renameSync() 。下面列出来了 fs 模块中的一些常用方法,都只介绍异步操作的版本。
test.js和myModule.js文件准备好了木?把下面这段代码copy到test.js中执行一次
var fs = require('fs');
fs.unlink('./myModule.js', function (err) {
if (err) throw err;
console.log('successfully deleted myModule.js');
});
如果没有报error,那么myModule.js就被删除了,就是这么简单

这只是一个简单的例子,感兴趣的话自己去多多尝试,实践出真理。由于篇幅原因就不多举例了。^_^
学习Node的总结:
1.对于一个linux的命令和shell知识几乎为零的我来说,这段时间又学到了不少关于linux知识;vim真是一个强大的编辑器,不用鼠标的感觉真的很好;而且有一点对我来说很重要,在linux下编程很cool,尤其是在团队中都是使用windows的,装装更健康^_^。
2.理解了服务端JavaScript的一个成功框架-Node,以及它的一些优势和使用的方式,这篇文章就是最好的总结,当然,这只会是一个开始。
3.对于没有进入那么梦想的公司其实是有那么点遗憾,不过生活就应该要这样,有波折有起伏,这正是我需要并且期待的...那么新的生活还是要继续,做自己的舵手,把握好自己的方向,过去的就让它过去吧。
一些想对大伙说的话:
1. 在这我得打击一部分人的积极性。假如你对后台技术不够了解或者没接触过服务端语言,不知道I/O这些知识,没有后台处理流程这种概念,那么......Node并不是一门适合入门的服务端技术。为什么这么说:
a.重点就是中文实例少,文章少,想系统的学习会比较麻烦,所以在使用过程中总有一种不成熟的感觉,当然主要还是因为我对它不熟悉所造成的。国内使用Node的公司确实不多,当然国外还是有不少了,从cnodejs.org截了一个图:

b.对没有经验的朋友来说node其实并不好上手,从最简单“Hello world”就可以看出来(各种运行环境和安装细节的了解都得费点功夫),不要以jQuery库为比较,所处理的事物不同,学习的成本也不同 - 所以不太建议作为新手入门的服务端技术,如果想学习一门服务端语言PHP和Python都是不错的选择,因为:书多 例子多 框架多 上手简单 容易理解 搭建方便...
c.以上都是我个人善意的建议,由于水平有限,请大家多多指教,希望嘴下留情。
2. 关于Node的书写规范和具体技巧本人就不献丑了,自己写Node的代码也不多,不过面向对象的编程思想在哪都是好使的。
3. 希望这篇文章能对大家学习Node有用,如果觉得这文章也算用心,请劳驾点右下角的推荐。
推荐几个学习Node的网址:
http://nodejs.org/
http://cnodejs.org/ 由淘宝人建立的社区,内有Node中文文档
http://www.oschina.net/p/nodejs/
http://www.ibm.com/developerworks/cn/opensource/os-nodejs/index.html
注:最终领导决定放弃Node而使用Python,可是这不会影响我对Node的喜爱。我说过,这篇文章只会是一个开始。
PHP Mailer中文说明
A开头:
$AltBody–属性
出自:PHPMailer::$AltBody
文件:class.phpmailer.php
说明:该属性的设置是在邮件正文不支持HTML的备用显示
AddAddress–方法
出自:PHPMailer::AddAddress(),文件:class.phpmailer.php
说明:增加收件人。参数1为收件人邮箱,参数2为收件人称呼。例AddAddress("xiaoxiaoxiaoyu@xiaoxiaoyu.cn","xiaoxiaoyu"),但参数2可选,AddAddress()也是可以的。
函数原型:public function AddAddress($address, $name = ”) {}
AddAttachment–方法
出自:PHPMailer::AddAttachment()
文件:class.phpmailer.php。
说明:增加附件。
参数:路径,名称,编码,类型。其中,路径为必选,其他为可选
函数原型:
AddAttachment($path, $name = ”, $encoding = ‘base64′, $type = ‘application/octet-stream’){}
AddBCC–方法
出自:PHPMailer::AddBCC()
文件:class.phpmailer.php
说明:增加一个密送。抄送和密送的区别请看[SMTP发件中的密送和抄送的区别] 。
参数1为地址,参数2为名称。注意此方法只支持在win32下使用SMTP,不支持mail函数
函数原型:public function AddBCC($address, $name = ”){}
AddCC –方法
出自:PHPMailer::AddCC()
文件:class.phpmailer.php
说明:增加一个抄送。抄送和密送的区别请看[SMTP发件中的密送和抄送的区别] 。
参数1为地址,参数2为名称注意此方法只支持在win32下使用SMTP,不支持mail函数
函数原型:public function AddCC($address, $name = ”) {}
AddCustomHeader–方法
出自:PHPMailer::AddCustomHeader()
文件:class.phpmailer.php
说明:增加一个自定义的E-mail头部。
参数为头部信息
函数原型:public function AddCustomHeader($custom_header){}
AddEmbeddedImage –方法
出自:PHPMailer::AddEmbeddedImage()
文件:class.phpmailer.php
说明:增加一个嵌入式图片
参数:路径,返回句柄[,名称,编码,类型]
函数原型:public function AddEmbeddedImage($path, $cid, $name = ”, $encoding = ‘base64′, $type = ‘application/octet-stream’) {}
提示:AddEmbeddedImage(PICTURE_PATH. "index_01.jpg ", "img_01 ", "index_01.jpg ");
在html中引用<img src= "cid:img_01 ">
AddReplyTo–方法
出自:PHPMailer:: AddReplyTo()
文件:class.phpmailer.php
说明:增加回复标签,如"Reply-to"
参数1地址,参数2名称
函数原型:public function AddReplyTo($address, $name = ”) {}
AddStringAttachment-方法
出自:PHPMailer:: AddStringAttachment()
文件:class.phpmailer.php
说明:增加一个字符串或二进制附件(Adds a string or binary attachment (non-filesystem) to the list.?)
参数:字符串,文件名[,编码,类型]
函数原型:public function AddStringAttachment($string, $filename, $encoding = ‘base64′, $type = ‘application/octet-stream’) {}
Authenticate–方法
出自:SMTP::Authenticate()
文件:class.smtp.php
说明:开始SMTP认证,必须在Hello()之后调用,如果认证成功,返回true,
参数1用户名,参数2密码
函数原型:public function Authenticate($username, $password) {}
B开头
$Body–属性
出自:PHPMailer::$Body
文件: class.phpmailer.php
说明:邮件内容,HTML或Text格式
C开头
$CharSet–属性
出自:PHPMailer::$CharSet
文件:class.phpmailer.php
说明:邮件编码,默认为iso-8859-1
$ConfirmReadingTo–属性
出自:PHPMailer::$ConfirmReadingTo 文件class.phpmailer.php
说明:回执?
$ContentType–属性
出自:PHPMailer::$ContentType
文件: class.phpmailer.php
说明:文档的类型,默认为"text/plain"
$CRLF–属性
出自:PHPMailer::$ContentType
文件:class.phpmailer.php
说明:SMTP回复结束的分隔符(SMTP reply line ending?)
class.phpmailer.php–对象
出自:class.phpmailer.php
文件: class.phpmailer.php
说明:phpmailer对象
class.smtp.php–对象
出自:class.smtp.php 文件: class.smtp.php
说明:SMTP功能的对象
ClearAddresses–方法
出自:PHPMailer::ClearAddresses()
文件: class.phpmailer.php
说明:清除收件人,为下一次发件做准备。返回类型是void
ClearAllRecipients–方法
出自:PHPMailer::ClearAllRecipients()
文件: class.phpmailer.php
说明:清除所有收件人,包括CC(抄送)和BCC(密送)
ClearAttachments–方法
出自:PHPMailer::ClearAttachments()
文件: class.phpmailer.php
说明:清楚附件
ClearBCCs–方法
出自:PHPMailer::ClearBCCs() 文件 class.phpmailer.php
说明:清楚BCC (密送)
ClearCustomHeaders–方法
出自:PHPMailer::ClearCustomHeaders()
文件: class.phpmailer.php
说明:清楚自定义头部
ClearReplyTos–方法
出自:PHPMailer::ClearReplyTos()
文件: class.phpmailer.php
说明:清楚回复人
Close–方法
出自:SMTP::Close()
文件: class.smtp.php
说明:关闭一个SMTP连接
Connect–方法
出自:SMTP::Connect()
文件: class.smtp.php
说明:建立一个SMTP连接[/color]Mailer.html
$ContentType–属性
出自:PHPMailer::$ContentType
文件: class.phpmailer.php
说明:文档的类型,默认为"text/plain"
D开头
$do_debug–属性
出自:SMTP::$do_debug
文件:class.smtp.php
说明:SMTP调试输出
Data-方法
出自:SMTP::Data()
文件:class.smtp.php
说明:向服务器发送一个数据命令和消息信息(sendsthemsg_datatotheserver)
E开头
$Encoding–属性
出自:PHPMailer::$Encoding
文件:class.phpmailer.php
说明:设置邮件的编码方式,可选:"8bit","7bit","binary","base64",和"quoted-printable".
$ErrorInfo–属性
出自:PHPMailer::$ErrorInfo
文件:class.phpmailer.php
说明:返回邮件SMTP中的最后一个错误信息
Expand–方法
出自:SMTP::Expand()
文件:class.smtp.php
说明:返回邮件列表中所有用户。成功则返回数组,否则返回false(Expandtakesthenameandaskstheservertolistallthepeoplewhoaremembersofthe_list_.Expandwillreturnbackandarrayoftheresultorfalseifanerroroccurs.)
F开头:
$From–属性
出自:PHPMailer::$From文件class.phpmailer.php
说明:发件人E-mail地址
$FromName–属性
出自:PHPMailer::$FromName
文件:class.phpmailer.php
说明:发件人称呼
H开头:
$Helo–属性
出自:PHPMailer::$Helo
文件:class.phpmailer.php
说明:设置SMTPHelo,默认是$Hostname(SetstheSMTPHELOofthemessage(Defaultis$Hostname).)
$Host–属性
出自:PHPMailer::$Host
文件:class.phpmailer.php
说明:设置SMTP服务器,格式为:主机名[端口号],如smtp1.example.com:25和smtp2.example.com都是合法的
$Hostname–属性
出自:PHPMailer::$Hostname
文件:class.phpmailer.php
说明:设置在Message-Id和andReceivedheaders中的hostname并同时被$Helo使用。如果为空,默认为SERVER_NAME或’localhost.localdomain"
Hello–方法
出自:SMTP::Hello()
文件:class.smtp.php
说明:向SMTP服务器发送HELO命令
Help–方法
出自:SMTP::Help()
文件:class.smtp.php
说明:如果有关键词,得到关键词的帮助信息
I开头:
IsError–方法
出自:PHPMailer::IsError()
文件:class.phpmailer.php
说明:返回是否有错误发生
IsHTML–方法
出自:PHPMailer::IsHTML()
文件:class.phpmailer.php
说明:设置信件是否是HTML格式
IsMail–方法
出自:PHPMailer::IsMail()
文件:class.phpmailer.php
说明:设置是否使用php的mail函数发件
IsQmail–方法
出自:PHPMailer::IsQmail()
文件:class.phpmailer.php
说明:设置是否使用qmailMTA来发件
IsSendmail–方法
出自:PHPMailer::IsSendmail()
文件:class.phpmailer.php
说明:是否使用$Sendmail程序来发件
IsSMTP–方法
出自:PHPMailer::IsSMTP()
文件:class.phpmailer.php
说明:是否使用SMTP来发件
M开头:
$Mailer–属性
出自:PHPMailer::$Mailer
文件:class.phpmailer.php
说明:发件方式,("mail","sendmail",or"smtp").中的一个
Mail–方法
出自:SMTP::Mail()
文件:class.smtp.php
说明:从$from中一个邮件地址开始处理,返回true或false。如果是true,则开始发件
N开头:
Noop–方法
出自:SMTP::Noop()
文件:class.smtp.php
说明:向SMTP服务器发送一个NOOP命令
P开头:
$Password–属性
出自:PHPMailer::$Password
文件:class.phpmailer.php
说明:设置SMTP的密码
$PluginDir–属性
出自:PHPMailer::$PluginDir
文件:class.phpmailer.php
说明:设置phpmailer的插件目录,仅在smtpclass不在phpmailer目录下有效
$Port–属性
出自:PHPMailer::$Port
文件:class.phpmailer.php
说明:设置SMTP的端口号
$Priority–属性
出自:PHPMailer::$Priority
文件:class.phpmailer.php
说明:设置邮件投递优先等级。1=紧急,3=普通,5=不急
PHPMailer–对象
出自:PHPMailer
文件:class.phpmailer.php
说明:PHPMailer-PHPemailtransportclass
Q开头
Quit–方法
出自:SMTP::Quit()
文件:class.smtp.php
说明:向服务器发送Quit命令,如果没有错误发生。那么关闭sock,不然$close_on_error为true
R开头
Recipient–方法
出自:SMTP::Recipient()
文件:class.smtp.php
说明:使用To向SMTP发送RCPT命令,参数为:$to
Reset–方法
出自:SMTP::Reset()
文件:class.smtp.php
说明:发送RSET命令从而取消处理中传输。成功则返回true,否则为false
S开头:
$Sender–属性
出自:PHPMailer::$Sender
文件:class.phpmailer.php
说明:SetstheSenderemail(Return-Path)ofthemessage.Ifnotempty,willbesentvia-ftosendmailoras’MAILFROM’insmtpmode.
$Sendmail–属性
出自:PHPMailer::$Sendmail
文件:class.phpmailer.php
说明:设置发件程序的目录
$SMTPAuth–属性
出自:PHPMailer::$SMTPAuth
文件:class.phpmailer.php
说明:设置SMTP是否需要认证,使用Username和Password变量
$SMTPDebug–属性
出自:PHPMailer::$SMTPDebug
文件:class.phpmailer.php
说明:设置SMTP是否调试输出?
$SMTPKeepAlive–属性
出自:PHPMailer::$SMTPKeepAlive
文件:class.phpmailer.php
说明:在每次发件后不关闭连接。如果为true,则,必须使用SmtpClose()来关闭连接
$SMTP_PORT–属性
出自:SMTP::$SMTP_PORT
文件:class.smtp.php
说明:设置SMTP端口
$Subject–属性
出自:PHPMailer::$Subject
文件:class.phpmailer.php
说明:设置信件的主题
Send–方法
出自:SMTP::Send()
文件:class.smtp.php
说明:从指定的邮件地址开始一个邮件传输
Send–方法
出自:PHPMailer::Send()
文件:class.phpmailer.php
说明:创建邮件并制定发件程序。如果发件不成功,则返回false,请使用ErrorInfo来查看错误信息
SendAndMail–方法
出自:SMTP::SendAndMail()
文件:class.smtp.php
说明:从指定的邮件地址开始一个邮件传输
SendOrMail–方法
出自:SMTP::SendOrMail()
文件:class.smtp.php
说明:从指定的邮件地址开始一个邮件传输
SetLanguage–方法
出自:PHPMailer::SetLanguage()
文件:class.phpmailer.php
说明:设置phpmailer错误信息的语言类型,如果无法加载语言文件,则返回false,默认为english
SMTP–方法
出自:SMTP::SMTP()
文件:class.smtp.php
说明:初始化一个对象以便数据处于一个已知的状态
SMTP–对象
出自:SMTP
文件:class.smtp.php
说明:SMTP对象
SmtpClose–方法
出自:PHPMailer::SmtpClose()
文件:class.phpmailer.php
说明:如果有活动的SMTP则关闭它。
T开头
$Timeout–属性
出自:PHPMailer::$Timeout
文件:class.phpmailer.php
说明:设置SMTP服务器的超时(单位:秒)。注意:在win32下,该属性无效
Turn–方法
出自:SMTP::Turn()
文件:class.smtp.php
说明:这是一个可选的SMTP参数,目前phpmailer并不支持他,可能未来支持
U开头
$Username–属性
出自:PHPMailer::$Username
文件:class.phpmailer.php
说明:设置SMTP用户名
V开头
$Version–属性
出自:PHPMailer::$Version
文件:class.phpmailer.php
说明:返回Phpmailer的版本
Verify–方法
出自:SMTP::Verify()
文件:class.smtp.php
说明:通过服务器检查用户名是否经过验证
W开头:
$WordWrap–属性
出自:PHPMailer::$WordWrap
文件:class.phpmailer.php
说明:设置每行最大字符数,超过改数后自动换行
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
