PHP生成随机红包高级方法
/** 传输数字必须为正整数,需要小数通过$bonus_float传值进行换算
* @param $bonus_total (必填) 红包总额
* @param $bonus_count (必填) 红包个数
* @param $bonus_max (选填) 每个小红包的最大额 最大值要大于平均值
* @param $bonus_min (选填) 每个小红包的最小额
* @param $bonus_float (选填 Y元J角F分) 红包传入单位
* @return 存放生成的每个小红包的值的一维数组
*/
function getBonus($bonus_total, $bonus_count=20, $bonus_max=0, $bonus_min=1, $bonus_float='Y') {
$total_money = 0;
$arr1 = array();
$arr2 = array();
$res = array();
// 转换传入金额单位 Y元 J角 F分
$tmp_float = $bonus_float;
if($bonus_float=='Y'){ $bonus_float = 1; $num_fmt = 0;}
if($bonus_float=='J'){ $bonus_float = 10; $num_fmt = 1;}
if($bonus_float=='F'){ $bonus_float = 100; $num_fmt = 2;}
// 每人红包平均值
$average = $bonus_total / $bonus_count;
// 防止传入参数越界
if($average > $bonus_max){ echo $bonus_max = round(($bonus_total-$average)/$bonus_count,0)+round($average,0); }
if($average < $bonus_min){ echo $bonus_min = 1; }
$range1 = ($average - $bonus_min)*($average - $bonus_min);
$range2 = ($bonus_max - $average)*($bonus_max - $average);
// 生成随机红包逻辑
for ( $i = 0; $i < $bonus_count; $i++) { if (rand($bonus_min, $bonus_max) > $average) {
$temp = $bonus_min + intval(sqrt(rand(0, (intval($range1)-1))));
$arr1[$i] = $temp;
$bonus_total -= $temp;
} else {
$temp = $bonus_max - intval(sqrt(rand(0, (intval($range2)-1))));
$arr1[$i] = $temp;
$bonus_total -= $temp;
}
}
while ($bonus_total > 0) {
for ($i = 0; $i < $bonus_count; $i++) { if ($bonus_total > 0 && $arr1[$i] < $bonus_max) {
$arr1[$i]++;
$bonus_total--;
}
}
}
while ($bonus_total < 0) {
for ($i = 0; $i < $bonus_count; $i++) {
if ($bonus_total < 0 && $arr1[$i] > $bonus_min) {
$arr1[$i]--;
$bonus_total++;
}
}
}
// 输出格式化数据结果
for ($i = 0; $i < $bonus_count; $i++) {
$arr1[$i] = number_format($arr1[$i]/$bonus_float,$num_fmt,'.','');
//统计每个钱数的红包数量,检查是否接近正态分布
$total_money += $arr1[$i];
if(isset($arr2[$arr1[$i]])){ $arr2[$arr1[$i]] += 1; }else{ $arr2[$arr1[$i]] = 1; }
}
ksort($arr2);
$res["total"] = $total_money."(Y)";
$res["bnmax"] = $bonus_max."(".$tmp_float.")";
$res["bnmin"] = $bonus_min."(".$tmp_float.")";
$res["money"] = $arr1;
$res["count"] = $arr2;
return $res;
}
$bonus_total = 2000;
$bonus_count = 30;
$bonus_max = 90; //最大值要大于平均值
$bonus_min = 1;
$bonus_float = "Y"; //
$result_bonus = getBonus($bonus_total, $bonus_count,$bonus_max);
echo "
";
print_r($result_bonus);
Array
(
[total] => 2000(Y)
[bnmax] => 90(Y)
[bnmin] => 1(Y)
[money] => Array
(
[0] => 74
[1] => 24
[2] => 67
[3] => 73
[4] => 67
[5] => 47
[6] => 69
[7] => 75
[8] => 63
[9] => 44
[10] => 77
[11] => 76
[12] => 70
[13] => 76
[14] => 76
[15] => 72
[16] => 73
[17] => 85
[18] => 68
[19] => 72
[20] => 76
[21] => 68
[22] => 55
[23] => 67
[24] => 65
[25] => 75
[26] => 70
[27] => 71
[28] => 65
[29] => 40
)
[count] => Array
(
[24] => 1
[40] => 1
[44] => 1
[47] => 1
[55] => 1
[63] => 1
[65] => 2
[67] => 3
[68] => 2
[69] => 1
[70] => 2
[71] => 1
[72] => 2
[73] => 2
[74] => 1
[75] => 2
[76] => 4
[77] => 1
[85] => 1
)
)
二维码的生成细节和原理
二维码又称QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的Bar Code条形码能存更多的信息,也能表示更多的数据类型:比如:字符,数字,日文,中文等等。这两天学习了一下二维码图片生成的相关细节,觉得这个玩意就是一个密码算法,在此写一这篇文章 ,揭露一下。供好学的人一同学习之。
关于QR Code Specification,可参看这个PDF:http://raidenii.net/files/datasheets/misc/qr_code.pdf
基础知识
首先,我们先说一下二维码一共有40个尺寸。官方叫版本Version。Version 1是21 x 21的矩阵,Version 2是 25 x 25的矩阵,Version 3是29的尺寸,每增加一个version,就会增加4的尺寸,公式是:(V-1)*4 + 21(V是版本号) 最高Version 40,(40-1)*4+21 = 177,所以最高是177 x 177 的正方形。
下面我们看看一个二维码的样例:
定位图案
- Position Detection Pattern是定位图案,用于标记二维码的矩形大小。这三个定位图案有白边叫Separators for Postion Detection Patterns。之所以三个而不是四个意思就是三个就可以标识一个矩形了。
- Timing Patterns也是用于定位的。原因是二维码有40种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了。
- Alignment Patterns 只有Version 2以上(包括Version2)的二维码需要这个东东,同样是为了定位用的。
功能性数据
- Format Information 存在于所有的尺寸中,用于存放一些格式化数据的。
- Version Information 在 >= Version 7以上,需要预留两块3 x 6的区域存放一些版本信息。
数据码和纠错码
- 除了上述的那些地方,剩下的地方存放 Data Code 数据码 和 Error Correction Code 纠错码。
数据编码
我们先来说说数据编码。QR码支持如下的编码:
Numeric mode 数字编码,从0到9。如果需要编码的数字的个数不是3的倍数,那么,最后剩下的1或2位数会被转成4或7bits,则其它的每3位数字会被编成 10,12,14bits,编成多长还要看二维码的尺寸(下面有一个表Table 3说明了这点)
Alphanumeric mode 字符编码。包括 0-9,大写的A到Z(没有小写),以及符号$ % * + – . / : 包括空格。这些字符会映射成一个字符索引表。如下所示:(其中的SP是空格,Char是字符,Value是其索引值) 编码的过程是把字符两两分组,然后转成下表的45进制,然后转成11bits的二进制,如果最后有一个落单的,那就转成6bits的二进制。而编码模式和字符的个数需要根据不同的Version尺寸编成9, 11或13个二进制(如下表中Table 3)
Byte mode, 字节编码,可以是0-255的ISO-8859-1字符。有些二维码的扫描器可以自动检测是否是UTF-8的编码。
Kanji mode 这是日文编码,也是双字节编码。同样,也可以用于中文编码。日文和汉字的编码会减去一个值。如:在0X8140 to 0X9FFC中的字符会减去8140,在0XE040到0XEBBF中的字符要减去0XC140,然后把结果前两个16进制位拿出来乘以0XC0,然后再加上后两个16进制位,最后转成13bit的编码。如下图示例:
Extended Channel Interpretation (ECI) mode 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码。
Structured Append mode 用于混合编码,也就是说,这个二维码中包含了多种编码格式。
FNC1 mode 这种编码方式主要是给一些特殊的工业或行业用的。比如GS1条形码之类的。
简单起见,后面三种不会在本文 中讨论。
下面两张表中,
- Table 2 是各个编码格式的“编号”,这个东西要写在Format Information中。注:中文是1101
- Table 3 表示了,不同版本(尺寸)的二维码,对于,数字,字符,字节和Kanji模式下,对于单个编码的2进制的位数。(在二维码的规格说明书中,有各种各样的编码规范表,后面还会提到)
下面我们看几个示例,
示例一:数字编码
在Version 1的尺寸下,纠错级别为H的情况下,编码: 01234567
1. 把上述数字分成三组: 012 345 67
2. 把他们转成二进制: 012 转成 0000001100; 345 转成 0101011001; 67 转成 1000011。
3. 把这三个二进制串起来: 0000001100 0101011001 1000011
4. 把数字的个数转成二进制 (version 1-H是10 bits ): 8个数字的二进制是 0000001000
5. 把数字编码的标志0001和第4步的编码加到前面: 0001 0000001000 0000001100 0101011001 1000011
示例二:字符编码
在Version 1的尺寸下,纠错级别为H的情况下,编码: AC-42
1. 从字符索引表中找到 AC-42 这五个字条的索引 (10,12,41,4,2)
2. 两两分组: (10,12) (41,4) (2)
3.把每一组转成11bits的二进制:
(10,12) 10*45+12 等于 462 转成 00111001110
(41,4) 41*45+4 等于 1849 转成 11100111001
(2) 等于 2 转成 000010
4. 把这些二进制连接起来:00111001110 11100111001 000010
5. 把字符的个数转成二进制 (Version 1-H为9 bits ): 5个字符,5转成 000000101
6. 在头上加上编码标识 0010 和第5步的个数编码: 0010 000000101 00111001110 11100111001 000010
结束符和补齐符
假如我们有个HELLO WORLD的字符串要编码,根据上面的示例二,我们可以得到下面的编码,
| 编码 | 字符数 | HELLO WORLD的编码 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 |
我们还要加上结束符:
| 编码 | 字符数 | HELLO WORLD的编码 | 结束 |
| 0010 | 000001011 | 01100001011 01111000110 10001011100 10110111000 10011010100 001101 | 0000 |
按8bits重排
如果所有的编码加起来不是8个倍数我们还要在后面加上足够的0,比如上面一共有78个bits,所以,我们还要加上2个0,然后按8个bits分好组:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000
补齐码(Padding Bytes)
最后,如果如果还没有达到我们最大的bits数的限制,我们还要加一些补齐码(Padding Bytes),Padding Bytes就是重复下面的两个bytes:11101100 00010001 (这两个二进制转成十进制是236和17,我也不知道为什么,只知道Spec上是这么写的)关于每一个Version的每一种纠错级别的最大Bits限制,可以参看QR Code Spec的第28页到32页的Table-7一表。
假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要104个bits,而我们上面只有80个bits,所以,还需要补24个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
上面的编码就是数据码了,叫Data Codewords,每一个8bits叫一个codeword,我们还要对这些数据码加上纠错信息。
纠错码
上面我们说到了一些纠错级别,Error Correction Code Level,二维码中有四种级别的纠错,这就是为什么二维码有残缺还能扫出来,也就是为什么有人在二维码的中心位置加入图标。
| 错误修正容量 | |
| L水平 | 7%的字码可被修正 |
| M水平 | 15%的字码可被修正 |
| Q水平 | 25%的字码可被修正 |
| H水平 | 30%的字码可被修正 |
那么,QR是怎么对数据码加上纠错码的?首先,我们需要对数据码进行分组,也就是分成不同的Block,然后对各个Block进行纠错编码,对于如何分组,我们可以查看QR Code Spec的第33页到44页的Table-13到Table-22的定义表。注意最后两列:
- Number of Error Code Correction Blocks :需要分多少个块。
- Error Correction Code Per Blocks:每一个块中的code个数,所谓的code的个数,也就是有多少个8bits的字节。
举个例子:上述的Version 5 + Q纠错级:需要4个Blocks(2个Blocks为一组,共两组),头一组的两个Blocks中各15个bits数据 + 各 9个bits的纠错码(注:表中的codewords就是一个8bits的byte)(再注:最后一例中的(c, k, r )的公式为:c = k + 2 * r,因为后脚注解释了:纠错码的容量小于纠错码的一半)
下图给一个5-Q的示例(因为二进制写起来会让表格太大,所以,我都用了十进制,我们可以看到每一块的纠错码有18个codewords,也就是18个8bits的二进制数)
| 组 | 块 | 数据 | 对每个块的纠错码 |
| 1 | 1 | 67 85 70 134 87 38 85 194 119 50 6 18 6 103 38 | 213 199 11 45 115 247 241 223 229 248 154 117 154 111 86 161 111 39 |
| 2 | 246 246 66 7 118 134 242 7 38 86 22 198 199 146 6 | 87 204 96 60 202 182 124 157 200 134 27 129 209 17 163 163 120 133 | |
| 2 | 1 | 182 230 247 119 50 7 118 134 87 38 82 6 134 151 50 7 | 148 116 177 212 76 133 75 242 238 76 195 230 189 10 108 240 192 141 |
| 2 | 70 247 118 86 194 6 151 50 16 236 17 236 17 236 17 236 | 235 159 5 173 24 147 59 33 106 40 255 172 82 2 131 32 178 236 |
注:二维码的纠错码主要是通过Reed-Solomon error correction(里德-所罗门纠错算法)来实现的。对于这个算法,对于我来说是相当的复杂,里面有很多的数学计算,比如:多项式除法,把1-255的数映射成2的n次方(0<=n<=255)的伽罗瓦域Galois Field之类的神一样的东西,以及基于这些基础的纠错数学公式,因为我的数据基础差,对于我来说太过复杂,所以我一时半会儿还有点没搞明白,还在学习中,所以,我在这里就不展开说这些东西了。还请大家见谅了。(当然,如果有朋友很明白,也繁请教教我)
最终编码
穿插放置
如果你以为我们可以开始画图,你就错了。二维码的混乱技术还没有玩完,它还要把数据码和纠错码的各个codewords交替放在一起。如何交替呢,规则如下:
对于数据码:把每个块的第一个codewords先拿出来按顺度排列好,然后再取第一块的第二个,如此类推。如:上述示例中的Data Codewords如下:
| 块 1 | 67 | 85 | 70 | 134 | 87 | 38 | 85 | 194 | 119 | 50 | 6 | 18 | 6 | 103 | 38 | |
| 块 2 | 246 | 246 | 66 | 7 | 118 | 134 | 242 | 7 | 38 | 86 | 22 | 198 | 199 | 146 | 6 | |
| 块 3 | 182 | 230 | 247 | 119 | 50 | 7 | 118 | 134 | 87 | 38 | 82 | 6 | 134 | 151 | 50 | 7 |
| 块 4 | 70 | 247 | 118 | 86 | 194 | 6 | 151 | 50 | 16 | 236 | 17 | 236 | 17 | 236 | 17 | 236 |
我们先取第一列的:67, 246, 182, 70
然后再取第二列的:67, 246, 182, 70, 85,246,230 ,247
如此类推:67, 246, 182, 70, 85,246,230 ,247 ……… ……… ,38,6,50,17,7,236
对于纠错码,也是一样:
| 块 1 | 213 | 199 | 11 | 45 | 115 | 247 | 241 | 223 | 229 | 248 | 154 | 117 | 154 | 111 | 86 | 161 | 111 | 39 |
| 块 2 | 87 | 204 | 96 | 60 | 202 | 182 | 124 | 157 | 200 | 134 | 27 | 129 | 209 | 17 | 163 | 163 | 120 | 133 |
| 块 3 | 148 | 116 | 177 | 212 | 76 | 133 | 75 | 242 | 238 | 76 | 195 | 230 | 189 | 10 | 108 | 240 | 192 | 141 |
| 块 4 | 235 | 159 | 5 | 173 | 24 | 147 | 59 | 33 | 106 | 40 | 255 | 172 | 82 | 2 | 131 | 32 | 178 | 236 |
和数据码取的一样,得到:213,87,148,235,199,204,116,159,…… …… 39,133,141,236
然后,再把这两组放在一起(纠错码放在数据码之后)得到:
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236
这就是我们的数据区。
Remainder Bits
最后再加上Reminder Bits,对于某些Version的QR,上面的还不够长度,还要加上Remainder Bits,比如:上述的5Q版的二维码,还要加上7个bits,Remainder Bits加零就好了。关于哪些Version需要多少个Remainder bit,可以参看QR Code Spec的第15页的Table-1的定义表。
画二维码图
Position Detection Pattern
首先,先把Position Detection图案画在三个角上。(无论Version如何,这个图案的尺寸就是这么大)
Alignment Pattern
然后,再把Alignment图案画上(无论Version如何,这个图案的尺寸就是这么大)
关于Alignment的位置,可以查看QR Code Spec的第81页的Table-E.1的定义表(下表是不完全表格)
下图是根据上述表格中的Version8的一个例子(6,24,42)
Timing Pattern
接下来是Timing Pattern的线(这个不用多说了)
Format Information
再接下来是Formation Information,下图中的蓝色部分。
Format Information是一个15个bits的信息,每一个bit的位置如下图所示:(注意图中的Dark Module,那是永远出现的)
这15个bits中包括:
- 5个数据bits:其中,2个bits用于表示使用什么样的Error Correction Level, 3个bits表示使用什么样的Mask
- 10个纠错bits。主要通过BCH Code来计算
然后15个bits还要与101010000010010做XOR操作。这样就保证不会因为我们选用了00的纠错级别和000的Mask,从而造成全部为白色,这会增加我们的扫描器的图像识别的困难。
下面是一个示例:
关于Error Correction Level如下表所示:
关于Mask图案如后面的Table 23所示。
Version Information
再接下来是Version Information(版本7以后需要这个编码),下图中的蓝色部分。
Version Information一共是18个bits,其中包括6个bits的版本号以及12个bits的纠错码,下面是一个示例:
而其填充位置如下:
数据和数据纠错码
然后是填接我们的最终编码,最终编码的填充方式如下:从左下角开始沿着红线填我们的各个bits,1是黑色,0是白色。如果遇到了上面的非数据区,则绕开或跳过。
掩码图案
这样下来,我们的图就填好了,但是,也许那些点并不均衡,如果出现大面积的空白或黑块,会告诉我们扫描识别的困难。所以,我们还要做Masking操作(靠,还嫌不复杂)QR的Spec中说了,QR有8个Mask你可以使用,如下所示:其中,各个mask的公式在各个图下面。所谓mask,说白了,就是和上面生成的图做XOR操作。Mask只会和数据区进行XOR,不会影响功能区。(注:选择一个合适的Mask也是有算法的)
其Mask的标识码如下所示:(其中的i,j分别对应于上图的x,y)
下面是Mask后的一些样子,我们可以看到被某些Mask XOR了的数据变得比较零散了。
Mask过后的二维码就成最终的图了。
好了,大家可以去尝试去写一下QR的编码程序,当然,你可以用网上找个Reed Soloman的纠错算法的库,或是看看别人的源代码是怎么实现这个繁锁的编码。
(全文完)
web页面快速生成二维码的两种实用方法
二维码是桌面和移动端快速分享的高效手段之一,这里介绍两个不错的快速开发二维码的方法,和大家分享一下~~
方法1:使用新浪提供的服务
这种方式简单快速,在服务端生成一个二维码的图片,兼容性比较好,你无需自己处理任何相关二维码的生成,只需要提供一端文字或者url即可,方法如下:
生成效果如下:

大家扫一扫就可以访问极客标签主站了~~
方法2: 使用jQuery插件qrcode
QRcode是一个jQuery插件,可以使用javascript快速帮助你生成相关的二维码
相关代码如下:
- var qrcode = new QRCode("qrcode", {
- text: "http://www.gbtags.com",
- width: 260,
- height: 260,
- colorDark: '#efb73e',
- colorLight: "#ffffff"
- });
生成效果如下:

如果对这个插件有兴趣,推荐阅读这节课程: QRcode的使用
以上是两种比较实用的生成二维码的方法, 懒人推荐使用第一种, 简单快速, 如果需要深度自定义的话,推荐自己使用JS来实现相关的二维码,具体看大家需求, 极客标签的代码分享使用的是第一种,大家可以参考一下,如下:

用 Flora_Pac.py 生成自动翻墙的 pac 文件
源于人们对自由的向往,翻墙技术已渐趋成熟。愿意花点钱,购买海外 VPN 和 ssh 主机用于自由获取信息是目前比较有效的手段。如我之前文章中提及,这两种方式都有需要筛选出那些网站在墙外,那些网站在墙内,以较节约、高速的方式访问网络。八仙过海,各显神通,不少帮助人们解决这一问题,降低翻墙门槛的小项目出现了。较具代表性的有 chnroutes(http://code.google.com/p/chnroutes/) 项目和 autoproxy-gfwlist(http://code.google.com/p/autoproxy-gfwlist/) 项目。前者修改路由表,配合各种 VPN 使用,后者可以配合 AutoProxy for Firefox(https://addons.mozilla.org/firefox/addon/11009) 或导出(https://autoproxy2pac.appspot.com/)为 pac 文件,配合各种代理服务器,包括 ssh -D 使用。他们的原理稍有差异,chnroutes 只区分国内外 IP 段,让国外地址全部走翻墙路线,autoproxy-gfwlist 项目则精确记录着那些网站被墙。
我以往喜欢 ssh -D 生成 SOCKS 代理后,搭配自己的 pac 文件翻墙。最近由于各种原因转到了 VPN 阵营。感觉 VPN 搭配 chnroutes 的确很舒服,不用再关心那些网站被墙,不会因为 gfwlist 更新延迟而影响访问。于是我在想,有没有办法让使用 ssh -D 或者其他翻墙代理的用户能和使用 VPN 的用户那样省心呢?于是我站在巨人的肩膀上,基于 chnroutes 项目,结合 pac 文件的 dnsResolve() 和 isInNet() 函数,开发了 Flora_Pac 这个小项目。
Flora_Pac 使用 Python 开发,能自动抓取 apnic.net 的 IP 数据,找出所有国内的 IP 地址段,生成能让浏览器自动判断国内外 IP 地址的 pac 文件,让代理用户有等价于 VPN + chnroutes 的翻墙体验。Flora_Pac 使用十分简单,兼容各种平台:
####### 获得帮助:
$ python flora_pac.py -h
usage: flora_pac.py [-h] [-x [PROXY]]
Generate proxy auto-config rules.
optional arguments:
-h, --help show this help message and exit
-x [PROXY], --proxy [PROXY]
Proxy Server, examples:
SOCKS 127.0.0.1:8964;
SOCKS5 127.0.0.1:8964;
PROXY 127.0.0.1:8964
####### 生成 pac 文件,国外 IP 通过代理 SOCKS 代理 127.0.0.1:8964 访问:
$ python flora_pac.py -x 'SOCKS 127.0.0.1:8964'
Fetching data from apnic.net, it might take a few minutes, please wait...
Rules: 3460 items.
Usage: Use the newly created flora_pac.pac as your web browser's automatic proxy configuration (.pac) file.
####### 生成 pac 文件,国外 IP 通过代理 HTTP 代理 127.0.0.1:8964 访问:
$ python flora_pac.py -x 'PROXY 127.0.0.1:8964'
Fetching data from apnic.net, it might take a few minutes, please wait...
Rules: 3460 items.
Usage: Use the newly created flora_pac.pac as your web browser's automatic proxy configuration (.pac) file.
程序跑完后,就会在当前目录产生 flora_pac.pac 文件,把它设为浏览器或系统代理设置的 pac 文件即可。
项目代码我放在 github 上开源了:https://github.com/Leask/Flora_Pac,其中 fetch_ip_data 函数 fork 自 chnroutes 项目。
不方便上 github 的朋友,直接复制以下代码保存为 flora_pac.py 就可以跑了:
#!/usr/bin/env python
#
# Flora_Pac by @leaskh
# www.leaskh.com, i@leaskh.com
#
# based on chnroutes project (by Numb.Majority@gmail.com)
#
import re
import urllib2
import argparse
import math
def generate_pac(proxy):
results = fetch_ip_data()
pacfile = 'flora_pac.pac'
rfile = open(pacfile, 'w')
strLines = (
"// Flora_Pac by @leaskh"
"\n// www.leaskh.com, i@leaskh.com"
"\n"
"\nfunction FindProxyForURL(url, host)"
"\n{"
"\n"
"\n var list = ["
)
intLines = 0
for ip,mask,_ in results:
if intLines > 0:
strLines = strLines + ','
intLines = intLines + 1
strLines = strLines + "\n ['%s', '%s']"%(ip, mask)
strLines = strLines + (
"\n ];"
"\n"
"\n var ip = dnsResolve(host);"
"\n"
"\n for (var i in list) {"
"\n if (isInNet(ip, list[i][0], list[i][1])) {"
"\n return 'DIRECT';"
"\n }"
"\n }"
"\n"
"\n return '%s';"
"\n"
"\n}"
"\n"%(proxy)
)
rfile.write(strLines)
rfile.close()
print ("Rules: %d items.\n"
"Usage: Use the newly created %s as your web browser's automatic "
"proxy configuration (.pac) file."%(intLines, pacfile))
def fetch_ip_data():
#fetch data from apnic
print "Fetching data from apnic.net, it might take a few minutes, please wait..."
url=r'http://ftp.apnic.net/apnic/stats/apnic/delegated-apnic-latest'
data=urllib2.urlopen(url).read()
cnregex=re.compile(r'apnic\|cn\|ipv4\|[0-9\.]+\|[0-9]+\|[0-9]+\|a.*',re.IGNORECASE)
cndata=cnregex.findall(data)
results=[]
for item in cndata:
unit_items=item.split('|')
starting_ip=unit_items[3]
num_ip=int(unit_items[4])
imask=0xffffffff^(num_ip-1)
#convert to string
imask=hex(imask)[2:]
mask=[0]*4
mask[0]=imask[0:2]
mask[1]=imask[2:4]
mask[2]=imask[4:6]
mask[3]=imask[6:8]
#convert str to int
mask=[ int(i,16 ) for i in mask]
mask="%d.%d.%d.%d"%tuple(mask)
#mask in *nix format
mask2=32-int(math.log(num_ip,2))
results.append((starting_ip,mask,mask2))
return results
if __name__=='__main__':
parser=argparse.ArgumentParser(description="Generate proxy auto-config rules.")
parser.add_argument('-x', '--proxy',
dest = 'proxy',
default = 'SOCKS 127.0.0.1:8964',
nargs = '?',
help = "Proxy Server, examples: "
"SOCKS 127.0.0.1:8964; "
"SOCKS5 127.0.0.1:8964; "
"PROXY 127.0.0.1:8964")
args = parser.parse_args()
generate_pac(args.proxy)
我想,应该过不了多久就要解放了。期待着有那么一天:我们能一起呼吸自由的空气,我们不再需要折腾各种翻墙玩意。那时,生活应该会更美好一些吧。
公钥私钥的生成与维护
0.在cd用户主目录(~) 进入用户目录,建立.ssh目录
1.在一个linux机器,自己的目录下执行 ssh-keygen -t rsa -C 自己名字的全拼@xxxx.com。 比如我的就用
ssh-keygen -t rsa -C shaozhuqing@xxxx.com
2.接下来,会出现Enter file in which to save the key
(/home/shaozq/.ssh/id_rsa): 这时, 起名字为 id_rsa
3.接下来,会出现Enter passphrase (empty for no passphrase):
这就相当于给自己的git访问加个密码, 这个内容必须要设置,不得为空。
4.接下来,需要再次输入passphrase
5.用默认的名称就可以/home/{username}/.
6.最后,会有如下提示:
Your identification has been saved in id_rsa.
Your public key has been saved in id_rsa.pub.
The key fingerprint is:
2c:31:aa:88:1c:da:0d:3b:74:68:
7.将生成的公钥(id_rsa.pub)加到.ssh/
8.将生成的公钥和私钥sz到本地机器(
9.
10.通过publicKey进行登录
11.将生成的公钥发给git管理员
12.git管理员将新成员的公钥(id_rsa.pub)
最常用的生成静态标签云网站
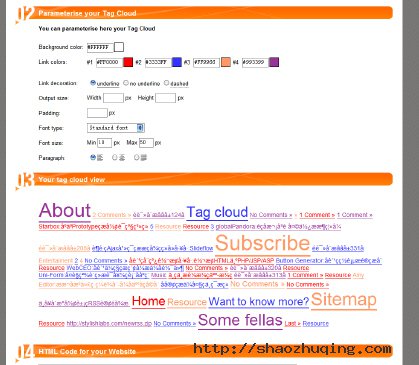
生成静态标签云:
这个工具同样可以生成一个静态的标签云图,你只需要输入你的网页地址,或是手动输入Tag的关键词和网页。还可以配置标签云的背景颜色,输出宽高,Tag链接的文字颜色,是否使用下划线以及是实线还是虚张,文字字体,以及Tag字体的最大尺寸和最小尺寸,标签云的排版等。
生成后的效果图:
http://www.tagcloud-generator.com/
这是一个德国网站提供的标签云生成器,功能较少,不过可以加入自己的CSS样式文件,比较适合对CSS有一定基础的朋友。支持生成英文和德文的 Tag cloud。中文同样是乱码。不过我忽然想到,不管是哪个标签云生成器,所有生成的乱码,其实都可以在生成代码后再把乱码更改成中文字符就可以了。只是那 要好像就变得麻烦了
生成后的效果图:
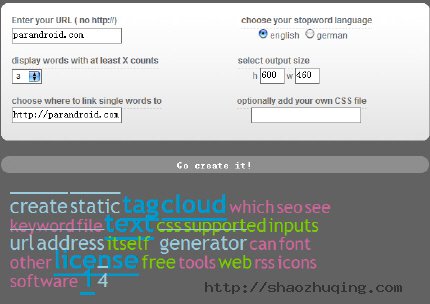
这是一个在线的网络服务应用,它可以提供把你网页的关键字密度以一个可视化、漂亮的标签云显示出来。(使用了C SS和H TML)。
支持输入文本,提交网页地址,上传文本文件,它就会自动抓取页面里面的关键词,并根据关键词的使用频率生成一个标签云和相应的代码,若要使用,你只需要把代码粘贴到你的网页就可以了。
下面我输入http://hi.baidu.com/yuanbiaoji后得到的标签云截图:
生成后的效果:

支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
