Centos安装PHP的IMAP模块LNMP
学习记录一些 Linux 上的东西:
1.首先 ssh 连接上你的服务器:然后执行以下代码:
|
1
2
3
4
|
yum install -y libc-client-devel
ln -s /usr/lib64/libc-client.so /usr/lib/libc-client.so
ln -s /usr/lib64/libkrb5.so /usr/lib/libkrb5.so
ln -s /usr/lib64/libssl.so /usr/lib/libssl.so
|
2.然后准备安装:
|
1
2
3
4
5
6
|
#根据自己的 php 安装包路径填写 如果没有发现文件请解压相关文件夹
cd /root/lnmp1.3-full/src/php-7.0.8/ext/imap
/usr/local/php/bin/phpize
./configure -with-imap -with-php-config=/usr/local/php/bin/php-config --with-kerberos=/usr --with-imap-ssl=/usr
make
make install
|
3.然后把编译好的静态模块添加进 php.ini 文件就好:
|
1
2
3
|
vim /usr/local/php/etc/php.ini
#把下面一段代码插入最底部即可
extension = "imap.so"
|
4.然后重启 PHP:
|
1
|
lnmp php-fpm restart
|
WebSocket全双工通信入门教程
1. 什么是WebSocket
WebSocket protocol 是HTML5一种新的协议。它实现了浏览器与服务器全双工通信(full-duplex)。一开始的握手需要借助HTTP请求完成。
1. 传统的web通信方式
1. 工作模式:客户端请求-服务端响应
2. 适用场景:信息变化不是特别频繁的场合,如网页刷新
3. 不适用场景:在线游戏,实时监控
4. 问题
占用网络传输带宽:每次请求和应答都带有完整的Http头,这就增加了每次传输的数据量。
实时性差:在全双工通信时常采用轮询进行。
2. 改进版web通信方式
1. 轮询
1. 基于polling(轮询)技术:以频繁请求方式来保持客户端和服务端的同步
2. 问题:客户端的频繁的请求,服务端的数据无变化,造成通信低效
2. 长轮询
1. 当服务端没有数据更新的时候,连接会保持一段时间周期直到数据或者状态改变或者过期,以此减少无效的客户端和服务端的交互
2. 当服务端数据变更频繁的话,这种机制和定时轮询毫无区别
3. 流技术
1. 在客户端页面通过一个隐藏的窗口向服务端发出一个长连接请求。服务端接到这个请求后作出回应并不断更新链接状态以保证客户端和服务端的连接不过期。
2. 浏览器设计兼容和并发处理问题。
4. websocket
1. 概念:是html5开始提供的一种在单个TCP连接上进行全双工通讯协议。Websocket通信协议与2011年倍IETF定为标准RFC 6455,Websocket API被W3C定为标准。
2. 原理和TCP一样,只需做一个握手动作,就可以形成一条快速通道。
1. 客户端发起http请求,附加头信息为:“Upgrade Websocket”
2. 服务端解析,并返回握手信息,从而建立连接
3. 传输数据(双向)
4. 断开连接
3. 数据传输过程
1. 以帧形式进行传输
1. 大数据分片
2. 支持边生成数据,把你传递消息
2. 说明
1. 客户端到服务端的数据帧必须进行掩码处理,服务端拖接收到未经掩码处理的数据帧,须主动关闭连接
2. 服务端到客户端的数据一定不能加掩码,客户端接收到经过掩码的实际帧,须主动关闭连接
3. 发现错误的一方可以发送close帧,关闭连接。
4. 优势
1. 数据传输量大
2. 稳定性高
5. 支持浏览器
1. Firefox 4、Chrome 4、Opera 10.70以及Safari 5等浏览器的支持
2. websocket案例说明
1. 客户端
1. 创建Websocket实例
ws = new WebSocket("ws://127.0.0.1:10000/Server_Test.php");
1. 服务器IP:ws://127.0.0.1
2. 服务器端口:10000
3. 服务程序:Server_Test.php
2. 建立连接后回调函数
ws.onopen = function(event){}
3. 收到服务端消息后回调函数
ws.onmessage = function(event){}
4. 关闭连接后回调函数
ws.onclose = function(event){}
5. 连接错误后回调函数
ws.onerror = function(event)
6. 发送数据
ws.send('服务器,您好');
7. 查看当前连接状态
alert(ws.readyState)
2. 服务端
1. 创建服务端WebSocket对象,等待客户端接入
$master = WebSocket("localhost",10000);
首先创建Websocket,然后服务端监听相应端口,等待客户端接入
function WebSocket($address,$port){
$master=socket_create(AF_INET, SOCK_STREAM, SOL_TCP) or die("socket_create() failed");
socket_set_option($master, SOL_SOCKET, SO_REUSEADDR, 1) or die("socket_option() failed");
socket_bind($master, $address, $port) or die("socket_bind() failed");
socket_listen($master,20) or die("socket_listen() failed");
echo "Server Started : ".date('Y-m-d H:i:s')."\n";
echo "Master socket : ".$master."\n";
echo "Listening on : ".$address." port ".$port."\n\n";
return $master;
}
2. 从WebSocket中读取数据
$buffer = socket_read($socket,2048);
3. 当收到客户端首次连接请求后,生成握手信息并回复
$return_str = dohandshake($buffer);
socket_write($socket,$return_str,strlen($return_str));
4. 连接后,即可接收并解析出客户端的数据
$buffer = socket_read($socket,2048);
$data_str = decode($buffer);
5. 接收到用户数据后,直接回复客户端
socket_write($socket,$return_str,strlen($return_str));
6. 断开连接
socket_close($socket);
7. 以上6步完成全双工通信
3. 本案例说明
1. 目前只可传文本,byte传输还需进一步研究
3. 案例运行流程
首先需要安装PHP study,然后将服务端代码放到PHP study可执行目录下,最后使用浏览器打开客户端代码去访问服务器即可进行通信。
1. 安装PHP study,然后将PHP文件放到 D:\phpStudy\WWW
2. 设置PHP study端口:
3. 在客户端程序中通过url去访问服务器:
4. 调试说明
1. 客户端代码
1. html代码使用Hbuilder编辑完成
2. 打印信息使用
console.log("已经与服务器建立了连接rn当前连接状态:" + this.readyState);
3. 打印信息可以实时输出到控制台
2. 服务端代码
1. 服务端代码编辑同样在Hbuilder中完成
2. 服务端代码调试工具推荐使用Xdebug,我们目前使用的是打印错误日志方式进行调试
error_log("客户端发送数据: $data_str \r\n", 3, "D:/phpStudy/WWW/error.log");
3. 注意,D:/phpStudy/WWW/error.log为日志输出路径
5. 参考资料
1. 认识Websocket:http://www.itpub.net/thread-1373652-1-1.html###
2. 认识Websocket (较全面):https://my.oschina.net/u/1266171/blog/357488
3. websocket讲解:http://wenku.baidu.com/link?url=q-RIde8I-ScuPv6wO1APa8lfX47B-6meTdm7LTNyCcSsSxOqnqzt7WtKEXzwl6YpAVG5KzMcAMRTusknr_6T9w5RC7qbZGa0elRy6b4sTZi
4. Websocket在线测试工具:http://www.blue-zero.com/WebSocket/
5. 客户端很简单,关键是服务端代码:http://www.yxsss.com/sg.php?fp=0&tag=websocket
6. 使用php创建WebSocket服务:http://www.oschina.net/code/snippet_1029305_22256
7. PHP服务器:http://www.oschina.net/code/snippet_230665_21329
8. 在线聊天室程序:http://www.yxsss.com/ui/sk.html
9. 在线聊天室程序详解:http://www.bitscn.com/pdb/php/201609/732585.html
http://www.111cn.net/phper/php-cy/120076.htm
10. 服务端代码详解:http://zhidao.baidu.com/link?url=cbPCqd2rdNUMqHNKhQKEqF2j5carf01upT6PHGpFFPVLZv7ef5q5avksGyNd5P06nvIltLgHCPN68YZ6Emp2ytT4NVyi1-7CUkghun4zT1i
11. java实现Websocket:http://blog.csdn.net/u011677147/article/details/47038259
非常详细的/etc/passwd解释
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
desktop:x:80:80:desktop:/var/lib/menu/kde:/sbin/nologin
mengqc:x:500:500:mengqc:/home/mengqc:/bin/bash
在该文件中,每一行用户记录的各个数据段用“:”分隔,分别定义了用户的各方面属性。各个字段的顺序和含义如下:
注册名:口令:用户标识号:组标识号:用户名:用户主目录:命令解释程序
(1)注册名(login_name):用于区分不同的用户。在同一系统中注册名是惟一的。在很多系统上,该字段被限制在8个字符(字母或数字)的长度之内;并且要注意,通常在Linux系统中对字母大小写是敏感的。这与MSDOS/Windows是不一样的。
(2)口令(passwd):系统用口令来验证用户的合法性。超级用户root或某些高级用户可以使用系统命令passwd来更改系统中所有用户的口令,普通用户也可以在登录系统后使用passwd命令来更改自己的口令。
现在的Unix/Linux系统中,口令不再直接保存在passwd文件中,通常将passwd文件中的口令字段使用一个“x”来代替,将/etc /shadow作为真正的口令文件,用于保存包括个人口令在内的数据。当然shadow文件是不能被普通用户读取的,只有超级用户才有权读取。
此外,需要注意的是,如果passwd字段中的第一个字符是“*”的话,那么,就表示该账号被查封了,系统不允许持有该账号的用户登录。
(3)用户标识号(UID):UID是一个数值,是Linux系统中惟一的用户标识,用于区别不同的用户。在系统内部管理进程和文件保护时使用 UID字段。在Linux系统中,注册名和UID都可以用于标识用户,只不过对于系统来说UID更为重要;而对于用户来说注册名使用起来更方便。在某些特 定目的下,系统中可以存在多个拥有不同注册名、但UID相同的用户,事实上,这些使用不同注册名的用户实际上是同一个用户。
(4)组标识号(GID):这是当前用户的缺省工作组标识。具有相似属性的多个用户可以被分配到同一个组内,每个组都有自己的组名,且以自己的组标 识号相区分。像UID一样,用户的组标识号也存放在passwd文件中。在现代的Unix/Linux中,每个用户可以同时属于多个组。除了在 passwd文件中指定其归属的基本组之外,还在/etc/group文件中指明一个组所包含用户。
(5)用户名(user_name):包含有关用户的一些信息,如用户的真实姓名、办公室地址、联系电话等。在Linux系统中,mail和finger等程序利用这些信息来标识系统的用户。
(6)用户主目录(home_directory):该字段定义了个人用户的主目录,当用户登录后,他的Shell将把该目录作为用户的工作目录。 在Unix/Linux系统中,超级用户root的工作目录为/root;而其它个人用户在/home目录下均有自己独立的工作环境,系统在该目录下为每 个用户配置了自己的主目录。个人用户的文件都放置在各自的
主目录下。
(7)命令解释程序(Shell):Shell是当用户登录系统时运行的程序名称,通常是一个Shell程序的全路径名,
如/bin/bash。
需要注意的是,系统管理员通常没有必要直接修改passwd文件,Linux提供一些账号管理工具帮助系统管理员来创建和维护用户账号。
Linux口令管理之/etc/passwd文件
/etc/passwd文件是Linux/UNIX安全的关键文件之一.该文件用于用户登录时校验 用户的口令,当然应当仅对root可写.文件中每行的一般格式为:
LOGNAME:PASSWORD:UID:GID:USERINFO:HOME:SHELL
每行的头两项是登录名和加密后的口令,后面的两个数是UID和GID,接着的 一项是系统管理员想写入的有关该用户的任何信息,最后两项是两个路径名: 一个是分配给用户的HOME目录,第二个是用户登录后将执行的shell(若为空格则 缺省为/bin/sh).
(1)口令时效
/etc/passwd文件的格式使系统管理员能要求用户定期地改变他们的口令. 在口令文件中可以看到,有些加密后的口令有逗号,逗号后有几个字符和一个 冒号.如:
steve:xyDfccTrt180x,M.y8:0:0:admin:/:/bin/sh
restrict:pomJk109Jky41,.1:0:0:admin:/:/bin/sh
pat:xmotTVoyumjls:0:0:admin:/:/bin/sh
可以看到,steve的口令逗号后有4个字符,restrict有2个,pat没有逗号.
逗号后第一个字符是口令有效期的最大周数,第二个字符决定了用户再次 修改口信之前,原口令应使用的最小周数(这就防止了用户改了新口令后立刻 又改回成老口令).其余字符表明口令最新修改时间.
要能读懂口令中逗号后的信息,必须首先知道如何用passwd_esc计数,计 数的方法是:
.=0 /=1 0-9=2-11 A-Z=12-37 a-z=38-63
系统管理员必须将前两个字符放进/etc/passwd文件,以要求用户定期的 修改口令,另外两个字符当用户修改口令时,由passwd命令填入.
注意:若想让用户修改口令,可在最后一次口令被修改时,放两个".",则下 一次用户登录时将被要求修改自己的口令.
有两种特殊情况:
. 最大周数(第一个字符)小于最小周数(第二个字符),则不允许用户修改 口令,仅超级用户可以修改用户的口令.
. 第一个字符和第二个字符都是".",这时用户下次登录时被要求修改口 令,修改口令后,passwd命令将"."删除,此后再不会要求用户修改口令.
(2)UID和GID
/etc/passwd中UID信息很重要,系统使用UID而不是登录名区别用户.一般 来说,用户的UID应当是独一无二的,其他用户不应当有相同的UID数值.根据惯 例,从0到99的UID保留用作系统用户的UID(root,bin,uucp等).
如果在/etc/passwd文件中有两个不同的入口项有相同的UID,则这两个用 户对相互的文件具有相同的存取权限.
/etc /group文件含有关于小组的信息,/etc/passwd中的每个GID在本文件中 应当有相应的入口项,入口项中列出了小组名和小组中的用户.这样可方便地了 解每个小组的用户,否则必须根据GID在/etc/passwd文件中从头至尾地寻找同组 用户.
/etc/group文件对小组的许可权限的控制并不是必要的,因为系统用UID,GID (取自/etc/passwd)决定文件存取权限,即使/etc/group文件不存在于系统中,具 有相同的GID用户也可以小组的存取许可权限共享文件.
小组就像登录用户一样可以有口令.如果/etc/group文件入口项的第二个域 为非空,则将被认为是加密口令,newgrp命令将要求用户给出口令,然后将口令加 密,再与该域的加密口令比较.
给 小组建立口令一般不是个好作法.第一,如果小组内共享文件,若有某人猜 着小组口令,则该组的所有用户的文件就可能泄漏;其次,管理小组口令很费事, 因为对于小组没有类似的passwd命令.可用/usr/lib/makekey生成一个口令写入 /etc/group.
以下情况必须建立新组:
(1)可能要增加新用户,该用户不属于任何一个现有的小组.
(2)有的用户可能时常需要独自为一个小组.
(3)有的用户可能有一个SGID程序,需要独自为一个小组.
(4)有时可能要安装运行SGID的软件系统,该软件系统需要建立一个新组.
要 增加一个新组,必须编辑该文件,为新组加一个入口项. 由于用户登录时,系统从/etc/passwd文件中取GID,而不是从/etc/group中 取GID,所以group文件和口令文件应当具有一致性.对于一个用户的小组,UID和 GID应当是相同的.多用户小组的GID应当不同于任何用户的UID,一般为5位数,这 样在查看/etc/passwd文件时,就可根据5位数据的GID识别多用户小组,这将减少 增加新组,新用户时可能产生的混淆.
linux下详解ftp的常用功能
一、简介:
FTP(File Transfer Protocol, FTP)是TCP/IP网络上两台计算机传送文件的协议,FTP是在TCP/IP网络和INTERNET上最早使用的协议之一,它属于网络协议组的应用层。FTP客户机可以给服务器发出命令来下载文件,上载文件,创建或改变服务器上的目录。
 概述:
概述:
FTP是应用层的协议,它基于传输层,为用户服务,它们负责进行文件的传输。FTP是一个8位的客户端-服务器协议,能操作任何类型的文件而不需要进一步处理,就像MIME或Unencode一样。但是,FTP有着极高的延时,这意味着,从开始请求到第一次接收需求数据之间的时间会非常长,并且不时的必需执行一些冗长的登陆进程。

FTP服务一般运行在20和21两个端口。端口20用于在客户端和服务器之间传输数据流,而端口21用于传输控制流,并且是命令通向ftp服务器的进口。当数据通过数据流传输时,控制流处于空闲状态。而当控制流空闲很长时间后,客户端的防火墙会将其会话置为超时,这样当大量数据通过防火墙时,会产生一些问题。此时,虽然文件可以成功的传输,但因为控制会话会被防火墙断开,传输会产生一些错误。
主动和被动模式
FTP有两种使用模式:主动和被动。主动模式要求客户端和服务器端同时打开并且监听一个端口以建立连接。在这种情况下,客户端由于安装了防火墙会产生一些问题。所以,创立了被动模式。被动模式只要求服务器端产生一个监听相应端口的进程,这样就可以绕过客户端安装了防火墙的问题。
一个主动模式的FTP连接建立要遵循以下步骤:
1.客户端打开一个随机的端口(端口号大于1024,在这里,我们称它为x),同时一个FTP进程连接至服务器的21号命令端口。此时,源端口为随机端口x,在客户端,远程端口为21,在服务器。
2.客户端开始监听端口(x+1),同时向服务器发送一个端口命令(通过服务器的21号命令端口),此命令告诉服务器客户端正在监听的端口号并且已准备好从此端口接收数据。这个端口就是我们所知的数据端口。
3.服务器打开20号源端口并且建立和客户端数据端口的连接。此时,源端口为20,远程数据端口为(x+1)。
4.客户端通过本地的数据端口建立一个和服务器20号端口的连接,然后向服务器发送一个应答,告诉服务器它已经建立好了一个连接。
被动模式FTP:
为了解决服务器发起到客户的连接的问题,人们开发了一种不同的FTP连接方式。这就是所谓的被动方式,或者叫做PASV,当客户端通知服务器它处于被动模式时才启用。
在被动方式FTP中,命令连接和数据连接都由客户端发起,这样就可以解决从服务器到客户端的数据端口的入方向连接被防火墙过滤掉的问题。
当开启一个 FTP连接时,客户端打开两个任意的非特权本地端口(N > 1024和N+1)。第一个端口连接服务器的21端口,但与主动方式的FTP不同,客户端不会提交PORT命令并允许服务器来回连它的数据端口,而是提交 PASV命令。这样做的结果是服务器会开启一个任意的非特权端口(P > 1024),并发送PORT P命令给客户端。然后客户端发起从本地端口N+1到服务器的端口P的连接用来传送数据。
对于服务器端的防火墙来说,必须允许下面的通讯才能支持被动方式的FTP:
1. 从任何大于1024的端口到服务器的21端口 (客户端的初始化连接)
2. 服务器的21端口到任何大于1024的端口 (服务器响应到客户端的控制端口的连接)
3. 从任何大于1024端口到服务器的大于1024端口 (客户端初始化数据连接到服务器指定的任意端口)
4. 服务器的大于1024端口到远程的大于1024的端口(服务器发送ACK响应和数据到客户端的数据端口)
二、常用举例:
(注意:以下根据配置文档举出常见实例)
1.安装ftp
[root@gjp99 ~]# mkdir /mnt/cdrom
[root@gjp99 ~]# mount /dev/cdrom /mnt/cdrom
mount: block device /dev/cdrom is write-protected, mounting read-only
[root@gjp99 ~]# cd /mnt/cdrom/Server
[root@gjp99 Server]# ll vsftp*
-r--r--r-- 86 root root 143838 Jul 24 2009 vsftpd-2.0.5-16.el5.i386.rpm
[root@gjp99 Server]# rpm -qip vsftpd-2.0.5-16.el5.i386.rpm
warning: vsftpd-2.0.5-16.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Name : vsftpd Relocations: (not relocatable)
Version : 2.0.5 Vendor: Red Hat, Inc.
Release : 16.el5 Build Date: Wed 13 May 2009 08:47:15 PM CST
Install Date: (not installed) Build Host: hs20-bc1-2.build.redhat.com
Group : System Environment/Daemons Source RPM: vsftpd-2.0.5-16.el5.src.rpm
Size : 291690 License: GPL
Signature : DSA/SHA1, Fri 24 Jul 2009 08:34:20 PM CST, Key ID 5326810137017186
Packager : Red Hat, Inc. <http://bugzilla.redhat.com/bugzilla>
URL : http://vsftpd.beasts.org/
Summary : vsftpd - Very Secure Ftp Daemon
Description :
vsftpd is a Very Secure FTP daemon. It was written completely from
scratch.
[root@gjp99 Server]# rpm -ivh vsftpd-2.0.5-16.el5.i386.rpm
warning: vsftpd-2.0.5-16.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:vsftpd ################################# [100%]
[root@gjp99 Server]# rpm -ql vsftpd |less
/etc/pam.d/vsftpd 可插拔验证模块
/etc/rc.d/init.d/vsftpd 控制脚本
/etc/vsftpd/vsftpd.conf 主配置文档
/var/ftp 匿名账号的默认目录
/var/ftp/pub
[root@gjp99 Server]# man 5 vsftpd.conf 配置手册
[root@gjp99 Server]# service vsftpd start
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 Server]# chkconfig vsftpd on 开机启动
2. 关于账号的详细配置
2.1.匿名账号:
无需输入用户名和口令! 用户名:anonymous 密码:回车或者邮箱账号
支持匿名账号:配置文档
[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf
12 anonymous_enable=YES

2.2 本地账号:
有一定的危害性, 存放在:/etc/passwd /etc/shadow
14 # Uncomment this to allow local users to log in.
15 local_enable=YES
[root@gjp99 ~]# useradd gjp1
[root@gjp99 ~]# passwd gjp1
Changing password for user gjp1.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# cd /home/gjp1
[root@gjp99 gjp1]# ll
total 0
[root@gjp99 gjp1]# echo "welcome to access me " >>index.html
[root@gjp99 gjp1]# ll
total 4
-rw-r--r-- 1 root root 22 Aug 3 14:36 index.html


2.3 用户通过网络访问资源,
网络权限[ftp http] 本地权限[相当于windows下的ntfs]
网络权限与本地权限 如果相同 ,则相同,如果不同,则选择最小的!
![]() 网络权限可写
网络权限可写
如果本地权限也可写,则访问时可写!
[root@gjp99 home]# ll
total 4
drwx------ 3 gjp1 gjp1 4096 Aug 3 15:00 gjp1

还可以删除!
2.4 屏蔽某些权限
文件的权限默认是666,目录的权限默认是777
![]() 屏蔽掉某些权限: 所有者 用户 组
屏蔽掉某些权限: 所有者 用户 组
刚才上传的文件在666的基础上屏蔽022 则结果是644,查看
[root@gjp99 gjp1]# ll
total 108
-rw-r--r-- 1 root root 22 Aug 3 14:36 index.html
-rw-r--r-- 1 gjp1 gjp1 100864 Aug 3 15:00 ??目实训2.doc
网络权限已可写,为什么匿名账号还不能上传呀?

[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xr-x 2 root root 4096 May 13 2009 /var/ftp/pub
pub文件夹的所有者及组都是root,只有管理员可写,其他用户不可写,由于网络权限与本地权限不同,所以选择范围比较小的,
2.5 上传功能
![]()
[root@gjp99 home]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xr-x 2 root root 4096 May 13 2009 /var/ftp/pub
[root@gjp99 home]# chmod o+wt /var/ftp/pub 注意权限不仅加w,还加t
[root@gjp99 home]# ll -d /var/ftp/pub
drwxr-xrwt 2 root root 4096 May 13 2009 /var/ftp/pub 加t是仅有创建者能够删除文件!

改名,删除,创建文件夹都不可以了?
2.6 匿名用户可以创建文件夹
31 anon_mkdir_write_enable=YES 匿名用户创建文件夹
man 5 vsftpd.conf

32 anon_other_write_enable=YES 增加此行! //文件夹可以重命名,可以删除文件,上传

 文件却无法下载
文件却无法下载
2.7 文件如何下载?
[root@gjp99 home]# ll /var/ftp/pub //发现文件没有读取权限
[root@gjp99 home]# ll /var/ftp/pub
total 56
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw------- 1 ftp ftp 24774 Aug 3 15:55 tec.docx
任意一个文件给他个读取权限测试!
[root@gjp99 home]# chmod o+r /var/ftp/pub/tec.docx 给其他用户读权限
[root@gjp99 home]# ll /var/ftp/pub
total 56
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw----r-- 1 ftp ftp 24774 Aug 3 15:55 tec.docx
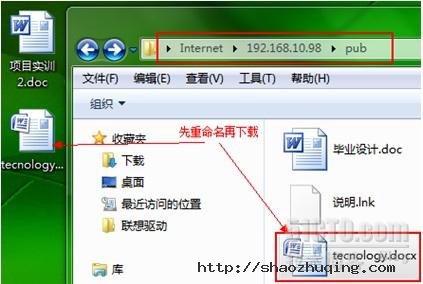
24 anon_umask=073 增加此行,问题简化
现在在上传点文件做测试!

[root@gjp99 home]# ll /var/ftp/pub 自动带了一个r(刚上传过来的文件)
total 256
-rw------- 1 ftp ftp 23040 Aug 3 15:32 ??业????.doc
-rw----r-- 1 ftp ftp 165835 Aug 3 16:10 guo.docx
-rw----r-- 1 ftp ftp 32272 Aug 3 16:10 ji.docx
-rw------- 1 ftp ftp 753 Aug 3 15:47 ???.lnk
-rw----r-- 1 ftp ftp 24774 Aug 3 15:55 tecnology.docx
2.8 如何备份交换机上的系统?


只支持命令行方式访问!

2.9 如何访问ftp服务器?



2.10 如何提示友好信息?
37 dirmessage_enable=YES
测试:友好提示!

2.11 如何开启ftp的日志功能?
日志文件默认目录 /var/log/却找不到!因为日志功能默认未打开!
打开日志功能:
![]()
![]()
![]()
service vsftpd restart
[root@gjp99 pub]# lftp 127.0.0.1 //无需验证就可以登录
lftp 127.0.0.1:~> dir
drwxr-xrwt 2 0 0 4096 Aug 03 08:38 pub
lftp 127.0.0.1:/> bye
[root@gjp99 pub]# ftp 127.0.0.1 // 需要用户验证
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password:
[root@gjp99 pub]# ll /var/log/vsftpd.log 该日志文件已存在!
-rw------- 1 root root 0 Aug 3 16:52 /var/log/vsftpd.log
2.12 如何让日志功能生效?
查手册 man 5 vsftpd.conf

56 log_ftp_protocol=YES 增加此行
57 #
58 # Switches between logging into vsftpd_log_file and xferlog_file files.
59 # NO writes to vsftpd_log_file, YES to xferlog_file
60 xferlog_std_format=NO 日志格式禁掉

[root@gjp99 pub]# tail -f /var/log/vsftpd.log //才能使用
Fri Aug 3 09:38:52 2012 [pid 21331] CONNECT: Client "192.168.10.2"
Fri Aug 3 09:38:52 2012 [pid 21331] FTP response: Client "192.168.10.2", "220 (vsFTPd 2.0.5)"
Fri Aug 3 09:38:55 2012 [pid 21331] FTP command: Client "192.168.10.2", "USER gjp1"
Fri Aug 3 09:38:55 2012 [pid 21331] [gjp1] FTP response: Client "192.168.10.2", "331 Please specify the password."
Fri Aug 3 09:38:57 2012 [pid 21331] [gjp1] FTP command: Client "192.168.10.2", "PASS <password>"
Fri Aug 3 09:38:57 2012 [pid 21330] [gjp1] OK LOGIN: Client "192.168.10.2"
Fri Aug 3 09:38:57 2012 [pid 21332] [gjp1] FTP response: Client "192.168.10.2", "230 Login successful."
2.13 拒绝服务攻击的一种方法:
拒绝某人利用某个邮箱账号作为匿名账号的密码进行登录
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password: 密码为: gjp@sina.com (即使不知道是否存在就能登录)
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,88,15)
150 Here comes the directory listing.
drwxr-xrwt 2 0 0 4096 Aug 03 09:11 pub
226 Directory send OK

[root@gjp99 pub]# echo gjp@sina.com >>/etc/vsftpd/banned_emails
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): anonymous
331 Please specify the password.
Password:
530 Login incorrect.
Login failed.
[root@gjp99 ~]# useradd user1
[root@gjp99 ~]# passwd
Changing password for user root.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/home/user1"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,201,20)
150 Here comes the directory listing.
drwxr-xr-x 2 0 0 4096 Aug 03 04:05 bin
drwxr-xr-x 4 0 0 1024 Aug 02 13:26 boot
drwxr-xr-x 11 0 0 4260 Aug 03 05:42 dev
drwxr-xr-x 93 0 0 12288 Aug 03 10:06 etc
ftp> cd boot
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,89,202)
150 Here comes the directory listing.
-rw-r--r-- 1 0 0 954947 Aug 18 2009 System.map-2.6.18-164.el5
-rw-r--r-- 1 0 0 68663 Aug 18 2009 config-2.6.18-164.el5
drwxr-xr-x 2 0 0 1024 Aug 02 13:30 grub
-rw------- 1 0 0 2601298 Aug 02 13:26 initrd-2.6.18-164.el5.img
drwx------ 2 0 0 12288 Aug 02 21:18 lost+found
-rw-r--r-- 1 0 0 107405 Aug 18 2009 symvers-2.6.18-164.el5.gz
-rw-r--r-- 1 0 0 1855956 Aug 18 2009 vmlinuz-2.6.18-164.el5
226 Directory send OK.
可以查看许多内容,而且可以下载,没有安全性!
2.14 如何提高 ftp的安全性?
[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf

[root@gjp99 ~]# vim /etc/vsftpd/chroot_list
[root@gjp99 ~]# cat /etc/vsftpd/chroot_list
user1 //写入到该文件的账号都被禁锢了,没有写进来的可随意切换!
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# su – user1 该账号下存在属于自己的东西
[user1@gjp99 ~]$ ll
total 0
[user1@gjp99 ~]$ touch gjp.txt
[user1@gjp99 ~]$ vim gjp.txt
[user1@gjp99 ~]$ ll
total 4
-rw-rw-r-- 1 user1 user1 32 Sep 26 14:40 gjp.txt
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,119,140)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> bye
221 Goodbye.
[root@gjp99 ~]# useradd user2
[root@gjp99 ~]# passwd
Changing password for user root.
New UNIX password:
BAD PASSWORD: it is WAY too short
Retype new UNIX password:
passwd: all authentication tokens updated successfully.
[root@gjp99 ~]# su - user2
[user2@gjp99 ~]$ echo "user2" >> gjp2.txt
[user2@gjp99 ~]$ ll
total 4
-rw-rw-r-- 1 user2 user2 6 Sep 26 14:45 gjp2.txt
[user2@gjp99 ~]$ logout
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/home/user2"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,68,60)
150 Here comes the directory listing.
drwxr-xr-x 2 0 0 4096 Aug 03 04:05 bin
drwxr-xr-x 4 0 0 1024 Aug 02 13:26 boot
drwxr-xr-x 11 0 0 4220 Sep 26 06:26 dev
drwxr-xr-x 93 0 0 12288 Sep 26 06:48 etc
drwxr-xr-x 5 0 0 4096 Sep 26 06:44 home
(没有写入该文件的账号,如user2,则可以随意切换)
实现:放入该文件里的账号能够切换目录,没放进来的不能够切换目录,man 5 vsftpd.conf

[root@gjp99 ~]# vim /etc/vsftpd/vsftpd.conf
增加此功能; chroot_local_user=YES
[root@gjp99 ~]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1 放进去的却没有禁锢掉
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
257 "/home/user1"
ftp> cd /
250 Directory successfully changed.
ftp> quit
221 Goodbye.
[root@gjp99 ~]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2 没放进去的被禁锢了
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> pwd
257 "/"
ftp> cd /
250 Directory successfully changed.
ftp> dir
227 Entering Passive Mode (127,0,0,1,98,84)
150 Here comes the directory listing.
-rw-rw-r-- 1 502 502 6 Sep 26 06:45 gjp2.txt
226 Directory send OK.
ftp 的特性:
独立进程存放在: /etc/init.c /etc/rc.d/init.d 目录下!
超级守护进程:xinetd
112 listen=YES 表明独立的,不再依赖于超级守护进程
119 pam_service_name=vsftpd //ftp支持pam验证
可参考ftp的接口文件
[root@gjp99 pam.d]# vim /etc/pam.d/vsftpd 里面有相应的系统调用及参数
[root@gjp99 pam.d]# cd /etc/vsftpd
[root@gjp99 vsftpd]# ll
total 28
-rw-r--r-- 1 root root 13 Aug 3 18:00 banned_emails
-rw-r--r-- 1 root root 7 Sep 26 14:37 chroot_list
-rw------- 1 root root 125 May 13 2009 ftpusers 存入该文件的账号不能登录ftp
-rw------- 1 root root 361 May 13 2009 user_list 存入该文件的账号不能登录ftp
-rw------- 1 root root 4640 Sep 26 14:59 vsftpd.conf
-rwxr--r-- 1 root root 338 May 13 2009 vsftpd_conf_migrate.sh
[root@gjp99 vsftpd]# cat ftpusers
# Users that are not allowed to login via ftp
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
news
uucp
operator
games
nobody
user1 把user1添加进来作为测试!
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password: 需要输入密码,如果网络上有人抓包,则很不安全!
530 Login incorrect.
Login failed. 登录失败
把ftpusers中存放的账号user1删除,在user_list中输入user1测试!
[root@gjp99 vsftpd]# cat user_list
# vsftpd userlist
# If userlist_deny=NO, only allow users in this file
# If userlist_deny=YES (default), never allow users in this file, and
# do not even prompt for a password.
# Note that the default vsftpd pam config also checks /etc/vsftpd/ftpusers
# for users that are denied.
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
news
uucp
operator
games
nobody
user1
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
530 Permission denied. 没有提示让输入密码,直接拒绝掉了
Login failed.
为了防止管理员的密码被捕获,则不允许管理员ftp
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): root
530 Permission denied.
Login failed.
[root@gjp99 vsftpd]# vim user_list
# vsftpd userlist
# If userlist_deny=NO, only allow users in this file
在 /etc/vsftpd/vsftpd.conf中增加此功能: service vsftpd restart
下面测试:user1在这个文件下所以可以登录,user2不在该文件里,因此直接拒绝!
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,42,166)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> quit
221 Goodbye.
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user2
530 Permission denied.
Login failed.
/etc/vsftpd/vsftpd.conf 下的
122 tcp_wrappers=YES
查看某些应用支持的链接库:
[root@gjp99 vsftpd]# ldd /usr/sbin/vsftpd
linux-gate.so.1 => (0x00164000)
libssl.so.6 => /lib/libssl.so.6 (0x00a33000)
libwrap.so.0 => /lib/libwrap.so.0 (0x0067c000)
出现此文件,即说明支持tcp_wrappers=YES
需修改 /etc/hosts.allow /etc/hosts.deny
先看hosts.allow 再看hosts.deny 默认是允许的!

[root@gjp99 vsftpd]# cat /etc/hosts.allow
#
# hosts.allow This file describes the names of the hosts which are
# allowed to use the local INET services, as decided
# by the '/usr/sbin/tcpd' server.
#
vsftpd:192.168.10.2:allow 仅有192.168.10.2允许
[root@gjp99 vsftpd]# vim /etc/hosts.deny
[root@gjp99 vsftpd]# cat /etc/hosts.deny
#
# hosts.deny This file describes the names of the hosts which are
# *not* allowed to use the local INET services, as decided
# by the '/usr/sbin/tcpd' server.
#
# The portmap line is redundant, but it is left to remind you that
# the new secure portmap uses hosts.deny and hosts.allow. In particular
# you should know that NFS uses portmap!
vsftpd:all :deny 其他人拒绝
测试:windows下ftp

linux 下测试:
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
421 Service not available.
ftp> quit
只有192.168.10.2不可以,其他的都可以!
[root@gjp99 vsftpd]# vim /etc/hosts.allow 只在该文件下操作,hosts.deny 空着
6 vsftpd:192.168.10.2:deny
7 vsftpd:all:allow
测试:windows下:

linux下:
[root@gjp99 vsftpd]# ftp 127.0.0.1
Connected to 127.0.0.1.
220 (vsFTPd 2.0.5)
530 Please login with USER and PASS.
530 Please login with USER and PASS.
KERBEROS_V4 rejected as an authentication type
Name (127.0.0.1:root): user1
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> dir
227 Entering Passive Mode (127,0,0,1,208,223)
150 Here comes the directory listing.
-rw-rw-r-- 1 501 501 32 Sep 26 06:40 gjp.txt
226 Directory send OK.
ftp> quit
ftp的安全性
1. 协议 ftp 明文
2. 账号 匿名 本地账号(抓包,危险性较大) 最好选用虚拟账号
删除原有的安全特性,安装tshark
挂载光盘,安装抓包工具:
[root@gjp99 vsftpd]# mount /dev/cdrom /mnt/cdrom
mount: block device /dev/cdrom is write-protected, mounting read-only
[root@gjp99 vsftpd]# cd /mnt/cdrom/Server/
[root@gjp99 Server]# ll wireshark-*
-r--r--r-- 220 root root 11130359 Jun 11 2009 wireshark-1.0.8-1.el5_3.1.i386.rpm
-r--r--r-- 220 root root 686650 Jun 11 2009 wireshark-gnome-1.0.8-1.el5_3.1.i386.rpm
[root@gjp99 Server]# rpm -ivh libsmi-0.4.5-2.el5.i386.rpm 必须先安装此软件
warning: libsmi-0.4.5-2.el5.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:libsmi ################################# [100%]
[root@gjp99 Server]# rpm -ivh wire
wireless-tools-28-2.el5.i386.rpm
wireless-tools-devel-28-2.el5.i386.rpm
wireshark-1.0.8-1.el5_3.1.i386.rpm
wireshark-gnome-1.0.8-1.el5_3.1.i386.rpm
[root@gjp99 Server]# rpm -ivh wireshark-1.0.8-1.el5_3.1.i386.rpm
warning: wireshark-1.0.8-1.el5_3.1.i386.rpm: Header V3 DSA signature: NOKEY, key ID 37017186
Preparing... ################################# [100%]
1:wireshark ############################### [100%]
[root@gjp99 Server]# tshark -ni eth0 -R "tcp.dstport eq 21 "
Running as user "root" and group "root". This could be dangerous.
Capturing on eth0 已经在eth0上可以抓包了~
Xshell:\> ftp 192.168.10.98
Connecting to 192.168.10.98:21...
Connection established.
Escape character is '^@]'.
220 (vsFTPd 2.0.5)
Name (192.168.10.98:Administrator): user1
331 Please specify the password.
Password:
230 Login successful.
ftp:/home/user1>
抓包抓到的情况:
115.297511 192.168.10.2 -> 192.168.10.98 FTP Request: USER user1 用户名
115.497920 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=13 Ack=55 Win=65536 Len=0
116.968029 192.168.10.2 -> 192.168.10.98 FTP Request: PASS 123 密码
116.996447 192.168.10.2 -> 192.168.10.98 FTP Request: PWD
117.196785 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=28 Ack=97 Win=65536 Len=0
测试,是否能抓到管理员密码?
Xshell:\> ftp 192.168.10.98
Connecting to 192.168.10.98:21...
Connection established.
Escape character is '^@]'.
220 (vsFTPd 2.0.5)
Name (192.168.10.98:Administrator): root
530 Permission denied.
抓包抓不到密码:
243.383605 192.168.10.2 -> 192.168.10.98 FTP Request: USER root
243.583142 192.168.10.2 -> 192.168.10.98 TCP 53369 > 21 [ACK] Seq=12 Ack=45 Win=65536 Len=0
291.498211 192.168.10.2 -> 192.168.10.98 FTP Request: PWD
291.698623 192.168.10.2 -> 192.168.10.98 TCP 53368 > 21 [ACK] Seq=43 Ack=154 Win=65536 Len=0
ftps的搭建:
ftps=ftp+ssl
创建CA
[root@gjp99 Server]# cd /etc/pki
[root@gjp99 pki]# ll
total 32
drwx------ 3 root root 4096 Aug 2 21:22 CA
drwxr-xr-x 2 root root 4096 Aug 2 21:20 nssdb
drwxr-xr-x 2 root root 4096 Aug 2 21:21 rpm-gpg
drwxr-xr-x 5 root root 4096 Aug 2 21:22 tls
[root@gjp99 pki]# vim tls/openssl.cnf
45 dir = /etc/pki/CA # Where everything is kept
46 certs = $dir/certs # Where the issued certs are kept
47 crl_dir = $dir/crl # Where the issued crl are kept
48 database = $dir/index.txt # database index file.
49 #unique_subject = no # Set to 'no' to allow creation of
50 # several ctificates with same subject.
51 new_certs_dir = $dir/newcerts # default place for new certs.
52
53 certificate = $dir/cacert.pem # The CA certificate
54 serial = $dir/serial # The current serial number
55 crlnumber = $dir/crlnumber # the current crl number
56 # must be commented out to leave a V1 CRL
57 crl = $dir/crl.pem # The current CRL
58 private_key = $dir/private/cakey.pem# The private key
底行模式:![]()
88 countryName = optonal
89 stateOrProvinceName = optonal
90 organizationName = optonal

[root@gjp99 pki]# ll
total 32
drwx------ 3 root root 4096 Aug 2 21:22 CA
drwxr-xr-x 2 root root 4096 Aug 2 21:20 nssdb
drwxr-xr-x 2 root root 4096 Aug 2 21:21 rpm-gpg
drwxr-xr-x 5 root root 4096 Sep 26 17:04 tls
[root@gjp99 pki]# cd CA
[root@gjp99 CA]# ll
total 8
drwx------ 2 root root 4096 Jun 30 2009 private
[root@gjp99 CA]# mkdir crl certs newcerts
[root@gjp99 CA]# touch index.txt serial
[root@gjp99 CA]# echo "01">serial
[root@gjp99 CA]# openssl genrsa 1024 >private/cakey.pem
Generating RSA private key, 1024 bit long modulus
....++++++
......++++++
e is 65537 (0x10001)
[root@gjp99 CA]# chmod 600 private/*
[root@gjp99 CA]# openssl req -new -key private/cakey.pem -x509 -out cacert.pem
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CN]:
State or Province Name (full name) [Shang Hai]:
Locality Name (eg, city) [Shang Hai]:
Organization Name (eg, company) [My Company Ltd]:sec center
Organizational Unit Name (eg, section) []:tec
Common Name (eg, your name or your server's hostname) []:ca.net.net
Email Address []:
私钥 请求文件 证书
[root@gjp99 CA]# mkdir /etc/vsftpd/certs
[root@gjp99 CA]# cd /etc/vsftpd/certs/
[root@gjp99 certs]# openssl genrsa 1024 >vsftpd.key 创建钥匙
Generating RSA private key, 1024 bit long modulus
.......++++++
................................................................+++
e is 65537 (0x10001)
[root@gjp99 certs]# openssl req -new -key vsftpd.key -out vsftpd.csr 产生请求
You are about to be asked to enter information that will be inco
into your certificate request.
What you are about to enter is what is called a Distinguished Na
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [CN]:
State or Province Name (full name) [Shang Hai]:
Locality Name (eg, city) [Shang Hai]:
Organization Name (eg, company) [My Company Ltd]:bht
Organizational Unit Name (eg, section) []:tec
Common Name (eg, your name or your server's hostname) []:ftp.bht.com
Email Address []:
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
[root@gjp99 certs]# ll
total 8
-rw-r--r-- 1 root root 651 Sep 26 17:17 vsftpd.csr
-rw-r--r-- 1 root root 887 Sep 26 17:15 vsftpd.key
[root@gjp99 certs]# openssl ca -in vsftpd.csr -out vsftpd.cert 生成证书
Using configuration from /etc/pki/tls/openssl.cnf
Check that the request matches the signature
Signature ok
Certificate Details:
Serial Number: 1 (0x1)
Validity
Not Before: Sep 26 09:35:33 2012 GMT
Not After : Sep 26 09:35:33 2013 GMT
Subject:
countryName = CN
stateOrProvinceName = Shang Hai
organizationName = bht
organizationalUnitName = tec
commonName = ftp.bht.com
X509v3 extensions:
X509v3 Basic Constraints:
CA:FALSE
Netscape Comment:
OpenSSL Generated Certificate
X509v3 Subject Key Identifier:
4E:10:2C:A8:BA:A8:5E:16:D1:8E:BD:85:53:87:5C:5E:1D:B6:04:C1
X509v3 Authority Key Identifier:
keyid:DF:8C:0F:8C:D0:65:31:42:FB:AF:29:7A:52:51:4C:86:09:25:91:F4
Certificate is to be certified until Sep 26 09:35:33 2013 GMT (365 days)
Sign the certificate? [y/n]:y
1 out of 1 certificate requests certified, commit? [y/n]y
Write out database with 1 new entries
Data Base Updated
证书在哪?私钥在哪?
用man 5 vsftpd.conf
[root@gjp99 certs]# vim /etc/vsftpd/vsftpd.conf
增加以下功能:
rsa_cert_file=/etc/vsftpd/certs/vsftpd.cert
rsa_private_key_file=/etc/vsftpd/certs/vsftpd.key
ssl_tlsv1=YES
ssl_sslv3=YES
ssl_sslv2=YES
ssl_enable=YES
force_local_logins_ssl=YES
force_local_data_ssl=YES
[root@gjp99 certs]# service vsftpd restart
Shutting down vsftpd: [ OK ]
Starting vsftpd for vsftpd: [ OK ]
[root@gjp99 certs]# tshark -ni eth0 -R "tcp.dstport eq 21 "
Running as user "root" and group "root". This could be dangerous.
Capturing on eth0
C:\Users\Administrator>ftp 192.168.10.98 命令行下无法登录(由于使用了身份验证)
连接到 192.168.10.98。
220 (vsFTPd 2.0.5)
用户(192.168.10.98:(none)): user1
530 Non-anonymous sessions must use encryption.
登录失败。
使用客户端软件:



点击应用 点击连接!

点击 “接受一次”

1331.140451 192.168.10.2 -> 192.168.10.98 FTP Request: AUTH SSL
1331.147508 192.168.10.2 -> 192.168.10.98 FTP Request: \200\310\001\003\001\000
下面都是已加密的信息,已看不到密码!
PHP命名空间namespace/类别名 use/框架自动载入 机理
摘要: PHP 命名空间 namespace / 类别名 use / 框架自动载入 机理的
相比 PHP5.2 版本 PHP5.3 新增了三大主要新特性
命名空间
延迟静态绑定
lambda匿名函数
命名空间的出现也使PHP可以更加合理的组织项目结构,同时通过命名空间和自动载入机制一大批 PHP 的 MVC 框架也随之出现,明了的项目结构的同时也按需载入,进一步减轻内存压力,加快执行效率。
因为命名空间是对目录结构友好的
namespace Home\Controller;
class IndexController { }
而 PHP5.2 之前是按造类的下划线去做类似 命名空间 的定义的
class Home_Controller_IndexController { }
一、 命名空间 及 USE 的本质
php 的 use 关键字并不是立刻导入所use的类,它只是声明某类的完整类名(命名空间::类标示符),而后你在上下文中使用此类时系统才会根据 use 声明获取此类的完整类名 然后利用自动加载机制进行载入
namespace Home\Controller;
use Home\Model\User;
use Home\Model\Order as OrderList;
class IndexController {
public function index() {
//只有当你调用此类时,系统才会根据 use 声明获取此类的完整类名 然后利用自动加载机制进行载入
$user = new User();
$order = new OrderList();
}
}
就像如下的代码 自动载入函数是在 use 两个类之后方才实现的 因为 use 并不会立即使用此类 只有在你调用此类时系统才会在找不到此类的情况下通过 autoload 函数动态延迟加载,若仍加载不到,则报错
1、某命名空间下的类 的完整名称为 namespace\className,当在某命名空间上下文中访问其它命名空间下的类时,我们可以使用 use 做别名化,或者使用此类的完整名称,但要以 '\' 根命名空间开头,否则解释器会认为你是在当前命名空间上下文中调用,即 foo\bar 方式会以 currentNamespace\foo\bar的方式去加载
命名空间与linux文件系统很相似,'\' 代表根,不以根开始的皆认为以当前命名空间为基点
2、use 只是给你使用的类定义短别名,use foo\bar 后则new bar() 即new \foo\bar(),还有个小技巧,当我们同时引用不同命名空间下的类名相同的类时可以使用 as 为其定义一个新别名
use foo\bar\sameName as classA; use bar\foo\sameName as classB; new classA(); // new \foo\bar\sameName; new classB(); // new \bar\foo\sameName;
3、当我们通过 入口文件 加载参数配置 实例化一个应用主体 加载路由组件解析请求 分派控制器调用方法时,期间会调用其他的类,比如
use yii\web\Controller;
系统便会去通过自动载入函数做最一次载入尝试,若仍加载不到此类则报错
下面我们看下 Yii2 从入口文件开始一个应用实体后注册自动载入函数的流程
index.php
入口文件载入配置和系统框架时会使用require调用,因为现在还没有注册自动加载函数
载入 Yii bootstrap 文件时便通过 spl_autoload_register 注册了自动载入函数
Yii.php

Yii2的自动载入函数
继承至 BaseYii 它要做的就是根据你命名空间类型的类名去映射为此类所在的文件路径
比如 yii\web\Controller类会根据 yii 而映射到 YII2_PATH . '/web/Controller.php' 文件中,而这个文件则是命名空间为 yii\web 的 Controller 类,将此文件载入即可访问 yii\web\Controller 类

而我们自己编写的控制器或者模型则访问时为 'app\controllers\IndexController' 'app\models\EntryForm'
则 autoload 函数会根据 app 为 映射关键字将其定位到 controllers 或 models 文件夹下从而读取对应的文件即可载入相应的类,这也是为什么 类名 与 文件名 相互对应的原因所在,若不存在对应,则你只能通过固定的 require 某个文件去加载你写在其中的类了
扩展自己的类库
我们可以通过Yii2的自动载入机制灵活的归类我们自己写的工具类等,比如我想创建一个自己的组件库
你可以定义一个 yii\tools 命名空间的类文件 MyTools.php,比如
放入 vendor\yiisoft\yii2\tools 文件夹下,
通过
<?php
namespace app\controllers;
// yii一级命名空间 则 映射到 YII_PATH 下
// 根据 tools\MyTools 定位到 YII_PATH 下的 tools文件夹下的 MyTools.php
use yii\tools\MyTools;
use yii\web\Controller;
class MyController extends Controller {
}
?>
当然你也可以在你的项目目录下新建一个 tools 文件夹 把 MyTools.php 放进去,将里面的命名空间改为 app\tools 即可,系统会根据 app 映射到项目根目录 通过 tools\MyTools 把 tools文件夹下的 MyTools.php文件载入 即载入了 MyTools 类
三、剖析TP的自动载入
thinkphp的自动加载规则也一样,只不过 tp autoload函数并没有像 Yii2 basic 版预先定义一个项目根目录的映射规则, Yii2则是以 app 顶级命名空间为默认的应用命名空间,yii顶级命名空间作为框架命名空间,所以你只要把自己的类归属到项目根目录(app下)或 YII_PATH(框架路径) 下,然后放对文件路径即可,
tp的话有的你自己想tp可以在 APP_PATH 下放多个 module ,像其预先定义的 Home ,或者你可以 BIND_MODULE来帮定义一个自己的模块,这样在通过入口文件载入的应用实体做路由时便能判断你请求的是哪个模块下的控制器和方法
tp有几个系统占用的顶级命名空间

Think Org Behavior Com Vendor
而你自己的则会以 APP_PATH 为根目录进行加载,比如 Home\Controller\IndexController.class.php,当你访问 Index 时路由解析出来的类为 Home\Controller\IndexController,自动载入函数则根据 Home 非系统命名空间而定位到你的APP_PATH下进行加载,所以TP也可以自己定义的 AUTOLOAD_NAMESAPCE做自定义扩展
'AUTOLOAD_NAMESAPCE' => [ 'Tools' => APP_PATH . 'Vendor\Tools' ]这样便把 Tools 顶级命名空间注册到了自动载入函数中,当我们
use Tools\Extension\MyTools 时
传入 autoload 的 $class 即为 Tools\Extension\MyTools,得到的 $name 其实为一级命名空间名 这里为 Tools,Tools 不符合第一条件,在 else 中读取自定义的 AUTOLOAD_NAMESAPCE,发现我们有设置 键名为 Tools 的成员
便使用 dirname(键值)得到 APP_PATH . 'Vendor',我是觉得这里 dirname 写的有些鸡肋....所以便成功的映射定位出 Tools一级命名空间所在的文件目录为 APP_PATH . 'Vendor' 下,在与完整的类名 Tools\Extension\MyTools 拼接上 EXT即可定位到类文件,加载即可。
PHP生成随机红包高级方法
/** 传输数字必须为正整数,需要小数通过$bonus_float传值进行换算
* @param $bonus_total (必填) 红包总额
* @param $bonus_count (必填) 红包个数
* @param $bonus_max (选填) 每个小红包的最大额 最大值要大于平均值
* @param $bonus_min (选填) 每个小红包的最小额
* @param $bonus_float (选填 Y元J角F分) 红包传入单位
* @return 存放生成的每个小红包的值的一维数组
*/
function getBonus($bonus_total, $bonus_count=20, $bonus_max=0, $bonus_min=1, $bonus_float='Y') {
$total_money = 0;
$arr1 = array();
$arr2 = array();
$res = array();
// 转换传入金额单位 Y元 J角 F分
$tmp_float = $bonus_float;
if($bonus_float=='Y'){ $bonus_float = 1; $num_fmt = 0;}
if($bonus_float=='J'){ $bonus_float = 10; $num_fmt = 1;}
if($bonus_float=='F'){ $bonus_float = 100; $num_fmt = 2;}
// 每人红包平均值
$average = $bonus_total / $bonus_count;
// 防止传入参数越界
if($average > $bonus_max){ echo $bonus_max = round(($bonus_total-$average)/$bonus_count,0)+round($average,0); }
if($average < $bonus_min){ echo $bonus_min = 1; }
$range1 = ($average - $bonus_min)*($average - $bonus_min);
$range2 = ($bonus_max - $average)*($bonus_max - $average);
// 生成随机红包逻辑
for ( $i = 0; $i < $bonus_count; $i++) { if (rand($bonus_min, $bonus_max) > $average) {
$temp = $bonus_min + intval(sqrt(rand(0, (intval($range1)-1))));
$arr1[$i] = $temp;
$bonus_total -= $temp;
} else {
$temp = $bonus_max - intval(sqrt(rand(0, (intval($range2)-1))));
$arr1[$i] = $temp;
$bonus_total -= $temp;
}
}
while ($bonus_total > 0) {
for ($i = 0; $i < $bonus_count; $i++) { if ($bonus_total > 0 && $arr1[$i] < $bonus_max) {
$arr1[$i]++;
$bonus_total--;
}
}
}
while ($bonus_total < 0) {
for ($i = 0; $i < $bonus_count; $i++) {
if ($bonus_total < 0 && $arr1[$i] > $bonus_min) {
$arr1[$i]--;
$bonus_total++;
}
}
}
// 输出格式化数据结果
for ($i = 0; $i < $bonus_count; $i++) {
$arr1[$i] = number_format($arr1[$i]/$bonus_float,$num_fmt,'.','');
//统计每个钱数的红包数量,检查是否接近正态分布
$total_money += $arr1[$i];
if(isset($arr2[$arr1[$i]])){ $arr2[$arr1[$i]] += 1; }else{ $arr2[$arr1[$i]] = 1; }
}
ksort($arr2);
$res["total"] = $total_money."(Y)";
$res["bnmax"] = $bonus_max."(".$tmp_float.")";
$res["bnmin"] = $bonus_min."(".$tmp_float.")";
$res["money"] = $arr1;
$res["count"] = $arr2;
return $res;
}
$bonus_total = 2000;
$bonus_count = 30;
$bonus_max = 90; //最大值要大于平均值
$bonus_min = 1;
$bonus_float = "Y"; //
$result_bonus = getBonus($bonus_total, $bonus_count,$bonus_max);
echo "
";
print_r($result_bonus);
Array
(
[total] => 2000(Y)
[bnmax] => 90(Y)
[bnmin] => 1(Y)
[money] => Array
(
[0] => 74
[1] => 24
[2] => 67
[3] => 73
[4] => 67
[5] => 47
[6] => 69
[7] => 75
[8] => 63
[9] => 44
[10] => 77
[11] => 76
[12] => 70
[13] => 76
[14] => 76
[15] => 72
[16] => 73
[17] => 85
[18] => 68
[19] => 72
[20] => 76
[21] => 68
[22] => 55
[23] => 67
[24] => 65
[25] => 75
[26] => 70
[27] => 71
[28] => 65
[29] => 40
)
[count] => Array
(
[24] => 1
[40] => 1
[44] => 1
[47] => 1
[55] => 1
[63] => 1
[65] => 2
[67] => 3
[68] => 2
[69] => 1
[70] => 2
[71] => 1
[72] => 2
[73] => 2
[74] => 1
[75] => 2
[76] => 4
[77] => 1
[85] => 1
)
)
深入理解ob_flush和flush的区别和用法)
有关PHP的ob_flush()与flush()使用方法
注意:ob_flush()和flush()这两个函数一般要一起使用,顺序是先ob_flush(),然后flush(),它们的作用是刷新缓冲区。
这里具体的说下什么时候要用到刷新缓冲区和为什么要刷新缓冲区。
一、什么时候要刷新缓冲区
当程序中用到file_get_contents()和file_put_contens()这两个函数时,或程序中执行类似的“读写”功能或向浏览器执行输出操作时,会用到ob_flush()和flush()来刷新缓冲区。
二、为什么要刷新缓冲区
用file_get_contents()和file_put_content()为例进行讲解。
file_get_contents()和file_put_conents()这两个函数分别执行读取数据和写入数据操作,数据是先被读到内存中然后在写入文件中的,因为读取的速度比写入的速度要快,所以当你的数据被读完的时候不代表数据也写入完毕,这个时候多读的内容就会被暂时放到缓冲区中(内存),在这里需要强调一下,其实数据读取和写入是两个非常快的动作哦。
还用一种解释(当程序向浏览器执行输出操作时),个别web服务器程序,特别是Win32下的web服务器程序,在发送结果到浏览器之前,仍然会缓存脚本的输出,直到程序结束为止。如果你不想让程序执行完毕才向浏器输出,那么你也可以用到ob_flush()和flush()来刷新缓存。
其实,flush()还有一种用途,就是在没结束程序之前就进行输出,即一个循环还没结束就可以把部分结果输出到浏览器上,这个效果很类似 ajax的异步传输效果。
深入理解ob_flush和flush的区别
ob_flush/flush在手册中的描述, 都是刷新输出缓冲区, 并且还需要配套使用, 所以会导致很多人迷惑…
其实, 他们俩的操作对象不同, 有些情况下, flush根本不做什么事情..
ob_*系列函数, 是操作PHP本身的输出缓冲区.
所以, ob_flush是刷新PHP自身的缓冲区.
而flush, 严格来讲, 这个只有在PHP做为apache的Module(handler或者filter)安装的时候, 才有实际作用. 它是刷新WebServer(可以认为特指apache)的缓冲区.
在apache module的sapi下, flush会通过调用sapi_module的flush成员函数指针, 间接的调用apache的api: ap_rflush刷新apache的输出缓冲区, 当然手册中也说了, 有一些apache的其他模块, 可能会改变这个动作的结果..
有些Apache的模块,比如mod_gzip,可能自己进行输出缓存,这将导致flush()函数产生的结果不会立即被发送到客户端浏览器。
甚至浏览器也会在显示之前,缓存接收到的内容。例如 Netscape浏览器会在接受到换行或 html 标记的开头之前缓存内容,并且在接受到 </table> 标记之前,不会显示出整个表格。
一些版本的 Microsoft Internet Explorer 只有当接受到的256个字节以后才开始显示该页面,所以必须发送一些额外的空格来让这些浏览器显示页面内容所以, 正确使用俩者的顺序是. 先ob_flush, 然后flush,
当然, 在其他sapi下, 不调用flush也可以, 只不过为了保证你代码的可移植性, 建议配套使用.
buffer ---- flush()
buffer是一个内存地址空间,Linux系统默认大小一般为4096(1kb),即一个内存页。主要用于存储速度不同步的设备或者优先级不同的 设备之间传办理数据的区域。通过buffer,可以使进程这间的相互等待变少。这里说一个通俗一点的例子,你打开文本编辑器编辑一个文件的时候,你每输入 一个字符,操作系统并不会立即把这个字符直接写入到磁盘,而是先写入到buffer,当写满了一个buffer的时候,才会把buffer中的数据写入磁 盘,当然当调用内核函数flush()的时候,强制要求把buffer中的脏数据写回磁盘。
同样的道理,当执行echo,print的时候,输出并没有立即通过tcp传给客户端浏览器显示, 而是将数据写入php buffer。php output_buffering机制,意味在tcp buffer之前,建立了一新的队列,数据必须经过该队列。当一个php buffer写满的时候,脚本进程会将php buffer中的输出数据交给系统内核交由tcp传给浏览器显示。所以,数据会依次写到这几个地方echo/pring -> php buffer -> tcp buffer -> browser
php output_buffering --- ob_flush()
默认情况下,php buffer是开启的,而且该buffer默认值是4096,即1kb。你可以通过在php.ini配置文件中找到output_buffering配置.当echo,print等输出用户数据的时候,输出数据都会写入到php output_buffering中,直到output_buffering写满,会将这些数据通过tcp传送给浏览器显示。你也可以通过 ob_start()手动激活php output_buffering机制,使得即便输出超过了1kb数据,也不真的把数据交给tcp传给浏览器,因为ob_start()将php buffer空间设置到了足够大 。只有直到脚本结束,或者调用ob_end_flush函数,才会把数据发送给客户端浏览器。
这两个函数的使用怕是很多人最迷惑的一个问题,手册上对两个函数的解释也语焉不详,没有明确的指出它们的区别,似乎二者的功能都是刷新输出缓存。但在我们文章一开始的代码中如果讲fush()替换成ob_flush(),程序就再不能正确执行了。显然,它们是有区别的,否则也手册中直接说明其中一个是另外一个函数的别名即可了,没必要分别说明。那么它们的区别到底是什么呢?
在没有开启缓存时,脚本输出的内容都在服务器端处于等待输出的状态 ,flush()可以将等待输出的内容立即发送到客户端。
开启缓存后,脚本输出的内容存入了输出缓存中 ,这时没有处于等待输出状态的内容,你直接使用flush()不会向客户端发出任何内容。而 ob_flush()的作用就是将本来存在输出缓存中的内容取出来,设置为等待输出状态,但不会直接发送到客户端 ,这时你就需要先使用 ob_flush()再使用flush(),客户端才能立即获得脚本的输出。
一. flush和ob_flush的正确顺序,正确应是,先ob_flush再flush,如下:
ob_flush();
flush();
如果Web服务器的操作系统是windows系统,那顺序颠倒或者不使用ob_flush()也不会出现问题。[有待求证 ] 但是在Linux系统上就无法刷新输出缓冲。
output buffering函数
1.bool ob_start ([ callback $output_callback [, int $chunk_size [, bool $erase ]]] )
激活output_buffering机制。一旦激活,脚本输出不再直接出给浏览器,而是先暂时写入php buffer内存区域。
php默认开启output_buffering机制,只不过,通过调用ob_start()函数据output_buffering值扩展到足够 大 。也可以指定$chunk_size来指定output_buffering的值。$chunk_size默认值是0,表示直到脚本运行结束,php buffer中的数据才会发送到浏览器。如果你设置了$chunk_size的大小 ,则表示只要buffer中数据长度达到了该值,就会将buffer中 的数据发送给浏览器。
当然,你可以通过指定$ouput_callback,来处理buffer中的数据。比如函数ob_gzhandler,将buffer中的数据压缩后再传送给浏览器。
第三个参数:是否擦除缓存,可选,默认是true,如果设置为false,则在脚本执行结束前,缓存都不会被清除。
2.ob_get_contents
获取一份php buffer中的数据拷贝。值得注意的是,你应该在ob_end_clean()函数调用前调用该函数,否则ob_get_contents()返回一个空字符中。
可以使用ob_get_contents()以字符串形式获取服务端缓存的数据,
使用ob_end_flush()则会输出被缓存起来的数据,并关闭缓存。
而使用ob_end_clean()则会静默的清除服务端缓存的数据,而不会有任何数据或其他行为。
服务端的缓存是堆叠起来的,也就是说你在开启了ob_start()后,关闭之前,在其内部还 可以开启另外一个缓存ob_start()。
不过你也要务必保证关闭缓存的操作和开启缓存的操作数量一样多。
ob_start() 可以指定一个回调函数来处理缓存数据,如果一个ob_start()内部嵌套了另一个ob_start(),我们假定,外层的ob_start(),编号是A,内层的ob_start()编号是B,它们各自制定了一个回调函数分别是functionA和functionB,那么在缓存B中的数据输出时,它会先辈funcitonB回调函数处理,再交给外层的functionA回调函数处理,之后才能输出到客户端。
另外,手册说,对于某些web服务器,比如apache,在使用回调函数有可能会改变程序当前的工作目录,解决方法是在回调函数中自行手动把工作目录修改回来,用chdir函数,这点似乎不常遇到,遇到的时候记得去查手册吧。
3.ob_end_flush与ob_end_clean
这二个函数有点相似,都会关闭ouptu_buffering机制。但不同的是,ob_end_flush只是把php buffer中的数据冲(flush/send)到客户端浏览器,而ob_clean_clean将php bufeer中的数据清空(erase),但不发送给客户端浏览器。
ob_end_flush调用之前 ,php buffer中的数据依然存在,ob_get_contents()依然可以获取php buffer中的数据拷贝。
而ob_end_flush()调用之后 ob_get_contents()取到的是空字符串,同时浏览器也接收不到输出,即没有任何输出。
可以使用ob_get_contents()以字符串形式获取服务端缓存的数据,使用ob_end_flush()则会输出被缓存起来的数据,并关闭缓存。
而使用ob_end_clean()则会静默的清除服务端缓存的数据,而不会有任何数据或其他行为。
ob_start() 和 ob_end_flush() 是一对很好的搭档,可以实现对输出的控制。当成一对出现理解起来就没什么问题,但是当他们两个各自出现次数增加时,就比较难理解了.
<?php ob_start(); echo 'level 1<br/> '; ob_start(); echo 'level 2<br/> '; ob_start(); echo 'level 3<br/> '; ob_end_flush(); ob_end_flush(); ob_end_flush();
很明显,结果为:
level 1
level 2
level 3
当程序修改一下,修改一个ob_end_flush() 变成 ob_end_clean() 成为以下这个,你觉得结果会是怎样呢?附上这几个函数的讲解:
- ob_clean — 清空(擦掉)输出缓冲区
- ob_end_clean — 清空(擦除)缓冲区并关闭输出缓冲
- ob_end_flush — 冲刷出(送出)输出缓冲区内容并关闭缓冲
- ob_flush — 冲刷出(送出)输出缓冲区中的内容
- ob_start — 打开输出控制缓冲
<?php ob_start(); echo 'level 1<br/> '; ob_start(); echo 'level 2<br/> '; ob_start(); echo 'level 3<br/> '; ob_end_clean();//修改处 ob_end_flush(); ob_end_flush();
结果:
level 1
level 2
可能你会认为ob_end_clean()会清除与他最近的ob_start()的输出;其实这个说法不是很全面,看下面的例子
<?php ob_start(); echo 'level 1<br/> '; ob_start(); echo 'level 2<br/> '; ob_start(); echo 'level 3<br/> '; ob_end_clean(); //第一次修改 ob_end_flush(); ob_end_clean(); //第二次修改
这次,什么都没有输出来。
中间不是有一个ob_flush()吗?按理来说应该是输出 level2 的。
其实造成这样的主要原因是输出的多级缓冲机制。这个程序例子有三个ob_start(),就意味着他有3个缓冲区A,B,C,而其实php程序本身也有一个最终输出的缓冲区,我们就把他叫做F。
在这个程序中他这几个缓冲区是有一定层次的,C->B->A->F,F层次最高,是程序最终的输出缓冲,我们按上面的程序来进行讲解。
刚开始。 F:null
ob_start();
新建缓冲区A。 A: null -> F:null
echo 'level 1<br/> ';
程序有输出,输出进入最低的缓冲区A A: 'level 1<br/>' -> F:null
ob_start(); 新建缓冲区B 。 B:null -> A: 'level 1<br/>' -> F:null
echo 'level 2<br/> ';
程序有输出,输出进入最低的缓冲区B B:'level 2<br/> ' -> A: 'level 1<br/>' ->F:null
ob_start();
新建缓冲区C C:null B:'level 2<br/> ' A: 'level 1<br/>' -> F:null
echo 'level 3<br/> ';
程序有输出,输出进入最低的缓冲区C C:'level 3<br/> ' -> B:'level 2<br/> ' -> A: 'level 1<br/>' -> F:null
ob_end_clean(); //第一次修改
缓冲区C被清空并关闭。 B:'level 2<br/> ' -> A: 'level 1<br/>' -> F:null
ob_end_flush();
缓冲区B输出到上一级的缓冲区A并关闭。 A: 'level 1<br/>level 2<br/> ' -> F:null
ob_end_clean(); //第二次修改缓冲区A被清空并关闭。 此时缓冲区A的东西还没真正输出到最终的F中,因此也就整个程序也就没有任何的输出了。
ob其他的函数还有很多,但只要能懂得这些机理应该也是不难懂的。附上其余函数
- flush — 刷新输出缓冲
- ob_clean — 清空(擦掉)输出缓冲区
- ob_end_clean — 清空(擦除)缓冲区并关闭输出缓冲
- ob_end_flush — 冲刷出(送出)输出缓冲区内容并关闭缓冲
- ob_flush — 冲刷出(送出)输出缓冲区中的内容
- ob_get_clean — 得到当前缓冲区的内容并删除当前输出缓。
- ob_get_contents — 返回输出缓冲区的内容
- ob_get_flush — 刷出(送出)缓冲区内容,以字符串形式返回内容,并关闭输出缓冲区。
- ob_get_length — 返回输出缓冲区内容的长度
- ob_get_level — 返回输出缓冲机制的嵌套级别
- ob_get_status — 得到所有输出缓冲区的状态
- ob_gzhandler — 在ob_start中使用的用来压缩输出缓冲区中内容的回调函数。ob_start callback function to gzip output buffer
- ob_implicit_flush — 打开/关闭绝对刷送
- ob_list_handlers — 列出所有使用中的输出处理程序。
- ob_start — 打开输出控制缓冲
- output_add_rewrite_var — 添加URL重写器的值(Add URL rewriter values)
- output_reset_rewrite_vars — 重设URL重写器的值(Reset URL rewriter values)
如何获取(GET)一杯咖啡——星巴克REST案例分析
我们已习惯于在大型中间件平台(比如那些实现CORBA、Web服务协议栈和J2EE的平台)之上构建分布式系统了。在这篇文章里,我们将采取另一种做法:我们把支撑Web运行的协议和文档格式视为一种应用平台,一种可通过轻量级中间件访问的平台。我们通过一个简单的客户-服务交互的例子,展示了Web在应用集成中的作用。在这篇文章里,我们以Web为主要设计理念,提炼并分享了我们下本书《GET /connected - Web-based integration》(暂定名称)里的一些想法。
引言
我们知道,集成领域是不断变化的。Web的影响以及敏捷实践的潮流正在挑战我们的关于“良好的集成由什么构成”的观念。集成(integration)并不是一种夹在系统之间的专业活动;与此相反,现在,集成是成功方案里的不可缺少的一部分。
然而,仍有许多人误解并低估Web在企业计算中的作用。即便是那些精通Web的人士,也常常要花费很大力气才能懂得,Web不是关于支持XML over HTTP的中间件方案,也不是一种简易的RPC机制。这是相当遗憾的,因为Web不是仅能提供简单的点对点连接,它还有更大的用处;它实际上是一个健壮的集成平台。
在这篇文章里,我们将展示Web的一些值得关注的用途,我们将视之为一种可塑的、健壮的平台,它能够对企业系统做很“酷”的事。另外,工作流是企业软件最具代表性的特征。
为什么要工作流?
工作流(workflows)是企业计算的主要特征,它们基本上都是用中间件实现的(至少在计算方面)。工作流把一项工作(work)划分为多个离散的步骤(steps)以及触发步骤转移的事件(events)。工作流所实现的整个业务流程常常跨越若干企业信息系统,这给工作流带来很多集成问题。
星巴克:统一标准的咖啡需要统一标准的集成
Web若要成为可用于企业集成的技术,它就必须支持工作流——从而可靠地协调不同系统间的交互,以实现更大的业务能力。
要恰如其份地介绍工作流,就免不了讲述一大堆跟领域相关的技术细节,而这不是本文的主旨,因此,我们选择了Gregor Hohpe的星巴克工作流这个比较好理解的例子来举例说明基于Web的集成的工作原理。在这篇受到大家欢迎的博客文章里,Gregor讲述了星巴克是如何形成一个解耦合的(decoupled)盈利生产线的:
“跟大部分餐饮企业一样,星巴克也主要致力于将订单处理的吞吐量最大化。顾客订单越多,收入就越多。为此,他们采取了异步处理的办法。你在点单时,收银员取出一只咖啡杯,在上面作上记号表明你点的是什么,然后把这个杯子放到队列里去。这里的队列指的是在咖啡机前排成一列的咖啡杯。正是这个队列将收银员与咖啡师解耦开,从而,即便在咖啡师一时忙不过来的时候,收银员仍然可以为顾客点单。他们可以在繁忙时段安排多个咖啡师,就像竞争消费者模式(Competing Consumer)里那样。”
Gregor是采用EAI技术(如面向消息的中间件)来讲解星巴克案例的,而我们将采用Web资源(支持统一接口的可寻址实体)来讲解同一案例。实际上,我们将展示Web技术何以能够具有跟传统EAI工具一样的可靠性,以及何以不仅仅是请求/响应协议之上的XML消息传递!
首先,我们很抱歉擅自设想了星巴克的工作流程,因为我们的目的并不是精确无误地描述星巴克,而是用基于Web的服务来讲解工作流。好的,既然讲清楚了这一点,那么我们现在开始吧。
简明陈述
因为我们在讲工作流,所以我们有必要理解构成工作流的状态(states)以及将工作流从一个状态转移到另一个状态的事件(events)。我们的例子里有两个工作流,我们把它们用状态机(state machines)表达出来了。这两个工作流是并行执行的。一个反映了顾客与星巴克服务之间的交互(如图1),另一个刻画了由咖啡师执行的一系列动作(如图2)。
在顾客工作流里,顾客为了得到某种口味的咖啡而与星巴克服务进行交互。我们假定该工作流里包含以下动作:顾客点单,付款,然后等待饮品。在点单与付款之间,顾客通常可以修改菜单,比方说请求改用半脱脂牛奶。 /p>

图1 顾客状态机
尽管顾客看不见咖啡师,但咖啡师也有自己的状态机;这个状态机是服务实现私有的。如图2所示,咖啡师在周而复始地等待下一个订单,制作饮品,然后收取费用。当一个订单被加入到咖啡师的队列中时,一次循环实例就开始了。当咖啡师完成订单并把饮品交付给顾客时,工作流就结束了。

图2 咖啡师的状态机
尽管这些看似跟基于Web的集成毫不相干,但这两个状态机里的每一个状态迁移,都代表着与Web资源的一次交互。每一次迁移,就是通过URI对资源实施HTTP操作,从而导致状态的改变。
GET和HEAD属于特例,因为它们不引起状态迁移。它们的作用是用于查看资源的当前状态。
我们节奏稍快了点。理解状态机和Web,不是那么容易一口吃个胖子的。所以,让我们在Web的背景下,来从头回顾一下整个场景,逐步慢慢深入。
顾客视角
我们将从一张简单的故事卡片开始,它启动整个流程:

这个故事里涉及一些有用的角色与实体。首先,里面有“顾客(Customer)”角色。显然,它是(隐含的)星巴克服务(Starbucks Service)的消费者。其次,里面有两个重要的实体(“咖啡”和“订单”),以及一个重要的交互(“点单”)——我们的工作流正是由它启动的。
要把订单提交给星巴克,我们只要把订单的表示(representation)POST给下面这个众所周知的星巴克点单URI即可: http://starbucks.example.org/order。

图3 点一杯咖啡
图3显示了向星巴克点单的交互过程。星巴克采用自己的XML格式来表达有关实体;需要关注的是,这个格式允许客户往里嵌入信息,以便进行点单——稍后我们会看到。实际提交的数据如图4所示。
在面向人类的Web(human Web)上,消费者和服务使用HTML作为表示格式(representation format)。HTML有自己特定的语义,所有浏览器都理解并接受这些语义,比如:代表“一个链接到其他文档或本文档内部某个书签的锚(anchor)”。消费者应用——浏览器——只是呈现HTML,状态机(也就是你!)用
GET和POST跟随链接。对于基于Web的集成也一样,只不过服务和消费者不仅要就交互协议达成一致,还要就表示的格式与语义统一意见。

图4 POST饮品订单
星巴克服务创建一个订单资源,然后把这个新资源的位置放在HTTP报头Location里返回给消费者。为方便起见,服务还要把这个新创建的订单资源的表示(representation)也放在响应里。发给消费者的响应如下所示。

图5 创建好了订单,等待付款
201 Created状态表明星巴克已经成功接受了订单。Location报头给出了新创建订单的URI。响应主体里的表示(representation)包含了所点饮品及其价格。另外,这个表示里还包含另一个资源的URI——星巴克希望我们与这个URI交互,以完成顾客工作流;我们稍后将用到它。
注意,该URI是放在
我们已经知道
201 Created状态代码表示“成功创建资源”的意思。对于这个例子以及一般的基于Web的集成,我们还需要其他一些有用的代码:
200 OK——它的意思是:一切正常;继续执行。
201 Created——我们刚刚创建了一个资源,一切正常。
202 Accepted——服务已经接受了我们的请求,并请我们对Location响应报头里的URI进行轮询(poll)。这在异步处理中相当有用。
303 See Other——我们需要跟另一个资源交互,应该不会出错。
400 Bad Request——我们的请求格式有问题,应重新格式化后再提交。
404 Not Found——服务因为偷懒(或者保密)没有告知请求失败的真实原因,但不管什么原因,我们都得应付它。
409 Conflict——服务器拒绝了我们更新资源状态的请求。我们需要获取资源的当前状态(要么检查响应实体主体,要么做一次GET操作),然后再作打算。
412 Precondition Failed——请求未被处理,因为Etag、If-Match或类似的“哨兵(guard)”报头的值不满足条件。我们需要考虑下一步怎么走。
417 Expectation Failed——幸亏核查一下,服务器不将接受你的请求,所以别真正发送那个请求。
500 Internal Server Error——最偷懒的响应。服务器出错了,而且什么原因都没说。祝你不要碰见它。
更新订单
星巴克很不错的一点就是,你可以按无数种不同的方式来定制自己的饮品。其实,考虑到某些高端客户极高的要求,也许让他们按化学公式来点单更好。但我们别那么贪心——至少开始的时候。我们来看另一张故事卡片:

回顾图4,显然我们在那里犯了一个错误:真正爱喝咖啡的人是不喜欢往浓咖啡里放太多热牛奶的。我们要改正那个问题。幸运地是,Web(或更确切地说,HTTP)以及我们的服务均为这样的改变提供了支持。
首先,我们要确认我们仍然可以修改订单。有时咖啡师动作很快,在我们想修改订单之前,他们就已经把咖啡做好了——于是,我们只有慢慢享用这杯热咖啡风味的牛奶了。不过,有时咖啡师会比较慢,这样我们就可以在订单得到咖啡师处理之前修改它了。为了知道我们是否还能修改订单,我们通过HTTP动词OPTIONS来向订单资源查询它接受哪些操作(如图6)。
| 请求 | 响应 |
OPTIONS /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK Allow: GET, PUT |
图6 看看有哪些选择(OPTIONS)
从图6我们可以知道,订单资源既是可读的(支持GET)、也是可更新的(支持PUT)。作为好网民,我们可以拿我们的新表示来做一次试验性的PUT操作,在真正PUT之前先用Expect报头来试一试(如图7)。
| 请求 | 响应 |
PUT /order/1234 HTTP 1.1 Host: starbucks.example.com Expect: 100-Continue |
100 Continue |
图7 看好再做(Look before you leap)
若我们不能修改订单了,那么对图7所示请求的响应将是417 Expectation Failed。不过,假定我们现在得到的响应是100 Continue,也就是说,我们可以用PUT来更新订单资源(如图8)。用PUT方法来提交更新后的资源表示(representation),实际上就相当于修改现有资源。在这个例子中,PUT请求里的新描述包含一个
尽管部分更新(partial updates)属于REST社区里比较难懂的理念争论之一,但这里我们采取一种实用的做法,我们假定:增加一杯浓咖啡的请求,是在现有资源状态的上下文中被处理的。因此,我们没必要在网络上传送整个资源表示,我们只要传送变化的部分即可。

图8 更新资源状态
如果我们能够成功提交(PUT)更新,那么我们会从服务器得到响应代码200,如图9所示。

图9 成功更新资源状态
检查OPTIONS和采用Expect报头并不能令我们避免碰到“后续的修改请求失败”的情况。因此,我们并不强制使用它。作为好网民,我们会以某种方式来应付405和409响应。
OPTIONS和Expect报头的使用应当被视为可选步骤。
尽管我们明智地使用Expect和OPTIONS,但有时PUT仍将失败;毕竟咖啡师也在一刻不停地工作——有时他们动作很敏捷!
若我们落后于咖啡师,我们在试图用PUT操作把更新提交给资源时会被告知。图10显示的就是一个常见的更新失败的响应。409 Conflict状态代码表明,若接受更新,将导致资源处于不一致的状态,所以没有进行更新。响应主体里显示出了我们试图PUT的表示(representation)与服务端资源状态之间的差异。按咖啡制作的话说,加得太晚了——咖啡师已经把热牛奶倒进去了。

图10 慢了一步
我们已经讲述了使用Expect和OPTIONS来尽量防止竞争条件。除此以外,我们还可以给我们的PUT请求加上If-Unmodified-Since或If-Match报头,以表达我们对服务的期望条件。If-Unmodified-Since采用时间戳,而If-Match采用原始订单的ETag1 。若订单状态自从被我们创建以来还没有改变过——也就是说,咖啡师还没有开始制作我们的咖啡——那么更新可以处理。若订单状态已经发生改变,那么我们会得到412 Precondition Failed响应。虽然我们因为慢了咖啡师一步而只能享用牛奶咖啡,但至少我们没有把资源转移到不一致的状态。
用Web进行一致的状态更新可以采取很多种模式。HTTP PUT是幂等的(idempotent),这样我们在进行状态更新时就用不着处理一些复杂事务了,不过仍有一些选择需要我们决定。下面是正确进行状态更新的一些方法:
1. 通过发送
OPTIONS请求,查询服务是否接受PUT操作。这一步是可选的。它可以告知客户端,此刻服务器允许对该资源做哪些操作,不过这无法保证服务器将永远支持那些操作。2. 使用
If-Unmodified-Since或If-Match报头,以避免服务器执行不必要的PUT操作。假如PUT后来失败了,那么你会得到412 Precondition Failed。此方法要求:要么资源是缓慢更新的,要么支持ETag;对于前者就用If-Unmodified-Since,对于后者就用If-Match。3. 立即用
PUT操作提交更新,并应付可能出现的409 Conflict响应。就算我们使用了(1)和(2),我们可能仍得应付这些响应,因为我们的“哨兵”和检查本质上都是乐观的。关于检测和处理不一致的更新,W3C有一个非规范性文档,该文档推荐采用ETag。ETags也是我们推荐采用的方法。
在完成那些更新咖啡订单的艰苦工作之后,按理说我们应当得到额外那杯浓咖啡了。所以我们现在假定已设法得到了额外那杯浓咖啡。当然,我们要付过款后星巴克才会把咖啡递给我们(其实他们也已经暗示过了!),所以我们还需要一张故事卡片:

还记得最初那个针对原始订单的响应吗?其中有个

关于next元素,有几点是值得指出的。首先,它处于一个不同的名称空间之下,因为状态迁移并不是只有星巴克需要。在这里,我们决定把这种用于状态迁移的URI放在一个公共的名称空间里,以便于重用(或甚至最终的标准化)。
其次,rel属性里嵌入了一则语义信息(你乐意的话,也可以称之为一种私有的微格式)。能够理解http://starbucks.example.org/payment这串文字的消费者,可以使用由uri属性标识的资源转移到工作流里的下一状态(付款)。
uri指向的是一个付款资源。根据type属性,我们已经知道预期的资源表示(representation)是XML格式的。我们可以向这个付款资源发送OPTIONS请求,看看它支持哪些HTTP操作。
微格式(microformat)是一种在现有文档里嵌入结构化、语义丰富的数据的方式。微格式在人类可读的Web上相当常见,它们用于往网页里增加结构化信息(如日程表)的 表示(representations)。不过,它们同样也可以方便地被用于集成。微格式术语是在微格式社区里达成一致的,不过我们也可以自由创建自己的 私有微格式,用于特定领域的语义标记。
尽管它们看上去没多大用,但如图10里那样的简单链接正是REST社区所呼吁的“将超媒体作为应用状态的引擎(hypermedia as the engine of application state)”的关键。更简单地说,URI代表了状态机里的状态迁移。正如我们在文章开始时所看到的,客户端是通过跟随链接的方式来操作应用程序的状态 机的。
如果你一时不能理解,不要感到奇怪。这一模型的最不可思议之处在于:状态机和工作流不是像WS-BPEL或WS-CDL那样事先描述好的,而是在你 经历各个状态的过程中逐步得到描述的。不过,一旦你的想明白了,你就会发现,跟随链接(following links)这种方式使得我们可以在应用的各种状态下向前推进。每次状态迁移时,当前资源的表示里都包含了指向可能的下一状态的链接以及它们所代表的状 态。另外,由于这些代表下一状态的资源是Web资源,所以我们知道如何使用它们。
在顾客工作流里,我们下一步要做的是为咖啡付款。我们可以由订单里的
消费者需要事先掌握多少关于一个服务的知识呢?我们已经说过了,服务和消费者在交互之前需要就它们将会交换的表示(representations)的语 义达成一致。可以将这些表示格式(representation formats)看成一组可能的状态和迁移。在消费者与服务交互时,服务选择可用的状态和迁移,并构造下一个表示。步向目标的过程是 动态发现的,而把这一过程中的各个部分串起来的方式是事先达成一致的。
在设计与开发过程中,消费者会就表示和迁移的语义与服务器达成一致。但谁也不能保证服务在其演化过程中会不会采用一种客户端预期之外的表示和迁移 (不过客户端还是知道如何处理它的)——那是Web松耦合的本质特性。尽管如此,在这些情况下就资源格式和表示达成一致超出了本文的范围。
我们下一步要做的是为咖啡付款。我们可以由订单表示的
| 请求 | 响应 |
OPTIONS/payment/order/1234 HTTP 1.1 Host: starbucks.example.com |
Allow: GET, PUT |
图11 获知如何付款
服务器返回的响应告诉我们,我们既可以读取付款(通过GET)、也可以更新它(通过PUT)。既然知道了金额,那么接下来,我们就把款项PUT给那个由付款链接标识的资源。当然,付款金额属于秘密信息,所以我们将通过认证2来保护该资源。
| 请求 |
PUT /payment/order/1234 HTTP 1.1 |
| 响应 |
201 Created |
图12 付款
为成功完成付款,我们只需按图12进行交互即可。一旦经认证的PUT返回一个201 Created响应,我们就可以庆祝付款成功、并拿到我们的饮品了。
不过事情也有出错的时候。当资金处于危险状态时,我们希望要么没出错、要么可以挽救错误3。付款时可能出现很多种容易想象的出错情况:
- 由于服务器宕机或其他原因,我们无法连接上服务器了;
- 在交互过程中,与服务器的连接被切断了;
- 服务器返回一个
4xx或5xx范围的错误状态。
幸运地是,Web可以帮助我们应付以上这些情况。对前两种情况(假定连接问题是瞬间的),我们可以反复做PUT请求,直至我们收到成功响应为止。如果前次PUT操作已经得到了成功处理,那么我们将收到一个200响应(本质上是一个来自服务器的空操作确认);如果本次PUT操作成功完成了付款,那么我们将收到一个201响应。在第三种情况中,如果服务器返回的响应代码是500、503或504,那么也可以做同样处理。
4xx范围的状态代码比较难处理,不过它们仍然指出了下一步怎么办。例如,400响应表明我们通过PUT请求提交的内容无法被服务器所理解,我们需要纠正后重新发送PUT请求。403响应则相反,它表明服务器能够理解我们的请求,但不知道如何履行(fulfil)它,而且服务器希望我们不要重试。对于这些情况,我们得在响应的有效负载(payload)里寻找其他的状态迁移(链接),换其他推进状态的路线。
在这个例子中,我们已经多次使用状态代码来指引客户端步向下一个交互了。状态代码是具有丰富语义的确认信息。让服务返回有意义状态代码,并且令客户 端懂得如何处理状态代码,这样一来,我们便给HTTP简单的请求响应机制增加了一层协调协议,从而提高了分布式系统的健壮性和可靠性。
一旦我们为自己的饮品买了单,我们这个工作流就算完成了,有关顾客的故事也就到此结束了。不过整个故事还没有完。现在我们进入到服务里面,看看星巴克的内部实现。
咖啡师视角
作为顾客,我们乐于把自己放在咖啡世界的中央,不过我们并不是咖啡服务的唯一消费者。从与咖啡师的“时间竞赛”中我们已经得知,咖啡服务还为包括咖啡师在内的其他一些相关方面提供服务。按照我们循序渐进的介绍方式,现在该推出另一张故事卡片了。

用Web的格式与协议来描述饮品列表是件很容易的事。用Atom提要(feeds)来表达列表之类的东西是相当不错的选择,它几乎可描述任何列表(比如未完成的咖啡订单),所以这里我们可以也采用它。咖啡师可以通过向该Atom提要的URI发送GET请求来访问它,对于未完成的订单,URI是http://starbucks.example.org/orders(如图13)。

图13 待制作饮品的Atom提要
星巴克是家相当繁忙的店,位于/orders的Atom提要更新相当频繁,所以咖啡师要不断轮询这个提要才能保证掌握最新信息。轮询通常被认为可伸缩性很差;但是,Web支持可伸缩性极强的轮询机制——我们稍后会看到。另外,由于星巴克每分钟要制作很多咖啡,所以承受住负荷是个重要问题。
这里我们有两个相抵触的需求。一方面,我们希望咖啡师通过经常轮询订单提要,以不断掌握最新信息;另一方面,我们又不希望给服务增添负担、或者徒然增加网 络流量。为防止我们的服务因过载而崩溃,我们将在我们服务之外,用一个逆向代理(reverse proxy)来缓存并提供被频繁访问的资源表示(如图14所示)。

图14 通过缓存提升可伸缩性
对于大多数资源(尤其是那些会被很多人访问的资源,如返回饮品列表的Atom提要),在宿主服务之外缓存它们是合理的。这样可以降低服务器负 载,提升可伸缩性。我们在架构里增设了Web缓存(逆向代理),再加上有缓存元数据,这样客户端获取资源时就不会给原服务器增添很大负担了。
缓存的有利一面是,它屏蔽掉了服务器的间隙性故障,并通过提高资源可用率来帮助灾难恢复。也就是说,即便星巴克服务出现了故障,咖啡师仍然可以继续工 作,因为订单信息是被代理缓存起来的。而且,假如咖啡师漏了某个订单的话(错误),恢复也很容易进行,因为订单具有很高的可用率。
是的,缓存可以把旧订单多保留一段时间,但对于像星巴克这样吞吐量很高的商户而言,这是不太理想的。为了把太旧的订单从缓存中清除,星巴克服务用
Expires
报头来声明一个响应可以被缓存多久。任何介于消费者与服务之间的缓存都应当服从这一指示,拒绝提供过期订单4,而是把请求转发到星巴克服务上,以获取最新的订单信息。
图13所示的响应对Atom提要的Expires报头进行了相应的设置,令饮品列表在10秒钟后过期。由于这 种缓存行为,服务器每分钟最多只要响应6次请求,其余请求将由缓存机制代劳。即便对于性能比较糟糕的服务,每分钟6个请求也属于容易处理的工作量了。在最 愉快的情况下(对星巴克服务来说),咖啡师的轮询请求是由本地缓存响应的,这样就不会给增加网络活动或服务器负荷了。
在我们的例子中,我们只设置了一个缓存来帮助提升主咖啡列表的可伸缩性。然而,在真实的基于Web的场景中,我们可以从多层缓存中受益。要在大规模环境中提升可伸缩性,利用现有Web缓存的优点是至关重要的。
Web以延迟换取了高度的可伸缩性。假如你的问题对延迟很敏感的话(比如外汇交易),那么就不太适合采用基于Web的方案了。但是,假如你可以接受“秒”数量级上的延迟,那么Web也许是个不错的平台。
既然我们已经成功解决了可伸缩性问题,那么我们继续来实现更多的功能。当咖啡师开始为你制作咖啡时,应当修改订单状态,以达到禁止更新的目的。从顾客的角度来看,这相当于我们无法再对我们的订单执行PUT操作了(如图6、7、8、9、10所示)。
幸运地是,我们可以利用一个已经定义好的协议——Atom发布协议(Atom Publishing Protocol,简称APP或AtomPub)——来实现这一目标。AtomPub是一个以Web中心(基于URI)的协议,用于管理Atom提要里的 条目(entries)。我们来仔细看看Atom提要(/orders)里代表咖啡的条目。

图15 咖啡订单对应的Atom条目
在图15所示的XML里,有几点值得注意。首先,它将我们的订单与Atom提要里的其他订单区分开了。其次,其中包含订单本身,即咖啡师制作咖啡所需的全部信息——包括我们要求增加一杯浓咖啡的重要信息!该订单对应的entry元素里有个link元素,它声明了本条目(entry)的编辑URI(edit)。这个编辑URI指向的是一个可以通过HTTP编辑的订单资源。(这里,可编辑资源的地址刚好跟订单资源本身的地址一样,不过这不是必须的。)
如果咖啡师要锁定订单资源、禁止它被修改,就可以通过该编辑URI来改变订单资源的状态。具体地讲,咖啡师可以用PUT请求把经修改的资源状态提交给这个编辑URI(如图16所示)。

图16 通过AtomPub设置订单状态
服务器一旦处理了如图16所示的PUT请求,它就会拒绝对位于/orders/1234的订单资源做除GET以外的操作。
现在订单处于稳定状态了,咖啡师可以毫无顾虑地继续制作咖啡了。当然,咖啡师只有知道我们已经付过款才会把咖啡给我们,所以咖啡师还要查询我们是否已经完 成付款。在真实的星巴克里,情况会略有不同:一般来说,我们是点单后立即付款的;然后,其他顾客站在周围,以免你拿走别人点的饮品。但在我们计算机化的版 本里,增加这一检查并不麻烦,所以我们来看倒数第二张故事卡片:

咖啡师只要向付款资源(该资源的URI在订单表示里给出了)发送GET请求,即可查询付款状态。
这里,顾客和咖啡师是通过订单表示里给出的链接得知付款资源的URI的。但有时,通过URI模版来访问资源也很方便。
URI模版(URI template)是一种描述知名URI的格式。它允许消费者通过修改URI里的部分字符来访问不同的资源。
Amazon的S3存储服务就是基于URI模版的。用户可以对由以下模版生成的URIs进行HTTP操作,从而对已保存的制品进行操作:
http://s3.amazonaws.com/{bucket_name}/{key_name}。为方便咖啡师(或其他经授权的星巴克系统)不用遍历所有订单即可访问各个付款资源,我们可以在我们的模型里设计一个类似的URL模版方案:
http://starbucks.example.org/payment/order/{order_id}。URI模版就像与消费者订立的契约,服务提供者须在服务演化过程中注意维持它们的稳定。由于这一潜在的耦合,有些Web集成工作者会有意避免采用URI模版。我们的建议是,仅当可推断的URIs(inferable URIs)很有帮助而且不会改变时才使用。
对于我们的例子,另一种办法是在
/payments处暴露一个提要,用它提供包含指向各个付款资源的(不可推断的)链接。该提要只有经授权的系统才能读取。最终,URI模版是不是一个相对超媒体来说安全而有效的捷径,要由服务设计者来决定。我们的建议是:要保守地使用URI模版!
当然,不是人人都可以查看付款信息的。我们不想让咖啡社区里会动歪脑筋的人查看他人的信用卡详细信息,因此,跟其他敏感的Web系统一样,我们利用请求认证来保护敏感资源。
如有未认证的用户或系统试图获取一个具体的付款信息,那么服务器会质询(challenge)它、要求它提供证书。(如图17)
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org |
401 Unauthorized WWW-Authenticate: Digest realm="starbucks.example.org", qop="auth", nonce="ab656...", opaque="b6a9..." |
图17 对付款资源的非授权访问受到质询
401状态(及其认证元数据)告诉我们,我们应当在请求里附上正确的证书、然后重新发送请求。重新用正确的证书发送请求(图18)后,我们得到了付款信息,并将之与代表订单总金额的资源http://starbucks.example.org/total/order/1234进行比较。
| 请求 | 响应 |
GET /payment/order/1234 HTTP 1.1 Host: starbucks.example.org Authorization: Digest username="barista joe" realm="starbucks.example.org“ nonce="..." uri="payment/order/1234" qop=auth nc=00000001 cnonce="..." reponse="..." opaque="..." |
200 OK |
图18 授权访问付款资源
一旦咖啡师制作好、交出咖啡并完成收款,他们就要在待处理饮品列表中删除相应的订单。如同前面一样,我们采用一个故事来讲解这个回合:

因为订单提要里的各个条目(entry)都标识着一个可编辑资源,而且有自己的URI,所以我们可以对各个订单资源做HTTP操作。如图19所示,咖啡师只要对相关条目(entry)所引用的资源做DELETE操作即可将它从列表中删除。
| 请求 | 响应 |
DELETE /order/1234 HTTP 1.1 Host: starbucks.example.org |
200 OK |
图19 删除已完成的订单
在条目被删除(DELETE)之后,再对订单提要做GET操作的话,返回的表示里将不再包含已删除(DELETE)的资源。假定我们的缓存工作正常、且我们已经设置了合理的缓存过期元数据的话,那么当你试图获取(GET)那个订单条目时将直接得到404 Not Found响应。
也许你已经注意到了,Atom发布协议可以满足我们对星巴克这个问题的大部分需求。如果我们想直接把位于/orders的Atom提要暴露给顾客的话,顾客就可以用Atom发布协议来向该提要发布饮品订单、甚至修改订单了。
演化:Web上的现实情况
因为我们的咖啡店是基于自描述的状态机(state machines)构建起来的,所以我们可以方便地根据业务需要改造我们的工作流。例如,星巴克也许会提供一种免费的网上促销活动:
- 7月——我们的星巴克店开业,并提供标准的工作流以及我们前面提到的状态迁移和表示(representation)。消费者知道用这些格式与表示跟我们的服务进行交互。
- 8月——星巴克新推出了一种免费网上促销的表示(representation)。我们的咖啡工作流将进行更新,以包含指向该网上促销资源的链接。由于URI的特性,链接可以是指向第三方的——这跟指向星巴克内部的资源一样简单。

- 因为表示里仍然包含原来的迁移点,所以现有消费者仍然可以实现它们的目标,只不过它们可能无法享受促销而已,因为这部分还没有写进它们的代码里去。
- 9月——消费者应用和服务都进行了有关升级,以便能够理解并使用免费的网上促销。
成功进行演化的关键在于,服务的消费者们要能够预料到改变。在每一步,服务不是直接跟资源绑定(例如通过URI模版),而是提供指向具名资源(named resources)的URIs,以便消费者与之交互。这些具名资源,有些是消费者不认识的、将被忽略的,有些是消费者已知的、想采用的状态迁移点。不管 采用哪种方式,这种方案使得服务可以优雅地演化,同时还能维持与消费者兼容。
你将使用的是一个相当热门的技术
交付咖啡是我们工作流的最后一步。我们已经点了单、修改了订单(也可能无法修改)、付过款并最终拿到了我们的咖啡。在柜台另一侧,星巴克也已经同样完成了收款和订单处理。
我们可以用Web来描述所有必需的交互。我们可以利用现有的Web模型处理一些简单的不愉快的事(例如无法修改处理中或已处理完毕的订单),而不必 自己发明新的异常或错误处理机制——我们所需的一切都是HTTP现成提供的。而且,即便发生了那些不愉快的事,客户端仍然可以向它们的目标迈进。
HTTP提供的特性起初看来是无关紧要的。但这个协议现在已经取得广泛的一致、并得到广泛的部署了,而且所有的软件与硬件都能一定程度上理解它。当 我们看到其他分布式计算技术(如WS-*)处于割据状态的格局时,我们意识到了HTTP享有的巨大成功,以及它在系统间集成方面的潜力。
甚至在非功能性方面,Web也是有益的。在我们碰到临时故障时,HTTP操作(GET、PUT和DELETE)的幂等性质令我们可以进行安全的重试;内在的缓存机制既屏蔽了故障,又有助于灾难恢复(通过增强的可用率);HTTPS和HTTP认证有助于基本的安全需求。
尽管我们的问题域是人为制造的,但我们所强调的技术同样可以应用于分布式计算环境。我们不会伪称Web很简单(除非你是天才),Web可以解决一切问题 (除非你是超级乐观的人,或受到REST信仰的感染),但事实上,在局部、企业级和Internet级进行系统集成,Web是个健壮的框架。
致谢
本文作者要向英国卡迪夫大学(Cardiff University)的Andrew Harrison表示感谢,是他启发了我们就Web上的“对话描述”进行讨论。
About the Authors
Jim Webber博士是ThoughtWorks公司的专业服务主管,他的工作是为全球客户进行可靠的分布式系统架构设计。此 前,Jim担任英国E-Science计划高级研究员,从事将Web服务实践及可靠面向服务计算的架构模式应用于网格计算的战略设计工作,他在Web及 Web服务架构与 开发方面具有广泛的经验。Jim还担任过惠普公司和Arjuna公司的架构师,他是业界首个Web服务事务方案的首席开发者。Jim是一位活跃的演说家, 他经常受邀出席 国际会议并发言。他还是一位活跃的作家,除了《Developing Enterprise Web Services - An Architect's Guide》这本书外,目前他正在撰写一本关于基于Web的集成的新书。Jim获得英国纽卡斯尔大学(University of Newcastle)的计算机科学学士学位和并行计算博士学位。他的博客地址是:http://jim.webber.name。
Savas Parastatidis是一位软件思想家,他的思考领域涉及系统和软件。他研究技术在eResearch里的运用,他尤其对云计算、知识表示与管理、社会网络感兴趣。他目前任职于微软研究院合作研究部。Savas喜欢在http://savas.parastatidis.name上写博客。
Ian Robinson帮助客户们创建可持续的面向服务的能力,令业务与IT从开始到实际运营始终保持齐合。他为微软公司写过关于采用微软技术实现面向服务系统的指南,还发表过文章讲述消费者驱动的服务契约及其在软件开发生命周期中的作用——该文章可以在《ThoughtWorks文集(The ThoughtWorks Anthology)》(Pragmatic Programmers,2008)及InfoQ中文站上找到。他经常在会议上做有关REST式企业开发及面向服务交付的测试驱动基础的讲演。
查看英文原文:How to GET a Cup of Coffee。
RESTful API 设计指南
网络应用程序,分为前端和后端两个部分。当前的发展趋势,就是前端设备层出不穷(手机、平板、桌面电脑、其他专用设备......)。
因此,必须有一种统一的机制,方便不同的前端设备与后端进行通信。这导致API构架的流行,甚至出现"API First"的设计思想。RESTful API是目前比较成熟的一套互联网应用程序的API设计理论。我以前写过一篇《理解RESTful架构》,探讨如何理解这个概念。
今天,我将介绍RESTful API的设计细节,探讨如何设计一套合理、好用的API。我的主要参考了两篇文章(1,2)。

一、协议
API与用户的通信协议,总是使用HTTPs协议。
二、域名
应该尽量将API部署在专用域名之下。
https://api.example.com
如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
https://example.org/api/
三、版本(Versioning)
应该将API的版本号放入URL。
https://api.example.com/v1/
另一种做法是,将版本号放在HTTP头信息中,但不如放入URL方便和直观。Github采用这种做法。
四、路径(Endpoint)
路径又称"终点"(endpoint),表示API的具体网址。
在RESTful架构中,每个网址代表一种资源(resource),所以网址中不能有动词,只能有名词,而且所用的名词往往与数据库的表格名对应。一般来说,数据库中的表都是同种记录的"集合"(collection),所以API中的名词也应该使用复数。
举例来说,有一个API提供动物园(zoo)的信息,还包括各种动物和雇员的信息,则它的路径应该设计成下面这样。
- https://api.example.com/v1/zoos
- https://api.example.com/v1/animals
- https://api.example.com/v1/employees
五、HTTP动词
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面五个(括号里是对应的SQL命令)。
- GET(SELECT):从服务器取出资源(一项或多项)。
- POST(CREATE):在服务器新建一个资源。
- PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
- PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
- DELETE(DELETE):从服务器删除资源。
还有两个不常用的HTTP动词。
- HEAD:获取资源的元数据。
- OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
- GET /zoos:列出所有动物园
- POST /zoos:新建一个动物园
- GET /zoos/ID:获取某个指定动物园的信息
- PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
- PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
- DELETE /zoos/ID:删除某个动物园
- GET /zoos/ID/animals:列出某个指定动物园的所有动物
- DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
六、过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
- ?limit=10:指定返回记录的数量
- ?offset=10:指定返回记录的开始位置。
- ?page=2&per_page=100:指定第几页,以及每页的记录数。
- ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
- ?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoo/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
七、状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
- 200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。
- 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
- 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务)
- 204 NO CONTENT - [DELETE]:用户删除数据成功。
- 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。
- 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。
- 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
- 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
- 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
- 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
- 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
- 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
状态码的完全列表参见这里。
八、错误处理(Error handling)
如果状态码是4xx,就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{ error: "Invalid API key" }
九、返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
十、Hypermedia API
RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
比如,当用户向api.example.com的根目录发出请求,会得到这样一个文档。
{"link": { "rel": "collection https://www.example.com/zoos", "href": "https://api.example.com/zoos", "title": "List of zoos", "type": "application/vnd.yourformat+json" }}
上面代码表示,文档中有一个link属性,用户读取这个属性就知道下一步该调用什么API了。rel表示这个API与当前网址的关系(collection关系,并给出该collection的网址),href表示API的路径,title表示API的标题,type表示返回类型。
Hypermedia API的设计被称为HATEOAS。Github的API就是这种设计,访问api.github.com会得到一个所有可用API的网址列表。
{ "current_user_url": "https://api.github.com/user", "authorizations_url": "https://api.github.com/authorizations", // ... }
从上面可以看到,如果想获取当前用户的信息,应该去访问api.github.com/user,然后就得到了下面结果。
{ "message": "Requires authentication", "documentation_url": "https://developer.github.com/v3" }
上面代码表示,服务器给出了提示信息,以及文档的网址。
十一、其他
(1)API的身份认证应该使用OAuth 2.0框架。
(2)服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
(完)
MySQL中的mysqldump命令使用详解
就用 --ignore-table=dbname.tablename参数就行了。
mysqldump -uusername -ppassword -h192.168.0.1 -P3306 dbname --ignore-table=dbname.dbtanles > dump.sql
导出要用到MySQL的mysqldump工具,基本用法是:
shell> mysqldump [OPTIONS] database [tables]
如果你不给定任何表,整个数据库将被导出。
通过执行mysqldump --help,你能得到你mysqldump的版本支持的选项表。
注意,如果你运行mysqldump没有--quick或--opt选项,mysqldump将在导出结果前装载整个结果集到内存中,如果你正在导出一个大的数据库,这将可能是一个问题。
mysqldump支持下列选项:
--add-locks 在每个表导出之前增加LOCK TABLES并且之后UNLOCK
TABLE。(为了使得更快地插入到MySQL)。
--add-drop-table 在每个create语句之前增加一个drop table。
--allow-keywords 允许创建是关键词的列名字。这由表名前缀于每个列名做到。
-c, --complete-insert 使用完整的insert语句(用列名字)。
-C, --compress 如果客户和服务器均支持压缩,压缩两者间所有的信息。
--delayed 用INSERT DELAYED命令插入行。
-e, --extended-insert 使用全新多行INSERT语法。(给出更紧缩并且更快的插入语句)
-#, --debug[=option_string] 跟踪程序的使用(为了调试)。
--help 显示一条帮助消息并且退出。
--fields-terminated-by=...
--fields-enclosed-by=...
--fields-optionally-enclosed-by=...
--fields-escaped-by=...
--fields-terminated-by=... 这些选择与-T选择一起使用,并且有相应的LOAD DATA
INFILE子句相同的含义。 LOAD DATA INFILE语法。
-F, --flush-logs 在开始导出前,洗掉在MySQL服务器中的日志文件。
-f, --force, 即使我们在一个表导出期间得到一个SQL错误,继续。
-h, --host=.. 从命名的主机上的MySQL服务器导出数据。缺省主机是localhost。
-l, --lock-tables. 为开始导出锁定所有表。
-t, --no-create-info 不写入表创建信息(CREATE TABLE语句)
-d, --no-data 不写入表的任何行信息。如果你只想得到一个表的结构的导出,这是很有用的!
--opt 同--quick --add-drop-table --add-locks --extended-insert --lock-tables。 应该给你为读入一个MySQL服务器的尽可能最快的导出。
-pyour_pass, --password[=your_pass] 与服务器连接时使用的口令。如果你不指定“=your_pass”部分,mysqldump需要来自终端的口令。
-P port_num, --port=port_num 与一台主机连接时使用的TCP/IP端口号。(这用于连接到localhost以外的主机,因为它使用
Unix套接字。)
-q, --quick 不缓冲查询,直接导出至stdout;使用mysql_use_result()做它。
-S /path/to/socket, --socket=/path/to/socket 与localhost连接时(它是缺省主机)使用的套接字文件。
-T, --tab=path-to-some-directory 对于每个给定的表,创建一个table_name.sql文件,它包含SQL
CREATE 命令,和一个table_name.txt文件,它包含数据。
注意:这只有在mysqldump运行在mysqld守护进程运行的同一台机器上的时候才工作。.txt文件的格式根据--fields-xxx和--lines--xxx选项来定。
-u user_name, --user=user_name 与服务器连接时,MySQL使用的用户名。缺省值是你的Unix登录名。
-O var=option, --set-variable var=option设置一个变量的值。可能的变量被列在下面。
-v, --verbose 冗长模式。打印出程序所做的更多的信息。
-V, --version 打印版本信息并且退出。
-w, --where='where-condition' 只导出被选择了的记录;注意引号是强制的!
"--where=user='jimf'" "-wuserid>1"
"-wuserid<1" 最常见的mysqldump使用可能制作整个数据库的一个备份: mysqldump --opt database >
backup-file.sql
但是它对用来自于一个数据库的信息充实另外一个MySQL数据库也是有用的:
mysqldump --opt database | mysql
--host=remote-host -C database 由于mysqldump导出的是完整的SQL语句,所以用mysql客户程序很容易就能把数据导入了:
shell> mysqladmin create
target_db_name shell> mysql
target_db_name < backup-file.sql 就是 shell> mysql 库名 < 文件名
几个常用用例:
1.导出整个数据库
mysqldump -u 用户名 -p 数据库名 > 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql
2.导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u wcnc -p smgp_apps_wcnc users> wcnc_users.sql
3.导出一个数据库结构
mysqldump -u wcnc -p -d --add-drop-table smgp_apps_wcnc >d:\wcnc_db.sql
-d 没有数据 --add-drop-table 在每个create语句之前增加一个drop table
4.导入数据库
常用source 命令
进入mysql数据库控制台,
如mysql -u root -p
mysql>use 数据库
然后使用source命令,后面参数为脚本文件(如这里用到的.sql)
mysql>source d:\wcnc_db.sql
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | ||||
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
