Git tag简介
一、轻量级标签
我们可以用 git tag不带任何参数创建一个标签(tag)指定某个提交(commit):
$ git tag stable-1 1b2e1d63ff
这样,我们可以用stable-1 作为提交(commit) "1b2e1d63ff" 的代称(refer)。
前面这样创建的是一个“轻量级标签",这种分支通常是从来不移动的。
如果你想为一个标签(tag)添加注释,或是为它添加一个签名(sign it cryptographically), 那么我们就需要创建一个 ”标签对象".
二、标签对象
如果有 "-a", "-s" 或是 "-u " 中间的一个命令参数被指定,那么就会创建 一个标签对象,并且需要一个标签消息(tag message). 如果没有"-m " 或是 "-F " 这些参数,那么就会启动一个编辑器来让用户输入标签消息(tag message).
当这样的一条命令执行后,一个新的对象被添加到Git对象库中,并且标签引用就指向了 一个标签对象,而不是指向一个提交(commit). 这样做的好处就是:你可以为一个标签 打处签名(sign), 方便你以后来查验这是不是一个正确的提交(commit).
下面是一个创建标签对象的例子:
$ git tag -a stable-1 1b2e1d63ff
标签对象可以指向任何对象,但是在通常情况下是一个提交(commit). (在Linux内核代 码中,第一个标签对象是指向一个树对象(tree),而不是指向一个提交(commit)).
三、签名的标签
如果你配有GPG key,那么你就很容易创建签名的标签.首先你要在你的 .git/config 或 ~.gitconfig里配好key.
下面是示例:
[user]
signingkey =
你也可以用命令行来配置:
$ git config (--global) user.signingkey
现在你可以直接用"-s" 参数来创“签名的标签”。
$ git tag -s stable-1 1b2e1d63ff
如果没有在配置文件中配GPG key,你可以用"-u“ 参数直接指定。
$ git tag -u
四、语法详解
语法
git tag [-a | -s | -u
Unless -f is given, the tag to be created must not yet exist in the .git/refs/tags/ directory.
If one of -a, -s, or -u
If -m
Otherwise just a tag reference for the SHA1 object name of the commit object is created (i.e. a lightweight tag).
A GnuPG signed tag object will be created when -s or -u
OPTIONS
-a
--annotate
Make an unsigned, annotated tag object
-s
--sign
Make a GPG-signed tag, using the default e-mail address’s key.
-u
--local-user=
Make a GPG-signed tag, using the given key.
-f
--force
Replace an existing tag with the given name (instead of failing)
-d
--delete
Delete existing tags with the given names.
-v
--verify
Verify the gpg signature of the given tag names.
-n
-l
--contains
Only list tags which contain the specified commit.
--points-at
Only list tags of the given object.
-m
--message=
Use the given tag message (instead of prompting). If multiple -m options are given, their values are concatenated as separate paragraphs. Implies -a if none of -a, -s, or -u
-F
--file=
Take the tag message from the given file. Use - to read the message from the standard input. Implies -a if none of -a, -s, or -u
--cleanup=
This option sets how the tag message is cleaned up. The
The name of the tag to create, delete, or describe. The new tag name must pass all checks defined by git-check-ref-format(1). Some of these checks may restrict the characters allowed in a tag name.
CONFIGURATION
By default, git tag in sign-with-default mode (-s) will use your committer identity (of the form "Your Name
[user]
signingkey =
DISCUSSION
On Re-tagging
What should you do when you tag a wrong commit and you would want to re-tag?
If you never pushed anything out, just re-tag it. Use "-f" to replace the old one. And you’re done.
But if you have pushed things out (or others could just read your repository directly), then others will have already seen the old tag. In that case you can do one of two things:
The sane thing. Just admit you screwed up, and use a different name. Others have already seen one tag-name, and if you keep the same name, you may be in the situation that two people both have "version X", but they actually have different "X"'s. So just call it "X.1" and be done with it.
The insane thing. You really want to call the new version "X" too, even though others have already seen the old one. So just use git tag -fagain, as if you hadn’t already published the old one.
However, Git does not (and it should not) change tags behind users back. So if somebody already got the old tag, doing a git pull on your tree shouldn’t just make them overwrite the old one.
If somebody got a release tag from you, you cannot just change the tag for them by updating your own one. This is a big security issue, in that people MUST be able to trust their tag-names. If you really want to do the insane thing, you need to just fess up to it, and tell people that you messed up. You can do that by making a very public announcement saying:
Ok, I messed up, and I pushed out an earlier version tagged as X. I
then fixed something, and retagged the *fixed* tree as X again.
If you got the wrong tag, and want the new one, please delete
the old one and fetch the new one by doing:
git tag -d X
git fetch origin tag X
to get my updated tag.
You can test which tag you have by doing
git rev-parse X
which should return 0123456789abcdef.. if you have the new version.
Sorry for the inconvenience.
Does this seem a bit complicated? It should be. There is no way that it would be correct to just "fix" it automatically. People need to know that their tags might have been changed.
On Automatic following
If you are following somebody else’s tree, you are most likely using remote-tracking branches (refs/heads/origin in traditional layout, orrefs/remotes/origin/master in the separate-remote layout). You usually want the tags from the other end.
On the other hand, if you are fetching because you would want a one-shot merge from somebody else, you typically do not want to get tags from there. This happens more often for people near the toplevel but not limited to them. Mere mortals when pulling from each other do not necessarily want to automatically get private anchor point tags from the other person.
Often, "please pull" messages on the mailing list just provide two pieces of information: a repo URL and a branch name; this is designed to be easily cut&pasted at the end of a git fetch command line:
Linus, please pull from
git://git..../proj.git master
to get the following updates...
becomes:
$ git pull git://git..../proj.git master
In such a case, you do not want to automatically follow the other person’s tags.
One important aspect of git is its distributed nature, which largely means there is no inherent "upstream" or "downstream" in the system. On the face of it, the above example might seem to indicate that the tag namespace is owned by the upper echelon of people and that tags only flow downwards, but that is not the case. It only shows that the usage pattern determines who are interested in whose tags.
A one-shot pull is a sign that a commit history is now crossing the boundary between one circle of people (e.g. "people who are primarily interested in the networking part of the kernel") who may have their own set of tags (e.g. "this is the third release candidate from the networking group to be proposed for general consumption with 2.6.21 release") to another circle of people (e.g. "people who integrate various subsystem improvements"). The latter are usually not interested in the detailed tags used internally in the former group (that is what "internal" means). That is why it is desirable not to follow tags automatically in this case.
It may well be that among networking people, they may want to exchange the tags internal to their group, but in that workflow they are most likely tracking each other’s progress by having remote-tracking branches. Again, the heuristic to automatically follow such tags is a good thing.
On Backdating Tags
If you have imported some changes from another VCS and would like to add tags for major releases of your work, it is useful to be able to specify the date to embed inside of the tag object; such data in the tag object affects, for example, the ordering of tags in the gitweb interface.
To set the date used in future tag objects, set the environment variable GIT_COMMITTER_DATE (see the later discussion of possible values; the most common form is "YYYY-MM-DD HH:MM").
For example:
$ GIT_COMMITTER_DATE="2006-10-02 10:31" git tag -s v1.0.1
DATE FORMATS
The GIT_AUTHOR_DATE, GIT_COMMITTER_DATE environment variables support the following date formats:
Git internal format
It is
RFC 2822
The standard email format as described by RFC 2822, for example Thu, 07 Apr 2005 22:13:13 +0200.
ISO 8601
Time and date specified by the ISO 8601 standard, for example 2005-04-07T22:13:13. The parser accepts a space instead of the T character as well.
Note
In addition, the date part is accepted in the following formats: YYYY.MM.DD, MM/DD/YYYY and DD.MM.YYYY.
结束
http://blog.csdn.net/hudashi/article/details/7664468
企业持续集成成熟度模型简介
构建—— 企业持续集成成熟度模型简介之一
当今软件开发领域的自动化推广相当显著,软件也越来越多的由大规模、分布式的团队开发完成,而严格的企业管理需求也是十分常见的。由此表现出来的敏捷软件开发和持续集成与企业开发项目的现实之间的碰撞也越来越显著。在软件开发的整个生命周期中,我们对自动化的投入在不断增加。在这方面的先行者已经跨过了团队级别的持续集成,而将他们的自动化成果与端到端的方案结合在一起了。这些在企业级持续集成方面的投入使得他们可以应对需求的变化,并快速交付高质量的软件,而且得到事半功倍的效果。尽管自动化有这么多的好处,但,对于自动化的采纳情况却并不均衡。比如,很多团队仍旧在手工、缓慢且高风险的部署中挣扎着;而某些团队却可以在一天内进行多次高效且足够安全的生产环境部署。其实,有很多方法或途径来改善我们的开发自动化,但是从哪里开始呢?
企业的多样性
当创建这篇指导书时,我们遇到的挑战就是:不同企业(甚至同一个企业的不同团队)都不具有统一性。医疗设备系统的某些需求可能就要比做游戏难,也可能比在电子商务网站上增加新功能要难,也可能会比创建一个内部SOA应用要难。因此,单一的成熟度模型不可能适应全部情况。因此,我们选择了企业持续集成的四个维度来衡量成熟度,它们分别是构建、部署、测试和报告。我们将每一个维度上所对应的实践归入某一等级之下,并解释为什么需要采纳(或不采纳)这些实践。通过这个模型,你可以了解业内在企业持续集成方面的平均水平,并可以据此反思,在哪些方面做得高于行业平均水平,还有哪些方面做得不足。这个模型所反映出来的评估尺度完全基于几年来数百个团队持第一手经验以及本领域的一些报告。为了解释如何使用这个模型,我们创建了三个有不同需求的企业案例。我们会分析他们的状况,并展示他们如何使用成熟度模型来计划哪些改进会给他们带来最高的投资回报率。
成熟度模型中的级别
在整篇文章中,企业持续集成不同维度的成熟级别会以相同的方式来阐述。级别分为:入门、新手、中等、进阶和疯狂。为了解释这些级别,下面我们举例说明各级别之间的关系。实例的出发点为:该过程为完全手工的,即某个工程师必须要手工执行一系列冗长且易出错的步骤来达到“将某个手工过程自动化”这一目标。那么对于这个“自动化某个过程”,它的成熟度模型如下所示:
团队最初是入门级,因为他们已经写了一些辅助脚本,用于该过程中那些特别慢或问题较多的部分进行了自动化。这种自动化的益处在于节省时间且减少错误。为了进一步提高,团队将所有辅助脚本串接起来,实现了整个过程的单一脚本自动化,即达到了中级。而这个单一脚本的回报就是:这个操作过程可以很容易交给别人去做。当团队打算提高到进阶级时,需要用某个应用软件来调用执行该脚本。这个应用软件可能在后台执行的,但一定是每次都在正确的条件、时机和位置上运行的。比如,这个应用软件可能只需要用户点一下鼠标,或者只需要在某个特定的时间调用这个脚本,自动传入一些参数来执行。
当然,进阶级或者疯狂级的定义都会随着时间的推移而改变。在持续集成诞生时,“代码提交后自动触发构建”就被认为是疯狂的,而在今天只能算是中级中的一个活动而已。
构建、部署、测试和报告
在我们的成熟度模型中,包括了四个维度,它们分别是构建、部署、测试和报告。这四个维度覆盖了整个端到端的构建生命周期,即从源代码直到产品。
构建
那种原始的以开发人员为中心的持续集成是为了从构建软件中得到快速的反馈。而当持续集成进入企业视角后,构建管理、项目之间的依赖以及构建过程上的管理控制都成为至关重要的元素了。大多数新项目一般在开始时,都是在开发机器上执行构建的,而且没有一个标准的过程。一个开发人员可能习惯于在他自己的IDE上进行构建,而另一个人可能写了一个构建脚本来做这件事。那些最不成熟的团队还会将那些使用这种过程构建出来的二进制文件部署并测试,甚至将其发布到生产环境中。这种因缺乏控制所导致的问题很快就显现出来了。因此,我们一开始就要找更好的方法。
成熟构建的第一步就是让构建过程标准化,并在非开发机器上进行正式的构建。使用非开发者机器进行构建意味着这种构建不会因开发者的机器环境发生了变化而导致污染。因为正式构建已经不在开发者的机器上进行,所以我们必然是每次都从某个固定的源文件控制中得到代码,并遵守一定的规则:比如每次都从某个分支签出最新版本,或者是打过某种标签的源代码等等。因些做到了这些之后,该团队就达到了入门级。
入门级的团队进一步采取行动,将构建步骤实现自动化执行。即构建服务器将指挥机器、按源代码签出规则得到源代码,并执行那些构建步骤,从而提供了初步受控的构建过程。典型的是:这些自动构建每日执行,尽管某些团队可能会一天执行两次以上。此时的团队就提高到了新手级。
而对中级的团队来说,他们开始更明显地关注并管理对于其它软件的依赖(包括子项目或第三方库)。中级使用依赖管理库来追踪这些库文件,并在构建时提供这些库文件,而不是使用某种口头约定方式。同样地,那些可能被其它构建所引用的构建也会通过依赖管理工具将其自身放在这个库中以便其它构建来引用。达到这一级别的控制后,自动构建就是很容易做到的了,而且也提供更有价值的反馈。中级团队采纳了持续构建(即每个开发人员提交时就自动构建或当依赖发生变化时)。所有的构建结果都被保存(可能放在一个网络服务器上,或干脆就在持续集成服务器上),并进行周期性的清理并标签以方便识别。规模大一些的团队将使用分布式构建设施来并行处理数量众多的构建。此时,对于很多组织来说,可以说满足了他们的需求。
对于更正规的组织(比如企业级)将会进一步做到进阶级,以控制构建过程。在这种环境下,团队象追踪源代码和依赖的变化一样,对构建过程的变化也进行记录跟踪。修改构建过程需要经过批准,对于登录官方构建机器,修改构建服务器配置等都是严格控制的。对于那种“服从是一个要素”的地方或那种将企业持续集成已成为一个生产系统的地方,应该将进阶级的受控构建过程做为目标。而对于没有这方面要求的其它团队来说,中级也就可以接受了。
另外,某些组织的管理控制规则更加严格,且要求必须能够完美地重新构建从前的发布版本(比如需要拿到与一年前的某次构建产物一模一样的产物)。这些组织将使用各种各样的技术来确保每个环境的可重复性。一些可能会有缜密细致地被版本控制化的脚本,在开始运行构建之前从安装操作系统开始来准备构建机器。另一些可能使用做好的虚拟机镜像来做类似的事情。我们把这种控制级别定义为疯狂级。因此,一些团队可能不需要达到这种方式。因为可能负担太大而收益太少。
部署—— 企业持续集成成熟度模型简介之二
部署是指将软件移动到它被测试的地方,或用户指定的某个位置,准备送给客户。对于web应用来说,这可能意味着将软件安装到某个web服务器上,并更新数据库或静态内容服务器。而对于一个视频游戏来说,这个测试部署可能是指安装这个软件版本到某些测试机器上,而产品部署则可能是指烧录一个光盘并给发行商。
部署最开始一般都是手工过程。部署工程师从某处拿到部署文件,再把它放到目标机器上,然后开始正式的安装过程。然而,这种手工过程会比较慢,而且部署失败率也可能要高一些。工程师常常被迫在晚上或周末加班,进行测试环境或生产环境的部署,因为这些环境平时需要正常运行,不能轻易地停止。更糟糕的是:每个环境很可能使用了不同的步骤进行手工操作(比如步骤前后顺序颠倒,这尤其容易发生在不同的操作人员之间),几乎无法保证:在某个环境上的成功部署表明在下一个环境中部署成功的可能性也同样高。

对于团队来说,抛弃完全的手工过程,使用一些辅助脚本或全过程脚本化是一个非常巨大的进步。纵观整个行业,大多数团队都会有一些辅助性脚本,但有完全脚本化部署方式的团队较少,特别是在受控环境中(如试运行环境或生产环境)。因此,业内在这方面的平均水平应该是在入门级。
而中级团队善于进行测试环境上的自动化部署。他们完全通过脚本以一键部署的方式在部分或全部的测试环境中进行部署。这大大解放了部署工程师,而且减少了测试人员因等待部署而浪费的时间。就像持续构建是中级构建团队的的特征一样,自动地部署到第一个测试环境是在部署这一维度上中级成熟度的标志。根据团队的动态性,在不打断测试人员工作的情况下,这种测试环境的自动部署应该发生在任何一次成功的持续构建之后或一天内的周期性部署。中级团队的最后一个特征是:建立标准化的各种环境部署顺序。虽然可能还会有一些环境变数,或两种部署方式,但在某个版本的全生命周期中(即从生产到部署上线),越早地成功部署,就意味着后续部署成功的可能性更大。达到这个级别是很多团队的目标。而进阶团队则把视线转到受控环境或生产环境上。部署到生产环境(或发布)只要按一下鼠标就行,生产环境发布就被自动触发,并有相应的发布版本可以进行灾难恢复。那些已经部署到内部测试环境的团队应该将目标定位到“进阶”:如果在所有环境中进行完全一致的部署过程,那么在生产环境部署时,会极大地减少最后一刻失败的可能性。进阶级团队的另一个特征是:将通过前面通过质量测试检验的版本全部自动地部署到部分或全部测试环境中。例如,得到测试经理的批准后,让某个构建版本自动地安装到压力测试环境中。
而疯狂级的团队的目标是“持续部署”,即自动部署到生产环境中而无需手工干预:得到一个版本后,自动部署到一系列的测试环境中。经过整个构建管道中的所有阶段,并且能通过所有的测试后,自动部署该版本到生产环境中。某些.com应用可以在一个小时之内就完成从源文件控制到发布的整个过程。显然,此时的自动化测试必须非常成熟,而且具有自动回滚和相应的监控手段。但是,在快节奏的竞争环境下,极其迅速地部署新功能也是一个核心竞争力,可以减轻大规模功能变更的风险。
测试—— 企业持续集成成熟度模型简介之三
持续集成一直同自动化测试相关联。这在马丁福勒的文章或更早期Steven McConnell对日构建和冒烟测试的相关实践描述中都有提及。而且在企业持续集成的领域中,我们会考虑很多种类型的自动化测试和手工测试。尽管如些,很多团队在测试方面还是比较弱。很常见的一个版本发布场景就是:某个团队完成一个版本后,手工测试一下基本功能就发布了。而其中的某一部分总是出错,而新功能也只做了少量测试。如果团队在测试方面比较成熟的话,他们能很快发现问题或缺陷,从而在生产率和信心方面都会有所增加。
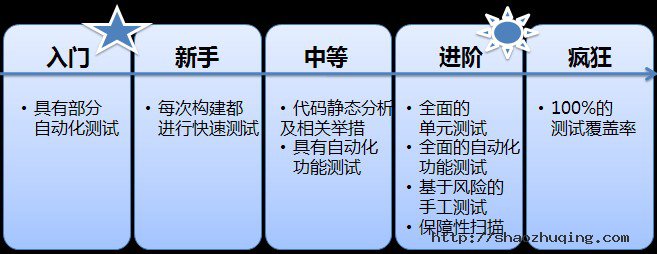
目前,大多数团队或多或少都会有某种形式的自动化测试。比如一小撮单元测试套件或一些脚本化的测试,用于确保软件的基本功能是可以工作的。这些基本的自动化回归测试能够较早及比较容易地发现那些基本功能性问题。入门级的团队 通常刚刚开始习惯于做这种自动化测试。
为了达到新手级成熟度 ,应该有一套快速测试在每次构建时都运行。这些测试给团队增加了信心:软件基本上在任何时间都能工作。测试一旦失败,开发团队会得到即时通知,从而在他们忘记这个问题的上下文之前就有机会去修复这些失败的测试。因此,对于这一级别来说,对测试失败通知的响应是非常重要的:如果一个团队测试失败却不响应的话,那它应该低于测试成熟度的入门级。
中级成熟度 的团队会在这些同快速构建同时执行的测试的基础之上,扩大测试范围。企业持续集成的成熟测试是以多种多样的测试集合为特性的。一个中级团队不仅有快速测试和手工测试,而且还有自动化的功能测试。中级团队常常让持续集成系统同时运行一些静态源代码分析。静态分析可能不是每次都运行,但一定会周期性运行。而且一旦产生了某种严重的静态质量问题的话,一定修复之后才能发布。
进阶级成熟度 是以“完整测试”为标志的。每种测试都提供其所能提供的最大价值。单元测试覆盖了系统中所有复杂代码与逻辑。功能测试覆盖了系统中所有的重要功能。也会有边界测试和随机测试。同时,还要频繁运行静态代码分析,并补充以工具支持的运行时分析和安全扫描来发现那些可能因测试不足或无法测试而遗漏的问题。测试可能被分配在多种系统下运行,以使能并行执行,从而提供快速的反馈。达到进阶级需要相当大的投入,然而对于那些缺陷的成本很高且需要能够保持高速前进的团队来说,对是非常重要的。假如没有这类需求的话,一般来说,中级可能是一个更适当的目标。
在极端的情况下(也就是疯狂级成熟度 ),某些团队追求100%的测试覆盖率。尽管100%测试覆盖率的定义在变化,但它反映出至少每行代码都被测试覆盖到。在某些软件中,存在一个收益递减的点,在这一点上,对某行代码的自动化测试的价值要小对写测试的成本。追求100%的测试覆盖率意味着团队会做一些浪费的测试,然而其目的有可能是阻止因某些测试很有价值但很难写而不写测试找藉口。满足并保持100%的测试覆盖率可能也是一个自豪感与动力的源泉。对于进阶级团队来说,如果曾经发现的确错过了一些非常重要的测试的话,要求100%的测试覆盖也未尚不可。但对于大多数团队来说,简直可以说是变态啦。
报告—— 企业持续集成成熟度模型简介之四
持续集成工具一直以来就负责报告最近一次构建的状态。报告是持续集成的一个至关重要的元素。在企业持续集成中,报告应包含所做软件的相关质量和内容方面的信息,以及与企业持续集成过程有关的度量信息。没有报告的团队就象一个没有雷达的飞机在飞行。如果没有人看测试结果的话,所有的测试都是无用的。同样,很多数据如果没有被提取成可消化利用的信息的话,就很难使用,一样可以视为无用。越成熟团队的报告,其可视化程度越高,有用的信息也会越多。

很多工具在构建过程中都会产生报告。在一个团队中,如果某人利用一些工具来产生报告,并分析它,之后会根据它来做出行动的话,这个团队就已经是入门级成熟度 了。注意:此级别上,如果团队的其他人想利用这些数据做些事情时,需要联系这个人,索要相关信息。当到了新手级成熟度 时,每个角色组(开发、测试、部署等)都会公布这类信息。一个构建服务器也可能提供一些信息,比如哪些代码变化了,源代码的分析报告、单元测试结果或编译错误等。测试人员也会公布他们自动测试和手工测试的结果报告。部署与发布人员会公布某个版本在生产环境的运行时长、记录的缺陷,以及发布速度等信息。但每个角色几乎各自为战,跨角色信息传递通常是手工完成的。事实上,这个级别应该是业内的平均水平,尽管很多企业有比较强大的跨角色或部门的展示能力。
中级成熟度 则有两个比较大的变化。第一个是每个角色组的关键信息集合可以被整个团队的其它人员访问。测试人员可以看到开发部分的信息:比如从上次测试人员测试过的版本到目前的版本有哪些文件变化了;开发人员能够知道测试人员正在测试哪个版本,目前的测试结果如何等。每个参与到版本生命周期的人都至少会得到对其有用的总结报告。有了更高的可视化程度,那么用于沟通基本数据所用的成本会减少,从而依据报告进行相应工作的时间就增加了。第二个是有历史报告。即不但有最近的活动报告,而且有过去的报告。比如可以拿出过去发布的测试数据与当前发布的数据进行对比。团队不但知道最近测试通过率是95%,还知道加了多少个测试,删除了多个测试,或者哪些测试之前通过了。95%的通过率比昨天的结果好,还是坏?我们是应该高兴,还是需要继续努力让它更高?
而进阶级团队 能够利用历史报告信息进行趋势分析。中级团队记录了每个测试的失败,而进阶级团队利用报告分析出哪些测试经常被破坏。还可能分析出修改哪些文件后更有可能使单元测试失败?哪些会让功能测试套件失败?通过识别那些经常出错的代码帮助团队来发现哪些代码应该多加测试或进行重新设计实现。在特定的报告中,会有从不同的竖井(不同的角色团队)汇总在一起得到的数据,并互相迭加引用。进阶级团队也是真正使用这些特定报告并会采取相应行动的团队。生成这些可操作的跨功能团队的报告应该是企业持续集成的目标。而疯狂级报告是关于预测的。这样的疯狂级团队会收集每次交付客户之后得到的反馈度量信息,如从缺陷报告和接收到的技术支持的需求抽取相关信息。根据当前的一次发布与过去的某次发布之间的数据对比,团队应该可以预测在发布后的第一周内技术支持的压力有多大(比如,可能会接到多少个问题反馈)。在这种模式下,他们可能问更多有意思的问题,而不只是简单的问一下“我们的特性都做完了吗?”
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
