浏览器差异 window.open
浏览器实现差异:
| 浏览器 | 无参数 | width,height | left,top | toolbar | location |
Directories
|
Status
|
Menubar |
Scrollbar
|
Resizable
|
screenX,screenY
|
FullScreen |
| 期待结果 | 有标签的 标签 无标签的 弹窗 |
尽量按指定 宽高弹窗 |
语义冲突的参数 相对parent页 left ,top位置 |
默认 无工具栏 yes 有工具栏 no 无工具栏 |
默认 有(r) yes 有(w) no 无 (r)只读,(w)可写 |
这玩意到底 是神马? 只有IE6支持 无期待结果 |
默认 无 yes 有 no 无 |
垃圾参数 无视. 只对早期 ie有效 |
默认auto yes auto no 无 |
默认 是 yes 是 no 否
|
真正语义上的参数 相对屏幕坐标 |
全屏显示 |
| IE | 6 弹窗
7-8 弹窗 9 标签 |
全部 ok | (注1) | 全部
默认无 yes 有
no 无
|
6 默认 无 yes 有(w) (toolbar也有了) no 无
7,8,9 |
6 toolbar去掉 location部分 7,8,9不支持 |
6,7,8 无视参数 始终 有 9 |
全部 无视参数 始终 无 |
全部 默认 否 yes 是 no 否 |
不支持 | 全部 支持 |
|
| Chrome | 全部 标签 | 全部 ok | 全部相对
父页面
left,top |
不支持此参数 弹窗木有工具栏 |
不支持此参数
始终有,且只读 |
不支持 | 无status bar | 1 无视参数 始终 无 2+ |
不支持此 参数,一律 可缩放 |
完全 ok | 不支持 | |
| FireFox | 1, 1.5 弹窗
2.0+ 标签 |
全部 ok |
全部 |
默认无
yes 有
no 无 |
1, 1.5, 2 默认 无 yes 有(r) no 无 3+ |
不支持
|
无视参数 始终 有 |
无视参数
始终 无
|
2- 默认 否 yes 是 no 否 3+ |
完全 ok
|
3.6- 不支持 4 |
|
| Safari | 3+ 弹窗 (Safari5 偏好设置 ,在标签中打开新 页面, 选项有-总是 ,永不,自动.默认是 永不.导致此问题.) |
3+ ok |
全部
left 相对父页面 (但当父窗体left的
位置导致新窗体不
能全部显示时,则
新窗体left,相对屏
幕为0,与ie7有些
相似)
top 相对屏幕
|
默认无
yes 有
no 无 |
默认 无 yes 有(w)(但 工具栏也有了) no 无 |
不支持
|
默认 无
yes 有 no 无 |
无视参数
始终 无
|
不支持此
参数,一律 可缩放 |
完全 ok
|
不支持
|
|
| Opera | 9.2+ 弹窗 | 9.2 tab
9.6+
标签(有宽高,可拖
拽.但无法离开父
窗口)
|
9.6+
相对父页面
的left,top
9.2 标签
|
9.2 tab
9.6+ 因其本质 |
9.2 tab
9.6+ 因其本质
是tab所以无视 此参数.共享 location
|
不支持
|
9.2 tab
9.6+ 因其本质
是tab所以无视 此参数.共享 statusbar
|
无视参数
始终 无
|
不支持此
参数,一律 可缩放 |
不支持
|
不支持
|
|
| 360安全 | 3.3+ 标签
3.612 弹窗 |
3.612 弹窗(无视 宽高参数parent 页面多大新弹窗 就多大) 其他版本 标签 |
3.612 left top 和parent页面 有关,但位置算 法很混乱. 其他版本 标签
|
3.612 弹窗无视 一切参数.显示 一个完整窗口 其他版本 标签
|
.. | .. | .. | .. | .. | .. | .. | .. |
| 360高速 | 两种内核都 标签 | IE内核 标签
chromium都 ok |
chromium
同chrome
其他内核 标签
|
..
|
.. | .. | .. | .. | .. | .. | .. | .. |
| 搜狗高速 | 两种内核都 标签 |
两种内核都 标签
|
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| TT | 标签 | 标签 |
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| QQ5 | 两种内核都 标签 |
两种内核都 标签
|
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| Maxthon2.5 | 标签 |
标签
|
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| Maxthon3 | 两种内核都 标签 | 两种内核都 标签 |
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| 世界之窗 | 标签 |
标签
|
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
| MyIe | 标签 |
标签
|
标签
|
.. | .. | .. | .. | .. | .. | .. | .. | .. |
第二参数target(name)相关:
用途:
差异:
.IE下name的值为null 或 undefined时,行为与其他浏览器有差异. 等价于 'null' 或 'undefined' .在期望打开多个窗口,又想设置其他窗口参数时,参数设置此2值.会被视为有效的name值. (解决办法,使用 '' 空字符,或'_blank'代替 null 或 undefined. 建议用优先考虑空字符,因为某些浏览器的早期版本不支持 _blank)
.Opera,Chrome 下,如果一个iframe的id,与window.open的第二参数name同名.也具备同样效果. 其他浏览器则无此现象.
.Opera9.6+ ,如果在另一个iframe内调用其self.open的第二参数name与其他iframe的name或id同名,则仍然会重新打开一个窗口. 而不是去操作该iframe.其他浏览器则无此问题
IE7. left 相对的位置,总是相对非最大化时,父页的left+10px左右偏移.(就是非最大化时,显示在哪,最大化时,就显示在哪.但并不总是相对非最大化时的父窗口left,比如在父窗口left很靠右的情况下,则其会新窗口会变成相对屏幕来显示)
IE8. left,top全部相对屏幕
IE9. left 同IE6类似top 相对屏幕总是0
p3p 简洁策略及浏览器支持情况
从技术角度看,使 Web站点支持 P3P 是一个很容易的过程。但是,它要求网络运营商在审视数据处理方式时比以前更加仔细,并要求他们协调域内各个主机上的策略和处理方式。以下是如何使站点支持P3P 技术的具体步骤。
2. 分析 cookie 的使用情况以及您的站点上的第三方内容。
3. 确定要对整个站点应用一个P3P策略还是对站点的不同部分应用不同的P3P 策略。
4. 为站点创建一个或几个 P3P 策略。
5. 为站点创建一个策略引用文件。
6. 为 P3P 配置服务器。
7. 测试站点,以确定它确实支持 P3P。
● 用户是否可以查找该站点的数据库中保存了自己的哪些个人信息。
● 如何解决与站点之间有关隐私的纠纷(如客户服务台、隐私封印以及与隐私相关的法律等)。
● 所收集数据的种类。
● 所收集数据的使用方式,以及用户是否能选择接受或拒绝这些用途。
● 信息是否会被共享以及何时被共享,用户是否有选择的权力。
● 对所收集的用户信息进行定期清除的策略。
简洁策略对应的 HTTP Response Header :
compact-policy-field = `CP="` compact-policy `"`
compact-policy = compact-token *(" " compact-token)
compact-token = compact-access |
compact-disputes = "DSP"
compact-remedies = "COR" | "MON" | "LAW"
compact-non-identifiable = "NID"
compact-purpose = "CUR" | "ADM" [creq] | "DEV" [creq] | "TAI" [creq] |
"PSA" [creq] | "PSD" [creq] | "IVA" [creq] | "IVD" [creq] |
"PUB" [creq] | "OTR" [creq]
compact-category = "PHY" | "ONL" | "UNI" | "PUR" | "FIN" | "COM" |
"NAV" | "INT" | "DEM" | "CNT" | "STA" | "POL" |
我们常用的简洁策略的 P3P头为 - P3P : CP=CAO PSA OUR (其实, CP=. 就可以了.或者其他任何值都是可以的)分别对应了 :
compact-access(访问) : CAO - contact-and-other
compact-purpose(目的) : PSA - pseudo-analysis .这个就不放解释了,字面意思很明显, 目的就是做身份验证、分析
compact-recipient(受体) : OUR - ours
ps : 其他项就不列举,基于浏览器中只有IE支持.(chrome 部分支持).这一事实.深入研究没有必要. 如果你有兴趣,可以去相关链接查看文档.
对于众多提示性的反馈,是十分符合 P3P隐私策略的.即用户代理应该在恰当的时候,提醒用户.
已测知的问题:
IE6 第三方cookie 在有p3p头(使用p3p简介策略时) ,JS虽然有读写权限,但是在写的时候有个bug. 即,对于某第三方页面,如果是首次读到.其P3P头的话,则 js的写权限是没有的.必须要第二次访问到这个页面,且这个页面存在第三方cookie操作时,才允许JS写入Cookie.当然,读是一直没问题的.
if(Safari4或Safari5){var ifm = document.createElement('iframe');ifm.name ="postforcookie";ifm.src="about:blank";document.body.appendChild(ifm);var form = document.createElement('form');form.target = 'postforcookie';form.action = '//www.php.com/test.php';document.body.appendChild(form);Cookie.setCookie = function () {form.submit();}}
默认不禁止第三方cookie的浏览器测试:
| 浏览器 | 默认允许第三方Cookie | 是否支持P3P | 禁止第三方Cookie后,配置P3P简明策略头的效果 | 补充 |
| IE6 | 否 | 是 |
HTTP可读写Cookie (第二次.直接Cache.也不行.除非第一次非Cache并读到p3p头.后面我会提到解决方案.) |
避免JS的写操作 |
|
IE7-IE9
|
否 | 是 | HTTP、JS,可随意读写. | - |
| FireFox | 是 | 否 | HTTP、JS都不可读写 | - |
| Chrome | 是 | 部分支持,趋势-否 | 趋势为HTTP、JS可读不可写. | - |
| Safari | 否 | 否 | HTTP、JS可读不可写 | 借助Post提交表单,实现写操作. |
| Opera | 是 |
否
|
JS可读写 HTTP可读不可写. |
- |
建议:
最后:
如果你非要用在ie6下,用js写cookie. 那么有一个很悲剧的做法.. 服务器端给资源配置可缓存.(包括反向代理和客户端.) 然后想办法在IE6的时候刷新一次页面.这样就ok了. 刷新时一定要用 location.reload(false) 即先忽略客户端缓存.尝试304服务器端校验客户端缓存可靠性..这样做的好处是.即保证了 cookie的写入性. 又保证,如果页面是静态资源.则反向代理的可用性.. 否则还是直接用动态资源,http方式去写好了. 需要注意的是.除了页面刷新.譬如其他方式加载页面资源.试图通过预读其p3p简介策略头.是无效的. 比如 用 script type="text/c" 方式去预读一次. 如果你有这个想法。还是早早放弃的好.
使用PowerDesigner画图详细教程
一、概念数据模型概述
1)能够比较真实地模拟现实世界
2)容易为人所理解
3)便于计算机实现
概念数据模型也称信息模型,它以实体-联系(Entity-RelationShip,简称E-R)理论为基础,并对这一理论进行了扩充。它从用户的观点出发对信息进行建模,主要用于数据库的概念级设计。
通常人们先将现实世界抽象为概念世界,然后再将概念世界转为机器世界。换句话说,就是先将现实世界中的客观对象抽象为实体(Entity)和联系 (Relationship),它并不依赖于具体的计算机系统或某个DBMS系统,这种模型就是我们所说的CDM;然后再将CDM转换为计算机上某个 DBMS所支持的数据模型,这样的模型就是物理数据模型,即PDM。
CDM是一组严格定义的模型元素的集合,这些模型元素精确地描述了系统的
1)数据结构表达为实体和属性;
2)数据操作表达为实体中的记录的插入、删除、修改、查询等操作;
3)完整性约束表达为数据的自身完整性约束(如数据类型、检查、规则等)和数据间的参照完整性约束(如联系、继承联系等);
实体(Entity),也称为实例,对应现实世界中可区别于其他对象的“事件”或“事物”。例如,学校中的每个学生,医院中的每个手术。
每个实体都有用来描述实体特征的一组性质,称之为属性,一个实体由若干个属性来描述。如学生实体可由学号、姓名、性别、出生年月、所在系别、入学年份等属性组成。
实体集(Entity Set)是具体相同类型及相同性质实体的集合。例如学校所有学生的集合可定义为“学生”实体集,“学生”实体集中的每个实体均具有学号、姓名、性别、出生年月、所在系别、入学年份等性质。
实体类型(Entity Type)是实体集中每个实体所具有的共同性质的集合,例如“患者”实体类型为:患者{门诊号,姓名,性别,年龄,身份证号.............}。实体是实体类型的一个实例,在含义明确的情况下,实体、实体类型通常互换使用。
实体类型中的每个实体包含唯一标识它的一个或一组属性,这些属性称为实体类型的标识符(Identifier),如“学号”是学生实体类型的标识符,“姓名”、“出生日期”、“信址”共同组成“公民”实体类型的标识符。
有些实体类型可以有几组属性充当标识符,选定其中一组属性作为实体类型的主标识符,其他的作为次标识符。

介绍PowerDesigner概念数据模型以及实体、属性创建。
1)选择File-->New,弹出如图所示对话框,选择CDM模型(即概念数据模型)建立模型。

2)完成概念数据模型的创建。以下图示,对当前的工作空间进行简单介绍。(以后再更详细说明)

3)选择新增的CDM模型,右击,在弹出的菜单中选择“Properties”属性项,弹出如图所示对话框。在“General”标签里可以输入所建模型 的名称、代码、描述、创建者、版本以及默认的图表等等信息。在“Notes”标签里可以输入相关描述及说明信息。当然再有更多的标签,可以点击 "More>>"按钮,这里就不再进行详细解释。

1)在CDM的图形窗口中,单击工具选项版上的Entity工具,再单击图形窗口的空白处,在单击的位置就出现一个实体符号。点击Pointer工具或右击鼠标,释放Entitiy工具。如图所示

2)双击刚创建的实体符号,打开下列图标窗口,在此窗口“General”标签中可以输入实体的名称、代码、描述等信息。

1)在上述窗口的“Attribute”选项标签上可以添加属性,如下图所示。

注意:
数据项中的“添加属性”和“重用已有数据项”这两项功能与模型中Data Item的Unique code 和Allow reuse选项有关。
P列表示该属性是否为主标识符;D列表示该属性是否在图形窗口中显示;M列表示该属性是否为强制的,即该列是否为空值。
如果一个实体属性为强制的,那么, 这个属性在每条记录中都必须被赋值,不能为空。
2)在上图所示窗口中,点击插入属性按钮,弹出属性对话框,如下图所示。

注意:这里涉及到域的概念,即一种标准的数据结构,它可应用至数据项或实体的属性上
一、定义属性的标准检查约束
标准检查约束是一组确保属性有效的表达式。在实体属性的特性窗口,打开如图所示的检查选项卡。

在这个选项卡可以定义属性的标准检查约束,窗口中每项的参数的含义,如下
参数说明Minimum属性可接受的最小数Maximum 属性可接受的最大数Default属性不赋值时,系统提供的默认值Unit单位,如公里、吨、元Format属性的数据显示格式Lowercase属性的赋值全部变为小写字母Uppercase属性的赋值全部变为大写字母Cannot modify该属性一旦赋值不能再修改List Of Values属性赋值列表,除列表中的值,不能有其他的值Label属性列表值的标签
二、定义属性的附加检查
当Standard checks 或Rules 不能满足检查的要求时,可以在Additional Checks选项卡的Server子页上,通过SQL语句中使用%MINMAX%、%LISTVAL%、%RULES%、%UPPER%、%LOWER%几个变量来定义Standard和Rule,如图所示

%MINMAX%、%LISTVAL%、%UPPER%、%LOWER%
在Standard Check中定义的Minimum 和Maximum、List values 、uppervalues、lowervalues
%RULES%
在Rules特性窗口Expression选项卡中定义的有效性规则表达式
一、标识符
标识符是实体中一个或多个属性的集合,可用来唯一标识实体中的一个实例。要强调的是,CDM中的标识符等价于PDM中的主键或候选键。
每个实体都必须至少有一个标识符。如果实体只有一个标识符,则它为实体的主标识符。如果实体有多个标识符,则其中一个被指定为主标识符,其余的标识符就是次标识符了。
二、如果定义主、次标识符
1)选择某个实体双击弹出实体的属性对话框。在Identifiers选项卡上可以进行实体标识符的定义。如下图所示

2)选择第一行“主标识符”,点击属性按钮或双击第一行“主标识符”,弹出属性对话框,如图所示

3)选择"Attributes"选项卡,再点击“Add Attributes”工具,弹出如图所示窗口,选择某个属性作为标识符就行了。

一、数据项
数据项(Data Item)是信息存储的最小单位,它可以附加在实体上作为实体的属性。
注意:模型中允许存在没有附加至任何实体上的数据项。
二、新建数据项
1)使用“Model”---> Data Items 菜单,在打开的窗口中显示已有的数据项的列表,点击 “Add a Row”按钮,创建一个新数据项,如图所示

2)当然您可以继续设置具体数据项的Code、DataType、Length等等信息。这里就不再详细说明了。
三、数据项的唯一性代码选项和重用选项
使用Tools--->Model Options->Model Settings。在Data Item组框中定义数据项的唯一性代码选项(Unique Code)与重用选项(Allow Reuse)。
注意:
如果选择Unique Code复选框 ,每个数据项在同一个命名空间有唯一的代码,而选择Allow reuse ,一个数据项可以充当多个实体的属性。

四、在实体中添加数据项
1)双击一个实体符号,打开该实体的属性窗口。
2)单击Attributes选项卡,打开如下图所示窗口

注意:
Add a DataItem 与 Reuse a DataItem的区别在于
Add a DataItem 情况下,选择一个已经存在的数据项,系统会自动复制所选择的数据项。如果您设置了UniqueCode选项,那系统在复制过程中,新数据项的Code会自动生成一个唯一的号码,否则与所选择的数据项完全一致。
Reuse a DataItem情况下,只引用不新增,就是引用那些已经存在的数据项,作为新实体的数据项
一、 联系
实体之间可以通过联系来相互关联。与实体和实体集对应,联系也可以分为联系和联系集,联系集是实体集之间的联系,联系是实体之间的联系,联系是具有方向性的。联系和联系集在含义明确的情况之下均可称为联系。
按照实体类型中实例之间的数量对应关系,通常可将联系分为4类,即一对一(ONE TO ONE)联系、一对多(ONE TO MANY)联系、多对一(MANY TO ONE)联系和多对多联系(MANY TO MANY)。
二、 建立联系
在CDM工具选项板中除了公共的工具外,还包括如下图所示的其它对象产生工具。

在图形窗口中创建两个实体后,单击“实体间建立联系”工具,单击一个实体,在按下鼠标左键的同时把光标拖至别一个实体上并释放鼠标左键,这样就在两个实体间创建了联系,右键单击图形窗口,释放Relationship工具。如下图所示


除了4种基本的联系之外,实体集与实体集之间还存在标定联系(Identify Relationship)、非标定联系(Non-Identify RelationShip)和递归联系(Recursive Relationship)。
注意:
在非标定联系中,一个实体集中的部分实例依赖于另一个实例集中的实例,在这种依赖联系中,每个实体必须至少有一个标识符。而在标定联系中,一个实体集中的 全部实例完全依赖于另个实体集中的实例,在这种依赖联系中一个实体必须至少有一个标识符,而另一个实体却可以没有自己的标识符。没有标识符的实体用它所依 赖的实体的标识符作为自己的标识符。
换句话来理解,在标定联系中,一个实体(选课)依赖 一个实体(学生),那么(学生)实体必须至少有一个标识符,而(选课)实体可以没有自己的标识符,没有标标识符的实体可以用实体(学生)的标识符作为自己的标识符。

例如:在“职工”实体集中存在很多的职工,这些职工之间必须存在一种领导与被领导的关系。又如“学生”实体信中的实体包含“班长”子实体集与“普通学生” 子实体集,这两个子实体集之间的联系就是一种递归联系。创建递归联系时,只需要单击“实体间建立联系”工具从实体的一部分拖至该实体的别一个部分即可。如 图

在两个实体间建立了联系后,双击联系线,打开联系特性窗口,如图所示。

如:“学生 to 课目 ” 组框中应该填写“拥有”,而在“课目To 学生”组框中填写“属于”。(在此只是举例说明,可能有些用词不太合理)。
Mandatory 表洋这个方向联系的强制关系。选中这个复选框,则在联系线上产生一个联系线垂直的竖线。不选择这个复选框则表示联系这个方向上是可选的,在联系线上产生一个小圆圈。
联系具有方向性,每个方向上都有一个基数。
举例,
“系”与“学生”两个实体之间的联系是一对多联系,换句话说“学生”和“系”之间的联系是多对一联系。而且一个学生必须属于一个系,并且只能属于一个系, 不能属于零个系,所以从“学生”实体至“系”实体的基数为“1,1”,从联系的另一方向考虑,一个系可以拥有多个学生,也可以没有任何学生,即零个学生, 所以该方向联系的基数就为“0,n”,如图所示

CDM是大多数开发者使用PD时最先创建的模型,也是整个数据库设计最高层的抽象。CDM是建立在传统的ER图模型理论之上的,ER图中有三大主要元素: 实体型,属性和联系。其中实体型对应到CDM中的Entity,属性对应到CDM中每个Entity的Attribute,在概念上基本上是一一对应的。 但在联系上,CDM有了比较大的扩展,除了保留ER图原有的RelationShip概念之外,还增加了Association,Inheritance 两种实体关系,下面就让我们分别看看这些关系的用法和之间的区别(下图中被标红的工具栏按钮就是用来向实体中添加这些关系的)。
![]()

一. RelationShip(联系)

1.mandatory
(1)教师--学生 联系
(2)学生--俱乐部 联系
上面的例子主要是从概念的角度来区分了mandatory和optional的区别。实际上如果把这个模型对应到我们最后生成的表,如果A-B间的联系对 A是mandatory的话,那么如果在A里面如果包含B的外键,这个外键不能为空值,反之可以为空值。后面我们谈到PDM和实际数据库的时候,大家会看 到这一点。
2.dependent
3.dominant
二.Association(关联)
三.Inheritance(继承)
前面已经介绍了CDM中关于实体间关系的主要内容,接下来我们就来看看根据这个CDM所生成的PDM是一个什么样子:
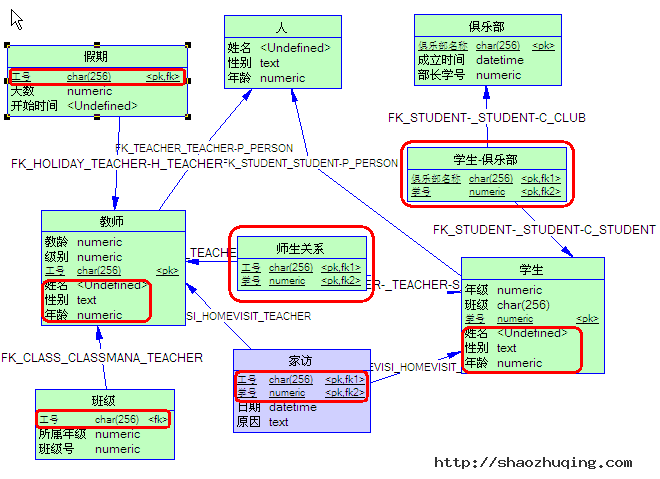
上图中所有标红的部分是我们最应该关注的内容,因为他们都是由于我们对实体型间的关系的定义而产生的,下面给出一些简单的说明。
1. “师生关系”和“学生俱乐部”这两个表是由于我们的多对多关系而产生的。
2. “假期”表的“工号”字段是由于我们将教师-假期关系指定为dependent而产生的。
3. “班级”表的“工号”字段是由于我们将教师-班级关系制定为dominant而产生的。
4. “家访”表中的“工号”和“学号”字段是由于家访是教师和学生实体型的association而产生的。
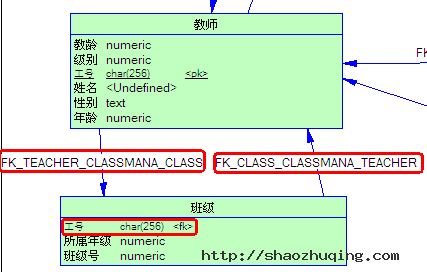
另外,记得我们在提到dominant属性的时候说过,一个没指定dominant方向的一对一联系将产生两个引用,下面我们就把原本的CDM中的教师- 班级关系进行一个小小的修改,去掉这个relationship的dominant定义,那么最终产生的PDM中教师表和班级表将互相包含对方的主键(由 于我们的班级表没有自己的主键,所以只能在班级表中看到多出来的列),截图如下:
史上最全装修流程
同样是建造,人和蜜蜂的区别就在于,蜜蜂的建造是本能的反映,而人在建造之前,脑海中首先会形成构思和框架。所以,如果把家装比喻成一场战役,那么家装的前期设计就是这场战役的“作战方案”,是家装的“灵魂环节”。
步骤/方法
(二)主体拆改进入到施工阶段,主体拆改是最先上的一个项目,主要包括拆墙、砌墙、铲墙皮、拆暖气、换塑钢窗等等。主体拆改说白了,就是先把工地的框架先搭起来。
(三)水电改造水电路改造之前,主体结构拆改应该基本完成了。在水电改造和主体拆改这两个环节之间,一些同学可能知道,还应该进行橱柜的第一次测量。其实所谓的橱柜第一次测量并没有什么实际内容,因为墙面和地面都没有处理,橱柜设计师不可能给出具体的设计尺寸,而只是就开发商预留的上水口、油烟机插座的位置,提出一些相关建议。主要包括:
Google AdSense常用名词解释
广告单元
广告单元由一段AdSense 广告代码所显示的一组广告。
链接单元
链接单元是一种广告格式,可显示一系列与某一网页内容相关的链接。用户点击链接后,便进入一个相关广告的网页。在我们的广告格式页,您可以查看所有可用链接单元格式的示例。
替代广告
替代广告可以在Google 不能向您的网页投放相关广告的情况下,保证您依然能够通过广告空间获得收入。通过指定图像或者所选广告服务器,可以确保广告空间始终得到有效的利用- 要么用于投放有针对性的AdSense 广告,要么用于投放您自己选择的内容。如果指定了替代广告,当您的网页没有可用的相关广告时,就会展示替代广告。这时,广告空间不会被标记为 “Google 提供的广告”。
公益广告
公益广告是当服务器找不到有针对性的广告或者Google 无法收集网页内容时投放到网页的非盈利组织广告。发布商不能从公益广告的点击次数中获得收入。
每次点击费用(CPC)
每次点击费用是每次用户点击广告时其所属广告客户要支付的费用。Google AdWords 拥有一个以每次点击费用为依据的定价系统。
点击率(CTR, click through rate)
广告点击次数与广告页的展示次数之比。
每千次展示费用(CPM)
CPM 是广告客户在其广告得到1000 次浏览并获得展示次数记录时为之支付的金额。
网页eCPM (effective cost per mille)
eCPM指的就是每一千次展示可以获得的广告收入,展示的单位可以是网页,广告单元,甚至是单个广告(在AdSense “高级报告”的“数据展示依据”下拉框中可以选择)。默认情况下,eCPM 指的都是千次网页展示(Pageview)收入。请注意,eCPM 只是用来反映网站盈利能力的参数,不代表您的收入。它是一个与网页展示次数无关的指标,这证明一点:一个网站的AdSense 可盈利趋势与网站的大小无关,它最终是由平均广告单价和广告的点击率决定的。
报告模板
报告模板是一种高级报告,其中包含您为了便于今后快速访问而命名并保存的设置。已保存报告模板将显示在“概述”页上,只需点击一下即可访问。所有报告模板都可通过电子邮件发送给您。
热门查询
AdSense 搜索广告发布商可以查看用户使用其AdSense 搜索广告框搜索的最热门的25 个字词。只有执行过一次以上的查询才会显示。
登录信息
AdSense 登录信息指帐户电子邮件。它是您用来登录Google AdSense 帐户的电子邮件地址。
IFRAME
IFRAME 是网站设计中使用的一种HTML 标记,可以将某个网页展示在其他网页内的框架中。
JavaScript
JavaScript 是常用于网页中的脚本语言。用来向您的网站加入Google 广告的广告代码即采用JavaScript 编写,您需要在浏览器中启用JavaScript,才能查看网站上的Google 广告。
内容相关广告
Google 利用搜索技术在我们联网中(包括AdSense 网站)的内容网页和产品上投放相关的广告。借助于我们对搜索索引中数十亿网页的内容的理解以及我们的网页抓取能力,我们的技术可以明确哪些关键字能够将用户引至相关网页。然后,我们根据这些关键字将广告与网页相匹配。
广告单元展示
每当用户浏览您的网页上的广告单元时,就会生成广告单元展示。例如,如果您的某张网页上展示了三个广告单元,该网页被浏览了两次,则您会获得六次广告单元展示和两次网页展示。
网址(URL) 过滤列表
AdSense 发布商在自己的帐户中创建并存储的列表,用于防止在自己的网站上投放来自某些网址的广告。在发布商将某一网址添加到此列表后,此网站列表的广告就不会投放到发布商的网站上。
竞争性广告
竞争性广告指贵网站上模仿Google 文字广告或看来与Google 文字广告相关的以网页内容定位的广告或文字广告。根据AdSense 计划政策中的规定,竞争性广告不得与Google 广告展示在同一网页或网站上。不过,我们允许联属链接及文字数量有限的链接。
帐户类型
通常,如果您的企业有20 名或更多员工,则应申请企业帐户。个人发布商或企业员工少于20 名
的,则应注册个人帐户。个人帐户与企业帐户在产品、服务或付款结构方面没有任何差别,在付款方式和支取流程上有所不同,企业帐户目前不支持西联汇款的方式,在支票托收时,这两种帐户需要提供给银行的证明材料也不相同。
收入份额
各个AdSense 发布商会获得广告客户对其广告的用户点击次数或展示次数所付费用的某一百分比的数额。该百分数称为收入份额。Google 不能透露AdSense 的收入份额。
帐户电子邮件
也叫作帐户相关邮件,是您用来登录AdSense 帐户的电子邮件地址。我们会将所有发送给您的关于AdSense 的邮件发送到该地址。
抓取工具
抓取工具又称为Spider 或Bot,是Google 用于对网页内容进行处理和编制索引的软件。AdSense抓取工具会通过访问您的网站来确定其内容,从而提供相关的广告。
无效点击或者展示
通过我们所禁止的方式所产生,而目的是想人为地增加发布商帐户上的点击或展示次数的点击与网页展示。Google 使用自己的专有技术分析所有广告点击与展示次数,以确定是否发生了任何无效点击行为,防止人为地增加广告客户的点击次数或发布商的收益。被我们判为无效的点击不会算入您的收益里。
链接单元的点击次数
在链接单元报告中,链接点击结果页中的广告所获得的点击次数。它不同于链接点击次数,链接点击次数是用户点击的链接单元中链接的次数,用户点击的结果是浏览广告页面。
链接展示次数
在链接单元报告中,链接单元被浏览的次数,无论链接是否被点击。
广告展示次数
只要有单个广告展示在您的网站上,就报告为一次广告展示。显示的广告数量因广告格式而异;例如,竖幅广告在您的网站上每显示一次,报告就会生成两次广告展示次数。另外请注意,根据广告单元中显示的是标准文字广告、扩展文字广告还是图片广告,广告单元中的广告数量可能不同。
链接点击次数
链接单元中链接的点击次数。
调整项
您的收入可能会由于多种原因而包含借记项或贷记项,所有此类项目都会在"付款历史"页上列出。可能的调整项包括:
AdSense 搜索广告费用:您的AdSense 搜索广告收入可能会与相关费用相抵。这种情况仅适用于少数发布商。有关详情,请浏览AdSense 支持中心。
支票费用:与特殊的支票递送方式或停止付款申请相关的费用
无效点击:发布商不会从被发现为无效的点击次数上获得付款。如果目前已显示在您报告中的点击被认定为无效,我们会调整相关收入,并向广告客户退还费用。
月末余额
“付款历史”页会在每个月末显示您AdSense 帐户中的余额。此金额反映的是在相应月末时的已确认收入。如果您帐户的月末余额大于$100 美元,且帐户中没有保留付款,我们就会安排在下个月向您付款。
目标网址
广告所链接到的网址。当用户通过点击广告访问广告客户的网站时,他们将看到此网页。如果您希望将某一网址添加到自己的网址过滤列表,以阻止此广告客户的广告出现在您的网站上,则需要知道此网址。
框架
网页可以带有框架,从而将一张网页划分成采用独立HTML 代码的多个部分。放置AdSense 广告代码的框架应该包含您希望据以定位广告的文本内容。
可通过电子邮件发送的报告
可通过电子邮件发送的报告是一种已保存报告模板,您可以使用帐户中的报告管理页设置日程,让报告通过电子邮件发送给您。
调色板
AdSense 为发布商提供了对出现在自己网站上的广告颜色进行自定义的功能。调色板有助于您确保广告的文字、背景以及边框颜色能够与网站的外观相配。为了增强多样性和新颖性,您甚至可以选择每次轮流使用最多4 个不同的调色板。
渠道
“付款历史”页会在每个月末显示您AdSense 帐户中的余额。此金额反映的是在相应月末时的已确认收入。如果您帐户的月末余额大于$100 美元,且帐户中没有保留付款,我们就会安排在下个月向您付款。
目标网址
广告所链接到的网址。当用户通过点击广告访问广告客户的网站时,他们将看到此网页。如果您希望将某一网址添加到自己的网址过滤列表,以阻止此广告客户的广告出现在您的网站上,则需要知道此网址。
帐户启动
您提交了AdSense 申请并确认了您的电子邮件地址后,AdSense 小组会在一两天之内评估您的申请,并向您发送一封通知电子邮件。如果您获准参与此计划,就可以登录到自己的新帐户,并将AdSense 广告代码复制并粘贴到网页中,从而开始投放广告。此操作会启动您的AdSense 帐户。
网页展示次数
每当用户浏览展示了Google 广告的网页时,就会生成一次网页展示。不考虑网页上展示的广告数量,我们仅计为一次网页展示。例如,如果您的某张网页上展示了三个广告单元,该网页被浏览了两次,则您会获得两次网页展示和六次广告单元展示。
番薯网报告分享
专业公司:
尼尔森数据
麦肯锡
Doubleclick
基础了解:
每个版块所占的比例
来源的途径
哪个版块的转化率最高
方法比意识更重要
清楚留住用户的核心价值是什么?
1、吸引鼠标(市场推广)
2、诱导鼠标(站点设计)
3、留住鼠标(服务运营)
4、寄生鼠标(服务定位)
品牌、核心优势、配套优势、共同优势
问题:迷失重点、求全求大、缺乏后劲、运营滞后、技术失衡、忽略感受
定位目标用户的需求:
1、用户基本特征
2、行为特征
3、媒体特征
4、需求潜力
匹配自身核心业务
1、哪些我可以做到最好
2、哪些不可能做好
3、哪些合作可做好
4、哪些与核心业务结合最紧密
5、那些需要我额外投入
6、哪些需要长期的运营
评估现有资源和能力
1、清楚自己现有的资源
2、自己能做好的服务中选择收益最快的
3、投入最合理项目中确定可持久性的服务
4、现有人员条件和管理模式是否能够匹配这些服务
5、多大程度上依赖内部跨部门的支持,能否成为内部瓶颈
6、学会做出必要的取舍,暂时放弃力所能及但看上去很美的项目
全面分析当前市场环境
1、市场占有率(改变习惯 、还是利用习惯)
2、主要受众
3、核心服务
沙盘:目标、条件
全乎利弊做出决断
运营管理:
基础流量分析
推广效果评估分析
访问忠诚度分析
消费行为分析
用户分级分析
极差的对应分析
http://baike.baidu.com/view/1679038.htm
谈工作方法和思路
最简单的工作方法和思路是PDCA循环,展开来就是凡事有记录,凡事有计划,凡事有执行,凡事有结果,凡事有改进,在这个过程中时刻体现目标驱动和用数据 说话。这个看起来很简单,做起来却不容易,而真正做的时候可以从最简单的记录和日志开始,然后过渡到GTD和目标管理,然后过渡到数据分析。
考虑下工作中经常涉及到要写的内容,无碍乎就是方案,建议,进展汇报,项目总结,工作总结,这些是工作中写的最多的内容。所有这些内容的写作都遵循一定的模式。
对于方案建议类的,其实本身就是一个分析和解决问题的过程,因此一定是包括了问题定义,问题分析和问题解决三方面的内容。而问题本身就是目标和现状之间的 差距才称为问题,因此问题定义可以展开为目标说明,问题和需求描述,现状分析等。而问题分析则重点是目标和现状之间的差距分析,可以先定性分析,再定量分 析;最好是问题解决,而问题解决本身有包括了提出解决方案,解决方案本身应该采用结构化决策的思路,提出多个解决方案进行对比选择最优的解决方案,最好是 解决方案的具体实施。这就是方案建议类文档的统一框架。
而对于项目工作总结,进展汇报的文档基本是一个项目管理生命周期的思路,即计划,执行,监控,结果。这类文档应该是先说项目目标和计划,再说项目执行的过 程,执行的结果,再来分析项目计划和执行的差距,最好来分析问题的根源,提出改进意见,以达到持续改进的目标。所以这类文档一定要体现目标驱动和用数据说 话。
大家都一同毕业,两三年后可能体现出很大的差距,这里面其实思路和思维两方面的内容。思路是一种态度和大方法的问题,思维是一种小方法和逻辑的问题。比如 思路有些人把工作当学习,有些人把工作当工作;有些人只会模仿,有些人细化思考;有些人以接受老事物为主,有些人以分享新事物为主,这些思路上的差别都直 接影响到思维。思路没有改,思维和方法上更加无法改。有了喜欢总结,不断思考和持续改进的大思路,才可能逐步改进思维能力,培养结构化思维和分析解决问题 能力。
工作的过程是学习的过程,是带着问题学习的过程,因此工作中的学习更加有针对性和价值。工作中的学习最重要的还是在能够解决工作中实际问题的情况下,拓展 该问题说相关的知识面,在没有工作束缚前提下能够主动关注工作相关的知识面和信息。工作中实际问题解决锻炼的是技能,知识面的拓展锻炼的是思维,而思维的 作用则是能够帮助你快速解决新的问题,不受已有知识和技能的约束。
我的绩效究竟如何,我现在的技能究竟在一个什么样的水平,我做出来的东西的速度和质量究竟如何?我们期望是能够给自己一个准确的定位,不要高估自己,也不要低估自己,那么我们必须要用数据来说话。只有清楚的知道了现在的位置才能够更好的去找寻下一个目标和位置。
2011年百度大更新时间规律分析
2011年1月份~12月份
自2008年开始自学网页设计和初涉SEO,吸取SEO论坛,站长之家,A5站长网等业内高手的经验,曾服务过的一些网站10余个网站的实战经验并参考和引用一些权威网站的专业数据,进行长期观察与统计,现就2011年1-11月百度大更新方面数据进行统计分析,如有不妥之处,请各位高手海涵。
如何在百度收录杂乱无章,浩瀚如海的整年数据中删繁执简,探索出一些适而可循的规律及一些小门道,相信每一个SEO们的心中都在琢磨这个问题的,什么做优化,什么建站,什么推广才能既省时又高效的方法。那么如何才能有一条简单易行的思路呢?
笔者长期服务于企业网站的运营,曾经困扰了很久,后试想着可不可用统计学的理论进行数据分析呢?于是就把2011年全年查询近3万多个站点的数据调出来,为求有一个合理的科学分析,数据随机抽取。部分数据结合并参考站长之家所观察的站点动态数据进行统计。
为了探索百度大更新的动态,故只抽取出3万多个站2011年一年之中的每天更新平均百分比数据,并把目标锁定在更新比例在75%以上进行筛选。通过每季度,每月,每周,每日的横向和纵向交叉分析,得出以下一些数据表。
声明:本文内容纯从统计学方面进行科学分析,不是带有传统迷信色彩。这只是统计总结,不是算命口诀。本人既不是 章鱼帝,也不是预言家,更不是某专家。万物在运动,世上没有一无不变的法则,但有蛛丝马迹的可循规律。从历史的数据统计进行分析,是可以把握一个概率问 题。个人观点仅供参考,千万不要把这张规律分析表当成什么武功秘芨,照搬硬套,也请不要以点概面,断章取义,这是仁者见仁,智者见智的问题,经验可参,灵活运用!笔者制作该规律表的目的不是哗众取宠,只是希望能为大伙节省一些盲目的时间,多一点生活空间。
百度大更新规律分析
1.每周数据分析
周一: 1-10月份,百度从不进行大更新
周二: 2月份和6月份,曾各大更新过一次,概率不高
周三: 2月份,7月份,9月份,曾各大更新过一次,但概率也算是平淡
周四: 是百度大更新频繁时期,1年之中,共出现过11次,尤其是下午至晚上这段时间
周五: 是百度大更新高峰期,1-11月份共出现过22次,据很多SEO高手的经验说是凌晨三点-四点左右百度进行最后一次调整后就少波动。早上8点-10点之间基本处于平稳态度。
周六: 百度大更新频率中幅度变化,共出现过7次
周日: 与周三一样,共出现过4次,大更新频率小幅度变化
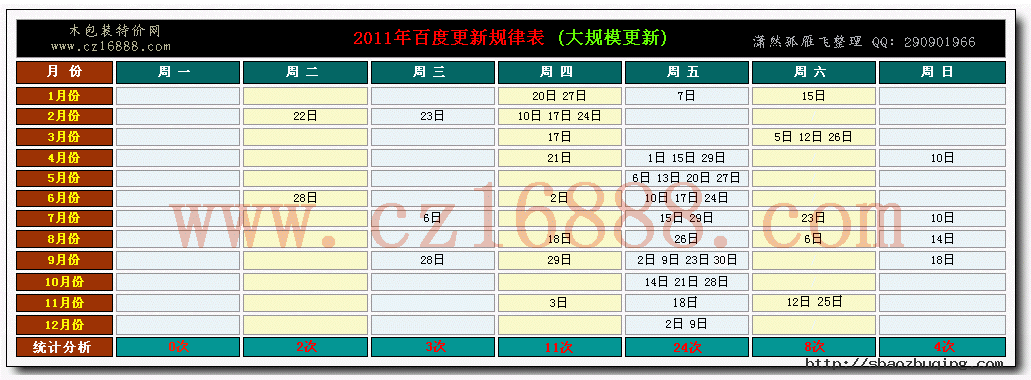
(点击看大图)
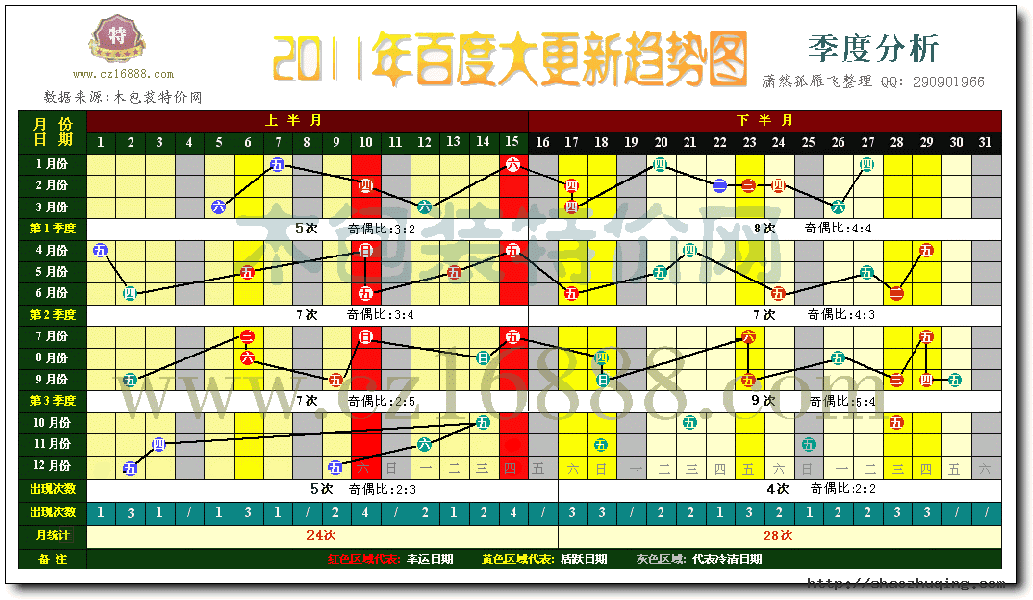
2.每月数据分析
从每个月份的统计来看,每月会更新4-5次,符合盛传已久的每周中规模更新一次的观点。
(点击看大图)
3. 全年数据分析
从全年的数据统计来看:
10号,15号是属于幸运日期,一年之中曾出现过4次。
6号,17号,18号,23号,28号,29号是属于活跃的日期,一年之中曾出现过3次。
2号,12号,14号,20号,21号,24号,26号,27号是属于平常的日期,一年之中曾出现过2次。
而4号,8号,11号,16号,19号,25号,31号则被百度打入冷宫,未曾出现过。

(点击看大图)
说明: 报表数据自2011.1-2011.12 随机抽样3万多个站点的进行统计和分析。
结 论:
一周一次小改变,一月一次大变动。
每周关注: 周四和周五两天,必须好好把握,特别是周五早晨一段时间,那一小段时间往往可以决定一周的排名。周六已属于非常活跃的日子,不要因为现是工作五天制就松懈 了绷紧的神经;周三和周日是属于最易爆冷的日子也需要在百度异常或者百度算法调整的一段时间内加以防范一下,当然“月经紊乱”的周期不是很长。周一是每周 上班的第一天,每周例会是必不可少的,工作安排和政策也需要一些时间,因此大伙可先松一口气。
上半月: 密切关注:10号,15号,其中15号是月中,百度必然进行1月2次大更新,同时也要防6号.6号是每月第一周,上月末如没有更新,那么6号左右肯定会进行一次更新。
下半月: 关注日期17号,18号,23号,28号,29号,如果上半月的15号没有进行更新,那么17号就要盯紧了,而23号是一些SEO前辈曾经得出的经验总 结,会进行大更新的日子,到了月底百度必然进行1次大洗盘,这是每月一次的月考,成绩是决定下月能否取得好排名的关键,而28号,29号这两天是每一个公 司员工向老板汇报业绩的日子。当然百度也不例外,下个月的计划肯定要布局好。
对于被贬入冷宫的日期,4号,8号,11号,16号,19号,25号,31号,概率不高,如果手头太忙了,我们姑且放过,让自己美美地合上眼,在梦中去上演一出《大话西游之SB大战》(SEO PK BaiDu) 哈…哈…
各位看官,也许心里有些纳闷,什么看以上数据和观点那么眼熟,没错确有点象体彩31选7或福彩双色球。笔者就是要以通俗和喜闻乐见的方式呈现给大家。
以上分析为一家之见,错误难免,数据和观点仅供参考,不正之处,望各位前辈多加指点。
附: 2011年1-11月百度大更新数据
数据由我整理统计,数据来源于:木包装特价网 统计日期: 2011年1月1日~11月23日
【 统计结果 】:
1. 【 每年数据 】
共1~11月份百度一年中曾进行48次大更新
※ 分析:
1-10月份总计: 46次
平均: 每月4.6次
2.【 每季数据 】
☆ 第1季度: 百度共进行13次大更新
☆ 第2季度: 百度共进行14次大更新
☆ 第3季度: 百度共进行16次大更新
☆ 第4季度: 因11.12月还在进行中,目前暂出现4次
※ 分析:
1-3季度总计: 43次
平均: 每季度14.3次平均:每月4.8次
3.【 每月数据 】
1月份: 百度共进行4次大更新
2月份: 百度共进行5次大更新
3月份: 百度共进行4次大更新
4月份: 百度共进行5次大更新
5月份: 百度共进行4次大更新
6月份: 百度共进行5次大更新
7月份: 百度共进行5次大更新
8月份: 百度共进行4次大更新
9月份: 百度共进行7次大更新
10月份:百度共进行3次大更新
11月份:还在进行中,目前暂出现3次
12月份:还在进行中…
※ 分析:
1-10月份总计:46次
(去掉一个最高值9月7次,去掉一个最低值10月3次,共8月36次)
平均:每月4.5次
4.【 每周数据 】
* 周一: 百度共进行0次大更新 (低谷期)
* 周二: 百度共进行2次大更新
* 周三: 百度共进行3次大更新
* 周四: 百度共进行10次大更新 (高峰期)
* 周五: 百度共进行16次大更新 (高峰期)
* 周六: 百度共进行8次大更新 (活跃期)
* 周日: 百度共进行4次大更新
※ 分析:
1-11月份一周总计:43次
1-10月份一周总计:41次
(去掉一个最高值周五16次-其中1次是11月份,去掉一个最低值周一0次,5个数据共计25次)平均:每月5次
5.【 每日数据 】
1号: 百度共进行1次大更新 2号: 百度共进行2次大更新 3号: 百度共进行1次大更新 4号: 百度共进行0次大更新
5号: 百度共进行1次大更新 6号: 百度共进行3次大更新 7号: 百度共进行1次大更新 8号: 百度共进行0次大更新
9号: 百度共进行1次大更新 10号: 百度共进行4次大更新 11号: 百度共进行0次大更新 12号: 百度共进行2次大更新
13号: 百度共进行1次大更新 14号: 百度共进行2次大更新 15号: 百度共进行4次大更新 16号: 百度共进行0次大更新
17号: 百度共进行3次大更新 18号: 百度共进行3次大更新 19号: 百度共进行0次大更新 20号: 百度共进行2次大更新
21号: 百度共进行2次大更新 22号: 百度共进行1次大更新 23号: 百度共进行3次大更新 24号: 百度共进行2次大更新
25号: 百度共进行0次大更新 26号: 百度共进行2次大更新 27号: 百度共进行2次大更新 28号: 百度共进行3次大更新
29号: 百度共进行3次大更新 30号: 百度共进行1次大更新 31号: 百度共进行0次大更新
※ 分析:
1-11月总计:49次
1-10月总计:46次

(点击看大图)
【 结 论 】:
⊙ 每年数据 (每月平均值4.6次)
⊙ 每季数据 (每月平均值4.5次)
⊙ 每月数据 (每月平均值4.5次)
⊙ 每周数据 (每月平均值5次)
⊙ 每日数据 (每月平均值4.4次)
从以上数据得出:
1. 百度每月大更新次数4-5次
2. 百度每周大更新次数1-2次 (以每月30天计算:30天/月÷7天/周 = 4.4周)
3. 每周峰期分析
◎ 高峰期–周四。周五。周四: 11个月之中出现过11次;周五: 1月份共出现过22次
◎ 活跃期–周六: 百度共进行7次大更新
◎ 低谷期–周一: 1-10月份,百度从不进行大更新
4. 活动日期分析
* 幸运日期: 10号,15号是属于幸运日期,一年之中曾出现过4次。
* 活跃日期: 6号,17号18号,23号,28号,29号是属于活跃的日期,一年之中曾出现过3次。
* 变异日期: 2号,12号,14号,18号,20号,21号,24号,26号,27号是属于最易爆冷的日期,一年之中曾出现过2次。
* 灰色日期: 4号,8号,11号,16号,19号,25号,31号未曾出现过
greasemonkey油猴子热门脚本推荐
greasemonkey油猴子通过上篇上手指南都有了一定了解,今天呢,我在这里为大家推荐一些符合中国人使用习惯的油猴子热门脚本。
PS:油猴子脚本都可以去脚本中心找,具体寻找方法在上手指南中我做了一些说明的。
安装之后,需要刷新一下网页,脚本才会生效哦。
根据楼下的一位朋友建议,把这个Userscripts Updater写在最前面吧:让脚本有新版本后可以自动升级!!!强烈推荐!本身脚本是不能自动升级的,需要用户自己去查找,安装这个脚本后,每次只要用户访问脚本中心,右上角就会多一个升级按钮,点击就能检查脚本更新了。PS:这个脚本还有一个小缺点,就是必须最先安装它,在它以后安装的脚本,它才能检测哦。
一 般人上网什么用的最多?一般回答都是搜索引擎,这两个扩展就是针对最大的中文引擎百度的,优化搜索结果,去广告的。具体效果嘛,在上手指南中演示 的就是baidumonkey了。(基于以前介绍的针对同一事物或同类型事件的扩展脚本不能同时安装的原则,这两个扩展只推荐安装一个。)
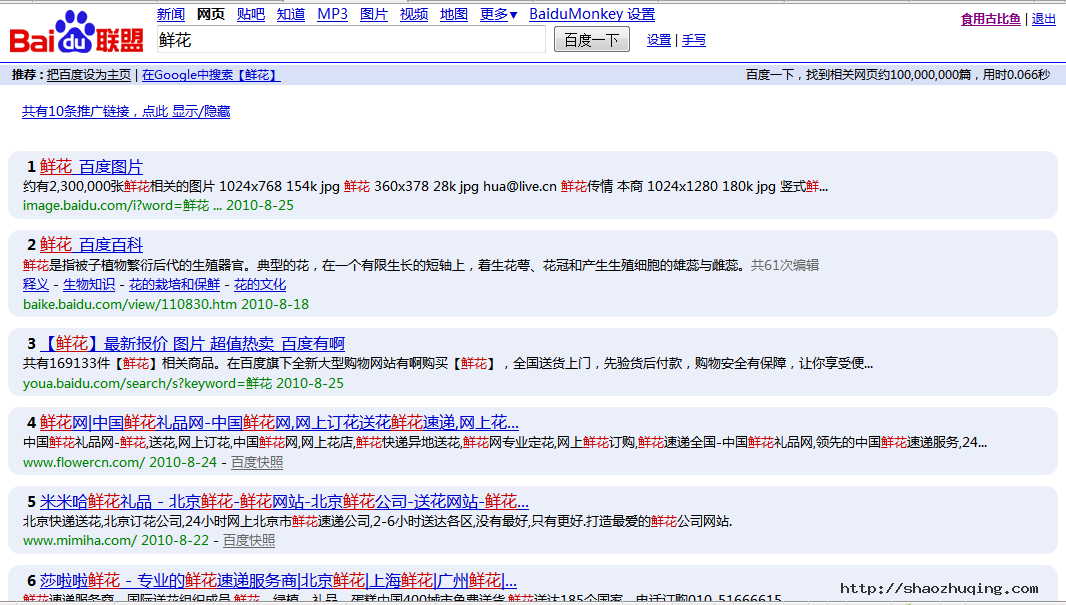
baidumonkey的效果图。
类似的这两个脚本就是针对google搜索结果优化的。去广告,高亮结果等等。(当然这两个也不能同时装)
PS:googleMonkeyR和baidumonkey属于功能简单易于上手型的脚本,而google++和baidu++都出自国内一位达人之手功能异常丰富还支持css自己定义,适合高手向的玩家。

GoogleMonkeyR的效果图
PS:一般这个脚本的设置都内嵌在生效网站的网页内,你找找看这个图就能发现他的设置按钮了,呵呵。
对了,这个GoogleMonkeyR一开始是不支持https加密google搜索的哦,你需要在设置里面添加一条google https的地址(用通配符*)

前面已经介绍过人人网改造器了,这个Kaixin001 Assistant和人人网改造器类似,不过功能弱点。在脚本中心搜kaixin001还有很多类似的,大家可以去看下。
PS:这一类脚本主要是方便大家使用sns社区,还有很多,不过有些sns游戏辅助脚本,功能很BT,小心大家认为你作弊哦。
这个扩展是很方便各位SEO或者想了解这个网站在世界上排名的人,安装之后,点F9就能在网页上显示一个小表格,显示了google,百度,雅虎,搜狗,搜搜,bing,有道对网站网页的收录数,外链数,还有PR值,alex排名等等。

PS:这个是火狐社区的数据,哎,不给力啊,PR值才0,希望大家共同努力,把火狐社区创建的更加繁荣。
这个可以叫作豆瓣社区的改造器吧,功能很强大。
全部功能在豆瓣网右上角有设置按钮,或者按Alt+Q可以查看。主要分为交流增强,贴图识别,快速搜索和其他功能几大类。
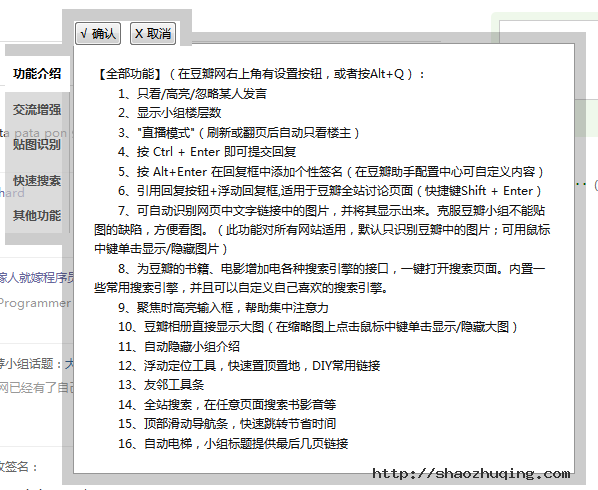

6.youkuSS
这个脚本优化youku看视频,可以任意缩放视频窗口,直接分析出视频下载链接。

还有一些其他脚本就不在这里不再敖述了,一般官方都有详细的介绍。在这里罗列一些使用比较多的扩展:
百度密语 可以在百度贴吧发送加密帖子的脚本,很强大哦。详细指南点我
verydou可以直接在豆瓣的影视和音乐等旁边显示verycd的下载搜索内容。
Google Book Downloader 直接在google book中生成图书的下载链接!! 不过还是图片格式的,残念~~
现在大概就想起了这些,如果大家发现有更过更好的扩展,就在留言中一起分享一下吧。
PS:现在开始整理些,楼下回复推荐的脚本吧。
AutoPagerize:不错的自动翻页脚本,支持google和百度(和googlemonkeyR脚本配合不错,其他几个脚本有点小问题)。不能和Aotopage扩展共用。
Scroll with Mouse Plus:无需用鼠标滚轴即可翻页的脚本,貌似在我这失效了。改了配置也没法启动。估计是我各类扩展脚本装太多的缘故吧~
顺道补充一个小技巧:某些脚本作者很懒,不愿意写个配置界面出来,就干脆把配置写在了代码里面,用户可以在油猴脚本界面,选中一个脚本,点击编辑就可看到脚本的源代码了。比如这个Scroll with Mouse Plus配置就在代码最前面。
Textarea Backup:自动备份输入框的小脚本,但是貌似我没找到使用方法。。和Textarea Cache扩展冲突?希望楼下使用这个脚本的用户介绍下。。
感谢真三狂热者推荐两个脚本:
Super_preloader:自动翻页拼接扩展,方便用户浏览论坛百度google等。与百度monkey兼容性不好。
Superprefetch :与Superpreloader同一个作者写的,支持键盘上的左右键翻页。两个脚本都带有预读功能,都支持鼠标手势。
网站分析职业生涯规划
明天分享读书报告《精通Web Analytics 2.0》相关资料
下面是网站分析大师Avinash的关于网站分析职业生涯规划的表格:
| Web Analytics Career | 纬度 | 个人贡献者 | 团队领导者 |
| 业务 | 角色 | CMO – 分析师 – 业务部门 | 副总裁(CMO)-分析主管-分析师(业务部门) |
| 技能 | 业务策略
Web analytics2.0衡量策略 有效的沟通者 统计方法与数学技能 JS技能 |
拥有领导能力的优秀分析师
激励下属 人际交往和沟通能力 |
|
| 提升 | 团队管理
数据策略 |
成长空间取决于公司的规模,业务部门领导者,不封顶 | |
| 技术 | 角色 | 业务团队 – 个人技术 – 网站分析提供商 | 总裁 – 分析经理 – 业务部门 |
| 技能 | 技术加码和工具运用顺利 | 启发与激励下属
人际交往能力 |
|
| 提升 | 转向业务,进入IT行业商业智能 | 基于ASP的分析有瓶颈,可以延伸到CRM,ERP等职位 |
个人业务的提升,大家是不是倍感压力和动力呢

{kind=link}
{kind=link}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
