PHP CodeIgniter框架源码解析
1.index.php :入口文件
|-->define('ENVIRONMENT') |主要用于设置errors日志输出级别
|-->$system_path |设置系统路径
|-->设置BASEPATH、FCPATH、SYSDIR、APPPATH等 |设置路径信息变量,为加载相应文件信息准备
|-->require_once BASEPATH.core/CodeIgniter.php | 最后加载CodeIgniter.php作为总控制器
2.CodeIgniter.php加载过程,主要用于加载core核心目录下相应文件
|-->require(BASEPATH.'core/Common.php'); |加载core目录下的Common文件,见2.1解析
|-->require(APPPATH.'config/'.ENVIRONMENT.'/constants.php'); |加载constants目录,与开发环境无关时直接使用config目录下的constants目录
|-->get_config(array('subclass_prefix' => $assign_to_config['subclass_prefix'])); |设置子文件,扩展类的前缀
|-->$BM =& load_class('Benchmark', 'core'); |加载benchmark类,mark记录当前的时间
|-->$EXT =& load_class('Hooks', 'core'); |加载core目录下的Hooks钩子类
|-->$EXT->_call_hook('pre_system'); |调用_call_hook(pre_system),根据pre_system内部调用_run_hook执行钩子,在系统开始正式工作前作预处理
|-->$CFG =& load_class('Config', 'core'); |继续执行core下的Config配置文件,
|-->$CFG->_assign_to_config($assign_to_config);
|-->|$this->set_item($key, $val); |解析指定给config的配置文件,实质为对config[]赋值
|-->$UNI =& load_class('Utf8', 'core'); |加载了UTF-8编码类,CI_Utf8
|-->$URI =& load_class('URI', 'core'); |加载core目录的URI类,CI_URI
|-->$RTR =& load_class('Router', 'core'); |设置route路由及覆盖信息,见2.2解析
|-->_set_routing()
|-->_set_overrides()
|-->$OUT =& load_class('Output', 'core'); |实例化输出类,加载core目录下的output文件
|-->$OUT->_display_cache($CFG, $URI) |判断是否存在页面缓存,是则输出文件
|-->$SEC =& load_class('Security', 'core'); |加载core目录下的安全处理文件
|-->$IN =& load_class('Input', 'core'); |实例化输入类,加载core目录下的input文件
|-->$LANG =& load_class('Lang', 'core'); |加载语言类
|-->require BASEPATH.'core/Controller.php'; |加载基本控制器类,见2.3解析
|-->require APPPATH.'core/'.$CFG->config['subclass_prefix'].'Controller.php'; |尝试加载扩展的自定义子类控制器
|-->include(APPPATH.'controllers/'.$RTR->fetch_directory().$RTR->fetch_class().'.php'); |加载自定义控制器下的控制器类
|-->$BM->mark('loading_time:_base_classes_end'); |设定一个benchmark测试点
|-->$class = $RTR->fetch_class(); |分别获取uri地址的控制器类名和方法名
|-->$method = $RTR->fetch_method();
|-->if ( ! class_exists($class) |判断方法及类是否合理
OR strncmp($method, '_', 1) == 0
OR in_array(strtolower($method), array_map('strtolower', get_class_methods('CI_Controller')))
)
|-->$EXT->_call_hook('pre_controller'); |处理器执行前进行预处理,并做benchmark设置
|-->$CI = new $class(); |获取执行的控制器实例,实例化构造器
|-->$EXT->_call_hook('post_controller_constructor'); |实例化控制器类后的钩子处理
|-->if (method_exists($CI, '_remap'))
|-->$CI->_remap($method, array_slice($URI->rsegments, 2)) |如果控制器存在_remap()方法,则执行, 判断条件$CI为控制器类
|-->else |判断方法在类当中的存在似,如果不存在,则设置
|-->call_user_func_array(array(&$CI, $method), array_slice($URI->rsegments, 2)); |最终传递参数供调用控制类方法
|-->$BM->mark('controller_execution_time_( '.$class.' / '.$method.' )_end'); |benchmark标记时间结束点
|-->$EXT->_call_hook('post_controller'); |控制器生存周期,在控制器执行完成后执行后续操作
|-->$OUT->_display(); |输出页面进行展示
|-->$EXT->_call_hook('post_system'); |请求生存周期完成后的终结操作
|-->$CI->db->close(); |自动关闭数据库资源
2.1 Core/Common.php加载
|-->function is_php($version) |用于比较版本号的函数
|-->function is_really_writable($file) |用于判断是否可以写文件,在不同的系统中可靠程度不同,
W中通过判断is_readonly,U中如果safe_mode为开则不确定性
|-->function load_class($class, $directory = 'libraries', $prefix = 'CI_') |用于加载目录下的PHP文件的class类
|-->foreach (array(APPPATH, BASEPATH) as $path) |分别在application和system目录下轮循
|-->file_exists($path.$directory.'/'.$class.'.php' |找到对应的PHP文件
|-->require($path.$directory.'/'.$class.'.php'); |require加载对应的PHP文件内的类,加了前缀,此处可扩展
|-->break; |如正确加载则退出,否则继续尝试加载文件
|-->file_exists(APPPATH.$directory.'/'.config_item('subclass_prefix').$class.'.php') |自扩展的class类,如My_Test
|-->if ($name === FALSE) |如果$name不存在,则exit()退出 ,(在自定义类加载时,此处可作为扩展点,增加边际条件)
|-->is_loaded($class); |确类已经加载
|-->$_classes[$class] = new $name(); |加载至静态的classes数祖中,用于缓存,调用时首先从classes中获取
|-->function is_loaded($class = '')
|-->设置$_is_loaded数祖,参数$class不为空,判断是否存在gf $_is_loaded,否则设置
|-->function &get_config($replace = array())|用于获取Config的实例化文件
|-->static $_config; |定义config类型
|-->$file_path = APPPATH.'config/config.php'; |确定application目录路径下定义的config.php的路径
|-->require($file_path); |加载application/config/config.php类
|-->count($replace) > 0 |对于config.php中定义的变量,如果有replace,则逐个替代
|-->foreach ($replace as $key => $val)
|-->$config[$key] = $val;
|-->return $_config[0] =& $config; |最后返回定义的config的结果集
|-->function config_item($item) |配置选项,从config的数祖对象中返还特殊的配置项
|-->$config =& get_config();
|-->$_config_item[$item] = $config[$item];
|-->function show_error |用于错误信息输出
|-->$_error =& load_class('Exceptions', 'core'); |加载Exceptions类
|-->echo $_error->show_error($heading, $message, 'error_general', $status_code); |直接输出错误
|-->function show_404 |用于输出404页面,输出的错误信息页面可配置
|-->function log_message |用于写日志信息
|-->$_log =& load_class('Log');
|-->$_log->write_log($level, $message, $php_error);
|-->function set_status_header |用于输出状态的heade信息
|-->function _exception_handler
|-->function remove_invisible_characters
|-->function html_escape |过滤HTML变量
|-->return htmlspecialchars($var, ENT_QUOTES, config_item('charset'));
2.2Router路由信息设置
|-->_set_routing()
|-->$segments = array() |根据目录,控制器,函数的触发器设定segment[]的uri段值,分别fetch()方法去取对象值
|-->include(APPPATH.'config/routes.php'); |加载config下的routes文件
|-->$this->routes |设置routes数祖值,从config的route中获取
|-->$this->default_controller |设置routes的控制器值,从config的route中获取
|-->return $this->_validate_request($segments); |验证uri的segment合法性
|-->$this->uri->_remove_url_suffix();$this->uri->_reindex_segments(); |进一步清理解析uri,使segment从1开始x
|-->_set_overrides() |根据$routing的值,重新设定directory、controller、function参数
|-->$this->set_directory($routing['directory']);
|-->$this->set_class($routing['controller']);
|-->$this->set_method($routing['function']);
2.3 core/Controller.php加载
|-->__construct() |构造函数
|-->self::$instance =& $this;
|-->foreach (is_loaded() as $var => $class) |根据is_loaded()的信息加载相应的类
|-->$this->$var =& load_class($class);
|-->$this->load =& load_class('Loader', 'core'); |加载core/Loader的php文件
|-->$this->load->initialize(); |主要用于autoload加载信息,如libraries、database等等
|-->function &get_instance |返回当前实例
|-->return self::$instance
扩展点:PHP自动加载机制在CodeIgniter中的应用
1.PHP自动加载机制:PHP5后,提供了类的自动加载机制,即类在加载时才被使用,即Lazy loading,共有二种方式
1.1: __autoload()通过扩展可实现,实质为设定规则加载相应路径的PHP文件(require、include方式)
1.2: 将autoload_func指向php文件,这个一般用c语言扩展实现
详见:http://blog.csdn.net/flyingpig4/article/details/7286438
2.在CodeIgniter中的应用
根据上述源码分析可知:CodeIgniter中所有的操作都是以Controller为起始,只需在Cotroller加载的过程中,
使__autoload()函数自动加载即可,目前的加载方式为在application/config/config.php中设置__autoload()
函数
GitHub托管BootStrap资源汇总
Twitter BootStrap已经火过大江南北,对于无法依赖美工的程序员来说,这一成熟前卫的前端框架简直就一神器,轻轻松松地实现出专业的UI效果。GitHub上相关的的开源项目更是层出不穷,在此整理列举一些感觉不错的组件或增强实现,供大家借鉴。
显示
- MESSENGER
替换alert()消息和其他用户交互通知。 - JQUERY.TOCIFY.JS
可以用Bootstrap或jQueryUI主题的Jquery表格组件。 - BOOTSTRAP-PROMPTS
实现替换alert(), prompt(),confirm()通知的Bootstrap组件。 - SUBNAV FOR BOOTSTRAP 2
一个展示如何在Bootstrap导航菜单中实现SubNavs的例子。 - JQUERY-BOOTSTRAP-SCRIPTING
基于BootStrap实现的JQuery对话框插件。 - BOOTSTRAP-LIGHTBOX
Bootstrap遮罩层(lightbox)对话框实现。 - MENTION.JS
轻量级的实现类似微博@username功能的输入感知插件。 - PINES NOTIFY
Bootstrap或jQuery UI适用的JavaScript通知。 - ACC-WIZARD
基于Bootstrap的“手风琴”排版向导。 - JQUERY-BOOTSTRAP-PAGINATION
一个简单但功能全面的分页组件,基于jQuery,同时支持Bootstrap。 - BANGBANG TAG INPUT
标签(tags)输入提示的JQuery插件。 - TOCIFY
Bootstrap风格的jQuery表格。 - SORICH87/BOOTSTRAP-TOUR
快速构建产品介绍的Bootstrap提示框(类似软件启动时的“每日一问”)。 - BOOTSTRAP-TAGS
顾名思义,Bootstrap标签(tags)功能的实现。 - BOOTSTRAP ARROWS
基于Bootstrap实现各种箭头图标。 - BOOTSTRAP-MODAL
Bootstrap消息提示对话框的扩展。 - PILLBOX FUEL UX
胶囊盒效果,经常用于tags显示与控制。 - DATAGRID FUEL UX
一个可以编辑、搜索、排序的表格组件,非常大方漂亮(Fuel UX的其他扩展也很不错)。 - BOOTMETRO
Windows8的Metro效果实现。 - BOOTSTRAP TOUR
另一款实现网站介绍(“每日一问”等)的Bootstrap提示框。 - JQUERY-SLIMSCROLL
局部带透明滚动条DIV的效果。 - BOOTSTRAP-PROGRESSBAR
多种颜色的Bootstrap进度条(貌似新版Bootstrap已实现此功能)。 - BOOTSTRAP HTML5 VIDEO PLAYER
基于Bootstrap UI的HTML5视频播放器插件。 - BOOTPAG
动态分页功能实现。 - BOOTSTRAP-IMAGE-GALLERY
Bootstrap模态对话框扩展,可用于图片展示站。 - TABLECLOTH.JS
表格扩展,可以进行改变主题、排序等操作。 - PAGEDOWN-BOOTSTRAP
一个简单的即时显示编辑框。 - MENU DROPDOWN ON HOVER PLUGIN
自动展开菜单的下拉菜单实现,可以很好地适应移动设备。 - CSS3 MICROSOFT MODERN BUTTONS
又一款Win8的Metro样式实现。 - LIGHTBOX
遮罩层扩展,可用于图片展示或登录框。 - D3 BOOTSTRAP POPOVERS
BootStrap实现的圆点,可用来表述数值大小。 - TWITTER BOOTSTRAP NOTIFICATIONS, FROM NIJIKO YONSKAI
提示框扩展。 - BOOTBOX.JS – ALERT, CONFIRM AND FLEXIBLE DIALOGS FOR TWITTER’S BOOTSTRAP FRAMEWORK
Bootbox.js是一个小巧的JavaScript库,允许你生成一个程序化的对话框.
表单
- BOOTSTRAP-ACKNOWLEDGEINPUTS
带验证提示的输入框改进。 - TREE.JS
出自FUEL UX的树形列表组件。 - WIZARD.JS
出自FUEL UX的step by step导航条。 - MAGICSUGGEST
具有联想功能的输入框,可用于搜索提示。 - BOOTSTRAP-DUALLISTBOX
Bootstrap实现的双重列表框组件(左右栏内容移动),适用于移动设备。 - JQUERY-SIMPLECOLORPICKER
jQuery颜色选择(吸管)功能。 - TWBOOTSTRAPJQVALPOPOVER
Bootstrap提示框实现Jquery验证提示 - BOOTSTRAP-WYSIHTML5-RAILS
一款基于Bootstrap的“所见即所得”在线编辑器。 - MY-BOOTSTRAP-DATETIMEPICKER
漂亮的日期/时间选择组件 - GOOGLE FONT SELECT
基于Google Font API的文字选择下拉框 - BOOTSTRAP-DATETIMEPICKER
又一款不错的日期选择组件 - BOOTSTRAP-MULTISELECT
基于JQuery的多选下拉菜单组件 - JQRANGESLIDER
范围滑动选择的jQuery插件 - JASNY BOOTSTRAP
Bootstrap扩展,增强了很多功能,如输入框、表单、图标等,值得一看。 - JQUERY-ADDRESSPICKER
地址选择输入框(支持google maps)。 - JQUERY FILE UPLOAD DEMO
JQuery文件上传组件,支持多文件选取和进度条。 - BOOTSTRAP CONTEXTMENU
基于BootStrap实现的右键菜单。 - SELECTBOXIT
BootStrap下拉菜单美化改进 - SPINNER – FUEL UX
数字输入框 - SEARCH FUEL UX
搜索框 - BOOTSTRAP-WYSIHTML5
支持HTML5的“所见即所得”在线编辑器 - SELECTBOX FORM HELPER
下拉菜单增强美化 - TYPEAHEAD EXTENSION
支持json数据回调的下拉菜单增强 - FINE UPLOADER
一款界面友好的上传组件。 - X-EDITABLE
点击链接即可编辑的编辑组件(结合ajax实现页面无刷新)。 - JQBOOTSTRAPVALIDATION
BootStrap可用的JQuery验证插件。 - PRETTYCHECKABLE
美化默认的单选和多选选择框。 - CHOSEN-LESS-BOOTSTRAP
美化选择组件,如下拉菜单,输入框等。 - BOOTSTRAP AJAX
基于Ajax的快速输入框 - BOOTSTRAP TOGGLE BUTTONS
ON/OFF切换,类似IOS上的UI风格
输入
- TIMEPICKER
界面很新颖的时间选择组件 - COMBOBOX FUEL UX
FUEL UX出品的美化下拉菜单 - TIMEZONE FORM HELPERS
时区选择下拉菜单 - LANGUAGES FORM HELPER
语言选择下拉菜单 - PHONE FORM HELPER
手机号码输入框 - COUNTRIES FORM HELPER
国家选择下拉菜单 - DATE RANGE PICKER
日期段选择组件 - DATEPICKER FOR BOOTSTRAP
日期选择组件 - COLORPICKER FOR BOOTSTRAP
又一款颜色选择器(吸管),效果很棒。
JavaScript 语言基础知识点总结(思维导图)
温故而知新 ———— 最近温习了一遍Javascript 语言,故把一些基础、概念性的东西分享一下。
(下面内容大都为条目、索引,是对知识点的概括,帮助梳理知识点,具体内容需要查阅资料)
JavaScript 数组 |
JavaScript 函数基础 |
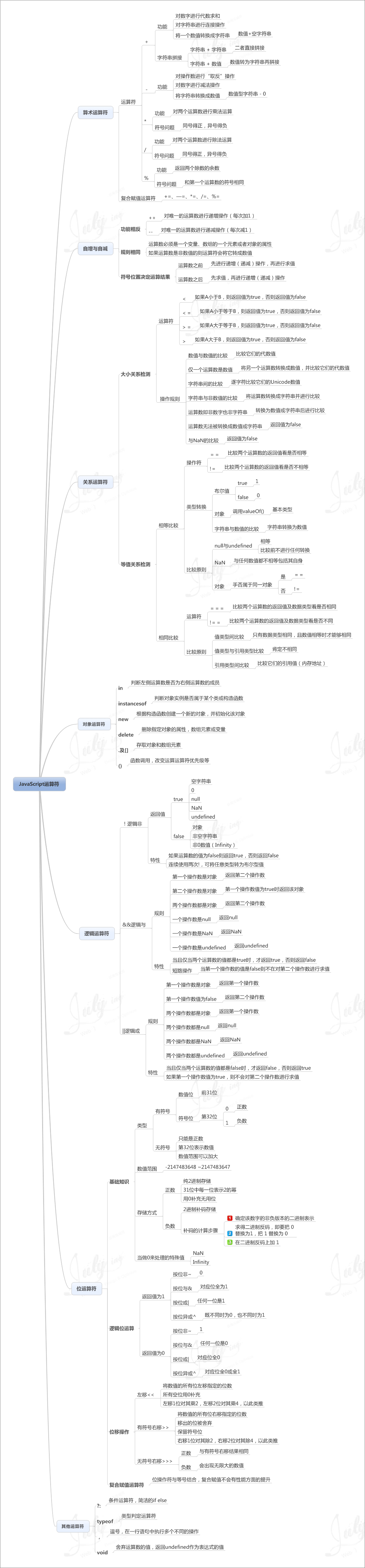
Javascript 运算符 |
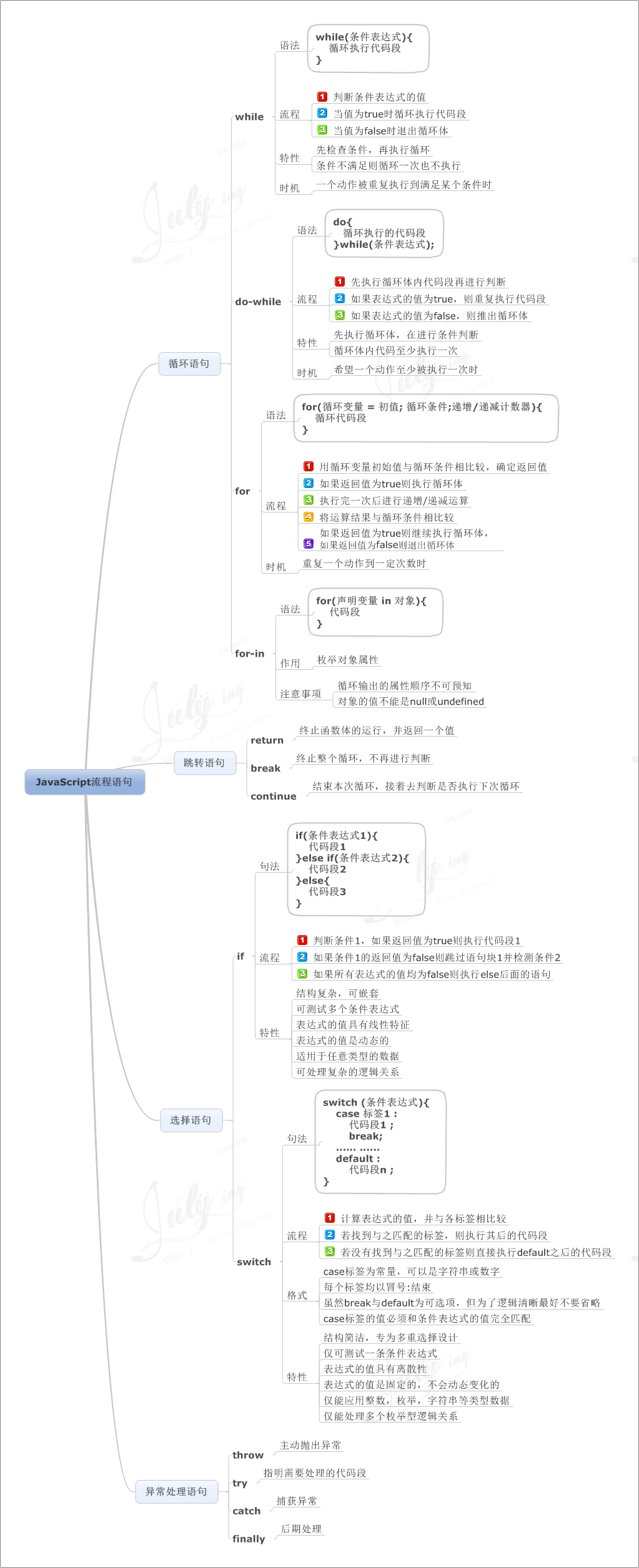
JavaScript 流程控制 |
JavaScript 正则表达式 |
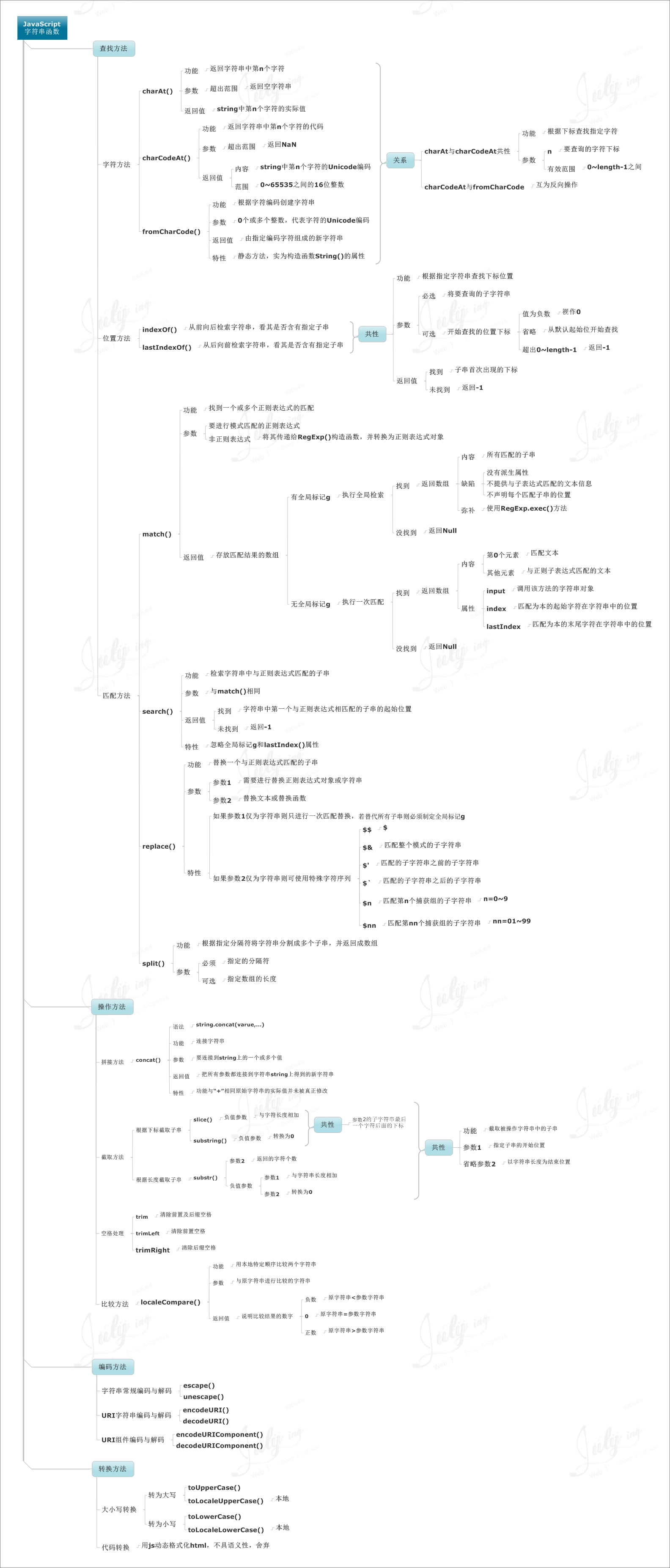
JavaScript 字符串函数 |
| JavaScript 数据类型 |
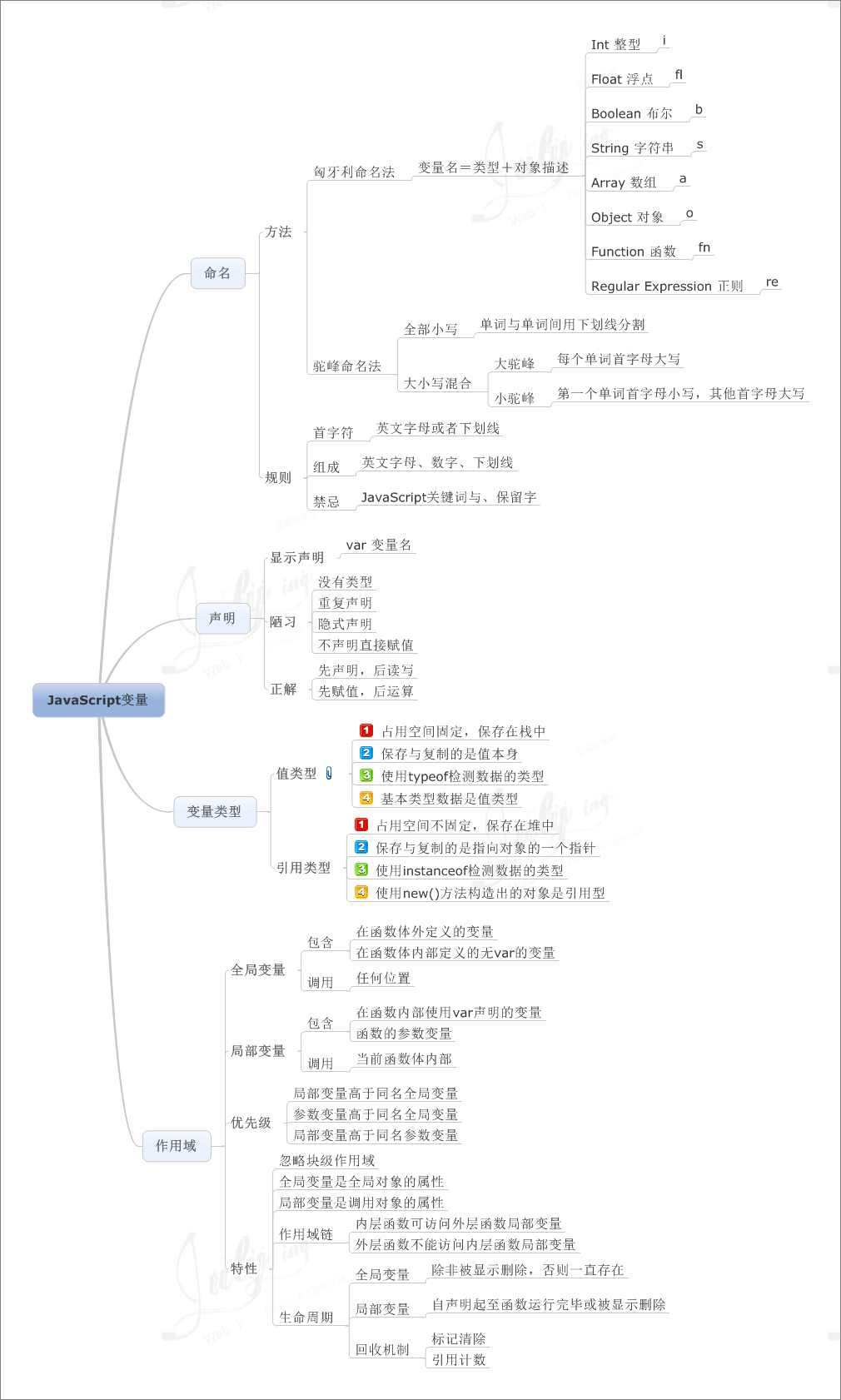
JavaScript 变量 |
Window 对象 |
DOM 基本操作 |
1.DOM基础操作

2.数组基础

3.函数基础

4.运算符
5.流程控制语句
6.正则表达式
7.字符串函数
8.数据类型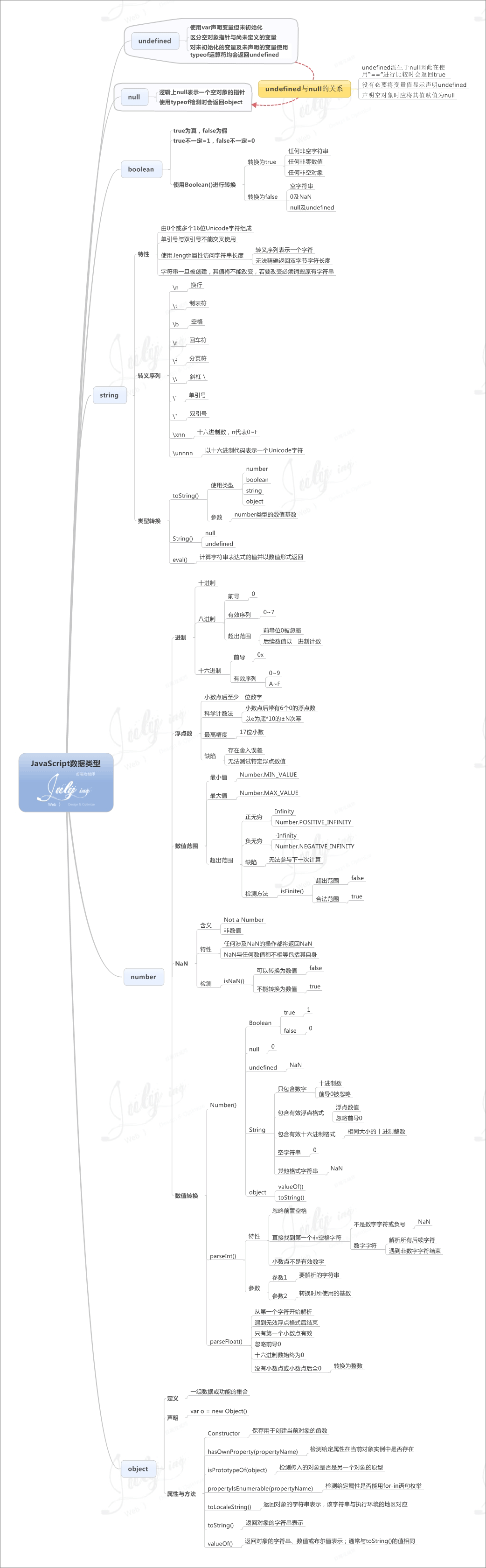
9.变量
10.window对象
Mysql 导入CSV数据
MYSQL LOAD DATA INFILE命令可以把csv平面文件中的数据导入到数据库中。
linux下:
- LOAD DATA INFILE '/home/test/dump/ip_location.csv'
- INTO TABLE ip_location
- CHARACTER SET utf8
- FIELDS TERMINATED BY ',' ENCLOSED BY '"';
--CHARACTER SET :mysql字符集,一定要加上,免去乱码麻烦
--INTO TABLE :导入到哪个表
--FIELDS TERMINATED BY :以什么作为分割符
-- ENCLOSED BY :被什么包围
windows:
- LOAD DATA INFILE "d:/insert_data.csv"
- REPLACE INTO TABLE DEMO
- CHARACTER SET gb2312
- FIELDS TERMINATED BY "," ENCLOSED BY ""
- LINES TERMINATED BY "\r\n";
--LINES TERMINATED BY:这个与linux不同,以什么作为一行的结尾。【原创】PHP超时处理全面总结
【 概述 】
在PHP开发中工作里非常多使用到超时处理到超时的场合,我说几个场景:
1. 异步获取数据如果某个后端数据源获取不成功则跳过,不影响整个页面展现
2. 为了保证Web服务器不会因为当个页面处理性能差而导致无法访问其他页面,则会对某些页面操作设置
3. 对于某些上传或者不确定处理时间的场合,则需要对整个流程中所有超时设置为无限,否则任何一个环节设置不当,都会导致莫名执行中断
4. 多个后端模块(MySQL、Memcached、HTTP接口),为了防止单个接口性能太差,导致整个前面获取数据太缓慢,影响页面打开速度,引起雪崩
5. 。。。很多需要超时的场合
这些地方都需要考虑超时的设定,但是PHP中的超时都是分门别类,各个处理方式和策略都不同,为了系统的描述,我总结了PHP中常用的超时处理的总结。
【Web服务器超时处理】
[ Apache ]
一般在性能很高的情况下,缺省所有超时配置都是30秒,但是在上传文件,或者网络速度很慢的情况下,那么可能触发超时操作。
目前 apache fastcgi php-fpm 模式 下有三个超时设置:
fastcgi 超时设置:
修改 httpd.conf 的fastcgi连接配置,类似如下:
| <IfModule mod_fastcgi.c> FastCgiExternalServer /home/forum/apache/apache_php/cgi-bin/php-cgi -socket /home/forum/php5/etc/php-fpm.sock
ScriptAlias /fcgi-bin/ "/home/forum/apache/apache_php/cgi-bin/" AddHandler php-fastcgi .php Action php-fastcgi /fcgi-bin/php-cgi AddType application/x-httpd-php .php </IfModule> |
缺省配置是 30s,如果需要定制自己的配置,需要修改配置,比如修改为100秒:(修改后重启 apache):
| <IfModule mod_fastcgi.c>
FastCgiExternalServer /home/forum/apache/apache_php/cgi-bin/php-cgi -socket /home/forum/php5/etc/php-fpm.sock -idle-timeout 100 ScriptAlias /fcgi-bin/ "/home/forum/apache/apache_php/cgi-bin/" AddHandler php-fastcgi .php Action php-fastcgi /fcgi-bin/php-cgi AddType application/x-httpd-php .php </IfModule>
|
如果超时会返回500错误,断开跟后端php服务的连接,同时记录一条apache错误日志:
[Thu Jan 27 18:30:15 2011] [error] [client 10.81.41.110] FastCGI: comm with server "/home/forum/apache/apache_php/cgi-bin/php-cgi" aborted: idle timeout (30 sec)
[Thu Jan 27 18:30:15 2011] [error] [client 10.81.41.110] FastCGI: incomplete headers (0 bytes) received from server "/home/forum/apache/apache_php/cgi-bin/php-cgi"
其他 fastcgi 配置参数说明:
| IdleTimeout 发呆时限ProcessLifeTime 一个进程的最长生命周期,过期之后无条件kill
MaxProcessCount 最大进程个数 DefaultMinClassProcessCount 每个程序启动的最小进程个数 DefaultMaxClassProcessCount 每个程序启动的最大进程个数 IPCConnectTimeout 程序响应超时时间 IPCCommTimeout 与程序通讯的最长时间,上面的错误有可能就是这个值设置过小造成的 MaxRequestsPerProcess 每个进程最多完成处理个数,达成后自杀 |
[ Lighttpd ]
配置:lighttpd.conf
Lighttpd配置中,关于超时的参数有如下几个(篇幅考虑,只写读超时,写超时参数同理):
主要涉及选项:
server.max-keep-alive-idle = 5
server.max-read-idle = 60
server.read-timeout = 0
server.max-connection-idle = 360
| --------------------------------------------------
# 每次keep-alive 的最大请求数, 默认值是16 server.max-keep-alive-requests = 100
# keep-alive的最长等待时间, 单位是秒,默认值是5 server.max-keep-alive-idle = 1200
# lighttpd的work子进程数,默认值是0,单进程运行 server.max-worker = 2
# 限制用户在发送请求的过程中,最大的中间停顿时间(单位是秒), # 如果用户在发送请求的过程中(没发完请求),中间停顿的时间太长,lighttpd会主动断开连接 # 默认值是60(秒) server.max-read-idle = 1200
# 限制用户在接收应答的过程中,最大的中间停顿时间(单位是秒), # 如果用户在接收应答的过程中(没接完),中间停顿的时间太长,lighttpd会主动断开连接 # 默认值是360(秒) server.max-write-idle = 12000
# 读客户端请求的超时限制,单位是秒, 配为0表示不作限制 # 设置小于max-read-idle时,read-timeout生效 server.read-timeout = 0
# 写应答页面给客户端的超时限制,单位是秒,配为0表示不作限制 # 设置小于max-write-idle时,write-timeout生效 server.write-timeout = 0
# 请求的处理时间上限,如果用了mod_proxy_core,那就是和后端的交互时间限制, 单位是秒 server.max-connection-idle = 1200 -------------------------------------------------- |
说明:
对于一个keep-alive连接上的连续请求,发送第一个请求内容的最大间隔由参数max-read-idle决定,从第二个请求起,发送请求内容的最大间隔由参数max-keep-alive-idle决定。请求间的间隔超时也由max-keep-alive-idle决定。发送请求内容的总时间超时由参数read-timeout决定。Lighttpd与后端交互数据的超时由max-connection-idle决定。
延伸阅读:
http://www.snooda.com/read/244
[ Nginx ]
配置:nginx.conf
| http {
#Fastcgi: (针对后端的fastcgi 生效, fastcgi 不属于proxy模式) fastcgi_connect_timeout 5; #连接超时 fastcgi_send_timeout 10; #写超时 fastcgi_read_timeout 10; #读取超时
#Proxy: (针对proxy/upstreams的生效) proxy_connect_timeout 15s; #连接超时 proxy_read_timeout 24s; #读超时 proxy_send_timeout 10s; #写超时 } |
说明:
Nginx 的超时设置倒是非常清晰容易理解,上面超时针对不同工作模式,但是因为超时带来的问题是非常多的。
延伸阅读:
http://hi.baidu.com/pibuchou/blog/item/a1e330dd71fb8a5995ee3753.html
http://hi.baidu.com/pibuchou/blog/item/7cbccff0a3b77dc60b46e024.html
http://hi.baidu.com/pibuchou/blog/item/10a549818f7e4c9df703a626.html
【PHP本身超时处理】
[ PHP-fpm ]
配置:php-fpm.conf
| <?xml version="1.0" ?>
<configuration> //... Sets the limit on the number of simultaneous requests that will be served. Equivalent to Apache MaxClients directive. Equivalent to PHP_FCGI_CHILDREN environment in original php.fcgi Used with any pm_style. #php-cgi的进程数量 <value name="max_children">128</value>
The timeout (in seconds) for serving a single request after which the worker process will be terminated Should be used when 'max_execution_time' ini option does not stop script execution for some reason '0s' means 'off' #php-fpm 请求执行超时时间,0s为永不超时,否则设置一个 Ns 为超时的秒数 <value name="request_terminate_timeout">0s</value>
The timeout (in seconds) for serving of single request after which a php backtrace will be dumped to slow.log file '0s' means 'off' <value name="request_slowlog_timeout">0s</value>
</configuration>
|
说明:
在 php.ini 中,有一个参数 max_execution_time 可以设置 PHP 脚本的最大执行时间,但是,在 php-cgi(php-fpm) 中,该参数不会起效。真正能够控制 PHP 脚本最大执行时:
<value name="request_terminate_timeout">0s</value>
就是说如果是使用 mod_php5.so 的模式运行 max_execution_time 是会生效的,但是如果是php-fpm模式中运行时不生效的。
延伸阅读:
http://blog.s135.com/file_get_contents/
[ PHP ]
配置:php.ini
选项:
max_execution_time = 30
或者在代码里设置:
ini_set("max_execution_time", 30);
set_time_limit(30);
说明:
对当前会话生效,比如设置0一直不超时,但是如果php的 safe_mode 打开了,这些设置都会不生效。
效果一样,但是具体内容需要参考php-fpm部分内容,如果php-fpm中设置了 request_terminate_timeout 的话,那么 max_execution_time 就不生效。
【后端&接口访问超时】
【HTTP访问】
一般我们访问HTTP方式很多,主要是:curl, socket, file_get_contents() 等方法。
如果碰到对方服务器一直没有响应的时候,我们就悲剧了,很容易把整个服务器搞死,所以在访问http的时候也需要考虑超时的问题。
[ CURL 访问HTTP]
CURL 是我们常用的一种比较靠谱的访问HTTP协议接口的lib库,性能高,还有一些并发支持的功能等。
CURL:
curl_setopt($ch, opt) 可以设置一些超时的设置,主要包括:
*(重要) CURLOPT_TIMEOUT 设置cURL允许执行的最长秒数。
*(重要) CURLOPT_TIMEOUT_MS 设置cURL允许执行的最长毫秒数。 (在cURL 7.16.2中被加入。从PHP 5.2.3起可使用。 )
CURLOPT_CONNECTTIMEOUT 在发起连接前等待的时间,如果设置为0,则无限等待。
CURLOPT_CONNECTTIMEOUT_MS 尝试连接等待的时间,以毫秒为单位。如果设置为0,则无限等待。 在cURL 7.16.2中被加入。从PHP 5.2.3开始可用。
CURLOPT_DNS_CACHE_TIMEOUT 设置在内存中保存DNS信息的时间,默认为120秒。
curl普通秒级超时:
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_TIMEOUT, 60); //只需要设置一个秒的数量就可以
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_USERAGENT, $defined_vars['HTTP_USER_AGENT']);
curl普通秒级超时使用:
curl_setopt($ch, CURLOPT_TIMEOUT, 60);
curl如果需要进行毫秒超时,需要增加:
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
或者是:
curl_setopt ( $ch, CURLOPT_NOSIGNAL, true); 是可以支持毫秒级别超时设置的
curl一个毫秒级超时的例子:
| <?php
if (!isset($_GET['foo'])) { // Client $ch = curl_init('http://example.com/'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_NOSIGNAL, 1); //注意,毫秒超时一定要设置这个 curl_setopt($ch, CURLOPT_TIMEOUT_MS, 200); //超时毫秒,cURL 7.16.2中被加入。从PHP 5.2.3起可使用 $data = curl_exec($ch); $curl_errno = curl_errno($ch); $curl_error = curl_error($ch); curl_close($ch);
if ($curl_errno > 0) { echo "cURL Error ($curl_errno): $curl_error\n"; } else { echo "Data received: $data\n"; } } else { // Server sleep(10); echo "Done."; } ?> |
其他一些技巧:
1. 按照经验总结是:cURL 版本 >= libcurl/7.21.0 版本,毫秒级超时是一定生效的,切记。
2. curl_multi的毫秒级超时也有问题。。单次访问是支持ms级超时的,curl_multi并行调多个会不准
[流处理方式访问HTTP]
除了curl,我们还经常自己使用fsockopen、或者是file操作函数来进行HTTP协议的处理,所以,我们对这块的超时处理也是必须的。
一般连接超时可以直接设置,但是流读取超时需要单独处理。
自己写代码处理:
$tmCurrent = gettimeofday();
$intUSGone = ($tmCurrent['sec'] - $tmStart['sec']) * 1000000
+ ($tmCurrent['usec'] - $tmStart['usec']);
if ($intUSGone > $this->_intReadTimeoutUS) {
return false;
}
或者使用内置流处理函数 stream_set_timeout() 和 stream_get_meta_data() 处理:
| <?php // Timeout in seconds
$timeout = 5; $fp = fsockopen("example.com", 80, $errno, $errstr, $timeout); if ($fp) { fwrite($fp, "GET / HTTP/1.0\r\n"); fwrite($fp, "Host: example.com\r\n"); fwrite($fp, "Connection: Close\r\n\r\n"); stream_set_blocking($fp, true); //重要,设置为非阻塞模式 stream_set_timeout($fp,$timeout); //设置超时 $info = stream_get_meta_data($fp); while ((!feof($fp)) && (!$info['timed_out'])) { $data .= fgets($fp, 4096); $info = stream_get_meta_data($fp); ob_flush; flush(); } if ($info['timed_out']) { echo "Connection Timed Out!"; } else { echo $data; } } |
file_get_contents 超时:
| <?php$timeout = array(
'http' => array( 'timeout' => 5 //设置一个超时时间,单位为秒 ) ); $ctx = stream_context_create($timeout); $text = file_get_contents("http://example.com/", 0, $ctx); ?> |
fopen 超时:
| <?php$timeout = array(
'http' => array( 'timeout' => 5 //设置一个超时时间,单位为秒 ) ); $ctx = stream_context_create($timeout); if ($fp = fopen("http://example.com/", "r", false, $ctx)) { while( $c = fread($fp, 8192)) { echo $c; } fclose($fp); } ?> |
【MySQL】
php中的mysql客户端都没有设置超时的选项,mysqli和mysql都没有,但是libmysql是提供超时选项的,只是我们在php中隐藏了而已。
那么如何在PHP中使用这个操作捏,就需要我们自己定义一些MySQL操作常量,主要涉及的常量有:
MYSQL_OPT_READ_TIMEOUT=11;
MYSQL_OPT_WRITE_TIMEOUT=12;
这两个,定义以后,可以使用 options 设置相应的值。
不过有个注意点,mysql内部实现:
1. 超时设置单位为秒,最少配置1秒
2. 但mysql底层的read会重试两次,所以实际会是 3 秒
重试两次 + 自身一次 = 3倍超时时间,那么就是说最少超时时间是3秒,不会低于这个值,对于大部分应用来说可以接受,但是对于小部分应用需要优化。
查看一个设置访问mysql超时的php实例:
| <?php//自己定义读写超时常量
if (!defined('MYSQL_OPT_READ_TIMEOUT')) { define('MYSQL_OPT_READ_TIMEOUT', 11); } if (!defined('MYSQL_OPT_WRITE_TIMEOUT')) { define('MYSQL_OPT_WRITE_TIMEOUT', 12); } //设置超时 $mysqli = mysqli_init(); $mysqli->options(MYSQL_OPT_READ_TIMEOUT, 3); $mysqli->options(MYSQL_OPT_WRITE_TIMEOUT, 1);
//连接数据库 $mysqli->real_connect("localhost", "root", "root", "test"); if (mysqli_connect_errno()) { printf("Connect failed: %s/n", mysqli_connect_error()); exit(); } //执行查询 sleep 1秒不超时 printf("Host information: %s/n", $mysqli->host_info); if (!($res=$mysqli->query('select sleep(1)'))) { echo "query1 error: ". $mysqli->error ."/n"; } else { echo "Query1: query success/n"; } //执行查询 sleep 9秒会超时 if (!($res=$mysqli->query('select sleep(9)'))) { echo "query2 error: ". $mysqli->error ."/n"; } else { echo "Query2: query success/n"; } $mysqli->close(); echo "close mysql connection/n"; ?> |
延伸阅读:
http://blog.csdn.net/heiyeshuwu/article/details/5869813
【Memcached】
[PHP扩展]
php_memcache 客户端:
连接超时:bool Memcache::connect ( string $host [, int $port [, int $timeout ]] )
在get和set的时候,都没有明确的超时设置参数。
libmemcached 客户端:在php接口没有明显的超时参数。
说明:所以说,在PHP中访问Memcached是存在很多问题的,需要自己hack部分操作,或者是参考网上补丁。
[C&C++访问Memcached]
客户端:libmemcached 客户端
说明:memcache超时配置可以配置小点,比如5,10个毫秒已经够用了,超过这个时间还不如从数据库查询。
下面是一个连接和读取set数据的超时的C++示例:
| //创建连接超时(连接到Memcached)
memcached_st* MemCacheProxy::_create_handle() { memcached_st * mmc = NULL; memcached_return_t prc; if (_mpool != NULL) { // get from pool mmc = memcached_pool_pop(_mpool, false, &prc); if (mmc == NULL) { __LOG_WARNING__("MemCacheProxy", "get handle from pool error [%d]", (int)prc); } return mmc; }
memcached_st* handle = memcached_create(NULL); if (handle == NULL){ __LOG_WARNING__("MemCacheProxy", "create_handle error"); return NULL; }
// 设置连接/读取超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_HASH, MEMCACHED_HASH_DEFAULT); memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_NO_BLOCK, _noblock); //参数MEMCACHED_BEHAVIOR_NO_BLOCK为1使超时配置生效,不设置超时会不生效,关键时候会悲剧的,容易引起雪崩 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_CONNECT_TIMEOUT, _connect_timeout); //连接超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_RCV_TIMEOUT, _read_timeout); //读超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_SND_TIMEOUT, _send_timeout); //写超时 memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_POLL_TIMEOUT, _poll_timeout);
// 设置一致hash // memcached_behavior_set_distribution(handle, MEMCACHED_DISTRIBUTION_CONSISTENT); memcached_behavior_set(handle, MEMCACHED_BEHAVIOR_DISTRIBUTION, MEMCACHED_DISTRIBUTION_CONSISTENT);
memcached_return rc; for (uint i = 0; i < _server_count; i++){ rc = memcached_server_add(handle, _ips[i], _ports[i]); if (MEMCACHED_SUCCESS != rc) { __LOG_WARNING__("MemCacheProxy", "add server [%s:%d] failed.", _ips[i], _ports[i]); } }
_mpool = memcached_pool_create(handle, _min_connect, _max_connect); if (_mpool == NULL){ __LOG_WARNING__("MemCacheProxy", "create_pool error"); return NULL; }
mmc = memcached_pool_pop(_mpool, false, &prc); if (mmc == NULL) { __LOG_WARNING__("MyMemCacheProxy", "get handle from pool error [%d]", (int)prc); } //__LOG_DEBUG__("MemCacheProxy", "get handle [%p]", handle); return mmc; }
//设置一个key超时(set一个数据到memcached) bool MemCacheProxy::_add(memcached_st* handle, unsigned int* key, const char* value, int len, unsigned int timeout) { memcached_return rc;
char tmp[1024]; snprintf(tmp, sizeof (tmp), "%u#%u", key[0], key[1]); //有个timeout值 rc = memcached_set(handle, tmp, strlen(tmp), (char*)value, len, timeout, 0); if (MEMCACHED_SUCCESS != rc){ return false; } return true; } |
//Memcache读取数据超时 (没有设置)
libmemcahed 源码中接口定义:
LIBMEMCACHED_API char *memcached_get(memcached_st *ptr,const char *key, size_t key_length,size_t *value_length,uint32_t *flags,memcached_return_t *error);
LIBMEMCACHED_API memcached_return_t memcached_mget(memcached_st *ptr,const char * const *keys,const size_t *key_length,size_t number_of_keys);
从接口中可以看出在读取数据的时候,是没有超时设置的。
延伸阅读:
http://hi.baidu.com/chinauser/item/b30af90b23335dde73e67608
http://libmemcached.org/libMemcached.html
【如何实现超时】
程序中需要有超时这种功能,比如你单独访问一个后端Socket模块,Socket模块不属于我们上面描述的任何一种的时候,它的协议也是私有的,那么这个时候可能需要自己去实现一些超时处理策略,这个时候就需要一些处理代码了。
[PHP中超时实现]
一、初级:最简单的超时实现 (秒级超时)
思路很简单:链接一个后端,然后设置为非阻塞模式,如果没有连接上就一直循环,判断当前时间和超时时间之间的差异。
php socket 中实现原始的超时:(每次循环都当前时间去减,性能会很差,cpu占用会较高)
| <? $host = "127.0.0.1";
$port = "80"; $timeout = 15; //timeout in seconds
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP) or die("Unable to create socket\n");
socket_set_nonblock($socket) //务必设置为阻塞模式 or die("Unable to set nonblock on socket\n");
$time = time(); //循环的时候每次都减去相应值 while (!@socket_connect($socket, $host, $port)) //如果没有连接上就一直死循环 { $err = socket_last_error($socket); if ($err == 115 || $err == 114) { if ((time() - $time) >= $timeout) //每次都需要去判断一下是否超时了 { socket_close($socket); die("Connection timed out.\n"); } sleep(1); continue; } die(socket_strerror($err) . "\n"); } socket_set_block($this->socket) //还原阻塞模式 or die("Unable to set block on socket\n"); ?> |
二、升级:使用PHP自带异步IO去实现(毫秒级超时)
说明:
异步IO:异步IO的概念和同步IO相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。异步IO将比特分成小组进行传送,小组可以是8位的1个字符或更长。发送方可以在任何时刻发送这些比特组,而接收方从不知道它们会在什么时候到达。
多路复用:复用模型是对多个IO操作进行检测,返回可操作集合,这样就可以对其进行操作了。这样就避免了阻塞IO不能随时处理各个IO和非阻塞占用系统资源的确定。
使用 socket_select() 实现超时
socket_select(..., floor($timeout), ceil($timeout*1000000));
select的特点:能够设置到微秒级别的超时!
使用socket_select() 的超时代码(需要了解一些异步IO编程的知识去理解)
| ### 调用类 ####
<?php $server = new Server; $client = new Client;
for (;;) { foreach ($select->can_read(0) as $socket) {
if ($socket == $client->socket) { // New Client Socket $select->add(socket_accept($client->socket)); } else { //there's something to read on $socket } } } ?>
### 异步多路复用IO & 超时连接处理类 ### <?php class select { var $sockets;
function select($sockets) {
$this->sockets = array();
foreach ($sockets as $socket) { $this->add($socket); } }
function add($add_socket) { array_push($this->sockets,$add_socket); }
function remove($remove_socket) { $sockets = array();
foreach ($this->sockets as $socket) { if($remove_socket != $socket) $sockets[] = $socket; }
$this->sockets = $sockets; }
function can_read($timeout) { $read = $this->sockets; socket_select($read,$write = NULL,$except = NULL,$timeout); return $read; }
function can_write($timeout) { $write = $this->sockets; socket_select($read = NULL,$write,$except = NULL,$timeout); return $write; } } ?> |
[C&C++中超时实现]
一般在Linux C/C++中,可以使用:alarm() 设置定时器的方式实现秒级超时,或者:select()、poll()、epoll() 之类的异步复用IO实现毫秒级超时。也可以使用二次封装的异步io库(libevent, libev)也能实现。
一、使用alarm中用信号实现超时 (秒级超时)
说明:Linux内核connect超时通常为75秒,我们可以设置更小的时间如10秒来提前从connect中返回。这里用使用信号处理机制,调用alarm,超时后产生SIGALRM信号 (也可使用select实现)
用 alarym 秒级实现 connect 设置超时代码示例:
| //信号处理函数static void connect_alarm(int signo)
{ debug_printf("SignalHandler"); return; }
//alarm超时连接实现 static void conn_alarm() { Sigfunc * sigfunc ; //现有信号处理函数 sigfunc=signal(SIGALRM, connect_alarm); //建立信号处理函数connect_alarm,(如果有)保存现有的信号处理函数 int timeout = 5;
//设置闹钟 if( alarm(timeout)!=0 ){ //... 闹钟已经设置处理 }
//进行连接操作 if (connect(m_Socket, (struct sockaddr *)&addr, sizeof(addr)) < 0 ) { if ( errno == EINTR ) { //如果错误号设置为EINTR,说明超时中断了 debug_printf("Timeout"); m_connectionStatus = STATUS_CLOSED; errno = ETIMEDOUT; //防止三次握手继续进行 return ERR_TIMEOUT; } else { debug_printf("Other Err"); m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } } alarm(0);//关闭时钟 signal(SIGALRM, sigfunc); //(如果有)恢复原来的信号处理函数 return; } |
//读取数据的超时设置
同样可以为 recv 设置超时,5秒内收不到任何应答就中断
signal( ... );
alarm(5);
recv( ... );
alarm(0);
static void sig_alarm(int signo){return;}
当客户端阻塞于读(readline,...)时,如果此时服务器崩了,客户TCP试图从服务器接收一个ACK,持续重传 数据分节,大约要等9分钟才放弃重传,并返回一个错误。因此,在客户读阻塞时,调用超时。
二、使用异步复用IO使用 (毫秒级超时)
异步IO执行流程:
1.首先将标志位设为Non-blocking模式,准备在非阻塞模式下调用connect函数
2.调用connect,正常情况下,因为TCP三次握手需要一些时间;而非阻塞调用只要不能立即完成就会返回错误,所以这里会返回EINPROGRESS,表示在建立连接但还没有完成。
3.在读套接口描述符集(fd_set rset)和写套接口描述符集(fd_set wset)中将当前套接口置位(用FD_ZERO()、FD_SET()宏),并设置好超时时间(struct timeval *timeout)
4.调用select( socket, &rset, &wset, NULL, timeout )
返回0表示connect超时,如果你设置的超时时间大于75秒就没有必要这样做了,因为内核中对connect有超时限制就是75秒。
//select 实现毫秒级超时示例:
| static void conn_select() {
// Open TCP Socket m_Socket = socket(PF_INET,SOCK_STREAM,0); if( m_Socket < 0 ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; }
struct sockaddr_in addr; inet_aton(m_Host.c_str(), &addr.sin_addr); addr.sin_port = htons(m_Port); addr.sin_family = PF_INET;
// Set timeout values for socket struct timeval timeouts; timeouts.tv_sec = SOCKET_TIMEOUT_SEC ; // const -> 5 timeouts.tv_usec = SOCKET_TIMEOUT_USEC ; // const -> 0 uint8_t optlen = sizeof(timeouts);
if( setsockopt( m_Socket, SOL_SOCKET, SO_RCVTIMEO,&timeouts,(socklen_t)optlen) < 0 ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; }
// Set the Socket to TCP Nodelay ( Send immediatly after a send / write command ) int flag_TCP_nodelay = 1; if ( (setsockopt( m_Socket, IPPROTO_TCP, TCP_NODELAY, (char *)&flag_TCP_nodelay, sizeof(flag_TCP_nodelay))) < 0) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } // Save Socket Flags int opts_blocking = fcntl(m_Socket, F_GETFL); if ( opts_blocking < 0 ) { return ERR_NET_SOCKET; } //设置为非阻塞模式 int opts_noblocking = (opts_blocking | O_NONBLOCK); // Set Socket to Non-Blocking if (fcntl(m_Socket, F_SETFL, opts_noblocking)<0) { return ERR_NET_SOCKET; } // Connect if ( connect(m_Socket, (struct sockaddr *)&addr, sizeof(addr)) < 0) { // EINPROGRESS always appears on Non Blocking connect if ( errno != EINPROGRESS ) { m_connectionStatus = STATUS_CLOSED; return ERR_NET_SOCKET; } // Create a set of sockets for select fd_set socks; FD_ZERO(&socks); FD_SET(m_Socket,&socks); // Wait for connection or timeout int fdcnt = select(m_Socket+1,NULL,&socks,NULL,&timeouts); if ( fdcnt < 0 ) { return ERR_NET_SOCKET; } else if ( fdcnt == 0 ) { return ERR_TIMEOUT; } } //Set Socket to Blocking again if(fcntl(m_Socket,F_SETFL,opts_blocking)<0) { return ERR_NET_SOCKET; }
m_connectionStatus = STATUS_OPEN; return 0; } |
说明:在超时实现方面,不论是什么脚本语言:PHP、Python、Perl 基本底层都是C&C++的这些实现方式,需要理解这些超时处理,需要一些Linux 编程和网络编程的知识。
延伸阅读:
http://blog.sina.com.cn/s/blog_4462f8560100tvgo.html
http://blog.csdn.net/thimin/article/details/1530839
http://hi.baidu.com/xjtdy888/item/93d9daefcc1d31d1ea34c992
http://blog.csdn.net/byxdaz/article/details/5461142
http://blog.163.com/xychenbaihu@yeah/blog/static/13222965520112163171778/
http://hi.baidu.com/suyupin/item/df10004decb620e91f19bcf5
http://stackoverflow.com/questions/7092633/connect-timeout-with-alarm
http://stackoverflow.com/questions/7089128/linux-tcp-connect-with-select-fails-at-testserver?lq=1
http://cppentry.com/bencandy.php?fid=54&id=1129
【 总结 】
1. PHP应用层如何设置超时?
PHP在处理超时层次有很多,不同层次,需要前端包容后端超时:
浏览器(客户端) -> 接入层 -> Web服务器 -> PHP -> 后端 (MySQL、Memcached)
就是说,接入层(Web服务器层)的超时时间必须大于PHP(PHP-FPM)中设置的超时时间,不然后面没处理完,你前面就超时关闭了,这个会很杯具。还有就是PHP的超时时间要大于PHP本身访问后端(MySQL、HTTP、Memcached)的超时时间,不然结局同前面。
2. 超时设置原则是什么?
如果是希望永久不超时的代码(比如上传,或者定期跑的程序),我仍然建议设置一个超时时间,比如12个小时这样的,主要是为了保证不会永久夯住一个php进程或者后端,导致无法给其他页面提供服务,最终引起所有机器雪崩。
如果是要要求快速响应的程序,建议后端超时设置短一些,比如连接500ms,读1s,写1s,这样的速度,这样能够大幅度减少应用雪崩的问题,不会让服务器负载太高。
3. 自己开发超时访问合适吗?
一般如果不是万不得已,建议用现有很多网络编程框架也好、基础库也好,里面一般都带有超时的实现,比如一些网络IO的lib库,尽量使用它们内置的,自己重复造轮子容易有bug,也不方便维护(不过如是是基于学习的目的就当别论了)。
4. 其他建议
超时在所有应用里都是大问题,在开发应用的时候都要考虑到。我见过一些应用超时设置上百秒的,这种性能就委实差了,我举个例子:
比如你php-fpm开了128个php-cgi进程,然后你的超时设置的是32s,那么我们如果后端服务比较差,极端情况下,那么最多每秒能响应的请求是:
128 / 32 = 4个
你没看错,1秒只能处理4个请求,那服务也太差了!虽然我们可以把php-cgi进程开大,但是内存占用,还有进程之间切换成本也会增加,cpu呀,内存呀都会增加,服务也会不稳定。所以,尽量设置一个合理的超时值,或者督促后端提高性能。
让你的IE6、7、8 都很好的支持HTML5标签
在旧有的浏览器里面,很多元素都是不支持的,即使解析出来也是内联标签。所以某位外国大牛就写了JS把文本中的一些标记替换成了块标签,从而解决了IE的很多历史遗留问题。这对于HTML5的使用推广来说是一个历史性的变革,也能很好的解决一些兼容性问题。
https://github.com/sebastianbergmann/php-code-coverage/pull/128
JS代码:
001 |
/** |
002 |
* @preserve HTML5 Shiv v3.6.2pre | @afarkas @jdalton @jon_neal @rem | MIT/GPL2 Licensed |
003 |
*/ |
004 |
;(function(window, document) { |
005 |
/*jshint evil:true */ |
006 |
/** version */ |
007 |
var version = '3.6.2pre'; |
008 |
009 |
/** Preset options */ |
010 |
var options = window.html5 || {}; |
011 |
012 |
/** Used to skip problem elements */ |
013 |
var reSkip = /^<|^(?:button|map|select|textarea|object|iframe|option|optgroup)$/i; |
014 |
015 |
/** Not all elements can be cloned in IE **/ |
016 |
var saveClones = /^(?:a|b|code|div|fieldset|h1|h2|h3|h4|h5|h6|i|label|li|ol|p|q|span|strong|style|table|tbody|td|th|tr|ul)$/i; |
017 |
018 |
/** Detect whether the browser supports default html5 styles */ |
019 |
var supportsHtml5Styles; |
020 |
021 |
/** Name of the expando, to work with multiple documents or to re-shiv one document */ |
022 |
var expando = '_html5shiv'; |
023 |
024 |
/** The id for the the documents expando */ |
025 |
var expanID = 0; |
026 |
027 |
/** Cached data for each document */ |
028 |
var expandoData = {}; |
029 |
030 |
/** Detect whether the browser supports unknown elements */ |
031 |
var supportsUnknownElements; |
032 |
033 |
(function() { |
034 |
try { |
035 |
var a = document.createElement('a'); |
036 |
a.innerHTML = '<xyz></xyz>'; |
037 |
//if the hidden property is implemented we can assume, that the browser supports basic HTML5 Styles |
038 |
supportsHtml5Styles = ('hidden' in a); |
039 |
040 |
supportsUnknownElements = a.childNodes.length == 1 || (function() { |
041 |
// assign a false positive if unable to shiv |
042 |
(document.createElement)('a'); |
043 |
var frag = document.createDocumentFragment(); |
044 |
return ( |
045 |
typeof frag.cloneNode == 'undefined' || |
046 |
typeof frag.createDocumentFragment == 'undefined' || |
047 |
typeof frag.createElement == 'undefined' |
048 |
); |
049 |
}()); |
050 |
} catch(e) { |
051 |
supportsHtml5Styles = true; |
052 |
supportsUnknownElements = true; |
053 |
} |
054 |
055 |
}()); |
056 |
057 |
/*--------------------------------------------------------------------------*/ |
058 |
059 |
/** |
060 |
* Creates a style sheet with the given CSS text and adds it to the document. |
061 |
* @private |
062 |
* @param {Document} ownerDocument The document. |
063 |
* @param {String} cssText The CSS text. |
064 |
* @returns {StyleSheet} The style element. |
065 |
*/ |
066 |
function addStyleSheet(ownerDocument, cssText) { |
067 |
var p = ownerDocument.createElement('p'), |
068 |
parent = ownerDocument.getElementsByTagName('head')[0] || ownerDocument.documentElement; |
069 |
070 |
p.innerHTML = 'x<style>' + cssText + '</style>'; |
071 |
return parent.insertBefore(p.lastChild, parent.firstChild); |
072 |
} |
073 |
074 |
/** |
075 |
* Returns the value of `html5.elements` as an array. |
076 |
* @private |
077 |
* @returns {Array} An array of shived element node names. |
078 |
*/ |
079 |
function getElements() { |
080 |
var elements = html5.elements; |
081 |
return typeof elements == 'string' ? elements.split(' ') : elements; |
082 |
} |
083 |
|
084 |
/** |
085 |
* Returns the data associated to the given document |
086 |
* @private |
087 |
* @param {Document} ownerDocument The document. |
088 |
* @returns {Object} An object of data. |
089 |
*/ |
090 |
function getExpandoData(ownerDocument) { |
091 |
var data = expandoData[ownerDocument[expando]]; |
092 |
if (!data) { |
093 |
data = {}; |
094 |
expanID++; |
095 |
ownerDocument[expando] = expanID; |
096 |
expandoData[expanID] = data; |
097 |
} |
098 |
return data; |
099 |
} |
100 |
101 |
/** |
102 |
* returns a shived element for the given nodeName and document |
103 |
* @memberOf html5 |
104 |
* @param {String} nodeName name of the element |
105 |
* @param {Document} ownerDocument The context document. |
106 |
* @returns {Object} The shived element. |
107 |
*/ |
108 |
function createElement(nodeName, ownerDocument, data){ |
109 |
if (!ownerDocument) { |
110 |
ownerDocument = document; |
111 |
} |
112 |
if(supportsUnknownElements){ |
113 |
return ownerDocument.createElement(nodeName); |
114 |
} |
115 |
if (!data) { |
116 |
data = getExpandoData(ownerDocument); |
117 |
} |
118 |
var node; |
119 |
120 |
if (data.cache[nodeName]) { |
121 |
node = data.cache[nodeName].cloneNode(); |
122 |
} else if (saveClones.test(nodeName)) { |
123 |
node = (data.cache[nodeName] = data.createElem(nodeName)).cloneNode(); |
124 |
} else { |
125 |
node = data.createElem(nodeName); |
126 |
} |
127 |
128 |
// Avoid adding some elements to fragments in IE < 9 because |
129 |
// * Attributes like `name` or `type` cannot be set/changed once an element |
130 |
// is inserted into a document/fragment |
131 |
// * Link elements with `src` attributes that are inaccessible, as with |
132 |
// a 403 response, will cause the tab/window to crash |
133 |
// * Script elements appended to fragments will execute when their `src` |
134 |
// or `text` property is set |
135 |
return node.canHaveChildren && !reSkip.test(nodeName) ? data.frag.appendChild(node) : node; |
136 |
} |
137 |
138 |
/** |
139 |
* returns a shived DocumentFragment for the given document |
140 |
* @memberOf html5 |
141 |
* @param {Document} ownerDocument The context document. |
142 |
* @returns {Object} The shived DocumentFragment. |
143 |
*/ |
144 |
function createDocumentFragment(ownerDocument, data){ |
145 |
if (!ownerDocument) { |
146 |
ownerDocument = document; |
147 |
} |
148 |
if(supportsUnknownElements){ |
149 |
return ownerDocument.createDocumentFragment(); |
150 |
} |
151 |
data = data || getExpandoData(ownerDocument); |
152 |
var clone = data.frag.cloneNode(), |
153 |
i = 0, |
154 |
elems = getElements(), |
155 |
l = elems.length; |
156 |
for(;i<l;i++){ |
157 |
clone.createElement(elems[i]); |
158 |
} |
159 |
return clone; |
160 |
} |
161 |
162 |
/** |
163 |
* Shivs the `createElement` and `createDocumentFragment` methods of the document. |
164 |
* @private |
165 |
* @param {Document|DocumentFragment} ownerDocument The document. |
166 |
* @param {Object} data of the document. |
167 |
*/ |
168 |
function shivMethods(ownerDocument, data) { |
169 |
if (!data.cache) { |
170 |
data.cache = {}; |
171 |
data.createElem = ownerDocument.createElement; |
172 |
data.createFrag = ownerDocument.createDocumentFragment; |
173 |
data.frag = data.createFrag(); |
174 |
} |
175 |
176 |
177 |
ownerDocument.createElement = function(nodeName) { |
178 |
//abort shiv |
179 |
if (!html5.shivMethods) { |
180 |
return data.createElem(nodeName); |
181 |
} |
182 |
return createElement(nodeName, ownerDocument, data); |
183 |
}; |
184 |
185 |
ownerDocument.createDocumentFragment = Function('h,f','return function(){' + |
186 |
'var n=f.cloneNode(),c=n.createElement;' + |
187 |
'h.shivMethods&&(' + |
188 |
// unroll the `createElement` calls |
189 |
getElements().join().replace(/\w+/g, function(nodeName) { |
190 |
data.createElem(nodeName); |
191 |
data.frag.createElement(nodeName); |
192 |
return 'c("' + nodeName + '")'; |
193 |
}) + |
194 |
');return n}' |
195 |
)(html5, data.frag); |
196 |
} |
197 |
198 |
/*--------------------------------------------------------------------------*/ |
199 |
200 |
/** |
201 |
* Shivs the given document. |
202 |
* @memberOf html5 |
203 |
* @param {Document} ownerDocument The document to shiv. |
204 |
* @returns {Document} The shived document. |
205 |
*/ |
206 |
function shivDocument(ownerDocument) { |
207 |
if (!ownerDocument) { |
208 |
ownerDocument = document; |
209 |
} |
210 |
var data = getExpandoData(ownerDocument); |
211 |
212 |
if (html5.shivCSS && !supportsHtml5Styles && !data.hasCSS) { |
213 |
data.hasCSS = !!addStyleSheet(ownerDocument, |
214 |
// corrects block display not defined in IE6/7/8/9 |
215 |
'article,aside,figcaption,figure,footer,header,hgroup,nav,section{display:block}'+ |
216 |
// adds styling not present in IE6/7/8/9 |
217 |
'mark{background:#FF0;color:#000}' |
218 |
); |
219 |
} |
220 |
if (!supportsUnknownElements) { |
221 |
shivMethods(ownerDocument, data); |
222 |
} |
223 |
return ownerDocument; |
224 |
} |
225 |
226 |
/*--------------------------------------------------------------------------*/ |
227 |
228 |
/** |
229 |
* The `html5` object is exposed so that more elements can be shived and |
230 |
* existing shiving can be detected on iframes. |
231 |
* @type Object |
232 |
* @example |
233 |
* |
234 |
* // options can be changed before the script is included |
235 |
* html5 = { 'elements': 'mark section', 'shivCSS': false, 'shivMethods': false }; |
236 |
*/ |
237 |
var html5 = { |
238 |
239 |
/** |
240 |
* An array or space separated string of node names of the elements to shiv. |
241 |
* @memberOf html5 |
242 |
* @type Array|String |
243 |
*/ |
244 |
'elements': options.elements || 'abbr article aside audio bdi canvas data datalist details figcaption figure footer header hgroup mark meter nav output progress section summary time video', |
245 |
246 |
/** |
247 |
* current version of html5shiv |
248 |
*/ |
249 |
'version': version, |
250 |
251 |
/** |
252 |
* A flag to indicate that the HTML5 style sheet should be inserted. |
253 |
* @memberOf html5 |
254 |
* @type Boolean |
255 |
*/ |
256 |
'shivCSS': (options.shivCSS !== false), |
257 |
258 |
/** |
259 |
* Is equal to true if a browser supports creating unknown/HTML5 elements |
260 |
* @memberOf html5 |
261 |
* @type boolean |
262 |
*/ |
263 |
'supportsUnknownElements': supportsUnknownElements, |
264 |
265 |
/** |
266 |
* A flag to indicate that the document's `createElement` and `createDocumentFragment` |
267 |
* methods should be overwritten. |
268 |
* @memberOf html5 |
269 |
* @type Boolean |
270 |
*/ |
271 |
'shivMethods': (options.shivMethods !== false), |
272 |
273 |
/** |
274 |
* A string to describe the type of `html5` object ("default" or "default print"). |
275 |
* @memberOf html5 |
276 |
* @type String |
277 |
*/ |
278 |
'type': 'default', |
279 |
280 |
// shivs the document according to the specified `html5` object options |
281 |
'shivDocument': shivDocument, |
282 |
283 |
//creates a shived element |
284 |
createElement: createElement, |
285 |
286 |
//creates a shived documentFragment |
287 |
createDocumentFragment: createDocumentFragment |
288 |
}; |
289 |
290 |
/*--------------------------------------------------------------------------*/ |
291 |
292 |
// expose html5 |
293 |
window.html5 = html5; |
294 |
295 |
// shiv the document |
296 |
shivDocument(document); |
297 |
298 |
}(this, document)); |
然后把html5shiv.js在head里面引入:
01 |
<!DOCTYPE HTML> |
02 |
<html lang="en-US"> |
03 |
<head> |
04 |
<meta charset="UTF-8"> |
05 |
<title></title> |
06 |
<script type="text/javascript" src="html5.js"></script> |
07 |
<style type="text/css"> |
08 |
nav { |
09 |
width:200px; |
10 |
height:100px; |
11 |
background:#f12; |
12 |
} |
13 |
</style> |
14 |
</head> |
15 |
<body> |
16 |
<nav>Springload</nav>Springload |
17 |
</body> |
18 |
</html> |
在IE8中打开查看你就会发现nav这个HTML5元素标签,可以正常使用和显示。
simple_html_dom使用小结
<?php
include "simple_html_dom.php" ; // Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '<br>';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '<br>';
// Create DOM from URL
$html = file_get_html('http://slashdot.org/');
// Find all article blocks
foreach($html->find('div.article') as $article) {
$item['title'] = $article->find('div.title', 0)->plaintext;
$item['intro'] = $article->find('div.intro', 0)->plaintext;
$item['details'] = $article->find('div.details', 0)->plaintext;
$articles[] = $item;
}
print_r($articles);
// Create DOM from string
$html = str_get_html('<div id="hello">Hello</div><div id="world">World</div>'); $html->find('div', 1)->class = 'bar';
$html->find('div[id=hello]', 0)->innertext = 'foo';
echo $html; // Output: <div id="hello">foo</div><div id="world" class="bar">World</div>
| Name | Description |
|---|---|
|
void
__construct ( [string $filename] ) |
Constructor, set the filename parameter will automatically load the contents, either text or file/url. |
|
string
plaintext |
Returns the contents extracted from HTML. |
|
void
clear () |
Clean up memory. |
|
void
load ( string $content ) |
Load contents from a string. |
|
string
save ( [string $filename] ) |
Dumps the internal DOM tree back into a string. If the $filename is set, result string will save to file. |
|
void
load_file ( string $filename ) |
Load contents from a from a file or a URL. |
|
void
set_callback ( string $function_name ) |
Set a callback function. |
|
mixed
find ( string $selector [, int $index] ) |
Find elements by the CSS selector. Returns the Nth element object if index is set, otherwise return an array of object. |
$ret = $html->find('a');
// Find (N)th anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', 0);
// Find lastest anchor, returns element object or null if not found (zero based)
$ret = $html->find('a', -1);
// Find all <div> with the id attribute
$ret = $html->find('div[id]');
// Find all <div> which attribute id=foo
$ret = $html->find('div[id=foo]');
$ret = $html->find('#foo');
// Find all element which class=foo
$ret = $html->find('.foo');
// Find all element has attribute id
$ret = $html->find('*[id]');
// Find all anchors and images
$ret = $html->find('a, img');
// Find all anchors and images with the "title" attribute
$ret = $html->find('a[title], img[title]');
$es = $html->find('ul li');
// Find Nested <div> tags
$es = $html->find('div div div');
// Find all <td> in <table> which
$es = $html->find('table.hello td');
// Find all td tags with attribite align=center in table tags
$es = $html->find(''table td[align=center]');
| Attribute Name | Usage |
|---|---|
| $e->tag | Read or write the tag name of element. |
| $e->outertext | Read or write the outer HTML text of element. |
| $e->innertext | Read or write the inner HTML text of element. |
| $e->plaintext | Read or write the plain text of element. |
$html = str_get_html("<div>foo <b>bar</b></div>");
$e = $html->find("div", 0);
echo $e->outertext; // Returns: " <div>foo <b>bar</b></div>"
echo $e->innertext; // Returns: " foo <b>bar</b>"
echo $e->plaintext; // Returns: " foo bar"
6.DOM traversing 方法
| Method | Description |
|---|---|
|
mixed
$e->children ( [int $index] ) |
Returns the Nth child object if index is set, otherwise return an array of children. |
|
element
$e->parent () |
Returns the parent of element. |
|
element
$e->first_child () |
Returns the first child of element, or null if not found. |
|
element
$e->last_child () |
Returns the last child of element, or null if not found. |
|
element
$e->next_sibling () |
Returns the next sibling of element, or null if not found. |
|
element
$e->prev_sibling () |
Returns the previous sibling of element, or null if not found. |
echo $html->find("#div1", 0)->children(1)->children(1)->children(2)->id;
// or
echo $html->getElementById("div1")->childNodes(1)->childNodes(1)->childNodes(2)->getAttribute('id');
function my_callback($element) {
// Hide all <b> tags
if ($element->tag=='b')
$element->outertext = '';
}
// Register the callback function with it's function name
$html->set_callback('my_callback');
// Callback function will be invoked while dumping
echo $html;
各种代码准确识别手机浏览器和Web浏览器访问
使用浏览器访问 此URL http://shaozhuqing.com/s/dmb
如果为移动设备会跳转到 http://shaozhuqing.com/s/dmb/mobile.php
本站提供以下各种代码准确识别手机浏览器和Web浏览器
下载请移步 http://shaozhuqing.com/s/dmb
"apache" => "download/detectmobilebrowser.htaccess.txt",
"asp" => "download/detectmobilebrowser.asp.txt",
"aspx" => "download/detectmobilebrowser.aspx.txt",
"coldfusion" => "download/detectmobilebrowser.cfm.txt",
"cs" => "download/detectmobilebrowser.cs.txt",
"iis" => "download/detectmobilebrowser.web.config.txt",
"jsp" => "download/detectmobilebrowser.jsp.txt",
"javascript" => "download/detectmobilebrowser.js.txt",
"jquery" => "download/detectmobilebrowser.jquery.txt",
"lasso" => "download/detectmobilebrowser.lasso.txt",
"nginx" => "download/detectmobilebrowser.conf.txt",
"node" => "download/detectmobilebrowser.nodejs.txt",
"php" => "download/detectmobilebrowser.php.txt",
"perl" => "download/detectmobilebrowser.pl.txt",
"python" => "download/detectmobilebrowser.middleware.py.txt",
"rails" => "download/detectmobilebrowser.rb.txt"
mysql 截取字符串
1. 字符串截取:left(str, length)
mysql> select left('linuxidc.com', 3);
+-------------------------+
| left('linuxidc.com', 3) |
+-------------------------+
| sql |
+-------------------------+
2. 字符串截取:right(str, length)
mysql> select right('linuxidc.com', 3);
+--------------------------+
| right('linuxidc.com', 3) |
+--------------------------+
| com |
+--------------------------+
3. 字符串截取:substring(str, pos); substring(str, pos, len)
3.1 从字符串的第 4 个字符位置开始取,直到结束。
mysql> select substring('linuxidc.com', 4);
+------------------------------+
| substring('linuxidc.com', 4) |
+------------------------------+
| study.com |
+------------------------------+
3.2 从字符串的第 4 个字符位置开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', 4, 2);
+---------------------------------+
| substring('linuxidc.com', 4, 2) |
+---------------------------------+
| st |
+---------------------------------+
3.3 从字符串的第 4 个字符位置(倒数)开始取,直到结束。
mysql> select substring('linuxidc.com', -4);
+-------------------------------+
| substring('linuxidc.com', -4) |
+-------------------------------+
| .com |
+-------------------------------+
3.4 从字符串的第 4 个字符位置(倒数)开始取,只取 2 个字符。
mysql> select substring('linuxidc.com', -4, 2);
+----------------------------------+
| substring('linuxidc.com', -4, 2) |
+----------------------------------+
| .c |
+----------------------------------+
我们注意到在函数 substring(str,pos, len)中, pos 可以是负值,但 len 不能取负值。
4. 字符串截取:substring_index(str,delim,count)
4.1 截取第二个 '.' 之前的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', 2);
+------------------------------------------------+
| substring_index('www.linuxidc.com', '.', 2) |
+------------------------------------------------+
| www |
+------------------------------------------------+
4.2 截取第二个 '.' (倒数)之后的所有字符。
mysql> select substring_index('www.linuxidc.com', '.', -2);
+-------------------------------------------------+
| substring_index('www.linuxidc.com', '.', -2) |
+-------------------------------------------------+
| com.cn |
+-------------------------------------------------+
4.3 如果在字符串中找不到 delim 参数指定的值,就返回整个字符串
mysql> select substring_index('www.linuxidc.com', '.coc', 1);
+---------------------------------------------------+
| substring_index('www.linuxidc.com', '.coc', 1) |
+---------------------------------------------------+
| www.linuxidc.com |
+---------------------------------------------------+
fgetcsv读取不了中文解决办法
fgetcsv读取不了中文
已设置setlocale(LC_ALL, 'zh_CN'),但在读取csv文件的时候,有时不能读取里面的中文,这是为什么?跟系统系统好像有关系!
------解决方案--------------------------------------------------------
文档编码和系统编码相同吗,不相同的话iconv把文档编码转成系统编码。
------解决方案--------------------------------------------------------
fgetcsv有BUG。
用这个函数吧。
- PHP code
function _fgetcsv(& $handle, $length = null, $d = ',', $e = '"') {
$d = preg_quote($d);
$e = preg_quote($e);
$_line = "";
$eof=false;
while ($eof != true) {
$_line .= (empty ($length) ? fgets($handle) : fgets($handle, $length));
$itemcnt = preg_match_all('/' . $e . '/', $_line, $dummy);
if ($itemcnt % 2 == 0)
$eof = true;
}
$_csv_line = preg_replace('/(?: |[ ])?$/', $d, trim($_line));
$_csv_pattern = '/(' . $e . '[^' . $e . ']*(?:' . $e . $e . '[^' . $e . ']*)*' . $e . '|[^' . $d . ']*)' . $d . '/';
preg_match_all($_csv_pattern, $_csv_line, $_csv_matches);
$_csv_data = $_csv_matches[1];
for ($_csv_i = 0; $_csv_i < count($_csv_data); $_csv_i++) {
$_csv_data[$_csv_i] = preg_replace('/^' . $e . '(.*)' . $e . '$/s', '$1' , $_csv_data[$_csv_i]);
$_csv_data[$_csv_i] = str_replace($e . $e, $e, $_csv_data[$_csv_i]);
}
return empty ($_line) ? false : $_csv_data;
}
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
